Archive
Guest post: Clustering and predicting NYC taxi activity
This is a guest post by Deepak Subburam, a data scientist who works at Tessellate.

from NYCTaxi.info
Greetings fellow Mathbabers! At Cathy’s invitation, I am writing here about NYCTaxi.info, a public service web app my co-founder and I have developed. It overlays on a Google map around you estimated taxi activity, as expected number of passenger pickups and dropoffs this current hour. We modeled these estimates from the recently released 2013 NYC taxi trips dataset comprising 173 million trips, the same dataset that Cathy’s post last week on deanonymization referenced. Our work will not help you stalk your favorite NYC celebrity, but guide your search for a taxi and maybe save some commute time. My writeup below shall take you through the four broad stages our work proceeded through: data extraction and cleaning , clustering, modeling, and visualization.
We extract three columns from the data: the longitude and latitude GPS coordinates of the passenger pickup or dropoff location, and the timestamp. We make no distinction between pickups and dropoffs, since both of these events imply an available taxicab at that location. The data was generally clean, with a very small fraction of a percent of coordinates looking bad, e.g. in the middle of the Hudson River. These coordinate errors get screened out by the clustering step that follows.
We cluster the pickup and dropoff locations into areas of high density, i.e. where many pickups and dropoffs happen, to determine where on the map it is worth making and displaying estimates of taxi activity. We rolled our own algorithm, a variation on heatmap generation, after finding existing clustering algorithms such as K-means unsuitable—we are seeking centroids of areas of high density rather than cluster membership per se. See figure below which shows the cluster centers as identified by our algorithm on a square-mile patch of Manhattan. The axes represent the longitude and latitude of the area; the small blue crosses a random sample of pickups and dropoffs; and the red numbers the identified cluster centers, in descending order of activity.

Taxi activity clusters
We then model taxi activity at each cluster. We discretize time into hourly intervals—for each cluster, we sum all pickups and dropoffs that occur each hour in 2013. So our datapoints now are triples of the form [<cluster>, <hour>, <activity>], with <hour> being some hour in 2013 and <activity> being the number of pickups and dropoffs that occurred in hour <hour> in cluster <cluster>. We then regress each <activity> against neighboring clusters’ and neighboring times’ <activity> values. This regression serves to smooth estimates across time and space, smoothing out effects of special events or weather in the prior year that don’t repeat this year. It required some tricky choices on arranging and aligning the various data elements; not technically difficult or maybe even interesting, but nevertheless likely better part of an hour at a whiteboard to explain. In other words, typical data science. We then extrapolate these predictions to 2014, by mapping each hour in 2014 to the most similar hour in 2013. So we now have a prediction at each cluster location, for each hour in 2014, the number of passenger pickups and dropoffs.
We display these predictions by overlaying them on a Google maps at the corresponding cluster locations. We round <activity> to values like 20, 30 to avoid giving users number dyslexia. We color the labels based on these values, using the black body radiation color temperatures for the color scale, as that is one of two color scales where the ordering of change is perceptually intuitive.
If you live in New York, we hope you find NYCTaxi.info useful. Regardless, we look forward to receiving any comments.

Guest post: The dangers of evidence-based sentencing
This is a guest post by Luis Daniel, a research fellow at The GovLab at NYU where he works on issues dealing with tech and policy. He tweets @luisdaniel12. Crossposted at the GovLab.
What is Evidence-based Sentencing?
For several decades, parole and probation departments have been using research-backed assessments to determine the best supervision and treatment strategies for offenders to try and reduce the risk of recidivism. In recent years, state and county justice systems have started to apply these risk and needs assessment tools (RNA’s) to other parts of the criminal process.
Of particular concern is the use of automated tools to determine imprisonment terms. This relatively new practice of applying RNA information into the sentencing process is known as evidence-based sentencing (EBS).
What the Models Do
The different parameters used to determine risk vary by state, and most EBS tools use information that has been central to sentencing schemes for many years such as an offender’s criminal history. However, an increasing amount of states have been utilizing static factors such as gender, age, marital status, education level, employment history, and other demographic information to determine risk and inform sentencing. Especially alarming is the fact that the majority of these risk assessment tools do not take an offender’s particular case into account.
This practice has drawn sharp criticism from Attorney General Eric Holder who says “using static factors from a criminal’s background could perpetuate racial bias in a system that already delivers 20% longer sentences for young black men than for other offenders.” In the annual letter to the US Sentencing Commission, the Attorney General’s Office states that “utilizing such tools for determining prison sentences to be served will have a disparate and adverse impact on offenders from poor communities already struggling with social ills.” Other concerns cite the probable unconstitutionality of using group-based characteristics in risk assessments.
Where the Models Are Used
It is difficult to precisely quantify how many states and counties currently implement these instruments, although at least 20 states have implemented some form of EBS. Some of the states or states with counties that have implemented some sort of EBS (any type of sentencing: parole, imprisonment, etc) are: Pennsylvania, Tennessee, Vermont, Kentucky, Virginia, Arizona, Colorado, California, Idaho, Indiana, Missouri, Nebraska, Ohio, Oregon, Texas, and Wisconsin.
The Role of Race, Education, and Friendship
Overwhelmingly states do not include race in the risk assessments since there seems to be a general consensus that doing so would be unconstitutional. However, even though these tools do not take race into consideration directly, many of the variables used such as economic status, education level, and employment correlate with race. African-Americans and Hispanics are already disproportionately incarcerated and determining sentences based on these variables might cause further racial disparities.
The very socioeconomic characteristics such as income and education level used in risk assessments are the characteristics that are already strong predictors of whether someone will go to prison. For example, high school dropouts are 47 times more likely to be incarcerated than people in their similar age group who received a four-year college degree. It is reasonable to suspect that courts that include education level as a risk predictor will further exacerbate these disparities.
Some states, such as Texas, take into account peer relations and considers associating with other offenders as a “salient problem”. Considering that Texas is in 4th place in the rate of people under some sort of correctional control (parole, probation, etc) and that the rate is 1 in 11 for black males in the United States it is likely that this metric would disproportionately affect African-Americans.
Sonja Starr’s paper
Even so, in some cases, socioeconomic and demographic variables receive significant weight. In her forthcoming paper in the Stanford Law Review, Sonja Starr provides a telling example of how these factors are used in presentence reports. From her paper:
For instance, in Missouri, pre-sentence reports include a score for each defendant on a scale from -8 to 7, where “4-7 is rated ‘good,’ 2-3 is ‘above average,’ 0-1 is ‘average’, -1 to -2 is ‘below average,’ and -3 to -8 is ‘poor.’ Unlike most instruments in use, Missouri’s does not include gender. However, an unemployed high school dropout will score three points worse than an employed high school graduate—potentially making the difference between “good” and “average,” or between “average” and “poor.” Likewise, a defendant under age 22 will score three points worse than a defendant over 45. By comparison, having previously served time in prison is worth one point; having four or more prior misdemeanor convictions that resulted in jail time adds one point (three or fewer adds none); having previously had parole or probation revoked is worth one point; and a prison escape is worth one point. Meanwhile, current crime type and severity receive no weight.
Starr argues that such simple point systems may “linearize” a variable’s effect. In the underlying regression models used to calculate risk, some of the variable’s effects do not translate linearly into changes in probability of recidivism, but they are treated as such by the model.
Another criticism Starr makes is that they often make predictions on an individual based on averages of a group. Starr says these predictions can predict with reasonable precision the average recidivism rate for all offenders who share the same characteristics as the defendant, but that does not make it necessarily useful for individual predictions.
The Future of EBS Tools
The Model Penal Code is currently in the process of being revised and is set to include these risk assessment tools in the sentencing process. According to Starr, this is a serious development because it reflects the increased support of these practices and because of the Model Penal Code’s great influence in guiding penal codes in other states. Attorney General Eric Holder has already spoken against the practice, but it will be interesting to see whether his successor will continue this campaign.
Even if EBS can accurately measure risk of recidivism (which is uncertain according to Starr), does that mean that a greater prison sentence will result in less future offenses after the offender is released? EBS does not seek to answer this question. Further, if knowing there is a harsh penalty for a particular crime is a deterrent to commit said crime, wouldn’t adding more uncertainty to sentencing (EBS tools are not always transparent and sometimes proprietary) effectively remove this deterrent?
Even though many questions remain unanswered and while several people have been critical of the practice, it seems like there is great support for the use of these instruments. They are especially easy to support when they are overwhelmingly regarded as progressive and scientific, something Starr refutes. While there is certainly a place for data analytics and actuarial methods in the criminal justice system, it is important that such research be applied with the appropriate caution. Or perhaps not at all. Even if the tools had full statistical support, the risk of further exacerbating an already disparate criminal justice system should be enough to halt this practice.
Both Starr and Holder believe there is a strong case to be made that the risk prediction instruments now in use are unconstitutional. But EBS has strong advocates, so it’s a difficult subject. Ultimately, evidence-based sentencing is used to determine a person’s sentencing not based on what the person has done, but who that person is.
Big Data’s Disparate Impact
Take a look at this paper by Solon Barocas and Andrew D. Selbst entitled Big Data’s Disparate Impact.
It deals with the question of whether current anti-discrimination law is equipped to handle the kind of unintentional discrimination and digital redlining we see emerging in some “big data” models (and that we suspect are hidden in a bunch more). See for example this post for more on this concept.
The short answer is no, our laws are not equipped.
Here’s the abstract:
This article addresses the potential for disparate impact in the data mining processes that are taking over modern-day business. Scholars and policymakers had, until recently, focused almost exclusively on data mining’s capacity to hide intentional discrimination, hoping to convince regulators to develop the tools to unmask such discrimination. Recently there has been a noted shift in the policy discussions, where some have begun to recognize that unintentional discrimination is a hidden danger that might be even more worrisome. So far, the recognition of the possibility of unintentional discrimination lacks technical and theoretical foundation, making policy recommendations difficult, where they are not simply misdirected. This article provides the necessary foundation about how data mining can give rise to discrimination and how data mining interacts with anti-discrimination law.
The article carefully steps through the technical process of data mining and points to different places within the process where a disproportionately adverse impact on protected classes may result from innocent choices on the part of the data miner. From there, the article analyzes these disproportionate impacts under Title VII. The Article concludes both that Title VII is largely ill equipped to address the discrimination that results from data mining. Worse, due to problems in the internal logic of data mining as well as political and constitutional constraints, there appears to be no easy way to reform Title VII to fix these inadequacies. The article focuses on Title VII because it is the most well developed anti-discrimination doctrine, but the conclusions apply more broadly because they are based on the general approach to anti-discrimination within American law.
I really appreciate this paper, because it’s an area I know almost nothing about: discrimination law and what are the standards for evidence of discrimination.
Sadly, what this paper explains to me is how very far we are away from anything resembling what we need to actually address the problems. For example, even in this paper, where the writers are well aware that training on historical data can unintentionally codify discriminatory treatment, they still seem to assume that the people who build and deploy models will “notice” this treatment. From my experience working in advertising, that’s not actually what happens. We don’t measure the effects of our models on our users. We only see whether we have gained an edge in terms of profit, which is very different.
Essentially, as modelers, we don’t humanize the people on the other side of the transaction, which prevents us from worrying about discrimination or even being aware of it as an issue. It’s so far from “intentional” that it’s almost a ridiculous accusation to make. Even so, it may well be a real problem and I don’t know how we as a society can deal with it unless we update our laws.
De-anonymizing what used to be anonymous: NYC taxicabs
Thanks to Artem Kaznatcheev, I learned yesterday about the recent work of Anthony Tockar in exploring the field of anonymization and deanonymization of datasets.
Specifically, he looked at the 2013 cab rides in New York City, which was provided under a FOIL request, and he stalked celebrities Bradley Cooper and Jessica Alba (and discovered that neither of them tipped the cabby). He also stalked a man who went to a slew of NYC titty bars: found out where the guy lived and even got a picture of him.
Previously, some other civic hackers had identified the cabbies themselves, because the original dataset had scrambled the medallions, but not very well.
The point he was trying to make was that we should not assume that “anonymized” datasets actually protect privacy. Instead we should learn how to use more thoughtful approaches to anonymizing stuff, and he proposes a method called “differential privacy,” which he explains here. It involves adding noise to the data, in a certain way, so that at the end any given person doesn’t risk too much of their own privacy by being included in the dataset versus being not included in the dataset.
Bottomline, it’s actually pretty involved mathematically, and although I’m a nerd and it doesn’t intimidate me, it does give me pause. Here are a few concerns:
- It means that most people, for example the person in charge of fulfilling FOIL requests, will not actually understand the algorithm.
- That means that, if there’s a requirement that such a procedure is used, that person will have to use and trust a third party to implement it. This leads to all sorts of problems in itself.
- Just to name one, depending on what kind of data it is, you have to implement differential privacy differently. There’s no doubt that a complicated mapping of datatype to methodology will be screwed up when the person doing it doesn’t understand the nuances.
- Here’s another: the third party may not be trustworthy and may have created a backdoor.
- Or they just might get it wrong, or do something lazy that doesn’t actually work, and they can get away with it because, again, the user is not an expert and cannot accurately evaluate their work.
Altogether I’m imagining that this is at best an expensive solution for very important datasets, and won’t be used for your everyday FOIL requests like taxicab rides unless the culture around privacy changes dramatically.
Even so, super interesting and important work by Anthony Tockar. Also, if you think that’s cool, take a look at my friend Luis Daniel‘s work on de-anonymizing the Stop & Frisk data.
Upcoming data journalism and data ethics conferences
Today
Today I’m super excited to go to the opening launch party of danah boyd’s Data and Society. Data and Society has a bunch of cool initiatives but I’m particularly interested in their Council for Big Data, Ethics, and Society. They were the people that helped make the Podesta Report on Big Data as good as it was. There will be a mini-conference this afternoon I’m looking forward to very much. Brilliant folks doing great work and talking to each other across disciplinary lines, can’t get enough of that stuff.
This weekend
This coming Saturday I’ll be moderating a panel called Spotlight on Data-Driven Journalism: The job of a data journalist and the impact of computational reporting in the newsroom at the New York Press Club Conference on Journalism. The panelists are going to be great:
- John Keefe @jkeefe, Sr. editor, data news & J-technology, WNYC
- Maryanne Murray @lightnosugar, Global head of graphics, Reuters
- Zach Seward @zseward, Quartz
- Chris Walker @cpwalker07, Dir., data visualization, Mic News
The full program is available here.
December 12th
In mid-December I’m on a panel myself at the Fairness, Accountability, and Transparency in Machine Learning Conference in Montreal. This conference seems to directly take up the call of the Podesta Report I mentioned above, and seeks to provide further research into the dangers of “encoding discrimination in automated decisions”. Amazing! So glad this is happening and that I get to be part of it. Here are some questions that will be taken up at this one-day conference (more information here):
- How can we achieve high classification accuracy while eliminating discriminatory biases? What are meaningful formal fairness properties?
- How can we design expressive yet easily interpretable classifiers?
- Can we ensure that a classifier remains accurate even if the statistical signal it relies on is exposed to public scrutiny?
- Are there practical methods to test existing classifiers for compliance with a policy?
Reverse-engineering Chinese censorship
This recent paper written by Gary King, Jennifer Pan, and Margaret Roberts explores the way social media posts are censored in China. It’s interesting, take a look, or read this article on their work.
Here’s their abstract:
Existing research on the extensive Chinese censorship organization uses observational methods with well-known limitations. We conducted the first large-scale experimental study of censorship by creating accounts on numerous social media sites, randomly submitting different texts, and observing from a worldwide network of computers which texts were censored and which were not. We also supplemented interviews with confidential sources by creating our own social media site, contracting with Chinese firms to install the same censoring technologies as existing sites, and—with their software, documentation, and even customer support—reverse-engineering how it all works. Our results offer rigorous support for the recent hypothesis that criticisms of the state, its leaders, and their policies are published, whereas posts about real-world events with collective action potential are censored.
Interesting that they got so much help from the Chinese to censor their posts. Also keep in mind a caveat from the article:
Yu Xie, a sociologist at the University of Michigan, Ann Arbor, says that although the study is methodologically sound, it overemphasizes the importance of coherent central government policies. Political outcomes in China, he notes, often rest on local officials, who are evaluated on how well they maintain stability. Such officials have a “personal interest in suppressing content that could lead to social movements,” Xie says.
I’m a sucker for reverse-engineering powerful algorithms, even when there are major caveats.
Ello, Enron, and the future of data privacy
If you think Ello is the newest safest social media platform, you might want to think again.
Or at the very least, go ahead and read this piece by my data journalist buddy Meredith Broussard, entitled ‘Ello, social media newcomer! Goodbye, data security fears?. Meredith has read the fine print in Ello’s security policy, and it’s not great news.
Notices of the AMS is killing it
I am somewhat surprised to hear myself say this, but this month’s Notices of the AMS is killing it. Generally speaking I think of it as rather narrowly focused but things seem to be expanding and picking up. Scanning the list of editors, they do seem to have quite a few people that want to address wider public issues that touch and are touched by mathematicians.
First, there’s an article about how the h-rank of an author is basically just the square root of the number of citations for that author. It’s called Critique of Hirsch’s Citation Index: A Combinatorial Fermi Problem and it’s written by Alexander Yong. Doesn’t surprised me too much, but there you go, people often fall in love with new fancy metrics that turn out to be simple transformations of old discarded metrics.
Second, and even more interesting to me, there’s an article that explains the mathematical vapidness of a widely cited social science paper. It’s called Does Diversity Trump Ability? An Example of the Misuse of Mathematics in the Social Sciences and it’s written by Abby Thompson. My favorite part of paper:

Oh, and here’s another excellent take-down of a part of that paper:

Let me just take this moment to say, right on, Notices of the AMS! And of course, right on Alexander Yong and Abby Thompson!
Chameleon models
Here’s an interesting paper I’m reading this morning (hat tip Suresh Naidu) entitled Chameleons: The Misuse of Theoretical Models in Finance and Economics written by Paul Pfleiderer. The paper introduces the useful concept of chameleon models, defined in the following diagram:
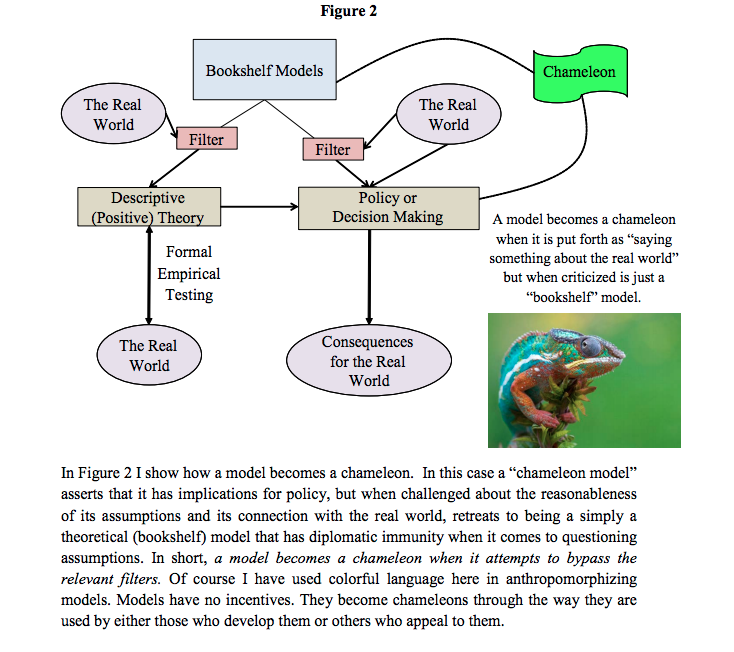
Pfleiderer provides some examples of chameleon models, and also takes on the Milton Friedman argument that we shouldn’t judge a model by its assumptions but rather by its predictions (personally I think this is largely dependent on the way a model is used; the larger the stakes, the more the assumptions matter).
I like the term, and I think I might use it. I also like the point he makes that it’s really about usage. Most models are harmless until they are used as political weapons. Even the value-added teacher model could be used to identify school systems that need support, although in the current climate of distorted data due to teaching to the test and cheating, I think the signal is probably very slight.
Women not represented in clinical trials
This recent NYTimes article entitled Health Researchers Will Get $10.1 Million to Counter Gender Bias in Studies spelled out a huge problem that kind of blows me away as a statistician (and as a woman!).
Namely, they have recently decided over at the NIH, which funds medical research in this country, that we should probably check to see how women’s health are affected by drugs, and not just men’s. They’ve decided to give “extra money” to study this special group, namely females.
Here’s the bizarre and telling explanation for why most studies have focused on men and excluded women:
Traditionally many investigators have worked only with male lab animals, concerned that the hormonal cycles of female animals would add variability and skew study results.
Let’s break down that explanation, which I’ve confirmed with a medical researcher is consistent with the culture.
If you are afraid that women’s data would “skew study results,” that means you think the “true result” is the result that works for men. Because adding women’s data would add noise to the true signal, that of the men’s data. What?! It’s an outrageous perspective. Let’s take another look at this reasoning, from the article:
Scientists often prefer single-sex studies because “it reduces variability, and makes it easier to detect the effect that you’re studying,” said Abraham A. Palmer, an associate professor of human genetics at the University of Chicago. “The downside is that if there is a difference between male and female, they’re not going to know about it.”
Ummm… yeah. So instead of testing the effect on women, we just go ahead and optimize stuff for men and let women just go ahead and suffer the side effects of the treatment we didn’t bother to study. After all, women only comprise 50.8% of the population, they won’t mind.
This is even true for migraines, where 2/3rds of migraine sufferers are women.
One reason they like to exclude women: they have periods, and they even sometimes get pregnant, which is confusing for people who like to have clean statistics (on men’s health). In fact my research contact says that traditionally, this bias towards men in clinical trials was said to protect women because they “could get pregnant” and then they’d be in a clinical trial while pregnant. OK.
I’d like to hear more about who is and who isn’t in clinical trials, and why.
The business of public education
I’ve been writing my book, and I’m on chapter 4 right now, which is tentatively entitled Feedback Loops In Education. I’m studying the enormous changes in primary and secondary education that have occurred since the “data-driven” educational reform movement started with No Child Left Behind in 2001.
Here’s the issue I’m having writing this chapter. Things have really changed in the last 13 years, it’s really incredible how much money and politics – and not education – are involved. In fact I’m finding it difficult to write the chapter without sounding like a wingnut conspiracy theorist. Because that’s how freaking nuts things are right now.
On the one hand you have the people who believe in the promise of educational data. They are often pro-charter schools, anti-tenure, anti-union, pro-testing, and are possibly personally benefitting from collecting data about children and then sold to commercial interests. Privacy laws are things to bypass for these people, and the way they think about it is that they are going to improve education with all this amazing data they’re collecting. Because, you know, it’s big data, so it has to be awesome. They see No Child Left Behind and Race To The Top as business opportunities.
On the other hand you have people who do not believe in the promise of educational data. They believe in public education, and are maybe even teachers themselves. They see no proven benefits of testing, or data collection and privacy issues for students, and they often worry about job security, and public shaming and finger-pointing, and the long term consequences on children and teachers of this circus of profit-seeking “educational” reformers. Not to mention that none of this recent stuff is addressing the very real problems we have.
As it currently stands, I’m pretty much part of the second group. There just aren’t enough data skeptics in the first group to warrant my respect, and there’s way too much money and secrecy around testing and “value-added models.” And the politics of the anti-tenure case are ugly and I say that even though I don’t think teacher union leaders are doing themselves many favors.
But here’s the thing, it’s not like there could never be well-considered educational experiments that use data and have strict privacy measures in place, the results of which are not saved to individual records but are lessons learned for educators, and, it goes without saying, are strictly non-commercial. There is a place for testing, but not as a punitive measure but rather as a way of finding where there are problems and devoting resources to it. The current landscape, however, is so split and so acrimonious, it’s kind of impossible to imagine something reasonable happening.
It’s too bad, this stuff is important.
When your genetic information is held against you
My friend Jan Zilinsky recently sent me this blogpost from the NeuroCritic which investigates the repercussions of having biomarkers held against individuals.
In this case, the biomarker was in the brain and indicated a propensity for taking financial risks. Or maybe it didn’t really – the case wasn’t closed – but that was the idea, and the people behind the research mentioned three times in 8 pages that policy makers might want to use already available brain scans to figure out which populations or individuals would be at risk. Here’s an excerpt from their paper:
Our finding suggests the existence of a simple biomarker for risk attitude, at least in the midlife [sic] population we examined in the northeastern United States. … If generalized to other groups, this finding will also imply that individual risk attitudes could, at least to some extent, be measured in many existing medical brain scans, potentially offering a tool for policy makers seeking to characterize the risk attitudes of populations.
The way the researchers did their tests was, as usual, to have them play artificial games of chance and see how different people strategized, and how their brains were different.
Here’s another article I found on biomarkers and risk for psychosis, here’s one on biomarkers and risk for PTSD.
Studies like this are common and I don’t see a reason they won’t become even more common. The question is how we’re going to use them. Here’s a nasty way I could imagine they get used: when you apply for a job, you fill in a questionnaire that puts you into a category, and then people can see what biomarkers are typical for that category, and what the related health risks look like, and then they can decide whether to hire you. Not getting hired doesn’t say anything about your behaviors, just what happens with “people like you”.
I’m largely sidestepping the issue of accuracy. It’s quite likely that, at an individual level, many such predictions will be inaccurate but could still be used by commercial interests – and even be profitable – even so.
In the best case scenario, we would use such knowledge strictly to help people stay healthy. In the worst case, we have a system whereby people are judged by their biomarkers and not their behavior. If there were ever a case for regulation, I think this is it.
Reverse-engineering the college admissions process
I just finished reading a fascinating article from Bloomberg BusinessWeek about a man who claims to have reverse-engineered the admission processes at Ivy League colleges (hat tip Jan Zilinsky).
His name is Steven Ma, and as befits an ex-hedge funder, he has built an algorithm of sorts to work well with both the admission algorithms at the “top 50 colleges,” and the US News & World Report model which defines which colleges are in the “to 50.” It’s a huge modeling war that you can pay to engage in.
Ma is a salesman too: he guarantees that a given high-school kid will get into a top school, your money back. In other words he has no problem working with probabilities and taking risks that he think are likely to pay off and that make the parents willing to put down huge sums. Here’s an example of a complicated contract he developed with one family:
After signing an agreement in May 2012, the family wired Ma $700,000 over the next five months—before the boy had even applied to college. The contract set out incentives that would pay Ma as much as $1.1 million if the son got into the No. 1 school in U.S. News’ 2012 rankings. (Harvard and Princeton were tied at the time.) Ma would get nothing, however, if the boy achieved a 3.0 GPA and a 1600 SAT score and still wasn’t accepted at a top-100 college. For admission to a school ranked 81 to 100, Ma would get to keep $300,000; schools ranked 51 to 80 would let Ma hang on to $400,000; and for a top-50 admission, Ma’s payoff started at $600,000, climbing $10,000 for every rung up the ladder to No. 1.
He’s also interested in reverse-engineering the “winning essay” in conjunction with after-school activities:
With more capital—ThinkTank’s current valuation to potential investors is $60 million—Ma hopes to buy hundreds of completed college applications from the students who submitted them, along with the schools’ responses, and beef up his algorithm for the top 50 U.S. colleges. With enough data, Ma plans to build an “optimizer” that will help students, perhaps via an online subscription, choose which classes and activities they should take. It might tell an aspiring Stanford applicant with several AP classes in his junior year that it’s time to focus on becoming president of the chess or technology club, for example.
This whole college coaching industry reminds me a lot of financial regulation. We complicate the rules to the point where only very well-off insiders know exactly how to bypass the rules. To the extent that getting into one of these “top schools” actually does give young people access to power, influence, and success, it’s alarming how predictable the whole process has become.
Here’s a thought: maybe we should have disclosure laws about college coaching and prep? Or would those laws be gamed too?
Student evaluations: very noisy data
I’ve been sent this recent New York Times article by a few people (thanks!). It’s called Grading Teachers, With Data From Class, and it’s about how standardized tests are showing themselves to be inadequate to evaluate teachers, so a Silicon Valley-backed education startup called Panorama is stepping into the mix with a data collection process focused on student evaluations.
Putting aside for now how much this is a play for collecting information about the students themselves, I have a few words to say about the signal which one gets from student evaluations. It’s noisy.
So, for example, I was a calculus teacher at Barnard, teaching students from all over the Columbia University community (so, not just women). I taught the same class two semesters in a row: first in Fall, then in Spring.
Here’s something I noticed. The students in the Fall were young (mostly first semester frosh), eager, smart, and hard-working. They loved me and gave me high marks on all categories, except of course for the few students who just hated math, who would typically give themselves away by saying “I hate math and this class is no different.”
The students in the Spring were older, less eager, probably just as smart, but less hard-working. They didn’t like me or the class. In particular, they didn’t like how I expected them to work hard and challenge themselves. The evaluations came back consistently less excited, with many more people who hated math.
I figured out that many of the students had avoided this class and were taking it for a requirement, didn’t want to be there, and it showed. And the result was that, although my teaching didn’t change remarkably between the two semesters, my evaluations changed considerably.
Was there some way I could have gotten better evaluations from that second group? Absolutely. I could have made the class easier. That class wanted calculus to be cookie-cutter, and didn’t particularly care about the underlying concepts and didn’t want to challenge themselves. The first class, by contrast, had loved those things.
My conclusion is that, once we add “get good student evaluations” to the mix of requirements for our country’s teachers, we are asking for them to conform to their students’ wishes, which aren’t always good. Many of the students in this country don’t like doing homework (in fact most!). Only some of them like to be challenged to think outside their comfort zone. We think teachers should do those things, but by asking them to get good student evaluations we might be preventing them from doing those things. A bad feedback loop would result.
I’m not saying teachers shouldn’t look at student evaluations; far from it, I always did and I found them useful and illuminating, but the data was very noisy. I’d love to see teachers be allowed to see these evaluations without there being punitive consequences.
The bad teacher conspiracy
Any time I see an article about the evaluation system for teachers in New York State, I wince. People get it wrong so very often. Yesterday’s New York Times article written by Elizabeth Harris was even worse than usual.
First, her wording. She mentioned a severe drop in student reading and math proficiency rates statewide and attributed it to a change in the test to the Common Core, which she described as “more rigorous.”
The truth is closer to “students were tested on stuff that wasn’t in their curriculum.” And as you can imagine, if you are tested on stuff you didn’t learn, your score will go down (the Common Core has been plagued by a terrible roll-out, and the timing of this test is Exhibit A). Wording like this matters, because Harris is setting up her reader to attribute the falling scores to bad teachers.
Harris ends her piece with a reference to a teacher-tenure lawsuit: ‘In one of those cases, filed in Albany in July, court documents contrasted the high positive teacher ratings with poor student performance, and called the new evaluation system “deficient and superficial.” The suit said those evaluations were the “most highly predictive measure of whether a teacher will be awarded tenure.”’
In other words, Harris is painting a picture of undeserving teachers sneaking into tenure in spite of not doing their job. It’s ironic, because I actually agree with the statement that the new evaluation system is “deficient and superficial,” but in my case I think it is overly punitive to teachers – overly random, really, since it incorporates the toxic VAM model – but in her framing she is implying it is insufficiently punitive.
Let me dumb Harris’s argument down even further: How can we have 26% English proficiency among students and 94% effectiveness among teachers?! Let’s blame the teachers and question the legitimacy of tenure.
Indeed, after reading the article I felt like looking into whether Harris is being paid by David Welch, the Silicon Valley dude who has vowed to fight teacher tenure nationwide. More likely she just doesn’t understand education and is convinced by simplistic reasoning.
In either case, she clearly needs to learn something about statistics. For that matter, so do other people who drag out this “blame the teacher” line whenever they see poor performance by students.
Because here’s the thing. Beyond obvious issues like switching the content of the tests away from the curriculum, standardized test scores everywhere are hugely dependent on the poverty levels of students. Some data:

It’s not just in this country, either:

Considering how many poor kids we have in the U.S., we are actually doing pretty well.
The conclusion is that, unless you think bad teachers have somehow taken over poor schools everywhere and booted out the good teachers, and good teachers have taken over rich schools everywhere and booted out the bad teachers (which is supposed to be impossible, right?), poverty has much more of an effect than teachers.
Just to clarify this reasoning, let me give you another example: we could blame bad journalists for lower rates of newspaper readership at a given paper, but since newspaper readership is going down everywhere we’d be blaming journalists for what is a cultural issue.
Or, we could develop a process by which we congratulate specific policemen for a reduced crime rate, but then we’d have to admit that crime is down all over the country.
I’m not saying there aren’t bad teachers, because I’m sure there are. But by only focusing on rooting out bad teachers, we are ignoring an even bigger and harder problem. And no, it won’t be solved by privatizing and corporatizing public schools. We need to address childhood poverty. Here’s one more visual for the road:

A decision tree for decision trees
For a while now I’ve been thinking I should build a decision tree for deciding which algorithm to use on a given data project. And yes, I think it’s kind of cool that “decision tree” would be an outcome on my decision tree. Kind of like a nerd pun.
I’m happy to say that I finally started work on my algorithm decision tree, thanks to this website called gliffy.com which allows me to build flowcharts with an easy online tool. It was one of those moments when I said to myself, this morning at 6am, “there should be a start-up that allows me to build a flowchart online! Let me google for that” and it totally worked. I almost feel like I willed gliffy.com into existence.
So here’s how far I’ve gotten this morning:

Not far! But I also learned how to use the tool.
I looked around the web to see if I’m doing something that’s already been done and I came up with this:
I appreciate the effort but this is way more focused on the size of the data than I intend to be, at least for now. And here’s another one that’s even less like the one I want to build but is still impressive.
Because here’s what I want to focus on: what kind of question are you answering with which algorithm? For example, with clustering algorithms you are, you know, grouping similar things together. That one’s easy, kind of, although plenty of projects have ended up being clustering or classifying algorithms whose motivating questions did not originally take on the form “how would we group these things together?”.
In other words, the process of getting at algorithms from questions is somewhat orthogonal to the normal way algorithms are introduced, and for that reason taking me some time to decide what the questions are that I need to ask in my decision tree. Right about now I’m wishing I had taken notes when my Lede Program students asked me to help them with their projects, because embedded in those questions were some great examples of data questions in search of an algorithm.
Please give me advice!
Advertising vs. Privacy
I’ve was away over the weekend (apologies to Aunt Pythia fans!) and super busy yesterday but this morning I finally had a chance to read Ethan Zuckerman’s Atlantic piece entitled The Internet’s Original Sin, which was sent to me by my friend Ernest Davis.
Here’s the thing, Zuckerman gets lots of things right in the article. Most importantly, the inherent conflict between privacy and the advertisement-based economy of the internet:
Demonstrating that you’re going to target more and better than Facebook requires moving deeper into the world of surveillance—tracking users’ mobile devices as they move through the physical world, assembling more complex user profiles by trading information between data brokers.
Once we’ve assumed that advertising is the default model to support the Internet, the next step is obvious: We need more data so we can make our targeted ads appear to be more effective.
This is well said, and important to understand.
Here’s where Zuckerman goes a little too far in my opinion:
Outrage over experimental manipulation of these profiles by social networks and dating companies has led to heated debates amongst the technologically savvy, but hasn’t shrunk the user bases of these services, as users now accept that this sort of manipulation is an integral part of the online experience.
It is a mistake to assume that “users accept this sort of manipulation” because not everyone has stopped using Facebook. Facebook is, after all, an hours-long daily habit for an enormous number of people, and it’s therefore sticky. People don’t give up addictive habits overnight. But it doesn’t mean they are feeling the same way about Facebook that they did 4 years ago. People are adjusting their opinion of the user experience as that user experience is increasingly manipulated and creepy.
An analogy should be drawn to something like smoking, where the rates have gone way down since we all found out it is bad for you. People stopped smoking even though it is really hard for most people (and impossible for some).
We should instead be thinking longer term about what people will be willing to leave Facebook for. What is the social networking model of the future? What kind of minimum privacy protections will convince people they are safe (enough)?
And, most importantly, will we even have reasonable minimum protections, or will privacy be entirely commoditized, whereby only premium pay members will be protected, while the rest of us will be thrown to the dogs?
Illegal PayDay syndicate in New York busted
There’s an interesting and horrible New York Time story by Jessica Silver-Greenberg about a PayDay loan syndicate being run out of New York State. The syndicate consists of twelve companies owned by a single dude, Carey Vaughn Brown, with help from a corrupt lawyer and another corrupt COO. Manhattan District Attorneys are charging him and his helpers with usury under New York law.
The complexity of the operation was deliberate and intended to obscure the chain of events that would start with a New Yorker online looking for quick cash online and end with a predatory loan. They’d interface with a company called MyCashNow.com, which would immediately pass their application on to a bunch of other companies in different states or overseas.
Important context: in New York, the usury law caps interest rates at 25 percent annually, and these PayDay operations were charging between 350 and 650 percent annually. Also key, the usury laws apply to where the borrower is, not where the lender is, so even though some of the companies were located (at least on paper) in the West Indies, they were still breaking the law.
They don’t know exactly how big the operation was in New York, but one clue is that in 2012, one of the twelve companies had $50 million in proceeds from New York.
Here’s my question: how did MyCashNow.com advertise? Did it use Google ads, or Facebook ads, or something else, and if so, what were the attributes of the desperate New Yorkers that it looked for to do its predatory work?
One side of this is that vulnerable people were somehow targeted. The other side is that well-off people were not, which meant they didn’t see ads like this, which makes it harder for people like the Manhattan District Attorney to even know about shady operations like this.
The problem with charter schools
Today I read this article written by Allie Gross (hat tip Suresh Naidu), a former Teach for America teacher whose former idealism has long been replaced by her experiences in the reality of education in this country. Her article is entitled The Charter School Profiteers.
It’s really important, and really well written, and just one of the articles in the online magazine Jacobin that I urge you to read and to subscribe to. In fact that article is part of a series (here’s another which focuses on charter schools in New Orleans) and it comes with a booklet called Class Action: An Activist Teacher’s Handbook. I just ordered a couple of hard copies.
I’d really like you to read the article, but as a teaser here’s one excerpt, a rant which she completely backs up with facts on the ground:
You haven’t heard of Odeo, the failed podcast company the Twitter founders initially worked on? Probably not a big deal. You haven’t heard about the failed education ventures of the person now running your district? Probably a bigger deal.
When we welcome schools that lack democratic accountability (charter school boards are appointed, not elected), when we allow public dollars to be used by those with a bottom line (such as the for-profit management companies that proliferate in Michigan), we open doors for opportunism and corruption. Even worse, it’s all justified under a banner of concern for poor public school students’ well-being.
While these issues of corruption and mismanagement existed before, we should be wary of any education reformer who claims that creating an education marketplace is the key to fixing the ills of DPS or any large city’s struggling schools. Letting parents pick from a variety of schools does not weed out corruption. And the lax laws and lack of accountability can actually exacerbate the socioeconomic ills we’re trying to root out.
Nerding out: RSA on an iPython Notebook
Yesterday was a day filled with secrets and codes. In the morning, at The Platform, we had guest speaker Columbia history professor Matthew Connelly, who came and talked to us about his work with declassified documents. Two big and slightly depressing take-aways for me were the following:
- As records have become digitized, it has gotten easy for people to get rid of archival records in large quantities. Just press delete.
- As records have become digitized, it has become easy to trace the access of records, and in particular the leaks. Connelly explained that, to some extent, Obama’s harsh approach to leakers and whistleblowers might be explained as simply “letting the system work.” Yet another way that technology informs the way we approach human interactions.
After class we had section, in which we discussed the Computer Science classes some of the students are taking next semester (there’s a list here) and then I talked to them about prime numbers and the RSA crypto system.
I got really into it and wrote up an iPython Notebook which could be better but is pretty good, I think, and works out one example completely, encoding and decoding the message “hello”.
The underlying file is here but if you want to view it on the web just go here.




{kind=link}
{kind=link}