Archive
Teaching scores released
Anyone who reads this blog regularly knows how detestable I think it is that the teacher value-added model scores are being released but the underlying model is not.
We are being shown scores of teachers and we are even told the scores have a wide margin of error: someone who gets a 30 out of 100 could next year get a 70 out of 100 and nobody would be surprised (see this article).
Just to be clear, the underlying test doesn’t actually use a definition of a good teacher beyond what the score is. In other words, this model isn’t being trained by looking at examples of what is a “good teacher”. Instead, it derived from another model which predicts students’ test scores taking into account various factors. At the very most you can say the teacher model measures the ability teachers have to get their kids to score better or worse than expected on some standardized tests. Call it a “teaching to the test model”. Nothing about learning outside the test. Nothing about inspiring their students or being a role model or teaching how to think or preparing for college.
A “wide margin of error” on this value-added model then means they have trouble actually deciding if you are good at teaching to the test or not. It’s an incredibly noisy number and is affected by things like whether this year’s standardized tests were similar to last year’s.
Moreover, for an individual teacher with an actual score, being told there’s a wide margin of error is not helpful at all. On the other hand, if the model were open source (and hopefully the individual scores not public), then a given teacher could actually see their margin of error directly: it could even be spun as a way of seeing how to “improve”. Otherwise said, we’d actually be giving teachers tools to work with such a model, rather than simply making them targets.
update: Here’s an important comment from a friend of mine who works directly with New York City math teachers:
Thanks for commenting on this. I work with lots of public school math teachers around New York City, and have a sense of which of them are incredible teachers who inspire their students to learn, and which are effective at teaching to the test and managing their behavior.
Curiosity drove me to it, but I checked out their ratings. The results are disappointing and discouraging. The ones who are sending off intellectually engaged children to high schools were generally rated average or below, while the ones who are great classroom managers and prepare their lessons with priority to the tests were mostly rated as effective or above.
Besides the huge margin of uncertainty in this model, it’s clear that it misses many dimensions of great teaching. Worse, this model, now published, is an incentive for teachers to develop their style even more towards the tests.
If you don’t believe me or Japheth, listen to Bill Gates, who is against publicly shaming teachers (but loves the models). From his New York Times op-ed from last week:
Many districts and states are trying to move toward better personnel systems for evaluation and improvement. Unfortunately, some education advocates in New York, Los Angeles and other cities are claiming that a good personnel system can be based on ranking teachers according to their “value-added rating” — a measurement of their impact on students’ test scores — and publicizing the names and rankings online and in the media. But shaming poorly performing teachers doesn’t fix the problem because it doesn’t give them specific feedback.
If nothing else, the Bloomberg administration should also look into statistics regarding whether it’s become a more attractive or less attractive profession since he started publicly shaming teachers. Has introducing the models and publicly displaying the results had the intended effect of keeping good teachers and getting rid of bad ones, Mayor Bloomberg?
#OWS Alternative Banking update
Crossposted from the Alternative Banking Blog.
I wanted to mention a few things that have been going on with the Alternative Banking group lately.
- The Occupy the SEC group submitted their public comments last week on the Volcker Rule and got AMAZING press. See here for a partial list of articles that have been written about these incredible folks.
- Hey, did you notice something about that last link? Yeah, Alt Banking now has a blog! Woohoo! One of our members Nathan has been updating it and he’s doing a fine job. I love how he mentions Jeremy Lin when discussing derivatives.
- Alt Banking also has a separate suggested reading list page on the new blog. Please add to it!
- We just submitted a short letter as a public comment to the new Consumer Financial Protection Bureau regulation which gives them oversight powers on debt collectors and credit score bureaus. We basically told them to make credit score models open source (and I wasn’t even in the initial conversation about what we should say to these guys! Open source rules!!):
New online course: model thinking
There’s a new course starting soon, taught by Scott Page, about “model thinking” (hat tip David Laxer). The course web site is located here and some preview lectures are here. From the course description:
In this class, I present a starter kit of models: I start with models of tipping points. I move on to cover models explain the wisdom of crowds, models that show why some countries are rich and some are poor, and models that help unpack the strategic decisions of firm and politicians.
The models cover in this class provide a foundation for future social science classes, whether they be in economics, political science, business, or sociology. Mastering this material will give you a huge leg up in advanced courses. They also help you in life.
In other words, this guy is seriously ambitious. Usually around people who are this into modeling I get incredibly suspicious and skeptical, and this is no exception. I’ve watched the first two videos and I’ve come across the following phrases:
- Models make us think better
- Models are better than we are
- Models make us humble
The third one is particularly strange since his evidence that models make us humble seems to come from the Dutch tulip craze, where a linear model of price growth was proven wrong, and the recent housing boom, where people who modeled housing prices as always going up (i.e. most people) were wrong.
I think I would have replaced the above with the following:
- Models can make us come to faster conclusions, which can work as rules of thumb, but beware of when you are misapplying such shortcuts
- Models make us think we are better than we actually are: beware of overconfidence in what is probably a ridiculous oversimplification of what may be a complicated real-world situation
- Models sometimes fail spectacularly, and our overconfidence and misapplication of models helps them do so.
So in other words I’m looking forward to disagreeing with this guy a lot.
He seems really nice, by the way.
I should also mention that in spite of anticipating disagreeing fervently with this guy, I think what Coursera is doing by putting up online courses is totally cool. Check out some of their other offerings here.
The future of academic publishing
I’ve been talking a lot to mathematicians in the past few days about the future of mathematics publishing (partly because I gave a talk about Math in Business out at Northwestern).
It’s an exciting time, mathematicians seem really fed up with a particularly obnoxious Dutch publisher called Elsevier (tag line: “we charge this much because we can”), and a bunch of people have been boycotting them, both for submissions (they refuse to submit papers to the journals Elsevier publishes) and for editing (they resign as editors or refuse offers). One such mathematician is my friend Jordan, for example.
Here’s a page that simply collects information about the boycott. As you can see by looking at it, there’s an absolutely exploding amount of conversation around this topic, and rightly so: the publishing system in academic math is ancient and completely outdated. For one thing, nobody I’ve talked to actually reads journals anymore, they all read preprints from arXiv, and so the only purpose publishers provide right now is a referee system, but then again the mathematicians themselves do the refereeing. So publishers are more like the organizers of refereeing than anything else.
What’s next? Some people are really excited to start something completely new (I talked about this a bit already here and here) but others just want the same referee system done without all the money going to publishers. I think it would be a great start, but who would do the organizing and get to choose the referees etc? It’s both lots of work and potentially lots of bias in an already opaque system. Maybe it’s time for some crowd-sourcing in reviewing? That’s also work to set up and could potentially be gamed (if you send all your friends online to review your newest paper for example).
We clearly need to discuss.
For example, here’s a post (hat tip Roger Witte) about using arXiv.org as a collector of papers and putting a referee system on top of it, which would be called arXiv-review.org. There’s an infant google+ discussion group about what that referee system would look like.
Update: here’s another discussion taking place.
Are there other online discussions going on? Please comment if so, I’d like to know about them. I’m looking forward to what happens next!
Data Science needs more pedagogy
Yesterday Flowing Data posted an article about the history of data science (h/t Chris Wiggins). Turns out the field and the name were around at least as early as 2001, and statistician William Cleveland was all about planning it. He broke the field down into parts thus:
- Multidisciplinary Investigation (25%) — collaboration with subject areas
- Models and Methods for Data (20%) — more traditional applied statistics
- Computing with Data (15%) — hardware, software, and algorithms
- Pedagogy (15%) — how to teach the subject
- Tool Evaluation (5%) — keeping track of new tech
- Theory (20%) — the math behind the data
First of all this is a great list, and super prescient for the time. In fact it’s an even better description of data science than what’s actually happening.
The post mentions that we probably don’t see that much theory, but I’ve certainly seen my share of theory when I go to Meetups and such. Most of the time the theory is launched into straight away and I’m on my phone googling terms for half of the talk.
The post also mentions we don’t see much pedagogy, and here I strongly concur. By “pedagogy” I’m not talking about just teaching other people what you did or how you came up with a model, but rather how you thought about modeling and why you made the decisions you did, what the context was for those decisions and what the other options were (that you thought of). It’s more of a philosophy of modeling.
It’s not hard to pinpoint why we don’t get much in the way of philosophy. The field is teeming with super nerds who are focused on the very cool model they wrote and the very nerdy open source package they used, combined with some weird insight they gained as a physics Ph.D. student somewhere. It’s hard enough to sort out their terminology, never mind expecting a coherent explanation with broad context, explained vocabulary, and confessed pitfalls. The good news is that some of them are super smart and they share specific ideas and sometimes even code (yum).
In other words, most data scientists (who make cool models) think and talk at the level of 0.02 feet, whereas pedagogy is something you actually need to step back to see. I’m not saying that no attempt is ever made at this, but my experiences have been pretty bad. Even a simple, thoughtful comparison of how different fields (bayesian statisticians, machine learners, or finance quants) go about doing the same thing (like cleaning data, or removing outliers, or choosing a bayesian prior strength) would be useful, and would lead to insights like, why do these field do it this way whereas those fields do it that way? Is it because of the nature of the problems they are trying to solve?
A good pedagogical foundation for data science will allow us to not go down the same dead end roads as each other, not introduce the same biases in multiple models, and will make the entire field more efficient and better at communicating. If you know of a good reference for something like this, please tell me.
Let them game the model
One of the most common reasons I hear for not letting a model be more transparent is that, if they did that, then people would game the model. I’d like to argue that that’s exactly what they should do, and it’s not a valid argument against transparency.
Take as an example the Value-added model for teachers. I don’t think there’s any excuse for this model to be opaque: it is widely used (all of New York City public middle and high schools for example), the scores are important to teachers, especially when they are up for tenure, and the community responds to the corresponding scores for the schools by taking their kids out or putting their kids into those schools. There’s lots at stake.
Why would you not want this to be transparent? Don’t we usually like to know how to evaluate our performance on the job? I’d like to know it if being 4 minutes late to work was a big deal, or if I need to stay late on Tuesdays in order to be perceived as working hard. In other words, given that it’s high stakes it’s only fair to let people know how they are being measured and, thus, how to “improve” with respect to that measurement.
Instead of calling it “gaming the model”, we should see it as improving our scores, which, if it’s a good model, should mean being better teachers (or whatever you’re testing). If you tell me that when someone games the model, they aren’t actually becoming a better teacher, then I’d say that means your model needs to improve, not the teacher. Moreover, if that’s true, then without transparency or with transparency, in either case, you’re admitting that the model doesn’t measure the right thing. At least when it’s transparent the problems are more obvious and the modelers have more motivation to make the model measure the right thing.
Another example: credit scoring. Why are these models closed? They affect everyone all the time. How is Visa or Mastercard winning if they don’t tell us what we need to do to earn a good credit card interest rate? What’s the worst thing that could happen, that we are told explicitly that we need to pay our bills on time? I don’t see it. Unless the models are using something devious, like people’s race or gender, in which case I’d understand why they’d want to hide that model. I suspect they aren’t, because that would be too obvious, but I also suspect they might be using other kinds of inputs (like zip codes) that are correlated to race and/ or gender. That’s the kind of thing that argues for transparency, not against it. When a model is as important as credit scores are, I don’t see an argument for opacity.
Updating your big data model
When you are modeling for the sake of real-time decision-making you have to keep updating your model with new data, ideally in an automated fashion. Things change quickly in the stock market or the internet, and you don’t want to be making decisions based on last month’s trends.
One of the technical hurdles you need to overcome is the sheer size of the dataset you are using to first train and then update your model. Even after aggregating your model with MapReduce or what have you, you can end up with hundreds of millions of lines of data just from the past day or so, and you’d like to use it all if you can.
The problem is, of course, that over time the accumulation of all that data is just too unwieldy, and your python or Matlab or R script, combined with your machine, can’t handle it all, even with a 64 bit setup.
Luckily with exponential downweighting, you can update iteratively; this means you can take your new aggregated data (say a day’s worth), update the model, and then throw it away altogether. You don’t need to save the data anywhere, and you shouldn’t.
As an example, say you are running a multivariate linear regression. I will ignore bayesian priors (or, what is an example of the same thing in a different language, regularization terms) for now. Then in order to have an updated coefficient vector 



So the problem simplifies to, how can we update
As I described before in this post for example, you can use exponential downweighting. Whereas before I was expounding on how useful this method is for helping you care about new data more than old data, today my emphasis is on the other convenience, which is that you can throw away old data after updating your objects of interest.
So in particular, we will follow the general rule in updating an object $T$ that it’s just some part old, some part new:
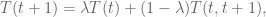
where by 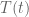
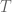
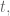


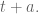
The speed at which I forget data is determined by my choice of 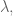
Specifically, I want to give an example of this update rule for the covariance matrix 
Namely, I claim that after updating 
Just to be really dumb, start with a univariate regression example, so where we have a single signal 

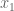


Now we get a new piece of data 
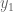

![[\mu x_1 x_2]](https://s0.wp.com/latex.php?latex=%5B%5Cmu+x_1+x_2%5D&bg=ffffff&fg=555555&s=0&c=20201002)

where by 
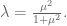
Things to convince yourself of:
- This works when we move from
pieces of data to
pieces of data.
- This works when we move from a univariate regression to a multivariate regression and we’re actually talking about square matrices.
- Same goes for the
- We don’t really have to worry about scaling; this uses the fact that everything in sight is quadratic in
, the downweighting scalar, and the final product we care about is
where, if we did decide to care about scalars, we would mutliply
- We don’t have to update one data point at a time. We can instead compute the `new part’ of the covariance matrix and the other thingy for a whole day’s worth of data, downweight our old estimate of the covariance matrix and other thingy, and then get a new version for both.
- We can also incorporate bayesian priors into the updating mechanism, although you have decide whether the prior itself needs to be downweighted or not; this depends on whether the prior is coming from a fading prior belief (like, oh I think the answer is something like this because all the studies that have been done say something kind of like that, but I’d be convinced otherwise if the new model tells me otherwise) or if it’s a belief that won’t be swayed (like, I think newer data is more important, so if I use lagged values of the quarterly earnings of these companies then the more recent earnings are more important and I will penalize the largeness of their coefficients less).

End result: we can cut our data up into bite-size chunks our computer can handle, compute our updates, and chuck the data. If we want to maintain some history we can just store the `new parts’ of the matrix and column vector per day. Then if we later decide our downweighting was too aggressive or not sufficiently aggressive, we can replay the summation. This is much more efficient as storage than holding on to the whole data set, because it depends only on the number of signals in the model (typically under 200) rather than the number of data points going into the model. So for each day you store a 200-by-200 matrix and a 200-by-1 column vector.
Followup: Change academic publishing
I really appreciate the amazing and immediate feedback I got from my post yesterday about changing the system of academic publishing. Let me gather the things I’ve learned or thought about in response:
First, I learned that mathoverflow is competitive and you “do well” on it if you’re quick and clever. Actually I didn’t know this, and since it is online I naively assumed people read it when they had time and so the answers to questions kind of drifted in over time. I kind of hate competitive math, and yes I wouldn’t like that to be the single metric deciding my tenure or job.
Next, ArXiv already existed when I left math, but I don’t think it’s all that good a “solution” either, because it’s treated mostly as a warehouse for papers, and there is not much feedback (although I’ve heard there’s way more in physics). Correct me if I’m wrong here.
I don’t want to sound like a pessimist, because the above two things really do function and add a lot to the community. I’m just pointing out that they aren’t perfect.
We, the mathematics community, should formally set out to be creative and thoughtful about different ways to collaborate and to document collaboration, and to score it for depth as well as helpfulness, etc. Let’s keep inventing stuff until we have a system which is respected and useful. The reason people may not be putting time into this right now is that they won’t be rewarded for it, but I say do it anyway and worry about that later. Let’s start brainstorming about what that system would look like.
That gets to another crucial point, which is that the people we have to convince are really not each other so much as deans and provosts of universities who are super conservative and want to be absolutely sure that the people they award tenure to are contributing citizens and will be for 40 years. We need to convince them to reconsider their definitions of “mathematical contributions”. How are we going to do this?
My first guess is that deans and provosts would listen to “experts in the field” quite a bit. This is good news, because it means that in some sense we just need to wait until the experts in the field come from the generation of people who invented (or at least appreciate) these tools. There are probably other issues though, which I don’t know about. I’d love to get comments from a dean or a provost on this one.
Change academic publishing
My last number theory paper just came out. I received it last week, so that makes it about 5 years since I submitted it – I know this since I haven’t even done number theory for 5 years. Actually I had already submitted it to a journal, and they took more than a year to reject it, so it’s been at least 6 years since I finished writing it.
One of the reasons I left academics was the painfully slow pace of being published, plus the feeling I got that, even when my papers did come out, nobody read them. I felt that way because I never read any papers, or at least I rarely read the new papers out of the new journals. I did read some older papers, ones that were recommended to me.
In other words I’m a pretty impatient person and the pace was killing me.
And I went to plenty of talks, but that process is of course very selective, and I would mostly be at a conference, or inside my own department. It led me to feel like I was mathematically isolated in my field as well as being incredibly impatient.
Plus, when you find yourself building a reputation more through giving talks and face-to-face interactions, you realize that much of that reputation is based on how you look and how well you give talks, and it stops seeming like mathematics is a just society, where everyone is judged based on their theorems. In fact it doesn’t feel like that at all.
I was really happy to see this article in the New York Times yesterday about how scientists are starting to collaborate online. This has got to be the future as far as I’m concerned. For example, the article mentions mathoverflow.net, which is a super awesome site where mathematicians pose and answer questions, and get brownie points if their answers are consistently good.
It’s funny how nowadays, to get tenure, you need to have a long list of publications, but brownie points for answering lots of questions on a community website for mathematicians doesn’t buy you anything. It’s totally ass backwards in terms of what we should actually be encouraging for a young mathematician. We should be hoping that young person is engaged in doing and explaining mathematics clearly, for its own sake. I can’t think of a better way of judging such a thing than mathoverflow.net points.
Maybe we also need to see that they can do original work. Why does it have to go through a 5 year process and be printed on paper? Why can’t we do it online and have other people read and rate (and correct) current research?
I know that people would respond that this would make lots of crappy papers seem on equal par with good, well thought-out papers, but I disagree. I think, first of all, that crap would be identified and buried, and that people would be more willing to referee online, since on the one hand it wouldn’t be resented, free work for publishers, and on the other hand, people would get more immediate and direct feedback and that would be cool and it would inspire people to work at it.
In other words, we can’t compare it to an ideal world where everyone’s papers are perfectly judged (not happening now) and where the good and important papers are widely read. We need to compare it to what we have now, which is highly dysfunctional.
That begs another huge question, which is why papers at all? Why not just contributions to projects that can be done online? For example my husband has an online open source project called the stacks project, but he feels like he can’t really urge anyone, especially if they’re young, to help out on it, because any work they do wouldn’t be recognized by their department. This is in spite of the fact that there’s already a system in place to describe who did what and who contributed what, and there are logs for corrections etc.; in other words, there’s a perfectly good way of seeing how much a given mathematician contributed to the project.
I honestly don’t see why we can’t, as a culture, acclimate to the computer age and start awarding tenure, or jobs, to people who have made major contributions to mathematics, rather than narrowly fulfilled some publisher’s fantasy. I also wonder if, when it finally happens, it will be a more enticing job prospect for smart but impatient people like myself who thrive on feedback. Probably so.
See also the follow-up post to this one.
Open Models (part 1)
A few days ago I posted about how riled up I was to see the Heritage Foundation publish a study about teacher pay which was obviously politically motivated. In the comment section a skeptical reader challenged me on a few things. He had some great points, and I’d love to address them all, but today I will only address the most important one, namely:
…the criticism about this particular study could be leveled to any study funded by any think tank, from the lowly ones, to the more prestigious ones, which have near-academic status (e.g. Brookings or Hoover). But indeed, most social scientists have a political bias. Piketty advised Segolene Goyal. Does it invalidate his study on inequality in America? Rogoff is a republican. Should one dismiss his work on debit crises? I think the best reaction is not to dismiss any study, or any author for that sake, on the basis of their political opinion, even if we dislike their pre-made tweets (which may have been prepared by editors that have nothing to do with the authors, by the way). Instead, the paper should be judged on its own merit. Even if we know we’ll disagree, a good paper can sharpen and challenge our prior convictions.
Agreed! Let’s judge papers on their own merits. However, how can we do that well? Especially when the data is secret and/or the model itself is only vaguely described, it’s impossible. I claim we need to demand more information in such cases, especially when the results of the study are taken seriously and policy decisions are potentially made based on them.
What should we do?
Addressing this problem of verifying modelling results is my goal with defining open source models. I’m not really inventing something new, but rather crystallizing and standardizing something that is already in the air (see below) among modelers who are sufficiently skeptical of the underlying incentives that modelers and their institutions have to look confident.
The basic idea is that we cannot and should not trust models that are opaque. We should all realize how sensitive models are to design decisions and tuning parameters. In the best case, this means we, the public, should have access to the model itself, manifested as a kind of app that we can play with.
Specifically, this means we can play around with the parameters and see how the model changes. We can input new data and see what the model spits out. We can retrain the model altogether with a slightly different assumption, or with new data, or with a different cross validation set.
The technology to allow us to do this all exists – even the various ways we can anonymize sensitive data so that it can still be semi-public. I will go further into how we can put this together in later posts. For now let me give you some indication of how badly this is needed.
Already in the Air
I was heartened yesterday to read this article from Bloomberg written by Victoria Stodden and Samuel Arbesman. In it they complain about how much of science depends on modeling and data, and how difficult it is to confirm studies when the data (and modeling) is being kept secret. They call on federal agencies to insist on data sharing:
Many people assume that scientists the world over freely exchange not only the results of their experiments but also the detailed data, statistical tools and computer instructions they employed to arrive at those results. This is the kind of information that other scientists need in order to replicate the studies. The truth is, open exchange of such information is not common, making verification of published findings all but impossible and creating a credibility crisis in computational science.
Federal agencies that fund scientific research are in a position to help fix this problem. They should require that all scientists whose studies they finance share the files that generated their published findings, the raw data and the computer instructions that carried out their analysis.
The ability to reproduce experiments is important not only for the advancement of pure science but also to address many science-based issues in the public sphere, from climate change to biotechnology.
How bad is it now?
You may think I’m exaggerating the problem. Here’s an article that you should read, in which the case is made that most published research is false. Now, open source modeling won’t fix all of that problem, since a large part of is it the underlying bias that you only publish something that looks important (you never publish results explaining all the things you tried but didn’t look statistically significant).
But think about it, that’s most published research. I’d like to posit that it’s the unpublished research that we should be really worried about. Note that banks and hedge funds don’t ever publish their research, obviously, because of proprietary reasons, but that this doesn’t improve the verifiability problems.
Indeed my experience is that very few people in the bank or hedge fund actually vet the underlying models, partly because they don’t want information to leak and partly because those models are really hard. You may argue that the models are carefully vetted, since big money is often at stake. But I’d reply that actually, you’d be surprised.
How about on the internet? Again, not published, and we don’t have reason to believe that they are more correct than published scientific models. And those models are being used day in and day out and are drawing conclusions about you (what is your credit score, whether you deserve a certain loan) every time you click.
We need a better way to verify models. I will attempt to outline specific ideas of how this should work in further posts.
Differential privacy
Do you know what’s awesome about writing a blog? Sometimes you’re left with a technical question, and someone with the technical answer comes right along and comments. It’s like magic.
That’s what happened to me when I wrote a post about privacy vs. openness and suggested that the world needs more people to think about anonymizing data. Along comes Aaron Roth who explains to me that the world is already doing that. Cool!
He sent me a few links to survey articles (here and here) on a concept called differential privacy. The truth is, though, I got confused and ended up just reading the wikipedia entry on it anyway.
The setup is that there is some data, stored in a database, and there’s some “release mechanism” that allows outside users to ask questions about the data- this is called querying for a statistic. Each row of the data is assumed to be associated with a person, so for example could contain their test scores on some medical test, as well as other private information that identifies them.
The basic question is, how can we set up the mechanism so that the users can get as much useful information as possible while never exposing an individual’s information?
Actually the exact condition posed is even a bit more nuanced: how can we set up the mechanism so that any individual, whether they are in the database or not, is indifferent to being taken out or added?
This is a kind of information theory question, and it’s tricky. First they define a metric of information loss or gain when you take out exactly one person from the database- how much do the resulting statistics change? Do they change enough for the outside user to infer (with confidence) what the statistics were for that lost record? If so, not good.
For example, if the user queries for the mean test score of a population with and without a given record (call the associated person the “flip-flopper” (my term)), and gets the exact answer both times, and knows how many people were in the population (besides the flip-flopper), then the user could figure out the exact test score of the flip-flopper.
One example of making this harder for the user, which is a bad one for a reason I’ll explain shortly, is to independently “add noise” to a given statistic after computing it. Then the answers aren’t exact in either case, so you’d have a low confidence in your resulting guess at the test score of the flip-flopper, assuming of course that the population is large and their test score isn’t a huge outlier.
But this is a crappy solution in the sense that I originally wanted to use an anonymization method for, namely to set up an open source data center to allow outside users (i.e. you) go query to their hearts’ content. A given user could simply query the same thing over and over, and after a million queries (depending on how much noise we’ve added) would get a very good approximation of the actual answer (i.e. the actual average test score). The added noise would be canceled out.
So instead, you’d have to add noise in a different way, i.e. not independently, to each statistic. Another possibility is to add noise to the original data, but that doesn’t feel as good to me, especially for the privacy of outliers, unless the noise is really noisy. But then again maybe that’s exactly what you do, so that any individual’s numbers are obfuscated but on a large enough scale you have a good sense of the statistics. I’ll have to learn more about it.
Aaron offered another possibility which I haven’t really understood yet, namely for the mechanism to be stateful. In fact I’m not sure what that means, but it seems to have something to do with it being aware of other databases. I’ve still got lots more to learn, obviously, which is exactly how I like to feel about interesting things.
Bloomberg engineering competition gets exciting
Stanford has bowed out of the Bloomberg administration’s competition for an engineering center in New York City. From the New York Times article:
Stanford University abruptly dropped out of the intense international competition to build an innovative science graduate school in New York City, releasing its decision on Friday afternoon. A short time later, its main rival in the contest, Cornell, announced a $350 million gift — the largest in its history — to underwrite its bid.
From what I’d heard, Stanford was the expected winner, with Cornell being a second place. This changes things, and potentially means that Columbia’s plan for a Data Science and Engineering Institute is still a possibility.
Cool and exciting, because I want that place to be really really good.
It also seems like the open data situation in New York is good and getting better. From the NYC Open Data website:
This catalog supplies hundreds of sets of public data produced by City agencies and other City organizations. The data sets are now available as APIs and in a variety of machine-readable formats, making it easier than ever to consume City data and better serve New York City’s residents, visitors, developer community and all!
Maybe New York will be a role model for good, balancing its reputation as the center of financial shenanigans.
‘Move Your Money’ app (#OWS)
One of the most aggravating things about the credit crisis, and the (lack of) response to the credit crisis, is that the banks were found to be gambling with the money of normal people. They took outrageous risks, relying on the F.D.I.C. insurance of deposits. It is clearly not a good system and shouldn’t be allowed.
In fact, the Volcker Rule, part of the Dodd-Frank bill which is supposed to set in place new regulations and rules for the financial industry, is supposed to address this very issue, or risky trading on deposits. Unfortunately, it’s unlikely that the Volcker Rule itself goes far enough – or its implementation, which is another question altogether. I’ve posted about this recently, and I have serious concerns about whether the gambling will stop. I’m not holding my breath.
Instead of waiting around for the regulators to wade through the ridiculously complicated mess which is the financial system, there’s another approach that’s gaining traction, namely draining the resources of the big banks themselves by moving our money from big banks to credit unions.
I’ve got a few posts about credit unions from my guest poster FogOfWar. The basic selling points are as follows: credit unions are non-profit, they are owned by the depositors (and each person has an equal vote- it doesn’t depend on the size of your deposits), and their missions are to serve the communities in which they operate.
There are two pieces of bad news about credit unions. The first is that, because they don’t spend money on advertising and branches (which is a good thing- it means they aren’t slapping on fees to do so), they are sometimes less convenient in the sense of having a nearby ATM or doing online banking. However, this is somewhat alleviated by the fact that there are networks of credit union ATM’s (if you know where to look).
The second piece of bad news is that you can’t just walk into a credit union and sign up. You need to be eligible for that credit union, which is technically defined as being in its field of membership.
There are various ways to be eligible. The most common ones are:
- where you live (for example, the Lower East Side People’s Federal Credit Union allows people from the Lower East Side and Harlem into the field of membership)
- where you work
- where you worship or volunteer
- if you are a member of a union or various kinds of affiliated groups (like for example if you’re Polish)
This “field of membership” issue can be really confusing. The rules vary enormously by credit union, and since there are almost 100 credit unions in New York City alone, that’s a huge obstacle for someone to move their money. There’s no place where the rules are laid out efficiently right now (there are some websites where you can search for credit unions by your zipcode but they seem to just list nearby credit union regardless of whether you qualify for them; this doesn’t really solve the problem).
To address this, a few of us in the #OWS Alternative Banking group are getting together a team to form an app which will allow people to enter their information (address, workplace, etc.) and some filtering criteria (want an ATM within 5 blocks of home, for example) and get back:
- a list of credit unions for which the user is eligible and which fit the filtering criteria
- for each credit union, a map of its location as well as the associated ATM’s
- link to the website of the credit union
- information about the credit union: its history, its charter and mission, the products it offers, the fee structure, and its investing philosophy
It’s a really exciting project and we’ve got wonderful people working on it. Specifically, Elizabeth Friedrich, who has amazing knowledge about credit unions inside New York City (our plan is to start withing NYC but then scale up once we’ve got a good interface to add new credit unions), Robyn Caplan, who is a database expert and has worked on similar kinds of matching problems before, and Dahlia Bock, a developer from ThoughtWorks, a development consulting company which regularly sponsors social justice projects.
The end goal is to have an app, which is usable on any phone or any browser (this is an idea modeled after thebostonglobe.com’s new look- it automatically adjusts the view depending on the size of your browser’s window) and which someone can use while they watch the Daily Show with Jon Stewart. In fact I’m hoping that once the app is ready to go, we go on the Daily Show and get Jon Stewart to sign up for a credit union on the show just to show people how easy it is.
We’re looking to recruit more developers to this project, which will probably be built in Ruby on Rails. It’s not an easy task: for example, the eligibility by location logic, for which we will probably use google maps, isn’t as easy as zipcodes. We will need to implement some more complicated logic, perhaps with an interface which allows people to choose specific streets and addresses. We are planning to keep this open source.
If you’re a Rails developer interested in helping, please send me your information by commenting below (I get to review comments before letting them be viewed publicly, so if you want to help, tell me and won’t ever make it a publicly viewable comment, I’ll just write back to your directly). And please tell your socially conscious nerd friends!
Quantitative tax modeling?
Yes, it’s true. I’m going to talk about taxes. Don’t leave! Wait! I promise I’m going to keep it sexy. Buckle up for the most titillating tax convo of your life. Or at least the most bizarre.
Think of us as Murakami characters. I am a young woman, symbol both of purity and of unearthly sexual power, and I’ve taken your hand and led you down a well. We are crawling in underground tunnels looking for an exit, or perhaps an entrance. This is where taxes live, down here, along with talking animals and Bob Dylan recordings.
Do you know what I hate? I hate it when people say stuff like, the Cain 9-9-9 tax plan is bad for rich people. Or that it’s good for rich people. I hate both, actually, because you hear both statements and they both seem to be backed up with numbers and it’s so confusing.
But then again, this stuff is pretty confusing. Even when I think about the most ridiculously stupid questions about money I get confused. Even just the question of “what is the 1%?”, which has been coming up a lot lately, is hard to answer, for the following reasons among others:
- By income? Or by wealth? This matters because most rich people have most of their wealth in savings. They may not make any salary! Living off dividends or some such.
- Measured by individual? Or household? This matters because people with good jobs tend to marry each other.
But you know what? Just give me the answer in any of the four cases above – they are all reasonable choices. And tell me exactly how you’re doing it – which reasonable choices exactly? Better yet, write an open-source program that does this computation and give it, and the data you’re using, to me so I can tweak it.
As I write about this I realize I should confess here and now: I know nothing about taxes. However, I do know something about modeling, and I think in a certain way that makes it easier for me to imagine a tax model. And to critique the way people try to talk about taxes and tax plans.
Here’s my point. Let’s separate the measurement of a tax plan from the tax plan itself- it’s too easy to find a pseudo-quantitative reason to hate a tax plan that you just happen to disagree with politically (for example, by finding a weird theoretical example of a rich person who doesn’t benefit from a given tax plan, without admitting that on average rich people benefit hugely from that tax plan). If we already agree on a model for measurement then we could try to resist the urge to spin, even to ourselves.
Of course we’ll never agree on a model for measurement, so instead we should have many different models, each with a set of “reasonable choices”.
Characteristically for Murakami characters, we do not shirk from the manual labor and repetition of creating a million mini universes of tax scenarios, like folding so many tiny origami unicorns. We write down our thoughts in English and translate back to Japanese, or python, which gives it an overall feeling of alien text, but it has internal consistency. We can represent anyone in this country, under any tax situation. We may even throw in corporate tax structure models while we wait for our spaghetti water to boil.
Once we have the measurement machine, we feed a given tax proposal to the machine and see what it spits out. Probably a lot, depending on how many “reasonable choices” we have agreed to.
Average them! Seriously, that’s what you do in your head. Right? If you hear that so-and-so’s flat tax plan is good for rich people if you consider one year but bad when you take into account retirement issues, or some such thing, then overall, in your head, you basically conclude that it’s kind of a wash.
So by average I mean a weighted average where the weights depend on how much you actually care and believe in the given model. So someone who’s about to retire is going to weight things differently than someone who’s still changing diapers.
What could the end result of such a system be? Perhaps a graph, of how taxes in 2009 (or whatever time period) would have looked like under the putative new plan, versus what they actually looked like. A graph whose x-axis is salary and whose y-axis indicates relative change in tax burden (by percent of taxable income or something like that) of the new plan compared to what actually happened.
It’s nice to use “what actually happened” models since the current tax code is impossibly difficult, so we can duck the issue of writing a script that has the same information just by pretending that nobody cheated on their taxes in 2009. Of course we may want adjust that once we have a model for how much people actually do cheat on their taxes.
If we have decided to build a corporate tax model as well, let’s draw another graph which compares “what happened” to “what would have happened” based on the size of the company. So two graphs. With code and data so we can see what the model is doing and we can argue about it. We’re at the bottom of the well looking up and we see hazy light.
Math in Business
Here’s an annotated version of my talk at M.I.T. a few days ago. There was a pretty good turnout, with lots of grad students, professors, and I believe some undergraduates.
What are the options?
First let’s talk about the different things you can do with a math degree.
Working as an academic mathematician
You all know about this, since you’re here. In fact most of your role models are probably professors. More on this.
Working at a government institution
I don’t have personal experience, but there are plenty of people I know who are perfectly happy working for the spooks or NASA.
Working as a quant in finance
This means trying to predict the market in one way or another, or modeling how the market works for the sake of measuring risk.
Working as a data scientist
This is my current job, and it is kind of vague, but it generally means dealing with huge data sets to locate, measure, visualize, and forecast patterns. Quants in finance are examples of data scientists, and they work in the most, or one of the most, developed subfield of data science.
Cultural Differences
I care a lot about the culture of my job, as I think women in general tend to. For that reason I’m going to try to give a quick and exaggerated description of the cultures of these various options and how they differ from each other.
Feedback is slow in academics
I’m still waiting for my last number theory paper to get published, and I left the field in 2007. That hurts. But in general it’s a place for people who have internal feedback mechanisms and don’t rely on external ones. If you’re a person who knows that you’re thinking about the most important question in the world and you don’t need anyone to confirm that, then academics may be a good cultural fit. If, on the other hand, you are wondering half the time why you’re working on this particular problem, and whether the answer really matters or ever will matter to someone, then academics will be a tough place for you to live.
Institutions are painfully bureaucratic
As I said before, I don’t have lots of personal experience here, but I’ve heard that good evidence that working at a government institution is sometimes painful in terms of waiting for things that should obviously happen actually happen. On the other hand I’ve also head lots of women say they like working for institutions and that they are encouraged to become managers and grow groups. We will talk more about this idea of being encouraged to be organized.
Finance firms are cut-throat
Again, exaggerating for effect, but there’s a side effect of being in a place whose success is determined along one metric (money), and that is that people are typically incredibly competitive with each other for their perceived value with respect to that metric. Kind of like a bunch of gerbils in a case with not quite enough food. On the other hand, if you love that food yourself, you might like that kind of struggle.
Startups are unstable
If you don’t mind wondering if your job is going to exist in 1 or 2 months, then you’ll love working at a startup. It’s an intense and exciting journey with a bunch of people you’d better trust or you’ll end up really hating them.
Outside academics, mathematicians have superpowers
One general note that you, being inside academics right now, may not be aware of: being really fucking good at math is considered a superpower by the people outside. This is because you can do stuff with your math that they actually don’t know how to do, no matter how much time they spend trying. This power is good and bad, but in any case it’s very different than you may be used to.
Going back to your role models: you see your professors, they’re obviously really smart, and you naturally may want to become just like them when you grow up. But looking around you, you notice there are lots of good math students here at M.I.T. (or wherever you are) and very few professor jobs. So there is this pyramid, where lots of people a the bottom are all trying to get these fancy jobs called math professorships.
Outside of math, though, it’s an inverted world. There are all of these huge data sets, needing analysis, and there are just very few places where people are getting trained to do stuff like that. So M.I.T. is this tiny place inside the world, which cannot possibly produce enough mathematicians to satisfy the demand.
Another way of saying this is that, as a student in math, you should absolutely be aware that it’s easier to get a really good job outside the realm of academics.
Outside academics, you get rewarded for organizational skills (punished within)
One other big cultural difference I want to mention is that inside academics, you tend to get rewarded for avoiding organizational responsibilities, with some exceptions perhaps if you organize conferences or have lots of grad students. Outside of academics, though, if you are good at organizing, you generally get rewarded and promoted and given more responsibility for managing a group of nerds. This is another personality thing- some math nerds love the escape from organizing, or just plain suck at it, and maybe love academics for that reason, whereas some math nerds are actually quite nurturing and don’t mind thinking about how systems should be set up and maintained, and if those people are in academics they tend to be given all of the “housekeeping” in the department, which is almost always bad for their career.
Mathematical Differences
Let’s discuss how the actual work you would do in these industries is different. Exaggeration for effect as usual.
Academic freedom is awesome but can come with insularity
If you really care about having the freedom to choose what math you do, then you absolutely need to stay in academics. There is simply no other place where you will have that freedom. I am someone who actually does have taste, but can get nerdy and interested in anything that is super technical and hard. My taste, in fact, is measured in part by how much I think the answer actually matters, defined in various ways: how many people care about the answer and how much of an impact would knowing the answer make? These properties are actually more likely to be present in a business setting. But some people are totally devoted to their specific field of mathematics.
The flip side of academic freedom is insularity; since each field of mathematics gets to find its way, there tend to be various people doing things that almost nobody understands and maybe nobody will ever care about. This is more or less frustrating to you depending on your personality. And it doesn’t happen in business: every question you seriously work on is important, or at least potentially important, for one reason or another to the business.
You don’t decide what to work on in business but the questions can be really interesting
Modeling with data is just plain fascinating, and moreover it’s an experimental science. Every new data set requires new approaches and techniques, and you feel like a mad scientist in a lab with various tools that you’ve developed hanging on the walls around you.
You can’t share proprietary information with the outside world when you work in business or for the government
The truth is, the actual models you create are often the crux of the profit in that business, and giving away the secrets is giving away the edge.
On the other hand, sometimes you can and it might make a difference
The techniques you develop are something you generally can share with the outside world. This emerging field of data science can potentially be put to concrete and good use (more on that later).
In business, more emphasis on shallower, short term results
It’s all about the deadlines, the clients, and what works.
On the other hand, you get much more feedback
It’s kind of nice that people care about solving urgent problems when… you’ve just solved an urgent problem.
Which jobs are good for women?
Part of what I wanted to relay today is those parts of these jobs that I think are particularly suitable for women, since I get lots of questions from young women in math wondering what to do with themselves.
Women tend to care about feedback
And they tend to be more sensitive to it. My favorite anecdote about this is that, when I taught I’d often (not always) see a huge gender difference right after the first midterm. I’d see a young woman coming to office hours fretting about an A- and I’d have to flag down a young man who got a C, and he’d say something like, “Oh, I’m not worried, I’ll just study and ace the final.” There’s a fundamental assumption going on here, and women tend to like more and more consistent feedback (especially positive feedback).
One of my most firm convictions about why there are not more women math professors out there is that there is virtually no feedback loop after graduating with a Ph.D., except for some lucky people (usually men) who have super involved and pushy advisors. Those people tend to be propelled by the will of their advisor to success, and lots of other people just stay in place in a kind of vacuum. I’ve seen lots of women lose faith in themselves and the concept of academics at this moment. I’m not sure how to solve this problem except by telling them that there’s more feedback in business. I do think that if people want to actually address the issue they need to figure this out.
Women tend to be better communicators
This is absolutely rewarded in business. The ability to hold meetings, understand people’s frustrations and confusions and explain in new terms so that they understand, and to pick up on priorities and pecking orders is absolutely essential to being successful, and women are good at these things because they require a certain amount of empathy.
In all of these fields, you need to be self-promoting
I mention this because, besides needing feedback and being good communicators, women tend to not be as self-promoting as men, and this is something that they should train themselves out of. Small things like not apologizing help, as does being very aware of taking credit for accomplishments. Where men tend to say, “then I did this…”, women tend to say, “then my group did this…”. I’m not advocating being a jerk, but I am advocating being hyper aware of language (including body language) and making sure you don’t single yourself out for not being a stand-out.
The tenure schedule sucks for women
I don’t think I need to add anything to this.
No “summers off” outside academics… but maybe that’s a good thing
Academics don’t actually take their summers off anyway. And typically the women are the ones who end up dealing more with the kids over the summer, which could be awesome if that’s what they want but also tends to add a bias in terms of who gets papers written.
How do I get a job like that?
Lots of people have written to me asking how to prepare themselves for a job in data science (I include finance in this category, but not the governmental institutions. I have no idea how to get a job at NASA or the NSA).
Get a Ph.D. (establish your ability to create)
I’m using “Ph.D.” as a placeholder here for something that proves you can do original creative building. But it’s a pretty good placeholder; if you don’t have a Ph.D. but you are a hacker and you’ve made something that works and does something new and clever, that may be sufficient too. But if you’ve just followed your nose, and done well in your courses then it will be difficult to convince someone to hire you. Doing the job well requires being able to create ad hoc methodology on the spot, because the assumptions in developed theory never actually happen with real data.
Know your way around a computer
Get to the point where you can make things work on your computer. Great if you know how unix and stuff like cronjobs (love that word) work, but at the very least know to google everything instead of bothering people.
Learn python or R, maybe java or C++
Python and R are the very basic tools of a data scientist, and they allow quick and dirty data cleaning, modeling, measuring, and forecasting. You absolutely need to know one of them, or at the very least matlab or SAS or STATA. The good news is that none of these are hard, they just take some time to get used to.
Acquire some data visualization skills
I would guess that half my time is spent visualizing my results in order to explain them to non-quants. A crucial skill (both the pictures and the explanations).
Learn basic statistics
And I mean basic. But on the other hand I mean really, really, learn it. So that when you come across something non-standard (and you will), you can rewrite the field to apply to your situation. So you need to have a strong handle on all the basic stuff.
Read up on machine learning
There are lots of machine learners out there, and they have a vocabulary all their own. Take the Stanford Machine Learning classor something to learn this language.
Emphasize your communication skills and follow-through
Most of the people you’ll be working with aren’t trained mathematicians, and they absolutely need to know that you will be able to explain your models to them. At the same time, it’s amazing how convincing it is when you tell someone, “I’m a really good communicator.” They believe you. This also goes back to my “do not be afraid to self-promote” theme.
Practice explaining what a confidence interval is
You’d be surprised how often this comes up, and you should be prepared, even in an interview. It’s a great way to prep for an interview: find someone who’s really smart, but isn’t a mathematician, and ask them to be skeptical. Then explain what a confidence interval is, while they complain that it makes no sense. Do this a bunch of times.
Other stuff
I wanted to throw in a few words about other related matters.
Data modeling is everywhere (good data modelers aren’t)
There’s an asston of data out there waiting to be analyzed. There are very few people that really know how to do this well.
The authority of the inscrutable
There’s also a lot of fraud out there, related to the fact that people generally are mathematically illiterate or are in any case afraid of or intimidated by math. When people want to sound smart they throw up an integral, and it’s a conversation stopper. It is a pretty evil manipulation, and it’s my opinion that mathematicians should be aware of this and try to stop it from happening. One thing you can do: explain that notation (like integrals) is a way of writing something in shorthand, the meaning of which you’ve already agreed on. Therefore, by definition, if someone uses notation without that prior agreement, it is utterly meaningless and adds rather than removes confusion.
Another aspect of the “authority of the inscrutable” is the overall way that people claimed to be measuring the risk of the mortgage-backed securities back before and during the credit crisis. The approach was, “hey you wouldn’t understand this, it’s math. But trust us, we have some wicked smart math Ph.D.’s back there who are thinking about this stuff.” This happens all the time in business and it’s the evil side of the superpower that is mathematics. It’s also easy to let this happen to you as a mathematician in business, because above all it’s flattering.
Open source data, open source modeling
I’m a huge proponent of having more visibility into the way that modeling affects us all in our daily lives (and if you don’t know that this is happening then I’ve got news for you). A particularly strong example is the Value-added modeling movement currently going on in this country which evaluates public teachers and schools. The models and training data (and any performance measurements) are proprietary. They should not be. If there’s an issue of anonymity, then go ahead and assign people randomly.
Not only should the data that’s being used to train the model be open source, but the model itself should be too, with the parameters and hyper-parameters in open-source code on a website that anyone can download and tweak. This would be a huge view into the robustness of the models, because almost any model has sub-modeling going on that dramatically affects the end result but that most modelers ignore completely as a source of error. Instead of asking them about that, just test it for yourself.
Meetups
The closest thing to academics lectures in data science is called “Meetups”. They are very cool. I wrote about them previously here. The point of them is to create a community where we can share our techniques (without giving away IP) and learn about new software packages. A huge plus for the mathematician in business, and also a great way to meet other nerds.
Data Without Borders
I also wanted to mention that, once you have a community of nerds such as is gathered at Meetups, it’s also nice to get them together with their diverse skills and interests and do something cool and valuable for the world, without it always being just about money. Data Without Borders is an organization I’ve become involved with that does just that, and there are many others as well.
Please feel free to comment or ask me more questions about any of this stuff. Hope it is helpful!
Datadive update
I left my datadive team at 9:15pm last night hard at work, visualizing the data in various ways as well as finding interesting inconsistencies. I will try to post some actual results later, but I want to wait for them to be (somewhat) finalized. For now I can make some observations.
- First, I really can’t believe how cool it is to meet all of these friendly and hard-working nerds who volunteered their entire weekend to clean and dig through data. It’s a really amazing group and I’m proud of how much they’ve done.
- Second, about half of the data scientists are women. Awesome and unusual to see so many nerd women outside of academics!
- Third, data cleaning is hard work and is a huge part of the job of a data scientist. I should never forget that. Having said that, though, we might want to spend some time before the next datadive pre-cleaning and formatting the data so that people have more time to jump into the analytics. As it is we learned a lot about data cleaning as a group, but next time we could learn a lot about comparing methodology.
- Statistical software packages such as Stata have trouble with large (250MB) files compared to python, probably because of the way they put everything into memory at once. So it’s cool that everyone comes to a datadive with their own laptop and language, but some thought should be put into what project they work on depending on this information.
- We read Gelman, Fagan and Kiss’s article about using the Stop and Frisk data to understand racial profiling, with the idea that we could test it out on more data or modify their methodology to slightly change the goal. However, they used crime statistics data that we don’t have and can’t find and which are essential to a good study.
- As an example of how crucial crime data like this is, if you hear the statement, “10% of the people living in this community are black but 50% of the people stopped and frisked are black,” it sounds pretty damning, but if you add “50% of crimes are committed by blacks” then it sound less so. We need that data for the purpose of analysis.
- Why is crime statistics data so hard to find? If you go to NYPD’s site and search for crime statistics, you get really very little information, which is not broken down by area (never mind x and y coordinates) or ethnicity. That stuff should be publicly available. In any case it’s interesting that the Stop and Frisk data is but the crime stats data isn’t.
- Oh my god check out our wiki, I just looked and I’m seeing some pretty amazing graphics. I saw some prototypes last night and I happen to know that some of these visualizations are actually movies, showing trends over time. Very cool!
- One last observation: this is just the beginning. The data is out there, the wiki is set up, and lots of these guys want to continue their work after this weekend is over. That’s what I’m talking about.
NYCLU: Stop Question and Frisk data
As I mentioned yesterday, I’m the data wrangler for the Data Without Borders datadive this weekend. There are three N.G.O.’s participating: NYCLU (mine), MIX, and UN Global Pulse. The organizations all pitched their data and their questions last night to the crowd of nerds, and this morning we are meeting bright and early (8am) to start crunching.
I’m particularly psyched to be working with NYCLU on Stop and Frisk data. The women I met from NYCLU last night had spent time at Occupy Wall Street the previous day giving out water and information to the protesters. How cool!
The data is available here. It’s zipped in .por format, which is to say it was collected and used in SPSS, a language that’s not open source. I wanted to get it into csv format for the data miners this morning, but I have been having trouble. Sometimes R can handle .por files but at least my install of R is having trouble with the years 2006-2009. Then we tried installing PSPP, which is an open source version of SPSS, and it seemed to be able to import the .por files and then export as csv, in the sense that it didn’t throw any errors, but actually when we looked we saw major flaws. Finally we found a program called StatTransfer, which seems to work (you can download a trial version for free) but unless you pay $179 for the package, it actually doesn’t transfer all of the lines of the file for you.
If anyone knows how to help, please make a comment, I’ll be checking my comments. Of course there could easily be someone at the datadive with SPSS on their computer, which would solve everything, but on the other hand it could also be a major pain and we could waste lots of precious analyzing time with formatting issues. I may just buckle down and pay $179 but I’d prefer to find an open source solution.
UPDATE (9:00am): Someone has SPSS! We’re totally getting that data into csv format. Next step: set up Dropbox account to share it.
UPDATE (9:21am): Have met about 5 or 6 adorable nerds who are eager to work on this sexy data set. YES!
UPDATE (10:02am): People are starting to work in small groups. One guy is working on turning the x- and y-coordinates into latitude and longitude so we can use mapping tools easier. These guys are awesome.
UPDATE (11:37am): Now have a mapping team of 4. Really interesting conversations going on about statistically rigorous techniques for human rights abuses. Looking for publicly available data on crime rates, no luck so far… also looking for police officer id’s on data set but that seems to be missing. Looking also to extend some basic statistics to all of the data set and aggregated by months rather than years so we can plot trends. See it all take place on our wiki!
UPDATE (12:24pm): Oh my god, we have a map. We have officer ID’s (maybe). We have awesome discussions around what bayesian priors are reasonable. This is awesome! Lunch soon, where we will discuss our morning, plan for the afternoon, and regroup. Exciting!
UPDATE (2:18pm): Nice. We just had lunch, and I managed to get a sound byte about every current project, and it’s just amazing how many different things are being tried. Awesome. Will update soon.
UPDATE (7:10pm): Holy shit I’ve been inside crunching data all day while the world explodes around me.
Data Without Borders: datadive weekend!
I’m really excited to be a part of the datadive this weekend organized by Data Without Borders. From their website:
Selected NGOs will work with data enthusiasts over the weekend to better understand their data, create analyses and insights, and receive free consultations.
I’ve been asked to be a “data wrangler” at the event, which means I’m going to help project manage one of the projects of the weekend, which is super exciting. It means I get to hear about cool ideas and techniques as they happen. We’re expecting quite a few data scientists, so the amount of nerdiness should be truly impressive, as well as the range of languages and computing power. I’m borrowing a linux laptop since my laptop isn’t powerful enough for the large data and the crunching. I’ve got both python and R ready to go.
I can’t say (yet) who the N.G.O. is or what exactly the data is or what the related questions are, but let me say, very very cool. One huge reason I started this blog was to use data science techniques to answer questions that could actually really matter to people. This is my first real experience with that kind of non-commercial question and data set, and it’s really fantastic. The results of the weekend will be saved and open.
I’ll be posting over the weekend about the project as well as showing interim results, so stay tuned!
Bayesian regressions (part 2)
In my first post about Bayesian regressions, I mentioned that you can enforce a prior about the size of the coefficients by fiddling with the diagonal elements of the prior covariance matrix. I want to go back to that since it’s a key point.
Recall the covariance matrix represents the covariance of the coefficients, so those diagonal elements correspond to the variance of the coefficients themselves, which is a natural proxy for their size.
For example, you may just want to make sure the coefficients don’t get too big, or in other words there’s a penalty for large coefficients. Actually there’s a name for just having this prior, and it’s called L2 regularization. You just set the prior to be 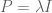
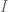

You’re going to end up adding this prior to the actual sample covariance matrix as measured by the data, so don’t worry about the prior matrix being invertible (but definitely do make sure it’s symmetrical).

Moreover, you can have many different priors, corresponding to different parts of the covariance matrix, and you can add them all up together to get a final prior.

From my first post, I had two priors, both on the coefficients of lagged values of some time series. First, I expect the signal to die out logarithmically or something as we go back in time, so I expect the size of the coefficients to die down as a power of some parameter. In other words, I’ll actually have two parameters: one for the decrease on each lag and one overall tuning parameter. My prior matrix will be diagonal and the 
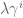
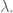
My second prior was that the entries should vary smoothly, which I claimed was enforceable by fiddling with the super and sub diagonals of the covariance matrix. This is because those entries describe the covariance between adjacent coefficients (and all of my coefficients in this simple example correspond to lagged values of some time series).
In other words, ignoring the variances of each variable (since we already have a handle on the variance from our first prior), we are setting a prior on the correlation between adjacent terms. We expect the correlation to be pretty high (and we can estimate it with historical data). I’ll work out exactly what that second prior is in a later post, but in the end we have two priors, both with tuning parameters, which we may be able to combine into one tuning parameter, which again determines the strength of the overall prior after adding the two up.
Because we are tamping down the size of the coefficients, as well as linking them through a high correlation assumption, the net effect is that we are decreasing the number of effective coefficients, and the regression has less work to do. Of course this all depends on how strong the prior is too; we could make the prior so weak that it has no effect, or we could make it so strong that the data doesn’t effect the result at all!
In my next post I will talk about combining priors with exponential downweighting.
Mortar Hawk: hadoop made easy
Yesterday a couple of guys from Mortar came to explain their hadoop platform. You can see a short demo here. I wanted to explain it at a really high level because it’s cool and a big deal for someone like me. I’m not a computer scientist by training, and Mortar allows me to work with huge amounts of data relatively easily. In other words, I’m not sure what ultimately will be the interface for analytics people like me to get access to massive data, but it will be something like this, if not this.
To back up one second, for people who are nodding off, here’s the thing. If you have terabytes of data to crunch, you can’t put it on your computer to take a look at it, and then crunch, because your computer is too small. So you need to pre-crunch. That’s pretty much the problem we need to solve, and people have solved it either one of two ways.
The first is to put your data onto a big relational database, on the cloud or something, and use SQL or some such language to do the crunching (and aggregating and what have you) until it’s small enough to deal with, and then download it and finish it off on your computer. The second solution, called MapReduce (the idea started at Google), or hadoop (the open-source implementation started at Yahoo) allows you to work on the raw data directly where it lies (e.g. on the Amazon cloud (where it’s actually Elastic MapReduce, which I believe is a fork of hadoop)), in iterative steps called mappings and reduction steps.
Actually there’s an argument to be made, apparently, because I heard it at the Strata conference, that data scientists should never use hadoop at all, that we should always just use relational databases. However, that doesn’t seem economical, the way it’s set up at my work anyway. Please comment if you have an opinion about this because it’s interesting to me how split the data science community seems to be about this issue.
On the other hand, if you can make using hadoop as easy as using SQL, then who cares? That’s kind of what’s happened with Mortar. Let me explain.
Mortar has a web-based interface with two windows. On top we have the pig window and on the bottom a python editor. The pig window is in charge and you can call python functions in the pig script if you have defined them below. Pig is something like SQL but is procedural, so you tell it when to join and when to aggregate and what functions to use in what order. Then pig figures out how to turn your code into map-reduce steps, including how many iterations. They say pig is good at this but my guess is that if you really don’t know anything about how map-reduce works then it’s possible to write pig code that’s super inefficient.
One cool feature, which I think comes from pig itself but in any case is nicely viewable through the Mortar interface, is that you can ask it to “illustrate” the resulting map-reduce code and it takes a small sample of your data and shows example data (of “every type” in a certain sense) at every step of the process. This is super useful as a bug-watching feature to see that it’s looking good with small data sets.
The interface is well designed and easy to use. Overall it reduces a pretty scary and giant data job to something that would probably take me about a week to feel comfortable. And new hires who know python can get up to speed really quickly.
There are some issues right now, but the Mortar guys seem eager to improve the product quickly. To name a few:
- it’s not yet connected to git (although you can save pig and python code you’ve already run),
- you can’t import most python modules except super basic ones like math (including ones you’ve written; right now you have to copy and paste into their editor),
- they won’t be able to ever let you import numpy because they are actually using jython and numpy is c-based,
- it doesn’t automatically shut down the cluster after your job is finished, and
- it doesn’t yet allow people to share a cluster
These last two mean that you have to be pretty on top of your stuff, which is too bad if you want to leave for the night and start a job and then bike home and feed your kids and put them to bed. Which is kind of my style.
Please tell me if any of you know other approaches that allow python-savvy (but not java savvy) analytics nerds access to hadoop in an easy way!



