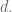Archive
The Lede Program students are rocking it
Yesterday was the end of the first half of the Lede Program, and the students presented their projects, which were really impressive. I am hoping some of them will be willing to put them up on a WordPress site or something like that in order to showcase them and so I can brag about them more explicitly. Since I didn’t get anyone’s permission yet, let me just say: wow.
During the second half of the program the students will do another project (or continue their first) as homework for my class. We’re going to start planning for that on the first day, so the fact that they’ve all dipped their toes into data projects is great. For example, during presentations yesterday I heard the following a number of times: “I spent most of my time cleaning my data” or “next time I will spend more time thinking about how to drill down in my data to find an interesting story”. These are key phrases for people learning lessons with data.
Since they are journalists (I’ve learned a thing or two about journalists and their mindset in the past few months) they love projects because they love deadlines and they want something they can add to their portfolio. Recently they’ve been learning lots of geocoding stuff, and coming up they’ll be learning lots of algorithms as well. So they’ll be well equipped to do some seriously cool shit for their final project. Yeah!
In addition to the guest lectures I’m having in The Platform, I’ll also be reviewing prerequisites for the classes many of them will be taking in the Computer Science department in the fall, so for example linear algebra, calculus, and basic statistics. I just bought them all a copy of How to Lie with Statistics as well as The Cartoon Guide to Statistics, both of which I adore. I’m also making them aware of Statistics Done Wrong, which is online. I am also considering The Cartoon Guide to Calculus, which I have but I haven’t read yet.
Keep an eye out for some of their amazing projects! I’ll definitely blog about them once they’re up.
The dark matter of big data
A tiny article in The Cap Times was recently published (hat tip Jordan Ellenberg) which describes the existence of a big data model which claims to help filter and rank school teachers based on their ability to raise student test scores. I guess it’s a kind of pre-VAM filtering system, and if it was hard to imagine a more vile model than the VAM, here you go. The article mentioned that the Madison School Board was deliberating on whether to spend $273K on this model.
One of the teachers in the district wrote her concerns about this model in her blog and then there was a debate at the school board meeting, and a journalist covered the meeting, so we know about it. But it was a close call, and this one could have easily slipped under the radar, or at least my radar.
Even so, now I know about it, and once I looked at the website of the company promoting this model, I found links to an article where they name a customer, for example in the Charlotte-Mecklenburg School District of North Carolina. They claim they only filter applications using their tool, they don’t make hiring decisions. Cold comfort for people who got removed by some random black box algorithm.
I wonder how many of the teachers applying to that district knew their application was being filtered through such a model? I’m going to guess none. For that matter, there are all sorts of application screening algorithms being regularly used of which applicants are generally unaware.
It’s just one example of the dark matter of big data. And by that I mean the enormous and growing clusters of big data models that are only inadvertently detectable by random small-town or small-city budget meeting journalism, or word-of-mouth reports coming out of conferences or late-night drinking parties with VC’s.
The vast majority of big data dark matter is still there in the shadows. You can only guess at its existence and its usage. Since the models themselves are proprietary, and are generally deployed secretly, there’s no reason for the public to be informed.
Let me give you another example, this time speculative, but not at all unlikely.
Namely, big data health models arising from the quantified self movement data. This recent Wall Street Journal article entitled Can Data From Your Fitbit Transform Medicine? articulated the issue nicely:
A recent review of 43 health- and fitness-tracking apps by the advocacy group Privacy Rights Clearinghouse found that roughly one-third of apps tested sent data to a third party not disclosed by the developer. One-third of the apps had no privacy policy. “For us, this is a big trust issue,” said Kaiser’s Dr. Young.
Consumer wearables fall into a regulatory gray area. Health-privacy laws that prevent the commercial use of patient data without consent don’t apply to the makers of consumer devices. “There are no specific rules about how those vendors can use and share data,” said Deven McGraw, a partner in the health-care practice at Manatt, Phelps, and Phillips LLP.
The key is that phrase “regulatory gray area”; it should make you think “big data dark matter lives here”.
When you have unprotected data that can be used as a proxy of HIPAA-protected medical data, there’s no reason it won’t be. So anyone who wants stands to benefit from knowing health-related information about you – think future employers who might help pay for future insurance claims – will be interested in using big data dark matter models gleaned from this kind of unregulated data.
To be sure, most people nowadays who wear fitbits are athletic, trying to improve their 5K run times. But the article explained that the medical profession is on the verge of suggesting a much larger population of patients use such devices. So it could get ugly real fast.
Secret big data models aren’t new, of course. I remember a friend of mine working for a credit card company a few decades ago. Her job was to model which customers to offer subprime credit cards to, and she was specifically told to target those customers who would end up paying the most in fees. But it’s become much much easier to do this kind of thing with the proliferation of so much personal data, including social media data.
I’m interested in the dark matter, partly as research for my book, and I’d appreciate help from my readers in trying to spot it when it pops up. For example, I remember begin told that a certain kind of online credit score is used to keep people on hold for customer service longer, but now I can’t find a reference to it anywhere. We should really compile a list at the boundaries of this dark matter. Please help! And if you don’t feel comfortable commenting, my email address is on the About page.
Correlation does not imply equality
One of the reasons I enjoy my blog is that I get to try out an argument and then see if readers can 1) poke holes in my arguement, or 2) if they misunderstand my argument, or 3) if they misunderstand something tangential to my argument.
Today I’m going to write about an issue of the third kind. Yesterday I talked about how I’d like to see the VAM scores for teachers directly compared to other qualitative scores or other VAM scores so we could see how reliably they regenerate various definitions of “good teaching.”
The idea is this. Many mathematical models are meant to replace a human-made model that is deemed too expensive to work out at scale. Credit scores were like that; take the work out of the individual bankers’ hands and create a mathematical model that does the job consistently well. The VAM was originally intended as such – in-depth qualitative assessments of teachers is expensive, so let’s replace them with a much cheaper option.
So all I’m asking is, how good a replacement is the VAM? Does it generate the same scores as a trusted, in-depth qualitative assessment?
When I made the point yesterday that I haven’t seen anything like that, a few people mentioned studies that show positive correlations between the VAM scores and principal scores.
But here’s the key point: positive correlation does not imply equality.
Of course sometimes positive correlation is good enough, but sometimes it isn’t. It depends on the context. If you’re a trader that makes thousands of bets a day and your bets are positively correlated with the truth, you make good money.
But on the other side, if I told you that there’s a ride at a carnival that has a positive correlation with not killing children, that wouldn’t be good enough. You’d want the ride to be safe. It’s a higher standard.
I’m asking that we make sure we are using that second, higher standard when we score teachers, because their jobs are increasingly on the line, so it matters that we get things right. Instead we have a machine that nobody understand that is positively correlated with things we do understand. I claim that’s not sufficient.
Let me put it this way. Say your “true value” as a teacher is a number between 1 and 100, and the VAM gives you a noisy approximation of your value, which is 24% correlated with your true value. And say I plot your value against the approximation according to VAM, and I do that for a bunch of teachers, and it looks like this:
 So maybe your “true value” as a teacher is 58 but the VAM gave you a zero. That would not just be frustrating to you, since it’s taken as an important part of your assessment. You might even lose your job. And you might get a score of zero many years in a row, even if your true score stays at 58. It’s increasingly unlikely, to be sure, but given enough teachers it is bound to happen to a handful of people, just by statistical reasoning, and if it happens to you, you will not think it’s unlikely at all.
So maybe your “true value” as a teacher is 58 but the VAM gave you a zero. That would not just be frustrating to you, since it’s taken as an important part of your assessment. You might even lose your job. And you might get a score of zero many years in a row, even if your true score stays at 58. It’s increasingly unlikely, to be sure, but given enough teachers it is bound to happen to a handful of people, just by statistical reasoning, and if it happens to you, you will not think it’s unlikely at all.
In fact, if you’re a teacher, you should demand a scoring system that is consistently the same as a system you understand rather than positively correlated with one. If you’re working for a teachers’ union, feel free to contact me about this.
One last thing. I took the above graph from this post. These are actual VAM scores for the same teacher in the same year but for two different class in the same subject – think 7th grade math and 8th grade math. So neither score represented above is “ground truth” like I mentioned in my thought experiment. But that makes it even more clear that the VAM is an insufficient tool, because it is only 24% correlated with itself.
Why Chetty’s Value-Added Model studies leave me unconvinced
Every now and then when I complain about the Value-Added Model (VAM), people send me links to recent papers written Raj Chetty, John Friedman, and Jonah Rockoff like this one entitled Measuring the Impacts of Teachers II: Teacher Value-Added and Student Outcomes in Adulthood or its predecessor Measuring the Impacts of Teachers I: Evaluating Bias in Teacher Value-Added Estimates.
I think I’m supposed to come away impressed, but that’s not what happens. Let me explain.
Their data set for students scores start in 1989, well before the current value-added teaching climate began. That means teachers weren’t teaching to the test like they are now. Therefore saying that the current VAM works because an retrograded VAM worked in 1989 and the 1990’s is like saying I must like blueberry pie now because I used to like pumpkin pie. It’s comparing apples to oranges, or blueberries to pumpkins.
I’m surprised by the fact that the authors don’t seem to make any note of the difference in data quality between pre-VAM and current conditions. They should know all about feedback loops; any modeler should. And there’s nothing like telling teachers they might lose their job to create a mighty strong feedback loop. For that matter, just consider all the cheating scandals in the D.C. area where the stakes were the highest. Now that’s a feedback loop. And by the way, I’ve never said the VAM scores are totally meaningless, but just that they are not precise enough to hold individual teachers accountable. I don’t think Chetty et al address that question.
So we can’t trust old VAM data. But what about recent VAM data? Where’s the evidence that, in this climate of high-stakes testing, this model is anything but random?
If it were a good model, we’d presumably be seeing a comparison of current VAM scores and current other measures of teacher success and how they agree. But we aren’t seeing anything like that. Tell me if I’m wrong, I’ve been looking around and I haven’t seen such comparisons. And I’m sure they’ve been tried, it’s not rocket science to compare VAM scores with other scores.
The lack of such studies reminds me of how we never hear about scientific studies on the results of Weight Watchers. There’s a reason such studies never see the light of day, namely because whenever they do those studies, they decide they’re better off not revealing the results.
And if you’re thinking that it would be hard to know exactly how to rate a teacher’s teaching in a qualitative, trustworthy way, then yes, that’s the point! It’s actually not obvious how to do this, which is the real reason we should never trust a so-called “objective mathematical model” when we can’t even decide on a definition of success. We should have the conversation of what comprises good teaching, and we should involve the teachers in that, and stop relying on old data and mysterious college graduation results 10 years hence. What are current 6th grade teachers even supposed to do about studies like that?
Note I do think educators and education researchers should be talking about these questions. I just don’t think we should punish teachers arbitrarily to have that conversation. We should have a notion of best practices that slowly evolve as we figure out what works in the long-term.
So here’s what I’d love to see, and what would be convincing to me as a statistician. If we see all sorts of qualitative ways of measuring teachers, and see their VAM scores as well, and we could compare them, and make sure they agree with each other and themselves over time. In other words, at the very least we should demand an explanation of how some teachers get totally ridiculous and inconsistent scores from one year to the next and from one VAM to the next, even in the same year.
The way things are now, the scores aren’t sufficiently sound be used for tenure decisions. They are too noisy. And if you don’t believe me, consider that statisticians and some mathematicians agree.
We need some ground truth, people, and some common sense as well. Instead we’re seeing retired education professors pull statistics out of thin air, and it’s an all-out war of supposed mathematical objectivity against the civil servant.
Review: House of Debt by Atif Mian and Amir Sufi
I just finished House of Debt by Atif Mian and Amir Sufi, which I bought as a pdf directly from the publisher.
This is a great book. It’s well written, clear, and it focuses on important issues. I did not check all of the claims made by the data but, assuming they hold up, the book makes two hugely important points which hopefully everyone can understand and debate, even if we don’t all agree on what to do about them.
First, the authors explain the insufficiency of monetary policy to get the country out of recession. Second, they suggest a new way to structure debt.
To explain these points, the authors do something familiar to statisticians: they think about distributions rather than averages. So rather than talking about how much debt there was, or how much the average price of houses fell, they talked about who was in debt, and where they lived, and which houses lost value. And they make each point carefully, with the natural experiments inherent in our cities due to things like available land and income, to try to tease out causation.
Their first main point is this: the financial system works against poor people (“borrowers”) much more than rich people (“lenders”) in times of crisis, and the response to the financial crisis exacerbated this discrepancy.
The crisis fell on poor people much more heavily: they were wiped out by the plummeting housing prices, whereas rich people just lost a bit of their wealth. Then the government stepped in and protected creditors and shareholders but didn’t renegotiate debt, which protected lenders but not borrowers. This is a large reason we are seeing so much increasing inequality and why our economy is stagnant. They make the case that we should have bailed out homeowners not only because it would have been fair but because it would have been helpful economically.
The authors looked into what actually caused the Great Recession, and they come to a startling conclusion: that the banking crisis was an effect, rather than a cause, of enormous household debt and consumer pull-back. Their narrative goes like this: people ran up debt, then started to pull back, and and as a result the banking system collapsed, as it was utterly dependent on ever-increasing debt. Moreover, the financial system did a very poor job of figuring out how to allocate capital and the people who made those loans were not adequately punished, whereas the people who got those loans were more than reasonably punished.
About half of the run-up of household debt was explained by home equity extraction, where people took out money from their home to spend on stuff. This is partly due to the fact that, in the meantime, wages were stagnant and home equity was a big thing and was hugely available.
But the authors also made the case that, even so, the bubble wasn’t directly caused by rising home valuations but rather to securitization and the creation of “financial innovation” which made investors believe they were buying safe products which were in fact toxic. In their words, securities are invented to exploit “neglected risks” (my experience working in a financial risk firm absolutely agrees to this; whenever you hear the phrase “financial innovation,” please interpret it to mean “an instrument whose risk hides somewhere in the creases that investors are not yet aware of”).
They make the case that debt access by itself elevates prices and build bubbles. In other words, it was the sausage factory itself, producing AAA-rated ABS CDO’s that grew the bubble.
Next, they talked about what works and what doesn’t, given this distributional way of looking at the household debt crisis. Specifically, monetary policy is insufficient, since it works through the banks, who are unwilling to lend to the poor who are already underwater, and only rich people benefit from cheap money and inflated markets. Even at its most extreme, the Fed can at most avoid deflation but it not really help create inflation, which is what debtors need.
Fiscal policy, which is to say things like helicopter money drops or added government jobs, paid by taxpayers, is better but it makes the wrong people pay – high income earners vs. high wealth owners – and isn’t as directly useful as debt restructuring, where poor people get a break and it comes directly from rich people who own the debt.
There are obstacles to debt restructuring, which are mostly political. Politicians are impotent in times of crisis, as we’ve seen, so instead of waiting forever for that to happen, we need a new kind of debt contract that automatically gets restructured in times of crisis. Such a new-fangled contract would make the financial system actually spread out risk better. What would that look like?
The authors give two examples, for mortgages and student debt. The student debt example is pretty simple: how quickly you need to pay back your loans depends in part on how many jobs there are when you graduate. The idea is to cushion the borrower somewhat from macro-economic factors beyond their control.
Next, for mortgages, they propose something the called the shared-responsibility mortgage. The idea here is to have, say, a 30-year mortgage as usual, but if houses in your area lost value, your principal and monthly payments would go down in a commensurate way. So if there’s a 30% drop, your payments go down 30%. To compensate the lenders for this loss-share, the borrowers also share the upside: 5% of capital gains are given to the lenders in the case of a refinancing.
In the case of a recession, the creditors take losses but the overall losses are smaller because we avoid the foreclosure feedback loops. It also acts as a form of stimulus to the borrowers, who are more likely to spend money anyway.
If we had had such mortgage contracts in the Great Recession, the authors estimate that it would have been worth a stimulus of $200 billion, which would have in turn meant fewer jobs lost and many fewer foreclosures and a smaller decline of housing prices. They also claim that shared-responsibility mortgages would prevent bubbles from forming in the first place, because of the fear of creditors that they would be sharing in the losses.
A few comments. First, as a modeler, I am absolutely sure that once my monthly mortgage payment is directly dependent on a price index, that index is going to be manipulated. Similarly as a college graduate trying to figure out how quickly I need to pay back my loans. And depending on how well that manipulation works, it could be a disaster.
Second, it is interesting to me that the authors make no mention of the fact that, for many forms of debt, restructuring is already a typical response. Certainly for commercial mortgages, people renegotiate their principal all the time. We can address the issue of how easy it is to negotiate principal directly by talking about standards in contracts.
Having said that I like the idea of having a contract that makes restructuring automatic and doesn’t rely on bypassing the very real organizational and political frictions that we see today.
Let me put it this way. If we saw debt contracts being written like this, where borrowers really did have down-side protection, then the people of our country might start actually feeling like the financial system was working for them rather than against them. I’m not holding my breath for this to actually happen.
Me & My Administrative Bloat
I am now part of the administrative bloat over at Columbia. I am non-faculty administration, tasked with directing a data journalism program. The program is great, and I’m not complaining about my job. But I will be honest, it makes me uneasy.
Although I’m in the Journalism School, which is in many ways separated from the larger university, I now have a view into how things got so bloated. And how they might stay that way, as well: it’s not clear that, at the end of my 6-month gig, on September 16th, I could hand my job over to any existing person at the J-School. They might have to replace me, or keep me on, with a real live full-time person in charge of this program.
There are good and less good reasons for that, but overall I think there exists a pretty sound argument for such a person to run such a program and to keep it good and intellectually vibrant. That’s another thing that makes me uneasy, although many administrative positions have less of an easy sell attached to them.
I was reminded of this fact of my current existence when I read this recent New York Times article about the administrative bloat in hospitals. From the article:
And studies suggest that administrative costs make up 20 to 30 percent of the United States health care bill, far higher than in any other country. American insurers, meanwhile, spent $606 per person on administrative costs, more than twice as much as in any other developed country and more than three times as much as many, according to a study by the Commonwealth Fund.
Compare that to this article entitled Administrators Ate My Tuition:
A comprehensive study published by the Delta Cost Project in 2010 reported that between 1998 and 2008, America’s private colleges increased spending on instruction by 22 percent while increasing spending on administration and staff support by 36 percent. Parents who wonder why college tuition is so high and why it increases so much each year may be less than pleased to learn that their sons and daughters will have an opportunity to interact with more administrators and staffers— but not more professors.
There are similarities and there are differences between the university and the medical situations.
A similarity is that people really want to be educated, and people really need to be cared for, and administrations have grown up around these basic facts, and at each stage they seem to be adding something either seemingly productive or vitally needed to contain the complexity of the existing machine, but in the end you have enormous behemoths of organizations that are much too complex and much too expensive. And as a reality check on whether that’s necessary, take a look at hospitals in Europe, or take a look at our own university system a few decades ago.
And that also points out a critical difference: the health care system is ridiculously complicated in this country, and in some sense you need all these people just to navigate it for a hospital. And ObamaCare made that worse, not better, even though it also has good aspects in terms of coverage.
Whereas the university system made itself complicated, it wasn’t externally forced into complexity, except if you count the US News & World Reports gaming that seems inescapable.
A neat solution to the high class jerk problem
You might have heard about the recent study entitled Higher social class predicts increased unethical behavior. In it, the authors figure out seven ways to measure the extent to which rich people are bigger assholes than poor people, a plan that works brilliantly every time.
What they term “unethical behavior” comes down to stuff like cutting off people and cars in an intersection, cheating in a game, and even stealing candy from a baby.
The authors also show that rich people are more likely to think of greed as good, and that attitude is sufficient to explain their feelings of entitlement. Another way of saying this it that, once you “account for greed feelings,” being rich doesn’t make you more likely to cheat.
I’d like to go one step further and ask, why do rich people think greed is good? A couple of things come to mind.
First, rich people rarely get arrested, and even when they are arrested, their experiences are very different and much less likely to end up with a serious sentence. Specifically, the fees are not onerous for the rich, and fancier lawyers do better jobs for the rich (by the way, in Finland, speeding tickets are on a sliding scale depending on the income of the perpetrator). It’s easy to think greed is good if you never get punished for cheating.
Second, rich people are examples of current or legacy winners in the current system, and that feeling that they have won leaks onto other feelings of entitlement. They have faith in the system to keep them from having to deal with consequences because so far so good.
Finally, some people deliberately judge that they can afford to be assholes. They are insulated from depending on other people because they have money. Who needs friends when you have resources?
Of course, not all rich people are greed-is-good obsessed assholes. But there are some that specialize in it. They call themselves Libertarians. Paypal founder Peter Thiel is one of their heroes.
Here’s some good news: some of those people intend to sail off on a floating country. Thiel is helping fund this concept. The only problem is, they all are so individualistic it’s hard for them to agree on ground rules and, you know, a process by which to decide things (don’t say government!).
This isn’t a new idea, but for some reason it makes me very happy. I mean, wouldn’t you love it if a good fraction of the people who cut you off in traffic got together and decided to leave town? I’m thinking of donating to that cause. Do they have a Kickstarter yet?
The business of big data audits: monetizing fairness
I gave a talk to the invitation-only NYC CTO Club a couple of weeks ago about my fears about big data modeling, namely:
- that big data modeling is discriminatory,
- that big data modeling increases inequality, and
- that big data modeling threatens democracy.
I had three things on my “to do” list for the audience of senior technologists, namely:
- test internal, proprietary models for discrimination,
- help regulators like the CFPB develop reasonable audits, and
- get behind certain models being transparent and publicly accessible, including credit scoring, teacher evaluations, and political messaging models.
Given the provocative nature of my talk, I was pleasantly surprised by the positive reception I was given. Those guys were great – interactive, talkative, and very thoughtful. I think it helped that I wasn’t trying to sell them something.
Even so, I shouldn’t have been surprised when one of them followed up with me to talk about a possible business model for “fairness audits.” The idea is that, what with the recent bad press about discrimination in big data modeling (some of the audience had actually worked with the Podesta team), there will likely be a business advantage to being able to claim that your models are fair. So someone should develop those tests that companies can take. Quick, someone, monetize fairness!
One reason I think this might actually work – and more importantly, be useful – is that I focused on “effects-based” discrimination, which is to say testing a model by treating it like a black box and seeing how it works on different inputs and gives different outputs. In other words, I want to give a resume-sorting algorithm different resumes with similar qualifications but different races. An algorithmically induced randomized experiment, if you will.
From the business perspective, a test that allows a model to remain a black box feels safe, because it does not require true transparency, and allows the “secret sauce” to remain secret.
One thing, though. I don’t think it makes too much sense to have a proprietary model for fairness auditing. In fact the way I was imagining this was to develop an open-source audit model that the CFPB could use. What I don’t want, and which would be worse than nothing, would be if some private company developed a proprietary “fairness audit” model that we cannot trust and would claim to solve the very real problems listed above.
Update: something like this is already happening for privacy compliance in the big data world (hat tip David Austin).
Was Jill Abramson’s firing a woman thing?
Need to be both nerdy and outraged today.
I’ve noticed something. When something shitty happens to me, and I’m complaining to a group of friends about it, I sometimes say something like “that only happened to me because I’m a woman.”
Now, first of all, I want to be clear, I’m no victim. I don’t let sexism get me down. In fact when I say something like that it usually is a coping mechanism to separate that person’s actions from my own actions, and to help me figure out what to do next. Usually I let it slide off of me and continue on my merry way.
But here’s where it’s weird. If I’m with a bunch of women friends, their immediate reaction is always the same: “hell yes, that bitch/ bastard is just a sexist fuck.” But if I’m with a bunch of man friend of mine, the reaction is very likely to be different: “oh, I don’t think there’s any reason to assume it was sexist. That guy/ girl is just an asshole.”
What it comes down to is priors. My prior is that there is sexism in the world, and it happens all the fucking time, especially to women with perceived power (or to women with no power whatsoever), and so when someone treats me or someone else badly, I do assume we should look into the sexism angle. It’s a natural choice, and Occam’s razor suggests it is involved.
So when Jill Abramson got fired, a bunch of the world’s women were like, those fuckers fired her because she is a powerful, take-no-bullshit woman, and if she’d been a man she would have been expected to act like a dick, but because she’s a woman they couldn’t handle it.
And a bunch of the world’s men were like, wow, I wonder what happened?
So, yes, now I have a prior on people’s priors on sexism, and I think men’s and women’s sexism priors are totally different. I can even explain it.
Men are men, so they don’t experience sexism. So they don’t update their priors like women do. Plus, because there is rarely a moment when an event or reaction is officially deemed “sexist,” men even categorize events differently than women (as discussed above), so even when they do update their prior, it is differently updated, partly because their prior is that nothing is sexist unless proven to be, since it’s so freaking unlikely, according to their prior.
Ezra Klein isn’t speculating, for example, but Emily Bell is, and I’m with her. That just strengthened my priors about other people’s priors.
A simple mathematical model of congressional geriatric penis pumps
This is a guest post written by Stephanie Yang and reposted from her blog. Stephanie and I went to graduate school at Harvard together. She is now a quantitative analyst living in New York City, and will be joining the data science team at Foursquare next month.
 Last week’s hysterical report by the Daily Show’s Samantha Bee on federally funded penis pumps contained a quote which piqued our quantitative interest. Listen carefully at the 4:00 mark, when Ilyse Hogue proclaims authoritatively:
Last week’s hysterical report by the Daily Show’s Samantha Bee on federally funded penis pumps contained a quote which piqued our quantitative interest. Listen carefully at the 4:00 mark, when Ilyse Hogue proclaims authoritatively:
“Statistics show that probably some our members of congress have a vested interested in having penis pumps covered by Medicare!”
Ilya’s wording is vague, and intentionally so. Statistically, a lot of things are “probably” true, and many details are contained in the word “probably”. In this post we present a simple statistical model to clarify what Ilya means.
First we state our assumptions. We assume that penis pumps are uniformly distributed among male Medicare recipients and that no man has received two pumps. These are relatively mild assumptions. We also assume that what Ilya refers to as “members of Congress [with] a vested interested in having penis pumps covered by Medicare,” specifically means male member of congress who received a penis pump covered by federal funds. Of course, one could argue that female members congress could also have a vested interested in penis pumps as well, but we do not want to go there.
Now the number crunching. According to the report, Medicare has spent a total of $172 million supplying penis pumps to recipients, at “360 bucks a pop.” This means a total of 478,000 penis pumps bought from 2006 to 2011.
45% of the current 49,435,610 Medicare recipients are male. In other words, Medicare bought one penis pump for every 46.5 eligible men. Inverting this, we can say that 2.15% of male Medicare recipients received a penis pump.
There are currently 128 members of congress (32 senators plus 96 representatives) who are males over the age of 65 and therefore Medicare-eligible. The probability that none of them received a federally funded penis pump is:
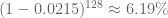
In other words, the chances of at least one member of congress having said penis pumps is 93.8%, which is just shy of the 95% confidence that most statisticians agree on as significant. In order to get to 95% confidence, we need a total of 138 male members of congress who are over the age of 65, and this has not happened yet as of 2014. Nevertheless, the estimate is close enough for us to agree with Ilya that there is probably someone member of congress who has one.
Is it possible that there two or more penis pump recipients in congress? We did notice that Ilya’s quote refers to plural members of congress. Under the assumptions laid out above, the probability of having at least two federally funded penis pumps in congress is:

Again, we would say this is probably true, though not nearly with the same amount of confidence as before. In order to reach 95% confidence that there are two or moreq congressional federally funded penis pump, we would need 200 or more Medicare-eligible males in congress, which is unlikely to happen anytime soon.
Note: As a corollary to these calculations, I became the first developer in the history of mankind to type the following command: git merge --squash penispump.
Defining poverty #OWS
I am always amazed by my Occupy group, and yesterday’s meeting was no exception. We decided to look into redefining the poverty line, and although the conversation took a moving and deeply philosophical turn, I’ll probably only have time to talk about the nuts and bolts of formulas this morning.
The poverty line, or technically speaking the “poverty threshold,” is the same as it was in 1964 when it was invented except for being adjusted for inflation via the CPI.
In the early 1960’s, it was noted that poor families spent about a third of their money on food. To build an “objective” measure of poverty, then, they decided to measure the cost of an “economic food budget” for a family of that size and then multiply that cost by 3.
Does that make sense anymore?
Well, no. Food has gotten a lot cheaper since 1964, and other stuff hasn’t. According to the following chart, which I got from The Atlantic, poor families now spend about one sixth of their money on food:

Rich people spend even less on food.
Now if you think about it, the formula should be more like “economic food budget” * 6, which would effectively double all the numbers.
Does this matter? Well, yes. Various programs like Medicare and Medicaid determine eligibility based on poverty. Also, the U.S. census measures poverty in our country using this yardstick. If we double those numbers we will be seeing a huge surge in the official numbers.
Not that we’d be capturing everyone even then. The truth is, in some locations, like New York, rent is so high that the formula would likely be needing even more adjustment. Although food is expensive too, so maybe the base “economic food budget” would simply need adjusting.
As usual the key questions are, what are we accomplishing with such a formula, and who is “we”?
SAT overhaul
There’s a good New York Times article by Todd Balf entitled The Story Behind the SAT Overhaul (hat tip Chris Wiggins).
In it is described the story of the new College Board President David Coleman, and how he decided to deal with the biggest problem with the SAT: namely, that it was pretty easy to prepare for the test, and the result was that richer kids did better, having more resources – both time and money – to prepare.
Here’s a visual from another NY Times blog on the issue:

Here’s my summary of the story.
At this point the SAT serves mainly to sort people by income. It’s no longer an appropriate way to gauge “IQ” as it was supposed to be when it was invented. Not to mention that colleges themselves have been playing a crazy game with respect to gaming the US News & World Reports college ranking model via their SAT scores. So it’s one feedback loop feeding into another.
How can we deal with this? One way is to stop using it. The article describes some colleges that have made SAT scores optional. They have not suffered, and they have more diversity.
But since the College Board makes their livelihood by testing people, they were never going to just shut down. Instead they’ve decided to explicitly make the SAT about content knowledge that they think high school students should know to signal college readiness.
And that’s good, but of course one can still prepare for that test. And since they’re acknowledging that now, they’re trying to set up the prep to make it more accessible, possibly even “free”.
But here’s the thing, it’s still online, and it still involves lots of time and attention, which still saps resources. I predict we will still see incredible efforts towards gaming this new model, and it will still break down by income, although possibly not quite as much, and possibly we will be training our kids to get good at slightly more relevant stuff.
I would love to see more colleges step outside the standardized testing field altogether.
An attempt to FOIL request the source code of the Value-added model
Last November I wrote to the Department of Education to make a FOIL request for the source code for the teacher value-added model (VAM).
Motivation
To explain why I’d want something like this, I think the VAM model sucks and I’d like to explore the actual source code directly. The white paper I got my hands on is cryptically written (take a look!) and doesn’t explain what the actual sensitivity to inputs are, for example. The best way to get at that is the source code.
Plus, since the New York Times and other news outlets published teacher’s VAM scores after a long battle and a FOIA request (see details about this here), I figured it’s only fair to also publicly release the actual black box which determines those scores.
Indeed without knowledge of what the model consists of, the VAM scoring regime is little more than a secret set of rules, with tremendous power over teachers and the teacher union, and also incorporates outrageous public shaming as described above.
I think teachers deserve better, and I want to illustrate the weaknesses of the model directly on an open models platform.
The FOIL request
Here’s the email I sent to foil@schools.nyc.gov on 11/22/13:
Dear Records Access Officer for the NYC DOE,
I’m looking to get a copy of the source code for the most recent value-added teacher model through a FOIA request. There are various publicly available descriptions of such models, for example here, but I’d like the actual underlying code.
Please tell me if I’ve written to the correct person for this FOIA request, thank you very much.
Best,
Cathy O’Neil
Since my FOIL request
In response to my request, on 12/3/13, 1/6/14, and 2/4/14 I got letters saying stuff was taking a long time since my request was so complicated. Then yesterday I got the following response:

If you follow the link you’ll get another white paper, this time from 2012-2013, which is exactly what I said I didn’t want in my original request.
I wrote back, not that it’s likely to work, and after reminding them of the text of my original request I added the following:
…
What you sent me is the newer version of the publicly available description of the model, very much like my link above. I specifically asked for the underlying code. That would be in a programming language like python or C++ or java.Can you to come back to me with the actual code? Or who should I ask?
Thanks very much,
Cathy
It strikes me as strange that it took them more than 3 months to send me a link to a white paper instead of the source code as I requested. Plus I’m not sure what they mean by “SED” but I’m guessing it means these guys, but I’m not sure of exactly who to send a new FOIL request.
Am I getting the runaround? Any suggestions?
JP Morgan suicides and the clustering illusion
Yesterday a couple of people sent me this article about mysterious deaths at JP Morgan. There’s no known connection between them, but maybe it speaks to some larger problem?
I don’t think so. A little back-of-the-envelope calculation tells me it’s not at all impressive, and this is nothing but media attention turned into conspiracy theory with the usual statistics errors.
Here are some numbers. We’re talking about 3 suicides over 3 weeks. According to wikipedia, JP Morgan has 255,000 employees, and also according to wikipedia, the U.S. suicide rate for men is 19.2 per 100,000 per year, and for women is 5.5. The suicide rates for Hong Kong and the UK, where two of the suicides took place, are much higher.
Let’s eyeball the overall rate at 19 since it’s male dominated and since may employees are overseas in higher-than-average suicide rate countries.
Since 3 weeks is about 1/17th of a year, we’d expect to see about 19/17 suicides per year per 100,000 employees, and seince we have 255,000 employees, that means about 19/17*2.55 = 2.85 suicides in that time. We had three.
This isn’t to say we’ve heard about all the suicides, just that we expect to see about one suicide a week considering how huge JP Morgan is. So let’s get over this, it’s normal. People commit suicide pretty regularly.
It’s very much like how we heard all about suicides at Foxconn, but then heard that the suicide rate at Foxconn is lower than the general Chinese population.
There is a common statistical problem called the clustering illusion, whereby actually random events look clustered sometimes. Here’s a 2-dimensional version of the clustering illusion:

There are little areas that look overly filled with (or strangely devoid of) dots.
Actually my calculation above points to something even dumber, which is that we expected 2.85 suicides and we saw 3, so it’s not even a proven cluster. Although it could be, because again we probably didn’t hear about all of them. Maybe it’s a cluster of “really obvious jump-from-a-building” suicides.
And I’m not saying JP Morgan is a nice place to work. I feel suicidal just thinking about working there myself. But I don’t want us to jump to any statistically unsupported conclusions.
Does making it easier to kill people result in more dead people?
A fascinating and timely study just came out about the “Stand Your Ground” laws. It was written by Cheng Cheng and Mark Hoekstra, and is available as a pdf here, although I found out about in a Reuters column written by Hoekstra. Here’s a longish but crucial excerpt from that column:
It is fitting that much of this debate has centered on Florida, which enacted its law in October of 2005. Florida provides a case study for this more general pattern. Homicide rates in Florida increased by 8 percent from the period prior to passing the law (2000-04) to the period after the law (2006-10).By comparison, national homicide rates fell by 6 percent over the same time period. This is a crude example, but it illustrates the more general pattern that exists in the homicide data published by the FBI.
The critical question for our research is whether this relative increase in homicide rates was caused by these laws. Several factors lead us to believe that laws are in fact responsible. First, the relative increase in homicide rates occurred in adopting states only after the laws were passed, not before. Moreover, there is no history of homicide rates in adopting states (like Florida) increasing relative to other states. In fact, the post-law increase in homicide rates in states like Florida was larger than any relative increase observed in the last 40 years. Put differently, there is no evidence that states like Florida just generally experience increases in homicide rates relative to other states, even when they don’t pass these laws.
We also find no evidence that the increase is due to other factors we observe, such as demographics, policing, economic conditions, and welfare spending. Our results remain the same when we control for these factors. Along similar lines, if some other factor were driving the increase in homicides, we’d expect to see similar increases in other crimes like larceny, motor vehicle theft and burglary. We do not. We find that the magnitude of the increase in homicide rates is sufficiently large that it is unlikely to be explained by chance.
In fact, there is substantial empirical evidence that these laws led to more deadly confrontations. Making it easier to kill people does result in more people getting killed.
If you take a look at page 33 of the paper, you’ll see some graphs of the data. Here’s a rather bad picture of them but it might give you the idea:

That red line is the same in each plot and refers to the log homicide rate in states without the Stand Your Ground law. The blue lines are showing how the log homicide rates looked for states that enacted such a law in a given year. So there’s a graph for each year.
In 2009 there’s only one “treatment” state, namely Montana, which has a population of 1 million, less than one third of one percent of the country. For that reason you see much less stable data. The authors did different analyses, sometimes weighted by population, which is good.
I have to admit, looking at these plots, the main thing I see in the data is that, besides Montana, we’re talking about states that have a higher homicide rate than usual, which could potentially indicate a confounding condition, and to address that (and other concerns) they conducted “falsification tests,” which is to say they studied whether crimes unrelated to Stand Your Ground type laws – larceny and motor vehicle theft – went up at the same time. They found that the answer is no.
The next point is that, although there seem to be bumps for 2005, 2006, and 2008 for the two years after the enactment of the law, there doesn’t for 2007 and 2009. And then even those states go down eventually, but the point is they don’t go down as much as the rest of the states without the laws.
It’s hard to do this analysis perfectly, with so few years of data. The problem is that, as soon as you suspect there’s a real effect, you’d want to act on it, since it directly translates into human deaths. So your natural reaction as a researcher is to “collect more data” but your natural reaction as a citizen is to abandon these laws as ineffective and harmful.
How to Lie With Statistics (in the Age of Big Data)
When I emailed my mom last month to tell her the awesome news about the book I’m writing she emailed me back the following:
i.e, A modern-day How to Lie with Statistics (1954), avail on Amazon
for $9.10. Love, Mom
That was her whole email. She’s never been very verbose, in person or electronically. Too busy hacking.
Even so, she gave me enough to go on, and I bought the book and recently read it. It was awesome and I recommend it to anyone who hasn’t read it – or read it recently. It’s a quick read and available as a free pdf download here.
The goal of the book is to demonstrate all the ways marketers, journalists, accountants, and sometimes even statisticians can bias your interpretation of statistical facts or even just confuse you into thinking something is true when it’s not. It’s illustrated as well, which is fun and often funny.

The author does things like talk about how you can present graphs to be very misleading – my favorite, because it happens to be my pet peeve, is the “growth chart” where the y-axis goes from 1400 to 1402 so things look like they’ve grown a huge amount because “0” isn’t represented anywhere. Or of course the chart that has no numbers at all so you don’t know what you’re looking at.

There are a few things that don’t translate: so for example, he has a big thing about how people say “average” but they don’t specify whether they mean “arithmetic mean” or “median.” Nowadays this is taken to mean the former (am I wrong?).
And also, it’s fascinating to see how culture has changed – many of his examples that involve race would be very different nowadays, and issues around women, and the idea that you could run a randomized experiment to give half the people polio vaccines and withhold them from the other half, when polio is a real threat that leaves children paralyzed, is really strange.
Also, many of the examples – there are hundreds – refer to the Great Depression and the recovery since then, and the assumptions are bizarrely different in 1954 than you see in 2014 (and I’d guess different than how it will be in 2024 but I hope I’m wrong). Specifically, it seems that many of the lies that people are propagating with statistics are to downplay their profits so as to not seem excessive. Can you imagine?!
One of the reasons I read this book, of course, was to see if my book really is a modern version of that one. And I have to say that many of the issues do not translate, but some of them do, in interesting ways.
Even the reason that many of them don’t is kind of interesting: in the age of big data, we often don’t even see charts of data so how can we be misled by them? In other words, the presumption is that the data is so big as to be inaccessible. Google doesn’t bother showing us the numbers. Plus they don’t have to since we use their services anyway.
The most transferrable tips on how to lie with statistics probably stem from discussions on the following topics:
- Selection bias (things like, of the people who responded to our poll, they are all happy with our service)
- Survivorship bias (things like, companies that have been in the S&P for 30 years have great stock performance)
- Confusing people about topic A by discussing a related but not directly relevant topic B. This is described in the book as a “semi-attached figure”
The last one is the most relevant, I believe. In the age of big data, and partly because the data is “too big” to take a real look at, we spend an amazing amount of time talking about how a model is measuring something we care about (teachers’ value, or how good a candidate is for a job) when in fact the model is doing something quite different (test scores, demographic data).
If we were aware of those discrepancies we’d have way more skepticism, but we’re intimidated by the size of the data and the complexity of the models.
A final point. For the most part that crucial big data issue of complexity isn’t addressed in the book. It kind of makes me pine for the olden days, except not really if I’m black, a woman, or at risk of being exposed to polio.
UPDATES: First, my bad for not understanding that, at the time, the polio vaccine wasn’t known to work, or even be harmful, so of course there were trials. I was speaking from the perspective of the present day when it seems obvious that it works. For that matter I’m not even sure it was the particular vaccine that ended up working that was being tested.
Second, I showed my mom this post and her response was perfect:
Glad you liked it! Love, Mom
Predictive risk models for prisoners with mental disorders
My friend Jordan Ellenberg sent me an article yesterday entitled Coin-flip judgement of psychopathic prisoners’ risk.
It was written by Seena Fazel, a researcher at the department of psychiatry at Oxford, and it concerns his research into the currently used predictive risk models for violence, repeat offense, and the like, which are supposedly tailored to people who have mental disorders like psychopathy.
Turns out there are a lot of these models, and they’re in use today in a bunch of countries. I did not know that. And they’re not just being used as extra, “good to know” information, but rather as a tool to assess important decisions for the prisoner. From the article:
Many US states use such tools to assess sexual offending risk and to help decide whether to exercise their powers to detain sexual offenders indefinitely after a prison term ends.
In England and Wales, these tools are part of the admission criteria for centres that treat people with dangerous and severe personality disorders. Outside North America, Europe and Australasia, similar approaches are increasingly popular, particularly in clinical settings, and there has been a steady growth of research from middle-income countries, such as China, documenting their use.
Also turns out, according to a meta-analysis done by Fazel, that these models don’t work very well, especially for the highest risk most violent population. And what’s super troubling is, as Fazel says, “In practice, the high false-positive rate probably means that some offenders spend longer in prison and secure hospital than their true risk would suggest.”
Talk about creepy.
This seems to be yet another example of a mathematical obfuscation and intimidation that gives people a false sense of having a good tool at hand. From the article:
Of course, sensible clinicians and judges take into account factors other than the findings of these instruments, but their misuse does complicate the picture. Some have argued that the veneer of scientific respectability surrounding such methods may lead to over-reliance on their findings, and that their complexity is difficult for the courts. Beyond concerns about public protection, liberty and costs of extended detention, there are worries that associated training and administration may divert resources from treatment.
The solution? Get people to acknowledge that the tools suck, and have a more transparent method of evaluating them. In this case, according to Fazel, it’s the researchers who are over-estimating the power of their models. But especially where it involves incarceration and the law, we have to maintain an adherence to a behavior-based methodology. It doesn’t make sense to put people in jail an extra 10 years because a crappy model said so.
This is a case, in my opinion, for an open model with a closed black box data set. The data itself is extremely sensitive and protected, but the model itself should be scrutinized.
The scienciness of economics
A few of you may have read this recent New York TImes op-ed (hat tip Suresh Naidu) by economist Raj Chetty entitled “Yes, Economics is a Science.” In it he defends the scienciness of economics by comparing it to the field of epidemiology. Let’s focus on these three sentences in his essay, which for me are his key points:
I’m troubled by the sense among skeptics that disagreements about the answers to certain questions suggest that economics is a confused discipline, a fake science whose findings cannot be a useful basis for making policy decisions.
That view is unfair and uninformed. It makes demands on economics that are not made of other empirical disciplines, like medicine, and it ignores an emerging body of work, building on the scientific approach of last week’s winners, that is transforming economics into a field firmly grounded in fact.
Chetty is conflating two issues in his first sentence. The first is whether economics can be approached as a science, and the second is whether, if you are an honest scientist, you push as hard as you can to implement your “results” as public policy. Because that second issue is politics, not science, and that’s where people like myself get really pissed at economists, when they treat their estimates as facts with no uncertainty.
In other words, I’d have no problem with economists if they behaved like the people in the following completely made-up story based on the infamous Reinhart-Rogoff paper with the infamous excel mistake.
Two guys tried to figure what public policy causes GDP growth by using historical data. They collected their data and did some analysis, and they later released both the spreadsheet and the data by posting them on their Harvard webpages. They also ran the numbers a few times with slightly different countries and slightly different weighting schemes and explained in their write-up that got different answers depending on the initial conditions, so therefore they couldn’t conclude much at all, because the error bars are just so big. Oh well.
You see how that works? It’s called science, and it’s not what economists are known to do. It’s what we all wish they’d do though. Instead we have economists who basically get paid to write papers pushing for certain policies.
Next, let’s talk about Chetty’s comparison of economics with medicine. It’s kind of amazing that he’d do this considering how discredited epidemiology is at this point, and how truly unscientific it’s been found to be, for essentially exactly the same reasons as above – initial conditions, even just changing which standard database you use for your tests, switch the sign of most of the results in medicine. I wrote this up here based on a lecture by David Madigan, but there’s also a chapter in my new book with Rachel Schutt based on this issue.
To briefly summarize, Madigan and his colleagues reproduce a bunch of epidemiological studies and come out with incredible depressing “sensitivity” results. Namely, that the majority of “statistically significant findings” change sign depending on seemingly trivial initial condition changes that the authors of the original studies often didn’t even explain.
So in other words, Chetty defends economics as “just as much science” as epidemiology, which I would claim is in the category “not at all a science.” In the end I guess I’d have to agree with him, but not in a good way.
Finally, let’s be clear: it’s a good thing that economists are striving to be scientists, when they are. And it’s of course a lot easier to do science in microeconomic settings where the data is plentiful than it is to answer big, macro-economic questions where we only have a few examples.
Even so, it’s still a good thing that economists are asking the hard questions, even when they can’t answer them, like what causes recessions and what determines growth. It’s just crucial to remember that actual scientists are skeptical, even of their own work, and don’t pretend to have error bars small enough to make high-impact policy decisions based on their fragile results.
The case against algebra II
There’s an interesting debate described in this essay, Wrong Answer: the case against Algebra II, by Nicholson Baker (hat tip Nicholas Evangelos) around the requirement of algebra II to go to college. I’ll do my best to summarize the positions briefly. I’m making some of the pro-side up since it wasn’t well-articulated in the article.
On the pro-algebra side, we have the argument that learning algebra II promotes abstract thinking. It’s the first time you go from thinking about ratios of integers to ratios of polynomial functions, and where you consider the geometric properties of these generalized fractions. It is a convenient litmus test for even more abstraction: sure, it’s kind of abstract, but on the other hand you can also for the most part draw pictures of what’s going on, to keep things concrete. In that sense you might see it as a launching pad for the world of truly abstract geometric concepts.
Plus, doing well in algebra II is a signal for doing well in college and in later life. Plus, if we remove it as a requirement we might as well admit we’re dumbing down college: we’re giving the message that you can be a college graduate even if you can’t do math beyond adding fractions. And if that’s what college means, why have college? What happened to standards? And how is this preparing our young people to be competitive on a national or international scale?
On the anti-algebra side, we see a lot of empathy for struggling and suffering students. We see that raising so-called standards only gives them more suffering but no more understanding or clarity. And although we’re not sure if that’s because the subject is taught badly or because the subject is inherently unappealing or unattainable, it’s clear that wishful thinking won’t close this gap.
Plus, of course doing well in algebra II is a signal for doing well in college, it’s a freaking prerequisite for going to college. We might as well have embroidery as a prerequisite and then be impressed by all the beautiful piano stool covers that result. Finally, the standards aren’t going up just because we’re training a new generation in how to game a standardized test in an abstract rote-memorization skill of formulas and rules. It’s more like learning student’s capacity for drudgery.
OK, so now I’m going to make comments.
While it’s certainly true that, in the best of situations, the content of algebra II promotes abstract and logical thinking, it’s easy for me to believe, based on my very small experience in the matter that, it’s much more often taught poorly, and the students are expected to memorize formulas and rules. This makes it easier to test but doesn’t add to anyone’s love for math, including people who actually love math.
Speaking of my experience, it’s an important issue. Keep in mind that asking the population of mathematicians what they think of removing a high school class is asking for trouble. This is a group of people who pretty much across the board didn’t have any problems whatsoever with the class in question and sailed through it, possibly with a teacher dedicated to teaching honors students. They likely can’t remember much about their experience, and if they can it probably wasn’t bad.
Plus, removing a math requirement, any math requirement, will seem to a mathematician like an indictment of their field as not as important as it used to be to the world, which is always a bad thing. In other words, even if someone’s job isn’t directly on the line with this issue of algebra II, which it undoubtedly is for thousands of math teachers and college teachers, then even so it’s got a slippery slope feel, and pretty soon we’re going to have math departments shrinking over this.
In other words, it shouldn’t surprised anyone that we have defensive and unsympathetic mathematicians on one side who cannot understand the arguments of the empathizers on the other hand.
Of course, it’s always a difficult decision to remove a requirement. It’s much easier to make the case for a new one than to take one away, except of course for the students who have to work for the ensuing credentials.
And another thing, not so long ago we’d hear people say that women don’t need education at all, or that peasants don’t need to know how to read. Saying that a basic math course should become and elective kind of smells like that too if you want to get histrionic about things.
For myself, I’m willing to get rid of all of it, all the math classes ever taught, at least as a thought experiment, and then put shit back that we think actually adds value. So I still think we all need to know our multiplication tables and basic arithmetic, and even basic algebra so we can deal with an unknown or two. But from then on it’s all up in the air. Abstract reasoning is great, but it can be done in context just as well as in geometry class.
And, coming as I now do from data science, I don’t see why statistics is never taught in high school (at least in mine it wasn’t, please correct me if I’m wrong). It seems pretty clear we can chuck trigonometry out the window, and focus on getting the average high school student up to the point of scientific literacy that she can read a paper in a medical journal and understand what the experiment was and what the results mean. Or at the very least be able to read media reports of the studies and have some sense of statistical significance. That’d be a pretty cool goal, to get people to be able to read the newspaper.
So sure, get rid of algebra II, but don’t stop there. Think about what is actually useful and interesting and mathematical and see if we can’t improve things beyond just removing one crappy class.
Plumping up darts
Someone asked me a math question the other day and I had fun figuring it out. I thought it would be nice to write it down.
So here’s the problem. You are getting to see sample data and you have to infer the underlying distribution. In fact you happen to know you’re getting draws – which, because I’m a basically violent person, I like to think of as throws of a dart – from a uniform distribution from 0 to some unknown 
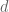

In other words, given 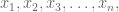
First, in order to simplify, note that all that really matters in terms of the estimate of 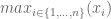
Next, note you might as well assume that 
With this set-up, you’ve rephrased the question like this: if you throw ![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=555555&s=0&c=20201002)
It’s obvious from this phrasing that, as 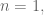
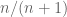
Start with a small case where you know the answer. For 

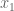
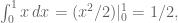
and we recover what we already know. In the next case, we need to integrate over two variables (same comment here, don’t have to divide by area of the 1×1 square base):
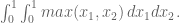
If you think about it, though, 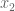
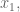

But that simplifies to:
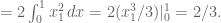
Let’s do the general case. It’s an n-fold integral over the maximum of all
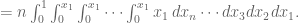
But this collapses to:
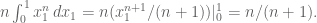
To finish the original question, take the maximum value in your collection of draws and multiply it by the plumping factor