Archive
Duke deans drop the ball on scientific misconduct
Former Duke University cancer researcher Anil Potti was found guilty of research misconduct yesterday by the federal Office of Research Integrity (ORI), after a multi-year investigation. You can read the story in Science, for example. His punishment is that he won’t do research without government-sponsored supervision for the next five years. Not exactly stiff.
This article also covers the ORI decision, and describes some of the people who suffered from poor cancer treatment because of his lies. Here’s an excerpt:
Shoffner, who had Stage 3 breast cancer, said she still has side effects from the wrong chemotherapy given to her in the Duke trial. Her joints were damaged, she said, and she suffered blood clots that prevent her from having knee surgery now. Of the eight patients who sued, Shoffner said, she is one of two survivors.
What’s interesting to me this morning is that both articles above mention the same reason for the initial investigation in his work. Namely, that he had padded his resume, pretending to be a Rhodes Scholar when he wasn’t. That fact was reported by a website called Cancer Letter in 2010.
But here’s the thing, back in 2008 a 3rd-year medical student named Bradford Perez sent the deans at Duke (according to Cancer Letter) a letter explaining that Potti’s lab was fabricating results. And for those of you who can read nerd, please go ahead and read his letter, it is extremely convincing. An excerpt:
Fifty-nine cell line samples with mRNA expression data from NCI-60 with associated radiation sensitivity were split in half to designate sensitive and resistant phenotypes. Then in developing the model, only those samples which fit the model best in cross validation were included. Over half of the original samples were removed. It is very possible that using these methods two samples with very little if any difference in radiation sensitivity could be in separate phenotypic categories. This was an incredibly biased approach which does little more than give the appearance of a successful cross validation.
Instead of taking up the matter seriously, the deans pressured Perez to keep quiet. And nothing more happened for two more years.
The good news: Bradford Perez seems to have gotten a perfectly good job.
The bad news: the deans at Duke suck. Unfortunately I don’t know exactly which deans and what their job titles are, but still: why are they not under investigation? What would deans have to do – or not do – to get in trouble? Is there any kind of accountability here?
Guest post: Open-Source Loan-Level Analysis of Fannie and Freddie
This is a guest post by Todd Schneider. You can read the full post with additional analysis on Todd’s personal site.
[M]ortgages were acknowledged to be the most mathematically complex securities in the marketplace. The complexity arose entirely out of the option the homeowner has to prepay his loan; it was poetic that the single financial complexity contributed to the marketplace by the common man was the Gordian knot giving the best brains on Wall Street a run for their money. Ranieri’s instincts that had led him to build an enormous research department had been right: Mortgages were about math.
The money was made, therefore, with ever more refined tools of analysis.
—Michael Lewis, Liar’s Poker (1989)
Fannie Mae and Freddie Mac began reporting loan-level credit performance data in 2013 at the direction of their regulator, the Federal Housing Finance Agency. The stated purpose of releasing the data was to “increase transparency, which helps investors build more accurate credit performance models in support of potential risk-sharing initiatives.”
The GSEs went through a nearly $200 billion government bailout during the financial crisis, motivated in large part by losses on loans that they guaranteed, so I figured there must be something interesting in the loan-level data. I decided to dig in with some geographic analysis, an attempt to identify the loan-level characteristics most predictive of default rates, and more. The code for processing and analyzing the data is all available on GitHub.
The “medium data” revolution
In the not-so-distant past, an analysis of loan-level mortgage data would have cost a lot of money. Between licensing data and paying for expensive computers to analyze it, you could have easily incurred costs north of a million dollars per year. Today, in addition to Fannie and Freddie making their data freely available, we’re in the midst of what I might call the “medium data” revolution: personal computers are so powerful that my MacBook Air is capable of analyzing the entire 215 GB of data, representing some 38 million loans, 1.6 billion observations, and over $7.1 trillion of origination volume. Furthermore, I did everything with free, open-source software.
What can we learn from the loan-level data?
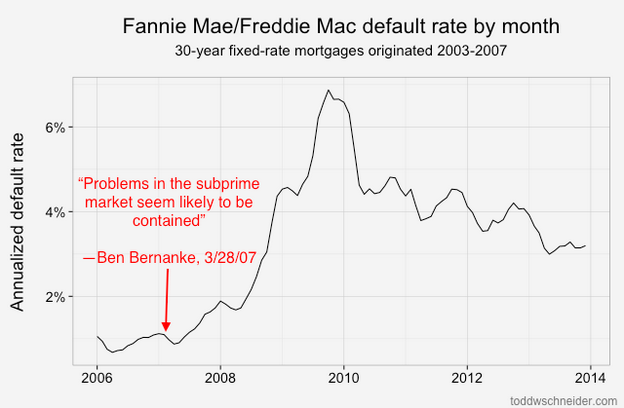
Loans originated from 2005-2008 performed dramatically worse than loans that came before them! That should be an extraordinarily unsurprising statement to anyone who was even slightly aware of the U.S. mortgage crisis that began in 2007:
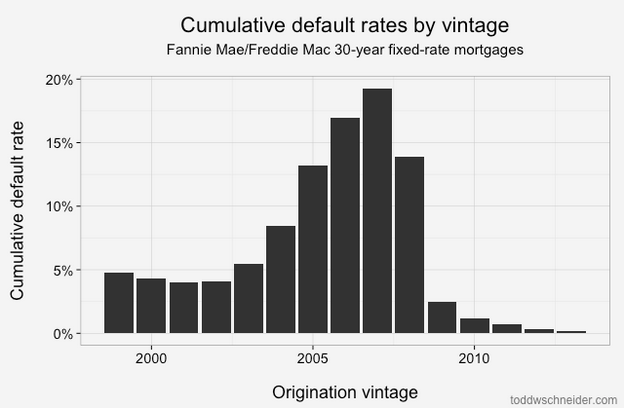
About 4% of loans originated from 1999 to 2003 became seriously delinquent at some point in their lives. The 2004 vintage showed some performance deterioration, and then the vintages from 2005 through 2008 show significantly worse performance: more than 15% of all loans originated in those years became distressed.
From 2009 through present, the performance has been much better, with fewer than 2% of loans defaulting. Of course part of that is that it takes time for a loan to default, so the most recent vintages will tend to have lower cumulative default rates while their loans are still young. But there has also been a dramatic shift in lending standards so that the loans made since 2009 have been much higher credit quality: the average FICO score used to be 720, but since 2009 it has been more like 765. Furthermore, if we look 2 standard deviations from the mean, we see that the low end of the FICO spectrum used to reach down to about 600, but since 2009 there have been very few loans with FICO less than 680:
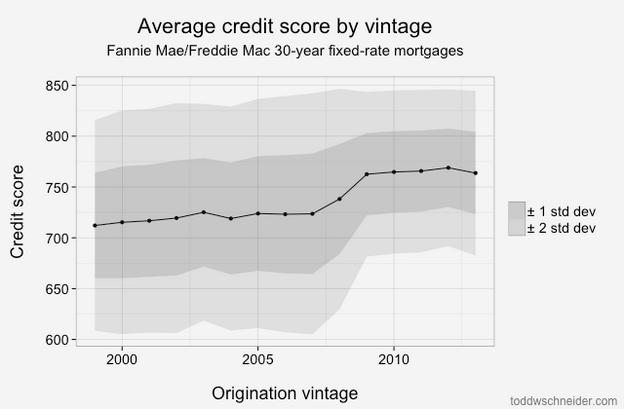
Tighter agency standards, coupled with a complete shutdown in the non-agency mortgage market, including both subprime and Alt-A lending, mean that there is very little credit available to borrowers with low credit scores (a far more difficult question is whether this is a good or bad thing!).
Geographic performance
Default rates increased everywhere during the bubble years, but some states fared far worse than others. I took every loan originated between 2005 and 2007, broadly considered to be the height of reckless mortgage lending, bucketed loans by state, and calculated the cumulative default rate of loans in each state:
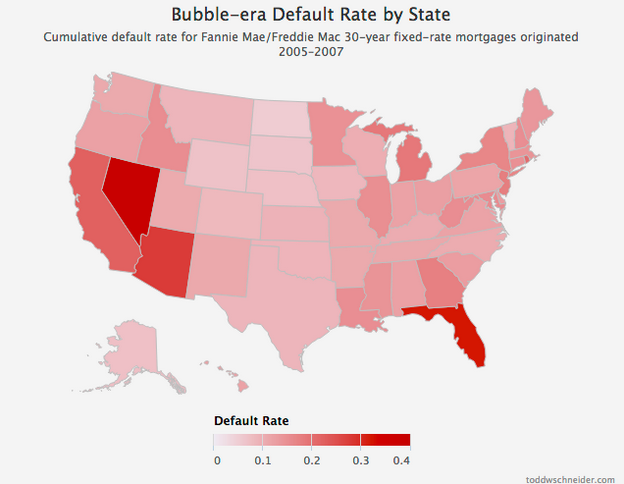
4 states in particular jump out as the worst performers: California, Florida, Arizona, and Nevada. Just about every state experienced significantly higher than normal default rates during the mortgage crisis, but these 4 states, often labeled the “sand states”, experienced the worst of it.
Read more
If you’re interested in more technical discussion, including an attempt to identify which loan-level variables are most correlated to default rates (the number one being the home price adjusted loan to value ratio), read the full post on toddwschneider.com, and be sure to check out the project on GitHub if you’d like to do your own data analysis.
China announces it is scoring its citizens using big data
Please go read the article in the Dutch newspaper de Volkskrant entitled China rates its own citizens – including online behavior (hat tip Ernie Davis).
In the article, it describes China’s plan to use big data techniques to score all of its citizens – with the help of China internet giants Alibaba, Baidu, and Tencent – in a kind of expanded credit score that includes behavior and reputation. So what you buy, who you’re friends with, and whether you seem sufficiently “socialist” are factors that affect your overall score.
Here’s a quote from a person working on the model, from Chinese Academy of Social Science, that is incredibly creepy:
When people’s behavior isn’t bound by their morality, a system must be used to restrict their actions
And here’s another quote from Rogier Creemers, an academic at Oxford who specializes in China:
Government and big internet companies in China can exploit ‘Big Data’ together in a way that is unimaginable in the West
I guess I’m wondering whether that’s really true. Given my research over the past couple of years, I see this kind of “social credit scoring” being widely implemented here in the United States.
Looking for big data reading suggestions
I have been told by my editor to take a look at the books already out there on big data to make sure my book hasn’t already been written. For example, today I’m set to read Robert Scheer’s They Know Everything About You: how data-collecting corporations and snooping government agencies are destroying democracy.
This book, like others I’ve already read and written about (Bruce Schneier’s Data and Goliath, Frank Pasquale’s Black Box Society, and Julia Angwin’s Dragnet Nation) are all primarily concerned with individual freedom and privacy, whereas my book is primarily concerned with social justice issues, and each chapter gives an example of how big data is being used a tool against the poor, against minorities, against the mentally ill, or against public school teachers.
Not that my book is entirely different from the above books, but the relationship is something like what I spelled out last week when I discussed the four political camps in the big data world. So far the books I’ve found are focused on the corporate angle or the privacy angle. There may also be books focused on the open data angle, but I’m guessing they have even less in common with my book, which focuses on the ways big data increase inequality and further alienate already alienated populations.
If any of you know of a book I should be looking at, please tell me!
The Police State is already here.
The thing that people like Snowden are worried about with respect to mass surveillance has already happened. It’s being carried out by police departments, though, not the NSA, and its targets are black men, not the general population.
Take a look at this incredible Guardian article written by Rose Hackman. Her title is, Is the online surveillance of black teenagers the new stop-and-frisk? but honestly that’s a pretty tame comparison if you think about the kinds of permanent electronic information that the police are collecting about black boys in Harlem as young as 10 years old.
Some facts about the program:
- 28,000 residents are being surveilled
- 300 “crews,” a designation that rises to “gangs” when there are arrests,
- Officers trawl Facebook, Instagram, Twitter, YouTube, and other social media for incriminating posts
- They pose as young women to gain access to “private” accounts
- Parents are not notified
- People never get off these surveillance lists
- In practice, half of court cases actually use social media data to put people away
- NYPD cameras are located all over Harlem as well
We need to limit the kind of information police can collect, and put limits on how discriminatory their collection practices are. As the article points out, white fraternity brothers two blocks away at Columbia University are not on the lists, even though there was a big drug bust in 2010.
For anyone who wonders what a truly scary police surveillance state looks like, they need look no further than what’s already happening for certain Harlem residents.
Workplace Personality Tests: a Cynical View
There’s a frightening article in the Wall Street Journal by Lauren Weber about personality tests people are now forced to take to get shitty jobs in customer calling centers and the like. Some statistics from the article include: 8 out of 10 of the top private employers use such tests, and 57% of employers overall in 2013, a steep rise from previous years.
The questions are meant to be ambiguous so you can’t game them if you are an applicant. For example, yes or no: “I have never understood why some people find abstract art appealing.”
At the end of the test, you get a red light, a yellow light, or a green light. Red lighted people never get an interview, and yellow lighted may or may not. Companies cited in the article use the tests to disqualify more than half their applicants without ever talking to them in person.
The argument for these tests is that, after deploying them, turnover has gone down by 25% since 2000. The people who make and sell personality tests say this is because they’re controlling for personality type and “company fit.”
I have another theory about why people no longer leave shitty jobs, though. First of all, the recession has made people’s economic lives extremely precarious. Nobody wants to lose a job. Second of all, now that everyone is using arbitrary personality tests, the power of the worker to walk off the job and get another job the next week has gone down. By the way, the usage of personality tests seems to correlate with a longer waiting period between applying and starting work, so there’s that disincentive as well.
Workplace personality tests are nothing more than voodoo management tools that empower employers. In fact I’ve compared them in the past to modern day phrenology, and I haven’t seen any reason to change my mind since then. The real “metric of success” for these models is the fact that employers who use them can fire a good portion of their HR teams.
Fingers crossed – book coming out next May
As it turns out, it takes a while to write a book, and then another few months to publish it.
I’m very excited today to tentatively announce that my book, which is tentatively entitled Weapons of Math Destruction: How Big Data Increases Inequality and Threatens Democracy, will be published in May 2016, in time to appear on summer reading lists and well before the election.
Fuck yeah! I’m so excited.
p.s. Fight for 15 is happening now.
The achievement gap: whose problem is it?
On Monday night I went to see Boston College professor Henry Braun speak about the Value-Added Model for teachers (VAM) at Teachers College, right here in my hood (hat tip Sendhil Revuluri).
I wrote about VAM recently, and I’m not a fan, so I was excited for the event. Here’s the poster from Monday:

The room was not entirely filled with anti-VAM activists such as myself, even though it was an informed audience. In fact one of the people I found myself talking to before the talk started mentioned that he’d worked on Wall Street, where they “culled” 10% of the workforce regularly – during downsizing phases – and how fantastic it was, how it kept standards high.
I mentioned that the question is, who gets decide which 10% and why, and he responded that it was all about profit, naturally. Being an easily provoked person, I found myself saying, well right, that’s the definition of success for Wall Street, and we can see how that’s turned out for everyone. He stared blankly at me.
I told that story because it irks me, still, how utterly unscathed individuals feel, who were or are part of the Wall Street culture. They don’t see any lesson to learn from that whole mess.
But even more than that, the same mindset which served the country so poorly is now somehow being held up as a success story, and applied to other fields like public education.
That brings me to the talk itself. Professor Braun did a very good job of explaining the VAM, and the inconsistencies, and the smallish correlations and unaccountable black box nature of the test.
But he then did more: he drew up a (necessarily vague) picture of the entire process by which a teacher is “assessed,” of which VAM plays a varying role, and he asked some important questions: how does this process affect the teaching profession? Does the scrutiny of each teacher in this way make students learn more? Does it make bad teachers get better? Does it make good teachers stay in the profession?
Great questions, but he didn’t even stop there. He went on to point something out that I’d never directly considered. Namely, why do we think individual responsibility – i.e. finger pointing at individual teachers – is going to improve the overall system? Here he suggested that there’s been a huge split in the profession between those who want to improve educational systems and those who want to assess teachers (and think that will “close the achievement gap”). The people who want to improve education talk about increasing communication between teachers in a school or between schools in a district, and they talk about improving and strengthening communities and cultures of learning.
By contrast the “assess the teachers” crowd is convinced that holding teachers individually accountable for the achievement of their students is the only possible approach. Fuck the school culture, fuck communicating with other teachers in the school. Fuck differences in curriculum or having old books or not having enough books due to unequal funding.
It got me thinking, especially since I read that book last week, The New Prophets of Capitalism (review here). That book explained how hollow Oprah’s urging to live a perfect life is to people whose situations are beyond their control. The problem with Oprah’s reasoning is that it ignores real systemic problems and issues that radically affect certain parts of the population and make it much harder to take her advice. It’s context free in a world where context is more and more meaningful.
So, whose problem is the achievement gap? Is it owned in tiny pieces by every teacher who dares to enter the profession? Is it owned by schools or school systems? Or is it owned by all of us, by the country as a whole? And if it is, how are we going to start working together to solve it?
Guest Post: A Discussion Of PARCC Testing
This is a guest post by Eugene Stern, who writes a blog at Sense Made Here, and Kristin Wald, who writes a blog at This Unique* Weblog. Crossposted on their blogs as well.
Today’s post is a discussion of education reform, standardized testing, and PARCC with my friend Kristin Wald, who has been extremely kind to this blog. Kristin taught high school English in the NYC public schools for many years. Today her kids and mine go to school together in Montclair. She has her own blog that gets orders of magnitude more readers than I do.
ES: PARCC testing is beginning in New Jersey this month. There’s been lots of anxiety and confusion in Montclair and elsewhere as parents debate whether to have their kids take the test or opt out. How do you think about it, both as a teacher and as a parent?
KW: My simple answer is that my kids will sit for PARCC. However, and this is where is gets grainy, that doesn’t mean I consider myself a cheerleader for the exam or for the Common Core curriculum in general.
In fact, my initial reaction, a few years ago, was to distance my children from both the Common Core and PARCC. So much so that I wrote to my child’s principal and teacher requesting that no practice tests be administered to him. At that point I had only peripherally heard about the issues and was extending my distaste for No Child Left Behind and, later, Race to the Top. However, despite reading about and discussing the myriad issues, I still believe in change from within and trying the system out to see kinks and wrinkles up-close rather than condemning it full force.
Standards
ES: Why did you dislike NCLB and Race to the Top? What was your experience with them as a teacher?
KW: Back when I taught in NYC, there was wiggle room if students and schools didn’t meet standards. Part of my survival as a teacher was to shut my door and do what I wanted. By the time I left the classroom in 2007 we were being asked to post the standards codes for the New York State Regents Exams around our rooms, similar to posting Common Core standards all around. That made no sense to me. Who was this supposed to be for? Not the students – if they’re gazing around the room they’re not looking at CC RL.9-10 next to an essay hanging on a bulletin board. I also found NCLB naïve in its “every child can learn it all” attitude. I mean, yes, sure, any child can learn. But kids aren’t starting out at the same place or with the same support. And anyone who has experience with children who have not had the proper support up through 11th grade knows they’re not going to do well, or even half-way to well, just because they have a kickass teacher that year.
Regarding my initial aversion to Common Core, especially as a high school English Language Arts teacher, the minimal appearance of fiction and poetry was disheartening. We’d already seen the slant in the NYS Regents Exam since the late 90’s.
However, a couple of years ago, a friend asked me to explain the reason The Bluest Eye, with its abuse and rape scenes, was included in Common Core selections, so I took a closer look. Basically, a right-wing blogger had excerpted lines and scenes from the novel to paint it as “smut” and child pornography, thus condemning the entire Common Core curriculum. My response to my friend ended up as “In Defense of The Bluest Eye.”
That’s when I started looking more closely at the Common Core curriculum. Learning about some of the challenges facing public schools around the country, I had to admit that having a required curriculum didn’t seem like a terrible idea. In fact, in a few cases, the Common Core felt less confining than what they’d had before. And you know, even in NYC, there were English departments that rarely taught women or minority writers. Without a strong leader in a department, there’s such a thing as too much autonomy. Just like a unit in a class, a school and a department should have a focus, a balance.
But your expertise is Mathematics, Eugene. What are your thoughts on the Common Core from that perspective?
ES: They’re a mix. There are aspects of the reforms that I agree with, aspects that I strongly disagree with, and then a bunch of stuff in between.
The main thing I agree with is that learning math should be centered on learning concepts rather than procedures. You should still learn procedures, but with a conceptual underpinning, so you understand what you’re doing. That’s not a new idea: it’s been in the air, and frustrating some parents, for 50 years or more. In the 1960’s, they called it New Math.
Back then, the reforms didn’t go so well because the concepts they were trying to teach were too abstract – too much set theory, in a nutshell, at least in the younger grades. So then there was a retrenchment, back to learning procedures. But these things seem to go in cycles, and now we’re trying to teach concepts better again. This time more flexibly, less abstractly, with more examples. At least that’s the hope, and I share that hope.
I also agree with your point about needing some common standards defining what gets taught at each grade level. You don’t want to be super-prescriptive, but you need to ensure some kind of consistency between schools. Otherwise, what happens when a kid switches schools? Math, especially, is such a cumulative subject that you really need to have some big picture consistency in how you teach it.
Assessment
ES: What I disagree with is the increased emphasis on standardized testing, especially the raised stakes of those tests. I want to see better, more consistent standards and curriculum, but I think that can and should happen without putting this very heavy and punitive assessment mechanism on top of it.
KW: Yes, claiming to want to assess ability (which is a good thing), but then connecting the results to a teacher’s effectiveness in that moment is insincere evaluation. And using a standardized test not created by the teacher with material not covered in class as a hard percentage of a teacher’s evaluation makes little sense. I understand that much of the exam is testing critical thinking, ability to reason and use logic, and so on. It’s not about specific content, and that’s fine. (I really do think that’s fine!) Linking teacher evaluations to it is not.
Students cannot be taught to think critically in six months. As you mentioned about the spiraling back to concepts, those skills need to be revisited again and again in different contexts. And I agree, tests needn’t be the main driver for raising standards and developing curriculum. But they can give a good read on overall strengths and weaknesses. And if PARCC is supposed to be about assessing student strengths and weaknesses, it should be informing adjustments in curriculum.
On a smaller scale, strong teachers and staffs are supposed to work as a team to influence the entire school and district with adjusted curriculum as well. With a wide reach like the Common Core, a worrying issue is that different parts of the USA will have varying needs to meet. Making adjustments for all based on such a wide collection of assessments is counterintuitive. Local districts (and the principals and teachers in them) need to have leeway with applying them to best suit their own students.
Even so, I do like some things about data driven curricula. Teachers and school administrators are some of the most empathetic and caring people there are, but they are still human, and biases exist. Teachers, guidance counselors, administrators can’t help but be affected by personal sympathies and peeves. Having a consistent assessment of skills can be very helpful for those students who sometimes fall through the cracks. Basically, standards: yes. Linking scores to teacher evaluation: no.
ES: Yes, I just don’t get the conventional wisdom that we can only tell that the reforms are working, at both the individual and group level, through standardized test results. It gives us some information, but it’s still just a proxy. A highly imperfect proxy at that, and we need to have lots of others.
I also really like your point that, as you’re rolling out national standards, you need some local assessment to help you see how those national standards are meeting local needs. It’s a safeguard against getting too cookie-cutter.
I think it’s incredibly important that, as you and I talk, we can separate changes we like from changes we don’t. One reason there’s so much noise and confusion now is that everything – standards, curriculum, testing – gets lumped together under “Common Core.” It becomes this giant kitchen sink that’s very hard to talk about in a rational way. Testing especially should be separated out because it’s fundamentally an issue of process, whereas standards and curriculum are really about content.
You take a guy like Cuomo in New York. He’s trying to increase the reliance on standardized tests in teacher evaluations, so that value added models based on test scores count for half of a teacher’s total evaluation. And he says stuff like this: “Everyone will tell you, nationwide, the key to education reform is a teacher evaluation system.” That’s from his State of the State address in January. He doesn’t care about making the content better at all. “Everyone” will tell you! I know for a fact that the people spending all their time figuring out at what grade level kids should start to learn about fractions aren’t going tell you that!
I couldn’t disagree with that guy more, but I’m not going to argue with him based on whether or not I like the problems my kids are getting in math class. I’m going to point out examples, which he should be well aware of by now, of how badly the models work. That’s a totally different discussion, about what we can model accurately and fairly and what we can’t.
So let’s have that discussion. Starting point: if you want to use test scores to evaluate teachers, you need a model because – I think everyone agrees on this – how kids do on a test depends on much more than how good their teacher was. There’s the talent of the kid, what preparation they got outside their teacher’s classroom, whether they got a good night’s sleep the night before, and a good breakfast, and lots of other things. As well as natural randomness: maybe the reading comprehension section was about DNA, and the kid just read a book about DNA last month. So you need a model to break out the impact of the teacher. And the models we have today, even the most state-of-the-art ones, can give you useful aggregate information, but they just don’t work at that level of detail. I’m saying this as a math person, and the American Statistical Association agrees. I’ve written about this here and here and here and here.
Having student test results impact teacher evaluations is my biggest objection to PARCC, by far.
KW: Yep. Can I just cut and paste what you’ve said? However, for me, another distasteful aspect is how technology is tangled up in the PARCC exam.
Technology
ES: Let me tell you the saddest thing I’ve heard all week. There’s a guy named Dan Meyer, who writes very interesting things about math education, both in his blog and on Twitter. He put out a tweet about a bunch of kids coming into a classroom and collectively groaning when they saw laptops on every desk. And the reason was that they just instinctively assumed they were either about to take a test or do test prep.
That feels like such a collective failure to me. Look, I work in technology, and I’m still optimistic that it’s going to have a positive impact on math education. You can use computers to do experiments, visualize relationships, reinforce concepts by having kids code them up, you name it. The new standards emphasize data analysis and statistics much more than any earlier standards did, and I think that’s a great thing. But using computers primarily as a testing tool is an enormous missed opportunity. It’s like, here’s the most amazing tool human beings have ever invented, and we’re going to use it primarily as a paperweight. And we’re going to waste class time teaching kids exactly how to use it as a paperweight. That’s just so dispiriting.
KW: That’s something that hardly occurred to me. My main objection to hosting the PARCC exam on computers – and giving preparation homework and assignments that MUST be done on a computer – is the unfairness inherent in accessibility. It’s one more way to widen the achievement gap that we are supposed to be minimizing. I wrote about it from one perspective here.
I’m sure there are some students who test better on a computer, but the playing field has to be evenly designed and aggressively offered. Otherwise, a major part of what the PARCC is testing is how accurately and quickly children use a keyboard. And in the aggregate, the group that will have scores negatively impacted will be children with less access to the technology used on the PARCC. That’s not an assessment we need to test to know. When I took the practice tests, I found some questions quite clear, but others were difficult not for content but in maneuvering to create a fraction or other concept. Part of that can be solved through practice and comfort with the technology, but then we return to what we’re actually testing.
ES: Those are both great points. The last thing you want to do is force kids to write math on a computer, because it’s really hard! Math has lots of specialized notation that’s much easier to write with pencil and paper, and learning how to write math and use that notation is a big part of learning the subject. It’s not easy, and you don’t want to put artificial obstacles in kids’ way. I want kids thinking about fractions and exponents and what they mean, and how to write them in a mathematical expression, but not worrying about how to put a numerator above a denominator or do a superscript or make a font smaller on a computer. Plus, why in the world would you limit what kids can express on a test to what they can input on a keyboard? A test is a proxy already, and this limits what it can capture even more.
I believe in using technology in education, but we’ve got the order totally backwards. Don’t introduce the computer as a device to administer tests, introduce it as a tool to help in the classroom. Use it for demos and experiments and illustrating concepts.
As far as access and fairness go, I think that’s another argument for using the computer as a teaching tool rather than a testing tool. If a school is using computers in class, then at least everyone has access in the classroom setting, which is a start. Now you might branch out from there to assignments that require a computer. But if that’s done right, and those assignments grow in an organic way out of what’s happening in the classroom, and they have clear learning value, then the school and the community are also morally obligated to make sure that everyone has access. If you don’t have a computer at home, and you need to do computer-based homework, then we have to get you computer access, after school hours, or at the library, or what have you. And that might actually level the playing field a bit. Whereas now, many computer exercises feel like they’re primarily there to get kids used to the testing medium. There isn’t the same moral imperative to give everybody access to that.
I really want to hear more about your experience with the PARCC practice tests, though. I’ve seen many social media threads about unclear questions, both in a testing context and more generally with the Common Core. It sounds like you didn’t think it was so bad?
KW: Well, “not so bad” in that I am a 45 year old who was really trying to take the practice exam honestly, but didn’t feel stressed about the results. However, I found the questions with fractions confusing in execution on the computer (I almost gave up), and some of the questions really had to be read more than once. Now, granted, I haven’t been exposed to the language and technique of the exam. That matters a lot. In the SAT, for example, if you don’t know the testing language and format it will adversely affect your performance. This is similar to any format of an exam or task, even putting together an IKEA nightstand.
There are mainly two approaches to preparation, and out of fear of failing, some school districts are doing hardcore test preparation – much like SAT preparation classes – to the detriment of content and skill-based learning. Others are not altering their classroom approaches radically; in fact, some teachers and parents have told me they hardly notice a difference. My unscientific observations point to a separation between the two that is lined in Socio-Economic Status. If districts feel like they are on the edge or have a lot to lose (autonomy, funding, jobs), if makes sense that they would be reactionary in dealing with the PARCC exam. Ironically, schools that treat the PARCC like a high-stakes test are the ones losing the most.
Opting Out
KW: Despite my misgivings, I’m not in favor of “opting out” of the test. I understand the frustration that has prompted the push some districts are experiencing, but there have been some compromises in New Jersey. I was glad to see that the NJ Assembly voted to put off using the PARCC results for student placement and teacher evaluations for three years. And I was relieved, though not thrilled, that the percentage of PARCC results to be used in teacher evaluations was lowered to 10% (and now put off). I still think it should not be a part of teacher evaluations, but 10% is an improvement.
Rather than refusing the exam, I’d prefer to see the PARCC in action and compare honest data to school and teacher-generated assessments in order to improve the assessment overall. I believe an objective state or national model is worth having; relying only on teacher-based assessment has consistency and subjective problems in many areas. And that goes double for areas with deeply disadvantaged students.
ES: Yes, NJ seems to be stepping back from the brink as far as model-driven teacher evaluation goes. I think I feel the same way you do, but if I lived in NY, where Cuomo is trying to bump up the weight of value added models in evaluations to 50%, I might very well be opting out.
Let me illustrate the contrast – NY vs. NJ, more test prep vs. less — with an example. My family is good friends with a family that lived in NYC for many years, and just moved to Montclair a couple months ago. Their older kid is in third grade, which is the grade level where all this testing starts. In their NYC gifted and talented public school, the test was this big, stressful thing, and it was giving the kid all kinds of test anxiety. So the mom was planning to opt out. But when they got to Montclair, the kid’s teacher was much more low key, and telling the kids not to worry. And once it became lower stakes, the kid wanted to take the test! The mom was still ambivalent, but she decided that here was an opportunity for her kid to get used to tests without anxiety, and that was the most important factor for her.
I’m trying to make two points here. One: whether or not you opt out depends on lots of factors, and people’s situations and priorities can be very different. We need to respect that, regardless of which way people end up going. Two: shame on us, as grown ups, for polluting our kids’ education with our anxieties! We need to stop that, and that extends both to the education policies we put in place and how we collectively debate those policies. I guess what I’m saying is: less noise, folks, please.
KW: Does this very long blog post count as noise, Eugene? I wonder how this will be assessed? There are so many other issues – private profits from public education, teacher autonomy in high performing schools, a lack of educational supplies and family support, and so on. But we have to start somewhere with civil and productive discourse, right? So, thank you for having the conversation.
ES: Kristin, I won’t try to predict anyone else’s assessment, but I will keep mine low stakes and say this has been a pleasure!
A critique of a review of a book by Bruce Schneier
I haven’t yet read Bruce Schneier’s new book, Data and Goliath: The Hidden Battles To Collect Your Data and Control Your World. I plan to in the coming days, while I’m traveling with my kids for spring break.
Even so, I already feel capable of critiquing this review of his book (hat tip Jordan Ellenberg), written by Columbia Business School Professor and Investment Banker Jonathan Knee. You see, I’m writing a book myself on big data, so I feel like I understand many of the issues intimately.
The review starts out flattering, but then it hits this turn:
When it comes to his specific policy recommendations, however, Mr. Schneier becomes significantly less compelling. And the underlying philosophy that emerges — once he has dispensed with all pretense of an evenhanded presentation of the issues — seems actually subversive of the very democratic principles that he claims animates his mission.
That’s a pretty hefty charge. Let’s take a look into Knee’s evidence that Schneier wants to subvert democratic principles.
NSA
First, he complains that Schneier wants the government to stop collecting and mining massive amounts of data in its search for terrorists. Knee thinks this is dumb because it would be great to have lots of data on the “bad guys” once we catch them.
Any time someone uses the phrase “bad guys,” it makes me wince.
But putting that aside, Knee is either ignorant of or is completely ignoring what mass surveillance and data dredging actually creates: the false positives, the time and money and attention, not to mention the potential for misuse and hacking. Knee’s opinion on that is simply that we normal citizens just don’t know enough to have an opinion on whether it works, including Schneier, and in spite of Schneier knowing Snowden pretty well.
It’s just like waterboarding – Knee says – we can’t be sure it isn’t a great fucking idea.
Wait, before we move on, who is more pro-democracy, the guy who wants to stop totalitarian social control methods, or the guy who wants to leave it to the opaque authorities?
Corporate Data Collection
Here’s where Knee really gets lost in Schneier’s logic, because – get this – Schneier wants corporate collection and sale of consumer data to stop. The nerve. As Knee says:
Mr. Schneier promotes no less than a fundamental reshaping of the media and technology landscape. Companies with access to large amounts of personal data would be “automatically classified as fiduciaries” and subject to “special legal restrictions and protections.”
That these limits would render illegal most current business models — under which consumers exchange enhanced access by advertisers for free services – does not seem to bother Mr. Schneier”
I can’t help but think that Knee cannot understand any argument that would threaten the business world as he knows it. After all, he is a business professor and an investment banker. Things seem pretty well worked out when you live in such an environment.
By Knee’s logic, even if the current business model is subverting democracy – which I also argue in my book – we shouldn’t tamper with it because it’s a business model.
The way Knee paints Schneier as anti-democratic is by using the classic fallacy in big data which I wrote about here:
Although professing to be primarily preoccupied with respect of individual autonomy, the fact that Americans as a group apparently don’t feel the same way as he does about privacy appears to have little impact on the author’s radical regulatory agenda. He actually blames “the media” for the failure of his positions to attract more popular support.
Quick summary: Americans as a group do not feel this way because they do not understand what they are trading when they trade their privacy. Commercial and governmental interests, meanwhile, are all united in convincing Americans not to think too hard about it. There are very few people devoting themselves to alerting people to the dark side of big data, and Schneier is one of them. It is a patriotic act.
Also, yes Professor Knee, “the media” generally speaking writes down whatever a marketer in the big data world says is true. There are wonderful exceptions, of course.
So, here’s a question for Knee. What if you found out about a threat on the citizenry, and wanted to put a stop to it? You might write a book and explain the threat; the fact that not everyone already agrees with you wouldn’t make your book anti-democratic, would it?
MLK
The rest of the review basically boils down to, “you don’t understand the teachings of the Reverend Dr. Martin Luther King Junior like I do.”
Do you know about Godwin’s law, which says that as soon as someone invokes the Nazis in an argument about anything, they’ve lost the argument?
I feel like we need another, similar rule, which says, if you’re invoking MLK and claiming the other person is misinterpreting him while you have him nailed, then you’ve lost the argument.
Data Justice Launches!
I’m super excited to announce that I’m teaming up with Nathan Newman and Frank Pasquale on a newly launched project called Data Justice and subtitled Challenging Rising Exploitation and Economic Inequality from Big Data.
Nathan Newman is the director of Data Justice and is a lawyer and policy advocate. You might remember his work with racial and economic profiling of Google ads. Frank Pasquale is a law professor at the University of Maryland and the author of a book I recently reviewed called The Black Box Society.
The mission for Data Justice can be read here and explains how we hope to build a movement on the data justice front by working across various disciplines like law, computer science, and technology. We also have a blog and a press release which I hope you have time to read.
Reforming the data-driven justice system
This article from the New York Times really interests me. It’s entitled Unlikely Cause Unites the Left and the Right: Justice Reform, and although it doesn’t specifically mention “data driven” approaches in justice reform, it describes “emerging proposals to reduce prison populations, overhaul sentencing, reduce recidivism and take on similar initiatives.”
I think this sentence, especially the reference to reducing recidivism, is code for the evidence-based sentencing that my friend Luis Daniel recently posted about. I recently finished a draft chapter in my book about such “big data” models, and after much research I can assure you that this stuff runs the gamut between putting poor people away for longer because they’re poor and actually focusing resources where they’re needed.
The idea that there’s a coalition that’s taking this on that includes both Koch Industries and the ACLU is fascinating and bizarre and – if I may exhibit a rare moment of optimism – hopeful. In particular I’m desperately hoping they have involved people who understand enough about modeling not to assume that the results of models are “objective”.
There are, in fact, lots of ways to set up data-gathering and usage in the justice system to actively fight against unfairness and unreasonably long incarcerations, rather than to simply codify such practices. I hope some of that conversation happens soon.
Creepy big data health models
There’s an excellent Wall Street Journal article by Joseph Walker, entitled Can a Smartphone Tell if You’re Depressed?, that describes a lot of creepy new big data projects going on now in healthcare, in partnership with hospitals and insurance companies.
Some of the models come in the form of apps, created and managed by private, third-party companies that try to predict depression in, for example, postpartum women. They don’t disclose what they are doing to many of the women, or the extent of what they’re doing, according to the article. They own the data they’ve collected at the end of the day and, presumably, can sell it to anyone interested in whether a woman is depressed. For example, future employers. To be clear, this data is generally not covered by HIPAA.
Perhaps the creepiest example is a voice analysis model:
Nurses employed by Aetna have used voice-analysis software since 2012 to detect signs of depression during calls with customers who receive short-term disability benefits because of injury or illness. The software looks for patterns in the pace and tone of voices that can predict “whether the person is engaged with activities like physical therapy or taking the right kinds of medications,” Michael Palmer, Aetna’s chief innovation and digital officer, says.
…
Patients aren’t informed that their voices are being analyzed, Tammy Arnold, an Aetna spokeswoman, says. The company tells patients the calls are being “recorded for quality,” she says.
“There is concern that with more detailed notification, a member may alter his or her responses or tone (intentionally or unintentionally) in an effort to influence the tool or just in anticipation of the tool,” Ms. Arnold said in an email.
In other words, in the name of “fear of gaming the model,” we are not disclosing the creepy methods we are using. Also, considering that the targets of this model are receiving disability benefits, I’m wondering if the real goal is to catch someone off their meds and disqualify them for further benefits or something along those lines. Since they don’t know they are being modeled, they will never know.
Conclusion: we need more regulation around big data in healthcare.
Big data and class
About a month ago there was an interesting article in the New York Times entitled Blowing Off Class? We Know. It discusses the “big data” movement in colleges around the country. For example, at Ball State, they track which students go to parties at the student center. Presumably to help them study for tests, or maybe to figure out which ones to hit up for alumni gifts later on.
There’s a lot to discuss in this article, but I want to focus today on one piece:
Big data has a lot of influential and moneyed advocates behind it, and I’ve asked some of them whether their enthusiasm might also be tinged with a little paternalism. After all, you don’t see elite institutions regularly tracking their students’ comings and goings this way. Big data advocates don’t dispute that, but they also note that elite institutions can ensure that their students succeed simply by being very selective in the first place.
The rest “get the students they get,” said William F. L. Moses, the managing director of education programs at the Kresge Foundation, which has given grants to the innovation alliance and to bolster data-analytics efforts at other colleges. “They have a moral obligation to help them succeed.”
This is a sentiment I’ve noticed a lot, although it’s not usually this obvious. Namely, the elite don’t need to be monitored, but the rabble does. The rich and powerful get to be quirky philosophers but the rest of the population need to be ranked and filed. And, by the way, we are spying on them for their own good.
In other words, never mind how big data creates and expands classism; classism already helps decide who is put into the realm of big data in the first place.
It feeds into the larger question of who is entitled to privacy. If you want to be strict about your definition of pricacy, you might say “nobody.” But if you recognize that privacy is a spectrum, where we have a variable amount of information being collected on people, and also a variable amount of control over people whose information we have collected, then upon study, you will conclude that privacy, or at least relative privacy, is for the rich and powerful. And it starts early.
Mortgage tax deductions and gentrification
Yesterday we had a tax expert come talk to us at the Alternative Banking group. We mostly focused on the mortgage tax deduction, whereby people don’t have to pay taxes on their mortgage. It’s the single biggest tax deduction in America for individuals.
At first blush, this doesn’t seem all that interesting, even if it’s strange. Whether people are benefitting directly from this, or through their rent being lower because their landlord benefits, it’s a fact of life for Americans. Whoopdedoo.
Generally speaking other countries don’t have a mortgage tax deduction, so we can judge whether it leads to overall more homeownership, which was presumably what it was intended for, and the data seems to suggest the answer there is no.
We can also imagine removing the mortgage tax deduction, and we quickly realize that such a move would seriously impair lots of people’s financial planning, so we’d have to do it very slowly if at all.
But before we imagine removing it, is it even a problem?
Well, yes, actually. Let’s think about it a little bit more, and for the sake of this discussion we will model the tax system very simply as progressive: the more income you collect yearly, the more taxes you pay. Also, there is a $1.1 million (or so) cap on the mortgage tax deduction, so it doesn’t apply to uber wealthy borrowers with huge houses. But for the rest of us it does apply.
OK now let’s think a little harder about what happens in the housing market when the government offers a tax deduction. Namely, the prices go up to compensate. It’s kind of like a rebate: this house is $100K with no deduction, but with a $20K deduction I can charge $120K for it.
But it’s a little more complicated than that, since people’s different income levels correspond to different deductions. So a lower middle class neighborhood’s houses will be inflated by less than an upper middle class neighborhood’s houses.
At first blush, this seems ok too: so richer people’s houses are inflated slightly more. It means it’s slightly harder for them to get in on the home ownership game, but it also means that, come time to sell, their house is worth more. For them, a $400K house is inflated not by 20% but by 35%, or whatever their tax bracket is.
So far so good? Now let’s add one more layer of complexity, namely that, actually, neighborhoods are not statically “upper middle class” or “lower middle class.” As a group neighborhoods, and their associated classes, represent a dynamical system, where certain kinds of neighborhoods expand or contract. Colloquially we refer to this as gentrification or going to hell, depending on which direction it is. Let’s explore the effect of the mortgage tax deduction on how that dynamical system operates.
Imagine a house which is exactly on the border between a middle class neighborhood and an upper-middle class neighborhood. If we imagine that it’s a middle class home, the price of it has only been inflated by a middle-class income tax bracket, so 20% for the sake of argument. But if we instead imagine it is in the upper-middle class neighborhood, it should really be inflated by 35%.
In other words, it’s under-priced from the perspective of the richer neighborhood. They will have an easier time affording it. The overall effect is that it is easier for someone from the richer neighborhood to snatch up that house, thereby extending their neighborhood a bit. Gentrification modeled.
Put it another way, the same house at the same price is more expensive for a poorer person because the mortgage tax deduction doesn’t affect everyone equally.
Another related point: if I’m a home builder, I will want to build homes with a maximal mark-up, a maximal inflation level. That will be for the richest people who haven’t actually exceeded the $1.1 million cap.
Conclusion: the mortgage tax deduction has an overall negative effect, encouraging gentrification, unfair competition, and too many homes for the wealthy. We should phase it out slowly, and also slowly lower the cap. At the very very least we should not let the cap rise, which will mean it effectively goes down over time as inflation does its thing.
If this has been tested or observed with data, please send me references.
Fairness, accountability, and transparency in big data models
As I wrote about already, last Friday I attended a one day workshop in Montreal called FATML: Fairness, Accountability, and Transparency in Machine Learning. It was part of the NIPS conference for computer science, and there were tons of nerds there, and I mean tons. I wanted to give a report on the day, as well as some observations.
First of all, I am super excited that this workshop happened at all. When I left my job at Intent Media in 2011 with the intention of studying these questions and eventually writing a book about them, they were, as far as I know, on nobody’s else’s radar. Now, thanks to the organizers Solon and Moritz, there are communities of people, coming from law, computer science, and policy circles, coming together to exchange ideas and strategies to tackle the problems. This is what progress feels like!
OK, so on to what the day contained and my copious comments.
Hannah Wallach
Sadly, I missed the first two talks, and an introduction to the day, because of two airplane cancellations (boo American Airlines!). I arrived in the middle of Hannah Wallach’s talk, the abstract of which is located here. Her talk was interesting, and I liked her idea of having social scientists partnered with data scientists and machine learning specialists, but I do want to mention that, although there’s a remarkable history of social scientists working within tech companies – say at Bell Labs and Microsoft and such – we don’t see that in finance at all, nor does it seem poised to happen. So in other words, we certainly can’t count on social scientists to be on hand when important mathematical models are getting ready for production.
Also, I liked Hannah’s three categories of models: predictive, explanatory, and exploratory. Even though I don’t necessarily think that a given model will fall neatly into one category or the other, they still give you a way to think about what we do when we make models. As an example, we think of recommendation models as ultimately predictive, but they are (often) predicated on the ability to understand people’s desires as made up of distinct and consistent dimensions of personality (like when we use PCA or something equivalent). In this sense we are also exploring how to model human desire and consistency. For that matter I guess you could say any model is at its heart an exploration into whether the underlying toy model makes any sense, but that question is dramatically less interesting when you’re using linear regression.
Anupam Datta and Michael Tschantz
Next up Michael Tschantz reported on work with Anupam Datta that they’ve done on Google profiles and Google ads. The started with google’s privacy policy, which I can’t find but which claims you won’t receive ads based on things like your health problems. Starting with a bunch of browsers with no cookies, and thinking of each of them as fake users, they did experiments to see what actually happened both to the ads for those fake users and to the google ad profiles for each of those fake users. They found that, at least sometimes, they did get the “wrong” kind of ad, although whether Google can be blamed or whether the advertiser had broken Google’s rules isn’t clear. Also, they found that fake “women” and “men” (who did not differ by any other variable, including their searches) were offered drastically different ads related to job searches, with men being offered way more ads to get $200K+ jobs, although these were basically coaching sessions for getting good jobs, so again the advertisers could have decided that men are more willing to pay for such coaching.
An issue I enjoyed talking about was brought up in this talk, namely the question of whether such a finding is entirely evanescent or whether we can call it “real.” Since google constantly updates its algorithm, and since ad budgets are coming and going, even the same experiment performed an hour later might have different results. In what sense can we then call any such experiment statistically significant or even persuasive? Also, IRL we don’t have clean browsers, so what happens when we have dirty browsers and we’re logged into gmail and Facebook? By then there are so many variables it’s hard to say what leads to what, but should that make us stop trying?
From my perspective, I’d like to see more research into questions like, of the top 100 advertisers on Google, who saw the majority of the ads? What was the economic, racial, and educational makeup of those users? A similar but different (because of the auction) question would be to reverse-engineer the advertisers’ Google ad targeting methodologies.
Finally, the speakers mentioned a failure on Google’s part of transparency. In your advertising profile, for example, you cannot see (and therefore cannot change) your marriage status, but advertisers can target you based on that variable.
Sorelle Friedler, Carlos Scheidegger, and Suresh Venkatasubramanian
Next up we had Sorelle talk to us about her work with two guys with enormous names. They think about how to make stuff fair, the heart of the question of this workshop.
First, if we included race in, a resume sorting model, we’d probably see negative impact because of historical racism. Even if we removed race but included other attributes correlated with race (say zip code) this effect would remain. And it’s hard to know exactly when we’ve removed the relevant attributes, but one thing these guys did was define that precisely.
Second, say now you have some idea of the categories that are given unfair treatment, what can you do? One thing suggested by Sorelle et al is to first rank people in each category – to assign each person a percentile in their given category – and then to use the “forgetful function” and only consider that percentile. So, if we decided at a math department that we want 40% women graduate students, to achieve this goal with this method we’d independently rank the men and women, and we’d offer enough spots to top women to get our quota and separately we’d offer enough spots to top men to get our quota. Note that, although it comes from a pretty fancy setting, this is essentially affirmative action. That’s not, in my opinion, an argument against it. It’s in fact yet another argument for it: if we know women are systemically undervalued, we have to fight against it somehow, and this seems like the best and simplest approach.
Ed Felten and Josh Kroll
After lunch Ed Felton and Josh Kroll jointly described their work on making algorithms accountable. Basically they suggested a trustworthy and encrypted system of paper trails that would support a given algorithm (doesn’t really matter which) and create verifiable proofs that the algorithm was used faithfully and fairly in a given situation. Of course, we’d really only consider an algorithm to be used “fairly” if the algorithm itself is fair, but putting that aside, this addressed the question of whether the same algorithm was used for everyone, and things like that. In lawyer speak, this is called “procedural fairness.”
So for example, if we thought we could, we might want to turn the algorithm for punishment for drug use through this system, and we might find that the rules are applied differently to different people. This algorithm would catch that kind of problem, at least ideally.
David Robinson and Harlan Yu
Next up we talked to David Robinson and Harlan Yu about their work in Washington D.C. with policy makers and civil rights groups around machine learning and fairness. These two have been active with civil rights group and were an important part of both the Podesta Report, which I blogged about here, and also in drafting the Civil Rights Principles of Big Data.
The question of what policy makers understand and how to communicate with them came up several times in this discussion. We decided that, to combat cherry-picked examples we see in Congressional Subcommittee meetings, we need to have cherry-picked examples of our own to illustrate what can go wrong. That sounds bad, but put it another way: people respond to stories, especially to stories with innocent victims that have been wronged. So we are on the look-out.
Closing panel with Rayid Ghani and Foster Provost
I was on the closing panel with Rayid Ghani and Foster Provost, and we each had a few minutes to speak and then there were lots of questions and fun arguments. To be honest, since I was so in the moment during this panel, and also because I was jonesing for a beer, I can’t remember everything that happened.
As I remember, Foster talked about an algorithm he had created that does its best to “explain” the decisions of a complicated black box algorithm. So in real life our algorithms are really huge and messy and uninterpretable, but this algorithm does its part to add interpretability to the outcomes of that huge black box. The example he gave was to understand why a given person’s Facebook “likes” made a black box algorithm predict they were gay: by displaying, in order of importance, which likes added the most predictive power to the algorithm.
[Aside, can anyone explain to me what happens when such an algorithm comes across a person with very few likes? I’ve never understood this very well. I don’t know about you, but I have never “liked” anything on Facebook except my friends’ posts.]
Rayid talked about his work trying to develop a system for teachers to understand which students were at risk of dropping out, and for that system to be fair, and he discussed the extent to which that system could or should be transparent.
Oh yeah, and that reminds me that, after describing my book, we had a pretty great argument about whether credit scoring models should be open source, and what that would mean, and what feedback loops that would engender, and who would benefit.
Altogether a great day, and a fantastic discussion. Thanks again to Solon and Moritz for their work in organizing it.
FATML and next Saturday’s Eric Garner protest
At the end of this week I’ll be heading up to Montreal to attend and participate in a one-day workshop called Fairness, Accountability, and Transparency in Machine Learning (FATML), as part of a larger machine learning conference called NIPS. It’s being organized by Solon Barocas and Moritz Hardt, who kindly put me on the closing panel of the day with Rayid Ghani, who among other things runs the Data Science for Social Good Summer Fellowship out of the University of Chicago, and Foster Provost, an NYU professor of Computer Science and the Stern School of Business.
On the panel, we will be discussing examples of data driven projects and decisions where fairness, accountability, and transparency came into play, or should have. I’ve got lots!
When I get back from Montreal, late on Saturday morning, I’m hoping to have the chance to make my way over to Washington Square Park at 2pm to catch a large Eric Garner protest. It’s actually a satellite protest from Washington D.C. called for by Rev. Al Sharpton and described as “National March Against Police Violence”. Here’s what I grabbed off twitter:

Inflation for the rich
I’m preparing for my weekly Slate Money podcast – this week, unequal public school funding, Taylor Swift versus Spotify, and the economics of weed, which will be fun – and I keep coming back to something I mentioned last week on Slate Money when we were talking about the end of the Fed program of quantitative easing (QE).
First, consider what QE comprised:
- QE1 (2008 – 2010): $1.65 trillion dollars invested in bonds and agency mortgage-back securities,
- QE2 (2010 – 2011): another $600 billion, cumulative $2.25 trillion, and
- QE3 (2012 – present): $85 billion per month, for a total of about $3.7 trillion overall.
Just to understand that total, compare it to the GDP of the U.S. in 2013, at 16.8 trillion. Or the federal tax spending in 2012, which was $3.6 trillion (versus $2.5 trillion in revenue!).
Anyhoo, the point is, we really don’t know exactly what happened because of all this money, because we can’t go back in time and do without the QE’s. We can only guess, and of course mention a few things that didn’t happen. For example, the people against it were convinced it would drive inflation up to crazy levels, which it hasn’t, although of course individual items and goods have gone up of course:
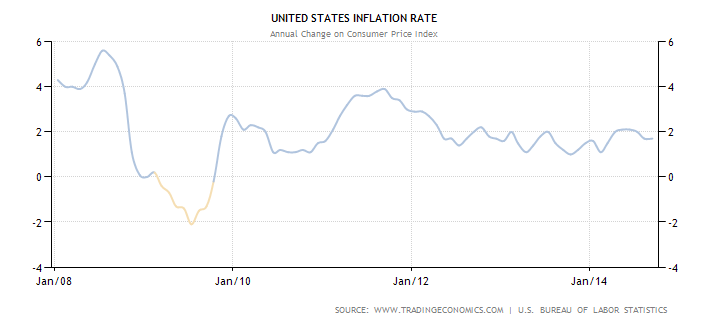
Well but remember, the inflation rate is calculated in some weird way that economists have decided on, and we don’t really understand or trust it, right? Actually, there are a bunch of ways to measure inflation, including this one from M.I.T., and most of them kinda agree that stuff isn’t crazy right now.
So did QE1, 2, and 3 have no inflationary effect at all? Were the haters wrong?
My argument is that it indeed caused inflation, but only for the rich, where by rich I mean investor class. The stock market is at an all time high, and rich people are way richer, and that doesn’t matter for any inflation calculation because the median income is flat, but it certainly matters for individuals who suddenly have a lot more money in their portfolios. They can compete for New York apartments and stuff.
As it turns out, there’s someone who agrees with me! You might recognize his name: billionaire and Argentinian public enemy #1 Paul Singer. According to Matt O’Brien of the Washington Post, Paul Singer is whining in his investor letter (excerpt here) about how expensive the Hamptons have gotten, as well as high-end art.
It’s “hyperinflation for the rich” and we are not feeling very bad for them. In fact it has made matters worse, when the very rich have even less in common with the average person. And just in case you’re thinking, oh well, all those Steve Jobs types deserve their hyper-inflated success, keep in mind that more and more of the people we’re talking about come from inherited wealth.
Tailored political ads threaten democracy
Not sure if you saw this recent New York Times article on the new data-driven political ad machines. Consider for example, the 2013 Virginia Governor campaign won by Terry McAuliffe:
…the McAuliffe campaign invested heavily in both the data and the creative sides to ensure it could target key voters with specialized messages. Over the course of the campaign, he said, it reached out to 18 to 20 targeted voter groups, with nearly 4,000 Facebook ads, more than 300 banner display ads, and roughly three dozen different pre-roll ads — the ads seen before a video plays — on television and online.
Now I want you to close your eyes and imagine what kind of numbers we will see for the current races, not to mention the upcoming presidential election.
What’s crazy to me about the Times article is that it never questions the implications of this movement. The biggest problem, it seems, is that the analytics have surpassed the creative work of making ads: there are too many segments of populations to tailor the political message to, and not enough marketers to massage those particular messages for each particular segment. I’m guessing that there will be more money and more marketers in the presidential campaign, though.
Translation: politicians can and will send different messages to individuals on Facebook, depending on what they think we want to hear. Not that politicians follow through with all their promises now – they don’t, of course – but imagine what they will say when they can make a different promise to each group. We will all be voting for slightly different versions of a given story. We won’t even know when the politician is being true to their word – which word?
This isn’t the first manifestation of different messages to different groups, of course. Romney’s famous “47%” speech was a famous example of tailored messaging to super rich donors. But on the other hand, it was secretly recorded by a bartender working the event. There will be no such bartenders around when people read their emails and see ads on Facebook.
I’m not the only person worried about this. For example, ProPublica studied this in Obama’s last campaign (see this description). But given the scale of the big data political ad operations now in place, there’s no way they – or anyone, really – can keep track of everything going on.
There are lots of ways that “big data” is threatening democracy. Most of the time, it’s by removing open discussions of how we make decisions and giving them to anonymous and inaccessible quants; think evidence-based sentencing or value-added modeling for teachers. But this political campaign ads is a more direct attack on the concept of a well-informed public choosing their leader.
The war against taxes (and the unmarried)
The American Enterprise Institute, conservative think-tank, is releasing a report today. It’s called For richer, for poorer: How family structures economic success in America, and there is also an event in DC today from 9:30am til 12:15pm that will be livestreamed. The report takes a look at statistics for various races and income levels at how marriage is associated with increased hours works and income, for men especially.
It uses a technique called the “fixed-effects model,” and since I’d never studied that I took a look at it on the wikipedia page, and in this worked-out example on Josh Blumenstock’s webpage of massage prices in various cities, and in this example, on Richard William’s webpage, where it’s also a logit model, for girls in and out of poverty.
The critical thing to know about fixed effects models is that we need more than one snapshot of an object of interest – in this case a person who is or isn’t married – in order to use that person as a control against themselves. So in 1990 Person A is 18 and unmarried, but in 2000 he is 28 and married, and makes way more money. Similarly, in 1990 Person B is 18 and unmarried, but in 2000 he is 28 and still unmarried, and makes more money but not quite as much more money as Person A.
The AEI report cannot claim causality – and even notes as much on page 8 of their report – so instead they talk about a bunch of “suggested causal relationships” between marriage and income. But really what they are seeing is that, as men get more hours at work, they also tend to get married. Not sure why the married thing would cause the hours, though. As women get married, they tend to work fewer hours. I’m guessing this is because pregnancy causes both.
The AEI report concludes, rightly, that people who get married, and come from homes where there were married parents, make more money. But that doesn’t mean we can “prescribe” marriage to a population and expect to see that effect. Causality is a bitch.
On the other hand, that’s not what the AEI says we should do. Instead, the AEI is recommending (what else?) tax breaks to encourage people to get married. Most bizarre of their suggestions, at least to me, is to expand tax benefits for single, childless adults to “increase their marriageability.” What? Isn’t that also an incentive to stay single and childless?
What I’m worried about is that this report will be cleverly marketed, using the phrase “fixed effects,” to make it seem like they have indeed proven “mathematically” that individuals, yet again, are to be blamed for the structural failure of our nation’s work problems, and if they would only get married already we’d all be ok and have great jobs. All problems will be solved by tax breaks.



