Archive
Looking for big data reading suggestions
I have been told by my editor to take a look at the books already out there on big data to make sure my book hasn’t already been written. For example, today I’m set to read Robert Scheer’s They Know Everything About You: how data-collecting corporations and snooping government agencies are destroying democracy.
This book, like others I’ve already read and written about (Bruce Schneier’s Data and Goliath, Frank Pasquale’s Black Box Society, and Julia Angwin’s Dragnet Nation) are all primarily concerned with individual freedom and privacy, whereas my book is primarily concerned with social justice issues, and each chapter gives an example of how big data is being used a tool against the poor, against minorities, against the mentally ill, or against public school teachers.
Not that my book is entirely different from the above books, but the relationship is something like what I spelled out last week when I discussed the four political camps in the big data world. So far the books I’ve found are focused on the corporate angle or the privacy angle. There may also be books focused on the open data angle, but I’m guessing they have even less in common with my book, which focuses on the ways big data increase inequality and further alienate already alienated populations.
If any of you know of a book I should be looking at, please tell me!
Driving While Black in the Bronx
This is the story of Q, a black man living in the Bronx, who kindly allowed me to interview him about his recent experience. The audio recording of my interview with him is available below as well.
Q was stopped in the Bronx driving a new car, the fourth time that week, by two rookie officers on foot. The officers told Q to “give me your fucking license,” and Q refused to produce his license, objecting to the tone of the officer’s request. When Q asked him why he was stopped, the officer told him that it was because of his tinted back windows, in spite of there being many other cars on the same block, and even next to him, with similarly tinted windows. Q decided to start recording the interaction on his phone after one of the cops used the n-word.
After a while seven cop cars came to the scene, and eventually a more polite policeman asked Q to produce his license, which he did. They brought him in, claiming they had a warrant for him. Q knew he didn’t actually have a warrant, but when he asked, they said it was a warrant for littering. It sounded like an excuse to arrest him because Q was arguing. He recorded them saying, “We should just lock this black guy up.”
They brought him to the precinct and Q asked him for a phone call. He needed to unlock his phone to get the phone number, and when he did, the policeman took his phone and ran out of the room. Q later found out his recordings had been deleted.
After a while he was assigned a legal aid lawyer, to go before a judge. Q asked the legal aid why he was locked up. She said there was no warrant on his record and that he’d been locked up for disorderly conduct. This was the third charge he’d heard about.
He had given up his car keys, his cell phone, his money, his watch and his house keys, all in different packages. When he went back to pick up his property while his white friend waited in the car, the people inside the office claimed they couldn’t find anything except his cell phone. They told him to come back at 9pm when the arresting officer would come in. Then Q’s white friend came in, and after Q explained the situation to him in front of the people working there, they suddenly found all of his possessions. Q thinks they assumed his friend was a lawyer because he was white and well dressed.
They took the starter plug out of his car as well, and he got his cell phone back with no videos. The ordeal lasted 12 hours altogether.
“The sad thing about it,” Q said, “is that it happens every single day. If you’re wearing a suit and tie it’s different, but when you’re wearing something fitted and some jeans, you’re treated as a criminal. It’s sad that people have to go through this on a daily basis, for what?”
Here’s the raw audio file of my interview with Q:
.
Fingers crossed – book coming out next May
As it turns out, it takes a while to write a book, and then another few months to publish it.
I’m very excited today to tentatively announce that my book, which is tentatively entitled Weapons of Math Destruction: How Big Data Increases Inequality and Threatens Democracy, will be published in May 2016, in time to appear on summer reading lists and well before the election.
Fuck yeah! I’m so excited.
p.s. Fight for 15 is happening now.
Fairness, accountability, and transparency in big data models
As I wrote about already, last Friday I attended a one day workshop in Montreal called FATML: Fairness, Accountability, and Transparency in Machine Learning. It was part of the NIPS conference for computer science, and there were tons of nerds there, and I mean tons. I wanted to give a report on the day, as well as some observations.
First of all, I am super excited that this workshop happened at all. When I left my job at Intent Media in 2011 with the intention of studying these questions and eventually writing a book about them, they were, as far as I know, on nobody’s else’s radar. Now, thanks to the organizers Solon and Moritz, there are communities of people, coming from law, computer science, and policy circles, coming together to exchange ideas and strategies to tackle the problems. This is what progress feels like!
OK, so on to what the day contained and my copious comments.
Hannah Wallach
Sadly, I missed the first two talks, and an introduction to the day, because of two airplane cancellations (boo American Airlines!). I arrived in the middle of Hannah Wallach’s talk, the abstract of which is located here. Her talk was interesting, and I liked her idea of having social scientists partnered with data scientists and machine learning specialists, but I do want to mention that, although there’s a remarkable history of social scientists working within tech companies – say at Bell Labs and Microsoft and such – we don’t see that in finance at all, nor does it seem poised to happen. So in other words, we certainly can’t count on social scientists to be on hand when important mathematical models are getting ready for production.
Also, I liked Hannah’s three categories of models: predictive, explanatory, and exploratory. Even though I don’t necessarily think that a given model will fall neatly into one category or the other, they still give you a way to think about what we do when we make models. As an example, we think of recommendation models as ultimately predictive, but they are (often) predicated on the ability to understand people’s desires as made up of distinct and consistent dimensions of personality (like when we use PCA or something equivalent). In this sense we are also exploring how to model human desire and consistency. For that matter I guess you could say any model is at its heart an exploration into whether the underlying toy model makes any sense, but that question is dramatically less interesting when you’re using linear regression.
Anupam Datta and Michael Tschantz
Next up Michael Tschantz reported on work with Anupam Datta that they’ve done on Google profiles and Google ads. The started with google’s privacy policy, which I can’t find but which claims you won’t receive ads based on things like your health problems. Starting with a bunch of browsers with no cookies, and thinking of each of them as fake users, they did experiments to see what actually happened both to the ads for those fake users and to the google ad profiles for each of those fake users. They found that, at least sometimes, they did get the “wrong” kind of ad, although whether Google can be blamed or whether the advertiser had broken Google’s rules isn’t clear. Also, they found that fake “women” and “men” (who did not differ by any other variable, including their searches) were offered drastically different ads related to job searches, with men being offered way more ads to get $200K+ jobs, although these were basically coaching sessions for getting good jobs, so again the advertisers could have decided that men are more willing to pay for such coaching.
An issue I enjoyed talking about was brought up in this talk, namely the question of whether such a finding is entirely evanescent or whether we can call it “real.” Since google constantly updates its algorithm, and since ad budgets are coming and going, even the same experiment performed an hour later might have different results. In what sense can we then call any such experiment statistically significant or even persuasive? Also, IRL we don’t have clean browsers, so what happens when we have dirty browsers and we’re logged into gmail and Facebook? By then there are so many variables it’s hard to say what leads to what, but should that make us stop trying?
From my perspective, I’d like to see more research into questions like, of the top 100 advertisers on Google, who saw the majority of the ads? What was the economic, racial, and educational makeup of those users? A similar but different (because of the auction) question would be to reverse-engineer the advertisers’ Google ad targeting methodologies.
Finally, the speakers mentioned a failure on Google’s part of transparency. In your advertising profile, for example, you cannot see (and therefore cannot change) your marriage status, but advertisers can target you based on that variable.
Sorelle Friedler, Carlos Scheidegger, and Suresh Venkatasubramanian
Next up we had Sorelle talk to us about her work with two guys with enormous names. They think about how to make stuff fair, the heart of the question of this workshop.
First, if we included race in, a resume sorting model, we’d probably see negative impact because of historical racism. Even if we removed race but included other attributes correlated with race (say zip code) this effect would remain. And it’s hard to know exactly when we’ve removed the relevant attributes, but one thing these guys did was define that precisely.
Second, say now you have some idea of the categories that are given unfair treatment, what can you do? One thing suggested by Sorelle et al is to first rank people in each category – to assign each person a percentile in their given category – and then to use the “forgetful function” and only consider that percentile. So, if we decided at a math department that we want 40% women graduate students, to achieve this goal with this method we’d independently rank the men and women, and we’d offer enough spots to top women to get our quota and separately we’d offer enough spots to top men to get our quota. Note that, although it comes from a pretty fancy setting, this is essentially affirmative action. That’s not, in my opinion, an argument against it. It’s in fact yet another argument for it: if we know women are systemically undervalued, we have to fight against it somehow, and this seems like the best and simplest approach.
Ed Felten and Josh Kroll
After lunch Ed Felton and Josh Kroll jointly described their work on making algorithms accountable. Basically they suggested a trustworthy and encrypted system of paper trails that would support a given algorithm (doesn’t really matter which) and create verifiable proofs that the algorithm was used faithfully and fairly in a given situation. Of course, we’d really only consider an algorithm to be used “fairly” if the algorithm itself is fair, but putting that aside, this addressed the question of whether the same algorithm was used for everyone, and things like that. In lawyer speak, this is called “procedural fairness.”
So for example, if we thought we could, we might want to turn the algorithm for punishment for drug use through this system, and we might find that the rules are applied differently to different people. This algorithm would catch that kind of problem, at least ideally.
David Robinson and Harlan Yu
Next up we talked to David Robinson and Harlan Yu about their work in Washington D.C. with policy makers and civil rights groups around machine learning and fairness. These two have been active with civil rights group and were an important part of both the Podesta Report, which I blogged about here, and also in drafting the Civil Rights Principles of Big Data.
The question of what policy makers understand and how to communicate with them came up several times in this discussion. We decided that, to combat cherry-picked examples we see in Congressional Subcommittee meetings, we need to have cherry-picked examples of our own to illustrate what can go wrong. That sounds bad, but put it another way: people respond to stories, especially to stories with innocent victims that have been wronged. So we are on the look-out.
Closing panel with Rayid Ghani and Foster Provost
I was on the closing panel with Rayid Ghani and Foster Provost, and we each had a few minutes to speak and then there were lots of questions and fun arguments. To be honest, since I was so in the moment during this panel, and also because I was jonesing for a beer, I can’t remember everything that happened.
As I remember, Foster talked about an algorithm he had created that does its best to “explain” the decisions of a complicated black box algorithm. So in real life our algorithms are really huge and messy and uninterpretable, but this algorithm does its part to add interpretability to the outcomes of that huge black box. The example he gave was to understand why a given person’s Facebook “likes” made a black box algorithm predict they were gay: by displaying, in order of importance, which likes added the most predictive power to the algorithm.
[Aside, can anyone explain to me what happens when such an algorithm comes across a person with very few likes? I’ve never understood this very well. I don’t know about you, but I have never “liked” anything on Facebook except my friends’ posts.]
Rayid talked about his work trying to develop a system for teachers to understand which students were at risk of dropping out, and for that system to be fair, and he discussed the extent to which that system could or should be transparent.
Oh yeah, and that reminds me that, after describing my book, we had a pretty great argument about whether credit scoring models should be open source, and what that would mean, and what feedback loops that would engender, and who would benefit.
Altogether a great day, and a fantastic discussion. Thanks again to Solon and Moritz for their work in organizing it.
Educational feedback loops in China and the U.S.
Today I want to discuss a recent review in New York Review of Books, on a new book entitled Who’s Afraid of the Big Bad Dragon? Why China Has the Best (and Worst) Education System in the World by Yong Zhao (hat tip Alex). The review was written by Diane Ravitch, an outspoken critic of No Child Left Behind, Race To The Top, and the Common Core.
You should read the review, it’s well written and convincing, at least to me. I’ve been studying these issues and devoted a large chunk of my book to the feedback loops described as they’ve played out in this country. Here are the steps I see, which are largely reflected in Ravitch’s review:
- Politicians get outraged about a growing “achievement gap” (whereby richer or whiter students get better test scores than poorer or browner students) and/or a “lack of international competitiveness” (whereby students in countries like China get higher international standardized test scores than U.S. students).
- The current president decides to “get tough on education,” which translates into new technology and way more standardized tests.
- The underlying message is that teachers and students and possibly parents are lazy and need to be “held accountable” to improve test scores. The even deeper assumption is that test scores are the way to measure quality of learning.
- Once there’s lots of attention being given to test scores, lots of things start happening in response (the “feedback loop”).
- For example, widespread cheating by students and teachers and principals, especially when teachers and principals get paid based on test performance.
- Also, well-off students get more and better test prep, so the achievement gap gets wider.
- Even just the test scores themselves lead to segregation by class: parents who can afford it move to towns with “better schools,” measured by test scores.
- International competitiveness doesn’t improve. But we’ve actually never been highly ranked since we started measuring this.
What Zhao’s book adds to this is how much worse it all is in China. Especially the cheating. My favorite excerpt from the book:
Teachers guess possible [test] items, companies sell answers and wireless cheating devices to students, and students engage in all sorts of elaborate cheating. In 2013, a riot broke out because a group of students in Hubei Province were stopped from executing the cheating scheme their parents purchased to ease their college entrance exam.
Ravitch adds after that that ‘an angry mob of two thousand people smashed cars and chanted, “We want fairness. There is no fairness if you do not let us cheat.”’
To be sure, the stakes in China are way higher. Test scores are incredibly important and allow people to have certain careers. But according to Zhao, this selection process, which is quite old, has stifled creativity in the Chinese educational system (so, in other words, test scores are the wrong way to measure learning, in part because of the feedback loop). He blames the obsession with test scores on the fact that no Chinese native has received a Nobel Prize since 1949, for example: the winners of that selection process are not naturally creative.
Furthermore, Zhao claims, the Chinese educational system stifles individuality and forces conformity. It is an authoritarian tool.
In that light, I guess we should be proud that our international scores are lower than China’s; maybe it is evidence that we’re doing something right.
I know that, as a parent, I am sensitive to these issues. I want my kids to have discipline in some ways, but I don’t want them to learn to submit themselves to an arbitrary system for no good reason. I like the fact that they question why they should do things like go to bed on time, and exercise regularly, and keep their rooms cleanish, and I encourage their questions, even while I know I’m kind of ruining their chances at happily working in a giant corporation and being a conformist drone.
This parenting style of mine, which I believe is pretty widespread, seems reasonable to me because, at least in my experience, I’ve gotten further by being smart and clever than by being exactly what other people have wanted me to be. And I’m glad I live in a society that rewards quirkiness and individuality.
Big Data’s Disparate Impact
Take a look at this paper by Solon Barocas and Andrew D. Selbst entitled Big Data’s Disparate Impact.
It deals with the question of whether current anti-discrimination law is equipped to handle the kind of unintentional discrimination and digital redlining we see emerging in some “big data” models (and that we suspect are hidden in a bunch more). See for example this post for more on this concept.
The short answer is no, our laws are not equipped.
Here’s the abstract:
This article addresses the potential for disparate impact in the data mining processes that are taking over modern-day business. Scholars and policymakers had, until recently, focused almost exclusively on data mining’s capacity to hide intentional discrimination, hoping to convince regulators to develop the tools to unmask such discrimination. Recently there has been a noted shift in the policy discussions, where some have begun to recognize that unintentional discrimination is a hidden danger that might be even more worrisome. So far, the recognition of the possibility of unintentional discrimination lacks technical and theoretical foundation, making policy recommendations difficult, where they are not simply misdirected. This article provides the necessary foundation about how data mining can give rise to discrimination and how data mining interacts with anti-discrimination law.
The article carefully steps through the technical process of data mining and points to different places within the process where a disproportionately adverse impact on protected classes may result from innocent choices on the part of the data miner. From there, the article analyzes these disproportionate impacts under Title VII. The Article concludes both that Title VII is largely ill equipped to address the discrimination that results from data mining. Worse, due to problems in the internal logic of data mining as well as political and constitutional constraints, there appears to be no easy way to reform Title VII to fix these inadequacies. The article focuses on Title VII because it is the most well developed anti-discrimination doctrine, but the conclusions apply more broadly because they are based on the general approach to anti-discrimination within American law.
I really appreciate this paper, because it’s an area I know almost nothing about: discrimination law and what are the standards for evidence of discrimination.
Sadly, what this paper explains to me is how very far we are away from anything resembling what we need to actually address the problems. For example, even in this paper, where the writers are well aware that training on historical data can unintentionally codify discriminatory treatment, they still seem to assume that the people who build and deploy models will “notice” this treatment. From my experience working in advertising, that’s not actually what happens. We don’t measure the effects of our models on our users. We only see whether we have gained an edge in terms of profit, which is very different.
Essentially, as modelers, we don’t humanize the people on the other side of the transaction, which prevents us from worrying about discrimination or even being aware of it as an issue. It’s so far from “intentional” that it’s almost a ridiculous accusation to make. Even so, it may well be a real problem and I don’t know how we as a society can deal with it unless we update our laws.
Upcoming data journalism and data ethics conferences
Today
Today I’m super excited to go to the opening launch party of danah boyd’s Data and Society. Data and Society has a bunch of cool initiatives but I’m particularly interested in their Council for Big Data, Ethics, and Society. They were the people that helped make the Podesta Report on Big Data as good as it was. There will be a mini-conference this afternoon I’m looking forward to very much. Brilliant folks doing great work and talking to each other across disciplinary lines, can’t get enough of that stuff.
This weekend
This coming Saturday I’ll be moderating a panel called Spotlight on Data-Driven Journalism: The job of a data journalist and the impact of computational reporting in the newsroom at the New York Press Club Conference on Journalism. The panelists are going to be great:
- John Keefe @jkeefe, Sr. editor, data news & J-technology, WNYC
- Maryanne Murray @lightnosugar, Global head of graphics, Reuters
- Zach Seward @zseward, Quartz
- Chris Walker @cpwalker07, Dir., data visualization, Mic News
The full program is available here.
December 12th
In mid-December I’m on a panel myself at the Fairness, Accountability, and Transparency in Machine Learning Conference in Montreal. This conference seems to directly take up the call of the Podesta Report I mentioned above, and seeks to provide further research into the dangers of “encoding discrimination in automated decisions”. Amazing! So glad this is happening and that I get to be part of it. Here are some questions that will be taken up at this one-day conference (more information here):
- How can we achieve high classification accuracy while eliminating discriminatory biases? What are meaningful formal fairness properties?
- How can we design expressive yet easily interpretable classifiers?
- Can we ensure that a classifier remains accurate even if the statistical signal it relies on is exposed to public scrutiny?
- Are there practical methods to test existing classifiers for compliance with a policy?
The business of public education
I’ve been writing my book, and I’m on chapter 4 right now, which is tentatively entitled Feedback Loops In Education. I’m studying the enormous changes in primary and secondary education that have occurred since the “data-driven” educational reform movement started with No Child Left Behind in 2001.
Here’s the issue I’m having writing this chapter. Things have really changed in the last 13 years, it’s really incredible how much money and politics – and not education – are involved. In fact I’m finding it difficult to write the chapter without sounding like a wingnut conspiracy theorist. Because that’s how freaking nuts things are right now.
On the one hand you have the people who believe in the promise of educational data. They are often pro-charter schools, anti-tenure, anti-union, pro-testing, and are possibly personally benefitting from collecting data about children and then sold to commercial interests. Privacy laws are things to bypass for these people, and the way they think about it is that they are going to improve education with all this amazing data they’re collecting. Because, you know, it’s big data, so it has to be awesome. They see No Child Left Behind and Race To The Top as business opportunities.
On the other hand you have people who do not believe in the promise of educational data. They believe in public education, and are maybe even teachers themselves. They see no proven benefits of testing, or data collection and privacy issues for students, and they often worry about job security, and public shaming and finger-pointing, and the long term consequences on children and teachers of this circus of profit-seeking “educational” reformers. Not to mention that none of this recent stuff is addressing the very real problems we have.
As it currently stands, I’m pretty much part of the second group. There just aren’t enough data skeptics in the first group to warrant my respect, and there’s way too much money and secrecy around testing and “value-added models.” And the politics of the anti-tenure case are ugly and I say that even though I don’t think teacher union leaders are doing themselves many favors.
But here’s the thing, it’s not like there could never be well-considered educational experiments that use data and have strict privacy measures in place, the results of which are not saved to individual records but are lessons learned for educators, and, it goes without saying, are strictly non-commercial. There is a place for testing, but not as a punitive measure but rather as a way of finding where there are problems and devoting resources to it. The current landscape, however, is so split and so acrimonious, it’s kind of impossible to imagine something reasonable happening.
It’s too bad, this stuff is important.
Christian Rudder’s Dataclysm
Here’s what I’ve spent the last couple of days doing: alternatively reading Christian Rudder’s new book Dataclysm and proofreading a report by AAPOR which discusses the benefits, dangers, and ethics of using big data, which is mostly “found” data originally meant for some other purpose, as a replacement for public surveys, with their carefully constructed data collection processes and informed consent. The AAPOR folk have asked me to provide tangible examples of the dangers of using big data to infer things about public opinion, and I am tempted to simply ask them all to read Dataclysm as exhibit A.
Rudder is a co-founder of OKCupid, an online dating site. His book mainly pertains to how people search for love and sex online, and how they represent themselves in their profiles.
Here’s something that I will mention for context into his data explorations: Rudder likes to crudely provoke, as he displayed when he wrote this recent post explaining how OKCupid experiments on users. He enjoys playing the part of the somewhat creepy detective, peering into what OKCupid users thought was a somewhat private place to prepare themselves for the dating world. It’s the online equivalent of a video camera in a changing booth at a department store, which he defended not-so-subtly on a recent NPR show called On The Media, and which was written up here.
I won’t dwell on that aspect of the story because I think it’s a good and timely conversation, and I’m glad the public is finally waking up to what I’ve known for years is going on. I’m actually happy Rudder is so nonchalant about it because there’s no pretense.
Even so, I’m less happy with his actual data work. Let me tell you why I say that with a few examples.
Who are OKCupid users?
I spent a lot of time with my students this summer saying that a standalone number wouldn’t be interesting, that you have to compare that number to some baseline that people can understand. So if I told you how many black kids have been stopped and frisked this year in NYC, I’d also need to tell you how many black kids live in NYC for you to get an idea of the scope of the issue. It’s a basic fact about data analysis and reporting.
When you’re dealing with populations on dating sites and you want to conclude things about the larger culture, the relevant “baseline comparison” is how well the members of the dating site represent the population as a whole. Rudder doesn’t do this. Instead he just says there are lots of OKCupid users for the first few chapters, and then later on after he’s made a few spectacularly broad statements, on page 104 he compares the users of OKCupid to the wider internet users, but not to the general population.
It’s an inappropriate baseline, made too late. Because I’m not sure about you but I don’t have a keen sense of the population of internet users. I’m pretty sure very young kids and old people are not well represented, but that’s about it. My students would have known to compare a population to the census. It needs to happen.
How do you collect your data?
Let me back up to the very beginning of the book, where Rudder startles us by showing us that the men that women rate “most attractive” are about their age whereas the women that men rate “most attractive” are consistently 20 years old, no matter how old the men are.
Actually, I am projecting. Rudder never actually specifically tells us what the rating is, how it’s exactly worded, and how the profiles are presented to the different groups. And that’s a problem, which he ignores completely until much later in the book when he mentions that how survey questions are worded can have a profound effect on how people respond, but his target is someone else’s survey, not his OKCupid environment.
Words matter, and they matter differently for men and women. So for example, if there were a button for “eye candy,” we might expect women to choose more young men. If my guess is correct, and the term in use is “most attractive”, then for men it might well trigger a sexual concept whereas for women it might trigger a different social construct; indeed I would assume it does.
Since this isn’t a porn site, it’s a dating site, we are not filtering for purely visual appeal; we are looking for relationships. We are thinking beyond what turns us on physically and asking ourselves, who would we want to spend time with? Who would our family like us to be with? Who would make us be attractive to ourselves? Those are different questions and provoke different answers. And they are culturally interesting questions, which Rudder never explores. A lost opportunity.
Next, how does the recommendation engine work? I can well imagine that, once you’ve rated Profile A high, there is an algorithm that finds Profile B such that “people who liked Profile A also liked Profile B”. If so, then there’s yet another reason to worry that such results as Rudder described are produced in part as a result of the feedback loop engendered by the recommendation engine. But he doesn’t explain how his data is collected, how it is prompted, or the exact words that are used.
Here’s a clue that Rudder is confused by his own facile interpretations: men and women both state that they are looking for relationships with people around their own age or slightly younger, and that they end up messaging people slightly younger than they are but not many many years younger. So forty year old men do not message twenty year old women.
Is this sad sexual frustration? Is this, in Rudder’s words, the difference between what they claim they want and what they really want behind closed doors? Not at all. This is more likely the difference between how we live our fantasies and how we actually realistically see our future.
Need to control for population
Here’s another frustrating bit from the book: Rudder talks about how hard it is for older people to get a date but he doesn’t correct for population. And since he never tells us how many OKCupid users are older, nor does he compare his users to the census, I cannot infer this.
Here’s a graph from Rudder’s book showing the age of men who respond to women’s profiles of various ages:

We’re meant to be impressed with Rudder’s line, “for every 100 men interested in that twenty year old, there are only 9 looking for someone thirty years older.” But here’s the thing, maybe there are 20 times as many 20-year-olds as there are 50-year-olds on the site? In which case, yay for the 50-year-old chicks? After all, those histograms look pretty healthy in shape, and they might be differently sized because the population size itself is drastically different for different ages.
Confounding
One of the worst examples of statistical mistakes is his experiment in turning off pictures. Rudder ignores the concept of confounders altogether, which he again miraculously is aware of in the next chapter on race.
To be more precise, Rudder talks about the experiment when OKCupid turned off pictures. Most people went away when this happened but certain people did not:

Some of the people who stayed on went on a “blind date.” Those people, which Rudder called the “intrepid few,” had a good time with people no matter how unattractive they were deemed to be based on OKCupid’s system of attractiveness. His conclusion: people are preselecting for attractiveness, which is actually unimportant to them.
But here’s the thing, that’s only true for people who were willing to go on blind dates. What he’s done is select for people who are not superficial about looks, and then collect data that suggests they are not superficial about looks. That doesn’t mean that OKCupid users as a whole are not superficial about looks. The ones that are just got the hell out when the pictures went dark.
Race
This brings me to the most interesting part of the book, where Rudder explores race. Again, it ends up being too blunt by far.
Here’s the thing. Race is a big deal in this country, and racism is a heavy criticism to be firing at people, so you need to be careful, and that’s a good thing, because it’s important. The way Rudder throws it around is careless, and he risks rendering the term meaningless by not having a careful discussion. The frustrating part is that I think he actually has the data to have a very good discussion, but he just doesn’t make the case the way it’s written.
Rudder pulls together stats on how men of all races rate women of all races on an attractiveness scale of 1-5. It shows that non-black men find their own race attractive and non-black men find black women, in general, less attractive. Interesting, especially when you immediately follow that up with similar stats from other U.S. dating sites and – most importantly – with the fact that outside the U.S., we do not see this pattern. Unfortunately that crucial fact is buried at the end of the chapter, and instead we get this embarrassing quote right after the opening stats:
And an unintentionally hilarious 84 percent of users answered this match question:
Would you consider dating someone who has vocalized a strong negative bias toward a certain race of people?
in the absolute negative (choosing “No” over “Yes” and “It depends”). In light of the previous data, that means 84 percent of people on OKCupid would not consider dating someone on OKCupid.
Here Rudder just completely loses me. Am I “vocalizing” a strong negative bias towards black women if I am a white man who finds white women and asian women hot?
Especially if you consider that, as consumers of social platforms and sites like OKCupid, we are trained to rank all the products we come across to ultimately get better offerings, it is a step too far for the detective on the other side of the camera to turn around and point fingers at us for doing what we’re told. Indeed, this sentence plunges Rudder’s narrative deeply into the creepy and provocative territory, and he never fully returns, nor does he seem to want to. Rudder seems to confuse provocation for thoughtfulness.
This is, again, a shame. A careful conversation about the issues of what we are attracted to, what we can imagine doing, and how we might imagine that will look to our wider audience, and how our culture informs those imaginings, are all in play here, and could have been drawn out in a non-accusatory and much more useful way.
Reverse-engineering the college admissions process
I just finished reading a fascinating article from Bloomberg BusinessWeek about a man who claims to have reverse-engineered the admission processes at Ivy League colleges (hat tip Jan Zilinsky).
His name is Steven Ma, and as befits an ex-hedge funder, he has built an algorithm of sorts to work well with both the admission algorithms at the “top 50 colleges,” and the US News & World Report model which defines which colleges are in the “to 50.” It’s a huge modeling war that you can pay to engage in.
Ma is a salesman too: he guarantees that a given high-school kid will get into a top school, your money back. In other words he has no problem working with probabilities and taking risks that he think are likely to pay off and that make the parents willing to put down huge sums. Here’s an example of a complicated contract he developed with one family:
After signing an agreement in May 2012, the family wired Ma $700,000 over the next five months—before the boy had even applied to college. The contract set out incentives that would pay Ma as much as $1.1 million if the son got into the No. 1 school in U.S. News’ 2012 rankings. (Harvard and Princeton were tied at the time.) Ma would get nothing, however, if the boy achieved a 3.0 GPA and a 1600 SAT score and still wasn’t accepted at a top-100 college. For admission to a school ranked 81 to 100, Ma would get to keep $300,000; schools ranked 51 to 80 would let Ma hang on to $400,000; and for a top-50 admission, Ma’s payoff started at $600,000, climbing $10,000 for every rung up the ladder to No. 1.
He’s also interested in reverse-engineering the “winning essay” in conjunction with after-school activities:
With more capital—ThinkTank’s current valuation to potential investors is $60 million—Ma hopes to buy hundreds of completed college applications from the students who submitted them, along with the schools’ responses, and beef up his algorithm for the top 50 U.S. colleges. With enough data, Ma plans to build an “optimizer” that will help students, perhaps via an online subscription, choose which classes and activities they should take. It might tell an aspiring Stanford applicant with several AP classes in his junior year that it’s time to focus on becoming president of the chess or technology club, for example.
This whole college coaching industry reminds me a lot of financial regulation. We complicate the rules to the point where only very well-off insiders know exactly how to bypass the rules. To the extent that getting into one of these “top schools” actually does give young people access to power, influence, and success, it’s alarming how predictable the whole process has become.
Here’s a thought: maybe we should have disclosure laws about college coaching and prep? Or would those laws be gamed too?
Student evaluations: very noisy data
I’ve been sent this recent New York Times article by a few people (thanks!). It’s called Grading Teachers, With Data From Class, and it’s about how standardized tests are showing themselves to be inadequate to evaluate teachers, so a Silicon Valley-backed education startup called Panorama is stepping into the mix with a data collection process focused on student evaluations.
Putting aside for now how much this is a play for collecting information about the students themselves, I have a few words to say about the signal which one gets from student evaluations. It’s noisy.
So, for example, I was a calculus teacher at Barnard, teaching students from all over the Columbia University community (so, not just women). I taught the same class two semesters in a row: first in Fall, then in Spring.
Here’s something I noticed. The students in the Fall were young (mostly first semester frosh), eager, smart, and hard-working. They loved me and gave me high marks on all categories, except of course for the few students who just hated math, who would typically give themselves away by saying “I hate math and this class is no different.”
The students in the Spring were older, less eager, probably just as smart, but less hard-working. They didn’t like me or the class. In particular, they didn’t like how I expected them to work hard and challenge themselves. The evaluations came back consistently less excited, with many more people who hated math.
I figured out that many of the students had avoided this class and were taking it for a requirement, didn’t want to be there, and it showed. And the result was that, although my teaching didn’t change remarkably between the two semesters, my evaluations changed considerably.
Was there some way I could have gotten better evaluations from that second group? Absolutely. I could have made the class easier. That class wanted calculus to be cookie-cutter, and didn’t particularly care about the underlying concepts and didn’t want to challenge themselves. The first class, by contrast, had loved those things.
My conclusion is that, once we add “get good student evaluations” to the mix of requirements for our country’s teachers, we are asking for them to conform to their students’ wishes, which aren’t always good. Many of the students in this country don’t like doing homework (in fact most!). Only some of them like to be challenged to think outside their comfort zone. We think teachers should do those things, but by asking them to get good student evaluations we might be preventing them from doing those things. A bad feedback loop would result.
I’m not saying teachers shouldn’t look at student evaluations; far from it, I always did and I found them useful and illuminating, but the data was very noisy. I’d love to see teachers be allowed to see these evaluations without there being punitive consequences.
Weapon of Math Destruction: “risk-based” sentencing models
There was a recent New York Times op-ed by Sonja Starr entitled Sentencing, by the Numbers (hat tip Jordan Ellenberg and Linda Brown) which described the widespread use – in 20 states so far and growing – of predictive models in sentencing.
The idea is to use a risk score to help inform sentencing of offenders. The risk is, I guess, supposed to tell us how likely the person is to commit another act in the future, although that’s not specified. From the article:
The basic problem is that the risk scores are not based on the defendant’s crime. They are primarily or wholly based on prior characteristics: criminal history (a legitimate criterion), but also factors unrelated to conduct. Specifics vary across states, but common factors include unemployment, marital status, age, education, finances, neighborhood, and family background, including family members’ criminal history.
I knew about the existence of such models, at least in the context of prisoners with mental disorders in England, but I didn’t know how widespread it had become here. This is a great example of a weapon of math destruction and I will be using this in my book.
A few comments:
- I’ll start with the good news. It is unconstitutional to use information such as family member’s criminal history against someone. Eric Holder is fighting against the use of such models.
- It is also presumably unconstitutional to jail someone longer for being poor, which is what this effectively does. The article has good examples of this.
- The modelers defend this crap as “scientific,” which is the worst abuse of science and mathematics imaginable.
- The people using this claim they only use it for as a way to mitigate sentencing, but letting a bunch of rich white people off easier because they are not considered “high risk” is tantamount to sentencing poor minorities more.
- It is a great example of confused causality. We could easily imagine a certain group that gets arrested more often for a given crime (poor black men, marijuana possession) just because the police have that practice for whatever reason (Stop & Frisk). Then model would then consider any such man at a higher risk of repeat offending, but that’s not because any particular person is actually more likely to do it, but because the police are more likely to arrest that person for it.
- It also creates a negative feedback loop on the most vulnerable population: the model will impose longer sentencing on the population it considers most risky, which will in turn make them even riskier in the future, if “length of time in prison previously” is used as an attribute in the model, which is surely is.
- Not to be cynical, but considering my post yesterday, I’m not sure how much momentum will be created to stop the use of such models, considering how discriminatory it is.
- Here’s an extreme example of preferential sentencing which already happens: rich dude Robert H Richards IV raped his 3-year-old daughter and didn’t go to jail because the judge ruled he “wouldn’t fare well in prison.”
- How great would it be if we used data and models to make sure rich people went to jail just as often and for just as long as poor people for the same crime, instead of the other way around?
Everyone has a crush on me
So I have been getting some feedback lately on how I always assume everyone has a crush on me. People know this is my typical assumption because I say things like, “oh yeah that guy totally has a crush on me.” And when I say “feedback,” what I mean is people joyfully accusing me of lying, or maybe just outraged by my preposterous claims, usually in a baffled and friendly manner. Just a few comments about this.
First of all, I also have a crush on everyone else. Just as often as I say “that lady has a crush on me,” I am known to say, “Oh my god I have a huge crush on her.” It’s more fun that way!
Second of all, there are all sorts of great consequences of thinking someone has a crush on you. To name a few:
- It’s not a sexual thing at all, it’s more like a willingness to think the other person is super awesome. I have crush on all sorts of people, men and women, etc. etc.. No categories left uncrushed except meanies.
- When you act like someone has a crush on you, they are more likely to develop a crush on you. This is perhaps the most important point and should be first, but I wanted to get the first point out of the way. It’s what I call a positive feedback loop.
- It makes you feel great to be around someone if they have a crush on you, or even if you just think they do.
- What’s the worst thing that can happen? Answer: that you’re wrong, and they don’t have a crush on you, but then they’ll just walk away thinking that you were weirdly happy to see them, which is not so bad, and may in fact make them crush out on you. See what I mean?
- It’s a nice world to live in where a majority of the people you run into have a crush on you. Try it and see for yourself!
Two great articles about standardized tests
In the past 12 hours I’ve read two fascinating articles about the crazy world of standardized testing. They’re both illuminating and well-written and you should take a look.
First, my data journalist friend Meredith Broussard has an Atlantic piece called Why Poor Schools Can’t Win At Standardized Testing wherein she tracks down the money and the books in the Philadelphia public school system (spoiler: there’s not enough of either), and she makes the connection between expensive books and high test scores.
Here’s a key phrase from her article:
Pearson came under fire last year for using a passage on a standardized test that was taken verbatim from a Pearson textbook.
The second article, in the New Yorker, is written by Rachel Aviv and is entitled Wrong Answer. It’s a close look, with interviews, of the cheating scandal from Atlanta, which I have been studying recently. The article makes the point that cheating is a predictable consequence of the high-stakes “data-driven” approach.
Here’s a key phrase from the Aviv article:
After more than two thousand interviews, the investigators concluded that forty-four schools had cheated and that a “culture of fear, intimidation and retaliation has infested the district, allowing cheating—at all levels—to go unchecked for years.” They wrote that data had been “used as an abusive and cruel weapon to embarrass and punish.”
Putting the two together, it’s pretty clear that there’s an acceptable way to cheat, which is by stocking up on expensive test prep materials in the form of testing company-sponsored textbooks, and then there’s the unacceptable way to cheat, which is where teachers change the answers. Either way the standardized test scoring regime comes out looking like a penal system rather than a helpful teaching aid.
Before I leave, some recent goodish news on the standardized testing front (hat tip Eugene Stern): Chris Christie just reduced the importance of value-added modeling for teacher evaluation down to 10% in New Jersey.
Great news: for-profit college Corinthian to close
I’ve talked before about the industry of for-profit colleges which exists largely to game the federal student loan program. They survive almost entirely on federal student loans of their students, while delivering terrible services and worthless credentials.
Well, good news: one of the worst of the bunch is closing its doors. Corinthian College, Inc (CCI) got caught lying about job placement of its graduates (in some cases, they said 100% when the truth was closer to 0%). They were also caught advertising programs they didn’t actually have.
But here’s what interests me the most, which I will excerpt from the California Office of the Attorney General:
CCI’s predatory marketing efforts specifically target vulnerable, low-income job seekers and single parents who have annual incomes near the federal poverty line. In internal company documents obtained by the Department of Justice, CCI describes its target demographic as “isolated,” “impatient,” individuals with “low self-esteem,” who have “few people in their lives who care about them” and who are “stuck” and “unable to see and plan well for future.”
I’d like to know more about how they did this. I’m guessing it was substantially online, and I’m guessing they got help from data warehousing services.
After skimming the complaint I’m afraid it doesn’t include such information, although it does say that the company advertised programs it didn’t have and then tricked potential students into filling out information about them so CCI could follow up and try to enroll them. Talk about predatory advertising!
Update: I’m getting some information by checking out their recent marketing job postings.
Why Chetty’s Value-Added Model studies leave me unconvinced
Every now and then when I complain about the Value-Added Model (VAM), people send me links to recent papers written Raj Chetty, John Friedman, and Jonah Rockoff like this one entitled Measuring the Impacts of Teachers II: Teacher Value-Added and Student Outcomes in Adulthood or its predecessor Measuring the Impacts of Teachers I: Evaluating Bias in Teacher Value-Added Estimates.
I think I’m supposed to come away impressed, but that’s not what happens. Let me explain.
Their data set for students scores start in 1989, well before the current value-added teaching climate began. That means teachers weren’t teaching to the test like they are now. Therefore saying that the current VAM works because an retrograded VAM worked in 1989 and the 1990’s is like saying I must like blueberry pie now because I used to like pumpkin pie. It’s comparing apples to oranges, or blueberries to pumpkins.
I’m surprised by the fact that the authors don’t seem to make any note of the difference in data quality between pre-VAM and current conditions. They should know all about feedback loops; any modeler should. And there’s nothing like telling teachers they might lose their job to create a mighty strong feedback loop. For that matter, just consider all the cheating scandals in the D.C. area where the stakes were the highest. Now that’s a feedback loop. And by the way, I’ve never said the VAM scores are totally meaningless, but just that they are not precise enough to hold individual teachers accountable. I don’t think Chetty et al address that question.
So we can’t trust old VAM data. But what about recent VAM data? Where’s the evidence that, in this climate of high-stakes testing, this model is anything but random?
If it were a good model, we’d presumably be seeing a comparison of current VAM scores and current other measures of teacher success and how they agree. But we aren’t seeing anything like that. Tell me if I’m wrong, I’ve been looking around and I haven’t seen such comparisons. And I’m sure they’ve been tried, it’s not rocket science to compare VAM scores with other scores.
The lack of such studies reminds me of how we never hear about scientific studies on the results of Weight Watchers. There’s a reason such studies never see the light of day, namely because whenever they do those studies, they decide they’re better off not revealing the results.
And if you’re thinking that it would be hard to know exactly how to rate a teacher’s teaching in a qualitative, trustworthy way, then yes, that’s the point! It’s actually not obvious how to do this, which is the real reason we should never trust a so-called “objective mathematical model” when we can’t even decide on a definition of success. We should have the conversation of what comprises good teaching, and we should involve the teachers in that, and stop relying on old data and mysterious college graduation results 10 years hence. What are current 6th grade teachers even supposed to do about studies like that?
Note I do think educators and education researchers should be talking about these questions. I just don’t think we should punish teachers arbitrarily to have that conversation. We should have a notion of best practices that slowly evolve as we figure out what works in the long-term.
So here’s what I’d love to see, and what would be convincing to me as a statistician. If we see all sorts of qualitative ways of measuring teachers, and see their VAM scores as well, and we could compare them, and make sure they agree with each other and themselves over time. In other words, at the very least we should demand an explanation of how some teachers get totally ridiculous and inconsistent scores from one year to the next and from one VAM to the next, even in the same year.
The way things are now, the scores aren’t sufficiently sound be used for tenure decisions. They are too noisy. And if you don’t believe me, consider that statisticians and some mathematicians agree.
We need some ground truth, people, and some common sense as well. Instead we’re seeing retired education professors pull statistics out of thin air, and it’s an all-out war of supposed mathematical objectivity against the civil servant.
Me & My Administrative Bloat
I am now part of the administrative bloat over at Columbia. I am non-faculty administration, tasked with directing a data journalism program. The program is great, and I’m not complaining about my job. But I will be honest, it makes me uneasy.
Although I’m in the Journalism School, which is in many ways separated from the larger university, I now have a view into how things got so bloated. And how they might stay that way, as well: it’s not clear that, at the end of my 6-month gig, on September 16th, I could hand my job over to any existing person at the J-School. They might have to replace me, or keep me on, with a real live full-time person in charge of this program.
There are good and less good reasons for that, but overall I think there exists a pretty sound argument for such a person to run such a program and to keep it good and intellectually vibrant. That’s another thing that makes me uneasy, although many administrative positions have less of an easy sell attached to them.
I was reminded of this fact of my current existence when I read this recent New York Times article about the administrative bloat in hospitals. From the article:
And studies suggest that administrative costs make up 20 to 30 percent of the United States health care bill, far higher than in any other country. American insurers, meanwhile, spent $606 per person on administrative costs, more than twice as much as in any other developed country and more than three times as much as many, according to a study by the Commonwealth Fund.
Compare that to this article entitled Administrators Ate My Tuition:
A comprehensive study published by the Delta Cost Project in 2010 reported that between 1998 and 2008, America’s private colleges increased spending on instruction by 22 percent while increasing spending on administration and staff support by 36 percent. Parents who wonder why college tuition is so high and why it increases so much each year may be less than pleased to learn that their sons and daughters will have an opportunity to interact with more administrators and staffers— but not more professors.
There are similarities and there are differences between the university and the medical situations.
A similarity is that people really want to be educated, and people really need to be cared for, and administrations have grown up around these basic facts, and at each stage they seem to be adding something either seemingly productive or vitally needed to contain the complexity of the existing machine, but in the end you have enormous behemoths of organizations that are much too complex and much too expensive. And as a reality check on whether that’s necessary, take a look at hospitals in Europe, or take a look at our own university system a few decades ago.
And that also points out a critical difference: the health care system is ridiculously complicated in this country, and in some sense you need all these people just to navigate it for a hospital. And ObamaCare made that worse, not better, even though it also has good aspects in terms of coverage.
Whereas the university system made itself complicated, it wasn’t externally forced into complexity, except if you count the US News & World Reports gaming that seems inescapable.
Text laundering
This morning I received this link on plagiarism software via the Columbia Journalism School mailing list – which is significantly more interesting than most faculty mailing lists, I might add.
In the article, the author, Neuroskeptic, describes the smallish bit of work one has to go through to “launder” text in order for the standard plagiarism detector software to deem it original. The example Neuroskeptic gives us is, ironically, from a research ethics program in Britain called PIE which Neuroskeptic is accusing of plagiarizing text:
PIE Original: You are invited to join the Publication Integrity and Ethics (herein referred to as PIE) as one of its founding members. PIE, a not-for profit organisation, offers free membership to all interested individuals. Please join us and become part of this exciting new movement in the world of publishing ethics; it is the professional home for authors, reviewers, editorial board members and editors-in-chief.
Neuroskeptic: You are invited to join Publication Integrity and Ethics (herein referred to as PIE) and become one of its founding members. PIE, a not-for profit organisation, offers interested individuals free membership. Please join this exciting new movement in the publishing ethics world; PIE is the professional home for reviewers, editorial board members, authors, and editors-in-chief.
This second, laundered piece of text got through software called Grammarly, and the first one didn’t.
Neuroskeptic made his or her point, and PIE has been adequately shamed into naming their sources. But I think the larger point is critical.
Namely, this is the problem with having standard software for things like plagiarism. If everyone uses the same tools, then anyone can launder their text sufficiently to jump through all the standard hoops and then be satisfied that they won’t get caught. You just keep running your text through the software, adding “the’s” and changing the beginning of sentences, until it comes out with a green light.
The rules aren’t that you can’t plagiarize, but instead that you can’t plagiarize without adequate laundering.
This reminds me of my previous post on essay correction software. As soon as you have a standard for that, or even a standard approach, you can automate writing essays that will get a good grade, by iteratively running a grading algorithm (or a series of grading algorithms) on your piece and adding big words or whatever until you get an “A” on all versions. You might need to input the topic and the length of the essay, but that’s it.
And if you think that someone smart enough to code this up deserves an A just for the effort, keep in mind that you can buy such software as well. So really it’s about who has money.
Far from believing in MOOC’s destroying the college campus and have everything online, in my cynical moments I’m starting to believe we’re going to have to talk to and test people face to face to be sure they aren’t using algorithms to cheat on tests.
Of course once our brains are directly wired into the web it won’t make a difference.
I burned my eyes reading the Wall Street Journal this morning
If you want to do yourself a favor, don’t read this editorial from the Wall Street Journal like I did. It’s an unsigned “Review & Outlook” piece which I’m guessing was written by Rupert Murdoch himself.
Entitled Telling Students to Earn Less: Obama now calls for reforming his bleeding college loan program, it’s a rant against Obama’s Pay As You Earn plan, and it’s vitriolic, illogical, and mean. It makes me honestly embarrassed for the remaining high-quality journalists working at the WSJ who have to put up with this. An excerpt:
Pay As You Earn allows students under certain circumstances to borrow an unlimited amount and then cap monthly payments at 10% of their discretionary income. If they choose productive work in the private economy, the loans are forgiven after 20 years. But if they choose to work in government or for a nonprofit, Uncle Sugar forgives their loans after 10 years.
Uncle Sugar? Is this intended to make us think about the Huckabee birth control debate?
Here’s the thing. I’m not someone who always wants people to talk about the President in hushed and solemn terms or anything. The president is fair game, as are his policies. And in Obama’s case, I am not a big fan. For that matter, I don’t think his education policy has any hope, even if it’s well-intentioned. But I just don’t understand how an article like this can be published in a respectable newspaper. It does not advance the debate.
For the record, college tuition has been going up for a while, way before Obama:
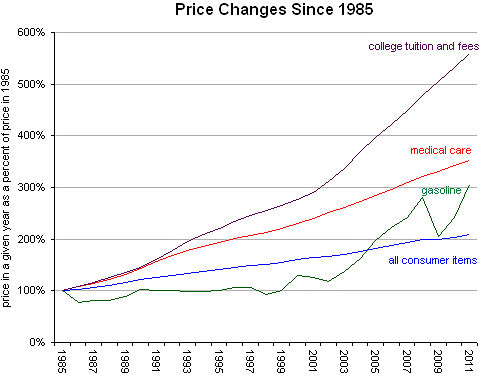
And it’s not just that tuition has been going up, at least at state school. It’s that state funding has been going down:

Next, it’s true that just supplying more loans to federal students doesn’t cut it: tuition rises to meet that ability to pay. In fact that’s part of what’s going on in the above picture.
What we have here is a feedback loop, and it’s hard to break. My personal approach would be to make state schools free to make the overall field competitive for college costs. And yes, that would mean the state pays the schools directly instead of handing out money to students in the form of loans. It’s called an investment in our future, and it also would help with the mobility problems we have. At some point I’m sure it seemed like a terrible idea to form a public elementary school system for free, but we don’t think so now (or do we, Rupert?).
The biggest gripe, if you can get through the article, is that Obama’s plan will allow students to pay off their loans with at most 10% of their salaries after college, and that certain people can stop paying after 10 years instead of 20. If you read from the excerpt above, this is an outrage and those unfairly entitled people are characterized as government and nonprofit workers, but the truth is the exemptions include people who work as police officers, as healthcare workers, in law, or in the military as well.
The ending of the article, which again I suggest you don’t read, is this:
The consequences for our economy are no less tragic than for the individual borrowers. They are being driven away from the path down which their natural ambition and talent might have taken them. President Obama keeps talking about reducing income equality. So why does he keep paying young people not to pursue higher incomes?
All I can say is, what? I get that Rupert or whoever wrote this likes private industry, but the claim that by encouraging a bunch of people to go into super high paying private jobs we will reduce income inequality is just weird. Has that person not understood the relationship between inequality and CEO pay?
I say if you are so gung-ho about private high-paying jobs, then you also need to embrace rising inequality. Do it in the name of free-market capitalism or something, but please stay logical.



