Archive
Stuff I’m reading
I’m too busy this morning for a real post but I thought I’d share a few things I’m reading today.
- Matt Stoller just came out with a long review of Timmy Geithner’s book: The Con Artist Wing of the Democratic Party. I like this because it explains some of the weird politics around, for example, the Mexican currency crisis that I only vaguely knew about.
- New York Magazine has a long profile of Stevie Cohen of SAC Capital insider trading fame: The Taming of the Trading Monster.
- The power of Google’s algorithms can make or break smaller websites: On the Future of Metafilter. See also How Google Is Killing The Best Site On The Internet.
- There is no such thing as a slut.
Podesta’s Big Data report to Obama: good but not great
This week I’m planning to read Obama’s new big data report written by John Podesta. So far I’ve only scanned it and read the associated recommendations.
Here’s one recommendation related to discrimination:
Expand Technical Expertise to Stop Discrimination. The detailed personal profiles held about many consumers, combined with automated, algorithm-driven decision-making, could lead—intentionally or inadvertently—to discriminatory outcomes, or what some are already calling “digital redlining.” The federal government’s lead civil rights and consumer protection agencies should expand their technical expertise to be able to identify practices and outcomes facilitated by big data analytics that have a discriminatory impact on protected classes, and develop a plan for investigating and resolving violations of law.
First, I’m very glad this has been acknowledged as an issue; it’s a big step forward from the big data congressional subcommittee meeting I attended last year for example, where the private-data-for-services fallacy was leaned on heavily.
So yes, a great first step. However, the above recommendation is clearly insufficient to the task at hand.
It’s one thing to expand one’s expertise – and I’d be more than happy to be a consultant for any of the above civil rights and consumer protection agencies, by the way – but it’s quite another to expect those groups to be able to effectively measure discrimination, never mind combat it.
Why? It’s just too easy to hide discrimination: the models are proprietary, and some of them are not even apparent; we often don’t even know we’re being modeled. And although the report brings up discriminatory pricing practices, it ignores redlining and reverse-redlining issues, which are even harder to track. How do you know if you haven’t been made an offer?
Once they have the required expertise, we will need laws that allow institutions like the CFPB to deeply investigate these secret models, which means forcing companies like Larry Summer’s Lending Club to give access to them, where the definition of “access” is tricky. That’s not going to happen just because the CFPB asks nicely.
Does making it easier to kill people result in more dead people?
A fascinating and timely study just came out about the “Stand Your Ground” laws. It was written by Cheng Cheng and Mark Hoekstra, and is available as a pdf here, although I found out about in a Reuters column written by Hoekstra. Here’s a longish but crucial excerpt from that column:
It is fitting that much of this debate has centered on Florida, which enacted its law in October of 2005. Florida provides a case study for this more general pattern. Homicide rates in Florida increased by 8 percent from the period prior to passing the law (2000-04) to the period after the law (2006-10).By comparison, national homicide rates fell by 6 percent over the same time period. This is a crude example, but it illustrates the more general pattern that exists in the homicide data published by the FBI.
The critical question for our research is whether this relative increase in homicide rates was caused by these laws. Several factors lead us to believe that laws are in fact responsible. First, the relative increase in homicide rates occurred in adopting states only after the laws were passed, not before. Moreover, there is no history of homicide rates in adopting states (like Florida) increasing relative to other states. In fact, the post-law increase in homicide rates in states like Florida was larger than any relative increase observed in the last 40 years. Put differently, there is no evidence that states like Florida just generally experience increases in homicide rates relative to other states, even when they don’t pass these laws.
We also find no evidence that the increase is due to other factors we observe, such as demographics, policing, economic conditions, and welfare spending. Our results remain the same when we control for these factors. Along similar lines, if some other factor were driving the increase in homicides, we’d expect to see similar increases in other crimes like larceny, motor vehicle theft and burglary. We do not. We find that the magnitude of the increase in homicide rates is sufficiently large that it is unlikely to be explained by chance.
In fact, there is substantial empirical evidence that these laws led to more deadly confrontations. Making it easier to kill people does result in more people getting killed.
If you take a look at page 33 of the paper, you’ll see some graphs of the data. Here’s a rather bad picture of them but it might give you the idea:

That red line is the same in each plot and refers to the log homicide rate in states without the Stand Your Ground law. The blue lines are showing how the log homicide rates looked for states that enacted such a law in a given year. So there’s a graph for each year.
In 2009 there’s only one “treatment” state, namely Montana, which has a population of 1 million, less than one third of one percent of the country. For that reason you see much less stable data. The authors did different analyses, sometimes weighted by population, which is good.
I have to admit, looking at these plots, the main thing I see in the data is that, besides Montana, we’re talking about states that have a higher homicide rate than usual, which could potentially indicate a confounding condition, and to address that (and other concerns) they conducted “falsification tests,” which is to say they studied whether crimes unrelated to Stand Your Ground type laws – larceny and motor vehicle theft – went up at the same time. They found that the answer is no.
The next point is that, although there seem to be bumps for 2005, 2006, and 2008 for the two years after the enactment of the law, there doesn’t for 2007 and 2009. And then even those states go down eventually, but the point is they don’t go down as much as the rest of the states without the laws.
It’s hard to do this analysis perfectly, with so few years of data. The problem is that, as soon as you suspect there’s a real effect, you’d want to act on it, since it directly translates into human deaths. So your natural reaction as a researcher is to “collect more data” but your natural reaction as a citizen is to abandon these laws as ineffective and harmful.
Intentionally misleading data from Scott Hodge of the Tax Foundation
Scott Hodge just came out with a column in the Wall Street Journal arguing that reducing income inequality is way too hard to consider. The title of his piece is Scott Hodge: Here’s What ‘Income Equality’ Would Look Like, and his basic argument is as follows.
First of all, the middle quintile already gets too much from the government as it stands. Second of all, we’d have to raise taxes to 74% for the top quintile to even stuff out. Clearly impossible, QED.
As to the first point, his argument, and his supporting data, is intentionally misleading, as I will explain below. As to his second point, he fails to mention that the top tax bracket has historically been much higher than 74%, even as recently as 1969, and the world didn’t end.
Hodge argues with data he took from a report from the CBO called The Distribution of Federal Spending and Taxes in 2006. This report distinguishes between transfers and spending. Here’s a chart to explain what that looks, before taxes are considered and by quintile, for non-elderly households (page 5 of the report):
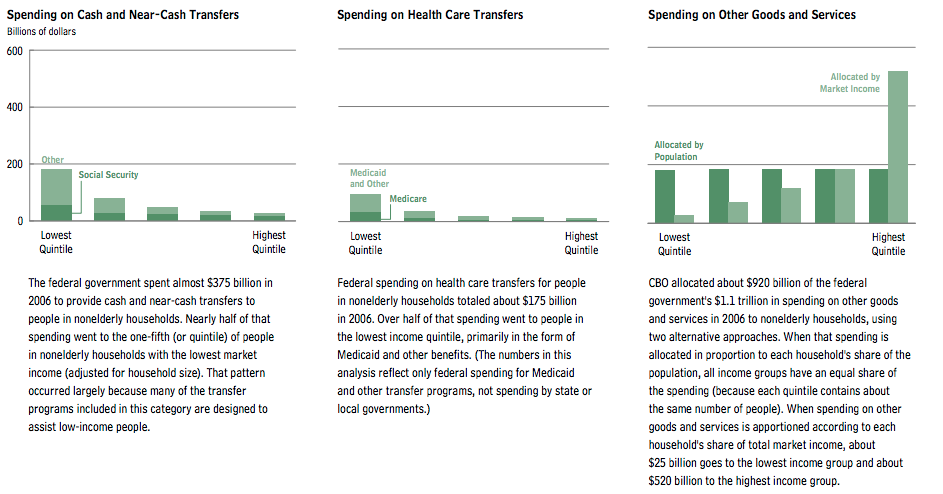
The stuff on the left corresponds to stuff like food stamps. The stuff in the middle is stuff like Medicaid. The stuff on the right is stuff like wars.
Here are a few things to take from the above:
- There’s way more general spending going on than transfers.
- Transfers are very skewed towards the lowest quintile, as would be expected.
- If you look carefully at the right-most graph, the light green version gives you a way of visualizing of how much more money the top quintile has versus the rest.
Now let’s break this down a bit further to include taxes. This is a key chart that Hodge referred to from this report (page 6 of the report):

OK, so note that in the middle chart, for the middle quintile, people pay more in taxes than they receive in transfers. On the right chart, for the middle quintile, which includes all spending, the middle quintile is about even, depending on how you measure it.
Now let’s go to what Hodge says in his column (emphasis mine):
Looking at prerecession data for non-elderly households in 2006 in “The Distribution of Federal Spending and Taxes in 2006,” the CBO found that those in the bottom fifth, or quintile, of the income scale received $9.62 in federal spending for every $1 they paid in federal taxes of all kinds. This isn’t surprising, since people with low incomes pay little in taxes but receive a lot of transfers.
Nor is it surprising that households in the top fifth received 17 cents in federal spending for every $1 they paid in all federal taxes. High-income households hand over a disproportionate amount in taxes relative to what they get back in spending.
What is surprising is that the middle quintile—the middle class—also got more back from government than they paid in taxes. These households received $1.19 in government spending for every $1 they paid in federal taxes.
In the first paragraph Hodge intentionally conflates the concept of “transfers” and “spending”. He continues to do this for the next two paragraphs, and in the last sentence, it is easy to imagine a middle-quintile family paying $100 in taxes and receiving $119 in food stamps. This is of course not true at all.
What’s nuts about this is that it’s mathematically equivalent to complaining that half the population is below median intelligence. Duh.
Since we have a skewed distribution of incomes, and therefore a skewed distribution of tax receipts as well as transfers, then in the context of a completely balanced budget, we would expect the middle quintile – which has a below-mean average income – to pay slightly less than the government spends on them. It’s a mathematical fact as long as our federal tax system isn’t regressive, which it’s not.
In other words, this guy is just framing stuff in a “middle class is lazy and selfish, what could rich people possibly be expected do about that?” kind of way. Who is this guy anyway?
Turns out that Hodge is the President of the Tax Foundation, which touts itself as “nonpartisan” but which has gotten funding from Big Oil and the Koch brothers. I guess it’s fair to say he has an agenda.
Matt Stoller is tearing up Tumblr
I’ve been super impressed by Matt Stoller’s recent foray into “tumbling”, which is kind of like blogging except it’s called tumbling. Even the spam emails from tumblr are worth following him, because sometimes they contain his newest posts.
His title is Observations on Credit and Surveillance but in fact the content is all over the map, reading original source documents to describe the connections between communism and U.S. slavery or Gerald Ford and Watergate, not to mention the 1894 Post Office Bank proposal.
Most interesting to me is the information he’s uncovered about data provisions in the TPP and the history of credit cards and debt collection.
Go take a look, he’s been on fire. I hope he keeps it going.
Journalism after Snowden
Last night I was lucky enough to grab a seat across Broadway at an event put on by Columbia Journalism School’s Tow Center called “Journalism after Snowden.”
It featured four distinguished panelists:
- Jill Abramson Executive Editor, The New York Times
- Janine Gibson Editor-in-Chief, Guardian U.S.
- David Schulz Outside Counsel to The Guardian and Partner, Levine, Sullivan Koch & Schulz LLP
- Cass Sunstein Member, President Obama’s Review Group on Intelligence and Communications Technologies and Robert Walmsley University Professor, Harvard University
First Janine talked about receiving the documents from Snowden, or “the source” as he was called, and spending a bunch of time with her team in verifying the documents as well as focusing on exactly two questions:
- Is this story true?
- Is this story in the public’s interest?
She and her team decided it passed both those tests and they published it. Then Jill Abramson chimed in to talk about how the New York Times got in on the story as well.
David Schulz, and also Lee Bollinger who started out the evening, framed the legal issues around newspapers publishing things in the context of national security here in the U.S., and although much of it was over my head I came away with the distinct impression that in this country, journalisms have historically had a protected space.
However, there have been exceptions recently, and very recently Director of National Intelligence James Clapper insinuated that dozens of journalists reporting on documents leaked by NSA whistleblower Edward Snowden were “accomplices” to a crime.
Those recent events, and Obama’s general campaign against whistleblowers, which are in direct contradiction to his campaign promises, have had a chilling effect on reporting and on reporters who work on national security issues, according to NY Times Executive Editor Jill Abramson.
There was some discussion about how difficult it was to have secure communication between Snowden and journalists, given the situation, and how crucial it is to be able to do so for journalists in order to protect their sources. The question came up of whether it even makes sense for a journalist to suggest to a source that they’d be protected, given how much surveillance now exists.
My favorite line of the night came when David Schulz pointed out that we normal citizens might not think we care about having secure communications, since we don’t intend to do top secret messaging, but even so the lack of secure messaging systems for other people effects what we learn about the world.
Finally, there was a poll taken by the moderator Emily Bell: are we better off because of Snowden? Not all of the panelists agreed, or rather Jill, Janine, and David seemed to think it was obvious but Cass demurred, which I guess was consistent with his being on a Review Group for Obama.
Personally, I don’t think it’s super cut and dry, but I do think we need to have people like Snowden, and whistleblowers more generally, and that in any case journalists absolutely need legal protection to do their jobs.
One last personal comment: I find it absolutely amazing that an entire profession like journalism would actually consider the public good as a major question they put before them before they choose what to work on. I’m coming from inside the tech industry and finance, where the only question that is ever asked is whether an idea is profitable and, secondarily, legal. It’s a refreshing perspective, although I’m guessing somewhat misleading.
I’m writing a book called Weapons of Math Destruction
I’m incredibly excited to announce that I am writing a book called Weapons of Math Destruction for Random House books, with my editor Amanda Cook. There will also be a subtitle which we haven’t decided on yet.
Here’s how this whole thing went down. First I met my amazing book agent Jay Mandel from William Morris though my buddy Jordan Ellenberg. As many of you know, Jordan is also writing a book but it’s much farther along in the process and has already passed the editing phase. Jordan’s book is called How Not To Be Wrong and it’s already available for pre-order on Amazon.
Anyhoo, Jay spent a few months with me telling me how to write a book proposal, and it was a pretty substantial undertaking actually and required more than just an outline. It was like a short treatment of all the chapters but then two chapters pretty filled in, including the first, and as you know the first is kind of like an advertisement for the whole rest of the book.
Then, once that proposal was ready, Jay started what he hoped would be a bidding war for the proposal among publishers. He had a whole list of people he talked to from all over the place in the publishing world.
What actually happened though was Amanda Cook from Crown Publishing, which is part of Random House, was the first person who was interested enough to talk to me about it, and then we hit it off really well, and she made a pre-emptive offer for the book so the full on bidding war didn’t end up needing to happen. And then just last week she announced the deal in what’s called the Publisher’s Marketplace, which is for people inside publishing to keep abreast of the deals and news. The actual link is here, but it’s behind a pay wall, so Amanda got me a screen shot:

If that font is too small, it says something like this:
Harvard math Ph.D., former Wall Street quant, and advisor to the Occupy movement Cathy O’Neil’s WEAPONS OF MATH DESTRUCTION, arguing that mathematical modeling has become a pervasive and destructive force in society—in finance, education, medicine, politics, and the workplace—and showing how current models exacerbate inequality and endanger democracy and how we might rein them in, to Amanda Cook at Crown in a pre-empt by Jay Mandel at William Morris Endeavor (NA).
So as you can tell I’m incredibly excited about the book, and I have tons of ideas about it, but of course I’d love my readers to weigh in on crucial examples of models and industries that you think might get overlooked.
Please, post a comment or send me an email (located on my About page) with your favorite example of a family of models (Value Added Model for teachers is already in!) or a specific model (Value-at-Risk model in finance in already!) that is illustrative of feedback loops, or perverted incentives, or creepy modeling, or some such concept that you imagine I’ll be writing about (or should be!). Thanks so much for your input!
One last thing. I’m aiming to finish the writing part by next Spring, and then the book is actually released about 9 months later. It takes a while. I’m super glad I have had the experience of writing a technical book with O’Reilly as well as the homemade brew Occupy Finance with my Occupy group so I know at least some of the ropes, but even so this is a bit more involved.
Judge Rakoff explains why no banker is in jail #OWS
United States District Judge Jed S. Rakoff is already kind of a hero to me, given that he’s the guy who rejected a “do not admit wrongdoing” settlement between Citigroup and the SEC over mortgage-backed securities fraud because, according to Rakoff, the proposed settlement was “neither fair, nor reasonable, nor adequate, nor in the public interest.”
More recently Rakoff has written a fine essay in the New York Review of Books entitled The Financial Crisis: Why Have No High-Level Executives Been Prosecuted? which I will summarize below but is well worth your time to read.
Rakoff’s essay
First Rakoff made the point that if there was no intentional fraud we should not scapegoat people and put them to jail. But on the other hand, if there was intentional fraud, then it’s a reflection on a dysfunctional justice system that nobody has gone to jail.
Then he examined that first possibility and found it unlikely, given that “… the Financial Crisis Inquiry Commission, in its final report, uses variants of the word “fraud” no fewer than 157 times in describing what led to the crisis…” In fact, fraud permeated at every level.
The Department of Justice (DOJ) has focused on explaining why nobody has gone to jail in spite of the existence of fraud. They have three reasons.
First, the DOJ claims it’s hard to prove intent for high-level management. But Rakoff demurs on this point, explaining that in cases of accounting fraud, “willful blindness” or “conscious disregard” is a well-established basis on which federal prosecutors have asked juries to infer intent.
Second, since many counterparties were “sophisticated,” it’s difficult to prove “reliance“. Again Rakoff demurs, pointing out that “In actuality, in a criminal fraud case the government is never required to prove—ever—that one party to a transaction relied on the word of another.”
Third, because of the “Too Big To Jail” problem, namely that prosecuting fraud would kill the economy. To this, Rakoff points out what that means in terms of class: that poor people can be prosecuted but the rich are protected.
Next, Rakoff says what he thinks is actually happening. First he discounts the revolving door: he thinks lawyers are thoroughly incentivized to make a name for themselves. Then what? He’s got three reasons.
Well, first, people were distracted. The FBI was distracted by terrorists, and the SEC was focused on Ponzi schemes and insider trading. The DOJ was inexperienced and the Southern District US Attorney’s Office was also focused on insider trading. And given the complexity and incentives, it’s hard for a given lawyer to decide to go with an MBS case instead of insider trading.
Second, the government had direct conflict in the fraud, given that the Fed and the regulators had deregulated everything in sight and then kept interest rates low to keep the mortgage machine going. They also meddled a lot during the crisis, deciding which failing bank should be taken over by whom. It made it hard for them to admit shit went wrong.
Finally, it’s because it’s now in vogue to prosecute corporations instead of people, but that really doesn’t work. Here’s Rakoff on this prosecutorial method:
Although it is supposedly justified because it prevents future crimes, I suggest that the future deterrent value of successfully prosecuting individuals far outweighs the prophylactic benefits of imposing internal compliance measures that are often little more than window-dressing. Just going after the company is also both technically and morally suspect. It is technically suspect because, under the law, you should not indict or threaten to indict a company unless you can prove beyond a reasonable doubt that some managerial agent of the company committed the alleged crime; and if you can prove that, why not indict the manager? And from a moral standpoint, punishing a company and its many innocent employees and shareholders for the crimes committed by some unprosecuted individuals seems contrary to elementary notions of moral responsibility.
And then his final conclusion:
So you don’t go after the companies, at least not criminally, because they are too big to jail; and you don’t go after the individuals, because that would involve the kind of years-long investigations that you no longer have the experience or the resources to pursue.
Comments
First, I am super grateful for Judge Rakoff’s essay, because as an experienced lawyer he has way more ammunition than I do to explain this stuff from the perspective of what is actually done in law. The “willful blindness” issue is particularly ridiculous. I’m glad to hear that courts have a way to deal with that problem, even if they aren’t using their tools against Jamie Dimon.
I am also grateful to hear him make the point that widespread fraud, unprosecuted, is not simply a theoretical issue. It exposes the dysfunctionality of our justice system and it exposes basic unfairness in society, where depending on how rich you are and how complicated your crime is, you can avoid going to jail. Personally, in the past few months I’ve gone from being angry at the bankers to being angry at the prosecutors.
Finally, I disagree with Rakoff on one point. Namely, his argument against the negative effect of the revolving door. His argument, I stipulate, only works for lawyers in a US Attorney’s office. I don’t think the average SEC lawyer or economist, or for that matter an employee at any captured regulator, has that much incentive to take on a big MBS case and be hard-assed. I think we would have seen more cases if that were true.
Parents fighting back against sharing children’s data with InBloom
There is a movement afoot in New York (and other places) to allow private companies to house and mine tons of information about children and how they learn. It’s being touted as a great way to tailor online learning tools to kids, but it also raises all sorts of potential creepy modeling problems, and one very bad sign is how secretive everything is in terms of privacy issues. Specifically, it’s all being done through school systems and without consulting parents.
In New York it’s being done through InBloom, which I already mentioned here when I talked about big data and surveillance. In that post I related an EducationNewYork report which quoted an official from InBloom as saying that the company “cannot guarantee the security of the information stored … or that the information will not be intercepted when it is being transmitted.”
The issue is super important and timely, and parents have been left out of the loop, with no opt-out option, and are actively fighting back, for example with this petition from MoveOn (h/t George Peacock). And although the InBloomers claim that no data about their kids will ever be sold, that doesn’t mean it won’t be used by third parties for various mining purposes and possibly marketing – say for test prep tools. In fact that’s a major feature of InBloom’s computer and data infrastructure, the ability for third parties to plug into the data. Not cool that this is being done on the downlow.
Who’s behind this? InBloom is funded by the Bill & Melinda Gates foundation and the operating system for inBloom is being developed by the Amplify division (formerly Wireless Generation) of Rupert Murdoch’s News Corp. More about the Murdoch connection here.
Wait, who’s paying for this? Besides the Gates and Murdoch, New York has spent $50 million in federal grants to set up the partnership with InBloom. And it’s not only New York that is pushing back, according to this Salon article:
InBloom essentially offers off-site digital storage for student data—names, addresses, phone numbers, attendance, test scores, health records—formatted in a way that enables third-party education applications to use it. When inBloom was launched in February, the company announced partnerships with school districts in nine states, and parents were outraged. Fears of a “national database” of student information spread. Critics said that school districts, through inBloom, were giving their children’s confidential data away to companies who sought to profit by proposing a solution to a problem that does not exist. Since then, all but three of those nine states have backed out.
Finally, according to this nydailynews article, Bill de Blasio is coming out on the side of protecting children’s privacy as well. That’s a good sign, let’s hope he sticks with it.
I’m not against using technology to learn, and in fact I think it’s inevitable and possibly very useful. But first we need to have a really good, public discussion about how this data is being shared, controlled, and protected, and that simply hasn’t happened. I’m glad to see parents are aware of this as a problem.
Citigroup is the real reason we need the Volcker Rule
This is a guest post by Tom Adams, who spent over 20 years in the securitization business and now works as an attorney and consultant and expert witness on MBS, CDO and securitization related issues. Jointly posted with Naked Capitalism.
Volcker Rule
Last week, the rules for the Volcker Rule – that provision of the Dodd-Frank Legislation that was intended to prevent (reduce?) proprietary trading by banks – were finalized. As a consequence, there has been a lot of chatter among financial types around the internet about what the rule does and doesn’t do and how it is good or bad, etc. Much of the conversation falls into the category of noise and distraction about unintended consequences, impacts on liquidity and broad views of regulatory effectiveness.
Citigroup
I call it noise, because in my view the real purpose of the Volcker Rule is to prevent another Citigroup bailout and therefore the measure of its effectiveness is whether the rule would accomplish this.
As you may recall, Citigroup required the largest bailout in government history in 2008, going back to the government well for more bailout funds several times. The source of Citigroup’s pain was almost entirely due to its massive investment in the ABS CDO machine. Of course, at the time of Citi’s bailout, there was a lot of noise about the potential financial system collapse and the risk posed by numerous other banks and institutions, so Citi as the main target of the TARP bailout, and ABS CDOs as the main cause of Citi’s pain, often gets lost in the folds of history.
The CDO market
In the years leading up to the financial crisis, Citi was an active underwriter for CDO’s backed by mortgage backed securities. Selling these securities was a lucrative business for Citi and other banks – far more lucrative than the selling of the underlying MBS. The hard part of selling was finding someone to take the highest risk piece (called the equity) of the CDO, but that problem got solved when Magnetar and other hedge funds came along with their ingenious shorting scheme.
The next hardest part was finding someone to take the risk of the very large senior class of the CDO, often known as the super-senior class (it was so named because it was enhanced at levels above that needed for a AAA rating).
For a time, Citi relied on a few overseas buyers and some insurance companies – like AIG and monoline bond insurers – to take on that risk. In addition, the MBS market became heavily reliant upon CDOs to buy up the lower rated bonds from MBS securitizations.
As the frenzy of MBS selling escalated, though, the number of parties willing to take on the super-seniors was unable to match the volume of CDOs being created (AIG, for instance, pulled back from insuring the bonds in 2006). Undeterred, Citi began to take down the super-senior bonds from the deals they were selling and holding them as “investments” which required very little capital because they were AAA.
This approach enabled Citi to continue the vey lucrative business of selling CDOs (to themselves!), which also enhanced their ability to create and sell MBS (to their CDOs), which enabled Citi to keep the music playing and the dance going, to paraphrase their then CEO Chuck Prince.
The CDO music stopped in July, 2007 with the rating agency downgrades of hundreds of the MBS bonds underlying the CDOs that had been created over the prior 24 months. MBS and CDO issuance effectively shut down the following month and remained shut throughout the crisis. The value of CDOs almost immediately began to plummet, leading to large mark-to-market losses for the parties that insured CDOs, such as Ambac and MBIA.
Citi managed to ignore the full extent of the declines in the value of the CDOs for nearly a year, until AIG ran into its troubles (itself a result of the mark-to-market declines in the values of its CDOs). When, in the fall of 2008, Citi finally fessed up to the problems it was facing, it turned out it was holding super-senior CDOs with a face value of about $150 billion which were now worth substantially less.
How much less? The market opinion at the time was probably around 10-20 cents on the dollar. Some of that value recovered in the last two years, but the bonds were considered fairly worthless for several years. Citi’s difficulty in determining exactly how little the CDOs were worth and how many they held was the primary reason for the repeated requests for additional bailout money.
Citi’s bailout is everyone’s bailout
The Citi bailout was a huge embarrassment for the company and the regulators that oversaw the company (including the Federal Reserve) for failing to prevent such a massive aid package. Some effort was made, at the time TARP money was distributed, to obscure Citi’s central role in the need for TARP and the panic the potential for a Citi failure was causing in the market and at the Treasury Department (see for example this story and the SIGTARP report). By any decent measure, Citi should have been broken up after this fiasco, but at least some effort should be made from a large bank ever needing such a bailout again, right?
Volcker’s Rule is Citi’s rule
So the test for whether the Volcker Rule is effective is fairly simple: will it prevent Citi, or some other large institution, from getting in this situation again? The rule is relatively complex and armies of lawyers are dissecting it for ways to arbitrage its words as we speak.
However, some evidence has emerged that the Volcker Rule would be effective in preventing another Citi fiasco. While the bulk of the rules don’t become effective until 2015, banks are required to move all “covered assets” from held to maturity to held for sale, which requires them to move the assets to a fair market valuation from… whatever they were using before.
Just this week, for example, Zions Bank announced that they were taking a substantial impairment because of that rule and moving a big chunk of CDOs (trust preferred securities, or TRUPS, were the underlying asset, although the determination would apparently apply to all CDOs) to fair market accounting from… whatever valuation they were using previously (not fair market?).
Here’s the key point. Had Citi been forced to do this as they acquired their CDOs, there is a decent chance they would have run into CDO capacity problems much sooner – they may not have been able to rely on the AAA ratings, they might have had to sell off some of the bonds before the market imploded, and they might have had to justify their valuations with actual data rather than self-serving models.
As a secondary consequence, they probably would have had to stop buying and originating mortgage loans and buying and selling MBS, because they wouldn’t have been able to help create CDOs to dump them into.
Given the size of Citi’s CDO portfolio, and the leverage that those CDOs had as it relates to underlying mortgage loans (one $1 billion CDO was backed by MBS from about $10 billion mortgages, $150 billion of CDOs would have been backed by MBS from about $1.5 trillion of mortgage loans, theoretically), if Citi had slowed their buying of CDOs, it might have had a substantial cooling effect on the mortgage market before the crisis hit.
Do we really want elite youth to get more elite?
I don’t know if you guys read this recent New York Times editorial entitled Even Gifted Students Can’t Keep Up: In Math and Science, the Best Fend for Themselves.
In it, they claim there’s some kind of crisis going on in this country for smart kids (defined as good test-takers). Mostly their evidence for this is that, among other countries, our super good test takers aren’t as prevalent as in other countries. Turns out we’re in the middle of the pack in terms of super scorers. From the article:
On the 2012 Program for International Student Assessment test, the most recent, 34 of 65 countries and school systems had a higher percentage of 15-year-olds scoring at the advanced levels in mathematics than the United States did.
Why is this a problem? As far as I can see they’ve come up with two reasons.
First, it’s “bad for American competitiveness,” whatever that means. Last time I checked we were still pretty dominant in various ways in terms of technology and science, and there are still plenty of very well-educated young people trying desperately to get visas to enter or stay in this country.
As an aside: it’s a super interesting question to think about how we, as a country, are increasingly ignorant about how our technology works, because so much technical knowledge has been off-shored. But that’s not the crisis these guys are addressing.
Second, it’s bad for the smart kids in this country, because “when the brightest students are not challenged academically, they lose steam and check out.”
I’ll pause in my summary of their article to make the following point. If that’s true, if bright kids who aren’t academically challenged at school start checking out more and more, then it makes just as much sense to me to see if there’s something they can check out towards.
In other words, what else is there for bright teenagers to do besides school? I’ll speak as a former bright teenager. When I lost interest in school, I got a lot of odd jobs in town cleaning houses and raking lawns, and then I used the money to buy lots of softcover books from a local bookstore. I don’t know why I didn’t just take them out of the library, where I also worked. It just didn’t seem as cool as owning my very own Brother Karamazov.
I learned a lot with my odd jobs in high school, which included being a part-time secretary, a barista, a math tutor, and working on a truck at the New England Produce Center. In fact I learned way more about how the world worked than I would have if I’d followed the advice of this editorial, which was to take lots more AP classes and then enter college when I was 14.
My theory is that, instead of obsessing over math scores in standardized tests, we concentrate on allowing our children to enrich their lives with adventures and experiences that they come up with and that are reasonably safe. So let’s start by encouraging widespread internships for younger kids, and not just minimum wage jobs at fast food joints. And not just for super test-takers either. Enrichment happens when kids learn about stuff that’s outside their usual rhythm and when there are no adults scripting their activities and telling them what to do or how many laps to swim.
Notice my emphasis on letting kids choose stuff. What drives me nuts just as much as the idea of further separating and isolating and venerating great test-takers, which as far as I’m concerned is the opposite way you should treat future successful people, is the idea that there should be such a well-defined funnel for children at all.
Yes, kids should all go to school and learn basic things. But the idea that, just because someone’s good at tests they should be treated as if they’re already running the Fed only increases the weird worshippy aspect of how our culture treats math nerds.
Plus, it’s a bizarre time to come up with this idea, considering how many online and live resources there are for nerd kids now compared to when I was a kid. If I’m a nerd teenager now, I can find plenty of ways to share nerdy questions and learn nerdy things online if I decide not to work in a coffee shop.
Finally, let me just take one last swipe at this idea from the perspective of “it’s meritocratic therefore it’s ok”. It’s just plain untrue that test-taking actually exposes talent. It’s well established that you can get better at these tests through practice, and that richer kids practice more. So the idea that we’re going to establish a level playing field and find minority kids to elevate this way is rubbish. If we do end up focusing more on the high end of test-takers, it will be completely dominated by the usual suspects.
In other words, this is a plan to make elite youth even more elite. And I don’t know about you, but my feeling is that’s not going to help our country overall.
Computer, do I really want to get married?
There’s a new breed of models out there nowadays that reads your face for subtle expressions of emotions, possibly stuff that normal humans cannot pick up on. You can read more about it here, but suffice it to say it’s a perfect target for computers – something that is free information, that can be trained over many many examples, and then deployed everywhere and anywhere, even without our knowledge since surveillance cameras are so ubiquitous.
Plus, there are new studies that show that, whether you’re aware of it or not, a certain “gut feeling”, which researchers can get at by asking a few questions, will expose whether your marriage is likely to work out.
Let’s put these two together. I don’t think it’s too much of a stretch to imagine that surveillance cameras strategically placed at an altar can now make predictions on the length and strength of a marriage.
Oh goodie!
I guess it brings up the following question: is there some information we are better off not knowing? I don’t think knowing my marriage is likely to be in trouble would help me keep the faith. And every marriage needs a good dose of faith.
I heard a radio show about Huntington’s disease. There’s no cure for it, but there is a simple genetic test to see if you’ve got it, and it usually starts in adulthood so there’s plenty of time for adults to see their parents degenerate and start to worry about themselves.
But here’s the thing, only 5% of people who have a 50% chance of having Huntington’s actually take that test. For them the value of not knowing that information is larger than knowing. Of course knowing you don’t have it is better still, but until that happens the ambiguity is preferable.
Maybe what’s critical is that there’s no cure. I mean, if there was therapy that would help Huntington’s disease sufferers delay it or ameliorate it, I think we’d see far more people taking that genetic marker test.
And similarly, if there were ways to save a marriage that is at risk, we might want to know on the altar what the prognosis is. Right?
I still don’t know. Somehow, when things get that personal and intimate, I’d rather be left alone, even if an algorithm could help me “optimize my love life”. But maybe that’s just me being old-fashioned, and maybe in 100 years people will treat their computers like love oracles.
Predictive risk models for prisoners with mental disorders
My friend Jordan Ellenberg sent me an article yesterday entitled Coin-flip judgement of psychopathic prisoners’ risk.
It was written by Seena Fazel, a researcher at the department of psychiatry at Oxford, and it concerns his research into the currently used predictive risk models for violence, repeat offense, and the like, which are supposedly tailored to people who have mental disorders like psychopathy.
Turns out there are a lot of these models, and they’re in use today in a bunch of countries. I did not know that. And they’re not just being used as extra, “good to know” information, but rather as a tool to assess important decisions for the prisoner. From the article:
Many US states use such tools to assess sexual offending risk and to help decide whether to exercise their powers to detain sexual offenders indefinitely after a prison term ends.
In England and Wales, these tools are part of the admission criteria for centres that treat people with dangerous and severe personality disorders. Outside North America, Europe and Australasia, similar approaches are increasingly popular, particularly in clinical settings, and there has been a steady growth of research from middle-income countries, such as China, documenting their use.
Also turns out, according to a meta-analysis done by Fazel, that these models don’t work very well, especially for the highest risk most violent population. And what’s super troubling is, as Fazel says, “In practice, the high false-positive rate probably means that some offenders spend longer in prison and secure hospital than their true risk would suggest.”
Talk about creepy.
This seems to be yet another example of a mathematical obfuscation and intimidation that gives people a false sense of having a good tool at hand. From the article:
Of course, sensible clinicians and judges take into account factors other than the findings of these instruments, but their misuse does complicate the picture. Some have argued that the veneer of scientific respectability surrounding such methods may lead to over-reliance on their findings, and that their complexity is difficult for the courts. Beyond concerns about public protection, liberty and costs of extended detention, there are worries that associated training and administration may divert resources from treatment.
The solution? Get people to acknowledge that the tools suck, and have a more transparent method of evaluating them. In this case, according to Fazel, it’s the researchers who are over-estimating the power of their models. But especially where it involves incarceration and the law, we have to maintain an adherence to a behavior-based methodology. It doesn’t make sense to put people in jail an extra 10 years because a crappy model said so.
This is a case, in my opinion, for an open model with a closed black box data set. The data itself is extremely sensitive and protected, but the model itself should be scrutinized.
PDF Liberation Hackathon: January 17-19
This is a guest post by Marc Joffe, the principal consultant at Public Sector Credit Solutions, an organization that provides data and analysis related to sovereign and municipal securities. Previously, Joffe was a Senior Director at Moody’s Analytics.
As Cathy has argued, open source models can bring much needed transparency to scientific research, finance, education and other fields plagued by biased, self-serving analytics. Models often need large volumes of data, and if the model is to be run on an ongoing basis, regular data updates are required.
Unfortunately, many data sets are not ready to be loaded into your analytical tool of choice; they arrive in an unstructured form and must be organized into a consistent set of rows and columns. This cleaning process can be quite costly. Since open source modeling efforts are usually low dollar operations, the costs of data cleaning may prove to be prohibitive. Hence no open model – distortion and bias continue their reign.
Much data comes to us in the form of PDFs. Say, for example, you want to model student loan securitizations. You will be confronted with a large number of PDF servicing reports that look like this. A corporation or well funded research institution can purchase an expensive, enterprise-level ETL (Extract-Transform-Load) tool to migrate data from the PDFs into a database. But this is not much help to insurgent modelers who want to produce open source work.
Data journalists face a similar challenge. They often need to extract bulk data from PDFs to support their reporting. Examples include IRS Form 990s filed by non-profits and budgets issued by governments at all levels.
The data journalism community has responded to this challenge by developing software to harvest usable information from PDFs. Examples include Tabula, a tool written by Knight-Mozilla OpenNews Fellow Manuel Aristarán, extracts data from PDF tables in a form that can be readily imported to a spreadsheet – if the PDF was “printed” from a computer application. Introduced earlier this year, Tabula continues to evolve thanks to the volunteer efforts of Manuel, with help from OpenNews Fellow Mike Tigas and New York Times interactive developer Jeremy Merrill. Meanwhile, DocHive, a tool whose continuing development is being funded by a Knight Foundation grant, addresses PDFs that were created by scanning paper documents. DocHive is a project of Raleigh Public Record and is led by Charles and Edward Duncan.
These open source tools join a number of commercial offerings such as Able2Extract and ABBYY Fine Reader that extract data from PDFs. A more comprehensive list of open source and commercial resources is available here.
Unfortunately, the free and low cost tools available to modelers, data journalists and transparency advocates have limitations that hinder their ability to handle large scale tasks. If, like me, you want to submit hundreds of PDFs to a software tool, press “Go” and see large volumes of cleanly formatted data, you are out of luck.
It is for this reason that I am working with The Sunlight Foundation and other sponsors to stage the PDF Liberation Hackathon from January 17-19, 2014. We’ll have hack sites at Sunlight’s Washington DC office and at RallyPad in San Francisco. Developers can also join remotely because we will publish a number of clearly specified PDF extraction challenges before the hackathon.
Participants can work on one of the pre-specified challenges or choose their own PDF extraction projects. Ideally, hackathon teams will use (and hopefully improve upon) open source tools to meet the hacking challenges, but they will also be allowed to embed commercial tools into their projects as long as their licensing cost is less than $1000 and an unlimited trial is available.
Prizes of up to $500 will be awarded to winning entries. To receive a prize, a team must publish their source code on a GitHub public repository. To join the hackathon in DC or remotely, please sign up at Eventbrite; to hack with us in SF, please sign up via this Meetup. Please also complete our Google Form survey. Also, if anyone reading this is associated with an organization in New York or Chicago that would like to organize an additional hack space, please contact me.
The PDF Liberation Hackathon is going to be a great opportunity to advance the state of the art when it comes to harvesting data from public documents. I hope you can join us.
The cost savings of food stamps cuts versus the cost increases of diabetes care
As many of you are aware, food stamps were recently cut in this country. This has had a brutal effect on people and families and on neighborhood food pantries, which are being swamped with new customers and increased need among their existing customers.
One thing that I come away with when I read articles describing this problem is how often they detail individuals who have been diagnosed with diabetes but can no longer afford to pay for appropriate food for their condition.
As a person with a family history of diabetes, and someone who has been actively avoiding sugars and carbs to control my blood sugar for the past couple of years, I have a tremendous amount of sympathy for these struggling people.
Let me put it another way. Eating well in this country is expensive, and I’ve had to spend real money on food here in New York City to avoid sugary and fast carb-laden food. I don’t think I could have done that on a skimpy food budget. It’s especially hard to imagine budgeting healthy food on a withering food stamp budget.
Because here’s the thing, and it’s not a secret: shitty food is cheap. If I need to buy lots of food (read: calories) for a small amount of money, I can do it easily, but it will be hell for my blood sugar control. I’m guessing I’d be a full-blown diabetic by now if I were poor and on food stamps.
And that brings me to my nerd question of the morning. How much money are we really saving by decreasing the food stamp allowance in this country, if we consider how many more people will be diagnosed diabetic as a result of the decreased quality of their diet? And how many people’s diabetes will get worse, and how much will that cost?
It’s not over, either: apparently more cuts are coming over the next 10 years (maybe by $4 billion, maybe by $40 billion). And although diabetes care costs have gone up 40% in the last 5 years ($245 billion in 2012 from $174 billion in 2007), that doesn’t mean they won’t go up way more in the next 10.
I’m not an expert on how this all works, but the scale is right – we’re talking billions of dollars nationally, so not small potatoes, and of course we’re also talking about people’s quality of life. Never mind in a moral context – I’m definitely of the mind that people should be able to eat – I’m wondering if the food stamp cuts make sense in a dollars and cents context.
Please tell me if you know of an analysis in this direction.
#AskJPM and public shaming #OWS
I don’t usually shill for companies but this morning I’m completely into how much of a circus my Twitter feed became yesterday when JP Morgan Chase’s PR team decided to open up to the public for questions. You can see from the immediate replies how this was going to go:

The questions asked which were tagged with #AskJPM are stunning and constitute a well-deserved public shaming of JP Morgan.
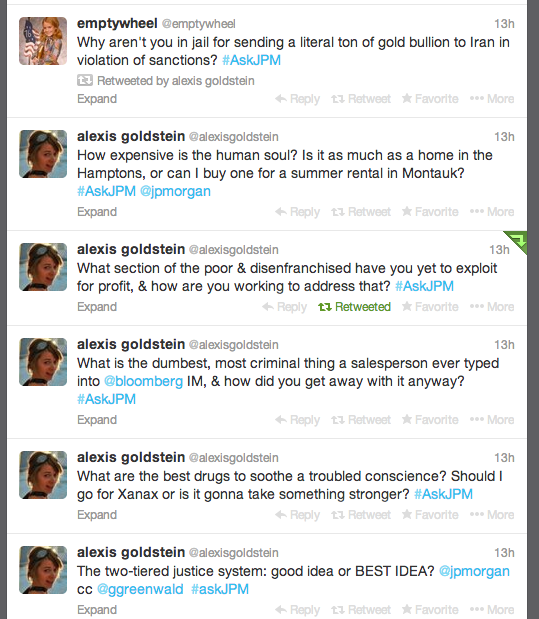
My friend and co-occupier Alexis Goldstein was absolutely killing it on Twitter, as usual. Here’s just a snippet from her feed:
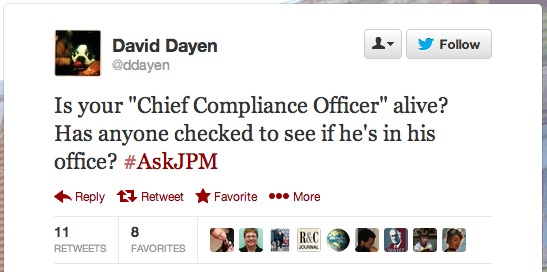
See also Dave Dayen’s choice question:
Needless to say the Q&A was canceled, but not until the #AskJPM hashtag went viral in an amazing way. See more examples here and here.
Update: Watch #AskJPM tweets read by Stacy Keach live on CNBC!!
You are not a loan: Rolling Jubilee eradicates $15,000,000 worth of debt #OWS
This is super cool. Occupy Wall Street’s Strike Debt group has bought up almost $15 million dollars worth of mostly medical debt which was owned by 2,700 people across 45 states and Puerto Rico. They used donations they’ve been collecting over the last year. There’s more information about this action in this Guardian piece.
Here’s what I like about this. By freeing people of medical debt in particular, which is the biggest cause of bankruptcy filings, it emphasizes the lie of the “moral sin” often associated with crushing debt.
In other words, instead of imagining poor and debt-ridden people as lazy and glibly unable to keep their promises, the Rolling Jubilee action bestows a much-needed act of compassion for some of the millions of the unlucky people in this country caught in a dysfunctional health and credit system.
And while it’s true that it is making a small dent in the debt problem, in dollars and cents terms, I think the Strike Debt’s debt action, and its Debt Resistors’ Operation Manual, has made huge strides in how people think about debt in this country, which is tremendously important.

Yves Smith and Dean Baker discuss the Trans Pacific Partnership #OWS
Last night I watched this interview by Yves Smith and Dean Baker on billmoyers.com. I recommend it for everyone interested in learning about the secret “free trade” agreement currently under negotiation between the U.S. and a bunch of other countries which touch the Pacific Ocean.
The interview will explain why “free trade” is in quotes, because it’s really more about protecting corporate interests and extending patents than about reducing obstacles to trade:
As a member of Alt Banking, I’m particularly outraged by the financial regulation part of the treaty, which sound like a race to the bottom in terms of common laws between the countries. But probably the worst part of the treaty is related to pharmaceutical protectionism.
Near the end of the interview there’s an appeal, involving a monetary award, for people on the inside to come out and show the world exactly what the contents of the treaty contain. The award is sponsored by WikiLeaks and is crowdsourced: it currently stands at $61,252. So you can add to it if you want to sweeten the pot.
Are PayDay lenders better than banks? #OWS
Sometimes my plan of getting up super early to write on my blog fails, and this is one of those days. But I’m still going to ask you to read this article from the New Yorker written by Lisa Servon and entitled, “The High Cost, For The Poor, Of Using A Bank.” Here’s a key passage, but the whole thing is amazing, and yes, I’ve invited her to my Occupy group already:
To understand why, consider loans of small amounts. People criticize payday loans for their high annual percentage rates (APR), which range from three hundred per cent to six hundred per cent. Payday lenders argue that APR is the wrong measure: the loans, they say, are designed to be repaid in as little as two weeks. Consumer advocates counter that borrowers typically take out nine of these loans each year, and end up indebted for more than half of each year.
But what alternative do low-income borrowers have? Banks have retreated from small-dollar credit, and many payday borrowers do not qualify anyway. It happens that banks offer a de-facto short-term, high-interest loan. It’s called an overdraft fee. An overdraft is essentially a short-term loan, and if it had a repayment period of seven days, the APR for a typical incident would be over five thousand per cent.
It makes me wonder whether, if someone did a careful analysis with all-in costs including time and travel, whether PayDay Lenders are not actually a totally rational choice for the poor.
Make Rich People Read Chekhov
There have been two articles in the New York Times very recently concerning empathy.
First, there was this Opinionator piece about how rich people have less empathy. Second, there was this Well blogpost which reports on a study that implies you can improve your empathy skills, at least in the short term, by reading literary fiction like Chekhov.
Empathy means understanding and sharing the feelings of other people. So what do these two columns actually refer to?
For rich people, it’s mostly about attention rather than empathy. The idea is that researchers study how people pay attention to people (answer: they pay attention to high status people more), and found that rich people don’t do it much at all. They claim attention is a prerequisite for empathy, and that there’s a negative feedback loop going on with the rich, a lack of empathy, and increasing inequality.
As for the literary fiction column, it cites a study in which what they measure is something a little bit different, namely the “theory of mind” of a person after reading Checkhov versus something else. The concept of the theory of mind is that we have internal models of other people’s mindset, and actually they claim to be able to separate this into two parts, cognitive and affective. So if I have a realistic impression of what you’re feeling, we say that my affective theory of mind is good, whereas if I have a realistic impression of how you’re planning to act, that’s called nailing a cognitive theory of mind.
A few comments:
- I’m not so sure about the attention-leads-to-empathy assumption. Sometimes I am on a subway and I start sensing people’s emotions around me whether I like it or not, even when I’m trying not to pay attention to them. For me empathy is like smell, and some people are incredibly smelly, especially on the subway.
- On the other hand it resonates with me that rich people have less empathy. Certainly this seemed to be the case when I worked at D.E. Shaw, although it might have been a self-selection thing: maybe people who are not empathetic are attracted to working at a hedge fund.
- In any case, there’s a tremendous disconnect between regular people and the attitude of finance people, along the lines of “I’m smarter than those people so I deserve to be rich”, and I ascribe much of this disconnect to a lack of empathy.
- In both of these columns, though, the question was how well do you pay attention to, and read, people in the same room with you. Unfortunately that’s not a good enough question, at least if you’re worried about that negative feedback loop, if you think about the real world. In the real world, even in New York, rich people don’t spend lots of time in the same room with anyone except other rich people. So it’s a bigger problem to address than what you might at first think.
- Having said that, I don’t claim that if everyone just had more empathy all our problems would be solved. Even so I do think it might help. Certainly my sensitivity to other people’s emotions deeply affects me and my actions and goals, but of course that’s too little evidence to go by.
- In any case it’s an interesting thought experiment to imagine a world of increased empathy. I like that it’s being considered as a basic attribute of interest, and that it seems tweakable.
- Conclusion: before talking to someone I perceive as unempathetic, I will bust out a Checkov short story (this one) and demand they read it on the spot. That should really help.



