Combining priors and downweighting in linear regression
This is a continuation of yesterday’s post about understand priors on linear regression as minimizing penalty functions.
Today I want to talk about how we can pair different kinds of priors with exponential downweighting. There are two different kinds of priors, namely persistent priors and kick-off priors (I think I’m making up these terms, so there may be other official terms for these things).
Persistent Priors
Sometimes you want a prior to exist throughout the life of the model. Most “small coefficients” or “smoothness” priors are like this. In such a situation, you will aggregate today’s data (say), which means creating an 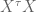

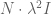
Kick-Off Priors
Other times you just want your linear regression to start off kind of “knowing” what the expected answer is. In this case you only add the prior terms to the first day’s
Example
This is confusing so I’m going to work out an example. Let’s say we have a model where we have a prior that the 1) 

Then on the first day, we find the 
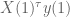
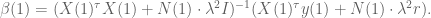
How should we choose 

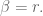

On the second day, we downweight data from the first day, and thus we also downweight the
However, we still want to remind the model to make the coefficients small – in other words a separate prior on the size of coefficients. So in fact, on the first day we will have two priors in effect, one as above and the other a simple prior on the covariance term, namely we add 
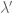

And just to be really precise, of we denote by 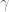
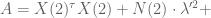
![\gamma[X(1)^\tau X(1) + N(1) \cdot \lambda^2 I + N(1) \cdot (\lambda')^2 I]](https://s0.wp.com/latex.php?latex=%5Cgamma%5BX%281%29%5E%5Ctau+X%281%29+%2B+N%281%29+%5Ccdot+%5Clambda%5E2+I+%2B+N%281%29+%5Ccdot+%28%5Clambda%27%29%5E2+I%5D&bg=ffffff&fg=555555&s=0&c=20201002)
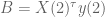
![+ \gamma[X(1)^\tau y(1) + N(1) \cdot \lambda^2 r]](https://s0.wp.com/latex.php?latex=%2B+%5Cgamma%5BX%281%29%5E%5Ctau+y%281%29+%2B+N%281%29+%5Ccdot+%5Clambda%5E2+r%5D&bg=ffffff&fg=555555&s=0&c=20201002)





Didn’t know that. Why do you use the downweighting, if I may ask?
More generally, why do you use regression in financial analysis?
I speak as an outsider, I can’t image why one would want to fit financial data with a smooth function.
Thanks.
LikeLike
You always want to downweight older data, because a golden rule of financial modeling is that more recent market data is more relevant. Exponential downweighting more or less simulates the memory of the market.
You use regression because the signal you’re trying to model is incredibly noisy, and it would be silly to imagine being able to approximate it with something more complex than a linear function.
LikeLike
Thanks.
I did’t understand downweighting because I couldn’t see (still can’t) the need for regression. Are you talking about tick data? In that case, with a linear function, we are talking of just some kind of trend.
Again, thanks for the response.
LikeLike
Why do you say trend? Linear regression helps you decide whether certain events have forecasting powers for later events. I’m not restricted to using earlier values of the S&P index to forecast later values of the S&P index. I could use anything to predict anything else.
LikeLike
Thanks for this post. I think it’s exactly the idea I was looking for my problem. If you could give me your thoughts on this I’d really appreciate it.
The problem is estimating value for NBA players. Each player can be thought of as having a coefficient beta that we are trying to find from the regression. The data for the regression comes from point differential (+/-) for each matchup of 10 players during a possession of a game.
I was thinking of combining priors, one based on the previous season, which inferring from your post here would be the “kickoff” prior. The other prior is from the current season based on “box score” statistics (which can also be used to give an estimate of player value). In fact, it seems that there could even be another “persistent” prior on the shape of the distribution.
LikeLike