Archive
On trusting experts, climate change research, and scientific translators
Stephanie Tai has written a thoughtful response on Jordan Ellenberg’s blog to my discussion with Jordan regarding trusting experts (see my Nate Silver post and the follow-up post for more context).
Trusting experts
Stephanie asks three important questions about trusting experts, which I paraphrase here:
- What does it take to look into a model yourself? How deeply must you probe?
- How do you avoid being manipulated when you do so?
- Why should we bother since stuff is so hard and we each have a limited amount of time?
I must confess I find the first two questions really interesting and I want to think about them, but I have a very little patience with the last question.
Here’s why:
- I’ve seen too many people (individual modelers) intentionally deflect investigations into models by setting them up as so hard that it’s not worth it (or at least it seems not worth it). They use buzz words and make it seem like there’s a magical layer of their model which makes it too difficult for mere mortals. But my experience (as an arrogant, provocative, and relentless questioner) is that I can always understand a given model if I’m talking to someone who really understands it and actually wants to communicate it.
- It smacks of an excuse rather than a reason. If it’s our responsibility to understand something, then by golly we should do it, even if it’s hard.
- Too many things are left up to people whose intentions are not reasonable using this “too hard” argument, and it gives those people reason to make entire systems seem too difficult to penetrate. For a great example, see the financial system, which is consistently too complicated for regulators to properly regulate.
I’m sure I seem unbelievably cynical here, but that’s where I got by working in finance, where I saw first-hand how manipulative and manipulated mathematical modeling can become. And there’s no reason at all such machinations wouldn’t translate to the world of big data or climate modeling.
Climate research
Speaking of climate modeling: first, it annoys me that people are using my “distrust the experts” line to be cast doubt on climate modelers.
People: I’m not asking you to simply be skeptical, I’m saying you should look into the models yourself! It’s the difference between sitting on a couch and pointing at a football game on TV and complaining about a missed play and getting on the football field yourself and trying to figure out how to throw the ball. The first is entertainment but not valuable to anyone but yourself. You are only adding to the discussion if you invest actual thoughtful work into the matter.
To that end, I invited an expert climate researcher to my house and asked him to explain the climate models to me and my husband, and although I’m not particularly skeptical of climate change research (more on that below when I compare incentives of the two sides), I asked obnoxious, relentless questions about the model until I was satisfied. And now I am satisfied. I am considering writing it up as a post.
As an aside, if climate researchers are annoyed by the skepticism, I can understand that, since football fans are an obnoxious group, but they should not get annoyed by people who want to actually do the work to understand the underlying models.
Another thing about climate research. People keep talking about incentives, and yes I agree wholeheartedly that we should follow the incentives to understand where manipulation might be taking place. But when I followed the incentives with respect to climate modeling, they bring me straight to climate change deniers, not to researchers.
Do we really think these scientists working with their research grants have more at stake than multi-billion dollar international companies who are trying to ignore the effect of their polluting factories on the environment? People, please. The bulk of the incentives are definitely with the business owners. Which is not to say there are no incentives on the other side, since everyone always wants to feel like their research is meaningful, but let’s get real.
Scientific translators
I like this idea Stephanie comes up with:
Some sociologists of science suggest that translational “experts”–that is, “experts” who aren’t necessarily producing new information and research, but instead are “expert” enough to communicate stuff to those not trained in the area–can help bridge this divide without requiring everyone to become “experts” themselves. But that can also raise the question of whether these translational experts have hidden agendas in some way. Moreover, one can also raise questions of whether a partial understanding of the model might in some instances be more misleading than not looking into the model at all–examples of that could be the various challenges to evolution based on fairly minor examples that when fully contextualized seem minor but may pop out to someone who is doing a less systematic inquiry.
First, I attempt to make my blog something like a platform for this, and I also do my best to make my agenda not at all hidden so people don’t have to worry about that.
This raises a few issues for me:
- Right now we depend mostly on press to do our translations, but they aren’t typically trained as scientists. Does that make them more prone to being manipulated? I think it does.
- How do we encourage more translational expertise to emerge from actual experts? Currently, in academia, the translation to the general public of one’s research is not at all encouraged or rewarded, and outside academia even less so.
- Like Stephanie, I worry about hidden agendas and partial understandings, but I honestly think they are secondary to getting a robust system of translation started to begin with, which would hopefully in turn engage the general public with the scientific method and current scientific knowledge. In other words, the good outweighs the bad here.
Open data is not a panacea
I’ve talked a lot recently about how there’s an information war currently being waged on consumers by companies that troll the internet and collect personal data, search histories, and other “attributes” in data warehouses which then gets sold to the highest bidders.
It’s natural to want to balance out this information asymmetry somehow. One such approach is open data, defined in Wikipedia as the idea that certain data should be freely available to everyone to use and republish as they wish, without restrictions from copyright, patents or other mechanisms of control.
I’m going to need more than one blog post to think this through, but I wanted to make two points this morning.
The first is my issue with the phrase “freely available to everyone to use”. What does that mean? Having worked in futures trading, where we put trading machines and algorithms in close proximity with exchanges for large fees so we can get to the market data a few nanoseconds before anyone else, it’s clear to me that availability and access to data is an incredibly complicated issue.
And it’s not just about speed. You can have hugely important, rich, and large data sets sitting in a lump on a publicly available website like wikipedia, and if you don’t have fancy parsing tools and algorithms you’re not going to be able to make use of it.
When important data goes public, the edge goes to the most sophisticated data engineer, not the general public. The Goldman Sachs’s of the world will always know how to make use of “freely available to everyone” data before the average guy.
Which brings me to my second point about open data. It’s general wisdom that we should hope for the best but prepare for the worst. My feeling is that as we move towards open data we are doing plenty of the hoping part but not enough of the preparing part.
If there’s one thing I learned working in finance, it’s not to be naive about how information will be used. You’ve got to learn to think like an asshole to really see what to worry about. It’s a skill which I don’t regret having.
So, if you’re giving me information on where public schools need help, I’m going to imagine using that information to cut off credit for people who live nearby. If you tell me where environmental complaints are being served, I’m going to draw a map and see where they aren’t being served so I can take my questionable business practices there.
I’m not saying proponents of open data aren’t well-meaning, they often seem to be. And I’m not saying that the bad outweighs the good, because I’m not sure. But it’s something we should figure out how to measure, and in this information war it’s something we should keep a careful eye on.
Corporations don’t act like people
Corporations may be legally protected like people, but they don’t act selfishly like people do.
I’ve written about this before here, when I was excitedly reading Liquidated by Karen Ho, but recent overheard conversations have made me realize that there’s still a feeling out there that “the banks” must not have understood how flawed the models were because otherwise they would have avoided them out of a sense of self-preservation.
Important: “the banks” don’t think or do things, people inside the banks think and do things. In fact, the people inside the banks think about themselves and their own chances of getting big bonuses/ getting fired, and they don’t think about the bank’s future at all. The exception may be the very tip top brass of management, who may or may not care about the future of their institutions just as a legacy reputation issue. But in any case their nascent reputation fears, if they existed at all, did not seem to overwhelm their near-term desire for lots of money.
Example: I saw Robert Rubin on stage well before the major problems at Citi in a discussion about how badly the mortgage-backed securities market was apt to perform in the very near future. He did not seem to be too stupid to understand what the conversation was about, but that didn’t stop him from ignoring the problem at Citigroup whilst taking in $126 million dollars. The U.S. government, in the meantime, bailed out Citigroup to the tune of $45 billion with another guarantee of $300 billion.
Here’s a Bloomberg BusinessWeek article excerpt about how he saw his role:
Rubin has said that Citigroup’s losses were the result of a financial force majeure. “I don’t feel responsible, in light of the facts as I knew them in my role,” he told the New York Times in April 2008. “Clearly, there were things wrong. But I don’t know of anyone who foresaw a perfect storm, and that’s what we’ve had here.”
In March 2010, Rubin elaborated in testimony before the Financial Crisis Inquiry Commission. “In the world of trading, the world I have lived in my whole adult life, there is always a very important distinction between what you could have reasonably known in light of the facts at the time and what you know with the benefit of hindsight,” he said. Pressed by FCIC Executive Director Thomas Greene about warnings he had received regarding the risk in Citigroup’s mortgage portfolio, Rubin was opaque: “There is always a tendency to overstate—or over-extrapolate—what you should have extrapolated from or inferred from various events that have yielded warnings.”
Bottomline: there’s no such thing as a bank’s desire for self-preservation. Let’s stop thinking about things that way.
Whom can you trust?
My friend Jordan has written a response to yesterday’s post about Nate Silver. He is a major fan of Silver and contends that I’m not fair to him:
I think Cathy’s distrust is warranted, but I think Silver shares it. The central concern of his chapter on weather prediction is the vast difference in accuracy between federal hurricane forecasters, whose only job is to get the hurricane track right, and TV meteorologists, whose very different incentive structure leads them to get the weather wrong on purpose. He’s just as hard on political pundits and their terrible, terrible predictions, which are designed to be interesting, not correct.
To this I’d say, Silver mocks TV meteorologists and political pundits in a dismissive way, as not being scientific enough. That’s not the same as taking them seriously and understanding their incentives, and it doesn’t translate to the much more complicated world of finance.
In any case, he could have understood incentives in every field except finance and I’d still be mad, because my direct experience with finance made me understand it, and the outsized effect it has on our economy makes it hugely important.
But Jordan brings up an important question about trust:
But what do you do with cases like finance, where the only people with deep domain knowledge are the ones whose incentive structure is socially suboptimal? (Cathy would use saltier language here.) I guess you have to count on mavericks like Cathy, who’ve developed the domain knowledge by working in the financial industry, but who are now separated from the incentives that bind the insiders.
But why do I trust what Cathy says about finance?
Because she’s an expert.
Is Cathy OK with this?
No, Cathy isn’t okay with this. The trust problem is huge, and I address it directly in my post:
This raises a larger question: how can the public possibly sort through all the noise that celebrity-minded data people like Nate Silver hand to them on a silver platter? Whose job is it to push back against rubbish disguised as authoritative scientific theory?
It’s not a new question, since PR men disguising themselves as scientists have been around for decades. But I’d argue it’s a question that is increasingly urgent considering how much of our lives are becoming modeled. It would be great if substantive data scientists had a way of getting together to defend the subject against sensationalist celebrity-fueled noise.
One hope I nurture is that, with the opening of the various data science institutes such as the one at Columbia which was a announced a few months ago, there will be a way to form exactly such a committee. Can we get a little peer review here, people?
I do think domain-expertise-based peer review will help, but not when the entire field is captured, like in some subfields of medical research and in some subfields of economics and finance (for a great example see Glen Hubbard get destroyed in Matt Taibbi’s recent blogpost for selling his economic research).
The truth is, some fields are so yucky that people who want to do serious research just leave because they are disgusted. Then the people who remain are the “experts”, and you can’t trust them.
The toughest part is that you don’t know which fields are like this until you try to work inside them.
Bottomline: I’m telling you not to trust Nate Silver, and I would also urge you not to trust any one person, including me. For that matter don’t necessarily trust crowds of people either. Instead, carry a healthy dose of skepticism and ask hard questions.
This is asking a lot, and will get harder as time goes on and as the world becomes more complicated. On the one hand, we need increased transparency for scientific claims like projects such as runmycode provide. On the other, we need to understand the incentive structure inside a field like finance to make sure it is aligned with its stated mission.
Nate Silver confuses cause and effect, ends up defending corruption
Crossposted on Naked Capitalism
I just finished reading Nate Silver’s newish book, The Signal and the Noise: Why so many predictions fail – but some don’t.
The good news
First off, let me say this: I’m very happy that people are reading a book on modeling in such huge numbers – it’s currently eighth on the New York Times best seller list and it’s been on the list for nine weeks. This means people are starting to really care about modeling, both how it can help us remove biases to clarify reality and how it can institutionalize those same biases and go bad.
As a modeler myself, I am extremely concerned about how models affect the public, so the book’s success is wonderful news. The first step to get people to think critically about something is to get them to think about it at all.
Moreover, the book serves as a soft introduction to some of the issues surrounding modeling. Silver has a knack for explaining things in plain English. While he only goes so far, this is reasonable considering his audience. And he doesn’t dumb the math down.
In particular, Silver does a nice job of explaining Bayes’ Theorem. (If you don’t know what Bayes’ Theorem is, just focus on how Silver uses it in his version of Bayesian modeling: namely, as a way of adjusting your estimate of the probability of an event as you collect more information. You might think infidelity is rare, for example, but after a quick poll of your friends and a quick Google search you might have collected enough information to reexamine and revise your estimates.)
The bad news
Having said all that, I have major problems with this book and what it claims to explain. In fact, I’m angry.
It would be reasonable for Silver to tell us about his baseball models, which he does. It would be reasonable for him to tell us about political polling and how he uses weights on different polls to combine them to get a better overall poll. He does this as well. He also interviews a bunch of people who model in other fields, like meteorology and earthquake prediction, which is fine, albeit superficial.
What is not reasonable, however, is for Silver to claim to understand how the financial crisis was a result of a few inaccurate models, and how medical research need only switch from being frequentist to being Bayesian to become more accurate.
Let me give you some concrete examples from his book.
Easy first example: credit rating agencies
The ratings agencies, which famously put AAA ratings on terrible loans, and spoke among themselves as being willing to rate things that were structured by cows, did not accidentally have bad underlying models. The bankers packaging and selling these deals, which amongst themselves they called sacks of shit, did not blithely believe in their safety because of those ratings.
Rather, the entire industry crucially depended on the false models. Indeed they changed the data to conform with the models, which is to say it was an intentional combination of using flawed models and using irrelevant historical data (see points 64-69 here for more (Update: that link is now behind the paywall)).
In baseball, a team can’t create bad or misleading data to game the models of other teams in order to get an edge. But in the financial markets, parties to a model can and do.
In fact, every failed model is actually a success
Silver gives four examples what he considers to be failed models at the end of his first chapter, all related to economics and finance. But each example is actually a success (for the insiders) if you look at a slightly larger picture and understand the incentives inside the system. Here are the models:
- The housing bubble.
- The credit rating agencies selling AAA ratings on mortgage securities.
- The financial melt-down caused by high leverage in the banking sector.
- The economists’ predictions after the financial crisis of a fast recovery.
Here’s how each of these models worked out rather well for those inside the system:
- Everyone involved in the mortgage industry made a killing. Who’s going to stop the music and tell people to worry about home values? Homeowners and taxpayers made money (on paper at least) in the short term but lost in the long term, but the bankers took home bonuses that they still have.
- As we discussed, this was a system-wide tool for building a money machine.
- The financial melt-down was incidental, but the leverage was intentional. It bumped up the risk and thus, in good times, the bonuses. This is a great example of the modeling feedback loop: nobody cares about the wider consequences if they’re getting bonuses in the meantime.
- Economists are only putatively trying to predict the recovery. Actually they’re trying to affect the recovery. They get paid the big bucks, and they are granted authority and power in part to give consumers confidence, which they presumably hope will lead to a robust economy.
Cause and effect get confused
Silver confuses cause and effect. We didn’t have a financial crisis because of a bad model or a few bad models. We had bad models because of a corrupt and criminally fraudulent financial system.
That’s an important distinction, because we could fix a few bad models with a few good mathematicians, but we can’t fix the entire system so easily. There’s no math band-aid that will cure these boo-boos.
I can’t emphasize this too strongly: this is not just wrong, it’s maliciously wrong. If people believe in the math band-aid, then we won’t fix the problems in the system that so desperately need fixing.
Why does he make this mistake?
Silver has an unswerving assumption, which he repeats several times, that the only goal of a modeler is to produce an accurate model. (Actually, he made an exception for stock analysts.)
This assumption generally holds in his experience: poker, baseball, and polling are all arenas in which one’s incentive is to be as accurate as possible. But he falls prey to some of the very mistakes he warns about in his book, namely over-confidence and over-generalization. He assumes that, since he’s an expert in those arenas, he can generalize to the field of finance, where he is not an expert.
The logical result of this assumption is his definition of failure as something where the underlying mathematical model is inaccurate. But that’s not how most people would define failure, and it is dangerously naive.
Medical Research
Silver discusses both in the Introduction and in Chapter 8 to John Ioannadis’s work which reveals that most medical research is wrong. Silver explains his point of view in the following way:

I’m glad he mentions incentives here, but again he confuses cause and effect.
As I learned when I attended David Madigan’s lecture on Merck’s representation of Vioxx research to the FDA as well as his recent research on the methods in epidemiology research, the flaws in these medical models will be hard to combat, because they advance the interests of the insiders: competition among academic researchers to publish and get tenure is fierce, and there are enormous financial incentives for pharmaceutical companies.
Everyone in this system benefits from methods that allow one to claim statistically significant results, whether or not that’s valid science, and even though there are lives on the line.
In other words, it’s not that there are bad statistical approaches which lead to vastly over-reported statistically significant results and published papers (which could just as easily happen if the researchers were employing Bayesian techniques, by the way). It’s that there’s massive incentive to claim statistically significant findings, and not much push-back when that’s done erroneously, so the field never self-examines and improves their methodology. The bad models are a consequence of misaligned incentives.
I’m not accusing people in these fields of intentionally putting people’s lives on the line for the sake of their publication records. Most of the people in the field are honestly trying their best. But their intentions are kind of irrelevant.
Silver ignores politics and loves experts
Silver chooses to focus on individuals working in a tight competition and their motives and individual biases, which he understands and explains well. For him, modeling is a man versus wild type thing, working with your wits in a finite universe to win the chess game.
He spends very little time on the question of how people act inside larger systems, where a given modeler might be more interested in keeping their job or getting a big bonus than in making their model as accurate as possible.
In other words, Silver crafts an argument which ignores politics. This is Silver’s blind spot: in the real world politics often trump accuracy, and accurate mathematical models don’t matter as much as he hopes they would.
As an example of politics getting in the way, let’s go back to the culture of the credit rating agency Moody’s. William Harrington, an ex-Moody’s analyst, describes the politics of his work as follows:
In 2004 you could still talk back and stop a deal. That was gone by 2006. It became: work your tail off, and at some point management would say, ‘Time’s up, let’s convene in a committee and we’ll all vote “yes”‘.
To be fair, there have been moments in his past when Silver delves into politics directly, like this post from the beginning of Obama’s first administration, where he starts with this (emphasis mine):
To suggest that Obama or Geithner are tools of Wall Street and are looking out for something other than the country’s best interest is freaking asinine.
and he ends with:
This is neither the time nor the place for mass movements — this is the time for expert opinion. Once the experts (and I’m not one of them) have reached some kind of a consensus about what the best course of action is (and they haven’t yet), then figure out who is impeding that action for political or other disingenuous reasons and tackle them — do whatever you can to remove them from the playing field. But we’re not at that stage yet.
My conclusion: Nate Silver is a man who deeply believes in experts, even when the evidence is not good that they have aligned incentives with the public.
Distrust the experts
Call me “asinine,” but I have less faith in the experts than Nate Silver: I don’t want to trust the very people who got us into this mess, while benefitting from it, to also be in charge of cleaning it up. And, being part of the Occupy movement, I obviously think that this is the time for mass movements.
From my experience working first in finance at the hedge fund D.E. Shaw during the credit crisis and afterwards at the risk firm Riskmetrics, and my subsequent experience working in the internet advertising space (a wild west of unregulated personal information warehousing and sales) my conclusion is simple: Distrust the experts.
Why? Because you don’t know their incentives, and they can make the models (including Bayesian models) say whatever is politically useful to them. This is a manipulation of the public’s trust of mathematics, but it is the norm rather than the exception. And modelers rarely if ever consider the feedback loop and the ramifications of their predatory models on our culture.
Why do people like Nate Silver so much?
To be crystal clear: my big complaint about Silver is naivete, and to a lesser extent, authority-worship.
I’m not criticizing Silver for not understanding the financial system. Indeed one of the most crucial problems with the current system is its complexity, and as I’ve said before, most people inside finance don’t really understand it. But at the very least he should know that he is not an authority and should not act like one.
I’m also not accusing him of knowingly helping cover up the financial industry. But covering for the financial industry is an unfortunate side-effect of his naivete and presumed authority, and a very unwelcome source of noise at this moment when so much needs to be done.
I’m writing a book myself on modeling. When I began reading Silver’s book I was a bit worried that he’d already said everything I’d wanted to say. Instead, I feel like he’s written a book which has the potential to dangerously mislead people – if it hasn’t already – because of its lack of consideration of the surrounding political landscape.
Silver has gone to great lengths to make his message simple, and positive, and to make people feel smart and smug, especially Obama’s supporters.
He gets well-paid for his political consulting work and speaker appearances at hedge funds like D.E. Shaw and Jane Street, and, in order to maintain this income, it’s critical that he perfects a patina of modeling genius combined with an easily digested message for his financial and political clients.
Silver is selling a story we all want to hear, and a story we all want to be true. Unfortunately for us and for the world, it’s not.
How to push back against the celebrity-ization of data science
The truth is somewhat harder to understand, a lot less palatable, and much more important than Silver’s gloss. But when independent people like myself step up to denounce a given statement or theory, it’s not clear to the public who is the expert and who isn’t. From this vantage point, the happier, shorter message will win every time.
This raises a larger question: how can the public possibly sort through all the noise that celebrity-minded data people like Nate Silver hand to them on a silver platter? Whose job is it to push back against rubbish disguised as authoritative scientific theory?
It’s not a new question, since PR men disguising themselves as scientists have been around for decades. But I’d argue it’s a question that is increasingly urgent considering how much of our lives are becoming modeled. It would be great if substantive data scientists had a way of getting together to defend the subject against sensationalist celebrity-fueled noise.
One hope I nurture is that, with the opening of the various data science institutes such as the one at Columbia which was a announced a few months ago, there will be a way to form exactly such a committee. Can we get a little peer review here, people?
Conclusion
There’s an easy test here to determine whether to be worried. If you see someone using a model to make predictions that directly benefit them or lose them money – like a day trader, or a chess player, or someone who literally places a bet on an outcome (unless they place another hidden bet on the opposite outcome) – then you can be sure they are optimizing their model for accuracy as best they can. And in this case Silver’s advice on how to avoid one’s own biases are excellent and useful.
But if you are witnessing someone creating a model which predicts outcomes that are irrelevant to their immediate bottom-line, then you might want to look into the model yourself.
If Barofsky heads the SEC I’ll work for it
Neil Barofsky visited my Occupy group, Alternative Banking, this past Sunday. He was awesome.
We discussed the credit crisis, the recent outrageous HSBC ruling which quantified the cost banks near for money laundering for terrorists and drug lords at below cost, and the hopelessness, or on a good day the hope, of having a financial and regulatory system that will eventually work.
We discussed the incentives in the HAMP set-up, which explain why very few homeowners have actually received lasting relief from unaffordable mortgages. We discussed the incentives for fraud and other criminal behavior in the absence of real punishment, that too much money is being spent pursuing insider training because that’s what people understand how to do, and we discussed the reluctance of the regulators to litigate tough cases. We talked about how change has to come from the top, because all of these organizations are super hierarchical and require political will to get things done.
In the past year I was offered a job at the SEC, working as a quant in the enforcement division. Although I want to help sort out this mess, I haven’t felt that this job, which is relatively junior, would allow me to do that meaningfully.
But I came away from the meeting with Barofsky with this feeling: if we had someone in charge at the SEC like him who could speak truth to power and who is smart enough to see through economic jargon and bullshit well enough to understand incentives for fraud and lying, then I’d work there in a heartbeat.
Let’s just hope it doesn’t take another world-wide financial crisis before we get someone like that.
Can we put an ass-kicking skeptic in charge of the SEC?
The SEC has proven its dysfunctionality. Instead of being on top of the banks for misconduct, it consistently sets the price for it at below cost. Instead of examining suspicious records to root out Ponzi schemes, it ignores whistleblowers.
I think it’s time to shake up management over there. We need a loudmouth skeptic who is smart enough to sort through the bullshit, brave enough to stand up to bullies, and has a strong enough ego not to get distracted by threats about their future job security.
My personal favorite choice is Neil Barofsky, author of Bailout (which I blogged about here) and former Special Inspector General of TARP. Simon Johnson, Economist at MIT, agrees with me. From Johnson’s New York Times Economix blog:
… Neil Barofsky is the former special inspector general in charge of oversight for the Troubled Asset Relief Program. A career prosecutor, Mr. Barofsky tangled with the Treasury officials in charge of handing out support for big banks while failing to hold the same banks accountable — for example, in their treatment of homeowners. He confronted these powerful interests and their political allies repeatedly and on all the relevant details – both behind closed doors and in his compelling account, published this summer: “Bailout: An Inside Account of How Washington Abandoned Main Street While Rescuing Wall Street.”
His book describes in detail a frustration with the timidity and lack of sophistication in law enforcement’s approach to complex frauds. He could instantly remedy that if appointed — Mr. Barofsky is more than capable of standing up to Wall Street in an appropriate manner. He has enjoyed strong bipartisan support in the past and could be confirmed by the Senate (just as he was previously confirmed to his TARP position).
Barofsky isn’t the only person who would kick some ass as the head of the SEC – William Cohan thinks Eliot Spitzer would make a fine choice, and I agree. From his Bloomberg column (h/t Matt Stoller):
The idea that only one of Wall Street’s own can regulate Wall Street is deeply disturbing. If Obama keeps Walter on or appoints Khuzami or Ketchum, we would be better off blowing up the SEC and starting over.
I still believe the best person to lead the SEC at this moment remains former New York Governor Eliot Spitzer. He would fearlessly hold Wall Street accountable for its past sins, as he did when he was New York State attorney general and as he now does as a cable television host. (Disclosure: I am an occasional guest on his show.)
We need an SEC head who can inspire a new generation of investors to believe the capital markets are no longer rigged and that Wall Street cannot just capture every one of its Washington regulators.
How to evaluate a black box financial system
I’ve been blogging about evaluation methods for modeling, for example here and here, as part of the book I’m writing with Rachel Schutt based on her Columbia Data Science class this semester.
Evaluation methods are important abstractions that allow us to measure models based only on their output.
Using various metrics of success, we can contrast and compare two or more entirely different models. And it means we don’t care about their underlying structure – they could be based on neural nets, logistic regression, or decision trees, but for the sake of measuring the accuracy, or the ranking, or the calibration, the evaluation method just treats them like black boxes.
It recently occurred to me a that we could generalize this a bit, to systems rather than models. So if we wanted to evaluate the school system, or the political system, or the financial system, we could ignore the underlying details of how they are structured and just look at the output. To be reasonable we have to compare two systems that are both viable; it doesn’t make sense to talk about a current, flawed system relative to perfection, since of course every version of reality looks crappy compared to an ideal.
The devil is in the articulated evaluation metric, of course. So for the school system, we can ask various questions: Do our students know how to read? Do they finish high school? Do they know how to formulate an argument? Have they lost interest in learning? Are they civic-minded citizens? Do they compare well to other students on standardized tests? How expensive is the system?
For the financial system, we might ask things like: Does the average person feel like their money is safe? Does the system add to stability in the larger economy? Does the financial system mitigate risk to the larger economy? Does it put capital resources in the right places? Do fraudulent players inside the system get punished? Are the laws transparent and easy to follow?
The answers to those questions aren’t looking good at all: for example, take note of the recent Congressional report that blames Jon Corzine for MF Global’s collapse, pins him down on illegal and fraudulent activity, and then does absolutely nothing about it. To conserve space I will only use this example but there are hundreds more like this from the last few years.
Suffice it to say, what we currently have is a system where the agents committing fraud are actually glad to be caught because the resulting fines are on the one hand smaller than their profits (and paid by shareholders, not individual actors), and on the other hand are cemented as being so, and set as precedent.
But again, we need to compare it to another system, we can’t just say “hey there are flaws in this system,” because every system has flaws.
I’d like to compare it to a system like ours except where the laws are enforced.
That may sounds totally naive, and in a way it is, but then again we once did have laws, that were enforced, and the financial system was relatively tame and stable.
And although we can’t go back in a time machine to before Glass-Steagall was revoked and keep “financial innovation” from happening, we can ask our politicians to give regulators the power to simplify the system enough so that something like Glass-Steagall can once again work.
Free people from their debt: Rolling Jubilee (#OWS)
Do you remember the group Strike Debt? It’s an offshoot of Occupy Wall Street which came out with the Debt Resistors Operation Manual on the one-year anniversary of Occupy; I blogged about this here, very cool and inspiring.
Well, Strike Debt has come up with another awesome idea; they are fundraising $50,000 (to start with) by holding a concert called the People’s Bailout this coming Thursday, featuring Jeff Mangum of Neutral Milk Hotel, possibly my favorite band besides Bright Eyes.
Actually that’s just the beginning, a kick-off to the larger fundraising campaign called the Rolling Jubilee.
The main idea is this: once they have money, they buy people’s debts with it, much like debt collectors buy debt. It’s mostly pennies-on-the-dollar debt, because it’s late and there is only a smallish chance that, through harassment legal and illegal, they will coax the debtor or their family members to pay.
But instead of harassing people over the phone, the Strike Debt group is simply going to throw away the debt. They might even call people up to tell them they are officially absolved from their debt, but my guess is nobody will answer the phone, from previous negative conditioning.
Get tickets to the concert here, and if you can’t make it, send donations to free someone from their debt here.
In the meantime enjoy some NMH:
When are taxes low enough?
What with the unrelenting election coverage (go Elizabeth Warren!) it’s hard not to think about the game theory that happens in the intersection of politics and economics.
[Disclaimer: I am aware that no idea in here is originally mine, but when has that ever stopped me? Plus, I think when economists talk about this stuff they generally use jargon to make it hard to follow, which I promise not to do, and perhaps also insert salient facts which I don’t know, which I apologize for. In any case please do comment if I get something wrong.]
Lately I’ve been thinking about the push and pull of the individual versus the society when it comes to tax rates. Individuals all want lower tax rates, in the sense that nobody likes to pay taxes. On the other hand, some people benefit more from what the taxes pay for than others, and some people benefit less. It’s fair to say that very rich people see this interaction as one-sided against them: they pay a lot, they get back less.
Well, that’s certainly how it’s portrayed. I’m not willing to say that’s true, though, because I’d argue business owners and generally rich people get a lot back actually, including things like rule of law and nobody stealing their stuff and killing them because they’re rich, which if you think about it does happen in other places. In fact they’d be huge targets in some places, so you could argue that rich people get the most protection from this system.
But putting that aside by assuming the rule of law for a moment, I have a lower-level question. Namely, might we expect equilibrium at some point, where the super rich realize they need the country’s infrastructure and educational system, to hire people and get them to work at their companies and the companies they’ve invested in, and of course so they will have customers for their products and the products of the companies they’ve invested in.
So in other words you might expect that, at a certain point, these super rich people would actually say taxes are low enough. Of course, on top of having a vested interest in a well-run and educated society, they might also have sense of fairness and might not liking seeing people die of hunger, they might want to be able to defend the country in war, and of course the underlying rule of law thingy.
But the above argument has kind of broken down lately, because:
- So many companies are off-shoring their work to places where we don’t pay for infrastructure,
- and where we don’t educate the population,
- and our customers are increasingly international as well, although this is the weakest effect since Europeans can’t be counted on that so much what with their recession.
In other words, the incentive for an individual rich person to argue for lower taxes is getting more and more to be about the rule of law and not the well-run society argument. And let’s face it, it’s a lot cheaper to teach people how to use guns than it is to give them a liberal arts education. So the optimal tax rate for them would be… possibly very low. Maybe even zero, if they can just hire their own militias.
This is an example of a system of equilibrium failing because of changing constraints. There’s another similar example in the land of finance which involves credit default swaps (CDS), described very well in this NYTimes Dealbook entry by Stephen Lubben.
Namely, it used to be true that bond holders would try to come to the table and renegotiate debt when a company or government was in trouble. After all, it’s better to get 40% of their money back than none.
But now it’s possible to “insure” their bonds with CDS contracts, and in fact you can even bet on the failure of a company that way, so you actually can set it up where you’d make money when a company fails, whether you’re a bond holder or not. This means less incentive to renegotiate debt and more of an incentive to see companies go through bankruptcy.
For the record, the suggestion Lubben has, which is a good one, is to have a disclosure requirement on how much CDS you have:
In a paper to appear in the Journal of Applied Corporate Finance, co-written with Rajesh P. Narayanan of Louisiana State University, I argue that one good starting point might be the Williams Act.
In particular, the Williams Act requires shareholders to disclose large (5 percent or more) equity positions in companies.
Perhaps holders of default swap positions should face a similar requirement. Namely, when a triggering event occurs, a holder of swap contracts with a notional value beyond 5 percent of the reference entity’s outstanding public debt would have to disclose their entire credit-default swap position.
I like this idea: it’s simple and is analogous to what’s already established for equities (of course I’d like to see CDS regulated like insurance, which goes further).
[Note, however, that the equities problem isn’t totally solved through this method: you can always short your exposure to an equity using options, although it’s less attractive in equities than in bonds because the underlying in equities is usually more liquid than the derivatives and the opposite is true for bonds. In other words, you can just sell your equity stake rather than hedge it, whereas your bond you might not be able to get rid of as easily, so it’s convenient to hedge with a liquid CDS.]
Lubben’s not a perfect solution to the problem of creating incentives to make companies work rather than fail, since it adds overhead and complexity, and the last thing our financial system needs is more complexity. But it moves the incentives in the right direction.
It makes me wonder, is there an analogous rule, however imperfect, for tax rates? How do we get super rich people to care about infrastructure and education, when they take private planes and send their kids to private schools? It’s not fair to put a tax law into place, because the whole point is that rich people have more power in controlling tax laws in the first place.
Money market regulation: a letter to Geithner and Schapiro from #OWS Occupy the SEC and Alternative Banking
#OWS working groups Occupy the SEC and Alternative Banking have released an open letter to Timothy Geithner, Secretary of the U.S. Treasury, and Mary Schapiro, Chairman of the SEC, calling on them to put into place reasonable regulation of money market funds (MMF’s).
Here’s the letter, I’m super proud of it. If you don’t have enough context, I give a more background below.
What are MMFs?
Money market funds make up the overall money market, which is a way for banks and businesses to finance themselves with short-term debt. It sounds really boring, but as it turns out it’s a vital issue for the functioning of the financial system.
Really simply put, money market funds invest in things like short-term corporate debt (like 30-day GM debt) or bank debt (Goldman or Chase short-term debt) and stuff like that. Their investments also include deposits and U.S. bonds.
People like you and me can put our money into money market funds via our normal big banks like Bank of America. In face I was told by my BofA banker to do this around 2007. He said it’s like a savings account, only better. If you do invest in a MMF, you’re told how much over a dollar your investments are worth. The implicit assumption then is that you never actually lose money.
What happened in the crisis?
MMF’s were involved in some of the early warning signs of the financial crisis. In August and September 2007, there was a run on subprime-related asset backed commercial paper.
In 2008, some of the funds which had invested in short-term Lehman Brother’s debt had huge problems when Lehman went down, and they “broke the buck”. This caused wide-spread panic and a bunch of money market funds had people pulling money from them.
In order to avoid a run on the MMF’s, the U.S. stepped in and guaranteed that nobody would actually lose money. It was a perfect example of something we had to do at the time, because we would literally not have had a functioning financial system given how central the money markets were at the time, in financing the shadow banking system, but something we should have figured out how to improve on by now.
This is a huge issue and needs to be dealt with before the next crisis.
What happened in 2010?
In 2010, regulators put into place rules that tightened restrictions within a fund. Things like how much cash they had to have on hand (liquidity requirements) and how long the average duration of their investments could be. This helped address the problem of what happens within a given fund when investors take their money out of that fund.
What they didn’t do in 2010 was to control systemic issues, and in particular how to make the MMF’s robust to large-scale panic.
What about Schapiro’s two MMF proposals?
More recently, Mary Schapiro, Chairman of the SEC, made two proposals to address the systemic issues. In the first proposal, instead of having the NAV’s set at one dollar, everything is allowed to float, just like every other kind of mutual fund. The industry didn’t like it, claiming it would make MMF’s less attractive.
In the second proposal, Schapiro suggesting that MMF managers keep a buffer of capital and that a new, weird lagged way for people to remove their money from their MMF’s, namely if you want to withdraw your funds you’ll only get 97%, and later (after 30 days) you’ll get 3% if the market doesn’t take a loss. If it does take a loss, will get only part of that last 3%.
The goal of this was to distribute losses more evenly, and to give people pause in times of crisis from withdrawing too quickly and causing a bank-like run.
Unfortunately, both of Schapiro’s proposals didn’t get passed by the 5 SEC Commissioners in August 2012 – it needed a majority vote, but they only got 2.
What happened when Geithner and Blackrock entered the picture?
The third, most recent proposal, comes out of the FSOC, a new meta-regulator, whose chair is Timothy Geithner. The guys proposed to the SEC in a letter dated September 27th that they should do something about money market regulation. Specifically, the FSOC letter suggests that either the SEC should go with one of Schapiro’s two ideas or a new third one.
The third one is again proposing a weird way for people to take their money out of a MMF, but this time it definitely benefits people who are “first movers”, in other words people who see a problem first and get the hell out. It depends on a parameter, called a trigger, which right now is set at 25 basis points (so 25 cents if you have $100 invested).
Specifically, if the value of the fund falls below 99.75, any withdrawal from that point on will be subject to a “withdrawal fee,” defined to be the distance between the fund’s level and 100. So if the fund is at 99.75, you have to pay a 25 cent fee and you only get out 99.50, whereas if the fund is at 99.76, you actually get out 100. So in other words, there’s an almost 50 cents difference at this critical value.
Is this third proposal really any better than either of Schapiro’s first two?
The industry and Timmy: bff’s?
Here’s something weird: on the same day the FSOC letter was published, BlackRock, which is a firm that does an enormous amount of money market managing and so stands to win or lose big on money market regulation, published an article in which they trashed Schapiro’s proposals and embellished this third one.
In other words, it looks like Geithner has been talking directly to Blackrock about how the money market regulation should be written.
In fact Geithner has seemingly invited industry insiders to talk to him at the Treasury. And now we have his proposal, which benefits insiders and also seems to have all of the unattractiveness that the other proposals had in terms of risks for normal people, i.e. non-insiders. That’s weird.
Update: in this Bloomberg article from yesterday (hat tip Matt Stoller), it looks like Geithner may be getting a fancy schmancy job at BlackRock after the election. Oh!
What’s wrong with simple?
Personally, and I say this as myself and not representing anyone else, I don’t see what’s wrong with Schapiro’s first proposal to keep the NAV floating. If there’s risk, investors should know about it, period, end of story. I don’t want the taxpayers on the hook for this kind of crap.
Strata: one down, one to go
Yesterday I gave a talk called “Finance vs. Machine Learning” at Strata. It was meant to be a smack-down, but for whatever reason I couldn’t engage people to personify the two disciplines and have a wrestling match on stage. For the record, I offered to be on either side. Either they were afraid to hurt a girl or they were afraid to lose to a girl, you decide.
Unfortunately I didn’t actually get to the main motivation for the genesis of this talk, namely the realization I had a while ago that when machine learners talk about “ridge regression” or “Tikhonov regularization” or even “L2 regularization” it comes down to the same thing that quants call a very simple bayesian prior that your coefficients shouldn’t be too large. I talked about this here.
What I did have time for: I talked about “causal modeling” in the finance-y sense (discussion of finance vs. statistician definition of causal here), exponential downweighting with a well-chosen decay, storytelling as part of feature selection, and always choosing to visualize everything, and always visualizing the evolution of a statistic rather than a snapshot statistic.
They videotaped me but I don’t see it on the strata website yet. I’ll update if that happens.
This morning, at 9:35, I’ll be in a keynote discussion with Julie Steele for 10 minutes entitled “You Can’t Learn That in School”, which will be live streamed. It’s about whether data science can and should be taught in academia.
For those of you wondering why I haven’t blogged the Columbia Data Science class like I usually do Thursday, these talks are why. I’ll get to it soon, I promise! Last night’s talks by Mark Hansen, data vizzer extraordinaire and Ian Wong, Inference Scientist from Square, were really awesome.
We’re not just predicting the future, we’re causing the future
My friend Rachel Schutt, a statistician at Google who is teaching the Columbia Data Science course this semester that I’ve been blogging every Thursday morning, recently wrote a blog post about 10 important issues in data science, and one of them is the title of my post today.
This idea that our predictive models cause the future is part of the modeling feedback loop I blogged about here; it’s the idea that, once we’ve chosen a model, especially as it models human behavior (which includes the financial markets), then people immediately start gaming the model in one way or another, both weakening the effect that the model is predicting as well as distorting the system itself. This is important and often overlooked when people build models.
How do we get people to think about these things more carefully? I think it would help to have a checklist of properties of a model using best practices.
I got this idea recently as I’ve been writing a talk about how math is used outside academia (which you guys have helped me on). In it, I’m giving a bunch of examples of models with a few basic properties of well-designed models.
It was interesting just composing that checklist, and I’ll likely blog about this in the next few days, but needless to say one thing on the checklist was “evaluation method”.
Obvious point: if you have a model which has no well-defined evaluation model then you’re fucked. In fact, I’d argue, you don’t really even have a model until you’ve chosen and defended your evaluation method (I’m talking to you, value-added teacher modelers).
But what I now realize is that part of the evaluation method of the model should consist of an analysis of how the model can or will be gamed and how that gaming can or will distort the ambient system. It’s a meta-evaluation of the model, if you will.
Example: as soon as regulators agree to measure a firm’s risk with 95% VaR on a 0.97 decay factor, there’s all sorts of ways for companies to hide risk. That’s why the parameters (95, 0.97) cannot be fixed if we want a reasonable assessment of risk.
This is obvious to most people upon reflection, but it’s not systemically studied, because it’s not required as part of an evaluation method for VaR. Indeed a reasonable evaluation method for VaR is to ask whether the 95% loss is indeed breached only 5% of the time, but that clearly doesn’t tell the whole story.
One easy way to get around this is to require a whole range of parameters for % VaR as well as a whole range of decay factors. It’s not that much more work and it is much harder to game. In other words, it’s a robustness measurement for the model.
Gaming the Google mail filter and the modeling feedback loop
The gmail filter
If you’re like me, a large part of your life takes place in your gmail account. My gmail address is the only one I use, and I am extremely vigilant about reading emails – probably too much so.
On the flip side, I spend quite a bit of energy removing crap from my gmail. When I have the time and opportunity, and if I receive an unwanted email, I will set a gmail filter instead of just deleting. This is usually in response to mailing lists I get on by buying something online, so it’s not quite spam. For obvious spam I just click on the spam icon and it disappears.
You see, when I check out online to pay for my stuff, I am not incredibly careful about making sure I’m not signing up to be on a mailing list. I just figure I’ll filter anything I don’t want later.
Which brings me to the point. I’ve noticed lately that, more and more often, the filter doesn’t work, at least on the automatic setting. If you open an email you don’t want, you can click on “filter messages like these” and it will automatically fill out a filter form with the “from” email address that is listed.

More and more often, these quasi-spammers are getting around this somehow. I don’t know how they do it, because it’s not as simple as changing their “from” address every time, which would work pretty well. Somehow not even the email I’ve chosen to filter is actually deleted through this process.
I end up having to copy and paste the name of the product into a filter, but this isn’t a perfect solution either, since then if my friend emails me about this product I will automatically delete that genuine email.
The modeling feedback loop
This is a perfect example of the feedback loop of modeling; first there was a model which automatically filled out a filter form, then people in charge of sending out mailing lists for products realized they were being successfully filtered and figured out how to game the model. Now the model doesn’t work anymore.
The worst part of the gaming strategy is how well it works. If everybody uses the filter model, and you are the only person who games it, then you have a tremendous advantage over other marketers. So the incentive for gaming is very high.
Note this feedback loop doesn’t always exist: the stars and planets didn’t move differently just because Newton figured out his laws, and people don’t start writing with poorer penmanship just because we have machine learning algorithms that read envelopes at the post office.
But this feedback loop does seem to be associated with especially destructive models (think rating agency models for MBS’s and CDO’s). In particular, any model which is “gamed” to someone’s advantage probably exhibits something like this. It will work until the modelers strike back with a better model, in an escalation not unlike an arms race (note to ratings agency modelers: unless you choose to not make the model better even when people are clearly gaming it).
As far as I know, there’s nothing we can do about this feedback loop except to be keenly aware of it and be ready for war.
Philanthropy can do better than Rajat Gupta
Last night I was watching a YouTube video in between playoff games (both of which disappointed). Conan O’Brien was accepting an honorary patronage at the philosophical society of the University of Dublin. His speech was hilarious, and there was an extended, intimate Q&A session afterwards.
One thing he mentioned was an amended version of the (to me, very moving) words he had closed his last NBC Tonight Show with, “If you work really hard and you’re kind then amazing things will happen.” Namely, he wanted to add this sentence: “If you work really hard and you’re a huge asshole, then you can make tons of money on Wall Street.”
These wise words came back to me this morning when I read about Bill Gates and Kofi Annan’s letters to Judge Jed Rakoff regarding Goldman Sachs insider trader Rajat Gupta. The letters were intended to reduce sentencing, considering how unbelievably philanthropical Gupta had been as he was stealing all this money.
I’m not doubting that the dude did some good things with his ill-gotten gains. After all, I don’t have a letter from Bill Gates about how I helped remove malaria from the world.
But wait a minute, maybe that’s because I didn’t steal money from taxpayers like he did to put myself into the position of spending millions of dollars doing good things! Because I’m thinking that if I had the money that Gupta had, I might well have spent good money doing good things.
And therein lies the problem with this whole picture. He did some good (I’ll assume), but then again he had the advantage of being someone in our society who could do good, i.e. he was loaded. Wouldn’t it make more sense for us to set up a system wherein people could do good who are good, who have good ideas and great plans?
Unfortunately, those people exist, but they’re generally poor, or stuck in normal jobs making ends meet for their family, and they don’t get their plans heard. In particular they aren’t huge assholes stealing money and then trying to get out of trouble by hiring hugely expensive lawyers and leaning on their philanthropy buds.
The current system of grant-writing doesn’t at all support the people with good ideas: it doesn’t teach these “social inventors” how to build a charitable idea into a business plan. So what happens is that the good ideas drift away without the important detailed knowledge of how to surround it with resources. And generally the people with really innovative ideas aren’t by nature detail-oriented people who can figure out how to start a business, they’re kind of nerdy.
I’m serious, I think the government should sponsor something like a “philanthropy institute” for entrepreneurial non-revenue generating ideas that are good for society. People could come to open meetings and discuss their ideas for improving stuff, and there’d be full-time staff and fellows, with the goal of seizing upon good ideas and developing them like business plans.
Neil Barofsky on the Fed Stress Test
I recently started using Twitter, and I only follow 8 people, one of them being Neil Barofsky, author of Bailout, which I blogged about here (Twitter is a useful way to stalk your crushes, as Twitter users already know).
I’m glad I do follow him, because yesterday he tweeted (twatted?) about an article he wrote on LinkedIn which I never would have found otherwise. It’s called “Banks Rule While the Rest of us Drool,” and he gave credit to his daughter for that title, which is crushworthy in itself. It’s essentially a bloggy rant against a Wall Street Journal article which I had just read and was thinking of writing a ranty blog post against myself.
But now I don’t have to write it! I’ll just tell you about the WSJ article, quote from it a bit (and complain about it a bit since I can’t help myself), and then quote Barofsky’s awesome disgust with it. Here goes.
The Fed conducts stress tests on the banks, and they are making them secret, so the banks can’t game them, as well as requiring more frequent and better quality data. All good. From the WSJ article:
The Fed asks the big banks to submit reams of data and then publishes each bank’s potential loan losses and how much capital each institution would need to absorb them. Banks also submit plans of how they would deploy capital, including any plans to raise dividends or buy back stock.
After several institutions failed last year’s tests and had their capital plans denied, executives at many of the big banks began challenging the Fed to explain why there were such large gaps between their numbers and the Fed’s, according to people close to the banks.
Fed officials say they have worked hard to help bankers better understand the math, convening the Boston symposium and multiple conference calls. But they don’t want to hand over their models to the banks, in part because they don’t want the banks to game the numbers, officials say.
Just to be clear, when they say “large gaps”, I’m pretty sure the banks mean they are perfectly safe when the Fed thinks they’re undercapitalized. I am pretty sure the banks are arguing they should be giving huger bonuses to their C*O’s whereas the Fed thinks not. I’m just guessing on the direction, but I could be wrong, it’s not spelled out in the article.
Here’s another thing that drives me up the wall, from the WSJ article:
Banks say the Fed has asked them for too much, too fast. Some bankers, for instance, have complained the Fed now is demanding they include the physical address of properties backing loans on their books, not just the billing address for the borrower. Not all banks, it turns out, have that information readily available.
Daryl Bible, the chief risk officer at BB&T Corp., a Winston-Salem, N.C.-based bank with $179 billion in assets, challenged the Fed’s need for all of the data it is collecting, saying in a Sept. 4 comment letter to the regulator that “the reporting requirements appear to have advanced beyond the linkage of risk to capital and an organization’s viability,” burdening banks without adding any value to the stress test exercise. BB&T declined further comment.
Oh really? Can you, Daryl Bible, think of no reason at all we might want to know the addresses of the houses you gave bad mortgages to? Really? Do you really think you deserve to be a Chief Risk Officer of a firm with $179 billion in assets if your imagination of how to calculate risk is so puny?
But the most infuriating part of the article is at the end, and I’m going to let Neil take it away:
… at the end of the article the reporters reveal that the Fed recently “backed off” a requirement that the CFOs of the banks actually confirm that the numbers they are providing are accurate. The reason? The banks argued, and the Fed apparently agreed, that providing data about what’s going on in the banks is simply too “confusing for any CFO to be able to be sure his bank had gotten it right.” In other words, rather than demand personal accountability, the Fed seems to be content with relying on unverified and potentially inaccurate data. If this does not prove both the inherent unreliability of these tests and that the banks are still so hopelessly complex that their executives do not know what’s going on inside of them (See Whale, London), I’m not sure what would.
Dissolve the SEC
A few days ago I wrote about the $5 million fine the SEC gave to NYSE for allowing certain customers prices before other customers. I was baffled that the fine is so low- access like that allows the customers to make outrageous profits, and it seems like the resulting fine should be more along the lines of those profits, since kickbacks are probably in terms of percentages of take. The lawyer fees from this case on both sides is much higher than $5 million, for christ’s sakes.
But now I’m even more outraged by the newest smallest fine, this time an $800,000 fine for a dark pool trading firm eBX. From the Boston.com article:
Federal securities regulators on Wednesday charged Boston-based eBX LLC, a “dark pool” securities exchange, with failing to protect confidential trading information of customers and for failing to disclose that it let an outside firm use their trading data.
The Securities and Exchange Commission said eBX, which runs the alternative trading system LeveL ATS, agreed to settle the charges and to pay an $800,000 penalty.
You know that if I can actually consider paying the fine myself, then the fine is too small. It’s along the lines of the cost of college for my kids.
Look, I don’t care what it’s for: if the SEC finds you guilty of fraud, it should threaten to put you out of business. Otherwise why should they waste their time doing it?
On the one hand, I’m outraged that these fraudulent practices are being so lightly punished. Indeed it’s worse than no punishment at all to get such a light punishment, because it establishes precedent. Now exchanges know how much it costs to let certain traders get better access to data than others, and as long as they charge sufficiently, they’ll be sure to make profit on it. Similarly dark trading pools know how much to charge third-party data vendors for their clients’ “confidential trading information.” Awesome.
On the other hand, I’m outraged at the SEC for not picking their fights better and for general incompetence. Here they are nabbing firms for real fraud, and they can’t get more than $800,000? At the same time, they’ve decided to go into high frequency trading but what that seems to mean to them is that they’ll finally collect some tick data. I’ve got some news for them: it’s gonna take more than a little bit of data to understand that world.
The SEC needs to concentrate more on not trying to keep up with the HFT’ers of the world, since it’s a lost cause, and spend more time thinking through what policy changes they’d need to actually do their job well – for example, what would they need to get Citigroup and Bank of America to admit wrongdoing when they defraud their customers? Instead of wasting their time trying to keep up with HFT quants, what would they need to institute a transaction tax, or some other policy to slow down trading? What would they need to be able to shut down firms who sell confidential client trading information?
The SEC needs to write a list of policy demands, pronto.
And if the political pressure the SEC receives to not actually get anyone in trouble is too strong for them to do their job well, they should either quit in protest or make a huge stink about being kept from completing their mission.
I get it, I’ve talked to people inside the SEC who want to do a better job but feel like they aren’t being given the power to. But I say, enough with the resigned shrugs already, this stuff is out of control! Continuing in this way is giving the public the false impression that there’s someone on the case. Well, there’s someone on the case, all right, but they aren’t being allowed to or don’t see the point of doing their work. It’s bullshit.
I say dissolve the SEC so that people will no longer have any false hopes of meaningful financial reform.
I’ve been reading Sheila Bair’s book Bull by the Horns, and it’s really good. Maybe by the end of it I’ll have changed my mind and I’ll see a place for the SEC. Maybe I’ll have hope that these things have natural cycles and the SEC will have another day in the power position, like it had in the 1980’s. But right now I’m in the part of the book where the regulators, apart from the FDIC, are taking orders directly from financial lobbyists, and it makes me completely crazy.
Columbia Data Science course, week 5: GetGlue, time series, financial modeling, advanced regression, and ethics
I was happy to be giving Rachel Schutt’s Columbia Data Science course this week, where I discussed time series, financial modeling, and ethics. I blogged previous classes here.
The first few minutes of class were for a case study with GetGlue, a New York-based start-up that won the mashable breakthrough start-up of the year in 2011 and is backed by some of the VCs that also fund big names like Tumblr, etsy, foursquare, etc. GetGlue is part of the social TV space. Lead Scientist, Kyle Teague, came to tell the class a little bit about GetGlue, and some of what he worked on there. He also came to announce that GetGlue was giving the class access to a fairly large data set of user check-ins to tv shows and movies. Kyle’s background is in electrical engineering, he placed in the 2011 KDD cup (which we learned about last week from Brian), and he started programming when he was a kid.
GetGlue’s goal is to address the problem of content discovery within the movie and tv space, primarily. The usual model for finding out what’s on TV is the 1950’s TV Guide schedule, and that’s still how we’re supposed to find things to watch. There are thousands of channels and it’s getting increasingly difficult to find out what’s good on. GetGlue wants to change this model, by giving people personalized TV recommendations and personalized guides. There are other ways GetGlue uses Data Science but for the most part we focused on how this the recommendation system works. Users “check-in” to tv shows, which means they can tell people they’re watching a show. This creates a time-stamped data point. They can also do other actions such as like, or comment on the show. So this is a -tuple: {user, action, object} where the object is a tv show or movie. This induces a bi-partite graph. A bi-partite graph or network contains two types of nodes: users and tv shows. An edges exist between users and an tv shows, but not between users and users or tv shows and tv shows. So Bob and Mad Men are connected because Bob likes Mad Men, and Sarah and Mad Men and Lost are connected because Sarah liked Mad Men and Lost. But Bob and Sarah aren’t connected, nor are Mad Men and Lost. A lot can be learned from this graph alone.
But GetGlue finds ways to create edges between users and between objects (tv shows, or movies.) Users can follow each other or be friends on GetGlue, and also GetGlue can learn that two people are similar[do they do this?]. GetGlue also hires human evaluators to make connections or directional edges between objects. So True Blood and Buffy the Vampire Slayer might be similar for some reason and so the humans create an edge in the graph between them. There were nuances around the edge being directional. They may draw an arrow pointing from Buffy to True Blood but not vice versa, for example, so their notion of “similar” or “close” captures both content and popularity. (That’s a made-up example.) Pandora does something like this too.
Another important aspect is time. The user checked-in or liked a show at a specific time, so the -tuple extends to have a time-stamp: {user,action,object,timestamp}. This is essentially the data set the class has access to, although it’s slightly more complicated and messy than that. Their first assignment with this data will be to explore it, try to characterize it and understand it, gain intuition around it and visualize what they find.
Students in the class asked him questions around topics of the value of formal education in becoming a data scientist (do you need one? Kyle’s time spent doing signal processing in research labs was valuable, but so was his time spent coding for fun as a kid), what would be messy about a data set, why would the data set be messy (often bugs in the code), how would they know? (their QA and values that don’t make sense), what language does he use to prototype algorithms (python), how does he know his algorithm is good.
Then it was my turn. I started out with my data scientist profile:

As you can see, I feel like I have the most weakness in CS. Although I can use python pretty proficiently, and in particular I can scrape and parce data, prototype models, and use matplotlib to draw pretty pictures, I am no java map-reducer and I bow down to those people who are. I am also completely untrained in data visualization but I know enough to get by and give presentations that people understand.
Thought Experiment
I asked the students the following question:
What do you lose when you think of your training set as a big pile of data and ignore the timestamps?
They had some pretty insightful comments. One thing they mentioned off the bat is that you won’t know cause and effect if you don’t have any sense of time. Of course that’s true but it’s not quite what I meant, so I amended the question to allow you to collect relative time differentials, so “time since user last logged in” or “time since last click” or “time since last insulin injection”, but not absolute timestamps.
What I was getting at, and what they came up with, was that when you ignore the passage of time through your data, you ignore trends altogether, as well as seasonality. So for the insulin example, you might note that 15 minutes after your insulin injection your blood sugar goes down consistently, but you might not notice an overall trend of your rising blood sugar over the past few months if your dataset for the past few months has no absolute timestamp on it.
This idea, of keeping track of trends and seasonalities, is very important in financial data, and essential to keep track of if you want to make money, considering how small the signals are.
How to avoid overfitting when you model with time series
After discussing seasonality and trends in the various financial markets, we started talking about how to avoid overfitting your model.
Specifically, I started out with having a strict concept of in-sample (IS) and out-of-sample (OOS) data. Note the OOS data is not meant as testing data- that all happens inside OOS data. It’s meant to be the data you use after finalizing your model so that you have some idea how the model will perform in production.
Next, I discussed the concept of causal modeling. Namely, we should never use information in the future to predict something now. Similarly, when we have a set of training data, we don’t know the “best fit coefficients” for that training data until after the last timestamp on all the data. As we move forward in time from the first timestamp to the last, we expect to get different sets of coefficients as more events happen.
One consequence of this is that, instead of getting on set of coefficients, we actually get an evolution of each coefficient. This is helpful because it gives us a sense of how stable those coefficients are. In particular, if one coefficient has changed sign 10 times over the training set, then we expect a good estimate for it is zero, not the so-called “best fit” at the end of the data.
One last word on causal modeling and IS/OOS. It is consistent with production code. Namely, you are always acting, in the training and in the OOS simulation, as if you’re running your model in production and you’re seeing how it performs. Of course you fit your model in sample, so you expect it to perform better there than in production.
Another way to say this is that, once you have a model in production, you will have to make decisions about the future based only on what you know now (so it’s causal) and you will want to update your model whenever you gather new data. So your coefficients of your model are living organisms that continuously evolve.
Submodels of Models
We often “prepare” the data before putting it into a model. Typically the way we prepare it has to do with the mean or the variance of the data, or sometimes the log (and then the mean or the variance of that transformed data).
But to be consistent with the causal nature of our modeling, we need to make sure our running estimates of mean and variance are also causal. Once we have causal estimates of our mean 

Of course we may have other things to keep track of as well to prepare our data, and we might run other submodels of our model. For example we may choose to consider only the “new” part of something, which is equivalent to trying to predict something like 
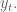

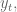
There are lots of choices here, but the point is it’s all causal, so you have to be careful when you train your overall model how to introduce your next data point and make sure the steps are all in order of time, and that you’re never ever cheating and looking ahead in time at data that hasn’t happened yet.
Financial time series
In finance we consider returns, say daily. And it’s not percent returns, actually it’s log returns: if 
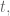
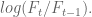
So if you start with S&P closing levels:

Then you get the following log returns:


What’s that mess? It’s crazy volatility caused by the financial crisis. We sometimes (not always) want to account for that volatility by normalizing with respect to it (described above). Once we do that we get something like this:

Which is clearly better behaved. Note this process is discussed in this post.
We could also normalize with respect to the mean, but we typically assume the mean of daily returns is 0, so as to not bias our models on short term trends.
Financial Modeling
One thing we need to understand about financial modeling is that there’s a feedback loop. If you find a way to make money, it eventually goes away- sometimes people refer to this as the fact that the “market learns over time”.
One way to see this is that, in the end, your model comes down to knowing some price is going to go up in the future, so you buy it before it goes up, you wait, and then you sell it at a profit. But if you think about it, your buying it has actually changed the process, and decreased the signal you were anticipating. That’s how the market learns – it’s a combination of a bunch of algorithms anticipating things and making them go away.
The consequence of this learning over time is that the existing signals are very weak. We are happy with a 3% correlation for models that have a horizon of 1 day (a “horizon” for your model is how long you expect your prediction to be good). This means not much signal, and lots of noise! In particular, lots of the machine learning “metrics of success” for models, such as measurements of precision or accuracy, are not very relevant in this context.
So instead of measuring accuracy, we generally draw a picture to assess models, namely of the (cumulative) PnL of the model. This generalizes to any model as well- you plot the cumulative sum of the product of demeaned forecast and demeaned realized. In other words, you see if your model consistently does better than the “stupidest” model of assuming everything is average.
If you plot this and you drift up and to the right, you’re good. If it’s too jaggedy, that means your model is taking big bets and isn’t stable.
Why regression?
From above we know the signal is weak. If you imagine there’s some complicated underlying relationship between your information and the thing you’re trying to predict, get over knowing what that is – there’s too much noise to find it. Instead, think of the function as possibly complicated, but continuous, and imagine you’ve written it out as a Taylor Series. Then you can’t possibly expect to get your hands on anything but the linear terms.
Don’t think about using logistic regression, either, because you’d need to be ignoring size, which matters in finance- it matters if a stock went up 2% instead of 0.01%. But logistic regression forces you to have an on/off switch, which would be possible but would lose a lot of information. Considering the fact that we are always in a low-information environment, this is a bad idea.
Note that although I’m claiming you probably want to use linear regression in a noisy environment, the actual terms themselves don’t have to be linear in the information you have. You can always take products of various terms as x’s in your regression. but you’re still fitting a linear model in non-linear terms.
Advanced regression
The first thing I need to explain is the exponential downweighting of old data, which I already used in a graph above, where I normalized returns by volatility with a decay of 0.97. How do I do this?
Working from this post again, the formula is given by essentially a weighted version of the normal one, where I weight recent data more than older data, and where the weight of older data is a power of some parameter 

We are actually dividing by the sum of the weights, but the weights are powers of some number s, so it’s a geometric sum and the sum is given by

One cool consequence of this formula is that it’s easy to update: if we have a new return 
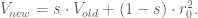
In fact this is the general rule for updating exponential downweighted estimates, and it’s one reason we like them so much- you only need to keep in memory your last estimate and the number

How do you choose your decay length? This is an art instead of a science, and depends on the domain you’re in. Think about how many days (or time periods) it takes to weight a data point at half of a new data point, and compare that to how fast the market forgets stuff.
This downweighting of old data is an example of inserting a prior into your model, where here the prior is “new data is more important than old data”. What are other kinds of priors you can have?
Priors
Priors can be thought of as opinions like the above. Besides “new data is more important than old data,” we may decide our prior is “coefficients vary smoothly.” This is relevant when we decide, say, to use a bunch of old values of some time series to help predict the next one, giving us a model like:
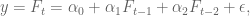
which is just the example where we take the last two values of the time series $F$ to predict the next one. But we could use more than two values, of course.
[Aside: in order to decide how many values to use, you might want to draw an autocorrelation plot for your data.]
The way you’d place the prior about the relationship between coefficients (in this case consecutive lagged data points) is by adding a matrix to your covariance matrix when you perform linear regression. See more about this here.
Ethics
I then talked about modeling and ethics. My goal is to get this next-gen group of data scientists sensitized to the fact that they are not just nerds sitting in the corner but have increasingly important ethical questions to consider while they work.
People tend to overfit their models. It’s human nature to want your baby to be awesome. They also underestimate the bad news and blame other people for bad news, because nothing their baby has done or is capable of is bad, unless someone else made them do it. Keep these things in mind.
I then described what I call the deathspiral of modeling, a term I coined in this post on creepy model watching.
I counseled the students to
- try to maintain skepticism about their models and how their models might get used,
- shoot holes in their own ideas,
- accept challenges and devise tests as scientists rather than defending their models using words – if someone thinks they can do better, than let them try, and agree on an evaluation method beforehand,
- In general, try to consider the consequences of their models.
I then showed them Emanuel Derman’s Hippocratic Oath of Modeling, which was made for financial modeling but fits perfectly into this framework. I discussed the politics of working in industry, namely that even if they are skeptical of their model there’s always the chance that it will be used the wrong way in spite of the modeler’s warnings. So the Hippocratic Oath is, unfortunately, insufficient in reality (but it’s a good start!).
Finally, there are ways to do good: I mentioned stuff like DataKind. There are also ways to be transparent: I mentioned Open Models, which is so far just an idea, but Victoria Stodden is working on RunMyCode, which is similar and very awesome.
Bad news wish list
You know that feeling you get when, a few years after you went to a wedding of your friends, you find out they’re getting a divorce?
It’s not a nice feeling. It’s work for you, and nasty work at that: you have to go back over your memories of those two in the past years, where you’d been projecting happiness and contentment all this time, and replace it with argument and bitterness. Not to mention the sorrow and sympathy you naturally bestow on your friends.
If it happens enough times, which it has to me, then going to weddings at all is kind of a funereal affair. I no longer project happy thoughts towards the newly married couple. If anything I worry for them and cross my fingers, hoping for the best. You may even say I’ve lost my faith in the institution.
Considering this, I can kind of understand why some religions don’t allow divorce. If you don’t allow it, then the bad news will never come out, and you won’t have to retroactively fit your internal model of other people’s lives to reality. You can go on blithely assuming everyone’s doing great. While we’re at it, no kids are getting neglected or abused because we don’t talk about that kind of thing.
By way of unreasonable analogy, I’d like to discuss the lack of conversation we’ve seen by the presidential campaigns on both sides about the state of the financial system. I’m starting to think it’s part of the religion of politicians that they never talk about this stuff, because they treat it as an embarrassing failure along the lines of a catholic divorce.
Or maybe I don’t have to be so philosophical about it- is it religion, or is it just money?
I had trouble following much about the two national conventions, because it made me so incensed that nothing was really being discussed, and that it was all so full of shit. But one thing I managed to glean from the coverage of the “events” being sponsored by the various lobbyist groups at the two conventions is that, whereas most lobbyists sponsor events at one of the conventions, like the NRA sponsors something at the Republican convention and the unions sponsor stuff at the Democratic convention, the financial lobbyists sponsor huge swanky events at both.
I interpret this to mean that they are paying to not be discussed as a platform issue. They seem to have paid enough, because I don’t hear anything from the Romney camp about shit Obama has or hasn’t done, or shit Geithner has or hasn’t done.
In fact, there’s a “Stories I’d like to See” column in Reuters column entitled “Tales of a TARP built to benefit bankers, and waiting for CEOs to pay the price”, and written by Stephen Brill, which discusses this exact issue in the context of Neil Barofsky’s book Bailout, which I blogged about here. From the column:
A presidential campaign that wanted to call out the Obama administration for being too friendly to Wall Street and the banks at the expense of Main Street would be using Bailout as the cheat sheet that keeps on giving. But with the Romney campaign’s attack coming from the opposite direction – that the president and his team have killed the economy by shackling Wall Street – and with Romney on record in favor of allowing the mortgage crisis to “bottom out” with no government intervention, the former Massachusetts governor and his team have no use for Bailout.
The second half of the article is really good, asking very commonsensical question about the recent settlement BofA got from the SEC for blatantly lying to shareholders around the time they acquired Merrill Lynch. Specifically the author notes that the (current) shareholders are left paying the (2008) shareholders, which is dumb, but the asshole Ken Lewis, who actually lied doesn’t seem to be getting into any trouble at all. From the column:
And, as long as we’re talking about harm done to shareholders, why wouldn’t we now see a new, post-settlement shareholders’ suit not against the company but targeted only at Lewis and some of his former colleagues who got Bank of America into this jam in the first place and just caused it to pay out $2.4 billion? (The plaintiffs here could be any current shareholders, because they are the ones who are writing the $2.4 billion check.) Again, did the company indemnify Lewis and other executives against shareholder suits, meaning that if a shareholder now sues Lewis over this $2.4 billion settlement, the shareholder is once again only suing himself?
Can someone please sort this out?
I really like this idea, that we have a list of topics for people to sort out, even though it’s going to be bad news. What other topics should we ask for on our bad news wish list?
Student loans are a regressive tax
I don’t think this approach of looking at student loans is new, but it’s new to me. A friend of mine mentioned this to me over the weekend.
For simplicity, assume everyone goes to college. Next, assume they all go to similar colleges – similar in cost and in quality. We will revisit these assumptions later. Finally, assume that costs of college keep going up the way they’re going and that student loan interest rates stay high.
What this means when you put it all together is that sufficiently rich people, or more likely their parents, will pay a one-time very large fee to attend college, but then they’ll be done with it. The rest of the people will be stuck paying monthly fees that will never go away. Moreover, because the interest rates are pretty high, the total amount non-rich people pay over their lifetime is substantially more than what rich people pay.
This is essentially a regressive tax, whereby poor people pay more than rich people.
Other points:
- The government student loans don’t have interest rates that are extremely high, but there’s a limit of how much you can borrow with that program, which leads many people even now to borrow privately at much higher rates.
- In the case of government-backed student loans this “tax” is essentially going to the government. In the case of private student loans, the private creditors are receiving the tax.
- Since you can’t discharge student debt via bankruptcy, even private student debt, it really is a life-long tax. It’s even true that if you haven’t paid off your student debt by the time you retire, your social security payments get cut.
- What about our assumptions that all schools have the same quality? Not true. Rich people tend to go to better schools. This means the poor are paying a tax for an inferior service. Of course, it’s also true that truly elite schools like Harvard have excellent financial support for their poorer students. This means there’s a two-tier school system if you’re poor: you can go to a normal school and pay tax, or you can excel and get into an elite school and it will be free.
- What about our assumption that all schools have the same cost? Of course not true; we can look for better quality education for a reasonable price.
- What about our assumption that everyone goes to college? Not true, but it’s still true that going to college and finishing sets you up for far better wage earning than if you only have a high school diploma. And although going to college and not finishing may not, nobody think they’re the ones who won’t finish.
Conclusion: Either we have to keep costs down or we have to make college government-subsidized or we have to make student loan interest rates really low or we have to offset this regressive tax with a highly progressive income tax.



