Columbia Data Science course, week 11: Estimating causal effects
The week in Rachel Schutt’s Data Science course at Columbia we had Ori Stitelman, a data scientist at Media6Degrees.
We also learned last night of a new Columbia course: STAT 4249 Applied Data Science, taught by Rachel Schutt and Ian Langmore. More information can be found here.
Ori’s background
Ori got his Ph.D. in Biostatistics from UC Berkeley after working at a litigation consulting firm. He credits that job with allowing him to understand data through exposure to tons of different data sets; since his job involved creating stories out of data to let experts testify at trials, e.g. for asbestos. In this way Ori developed his data intuition.
Ori worries that people ignore this necessary data intuition when they shove data into various algorithms. He thinks that when their method converges, they are convinced the results are therefore meaningful, but he’s here today to explain that we should be more thoughtful than that.
It’s very important when estimating causal parameters, Ori says, to understand the data-generating distributions and that involves gaining subject matter knowledge that allows you to understand if you necessary assumptions are plausible.
Ori says the first step in a data analysis should always be to take a step back and figure out what you want to know, write that down, and then find and use the tools you’ve learned to answer those directly. Later of course you have to decide how close you came to answering your original questions.
Thought Experiment
Ori asks, how do you know if your data may be used to answer your question of interest? Sometimes people think that because they have data on a subject matter then you can answer any question.
Students had some ideas:
- You need coverage of your parameter space. For example, if you’re studying the relationship between household income and holidays but your data is from poor households, then you can’t extrapolate to rich people. (Ori: but you could ask a different question)
- Causal inference with no timestamps won’t work.
- You have to keep in mind what happened when the data was collected and how that process affected the data itself
- Make sure you have the base case: compared to what? If you want to know how politicians are affected by lobbyists money you need to see how they behave in the presence of money and in the presence of no money. People often forget the latter.
- Sometimes you’re trying to measure weekly effects but you only have monthly data. You end up using proxies. Ori: but it’s still good practice to ask the precise question that you want, then come back and see if you’ve answered it at the end. Sometimes you can even do a separate evaluation to see if something is a good proxy.
- Signal to noise ratio is something to worry about too: as you have more data, you can more precisely estimate a parameter. You’d think 10 observations about purchase behavior is not enough, but as you get more and more examples you can answer more difficult questions.
Ori explains confounders with a dating example
Frank has an important decision to make. He’s perusing a dating website and comes upon a very desirable woman – he wants her number. What should he write in his email to her? Should he tell her she is beautiful? How do you answer that with data?
You could have him select a bunch of beautiful women and half the time chosen at random, tell them they’re beautiful. Being random allows us to assume that the two groups have similar distributions of various features (not that’s an assumption).
Our real goal is to understand the future under two alternative realities, the treated and the untreated. When we randomize we are making the assumption that the treated and untreated populations are alike.
OK Cupid looked at this and concluded:

But note:
- It could say more about the person who says “beautiful” than the word itself. Maybe they are otherwise ridiculous and overly sappy?
- The recipients of emails containing the word “beautiful” might be special: for example, they might get tons of email, which would make it less likely for Frank to get any response at all.
- For that matter, people may be describing themselves as beautiful.
Ori points out that this fact, that she’s beautiful, affects two separate things:
- whether Frank uses the word “beautiful” or not in his email, and
- the outcome (i.e. whether Frank gets the phone number).
For this reason, the fact that she’s beautiful qualifies as a confounder. The treatment is Frank writing “beautiful” in his email.
Causal graphs
Denote by 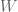
Denote by 
Denote by 
We are forming the following causal graph:

In a causal graph, each arrow means that the ancestor is a cause of the descendent, where ancestor is the node the arrow is coming out of and the descendent is the node the arrow is going into (see this book for more).
In our example with Frank, the arrow from beauty means that the woman being beautiful is a cause of Frank writing “beautiful” in the message. Both the man writing “beautiful” and and the woman being beautiful are direct causes of her probability to respond to the message.
Setting the problem up formally
The building blocks in understanding the above causal graph are:
- Ask question of interest.
- Make causal assumptions (denote these by
).
- Translate question into a formal quantity (denote this by
).
- Estimate quantity (denote this by
).
We need domain knowledge in general to do this. We also have to take a look at the data before setting this up, for example to make sure we may make the
Positivity Assumption. We need treatment (i.e. data) in all strata of things we adjust for. So if think gender is a confounder, we need to make sure we have data on women and on men. If we also adjust for age, we need data in all of the resulting bins.
Asking causal questions
What is the effect of ___ on ___?
This is the natural form of a causal question. Here are some examples:
- What is the effect of advertising on customer behavior?
- What is the effect of beauty on getting a phone number?
- What is the effect of censoring on outcome? (censoring is when people drop out of a study)
- What is the effect of drug on time until viral failure?, and the general case
- What is the effect of treatment on outcome?
Look, estimating causal parameters is hard. In fact the effectiveness of advertising is almost always ignored because it’s so hard to measure. Typically people choose metrics of success that are easy to estimate but don’t measure what they want! Everyone makes decision based on them anyway because it’s easier. This results in people being rewarded for finding people online who would have converted anyway.
Accounting for the effect of interventions
Thinking about that, we should be concerned with the effect of interventions. What’s a model that can help us understand that effect?
A common approach is the (randomized) A/B test, which involves the assumption that two populations are equivalent. As long as that assumption is pretty good, which it usually is with enough data, then this is kind of the gold standard.
But A/B tests are not always possible (or they are too expensive to be plausible). Often we need to instead estimate the effects in the natural environment, but then the problem is the guys in different groups are actually quite different from each other.
So, for example, you might find you showed ads to more people who are hot for the product anyway; it wouldn’t make sense to test the ad that way without adjustment.
The game is then defined: how do we adjust for this?
The ideal case
Similar to how we did this last week, we pretend for now that we have a “full” data set, which is to say we have god-like powers and we know what happened under treatment as well as what would have happened if we had not treated, as well as vice-versa, for every agent in the test.
Denote this full data set by
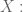

denotes the binary outcome if treated, and
denotes the binary outcome if untreated.
As a baseline check: if we observed this full data structure how would we measure the effect of A on Y? In that case we’d be all-powerful and we would just calculate:

Note that, since 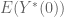

This would be calculating how much more likely someone is to convert if they see an ad.
Note these are outcomes you can really do stuff with. If you know people convert at 30% versus 10% in the presence of an ad, that’s real information. Similarly if they convert 3 times more often.
In reality people use silly stuff like log odds ratios, which nobody understands or can interpret meaningfully.
The ideal case with functions
In reality we don’t have god-like powers, and we have to make do. We will make a bunch of assumptions. First off, denote by 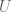


i.e. the attributes
i.e. the treatment depends in a nice way on some exogenous variables as well the attributes we know about living in
i.e. the outcome is just a function of the treatment, the attributes, and some exogenous variables.
Note the various
But we want to intervene on this causal graph as though it’s the intervention we actually want to make. i.e. what’s the effect of treatment
Let’s look at this from the point of view of the joint distribution 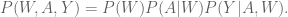
- the probability of a woman being beautiful,
- the probability that Frank writes and email to a her saying that she’s beautiful, and
- the probability that Frank gets her phone number.
What we really care about though is the distribution under intervention:
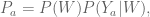
i.e. the probability knowing someone either got treated or not. To answer our question, we manipulate the value of 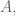
Assumptions
We are making a “Consistency Assumption / SUTVA” which can be expressed like this:
![]()
We have also assumed that we have no unmeasured confounders, which can be expressed thus:

We are also assuming positivity, which we discussed above.
Down to brass tacks
We only have half the information we need. We need to somehow map the stuff we have to the full data set as defined above. We make use of the following identity:

Recall we want to estimate 
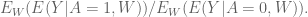
We’re going to discuss three methods to estimate this quantity, namely:
- MLE-based substitution estimator (MLE),
- Inverse probability estimators (IPTW),
- Double robust estimating equations (A-IPTW)
For the above models, it’s useful to think of there being two machines, called 

IPTW
In this method, which is also called importance sampling, we weight individuals that are unlikely to be shown an ad more than those likely. In other words, we up-sample in order to generate the distribution, to get the estimation of the actual effect.
To make sense of this, imagine that you’re doing a survey of people to see how they’ll vote, but you happen to do it at a soccer game where you know there are more young people than elderly people. You might want to up-sample the elderly population to make your estimate.
This method can be unstable if there are really small sub-populations that you’re up-sampling, since you’re essentially multiplying by a reciprocal.
The formula in IPTW looks like this:

Note the formula depends on the
In words, when 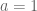

MLE
This method is based on the
This method is straight-forward: shove everyone in the machine and predict how the outcome would look under both treatment and non-treatment conditions, and take difference.
Note we don’t know anything about the underlying machine $latex Q$. It could be a logistic regression.
Get ready to get worried: A-IPTW
What if our machines are broken? That’s when we bring in the big guns: double robust estimators.
They adjust for confounding through the two machines we have on hand, 

and

Note: you are still screwed if both machines are broken. In some sense with a double robust estimator you’re hedging your bet.
“I’m glad you’re worried because I’m worried too.” – Ori
Simulate and test
I’ve shown you 3 distinct methods that estimate effects in observational studies. But they often come up with different answers. We set up huge simulation studies with known functions, i.e. where we know the functional relationships between everything, and then tried to infer those using the above three methods as well as a fourth method called TMLE (targeted maximal likelihood estimation).
As a side note, Ori encourages everyone to simulate data.
We wanted to know, which methods fail with respect to the assumptions? How well do the estimates work?
We started to see that IPTW performs very badly when you’re adjusting by very small thing. For example we found that the probability of someone getting sick is 132. That’s not between 0 and 1, which is not good. But people use these methods all the time.
Moreover, as things get more complicated with lots of nodes in our causal graph, calculating stuff over long periods of time, populations get sparser and sparser and it has an increasingly bad effect when you’re using IPTW. In certain situations your data is just not going to give you a sufficiently good answer.
Causal analysis in online display advertising
An overview of the process:
- We observe people taking actions (clicks, visits to websites, purchases, etc.).
- We use this observed data to build list of “prospects” (people with a liking for the brand).
- We subsequently observe same user during over the next few days.
- The user visits a site where a display ad spot exists and bid requests are made.
- An auction is held for display spot.
- If the auction is won, we display the ad.
- We observe the user’s actions after displaying the ad.
But here’s the problem: we’ve instituted confounders – if you find people who convert highly they think you’ve done a good job. In other words, we are looking at the treated without looking at the untreated.
We’d like to ask the question, what’s the effect of display advertising on customer conversion?
As a practical concern, people don’t like to spend money on blank ads. So A/B tests are a hard sell.
We performed some what-if analysis stipulated on the assumption that the group of users that sees ad is different. Our process was as follows:
- Select prospects that we got a bid request for on day 0
- Observe if they were treated on day 1. For those treated set
and those not treated set
collect attributes
- Create outcome window to be the next five days following treatment; observe if outcome event occurs (visit to the website whose ad was shown).
- Estimate model parameters using the methods previously described (our three methods plus TMLE).
Here are some results:

Note results vary depending on the method. And there’s no way to know which method is working the best. Moreover, this is when we’ve capped the size of the correction in the IPTW methods. If we don’t then we see ridiculous results:





Brava! You’ve succeeded in making sex boring (or, at least, merely equivalent to sliced bread).
LikeLike
That hurt!
LikeLike
Sorry, not meant to. Just trying to push the topic forward (without having an answer).
LikeLike
Thank you for blogging the class! Do you have suggestions on supplemental reading to fill in gaps such as meaning of the “g machine, i.e. the machine that estimates the treatment probability based on attributes”? I am looking forward to your book.
LikeLike