Archive
Stuff I’m reading
- A fascinating conversation with Gerald Posner, author of God’s Bankers: a History of Money and Power at the Vaticas, with crazy and horrible details of the Vatican’s bank’s dealings with the Nazis (hat tip Aryt Alasti). Also a review of the book in the New York Times.
- Nerding out on an interesting blog post by Laura McClay, who describes her involvement researching flood insurance (hat tip Jordan Ellenberg). One of my favorite point about insurance comes up in this piece, namely if you price insurance too accurately, it fails in its most basic function, and gets too expensive for those at highest risk.
- There’s a new social network created specifically to get people more involved in politics. It’s called Brigade, and it gets users to answer a bunch of questions about their beliefs. The business model hasn’t been unveiled yet, but this is information that political campaigns would find very valuable. Also see Alex Howard’s take. Could be scary, could be useful.
Guest post: Open-Source Loan-Level Analysis of Fannie and Freddie
This is a guest post by Todd Schneider. You can read the full post with additional analysis on Todd’s personal site.
[M]ortgages were acknowledged to be the most mathematically complex securities in the marketplace. The complexity arose entirely out of the option the homeowner has to prepay his loan; it was poetic that the single financial complexity contributed to the marketplace by the common man was the Gordian knot giving the best brains on Wall Street a run for their money. Ranieri’s instincts that had led him to build an enormous research department had been right: Mortgages were about math.
The money was made, therefore, with ever more refined tools of analysis.
—Michael Lewis, Liar’s Poker (1989)
Fannie Mae and Freddie Mac began reporting loan-level credit performance data in 2013 at the direction of their regulator, the Federal Housing Finance Agency. The stated purpose of releasing the data was to “increase transparency, which helps investors build more accurate credit performance models in support of potential risk-sharing initiatives.”
The GSEs went through a nearly $200 billion government bailout during the financial crisis, motivated in large part by losses on loans that they guaranteed, so I figured there must be something interesting in the loan-level data. I decided to dig in with some geographic analysis, an attempt to identify the loan-level characteristics most predictive of default rates, and more. The code for processing and analyzing the data is all available on GitHub.
The “medium data” revolution
In the not-so-distant past, an analysis of loan-level mortgage data would have cost a lot of money. Between licensing data and paying for expensive computers to analyze it, you could have easily incurred costs north of a million dollars per year. Today, in addition to Fannie and Freddie making their data freely available, we’re in the midst of what I might call the “medium data” revolution: personal computers are so powerful that my MacBook Air is capable of analyzing the entire 215 GB of data, representing some 38 million loans, 1.6 billion observations, and over $7.1 trillion of origination volume. Furthermore, I did everything with free, open-source software.
What can we learn from the loan-level data?
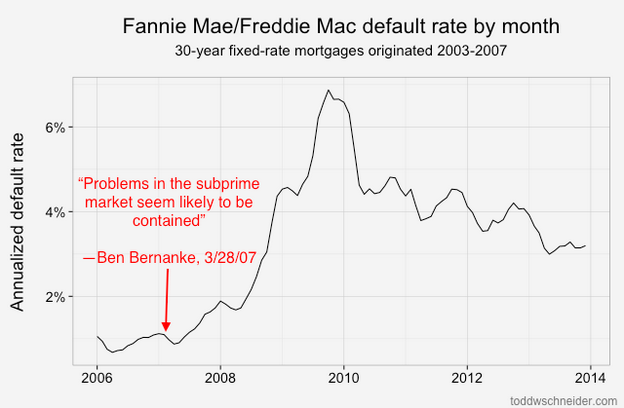
Loans originated from 2005-2008 performed dramatically worse than loans that came before them! That should be an extraordinarily unsurprising statement to anyone who was even slightly aware of the U.S. mortgage crisis that began in 2007:
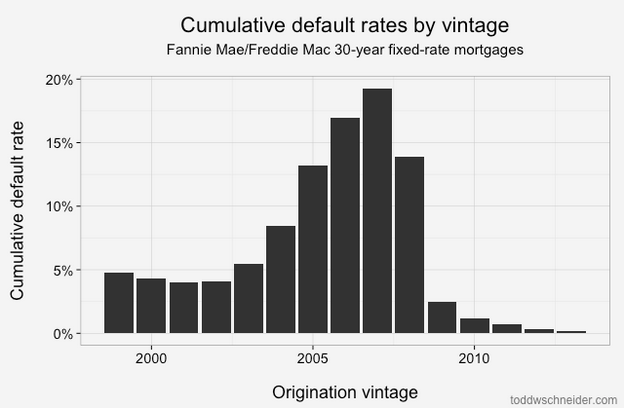
About 4% of loans originated from 1999 to 2003 became seriously delinquent at some point in their lives. The 2004 vintage showed some performance deterioration, and then the vintages from 2005 through 2008 show significantly worse performance: more than 15% of all loans originated in those years became distressed.
From 2009 through present, the performance has been much better, with fewer than 2% of loans defaulting. Of course part of that is that it takes time for a loan to default, so the most recent vintages will tend to have lower cumulative default rates while their loans are still young. But there has also been a dramatic shift in lending standards so that the loans made since 2009 have been much higher credit quality: the average FICO score used to be 720, but since 2009 it has been more like 765. Furthermore, if we look 2 standard deviations from the mean, we see that the low end of the FICO spectrum used to reach down to about 600, but since 2009 there have been very few loans with FICO less than 680:
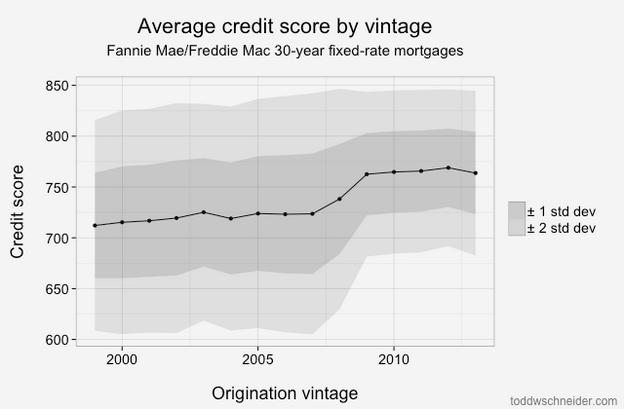
Tighter agency standards, coupled with a complete shutdown in the non-agency mortgage market, including both subprime and Alt-A lending, mean that there is very little credit available to borrowers with low credit scores (a far more difficult question is whether this is a good or bad thing!).
Geographic performance
Default rates increased everywhere during the bubble years, but some states fared far worse than others. I took every loan originated between 2005 and 2007, broadly considered to be the height of reckless mortgage lending, bucketed loans by state, and calculated the cumulative default rate of loans in each state:
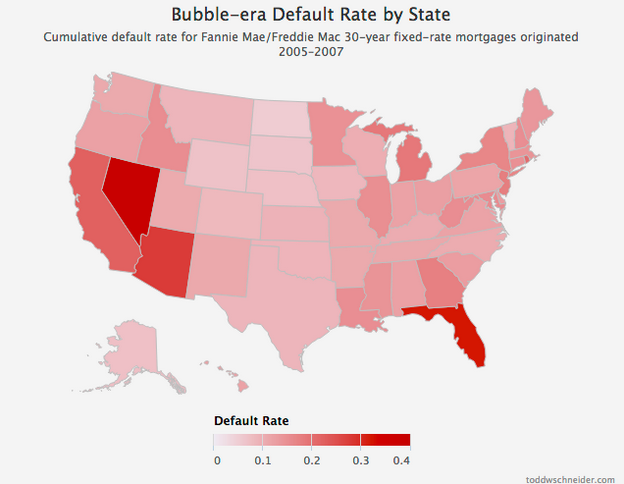
4 states in particular jump out as the worst performers: California, Florida, Arizona, and Nevada. Just about every state experienced significantly higher than normal default rates during the mortgage crisis, but these 4 states, often labeled the “sand states”, experienced the worst of it.
Read more
If you’re interested in more technical discussion, including an attempt to identify which loan-level variables are most correlated to default rates (the number one being the home price adjusted loan to value ratio), read the full post on toddwschneider.com, and be sure to check out the project on GitHub if you’d like to do your own data analysis.
The market for your personal data is maturing
As everyone knows, nobody reads their user agreements when they sign up for apps or services. Even if they did, it wouldn’t matter, because most of them stipulate that they can change at any moment. That moment has come.
You might not be concerned, but I’d like to point out that there’s a reason you’re not. Namely, you haven’t actually seen what this enormous loss of privacy translates into yet.
You see, there’s also a built in lag where we’ve given up our data, and are happily using the corresponding services, but we haven’t yet seen evidence that our data was actually worth something. The lag represents the time it takes for the market in personal data to mature. It also represents the patience that Silicon Valley venture capitalists have or do not have between the time of user acquisition and profit. The less patience they have, the sooner they want to exploit the user data.
The latest news (hat tip Gary Marcus) gives us reason to think that V.C. patience is running dry, and the corresponding market in personal data is maturing. Turns out that EBay and PayPal recently changed their user agreements so that, if you’re a user of either of those services, you will receive marketing calls using any phone number you’ve provided them or that they have “have otherwise obtained.” There is no possibility to opt out, except perhaps to abandon the services. Oh, and they might also call you for surveys or debt collections. Oh, and they claim their intention is to “benefit our relationship.”
Presumably this means they might have bought your phone number from a data warehouse giant like Acxiom, if you didn’t feel like sharing it. Presumably this also means that they will use your shopping history to target the phone calls to be maximally “tailored” for you.
I’m mentally tacking this new fact on the same board as I already have the Verizon/AOL merger, which is all about AOL targeting people with ads based on Verizon’s GPS data, and the recent broohaha over RadioShack’s attempt to sell its user data at auction in order to pay off creditors. That didn’t go through, but it’s still a sign that the personal data market is ripening, and in particular that such datasets are becoming assets as important as land or warehouses.
Given how much venture capitalists like to brag about their return, I think we have reason to worry about the coming wave of “innovative” uses of our personal data. Telemarketing is the tip of the iceberg.
Starting work at the GovLab soon
Guys! Exciting changes are afoot.
I’m extremely happy to say that I finished my first draft of my book, and although it’s not the end of that story, it’s still rather exhilarating. As of now the publication date is May 2016. My editor is reading it this week. Fingers crossed, everyone.
In the meantime, I’ve also recently heard that a grant proposal that I was on came through. This will have me working on interesting data questions from the Department of Justice out of the GovLab, which is run by Beth Noveck. It’ll be part time for now, at least until my book is done and until the Occupy Summer School is over, which is taking place more or less across the street from GovLab in downtown Brooklyn.
One thing that’s particularly great about being almost done with the book is that I’m looking forward to getting back to short-form writing. I’ve been so involved in the book, but as you can imagine it’s a very different mindset than a blogpost. When you write a book you have to carry around in your head an enormous amount of context, but when you write a blogpost you just need to have one idea and to say it well. It also helps if you’re annoyed (right, Eugene?).
Anyhoo, I’m pretty good at being annoyed, and I love and miss being mathbabe, so I’m more or less psyched to be coming back more consistently to this format soon. Although the life of a book writer is pretty awesome too, and I will definitely miss it. My favorite part has been the magical ability to connect with people who are experts on subjects I’m trying to learn about. Turns out people are extremely generous with their time and expertise, and I am grateful for that!
China announces it is scoring its citizens using big data
Please go read the article in the Dutch newspaper de Volkskrant entitled China rates its own citizens – including online behavior (hat tip Ernie Davis).
In the article, it describes China’s plan to use big data techniques to score all of its citizens – with the help of China internet giants Alibaba, Baidu, and Tencent – in a kind of expanded credit score that includes behavior and reputation. So what you buy, who you’re friends with, and whether you seem sufficiently “socialist” are factors that affect your overall score.
Here’s a quote from a person working on the model, from Chinese Academy of Social Science, that is incredibly creepy:
When people’s behavior isn’t bound by their morality, a system must be used to restrict their actions
And here’s another quote from Rogier Creemers, an academic at Oxford who specializes in China:
Government and big internet companies in China can exploit ‘Big Data’ together in a way that is unimaginable in the West
I guess I’m wondering whether that’s really true. Given my research over the past couple of years, I see this kind of “social credit scoring” being widely implemented here in the United States.
Looking for big data reading suggestions
I have been told by my editor to take a look at the books already out there on big data to make sure my book hasn’t already been written. For example, today I’m set to read Robert Scheer’s They Know Everything About You: how data-collecting corporations and snooping government agencies are destroying democracy.
This book, like others I’ve already read and written about (Bruce Schneier’s Data and Goliath, Frank Pasquale’s Black Box Society, and Julia Angwin’s Dragnet Nation) are all primarily concerned with individual freedom and privacy, whereas my book is primarily concerned with social justice issues, and each chapter gives an example of how big data is being used a tool against the poor, against minorities, against the mentally ill, or against public school teachers.
Not that my book is entirely different from the above books, but the relationship is something like what I spelled out last week when I discussed the four political camps in the big data world. So far the books I’ve found are focused on the corporate angle or the privacy angle. There may also be books focused on the open data angle, but I’m guessing they have even less in common with my book, which focuses on the ways big data increase inequality and further alienate already alienated populations.
If any of you know of a book I should be looking at, please tell me!
Putting the dick pic on the Snowden story
I’m on record complaining about how journalists dumb down stories in blind pursuit of “naming the victim” or otherwise putting a picture on the story.
But then again, sometimes that’s exactly what you need to do, especially when the story is super complicated. Case in point: the Snowden revelations story.
In the past 2 weeks I’ve seen the Academy Award winning feature length film CitizenFour, I’ve read Bruce Schneier’s recent book, Data and Goliath: The Hidden Battles To Collect Your Data And Control Your World, and finally I watched John Oliver’s recent Snowden episode.
They were all great in their own way. I liked Schneier’s book, it was a quick read, and I’d recommend it to people who want to know more than Oliver’s interview shows us. He’s very very smart, incredibly well informed, and almost completely reasonable (unlike this review).
To be honest, though, when I recommend something to other people, I pick John Oliver’s approach; he cleverly puts the dick pic on the story (you have to reset it to the beginning):
Here’s the thing that I absolutely love about Oliver’s interview. He’s not absolutely smitten by Snowden, but he recognizes Snowden’s goal, and makes it absolutely clear what it means to people using the handy use case of how nude pictures get captured in the NSA dragnets. It is really brilliant.
Compared to Schneier’s book, Oliver is obviously not as informational. Schneier is a world-wide expert on security, and gives us real details on which governmental programs know what and how. But honestly, unless you’re interested in becoming a security expert, that isn’t so important. I’m a tech nerd and even for me the details were sometimes overwhelming.
Here’s what I want to concentrate on. In the last part of the book, Schneier suggests all sorts of ways that people can protect their own privacy, using all sorts of encryption tools and so on. He frames it as a form of protest, but it seems like a LOT of work to me.
Compare that to my favorite part of the Oliver interview, when Oliver asks Snowden (starting at minute 30:28 in the above interview) if we should “just stop taking dick pics.” Snowden’s answer is no: changing what we normally do because of surveillance is a loss of liberty, even if it’s dumb.
I agree, which is why I’m not going to stop blabbing my mouth off everywhere (I don’t actually send naked pictures of myself to people, I think that’s a generational thing).
One last thing I can’t resist saying, and which Schneier discusses at length: almost every piece of data collected about us by our government is more or less for sale anyway. Just think about that. It is more meaningful for people worried about large scale discrimination, like me, than it is for people worried about case-by-case pinpointed governmental acts of power and suppression.
Or, put it this way: when we are up in arms about the government having our dick pics, we forget that so do our phones, and so does Facebook, or Snapchat, not to mention all the backups on the cloud somewhere.
Workplace Personality Tests: a Cynical View
There’s a frightening article in the Wall Street Journal by Lauren Weber about personality tests people are now forced to take to get shitty jobs in customer calling centers and the like. Some statistics from the article include: 8 out of 10 of the top private employers use such tests, and 57% of employers overall in 2013, a steep rise from previous years.
The questions are meant to be ambiguous so you can’t game them if you are an applicant. For example, yes or no: “I have never understood why some people find abstract art appealing.”
At the end of the test, you get a red light, a yellow light, or a green light. Red lighted people never get an interview, and yellow lighted may or may not. Companies cited in the article use the tests to disqualify more than half their applicants without ever talking to them in person.
The argument for these tests is that, after deploying them, turnover has gone down by 25% since 2000. The people who make and sell personality tests say this is because they’re controlling for personality type and “company fit.”
I have another theory about why people no longer leave shitty jobs, though. First of all, the recession has made people’s economic lives extremely precarious. Nobody wants to lose a job. Second of all, now that everyone is using arbitrary personality tests, the power of the worker to walk off the job and get another job the next week has gone down. By the way, the usage of personality tests seems to correlate with a longer waiting period between applying and starting work, so there’s that disincentive as well.
Workplace personality tests are nothing more than voodoo management tools that empower employers. In fact I’ve compared them in the past to modern day phrenology, and I haven’t seen any reason to change my mind since then. The real “metric of success” for these models is the fact that employers who use them can fire a good portion of their HR teams.
Fingers crossed – book coming out next May
As it turns out, it takes a while to write a book, and then another few months to publish it.
I’m very excited today to tentatively announce that my book, which is tentatively entitled Weapons of Math Destruction: How Big Data Increases Inequality and Threatens Democracy, will be published in May 2016, in time to appear on summer reading lists and well before the election.
Fuck yeah! I’m so excited.
p.s. Fight for 15 is happening now.
Open Data conference at Berkeley Center for Law & Technology this Friday
I’m excited to be involved with an interesting and important conference this coming Friday at UC Berkeley, held by the Berkeley Center for Law & Technology as well as the student-run journal, the Berkeley Technology Law Journal.
It’s a one day event, entitled Open Data: Addressing Privacy, Security, and Civil Rights Challenges, and it’s got the following blurb:
How can open data promote trust in government without creating a transparent citizenry? Governments at all levels are releasing large datasets for analysis by anyone for any purpose—“Open Data.” Using Open Data, entrepreneurs may create new products and services, and citizens may use it to gain insight into the government. A plethora of time saving and other useful applications have emerged from Open Data feeds, including more accurate traffic information, real-time arrival of public transportation, and information about crimes in neighborhoods.
The program is here, and as you’ll see I’m participating in two ways. First, I’m giving a tutorial first thing in the morning on “doing data science,” which is to say I’m doing my best to explain to a room full of lawyers, in 40 minutes, what it is that modelers actually do with data, and how there might be ethical concerns. Feel free to give me advice on this talk!
Then at the end of the day, I’m in charge of “responding” to Panel 3. Since this is something we don’t have in academic math conferences or talks, I had to ask my lawyer friend what it means to respond, and his answer was that I just take notes during the panel discussion and then I get to comment on stuff I’ve heard. This will be my chance to talk about whether the laws they are talking about, or the proposed changes in the laws, make sense to the world of modeling.
I’m a bit concerned that I simply won’t understand what they’re talking about, since they are experts in this field of security and privacy law which I know very little about, but in any case I’m looking forward to learning a lot on Friday.
A/B testing in politics
As research for my book I’m studying the way people use big data techniques, mostly from the marketing world, in politics. So naturally I was intrigued by Kyle Rush’s blogpost about A/B testing on the Obama campaign. Kyle was the Deputy Director of Frontend Web Development at Obama for America.
In case you don’t know the lingo, A/B testing is a test done by marketers to decide which of two ad designs is more effective – the ad with the dark blue background or the ad with the dark red background, for example. But in this case it was more like, the ad with Obama’s family or the ad with Obama’s family and the American flag in the background.
The idea is, as a marketer, you offer your target audience both ads – actually, any individual in the target audience either sees ad A or ad B, randomly – and then, after enough people have seen the ads, you see which population responds more, and you go with that version. Then you move on to the next test, where you keep the characteristic that just won and you test some other aspect of the ad, like the font.
As a mathematical testing framework, A/B testing is interesting and has structural complications – how do you know you’re getting a global maximum instead of a local maximum? In other words, if you’d first tested the font, and then the background color, would you have ended up with a “better ad”? What if there are 50 things you’d like to test, how do you decide which order to test them in?
But that’s not what interests me about Kyle’s Obama A/B testing blogpost. Rather, I’m fascinated by the definition of success that was chosen.
After all, an A/B test is all about which ad “works better,” so there has to be some way to measure success, and it has to be measured in real time if you want to go through many iterations of your ad.
In the case of the Obama campaign, there were two definitions of success, or maybe three: how often people signed up to be on Obama’s newsletter, how often they gave money, and how much money they gave. I infer this from Kyle’s braggy second sentence, “Overall we executed about 500 a/b tests on our web pages in a 20 month period which increased donation conversions by 49% and sign up conversions by 161%.” Those were the measures Kyle and his team was optimizing on.
Most of the blog post focused on getting people to donate more, and specifically on getting them to fill out the credit card donation page form. Here’s what they A/B tested:
Our plan was to separate the field groups into four smaller steps so that users did not feel overwhelmed by the length of the form. Essentially the idea was to get users to the top of the mountain by showing them a small incline rather than a steep slope.
What I find super interesting about this stuff (and of course this not the only “data science” that was used in Obama’s campaign, there was a separate team focused on getting Facebook users to share their friends’ lists and such) is that nowhere is there even a slight nod to the question of whether this stuff will improve or even maintain democracy. They don’t even discuss how maintainable this is.
I mean, we gave the Obama analytics team lots of credit for stuff, but in the end what they did was optimize a bunch of people’s donation money. Is that something we should cheer? It seems more like an arms race with the Republican party, in which the Democrats pulled ahead temporarily. And all it means is that the fight for donations will be even more manipulative, by both sides, by the next presidential election cycle.
As Felix Salmon pointed out to me over beer and sausages last week, the problem with big data in politics is that the easiest thing you can measure in politics is money, which means everything is optimized to that metric of success, leaving all other considerations ignored and probably stifled. And yes, “sign ups” are also measurable, but they more or less correspond to people who will receive weekly or daily requests for money from the candidate.
Readers, please tell me I’m wrong. Or suggest a way we can measure something and optimize to something that is less cynical than the size of a war chest.
A critique of a review of a book by Bruce Schneier
I haven’t yet read Bruce Schneier’s new book, Data and Goliath: The Hidden Battles To Collect Your Data and Control Your World. I plan to in the coming days, while I’m traveling with my kids for spring break.
Even so, I already feel capable of critiquing this review of his book (hat tip Jordan Ellenberg), written by Columbia Business School Professor and Investment Banker Jonathan Knee. You see, I’m writing a book myself on big data, so I feel like I understand many of the issues intimately.
The review starts out flattering, but then it hits this turn:
When it comes to his specific policy recommendations, however, Mr. Schneier becomes significantly less compelling. And the underlying philosophy that emerges — once he has dispensed with all pretense of an evenhanded presentation of the issues — seems actually subversive of the very democratic principles that he claims animates his mission.
That’s a pretty hefty charge. Let’s take a look into Knee’s evidence that Schneier wants to subvert democratic principles.
NSA
First, he complains that Schneier wants the government to stop collecting and mining massive amounts of data in its search for terrorists. Knee thinks this is dumb because it would be great to have lots of data on the “bad guys” once we catch them.
Any time someone uses the phrase “bad guys,” it makes me wince.
But putting that aside, Knee is either ignorant of or is completely ignoring what mass surveillance and data dredging actually creates: the false positives, the time and money and attention, not to mention the potential for misuse and hacking. Knee’s opinion on that is simply that we normal citizens just don’t know enough to have an opinion on whether it works, including Schneier, and in spite of Schneier knowing Snowden pretty well.
It’s just like waterboarding – Knee says – we can’t be sure it isn’t a great fucking idea.
Wait, before we move on, who is more pro-democracy, the guy who wants to stop totalitarian social control methods, or the guy who wants to leave it to the opaque authorities?
Corporate Data Collection
Here’s where Knee really gets lost in Schneier’s logic, because – get this – Schneier wants corporate collection and sale of consumer data to stop. The nerve. As Knee says:
Mr. Schneier promotes no less than a fundamental reshaping of the media and technology landscape. Companies with access to large amounts of personal data would be “automatically classified as fiduciaries” and subject to “special legal restrictions and protections.”
That these limits would render illegal most current business models — under which consumers exchange enhanced access by advertisers for free services – does not seem to bother Mr. Schneier”
I can’t help but think that Knee cannot understand any argument that would threaten the business world as he knows it. After all, he is a business professor and an investment banker. Things seem pretty well worked out when you live in such an environment.
By Knee’s logic, even if the current business model is subverting democracy – which I also argue in my book – we shouldn’t tamper with it because it’s a business model.
The way Knee paints Schneier as anti-democratic is by using the classic fallacy in big data which I wrote about here:
Although professing to be primarily preoccupied with respect of individual autonomy, the fact that Americans as a group apparently don’t feel the same way as he does about privacy appears to have little impact on the author’s radical regulatory agenda. He actually blames “the media” for the failure of his positions to attract more popular support.
Quick summary: Americans as a group do not feel this way because they do not understand what they are trading when they trade their privacy. Commercial and governmental interests, meanwhile, are all united in convincing Americans not to think too hard about it. There are very few people devoting themselves to alerting people to the dark side of big data, and Schneier is one of them. It is a patriotic act.
Also, yes Professor Knee, “the media” generally speaking writes down whatever a marketer in the big data world says is true. There are wonderful exceptions, of course.
So, here’s a question for Knee. What if you found out about a threat on the citizenry, and wanted to put a stop to it? You might write a book and explain the threat; the fact that not everyone already agrees with you wouldn’t make your book anti-democratic, would it?
MLK
The rest of the review basically boils down to, “you don’t understand the teachings of the Reverend Dr. Martin Luther King Junior like I do.”
Do you know about Godwin’s law, which says that as soon as someone invokes the Nazis in an argument about anything, they’ve lost the argument?
I feel like we need another, similar rule, which says, if you’re invoking MLK and claiming the other person is misinterpreting him while you have him nailed, then you’ve lost the argument.
Data Justice Launches!
I’m super excited to announce that I’m teaming up with Nathan Newman and Frank Pasquale on a newly launched project called Data Justice and subtitled Challenging Rising Exploitation and Economic Inequality from Big Data.
Nathan Newman is the director of Data Justice and is a lawyer and policy advocate. You might remember his work with racial and economic profiling of Google ads. Frank Pasquale is a law professor at the University of Maryland and the author of a book I recently reviewed called The Black Box Society.
The mission for Data Justice can be read here and explains how we hope to build a movement on the data justice front by working across various disciplines like law, computer science, and technology. We also have a blog and a press release which I hope you have time to read.
Reforming the data-driven justice system
This article from the New York Times really interests me. It’s entitled Unlikely Cause Unites the Left and the Right: Justice Reform, and although it doesn’t specifically mention “data driven” approaches in justice reform, it describes “emerging proposals to reduce prison populations, overhaul sentencing, reduce recidivism and take on similar initiatives.”
I think this sentence, especially the reference to reducing recidivism, is code for the evidence-based sentencing that my friend Luis Daniel recently posted about. I recently finished a draft chapter in my book about such “big data” models, and after much research I can assure you that this stuff runs the gamut between putting poor people away for longer because they’re poor and actually focusing resources where they’re needed.
The idea that there’s a coalition that’s taking this on that includes both Koch Industries and the ACLU is fascinating and bizarre and – if I may exhibit a rare moment of optimism – hopeful. In particular I’m desperately hoping they have involved people who understand enough about modeling not to assume that the results of models are “objective”.
There are, in fact, lots of ways to set up data-gathering and usage in the justice system to actively fight against unfairness and unreasonably long incarcerations, rather than to simply codify such practices. I hope some of that conversation happens soon.
Big data and class
About a month ago there was an interesting article in the New York Times entitled Blowing Off Class? We Know. It discusses the “big data” movement in colleges around the country. For example, at Ball State, they track which students go to parties at the student center. Presumably to help them study for tests, or maybe to figure out which ones to hit up for alumni gifts later on.
There’s a lot to discuss in this article, but I want to focus today on one piece:
Big data has a lot of influential and moneyed advocates behind it, and I’ve asked some of them whether their enthusiasm might also be tinged with a little paternalism. After all, you don’t see elite institutions regularly tracking their students’ comings and goings this way. Big data advocates don’t dispute that, but they also note that elite institutions can ensure that their students succeed simply by being very selective in the first place.
The rest “get the students they get,” said William F. L. Moses, the managing director of education programs at the Kresge Foundation, which has given grants to the innovation alliance and to bolster data-analytics efforts at other colleges. “They have a moral obligation to help them succeed.”
This is a sentiment I’ve noticed a lot, although it’s not usually this obvious. Namely, the elite don’t need to be monitored, but the rabble does. The rich and powerful get to be quirky philosophers but the rest of the population need to be ranked and filed. And, by the way, we are spying on them for their own good.
In other words, never mind how big data creates and expands classism; classism already helps decide who is put into the realm of big data in the first place.
It feeds into the larger question of who is entitled to privacy. If you want to be strict about your definition of pricacy, you might say “nobody.” But if you recognize that privacy is a spectrum, where we have a variable amount of information being collected on people, and also a variable amount of control over people whose information we have collected, then upon study, you will conclude that privacy, or at least relative privacy, is for the rich and powerful. And it starts early.
Wage Gaps Don’t Magically Get Smaller Because Big Data
Today, just a rant. Sorry. I mean, I’m not a perfect person either, and of course that’s glaringly obvious, but this fluff piece from Wired, written by Pam Wikham of Raytheon, is just aggravating.
The title is Big Data, Smaller Wage Gap? and, you know, it almost gives us the impression that she has a plan to close the wage gap using big data, or alternatively an argument that the wage gap will automatically close with the advent of big data techniques. It turns out to be the former, but not really.
After complaining about the wage gap for women in general, and after we get to know how much she loves her young niece, here’s the heart of the plan (emphasis mine, on the actual plan parts of the plan):
Analytics and microtargeting aren’t just for retailers and politicians — they can help us grow the ranks of executive women and close the gender wage gap. Employers analyze who clicked on internal job postings, and we can pursue qualified women who looked but never applied. We can go beyond analyzing the salary and rank histories of women who have left our companies. We can use big data analytics to tell us what exit interviews don’t.
Facebook posts, Twitter feeds and LinkedIn groups provide a trove of valuable intel from ex-employees. What they write is blunt, candid and useful. All the data is there for the taking — we just have to collect it and figure out what it means. We can delve deep into whether we’re promoting the best people, whether we’re doing enough to keep our ranks diverse, whether potential female leaders are being left behind and, importantly, why.
That’s about it, after that she goes back to her niece.
Here’s the thing, I’m not saying it’s not an important topic, but that plan doesn’t seem worthy of the title of the piece. It’s super vague and fluffy and meaningless. I guess, if I had to give it meaning, it would be that she’s proposing to understand internal corporate sexism using data, rather than assuming “data is objective” and that all models will make things better. And that’s one tiny step, but it’s not much. It’s really not enough.
Here’s an idea, and it kind of uses big data, or at least small data, so we might be able to sell it. Ask people in your corporate structure what the actual characteristics are of people they promote, and how they are measured, or if they are measured, and look at the data to see if what they say is consistent with what they do, and whether those characteristics are inherently sexist. It’s a very specific plan and no fancy mathematical techniques are necessary, but we don’t have to tell anyone that.
What combats sexism is a clarification and transparent description of job requirements and a willingness to follow through. Look at blind orchestra auditions for a success story there. By contrast, my experience with the corporate world is that, when hiring or promoting, they often list a long series of unmeasurable but critical properties like “good cultural fit” and “leadership qualities” that, for whatever reason, more men are rated high on than women.
What would a data-driven Congress look like?
Recently I’ve seen two very different versions of what a more data-driven Congress would look like, both emerging from the recent cruddy Cromnibus bill mess.
First, there’s this Bloomberg article, written by the editors, about using data to produce evidence on whether a given policy is working or not. Given what I know about how data is produced, and how definitions of success are politically manipulated, I don’t have much hope for this idea.
Second, there was a reader’s comments on this New York Times article, also about the Cromnibus bill. Namely, the reader was calling on the New York Times to not only explore a few facts about what was contained in the bill, but lay it out with more numbers and more consistency. I think this is a great idea. What if, when Congress gave us a shitty bill, we could see stuff like:
- how much money is allocated to each thing, both raw dollars and as a percentage of the whole bill,
- who put it in the omnibus bill,
- the history of that proposed spending, and the history of voting,
- which lobbyists were pushing it, and who gets paid by them, and ideally
- all of this would be in an easy-to-use interactive.
That’s the kind of data that I’d love to see. Data journalism is an emerging field, and we might not be there yet, but it’s something to strive for.
Fairness, accountability, and transparency in big data models
As I wrote about already, last Friday I attended a one day workshop in Montreal called FATML: Fairness, Accountability, and Transparency in Machine Learning. It was part of the NIPS conference for computer science, and there were tons of nerds there, and I mean tons. I wanted to give a report on the day, as well as some observations.
First of all, I am super excited that this workshop happened at all. When I left my job at Intent Media in 2011 with the intention of studying these questions and eventually writing a book about them, they were, as far as I know, on nobody’s else’s radar. Now, thanks to the organizers Solon and Moritz, there are communities of people, coming from law, computer science, and policy circles, coming together to exchange ideas and strategies to tackle the problems. This is what progress feels like!
OK, so on to what the day contained and my copious comments.
Hannah Wallach
Sadly, I missed the first two talks, and an introduction to the day, because of two airplane cancellations (boo American Airlines!). I arrived in the middle of Hannah Wallach’s talk, the abstract of which is located here. Her talk was interesting, and I liked her idea of having social scientists partnered with data scientists and machine learning specialists, but I do want to mention that, although there’s a remarkable history of social scientists working within tech companies – say at Bell Labs and Microsoft and such – we don’t see that in finance at all, nor does it seem poised to happen. So in other words, we certainly can’t count on social scientists to be on hand when important mathematical models are getting ready for production.
Also, I liked Hannah’s three categories of models: predictive, explanatory, and exploratory. Even though I don’t necessarily think that a given model will fall neatly into one category or the other, they still give you a way to think about what we do when we make models. As an example, we think of recommendation models as ultimately predictive, but they are (often) predicated on the ability to understand people’s desires as made up of distinct and consistent dimensions of personality (like when we use PCA or something equivalent). In this sense we are also exploring how to model human desire and consistency. For that matter I guess you could say any model is at its heart an exploration into whether the underlying toy model makes any sense, but that question is dramatically less interesting when you’re using linear regression.
Anupam Datta and Michael Tschantz
Next up Michael Tschantz reported on work with Anupam Datta that they’ve done on Google profiles and Google ads. The started with google’s privacy policy, which I can’t find but which claims you won’t receive ads based on things like your health problems. Starting with a bunch of browsers with no cookies, and thinking of each of them as fake users, they did experiments to see what actually happened both to the ads for those fake users and to the google ad profiles for each of those fake users. They found that, at least sometimes, they did get the “wrong” kind of ad, although whether Google can be blamed or whether the advertiser had broken Google’s rules isn’t clear. Also, they found that fake “women” and “men” (who did not differ by any other variable, including their searches) were offered drastically different ads related to job searches, with men being offered way more ads to get $200K+ jobs, although these were basically coaching sessions for getting good jobs, so again the advertisers could have decided that men are more willing to pay for such coaching.
An issue I enjoyed talking about was brought up in this talk, namely the question of whether such a finding is entirely evanescent or whether we can call it “real.” Since google constantly updates its algorithm, and since ad budgets are coming and going, even the same experiment performed an hour later might have different results. In what sense can we then call any such experiment statistically significant or even persuasive? Also, IRL we don’t have clean browsers, so what happens when we have dirty browsers and we’re logged into gmail and Facebook? By then there are so many variables it’s hard to say what leads to what, but should that make us stop trying?
From my perspective, I’d like to see more research into questions like, of the top 100 advertisers on Google, who saw the majority of the ads? What was the economic, racial, and educational makeup of those users? A similar but different (because of the auction) question would be to reverse-engineer the advertisers’ Google ad targeting methodologies.
Finally, the speakers mentioned a failure on Google’s part of transparency. In your advertising profile, for example, you cannot see (and therefore cannot change) your marriage status, but advertisers can target you based on that variable.
Sorelle Friedler, Carlos Scheidegger, and Suresh Venkatasubramanian
Next up we had Sorelle talk to us about her work with two guys with enormous names. They think about how to make stuff fair, the heart of the question of this workshop.
First, if we included race in, a resume sorting model, we’d probably see negative impact because of historical racism. Even if we removed race but included other attributes correlated with race (say zip code) this effect would remain. And it’s hard to know exactly when we’ve removed the relevant attributes, but one thing these guys did was define that precisely.
Second, say now you have some idea of the categories that are given unfair treatment, what can you do? One thing suggested by Sorelle et al is to first rank people in each category – to assign each person a percentile in their given category – and then to use the “forgetful function” and only consider that percentile. So, if we decided at a math department that we want 40% women graduate students, to achieve this goal with this method we’d independently rank the men and women, and we’d offer enough spots to top women to get our quota and separately we’d offer enough spots to top men to get our quota. Note that, although it comes from a pretty fancy setting, this is essentially affirmative action. That’s not, in my opinion, an argument against it. It’s in fact yet another argument for it: if we know women are systemically undervalued, we have to fight against it somehow, and this seems like the best and simplest approach.
Ed Felten and Josh Kroll
After lunch Ed Felton and Josh Kroll jointly described their work on making algorithms accountable. Basically they suggested a trustworthy and encrypted system of paper trails that would support a given algorithm (doesn’t really matter which) and create verifiable proofs that the algorithm was used faithfully and fairly in a given situation. Of course, we’d really only consider an algorithm to be used “fairly” if the algorithm itself is fair, but putting that aside, this addressed the question of whether the same algorithm was used for everyone, and things like that. In lawyer speak, this is called “procedural fairness.”
So for example, if we thought we could, we might want to turn the algorithm for punishment for drug use through this system, and we might find that the rules are applied differently to different people. This algorithm would catch that kind of problem, at least ideally.
David Robinson and Harlan Yu
Next up we talked to David Robinson and Harlan Yu about their work in Washington D.C. with policy makers and civil rights groups around machine learning and fairness. These two have been active with civil rights group and were an important part of both the Podesta Report, which I blogged about here, and also in drafting the Civil Rights Principles of Big Data.
The question of what policy makers understand and how to communicate with them came up several times in this discussion. We decided that, to combat cherry-picked examples we see in Congressional Subcommittee meetings, we need to have cherry-picked examples of our own to illustrate what can go wrong. That sounds bad, but put it another way: people respond to stories, especially to stories with innocent victims that have been wronged. So we are on the look-out.
Closing panel with Rayid Ghani and Foster Provost
I was on the closing panel with Rayid Ghani and Foster Provost, and we each had a few minutes to speak and then there were lots of questions and fun arguments. To be honest, since I was so in the moment during this panel, and also because I was jonesing for a beer, I can’t remember everything that happened.
As I remember, Foster talked about an algorithm he had created that does its best to “explain” the decisions of a complicated black box algorithm. So in real life our algorithms are really huge and messy and uninterpretable, but this algorithm does its part to add interpretability to the outcomes of that huge black box. The example he gave was to understand why a given person’s Facebook “likes” made a black box algorithm predict they were gay: by displaying, in order of importance, which likes added the most predictive power to the algorithm.
[Aside, can anyone explain to me what happens when such an algorithm comes across a person with very few likes? I’ve never understood this very well. I don’t know about you, but I have never “liked” anything on Facebook except my friends’ posts.]
Rayid talked about his work trying to develop a system for teachers to understand which students were at risk of dropping out, and for that system to be fair, and he discussed the extent to which that system could or should be transparent.
Oh yeah, and that reminds me that, after describing my book, we had a pretty great argument about whether credit scoring models should be open source, and what that would mean, and what feedback loops that would engender, and who would benefit.
Altogether a great day, and a fantastic discussion. Thanks again to Solon and Moritz for their work in organizing it.
Video cameras won’t solve the #EricGarner situation, but they will help
As many thoughtful people have pointed out already, Eric Garner’s case proves that video evidence is not a magic bullet to combat and punish undue police brutality. The Grand Jury deemed such evidence insufficient for an indictment, even if the average person watching the video cannot understand that point of view.
Even so, it would be a mistake to dismiss video cameras on police as entirely a bad idea. We shouldn’t assume no progress could be made simply because there’s an example which lets us down. I am no data evangelist, but neither am I someone who dismisses data. It can be powerful and we should use its power when we can.
And before I try to make the general case for video cameras on cops, let me make one other point. The Eric Garner video has already made progress in one arena, namely public opinion. Without the video, we wouldn’t be seeing nationwide marches protesting the outrageous police conduct.
A few of my data nerd thoughts:
- If cops were required to wear cameras, we’d have more data. We should think of that as building evidence, with the potential to use it to sway grand juries, criminal juries, judges, or public opinion.
- One thing I said time after time to my students this summer at the data journalism program I directed is the following: a number by itself is usually meaningless. What we need is to compare that number to a baseline. The baseline could be the average number for a population, or the median, or some range of 5th to 95th percentiles, or how it’s changed over time, or whatnot. But in order to gauge any baseline you need data.
- So in the case of police videotapes, we’d need to see how cops usually handle a situation, or how cops from other precincts handle similar situations, or the extremes of procedures in such situations, or how police have changed their procedures over time. And if we think the entire approach is heavy handed, we can also compare the data to the police manual, or to other countries, or what have you. More data is better for understanding aggregate approaches, and aggregate understanding makes it easier to fit a given situation into context.
- Finally, the cameras might also change their behavior when they are policing, knowing they are being taped. That’s believable but we shouldn’t depend on it.
- And also, we have to be super careful about how we use video evidence, and make sure it isn’t incredibly biased due to careful and unfair selectivity by the police. So, some cops are getting in trouble for turning off their cameras at critical moments, or not turning them on ever.
Let’s take a step back and think about how large-scale data collection and mining works, for example in online advertising. A marketer collects a bunch of data. And knowing a lot about one person doesn’t necessarily help them, but if they know a lot about most people, it statistically speaking does help them sell stuff. A given person might not be in the mood to buy, or might be broke, but if you dangle desirable good in front of a whole slew of people, you make sales. It’s a statistical play which, generally speaking, works.
In this case, we are the marketer, and the police are the customers. We want a lot of information about how they do their job so when the time comes we have some sense of “normal police behavior” and something to compare a given incident to or a given cop to. We want to see how they do or don’t try to negotiate peace, and with whom. We want to see the many examples of good and great policing as well as the few examples of terrible, escalating policing.
Taking another step back, if the above analogy seems weird, there’s a reason for that. In general data is being collected on the powerless, on the consumers, on the citizens, or the job applicants, and we should be pushing for more and better data to be collected instead on the powerful, on the police, on the corporations, and on the politicians. There’s a reason there is a burgeoning privacy industry for rich and powerful people.
For example, we want to know how many people have been killed by the police, but even a statistic that important is incredibly hard to come by (see this and this for more on that issue). However, it’s never been easier for the police to collect data on us and act on suspicions of troublemakers, however that is defined.
Another example – possibly the most extreme example of all – comes this very week from the reports on the CIA and torture. That is data and evidence we should have gotten much earlier, and as the New York Times demands, we should be able to watch videos of waterboarding and decide for ourselves whether it constitutes torture.
So yes, let’s have video cameras on every cop. It is not a panacea, and we should not expect it to solve our problems over night. In fact video evidence, by itself, will not solve any problem. We should think it as a mere evidence collecting device, and use it in the public discussion of how the most powerful among us treat the least powerful. But more evidence is better.
Finally, there’s the very real question of who will have access to the video footage, and whether the public will be allowed to see it at all. It’s a tough question, which will take a while to sort out (FOIL requests!), but until then, everyone should know that it is perfectly legal to videotape police in every place in this country. So go ahead and make a video with your camera when you suspect weird behavior.
Will Demographics Solve the College Tuition Problem? (A: I Don’t Know)
I’ve got two girls in middle school. They are lovely and (in my opinion as a proud dad) smart. I wonder, on occasion, what college will they go to and what their higher education experience will be like? No matter how lovely or smart my daughters are, though, it will be hard to fork over all of that tuition money. It sure would be nice if college somehow got cheaper by the time my daughters are ready in 6 or 8 years!
How likely is this? There has been plenty of coverage about how the cost of college has risen so dramatically over the past decades. A number of smart people have argued that the reason tuition has increased so much is because of all of the amenities that schools have built in recent years. Others are unconvinced that’s the reason, pointing out that increased spending by universities grew at a lower than the rate of tuition increases. Perhaps schools have been buoyed by a rising demographic trend – but it’s clear tuition increases have had a great run.
One way colleges have been able to keep increasing tuitions is by competing aggressively for wealthy students who can pay the full price of tuition (which also enables the schools to offer more aid to less than wealthy students). The children of the wealthy overseas are particularly desirable targets, apparently. I heard a great quote yesterday about this by Brad Delong – that his school, Berkeley, and other top universities presumably had become “finishing school[s] for the superrich of Asia.” It’s an odd sort of competition, though, where schools are competing for a particular customer (wealthy students) by raising prices. Presumably, this suggests that colleges have had pricing power to raise tuition due to increased demand (perhaps aided by increase in student loans, but that’s an argument for another day).
Will colleges continue to have this pricing power? For the optimistic future tuition payer, there are some signs that university pricing power may be eroding. Tuition increased at a slower rate this year (a bit more than 3%) but still at a rate that well exceeds inflation. And law schools are already resorting to price cutting after precipitous declines in applications – down 37% in 2014 compared to 2010!
College enrollment trends are a mixed bag and frequently obscured by studies from in-industry sources. Clearly, the 1990s and 2000s were a time a great growth for colleges – college enrollment grew by 48% from 1990 (12 million students) to 2012 (17.7 million). But 2010 appears to be the recent peak and enrollment fell by 2% from 2010 to 2012. In addition, overall college enrollment declined by 2.3% in 2014, although this decline is attributed to the 9.6% decline in two-year colleges while 4-year college enrollment actually increased by 1.2%.
It makes sense that the recent college enrollment trend would be down – the number of high school graduates appears to have peaked in 2010 at 3.3 million or so and is projected to decline to about 3.1 million in 2016 and stay lowish for the next few years. The US Census reports that there was a bulge of kids that are college age now (i.e. there were 22.04 million 14-19 year olds at the 2010 Census), but there are about 1.7 million fewer kids that are my daughters’ age (i.e., 5-9 year olds in the 2010 Census). That’s a pretty steep drop off (about 8%) in this pool of potential college students. These demographic trends have got some people worried. Moody’s, which rates the debt of a lot of colleges, has been downgrading a lot of smaller schools and says that this type of school has already been hit by declining enrollment and revenue. One analyst went so far as to warn of a “death spiral” at some schools due to declining enrollment. Moody’s analysis of declining revenue is an interesting factor, in light of reports of ever-increasing tuition. Last year Moody’s reported that 40% of colleges or universities (that were rated) faced stagnant or declining net tuition revenue.
Speaking strictly, again, as a future payer of my daughters’ college tuition, falling college age population and falling enrollment would seem to point to the possibility that tuition will be lower for my kids when the time comes. Plus there are a lot of other factors that seem to be lining up against the prospects for college tuition – like continued flat or declining wages, the enormous student loan bubble (it can’t keep growing, right?), the rise of online education…
And yet, I’m not feeling that confident. Elite universities (and it certainly would be nice if my girls could get into such a school) seem to have found a way to collect a lot of tuition from foreign students (it’s hard to find a good data source for that though) which protects them from the adverse demographic and economic trends. I’ve wondered if US students could get turned off by the perception that top US schools have too many foreign students and are too much, as Delong says, elite finishing schools. But that’s hard to predict and may take many years to reach a tipping point. Plus if tuition and enrollment drop a lot, that may cripple the schools that have taken out a lot of debt to build all of those nice amenities. A Harvard Business School professor rather bearishly projects that as many as half of the 4,000 US colleges and universities may fail in the next 15 years. Would a sharp decrease in the number of colleges due to falling enrollment have the effect of reducing competition at the remaining schools? If so, what impact would that have on tuition?
Both college tuition and student loans have been described as bubbles thanks to their recent rate of growth. At some point, bubbles burst (in theory). As someone who watched, first hand and with great discomfort, the growth of the subprime and housing bubbles before the crisis, I’ve painfully learned that bubbles can last much longer than you would rationally expect. And despite all sorts of analysis and calculation about what should happen, the thing that triggers the bursting of the bubble is really hard to predict. As is when it will happen. To the extent I’ve learned a lesson from mortgage land, it’s that you shouldn’t do anything stupid in anticipation of the bubble either bursting or continuing. So, as much as I hope and even expect that the trend for increased college tuition will reverse in the coming years, I guess I’ll have to keep on trying to save for when my daughters will be heading off to college.



