Why Credit Unions? (#OWS) (part 1)
This is a guest post by FogOfWar. See also the “Credit Unions in NYC flyer“.
Moving your money from a megabank to a credit union or community development bank makes for a good sound bite, but is it really an action that can have an impact in the right direction? I think so (although the matter is not free from doubt), and thought it would be worthwhile to lay out thoughts on the subject as a follow-up to the “What is a Credit Union?” post.
I’ll focus this discussion on credit unions, rather than community development banks or smaller locally owned banks as that’s where my knowledge lies.
Credit Unions are not Too Big To Fail
A quick google search indicates the largest credit union in America is Navy FCU with $34Bn in assets. (Internationally, it may be the Dutch Rabobank, although I’ve never gotten a good handle on whether Rabo is still a cooperative or not.) Individual credit unions fail regularly, just like individual banks, but there isn’t one CU that’s in danger of crashing the entire financial system in the same manner as BAC, C, JPM or WF.
During the 2008 crisis and aftermath the only credit unions that got a federal bailout were the corporate credit unions. There’s a good article about that here. The corporate credit unions definitely got into trouble buying structured products and I don’t want to gloss this fact over. There’s a split between the retail credit unions, who are going to have to pay for these mistakes, and the corporate credit unions which made the bad investments as well as the NCUA, who was asleep at the switch when the corporate CUs were making that investment. Also worth noting that the NCUA has filed suit against the banks for selling crap product to the corporate CUs.
The corporate credit union bailout was small proportionate to the overall credit union size. $30 bn of gov’t backed bonds equates to $270 bn proportionate for banks—less than ½ of the official state of TARP and a small fraction of the overall size of the taxpayer support given to the large (non-CU) banks indirectly through TAF, TSLF, PDFC, TARP, TALF, etc.,… (see this for an explanation of term).
All in all, I’d say CUs come out somewhat ahead by this measure.
Volker Rule/Glass Steagall
Unlike commercial banks, credit unions never revoked the Glass Steagall act and remained segmented as “pure” traditional banking entities. This means that CUs don’t mingle traditional banking (deposits, checking accounts, loans to customers), with investment banking activities (IPOs, M&A advisory) or derivatives trading or sales desks, let alone prop desk frontrunning of client information.
There’s a lot of ink out there on Volker and Glass Steagall. In short, it seems like a good idea, if not sufficient as a complete solution, to keep traditional banking segmented from investment banking and proprietary trading. The core point is that trading risk should not infect the core banking business putting it (and the taxpayer standing behind the federal deposit insurance) at risk. Very good recent example of this here.
CUs come out dramatically ahead on this measure.
Lobbying—just as bad?
Credit Unions do lobby, largely through two groups, CUNA and NAFCU. In fact, NAFCU has been an opponent of the CPFB, and the CU lobby got itself removed from the debit swipe fee cap.
There was a time I can remember when CUNA and NAFCU just went up to the hill to remind Congress that they existed and defend against the ABA’s occasional attempts to change the tax status of CUs. It seems times have, rather unfortunately, changed.
Regrettably, no advantage to Credit Unions here.
Part 2 will talk about investments in local communities, democratic control (the good, the bad and the ugly) and securitization/mortgage transfers.
FoW
Math in Business
Here’s an annotated version of my talk at M.I.T. a few days ago. There was a pretty good turnout, with lots of grad students, professors, and I believe some undergraduates.
What are the options?
First let’s talk about the different things you can do with a math degree.
Working as an academic mathematician
You all know about this, since you’re here. In fact most of your role models are probably professors. More on this.
Working at a government institution
I don’t have personal experience, but there are plenty of people I know who are perfectly happy working for the spooks or NASA.
Working as a quant in finance
This means trying to predict the market in one way or another, or modeling how the market works for the sake of measuring risk.
Working as a data scientist
This is my current job, and it is kind of vague, but it generally means dealing with huge data sets to locate, measure, visualize, and forecast patterns. Quants in finance are examples of data scientists, and they work in the most, or one of the most, developed subfield of data science.
Cultural Differences
I care a lot about the culture of my job, as I think women in general tend to. For that reason I’m going to try to give a quick and exaggerated description of the cultures of these various options and how they differ from each other.
Feedback is slow in academics
I’m still waiting for my last number theory paper to get published, and I left the field in 2007. That hurts. But in general it’s a place for people who have internal feedback mechanisms and don’t rely on external ones. If you’re a person who knows that you’re thinking about the most important question in the world and you don’t need anyone to confirm that, then academics may be a good cultural fit. If, on the other hand, you are wondering half the time why you’re working on this particular problem, and whether the answer really matters or ever will matter to someone, then academics will be a tough place for you to live.
Institutions are painfully bureaucratic
As I said before, I don’t have lots of personal experience here, but I’ve heard that good evidence that working at a government institution is sometimes painful in terms of waiting for things that should obviously happen actually happen. On the other hand I’ve also head lots of women say they like working for institutions and that they are encouraged to become managers and grow groups. We will talk more about this idea of being encouraged to be organized.
Finance firms are cut-throat
Again, exaggerating for effect, but there’s a side effect of being in a place whose success is determined along one metric (money), and that is that people are typically incredibly competitive with each other for their perceived value with respect to that metric. Kind of like a bunch of gerbils in a case with not quite enough food. On the other hand, if you love that food yourself, you might like that kind of struggle.
Startups are unstable
If you don’t mind wondering if your job is going to exist in 1 or 2 months, then you’ll love working at a startup. It’s an intense and exciting journey with a bunch of people you’d better trust or you’ll end up really hating them.
Outside academics, mathematicians have superpowers
One general note that you, being inside academics right now, may not be aware of: being really fucking good at math is considered a superpower by the people outside. This is because you can do stuff with your math that they actually don’t know how to do, no matter how much time they spend trying. This power is good and bad, but in any case it’s very different than you may be used to.
Going back to your role models: you see your professors, they’re obviously really smart, and you naturally may want to become just like them when you grow up. But looking around you, you notice there are lots of good math students here at M.I.T. (or wherever you are) and very few professor jobs. So there is this pyramid, where lots of people a the bottom are all trying to get these fancy jobs called math professorships.
Outside of math, though, it’s an inverted world. There are all of these huge data sets, needing analysis, and there are just very few places where people are getting trained to do stuff like that. So M.I.T. is this tiny place inside the world, which cannot possibly produce enough mathematicians to satisfy the demand.
Another way of saying this is that, as a student in math, you should absolutely be aware that it’s easier to get a really good job outside the realm of academics.
Outside academics, you get rewarded for organizational skills (punished within)
One other big cultural difference I want to mention is that inside academics, you tend to get rewarded for avoiding organizational responsibilities, with some exceptions perhaps if you organize conferences or have lots of grad students. Outside of academics, though, if you are good at organizing, you generally get rewarded and promoted and given more responsibility for managing a group of nerds. This is another personality thing- some math nerds love the escape from organizing, or just plain suck at it, and maybe love academics for that reason, whereas some math nerds are actually quite nurturing and don’t mind thinking about how systems should be set up and maintained, and if those people are in academics they tend to be given all of the “housekeeping” in the department, which is almost always bad for their career.
Mathematical Differences
Let’s discuss how the actual work you would do in these industries is different. Exaggeration for effect as usual.
Academic freedom is awesome but can come with insularity
If you really care about having the freedom to choose what math you do, then you absolutely need to stay in academics. There is simply no other place where you will have that freedom. I am someone who actually does have taste, but can get nerdy and interested in anything that is super technical and hard. My taste, in fact, is measured in part by how much I think the answer actually matters, defined in various ways: how many people care about the answer and how much of an impact would knowing the answer make? These properties are actually more likely to be present in a business setting. But some people are totally devoted to their specific field of mathematics.
The flip side of academic freedom is insularity; since each field of mathematics gets to find its way, there tend to be various people doing things that almost nobody understands and maybe nobody will ever care about. This is more or less frustrating to you depending on your personality. And it doesn’t happen in business: every question you seriously work on is important, or at least potentially important, for one reason or another to the business.
You don’t decide what to work on in business but the questions can be really interesting
Modeling with data is just plain fascinating, and moreover it’s an experimental science. Every new data set requires new approaches and techniques, and you feel like a mad scientist in a lab with various tools that you’ve developed hanging on the walls around you.
You can’t share proprietary information with the outside world when you work in business or for the government
The truth is, the actual models you create are often the crux of the profit in that business, and giving away the secrets is giving away the edge.
On the other hand, sometimes you can and it might make a difference
The techniques you develop are something you generally can share with the outside world. This emerging field of data science can potentially be put to concrete and good use (more on that later).
In business, more emphasis on shallower, short term results
It’s all about the deadlines, the clients, and what works.
On the other hand, you get much more feedback
It’s kind of nice that people care about solving urgent problems when… you’ve just solved an urgent problem.
Which jobs are good for women?
Part of what I wanted to relay today is those parts of these jobs that I think are particularly suitable for women, since I get lots of questions from young women in math wondering what to do with themselves.
Women tend to care about feedback
And they tend to be more sensitive to it. My favorite anecdote about this is that, when I taught I’d often (not always) see a huge gender difference right after the first midterm. I’d see a young woman coming to office hours fretting about an A- and I’d have to flag down a young man who got a C, and he’d say something like, “Oh, I’m not worried, I’ll just study and ace the final.” There’s a fundamental assumption going on here, and women tend to like more and more consistent feedback (especially positive feedback).
One of my most firm convictions about why there are not more women math professors out there is that there is virtually no feedback loop after graduating with a Ph.D., except for some lucky people (usually men) who have super involved and pushy advisors. Those people tend to be propelled by the will of their advisor to success, and lots of other people just stay in place in a kind of vacuum. I’ve seen lots of women lose faith in themselves and the concept of academics at this moment. I’m not sure how to solve this problem except by telling them that there’s more feedback in business. I do think that if people want to actually address the issue they need to figure this out.
Women tend to be better communicators
This is absolutely rewarded in business. The ability to hold meetings, understand people’s frustrations and confusions and explain in new terms so that they understand, and to pick up on priorities and pecking orders is absolutely essential to being successful, and women are good at these things because they require a certain amount of empathy.
In all of these fields, you need to be self-promoting
I mention this because, besides needing feedback and being good communicators, women tend to not be as self-promoting as men, and this is something that they should train themselves out of. Small things like not apologizing help, as does being very aware of taking credit for accomplishments. Where men tend to say, “then I did this…”, women tend to say, “then my group did this…”. I’m not advocating being a jerk, but I am advocating being hyper aware of language (including body language) and making sure you don’t single yourself out for not being a stand-out.
The tenure schedule sucks for women
I don’t think I need to add anything to this.
No “summers off” outside academics… but maybe that’s a good thing
Academics don’t actually take their summers off anyway. And typically the women are the ones who end up dealing more with the kids over the summer, which could be awesome if that’s what they want but also tends to add a bias in terms of who gets papers written.
How do I get a job like that?
Lots of people have written to me asking how to prepare themselves for a job in data science (I include finance in this category, but not the governmental institutions. I have no idea how to get a job at NASA or the NSA).
Get a Ph.D. (establish your ability to create)
I’m using “Ph.D.” as a placeholder here for something that proves you can do original creative building. But it’s a pretty good placeholder; if you don’t have a Ph.D. but you are a hacker and you’ve made something that works and does something new and clever, that may be sufficient too. But if you’ve just followed your nose, and done well in your courses then it will be difficult to convince someone to hire you. Doing the job well requires being able to create ad hoc methodology on the spot, because the assumptions in developed theory never actually happen with real data.
Know your way around a computer
Get to the point where you can make things work on your computer. Great if you know how unix and stuff like cronjobs (love that word) work, but at the very least know to google everything instead of bothering people.
Learn python or R, maybe java or C++
Python and R are the very basic tools of a data scientist, and they allow quick and dirty data cleaning, modeling, measuring, and forecasting. You absolutely need to know one of them, or at the very least matlab or SAS or STATA. The good news is that none of these are hard, they just take some time to get used to.
Acquire some data visualization skills
I would guess that half my time is spent visualizing my results in order to explain them to non-quants. A crucial skill (both the pictures and the explanations).
Learn basic statistics
And I mean basic. But on the other hand I mean really, really, learn it. So that when you come across something non-standard (and you will), you can rewrite the field to apply to your situation. So you need to have a strong handle on all the basic stuff.
Read up on machine learning
There are lots of machine learners out there, and they have a vocabulary all their own. Take the Stanford Machine Learning classor something to learn this language.
Emphasize your communication skills and follow-through
Most of the people you’ll be working with aren’t trained mathematicians, and they absolutely need to know that you will be able to explain your models to them. At the same time, it’s amazing how convincing it is when you tell someone, “I’m a really good communicator.” They believe you. This also goes back to my “do not be afraid to self-promote” theme.
Practice explaining what a confidence interval is
You’d be surprised how often this comes up, and you should be prepared, even in an interview. It’s a great way to prep for an interview: find someone who’s really smart, but isn’t a mathematician, and ask them to be skeptical. Then explain what a confidence interval is, while they complain that it makes no sense. Do this a bunch of times.
Other stuff
I wanted to throw in a few words about other related matters.
Data modeling is everywhere (good data modelers aren’t)
There’s an asston of data out there waiting to be analyzed. There are very few people that really know how to do this well.
The authority of the inscrutable
There’s also a lot of fraud out there, related to the fact that people generally are mathematically illiterate or are in any case afraid of or intimidated by math. When people want to sound smart they throw up an integral, and it’s a conversation stopper. It is a pretty evil manipulation, and it’s my opinion that mathematicians should be aware of this and try to stop it from happening. One thing you can do: explain that notation (like integrals) is a way of writing something in shorthand, the meaning of which you’ve already agreed on. Therefore, by definition, if someone uses notation without that prior agreement, it is utterly meaningless and adds rather than removes confusion.
Another aspect of the “authority of the inscrutable” is the overall way that people claimed to be measuring the risk of the mortgage-backed securities back before and during the credit crisis. The approach was, “hey you wouldn’t understand this, it’s math. But trust us, we have some wicked smart math Ph.D.’s back there who are thinking about this stuff.” This happens all the time in business and it’s the evil side of the superpower that is mathematics. It’s also easy to let this happen to you as a mathematician in business, because above all it’s flattering.
Open source data, open source modeling
I’m a huge proponent of having more visibility into the way that modeling affects us all in our daily lives (and if you don’t know that this is happening then I’ve got news for you). A particularly strong example is the Value-added modeling movement currently going on in this country which evaluates public teachers and schools. The models and training data (and any performance measurements) are proprietary. They should not be. If there’s an issue of anonymity, then go ahead and assign people randomly.
Not only should the data that’s being used to train the model be open source, but the model itself should be too, with the parameters and hyper-parameters in open-source code on a website that anyone can download and tweak. This would be a huge view into the robustness of the models, because almost any model has sub-modeling going on that dramatically affects the end result but that most modelers ignore completely as a source of error. Instead of asking them about that, just test it for yourself.
Meetups
The closest thing to academics lectures in data science is called “Meetups”. They are very cool. I wrote about them previously here. The point of them is to create a community where we can share our techniques (without giving away IP) and learn about new software packages. A huge plus for the mathematician in business, and also a great way to meet other nerds.
Data Without Borders
I also wanted to mention that, once you have a community of nerds such as is gathered at Meetups, it’s also nice to get them together with their diverse skills and interests and do something cool and valuable for the world, without it always being just about money. Data Without Borders is an organization I’ve become involved with that does just that, and there are many others as well.
Please feel free to comment or ask me more questions about any of this stuff. Hope it is helpful!
Some really terrible ideas
I’m in the middle of writing up my talk about “math in business”. Turns out I can talk faster than I can type, since it’s taking me much longer to write this up that in took for me to say.
In the meantime I want to share with you some really terrible ideas I’ve seen in the news lately.
The prize goes to this idea of how to make the ratings agencies better in Europe. Namely, by banning them when they don’t like them. From the Wall Street Journal article:
In a press conference, Barnier acknowledged this was a “difficult” issue and said that Europe needed to “reduce its dependency on ratings.”
While Barnier gave no further details on the idea of banning some sovereign ratings, a person familiar with the situation explained when the ratings suspension or ban could be appropriate.
The official said the ban would only be used in a “specific” set of circumstances.
That could include if the consequences of a ratings move led to “volatility” or a threat to financial stability. The person also said that the ratings could be banned if there were “imminent changes to the creditworthiness of a state because of negotiations” on a bailout program.
It would be one thing if we had gotten the overall impression that the ratings agencies have been exaggerating a problem through their sovereign ratings… but I don’t have that impression, do you? Um, I have an idea, instead of banning them, how about we instead force them to explain their reasoning? How is turning off the heart rate monitor going to help the patient?
Next up, I just want to say how much I hate articles with misleading titles like this one. Now that I link to it I realize the title has been changed from “Jobless Claims in U.S. Dropped Last Week” to “Jobless Claims in U.S. Decreased Last Week.” This is slightly better but I’ll still complain: the drop from 409,000 to 403,000 is clearly not statistically significant, as anyone who knows any statistics could see just by how small that relative shift is. But even worse if you read the article, you’ll see that last week’s numbers had come in at 404,000 at this week had been corrected to 409,000. So the actual news should have read “U.S. Jobless Claims Changed Not At All”. I guess that’s not a snazzy title.
Here’s not such a bad idea: making people own the underlying sovereign bonds if they buy CDS contracts on them. I’ve seen enough damage cause by “not knowing where the CDS’s live” with regard to Greek debt to know that uncontrolled selling of CDS contracts needs to be curbed – even better if we can make people transparent about their holdings, of course, but that’s kind of a pipe dream.
However, you’ll notice in the article that it’s kind of a weird rule, where countries can “opt out” of the ban if they want to. When would they want to do that? From the Bloomberg article:
The opt out-clause won over some critics of possible bans.
“I never signed up to the belief that a ban on uncovered sovereign CDS would have any positive impact,” Syed Kamall, who represents London in the EU Parliament, said in an e-mailed statement. “However, I’m reassured that member states will have the ability to opt out of the ban, if they see signals that sovereign debt markets are distressed.”
So, I’m guessing that means that some people think that when nobody’s willing to buy their bonds, they will become willing if they can find some A.I.G.-like entity that is willing to sell CDS contracts on those bonds for way less than they’re worth? I don’t get it. Please explain if you do.
And also I don’t like how this idea of no naked CDS contracts is being lumped in with the idea of no short selling- maybe because there’s also the word “naked” associated with that? Let’s not get confused: naked short selling is already illegal. But short selling itself isn’t and shouldn’t be.
Topology of financial modeling
After my talk on Monday there were lots of questions and comments, which is always awesome (will blog the contents soon).
One person in the audience asked me if I’d ever heard of CompTop, which I hadn’t. And actually, even though I vaguely understand what they’re talking about, I still don’t understand it sufficiently to blog about it- but it reminds me of something else which I would like to blog about, and which combines topology and modeling.
Maybe they’re even the same thing! But if so (especially if so), I’d like to get my idea down onto electronic paper before I read theirs. This is kind of like my thing about not googling something until you’ve tried to work it out for yourself.
So here’s the setup. In different fields in finance, there’s a “space” you work in. I worked in Futures, which you’ve heard of because when they talk about the price of barrels of oil going up (or maybe down, but you don’t hear about it as much when that happens), they are actually talking about futures prices. This also happens with basic food prices such as corn and wheat; corn and oil are linked of course through ethanol production. There are also futures on the S&P (or any other major stock index), bonds, currencies, other commodities, or even options on stock indices.
The general idea, which is given away by the name, is that when you buy a futures contract, you are placing a bet on the future price of something. Futures were started as a way for farmers to hedge their risks when they were growing food. But clearly other things have happened since then.
There’s a way of measuring the dimension of this space of instruments, which is less trivial than counting them. For example, there is a “2 year U.S. bond” future as well as a “5 year U.S. bond future” and you may guess (and you’d be right) that these don’t really represent independent dimensions.
Indeed there’s a concept of independence which one can use coming from statistics (so, statistical independence), which is pretty subjective in that it depends on what time period and how much data you use to measure it (and lately we’ve seen less independence in general). But even so, you can go blithely forward and count how many dimensions your space has, and you generally got something like 15, at least before the credit crisis hit. This process is called PCA, and I’ll write a post on it sometime.
Depending on which instruments you counted, and how liquid you expected them to be, you could get a few more “independent” instruments, but you also may be fooling yourself with idiosyncratic noise caused by those instruments being not very liquid. So there are some subtleties.
Once you have your space measured in terms of dimension, you can choose a basis and look at things along the basis vectors. You can see how your different models behave, for example. You might see how the bond model you worked on places no bet on the basis vectors corresponding to lean hog futures.
That made me wonder the following question. If we can measure the space of instruments, can we also measure the space of models? Is this some kind of dual? If so, is there some kind of natural upper bound on the number of (independent) models we could ever have which all make profit?
Note there’s also a way of making sure that models are statistically independent, so this part of the question is well-defined. But it’s not clear what property of the space of instruments you are measuring when you ask for a model on that space which “makes profit”.
Another related question is whether such a question can really only be asked at a given time horizon (if it can be asked at all). I’ll explain.
The horizon of a model is essentially how long you expect a given bet to last in terms of time. For example, a weekly horizon model is something you’d typically only see on a slow-moving instrument class like bonds. There are plenty of daily models on equities, but there are also incredibly hyper fast “high frequency” models, say on currencies, which care about the speed of light and how different computers in the same room, being at different internal temperatures, can’t place consistent timestamps on ticker data.
These different horizons have such different textures, it makes me wonder if the question of an upper bound on the number of profitable models, if true, is true at each horizon.
Another related question: what about topological weirdness inside the space of instruments? If you plot some of this (take as a baby model three instruments that are essentially independent, choose a time horizon, and plot the simultaneous returns) the main characteristic you’ll see is that it’s a bounded blob. But inside that blob are certainly inconsistencies; in particular the density is not everywhere the same. Is the lack of consistency a signal that there’s a model there? Does the market know about holes, for example? Maybe not, which would mean that the space of (profitable) models is perhaps better understood as a space whose basis consists of something like “holes in the instrument space”, rather than a dual.
This is verging on something like what CompTop is talking about. Maybe. I’ll have to go read what they’re doing now.
David Graeber on Occupy Wall Street
Could I love David Graeber any more? He wrote a fantastic book which I’ve blogged about here just in case you missed it.
Check out his account, cross posted from Naked Capitalism, on being one of the original Occupiers of Wall Street (I feel like I should have guessed this but I didn’t).
I hope he gets onto the Alternative Banking working group.
Alternative Banking System
I just got invited to join the Alternative Banking System working group from Occupy Wall Street. It’s run by Carne Ross, who has written a book called the Leaderless Revolution. I’m excited to meet the group this coming weekend. It looks like there will be many interesting and unconventional thinkers there.
I got back last night from my Cambridge, where I spoke to people about doing math in business. I will write up my notes from that talk soon and post them, and they will include my suggestions for how to prepare yourself to be a data scientist if you’re an academic mathematician. This is a first stab at a longer term project I have to define a possible “data science curriculum”.
What is a Credit Union? (#OWS)
This is a guest post by FogOfWar:
There’s been a call (associated with the “Occupy Wall Street” movement) for consumers to move their bank accounts from large TBTF banks into local credit unions. Nov. 5th is the target date. This is a similar message to one Arianna Huffington gave a few years back.
The above inspire a quick post on the subject of “What is a Credit Union and why is it different from a mega-bank?”
What can I do at a Credit Union?
Pretty much all the same stuff you can do at a bank. They have checking accounts (although they call them “share accounts”, it’s the same thing), savings accounts, CDs, credit cards, debit cards, auto loans, mortgages, lines of credit. All of the stuff a normal bank offers. Some of the smaller CUs (just like some of the smaller banks) don’t offer everything, but it’s substantially the same.
The only difference in services is that you generally can’t make investments (stocks, bonds, etc.) through your credit union. IMHO, this isn’t much of a downside, as the brokers associated with major banks generally aren’t as good as the standalone retail brokers (like Fidelity, Vanguard, TIAA-CREF, etc.)
The other difference is that you can’t just walk off the street and open a credit union account; you have to be eligible in their “field of membership” (more on that below).
How are the rates?
It varies, but in general you’ll get better rates at a credit union than at a bank (certainly than at a megabank). An easy way to check is to look at your checking account statement now (or call your bank) and see what the APY is (Annual Percentage Yield), and then check the credit union to see the APY on their basic share draft account.
There are credit unions with sucky rates out there (often the really small ones—they have a lot of operational costs), but I’ve usually found that I get better rates on savings and better rates on loans from a CU.
What’s the real difference?
The real difference is ownership. Banks are owned by outside investors—usually people who own the stock for a big bank—and they need to pay those owners a profit in the form of dividends (or share repurchases which are economically equivalent). Credit Unions are owned by their depositors (called “members”). That’s why the “checking account” is called a “share account”—you own a “share” (another name for stock) in the credit union. The board of directors is elected at an annual meeting, one person, one vote. BoD members are not paid for serving on the board.
This also explains why Credit Unions can offer better rates: they don’t have to pay a profit to their stockholders, instead that “profit” is returned back to you, the owners. Note that CUs are also exempt from corporate tax, and this makes some difference, but IMHO, it’s the absence of needing to pay dividends that really gives CUs the ability to pay better rates to their customer/owners.
Am I supporting the community when I deposit with a Credit Union?
There’s a good argument that yes, you are. Credit Union’s make loans back to the people in their membership. So the money you put on deposit is being leant back to people in the community of the credit union. Credit unions don’t trade derivatives or run speculative investment books. By and large they make loans to members and then hold on to those loans (i.e., they don’t “securitize” those loans out to other people).
For those who know the movie It’s a Wonderful Life, it’s a pretty good description of how a credit union can work within a community. Technically the movie describes a Thrift (somewhat similar), but it could just as easily been about a CU.
Who is eligible to join a Credit Union?
Each credit union has a “field of membership”. Some are employment-based, so you are eligible if you or an immediate family member works at a certain place. For example, NBC has a credit union for its NY employees. Note that NBC does not own the credit union, the CU is owned by its members (one person, one vote), it’s just that the credit union is there for NBC employees.
Some credit unions are associational. A good example of this is church credit unions (which are pretty common). There are also Community Development Credit Unions, which are set in lower-income areas and anyone in the area can join (Lower East Side People’s FCU is a good example).
There are a number of educational credit unions—these vary, but often faculty, students, employees and alumni are all eligible to join. Again, note that the university does not own the credit union—the CU is owned by the members—it’s just the prerequisite to join that particular credit union.
How do I find a credit union I can join?
There are some “credit union locators” online, but the one’s I’ve seen kinda suck. I’d say try a Google search. So if you live in Boise, I’d search for “Boise Credit Unions”. You can also try www.ncua.gov, which will give you all the credit unions in a particular area. I tend to like the larger credit unions (at least $20m in assets), as they tend to have hit a size where they’re operationally more together (making mistakes on your money is no fun).
You can also ask at the HR department at your job “hey, does working here make me eligible to join a credit union?” If they say “no”, you can say “why not? Is anyone working on having us join up with a good CU?”
Are there any downsides?
There aren’t a lot of ATMs, so every time you need cash & use a bank ATM, you’ll be paying that ridiculous fee. This can definitely suck, although one way around it is to have a debit card and take cash back all the time when you buy stuff (there’s no charge for taking cash back on a debit card—it’s just a question of whether the merchant lets you do it, and most supermarkets and drug stores do).
Also, this makes depositing paper checks a pain in the ass: you actually have to put them in an envelope and mail them to the credit union. How did society function before we had the internet?
Also, if it’s a work credit union, you can check to see if they have a branch at your office—this can make things a lot easier.
Anyway, that’s a quick rundown. Sure I missed something, but I’ll drop it in the comments if I remember later.
Here’s a flyer I made for OWS which contains information on a few credit unions in New York City:
FoW
Datadive update
I left my datadive team at 9:15pm last night hard at work, visualizing the data in various ways as well as finding interesting inconsistencies. I will try to post some actual results later, but I want to wait for them to be (somewhat) finalized. For now I can make some observations.
- First, I really can’t believe how cool it is to meet all of these friendly and hard-working nerds who volunteered their entire weekend to clean and dig through data. It’s a really amazing group and I’m proud of how much they’ve done.
- Second, about half of the data scientists are women. Awesome and unusual to see so many nerd women outside of academics!
- Third, data cleaning is hard work and is a huge part of the job of a data scientist. I should never forget that. Having said that, though, we might want to spend some time before the next datadive pre-cleaning and formatting the data so that people have more time to jump into the analytics. As it is we learned a lot about data cleaning as a group, but next time we could learn a lot about comparing methodology.
- Statistical software packages such as Stata have trouble with large (250MB) files compared to python, probably because of the way they put everything into memory at once. So it’s cool that everyone comes to a datadive with their own laptop and language, but some thought should be put into what project they work on depending on this information.
- We read Gelman, Fagan and Kiss’s article about using the Stop and Frisk data to understand racial profiling, with the idea that we could test it out on more data or modify their methodology to slightly change the goal. However, they used crime statistics data that we don’t have and can’t find and which are essential to a good study.
- As an example of how crucial crime data like this is, if you hear the statement, “10% of the people living in this community are black but 50% of the people stopped and frisked are black,” it sounds pretty damning, but if you add “50% of crimes are committed by blacks” then it sound less so. We need that data for the purpose of analysis.
- Why is crime statistics data so hard to find? If you go to NYPD’s site and search for crime statistics, you get really very little information, which is not broken down by area (never mind x and y coordinates) or ethnicity. That stuff should be publicly available. In any case it’s interesting that the Stop and Frisk data is but the crime stats data isn’t.
- Oh my god check out our wiki, I just looked and I’m seeing some pretty amazing graphics. I saw some prototypes last night and I happen to know that some of these visualizations are actually movies, showing trends over time. Very cool!
- One last observation: this is just the beginning. The data is out there, the wiki is set up, and lots of these guys want to continue their work after this weekend is over. That’s what I’m talking about.
NYCLU: Stop Question and Frisk data
As I mentioned yesterday, I’m the data wrangler for the Data Without Borders datadive this weekend. There are three N.G.O.’s participating: NYCLU (mine), MIX, and UN Global Pulse. The organizations all pitched their data and their questions last night to the crowd of nerds, and this morning we are meeting bright and early (8am) to start crunching.
I’m particularly psyched to be working with NYCLU on Stop and Frisk data. The women I met from NYCLU last night had spent time at Occupy Wall Street the previous day giving out water and information to the protesters. How cool!
The data is available here. It’s zipped in .por format, which is to say it was collected and used in SPSS, a language that’s not open source. I wanted to get it into csv format for the data miners this morning, but I have been having trouble. Sometimes R can handle .por files but at least my install of R is having trouble with the years 2006-2009. Then we tried installing PSPP, which is an open source version of SPSS, and it seemed to be able to import the .por files and then export as csv, in the sense that it didn’t throw any errors, but actually when we looked we saw major flaws. Finally we found a program called StatTransfer, which seems to work (you can download a trial version for free) but unless you pay $179 for the package, it actually doesn’t transfer all of the lines of the file for you.
If anyone knows how to help, please make a comment, I’ll be checking my comments. Of course there could easily be someone at the datadive with SPSS on their computer, which would solve everything, but on the other hand it could also be a major pain and we could waste lots of precious analyzing time with formatting issues. I may just buckle down and pay $179 but I’d prefer to find an open source solution.
UPDATE (9:00am): Someone has SPSS! We’re totally getting that data into csv format. Next step: set up Dropbox account to share it.
UPDATE (9:21am): Have met about 5 or 6 adorable nerds who are eager to work on this sexy data set. YES!
UPDATE (10:02am): People are starting to work in small groups. One guy is working on turning the x- and y-coordinates into latitude and longitude so we can use mapping tools easier. These guys are awesome.
UPDATE (11:37am): Now have a mapping team of 4. Really interesting conversations going on about statistically rigorous techniques for human rights abuses. Looking for publicly available data on crime rates, no luck so far… also looking for police officer id’s on data set but that seems to be missing. Looking also to extend some basic statistics to all of the data set and aggregated by months rather than years so we can plot trends. See it all take place on our wiki!
UPDATE (12:24pm): Oh my god, we have a map. We have officer ID’s (maybe). We have awesome discussions around what bayesian priors are reasonable. This is awesome! Lunch soon, where we will discuss our morning, plan for the afternoon, and regroup. Exciting!
UPDATE (2:18pm): Nice. We just had lunch, and I managed to get a sound byte about every current project, and it’s just amazing how many different things are being tried. Awesome. Will update soon.
UPDATE (7:10pm): Holy shit I’ve been inside crunching data all day while the world explodes around me.
Data Without Borders: datadive weekend!
I’m really excited to be a part of the datadive this weekend organized by Data Without Borders. From their website:
Selected NGOs will work with data enthusiasts over the weekend to better understand their data, create analyses and insights, and receive free consultations.
I’ve been asked to be a “data wrangler” at the event, which means I’m going to help project manage one of the projects of the weekend, which is super exciting. It means I get to hear about cool ideas and techniques as they happen. We’re expecting quite a few data scientists, so the amount of nerdiness should be truly impressive, as well as the range of languages and computing power. I’m borrowing a linux laptop since my laptop isn’t powerful enough for the large data and the crunching. I’ve got both python and R ready to go.
I can’t say (yet) who the N.G.O. is or what exactly the data is or what the related questions are, but let me say, very very cool. One huge reason I started this blog was to use data science techniques to answer questions that could actually really matter to people. This is my first real experience with that kind of non-commercial question and data set, and it’s really fantastic. The results of the weekend will be saved and open.
I’ll be posting over the weekend about the project as well as showing interim results, so stay tuned!
Wall Street and the protests
Today I want to update you on my involvement with the Occupy Wall Street protest and also make an observation about the defensive behavior we see by the Wall Streeters themselves.
Update
Yesterday after work I went back to the protests and looked around to offer a teach-in. Unfortunately it hadn’t been sufficiently organized: the contact who had originally invited me wasn’t around, and hadn’t confirmed with me on email, and nobody else knew anything. It was also very windy, threatening rain, and the noise of the drumming was overbearing. There were drumming circles on two of the four corners of the square, and in the other two corners there were already meetings going on. It would be great if the protests could restrict the drumming area so that people could actually talk.
However, I kind of suspected this would happen, so I wasn’t disappointed. I handed out some flyers with a few friends that met me down there, and I met a few new really interesting and engaging people. I got re-invited to give a teach-in by a very nice man named Rock, who took my information. Rock suggested a daytime talk sometime around noon, and this sounds about right. Hopefully this will pan out, but even if it doesn’t now I have a flyer to distribute and it’s a conversation starter if nothing else. One of my friends also suggested having a t-shirt made with the phrase, “ask me about the financial system” printed on it. I think this is a great idea. I will go back down and be involved when I can make the time.
Also, I wanted to share Matt Taibbi’s column about the protest. His five top demands have a lot in common with the ones we came up with here.
Act Crazy
You know how some people win fights even though they’re not big or strong? They act totally crazy and angry, and it works because it confuses their opponents. This is what I think the tactic of the big bosses on Wall Street is right now. They’ve got Tim Geithner talking about it:
“They react to what is pretty modest, common sense observations about the system as if they are deep affronts to the dignity of their profession. And I don’t understand why they are so sensitive,” Geithner said at a forum hosted by The Atlantic and the Aspen Institute.
We’ve also seen Paul Krugman address this:
Last year, you may recall, a number of financial-industry barons went wild over very mild criticism from President Obama. They denounced Mr. Obama as being almost a socialist for endorsing the so-called Volcker rule, which would simply prohibit banks backed by federal guarantees from engaging in risky speculation. And as for their reaction to proposals to close a loophole that lets some of them pay remarkably low taxes — well, Stephen Schwarzman, chairman of the Blackstone Group, compared it to Hitler’s invasion of Poland.
The overall idea is to act like they are the victims somehow. Actually there’s another article in Bloomberg about the Wall St suffering, which I find fascinating as a phrase, and which contains passages like this one:
Bankers aren’t optimistic about those gains. Options Group’s Karp said he met last month over tea at the Gramercy Park Hotel in New York with a trader who made $500,000 last year at one of the six largest U.S. banks.
The trader, a 27-year-old Ivy League graduate, complained that he has worked harder this year and will be paid less. The headhunter told him to stay put and collect his bonus.
Here’s the thing. They are suffering, in exactly the same way that a child who is spoiled suffers when they are told they can’t get a toy in a store that they want even though they have one at home just like it. But that’s not real need, that’s a temper tantrum. It’s the parents’ responsibility to ignore that kind of posturing and establish reasonable expectations. But the analogy becomes kind of painful here, because who are the parents?
I guess you’d want them to be the government, or the regulators, but the problem is that those groups have shown the same lack of imagination (or fear) of a new world as the people on Wall Street.
So even though the protests are disorganized and sometimes annoying, the very fact that they are putting pressure on the system to fundamentally change is why I will continue to support them.

Bayesian regressions (part 2)
In my first post about Bayesian regressions, I mentioned that you can enforce a prior about the size of the coefficients by fiddling with the diagonal elements of the prior covariance matrix. I want to go back to that since it’s a key point.
Recall the covariance matrix represents the covariance of the coefficients, so those diagonal elements correspond to the variance of the coefficients themselves, which is a natural proxy for their size.
For example, you may just want to make sure the coefficients don’t get too big, or in other words there’s a penalty for large coefficients. Actually there’s a name for just having this prior, and it’s called L2 regularization. You just set the prior to be 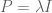
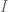

You’re going to end up adding this prior to the actual sample covariance matrix as measured by the data, so don’t worry about the prior matrix being invertible (but definitely do make sure it’s symmetrical).

Moreover, you can have many different priors, corresponding to different parts of the covariance matrix, and you can add them all up together to get a final prior.

From my first post, I had two priors, both on the coefficients of lagged values of some time series. First, I expect the signal to die out logarithmically or something as we go back in time, so I expect the size of the coefficients to die down as a power of some parameter. In other words, I’ll actually have two parameters: one for the decrease on each lag and one overall tuning parameter. My prior matrix will be diagonal and the 
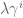
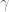
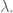
My second prior was that the entries should vary smoothly, which I claimed was enforceable by fiddling with the super and sub diagonals of the covariance matrix. This is because those entries describe the covariance between adjacent coefficients (and all of my coefficients in this simple example correspond to lagged values of some time series).
In other words, ignoring the variances of each variable (since we already have a handle on the variance from our first prior), we are setting a prior on the correlation between adjacent terms. We expect the correlation to be pretty high (and we can estimate it with historical data). I’ll work out exactly what that second prior is in a later post, but in the end we have two priors, both with tuning parameters, which we may be able to combine into one tuning parameter, which again determines the strength of the overall prior after adding the two up.
Because we are tamping down the size of the coefficients, as well as linking them through a high correlation assumption, the net effect is that we are decreasing the number of effective coefficients, and the regression has less work to do. Of course this all depends on how strong the prior is too; we could make the prior so weak that it has no effect, or we could make it so strong that the data doesn’t effect the result at all!
In my next post I will talk about combining priors with exponential downweighting.
Koo: don’t be surprised by the crappy economy
First I wanted to thank you for the wonderful comments I’ve been enjoying and compiling from my last post about what’s corrupt about the financial system and what should be done about it. Even if I don’t end up doing the teach-in (hopefully I will! In any case I’ll go down there, even if it’s just to try to set up the teach-in for a later date) I think this is a really fantastic and important discussion. I’m putting together a final list of issues tonight and I think I’ll make a flyer to bring tomorrow, so if I don’t actually conduct the teach-in (yet) I’ll at least be able to give the info booth the flyers.
And it’s not too late! Please keep the comments coming.
Today I want to start a discussion on Richard Koo’s book, which is about Japan’s so-called “lost decade” (a reader suggested this book to me, and it’s fascinating, so thanks! And please feel free to make more suggestions for my reading list).
You can actually get a pretty good overview of his book by watching this excellent interview by Koo. For those of you, like me, whose sound doesn’t work on their computers, here’s his basic thesis:
- After the housing bubble in Japan burst, a bunch of firms, banks and otherwise, became technically insolvent. This meant that, although they had cash flow, they owed more than their assets.
- Because they were insolvent, they didn’t maximize profits like in normal times; instead they minimized debts.
- In other words, they didn’t borrow money to grow their businesses, like you’d expect in normal circumstances, which is proved by looking at data showing that corporate borrowing went down even as interest rates lowered to zero.
- The CEO’s didn’t talk about this because they don’t want anyone to know they’re insolvent!
- Investors are also somewhat blind to this, because they typically look at growth and cash flow issues.
- Japan’s government made massive investments in order to cover the lack of private investments.
- Rather than this being a mistake, this was absolutely essential to the Japanese economy and prevented a massive depression.
- Moreover, the idea that Japan had a lost decade is false: actually, there was a lot going on in that decade (actually, 15 years) but people didn’t see it. Namely, the balance sheets were slowly improved over the entire economy.
- This is a lesson for us all: any time there’s a massive credit bubble which breaks, we can expect a balance sheet recession where behavior like this is the rule. The U.S. economy right now is an example of this.
I have a few comments about this. I wanted to mention that I’m only about halfway through the book so it’s possible that Koo addresses some of these issues but on the other hand the book was published in 2009 but was clearly written before the U.S. credit crisis was really full-blown:
- A friend of mine who recently traveled to Japan noted that the people there live extremely well. In fact, if he hadn’t been told that their country has been in recession for nearly twenty years then he’d have never guessed it. This supports Koo’s claim that the Japanese government absolutely did the right thing by bankrolling the economy when it did. It also brings up a very basic question: how do we measure success? And why do we listen to economists when they tell us how to define success?
- Not every country can do what Japan did in terms of investing in its economy, although the U.S. probably can. In other words, it depends on how other countries see your credit risk whether you can go ahead and bail out an entire economy.
- Some of the businesses in the U.S. are clearly not technically insolvent; we’ve already seen ample evidence of cash hoarding. On the other hand, I guess if sufficiently many are, then the overall environment can be affected like Koo describes.
- In general it makes me wonder, how many of the firms out there today are technically insolvent? How insolvent? How long will it take for those that are to either fail outright or pay back their loans? If we go by this article, then the answer is pretty alarming, at least for the banks.
In general I like Koo’s book in that it introduces a new paradigm which explains something as totally self-evident that had been mysterious. It’s pretty bad news for us, though, for two reasons. First, it means we could be in this (by which I mean stagnant growth) for a long, long time, and second, considering the hyperbolic political situation, it’s not clear that the government will end up responding appropriately, which means we may be in it for even longer.
What’s wrong with Wall Street and what should be done about it?
I am trying to figure out the top five (or so) most important corrupt and actionable issues related to the financial system. I’m going to compile this list in order to conduct a “teach-in” at the Occupy Wall Street protest next week. The tentative date is Wednesday, October 12, at 5:30pm.
I’d love to hear your thoughts: please tell me if I’m missing something or got something wrong or left something out.
The list I have so far:
- Investment bankers trading their books and taking outrageous risks which lead to government-backed bailouts because they are “too big to fail”. The related action in the U.S. might be the “Volcker rule” (i.e. reinstating something like Glass-Steagall); unfortunately it’s being watered down as you read this.
- Ratings agencies in collusion with their clients. The actions here would be changing the pay structure of the ratings agencies and opening up the methods, as well as having better regulatory oversight. We also need to change the structure of ratings agencies, and either make it easier to form an agency or make the agencies that already exist and have government protection actually accountable for their “opinions”.
- SEC and other regulators in collusion with the industry. The action here would be to nurture and maintain an adversarial relationship between regulators and bankers. We’ve seen too many people skip from the SEC to the banks they were regulating and then back. There should be rules against this (how about a minimum time requirement of 5 years between jobs on the opposite sides?). There should also be much better funding for the SEC and the other regulators, so they can actually meet their expanded mandate.
- Conflict of interest issues from economists and business school professors. If you’ve seen “Inside Job” then you’ll know all about how professors at various universities use their credentials to back up questionable practices. Moreover, they are often not even required to expose their industry connections when they do expert witnessing or write “academic” papers. The action here would be, at the very least, to force full disclosure for all such appearances and all publications. I’ve heard some good news in this direction but there obviously should be a standard.
- Rampant buying of politicians and influence of lobbyists from the financial industry. This is maybe more of a political problem than a financial one so I’m willing to chuck this off the list. Please tell me if you have something else in mind. Someone has suggested the opaque and elevated pension fund management system. Although I consider that pretty corrupt, I’m not sure it’s as important as other issues to the average person. I’m on the fence.
Saturday afternoon quickie
Two things.
- If I see another fucking article about how the world is going to miss Steve Jobs I’m going to puke. He made and sold overpriced gadgets for fucks sake! It’s hero worship plain and simple, maybe even a sick cult.
- I am happy that I’ve been invited to give a “teach-in” at Occupy Wall Street next Wednesday at 5:30 (tentative date and time). I’ve promised an overview of the 5 top corrupt things in the financial system. I’d really appreciate your thoughts: what is your top 5 list? I want them to be both important and relatively actionable. So far I’ve got:
- Volcker rule (i.e. reinstating something like Glass-Steagall); it’s being watered down as you read this.
- Ratings agencies in collusion with their clients
- SEC and other regulators in collusion with the industry
- Rampant buying of politicians and influence of lobbyists from the financial industry
- Incredibly poor incentives for the individuals in the industry, both in terms of salary and whistleblowing
Habits
This is a guest post by my friend Tara Mathur:
I don’t need to read Tiger Mother to know that I don’t have one. I don’t remember either of my parents putting a lot of pressure on me to do things – even to study, although I developed that habit on my own.
As kids we develop some habits on our own, but we pick up a lot of habits from our parents.
We learn habits from our parents in a few ways. One is by mirroring them. For example, my parents have always read in bed before going to sleep and so have I; it’s so natural to me that until I got married I thought this was something everyone did.
Another is by having our parents make us do something repeatedly. For example, when we first brushed our teeth it probably seemed like a pain to do, but our parents kept making us do it, and it became automatic.
How can we cultivate new habits as adults?
(And am I the only one who associates the word “will-power” with pain and failure? People use that word when they’re talking about doing something really hard, against their natural tendencies. I hear that word and think, how is this gonna last?)
In the last few years I’ve become a big fan of a blog called Zen Habits written by Leo Babauta. He’s made big positive changes in his life – getting out of debt, quitting smoking, running marathons, starting a successful writing career – by focusing on habits rather than goals. Even though big goals are sexy and easy to get excited about, it’s the daily habits, built up baby step by baby step, which last and which comprise most of our life. By definition, when something is a habit we don’t have to rely on willl-power to stick with it. It’s effortless, automatic behavior. Leo emphasizes starting small and focusing on one habit at a time.
This could apply to any positive change we’d like to make in our life. BJ Fogg, a human behavior expert who runs the Persuasive Technology Lab at Stanford, sums up the three steps to cultivate a new habit as follows:
- Make it tiny. To create a new habit, you must first simplify the behavior. Make it tiny, even ridiculous. (examples: floss one tooth, walk for three minutes, do two push-ups)
- Find a spot. Find a spot in your existing routine where this tiny new behavior could fit. Put it after some act that is a solid habit for you, like brushing teeth or eating lunch. One key to a new habit is this simple: you need to find what it comes after.
- Train the cycle. Now focus on doing the tiny behavior as part of your routine – every day, on cycle. At first you’ll need reminders. But soon the tiny behavior will get more automatic. Keep the behavior simple until it becomes a solid habit. That’s the secret to success.
That’s it! He says. Just keep your tiny habit going. Believe in baby steps. Eventually it will naturally expand to the bigger behavior, without much effort.
(There are other tricks too. I’ve also read that you’ll pick up a habit more quickly if you surround yourself with people who already have the habit you want — though I’m not sure if it will last when you’re no longer around those people. Try it and see what works.)
Financial Terms Dictionary
I’ve got a bunch of things to mention today. First, I’ll be at M.I.T. in less than two weeks to give a talk to women in math about working in business. Feel free to come if you are around and interested!
Next, last night I signed up for this free online machine learning course being offered out of Stanford. I love this idea and I really think it’s going to catch on. There are groups here in New York that are getting together to talk about the class and do homework. Very cool!
Next, I’m going back to the protests after work. The media coverage has gotten better and Matt Stoller really wrote a great piece and called on people to stop criticizing and start helping, which is always my motto. For my part, I’m planning to set up some kind of Finance Q&A booth at the demonstration with some other friends of mine in finance. It’s going to be hard since I don’t have lots of time but we’ll try it and see. One of my artistic friends came up with this:
 Finally, one last idea. I wanted to find a funny way to help people understand financial and economic stuff, so I thought of starting a “Financial Terms Dictionary”, which would start with an obscure phrase that economists and bankers use and translate it into plain English. For example, under “injection of liquidity” you might see “the act of printing money and giving it to the banks”.
Finally, one last idea. I wanted to find a funny way to help people understand financial and economic stuff, so I thought of starting a “Financial Terms Dictionary”, which would start with an obscure phrase that economists and bankers use and translate it into plain English. For example, under “injection of liquidity” you might see “the act of printing money and giving it to the banks”.
I’d love comments and suggestions for the Financial Terms Dictionary! I’ll start a separate page for it if it catches on.
Bayesian regressions (part 1)
I’ve decided to talk about how to set up a linear regression with Bayesian priors because it’s super effective and not as hard as it sounds. Since I’m not a trained statistician, and certainly not a trained Bayesian, I’ll be coming at it from a completely unorthodox point of view. For a more typical “correct” way to look at it see for example this book (which has its own webpage).
The goal of today’s post is to abstractly discuss “bayesian priors” and illustrate their use with an example. In later posts, though, I promise to actually write and share python code illustrating bayesian regression.
The way I plan to be unorthodox is that I’m completely ignoring distributional discussions. My perspective is, I have some time series (the 

A “bayesian prior” can be thought of as equivalent to data you’ve already seen before starting on your dataset. Since we think of the signals (the 
The information you need to know about the
Let me illustrate with an example. Suppose you are working on the simplest possible model: you are taking a single time series and seeing how earlier values of 
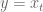
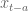
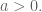
What is your prior for this? Turns out you already have one (two actually) if you work in finance. Namely, you expect the signal of the most recent data to be stronger than whatever signal is coming from older data (after you decide how many past signals to use by first looking at a lagged correlation plot). This is just a way of saying that the sizes of the coefficients should go down as you go further back in time. You can make a prior for that by working on the diagonal of the covariance matrix.
Moreover, you expect the signals to vary continuously- you (probably) don’t expect the third-from recent variable 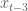
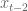
In my next post I’ll talk about how to combine exponential down-weighting of old data, which is sacrosanct in finance, with bayesian priors. Turns out it’s pretty interesting and you do it differently depending on circumstances. By the way, I haven’t found any references for this particular topic so please comment if you know of any.
My friend the coffee douche
About a year ago or so, I went with my friend to a new coffee store in lower Manhattan that he was super excited about. He knew the name of their espresso machine (the Slayer) and kept going on about how amazing the espresso made from this machine must be, if done right. I was happy to go, first because I needed coffee and second because I just like my friend and like it when people get really into things. On the way there I told him that the way he was waxing poetic about the Slayer really defined him as an all-out “coffee douche”. He took it well- in fact I think he actually loved the title. Coffee douches rarely get rewarded with titles, I realized.
I used to be a coffee douche myself. Or at least a potential coffee douche. I worked at Coffee Connection in my youth, which was eventually bought out by Starbucks but in its time gave lots of people in the Boston area pretty good coffee. I hung with the owner, especially once I decided to go to Berkeley, because that’s where he went for undergrad and where he learned to love good coffee (he told me he fell in love at Istanbul Express, I wonder if that place still exists). At some point I knew how many seconds of roasting produced each style (I never liked Italian Roast myself- too burnt) and the characteristics of the different coffees from all over the world (mmm… Sumatra).
Over time, though, I lost it. Something about having kids. I’m now at the level of carrying around Nodoz in my purse just in case I’m traveling and there’s no coffee machine in the hotel room (or in case those tiny little packages of grounds are insufficient). I still enjoy a good cup of Sumatra but I’m almost equally happy going to 7 Eleven. So you can see that coffee douchery is at best a fond memory for me.
When we got to the store, we were immediately asked at the door if we were “press”. Umm, no, what’s going on? It turned out that Sylvia was the guest barista! She was 3 time Brazilian pull champion!! I inferred that this meant there are actually competitions for making espresso. My friend was getting more and more excited and agitated. We got our pictures taken before and after the coffee drinks arrived. Or rather, our cups and saucers were- I think we may have only accidentally entered a frame or two. Sylvia was very gracious and hard-working at the same time. I think I managed to shake her hand, just for the celebrity moment of it all.
As an aside, I noticed something about the whole coffee movement thing when I was checking out Sylvia and her methods. Everything there has a fetishized whiff to it. The coffee machine was the Slayer, the various implements were wooden of some kind of hardwood that they were happy to explain in detail, and although I can’t remember all the names of the implements, I got the distinct impression that there may be a sex shop in the back room with leather and wooden tools very similar to the coffee tools. Maybe just me.
Here’s a close-up sexy shot of the Slayer (if you look carefully at the reflections you will note at least 3 people there admiring its shiny round parts), taken from the website of RBC coffee:

I don’t think I’ve ever been under such pressure to enjoy my espresso, but it was pretty good (I think). Near the end of drinking it, we seemed to be peppered with technical questions from the people there, including the owner of the store, the owner of the coffee plantation that supplied the store, and the guy who roasted the coffee beans. It was a triumvirate of coffee! I was glad I had my coffee douche with me!! He impressed them with his idiosyncratic knowledge (I remember his sympathy combined with pride when he mentioned that he was aware that there were laws against roasting in Manhattan but not in Brooklyn, so did they roast in Brooklyn? They did).
When I left, I was invigorated. Here are these people, completely obsessed and fascinated with coffee and everything pertaining to coffee. In some sense it struck me as a waste of time, but in a larger sense it was very very cool. That’s what’s interesting and fun about humans, after all, that they get totally nerdy and into things that other people can’t relate to, and they really improve our knowledge as a community about the best way to do that thing. There are probably people somewhere who are as into park benches as these guys are into coffee, and thanks to them the park benches are getting more and more comfy and beautifully designed and long-lasting, at least if you know where to go for really excellent park benches.




{kind=link}