Archive
Moneyball Diplomacy
I’m on a train again to D.C. to attend a conference on how to use big data to enhance U.S. diplomacy and development.
I’ll be on a panel in the afternoon called Diving Into Data, which has the following blurb attached to it:
Facebook processes over 500 terabytes of data each day. More than a half billion tweets are sent daily. And so the volume of data grows. Much of this data is superfluous and is of little value to foreign policy and development experts. But a portion does contain significant information and the challenge is how to find and make use of that data. What will a rigorous economic analysis of this data reveal and how could the findings be effectively applied? Looking beyond real-time awareness and some of the other well know uses of big data, this panel will explore how a more thorough in-depth analysis of big data could prove useful in providing insights and trends that could be applied in the formulation and implementation of foreign policy.
Also on the schedule today, two keynote speakers: Nassim Taleb, author of a few books I haven’t read but everyone else has, and Kenneth Neil Cukier, author of a “big data” article I really didn’t like which was published in Foreign Affairs and which I blogged about here under the title of “The rise of big brother, big data”.
The full schedule of the day is here.
Speaking of big brother, this conference will be particularly interesting to me considering the remarkable amount of news we’ve been learning about this week centered on the U.S. as a surveillance state. Actually nothing I’ve read has surprised me, considering what I learned when I read this opinion piece on the subject, and when I watched this video with former NSA mathematician-turned whistleblower, which I blogged about here back in August 2012.
Book out for early review
I’m happy to say that the book I’m writing with Rachel Schutt called Doing Data Science is officially out for early review. That means a few chapters which we’ve deemed “ready” have been sent to some prominent people in the field to see what they think. Thanks, prominent and busy people!
It also means that things are (knock on wood) wrapping up on the editing side. I’m cautiously optimistic that this book will be a valuable resource for people interested in what data scientists do, especially people interested in switching fields. The range of topics is broad, which I guess means that the most obvious complaint about the book will be that we didn’t cover things deeply enough, and perhaps that the level of pre-requisite assumptions is uneven. It’s hard to avoid.
Thanks to my awesome editor Courtney Nash over at O’Reilly for all her help!
And by the way, we have an armadillo on our cover, which is just plain cool:

How much would you pay to be my friend?
I am on my way to D.C. for a health analytics conference, where I hope to learn the state of the art for health data and modeling. So stay tuned for updates on that.
In the meantime, ponder this concept (hat tip Matt Stoller, who describes it as ‘neoliberal prostitution’). It’s a dating website called “What’s Your Price?” where suitors bid for dates.

What’s creepier, the sex-for-pay aspect of this, or the it’s-possibly-not-about-sex-it’s-about-dating aspect? I’m gonna go with the latter, personally, since it’s a new idea for me. What else can I monetize that I’ve been giving away too long for free?
Hey, kid, you want a bedtime story? It’s gonna cost you.
Let’s enjoy the backlash against hackathons
As much as I have loved my DataKind hackathons, where I get to meet a bunch of friendly nerds who are spend their weekend trying to solve problems using technology, I also have my reservations about the whole weekend hackathon culture, especially when:
- It’s a competition, so really you’re not solving problems as much as boasting, and/or
- you’re trying to solve a problem that nobody really cares about but which might make someone money, so you’re essentially working for free for a future VC asshole, and/or
- you kind of solve a problem that matters, but only for people like you (example below).
As Jake Porway mentions in this fine piece, having data and good intentions do not mean you can get serious results over a weekend. From his essay:
Without subject matter experts available to articulate problems in advance, you get results like those from the Reinvent Green Hackathon. Reinvent Green was a city initiative in NYC aimed at having technologists improve sustainability in New York. Winners of this hackathon included an app to help cyclists “bikepool” together and a farmer’s market inventory app. These apps are great on their own, but they don’t solve the city’s sustainability problems. They solve the participants’ problems because as a young affluent hacker, my problem isn’t improving the city’s recycling programs, it’s finding kale on Saturdays.
Don’t get me wrong, I’ve made some good friends and created some great collaborations via hackathons (and especially via Jake). But it only gets good when there’s major planning beforehand, a real goal, and serious follow-up. Actually a weekend hackathon is, at best, a platform from which to launch something more serious and sustained.
People who don’t get that are there for something other than that. What is it? Maybe this parody hackathon announcement can tell us.
It’s called National Day of Hacking Your Own Assumptions and Entitlement, and it has a bunch of hilarious and spot-on satirical commentary, including this definition of a hackathon:
Basically, a bunch of pallid millenials cram in a room and do computer junk. Harmless, but very exciting to the people who make money off the results.
This question from a putative participant of an “entrepreneur”-style hackathon:
“Why do we insist on applying a moral or altruistic gloss to our moneymaking ventures?”
And the internal thought process of a participant in a White House-sponsored hackathon:
I realized, especially in the wake of the White House murdering Aaron Swartz, persecuting/torturing Bradley Manning and threatening Jeremy Hammond with decades behind bars for pursuit of open information and government/corporate accountability that really, no-one who calls her or himself a “hacker” has any business partnering with an entity as authoritarian, secretive and tyrannical as the White House– unless of course you’re just a piece-of-shit money-grubbing disingenuous bootlicker who uses the mantle of “hackerdom” to add a thrilling and unjustified outlaw sheen to your dull life of careerist keyboard-poking for the status quo.
Technocrats and big data
Today I’m finally getting around to reporting on the congressional subcommittee I went to a few weeks ago on big data and analytics. Needless to say it wasn’t what I’d hoped.
My observations are somewhat disjointed, since there was no coherent discussion, so I guess I’ll just make a list:
- The Congressmen and women seem to know nothing more about the “Big Data Revolution” than what they’d read in the now-famous McKinsey report which talks about how we’ll need 180,000 data scientists in the next decade and how much money we’ll save and how competitive it will make our country.
- In other words, with one small exception I’ll discuss below, the Congresspeople were impressed, even awed, at the intelligence and power of the panelists. They were basically asking for advice on how to let big data happen on a bigger and better scale. Regulation never came up, it was all about, “how do we nurture this movement that is vital to our country’s health and future?”
- There were three useless panelists, all completely high on big data and making their money being like that. First there was a schmuck from the NSF who just said absolutely nothing, had been to a million panels before, and was simply angling to be invited to yet more.
- Next there was a guy who had started training data-ready graduates in some masters degree program. All he ever talked about is how programs like his should be funded, especially his, and how he was talking directly with employers in his area to figure out what to train his students to know.
- It was especially interesting to see how this second guy reacted when the single somewhat thoughtful and informed Congressman, whose name I didn’t catch because he came in and left quickly and his name tag was miniscule, asked him about whether or not he taught his students to be skeptical. The guy was like, I teach my students to be ready to deal with big data just like their employers want. The congressman was like, no that’s not what I asked, I asked whether they can be skeptical of perceived signals versus noise, whether they can avoid making huge costly mistakes with big data. The guy was like, I teach my students to deal with big data.
- Finally there was the head of IBM Research who kept coming up with juicy and misleading pro-data tidbits which made him sound like some kind of saint for doing his job. For example, he brought up the “premature infants are being saved” example I talked about in this post.
- The IBM guy was also the only person who ever mentioned privacy issues at all, and he summarized his, and presumably everyone else’s position on this subject, by saying “people are happy to give away their private information for the services they get in return.” Thanks, IBM guy!
- One more priceless moment was when one of the Congressmen asked the panel if industry has enough interaction with policy makers. The head of IBM Research said, “Why yes, we do!” Thanks, IBM guy!
I was reminded of this weird vibe and power dynamic, where an unchallenged mysterious power of big data rules over reason, when I read this New York Times column entitled Some Cracks in the Cult of Technocrats (hat tip Suresh Naidu). Here’s the leading paragraph:
We are living in the age of the technocrats. In business, Big Data, and the Big Brains who can parse it, rule. In government, the technocrats are on top, too. From Washington to Frankfurt to Rome, technocrats have stepped in where politicians feared to tread, rescuing economies, or at least propping them up, in the process.
The column was written by Chrystia Freeland and it discusses a recent paper entitled Economics versus Politics: Pitfalls of Policy Advice by Daron Acemoglu from M.I.T. and James Robinson from Harvard. A description of the paper from Freeland’s column:
Their critique is not the standard technocrat’s lament that wise policy is, alas, politically impossible to implement. Instead, their concern is that policy which is eminently sensible in theory can fail in practice because of its unintended political consequences.
In particular, they believe we need to be cautious about “good” economic policies that have the side effect of either reinforcing already dominant groups or weakening already frail ones.
“You should apply double caution when it comes to policies which will strengthen already powerful groups,” Dr. Acemoglu told me. “The central starting point is a certain suspicion of elites. You really cannot trust the elites when they are totally in charge of policy.”
Three examples they discuss in the paper: trade unions, financial deregulation in the U.S., privatization in Russia. Examples where something economists suggested would make the system better also acted to reinforce power of already powerful people.
If there’s one thing I might infer from my trip to Washington, it’s that the technocrats in charge nowadays, whose advice is being followed, may have subtly shifted away from deregulation economists and towards big data folks. Not that I’m holding my breath for Bob Rubin to be losing his grip any time soon.
Fight back against surveillance using TrackMeNot, TrackMeNot mobile?
After two days of travelling to the west coast and back, I’m glad to be back to my blog (and, of course, my coffee machine, which is the real source of my ability to blog every morning without distraction: it makes coffee at the push of a button, and that coffee has a delicious amount of caffeine).
Yesterday at the hotel I grabbed a free print edition of the Wall Street Journal to read on the plane, and I was super interested in this article called Phone Firm Sells Data on Customers. They talk about how phone companies (Verizon, specifically) are selling location data and browsing data about customers, how some people might be creeped out by this, and then they say:
The new offerings are also evidence of a shift in the relationship between carriers and their subscribers. Instead of merely offering customers a trusted conduit for communication, carriers are coming to see subscribers as sources of data that can be mined for profit, a practice more common among providers of free online services like Google Inc. and Facebook Inc.
Here’s the thing. It’s one thing to make a deal with the devil when I use Facebook: you give me something free, in return I let you glean information about me. But in terms of Verizon, I pay them like $200 per month for my family’s phone usage. That’s not free! Fuck you guys for turning around and selling my data!
And how are marketers going to use such location data? They will know how desperate you are for their goods and charge you accordingly. Like this for example, but on a much wider scale.
There are a two things I can do to object to this practice. First, I write this post and others, railing against such needless privacy invasion practices. Second, I can go to Verizon, my phone company, and get myself off the list. The instructions for doing so seem to be here, but I haven’t actually followed them yet.
Here’s what I wish a third option were: a mobile version of Trackmenot, which I learned about last week from Annelies Kamran.
Trackmenot, created by Daniel C. Howe and Helen Nissenbaum at what looks like the CS department of NYU, confuses the data gatherers by giving them an overload of bullshit information.
Specifically, it’s a Firefox add-on which sends you to all sorts of websites while you’re not actually using your browser. The data gatherers get endlessly confused about what kind of person you actually are this way, thereby fucking up the whole personal data information industry.
I have had this idea in the past, and I’m super happy it already exists. Now can someone do it for mobile please? Or even better, tell me it already exists?
Eben Moglen teaches us how not to be evil when data-mining
This is a guest post by Adam Obeng, a Ph.D. candidate in the Sociology Department at Columbia University. His work encompasses computational social science, social network analysis and sociological theory (basically anything which constitutes an excuse to sit in front of a terminal for unadvisably long periods of time). This post is Copyright Adam Obeng 2013 and licensed under a (Creative Commons Attribution-ShareAlike 3.0 Unported License). Crossposted on adamobeng.com.
Eben Moglen’s delivery leaves you in no doubt as to the sincerity of this sentiment. Stripy-tied, be-hatted and pocked-squared, he took to the stage at last week’s IDSE Seminar Series event without slides, but with engaging — one might say, prosecutorial — delivery. Lest anyone doubt his neckbeard credentials, he let slip that he had participated in the development of almost certainly the first networked email system in the United States, as well as mentioning his current work for the Freedom Box Foundation and the Software Freedom Law Center.
A superorganism called humankind
The content was no less captivating than the delivery: we were invited to consider the world where every human consciousness is connected by an artificial extra-skeletal nervous system, linking everyone into a new superorganism. What we refer to as data science is the nascent study of flows of neural data in that network. And having access to the data will entirely transform what the social sciences can explain: we will finally have a predictive understanding of human behaviour, based not on introspection but empirical science. It will do for the social sciences what Newton did for physics.
The reason the science of the nervous system – “this wonderful terrible art” – is optimised to study human behaviour is because consumption and entertainment are a large part of economic activity. The subjects of the network don’t own it. In a society which is more about consumption than production, the technology of economic power will be that which affects consumption. Indeed, what we produce becomes information about consumption which is itself used to drive consumption. Moglen is matter-of-fact: this will happen, and is happening.
And it’s also ineluctable that this science will be used to extend the reach of political authority, and it has the capacity to regiment human behaviour completely. It’s not entirely deterministic that it should happen at a particular place and time, but extrapolation from history suggests that somewhere, that’s how it’s going to be used, that’s how it’s going to come out, because it can. Whatever is possible to engineer will eventually be done. And once it’s happened somewhere, it will happen elsewhere. Unlike the components of other super-organisms, humans possess consciousness. Indeed, it is the relationship between sociality and consciousness that we call the human condition. The advent of the human species-being threatens that balance.
The Oppenheimer moment
Moglen’s vision of the future is, as he describes it, both familiar and strange. But his main point, is as he puts it, very modest: unless you are sure that this future is absolutely 0% possible, you should engage in the discussion of its ethics.
First, when the network is wrapped around every human brain, privacy will be nothing more than a relic of the human past. He believes that privacy is critical to creativity and freedom, but really the assumption that privacy – the ability to make decisions independent of the machines – should be preserved is axiomatic.
What is crucial about privacy is that it is not personal, or even bilateral, it is ecological: how others behave determine the meaning of the actions I take. As such, dealing with privacy requires an ecological ethics. It is irrelevant whether you consent to be delivered poisonous drinking water, we don’t regulate such resources by allowing individuals to make desicions about how unsafe they can afford their drinking water to be. Similarly, whether you opt in or opt out of being tracked online is irrelevant.
The existing questions of ethics that science has had to deal with – how to handle human subjects – are of no use here: informed consent is only sufficient when the risks to investigating a human subject produce apply only to that individual.
These ethical questions are for citizens, but perhaps even more so for those in the business of making products from personal information. Whatever goes on to be produced from your data will be trivially traced back to you. Whatever finished product you are used to make, you do not disappear from it. What’s more, the scientists are beholden to the very few secretive holders of data.
Consider, says Moglen,the question of whether punishment deters crime: there will be increasing amounts of data about it, but we’re not even going to ask – because no advertising sale depends on it. Consider also, the prospect of machines training humans, which is already beginning to happen. The Coursera business model is set to do to the global labour market what Google did to the global advertising market: auctioning off the good learners, found via their learning patterns, to to employers. Granted, defeating ignorance on a global scale is within grasp. But there are still ethical questions here, and evil is ethics undealt with.
One of the criticisms often levelled at techno-utopians is that the enabling power of technology can very easily be stymied by the human factors, the politics, the constants of our species, which cannot be overwritten by mere scientific progress. Moglen could perhaps be called a a techno-dystopian, but he has recognised that while the technology is coming, inevitably, how it will affect us depends on how we decide to use it.
But these decisions cannot just be made at the individual level, Moglen pointed out, we’ve changed everything except the way people think. I can’t say that I wholeheartedly agree with either Moglen’s assumptions or his conclusions, but he is obviously asking important questions, and he has shown the form in which they need to be asked.
Another doubt: as a social scientist, I’m also not convinced that having all these data available will make all human behaviour predictable. We’ve catalogued a billion stars, the Large Hadron Collider has produced a hundred thousand million million bytes of data, and yet we’re still trying to find new specific solutions to the three-body problem. I don’t think that just having more data is enough. I’m not convinced, but I don’t think it’s 0% possible.
This post is Copyright Adam Obeng 2013 and licensed under a (Creative Commons Attribution-ShareAlike 3.0 Unported License).
WSJ: “When Your Boss Makes You Pay for Being Fat”
Going along with the theme of shaming which I took up yesterday, there was a recent Wall Street Journal article called “When Your Boss Makes You Pay for Being Fat” about new ways employers are trying to “encourage healthy living”, or otherwise described, “save money on benefits”. From the article:
Until recently, Michelin awarded workers automatic $600 credits toward deductibles, along with extra money for completing health-assessment surveys or participating in a nonbinding “action plan” for wellness. It adopted its stricter policy after its health costs spiked in 2012.
Now, the company will reward only those workers who meet healthy standards for blood pressure, glucose, cholesterol, triglycerides and waist size—under 35 inches for women and 40 inches for men. Employees who hit baseline requirements in three or more categories will receive up to $1,000 to reduce their annual deductibles. Those who don’t qualify must sign up for a health-coaching program in order to earn a smaller credit.
A few comments:
- This policy combines the critical characteristics of shaming, namely 1) a complete lack of empathy and 2) the shifting of blame for a problem entirely onto one segment of the population even though the “obesity epidemic” is a poorly understood cultural phenomenon.
- To the extent that there may be push-back against this or similar policies inside the workplace, there will be very little to stop employers from not hiring fat people in the first place.
- Or for that matter, what’s going to stop employers from using people’s full medical profiles (note: by this I mean the unregulated online profile that Acxiom and other companies collect about you and then sell to employers or advertisers for medical stuff – not the official medical records which are regulated) against them in the hiring process? Who owns the new-fangled health analytics models anyway?
- We do that already to poor people by basing their acceptance on credit scores.
E-discovery and the public interest (part 2)
Yesterday I wrote this short post about my concerns about the emerging field of e-discovery. As usual the comments were amazing and informative. By the end of the day yesterday I realized I needed to make a much more nuanced point here.
Namely, I see a tacit choice being made, probably by judges or court-appointed “experts”, on how machine learning is used in discovery, and I think that the field could get better or worse. I think we need to urgently discuss this matter, before we wander into a crazy place.
And to be sure, the current discovery process is fraught with opacity and human judgment, so complaining about those features being present in a machine learning version of discovery is unreasonable – the question is whether it’s better or worse than the current system.
Making it worse: private code, opacity
The way I see it, if we allow private companies to build black box machines that we can’t peer into, nor keep track of as they change versions, then we’ll never know why a given set of documents was deemed “relevant” in a given case. We can’t, for example, check to see if the code was modified to be more friendly to a given side.
Besides the healthy response to this new revenue source of competition for clients, the resulting feedback loop will likely be a negative one, whereby private companies use the cheapest version they can get away with to achieve the best results (for their clients) that they can argue for.
Making it better: open source code, reproducibility
What we should be striving for is to use only open source software, saved in a repository so we can document exactly what happened with a given corpus and a given version of the tools. It will still be an industry to clean the data and feed in the documents, train the algorithm (whilst documenting how that works), and interpreting the results. Data scientists will still get paid.
In other words, instead of asking for interpretability, which is a huge ask considering the massive scale of the work being done, we should, at the very least, be able to ask for reproducibility of the e-discovery, as well as transparency in the code itself.
Why reproducibility? Then we can go back in time, or rather scholars can, and test how things might have changed if a different version of the code were used, for example. This could create a feedback loop crucial to improve the code itself over time, and to improve best practices for using that code.
E-discovery and the public interest
Today I want to bring up a few observations and concerns I have about the emergence of a new field in machine learning called e-discovery. It’s the algorithmic version of discovery, so I’ll start there.
Discovery is part of the process in a lawsuit where relevant documents are selected, pored over, and then handed to the other side. Nowadays, of course, there are more and more documents, almost all electronic, typically including lots of e-mails.
If you’re talking about a big lawsuit, there could be literally millions of documents to wade through, and that takes a lot of time for humans to do, and it can be incredibly expensive and time-consuming. Enter the algorithm.
With advances in Natural Language Processing (NLP), a machine algorithm can sort emails or documents by topic (after getting the documents into machine-readable form, cleaning, and deduping) and can in general do a pretty good job of figuring out whether a given email is “relevant” to the case.
And this is already happening – the Wall Street Journal recently reported that the Justice Department allowed e-discovery for a case involving the merger of two beer companies. From the article:
With the blessing of the Justice Department’s antitrust division, the lawyers loaded the documents into a program and manually reviewed a batch to train the software to recognize relevant documents. The manual review was repeated until the Justice Department and Constellation were satisfied that the program could accurately predict relevance in the rest of the documents. Lawyers for Constellation and Crown Imports used software developed by kCura Corp., which lists the Justice Department as a client.
In the end, Constellation and Crown Imports turned over hundreds of thousands of documents to antitrust investigators.
Here are some of my questions/ concerns:
- These algorithms are typically not open source – companies like kCura make good money doing these jobs.
- That means that they could be wrong, possibly in subtle ways.
- Or maybe not so subtle ways: maybe they’ve been trained to find documents that are both “relevant” and “positive” for a given side.
- In any case, the laws of this country will increasingly depend on a black box algorithm that is no accessible to the average citizen.
- Is that in the public’s interest?
- Is that even constitutional?
The NYC Data Skeptics Meetup
One thing I’m super excited about at work is the new NYC Data Skeptics Meetup we’re organizing. Here’s the description of our mission:
The hype surrounding Big Data and Data Science is at a fever pitch with promises to solve the world’s business and social problems, large and small. How accurate or misleading is this message? How is it helping or damaging people, and which people? What opportunities exist for data nerds and entrepreneurs that examine the larger issues with a skeptical view?
This Meetup focuses on mathematical, ethical, and business aspects of data from a skeptical perspective. Guest speakers will discuss the misuse of and best practices with data, common mistakes people make with data and ways to avoid them, how to deal with intentional gaming and politics surrounding mathematical modeling, and taking into account the feedback loops and wider consequences of modeling. We will take deep dives into models in the fields of Data Science, statistics, finance, economics, healthcare, and public policy.
This is an independent forum and open to anyone sharing an interest in the larger use of data. Technical aspects will be discussed, but attendees do not need to have a technical background.
A few things:
- Please join us!
- I wouldn’t blame you for not joining until we have a confirmed speaker, so please suggest speakers for us! I have a bunch of people in mind I’d absolutely love to see but I’d love more ideas. And I’m thinking broadly here – of course data scientists and statisticians and economists, but also lawyers, sociologists, or anyone who works with data or the effects of data.
- If you are skeptical of the need for yet another data-oriented Meetup (or other regular meeting), please think about it this way: there are not that many currently active groups which aren’t afraid to go into the technical weeds and also not obsesses with a simplistic, sound bite business take-away. But please tell me if I’m wrong, I’d love to reach out to people doing similar things.
- Suggest a better graphic for our Meetup than our current portrait of Isaac Asimov.
The rise of big data, big brother
I recently read an article off the newsstand called The Rise of Big Data.
It was written by Kenneth Neil Cukier and Viktor Mayer-Schoenberger and it was published in the May/June 2013 edition of Foreign Affairs, which is published by the Council on Foreign Relations (CFR). I mention this because CFR is an influential think tank, filled with powerful insiders, including people like Robert Rubin himself, and for that reason I want to take this view on big data very seriously: it might reflect the policy view before long.
And if I think about it, compared to the uber naive view I came across last week when I went to the congressional hearing about big data and analytics, that would be good news. I’ll write more about it soon, but let’s just say it wasn’t everything I was hoping for.
At least Cukier and Mayer-Schoenberger discuss their reservations regarding “big data” in this article. To contrast this with last week, it seemed like the only background material for the hearing, at least for the congressmen, was the McKinsey report talking about how sexy data science is and how we’ll need to train an army of them to stay competitive.
So I’m glad it’s not all rainbows and sunshine when it comes to big data in this article. Unfortunately, whether because they’re tied to successful business interests, or because they just haven’t thought too deeply about the dark side, their concerns seem almost token, and their examples bizarre.
The article is unfortunately behind the pay wall, but I’ll do my best to explain what they’ve said.
Datafication
First they discuss the concept of datafication, and their example is how we quantify friendships with “likes”: it’s the way everything we do, online or otherwise, ends up recorded for later examination in someone’s data storage units. Or maybe multiple storage units, and maybe for sale.
They formally define later in the article as a process:
… taking all aspect of life and turning them into data. Google’s augmented-reality glasses datafy the gaze. Twitter datafies stray thoughts. LinkedIn datafies professional networks.
Datafication is an interesting concept, although as far as I can tell they did not coin the word, and it has led me to consider its importance with respect to intentionality of the individual.
Here’s what I mean. We are being datafied, or rather our actions are, and when we “like” someone or something online, we are intending to be datafied, or at least we should expect to be. But when we merely browse the web, we are unintentionally, or at least passively, being datafied through cookies that we might or might not be aware of. And when we walk around in a store, or even on the street, we are being datafied in an completely unintentional way, via sensors or Google glasses.
This spectrum of intentionality ranges from us gleefully taking part in a social media experiment we are proud of to all-out surveillance and stalking. But it’s all datafication. Our intentions may run the gambit but the results don’t.
They follow up their definition in the article, once they get to it, with a line that speaks volumes about their perspective:
Once we datafy things, we can transform their purpose and turn the information into new forms of value
But who is “we” when they write it? What kinds of value do they refer to? As you will see from the examples below, mostly that translates into increased efficiency through automation.
So if at first you assumed they mean we, the American people, you might be forgiven for re-thinking the “we” in that sentence to be the owners of the companies which become more efficient once big data has been introduced, especially if you’ve recently read this article from Jacobin by Gavin Mueller, entitled “The Rise of the Machines” and subtitled “Automation isn’t freeing us from work — it’s keeping us under capitalist control.” From the article (which you should read in its entirety):
In the short term, the new machines benefit capitalists, who can lay off their expensive, unnecessary workers to fend for themselves in the labor market. But, in the longer view, automation also raises the specter of a world without work, or one with a lot less of it, where there isn’t much for human workers to do. If we didn’t have capitalists sucking up surplus value as profit, we could use that surplus on social welfare to meet people’s needs.
The big data revolution and the assumption that N=ALL
According to Cukier and Mayer-Schoenberger, the Big Data revolution consists of three things:
- Collecting and using a lot of data rather than small samples.
- Accepting messiness in your data.
- Giving up on knowing the causes.
They describe these steps in rather grand fashion, by claiming that big data doesn’t need to understand cause because the data is so enormous. It doesn’t need to worry about sampling error because it is literally keeping track of the truth. The way the article frames this is by claiming that the new approach of big data is letting “N = ALL”.
But here’s the thing, it’s never all. And we are almost always missing the very things we should care about most.
So for example, as this InfoWorld post explains, internet surveillance will never really work, because the very clever and tech-savvy criminals that we most want to catch are the very ones we will never be able to catch, since they’re always a step ahead.
Even the example from their own article, election night polls, is itself a great non-example: even if we poll absolutely everyone who leaves the polling stations, we still don’t count people who decided not to vote in the first place. And those might be the very people we’d need to talk to to understand our country’s problems.
Indeed, I’d argue that the assumption we make that N=ALL is one of the biggest problems we face in the age of Big Data. It is, above all, a way of excluding the voices of people who don’t have the time or don’t have the energy or don’t have the access to cast their vote in all sorts of informal, possibly unannounced, elections.
Those people, busy working two jobs and spending time waiting for buses, become invisible when we tally up the votes without them. To you this might just mean that the recommendations you receive on Netflix don’t seem very good because most of the people who bother to rate things are Netflix are young and have different tastes than you, which skews the recommendation engine towards them. But there are plenty of much more insidious consequences stemming from this basic idea.
Another way in which the assumption that N=ALL can matter is that it often gets translated into the idea that data is objective. Indeed the article warns us against not assuming that:
… we need to be particularly on guard to prevent our cognitive biases from deluding us; sometimes, we just need to let the data speak.
And later in the article,
In a world where data shape decisions more and more, what purpose will remain for people, or for intuition, or for going against the facts?
This is a bitch of a problem for people like me who work with models, know exactly how they work, and know exactly how wrong it is to believe that “data speaks”.
I wrote about this misunderstanding here, in the context of Bill Gates, but I was recently reminded of it in a terrifying way by this New York Times article on big data and recruiter hiring practices. From the article:
“Let’s put everything in and let the data speak for itself,” Dr. Ming said of the algorithms she is now building for Gild.
If you read the whole article, you’ll learn that this algorithm tries to find “diamond in the rough” types to hire. A worthy effort, but one that you have to think through.
Why? If you, say, decided to compare women and men with the exact same qualifications that have been hired in the past, but then, looking into what happened next you learn that those women have tended to leave more often, get promoted less often, and give more negative feedback on their environments, compared to the men, your model might be tempted to hire the man over the woman next time the two showed up, rather than looking into the possibility that the company doesn’t treat female employees well.
In other words, ignoring causation can be a flaw, rather than a feature. Models that ignore causation can add to historical problems instead of addressing them. And data doesn’t speak for itself, data is just a quantitative, pale echo of the events of our society.
Some cherry-picked examples
One of the most puzzling things about the Cukier and Mayer-Schoenberger article is how they chose their “big data” examples.
One of them, the ability for big data to spot infection in premature babies, I recognized from the congressional hearing last week. Who doesn’t want to save premature babies? Heartwarming! Big data is da bomb!
But if you’re going to talk about medicalized big data, let’s go there for reals. Specifically, take a look at this New York Times article from last week where a woman traces the big data footprints, such as they are, back in time after receiving a pamphlet on living with Multiple Sclerosis. From the article:
Now she wondered whether one of those companies had erroneously profiled her as an M.S. patient and shared that profile with drug-company marketers. She worried about the potential ramifications: Could she, for instance, someday be denied life insurance on the basis of that profile? She wanted to track down the source of the data, correct her profile and, if possible, prevent further dissemination of the information. But she didn’t know which company had collected and shared the data in the first place, so she didn’t know how to have her entry removed from the original marketing list.
Two things about this. First, it happens all the time, to everyone, but especially to people who don’t know better than to search online for diseases they actually have. Second, the article seems particularly spooked by the idea that a woman who does not have a disease might be targeted as being sick and have crazy consequences down the road. But what about a woman is actually is sick? Does that person somehow deserve to have their life insurance denied?
The real worries about the intersection of big data and medical records, at least the ones I have, are completely missing from the article. Although they did mention that “improving and lowering the cost of health care for the world’s poor” inevitable will lead to “necessary to automate some tasks that currently require human judgment.” Increased efficiency once again.
To be fair, they also talked about how Google tried to predict the flu in February 2009 but got it wrong. I’m not sure what they were trying to say except that it’s cool what we can try to do with big data.
Also, they discussed a Tokyo research team that collects data on 360 pressure points with sensors in a car seat, “each on a scale of 0 to 256.” I think that last part about the scale was added just so they’d have more numbers in the sentence – so mathematical!
And what do we get in exchange for all these sensor readings? The ability to distinguish drivers, so I guess you’ll never have to share your car, and the ability to sense if a driver slumps, to either “send an alert or atomatically apply brakes.” I’d call that a questionable return for my investment of total body surveillance.
Big data, business, and the government
Make no mistake: this article is about how to use big data for your business. It goes ahead and suggests that whoever has the biggest big data has the biggest edge in business.
Of course, if you’re interested in treating your government office like a business, that’s gonna give you an edge too. The example of Bloomberg’s big data initiative led to efficiency gain (read: we can do more with less, i.e. we can start firing government workers, or at least never hire more).
As for regulation, it is pseudo-dealt with via the discussion of market dominance. We are meant to understand that the only role government can or should have with respect to data is how to make sure the market is working efficiently. The darkest projected future is that of market domination by Google or Facebook:
But how should governments apply antitrust rules to big data, a market that is hard to define and is constantly changing form?
In particular, no discussion of how we might want to protect privacy.
Big data, big brother
I want to be fair to Cukier and Mayer-Schoenberger, because they do at least bring up the idea of big data as big brother. Their topic is serious. But their examples, once again, are incredibly weak.
Should we find likely-to-drop-out boys or likely-to-get-pregnant girls using big data? Should we intervene? Note the intention of this model would be the welfare of poor children. But how many models currently in production are targeting that demographic with that goal? Is this in any way at all a reasonable example?
Here’s another weird one: they talked about the bad metric used by US Secretary of Defense Robert McNamara in the Viet Nam War, namely the number of casualties. By defining this with the current language of statistics, though, it gives us the impression that we could just be super careful about our metrics in the future and: problem solved. As we experts in data know, however, it’s a political decision, not a statistical one, to choose a metric of success. And it’s the guy in charge who makes that decision, not some quant.
Innovation
If you end up reading the Cukier and Mayer-Schoenberger article, please also read Julie Cohen’s draft of a soon-to-be published Harvard Law Review article called “What Privacy is For” where she takes on big data in a much more convincing and skeptical light than Cukier and Mayer-Schoenberger were capable of summoning up for their big data business audience.
I’m actually planning a post soon on Cohen’s article, which contains many nuggets of thoughtfulness, but for now I’ll simply juxtapose two ideas surrounding big data and innovation, giving Cohen the last word. First from the Cukier and Mayer-Schoenberger article:
Big data enables us to experiment faster and explore more leads. These advantages should produce more innovation
Second from Cohen, where she uses the term “modulation” to describe, more or less, the effect of datafication on society:
When the predicate conditions for innovation are described in this way, the problem with characterizing privacy as anti-innovation becomes clear: it is modulation, not privacy, that poses the greater threat to innovative practice. Regimes of pervasively distributed surveillance and modulation seek to mold individual preferences and behavior in ways that reduce the serendipity and the freedom to tinker on which innovation thrives. The suggestion that innovative activity will persist unchilled under conditions of pervasively distributed surveillance is simply silly; it derives rhetorical force from the cultural construct of the liberal subject, who can separate the act of creation from the fact of surveillance. As we have seen, though, that is an unsustainable fiction. The real, socially-constructed subject responds to surveillance quite differently—which is, of course, exactly why government and commercial entities engage in it. Clearing the way for innovation requires clearing the way for innovative practice by real people, by preserving spaces within which critical self-determination and self-differentiation can occur and by opening physical spaces within which the everyday practice of tinkering can thrive.
Big data and surveillance
You know how, every now and then, you hear someone throw out a statistic that implies almost all of the web is devoted to porn?
Well, that turns out to be a false myth, which you can read more about here – although once upon a time it was kind of true, before women started using the web in large numbers and before there was Netflix streaming.
Here’s another myth along the same lines which I think might actually be true: almost all of big data is devoted to surveillance.
Of course, data is data, and you could define “surveillance” broadly (say as “close observation”), to make the above statement a tautology. To what extent is Google’s data, collected about you, a surveillance database, if they only use it to tailor searches and ads?
On the other hand, something that seems unthreatening now can become creepy soon: recall the NSA whistleblower who last year described how the government stores an enormous amount of the “electronic communications” in this country to keep close tabs on us.
The past
Back in 2011, computerworld.com published an article entitled “Big data to drive a surveillance society” and makes the case that there is a natural competition among corporations with large databases to collect more data, have it more interconnected (knowing now only a person’s shopping habits but also their location and age, say) and have the analytics work faster, even real-time, so they can peddle their products faster and better than the next guy.
Of course, not everyone agrees to talk about this “natural competition”. From the article:
Todd Papaioannou, vice president of cloud architecture at Yahoo, said instead of thinking about big data analytics as a weapon that empowers corporate Big Brothers, consumers should regard it as a tool that enables a more personalized Web experience.
“If someone can deliver a more compelling, relevant experience for me as a consumer, then I don’t mind it so much,” he said.
Thanks for telling us consumers how great this is, Todd. Later in the same article Todd says, “Our approach is not to throw any data away.”
The present
Fast forward to 2013, when defence contractor Raytheon is reported to have a new piece of software, called Riot, which is cutting-edge in the surveillance department.
The name Riot refers to “Rapid Information Overlay Technology” and it can locate individuals with longitude and latitudes, using cell phone data, and make predictions as well, using data scraped from Facebook, Twitter, and Foursquare. A video explains how they do it. From the op-ed:
The possibilities for RIOT are hideous at consumer level. This really is the stalker’s dream technology. There’s also behavioural analysis to predict movements in the software. That’s what Big Data can do, and if it’s not foolproof, there are plenty of fools around the world to try it out on.
US employers, who have been creating virtual Gulags of surveillance for employees with much less effective technology, will love this. “We know what you do” has always been a working option for coercion. The fantastic levels of paranoia involved in the previous generations of surveillance technology will be truly gratified by RIOT.
The future
Lest we think that our children are not as affected by such stalking software, since they don’t spend as much time on social media and often don’t have cellphones, you should also be aware that educational data is now being collected about individual learners in the U.S. at an enormous scale and with very little oversight.
This report from educationnewyork.com (hat tip Matthew Cunningham-Cook) explains recent changes in privacy laws for children, which happen to coincide with how much data is being collected (tons) and how much money is in the analysis of that data (tons):
Schools are a rich source of personal information about children that can be legally and illegally accessed by third parties.With incidences of identity theft, database hacking, and sale of personal information rampant, there is an urgent need to protect students’ rights under FERPA and raise awareness of aspects of the law that may compromise the privacy of students and their families.
In 2008 and 2011, amendments to FERPA gave third parties, including private companies,increased access to student data. It is significant that in 2008, the amendments to FERPA expanded the definitions of “school officials” who have access to student data to include “contractors, consultants, volunteers, and other parties to whom an educational agency or institution has outsourced institutional services or functions it would otherwise use employees to perform.” This change has the effect of increasing the market for student data.
There are lots of contractors and consultants, for example inBloom, and they are slightly less concerned about data privacy issues than you might be:
inBloom has stated that it “cannot guarantee the security of the information stored … or that the information will not be intercepted when it is being transmitted.”
The article ends with this:
The question is: Should we compromise and endanger student privacy to support a centralized and profit-driven education reform initiative? Given this new landscape of an information and data free-for-all, and the proliferation of data-driven education reform initiatives like CommonCore and huge databases of student information, we’ve arrived at a time when once a child enters a public school,their parents will never again know who knows what about their children and about their families. It is now up to individual states to find ways to grant students additional privacy protections.
No doubt about it: our children are well on their way to being the most stalked generation.
Privacy policy
One of the reasons I’m writing this post today is that I’m on a train to D.C. to sit in a Congressional hearing where Congressmen will ask “big data experts” questions about big data and analytics. The announcement is here, and I’m hoping to get into it.
The experts present are from IBM, the NSF, and North Carolina State University. I’m wondering how they got picked and what their incentives are. If I get in I will write a follow-up post on what happened.
Here’s what I hope happens. First, I hope it’s made clear that anonymization doesn’t really work with large databases. Second, I hope it’s clear that there’s no longer a very clear dividing line between sensitive data and nonsensitive data – you’d be surprised how much can be inferred about your sensitive data using only nonsensitive data.
Next, I hope it’s clear that the very people who should be worried the most about their data being exposed and freely available are the ones who don’t understand the threat. This means that merely saying that people should protect their data more is utterly insufficient.
Next, we should understand what policies already in place look like in Europe:

Finally, we should focus not only the collection of data, but on the usage of data. Just because you have a good idea of my age, race, education level, income, and HIV status doesn’t mean you should be able to use that information against me whenever you want.
In particular, it should not be legal for companies that provide loans or insurance to use whatever information they can buy from Acxiom about you. It should be a highly regulated set of data that allows for such decisions.
How to reinvent yourself, nerd version
I wanted to give this advice today just in case it’s useful to someone. It’s basically the way I went about reinventing myself from being a quant in finance to being a data scientist in the tech scene.
In other words, many of the same skills but not all, and many of the same job description elements but not all.
The truth is, I didn’t even know the term “data scientist” when I started my job hunt, so for that reason I think it’s possibly good and useful advice: if you follow it, you may end up getting a great job you don’t even know exists right now.
Also, I used this advice yesterday on my friend who is trying to reinvent himself, and he seemed to find it useful, although time will tell how much – let’s see if he gets a new job soon!
Here goes.
- Write a list of things you like about jobs: learning technical stuff, managing people, whatever floats your boat.
- Next, write a list of things you don’t like: being secretive, no vacation, office politics, whatever. Some people hate working with “dumb people” but some people can’t stand “arrogant people”. It makes a huge difference actually.
- Next, write a list of skills you have: python, basic statistics, math, managing teams, smelling a bad deal, stuff like that. This is probably the most important list, so spend some serious time on it.
- Finally, write a list of skills you don’t have that you wish you did: hadoop, knowing when to stop talking, stuff like that.
Once you have your lists, start going through LinkedIn by cross-searching for your preferred city and a keyword from one of your lists (probably the “skills you have” list).
Every time you find a job that you think you’d like to have, take note of what skills it lists that you don’t have, the name of the company, and your guess on a scale of 1-10 of how much you’d like the job into a spreadsheet or at least a file. This last part is where you use the “stuff I like” and “stuff I don’t like” lists.
And when you’ve done this for a long time, like you made it your job for a few hours a day for at least a few weeks, then do some wordcounts on this file, preferably using a command line script to add to the nerdiness, to see which skills you’d need to get which jobs you’d really like.
Note LinkedIn is not an oracle: it doesn’t have every job in the world (although it might have most jobs you could ever get), and the descriptions aren’t always accurate.
For example, I think companies often need managers of software engineers, but they never advertise for managers of software engineers. They advertise for software engineers, and then let them manage if they have the ability to, and sometimes even if they don’t. But even in that case I think it makes sense: engineers don’t want to be managed by someone they think isn’t technical, and the best way to get someone who is definitely technical is just to get another engineer.
In other words, sometimes the “job requirements” data on LInkedIn dirty, but it’s still useful. And thank god for LinkedIn.
Next, make sure your LinkedIn profile is up-to-date and accurate, and that your ex-coworkers have written letters for you and endorsed you for your skills.
Finally, buy a book or two to learn the new skills you’ve decided to acquire based on your research. I remember bringing a book on Bayesian statistics to my interview for a data scientist. I wasn’t all the way through the book, and my boss didn’t even know enough to interview me on that subject, but it didn’t hurt him to see that I was independently learning stuff because I thought it would be useful, and it didn’t hurt to be on top of that stuff when I started my new job.
What I like about this is that it looks for jobs based on what you want rather than what you already know you can do. It’s in some sense the dual method to what people usually do.
War of the machines, college edition
A couple of people have sent me this recent essay (hat tip Leon Kautsky) written by Elijah Mayfield on the education technology blog e-Literate, described on their About page as “a hobby weblog about educational technology and related topics that is maintained by Michael Feldstein and written by Michael and some of his trusted colleagues in the field of educational technology.”
Mayfield’s essay is entitled “Six Ways the edX Announcement Gets Automated Essay Grading Wrong”. He’s referring to the recent announcement, which was written about in the New York Times last week, about how professors will soon be replaced by computers in grading essays. He claims they got it all wrong and there’s nothing to worry about.
I wrote about this idea too, in this post, and he hasn’t addressed my complaints at all.
First, Mayfield’s points:
- Journalists sensationalize things.
- The machine is identifying things in the essays that are associated with good writing vs. bad writing, much like it might learn to distinguish pictures of ducks from pictures of houses.
- It’s actually not that hard to find the duck and has nothing to do with “creativity” (look for webbed feet).
- If the machine isn’t sure it can spit back the essay to the professor to read (if the professor is still employed).
- The machine doesn’t necessarily reward big vocabulary words, except when it does.
- You’d need thousands of training examples (essays on a given subject) to make this actually work.
- What’s so really wonderful is that a student can get all his or her many drafts graded instantaneously, which no professor would be willing to do.
Here’s where I’ll start, with this excerpt from near the end:
“Can machine learning grade essays?” is a bad question. We know, statistically, that the algorithms we’ve trained work just as well as teachers for churning out a score on a 5-point scale. We know that occasionally it’ll make mistakes; however, more often than not, what the algorithms learn to do are reproduce the already questionable behavior of humans. If we’re relying on machine learning solely to automate the process of grading, to make it faster and cheaper and enable access, then sure. We can do that.
OK, so we know that the machine can grade essays written for human consumption pretty accurately. But it hasn’t had to deal with essays written for machine consumption yet. There’s major room for gaming here, and only a matter of time before there’s a competing algorithm to build a great essay. I even know how to train that algorithm. Email me privately and we can make a deal on profit-sharing.
And considering that students will be able to get their drafts graded as many times as they want, as Mayfield advertised, this will only be easier. If I build an essay that I think should game the machine, by putting in lots of (relevant) long vocabulary words and erudite phrases, then I can always double check by having the system give me a grade. If it doesn’t work, I’ll try again.
And the essays built this way won’t get caught via the fraud detection software that finds plagiarism, because any good essay-builder will only steal smallish phrases.
One final point. The fact that the machine-learning grading algorithm only works when it’s been trained on thousands of essays points to yet another depressing trend: large-scale classes with the same exact assignments every semester so last year’s algorithm can be used, in the name of efficiency.
But that means last year’s essay-building algorithm can be used as well. Pretty soon it will just be a war of the machines.
New creepy model: job hiring software
Warmup: Automatic Grading Models
Before I get to my main take-down of the morning, let me warm up with an appetizer of sorts: have you been hearing a lot about new models that automatically grade essays?
Does it strike you that’s there’s something wrong with that idea but you don’t know what it is?
Here’s my take. While it’s true that it’s possible to train a model to grade essays similarly to what a professor now does, that doesn’t mean we can introduce automatic grading – at least not if the students in question know that’s what we’re doing.
There’s a feedback loop, whereby if the students know their essays will be automatically graded, then they will change what they’re doing to optimize for good automatic grades rather than, say, a cogent argument.
For example, a student might download a grading app themselves (wouldn’t you?) and run their essay through the machine until it gets a great grade. Not enough long words? Put them in! No need to make sure the sentences make sense, because the machine doesn’t understand grammar!
This is, in fact, a great example where people need to take into account the (obvious when you think about them) feedback loops that their models will enter in actual use.
Job Hiring Models
Now on to the main course.
In this week’s Economist there is an essay about the new widely-used job hiring software and how awesome it is. It’s so efficient! It removes the biases of of those pesky recruiters! Here’s an excerpt from the article:
The problem with human-resource managers is that they are human. They have biases; they make mistakes. But with better tools, they can make better hiring decisions, say advocates of “big data”.
So far “the machine” has made observations such as:
- Good if candidate uses browser you need to download like Chrome.
- Not as bad as one might expect to have a criminal record.
- Neutral on job hopping.
- Great if you live nearby.
- Good if you are on Facebook.
- Bad if you’re on Facebook and every other social networking site as well.
Now, I’m all for learning to fight against our biases and hire people that might not otherwise be given a chance. But I’m not convinced that this will happen that often – the people using the software can always train the model to include their biases and then point to the machine and say “The machine told me to do it”. True.
What I really object to, however, is the accumulating amount of data that is being collected about everyone by models like this.
It’s one thing for an algorithm to take my CV in and note that I misspelled my alma mater, but it’s a different thing altogether to scour the web for my online profile trail (via Acxiom, for example), to look up my credit score, and maybe even to see my persistence score as measured by my past online education activities (soon available for your 7-year-old as well!).
As a modeler, I know how hungry the model can be. It will ask for all of this data and more. And it will mean that nothing you’ve ever done wrong, no fuck-up that you wish to forget, will ever be forgotten. You can no longer reinvent yourself.
Forget mobility, forget the American Dream, you and everyone else will be funneled into whatever job and whatever life the machine has deemed you worthy of. WTF.
Guest post by Julia Evans: How I got a data science job
This is a guest post by Julia Evans. Julia is a data scientist & programmer who lives in Montréal. She spends her free time these days playing with data and running events for women who program or want to — she just started a Montréal chapter of pyladies to teach programming, and co-organize a monthly meetup called Montréal All-Girl Hack Night for women who are developers.
I asked mathbabe a question a few weeks ago saying that I’d recently started a data science job without having too much experience with statistics, and she asked me to write something about how I got the job. Needless to say I’m pretty honoured to be a guest blogger here 🙂 Hopefully this will help someone!
Last March I decided that I wanted a job playing with data, since I’d been playing with datasets in my spare time for a while and I really liked it. I had a BSc in pure math, a MSc in theoretical computer science and about 6 months of work experience as a programmer developing websites. I’d taken one machine learning class and zero statistics classes.
In October, I left my web development job with some savings and no immediate plans to find a new job. I was thinking about doing freelance web development. Two weeks later, someone posted a job posting to my department mailing list looking for a “Junior Data Scientist”. I wrote back and said basically “I have a really strong math background and am a pretty good programmer”. This email included, embarrassingly, the sentence “I am amazing at math”. They said they’d like to interview me.
The interview was a lunch meeting. I found out that the company (Via Science) was opening a new office in my city, and was looking for people to be the first employees at the new office. They work with clients to make predictions based on their data.
My interviewer (now my manager) asked me about my role at my previous job (a little bit of everything — programming, system administration, etc.), my math background (lots of pure math, but no stats), and my experience with machine learning (one class, and drawing some graphs for fun). I was asked how I’d approach a digit recognition problem and I said “well, I’d see what people do to solve problems like that, and I’d try that”.
I also talked about some data visualizations I’d worked on for fun. They were looking for someone who could take on new datasets and be independent and proactive about creating model, figuring out what is the most useful thing to model, and getting more information from clients.
I got a call back about a week after the lunch interview saying that they’d like to hire me. We talked a bit more about the work culture, starting dates, and salary, and then I accepted the offer.
So far I’ve been working here for about four months. I work with a machine learning system developed inside the company (there’s a paper about it here). I’ve spent most of my time working on code to interface with this system and make it easier for us to get results out of it quickly. I alternate between working on this system (using Java) and using Python (with the fabulous IPython Notebook) to quickly draw graphs and make models with scikit-learn to compare our results.
I like that I have real-world data (sometimes, lots of it!) where there’s not always a clear question or direction to go in. I get to spend time figuring out the relevant features of the data or what kinds of things we should be trying to model. I’m beginning to understand what people say about data-wrangling taking up most of their time. I’m learning some statistics, and we have a weekly Friday seminar series where we take turns talking about something we’ve learned in the last few weeks or introducing a piece of math that we want to use.
Overall I’m really happy to have a job where I get data and have to figure out what direction to take it in, and I’m learning a lot.
K-Nearest Neighbors: dangerously simple
I spend my time at work nowadays thinking about how to start a company in data science. Since there are tons of companies now collecting tons of data, and they don’t know what do to do with it, nor who to ask, part of me wants to design (yet another) dumbed-down “analytics platform” so that business people can import their data onto the platform, and then perform simple algorithms themselves, without even having a data scientist to supervise.
After all, a good data scientist is hard to find. Sometimes you don’t even know if you want to invest in this whole big data thing, you’re not sure the data you’re collecting is all that great or whether the whole thing is just a bunch of hype. It’s tempting to bypass professional data scientists altogether and try to replace them with software.
I’m here to say, it’s not clear that’s possible. Even the simplest algorithm, like k-Nearest Neighbor (k-NN), can be naively misused by someone who doesn’t understand it well. Let me explain.
Say you have a bunch of data points, maybe corresponding to users on your website. They have a bunch of attributes, and you want to categorize them based on their attributes. For example, they might be customers that have spent various amounts of money on your product, and you can put them into “big spender”, “medium spender”, “small spender”, and “will never buy anything” categories.
What you really want, of course, is a way of anticipating the category of a new user before they’ve bought anything, based on what you know about them when they arrive, namely their attributes. So the problem is, given a user’s attributes, what’s your best guess for that user’s category?
Let’s use k-Nearest Neighbors. Let k be 5 and say there’s a new customer named Monica. Then the algorithm searches for the 5 customers closest to Monica, i.e. most similar to Monica in terms of attributes, and sees what categories those 5 customers were in. If 4 of them were “medium spenders” and 1 was “small spender”, then your best guess for Monica is “medium spender”.
Holy shit, that was simple! Mathbabe, what’s your problem?
The devil is all in the detail of what you mean by close. And to make things trickier, as in easier to be deceptively easy, there are default choices you could make (and which you would make) which would probably be totally stupid. Namely, the raw numbers, and Euclidean distance.
So, for example, say your customer attributes were: age, salary, and number of previous visits to your website. Don’t ask me how you know your customer’s salary, maybe you bought info from Acxiom.
So in terms of attribute vectors, Monica’s might look like:

And the nearest neighbor to Monica might look like:
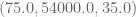
In other words, because you’re including the raw salary numbers, you are thinking of Monica, who is 22 and new to the site, as close to a 75-year old who comes to the site a lot. The salary, being of a much larger scale, is totally dominating the distance calculation. You might as well have only that one attribute and scrap the others.
Note: you would not necessarily think about this problem if you were just pressing a big button on a dashboard called “k-NN me!”
Of course, it gets trickier. Even if you measured salary in thousands (so Monica would now be given the attribution vector 
Another problem is redundancy – if you have a bunch of attributes that are essentially redundant, i.e. that are highly correlated to each other, then including them all is tantamount to multiplying the scale of that factor.
Another problem is not all your attributes are even numbers, so you have string attributes. You might think you can solve this by using 0’s and 1’s, but in the case of k-NN, that becomes just another scaling problem.
One way around this might be to first use some kind of dimension-reducing algorithm, like PCA, to figure out what attribute combinations to actually use from the get-go. That’s probably what I’d do.
But that means you’re using a fancy algorithm in order to use a completely stupid algorithm. Not that there’s anything wrong with that, but it indicates the basic problem, which is that doing data analysis carefully is actually pretty hard and maybe should be done by professionals, or at least under the supervision of a one.
Value-added model doesn’t find bad teachers, causes administrators to cheat
There’ve been a couple of articles in the past few days about teacher Value-Added Testing that have enraged me.
If you haven’t been paying attention, the Value-Added Model (VAM) is now being used in a majority of the states (source: the Economist):

But it gives out nearly random numbers, as gleaned from looking at the same teachers with two scores (see this previous post). There’s a 24% correlation between the two numbers. Note that some people are awesome with respect to one score and complete shit on the other score:

Final thing you need to know about the model: nobody really understands how it works. It relies on error terms of an error-riddled model. It’s opaque, and no teacher can have their score explained to them in Plain English.
Now, with that background, let’s look into these articles.
First, there’s this New York Times article from yesterday, entitled “Curious Grade for Teachers: Nearly All Pass”. In this article, it describes how teachers are nowadays being judged using a (usually) 50/50 combination of classroom observations and VAM scores. This is different from the past, which was only based on classroom observations.
What they’ve found is that the percentage of teachers found “effective or better” has stayed high in spite of the new system – the numbers are all over the place but typically between 90 and 99 percent of teachers. In other words, the number of teachers that are fingered as truly terrible hasn’t gone up too much. What a fucking disaster, at least according to the NYTimes, which seems to go out of its way to make its readers understand how very much high school teachers suck.
A few things to say about this.
- Given that the VAM is nearly a random number generator, this is good news – it means they are not trusting the VAM scores blindly. Of course, it still doesn’t mean that the right teachers are getting fired, since half of the score is random.
- Another point the article mentions is that failing teachers are leaving before the reports come out. We don’t actually know how many teachers are affected by these scores.
- Anyway, what is the right number of teachers to fire each year, New York Times? And how did you choose that number? Oh wait, you quoted someone from the Brookings Institute: “It would be an unusual profession that at least 5 percent are not deemed ineffective.” Way to explain things so scientifically! It’s refreshing to know exactly how the army of McKinsey alums approach education reform.
- The overall article gives us the impression that if we were really going to do our job and “be tough on bad teachers,” then we’d weight the Value-Added Model way more. But instead we’re being pussies. Wonder what would happen if we weren’t pussies?
The second article explained just that. It also came from the New York Times (h/t Suresh Naidu), and it was a the story of a School Chief in Atlanta who took the VAM scores very very seriously.
What happened next? The teachers cheated wildly, changing the answers on their students’ tests. There was a big cover-up, lots of nasty political pressure, and a lot of good people feeling really bad, blah blah blah. But maybe we can take a step back and think about why this might have happened. Can we do that, New York Times? Maybe it had to do with the $500,000 in “performance bonuses” that the School Chief got for such awesome scores?
Let’s face it, this cheating scandal, and others like it (which may never come to light), was not hard to predict (as I explain in this post). In fact, as a predictive modeler, I’d argue that this cheating problem is the easiest thing to predict about the VAM, considering how it’s being used as an opaque mathematical weapon.
Guest Post SuperReview Part III of VI: The Occupy Handbook Part I and a little Part II: Where We Are Now
Whattup.
Moving on from Lewis’ cute Bloomberg column reprint, we come to the next essay in the series:
The Widening Gyre: Inequality, Polarization, and the Crisis by Paul Krugman and Robin Wells
Indefatigable pair Paul Krugman and Robin Wells (KW hereafter) contribute one of the several original essays in the book, but the content ought to be familiar if you read the New York Times, know something about economics or practice finance. Paul Krugman is prolific, and it isn’t hard to be prolific when you have to rewrite essentially the same column every week; question, are there other columnists who have been so consistently right yet have failed to propose anything that the polity would adopt? Political failure notwithstanding, Krugman leaves gems in every paragraph for the reader new to all this. The title “The Widening Gyre” comes from an apocalyptic William Yeats Butler poem. In this case, Krugman and Wells tackle the problem of why the government responded so poorly to the crisis. In their words:
By 2007, America was about as unequal as it had been on the eve of the Great Depression – and sure enough, just after hitting this milestone, we lunged into the worst slump since the Depression. This probably wasn’t a coincidence, although economists are still working on trying to understand the linkages between inequality and vulnerability to economic crisis.
Here, however, we want to focus on a different question: why has the response to crisis been so inadequate? Before financial crisis struck, we think it’s fair to say that most economists imagined that even if such a crisis were to happen, there would be a quick and effective policy response [editor’s note: see Kautsky et al 2016 for a partial explanation]. In 2003 Robert Lucas, the Nobel laureate and then president of the American Economic Association, urged the profession to turn its attention away from recessions to issues of longer-term growth. Why? Because he declared, the “central problem of depression-prevention has been solved, for all practical purposes, and has in fact been solved for many decades.”
Famous last words from Professor Lucas. Nevertheless, the curious failure to apply what was once the conventional wisdom on a useful scale intrigues me for two reasons. First, most political scientists suggest that democracy, versus authoritarian system X, leads to better outcomes for two reasons.
1. Distributional – you get a nicer distribution of wealth (possibly more productivity for complicated macro reasons); economics suggests that since people are mostly envious and poor people have rapidly increasing utility in wealth, democracy’s tendency to share the wealth better maximizes some stupid social welfare criterion (typically, Kaldor-Hicks efficiency).
2. Information – democracy is a better information aggregation system than dictatorship and an expanded polity makes better decisions beyond allocation of produced resources. The polity must be capable of learning and intelligent OR vote randomly if uninformed for this to work. While this is the original rigorous justification for democracy (first formalized in the 1800s by French rationalists), almost no one who studies these issues today believes one-person one-vote democracy better aggregates information than all other systems at a national level. “Well Leon,” some knave comments, “we don’t live in a democracy, we live in a Republic with a president…so shouldn’t a small group of representatives better be able to make social-welfare maximizing decisions?” Short answer: strong no, and US Constitutionalism has some particularly nasty features when it comes to political decision-making.
Second, KW suggest that the presence of extreme wealth inequalities act like a democracy disabling virus at the national level. According to KW extreme wealth inequalities perpetuate themselves in a way that undermines both “nice” features of a democracy when it comes to making regulatory and budget decisions.* Thus, to get better economic decision-making from our elected officials, a good intermediate step would be to make our tax system more progressive or expand Medicare or Social Security or…Well, we have a lot of good options here. Of course, for mathematically minded thinkers, this begs the following question: if we could enact so-called progressive economic policies to cure our political crisis, why haven’t we done so already? What can/must change for us to do so in the future? While I believe that the answer to this question is provided by another essay in the book, let’s take a closer look at KW’s explanation at how wealth inequality throws sand into the gears of our polity. They propose four and the following number scheme is mine:
1. The most likely explanation of the relationship between inequality and polarization is that the increased income and wealth of a small minority has, in effect bought the allegiance of a major political party…Needless to say, this is not an environment conducive to political action.
2. It seems likely that this persistence [of financial deregulation] despite repeated disasters had a lot do with rising inequality, with the causation running in both directions. On the one side the explosive growth of the financial sector was a major source of soaring incomes at the very top of the income distribution. On the other side, the fact that the very rich were the prime beneficiaries of deregulation meant that as this group gained power- simply because of its rising wealth- the push for deregulation intensified. These impacts of inequality on ideology did not in 2008…[they] left us incapacitated in the face of crisis.
3. Conservatives have always seen seen [Keynesian economics] as the thin edge of the wedge: concede that the government can play a useful role in fighting slumps, and the next thing you know we’ll be living under socialism.
4. [Krugman paraphrasing Kalecki] Every widening of state activity is looked upon by business with suspicion, but the creation of employment by government spending has a special aspect which makes the opposition particularly intense. Under a laissez-faire system the level of employment to a great extend on the so-called state of confidence….This gives capitalists a powerful indirect control over government policy: everything which may shake the state of confidence must be avoided because it would cause an economic crisis.
All of these are true to an extent. Two are related to the features of a particular policy position that conservatives don’t like (countercyclical spending) and their cost will dissipate if the economy improves. Isn’t it the case that most proponents and beneficiaries of financial liberalization are Democrats? (Wall Street mostly supported Obama in 08 and barely supported Romney in 12 despite Romney giving the house away). In any case, while KW aren’t big on solutions they certainly have a strong grasp of the problem.
Take a Stand: Sit In by Phillip Dray
As the railroad strike of 1877 had led eventually to expanded workers’ rights, so the Greensboro sit-in of February 1, 1960, helped pave the way for passage of the Civil Rights Act of 1964 and the Voting Rights Act of 1965. Both movements remind us that not all successful protests are explicit in their message and purpose; they rely instead on the participants’ intuitive sense of justice. [28]
I’m not the only author to have taken note of this passage as particularly important, but I am the only author who found the passage significant and did not start ranting about so-called “natural law.” Chronicling the (hitherto unknown-to-me) history of the Great Upheaval, Dray does a great job relating some important moments in left protest history to the OWS history. This is actually an extremely important essay and I haven’t given it the time it deserves. If you read three essays in this book, include this in your list.
Inequality and Intemperate Policy by Raghuram Rajan (no URL, you’ll have to buy the book)
Rajan’s basic ideas are the following: inequality has gotten out of control:
Deepening income inequality has been brought to the forefront of discussion in the United States. The discussion tends to center on the Croesus-like income of John Paulson, the hedge fund manager who made a killing in 2008 betting on a financial collapse and netted over $3 billion, about seventy-five-thousand times the average household income. Yet a more worrying, everyday phenomenon that confronts most Americans is the disparity in income growth rates between a manager at the local supermarket and the factory worker or office assistant. Since the 1970s, the wages of the former, typically workers at the ninetieth percentile of the wage distribution in the United States, have grown much faster than the wages of the latter, the typical median worker.
But American political ideologies typically rule out the most direct responses to inequality (i.e. redistribution). The result is a series of stop-gap measures that do long-run damage to the economy (as defined by sustainable and rising income levels and full employment), but temporarily boost the consumption level of lower classes:
It is not surprising then, that a policy response to rising inequality in the United States in the 1990s and 200s – whether carefully planned or chosen as the path of least resistance – was to encourage lending to households, especially but not exclusively low-income ones, with the government push given to housing credit just the most egregious example. The benefit – higher consumption – was immediate, whereas paying the inevitable bill could be postponed into the future. Indeed, consumption inequality did not grow nearly as much as income inequality before the crisis. The difference was bridged by debt. Cynical as it may seem, easy credit has been used as a palliative success administrations that been unable to address the deeper anxieties of the middle class directly. As I argue in my book Fault Lines, “Let them eat credit” could well summarize the mantra of the political establishment in the go-go years before the crisis.
Why should you believe Raghuram Rajan? Because he’s one of the few guys who called the first crisis and tried to warn the Fed.
A solid essay providing a more direct link between income inequality and bad policy than KW do.
The 5 Percent by Michael Hiltzik
The 5 percent’s [consisting of the seven million Americans who, in 1934, were sixty-five and older] protests coalesced as the Townsend movement, launched by a sinewy midwestern farmer’s son and farm laborer turned California physician. Francis Townsend was a World War I veteran who had served in the Army Medical Corps. He had an ambitious, and impractical plan for a federal pension program. Although during its heyday in the 1930s the movement failed to win enactment of its [editor’s note: insane] program, it did play a critical role in contemporary politics. Before Townsend, America understood the destitution of its older generations only in abstract terms; Townsend’s movement made it tangible. “It is no small achievment to have opened the eyes of even a few million Americans to these facts,” Bruce Bliven, editor of the New Republic observed. “If the Townsend Plan were to die tomorrow and be completely forgotten as miniature golf, mah-jongg, or flinch [editor’s note: everything old is new again], it would still have left some sedimented flood marks on the national consciousness.” Indeed, the Townsend movement became the catalyst for the New Deal’s signal achievement, the old-age program of Social Security. The history of its rise offers a lesson for the Occupy movement in how to convert grassroots enthusiasm into a potent political force – and a warning about the limitations of even a nationwide movement.
Does the author live up to the promises of this paragraph? Is the whole essay worth reading? Does FDR give in to the people’s demands and pass Social Security?!
Yes to all. Read it.
Hidden in Plain Sight by Gillian Tett (no URL, you’ll have to buy the book)
This is a great essay. I’m going to outsource the review and analysis to:
http://beyoubesure.com/2012/10/13/generation-lost-lazy-afraid/
because it basically sums up my thoughts. You all, go read it.
What Good is Wall Street? by John Cassidy
If you know nothing about Wall Street, then the essay is worth reading, otherwise skip it. There are two common ways to write a bad article in financial journalism. First, you can try to explain tiny index price movements via news articles from that day/week/month. “Shares in the S&P moved up on good news in Taiwan today,” that kind of nonsense. While the news and price movements might be worth knowing for their own sake, these articles are usually worthless because no journalist really knows who traded and why (theorists might point out even if the journalists did know who traded to generate the movement and why, it’s not clear these articles would add value – theorists are correct).
The other way, the Cassidy! way is to ask some subgroup of American finance what they think about other subgroups in finance. High frequency traders think iBankers are dumb and overpaid, but HFT on the other hand, provides an extremely valuable service – keeping ETFs cheap, providing liquidity and keeping shares the right level. iBankers think prop-traders add no value, but that without iBanking M&A services, American manufacturing/farmers/whatever would cease functioning. Low speed prop-traders think that HFT just extracts cash from dumb money, but prop-traders are reddest blooded American capitalists, taking the right risks and bringing knowledge into the markets. Insurance hates hedge funds, hedge funds hate the bulge bracket, the bulge bracket hates the ratings agencies, who hate insurance and on and on.
You can spit out dozens of articles about these catty and tedious rivalries (invariably claiming that financial sector X, rivals for institutional cash with Y, “adds no value”) and learn nothing about finance. Cassidy writes the article taking the iBankers side and surprises no one (this was originally published as an article in The New Yorker).
Your House as an ATM by Bethany McLean
Ms. McLean holds immense talent. It was always pretty obvious that the bottom twenty-percent, i.e. the vast majority of subprime loan recipients, who are generally poor at planning, were using mortgages to get quick cash rather than buy houses. Regulators and high finance, after resisting for a good twenty years, gave in for reasons explained in Rajan’s essay.
Against Political Capture by Daron Acemoglu and James A. Robinson (sorry I couldn’t find a URL, for this original essay you’ll have to buy the book).
A legit essay by a future Nobelist in Econ. Read it.
A Nation of Business Junkies by Arjun Appadurai
Anthro-hack Appadurai writes:
I first came to this country in 1967. I have been either a crypto-anthropologist or professional anthropologist for most of the intervening years. Still, because I came here with an interest in India and took the path of least resistance in choosing to retain India as my principal ethnographic referent, I have always been reluctant to offer opinions about life in these United States.
His instincts were correct. The essay reads like an old man complaining about how bad the weather is these days. Skip it.
Causes of Financial Crises Past and Present: The Role of This-Time-Is-Different Syndrome by Carmen M. Reinhart and Kenneth S. Rogoff
Editor Byrne has amazing powers of persuasion or, a lot of authors have had some essays in the desk-drawer they were waiting for an opportunity to publish. In any case, Rogoff and Reinhart (RR hereafter) have summed up a couple hundred studies and two of their books in a single executive summary and given it to whoever buys The Occupy Handbook. Value. RR are Republicans and the essay appears to be written in good faith (unlike some people *cough* Tyler Cowen and Veronique de Rugy *cough*). RR do a great job discovering and presenting stylized facts about financial crises past and present. What to expect next? A couple national defaults and maybe a hyperinflation or two.
Government As Tough Love by Robert Shiller as interviewed by Brandon Adams (buy the book)!
Shiller has always been ahead of the curve. In 1981, he wrote a cornerstone paper in behavioral finance at a time when the field was in its embryonic stages. In the early 1990s, he noticed insufficient attention was paid to real estate values, despite their overwhelming importance to personal wealth levels; this led him to create, along with Karl E. Case, the Case-Shiller index – now the Case-Shiller Home Prices Indices. In March 2000**, Shiller published Irrational Exuberance, arguing that U.S. stocks were substantially overvalued and due for a tumble. [Editor’s note: what Brandon Adams fails to mention, but what’s surely relevant is that Shiller also called the subprime bubble and re-released Irrational Exuberance in 2005 to sound the alarms a full three years before The Subprime Solution]. In 2008, he published The Subprime Solution, which detailed the origins of the housing crisis and suggested innovative policy responses for dealing with the fallout. These days, one of his primary interests is neuroeconomics, a field that relates economic decision-making to brain function as measured by fMRIs.
Shiller is basically a champ and you should listen to him.
Shiller was disappointed but not surprised when governments bailed out banks in extreme fashion while leaving the contracts between banks and homeowners unchanged. He said, of Hank Paulson, “As Treasury secretary, he presented himself in a very sober and collected way…he did some bailouts that benefited Goldman Sachs, among others. And I can imagine that they were well-meaning, but I don’t know that they were totally well-meaning, because the sense of self-interest is hard to clean out of your mind.”
Shiller understates everything.
Verdict: Read it.
And so, we close our discussion of part I. Moving on to part II:
In Ms. Byrne’s own words:
Part 2, “Where We Are Now,” which covers the present, both in the United States and abroad, opens with a piece by the anthropologist David Graeber. The world of Madison Avenue is far from the beliefs of Graeber, an anarchist, but it’s Graeber who arguably (he says he didn’t do it alone) came up with the phrase “We Are the 99 percent.” As Bloomberg Businessweek pointed out in October 2011, during month two of the Occupy encampments that Graeber helped initiate and three moths after the publication of his Debt: The First 5,000 Years, “David Graeber likes to say that he had three goals for the year: promote his book, learn to drive, and launch a worldwide revolution. The first is going well, the second has proven challenging and the third is looking up.” Graeber’s counterpart in Chile can loosely be said to be Camila Vallejo, the college undergraduate, pictured on page 219, who, at twenty-three, brought the country to a standstill. The novelist and playwright Ariel Dorfman writes about her and about his own self-imposed exile from Chile, and his piece is followed by an entirely different, more quantitative treatment of the subject. This part of the book also covers the indignados in Spain, who before Occupy began, “occupied” the public squares of Madrid and other cities – using, as the basis for their claim on the parks could be legally be slept in, a thirteenth-century right granted to shepherds who moved, and still move, their flocks annually.
In other words, we’re in occupy is the hero we deserve, but not the hero we need territory here.
*Addendum 1: Some have suggested that it’s not the wealth inequality that ought to be reduced, but the democratic elements of our system. California’s terrible decision–making resulting from its experiments with direct democracy notwithstanding, I would like to stay in the realm of the sane.
**Addendum 2: Yes, Shiller managed to get the book published the week before the crash. Talk about market timing.




{kind=link}
{kind=link}