The overburdened prior
At my new job I’ve been spending my time editing my book with Rachel Schutt (who is joining me at JRL next week! Woohoo!). It’s called Doing Data Science and it’s based on these notes I took when she taught a class on data science at Columbia last semester. Right now I’m working on the alternating least squares chapter, where we learned from Matt Gattis how to build and optimize a recommendation system. A very cool algorithm.
However, to be honest I’ve started to feel very sorry for the one parameter we call 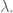
Let me tell you, the world is asking too much from this little guy, and moreover most of the big-data world is too indifferent to its plight. Let me explain.

First, he’s supposed to reflect an actual prior belief – namely, his size is supposed to reflect a mathematical vision of how big we think the coefficients in our solution should be.
In an ideal world, we would think deeply about this question of size before looking at our training data, and think only about the scale of our data (i.e. the input), the scale of the preferences (i.e. the recommendation system output) and the quality and amount of training data we have, and using all of that, we’d figure out our prior belief on the size or at least the scale of our hoped-for solution.
I’m not statistician, but that’s how I imagine I’d spend my days if I were: thinking through this reasoning carefully, and even writing it down carefully, before I ever start my training. It’s a discipline like any other to carefully state your beliefs beforehand so you know you’re not just saying what the data wants to hear.
But then there’s the next thing we ask of our parameter 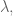
Because our algorithm isn’t a closed form solution, but rather we are discovering coefficients of two separate matrices 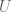
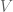

The fact that this algorithm will in fact stop is not obvious, and in fact it isn’t always true.
It is (mostly*) true, however, if our little
And people say that all the time. When you say, “hey what if that algorithm doesn’t converge?” They say, “oh if
But that’s kind of like worrying about your teenage daughter getting pregnant so you lock her up in her room all the time. You’ve solved the immediate problem by sacrificing an even bigger goal.
Because let’s face it, if the prior
By the way, there’s a discipline here too, and I’d suggest that if the algorithm doesn’t converge you might also want to consider reducing your number of latent variables rather than increasing your
Finally, we have one more job for our little
In other words, in reality most of the above nonsense about
This is one example among many where having the ability to push a button that makes something hard seem really easy might be doing more harm than good. In this case the button says “optimize with respect to
I’ve said it before and I’ll say it again: you do need to know about inverting a matrix, and other math too, if you want to be a good data scientist.
* There’s a change-of-basis ambiguity that’s tough to get rid of here, since you only choose the number of latent variables, not their order. This doesn’t change the overall penalty term, so you can minimize that with large enough




Château Descartes (A Cautionary Tale)
LikeLike
Two things some quants tend to loose sight of:
1. Qualitative judgment has value beyond what you can see in the data.
2. What fits well in sample may not fit as well out of sample.
I find that even when the data is weak and the qualitative argument for the Bayesian prior is sufficiently strong, many people are afraid of putting weight on the prior. Maybe putting undue weight on the data just makes people feel like they are doing something, sort of like overtrading stocks.
LikeLike
When I took econometrics, personal computers had just reached the point where you could easily just run your data through the computer and get Rho, etc. I spent MONTHS doing matrix algebra because the prof was worried that we would work in a world where the computer did all the work on the data, and we were unable to recognize when the data were garbage, or when the information the computer gave did not make sense.
That world came to pass really rather quickly. I’m grateful every day that man made us torture so many matrices, even if it was really boring at the time. Because like that poor kid who sees ghosts, I see bad data – or the output of bad data. It’s everywhere.
LikeLike
Great post, thank.
LikeLike
/thanks
LikeLike
Great post, Cathy — I endorse there being more frequent technical posts on this blog!
LikeLike
I’m looking forward to your book. You might call my work data science, but my background is very different from yours so the overlap between the methods you talk about and the methods I use is fairly small.
LikeLike