Archive
The overburdened prior
At my new job I’ve been spending my time editing my book with Rachel Schutt (who is joining me at JRL next week! Woohoo!). It’s called Doing Data Science and it’s based on these notes I took when she taught a class on data science at Columbia last semester. Right now I’m working on the alternating least squares chapter, where we learned from Matt Gattis how to build and optimize a recommendation system. A very cool algorithm.
However, to be honest I’ve started to feel very sorry for the one parameter we call 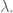
Let me tell you, the world is asking too much from this little guy, and moreover most of the big-data world is too indifferent to its plight. Let me explain.

First, he’s supposed to reflect an actual prior belief – namely, his size is supposed to reflect a mathematical vision of how big we think the coefficients in our solution should be.
In an ideal world, we would think deeply about this question of size before looking at our training data, and think only about the scale of our data (i.e. the input), the scale of the preferences (i.e. the recommendation system output) and the quality and amount of training data we have, and using all of that, we’d figure out our prior belief on the size or at least the scale of our hoped-for solution.
I’m not statistician, but that’s how I imagine I’d spend my days if I were: thinking through this reasoning carefully, and even writing it down carefully, before I ever start my training. It’s a discipline like any other to carefully state your beliefs beforehand so you know you’re not just saying what the data wants to hear.
But then there’s the next thing we ask of our parameter 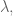
Because our algorithm isn’t a closed form solution, but rather we are discovering coefficients of two separate matrices 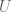
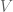

The fact that this algorithm will in fact stop is not obvious, and in fact it isn’t always true.
It is (mostly*) true, however, if our little
And people say that all the time. When you say, “hey what if that algorithm doesn’t converge?” They say, “oh if
But that’s kind of like worrying about your teenage daughter getting pregnant so you lock her up in her room all the time. You’ve solved the immediate problem by sacrificing an even bigger goal.
Because let’s face it, if the prior
By the way, there’s a discipline here too, and I’d suggest that if the algorithm doesn’t converge you might also want to consider reducing your number of latent variables rather than increasing your
Finally, we have one more job for our little
In other words, in reality most of the above nonsense about
This is one example among many where having the ability to push a button that makes something hard seem really easy might be doing more harm than good. In this case the button says “optimize with respect to
I’ve said it before and I’ll say it again: you do need to know about inverting a matrix, and other math too, if you want to be a good data scientist.
* There’s a change-of-basis ambiguity that’s tough to get rid of here, since you only choose the number of latent variables, not their order. This doesn’t change the overall penalty term, so you can minimize that with large enough
There should be a macho way to say “I don’t know”
I recently gave an interview with Russ Roberts at EconTalk, which was fun and which has generated a lot of interesting feedback for me. I had no idea so many people listened to that podcast. Turns out it’ll eventually add up to something like 50,000, with half of those people listening this week. Cool!
One thing Russ and I talked about is still on my mind. Namely, how many problems are the direct result of people pretending to understand something, or exaggerating the certainty of an uncertain quantity. People just don’t acknowledge errorbars when they should!
What up, people?
Part of the problem exists because when we model something, the model typically just comes out with a single answer, usually a number, and it seems so certain to us, so tangible, even when we know that slightly different starting conditions or inputs to our models would have resulted in a different number.
So for example, an SAT score. We know that, on a different day with a different amount of sleep or a different test, we might score significantly differently. And yet the score is the score, and it’s hugely important and we brand ourselves with it as if it’s some kind of final word.
But another part of this problem is that people are seldom incentivized to admit they don’t know something. Indeed the ones we hear from the most are professional opinion-holders, and they are going to lose their audience and their gigs if they go on air saying, “I’m not sure what’s going to happen with [the economy], we’ve honestly never been in this situation before and our data is just not sufficient to make a prediction that’s worth its weight.”
You can replace “the economy” by anything and the problem still holds.
Who’s going to say that?? Someone who doesn’t mind losing their job is who. Which is too bad, because honest people do say that quite a large portion of the time. So professional opinion-holders are kind of trained to be dishonest in this way.
And so are TED talks, but that’s a vent for another day.
I wish there were a macho way to admit you didn’t know something, so people could understand that admitting uncertainty isn’t equivalent to being wishy-washy.
I mean, sometimes I want to bust out and say, “I don’t know that, and neither do you, motherfucker!” but I’m not sure how well that would go over. Some people get touchy about profanity.
But it’s getting there, and it points to something ironic about this uncertainty-as-wishy-washiness: it is sometimes macho to point out that other people are blowing smoke. In other words, I can be a whistle blower on other people’s illusion of certainty even when I can’t make being uncertain sound cool.
I think that explains, to some extent, why so many people end up criticizing other people for false claims rather than making a stance on uncertainty themselves. The other reason of course is that it’s easier to blow holes in other people’s theories, once stated, than it is to come up with a foolproof theory of one’s own.
Any suggestions for macho approaches to errorbars?
Bill Gates is naive, data is not objective
In his recent essay in the Wall Street Journal, Bill Gates proposed to “fix the world’s biggest problems” through “good measurement and a commitment to follow the data.” Sounds great!
Unfortunately it’s not so simple.
Gates describes a positive feedback loop when good data is collected and acted on. It’s hard to argue against this: given perfect data-collection procedures with relevant data, specific models do tend to improve, according to their chosen metrics of success. In fact this is almost tautological.
As I’ll explain, however, rather than focusing on how individual models improve with more data, we need to worry more about which models and which data have been chosen in the first place, why that process is successful when it is, and – most importantly – who gets to decide what data is collected and what models are trained.
Take Gates’s example of Ethiopia’s commitment to health care for its people. Let’s face it, it’s not new information that we should ensure “each home has access to a bed net to protect the family from malaria, a pit toilet, first-aid training and other basic health and safety practices.” What’s new is the political decision to do something about it. In other words, where Gates credits the measurement and data-collection for this, I’d suggest we give credit to the political system that allowed both the data collection and the actual resources to make it happen.
Gates also brings up the campaign to eradicate polio and how measurement has helped so much there as well. Here he sidesteps an enormous amount of politics and debate about how that campaign has been fought and, more importantly, how many scarce resources have been put towards it. But he has framed this fight himself, and has collected the data and defined the success metric, so that’s what he’s focused on.
Then he talks about teacher scoring and how great it would be to do that well. Teachers might not agree, and I’d argue they are correct to be wary about scoring systems, especially if they’ve experienced the random number generator called the Value Added Model. Many of the teacher strikes and failed negotiations are being caused by this system where, again, the people who own the model have the power.
Then he talks about college rankings and suggests we replace the flawed US News & World Reports system with his own idea, namely “measures of which colleges were best preparing their graduates for the job market”. Note I’m not arguing for keeping that US News & World Reports model, which is embarrassingly flawed and is consistently gamed. But the question is, who gets to choose the replacement?
This is where we get the closest to seeing him admit what’s really going on: that the person who defines the model defines success, and by obscuring this power behind a data collection process and incrementally improved model results, it seems somehow sanitized and objective when it’s not.
Let’s see some more example of data collection and model design not being objective:
- We see that cars are safer for men than women because the crash-test dummies are men.
- We see that cars are safer for thin people because the crash-test dummies are thin.
- We see drugs are safer and more effective for white people because blacks are underrepresented in clinical trials (which is a whole other story about power and data collection in itself).
- We see that Polaroid film used to only pick up white skin because it was optimized for white people.
- We see that poor people are uninformed by definition of how we take opinion polls (read the fine print).
Bill Gates seems genuinely interested in tackling some big problems in the world, and I wish more people thought long and hard about how they could contribute like that. But the process he describes so lovingly is in fact highly fraught and dangerous.
Don’t be fooled by the mathematical imprimatur: behind every model and every data set is a political process that chose that data and built that model and defined success for that model.
I don’t have to prove theorems to be a mathematician
I’m giving a talk at the Joint Mathematics Meeting on Thursday (it’s a 30 minute talk that starts at 11:20am, in Room 2 of the Upper Level of the San Diego Conference Center, I hope you come!).
I have to distill the talk from an hour-long talk I gave recently in the Stony Brook math department, which was stimulating.
Thinking about that talk brought something up for me that I think I want to address before the next talk. Namely, at the beginning of the talk I was explaining the title, “How Mathematics is Used Outside of Academia,” and I mentioned that most mathematicians that leave academia end up doing modeling.
I can’t remember the exact exchange, but I referred to myself at some point in this discussion as a mathematician outside of academia, at which point someone in the audience expressed incredulity:
him: Really? Are you still a mathematician? Do you prove theorems?
me: No, I don’t prove theorems any longer, now that I am a modeler… (confused look)
At the moment I didn’t have a good response to this, because he was using a different definition of “mathematician” than I was. For some reason he thought a mathematician must prove theorems.
I don’t think so. I had a conversation about this after my talk with Bob Beals, who was in the audience and who taught many years ago at the math summer program I did last summer. After getting his Ph.D. in math, Bob worked for the spooks, and now he works for RenTech. So he knows a lot about doing math outside academia too, and I liked his perspective on this question.
Namely, he wanted to look at the question through the lens of “grunt work”, which is to say all of the actual work that goes into a “result.”
As a mathematician, of course, you don’t simply sit around all day proving theorems. Actually you spend most of your time working through examples to get a feel for the terrain, and thinking up simple ways to do what seems like hard things, and trying out ideas that fail, and going down paths that are dry. If you’re lucky, then at the end of a long journey like this, you will have a theorem.
The same basic thing happens in modeling. You spend lots of time with the data, getting to know it, and then trying out certain approaches, which sometimes, or often, end up giving you nothing interesting, and half the time you realize you were expecting the wrong thing so you have to change it entirely. In the end you may end up with a model which is useful. If you’re lucky.
There’s a lot of grunt work in both endeavors, and there’s a lot of hard thinking along the way, lots of ways for you to fool yourself that you’ve got something when you haven’t. Perhaps in modeling it’s easier to lie, which is a big difference indeed. But if you’re an honest modeler then I claim the difference in the process of getting an interesting and important result is not that different.
And, I claim, I am still being a mathematician while I’m doing it.
I totally trust experts, actually
I lied yesterday, as a friend at my Occupy meeting pointed out to me last night.
I made it seem like I look into every model before trusting it, and of course that’s not true. I eat food grown and prepared by other people daily. I go on airplanes and buses all the time, trusting that they will work and that they will be driven safely. I still have my money in a bank, and I also hire an accountant and sign my tax forms without reading them. So I’m a hypocrite, big-time.
There’s another thing I should clear up: I’m not claiming I understand everything about climate research just because I talked to an expert for 2 or 3 hours. I am certainly not an expert, nor am I planning to become one. Even so, I did learn a lot, and the research I undertook was incredibly useful to me.
So, for example, my father is a climate change denier, and I have heard him give a list of scientific facts to argue against climate change. I asked my expert to counter-argue these points, and he did so. I also asked him to explain the underlying model at a high level, which he did.
My conclusion wasn’t that I’ve looked carefully into the model and it’s right, because that’s not possible in such a short time. My conclusion was that this guy is trustworthy and uses logical argument, which he’s happy to share with interested people, and moreover he manages to defend against deniers without being intellectually defensive. In the end, I’m trusting him, an expert.
On the other hand, if I met another person with a totally different conclusion, who also impressed me as intellectually honest and curious, then I’d definitely listen to that guy too, and I’d be willing to change my mind.
So I do imbue models and theories with a limited amount of trust depending on how much sense they makes to me. I think that’s reasonable, and it’s in line with my advocacy of scientific interpreters. Obviously not all scientific interpreters would be telling the same story, but that’s not important – in fact it’s vital that they don’t, because it is a privilege to be allowed to listen to the different sides and be engaged in the debate.
If I sat down with an expert for a whole day, like my friend Jordan suggests, to determine if they were “right” on an issue where there’s argument among experts, then I’d fail, but even understanding what they were arguing about would be worthwhile and educational.
Let me say this another way: experts argue about what they don’t agree on, of course, since it would be silly for them to talk about what they do agree on. But it’s their commonality that we, the laypeople, are missing. And that commonality is often so well understood that we could understand it rather quickly if it was willingly explained to us. That would be a huge step.
So I wasn’t lying after all, if I am allowed to define the “it” that I did get at in the two hours with an expert. When I say I understood it, I didn’t mean everything, I meant a much larger chunk of the approach and method than I’d had before, and enough to evoke (limited) trust.
Something I haven’t addressed, which I need to think about more (please help!), is the question of what subjects require active skepticism. On of my commenters, Paul Stevens, brought this up:
… For me, lay people means John Q Public – public opinion because public opinion can shape policy. In practice, this only matters for a select few issues, such as climate change or science education. There is no impact to a lay person not understanding / believing in the Higgs particle for example.
On trusting experts, climate change research, and scientific translators
Stephanie Tai has written a thoughtful response on Jordan Ellenberg’s blog to my discussion with Jordan regarding trusting experts (see my Nate Silver post and the follow-up post for more context).
Trusting experts
Stephanie asks three important questions about trusting experts, which I paraphrase here:
- What does it take to look into a model yourself? How deeply must you probe?
- How do you avoid being manipulated when you do so?
- Why should we bother since stuff is so hard and we each have a limited amount of time?
I must confess I find the first two questions really interesting and I want to think about them, but I have a very little patience with the last question.
Here’s why:
- I’ve seen too many people (individual modelers) intentionally deflect investigations into models by setting them up as so hard that it’s not worth it (or at least it seems not worth it). They use buzz words and make it seem like there’s a magical layer of their model which makes it too difficult for mere mortals. But my experience (as an arrogant, provocative, and relentless questioner) is that I can always understand a given model if I’m talking to someone who really understands it and actually wants to communicate it.
- It smacks of an excuse rather than a reason. If it’s our responsibility to understand something, then by golly we should do it, even if it’s hard.
- Too many things are left up to people whose intentions are not reasonable using this “too hard” argument, and it gives those people reason to make entire systems seem too difficult to penetrate. For a great example, see the financial system, which is consistently too complicated for regulators to properly regulate.
I’m sure I seem unbelievably cynical here, but that’s where I got by working in finance, where I saw first-hand how manipulative and manipulated mathematical modeling can become. And there’s no reason at all such machinations wouldn’t translate to the world of big data or climate modeling.
Climate research
Speaking of climate modeling: first, it annoys me that people are using my “distrust the experts” line to be cast doubt on climate modelers.
People: I’m not asking you to simply be skeptical, I’m saying you should look into the models yourself! It’s the difference between sitting on a couch and pointing at a football game on TV and complaining about a missed play and getting on the football field yourself and trying to figure out how to throw the ball. The first is entertainment but not valuable to anyone but yourself. You are only adding to the discussion if you invest actual thoughtful work into the matter.
To that end, I invited an expert climate researcher to my house and asked him to explain the climate models to me and my husband, and although I’m not particularly skeptical of climate change research (more on that below when I compare incentives of the two sides), I asked obnoxious, relentless questions about the model until I was satisfied. And now I am satisfied. I am considering writing it up as a post.
As an aside, if climate researchers are annoyed by the skepticism, I can understand that, since football fans are an obnoxious group, but they should not get annoyed by people who want to actually do the work to understand the underlying models.
Another thing about climate research. People keep talking about incentives, and yes I agree wholeheartedly that we should follow the incentives to understand where manipulation might be taking place. But when I followed the incentives with respect to climate modeling, they bring me straight to climate change deniers, not to researchers.
Do we really think these scientists working with their research grants have more at stake than multi-billion dollar international companies who are trying to ignore the effect of their polluting factories on the environment? People, please. The bulk of the incentives are definitely with the business owners. Which is not to say there are no incentives on the other side, since everyone always wants to feel like their research is meaningful, but let’s get real.
Scientific translators
I like this idea Stephanie comes up with:
Some sociologists of science suggest that translational “experts”–that is, “experts” who aren’t necessarily producing new information and research, but instead are “expert” enough to communicate stuff to those not trained in the area–can help bridge this divide without requiring everyone to become “experts” themselves. But that can also raise the question of whether these translational experts have hidden agendas in some way. Moreover, one can also raise questions of whether a partial understanding of the model might in some instances be more misleading than not looking into the model at all–examples of that could be the various challenges to evolution based on fairly minor examples that when fully contextualized seem minor but may pop out to someone who is doing a less systematic inquiry.
First, I attempt to make my blog something like a platform for this, and I also do my best to make my agenda not at all hidden so people don’t have to worry about that.
This raises a few issues for me:
- Right now we depend mostly on press to do our translations, but they aren’t typically trained as scientists. Does that make them more prone to being manipulated? I think it does.
- How do we encourage more translational expertise to emerge from actual experts? Currently, in academia, the translation to the general public of one’s research is not at all encouraged or rewarded, and outside academia even less so.
- Like Stephanie, I worry about hidden agendas and partial understandings, but I honestly think they are secondary to getting a robust system of translation started to begin with, which would hopefully in turn engage the general public with the scientific method and current scientific knowledge. In other words, the good outweighs the bad here.
Nate Silver confuses cause and effect, ends up defending corruption
Crossposted on Naked Capitalism
I just finished reading Nate Silver’s newish book, The Signal and the Noise: Why so many predictions fail – but some don’t.
The good news
First off, let me say this: I’m very happy that people are reading a book on modeling in such huge numbers – it’s currently eighth on the New York Times best seller list and it’s been on the list for nine weeks. This means people are starting to really care about modeling, both how it can help us remove biases to clarify reality and how it can institutionalize those same biases and go bad.
As a modeler myself, I am extremely concerned about how models affect the public, so the book’s success is wonderful news. The first step to get people to think critically about something is to get them to think about it at all.
Moreover, the book serves as a soft introduction to some of the issues surrounding modeling. Silver has a knack for explaining things in plain English. While he only goes so far, this is reasonable considering his audience. And he doesn’t dumb the math down.
In particular, Silver does a nice job of explaining Bayes’ Theorem. (If you don’t know what Bayes’ Theorem is, just focus on how Silver uses it in his version of Bayesian modeling: namely, as a way of adjusting your estimate of the probability of an event as you collect more information. You might think infidelity is rare, for example, but after a quick poll of your friends and a quick Google search you might have collected enough information to reexamine and revise your estimates.)
The bad news
Having said all that, I have major problems with this book and what it claims to explain. In fact, I’m angry.
It would be reasonable for Silver to tell us about his baseball models, which he does. It would be reasonable for him to tell us about political polling and how he uses weights on different polls to combine them to get a better overall poll. He does this as well. He also interviews a bunch of people who model in other fields, like meteorology and earthquake prediction, which is fine, albeit superficial.
What is not reasonable, however, is for Silver to claim to understand how the financial crisis was a result of a few inaccurate models, and how medical research need only switch from being frequentist to being Bayesian to become more accurate.
Let me give you some concrete examples from his book.
Easy first example: credit rating agencies
The ratings agencies, which famously put AAA ratings on terrible loans, and spoke among themselves as being willing to rate things that were structured by cows, did not accidentally have bad underlying models. The bankers packaging and selling these deals, which amongst themselves they called sacks of shit, did not blithely believe in their safety because of those ratings.
Rather, the entire industry crucially depended on the false models. Indeed they changed the data to conform with the models, which is to say it was an intentional combination of using flawed models and using irrelevant historical data (see points 64-69 here for more (Update: that link is now behind the paywall)).
In baseball, a team can’t create bad or misleading data to game the models of other teams in order to get an edge. But in the financial markets, parties to a model can and do.
In fact, every failed model is actually a success
Silver gives four examples what he considers to be failed models at the end of his first chapter, all related to economics and finance. But each example is actually a success (for the insiders) if you look at a slightly larger picture and understand the incentives inside the system. Here are the models:
- The housing bubble.
- The credit rating agencies selling AAA ratings on mortgage securities.
- The financial melt-down caused by high leverage in the banking sector.
- The economists’ predictions after the financial crisis of a fast recovery.
Here’s how each of these models worked out rather well for those inside the system:
- Everyone involved in the mortgage industry made a killing. Who’s going to stop the music and tell people to worry about home values? Homeowners and taxpayers made money (on paper at least) in the short term but lost in the long term, but the bankers took home bonuses that they still have.
- As we discussed, this was a system-wide tool for building a money machine.
- The financial melt-down was incidental, but the leverage was intentional. It bumped up the risk and thus, in good times, the bonuses. This is a great example of the modeling feedback loop: nobody cares about the wider consequences if they’re getting bonuses in the meantime.
- Economists are only putatively trying to predict the recovery. Actually they’re trying to affect the recovery. They get paid the big bucks, and they are granted authority and power in part to give consumers confidence, which they presumably hope will lead to a robust economy.
Cause and effect get confused
Silver confuses cause and effect. We didn’t have a financial crisis because of a bad model or a few bad models. We had bad models because of a corrupt and criminally fraudulent financial system.
That’s an important distinction, because we could fix a few bad models with a few good mathematicians, but we can’t fix the entire system so easily. There’s no math band-aid that will cure these boo-boos.
I can’t emphasize this too strongly: this is not just wrong, it’s maliciously wrong. If people believe in the math band-aid, then we won’t fix the problems in the system that so desperately need fixing.
Why does he make this mistake?
Silver has an unswerving assumption, which he repeats several times, that the only goal of a modeler is to produce an accurate model. (Actually, he made an exception for stock analysts.)
This assumption generally holds in his experience: poker, baseball, and polling are all arenas in which one’s incentive is to be as accurate as possible. But he falls prey to some of the very mistakes he warns about in his book, namely over-confidence and over-generalization. He assumes that, since he’s an expert in those arenas, he can generalize to the field of finance, where he is not an expert.
The logical result of this assumption is his definition of failure as something where the underlying mathematical model is inaccurate. But that’s not how most people would define failure, and it is dangerously naive.
Medical Research
Silver discusses both in the Introduction and in Chapter 8 to John Ioannadis’s work which reveals that most medical research is wrong. Silver explains his point of view in the following way:

I’m glad he mentions incentives here, but again he confuses cause and effect.
As I learned when I attended David Madigan’s lecture on Merck’s representation of Vioxx research to the FDA as well as his recent research on the methods in epidemiology research, the flaws in these medical models will be hard to combat, because they advance the interests of the insiders: competition among academic researchers to publish and get tenure is fierce, and there are enormous financial incentives for pharmaceutical companies.
Everyone in this system benefits from methods that allow one to claim statistically significant results, whether or not that’s valid science, and even though there are lives on the line.
In other words, it’s not that there are bad statistical approaches which lead to vastly over-reported statistically significant results and published papers (which could just as easily happen if the researchers were employing Bayesian techniques, by the way). It’s that there’s massive incentive to claim statistically significant findings, and not much push-back when that’s done erroneously, so the field never self-examines and improves their methodology. The bad models are a consequence of misaligned incentives.
I’m not accusing people in these fields of intentionally putting people’s lives on the line for the sake of their publication records. Most of the people in the field are honestly trying their best. But their intentions are kind of irrelevant.
Silver ignores politics and loves experts
Silver chooses to focus on individuals working in a tight competition and their motives and individual biases, which he understands and explains well. For him, modeling is a man versus wild type thing, working with your wits in a finite universe to win the chess game.
He spends very little time on the question of how people act inside larger systems, where a given modeler might be more interested in keeping their job or getting a big bonus than in making their model as accurate as possible.
In other words, Silver crafts an argument which ignores politics. This is Silver’s blind spot: in the real world politics often trump accuracy, and accurate mathematical models don’t matter as much as he hopes they would.
As an example of politics getting in the way, let’s go back to the culture of the credit rating agency Moody’s. William Harrington, an ex-Moody’s analyst, describes the politics of his work as follows:
In 2004 you could still talk back and stop a deal. That was gone by 2006. It became: work your tail off, and at some point management would say, ‘Time’s up, let’s convene in a committee and we’ll all vote “yes”‘.
To be fair, there have been moments in his past when Silver delves into politics directly, like this post from the beginning of Obama’s first administration, where he starts with this (emphasis mine):
To suggest that Obama or Geithner are tools of Wall Street and are looking out for something other than the country’s best interest is freaking asinine.
and he ends with:
This is neither the time nor the place for mass movements — this is the time for expert opinion. Once the experts (and I’m not one of them) have reached some kind of a consensus about what the best course of action is (and they haven’t yet), then figure out who is impeding that action for political or other disingenuous reasons and tackle them — do whatever you can to remove them from the playing field. But we’re not at that stage yet.
My conclusion: Nate Silver is a man who deeply believes in experts, even when the evidence is not good that they have aligned incentives with the public.
Distrust the experts
Call me “asinine,” but I have less faith in the experts than Nate Silver: I don’t want to trust the very people who got us into this mess, while benefitting from it, to also be in charge of cleaning it up. And, being part of the Occupy movement, I obviously think that this is the time for mass movements.
From my experience working first in finance at the hedge fund D.E. Shaw during the credit crisis and afterwards at the risk firm Riskmetrics, and my subsequent experience working in the internet advertising space (a wild west of unregulated personal information warehousing and sales) my conclusion is simple: Distrust the experts.
Why? Because you don’t know their incentives, and they can make the models (including Bayesian models) say whatever is politically useful to them. This is a manipulation of the public’s trust of mathematics, but it is the norm rather than the exception. And modelers rarely if ever consider the feedback loop and the ramifications of their predatory models on our culture.
Why do people like Nate Silver so much?
To be crystal clear: my big complaint about Silver is naivete, and to a lesser extent, authority-worship.
I’m not criticizing Silver for not understanding the financial system. Indeed one of the most crucial problems with the current system is its complexity, and as I’ve said before, most people inside finance don’t really understand it. But at the very least he should know that he is not an authority and should not act like one.
I’m also not accusing him of knowingly helping cover up the financial industry. But covering for the financial industry is an unfortunate side-effect of his naivete and presumed authority, and a very unwelcome source of noise at this moment when so much needs to be done.
I’m writing a book myself on modeling. When I began reading Silver’s book I was a bit worried that he’d already said everything I’d wanted to say. Instead, I feel like he’s written a book which has the potential to dangerously mislead people – if it hasn’t already – because of its lack of consideration of the surrounding political landscape.
Silver has gone to great lengths to make his message simple, and positive, and to make people feel smart and smug, especially Obama’s supporters.
He gets well-paid for his political consulting work and speaker appearances at hedge funds like D.E. Shaw and Jane Street, and, in order to maintain this income, it’s critical that he perfects a patina of modeling genius combined with an easily digested message for his financial and political clients.
Silver is selling a story we all want to hear, and a story we all want to be true. Unfortunately for us and for the world, it’s not.
How to push back against the celebrity-ization of data science
The truth is somewhat harder to understand, a lot less palatable, and much more important than Silver’s gloss. But when independent people like myself step up to denounce a given statement or theory, it’s not clear to the public who is the expert and who isn’t. From this vantage point, the happier, shorter message will win every time.
This raises a larger question: how can the public possibly sort through all the noise that celebrity-minded data people like Nate Silver hand to them on a silver platter? Whose job is it to push back against rubbish disguised as authoritative scientific theory?
It’s not a new question, since PR men disguising themselves as scientists have been around for decades. But I’d argue it’s a question that is increasingly urgent considering how much of our lives are becoming modeled. It would be great if substantive data scientists had a way of getting together to defend the subject against sensationalist celebrity-fueled noise.
One hope I nurture is that, with the opening of the various data science institutes such as the one at Columbia which was a announced a few months ago, there will be a way to form exactly such a committee. Can we get a little peer review here, people?
Conclusion
There’s an easy test here to determine whether to be worried. If you see someone using a model to make predictions that directly benefit them or lose them money – like a day trader, or a chess player, or someone who literally places a bet on an outcome (unless they place another hidden bet on the opposite outcome) – then you can be sure they are optimizing their model for accuracy as best they can. And in this case Silver’s advice on how to avoid one’s own biases are excellent and useful.
But if you are witnessing someone creating a model which predicts outcomes that are irrelevant to their immediate bottom-line, then you might want to look into the model yourself.
Columbia Data Science course, week 14: Presentations
In the final week of Rachel Schutt’s Columbia Data Science course we heard from two groups of students as well as from Rachel herself.
Data Science; class consciousness
The first team of presenters consisted of Yegor, Eurry, and Adam. Many others whose names I didn’t write down contributed to the research, visualization, and writing.
First they showed us the very cool graphic explaining how self-reported skills vary by discipline. The data they used came from the class itself, which did this exercise on the first day:

so the star in the middle is the average for the whole class, and each star along the side corresponds to the average (self-reported) skills of people within a specific discipline. The dotted lines on the outside stars shows the “average” star, so it’s easier to see how things vary per discipline compared to the average.
Surprises: Business people seem to think they’re really great at everything except communication. Journalists are better at data wrangling than engineers.
We will get back to the accuracy of self-reported skills later.
We were asked, do you see your reflection in your star?
Also, take a look at the different stars. How would you use them to build a data science team? Would you want people who are good at different skills? Is it enough to have all the skills covered? Are there complementary skills? Are the skills additive, or do you need overlapping skills among team members?
Thought Experiment
If all data which had ever been collected were freely available to everyone, would we be better off?
Some ideas were offered:
- all nude photos are included. [Mathbabe interjects: it’s possible to not let people take nude pics of you. Just sayin’.]
- so are passwords, credit scores, etc.
- how do we make secure transactions between a person and her bank considering this?
- what does it mean to be “freely available” anyway?
The data of power; the power of data
You see a lot of people posting crap like this on Facebook:

But here’s the thing: the Berner Convention doesn’t exist. People are posting this to their walls because they care about their privacy. People think they can exercise control over their data but they can’t. Stuff like this give one a false sense of security.
In Europe the privacy laws are stricter, and you can request data from Irish Facebook and they’re supposed to do it, but it’s still not easy to successfully do.
And it’s not just data that’s being collected about you – it’s data you’re collecting. As scientists we have to be careful about what we create, and take responsibility for our creations.
As Francois Rabelais said,
Wisdom entereth not into a malicious mind, and science without conscience is but the ruin of the soul.

Or as Emily Bell from Columbia said,
Every algorithm is editorial.

We can’t be evil during the day and take it back at hackathons at night. Just as journalists need to be aware that the way they report stories has consequences, so do data scientists. As a data scientist one has impact on people’s lives and how they think.
Here are some takeaways from the course:
- We’ve gained significant powers in this course.
- In the future we may have the opportunity to do more.
- With data power comes data responsibility.
Who does data science empower?
The second presentation was given by Jed and Mike. Again, they had a bunch of people on their team helping out.
Thought experiment
Let’s start with a quote:
“Anything which uses science as part of its name isn’t political science, creation science, computer science.”
– Hal Abelson, MIT CS prof
Keeping this in mind, if you could re-label data science, would you? What would you call it?
Some comments from the audience:
- Let’s call it “modellurgy,” the craft of beating mathematical models into shape instead of metal
- Let’s call it “statistics”
Does it really matter what data science is? What should it end up being?
Chris Wiggins from Columbia contends there are two main views of what data science should end up being. The first stems from John Tukey, inventor of the fast fourier transform and the box plot, and father of exploratory data analysis. Tukey advocated for a style of research he called “data analysis”, emphasizing the primacy of data and therefore computation, which he saw as part of statistics. His descriptions of data analysis, which he saw as part of doing statistics, are very similar to what people call data science today.
The other prespective comes from Jim Gray, Computer Scientist from Microsoft. He saw the scientific ideals of the enlightenment age as expanding and evolving. We’ve gone from the theories of Darwin and Newton to experimental and computational approaches of Turing. Now we have a new science, a data-driven paradigm. It’s actually the fourth paradigm of all the sciences, the first three being experimental, theoretical, and computational. See more about this here.
Wait, can data science be both?

Note it’s difficult to stick Computer Science and Data Science on this line.
Statistics is a tool that everyone uses. Data science also could be seen that way, as a tool rather than a science.
Who does data science?
Here’s a graphic showing the make-up of Kaggle competitors. Teams of students collaborated to collect, wrangle, analyze and visualize this data:

The size of the blocks correspond to how many people in active competitions have an education background in a given field. We see that almost a quarter of competitors are computer scientists. The shading corresponds to how often they compete. So we see the business finance people do more competitions on average than the computer science people.
Consider this: the only people doing math competitions are math people. If you think about it, it’s kind of amazing how many different backgrounds are represented above.
We got some cool graphics created by the students who collaborated to get the data, process it, visualize it and so on.
Which universities offer courses on Data Science?

There will be 26 universities in total by 2013 that offer data science courses. The balls are centered at the center of gravity of a given state, and the balls are bigger if there are more in that state.
Where are data science jobs available?

Observations:
- We see more professional schools offering data science courses on the west coast.
- It would also would be interesting to see this corrected for population size.
- Only two states had no jobs.
- Massachusetts #1 per capita, then Maryland
Crossroads
McKinsey says there will be hundreds of thousands of data science jobs in the next few years. There’s a massive demand in any case. Some of us will be part of that. It’s up to us to make sure what we’re doing is really data science, rather than validating previously held beliefs.
We need to advance human knowledge if we want to take the word “scientist” seriously.
How did this class empower you?
You are one of the first people to take a data science class. There’s something powerful there.
Thank you Rachel!

Last Day of Columbia Data Science Class, What just happened? from Rachel’s perspective
Recall the stated goals of this class were:
- learn about what it’s like to be a data scientists
- be able to do some of what a data scientist does
Hey we did this! Think of all the guest lectures; they taught you a lot of what it’s like to be a data scientist, which was goal 1. Here’s what I wanted you guys to learn before the class started based on what a data scientist does, and you’ve learned a lot of that, which was goal 2:

Mission accomplished! Mission accomplished?
Thought experiment that I gave to myself last Spring
How would you design a data science class?
Comments I made to myself:
- It’s not a well-defined body of knowledge, subject, no textbook!
- It’s popularized and celebrated in the press and media, but there’s no “authority” to push back
- I’m intellectually disturbed by idea of teaching a course when the body of knowledge is ill-defined
- I didn’t know who would show up, and what their backgrounds and motivations would be
- Could it become redundant with a machine learning class?
My process
I asked questions of myself and from other people. I gathered information, and endured existential angst about data science not being a “real thing.” I needed to give it structure.
Then I started to think about it this way: while I recognize that data science has the potential to be a deep research area, it’s not there yet, and in order to actually design a class, let’s take a pragmatic approach: Recognize that data science exists. After all, there are jobs out there. I want to help students to be qualified for them. So let me teach them what it takes to get those jobs. That’s how I decided to approach it.
In other words, from this perspective, data science is what data scientists do. So it’s back to the list of what data scientists do. I needed to find structure on top of that, so the structure I used as a starting point were the data scientist profiles.
Data scientist profiles
This was a way to think about your strengths and weaknesses, as well as a link between speakers. Note it’s easy to focus on “technical skills,” but it can also be problematic in being too skills-based, as well as being problematic because it has no scale, and no notion of expertise. On the other hand it’s good in that it allows for and captures variability among data scientists.
I assigned weekly guest speakers topics related to their strengths. We held lectures, labs, and (optional) problem sessions. From this you got mad skillz:
- programming in R
- some python
- you learned some best practices about coding
From the perspective of machine learning,
- you know a bunch of algorithms like linear regression, logistic regression, k-nearest neighbors, k-mean, naive Bayes, random forests,
- you know what they are, what they’re used for, and how to implement them
- you learned machine learning concepts like training sets, test sets, over-fitting, bias-variance tradeoff, evaluation metrics, feature selection, supervised vs. unsupervised learning
- you learned about recommendation systems
- you’ve entered a Kaggle competition
Importantly, you now know that if there is an algorithm and model that you don’t know, you can (and will) look it up and figure it out. I’m pretty sure you’ve all improved relative to how you started.
You’ve learned some data viz by taking flowing data tutorials.
You’ve learned statistical inference, because we discussed
- observational studies,
- causal inference, and
- experimental design.
- We also learned some maximum likelihood topics, but I’d urge you to take more stats classes.
In the realm of data engineering,
- we showed you map reduce and hadoop
- we worked with 30 separate shards
- we used an api to get data
- we spent time cleaning data
- we’ve processed different kinds of data
As for communication,
- you wrote thoughts in response to blog posts
- you observed how different data scientists communicate or present themselves, and have different styles
- your final project required communicating among each other
As for domain knowledge,
- lots of examples were shown to you: social networks, advertising, finance, pharma, recommender systems, dallas art museum
I heard people have been asking the following: why didn’t we see more data science coming from non-profits, governments, and universities? Note that data science, the term, was born in for-profits. But the truth is I’d also like to see more of that. It’s up to you guys to go get that done!
How do I measure the impact of this class I’ve created? Is it possible to incubate awesome data science teams in the classroom? I might have taken you from point A to point B but you might have gone there anyway without me. There’s no counterfactual!
Can we set this up as a data science problem? Can we use a causal modeling approach? This would require finding students who were more or less like you but didn’t take this class and use propensity score matching. It’s not a very well-defined experiment.
But the goal is important: in industry they say you can’t learn data science in a university, that it has to be on the job. But maybe that’s wrong, and maybe this class has proved that.
What has been the impact on you or to the outside world? I feel we have been contributing to the broader discourse.
Does it matter if there was impact? and does it matter if it can be measured or not? Let me switch gears.
What is data science again?
Data science could be defined as:
- A set of best practices used in tech companies, which is how I chose to design the course
- A space of problems that could be solved with data
- A science of data where you can think of the data itself as units
The bottom two have the potential to be the basis of a rich and deep research discipline, but in many cases, the way the term is currently used is:
- Pure hype
But it doesn’t matter how we define it, as much as that I want for you:
- to be problem solvers
- to be question askers
- to think about your process
- to use data responsibly and make the world better, not worse.
More on being problem solvers: cultivate certain habits of mind
Here’s a possible list of things to strive for, taken from here:

Here’s the thing. Tons of people can implement k-nearest neighbors, and many do it badly. What matters is that you cultivate the above habits, remain open to continuous learning.
In education in traditional settings, we focus on answers. But what we probably should focus on is how a student behaves when they don’t know the answer. We need to have qualities that help us find the answer.
Thought experiment
How would you design a data science class around habits of mind rather than technical skills? How would you quantify it? How would you evaluate? What would students be able to write on their resumes?
Comments from the students:
- You’d need to keep making people doing stuff they don’t know how to do while keeping them excited about it.
- have people do stuff in their own domains so we keep up wonderment and awe.
- You’d use case studies across industries to see how things work in different contexts
More on being question-askers
Some suggestions on asking questions of others:
- start with assumption that you’re smart
- don’t assume the person you’re talking to knows more or less. You’re not trying to prove anything.
- be curious like a child, not worried about appearing stupid
- ask for clarification around notation or terminology
- ask for clarification around process: where did this data come from? how will it be used? why is this the right data to use? who is going to do what? how will we work together?
Some questions to ask yourself
- does it have to be this way?
- what is the problem?
- how can I measure this?
- what is the appropriate algorithm?
- how will I evaluate this?
- do I have the skills to do this?
- how can I learn to do this?
- who can I work with? Who can I ask?
- how will it impact the real world?
Data Science Processes
In addition to being problem-solvers and question-askers, I mentioned that I want you to think about process. Here are a couple processes we discussed in this course:
(1) Real World –> Generates Data –>
–> Collect Data –> Clean, Munge (90% of your time)
–> Exploratory Data Analysis –>
–> Feature Selection –>
–> Build Model, Build Algorithm, Visualize
–> Evaluate –>Iterate–>
–> Impact Real World
(2) Asking questions of yourselves and others –>
Identifying problems that need to be solved –>
Gathering information, Measuring –>
Learning to find structure in unstructured situations–>
Framing Problem –>
Creating Solutions –> Evaluating
Thought experiment
Come up with a business that improves the world and makes money and uses data
Comments from the students:
- autonomous self-driving cars you order with a smart phone
- find all the info on people and then show them how to make it private
- social network with no logs and no data retention
10 Important Data Science Ideas
Of all the blog posts I wrote this semester, here’s one I think is important:
10 Important Data Science Ideas
Confidence and Uncertainty
Let’s talk about confidence and uncertainty from a couple perspectives.
First, remember that statistical inference is extracting information from data, estimating, modeling, explaining but also quantifying uncertainty. Data Scientists could benefit from understanding this more. Learn more statistics and read Ben’s blog post on the subject.
Second, we have the Dunning-Kruger Effect.
Have you ever wondered why don’t people say “I don’t know” when they don’t know something? This is partly explained through an unconscious bias called the Dunning-Kruger effect.
Basically, people who are bad at something have no idea that they are bad at it and overestimate their confidence. People who are super good at something underestimate their mastery of it. Actual competence may weaken self-confidence.
Thought experiment
Design an app to combat the dunning-kruger effect.
Optimizing your life, Career Advice
What are you optimizing for? What do you value?
- money, need some minimum to live at the standard of living you want to, might even want a lot.
- time with loved ones and friends
- doing good in the world
- personal fulfillment, intellectual fulfillment
- goals you want to reach or achieve
- being famous, respected, acknowledged
- ?
- some weighted function of all of the above. what are the weights?
What constraints are you under?
- external factors (factors outside of your control)
- your resources: money, time, obligations
- who you are, your education, strengths & weaknesses
- things you can or cannot change about yourself
There are many possible solutions that optimize what you value and take into account the constraints you’re under.
So what should you do with your life?
Remember that whatever you decide to do is not permanent so don’t feel too anxious about it, you can always do something else later –people change jobs all the time
But on the other hand, life is short, so always try to be moving in the right direction (optimizing for what you care about).
If you feel your way of thinking or perspective is somehow different than what those around you are thinking, then embrace and explore that, you might be onto something.
I’m always happy to talk to you about your individual case.
Next Gen Data Scientists
The second blog post I think is important is this “manifesto” that I wrote:
Next-Gen Data Scientists. That’s you! Go out and do awesome things, use data to solve problems, have integrity and humility.
Here’s our class photo!

How math departments hire faculty
I just got back from a stimulating trip to Stony Brook to give the math colloquium there. I had a great time thanks to my gracious host Jason Starr (this guy, not this guy), and besides giving my talk (which I will give again in San Diego at the joint meetings next month) I enjoyed two conversations about the field of math which I think could be turned into data science projects. Maybe Ph.D. theses or something.
First, a system for deciding whether a paper on the arXiv is “good.” I will post about that on another day because it’s actually pretty involved and possible important.
Second is the way people hire in math departments. This conversation will generalize to other departments, some more than others.
So first of all, I want to think about how the hiring process actually works. There are people who look at folders of applicants, say for tenure-track jobs. Since math is a pretty disjointed field, a majority of the folders will only be understood well enough for evaluation purposes by a few people in the department.
So in other words, the department naturally splits into clusters more or less along field lines: there are the number theorists and then there are the algebraic geometers and then there are the low-dimensional topologists, say.
Each group of people reads the folders from the field or fields that they have enough expertise in to understand. Then from among those they choose some they want to go to bat for. It becomes a political battle, where each group tries to convince the other groups that their candidates are more qualified. But of course it’s really hard to know who’s telling the honest truth. There are probably lots of biases in play too, so people could be overstating their cases unconsciously.
Some potential problems with this system:
- if you are applying to a department where nobody is in your field, nobody will read your folder, and nobody will go to bat for you, even if you are really great. An exaggeration but kinda true.
- in order to be convincing that “your guy is the best applicant,” people use things like who the advisor is or which grad school this person went to more than the underlying mathematical content.
- if your department grows over time, this tends to mean that you get bigger clusters rather than more clusters. So if you never had a number theorist, you tend to never get one, even if you get more positions. This is a problem for grad students who want to become number theorists, but that probably isn’t enough to affect the politics of hiring.
So here’s my data science plan: test the above hypotheses. I said them because I think they are probably true, but it would be not be impossible to create the dataset to test them thoroughly and measure the effects.
The easiest and most direct one to test is the third: cluster departments by subject by linking the people with their published or arXiv’ed papers. Watch the department change over time and see how the clusters change and grow versus how it might happen randomly. Easy peasy lemon squeazy if you have lots of data. Start collecting it now!
The first two are harder but could be related to the project of ranking papers. In other words, you have to define “is really great” to do this. It won’t mean you can say with confidence that X should have gotten a job at University Y, but it would mean you could say that if X’s subject isn’t represented in University Y’s clusters, then X’s chances of getting a job there, all other things being equal, is diminished by Z% on average. Something like that.
There are of course good things about the clustering. For example, it’s not that much fun to be the only person representing a field in your department. I’m not actually passing judgment on this fact, and I’m also not suggesting a way to avoid it (if it should be avoided).
Columbia Data Science course, week 12: Predictive modeling, data leakage, model evaluation
This week’s guest lecturer in Rachel Schutt’s Columbia Data Science class was Claudia Perlich. Claudia has been the Chief Scientist at m6d for 3 years. Before that she was a data analytics group at the IBM center that developed Watson, the computer that won Jeopardy!, although she didn’t work on that project. Claudia got her Ph.D. in information systems at NYU and now teaches a class to business students in data science, although mostly she addresses how to assess data science work and how to manage data scientists. Claudia also holds a masters in Computer Science.
Claudia is a famously successful data mining competition winner. She won the KDD Cup in 2003, 2007, 2008, and 2009, the ILP Challenge in 2005, the INFORMS Challenge in 2008, and the Kaggle HIV competition in 2010.
She’s also been a data mining competition organizer, first for the INFORMS Challenge in 2009 and then for the Heritage Health Prize in 2011. Claudia claims to be retired from competition.
Claudia’s advice to young people: pick your advisor first, then choose the topic. It’s important to have great chemistry with your advisor, and don’t underestimate the importance.
Background
Here’s what Claudia historically does with her time:
- predictive modeling
- data mining competitions
- publications in conferences like KDD and journals
- talks
- patents
- teaching
- digging around data (her favorite part)
Claudia likes to understand something about the world by looking directly at the data.
Here’s Claudia’s skill set:
- plenty of experience doing data stuff (15 years)
- data intuition (for which one needs to get to the bottom of the data generating process)
- dedication to the evaluation (one needs to cultivate a good sense of smell)
- model intuition (we use models to diagnose data)
Claudia also addressed being a woman. She says it works well in the data science field, where her intuition is useful and is used. She claims her nose is so well developed by now that she can smell it when something is wrong. This is not the same thing as being able to prove something algorithmically. Also, people typically remember her because she’s a woman, even when she don’t remember them. It has worked in her favor, she says, and she’s happy to admit this. But then again, she is where she is because she’s good.
Someone in the class asked if papers submitted for journals and/or conferences are blind to gender. Claudia responded that it was, for some time, typically double-blind but now it’s more likely to be one-sided. And anyway there was a cool analysis that showed you can guess who wrote a paper with 80% accuracy just by knowing the citations. So making things blind doesn’t really help. More recently the names are included, and hopefully this doesn’t make things too biased. Claudia admits to being slightly biased towards institutions – certain institutions prepare better work.
Skills and daily life of a Chief Data Scientist
Claudia’s primary skills are as follows:
- Data manipulation: unix (sed, awk, etc), Perl, SQL
- Modeling: various methods (logistic regression, nearest neighbors, k-nearest neighbors, etc)
- Setting things up
She mentions that the methods don’t matter as much as how you’ve set it up, and how you’ve translated it into something where you can solve a question.
More recently, she’s been told that at work she spends:
- 40% of time as “contributor”: doing stuff directly with data
- 40% of time as “ambassador”: writing stuff, giving talks, mostly external communication to represent m6d, and
- 20% of time in “leadership” of her data group
At IBM it was much more focused in the first category. Even so, she has a flexible schedule at m6d and is treated well.
The goals of the audience
She asked the class, why are you here? Do you want to:
- become a data scientist? (good career choice!)
- work with data scientist?
- work for a data scientist?
- manage a data scientist?
Most people were trying their hands at the first, but we had a few in each category.
She mentioned that it matters because the way she’d talk to people wanting to become a data scientist would be different from the way she’d talk to someone who wants to manage them. Her NYU class is more like how to manage one.
So, for example, you need to be able to evaluate their work. It’s one thing to check a bubble sort algorithm or check whether a SQL server is working, but checking a model which purports to give the probability of people converting is different kettle of fish.
For example, try to answer this: how much better can that model get if you spend another week on it? Let’s face it, quality control is hard for yourself as a data miner, so it’s definitely hard for other people. There’s no easy answer.
There’s an old joke that comes to mind: What’s the difference between the scientist and a consultant? The scientists asks, how long does it take to get this right? whereas the consultant asks, how right can I get this in a week?
Insights into data
A student asks, how do you turn a data analysis into insights?
Claudia: this is a constant point of contention. My attitude is: I like to understand something, but what I like to understand isn’t what you’d consider an insight. My message may be, hey you’ve replaced every “a” by a “0”, or, you need to change the way you collect your data. In terms of useful insight, Ori’s lecture from last week, when he talked about causality, is as close as you get.
For example, decision trees you interpret, and people like them because they’re easy to interpret, but I’d ask, why does it look like it does? A slightly different data set would give you a different tree and you’d get a different conclusion. This is the illusion of understanding. I tend to be careful with delivering strong insights in that sense.
For more in this vein, Claudia suggests we look at Monica Rogati‘s talk “Lies, damn lies, and the data scientist.”
Data mining competitions
Claudia drew a distinction between different types of data mining competitions.
On the one hand you have the “sterile” kind, where you’re given a clean, prepared data matrix, a standard error measure, and where the features are often anonymized. This is a pure machine learning problem.
Examples of this first kind are: KDD Cup 2009 and 2011 (Netflix). In such competitions, your approach would emphasize algorithms and computation. The winner would probably have heavy machines and huge modeling ensembles.
On the other hand, you have the “real world” kind of data mining competition, where you’re handed raw data, which is often in lots of different tables and not easily joined, where you set up the model yourself and come up with task-specific evaluations. This kind of competition simulates real life more.
Examples of this second kind are: KDD cup 2007, 2008, and 2010. If you’re competing in this kind of competition your approach would involve understanding the domain, analyzing the data, and building the model. The winner might be the person who best understands how to tailor the model to the actual question.
Claudia prefers the second kind, because it’s closer to what you do in real life. In particular, the same things go right or go wrong.
How to be a good modeler
Claudia claims that data and domain understanding is the single most important skill you need as a data scientist. At the same time, this can’t really be taught – it can only be cultivated.
A few lessons learned about data mining competitions that Claudia thinks are overlooked in academics:
- Leakage: the contestants best friend and the organizers/practitioners worst nightmare. There’s always something wrong with the data, and Claudia has made an artform of figuring out how the people preparing the competition got lazy or sloppy with the data.
- Adapting learning to real-life performance measures beyond standard measures like MSE, error rate, or AUC (profit?)
- Feature construction/transformation: real data is rarely flat (i.e. given to you in a beautiful matrix) and good, practical solutions for this problem remains a challenge.
Leakage
Leakage refers to something that helps you predict something that isn’t fair. It’s a huge problem in modeling, and not just for competitions. Oftentimes it’s an artifact of reversing cause and effect.
Example 1: There was a competition where you needed to predict S&P in terms of whether it would go up or go down. The winning entry had a AUC (area under the ROC curve) of 0.999 out of 1. Since stock markets are pretty close to random, either someone’s very rich or there’s something wrong. There’s something wrong.
In the good old days you could win competitions this way, by finding the leakage.
Example 2: Amazon case study: big spenders. The target of this competition was to predict customers who spend a lot of money among customers using past purchases. The data consisted of transaction data in different categories. But a winning model identified that “Free Shipping = True” was an excellent predictor
What happened here? The point is that free shipping is an effect of big spending. But it’s not a good way to model big spending, because in particular it doesn’t work for new customers or for the future. Note: timestamps are weak here. The data that included “Free Shipping = True” was simultaneous with the sale, which is a no-no. We need to only use data from beforehand to predict the future.
Example 3: Again an online retailer, this time the target is predicting customers who buy jewelry. The data consists of transactions for different categories. A very successful model simply noted that if sum(revenue) = 0, then it predicts jewelry customers very well?
What happened here? The people preparing this data removed jewelry purchases, but only included people who bought something in the first place. So people who had sum(revenue) = 0 were people who only bought jewelry. The fact that you only got into the dataset if you bought something is weird: in particular, you wouldn’t be able to use this on customers before they finished their purchase. So the model wasn’t being trained on the right data to make the model useful. This is a sampling problem, and it’s common.
Example 4: This happened at IBM. The target was to predict companies who would be willing to buy “websphere” solutions. The data was transaction data + crawled potential company websites. The winning model showed that if the term “websphere” appeared on the company’s website, then they were great candidates for the product.
What happened? You can’t crawl the historical web, just today’s web.
Thought experiment
You’re trying to study who has breast cancer. The patient ID, which seemed innocent, actually has predictive power. What happened?

In the above image, red means cancerous, green means not. it’s plotted by patient ID. We see three or four distinct buckets of patient identifiers. It’s very predictive depending on the bucket. This is probably a consequence of using multiple databases, some of which correspond to sicker patients are more likely to be sick.
A student suggests: for the purposes of the contest they should have renumbered the patients and randomized.
Claudia: would that solve the problem? There could be other things in common as well.
A student remarks: The important issue could be to see the extent to which we can figure out which dataset a given patient came from based on things besides their ID.
Claudia: Think about this: what do we want these models for in the first place? How well can you predict cancer?
Given a new patient, what would you do? If the new patient is in a fifth bin in terms of patient ID, then obviously don’t use the identifier model. But if it’s still in this scheme, then maybe that really is the best approach.
This discussion brings us back to the fundamental problem that we need to know what the purpose of the model is and how is it going to be used in order to decide how to do it and whether it’s working.
Pneumonia
During an INFORMS competition on pneumonia predictions in hospital records, where the goal was to predict whether a patient has pneumonia, a logistic regression which included the number of diagnosis codes as a numeric feature (AUC of 0.80) didn’t do as well as the one which included it as a categorical feature (0.90). What’s going on?
This had to do with how the person prepared the data for the competition:

The diagnosis code for pneumonia was 486. So the preparer removed that (and replaced it by a “-1”) if it showed up in the record (rows are different patients, columns are different diagnoses, there are max 4 diagnoses, “-1” means there’s nothing for that entry).
Moreover, to avoid telling holes in the data, the preparer moved the other diagnoses to the left if necessary, so that only “-1″‘s were on the right.
There are two problems with this:
- If the column has only “-1″‘s, then you know it started out with only pneumonia, and
- If the column has no “-1″‘s, you know there’s no pneumonia (unless there are actually 5 diagnoses, but that’s less common).
This was enough information to win the competition.
Note: winning competition on leakage is easier than building good models. But even if you don’t explicitly understand and game the leakage, your model will do it for you. Either way, leakage is a huge problem.
How to avoid leakage
Claudia’s advice to avoid this kind of problem:
- You need a strict temporal cutoff: remove all information just prior to the event of interest (patient admission).
- There has to be a timestamp on every entry and you need to keep
- Removing columns asks for trouble
- Removing rows can introduce inconsistencies with other tables, also causing trouble
- The best practice is to start from scratch with clean, raw data after careful consideration
- You need to know how the data was created! I only work with data I pulled and prepared myself (or maybe Ori).
Evaluations
How do I know that my model is any good?
With powerful algorithms searching for patterns of models, there is a serious danger of over fitting. It’s a difficult concept, but the general idea is that “if you look hard enough you’ll find something” even if it does not generalize beyond the particular training data.
To avoid overfitting, we cross-validate and we cut down on the complexity of the model to begin with. Here’s a standard picture (although keep in mind we generally work in high dimensional space and don’t have a pretty picture to look at):

The picture on the left is underfit, in the middle is good, and on the right is overfit.
The model you use matters when it concerns overfitting:

So for the above example, unpruned decision trees are the most over fitting ones. This is a well-known problem with unpruned decision trees, which is why people use pruned decision trees.
Accuracy: meh
Claudia dismisses accuracy as a bad evaluation method. What’s wrong with accuracy? It’s inappropriate for regression obviously, but even for classification, if the vast majority is of binary outcomes are 1, then a stupid model can be accurate but not good (guess it’s always “1”), and a better model might have lower accuracy.
Probabilities matter, not 0’s and 1’s.
Nobody makes decisions on binary outcomes. I want to know the probability I have breast cancer, I don’t want to be told yes or no. It’s much more information. I care about probabilities.
How to evaluate a probability model
We separately evaluate the ranking and the calibration. To evaluate the ranking, we use the ROC curve and calculate the area under it, typically ranges from 0.5-1.0. This is independent of scaling and calibration. Here’s an example of how to draw an ROC curve:

Sometimes to measure rankings, people draw the so-called lift curve:

The key here is that the lift is calculated with respect to a baseline. You draw it at a given point, say 10%, by imagining that 10% of people are shown ads, and seeing how many people click versus if you randomly showed 10% of people ads. A lift of 3 means it’s 3 times better.
How do you measure calibration? Are the probabilities accurate? If the model says probability of 0.57 that I have cancer, how do I know if it’s really 0.57? We can’t measure this directly. We can only bucket those predictions and then aggregately compare those in that prediction bucket (say 0.50-0.55) to the actual results for that bucket.
For example, here’s what you get when your model is an unpruned decision tree, where the blue diamonds are buckets:
 A good model would show buckets right along the x=y curve, but here we’re seeing that the predictions were much more extreme than the actual probabilities. Why does this pattern happen for decision trees?
A good model would show buckets right along the x=y curve, but here we’re seeing that the predictions were much more extreme than the actual probabilities. Why does this pattern happen for decision trees?
Claudia says that this is because trees optimize purity: it seeks out pockets that have only positives or negatives. Therefore its predictions are more extreme than reality. This is generally true about decision trees: they do not generally perform well with respect to calibration.
Logistic regression looks better when you test calibration, which is typical:

Takeaways:
- Accuracy is almost never the right evaluation metric.
- Probabilities, not binary outcomes.
- Separate ranking from calibration.
- Ranking you can measure with nice pictures: ROC, lift
- Calibration is measured indirectly through binning.
- Different models are better than others when it comes to calibration.
- Calibration is sensitive to outliers.
- Measure what you want to be good at.
- Have a good baseline.
Choosing an algorithm
This is not a trivial question and in particular small tests may steer you wrong, because as you increase the sample size the best algorithm might vary: often decision trees perform very well but only if there’s enough data.
In general you need to choose your algorithm depending on the size and nature of your dataset and you need to choose your evaluation method based partly on your data and partly on what you wish to be good at. Sum of squared error is maximum likelihood loss function if your data can be assumed to be normal, but if you want to estimate the median, then use absolute errors. If you want to estimate a quantile, then minimize the weighted absolute error.
We worked on predicting the number of ratings of a movie will get in the next year, and we assumed a poisson distributions. In this case our evaluation method doesn’t involve minimizing the sum of squared errors, but rather something else which we found in the literature specific to the Poisson distribution, which depends on the single parameter

Charity direct mail campaign
Let’s put some of this together.
Say we want to raise money for a charity. If we send a letter to every person in the mailing list we raise about $9000. We’d like to save money and only send money to people who are likely to give – only about 5% of people generally give. How can we do that?
If we use a (somewhat pruned, as is standard) decision tree, we get $0 profit: it never finds a leaf with majority positives.
If we use a neural network we still make only $7500, even if we only send a letter in the case where we expect the return to be higher than the cost.
This looks unworkable. But if you model is better, it’s not. A person makes two decisions here. First, they decide whether or not to give, then they decide how much to give. Let’s model those two decisions separately, using:

Note we need the first model to be well-calibrated because we really care about the number, not just the ranking. So we will try logistic regression for first half. For the second part, we train with special examples where there are donations.
Altogether this decomposed model makes a profit of $15,000. The decomposition made it easier for the model to pick up the signals. Note that with infinite data, all would have been good, and we wouldn’t have needed to decompose. But you work with what you got.
Moreover, you are multiplying errors above, which could be a problem if you have a reason to believe that those errors are correlated.
Parting thoughts
We are not meant to understand data. Data are outside of our sensory systems and there are very few people who have a near-sensory connection to numbers. We are instead meant to understand language.
We are not mean to understand uncertainty: we have all kinds of biases that prevent this from happening and are well-documented.
Modeling people in the future is intrinsically harder than figuring out how to label things that have already happened.
Even so we do our best, and this is through careful data generation, careful consideration of what our problem is, making sure we model it with data close to how it will be used, making sure we are optimizing to what we actually desire, and doing our homework in learning which algorithms fit which tasks.
O’Reilly book deal signed for “Doing Data Science”
I’m very happy to say I just signed a book contract with my co-author, Rachel Schutt, to publish a book with O’Reilly called Doing Data Science.
The book will be based on the class Rachel is giving this semester at Columbia which I’ve been blogging about here.
For those of you who’ve been reading along for free as I’ve been blogging it, there might not be a huge incentive to buy it, but I can promise you more and better math, more explicit usable formulas, some sample code, and an overall better and more thought-out narrative.
It’s supposed to be published in May with a possible early release coming up at the end of February, in time for the O’Reilly Strata Santa Clara conference, where Rachel will be speaking about it and about other stuff curriculum related. Hopefully people will pick it up in time to teach their data science courses in Fall 2013.
Speaking of Rachel, she’s also been selected to give a TedXWomen talk at Barnard on December 1st, which is super exciting. She’s talking about advocating for the social good using data. Unfortunately the event is invitation-only, otherwise I’d encourage you all to go and hear her words of wisdom. Update: word on the street is that it will be video-taped.
Columbia Data Science course, week 11: Estimating causal effects
The week in Rachel Schutt’s Data Science course at Columbia we had Ori Stitelman, a data scientist at Media6Degrees.
We also learned last night of a new Columbia course: STAT 4249 Applied Data Science, taught by Rachel Schutt and Ian Langmore. More information can be found here.
Ori’s background
Ori got his Ph.D. in Biostatistics from UC Berkeley after working at a litigation consulting firm. He credits that job with allowing him to understand data through exposure to tons of different data sets; since his job involved creating stories out of data to let experts testify at trials, e.g. for asbestos. In this way Ori developed his data intuition.
Ori worries that people ignore this necessary data intuition when they shove data into various algorithms. He thinks that when their method converges, they are convinced the results are therefore meaningful, but he’s here today to explain that we should be more thoughtful than that.
It’s very important when estimating causal parameters, Ori says, to understand the data-generating distributions and that involves gaining subject matter knowledge that allows you to understand if you necessary assumptions are plausible.
Ori says the first step in a data analysis should always be to take a step back and figure out what you want to know, write that down, and then find and use the tools you’ve learned to answer those directly. Later of course you have to decide how close you came to answering your original questions.
Thought Experiment
Ori asks, how do you know if your data may be used to answer your question of interest? Sometimes people think that because they have data on a subject matter then you can answer any question.
Students had some ideas:
- You need coverage of your parameter space. For example, if you’re studying the relationship between household income and holidays but your data is from poor households, then you can’t extrapolate to rich people. (Ori: but you could ask a different question)
- Causal inference with no timestamps won’t work.
- You have to keep in mind what happened when the data was collected and how that process affected the data itself
- Make sure you have the base case: compared to what? If you want to know how politicians are affected by lobbyists money you need to see how they behave in the presence of money and in the presence of no money. People often forget the latter.
- Sometimes you’re trying to measure weekly effects but you only have monthly data. You end up using proxies. Ori: but it’s still good practice to ask the precise question that you want, then come back and see if you’ve answered it at the end. Sometimes you can even do a separate evaluation to see if something is a good proxy.
- Signal to noise ratio is something to worry about too: as you have more data, you can more precisely estimate a parameter. You’d think 10 observations about purchase behavior is not enough, but as you get more and more examples you can answer more difficult questions.
Ori explains confounders with a dating example
Frank has an important decision to make. He’s perusing a dating website and comes upon a very desirable woman – he wants her number. What should he write in his email to her? Should he tell her she is beautiful? How do you answer that with data?
You could have him select a bunch of beautiful women and half the time chosen at random, tell them they’re beautiful. Being random allows us to assume that the two groups have similar distributions of various features (not that’s an assumption).
Our real goal is to understand the future under two alternative realities, the treated and the untreated. When we randomize we are making the assumption that the treated and untreated populations are alike.
OK Cupid looked at this and concluded:

But note:
- It could say more about the person who says “beautiful” than the word itself. Maybe they are otherwise ridiculous and overly sappy?
- The recipients of emails containing the word “beautiful” might be special: for example, they might get tons of email, which would make it less likely for Frank to get any response at all.
- For that matter, people may be describing themselves as beautiful.
Ori points out that this fact, that she’s beautiful, affects two separate things:
- whether Frank uses the word “beautiful” or not in his email, and
- the outcome (i.e. whether Frank gets the phone number).
For this reason, the fact that she’s beautiful qualifies as a confounder. The treatment is Frank writing “beautiful” in his email.
Causal graphs
Denote by 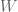
Denote by 
Denote by 
We are forming the following causal graph:

In a causal graph, each arrow means that the ancestor is a cause of the descendent, where ancestor is the node the arrow is coming out of and the descendent is the node the arrow is going into (see this book for more).
In our example with Frank, the arrow from beauty means that the woman being beautiful is a cause of Frank writing “beautiful” in the message. Both the man writing “beautiful” and and the woman being beautiful are direct causes of her probability to respond to the message.
Setting the problem up formally
The building blocks in understanding the above causal graph are:
- Ask question of interest.
- Make causal assumptions (denote these by
).
- Translate question into a formal quantity (denote this by
).
- Estimate quantity (denote this by
).
We need domain knowledge in general to do this. We also have to take a look at the data before setting this up, for example to make sure we may make the
Positivity Assumption. We need treatment (i.e. data) in all strata of things we adjust for. So if think gender is a confounder, we need to make sure we have data on women and on men. If we also adjust for age, we need data in all of the resulting bins.
Asking causal questions
What is the effect of ___ on ___?
This is the natural form of a causal question. Here are some examples:
- What is the effect of advertising on customer behavior?
- What is the effect of beauty on getting a phone number?
- What is the effect of censoring on outcome? (censoring is when people drop out of a study)
- What is the effect of drug on time until viral failure?, and the general case
- What is the effect of treatment on outcome?
Look, estimating causal parameters is hard. In fact the effectiveness of advertising is almost always ignored because it’s so hard to measure. Typically people choose metrics of success that are easy to estimate but don’t measure what they want! Everyone makes decision based on them anyway because it’s easier. This results in people being rewarded for finding people online who would have converted anyway.
Accounting for the effect of interventions
Thinking about that, we should be concerned with the effect of interventions. What’s a model that can help us understand that effect?
A common approach is the (randomized) A/B test, which involves the assumption that two populations are equivalent. As long as that assumption is pretty good, which it usually is with enough data, then this is kind of the gold standard.
But A/B tests are not always possible (or they are too expensive to be plausible). Often we need to instead estimate the effects in the natural environment, but then the problem is the guys in different groups are actually quite different from each other.
So, for example, you might find you showed ads to more people who are hot for the product anyway; it wouldn’t make sense to test the ad that way without adjustment.
The game is then defined: how do we adjust for this?
The ideal case
Similar to how we did this last week, we pretend for now that we have a “full” data set, which is to say we have god-like powers and we know what happened under treatment as well as what would have happened if we had not treated, as well as vice-versa, for every agent in the test.
Denote this full data set by
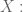

denotes the binary outcome if treated, and
denotes the binary outcome if untreated.
As a baseline check: if we observed this full data structure how would we measure the effect of A on Y? In that case we’d be all-powerful and we would just calculate:

Note that, since 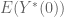

This would be calculating how much more likely someone is to convert if they see an ad.
Note these are outcomes you can really do stuff with. If you know people convert at 30% versus 10% in the presence of an ad, that’s real information. Similarly if they convert 3 times more often.
In reality people use silly stuff like log odds ratios, which nobody understands or can interpret meaningfully.
The ideal case with functions
In reality we don’t have god-like powers, and we have to make do. We will make a bunch of assumptions. First off, denote by 

i.e. the attributes
i.e. the treatment depends in a nice way on some exogenous variables as well the attributes we know about living in
i.e. the outcome is just a function of the treatment, the attributes, and some exogenous variables.
Note the various
But we want to intervene on this causal graph as though it’s the intervention we actually want to make. i.e. what’s the effect of treatment
Let’s look at this from the point of view of the joint distribution 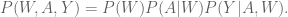
- the probability of a woman being beautiful,
- the probability that Frank writes and email to a her saying that she’s beautiful, and
- the probability that Frank gets her phone number.
What we really care about though is the distribution under intervention:
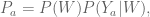
i.e. the probability knowing someone either got treated or not. To answer our question, we manipulate the value of 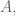
Assumptions
We are making a “Consistency Assumption / SUTVA” which can be expressed like this:
![]()
We have also assumed that we have no unmeasured confounders, which can be expressed thus:

We are also assuming positivity, which we discussed above.
Down to brass tacks
We only have half the information we need. We need to somehow map the stuff we have to the full data set as defined above. We make use of the following identity:

Recall we want to estimate 
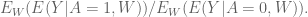
We’re going to discuss three methods to estimate this quantity, namely:
- MLE-based substitution estimator (MLE),
- Inverse probability estimators (IPTW),
- Double robust estimating equations (A-IPTW)
For the above models, it’s useful to think of there being two machines, called 

IPTW
In this method, which is also called importance sampling, we weight individuals that are unlikely to be shown an ad more than those likely. In other words, we up-sample in order to generate the distribution, to get the estimation of the actual effect.
To make sense of this, imagine that you’re doing a survey of people to see how they’ll vote, but you happen to do it at a soccer game where you know there are more young people than elderly people. You might want to up-sample the elderly population to make your estimate.
This method can be unstable if there are really small sub-populations that you’re up-sampling, since you’re essentially multiplying by a reciprocal.
The formula in IPTW looks like this:

Note the formula depends on the
In words, when 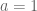

MLE
This method is based on the
This method is straight-forward: shove everyone in the machine and predict how the outcome would look under both treatment and non-treatment conditions, and take difference.
Note we don’t know anything about the underlying machine $latex Q$. It could be a logistic regression.
Get ready to get worried: A-IPTW
What if our machines are broken? That’s when we bring in the big guns: double robust estimators.
They adjust for confounding through the two machines we have on hand, 

and

Note: you are still screwed if both machines are broken. In some sense with a double robust estimator you’re hedging your bet.
“I’m glad you’re worried because I’m worried too.” – Ori
Simulate and test
I’ve shown you 3 distinct methods that estimate effects in observational studies. But they often come up with different answers. We set up huge simulation studies with known functions, i.e. where we know the functional relationships between everything, and then tried to infer those using the above three methods as well as a fourth method called TMLE (targeted maximal likelihood estimation).
As a side note, Ori encourages everyone to simulate data.
We wanted to know, which methods fail with respect to the assumptions? How well do the estimates work?
We started to see that IPTW performs very badly when you’re adjusting by very small thing. For example we found that the probability of someone getting sick is 132. That’s not between 0 and 1, which is not good. But people use these methods all the time.
Moreover, as things get more complicated with lots of nodes in our causal graph, calculating stuff over long periods of time, populations get sparser and sparser and it has an increasingly bad effect when you’re using IPTW. In certain situations your data is just not going to give you a sufficiently good answer.
Causal analysis in online display advertising
An overview of the process:
- We observe people taking actions (clicks, visits to websites, purchases, etc.).
- We use this observed data to build list of “prospects” (people with a liking for the brand).
- We subsequently observe same user during over the next few days.
- The user visits a site where a display ad spot exists and bid requests are made.
- An auction is held for display spot.
- If the auction is won, we display the ad.
- We observe the user’s actions after displaying the ad.
But here’s the problem: we’ve instituted confounders – if you find people who convert highly they think you’ve done a good job. In other words, we are looking at the treated without looking at the untreated.
We’d like to ask the question, what’s the effect of display advertising on customer conversion?
As a practical concern, people don’t like to spend money on blank ads. So A/B tests are a hard sell.
We performed some what-if analysis stipulated on the assumption that the group of users that sees ad is different. Our process was as follows:
- Select prospects that we got a bid request for on day 0
- Observe if they were treated on day 1. For those treated set
and those not treated set
collect attributes
- Create outcome window to be the next five days following treatment; observe if outcome event occurs (visit to the website whose ad was shown).
- Estimate model parameters using the methods previously described (our three methods plus TMLE).
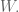
Here are some results:

Note results vary depending on the method. And there’s no way to know which method is working the best. Moreover, this is when we’ve capped the size of the correction in the IPTW methods. If we don’t then we see ridiculous results:

Medical research needs an independent modeling panel
I am outraged this morning.
I spent yesterday morning writing up David Madigan’s lecture to us in the Columbia Data Science class, and I can hardly handle what he explained to us: the entire field of epidemiological research is ad hoc.
This means that people are taking medication or undergoing treatments that may do they harm and probably cost too much because the researchers’ methods are careless and random.
Of course, sometimes this is intentional manipulation (see my previous post on Vioxx, also from an eye-opening lecture by Madigan). But for the most part it’s not. More likely it’s mostly caused by the human weakness for believing in something because it’s standard practice.
In some sense we knew this already. How many times have we read something about what to do for our health, and then a few years later read the opposite? That’s a bad sign.
And although the ethics are the main thing here, the money is a huge issue. It required $25 million dollars for Madigan and his colleagues to implement the study on how good our current methods are at detecting things we already know. Turns out they are not good at this – even the best methods, which we have no reason to believe are being used, are only okay.
Okay, $25 million dollars is a lot, but then again there are literally billions of dollars being put into the medical trials and research as a whole, so you might think that the “due diligence” of such a large industry would naturally get funded regularly with such sums.
But you’d be wrong. Because there’s no due diligence for this industry, not in a real sense. There’s the FDA, but they are simply not up to the task.
One article I linked to yesterday from the Stanford Alumni Magazine, which talked about the work of John Ioannidis (I blogged about his work here called “Why Most Published Research Findings Are False“), summed the situation up perfectly (emphasis mine):
When it comes to the public’s exposure to biomedical research findings, another frustration for Ioannidis is that “there is nobody whose job it is to frame this correctly.” Journalists pursue stories about cures and progress—or scandals—but they aren’t likely to diligently explain the fine points of clinical trial bias and why a first splashy result may not hold up. Ioannidis believes that mistakes and tough going are at the essence of science. “In science we always start with the possibility that we can be wrong. If we don’t start there, we are just dogmatizing.”
It’s all about conflict of interest, people. The researchers don’t want their methods examined, the pharmaceutical companies are happy to have various ways to prove a new drug “effective”, and the FDA is clueless.
Another reason for an AMS panel to investigate public math models. If this isn’t in the public’s interest I don’t know what is.
Columbia Data Science course, week 10: Observational studies, confounders, epidemiology
This week our guest lecturer in the Columbia Data Science class was David Madigan, Professor and Chair of Statistics at Columbia. He received a bachelors degree in Mathematical Sciences and a Ph.D. in Statistics, both from Trinity College Dublin. He has previously worked for AT&T Inc., Soliloquy Inc., the University of Washington, Rutgers University, and SkillSoft, Inc. He has over 100 publications in such areas as Bayesian statistics, text mining, Monte Carlo methods, pharmacovigilance and probabilistic graphical models.
So Madigan is an esteemed guest, but I like to call him an “apocalyptic leprechaun”, for reasons which you will know by the end of this post. He’s okay with that nickname, I asked his permission.
Madigan came to talk to us about observation studies, of central importance in data science. He started us out with this:
Thought Experiment
We now have detailed, longitudinal medical data on tens of millions of patients. What can we do with it?
To be more precise, we have tons of phenomenological data: this is individual, patient-level medical record data. The largest of the databases has records on 80 million people: every prescription drug, every condition ever diagnosed, every hospital or doctor’s visit, every lab result, procedures, all timestamped.
But we still do things like we did in the Middle Ages; the vast majority of diagnosis and treatment is done in a doctor’s brain. Can we do better? Can you harness these data to do a better job delivering medical care?
Students responded:
1) There was a prize offered on Kaggle, called “Improve Healthcare, Win $3,000,000.” predicting who is going to go to the hospital next year. Doesn’t that give us some idea of what we can do?
Madigan: keep in mind that they’ve coarsened the data for proprietary reasons. Hugely important clinical problem, especially as a healthcare insurer. Can you intervene to avoid hospitalizations?
2) We’ve talked a lot about the ethical uses of data science in this class. It seems to me that there are a lot of sticky ethical issues surrounding this 80 million person medical record dataset.
Madigan: Agreed! What nefarious things could we do with this data? We could gouge sick people with huge premiums, or we could drop sick people from insurance altogether. It’s a question of what, as a society, we want to do.
What is modern academic statistics?
Madigan showed us Drew Conway’s Venn Diagram that we’d seen in week 1:
 Madigan positioned the modern world of the statistician in the green and purple areas.
Madigan positioned the modern world of the statistician in the green and purple areas.
It used to be the case, say 20 years ago, according to Madigan, that academic statistician would either sit in their offices proving theorems with no data in sight (they wouldn’t even know how to run a t-test) or sit around in their offices and dream up a new test, or a new way of dealing with missing data, or something like that, and then they’d look around for a dataset to whack with their new method. In either case, the work of an academic statistician required no domain expertise.
Nowadays things are different. The top stats journals are more deep in terms of application areas, the papers involve deep collaborations with people in social sciences or other applied sciences. Madigan is setting an example tonight by engaging with the medical community.
Madigan went on to make a point about the modern machine learning community, which he is or was part of: it’s a newish academic field, with conferences and journals, etc., but is characterized by what stats was 20 years ago: invent a method, try it on datasets. In terms of domain expertise engagement, it’s a step backwards instead of forwards.
Comments like the above make me love Madigan.
Very few academic statisticians have serious hacking skills, with Mark Hansen being an unusual counterexample. But if all three is what’s required to be called data science, then I’m all for data science, says Madigan.
Madigan’s timeline
Madigan went to college in 1980, specialized on day 1 on math for five years. In final year, he took a bunch of stats courses, and learned a bunch about computers: pascal, OS, compilers, AI, database theory, and rudimentary computing skills. Then came 6 years in industry, working at an insurance company and a software company where he specialized in expert systems.
It was a mainframe environment, and he wrote code to price insurance policies using what would now be described as scripting languages. He also learned about graphics by creating a graphic representation of a water treatment system. He learned about controlling graphics cards on PC’s, but he still didn’t know about data.
Then he got a Ph.D. and went into academia. That’s when machine learning and data mining started, which he fell in love with: he was Program Chair of the KDD conference, among other things, before he got disenchanted. He learned C and java, R and S+. But he still wasn’t really working with data yet.
He claims he was still a typical academic statistician: he had computing skills but no idea how to work with a large scale medical database, 50 different tables of data scattered across different databases with different formats.
In 2000 he worked for AT&T labs. It was an “extreme academic environment”, and he learned perl and did lots of stuff like web scraping. He also learned awk and basic unix skills.
It was life altering and it changed everything: having tools to deal with real data rocks! It could just as well have been python. The point is that if you don’t have the tools you’re handicapped. Armed with these tools he is afraid of nothing in terms of tackling a data problem.
In Madigan’s opinion, statisticians should not be allowed out of school unless they know these tools.
He then went to a internet startup where he and his team built a system to deliver real-time graphics on consumer activity.
Since then he’s been working in big medical data stuff. He’s testified in trials related to medical trials, which was eye-opening for him in terms of explaining what you’ve done: “If you’re gonna explain logistical regression to a jury, it’s a different kind of a challenge than me standing here tonight.” He claims that super simple graphics help.
Carrotsearch
As an aside he suggests we go to this website, called carrotsearch, because there’s a cool demo on it.
What is an observational study?
Madigan defines it for us:
An observational study is an empirical study in which the objective is to elucidate cause-and-effect relationships in which it is not feasible to use controlled experimentation.
In tonight’s context, it will involve patients as they undergo routine medical care. We contrast this with designed experiment, which is pretty rare. In fact, Madigan contends that most data science activity revolves around observational data. Exceptions are A/B tests. Most of the time, the data you have is what you get. You don’t get to replay a day on the market where Romney won the presidency, for example.
Observational studies are done in contexts in which you can’t do experiments, and they are mostly intended to elucidate cause-and-effect. Sometimes you don’t care about cause-and-effect, you just want to build predictive models. Madigan claims there are many core issues in common with the two.
Here are some examples of tests you can’t run as designed studies, for ethical reasons:
- smoking and heart disease (you can’t randomly assign someone to smoke)
- vitamin C and cancer survival
- DES and vaginal cancer
- aspirin and mortality
- cocaine and birthweight
- diet and mortality
Pitfall #1: confounders
There are all kinds of pitfalls with observational studies.
For example, look at this graph, where you’re finding a best fit line to describe whether taking higher doses of the “bad drug” is correlated to higher probability of a heart attack:

It looks like, from this vantage point, the more drug you take the fewer heart attacks you have. But there are two clusters, and if you know more about those two clusters, you find the opposite conclusion:

Note this picture was rigged it so the issue is obvious. This is an example of a “confounder.” In other words, the aspirin-taking or non-aspirin-taking of the people in the study wasn’t randomly distributed among the people, and it made a huge difference.
It’s a general problem with regression models on observational data. You have no idea what’s going on.
Madigan: “It’s the wild west out there.”
Wait, and it gets worse. It could be the case that within each group there males and females and if you partition by those you see that the more drugs they take the better again. Since a given person either is male or female, and either takes aspirin or doesn’t, this kind of thing really matters.
This illustrates the fundamental problem in observational studies, which is sometimes called Simpson’s Paradox.
[Remark from someone in the class: if you think of the original line as a predictive model, it’s actually still the best model you can obtain knowing nothing more about the aspirin-taking habits or genders of the patients involved. The issue here is really that you’re trying to assign causality.]
The medical literature and observational studies
As we may not be surprised to hear, medical journals are full of observational studies. The results of these studies have a profound effect on medical practice, on what doctors prescribe, and on what regulators do.
For example, in this paper, entitled “Oral bisphosphonates and risk of cancer of oesophagus, stomach, and colorectum: case-control analysis within a UK primary care cohort,” Madigan report that we see the very same kind of confounding problem as in the above example with aspirin. The conclusion of the paper is that the risk of cancer increased with 10 or more prescriptions of oral bisphosphonates.
It was published on the front page of new york times, the study was done by a group with no apparent conflict of interest and the drugs are taken by millions of people. But the results were wrong.
There are thousands of examples of this, it’s a major problem and people don’t even get that it’s a problem.
Randomized clinical trials
One possible way to avoid this problem is randomized studies. The good news is that randomization works really well: because you’re flipping coins, all other factors that might be confounders (current or former smoker, say) are more or less removed, because I can guarantee that smokers will be fairly evenly distributed between the two groups if there are enough people in the study.
The truly brilliant thing about randomization is that randomization matches well on the possible confounders you thought of, but will also give you balance on the 50 million things you didn’t think of.
So, although you can algorithmically find a better split for the ones you thought of, that quite possible wouldn’t do as well on the other things. That’s why we really do it randomly, because it does quite well on things you think of and things you don’t.
But there’s bad news for randomized clinical trials as well. First off, it’s only ethically feasible if there’s something called clinical equipoise, which means the medical community really doesn’t know which treatment is better. If you know have reason to think treating someone with a drug will be better for them than giving them nothing, you can’t randomly not give people the drug.
The other problem is that they are expensive and cumbersome. It takes a long time and lots of people to make a randomized clinical trial work.
In spite of the problems, randomized clinical trials are the gold standard for elucidating cause-and-effect relationships.
Rubin causal model
The Rubin causal model is a mathematical framework for understanding what information we know and don’t know in observational studies.
It’s meant to investigate the confusion when someone says something like “I got lung cancer because I smoked”. Is that true? If so, you’d have to be able to support the statement, “If I hadn’t smoked I wouldn’t have gotten lung cancer,” but nobody knows that for sure.
Define:
to be the treatment applied to unit
(0 = control, 1= treatment),
to be the response for unit
,
to be the response for unit
.
Then the unit level causal effect is 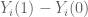
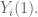
Example: 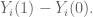
Of course, on a population level we do know how to infer that there are quite a few “1”‘s among the population, but we will never be able to assign a given individual that number.
This is sometimes called the fundamental problem of causal inference.
Confounding and Causality
Let’s say we have a population of 100 people that takes some drug, and we screen them for cancer. Say 30 out of them get cancer, which gives them a cancer rate of 0.30. We want to ask the question, did the drug cause the cancer?
To answer that, we’d have to know what would’ve happened if they hadn’t taken the drug. Let’s play God and stipulate that, had they not taken the drug, we would have seen 20 get cancer, so a rate of 0.20. We typically say the causal effect is the ration of these two numbers (i.e. the increased risk of cancer), so 1.5.
But we don’t have God’s knowledge, so instead we choose another population to compare this one to, and we see whether they get cancer or not, whilst not taking the drug. Say they have a natural cancer rate of 0.10. Then we would conclude, using them as a proxy, that the increased cancer rate is the ratio 0.30 to 0.10, so 3. This is of course wrong, but the problem is that the two populations have some underlying differences that we don’t account for.
If these were the “same people”, down to the chemical makeup of each other molecules, this “by proxy” calculation would work of course.
The field of epidemiology attempts to adjust for potential confounders. The bad news is that it doesn’t work very well. One reason is that they heavily rely on stratification, which means partitioning the cases into subcases and looking at those. But there’s a problem here too.
Stratification can introduce confounding.
The following picture illustrates how stratification could make the underlying estimates of the causal effects go from good to bad:

In the top box, the values of b and c are equal, so our causal effect estimate is correct. However, when you break it down by male and female, you get worse estimates of causal effects.
The point is, stratification doesn’t just solve problems. There are no guarantees your estimates will be better if you stratify and all bets are off.
What do people do about confounding things in practice?
In spite of the above, experts in this field essentially use stratification as a major method to working through studies. They deal with confounding variables by essentially stratifying with respect to them. So if taking aspirin is believed to be a potential confounding factor, they stratify with respect to it.
For example, with this study, which studied the risk of venous thromboembolism from the use of certain kinds of oral contraceptives, the researchers chose certain confounders to worry about and concluded the following:
After adjustment for length of use, users of oral contraceptives were at least twice the risk of clotting compared with user of other kinds of oral contraceptives.
This report was featured on ABC, and it was a big hoo-ha.
Madigan asks: wouldn’t you worry about confounding issues like aspirin or something? How do you choose which confounders to worry about? Wouldn’t you worry that the physicians who are prescribing them are different in how they prescribe? For example, might they give the newer one to people at higher risk of clotting?
Another study came out about this same question and came to a different conclusion, using different confounders. They adjusted for a history of clots, which makes sense when you think about it.
This is an illustration of how you sometimes forget to adjust for things, and the outputs can then be misleading.
What’s really going on here though is that it’s totally ad hoc, hit or miss methodology.
Another example is a study on oral bisphosphonates, where they adjusted for smoking, alcohol, and BMI. But why did they choose those variables?
There are hundreds of examples where two teams made radically different choices on parallel studies. We tested this by giving a bunch of epidemiologists the job to design 5 studies at a high level. There was zero consistency. And an addition problem is that luminaries of the field hear this and say: yeah yeah yeah but I would know the right way to do it.
Is there a better way?
Madigan and his co-authors examined 50 studies, each of which corresponds to a drug and outcome pair, e.g. antibiotics with GI bleeding.
They ran about 5,000 analyses for every pair. Namely, they ran every epistudy imaginable on, and they did this all on 9 different databases.
For example, they looked at ACE inhibitors (the drug) and swelling of the heart (outcome). They ran the same analysis on the 9 different standard databases, the smallest of which has records of 4,000,000 patients, and the largest of which has records of 80,000,000 patients.
In this one case, for one database the drug triples the risk of heart swelling, but for another database it seems to have a 6-fold increase of risk. That’s one of the best examples, though, because at least it’s always bad news – it’s consistent.
On the other hand, for 20 of the 50 pairs, you can go from statistically significant in one direction (bad or good) to the other direction depending on the database you pick. In other words, you can get whatever you want. Here’s a picture, where the heart swelling example is at the top:

Note: the choice of database is never discussed in any of these published epidemiology papers.
Next they did an even more extensive test, where they essentially tried everything. In other words, every time there was a decision to be made, they did it both ways. The kinds of decisions they tweaker were of the following types: which database you tested on, the confounders you accounted for, the window of time you care about examining (spoze they have a heart attack a week after taking the drug, is it counted? 6 months?)
What they saw was that almost all the studies can get either side depending on the choices.
Final example, back to oral bisphosphonates. A certain study concluded that it causes esophageal cancer, but two weeks later JAMA published a paper on same issue which concluded it is not associated to elevated risk of esophageal cancer. And they were even using the same database. This is not so surprising now for us.
OMOP Research Experiment
Here’s the thing. Billions upon billions of dollars are spent doing these studies. We should really know if they work. People’s lives depend on it.
Madigan told us about his “OMOP 2010.2011 Research Experiment”
They took 10 large medical databases, consisting of a mixture of claims from insurance companies and EHR (electronic health records), covering records of 200 million people in all. This is big data unless you talk to an astronomer.
They mapped the data to a common data model and then they implemented every method used in observational studies in healthcare. Altogether they covered 14 commonly used epidemiology designs adapted for longitudinal data. They automated everything in sight. Moreover, there were about 5000 different “settings” on the 14 methods.
The idea was to see how well the current methods do on predicting things we actually already know.
To locate things they know, they took 10 old drug classes: ACE inhibitors, beta blockers, warfarin, etc., and 10 outcomes of interest: renal failure, hospitalization, bleeding, etc.
For some of these the results are known. So for example, warfarin is a blood thinner and definitely causes bleeding. There were 9 such known bad effects.
There were also 44 known “negative” cases, where we are super confident there’s just no harm in taking these drugs, at least for these outcomes.
The basic experiment was this: run 5000 commonly used epidemiological analyses using all 10 databases. How well do they do at discriminating between reds and blues?
This is kind of like a spam filter test. We have training emails that are known spam, and you want to know how well the model does at detecting spam when it comes through.
Each of the models output the same thing: a relative risk (causal effect estimate) and an error.
This was an attempt to empirically evaluate how well does epidemiology work, kind of the quantitative version of John Ioannidis’s work. we did the quantitative thing to show he’s right.
Why hasn’t this been done before? There’s conflict of interest for epidemiology – why would they want to prove their methods don’t work? Also, it’s expensive, it cost $25 million dollars (of course that pales in comparison to the money being put into these studies). They bought all the data, made the methods work automatically, and did a bunch of calculations in the Amazon cloud. The code is open source.
In the second version, we zeroed in on 4 particular outcomes. Here’s the $25,000,000 ROC curve:

To understand this graph, we need to define a threshold, which we can start with at 2. This means that if the relative risk is estimated to be above 2, we call it a “bad effect”, otherwise call it a “good effect.” The choice of threshold will of course matter.
If it’s high, say 10, then you’ll never see a 10, so everything will be considered a good effect. Moreover these are old drugs and it wouldn’t be on the market. This means your sensitivity will be low, and you won’t find any real problem. That’s bad! You should find, for example, that warfarin causes bleeding.
There’s of course good news too, with low sensitivity, namely a zero false-positive rate.
What if you set the threshold really low, at -10? Then everything’s bad, and you have a 100% sensitivity but very high false positive rate.
As you vary the threshold from very low to very high, you sweep out a curve in terms of sensitivity and false-positive rate, and that’s the curve we see above. There is a threshold (say 1.8) for which your false positive rate is 30% and your sensitivity is 50%.
This graph is seriously problematic if you’re the FDA. A 30% false-positive rate is out of control. This curve isn’t good.
The overall “goodness” of such a curve is usually measured as the area under the curve: you want it to be one, and if your curve lies on diagonal the area is 0.5. This is tantamount to guessing randomly. So if your area under the curve is less than 0.5, it means your model is perverse.
The area above is 0.64. Moreover, of the 5000 analysis we ran, this is the single best analysis.
But note: this is the best if I can only use the same method for everything. In that case this is as good as it gets, and it’s not that much better than guessing.
But no epidemiology would do that!
So what they did next was to specialize the analysis to the database and the outcome. And they got better results: for the medicare database, and for acute kidney injury, their optimal model gives them an AUC of 0.92. They can achieve 80% sensitivity with a 10% false positive rate.

They did this using a cross-validation method. Different databases have different methods attached to them. One winning method is called “OS”, which compares within a given patient’s history (so compares times when patient was on drugs versus when they weren’t). This is not widely used now.
The epidemiologists in general don’t believe the results of this study.
If you go to http://elmo/omop.org, you can see the AUM for a given database and a given method.
Note the data we used was up to mid-2010. To update this you’d have to get latest version of database, and rerun the analysis. Things might have changed.
Moreover, an outcome for which nobody has any idea on what drugs cause what outcomes you’re in trouble. This only applies to when we have things to train on where we know the outcome pretty well.
Parting remarks
Keep in mind confidence intervals only account for sampling variability. They don’t capture bias at all. If there’s bias, the confidence interval or p-value can be meaningless.
What about models that epidemiologists don’t use? We have developed new methods as well (SCCS). we continue to do that, but it’s a hard problem.
Challenge for the students: we ran 5000 different analyses. Is there a good way of combining them to do better? weighted average? voting methods across different strategies?
Note the stuff is publicly available and might make a great Ph.D. thesis.
The zit model
When my mom turned 42, I was 12 and a total wise-ass. For her present I bought her a coffee mug that had on it the phrase “Things could be worse. You could be old and still have zits”, to tease her about her bad skin. Considering how obnoxious that was, she took it really well and drank out of the mug for years.
Well, I’m sure you can all see where this is going. I’m now 40 and I have zits. I was contemplating this in the bath yesterday, wondering if I’d ever get rid of my zits and wondering if taking long hot baths helps or not. They come and go, so it seems vaguely controllable.
Then I had a thought: well, I could collect data and see what helps. After all, I don’t always have zits. I could keep a diary of all the things that I think might affect the situation: what I eat (I read somewhere that eating cheese makes you have zits), how often I take baths vs. showers, whether I use zit cream, my hormones, etc. and certainly whether or not I have zits on a given day or not.
The first step would be to do some research on the theories people have about what causes zits, and then set up a spreadsheet where I could efficiently add my daily data. Maybe a google form! I’m wild about google forms.
After collecting this data for some time I could build a model which tries to predict zittage, to see which of those many inputs actually have signal for my personal zit model.
Of course I expect a lag between the thing I do or eat or use and the actual resulting zit, and I don’t know what that lag is (do you get zits the day after you eat cheese? or three days after eating cheese?), so I’ll expect some difficulty with this or even over fitting.
Even so, this just might work!

Then I immediately felt tired because, if you think about spending your day collecting information like that about your potential zits, then you must be totally nuts.
I mean, I can imagine doing it just for fun, or to prove a point, or on a dare (there are few things I won’t do on a dare), but when it comes down to it I really don’t care that much about my zits.
Then I started thinking about technology and how it could help me with my zit model. I mean, you know about those bracelets you can wear that count your steps and then automatically record them on your phone, right? Well, how long until those bracelets can be trained to collect any kind of information you can imagine?
- Baths? No problem. I’m sure they can detect moisture and heat.
- Cheese eating? Maybe you’d have to say out loud what you’re eating, but again not a huge problem.
- Hormones? I have no idea but let’s stipulate plausible: they already have an ankle bracelet that monitors blood alcohol levels.
- Whether you have zits? Hmmm. Let’s say you could add any variable you want with voice command.
In other words, in 5 years this project will be a snap when I have my handy dandy techno bracelet which collects all the information I want. And maybe whatever other information as well, because information storage is cheap. I’ll have a bounty of data for my zit model.
This is exciting stuff. I’m looking forward to building the definitive model, from which I can conclude that eating my favorite kind of cheese does indeed give me zits. And I’ll say to myself, worth it!
Columbia Data Science course, week 9: Morningside Analytics, network analysis, data journalism
Our first speaker this week in Rachel Schutt‘s Columbia Data Science course was John Kelly from Morningside Analytics, who came to talk to us about network analysis.
John Kelly
Kelly has four diplomas from Columbia, starting with a BA in 1990 from Columbia College, followed by a Masters, MPhil and Ph.D. in Columbia’s school of Journalism. He explained that studying communications as a discipline can mean lots of things, but he was interested in network sociology and statistics in political science.
Kelly spent a couple of terms at Stanford learning survey design and game theory and other quanty stuff. He describes the Columbia program in communications as a pretty DIY set-up, where one could choose to focus on the role of communication in society, the impact of press, impact of information flow, or other things. Since he was interested in quantitative methods, he hunted them down, doing his master’s thesis work with Marc Smith from Microsoft. He worked on political discussions and how they evolve as networks (versus other kinds of discussions).
After college and before grad school, Kelly was an artist, using computers to do sound design. He spent 3 years as the Director of Digital Media here at Columbia School of the Arts.
Kelly taught himself perl and python when he spent a year in Viet Nam with his wife.
Kelly’s profile
Kelly spent quite a bit of time describing how he sees math, statistics, and computer science (including machine learning) as tools he needs to use and be good at in order to do what he really wants to do.
But for him the good stuff is all about domain expertise. He want to understand how people come together, and when they do, what is their impact on politics and public policy. His company Morningside Analytics has clients like think tanks and political organizations and want to know how social media affects and creates politics. In short, Kelly wants to understand society, and the math and stats allows him to do that.
Communication and presentations are how he makes money, so that’s important, and visualizations are integral to both domain expertise and communications, so he’s essentially a viz expert. As he points out, Morningside Analytics doesn’t get paid to just discover interesting stuff, but rather to help people use it.
Whereas a company such SocialFlow is venture funded, which means you can run a staff even if you don’t make money, Morningside is bootstrapped. It’s a different life, where we eat what we sow.
Case-attribute data vs. social network data
Kelly has a strong opinion about standard modeling through case-attribute data, which is what you normally see people feed to models with various “cases” (think people) who have various “attributes” (think age, or operating system, or search histories).
Maybe because it’s easy to store in databases or because it’s easy to collect this kind of data, there’s been a huge bias towards modeling with case-attribute data.
Kelly thinks it’s missing the point of the questions we are trying to answer nowadays. It started, he said, in the 1930’s with early market research, and it was soon being applied applied to marketing as well as politicals.
He named Paul Lazarsfeld and Elihu Katz as trailblazing sociologists who came here from Europe and developed the field of social network analysis. This is a theory based not only on individual people but also the relationships between them.
We could do something like this for the attributes of a data scientist, and we might have an arrow point from math to stats if we think math “underlies” statistics in some way. Note the arrows don’t always mean the same thing, though, and when you specify a network model to test a theory it’s important you make the arrows well-defined.
To get an idea of why network analysis is superior to case-attribute data analysis, think about this. The federal government spends money to poll people in Afghanistan. The idea is to see what citizens want and think to determine what’s going to happen in the future. But, Kelly argues, what’ll happen there isn’t a function of what individuals think, it’s a question of who has the power and what they think.
Similarly, imagine going back in time and conducting a scientific poll of the citizenry of Europe in 1750 to determine the future politics. If you knew what you were doing you’d be looking at who’s marrying who among the royalty.
In some sense the current focus on case-attribute data is a problem of what’s “under the streetlamp” – people are used to doing it that way.
Kelly wants us to consider what he calls the micro/macro (i.e. individual versus systemic) divide: when it comes to buying stuff, or voting for a politician in a democracy, you have a formal mechanism for bridging the micro/macro divide, namely markets for buying stuff and elections for politicians. But most of the world doesn’t have those formal mechanisms, or indeed they have a fictive shadow of those things. For the most part we need to know enough about the actual social network to know who has the power and influence to bring about change.
Kelly claims that the world is a network much more than it’s a bunch of cases with attributes. For example, if you only understand how individuals behave, how do you tie things together?
History of social network analysis
Social network analysis basically comes from two places: graph theory, where Euler solved the Seven Bridges of Konigsberg problem, and sociometry, started by Jacob Moreno in the 1970’s, just as early computers got good at making large-scale computations on large data sets.
Social network analysis was germinated by Harrison White, emeritus at Columbia (emeritus), contemporaneously with Columbia sociologist Robert Merton. Their essential idea was that people’s actions have to be related to their attributes, but to really understand them you also need to look at the networks that enable them to do something.
Core entities for network models
Kelly gave us a bit of terminology from the world of social networks:
- actors (or nodes in graph theory speak): these can be people, or websites, or what have you
- relational ties (edges in graph theory speak): for example, an instance of liking someone or being friends
- dyads: pairs of actors
- triads: triplets of actors; there are for example, measures of triadic closure in networks
- subgroups: a subset of the whole set of actors, along with their relational ties
- group: the entirety of a “network”, easy in the case of Twitter but very hard in the case of e.g. “liberals”
- relation: for example, liking another person
- social network: all of the above
Types of Networks
There are different types of social networks.
For example, in one-node networks, the simplest case, you have a bunch of actors connected by ties. This is a construct you’d use to display a Facebook graph for example.
In two-node networks, also called bipartite graphs, the connections only exist between two formally separate classes of objects. So you might have people on the one hand and companies on the other, and you might connect a person to a company if she is on the board of that company. Or you could have people and the things they’re possibly interested in, and connect them if they really are.
Finally, there are ego networks, which is typically the part of the network surrounding a single person. So for example it could be just the subnetwork of my friends on Facebook, who may also know each other in certain cases. Kelly reports that people with higher socioeconomic status have more complicated ego networks. You can see someone’s level of social status by looking at their ego network.
What people do with these networks
The central question people ask when given a social network is, who’s important here?
This leads to various centrality measures. The key ones are:
- degree – This counts how many people are connected to you.
- closeness – If you are close to everyone, you have a high closeness score.
- betweenness – People who connect people who are otherwise separate. If information goes through you, you have a high betweenness score.
- eigenvector – A person who is popular with the popular kids has high eigenvector centrality. Google’s page rank is an example.
A caveat on the above centrality measures: the measurement people form an industry that try to sell themselves as the authority. But experience tells us that each has their weaknesses and strengths. The main thing is to know you’re looking at the right network.
For example, if you’re looking for a highly influential blogger in the muslim brotherhood, and you write down the top 100 bloggers in some large graph of bloggers, and start on the top of the list, and go down the list looking for a muslim brotherhood blogger, it won’t work: you’ll find someone who is both influential in the large network and who blogs for the muslim brotherhood, but they won’t be influential with the muslim brotherhood, but rather with transnational elites in the larger network. In other words, you have to keep in mind the local neighborhood of the graph.
Another problem with measures: experience dictates that, although something might work with blogs, when you work with Twitter you’ll need to get out new tools. Different data and different ways people game centrality measures make things totally different. For example, with Twitter, people create 5000 Twitter bots that all follow each other and some strategic other people to make them look influential by some measure (probably eigenvector centrality). But of course this isn’t accurate, it’s just someone gaming the measures.
Some network packages exist already and can compute the various centrality measures mentioned above:
- NodeXL, a plugin for Excel,
- NetworkX for python,
- igraph also for python,
- statnet for R, and
- Jure Leskovec at Stanford is creating new network package for C which should be awesome.
Thought experiment
You’re part of an elite, well-funded think tank in DC. You can hire people and you have $10million to spend. Your job is to empirically predict the future political evolution of Egypt. What kinds of political parties will there be? What is the country of Egypt gonna look like in 5, 10, or 20 years? You have access to exactly two of the following datasets for all Egyptians:
- The Facebook network,
- The Twitter network,
- A complete record of who went to school with who,
- The SMS/phone records,
- The network data on members of all political organizations and private companies, and
- Where everyone lives and who they talk to.
Note things change over time- people might migrate off of Facebook, or political discussions might need to go underground if blogging is too public. Facebook alone gives a lot of information but sometimes people will try to be stealth. Phone records might be better representation for that reason.
If you think the above is ambitious, recall Siemens from Germany sold Iran software to monitor their national mobile networks. In fact, Kelly says, governments are putting more energy into loading field with allies, and less with shutting down the field. Pakistan hires Americans to do their pro-Pakistan blogging and Russians help Syrians.
In order to answer this question, Kelly suggests we change the order of our thinking. A lot of the reasoning he heard from the class was based on the question, what can we learn from this or that data source? Instead, think about it the other way around: what would it mean to predict politics in a society? what kind of data do you need to know to do that? Figure out the questions first, and then look for the data to help me answer them.
Morningside Analytics
Kelly showed us a network map of 14 of the world’s largest blogospheres. To understand the pictures, you imagine there’s a force, like a wind, which sends the nodes (blogs) out to the edge, but then there’s a counteracting force, namely the links between blogs, which attach them together.
Here’s an example of the arabic blogosphere:

The different colors represent countries and clusters of blogs. The size of each dot is centrality through degree, so the number of links to other blogs in the network. The physical structure of the blogosphere gives us insight.
If we analyze text using NLP, thinking of the blog posts as a pile of text or a river of text, then we see the micro or macro picture only – we lose the most important story. What’s missing there is social network analysis (SNA) which helps us map and analyze the patterns of interaction.
The 12 different international blogospheres, for example, look different. We infer that different societies have different interests which give rise to different patterns.
But why are they different? After all, they’re representations of some higher dimensional thing projected onto two dimensions. Couldn’t it be just that they’re drawn differently? Yes, but we do lots of text analysis that convinces us these pictures really are showing us something. We put an effort into interpreting the content qualitatively.
So for example, in the French blogosphere, we see a cluster that discusses gourmet cooking. In Germany we see various blobs discussing politics and lots of weird hobbies. In English we see two big blobs [mathbabe interjects: gay porn and straight porn?] They turn out to be conservative vs. liberal blogs.
In Russian, their blogging networks tend to force people to stay within the networks, which is why we see very well defined partitioned blobs.
The proximity clustering is done using the Fruchterman-Reingold algorithm, where being in the same neighborhood means your neighbors are connected to other neighbors, so really a collective phenomenon of influence.. Then we interpret the segments. Here’s an example of English language blogs:

Think about social media companies: they are each built around the fact that they either have the data or that they have a toolkit – a patented sentiment engine or something, a machine that goes ping.
But keep in mind that social media is heavily a product of organizations that pay to move the needle (i.e. game the machine that goes ping). To decipher that game you need to see how it works, you need to visualize.
So if you are wondering about elections, look at people’s blogs within “the moms” or “the sports fans”. This is more informative than looking at partisan blogs where you already know the answer.
Kelly walked us through an analysis, once he has binned the blogosphere into its segments, of various types of links to partisan videos like MLK’s “I have a dream” speech and a gotcha video from the Romney campaign. In the case of the MLK speech, you see that it gets posted in spurts around the election cycle events all over the blogosphere, but in the case of the Romney campaign video, you see a concerted effort by conservative bloggers to post the video in unison.
That is to say, if you were just looking at a histogram of links, a pure count, it might look as if it had gone viral, but if you look at it through the lens of the understood segmentation of the blogosphere, it’s clearly a planned operation to game the “virality” measures.
Kelly also works with the Berkman Center for Internet and Society at Harvard. He analyzed the Iranian blogosphere in 2008 and again in 2011 and he found much the same in terms of clustering – young anti-government democrats, poetry, conservative pro-regime clusters dominated in both years.
However, only 15% of the blogs are the same 2008 to 2011.
So, whereas people are often concerned about individuals (case-attribute model), the individual fish are less important than the schools of fish. By doing social network analysis, we are looking for the schools, because that way we learn about the salient interests of the society and how those interests are they stable over time.
The moral of this story is that we need to focus on meso-level patterns, not micro- or macro-level patterns.
John Bruner
Our second speaker of the night was John Bruner, an editor at O’Reilly who previously worked as the data editor at Forbes. He is broad in his skills: he does research and writing on anything that involved data. Among other things at Forbes, he worked on an internal database on millionaires on which he ran simple versions of social media dynamics.
Writing technical journalism
Bruner explained the term “data journalism” to the class. He started this by way of explaining his own data scientist profile.
First of all, it involved lots of data viz. A visualization is a fast way of describing the bottomline of a data set. And at a big place like the NYTimes, data viz is its own discipline and you’ll see people with expertise in parts of dataviz – one person will focus on graphics while someone else will be in charge of interactive dataviz.
CS skills are pretty important in data journalism too. There are tight deadlines, and the data journalist has to be good with their tools and with messy data (because even federal data is messy). One has to be able to handle arcane formats or whatever, and often this means parcing stuff in python or what have you. Bruner uses javascript and python and SQL and Mongo among other tools.
Bruno was a math major in college at University of Chicago, then he went into writing at Forbes, where he slowly merged back into quantitative stuff while there. He found himself using mathematics in his work in preparing good representations of the research he was uncovering about, for example, contributions of billionaires to politicians using circles and lines.
Statistics, Bruno says, informs the way you think about the world. It inspires you to write things: e.g., the “average” person is a woman with 250 followers but the median open twitter account has 0 followers. So the median and mean are impossibly different because the data is skewed. That’s an inspiration right there for a story.
Bruno admits to being a novice in machine learning.However, he claims domain expertise as quite important. With exception to people who can specialize in one subject, say at a governmental office or a huge daily, for smaller newspaper you need to be broad, and you need to acquire a baseline layer of expertise quickly.
Of course communications and presentations are absolutely huge for data journalists. Their fundamental skill is translation: taking complicated stories and deriving meaning that readers will understand. They also need to anticipate questions, turn them into quantitative experiments, and answer them persuasively.
A bit of history of data journalism
Data journalism has been around for a while, but until recently (computer-assisted reporting) was a domain of Excel power users. Still, if you know how to write an excel program, you’re an elite.
Things started to change recently: more data became available to us in the form of API’s, new tools and less expensive computing power, so we can analyze pretty large data sets on your laptop. Of course excellent viz tools make things more compelling, flash is used for interactive viz environments, and javascript is getting way better.
Programming skills are now widely enough held so that you can find people who are both good writers and good programmers. Many people are english majors and know enough about computers to make it work, for example, or CS majors who can write.
In big publications like the NYTimes, the practice of data journalism is divided into fields: graphics vs. interactives, research, database engineers, crawlers, software developers, domain expert writers. Some people are in charge of raising the right questions but hand off to others to do the analysis. Charles Duhigg at the NYTimes, for example, studied water quality in new york, and got a FOIA request to the State of New York, and knew enough to know what would be in that FOIA request and what questions to ask but someone else did the actual analysis.
At a smaller place, things are totally different. Whereas the NYTimes has 1000 people on its newsroom floor, the Economist has maybe 130, and Forbes has 70 or 80 people in their newsrooms. If you work for anything beside a national daily, you end up doing everything by yourself: you come up with question, you go get the data, you do the analysis, then you write it up.
Of course you also help and collaborate with your colleagues when you can.
Advice Bruno has for the students in initiating a data journalism project: don’t have a strong thesis before you’ve interviewed the experts. Go in with a loose idea of what you’re searching for and be willing to change your mind and pivot if the experts lead you in a new and interesting direction.
An AMS panel to examine public math models?
On Saturday I gave a talk at the AGNES conference to a room full of algebraic geometers. After introducing myself and putting some context around my talk, I focused on a few models:
- VaR,
- VAM,
- Credit scoring,
- E-scores (online version of credit scores), and
- The h-score model (I threw this in for the math people and because it’s an egregious example of a gameable model).
I wanted to formalize the important and salient properties of a model, and I came up with this list:
- Name – note the name often gives off a whiff of political manipulation by itself
- Underlying model – regression? decision tree?
- Underlying assumptions – normal distribution of market returns?
- Input/output – dirty data?
- Purported/political goal – how is it actually used vs. how its advocates claim they’ll use it?
- Evaluation method – every model should come with one. Not every model does. A red flag.
- Gaming potential – how does being modeled cause people to act differently?
- Reach – how universal and impactful is the model and its gaming?
In the case of VAM, it doesn’t have an evaluation method. There’s been no way for teachers to know if the model that they get scored on every year is doing a good job, even as it’s become more and more important in tenure decisions (the Chicago strike was largely related to this issue, as I posted here).
Here was my plea to the mathematical audience: this is being done in the name of mathematics. The authority that math is given by our culture, which is enormous and possibly not deserved, is being manipulated by people with vested interests.
So when the objects of modeling, the people and the teachers who get these scores, ask how those scores were derived, they’re often told “it’s math and you wouldn’t understand it.”
That’s outrageous, and mathematicians shouldn’t stand for it. We have to get more involved, as a community, with how mathematics is wielded on the population.
On the other hand, I wouldn’t want mathematicians as a group to get co-opted by these special interest groups either and become shills for the industry. We don’t want to become economists, paid by this campaign or that to write papers in favor of their political goals.
To this end, someone in the audience suggested the AMS might want to publish a book of ethics for mathematicians akin to the ethical guidelines that are published for the society of pyschologists and lawyers. His idea is that it would be case-study based, which seems pretty standard. I want to give this some more thought.
We want to make ourselves available to understand high impact, public facing models to ensure they are sound mathematically, have reasonable and transparent evaluation methods, and are very high quality in terms of proven accuracy and understandability if they are used on people in high stakes situations like tenure.
One suggestion someone in the audience came up with is to have a mathematician “mechanical turk” service where people could send questions to a group of faceless mathematicians. Although I think it’s an intriguing idea, I’m not sure it would work here. The point is to investigate so-called math models that people would rather no mathematician laid their eyes on, whereas mechanical turks only answer questions someone else comes up with.
In other words, there’s a reason nobody has asked the opinion of the mathematical community on VAM. They are using the authority of mathematics without permission.
Instead, I think the math community should form something like a panel, maybe housed inside the American Mathematical Society (AMS), that trolls for models with the following characteristics:
- high impact – people care about these scores for whatever reason
- large reach – city-wide or national
- claiming to be mathematical – so the opinion of the mathematical community matters, or should,
After finding such a model, the panel should publish a thoughtful, third-party analysis of its underlying mathematical soundness. Even just one per year would have a meaningful effect if the models were chosen well.
As I said to someone in the audience (which was amazingly receptive and open to my message), it really wouldn’t take very long for a mathematician to understand these models well enough to have an opinion on them, especially if you compare it to how long it would take a policy maker to understand the math. Maybe a week, with the guidance of someone who is an expert in modeling.
So in other words, being a member of such a “public math models” panel could be seen as a community service job akin to being an editor for a journal: real work but not something that takes over your life.
Now’s the time to do this, considering the explosion of models on everything in sight, and I believe mathematicians are the right people to take it on, considering they know how to admit they’re wrong.
Tell me what you think.
Columbia Data Science course, week 8: Data visualization, broadening the definition of data science, Square, fraud detection
This week in Rachel Schutt’s Columbia Data Science course we had two excellent guest speakers.
The first speaker of the night was Mark Hansen, who recently came from UCLA via the New York Times to Columbia with a joint appointment in journalism and statistics. He is a renowned data visualization expert and also an energetic and generous speaker. We were lucky to have him on a night where he’d been drinking an XXL latte from Starbucks to highlight his natural effervescence.
Mark started by telling us a bit about Gabriel Tarde (1843-1904).

Tarde was a sociologist who believed that the social sciences had the capacity to produce vastly more data than the physical sciences. His reasoning was as follows.
The physical sciences observe from a distance: they typically model or incorporate models which talk about an aggregate in some way – for example, biology talks about the aggregate of our cells. What Tarde pointed out was that this is a deficiency, basically a lack of information. We should instead be tracking every atom.
This is where Tarde points out that in the social realm we can do this, where cells are replaced by people. We can collect a huge amount of information about those individuals.
But wait, are we not missing the forest for the trees when we do this? Bruno Latour weighs in on his take of Tarde as follows:
“But the ‘whole’ is now nothing more than a provisional visualization which can be modified and reversed at will, by moving back to the individual components, and then looking for yet other tools to regroup the same elements into alternative assemblages.”
In 1903, Tarde even foresees the emergence of Facebook, although he refers to a “daily press”:
“At some point, every social event is going to be reported or observed.”
Mark then laid down the theme of his lecture using a 2009 quote of Bruno Latour:
“Change the instruments and you will change the entire social theory that goes with them.”
Kind of like that famous physics cat, I guess, Mark (and Tarde) want us to newly consider
- the way the structure of society changes as we observe it, and
- ways of thinking about the relationship of the individual to the aggregate.
Mark’s Thought Experiment:
As data become more personal, as we collect more data about “individuals”, what new methods or tools do we need to express the fundamental relationship between ourselves and our communities, our communities and our country, our country and the world? Could we ever be satisfied with poll results or presidential approval ratings when we can see the complete trajectory of public opinions, individuated and interacting?
What is data science?
Mark threw up this quote from our own John Tukey:
“The best thing about being a statistician is that you get to play in everyone’s backyard”
But let’s think about that again – is it so great? Is it even reasonable? In some sense, to think of us as playing in other people’s yards, with their toys, is to draw a line between “traditional data fields” and “everything else”.
It’s maybe even implying that all our magic comes from the traditional data fields (math, stats, CS), and we’re some kind of super humans because we’re uber-nerds. That’s a convenient way to look at it from the perspective of our egos, of course, but it’s perhaps too narrow and arrogant.
And it begs the question, what is “traditional” and what is “everything else” anyway?
Mark claims that everything else should include:
- social science,
- physical science,
- geography,
- architecture,
- education,
- information science,
- architecture,
- digital humanities,
- journalism,
- design,
- media art
There’s more to our practice than being technologists, and we need to realize that technology itself emerges out of the natural needs of a discipline. For example, GIS emerges from geographers and text data mining emerges from digital humanities.
In other words, it’s not math people ruling the world, it’s domain practices being informed by techniques growing organically from those fields. When data hits their practice, each practice is learning differently; their concerns are unique to that practice.
Responsible data science integrates those lessons, and it’s not a purely mathematical integration. It could be a way of describing events, for example. Specifically, it’s not necessarily a quantifiable thing.
Bottom-line: it’s possible that the language of data science has something to do with social science just as it has something to do with math.
Processing
Mark then told us a bit about his profile (“expansionist”) and about the language processing, in answer to a question about what is different when a designer takes up data or starts to code.
He explained it by way of another thought experiment: what is the use case for a language for artists? Students came up with a bunch of ideas:
- being able to specify shapes,
- faithful rendering of what visual thing you had in mind,
- being able to sketch,
- 3-d,
- animation,
- interactivity,
- Mark added publishing – artists must be able to share and publish their end results.
It’s java based, with a simple “publish” button, etc. The language is adapted to the practice of artists. He mentioned that teaching designers to code meant, for him, stepping back and talking about iteration, if statements, etc., of in other words stuff that seemed obvious to him but is not obvious to someone who is an artist. He needed to unpack his assumptions, which is what’s fun about teaching to the uninitiated.
He next moved on to close versus distant reading of texts. He mentioned Franco Moretti from Stanford. This is for Franco:

Franco thinks about “distant reading”, which means trying to get a sense of what someone’s talking about without reading line by line. This leads to PCA-esque thinking, a kind of dimension reduction of novels.
In other words, another cool example of how data science should integrate the way the experts in various fields figure it out. We don’t just go into their backyards and play, maybe instead we go in and watch themplay and formalize and inform their process with our bells and whistles. In this way they can teach us new games, games that actually expand our fundamental conceptions of data and the approaches we need to analyze them.
Mark’s favorite viz projects
1) Nuage Vert, Helen Evans & Heiko Hansen: a projection onto a power plant’s steam cloud. The size of the green projection corresponds to the amount of energy the city is using. Helsinki and Paris.

2) One Tree, Natalie Jeremijenko: The artist cloned trees and planted the genetically identical seeds in several areas. Displays among other things the environmental conditions in each area where they are planted.

3) Dusty Relief, New Territories: here the building collects pollution around it, displayed as dust.

4) Project Reveal, New York Times R&D lab: this is a kind of magic mirror which wirelessly connects using facial recognition technology and gives you information about yourself. As you stand at the mirror in the morning you get that “come-to-jesus moment” according to Mark.

5) Million Dollar Blocks, Spatial Information Design Lab (SIDL): So there are crime stats for google maps, which are typically painful to look at. The SIDL is headed by Laura Kurgan, and in this piece she flipped the statistics. She went into the prison population data, and for every incarcerated person, she looked at their home address, measuring per home how much money the state was spending to keep the people who lived there in prison. She discovered that some blocks were spending $1,000,000 to keep people in prison.

Moral of the above: just because you can put something on the map, doesn’t mean you should. Doesn’t mean there’s a new story. Sometimes you need to dig deeper and flip it over to get a new story.
New York Times lobby: Moveable Type
Mark walked us through a project he did with Ben Rubin for the NYTimes on commission (and he later went to the NYTimes on sabbatical). It’s in the lobby of their midtown headquarters at 8th and 42nd.

It consists of 560 text displays, two walls with 280 on each, and the idea is they cycle through various “scenes” which each have a theme and an underlying data science model.
For example, in one there are waves upon waves of digital ticker-tape like scenes which leave behind clusters of text, and where each cluster represents a different story from the paper. The text for a given story highlights phrases which make a given story different from others in some information-theory sense.
In another scene the numbers coming out of stories are highlighted, so you might see on a given box “18 gorillas”. In a third scene, crossword puzzles play themselves with sounds of pencil and paper.
The display boxes themselves are retro, with embedded linux processors running python, and a sound card on each box, which makes clicky sounds or wavy sounds or typing sounds depending on what scene is playing.

The data taken in is text from NY Times articles, blogs, and search engine activity. Every sentence is parsed using Stanford NLP techniques, which diagrams sentences.
Altogether there are about 15 “scenes” so far, and it’s code so one can keep adding to it. Here’s an interview with them about the exhibit:
Project Cascade: Lives on a Screen
Mark next told us about Cascade, which was joint work with Jer Thorp data artist-in-residence at the New York Times. Cascade came about from thinking about how people share New York Times links on Twitter. It was in partnerships with bitly.
The idea was to collect enough data so that we could see someone browse, encode the link in bitly, tweet that encoded link, see other people click on that tweet and see bitly decode the link, and then see those new people browse the New York Times. It’s a visualization of that entire process, much as Tarde suggested we should do.
There were of course data decisions to be made: a loose matching of tweets and clicks through time, for example. If 17 different tweets have the same url they don’t know which one you clicked on, so they guess (the guess actually seemed to involve probabilistic matching on time stamps so it’s an educated guess). They used the Twitter map of who follows who. If someone you follow tweets about something before you do then it counts as a retweet. It covers any nytimes.com link.

Here’s a NYTimes R&D video about Project Cascade:
Note: this was done 2 years ago, and Twitter has gotten a lot bigger since then.
Cronkite Plaza
Next Mark told us about something he was working on which just opened 1.5 months ago with Jer and Ben. It’s also news related, but this is projecting on the outside of a building rather than in the lobby; specifically, the communications building at UT Austin, in Cronkite Plaza.

The majority of the projected text is sourced from Cronkite’s broadcasts, but also have local closed-captioned news sources. One scene of this project has extracted the questions asked during local news – things like “how did she react?” or “What type of dog would you get?”. The project uses 6 projectors.
Goals of these exhibits
They are meant to be graceful and artistic, but should also teach something. At the same time we don’t want to be overly didactic. The aim is to live in between art and information. It’s a funny place: increasingly we see a flattening effect when tools are digitized and made available, so that statisticians can code like a designer (we can make things that look like design) and similarly designers can make something that looks like data.
What data can we get? Be a good investigator: a small polite voice which asks for data usually gets it.
eBay transactions and books
Again working jointly with Jer Thorp, Mark investigated a day’s worth of eBay’s transactions that went through Paypal and, for whatever reason, two years of book sales. How do you visualize this? Take a look at the yummy underlying data:

Here’s how they did it (it’s ingenious). They started with the text of Death of a Salesman by Arthur Miller. They used a mechanical turk mechanism to locate objects in the text that you can buy on eBay.
When an object is found it moves it to a special bin, so “chair” or “flute” or “table.” When it has a few collected buy-able objects, it then takes the objects and sees where they are all for sale on the day’s worth of transactions, and looks at details on outliers and such. After examining the sales, the code will find a zipcode in some quiet place like Montana.
Then it flips over to the book sales data, looks at all the books bought or sold in that zip code, picks a book (which is also on Project Gutenberg), and begins to read that book and collect “buyable” objects from that. And it keeps going. Here’s a video:
Public Theater Shakespeare Machine
The last thing Mark showed us is is joint work with Rubin and Thorp, installed in the lobby of the Public Theater. The piece itself is an oval structure with 37 bladed LED displays, set above the bar.
There’s one blade for each of Shakespeare’s plays. Longer plays are in the long end of the oval, Hamlet you see when you come in.

The data input is the text of each play. Each scene does something different – for example, it might collect noun phrases that have something to do with body from each play, so the “Hamlet” blade will only show a body phrase from Hamlet. In another scene, various kinds of combinations or linguistic constructs are mined:
- “high and might” “good and gracious” etc.
- “devilish-holy” “heart-sore” “ill-favored” “sea-tossed” “light-winged” “crest-fallen” “hard-favoured” etc.
Note here that the digital humanities, through the MONK Project, offered intense xml descriptions of the plays. Every single word is given hooha and there’s something on the order of 150 different parts of speech.
As Mark said, it’s Shakespeare so it stays awesome no matter what you do, but here we see we’re successively considering words as symbols, or as thematic, or as parts of speech. It’s all data.
Ian Wong from Square
Next Ian Wong, an “Inference Scientist” at Square who dropped out of an Electrical Engineering Ph.D. program at Stanford talked to us about Data Science in Risk.
He conveniently started with his takeaways:
- Machine learning is not equivalent to R scripts. ML is founded in math, expressed in code, and assembled into software. You need to be an engineer and learn to write readable, reusable code: your code will be reread more times by other people than by you, so learn to write it so that others can read it.
- Data visualization is not equivalent to producing a nice plot. Rather, think about visualizations as pervasive and part of the environment of a good company.
- Together, they augment human intelligence. We have limited cognitive abilities as human beings, but if we can learn from data, we create an exoskeleton, an augmented understanding of our world through data.
Square
Square was founded in 2009. There were 40 employees in 2010, and there are 400 now. The mission of the company is to make commerce easy. Right now transactions are needlessly complicated. It takes too much to understand and to do, even to know where to start for a vendor. For that matter, it’s too complicated for buyers as well. The question we set out to ask is, how do we make transactions simple and easy?
We send out a white piece of plastic, which we refer to as the iconic square. It’s something you can plug into your phone or iPad. It’s simple and familiar, and it makes it easy to use and to sell.
It’s even possible to buy things hands-free using the square. A buyer can open a tab on their phone so that they can pay by saying their name.. Then the merchant taps your name on their screen. This makes sense if you are a frequent visitor to a certain store like a coffee shop.
Our goal is to make it easy for sellers to sign up for Square and accept payments. Of course, it’s also possible that somebody may sign up and try to abuse the service. We are therefore very careful at Square to avoid losing money on sellers with fraudulent intentions or bad business models.
The Risk Challenge
At Square we need to balance the following goals:
- to provide a frictionless and delightful experience for buyers and sellers,
- to fuel rapid growth, and in particular to avoid inhibiting growth through asking for too much information of new sellers, which adds needless barriers to joining, and
- to maintain low financial loss.
Today we’ll just focus on the third goal through detection of suspicious activity. We do this by investing in machine learning and viz. We’ll first discuss the machine learning aspects.
Part 1: Detecting suspicious activity using machine learning
First of all, what’s suspicious? Examples from the class included:
- lots of micro transactions occurring,
- signs of money laundering,
- high frequency or inconsistent frequency of transactions.
Example: Say Rachel has a food truck, but then for whatever reason starts to have $1000 transactions (mathbabe can’t help but insert that Rachel might be a food douche which would explain everything).
On the one hand, if we let money go through, Square is liable in the case it was unauthorized. Technically the fraudster, so in this case Rachel would be liable, but our experience is that usually fraudsters are insolvent, so it ends up on Square.
On the other hand, the customer service is bad if we stop payment on what turn out to be real payments. After all, what if she’s innocent and we deny the charges? She will probably hate us, may even sully our reputation, and in any case our trust is lost with her after that.
This example crystallizes the important challenges we face: false positives erode customer trust, false negatives make us lose money.
And since Square processes millions of dollars worth of sales per day, we need to do this systematically and automatically. We need to assess the risk level of every event and entity in our system.
So what do we do?
First of all, we take a look at our data. We’ve got three types:
- payment data, where the fields are transaction_id, seller_id, buyer_id, amount, success (0 or 1), timestamp,
- seller data, where the fields are seller_id, sign_up_date, business_name, business_type, business_location,
- settlement data, where the fields are settlement_id, state, timestamp.
Important fact: we settle to our customers the next day so we don’t have to make our decision within microseconds. We have a few hours. We’d like to do it quickly of course, but in certain cases we have time for a phone call to check on things.
So here’s the process: given a bunch (as in hundreds or thousands) of payment events, we throw each through the risk engine, and then send some iffy looking ones on to a “manual review”. An ops team will then review the cases on an individual basis. Specifically, anything that looks rejectable gets sent to ops, which make phone calls to double check unless it’s super outrageously obviously fraud.
Also, to be clear, there are actually two kinds of fraud to worry about, seller-side fraud and buyer-side fraud. For the purpose of this discussion, we’ll focus on the former.
So now it’s a question of how we set up the risk engine. Note that we can think of the risk engine as putting things in bins, and those bins each have labels. So we can call this a labeling problem.
But that kind of makes it sound like unsupervised learning, like a clustering problem, and although it shares some properties with that, it’s certainly not that simple – we don’t reject a payment and then merely stand pat with that label, because as we discussed we send it on to an ops team to assess it independently. So in actuality we have a pretty complicated set of labels, including for example:
- initially rejected but ok,
- initially rejected and bad,
- initially accepted but on further consideration might have been bad,
- initially accepted and things seem ok,
- initially accepted and later found to be bad, …
So in other words we have ourselves a semi-supervised learning problem, straddling the worlds of supervised and unsupervised learning. We first check our old labels, and modify them, and then use them to help cluster new events using salient properties and attributes common to historical events whose labels we trust. We are constantly modifying our labels even in retrospect for this reason.
We estimate performance using precision and recall. Note there are very few positive examples so accuracy is not a good metric of success, since the “everything looks good” model is dumb but has good accuracy.
Labels are what Ian considered to be the “neglected half of the data” (recall T = {(x_i, y_i)}). In undergrad statistics education and in data mining competitions, the availability of labels is often taken for granted. In reality, labels are tough to define and capture. Labels are really important. It’s not just objective function, it is the objective.
As is probably familiar to people, we have a problem with sparsity of features. This is exacerbated by class imbalance (i.e., there are few positive samples). We also don’t know the same information for all of our sellers, especially when we have new sellers. But if we are too conservative we start off on the wrong foot with new customers.
Also, we might have a data point, say zipcode, for every seller, but we don’t have enough information in knowing the zipcode alone because so few sellers share zipcodes. In this case we want to do some clever binning of the zipcodes, which is something like sub model of our model.
Finally, and this is typical for predictive algorithms, we need to tweak our algorithm to optimize it- we need to consider whether features interact linearly or non-linearly, and to account for class imbalance.. We also have to be aware of adversarial behavior. An example of adversarial behavior in e-commerce is new buyer fraud, where a given person sets up 10 new accounts with slightly different spellings of their name and address.
Since models degrade over time, as people learn to game them, we need to continually retrain models. The keys to building performance models are as follows:
- it’s not a black box. You can’t build a good model by assuming that the algorithm will take care of everything. For instance, I need to know why I am misclassifying certain people, so I’ll need to roll up my sleeves and dig into my model.
- We need to perform rapid iterations of testing, with experiments like you’d do in a science lab. If you’re not sure whether to try A or B, then try both.
- When you hear someone say, “So which models or packages do you use?” then you’ve got someone who doesn’t get it. Models and/or packages are not magic potion.
Mathbabe cannot resist paraphrasing Ian here as saying “It’s not about the package. it’s about what you do with it.” But what Ian really thinks it’s about, at least for code, is:
- readability
- reusability
- correctness
- structure
- hygiene
So, if you’re coding a random forest algorithm and you’ve hardcoded the number of trees: you’re an idiot. put a friggin parameter there so people can reuse it. Make it tweakable. And write the tests for pity’s sake; clean code and clarity of thought go together.
At Square we try to maintain reusability and readability — we structure our code in different folders with distinct, reusable components that provide semantics around the different parts of building a machine learning model: model, signal, error, experiment.
We only write scripts in the experiments folder where we either tie together components from model, signal and error or we conduct exploratory data analysis. It’s more than just a script, it’s a way of thinking, a philosophy of approach.
What does such a discipline give you? Every time you run an experiment your should incrementally increase your knowledge. This discipline helps you make sure you don’t do the same work again. Without it you can’t even figure out the things you or someone else has already attempted.
For more on what every project directory should contain, see Project Template, written by John Myles White.
We had a brief discussion of how reading other people’s code is a huge problem, especially when we don’t even know what clean code looks like. Ian stayed firm on his claim that “if you don’t write production code then you’re not productive.”
In this light, Ian suggests exploring and actively reading Github’s repository of R code. He says to try writing your own R package after reading this. Also, he says that developing an aesthetic sense for code is analogous to acquiring the taste for beautiful proofs; it’s done through rigorous practice and feedback from peers and mentors. The problem is, he says, that statistics instructors in schools usually do not give feedback on code quality, nor are they qualified to.
For extra credit, Ian suggests the reader contrasts the implementations of the caret package (poor code) with scikit-learn (clean code).
Important things Ian skipped
- how is a model “productionized”?
- how are features computed in real-time to support these models?
- how do we make sure “what we see is what we get”, meaning the features we build in a training environment will be the ones we see in real-time. Turns out this is a pretty big problem.
- how do you test a risk engine?
Next Ian talked to us about how Square uses visualization.
Data Viz at Square
Ian talked to us about a bunch of different ways the Inference Team at Square use visualizations to monitor the transactions going on at any given time. He mentioned that these monitors aren’t necessarily trying to predict fraud per se but rather provides a way of keeping an eye on things to look for trends and patterns over time and serves as the kind of “data exoskeleton” that he mentioned at the beginning. People at Square believe in ambient analytics, which means passively ingesting data constantly so you develop a visceral feel for it.
After all, it is only by becoming very familiar with our data that we even know what kind of patterns are unusual or deserve their own model. To go further into the philosophy of this approach, he said two thing:
“What gets measured gets managed,” and “You can’t improve what you don’t measure.”
He described a workflow tool to review users, which shows features of the seller, including the history of sales and geographical information, reviews, contact info, and more. Think mission control.
In addition to the raw transactions, there are risk metrics that Ian keeps a close eye on. So for example he monitors the “clear rates” and “freeze rates” per day, as well as how many events needed to be reviewed. Using his fancy viz system he can get down to which analysts froze the most today and how long each account took to review, and what attributes indicate a long review process.
In general people at Square are big believers in visualizing business metrics (sign-ups, activations, active users, etc.) in dashboards; they think it leads to more accountability and better improvement of models as they degrade. They run a kind of constant EKG of their business through ambient analytics.
Ian ended with his data scientist profile. He thinks it should be on a logarithmic scale, since it doesn’t take very long to be okay at something (good enough to get by) but it takes lots of time to get from good to great. He believes that productivity should also be measured in log-scale, and his argument is that leading software contributors crank out packages at a much higher rate than other people.
Ian’s advice to aspiring data scientists
- play with real data
- build a good foundation in school
- get an internship
- be literate, not just in statistics
- stay curious
Ian’s thought experiment
Suppose you know about every single transaction in the world as it occurs. How would you use that data?
Strata: one down, one to go
Yesterday I gave a talk called “Finance vs. Machine Learning” at Strata. It was meant to be a smack-down, but for whatever reason I couldn’t engage people to personify the two disciplines and have a wrestling match on stage. For the record, I offered to be on either side. Either they were afraid to hurt a girl or they were afraid to lose to a girl, you decide.
Unfortunately I didn’t actually get to the main motivation for the genesis of this talk, namely the realization I had a while ago that when machine learners talk about “ridge regression” or “Tikhonov regularization” or even “L2 regularization” it comes down to the same thing that quants call a very simple bayesian prior that your coefficients shouldn’t be too large. I talked about this here.
What I did have time for: I talked about “causal modeling” in the finance-y sense (discussion of finance vs. statistician definition of causal here), exponential downweighting with a well-chosen decay, storytelling as part of feature selection, and always choosing to visualize everything, and always visualizing the evolution of a statistic rather than a snapshot statistic.
They videotaped me but I don’t see it on the strata website yet. I’ll update if that happens.
This morning, at 9:35, I’ll be in a keynote discussion with Julie Steele for 10 minutes entitled “You Can’t Learn That in School”, which will be live streamed. It’s about whether data science can and should be taught in academia.
For those of you wondering why I haven’t blogged the Columbia Data Science class like I usually do Thursday, these talks are why. I’ll get to it soon, I promise! Last night’s talks by Mark Hansen, data vizzer extraordinaire and Ian Wong, Inference Scientist from Square, were really awesome.
Columbia Data Science course, week 7: Hunch.com, recommendation engines, SVD, alternating least squares, convexity, filter bubbles
Last night in Rachel Schutt’s Columbia Data Science course we had Matt Gattis come and talk to us about recommendation engines. Matt graduated from MIT in CS, worked at SiteAdvisor, and co-founded hunch as its CTO, which recently got acquired by eBay. Here’s what Matt had to say about his company:
Hunch
Hunch is a website that gives you recommendations of any kind. When we started out it worked like this: we’d ask you a bunch of questions (people seem to love answering questions), and then you could ask the engine questions like, what cell phone should I buy? or, where should I go on a trip? and it would give you advice. We use machine learning to learn and to give you better and better advice.
Later we expanded into more of an API where we crawled the web for data rather than asking people direct questions. We can also be used by third party to personalize content for a given site, a nice business proposition which led eBay to acquire us. My role there was doing the R&D for the underlying recommendation engine.
Matt has been building code since he was a kid, so he considers software engineering to be his strong suit. Hunch is a cross-domain experience so he doesn’t consider himself a domain expert in any focused way, except for recommendation systems themselves.
The best quote Matt gave us yesterday was this: “Forming a data team is kind of like planning a heist.” He meant that you need people with all sorts of skills, and that one person probably can’t do everything by herself. Think Ocean’s Eleven but sexier.
A real-world recommendation engine
You have users, and you have items to recommend. Each user and each item has a node to represent it. Generally users like certain items. We represent this as a bipartite graph. The edges are “preferences”. They could have weights: they could be positive, negative, or on a continuous scale (or discontinuous but many-valued like a star system). The implications of this choice can be heavy but we won’t get too into them today.

So you have all this training data in the form of preferences. Now you wanna predict other preferences. You can also have metadata on users (i.e. know they are male or female, etc.) or on items (a product for women).
For example, imagine users came to your website. You may know each user’s gender, age, whether they’re liberal or conservative, and their preferences for up to 3 items.
We represent a given user as a vector of features, sometimes including only their meta data, sometimes including only their preferences (which would lead to a sparse vector since you don’t know all their opinions) and sometimes including both, depending on what you’re doing with the vector.
Nearest Neighbor Algorithm?
Let’s review nearest neighbor algorithm (discussed here): if we want to predict whether a user A likes something, we just look at the user B closest to user A who has an opinion and we assume A’s opinion is the same as B’s.
To implement this you need a definition of a metric so you can measure distance. One example: Jaccard distance, i.e. the number of things preferences they have in common divided by the total number of things. Other examples: cosine similarity or euclidean distance. Note: you might get a different answer depending on which metric you choose.
What are some problems using nearest neighbors?
- There are too many dimensions, so the closest neighbors are too far away from each other. There are tons of features, moreover, that are highly correlated with each other. For example, you might imagine that as you get older you become more conservative. But then counting both age and politics would mean you’re double counting a single feature in some sense. This would lead to bad performance, because you’re using redundant information. So we need to build in an understanding of the correlation and project onto smaller dimensional space.
- Some features are more informative than others. Weighting features may therefore be helpful: maybe your age has nothing to do with your preference for item 1. Again you’d probably use something like covariances to choose your weights.
- If your vector (or matrix, if you put together the vectors) is too sparse, or you have lots of missing data, then most things are unknown and the Jaccard distance means nothing because there’s no overlap.
- There’s measurement (reporting) error: people may lie.
- There’s a calculation cost – computational complexity.
- Euclidean distance also has a scaling problem: age differences outweigh other differences if they’re reported as 0 (for don’t like) or 1 (for like). Essentially this means that raw euclidean distance doesn’t explicitly optimize.
- Also, old and young people might think one thing but middle-aged people something else. We seem to be assuming a linear relationship but it may not exist
- User preferences may also change over time, which falls outside the model. For example, at Ebay, they might be buying a printer, which makes them only want ink for a short time.
- Overfitting is also a problem. The one guy is closest, but it could be noise. How do you adjust for that? One idea is to use k-nearest neighbor, with say k=5.
- It’s also expensive to update the model as you add more data.
Matt says the biggest issues are overfitting and the “too many dimensions” problem. He’ll explain how he deals with them.
Going beyond nearest neighbor: machine learning/classification
In its most basic form, we’ve can model separately for each item using a linear regression. Denote by 

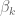


Remember, this model only works for one item. We need to build as many models as we have items. We know how to solve the above per item by linear algebra. Indeed one of the drawbacks is that we’re not using other items’ information at all to create the model for a given item.
This solves the “weighting of the features” problem we discussed above, but overfitting is still a problem, and it comes in the form of having huge coefficients when we don’t have enough data (i.e. not enough opinions on given items). We have a bayesian prior that these weights shouldn’t be too far out of whack, and we can implement this by adding a penalty term for really large coefficients.
This ends up being equivalent to adding a prior matrix to the covariance matrix. how do you choose lambda? Experimentally: use some data as your training set, evaluate how well you did using particular values of lambda, and adjust.
Important technical note: You can’t use this penalty term for large coefficients and assume the “weighting of the features” problem is still solved, because in fact you’re implicitly penalizing some coefficients more than others. The easiest way to get around this is to normalize your variables before entering them into the model, similar to how we did it in this earlier class.
The dimensionality problem
We still need to deal with this very large problem. We typically use both Principal Component Analysis (PCA) and Singular Value Decomposition (SVD).
To understand how this works, let’s talk about how we reduce dimensions and create “latent features” internally every day. For example, we invent concepts like “coolness” – but I can’t directly measure how cool someone is, like I could weigh them or something. Different people exhibit pattern of behavior which we internally label to our one dimension of “coolness”.
We let the machines do the work of figuring out what the important “latent features” are. We expect them to explain the variance in the answers to the various questions. The goal is to build a model which has a representation in a lower dimensional subspace which gathers “taste information” to generate recommendations.
SVD
Given a matrix 

Here 




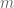

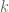
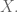
The rows of 
Important properties:
- The columns of
- So we can order the columns by singular values.
- We can take lower rank approximation of X by throwing away part of
In this way we might have
- There is an important interpretation to the values in the matrices
For example, we can see, by using SVD, that “the most important latent feature” is often something like seeing if you’re a man or a woman.
[Question: did you use domain expertise to choose questions at Hunch? Answer: we tried to make them as fun as possible. Then, of course, we saw things needing to be asked which would be extremely informative, so we added those. In fact we found that we could ask merely 20 questions and then predict the rest of them with 80% accuracy. They were questions that you might imagine and some that surprised us, like competitive people v. uncompetitive people, introverted v. extroverted, thinking v. perceiving, etc., not unlike MBTI.]
More details on our encoding:
- Most of the time the questions are binary (yes/no).
- We create a separate variable for every variable.
- Comparison questions may be better at granular understanding, and get to revealed preferences, but we don’t use them.
Note if we have a rank 

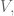
Note that the problem of sparsity or missing data is not fixed by the above SVD approach, nor is the computational complexity problem; SVD is expensive.
PCA
Now we’re still looking for 
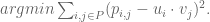
Let me explain. We denote by 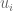



Then the dot product 

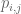
So, we want to find the best choices of
Now we have a parameter, namely the number 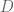
How do we choose 
But how do we actually find

Alternating Least Squares
This optimization doesn’t have a nice closed formula like ordinary least squares with one set of coefficients. Instead, we use an iterative algorithm like with gradient descent. As long as your problem is convex you’ll converge ok (i.e. you won’t find yourself at a local but not global maximum), and we will force our problem to be convex using regularization.
Algorithm:
- Pick a random
- Optimize
- Optimize
- Keep doing the above two steps until you’re not changing very much at all.
Example: Fix

The way we do this optimization is user by user. So for user

where
But wait a minute, this is the same as linear least squares, and has a closed form solution! In other words, set:

where 

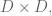
When you fix U and optimize V, it’s analogous; you only ever have to consider the users that rated that movie, which may be pretty large, but you’re only ever inverting a 
Another cool thing: since each user is only dependent on their item’s preferences, we can parallelize this update of
There are lots of different versions of this. Sometimes you need to extend it to make it work in your particular case.
Note: as stated this is not actually convex, but similar to the regularization we did for least squares, we can add a penalty for large entries in
You can add new users, new data, keep optimizing U and V. You can choose which users you think need more updating. Or if they have enough ratings, you can decide not to update the rest of them.
As with any machine learning model, you should perform cross-validation for this model – leave out a bit and see how you did. This is a way of testing overfitting problems.
Thought experiment – filter bubbles
What are the implications of using error minimization to predict preferences? How does presentation of recommendations affect the feedback collected?
For example, can we end up in local maxima with rich-get-richer effects? In other words, does showing certain items at the beginning “give them an unfair advantage” over other things? And so do certain things just get popular or not based on luck?
How do we correct for this?



