A decision tree for decision trees
For a while now I’ve been thinking I should build a decision tree for deciding which algorithm to use on a given data project. And yes, I think it’s kind of cool that “decision tree” would be an outcome on my decision tree. Kind of like a nerd pun.
I’m happy to say that I finally started work on my algorithm decision tree, thanks to this website called gliffy.com which allows me to build flowcharts with an easy online tool. It was one of those moments when I said to myself, this morning at 6am, “there should be a start-up that allows me to build a flowchart online! Let me google for that” and it totally worked. I almost feel like I willed gliffy.com into existence.
So here’s how far I’ve gotten this morning:

Not far! But I also learned how to use the tool.
I looked around the web to see if I’m doing something that’s already been done and I came up with this:
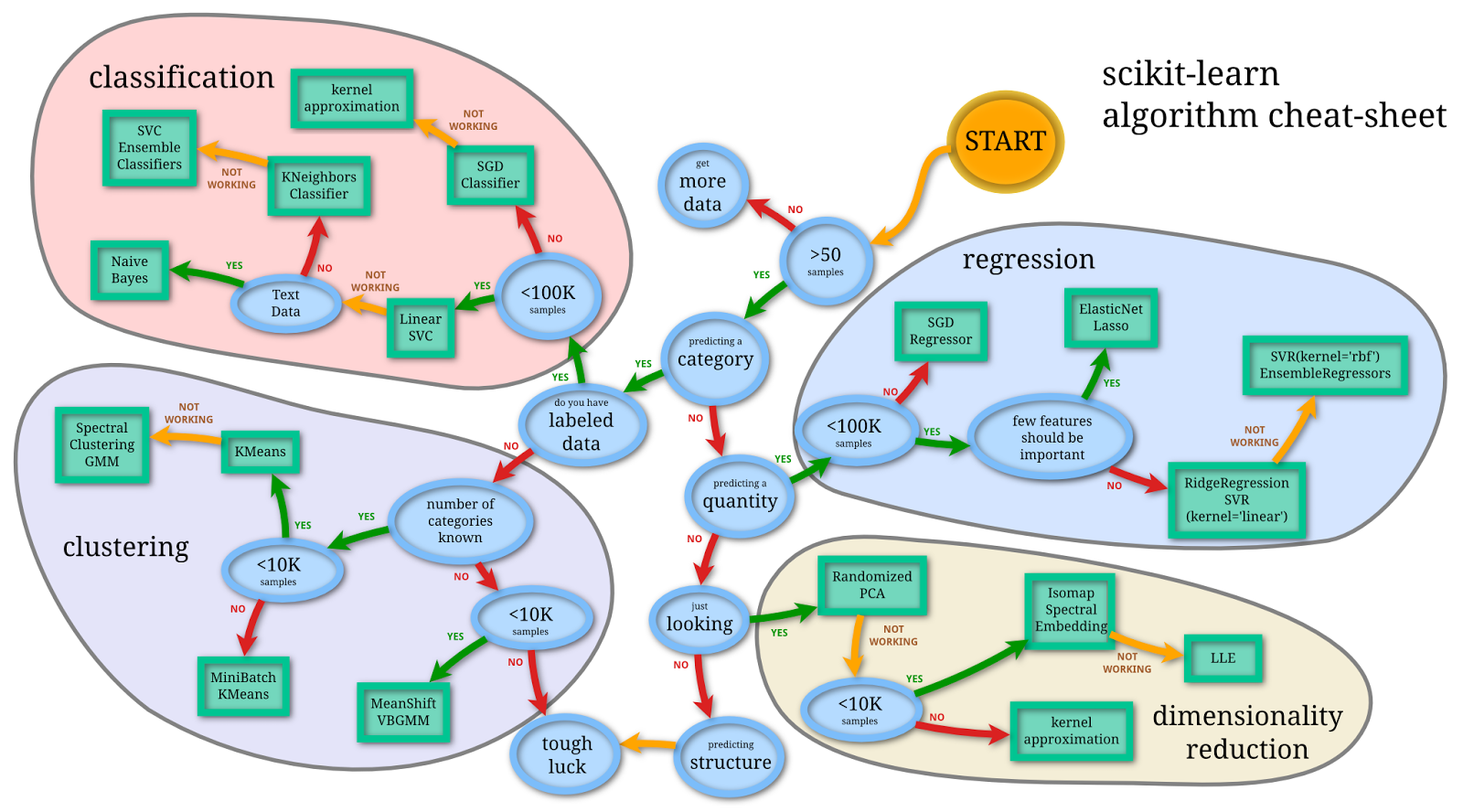
I appreciate the effort but this is way more focused on the size of the data than I intend to be, at least for now. And here’s another one that’s even less like the one I want to build but is still impressive.
Because here’s what I want to focus on: what kind of question are you answering with which algorithm? For example, with clustering algorithms you are, you know, grouping similar things together. That one’s easy, kind of, although plenty of projects have ended up being clustering or classifying algorithms whose motivating questions did not originally take on the form “how would we group these things together?”.
In other words, the process of getting at algorithms from questions is somewhat orthogonal to the normal way algorithms are introduced, and for that reason taking me some time to decide what the questions are that I need to ask in my decision tree. Right about now I’m wishing I had taken notes when my Lede Program students asked me to help them with their projects, because embedded in those questions were some great examples of data questions in search of an algorithm.
Please give me advice!




{kind=link}
{kind=link}
Reblogged this on dcharli819's Blog and commented:
yea that wili kinder improve ones consistence on achieving his goal
LikeLike
I am not sure it fits with your concept but I have a question that I would have to ask myself when deciding what method to choose:
“How would the final model need to be used and by whom?”
I.e. assume you have a bunch of stuff that you want to label/categorize.
A simple decision tree ends gets its classifications right 93.67% of the time when applied to the control group you set apart for testing.
A decisiont tree forest manages 98.67% when trained with the same data and applied to the same testing set.
So the latter is better, but the decision tree is something you can implement in a handful of statements, even in assembler (nice if you need to use it in an embedded device) or can easily draw as a flowchart and print it on carton milks, or in a leaflet, or whatever, and most people will be able to follow it without needing a computer.
If this is used in the contect of larger application, like, I dunno, processing CVs for recruiting, the extra complexity could be considered a sunken cost and you’d go for the more accurate tool.
LikeLike
Definitely want to ask how important interpretability is.
LikeLike
And do you think this should be “early” in the decision process (i.e. one of the first if not the first question) or closer to the “leaves” of the tree?
LikeLike
I’m thinking early.
LikeLike
One of my advisors, Fatma Mili, did some work on problems like this, seems like 10 or 15 years ago. She went off to some other university, and I’m not in a place where I can do effective searching right now, but it might be worth sending out a probe …
LikeLike
These things tend to be “I have some data, what can I do with it?” rather than “What do I want to know and therefore what data should I collect and analyze to help me answer the question?”.
When I coach people I always start with what they really want to know, which then leads them to understand the data they have is usually not helpful in answering that question. Then the real (personal) insight begins. Do they (a) go off and analyze the data anyway so they can complete the “assignment”, or (b) start collecting the data they need to answer the relevant question(s).
LikeLike
Hope this may be relevant/helpful, too:
https://hips.seas.harvard.edu/blog/2013/02/04/predictive-learning-vs-representation-learning/
LikeLike
It seems like a herculean task to do this problem justice. There are so many conditions on the data that one might want to cover, and it is easy to miss out on advances in fields one isn’t really a part of. For instance, I mainly work with network (graph) data, but that type of data doesn’t appear anywhere in your tree. (Yes, of course, networks might not be within your scope, which is fine.) The dlib version includes some networks stuff, but it’s basically 10 years out of date, and there’s been a lot of really great stuff in the past 10 years. I wonder if some kind of curated crowdsourced approach might be necessary, which would leverage other people’s expertise in unfamiliar areas.
LikeLike
A very admirable task!
I still use the 5Ws + Q. Who, what, why, when, and with what quality. (Subjects, objects, questions, frequency and time, what is considered good enough/how frequent is this done/quality do data and results).That usually gets a whiteboard full.
Also, typically the starting point is either:
1. Here is some data. Find something interesting.
2. I have a very specific question I want to answer.
LikeLike