Bayesian regressions (part 2)
In my first post about Bayesian regressions, I mentioned that you can enforce a prior about the size of the coefficients by fiddling with the diagonal elements of the prior covariance matrix. I want to go back to that since it’s a key point.
Recall the covariance matrix represents the covariance of the coefficients, so those diagonal elements correspond to the variance of the coefficients themselves, which is a natural proxy for their size.
For example, you may just want to make sure the coefficients don’t get too big, or in other words there’s a penalty for large coefficients. Actually there’s a name for just having this prior, and it’s called L2 regularization. You just set the prior to be 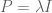
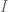

You’re going to end up adding this prior to the actual sample covariance matrix as measured by the data, so don’t worry about the prior matrix being invertible (but definitely do make sure it’s symmetrical).

Moreover, you can have many different priors, corresponding to different parts of the covariance matrix, and you can add them all up together to get a final prior.

From my first post, I had two priors, both on the coefficients of lagged values of some time series. First, I expect the signal to die out logarithmically or something as we go back in time, so I expect the size of the coefficients to die down as a power of some parameter. In other words, I’ll actually have two parameters: one for the decrease on each lag and one overall tuning parameter. My prior matrix will be diagonal and the 
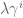
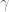
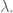
My second prior was that the entries should vary smoothly, which I claimed was enforceable by fiddling with the super and sub diagonals of the covariance matrix. This is because those entries describe the covariance between adjacent coefficients (and all of my coefficients in this simple example correspond to lagged values of some time series).
In other words, ignoring the variances of each variable (since we already have a handle on the variance from our first prior), we are setting a prior on the correlation between adjacent terms. We expect the correlation to be pretty high (and we can estimate it with historical data). I’ll work out exactly what that second prior is in a later post, but in the end we have two priors, both with tuning parameters, which we may be able to combine into one tuning parameter, which again determines the strength of the overall prior after adding the two up.
Because we are tamping down the size of the coefficients, as well as linking them through a high correlation assumption, the net effect is that we are decreasing the number of effective coefficients, and the regression has less work to do. Of course this all depends on how strong the prior is too; we could make the prior so weak that it has no effect, or we could make it so strong that the data doesn’t effect the result at all!
In my next post I will talk about combining priors with exponential downweighting.




Another neat use of priors in multiple linear regression is leveraging knowledge about one regression coefficient to constrain inference about a different regression coefficient, when the predictors are correlated. Let me unpack that a bit. First, suppose that two predictors are correlated, as often happens in real data. Next, suppose we have some previous data that indicate reasonable values for the regression coefficient on only one of the predictors. Then, we collect some new data involving both predictors. The prior knowledge about the one regression coefficient will constrain the posterior of the second regression coefficient. I discuss this on p. 468 of my book (which is an accessible treatment of MCMC approaches to Bayesian inference).
LikeLike