Archive
The fight for 15
Whenever I hear an argument about the possibility of raising the minimum wage to $15 per hour, it sounds like this. Person A, who is for it, makes the case that it’s too difficult to live on minimum wage earnings, and it doesn’t make sense for someone working full time to struggle so much to feed their kids. Person B, who’s against it, says that 15 is too high, that too many employers will be unwilling to pay for unskilled workers at that rate, and they will replace such people with machines instead of doing so. Essentially, they argue the bad will outweigh the good.
Full disclosure: I am often Person A. I once figured out that if you take someone’s hourly wage in dollars, and you multiply by 2, then you get their yearly wages in thousands of dollars. That means an income of $100K per year is $50 per hour. That means an income of the current New York minimum wage, $8.75 per hour, is a measly $17.5K per year, which would be absolutely crazy to try to live on, according to my reckoning. In other words, I think about what I could theoretically live on, if I had a minimum wage job, and I have extreme sympathy for people who try to.
Let’s get back to Person B’s argument. It’s weird because it sounds like Person B is arguing for the sake of the poor, but they’re ignoring the vital question of what is a living wage. Let me give you an analogy.
You have a sick population, and they all need 3 pills per day to stay well. The pills are expensive, though, and so the people in charge of pill distribution give most people 2 pills per day. They argue that, if they gave out 3 pills per day to everyone, some people would have no pills. For the sake of those theoretical people, then, they give out only 2, and everyone remains sick.
In other words, for the sake of holding on to crappy jobs that pay below living wages, and where the employees need food stamps to survive, we don’t raise the bar so they can actually sustain someone in a basic way. It’s almost like we’re desperate to hold on to them because otherwise our unemployment rate would be higher.
I say, figure out what a living wage is, and raise the minimum wage to that level. I actually don’t know what the magic number should be, exactly. Is 15 big enough? Maybe it is, in some places, but maybe in others it’s actually smaller. It doesn’t have to be the same throughout the country. But for as long as we live in a country where the model is that a job is supposed to support you, we should make sure it actually does.
The Chef Shortage, Explained
This is a guest post by Sam Kanson-Benanav, a chef who has managed restaurants in Minnesota, Wisconsin, and New York City. He spent two years in the studying global resource marketplaces in the Amazon rainforest, and his favorite food is a french omelet.
Despite my desperate attempts at a career change, I’ve become fairly inured to the fact I work in one of the most job secure industries in America. And I’m not a tenured professor.
I am a professional restaurant person – cook, manager, server, and bartender (on nights when a bartender doesn’t show up). As a recent Washington Post article highlights: it has become increasingly more difficult for kitchens to staff their teams with proper talent. We could ponder a litany of reasons why talented cooks are not flocking to the kitchens, but if you prefer to stop reading now, just reference Mathbabe’s entirely accurate post on labor shortages.
Or, we could just pay cooks more. As it turns out, money is a very effective motivator, but restaurants employ two cannibalizing labor models based on fundamentally contrasting motivators: tipping and wages. I’ll take these on separately.
Tipping servers suppress wages for the kitchen
We already know tipping is a bad system, which bears less correlation to the actual quality of service you receive than to the color or gender of your server. It’s an external rewards based system akin to paying your employees a negligible wage with a constant cash bonus, a historically awful way to run a business.
In other words, restaurant owners are able to pass off the cost of labor for employing servers onto their consumers. That means they factor into their menu prices only the cost of labor for the kitchen, which remains considerable in the labor-intensive low margin restaurant world. Thankfully, we are all alcoholics and willing to pay 400% markups on our beer and only a 30% markup on our burgers. Nevertheless, the math here rarely works in a cook’s favor.
For a restaurant to remain a viable business, a cook (and dishwasher’s) hourly wage must be low, even as bartenders and servers walk away with considerable more cash.
In the event that a restaurant, under this conventional model, would like to raise its prices and better compensate its cooks, it cannot do so without also raising wages for its servers. Every dollar increase in the price of line item on your receipt increases a consumers cost by $1.20 , the server happily pocketing the difference.
Unfair? Yes. Inefficient? Certainly. Is change possible? Probably not.
Let’s assume change is possible
Some restaurants are doing away with this trend, in a worthy campaign to better price the cost of your meal, and compensate cooks more for their work. These restaurants charge a 20% administration fee, which becomes part of their combined revenue—the total pool of cash from which they can pay all their employees at set hourly rates.
That’s different then an automatic service fee you might find at the end of your bill at a higher end restaurant or when dining with a large group. It’s a pre tax charge that repackages the cost of a meal by charging a combined 30% tax on the consumer (8% sales tax on 20% service tax) allowing business owners to allocate funds for labor at their discretion rather than obligate them to give it all to service staff.
Under this model cooks now may make a stunning $15-18 an hour, up from $12-$13, and servers $20-30, which is yes, down from their previous wages. That’s wealth redistribution in the restaurant world! For unscrupulous business owners, it could also incentive further wealth suppression by minimizing the amount a 20% administration fee that is utilized for labor, as busier nights no longer translate into higher tips for the service staff.
I am a progressive minded individual who recognizes the virtue of (sorry server, but let’s face it) fairer wages. Nevertheless, I’m concerned the precedents we’ve set for ourselves will make unilateral redistribution a lofty task.
There is not much incentive for an experienced server to take a considerable pay cut. The outcome is likelier to blur the lines between who is a server and who is a cook, or, a dilution in the level of service generally.
Wage Growth
Indeed wages are rising in the food industry, but at a paltry average of $12.48 an hour, there’s considerable room for growth before cooking becomes a viable career choice for the creative minded and educated talent the industry thirsts for. Celebrity chefs may glamorize the industry, but their presence in the marketplace is more akin to celebrity than chef, and their salaries have little bearing on real wage growth of labor force.
Unlike most other industries, a cook’s best chance and long term financial security is to work their way into ownership. Cooking is not an ideal position to age into: the physicality of the work and hours only become more grueling, and your wages will not increase substantially with time. This all to say – if the restaurant industry wants more cooks, it needs to be willing to pay a higher price upfront for them. This is not just a New York problem complicated by sky high rents. It’s as real in Wisconsin as it is Manhattan.
Ultimately paying cooks more is a question of reconciling two contrasting payment models. That’s a question of redistribution.
But “whoa Sam – you are a not an economist, this is purely speculative!” you say?
Possibly, and so far at least a couple of restaurants have been able to maintain normal operations under these alternative models, but their actions alone are unlikely to fill the labor shortage we see. Whether we are ultimately willing to pay servers less or pay considerably more for our meals remains to be seen, but, for what its worth, I’m currently looking for a serving job and I can tell you a few places I’m not applying to.
Guest post: Open-Source Loan-Level Analysis of Fannie and Freddie
This is a guest post by Todd Schneider. You can read the full post with additional analysis on Todd’s personal site.
[M]ortgages were acknowledged to be the most mathematically complex securities in the marketplace. The complexity arose entirely out of the option the homeowner has to prepay his loan; it was poetic that the single financial complexity contributed to the marketplace by the common man was the Gordian knot giving the best brains on Wall Street a run for their money. Ranieri’s instincts that had led him to build an enormous research department had been right: Mortgages were about math.
The money was made, therefore, with ever more refined tools of analysis.
—Michael Lewis, Liar’s Poker (1989)
Fannie Mae and Freddie Mac began reporting loan-level credit performance data in 2013 at the direction of their regulator, the Federal Housing Finance Agency. The stated purpose of releasing the data was to “increase transparency, which helps investors build more accurate credit performance models in support of potential risk-sharing initiatives.”
The GSEs went through a nearly $200 billion government bailout during the financial crisis, motivated in large part by losses on loans that they guaranteed, so I figured there must be something interesting in the loan-level data. I decided to dig in with some geographic analysis, an attempt to identify the loan-level characteristics most predictive of default rates, and more. The code for processing and analyzing the data is all available on GitHub.
The “medium data” revolution
In the not-so-distant past, an analysis of loan-level mortgage data would have cost a lot of money. Between licensing data and paying for expensive computers to analyze it, you could have easily incurred costs north of a million dollars per year. Today, in addition to Fannie and Freddie making their data freely available, we’re in the midst of what I might call the “medium data” revolution: personal computers are so powerful that my MacBook Air is capable of analyzing the entire 215 GB of data, representing some 38 million loans, 1.6 billion observations, and over $7.1 trillion of origination volume. Furthermore, I did everything with free, open-source software.
What can we learn from the loan-level data?
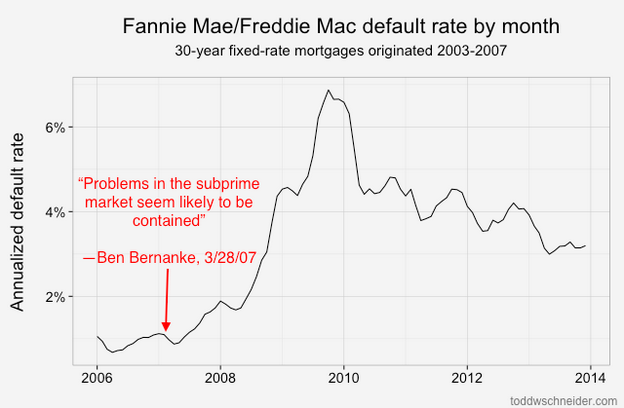
Loans originated from 2005-2008 performed dramatically worse than loans that came before them! That should be an extraordinarily unsurprising statement to anyone who was even slightly aware of the U.S. mortgage crisis that began in 2007:
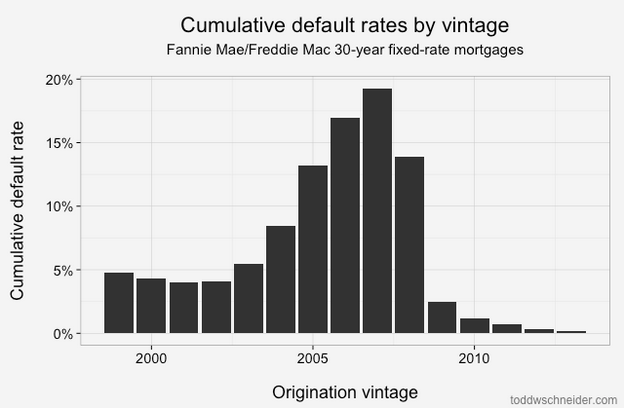
About 4% of loans originated from 1999 to 2003 became seriously delinquent at some point in their lives. The 2004 vintage showed some performance deterioration, and then the vintages from 2005 through 2008 show significantly worse performance: more than 15% of all loans originated in those years became distressed.
From 2009 through present, the performance has been much better, with fewer than 2% of loans defaulting. Of course part of that is that it takes time for a loan to default, so the most recent vintages will tend to have lower cumulative default rates while their loans are still young. But there has also been a dramatic shift in lending standards so that the loans made since 2009 have been much higher credit quality: the average FICO score used to be 720, but since 2009 it has been more like 765. Furthermore, if we look 2 standard deviations from the mean, we see that the low end of the FICO spectrum used to reach down to about 600, but since 2009 there have been very few loans with FICO less than 680:
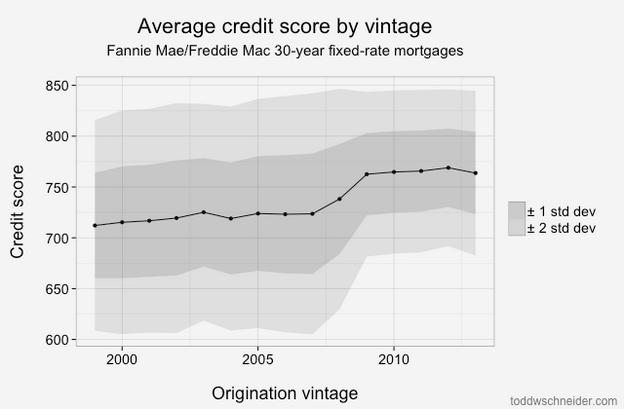
Tighter agency standards, coupled with a complete shutdown in the non-agency mortgage market, including both subprime and Alt-A lending, mean that there is very little credit available to borrowers with low credit scores (a far more difficult question is whether this is a good or bad thing!).
Geographic performance
Default rates increased everywhere during the bubble years, but some states fared far worse than others. I took every loan originated between 2005 and 2007, broadly considered to be the height of reckless mortgage lending, bucketed loans by state, and calculated the cumulative default rate of loans in each state:
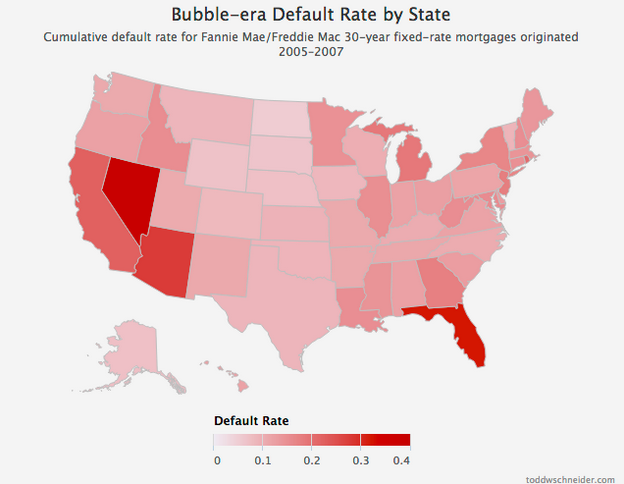
4 states in particular jump out as the worst performers: California, Florida, Arizona, and Nevada. Just about every state experienced significantly higher than normal default rates during the mortgage crisis, but these 4 states, often labeled the “sand states”, experienced the worst of it.
Read more
If you’re interested in more technical discussion, including an attempt to identify which loan-level variables are most correlated to default rates (the number one being the home price adjusted loan to value ratio), read the full post on toddwschneider.com, and be sure to check out the project on GitHub if you’d like to do your own data analysis.
The market for your personal data is maturing
As everyone knows, nobody reads their user agreements when they sign up for apps or services. Even if they did, it wouldn’t matter, because most of them stipulate that they can change at any moment. That moment has come.
You might not be concerned, but I’d like to point out that there’s a reason you’re not. Namely, you haven’t actually seen what this enormous loss of privacy translates into yet.
You see, there’s also a built in lag where we’ve given up our data, and are happily using the corresponding services, but we haven’t yet seen evidence that our data was actually worth something. The lag represents the time it takes for the market in personal data to mature. It also represents the patience that Silicon Valley venture capitalists have or do not have between the time of user acquisition and profit. The less patience they have, the sooner they want to exploit the user data.
The latest news (hat tip Gary Marcus) gives us reason to think that V.C. patience is running dry, and the corresponding market in personal data is maturing. Turns out that EBay and PayPal recently changed their user agreements so that, if you’re a user of either of those services, you will receive marketing calls using any phone number you’ve provided them or that they have “have otherwise obtained.” There is no possibility to opt out, except perhaps to abandon the services. Oh, and they might also call you for surveys or debt collections. Oh, and they claim their intention is to “benefit our relationship.”
Presumably this means they might have bought your phone number from a data warehouse giant like Acxiom, if you didn’t feel like sharing it. Presumably this also means that they will use your shopping history to target the phone calls to be maximally “tailored” for you.
I’m mentally tacking this new fact on the same board as I already have the Verizon/AOL merger, which is all about AOL targeting people with ads based on Verizon’s GPS data, and the recent broohaha over RadioShack’s attempt to sell its user data at auction in order to pay off creditors. That didn’t go through, but it’s still a sign that the personal data market is ripening, and in particular that such datasets are becoming assets as important as land or warehouses.
Given how much venture capitalists like to brag about their return, I think we have reason to worry about the coming wave of “innovative” uses of our personal data. Telemarketing is the tip of the iceberg.
Sharing insurance costs with the sharing economy
One consequence of the “sharing economy” that hasn’t been widely discussed, at least as far as I’ve seen, is how the externalities are being absorbed. Specifically, insurance costs.
Maybe because it’s an ongoing process, but for both Uber and AirBnB, the companies tell individuals who drive that their primary car insurance should be in use, and they tell individual home- or apartment-dwellers that their renters insurance should apply.
In other words, if something goes wrong, the wishful thinking goes, the private, individual insurance plans should kick in.
When people have tried to verify this, however, they responses have been mixed and mostly negative. The insurance companies obviously don’t want to cover a huge number of people for circumstances they didn’t expect when they offered the coverage.
So, if an Uber driver gets into an accident while ferrying a passenger, it’s not clear whether their primary insurance will cover it. It’s even less clear if the driver is using the Uber app and is on their way to get a passenger. Similarly, if an AirBnB guest falls because of a broken staircase, it’s not clear who is supposed to pay for the damages to the person or the staircase. What if the guest burns down the house?
So far I don’t think it’s been fully decided, but I think one of two things could happen.
In the first scenario, the insurance companies will really refuse to cover such things. To do this they will have to have a squad of investigators who somehow make sure the customer in question was or was not hosting a guest or driving a customer. That would involve suspicion and some amount of harassment, which customers don’t like.
In the second scenario, which I think is more likely given the above, the insurance companies will quietly pay for the damages accrued by Uber and AirBnB usage. They won’t advertise this, and if asked, they will discourage any customer from doing stuff like that, but they also won’t actually refuse to pay the costs, which they will simply transfer to the larger pool of customers. It doesn’t really matter to them at all, in fact, as long as they are not the only insurance company with this problem.
That will mean that the quants who figure out the costs of insurance will see their numbers change over time, depending on how much more the insurance is being called into action. I expect this to happen a lot more for Uber drivers, because if you are an Uber driver 40 hours a week, that means you’re always in your car. So our insurance costs will go up in proportion to how many people become Uber drivers. I expect this to happen somewhat more for AirBnB renters, because the house or apartment is in constant use; if it’s being rented by rowdy partiers, all the more. Our renters insurance will go up in proportion to how many people are AirBnB renters.
That reminds me of a story my dad used to like telling, whereby a friend of his rented out his Cambridge house to a Harvard professor, and when he came back it was totally trashed, including what looked like a bonfire pit in the living room. The professor in question was Timothy Leary.
Anyhoo, my overall conclusion is that the new “sharing economy” businesses really will end up sharing something with the rest of us soon, namely the cost of insurance. We will all be paying more for car insurance and home- or renters-insurance if my guess is accurate. Thanks, guys.
Fingers crossed – book coming out next May
As it turns out, it takes a while to write a book, and then another few months to publish it.
I’m very excited today to tentatively announce that my book, which is tentatively entitled Weapons of Math Destruction: How Big Data Increases Inequality and Threatens Democracy, will be published in May 2016, in time to appear on summer reading lists and well before the election.
Fuck yeah! I’m so excited.
p.s. Fight for 15 is happening now.
Predatory credit score-based insurance fees
I’ve been looking into who uses credit scores – FICO scores or other alternative scores – and I’ve found that the insurance industry is a major user.
Homeowners insurance rates, for example, varies wildly by state depending on what kind of credit score you have, often more than doubling for people with poor credit versus people with excellent credit. This is in spite of the fact that homeowners insurance applies not to the payments of mortgages but rather to the contents of an apartment or home.
Similarly, auto insurance rates vary by credit score, even though someone with a poor credit score isn’t obviously a bad driver. For example, in Maryland, people with bad credit scores can be charged 40% more just for having bad credit scores.
Statistics like this make me wonder, how much of this price discrimination comes from the insurance companies trying to understand and account for actual risk, and how much comes from their understanding that poorer people have fewer options and will simply pay predatory rates?
And just in case you’re a believer in free markets and fair competition, and think such predatory behavior would be whisked away in a competitive market, insurance companies actually target people who don’t shop around and charge them more. In other words, it’s not a free market if not everyone actually has good information.
Tell me if you have more examples like this, I’m a collector!
Review: The New Prophets of Capital
Last night I finished reading Nicole Aschoff’s new book, The New Prophets of Capital, which was published as part of the Jacobin series of books. Here’s a description from their website of their book series:
The Jacobin series features short interrogations of politics, economics, and culture from a socialist perspective, as an avenue to radical political practice. The books offer critical analysis and engagement with the history and ideas of the Left in an accessible format.
And by the way, if you don’t know what Jacobin magazine is, you should take a look. I recently signed up to receive the paper versions of all of their magazines and books, which was my version of a donation to a good and very thoughtful cause.
Aschoff’s book explores the storytelling nature of modern capitalism and neoliberalism, and focuses on the underlying assumptions, as seen through four larger-than-life figures: Sheryl Sandberg, Whole Foods founder John Mackey, Oprah, and Bill (and Melinda) Gates.
She does a good job of explaining, in plain, non-academic English, what’s wrong with these people’s messages. If you’re wondering what exactly bothers you about the Lean In movement, for example, take a look at the chapter on Sandberg, the book is worth it just for that.
The book is short, only 6 chapters. The first chapter gives reasoning for the book, describing how storytelling matters when we think about how culture works, and then the heart of the book follows with a chapter on each person listed above – the “prophets” – with their particular flavor. There’s also a concluding chapter, which is the least convincing, as it was extremely condensed and left too much reasoning unexplained.
The unifying theme throughout the four chapters devoted to the prophets is how these four people manage to be both public critics and private protectors of the current economic system, with an emphasis on protection.
So when Sandberg tells us to lean in, she’s telling us to conform to the way things are, not to threaten it in any way. When Oprah tells us that we have it in ourselves to live fantabulous lives, she’s giving us personal responsibility to be happy and fulfilled, and structural inequality is not acknowledged or recognized. When John Mackey or Bill Gates sees a problem, they set up a “free market solution” to that problem, even though, by definition, poor people don’t have money to pay for what they need.
While none of the book’s material was entirely new to me, it was interesting to see the connections deliberately made between the prevalent high-level business mindset and the individual choices we make for ourselves based on how we imagine the world works. If I really believed the Sandberg line, I’d still be working at a hedge fund, doing my best to please my colleagues and ignore my kids. If I had bought into Oprah’s context-free attitude, I’d blame people for their poverty and think it amounts to bad decision making.
The book isn’t entirely consistent. It maintains both that Bill Gates believes entirely in a free market and that he undemocratically influences education reform in this country with his money. Maybe those are consistent claims but it’s not obvious to me (although I agree with the undemocratic nature of his mega-philanthropy).
It’s a good book. I’d like a bunch of people to read it so we can have a discussion group. I also get the impression that Aschoff could write one of these a year, and I plan to follow her work.
A critique of a review of a book by Bruce Schneier
I haven’t yet read Bruce Schneier’s new book, Data and Goliath: The Hidden Battles To Collect Your Data and Control Your World. I plan to in the coming days, while I’m traveling with my kids for spring break.
Even so, I already feel capable of critiquing this review of his book (hat tip Jordan Ellenberg), written by Columbia Business School Professor and Investment Banker Jonathan Knee. You see, I’m writing a book myself on big data, so I feel like I understand many of the issues intimately.
The review starts out flattering, but then it hits this turn:
When it comes to his specific policy recommendations, however, Mr. Schneier becomes significantly less compelling. And the underlying philosophy that emerges — once he has dispensed with all pretense of an evenhanded presentation of the issues — seems actually subversive of the very democratic principles that he claims animates his mission.
That’s a pretty hefty charge. Let’s take a look into Knee’s evidence that Schneier wants to subvert democratic principles.
NSA
First, he complains that Schneier wants the government to stop collecting and mining massive amounts of data in its search for terrorists. Knee thinks this is dumb because it would be great to have lots of data on the “bad guys” once we catch them.
Any time someone uses the phrase “bad guys,” it makes me wince.
But putting that aside, Knee is either ignorant of or is completely ignoring what mass surveillance and data dredging actually creates: the false positives, the time and money and attention, not to mention the potential for misuse and hacking. Knee’s opinion on that is simply that we normal citizens just don’t know enough to have an opinion on whether it works, including Schneier, and in spite of Schneier knowing Snowden pretty well.
It’s just like waterboarding – Knee says – we can’t be sure it isn’t a great fucking idea.
Wait, before we move on, who is more pro-democracy, the guy who wants to stop totalitarian social control methods, or the guy who wants to leave it to the opaque authorities?
Corporate Data Collection
Here’s where Knee really gets lost in Schneier’s logic, because – get this – Schneier wants corporate collection and sale of consumer data to stop. The nerve. As Knee says:
Mr. Schneier promotes no less than a fundamental reshaping of the media and technology landscape. Companies with access to large amounts of personal data would be “automatically classified as fiduciaries” and subject to “special legal restrictions and protections.”
That these limits would render illegal most current business models — under which consumers exchange enhanced access by advertisers for free services – does not seem to bother Mr. Schneier”
I can’t help but think that Knee cannot understand any argument that would threaten the business world as he knows it. After all, he is a business professor and an investment banker. Things seem pretty well worked out when you live in such an environment.
By Knee’s logic, even if the current business model is subverting democracy – which I also argue in my book – we shouldn’t tamper with it because it’s a business model.
The way Knee paints Schneier as anti-democratic is by using the classic fallacy in big data which I wrote about here:
Although professing to be primarily preoccupied with respect of individual autonomy, the fact that Americans as a group apparently don’t feel the same way as he does about privacy appears to have little impact on the author’s radical regulatory agenda. He actually blames “the media” for the failure of his positions to attract more popular support.
Quick summary: Americans as a group do not feel this way because they do not understand what they are trading when they trade their privacy. Commercial and governmental interests, meanwhile, are all united in convincing Americans not to think too hard about it. There are very few people devoting themselves to alerting people to the dark side of big data, and Schneier is one of them. It is a patriotic act.
Also, yes Professor Knee, “the media” generally speaking writes down whatever a marketer in the big data world says is true. There are wonderful exceptions, of course.
So, here’s a question for Knee. What if you found out about a threat on the citizenry, and wanted to put a stop to it? You might write a book and explain the threat; the fact that not everyone already agrees with you wouldn’t make your book anti-democratic, would it?
MLK
The rest of the review basically boils down to, “you don’t understand the teachings of the Reverend Dr. Martin Luther King Junior like I do.”
Do you know about Godwin’s law, which says that as soon as someone invokes the Nazis in an argument about anything, they’ve lost the argument?
I feel like we need another, similar rule, which says, if you’re invoking MLK and claiming the other person is misinterpreting him while you have him nailed, then you’ve lost the argument.
Illegitimate international debt
How do you declare international debt illegitimate?
When is debt so odious that the taxpayers of a government have no obligation to pay it back?
This is a huge, important question. It’s a question currently plaguing Argentina and Greece, for example. Individuals in both countries have explained to me that the debt was taken on by previous regimes that stuffed their own pockets, and then amplified by terrible deals with predatory investment banks. The average individual citizen feels very little personal responsibility to pay that debt back, consisting as it does of interest payments to the banking system.
The movie we showed at Alt Banking last week, Who’s Saving Whom, also made the case that Spain could declare its taxpayer debt illegitimate, considering that the banking system got bailed out on the taxpayer dime.
Well, now the Center for Global Development has come up with an idea in this direction, called Preemptive Contract Sanctions (hat tip Philip Sterne). They’re aiming it at Syrian debt for Russian arms, and claiming that this debt is odious and illegitimate from the outset. The idea is, if the international community can get together and agree that such debt is odious, and that they will not lift a finger in the future to help the borrower get their money back, then it would be harder to borrow the money, and maybe even impossible, and it wouldn’t saddle future citizens of Syria with that burden.
It’s an interesting idea – see the video here:
It wouldn’t necessarily help solve the current debt crises of Argentina and Greece, which built up over many years, but I like the idea of all debt living on a spectrum of morality. Too often when contracts enter the financial system, they are utterly sanitized and legitimized in the eyes of the international community.
Affordable Housing Needs a Reset #OWS
I’m super proud of the latest Huffington Post piece that Alt Banking put out entitled Affordable Housing Needs a Reset. Here’s an excerpt:
We’ve been hearing a lot lately from New York Mayor de Blasio on his affordable housing plan. He says he will “build or preserve” 200,000 housing units, but the plan would only build 8,000 units a year. Unless it is radically changed, the mayor’s plan will squander public assets, enrich real estate developers, but do very little for the record number of people living in the shelter system or at risk of landing there.
Let’s first talk about how the term “affordable housing” is defined and whether it jives with our concept of the kinds of places New Yorkers can actually afford to live in. The mayor’s plan defines an apartment renting for $41,500 a year as affordable because a family of four with $138,435 in income can afford it ― even though that is more than twice the actual New York City median 4-person household income of $63,000. That is, most New Yorkers cannot afford an “affordable apartment” by the mayor’s standards.
The mayor’s plan tracks the pattern New York City has religiously followed for quite some time of trying to “incentivize” private development. The city effectively pays a fortune to private developers to build this kind of stuff. Here is a frightening statistic from the Association for Neighborhood and Housing Development: in 2013, New York City gave private developers a pass on $1.2 billion in taxes in order to stimulate the building of 153,000 units of housing ― just 12,000 of which met the messed-up definition of affordability. Hard to believe we couldn’t have done a lot better by simply collecting those taxes.
Read the rest of the essay here.
Mortgage tax deductions and gentrification
Yesterday we had a tax expert come talk to us at the Alternative Banking group. We mostly focused on the mortgage tax deduction, whereby people don’t have to pay taxes on their mortgage. It’s the single biggest tax deduction in America for individuals.
At first blush, this doesn’t seem all that interesting, even if it’s strange. Whether people are benefitting directly from this, or through their rent being lower because their landlord benefits, it’s a fact of life for Americans. Whoopdedoo.
Generally speaking other countries don’t have a mortgage tax deduction, so we can judge whether it leads to overall more homeownership, which was presumably what it was intended for, and the data seems to suggest the answer there is no.
We can also imagine removing the mortgage tax deduction, and we quickly realize that such a move would seriously impair lots of people’s financial planning, so we’d have to do it very slowly if at all.
But before we imagine removing it, is it even a problem?
Well, yes, actually. Let’s think about it a little bit more, and for the sake of this discussion we will model the tax system very simply as progressive: the more income you collect yearly, the more taxes you pay. Also, there is a $1.1 million (or so) cap on the mortgage tax deduction, so it doesn’t apply to uber wealthy borrowers with huge houses. But for the rest of us it does apply.
OK now let’s think a little harder about what happens in the housing market when the government offers a tax deduction. Namely, the prices go up to compensate. It’s kind of like a rebate: this house is $100K with no deduction, but with a $20K deduction I can charge $120K for it.
But it’s a little more complicated than that, since people’s different income levels correspond to different deductions. So a lower middle class neighborhood’s houses will be inflated by less than an upper middle class neighborhood’s houses.
At first blush, this seems ok too: so richer people’s houses are inflated slightly more. It means it’s slightly harder for them to get in on the home ownership game, but it also means that, come time to sell, their house is worth more. For them, a $400K house is inflated not by 20% but by 35%, or whatever their tax bracket is.
So far so good? Now let’s add one more layer of complexity, namely that, actually, neighborhoods are not statically “upper middle class” or “lower middle class.” As a group neighborhoods, and their associated classes, represent a dynamical system, where certain kinds of neighborhoods expand or contract. Colloquially we refer to this as gentrification or going to hell, depending on which direction it is. Let’s explore the effect of the mortgage tax deduction on how that dynamical system operates.
Imagine a house which is exactly on the border between a middle class neighborhood and an upper-middle class neighborhood. If we imagine that it’s a middle class home, the price of it has only been inflated by a middle-class income tax bracket, so 20% for the sake of argument. But if we instead imagine it is in the upper-middle class neighborhood, it should really be inflated by 35%.
In other words, it’s under-priced from the perspective of the richer neighborhood. They will have an easier time affording it. The overall effect is that it is easier for someone from the richer neighborhood to snatch up that house, thereby extending their neighborhood a bit. Gentrification modeled.
Put it another way, the same house at the same price is more expensive for a poorer person because the mortgage tax deduction doesn’t affect everyone equally.
Another related point: if I’m a home builder, I will want to build homes with a maximal mark-up, a maximal inflation level. That will be for the richest people who haven’t actually exceeded the $1.1 million cap.
Conclusion: the mortgage tax deduction has an overall negative effect, encouraging gentrification, unfair competition, and too many homes for the wealthy. We should phase it out slowly, and also slowly lower the cap. At the very very least we should not let the cap rise, which will mean it effectively goes down over time as inflation does its thing.
If this has been tested or observed with data, please send me references.
What Happens as a Bubble Deflates?
Having written a couple of guest posts about bubbles possibly inflating (college tuition, high end Manhattan condos), I thought it might be interesting to consider what a deflating bubble looks like.
A number of observers point to the oil markets, where the price of crude has fallen by about 30% since June of this year, to a multi-year low today of about $75.50 per barrel. Just last spring, Bloomberg was reporting on how the drilling and exploration business in the US was heavily dependent on the issuance of junk rated debt – over $160 billion worth by some measures – to fund the shale drilling that has been so popular lately. The junk debt had been popular because it was a source of relatively cheap funds, thanks in part to the Federal Reserve’s efforts with Quantitative Easing to drive down bond yields. Oil and shale exploration are expensive and there are quite a few people that believe that certain types of exploration only make economic sense when the price of oil is above a certain level – say $80 a barrel (or perhaps even higher). Now that the price of oil has plummeted, there is a possibility that a whole collection of oil drillings and mines are underwater, so to speak, and no longer profitable.
Funding a bunch of expensive exploration with junk bonds makes things complicated and speculative. For instance, a substantial portion of these junk offerings were purchased by issuers of collateralized loan obligations (CLO) and then rated (up to the AAA level), securitized and distributed to an audience of investors who may or may not have been investing in energy related debt otherwise. CLOs are being issued at a record pace, by the way, and 2014 is on track to be the highest issuance year ever, exceeding the pre-crisis peak in 2007 of $93 billion. If the energy exploration companies that issued junk debt are no longer profitable and getting squeezed by the falling price of oil, will that lead to a bunch of companies defaulting and then sending shockwaves through the securitized market, via CLOs? (Note – the CLO market is much smaller than the subprime mortgage backed collateralized debt obligation market got to be before the 2007 implosion and energy companies are only a portion of the total issuance).
One thing that happens when investable asset prices fall, is that a bunch of people think that maybe it means there’s a new buying opportunity – a chance to get a hot asset at a cheap price on the expectation that prices will spring back up again soon. That’s what a bunch of hedge funds did a couple of weeks ago, betting that the sharp fall in oil would turn around. And then it fell another 6 or 7% to today’s levels. If oil prices continue to fall, as some speculate may happen, that would be called “catching a falling knife” and the investors may end up feeling rather burned by their optimism. Once cut by the falling knife, some investors become reluctant to come back a re-test their theory on rising prices, and this can contribute to a negative spiral for the falling asset.
I learned from my father-in-law, who worked at an oil company his whole life until he retired, that the oil business is always complicated. Up and down, supply and demand; they don’t work the way you’d think they would. When oil prices go down, gasoline gets cheaper, so people drive more, which drives prices back up (unless people are driving less and buying fewer cars, as appears to be happening now, perhaps because of those darn millennials and their urbanization and bike riding). Plus, there’s international politics, with Russian, OPEC, the Middle East, China the drive for energy independence, solar power, etc. On the other hand, gasoline and home heating oil and such are getting cheaper, which is a nice bonus for consumers, particularly in more car dependent regions. The economy benefits from the effect of extra money in the hands of consumers as that money gets spent elsewhere (other than on oil executives third or fourth homes, presumably). Oil is complicated.
But oil can and does crash. When it does, it can have a wider adverse impact on local oil-dependent economies, like Texas in the 80’s or perhaps, North Dakota, today. While there are a number of mysterious factors at play in the current fall in oil prices, the knock-on effects are starting to pile up. Oil producers are cutting production, idling rigs and cutting prices to stay competitive. The somewhat worried sounding consensus is that there is “too much oil supply” currently. The speculative portion of the oil market will be hit hardest, i.e. the junk-debt fueled shale companies. At some point, investors in the CLOs (and regular debt) backed by this highly leveraged debt from companies that aren’t profitable anymore, are going to get nervous (yields on such debt are already quite a bit higher) and start selling. In all likelihood, some exploration companies will fail. I wouldn’t describe it as a fear environment yet – in many cases the junk debt from exploration companies doesn’t come due for a few years – but the seeds of worry have been planted on fertile ground. One observer described the current environment as a “negative bubble”, with a herd mentality driving investors away from any optimistic assumptions for the market.
Why should we care? For most consumers, the most likely impact of a continuing deflation in oil prices will, as I mentioned, be cheaper gas and heating costs. When the housing market crashed, the negative impact was mostly felt by average Americans, as wealth was destroyed up and down the block, whereas the oil market seems very different and more removed. Still, it’s fascinating and instructive to watch the dynamics of a (potential) collapse of a bubble – on exploration, shale, oil prices, international politics – and the odds are high for unexpected consequences and global volatility. What will happen to the recent growth in solar and other renewable energies, if the price of the competing product gets much cheaper? What about the local politics of fracking? What kind of exposure do banks have to the oil markets and will it trigger any regulatory issues? What will happen to the international politicians, who like moving chess pieces around the Middle East map if oil-producing countries lose their political clout? Also, it’s odd that the Fed’s efforts to fight deflation have contributed, in part, to a price collapse of a crucial commodity, via QE-fueled easy money helping to push oil producers to dig up too much oil? How will the Fed react to this challenge?
I don’t know the answer, nor do I expect anyone else does either. But oil and energy are hugely important issues to most Americans (and the people of other countries, too, obviously) and to the national and global economies – not as big as housing, but pretty close. What happens in the next few months may affect many of us and it bears watching how our regulators, politicians, mega-companies and generals respond to the emerging (potential) collapse.
Time to Short 57th Street?
As a New Yorker, it’s hard to travel through the city these days without coming across construction sheds, scaffolding and giant cranes. New building construction is everywhere and much of it is for residential apartments. Midtown Manhattan and 57th Street in particular, sometimes referred to as “Billionaire’s Row”, seems to be overrun with giant new condo buildings going up (though the construction is hardly limited to that neighborhood). It’s not just my imagination. An astonishing number of super high end apartments are being built – one recent report estimated that 7,000 new apartments will be coming on line in the next two years. Sometimes, this can cause an average New Yorker like myself to get annoyed by the inconvenience of the construction sites, the altering of the city skyline, the rapid and radical changes to neighborhoods or the loss of an old, favorite haunt. It can some cause a person to shake their fists at the sky and ask how much longer can this madness go on? Just how many rich people in the are there in the world who don’t already have giant apartments in the city?
There are some people who are worried that the construction and development of some many high-end homes in New York might be entering a danger zone. There are signs that the pace of expensive condos may be slowing. London, a city similarly blessed with an influx of expensive apartments and the bankers and oligarchs who love them, has recently seen a sharp decline in high end home sales. The fall in the prices of the Ruble and oil may start to make some overseas buyers more reticent. The supply of high end homes may, perhaps, be exceeding demand, for now at least.
One New York City developer recently shared his concern and negative outlook for what he describes as a bubble in high end Manhattan real estate – he said he wished he could short 57th street! In other words, this developer doesn’t see a bright future for high end New York City condos and he thinks there would be more money to make by betting on the prices of these condos falling. Readers may recall that in 2007 a number of hedge fund managers, such as John Paulson and Magnetar, and investment banks, such as Deutsche Bank and Goldman Sachs, made boatloads of money by using Credit Default Swaps to bet that subprime mortgage backed securities would fall in value.
Is this possible? Is there a market for betting on individual apartment buildings or neighborhoods falling in value? Sort of? Yale Professor Robert Shiller helped create something known as the Case Shiller Home Price Futures Exchange, which trades on the CME. This exchange does let a person who might be inclined to make bets on the future price movements of Case Shiller’s national home price index, including either shorting (betting on a decline in price of homes underlying the index) or going long (betting on an increase in the prices of homes underlying the index). However, it is still a relatively new concept and is relatively thinly traded. In any event, the index is based on the home prices of the whole country (or at least the top ten regions of the country), so it really isn’t narrowly focused enough to get at the issue of over-priced billionaire condos in New York.
Alternatively, if you were a billionaire thinking about buying a $20 million pied-à-terre overlooking Central Park but worried that prices might go down, you could just decide not to buy right now. Unfortunately, this might not be very satisfying until condo prices did eventually fall and you got to tell everyone “I told you so.”
Why would someone want to be able to short this segment of the market? Is it just because they’re jealous of the rich and hope that they lose some (paper) wealth? In the stock market, short sellers sometimes get attacked for being bad for the market or harming otherwise nice companies. Defenders of short sellers (and there have been many similar defenses in recent years), however, argue that shorting stocks is good for market liquidity and price discovery. Short sellers expose fraud and correct mis-pricing in the market. Likewise, the hedge fund guys and bankers who shorted the subprime market argued in books like Michael Lewis’s The Big Short that they did provide a service (as well as make themselves wealthy) by helping to expose the shoddy mortgage underwriting practices and national housing bubble that dominated the early 2000s.
If there really is a bubble in multi-million dollar apartments in New York City, would New Yorkers benefit from having the bubble deflated or fraudulent apartment buyers or sellers exposed? Potentially. If this market is a bubble, it may have the effect of driving up land values throughout the neighborhood, or cause landlords to warehouse empty buildings in anticipation of future paydays. Pricking the bubble might prevent the speculative construction of buildings that don’t, subsequently, find enough apartment buyers and then end up in bankruptcy, sitting vacant and neglected for many years. If there really is a bubble, shouldn’t the speculative excesses of the billionaire condo market be exposed to price discovery and negative bets the way the subprime market was back in 2007?
Unfortunately, no such market really exists at this time. Until Professor Shiller decides to narrow his index and futures exchange down to just Manhattan’s 57th Street, or some clever trader comes up with a new way to trade property values, we may be stuck having to wave our fists angrily at the skyscrapers blotting out the sun. But it is interesting to think about.
Alt Banking in Huffington Post #OWS
Great news! The Alt Banking group had a piece published today in the Huffington Post entitled With Economic Justice For All, about our hopes for the next Attorney General.
For the sake of the essay, we coined the term “marble columns” to mean the opposite of “broken windows.” Instead of getting arrested for nothing, you never get arrested, as long as you work at a company with marble columns. For more, take a look at the whole piece!
Also, my good friend and bandmate Tom Adams (our band, the Tomtown Ramblers, is named after him) will be covering for me on mathbabe for the next few days while I’m away in Haiti. Please make him feel welcome!
Bitcoin provocations
Yesterday at the Alt Banking meeting we had a special speaker and member, Josh Snodgrass (not his real name), come talk to us about Bitcoin, the alternative “cryptocurrency”. I’ll just throw together some fun and provocative observations that came from the meeting.
- First, Josh demonstrated how quickly you can price alternative currencies, by giving out a few of our Alt Banking “52 Shades of Greed” cards and stipulating that the jacks (I had a jack) were worth 1 “occudollar” but the 2’s (I also had a 2) were worthy 1,000,000,000 occudollars. Then he paid me $1 for my jack, which made me a billionaire. After thinking for a minute, I paid him $5 to get my jack back, which made me a multibillionaire. Come to think of it I don’t think I got that $5 back after the meeting.
- There’s a place you can have lunch in the city that accepts Bitcoin. I think it’s called Pita City.
- The idea behind Bitcoin is that you don’t have to have a trustworthy middleman in order to buy stuff with it. But in fact, the “bitcoin wallet” companies are increasingly playing the role of the trusted middlemen, especially considering it takes on average 10 minutes, but sometimes up to 40 minutes, of computing time to finish a transaction. If you want to leave the lunch place after lunch, you’d better have a middleman that the shop owner trusts or you could be sitting there for a while.
- People compare bitcoin to other alternative currencies like the Ithaca Hours, but there are two very important differences.
- First, Ithaca Hours, and other local currencies, are explicitly intended to promote local businesses: you pay for your bread with them, and the bread company you give money to buys ingredients with them, and they need to buy from someone who accepts them, which is by construction a local business.
- Second, local currencies like the Madison East Side Babysitting Coop’s “popsicle currency” are very low tech, used my middle class people to represent labor, whereas Bitcoin is highly technical and used primarily by technologists and other fancy people.
- There is class divide and a sophistication divide here, in other words.
- Speaking of sophistication, we had an interesting discussion about whether it would ever make sense to have bitcoin banks and – yes – fractional reserve bitcoin banking. On the one hand, since there’s a limit to the number of overall bitcoins, you can’t have everyone pretending they can pay a positive interest rate on all the bitcoin every year, but on the other hand a given individual can always write a contract saying they’d accept 100 bitcoins now and pay back 103 in a year, because it might just be a bet on the dollar value of bitcoins in a year. And in the meantime that person can lend out bitcoins to people, knowing full well they won’t all be spent at once. Altogether that looks a lot like fractional reserve bitcoin banking, which would effectively increase the number of bitcoins in circulation.
- Also, what about derivatives based on bitcoins? Do they already exist?
- Remaining question: will bitcoins ever actually be usable and trustworthy for people to send money to their families across the world below the current cost? And below the cost of whatever disruptions are being formulated in the money business by Paypal and Google and whoever else?
Update: there will be a Bitcoin Hackathon at NYU next weekend (hat tip Chris Wiggins). More info here.
Inflation for the rich
I’m preparing for my weekly Slate Money podcast – this week, unequal public school funding, Taylor Swift versus Spotify, and the economics of weed, which will be fun – and I keep coming back to something I mentioned last week on Slate Money when we were talking about the end of the Fed program of quantitative easing (QE).
First, consider what QE comprised:
- QE1 (2008 – 2010): $1.65 trillion dollars invested in bonds and agency mortgage-back securities,
- QE2 (2010 – 2011): another $600 billion, cumulative $2.25 trillion, and
- QE3 (2012 – present): $85 billion per month, for a total of about $3.7 trillion overall.
Just to understand that total, compare it to the GDP of the U.S. in 2013, at 16.8 trillion. Or the federal tax spending in 2012, which was $3.6 trillion (versus $2.5 trillion in revenue!).
Anyhoo, the point is, we really don’t know exactly what happened because of all this money, because we can’t go back in time and do without the QE’s. We can only guess, and of course mention a few things that didn’t happen. For example, the people against it were convinced it would drive inflation up to crazy levels, which it hasn’t, although of course individual items and goods have gone up of course:
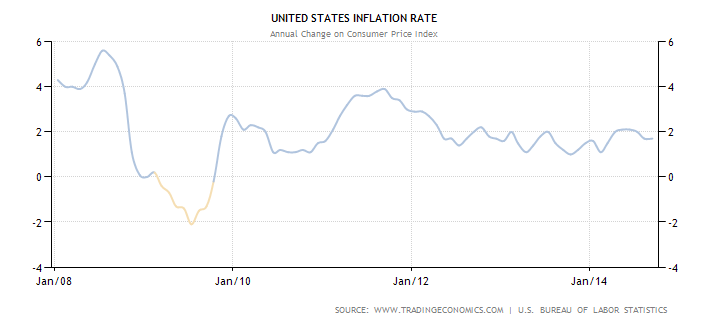
Well but remember, the inflation rate is calculated in some weird way that economists have decided on, and we don’t really understand or trust it, right? Actually, there are a bunch of ways to measure inflation, including this one from M.I.T., and most of them kinda agree that stuff isn’t crazy right now.
So did QE1, 2, and 3 have no inflationary effect at all? Were the haters wrong?
My argument is that it indeed caused inflation, but only for the rich, where by rich I mean investor class. The stock market is at an all time high, and rich people are way richer, and that doesn’t matter for any inflation calculation because the median income is flat, but it certainly matters for individuals who suddenly have a lot more money in their portfolios. They can compete for New York apartments and stuff.
As it turns out, there’s someone who agrees with me! You might recognize his name: billionaire and Argentinian public enemy #1 Paul Singer. According to Matt O’Brien of the Washington Post, Paul Singer is whining in his investor letter (excerpt here) about how expensive the Hamptons have gotten, as well as high-end art.
It’s “hyperinflation for the rich” and we are not feeling very bad for them. In fact it has made matters worse, when the very rich have even less in common with the average person. And just in case you’re thinking, oh well, all those Steve Jobs types deserve their hyper-inflated success, keep in mind that more and more of the people we’re talking about come from inherited wealth.
“Hand To Mouth” and the rationality of the poor
Here’s one thing that you do as a mathematician a lot: change the assumptions and see how wildly the conclusions change. You usually start with lots of assumptions, and then see how things change when they are taken away one by one: what if the ring isn’t commutative? What if it doesn’t have a “1”?
Of course, it’s easy enough to believe that we can no longer prove the same theorems when we don’t start with the same kinds of mathematical set-ups. But this kind of thing can also apply to non-mathematical scenarios as well.
So, for example, I’ve long thought that the “marshmallow” experiment is nearly universally misunderstood: kids wait for the marshmallow for exactly as long as it makes sense to them to wait. If they’ve been brought up in an environment where delayed gratification pays off, and where the rules don’t change in the meantime, and where they trust a complete stranger to tell them the truth, they wait, and otherwise they don’t – why would they? But since the researchers grew up in places where it made sense to go to grad school, and where they respect authority and authority is watching out for them, and where the rules once explained didn’t change, they never think about those assumptions. They just conclude that these kids have no will power.
Similarly, this GoodBooksRadio interview with Linda Tirado is excellent in explaining the rational behavior of poor people:
Tirado just came out with a book called Hand To Mouth: Living in Bootstrap America and was discussing it with Dr. John Cook, who was a fantastic interviewer. You might have come across Tirado’s writing – her essay on poverty that went viral, or the backlash against that essay. She’s clearly a tough cookie, a great writer, and an articulate speaker.
Among the things she explains is why poor people eat McDonalds food (it’s fast, cheap, and filling), why they don’t get much stuff done (their lives are filled with logistics), why they make bad decisions (stress), and, what’s possibly the most important, how much harder work it is to be poor than it is to be rich. She defines someone as “rich” if they don’t lease their furniture.
I’m looking forward to reading her book. As the Financial Times review says, “Hand to Mouth – written with scorching flair – should be read by every person lucky enough to have a disposable income.”
Core Econ: a free economics textbook
Today I want to tell you guys about core-econ.org, a free (although you do have to register) textbook my buddy Suresh Naidu is using this semester to teach out of and is also contributing to, along with a bunch of other economists.

This was obviously not taken in New York.
It’s super cool, and I wish a class like that had been available when I was an undergrad. In fact I took an economics course at UC Berkeley and it was a bad experience – I couldn’t figure out why anyone would think that people behaved according to arbitrary mathematical rules. There was no discussion of whether the assumptions were valid, no data to back it up. I decided that anybody who kept going had to be either religious or willing to say anything for money.
Not much has changed, and that means that Econ 101 is a terrible gateway for the subject, letting in people who are mostly kind of weird. This is a shame because, later on in graduate level economics, there really is no reason to use toy models of society without argument and without data; the sky’s the limit when you get through the bullshit at the beginning. The goal of the Core Econ project is to give students a taste for the good stuff early; the subtitle on the webpage is teaching economics as if the last three decades happened.
What does that mean? Let’s take a look at the first few chapters of the curriculum (the full list is here):
- The capitalist revolution
- Innovation and the transition from stagnation to rapid growth
- Scarcity, work and progress
- Strategy, altruism and cooperation
- Property, contract and power
- The firm and its employees
- The firm and its customers
Once you register, you can download a given chapter in pdf form. So I did that for Chapter 6, The firm and its employees, and here’s a screenshot of the first page:

Still dry but at least real.
The chapter immediately dives into a discussion of Apple and Foxconn. Interesting! Topical! Like, it might actually help you understand the newspaper!! Can you imagine that?
The project is still in beta version, so give it some time to smooth out the rough edges, but I’m pretty excited about it already. It has super high production values and will squarely compete with the standard textbooks and curriculums, which is a good thing, both because it’s good stuff and because it’s free.
The war against taxes (and the unmarried)
The American Enterprise Institute, conservative think-tank, is releasing a report today. It’s called For richer, for poorer: How family structures economic success in America, and there is also an event in DC today from 9:30am til 12:15pm that will be livestreamed. The report takes a look at statistics for various races and income levels at how marriage is associated with increased hours works and income, for men especially.
It uses a technique called the “fixed-effects model,” and since I’d never studied that I took a look at it on the wikipedia page, and in this worked-out example on Josh Blumenstock’s webpage of massage prices in various cities, and in this example, on Richard William’s webpage, where it’s also a logit model, for girls in and out of poverty.
The critical thing to know about fixed effects models is that we need more than one snapshot of an object of interest – in this case a person who is or isn’t married – in order to use that person as a control against themselves. So in 1990 Person A is 18 and unmarried, but in 2000 he is 28 and married, and makes way more money. Similarly, in 1990 Person B is 18 and unmarried, but in 2000 he is 28 and still unmarried, and makes more money but not quite as much more money as Person A.
The AEI report cannot claim causality – and even notes as much on page 8 of their report – so instead they talk about a bunch of “suggested causal relationships” between marriage and income. But really what they are seeing is that, as men get more hours at work, they also tend to get married. Not sure why the married thing would cause the hours, though. As women get married, they tend to work fewer hours. I’m guessing this is because pregnancy causes both.
The AEI report concludes, rightly, that people who get married, and come from homes where there were married parents, make more money. But that doesn’t mean we can “prescribe” marriage to a population and expect to see that effect. Causality is a bitch.
On the other hand, that’s not what the AEI says we should do. Instead, the AEI is recommending (what else?) tax breaks to encourage people to get married. Most bizarre of their suggestions, at least to me, is to expand tax benefits for single, childless adults to “increase their marriageability.” What? Isn’t that also an incentive to stay single and childless?
What I’m worried about is that this report will be cleverly marketed, using the phrase “fixed effects,” to make it seem like they have indeed proven “mathematically” that individuals, yet again, are to be blamed for the structural failure of our nation’s work problems, and if they would only get married already we’d all be ok and have great jobs. All problems will be solved by tax breaks.



