Why log returns?
There’s a nice blog post here by Quantivity which explains why we choose to define market returns using the log function:
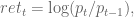
where 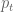

I mentioned this question briefly in this post, when I was explaining how people compute market volatility. I encourage anyone who is interested in this technical question to read that post, it really explains the reasoning well.
I wanted to add two remarks to the discussion, however, which actually argue for not using log returns, but instead using percentage returns in some situations.
The first is that the assumption of a log-normal distribution of returns, especially over a longer term than daily (say weekly or monthly) is unsatisfactory, because the skew of log-normal distribution is positive, whereas actual market returns for, say, S&P is negatively skewed (because we see bigger jumps down in times of panic). You can get lots of free market data here and try this out yourself empirically, but it also makes sense. Therefore when you approximate returns as log normal, you should probably stick to daily returns.
Second, it’s difficult to logically combine log returns with fat-tailed distributional assumptions, even for daily returns, although it’s very tempting to do so because assuming “fat tails” sometimes gives you more reasonable estimates of risk because of the added kurtosis. (I know some of you will ask why not just use no parametric family at all and just bootstrap or something from the empirical data you have- the answer is that you don’t ever have enough to feel like that will be representative of rough market conditions, even when you pool your data with other similar instruments. So instead you try different parametric families and compare.)
Mathematically there’s a problem: when you assume a student-t distribution (a standard choice) of log returns, then you are automatically assuming that the expected value of any such stock in one day is infinity! This is usually not what people expect about the market, especially considering that there does not exist an infinite amount of money (yet!). I guess it’s technically up for debate whether this is an okay assumption but let me stipulate that it’s not what people usually intend.
This happens even at small scale, so for daily returns, and it’s because the moment generating function is undefined for student-t distributions (the moment generating function’s value at 1 is the expected return, in terms of money, when you use log returns). We actually saw this problem occur at Riskmetrics, where of course we didn’t see “infinity” show up as a risk number but we saw, every now and then, ridiculously large numbers when we let people combine “log returns” with “student-t distributions.” A solution to this is to use percentage returns when you want to assume fat tails.




Cathy, could part of the reason that log returns are assumed be because there are a hell of a lot less nodes on the binomial tree, due to recombination? I’m going from memory here (been a while since I ran a binomial tree), but remember there’s a key point that uptick-downtick is the same value as downtick-uptick and without that the number of end nodes would be 2^(number of periods), rather than (number of periods)+1. so U(x)=x*(1+c) and D(x)=x/(1+c), which, over time gives you a lognormal distribution?
Am I misremembering? Could this be an example of mathematical laziness (OK, really necessity, because there isn’t enough computing power to model a non-recombinant tree) affecting analysis and results?
FoW
LikeLike
FogOfWar, are you just saying that log(⨯) → +? I think the reason for log’s prevalence is that ln ≈ % change in the linear approximation.
LikeLiked by 1 person
I’m rusty on my quant chops. Questions:
1. If I model a 2D random walk with percentage steps, rather than constant-move steps, is the resulting distribution of end results approaching a lognormal distribution (I think so). So, e.g., percentage steps starting at 1, with neutral returns and 10% move per step would be 1.1, 1/1.1 at t2, and
1.21, 1, 1/1.21 at t3, etc.
2. How practically hard is it to run a recombinant tree without lognormal returns?
LikeLike
Hudson’s linked article gives lots more reasons *not* to use
Also — since panics sometimes happen on a day, lognormal can’t be sufficient for intraday returns.
I’ve noticed that traders and certain (rational imho) kinds of investors avoid distributions altogether. Rather, they say “What’s the most I am likely to lose?” which is kind of like CVar.
Cathy, is it unrealistic to bootstrap with real data only because super-bad market days are so far in the past that we only have low-res records?
Lastly — did you ever use Cauchy? Someone I know is doing that — I have my opinion but I’d like to hear yours.
LikeLike
Quants move quickly to trinomial or jump-diffusion models as a second-order solution to address intra-period volatility spikes. Again my chops are rusty. Recall that trinomial gives you a lognormal distribution with fatter tails on the low end (the “tri-” adds to the binomial distribution a small probability in each period that the notional goes to zero instantly), not sure about jump-diffusion (maybe depends on the jump probability and magnitude–I didn’t get that far in my armchair-quant explorations). Cathy–thoughts?
Interesting comment on “traders think”. I agree, and have had similar experiences, but it’s important to think about what kind of trader. Banks are not monolithic institutions, and there are quant traders, who are algorithm-driven, and “traditional” traders who are–let’s just say–less algorithm-driven. It’s not that traditional traders are dumb or ignorant of math (not PhD level, but I’d say a majority of those on the “traditional” trading floor majored in a hard science undergrad and got very good grades–they’re generally not spooked off by the thought of doing math). It’s just that they have a different approach to the market.
LikeLike
The Quantivity link is very nice. Random thoughts–
Exp maps Brownian motion or random walks on (-oo,oo) to processes on (0,oo). Invariance under additive shifts and statistics for increments turn into scale invariance and statistics for log returns.
So it is very natural and convenient to use log returns for analysis or statistics on scale-invariant price series that live on (0,oo).
FWIW, if you build a model on (-oo,oo) in discrete time using iid increments with mean 0 and variance 1, then under the right scaling, it converges to a standard Brownian as delta t -> 0. (Donsker) Take exp, and you see a model built using scaled, finite-var, iid returns will converge to geometric Brownian motion where exp and log are natural.
Agree that the recombining property of binary trees is crucial to make the backward propagation of CRR-type computational methods efficient. This requires up and down multipliers that are reciprocals, which obviously exp(a) and exp(-a) satisfy but returns-type multipliers like 1+a and 1-a don’t.
For the purpose of getting away from vanilla models and generating skew and fat tails, binomial trees are too rigid, eg, they aren’t good to model locally varying volatility. You may have more luck with trinomial trees with varying probabilities (positive for stability) or grids.
And if you want things fatter than you can get with gaussian based dynamics, then I guess you pass to more general Levy processes with Student-t/Cauchy statistics.
Would be interesting to learn what people are doing with these fat tail distributions. You lose a lot with no higher moments, or even an expectation. And continuity is nice too, but the point is it may not be realistic for all things.
FWIW, square of log returns looks like the market standard for measuring realized variance. http://www.isda.org/cgi-bin/_isdadocsdownload/download.asp?DownloadID=131
LikeLike
Meucci argues that (for stocks) you should use log returns for estimation since they are invariants and arithmetic returns are not. However, he says optimization should occur on arithmetic returns since that is what you actually will receive as an investor.
As far as I can tell, E(X) is undefined if the degrees of freedom is less than 1 and Variance(X) is infinite if degrees of freedom is less than or equal to 2. Hence, your problem is that you have some extreme outliers that have caused you to estimate the degrees of freedom to be very small. My solution is to clean the data in order to reduce the impact of outliers before estimating any t-distribution.
LikeLike
You write: “when you assume a student-t distribution (a standard choice) of log returns, then you are automatically assuming that the expected value of any such stock in one day is infinity!” This is not true in general. The kth moment is finite is k<n, where n=dof, which is clearly the relevant empirical case.
LikeLike
I’m not talking about the kth moment but rather the moment generating function, which is always undefined.
LikeLike
I am a novice but here: “The first is that the assumption of a log-normal distribution of returns, especially over a longer term than daily (say weekly or monthly) is unsatisfactory…”, don’t you mean log-normal distribution of prices because that’s what log-returns are meant to be assuming – price are log-normal, hence returns are normal?
LikeLike
Hmmm… no. Prices themselves are never what we care about, we only care about the change of prices. There are lots of ways to do this but they never involve prices themselves, and usually they are set to be scale-independent. So you could take “difference between today’s close and yesterday’s close” but then it would matter if it’s 10 today and was 9 yesterday instead of 100 today and was 90 yesterday, which seems stupid. So instead we take percentage change, which is the standard “return” most people think about (i.e. when they invest $100 and get a 5% change, that means they end up with $105). But instead we use “log returns”, log(today’s price/yesterday’s price).
I do think I was being sloppy though. When I say log-normal distribution of returns, I really should have said normal distribution of log returns. If you look at wikipedia you realize this would be equivalent to saying “log normal distributions of ratios (today’s price)/(yesterday’s price).”
I hope that helps, Cathy
LikeLike
You’re so interesting! I do not believe I’ve truly read something like that before. So good to discover somebody with a few genuine thoughts on this subject matter. Seriously.. thank you for starting this up. This web site is something that is needed on the internet, someone with a little originality!
LikeLiked by 1 person
This is a good discussion, as far as it goes. The body of the 99% of the frequencies of daily returns are well behaved under any of the distributional assumptions as noted. The problem, of course, are the 1% of returns in the “fat” tails — the extreme values.
The point to note here is that there have been multiple — multiple! — daily market moves in the past 25 years of such magnitude that, based on any of the functional forms as discussed, would be expected to occur on at most one day out of maybe 25,000 trading days or about 1 in 100 years. But to take just one example, in Oct 1987 the market dropped 22.6% in one day — an event that under exponential assumptions should occur once in 520 million years.
More to the point, frequency distributions assume independence of daily returns but, again in the tails, we see that there can be bursts of dependence. On multiple occasions in the past 25 years there have been sequential daily return moves greater than 10%. So, a 10% probability move to the power of 3 days in a row is an event on the order of one in a billion trading days…an impossibility given the assumptions as discussed.
Clearly, there is a big problem with any of the approaches that are most widely used in the markets today in explaining the widely divergent behaviors between the body of the distributions versus the tails. The intractability inherent in adopting the more extreme valued distributional assumptions seems to be the barrier to their wider use, e.g., neither Levy and Cauchy have defined higher moments. But you don’t have to be Nassim Taleb to know that these outliers are not anomalous and reveal fundamental market properties. These are delicate problems that remain hotly contested areas of research.
LikeLike