Columbia Data Science course, week 4: K-means, Classifiers, Logistic Regression, Evaluation
This week our guest lecturer for the Columbia Data Science class was Brian Dalessandro. Brian works at Media6Degrees as a VP of Data Science, and he’s super active in the research community. He’s also served as co-chair of the KDD competition.
Before Brian started, Rachel threw us a couple of delicious data science tidbits.
The Process of Data Science
First we have the Real World. Inside the Real World we have:
- Users using Google+
- People competing in the Olympics
- Spammers sending email
From this we draw raw data, e.g. logs, all the olympics records, or Enron employee emails. We want to process this to make it clean for analysis. We use pipelines of data munging, joining, scraping, wrangling or whatever you want to call it and we use tools such as:
- python
- shell scripts
- R
- SQL
We eventually get the data down to a nice format, say something with columns:
name event year gender event time
Note: this is where you typically start in a standard statistics class. But it’s not where we typically start in the real world.
Once you have this clean data set, you should be doing some kind of exploratory data analysis (EDA); if you don’t really know what I’m talking about then look at Rachel’s recent blog post on the subject. You may realize that it isn’t actually clean.
Next, you decide to apply some algorithm you learned somewhere:
- k-nearest neighbor
- regression
- Naive Bayes
- (something else),
depending on the type of problem you’re trying to solve:
- classification
- prediction
- description
You then:
- interpret
- visualize
- report
- communicate
At the end you have a “data product”, e.g. a spam classifier.
K-means
So far we’ve only seen supervised learning. K-means is the first unsupervised learning technique we’ll look into. Say you have data at the user level:
- G+ data
- survey data
- medical data
- SAT scores
Assume each row of your data set corresponds to a person, say each row corresponds to information about the user as follows:
age gender income Geo=state household size
Your goal is to segment them, otherwise known as stratify, or group, or cluster. Why? For example:
- you might want to give different users different experiences. Marketing often does this.
- you might have a model that works better for specific groups
- hierarchical modeling in statistics does something like this.
One possibility is to choose the groups yourself. Bucket users using homemade thresholds. Like by age, 20-24, 25-30, etc. or by income. In fact, say you did this, by age, gender, state, income, marital status. You may have 10 age buckets, 2 gender buckets, and so on, which would result in 10x2x50x10x3 = 30,000 possible bins, which is big.
You can picture a five dimensional space with buckets along each axis, and each user would then live in one of those 30,000 five-dimensional cells. You wouldn’t want 30,000 marketing campaigns so you’d have to bin the bins somewhat.
Wait, what if you want to use an algorithm instead where you could decide on the number of bins? K-means is a “clustering algorithm”, and k is the number of groups. You pick k, a hyper parameter.
2-d version
Say you have users with #clicks, #impressions (or age and income – anything with just two numerical parameters). Then k-means looks for clusters on the 2-d plane. Here’s a stolen and simplistic picture that illustrates what this might look like:

The general algorithm is just the same picture but generalized to d dimensions, where d is the number of features for each data point.
Here’s the actual algorithm:
- randomly pick K centroids
- assign data to closest centroid.
- move the centroids to the average location of the users assigned to it
- repeat until the assignments don’t change
It’s up to you to interpret if there’s a natural way to describe these groups.
This is unsupervised learning and it has issues:
- choosing an optimal k is also a problem although
, where n is number of data points.
- convergence issues – the solution can fail to exist (the configurations can fall into a loop) or “wrong”
- but it’s also fast
- interpretability can be a problem – sometimes the answer isn’t useful
- in spite of this, there are broad applications in marketing, computer vision (partition an image), or as a starting point for other models.
One common tool we use a lot in our systems is logistic regression.
Thought Experiment
Brian now asked us the following:
How would data science differ if we had a “grand unified theory of everything”?
He gave us some thoughts:
- Would we even need data science?
- Theory offers us a symbolic explanation of how the world works.
- What’s the difference between physics and data science?
- Is it just accuracy? After all, Newton wasn’t completely precise, but was pretty close.
If you think of the sciences as a continuum, where physics is all the way on the right, and as you go left, you get more chaotic, then where is economics on this spectrum? Marketing? Finance? As we go left, we’re adding randomness (and as a clever student points out, salary as well).
Bottomline: if we could model this data science stuff like we know how to model physics, we’d know when people will click on what ad. The real world isn’t this understood, nor do we expect to be able to in the future.
Does “data science” deserve the word “science” in its name? Here’s why maybe the answer is yes.
We always have more than one model, and our models are always changing.
The art in data science is this: translating the problem into the language of data science
The science in data science is this: given raw data, constraints and a problem statement, you have an infinite set of models to choose from, with which you will use to maximize performance on some evaluation metric, that you will have to specify. Every design choice you make can be formulated as an hypothesis, upon which you will use rigorous testing and experimentation to either validate or refute.
Never underestimate the power of creativity: usually people have vision but no method. As the data scientist, you have to turn it into a model within the operational constraints. You need to optimize a metric that you get to define. Moreover, you do this with a scientific method, in the following sense.
Namely, you hold onto your existing best performer, and once you have a new idea to prototype, then you set up an experiment wherein the two best models compete. You therefore have a continuous scientific experiment, and in that sense you can justify it as a science.
Classifiers
Given
- data
- a problem, and
- constraints,
we need to determine:
- a classifier,
- an optimization method,
- a loss function,
- features, and
- an evaluation metric.
Today we will focus on the process of choosing a classifier.
Classification involves mapping your data points into a finite set of labels or the probability of a given label or labels. Examples of when you’d want to use classification:
- will someone click on this ad?
- what number is this?
- what is this news article about?
- is this spam?
- is this pill good for headaches?
From now on we’ll talk about binary classification only (0 or 1).
Examples of classification algorithms:
- decision tree
- random forests
- naive bayes
- k-nearest neighbors
- logistic regression
- support vector machines
- neural networks
Which one should we use?
One possibility is to try them all, and choose the best performer. This is fine if you have no constraints or if you ignore constraints. But usually constraints are a big deal – you might have tons of data or not much time or both.
If I need to update 500 models a day, I do need to care about runtime. these end up being bidding decisions. Some algorithms are slow – k-nearest neighbors for example. Linear models, by contrast, are very fast.
One under-appreciated constraint of a data scientist is this: your own understanding of the algorithm.
Ask yourself carefully, do you understand it for real? Really? Admit it if you don’t. You don’t have to be a master of every algorithm to be a good data scientist. The truth is, getting the “best-fit” of an algorithm often requires intimate knowledge of said algorithm. Sometimes you need to tweak an algorithm to make it fit your data. A common mistake for people not completely familiar with an algorithm is to overfit.
Another common constraint: interpretability. You often need to be able to interpret your model, for the sake of the business for example. Decision trees are very easy to interpret. Random forests, on the other hand, not so much, even though it’s almost the same thing, but can take exponentially longer to explain in full. If you don’t have 15 years to spend understanding a result, you may be willing to give up some accuracy in order to have it easy to understand.
Note that credit cards have to be able to explain their models by law so decision trees make more sense than random forests.
How about scalability? In general, there are three things you have to keep in mind when considering scalability:
- learning time: how much time does it take to train the model?
- scoring time: how much time does it take to give a new user a score once the model is in production?
- model storage: how much memory does the production model use up?
Here’s a useful paper to look at when comparing models: “An Empirical Comparison of Supervised Learning Algorithms”, from which we learn:
- Simpler models are more interpretable but aren’t as good performers.
- The question of which algorithm works best is problem dependent
- It’s also constraint dependent
At M6D, we need to match clients (advertising companies) to individual users. We have logged the sites they have visited on the internet. Different sites collect this information for us. We don’t look at the contents of the page – we take the url and hash it into some random string and then we have, say, the following data about a user we call “u”:
u = <xyz, 123, sdqwe, 13ms>
This means u visited 4 sites and their urls hashed to the above strings. Recall last week we learned spam classifier where the features are words. We aren’t looking at the meaning of the words. So the might as well be strings.
At the end of the day we build a giant matrix whose columns correspond to sites and whose rows correspond to users, and there’s a “1” if that user went to that site.
To make this a classifier, we also need to associate the behavior “clicked on a shoe ad”. So, a label.
Once we’ve labeled as above, this looks just like spam classification. We can now rely on well-established methods developed for spam classification – reduction to a previously solved problem.
Logistic Regression
We have three core problems as data scientists at M6D:
- feature engineering,
- user level conversion prediction,
- bidding.
We will focus on the second. We use logistic regression– it’s highly scalable and works great for binary outcomes.
What if you wanted to do something else? You could simply find a threshold so that, above you get 1, below you get 0. Or you could use a linear model like linear regression, but then you’d need to cut off below 0 or above 1.
What’s better: fit a function that is bounded in side [0,1]. For example, the logit function

wanna estimate

To make this a linear model in the outcomes 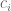

The parameter 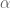
If you had no information except the base rate, the average prediction would be just that. In a logistical regression,
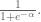
The slope 
Our immediate modeling goal is to use our training data to find the best choices for 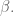
The likelihood function 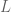


where we are assuming the data points 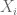
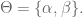
We then search for the parameters that maximize this having observed our data:

The probability of a single observation is

where 
Similar to last week, we now take the log and get something convex, so it has to have a global maximum. Finally, we use numerical techniques to find it, which essentially follow the gradient like Newton’s method from calculus. Computer programs can do this pretty well. These algorithms depend on a step size, which we will need to adjust as we get closer to the global max or min – there’s an art to this piece of numerical optimization as well. Each step of the algorithm looks something like this:

where remember we are actually optimizing our parameters 

“Flavors” of Logistic Regression for convex optimization.
The Newton’s method we described above is also called Iterative Reweighted Least Squares. It uses the curvature of log-likelihood to choose appropriate step direction. The actual calculation involves the Hessian matrix, and in particular requires its inversion, which is a kxk matrix. This is bad when there’s lots of features, as in 10,000 or something. Typically we don’t have that many features but it’s not impossible.
Another possible method to maximize our likelihood or log likelihood is called Stochastic Gradient Descent. It approximates gradient using a single observation at a time. The algorithm updates the current best-fit parameters each time it sees a new data point. The good news is that there’s no big matrix inversion, and it works well with huge data and with sparse features; it’s a big deal in Mahout and Vowpal Wabbit. The bad news is it’s not such a great optimizer and it’s very dependent on step size.
Evaluation
We generally use different evaluation metrics for different kind of models.
First, for ranking models, where we just want to know a relative rank versus and absolute score, we’d look to one of:
Second, for classification models, we’d look at the following metrics:
- lift: how much more people are buying or clicking because of a model
- accuracy: how often the correct outcome is being predicted
- f-score
- precision
- recall
Finally, for density estimation, where we need to know an actual probability rather than a relative score, we’d look to:
In general it’s hard to compare lift curves but you can compare AUC (area under the receiver operator curve) – they are “base rate invariant.” In other words if you bring the click-through rate from 1% to 2%, that’s 100% lift but if you bring it from 4% to 7% that’s less lift but more effect. AUC does a better job in such a situation when you want to compare.
Density estimation tests tell you how well are you fitting for conditional probability. In advertising, this may arise if you have a situation where each ad impression costs $c and for each conversion you receive $q. You will want to target every conversion that has a positive expected value, i.e. whenever

But to do this you need to make sure the probability estimate on the left is accurate, which in this case means something like the mean squared error of the estimator is small. Note a model can give you good rankings but bad P estimates.
Similarly, features that rank highly on AUC don’t necessarily rank well with respect to mean absolute error. So feature selection, as well as your evaluation method, is completely context-driven.




Nice summary.
LikeLike