Columbia Data Science course, week 5: GetGlue, time series, financial modeling, advanced regression, and ethics
I was happy to be giving Rachel Schutt’s Columbia Data Science course this week, where I discussed time series, financial modeling, and ethics. I blogged previous classes here.
The first few minutes of class were for a case study with GetGlue, a New York-based start-up that won the mashable breakthrough start-up of the year in 2011 and is backed by some of the VCs that also fund big names like Tumblr, etsy, foursquare, etc. GetGlue is part of the social TV space. Lead Scientist, Kyle Teague, came to tell the class a little bit about GetGlue, and some of what he worked on there. He also came to announce that GetGlue was giving the class access to a fairly large data set of user check-ins to tv shows and movies. Kyle’s background is in electrical engineering, he placed in the 2011 KDD cup (which we learned about last week from Brian), and he started programming when he was a kid.
GetGlue’s goal is to address the problem of content discovery within the movie and tv space, primarily. The usual model for finding out what’s on TV is the 1950’s TV Guide schedule, and that’s still how we’re supposed to find things to watch. There are thousands of channels and it’s getting increasingly difficult to find out what’s good on. GetGlue wants to change this model, by giving people personalized TV recommendations and personalized guides. There are other ways GetGlue uses Data Science but for the most part we focused on how this the recommendation system works. Users “check-in” to tv shows, which means they can tell people they’re watching a show. This creates a time-stamped data point. They can also do other actions such as like, or comment on the show. So this is a -tuple: {user, action, object} where the object is a tv show or movie. This induces a bi-partite graph. A bi-partite graph or network contains two types of nodes: users and tv shows. An edges exist between users and an tv shows, but not between users and users or tv shows and tv shows. So Bob and Mad Men are connected because Bob likes Mad Men, and Sarah and Mad Men and Lost are connected because Sarah liked Mad Men and Lost. But Bob and Sarah aren’t connected, nor are Mad Men and Lost. A lot can be learned from this graph alone.
But GetGlue finds ways to create edges between users and between objects (tv shows, or movies.) Users can follow each other or be friends on GetGlue, and also GetGlue can learn that two people are similar[do they do this?]. GetGlue also hires human evaluators to make connections or directional edges between objects. So True Blood and Buffy the Vampire Slayer might be similar for some reason and so the humans create an edge in the graph between them. There were nuances around the edge being directional. They may draw an arrow pointing from Buffy to True Blood but not vice versa, for example, so their notion of “similar” or “close” captures both content and popularity. (That’s a made-up example.) Pandora does something like this too.
Another important aspect is time. The user checked-in or liked a show at a specific time, so the -tuple extends to have a time-stamp: {user,action,object,timestamp}. This is essentially the data set the class has access to, although it’s slightly more complicated and messy than that. Their first assignment with this data will be to explore it, try to characterize it and understand it, gain intuition around it and visualize what they find.
Students in the class asked him questions around topics of the value of formal education in becoming a data scientist (do you need one? Kyle’s time spent doing signal processing in research labs was valuable, but so was his time spent coding for fun as a kid), what would be messy about a data set, why would the data set be messy (often bugs in the code), how would they know? (their QA and values that don’t make sense), what language does he use to prototype algorithms (python), how does he know his algorithm is good.
Then it was my turn. I started out with my data scientist profile:

As you can see, I feel like I have the most weakness in CS. Although I can use python pretty proficiently, and in particular I can scrape and parce data, prototype models, and use matplotlib to draw pretty pictures, I am no java map-reducer and I bow down to those people who are. I am also completely untrained in data visualization but I know enough to get by and give presentations that people understand.
Thought Experiment
I asked the students the following question:
What do you lose when you think of your training set as a big pile of data and ignore the timestamps?
They had some pretty insightful comments. One thing they mentioned off the bat is that you won’t know cause and effect if you don’t have any sense of time. Of course that’s true but it’s not quite what I meant, so I amended the question to allow you to collect relative time differentials, so “time since user last logged in” or “time since last click” or “time since last insulin injection”, but not absolute timestamps.
What I was getting at, and what they came up with, was that when you ignore the passage of time through your data, you ignore trends altogether, as well as seasonality. So for the insulin example, you might note that 15 minutes after your insulin injection your blood sugar goes down consistently, but you might not notice an overall trend of your rising blood sugar over the past few months if your dataset for the past few months has no absolute timestamp on it.
This idea, of keeping track of trends and seasonalities, is very important in financial data, and essential to keep track of if you want to make money, considering how small the signals are.
How to avoid overfitting when you model with time series
After discussing seasonality and trends in the various financial markets, we started talking about how to avoid overfitting your model.
Specifically, I started out with having a strict concept of in-sample (IS) and out-of-sample (OOS) data. Note the OOS data is not meant as testing data- that all happens inside OOS data. It’s meant to be the data you use after finalizing your model so that you have some idea how the model will perform in production.
Next, I discussed the concept of causal modeling. Namely, we should never use information in the future to predict something now. Similarly, when we have a set of training data, we don’t know the “best fit coefficients” for that training data until after the last timestamp on all the data. As we move forward in time from the first timestamp to the last, we expect to get different sets of coefficients as more events happen.
One consequence of this is that, instead of getting on set of coefficients, we actually get an evolution of each coefficient. This is helpful because it gives us a sense of how stable those coefficients are. In particular, if one coefficient has changed sign 10 times over the training set, then we expect a good estimate for it is zero, not the so-called “best fit” at the end of the data.
One last word on causal modeling and IS/OOS. It is consistent with production code. Namely, you are always acting, in the training and in the OOS simulation, as if you’re running your model in production and you’re seeing how it performs. Of course you fit your model in sample, so you expect it to perform better there than in production.
Another way to say this is that, once you have a model in production, you will have to make decisions about the future based only on what you know now (so it’s causal) and you will want to update your model whenever you gather new data. So your coefficients of your model are living organisms that continuously evolve.
Submodels of Models
We often “prepare” the data before putting it into a model. Typically the way we prepare it has to do with the mean or the variance of the data, or sometimes the log (and then the mean or the variance of that transformed data).
But to be consistent with the causal nature of our modeling, we need to make sure our running estimates of mean and variance are also causal. Once we have causal estimates of our mean 

Of course we may have other things to keep track of as well to prepare our data, and we might run other submodels of our model. For example we may choose to consider only the “new” part of something, which is equivalent to trying to predict something like 
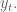

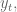
There are lots of choices here, but the point is it’s all causal, so you have to be careful when you train your overall model how to introduce your next data point and make sure the steps are all in order of time, and that you’re never ever cheating and looking ahead in time at data that hasn’t happened yet.
Financial time series
In finance we consider returns, say daily. And it’s not percent returns, actually it’s log returns: if 
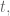
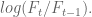
So if you start with S&P closing levels:

Then you get the following log returns:


What’s that mess? It’s crazy volatility caused by the financial crisis. We sometimes (not always) want to account for that volatility by normalizing with respect to it (described above). Once we do that we get something like this:

Which is clearly better behaved. Note this process is discussed in this post.
We could also normalize with respect to the mean, but we typically assume the mean of daily returns is 0, so as to not bias our models on short term trends.
Financial Modeling
One thing we need to understand about financial modeling is that there’s a feedback loop. If you find a way to make money, it eventually goes away- sometimes people refer to this as the fact that the “market learns over time”.
One way to see this is that, in the end, your model comes down to knowing some price is going to go up in the future, so you buy it before it goes up, you wait, and then you sell it at a profit. But if you think about it, your buying it has actually changed the process, and decreased the signal you were anticipating. That’s how the market learns – it’s a combination of a bunch of algorithms anticipating things and making them go away.
The consequence of this learning over time is that the existing signals are very weak. We are happy with a 3% correlation for models that have a horizon of 1 day (a “horizon” for your model is how long you expect your prediction to be good). This means not much signal, and lots of noise! In particular, lots of the machine learning “metrics of success” for models, such as measurements of precision or accuracy, are not very relevant in this context.
So instead of measuring accuracy, we generally draw a picture to assess models, namely of the (cumulative) PnL of the model. This generalizes to any model as well- you plot the cumulative sum of the product of demeaned forecast and demeaned realized. In other words, you see if your model consistently does better than the “stupidest” model of assuming everything is average.
If you plot this and you drift up and to the right, you’re good. If it’s too jaggedy, that means your model is taking big bets and isn’t stable.
Why regression?
From above we know the signal is weak. If you imagine there’s some complicated underlying relationship between your information and the thing you’re trying to predict, get over knowing what that is – there’s too much noise to find it. Instead, think of the function as possibly complicated, but continuous, and imagine you’ve written it out as a Taylor Series. Then you can’t possibly expect to get your hands on anything but the linear terms.
Don’t think about using logistic regression, either, because you’d need to be ignoring size, which matters in finance- it matters if a stock went up 2% instead of 0.01%. But logistic regression forces you to have an on/off switch, which would be possible but would lose a lot of information. Considering the fact that we are always in a low-information environment, this is a bad idea.
Note that although I’m claiming you probably want to use linear regression in a noisy environment, the actual terms themselves don’t have to be linear in the information you have. You can always take products of various terms as x’s in your regression. but you’re still fitting a linear model in non-linear terms.
Advanced regression
The first thing I need to explain is the exponential downweighting of old data, which I already used in a graph above, where I normalized returns by volatility with a decay of 0.97. How do I do this?
Working from this post again, the formula is given by essentially a weighted version of the normal one, where I weight recent data more than older data, and where the weight of older data is a power of some parameter 

We are actually dividing by the sum of the weights, but the weights are powers of some number s, so it’s a geometric sum and the sum is given by

One cool consequence of this formula is that it’s easy to update: if we have a new return 
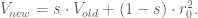
In fact this is the general rule for updating exponential downweighted estimates, and it’s one reason we like them so much- you only need to keep in memory your last estimate and the number

How do you choose your decay length? This is an art instead of a science, and depends on the domain you’re in. Think about how many days (or time periods) it takes to weight a data point at half of a new data point, and compare that to how fast the market forgets stuff.
This downweighting of old data is an example of inserting a prior into your model, where here the prior is “new data is more important than old data”. What are other kinds of priors you can have?
Priors
Priors can be thought of as opinions like the above. Besides “new data is more important than old data,” we may decide our prior is “coefficients vary smoothly.” This is relevant when we decide, say, to use a bunch of old values of some time series to help predict the next one, giving us a model like:
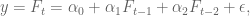
which is just the example where we take the last two values of the time series $F$ to predict the next one. But we could use more than two values, of course.
[Aside: in order to decide how many values to use, you might want to draw an autocorrelation plot for your data.]
The way you’d place the prior about the relationship between coefficients (in this case consecutive lagged data points) is by adding a matrix to your covariance matrix when you perform linear regression. See more about this here.
Ethics
I then talked about modeling and ethics. My goal is to get this next-gen group of data scientists sensitized to the fact that they are not just nerds sitting in the corner but have increasingly important ethical questions to consider while they work.
People tend to overfit their models. It’s human nature to want your baby to be awesome. They also underestimate the bad news and blame other people for bad news, because nothing their baby has done or is capable of is bad, unless someone else made them do it. Keep these things in mind.
I then described what I call the deathspiral of modeling, a term I coined in this post on creepy model watching.
I counseled the students to
- try to maintain skepticism about their models and how their models might get used,
- shoot holes in their own ideas,
- accept challenges and devise tests as scientists rather than defending their models using words – if someone thinks they can do better, than let them try, and agree on an evaluation method beforehand,
- In general, try to consider the consequences of their models.
I then showed them Emanuel Derman’s Hippocratic Oath of Modeling, which was made for financial modeling but fits perfectly into this framework. I discussed the politics of working in industry, namely that even if they are skeptical of their model there’s always the chance that it will be used the wrong way in spite of the modeler’s warnings. So the Hippocratic Oath is, unfortunately, insufficient in reality (but it’s a good start!).
Finally, there are ways to do good: I mentioned stuff like DataKind. There are also ways to be transparent: I mentioned Open Models, which is so far just an idea, but Victoria Stodden is working on RunMyCode, which is similar and very awesome.



