Archive
Explain your revenue model to me so I’ll know how I’m paying for this free service
When you find a website that claims to be free for users, we should know to be automatically suspicious. What is sustaining this service? How could you possibly have 35 people working at the underlying company without a revenue source?
We’ve been trained to not think about this, as web surfers, because everything seems, on its face, to be free, until it isn’t, which seems outright objectionable (as I wrote about here). Or is it? Maybe it’s just more honest.
When I go to the newest free online learning site, I’d like to know how they plan to eventually make money. If I’m registering on the site, do I need to worry that they will turn around and sell my data? Is it just advertising? Are they going to keep the good stuff away from me unless I pay?
And it’s not enough to tell me it’s making no revenue yet, that it’s being funded somehow for now without revenue. Because wherever there is funding, there are strings attached.
If the NSF has given a grant for this project, then you can bet the project never involves attacking the NSF for incompetence and politics. If it’s a VC firm, then you’d better believe they are actively figuring out how to make a major return on their investment. So even if they’re not selling your registration and click data now, they have plans for it.
So in other words, I want to know how you’re being funded, who’s giving you the money, and what your revenue model is. Unless you are independently wealthy and want to give back to the community by slaving away on a project, or you’re doing it in your spare time, then I know I’m somehow paying for this.
Just in the spirit of disclosure and transparency, I have no income and I pay a bit for my WordPress site.
Another death spiral of modeling: e-scores
Yesterday my friend and fellow Occupier Suresh sent me this article from the New York Times.
It’s something I knew was already happening somewhere, but I didn’t know the perpetrators would be quite so proud of themselves as they are; on the other hand I’m also not surprised, because people making good money on mathematical models rarely take the time to consider the ramifications of those models. At least that’s been my experience.
So what have these guys created? It’s basically a modern internet version of a credit score, without all the burdensome regulation that comes with it. Namely, they collect all kinds of information about people on the web, anything they can get their hands on, which includes personal information like physical and web addresses, phone number, google searches, purchases, and clicks of each person, and from that they create a so-called “e-score” which evaluates how much you are worth to a given advertiser or credit card company or mortgage company or insurance company.
Some important issues I want to bring to your attention:
- Credit scores are regulated, and in particular the disallow the use of racial information, whereas these e-scores are completely unregulated and can use whatever information they can gather (which is a lot). Not that credit score models are open source: they aren’t, so we don’t know if they are using variables correlated to race (like zip code). But still, there is some effort to protect people from outrageous and unfair profiling. I never though I’d be thinking of credit scoring companies as the good guys, but it is what it is.
- These e-scores are only going for max pay-out, not default risk. So, for the sake of a credit card company, the ideal customer is someone who pays the minimum balance month after month, never finishing off the balance. That person would have a higher e-score than someone who pays off their balance every month, although presumably that person would have a lower credit score, since they are living more on the edge of insolvency.
- Not that I need to mention this, but this is the ultimate in predatory modeling: every person is scored based on their ability to make money for the advertiser/ insurance company in question, based on any kind of ferreted-out information available. It’s really time for everyone to have two accounts, one for normal use, including filling out applications for mortgages and credit cards and buying things, and the second for sensitive google searches on medical problems and such.
- Finally, and I’m happy to see that the New York Times article noticed this and called it out, this is the perfect setup for the death spiral of modeling that I’ve mentioned before: people considered low value will be funneled away from good deals, which will give them bad deals, which will put them into an even tighter pinch with money because they’re being nickeled and timed and paying high interest rates, which will make them even lower value.
- A model like this is hugely scalable and valuable for a given advertiser.
- Therefore, this model can seriously contribute to our problem of increasing inequality.
- How can we resist this? It’s time for some rules on who owns personal information.
Update on organic food
So I’m back from some town in North Ontario (please watch this video to get an idea). I spent four days on a tiny little island on Lake Huron with my family and some wonderful friends, swimming, boating, picnicking, and reading the Omnivore’s Dilemma by Michael Pollan whenever I could.
It was a really beautiful place but really far away, especially since my husband jumped gleefully into the water from a high rock with his glasses on so I had to drive all the way back without help. But what I wanted to mention to you is that, happily, I managed to finish the whole book – a victory considering the distractions.
I was told to read the book by a bunch of people who read my previous post on organic food and why I don’t totally get it: see the post here and be sure to read the comments.
One thing I have to give Pollan, he has written a book that lots of people read. I took notes on his approach and style because I want to write a book myself. And it’s not that I read statistics on the book sales – I know people read the book because, even though I hadn’t, lots of facts and passages were eerily familiar to me, which means people I know have quoted the book to me. That’s serious!
In other words, there’s been feedback from this book to the culture and how we think about organic food vs. industrial farming. I can’t very well argue that I already knew most of the stuff in the book, even though I did, because I probably only know it because he wrote the book on it and it’s become part of our cultural understanding.
I terms of the content, first, I’ll complain, then I’ll compliment.
Complaint #1: the guy is a major food snob (one might even say douche). He spends like four months putting together a single “hunting and gathering” meal with the help of his friends the Chez Panisse chefs. It’s kind of like a “lives of the rich and famous” episode in that section of the book, which is to say voyeuristic, painfully smug, and self-absorbed. It’s hard to find this guy wise when he’s being so precious.
Complaint #2: a related issue, which is that he never does the math on whether a given lifestyle is actually accessible for the average person. He mentions that the locally grown food is more expensive, but he also suggests that poor people now spend less of their income on food than they used to, implying that maybe they have extra cash on hand to buy local free-range chickens, not to mention that they’d need the time and a car and gas to drive to the local farms to buy this stuff (which somehow doesn’t seem to figure into his carbon footprint calculation of that lifestyle). I don’t think there’s all that much extra time and money on people’s hands these days, considering how many people are now living on food stamps (I will grant that he wrote this book before the credit crisis so he didn’t anticipate that).
Complaint #3: he doesn’t actually give a suggestion for what to do about this to the average person. In the end this book creates a way for well-to-do people to feel smug about their food choices but doesn’t forge a path otherwise, besides a vague idea that not eating processed food would be good. I know I’m asking a lot, but specific and achievable suggestions would have been nice. Here’s where my readers can say I missed something – please comment!
Compliment #1: he really educates the reader on how much the government farm subsidies distort the market, especially for corn, and how the real winners are the huge businesses like ConAgra and Monsanto, not the farmers themselves.
Compliment #2: he also explains the nastiness of processed food and large-scale cow, pig, and chicken farms. Yuck.
Compliment #3: My favorite part is that he describes the underlying model of the food industry as overly simplistic. He points out that, by just focusing on the chemicals like nitrogen and carbon in the soil, we have ignored all sorts of other important things that are also important to a thriving ecosystem. So, he explains, simply adding nitrogen to the soil in the form of fertilizer doesn’t actually solve the problem of growing things quickly. Well, it does do that, but it introduces other problems like pollution.
This is a general problem with models: they almost by definition simplify the world, but if they are successful, they get hugely scaled, and then the things they ignore, and the problems that arise from that ignorance, are amplified. There’s a feedback loop filled with increasingly devastating externalities. In the case of farming, the externalities take the form of pollution, unsustainable use of petrochemicals, sick cows and chickens, and nasty food-like items made from corn by-products.
Another example is teacher value-added models: the model is bad, it is becoming massively scaled, and the externalities are potentially disastrous (teaching to the test, the best teachers leaving the system, enormous amount of time and money spent on the test industry, etc.).
But that begs the question, what should we do about it? Should we well-to-do people object to the existence of the model and send our kids to the private schools where the teachers aren’t subject to that model? Or should we acknowledge it exists, it isn’t going away, and it needs to be improved?
It’s a similar question for the food system and the farming model: do we save ourselves and our family, because we can, or do we confront the industry and force them to improve their models?
I say we do both! Let’s not ignore our obligation to agitate for better farming practices for the enormous industry that already exists and isn’t going away. I don’t think the appropriate way to behave is to hole up with your immediate family and make sure your kids are eating wholesome food. That’s too small and insular! It’s important to think of ways to fight back against the system itself if we believe it’s corrupt and is ruining our environment.
For me that means being part of Occupy, joining movements and organization fighting against lobbyist power (here’s one that fights against BigFood lobbyists), and broadly educating people about statistics and mathematical modeling so that modeling flaws and externalities are understood, discussed, and minimized.
Datadive weekend with DataKind September 7-9
I’ll be a data ambassador at an upcoming DataKind weekend, working with a team on New York City open government data.
DataKind, formerly known as Data Without Borders, is a very cool, not at all creepy organization that brings together data nerds with typically underfunded NGO’s in various ways, including datadive weekends, which are like hack-a-thons for data nerds.
I have blogged a few times about working with them, because I’ve done this before working with the NYCLU on stop-and-frisk data (check out my update here as well). By the way, stop-and-frisk events have gone down 34% in recent months. I feel pretty good about being even tangentially involved in that fact.
This time we’re working with mostly New York City parks data, so stuff like trees and storm safety and 311 calls.
The event starts on Friday, September 7th, with an introduction to the data and the questions and some drinks, then it’s pretty much all day Saturday, til midnight, and then there are presentations Sunday morning (September 9th). It’s always great to meet fellow nerds, exchange technical information and gossip, and build something cool together.
Registration is here, sign up quick!
Why the internet is creepy
Recently I’ve been seeing various articles and opinion pieces that say that Facebook should pay its users to use it, or give a cut of the proceeds when they sell personal data, or something along those lines.
This strikes me a naive to a surprising degree; it means people really don’t understand how web businesses work. How can people simultaneously complain that Facebook isn’t a viable business and that they don’t pay their users for their data?
People have gotten used to getting free services, and they assume that infrastructure somehow just exists, and they want to have that infrastructure, and use it, and never see ads and never have their data used, or get paid whenever someone uses their data.
But you can’t have all of that at the same time!
These companies need to monetize somehow, and instead of asking users for money directly, which isn’t the current culture, they get creepy with data. The fact that there are basically no rules about personal information (aside from some medical information) means that the creepiness limit is extreme, and possibly hasn’t been reached yet.
What are the alternatives? I can think of a few, none of them particularly wonderful:
- Legislate privacy laws to make personal data sharing or storing illegal without explicit consent for each use (right now you just sign away all your rights at once when you sign up for the service, but that could and probably should change). This would kill the internet as we know it. In the short term the consequences would be extreme. Besides the fact that some people would save and use data illegally, which would be very hard to track and to stop, places like Twitter, Facebook, and Google would have no revenue model. An interesting thought experiment on what would happen after this.
- Make people pay for services, either through micro-payments or subscription services like Netflix. This would maybe work, but only for people with credit cards and money to spare. So it would also change access to the internet, and not in a good way.
- Wikipedia-style donation-based services. This is clearly a tough model, and they always seem to be on the edge of solvency.
- Get the government to provide these services as meaningful infrastructure for society, like highways. Imagine what Google Government would be like.
- Some combination of the above.
Am I missing something?
VAM shouldn’t be used for tenure
I recently read a New York Times “Room for Debate” discussion on the teacher Value-added model (VAM) and whether it’s fair.
I’ve blogged a few times about this model and I think it’s crap (see this prior post which is entitled “The Value Added Model Sucks” for example).
One thing I noticed about the room for debate is that the two most pro-VAM talking heads (this guy and this guy) both quoted the same paper, written by Dan Goldhaber and Michael Hansen, called “Assessing the Potential of Using Value-Added Estimates of Teacher Job Performance for Making Tenure Decisions,” which you can download here.
Looking at the paper, I don’t really think it’s a very good resource if you want to argue for tenure-decisions based on VAM, but I guess it’s one of those things, where they don’t expect you actually do the homework.
For example, they admit that year-to-year scores are only correlated between 20% and 50% for the same teacher (page 4). But then they go on to say that, if you average two or more years in a row, these correlations go up (page 4). I’m wondering if that’s just because they calculate the correlations that come from the same underlying data, in which case of course the correlations go up. They aren’t precise enough at that point to make me convinced they did this carefully.
But it doesn’t matter, because when teachers are up for tenure, they have one or two scores, that’s it. So the fact that 17 years of scores, on average, has actual information, even if true, is irrelevant. The point is that we are asking whether one or two scores, in a test that has 20-50% correlation year-to-year, is sufficiently accurate and precise to decide on someone’s job. And by the way, in my post the correlation of teachers’ scores for the same year in the same subject was 24%, so I’m guess we should lean more towards the bottom of this scale for accuracy.
This is ludicrous. Can you imagine being told you can’t keep your job because of a number that imprecise? I’m grasping for an analogy, but it’s something like getting tenure as a professor based on what an acquaintance you’ve never met head about your reputation while he was drunk at a party. Maddening. And I can’t imagine it’s attracting more good people to the trade. I’d walk the other way if I heard about this.
The reason the paper is quoted so much is that it looks at a longer-term test to see whether early-career VAM scores have predictive power for the students more than 11 years later. However, it’s for one data set in North Carolina, and the testing actually happened in 1995 (page 6), so before the testing culture really took over (an important factor), and they clearly exclude any teacher whose paperwork is unavailable or unclear, as well as small classes (page 7), which presumably means any special-ed kids. Moreover, they admit they don’t really know if the kids are actual students of the teacher who proctored the tests (page 6).
Altogether a different set-up than the idiosyncratic, real-world situation faced by actual teachers, whose tenure decision is actually being made based on one or two hugely noisy numbers.
I’m not a huge fan of tenure, and I want educators to be accountable to being good teachers just like everyone else who cares about this stuff, but this is pseudo-science.
I’m still obsessed with the idea that people would know how crappy this stuff is if we could get our hands on the VAM itself and set something up where people could test robustness directly, by putting in their information and seeing how their score would change based on how many kids they had in their class etc..
Statisticians aren’t the problem for data science. The real problem is too many posers
Crossposted on Naked Capitalism
Cosma Shalizi
I recently was hugely flattered by my friend Cosma Shalizi’s articulate argument against my position that data science distinguishes itself from statistics in various ways.
Cosma is a well-read broadly educated guy, and a role model for what a statistician can be, not that every statistician lives up to hist standard. I’ve enjoyed talking to him about data, big data, and working in industry, and I’ve blogged about his blogposts as well.
That’s not to say I agree with absolutely everything Cosma says in his post: in particular, there’s a difference between being a master at visualizations for the statistics audience and being able to put together a power point presentation for a board meeting, which some data scientists in the internet start-up scene definitely need to do (mostly this is a study in how to dumb stuff down without letting it become vapid, and in reading other people’s minds in advance to see what they find sexy).
And communications skills are a funny thing; my experience is communicating with an academic or a quant is a different kettle of fish than communicating with the Head of Product. Each audience has its own dialect.
But I totally believe that any statistician who willingly gets a job entitled “Data Scientist” would be able to do these things, it’s a self-selection process after all.
Statistics and Data Science are on the same team
I think that casting statistics as the enemy of data science is a straw man play. The truth is, an earnest, well-trained and careful statistician in a data scientist role would adapt very quickly to it and flourish as well, if he or she could learn to stomach the business-speak and hype (which changes depending on the role, and for certain data science jobs is really not a big part of it, but for others may be).
It would be a petty argument indeed to try to make this into a real fight. As long as academic statisticians are willing to admit they don’t typically spend just as much time (which isn’t to say they never spend as much time) worrying about how long it will take to train a model as they do wondering about the exact conditions under which a paper will be published, and as long as data scientists admit that they mostly just redo linear regression in weirder and weirder ways, then there’s no need for a heated debate at all.
Let’s once and for all shake hands and agree that we’re here together, and it’s cool, and we each have something to learn from the other.
Posers
What I really want to rant about today though is something else, namely posers. There are far too many posers out there in the land of data scientists, and it’s getting to the point where I’m starting to regret throwing my hat into that ring.
Without naming names, I’d like to characterize problematic pseudo-mathematical behavior that I witness often enough that I’m consistently riled up. I’ll put aside hyped-up, bullshit publicity stunts and generalized political maneuvering because I believe that stuff speaks for itself.
My basic mathematical complaint is that it’s not enough to just know how to run a black box algorithm. You actually need to know how and why it works, so that when it doesn’t work, you can adjust. Let me explain this a bit by analogy with respect to the Rubik’s cube, which I taught my beloved math nerd high school students to solve using group theory just last week.
Rubiks
First we solved the “position problem” for the 3-by-3-by-3 cube using 3-cycles, and proved it worked, by exhibiting the group acting on the cube, understanding it as a subgroup of 
I did this three times, with the three classes, and each time a student would ask me if the algorithm is efficient. No, it’s not efficient, it takes about 4 minutes, and other people can solve it way faster, I’d explain. But the great thing about this algorithm is that it seamlessly generalizes to other problems. Using similar sign arguments and basic 3-cycle moves, you can solve the 7-by-7-by-7 (or any of them actually) and many other shaped Rubik’s-like puzzles as well, which none of the “efficient” algorithms can do.
Something I could have mentioned but didn’t is that the efficient algorithms are memorized by their users, are basically black-box algorithms. I don’t think people understand to any degree why they work. And when they are confronted with a new puzzle, some of those tricks generalize but not all of them, and they need new tricks to deal with centers that get scrambled with “invisible orientations”. And it’s not at all clear they can solve a tetrahedron puzzle, for example, with any success.
Democratizing algorithms: good and bad
Back to data science. It’s a good thing that data algorithms are getting democratized, and I’m all for there being packages in R or Octave that let people run clustering algorithms or steepest descent.
But, contrary to the message sent by much of Andrew Ng’s class on machine learning, you actually do need to understand how to invert a matrix at some point in your life if you want to be a data scientist. And, I’d add, if you’re not smart enough to understand the underlying math, then you’re not smart enough to be a data scientist.
I’m not being a snob. I’m not saying this because I want people to work hard. It’s not a laziness thing, it’s a matter of knowing your shit and being for real. If your model fails, you want to be able to figure out why it failed. The only way to do that is to know how it works to begin with. Even if it worked in a given situation, when you train on slightly different data you might run into something that throws it for a loop, and you’d better be able to figure out what that is. That’s your job.
As I see it, there are three problems with the democratization of algorithms:
- As described already, it lets people who can load data and press a button describe themselves as data scientists.
- It tempts companies to never hire anyone who actually knows how these things work, because they don’t see the point. This is a mistake, and could have dire consequences, both for the company and for the world, depending on how widely their crappy models get used.
- Businesses might think they have awesome data scientists when they don’t. That’s not an easy problem to fix from the business side: posers can be fantastically successful exactly because non-data scientists who hire data scientists in business, i.e. business people, don’t know how to test for real understanding.
How do we purge the posers?
We need to come up with a plan to purge the posers, they are annoying and making a bad name for data science.
One thing that will be helpful in this direction is Rachel Schutt’s Data Science class at Columbia next semester, which is going to be a much-needed bullshit free zone. Note there’s been a time change that hasn’t been reflected on the announcement yet, namely it’s going to be once a week, Wednesdays for three hours starting at 6:15pm. I’m looking forward to blogging on the contents of these lectures.
Columbia Data Science Institute: it’s gonna happen
So Bloomberg finally got around to announcing the Columbia Data Science Institute is really going to happen. The details as we know them now:
- It’ll be at the main campus, not Manhattanville.
- It’ll hire 75 faculty over the next decade (specifically, 30 new faculty by launch in August 2016 and 75 by 2030, so actually more than a decade but who’s counting?).
- It will contain a New Media Center, a Smart Cities Center, a Health Analytics Center, a Cybersecurity Center, and a Financial Analytics Center.
- The city is pitching in $15 million whereas Columbia is ponying up $80 million.
- Columbia Computer Science professor Kathy McKeown will be the Director and Civil Engineering professor Patricia Culligan will be the Institute’s Deputy Director.
How much of data science is busy work?
I’m at math camp, about to start the first day (4 hours of teaching a day, 3 hours of problem session) with my three junior staff (last year I only had one!). I expect I’ll be blogging quite a bit in the next few days about math camp stuff but today I wanted to respond to this blog post, entitled “The Fallacy of the Data Scientist Shortage”. I found this on Data Science Central which I had never known about but looks to be a good resource.
The author, Neil Radan, makes the point that, although we seem to have a shortage of data scientists, mostly what they do can be done by non-specialists. Just as you waste your time during a plane trip on things like security, waiting to board, and taxiing, the average data scientist spends most of her time cleaning data and moving it around.
If I understand this post correctly, they are saying that, because data scientists don’t spend that much time doing creative stuff, they can be replaced by someone who is good with data.
Hmm… let’s first go back to the idea that data scientists spend most of their time cleaning and moving data. This is true, but what do we conclude from it? It’s something like saying concert cellists spend most of their time practicing scales and rosining their bows, and don’t do all that much actual performing. Or, you could compare it to math professors who spend most of their time meeting (or avoiding) students and not much time proving new theorems.
My point is that this fact of time management is maybe a universal rule. Or even better, it may be a universal rule for creative endeavors. If you’re a truck driver then you can fairly said you worked the whole time you drove across the country, at a pretty consistent pace. But if you’re doing something that requires thought and puzzling then the nature of things is that it isn’t an 8-hour-a-day activity.
It’s more like, as a data scientist, you work hard to see the data in a certain way, which takes lots of time depending on how much data you have, then you make a decision based on what you’ve seen, then you set up the next test.
And I don’t think this can be done by someone who is strictly good at moving around data but isn’t trained as a modeler or statistician or the like. Because the hard part isn’t the data munging, it’s the part where you decide what test to perform that will give you the maximum information, and also the part where you look at the results and decipher them – decide whether they are what you expected, and if not, what could explain what you’re seeing.
I do think that data scientists can and should be paired with people who are experts at data moving and cleaning, because then the whole process is more efficient. Maybe data scientists can be brought in as 2-hour-per-day consultants or something, and the rest of the time there can be some engineers working on their tests. That might work.
The fake problem of fake geek girls, and how to be a sexy man nerd
My friend Rachel Schutt recently sent me this Forbes article by Tara Tiger Brown on the so-called problem of too many fake geek girls stealing the thunder and limelight from us true geek girls.
The working definition of geek seems to be someone who is obsessively interested in something (I would argue that you don’t get to be a geek if your obsession is art, for example, I’d like to define it to be an obsession with something technical). She also claims that “true geeks” don’t do something for airtime. From the article:
Girls who genuinely like their hobby or interest and document what they are doing to help others, not garner attention, are true geeks. The ones who think about how to get attention and then work on a project in order to maximize their klout, are exhibitionists.
I kind of like this but I kind of don’t too. I like this because, like you, I have run into many many people (men and women) who loudly claim technical knowledge that they don’t seem to actually have, which is annoying and exhibitionistic. And yes, it’s annoying to see people like that doing things like giving things like Ted talks on “big data” when you seriously doubt they know how to program a linear regression. But again, men and women.
At the same time, there’s no reason someone can’t be both a true geek and an exhibitionist, and it seems kind of funny for a Forbes magazine writer to be claiming the authentic rights to the former but not the latter.
If there’s one thing I’d like to avoid, it’s peer pressure that, as a girl geek, I have to have a certain personality. I like the fact that girl geeks are sometimes shy and sometimes outspoken, sometimes humble and sometimes arrogant, sometimes demure and sometimes slutty. It makes it way more interesting during technical chats.
What’s the asymmetry between men and women here? According to Tara Tiger Brown, women think they’ll get attention from men by acting like a geek but my experience is that men don’t think they’ll get attention from women by acting like a geek.
I think this is a mistake that man geeks are making. For me, and for essentially all my female friends, being really fucking good at some thing is extremely sexy. Man geeks are, therefore, very sexy, if they are in fact really fucking good at something and not just posing. Maybe they just need to realize that and own it a bit more.
Next time, instead of apologizing for doing something nerdy, I suggest you (a man geek I’m imagining talking to right now) figure out how to describe what skill you mastered and talk about it as an accomplishment.
No: I’m kind of tired today, sorry. I stayed up all night playing with my computer. Should we reschedule?
Yes: Last night I implemented dynamic logistic regression and managed to get it to converge on 30 terabytes of streaming data in under 3 hours. And it’s all open source, I just checked in into github. That was awesome! But now I need to sleep. Wanna take a nap with me?
Regulation is not a dirty word
Regulation has gotten a bad rap recently. It’s a combination of it being associated to finance, or big business, and it being complicated, and involving lobbyists and lawyers – it’s sleazy and collusive by proxy, and there are specific regulators that haven’t exactly been helping the cause. Most importantly, though, the concept of regulation has been slapped with a label of “bad for business = bad for the struggling economy”.
But I’d like to argue that regulation is not a dirty word – it’s vital to a functioning economy and culture.
And the truth is, we are lacking strong and enforced regulation on businesses in this country. Sometimes we don’t have the regulation, but sometimes we do and we don’t enforce it. I want to give three examples from yesterday’s news on what we’re doing wrong.
First, consider this article about data and privacy in the internet age. It starts out by scaring you to death about how all of your information, even your DNA code, is on the web, freely accessible to predatory data gatherers. All true. And then at the end it’s got this line:
“Regulation is coming,” she says. “You may not like it, you may close your eyes and hold your nose, but it is coming.”
What? How is regulation the problem here? The problem is that there’s no regulation, it’s the wild west, and a given individual has virtually no chance against enormous corporate data collectors with their very own quant teams figuring out your next move. This is a perfect moment for concerned citizens to get into the debate about who owns their data (my proposed answer: the individual owns their own data, not the corporation that has ferreted it out of an online persona) and how that data can be used (my proposed answer: never, without my explicit permission).
Next, look at this article where Bank of America knew about the massive losses on Merrill after agreeing to acquire them in September 2008 but its CEO Ken Lewis lied to shareholders to get them to vote for the acquisition in December 2008. The fact that Lewis lied about Merrill’s expected losses is not up for debate. From the article:
… Mr. Singer declined to comment on the filing. But the document submitted to the court said that Mr. Lewis’s “sworn admissions leave no genuine dispute that his statement at the December 5 shareholder meeting reiterating the bank’s prior accretion and dilution calculations was materially false when made.”
What I want to draw your attention to is the following line from the article (emphasis mine):
…the former chief executive did not disclose the losses because he had been advised by the bank’s law firm, Wachtell, Lipton, Rosen & Katz, and by other bank executives that it was not necessary.
Just to be clear, Lewis didn’t want to tell bad news to shareholders about the acquisition, because then he’d lost his shiny new investment bank, and he checked with his lawyers and they decided he didn’t need to admit the truth. That is a pure case of unenforced regulation. It is actually illegal to do this, but the lawyers were betting they could get away with it anyway.
Finally, consider this video describing what was happening inside MF Global in the days leading up to its collapse. Namely, the borrowing of customer money is hard to track because they did it all by hand. No, I’m sorry. Nobody does stuff with money without using a computer anymore. The only reason to do this by hand is to avoid leaving a paper trail because you know you’re about to do something illegal. I’m no accounting regulation expert but I’m sure this is illegal. Another case of unenforced regulation, or at worst, regulation that should exist.
Why do people think regulation is bad again? Does it really stifle business? Is it bad for the economy? In the above cases, consider this. The fact that we don’t have clear rules will cause plenty of people to avoid using all sorts of social media at all for fear of their data being manipulated. We have plenty of people avoiding investing in banks because they don’t trust the statements of bank CEO’s. And we have people avoiding becoming customers of futures exchanges for fear their money will be stolen. These facts are definitely bad for the economy.
The truth is, business thrives in environments of clear rules and good enforcement. That means strong, relevant, and enforced regulation.
Combining priors and downweighting in linear regression
This is a continuation of yesterday’s post about understand priors on linear regression as minimizing penalty functions.
Today I want to talk about how we can pair different kinds of priors with exponential downweighting. There are two different kinds of priors, namely persistent priors and kick-off priors (I think I’m making up these terms, so there may be other official terms for these things).
Persistent Priors
Sometimes you want a prior to exist throughout the life of the model. Most “small coefficients” or “smoothness” priors are like this. In such a situation, you will aggregate today’s data (say), which means creating an 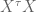

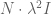
Kick-Off Priors
Other times you just want your linear regression to start off kind of “knowing” what the expected answer is. In this case you only add the prior terms to the first day’s
Example
This is confusing so I’m going to work out an example. Let’s say we have a model where we have a prior that the 1) 

Then on the first day, we find the 
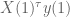
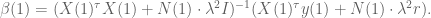
How should we choose 

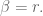

On the second day, we downweight data from the first day, and thus we also downweight the
However, we still want to remind the model to make the coefficients small – in other words a separate prior on the size of coefficients. So in fact, on the first day we will have two priors in effect, one as above and the other a simple prior on the covariance term, namely we add 
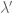

And just to be really precise, of we denote by 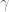
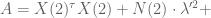
![\gamma[X(1)^\tau X(1) + N(1) \cdot \lambda^2 I + N(1) \cdot (\lambda')^2 I]](https://s0.wp.com/latex.php?latex=%5Cgamma%5BX%281%29%5E%5Ctau+X%281%29+%2B+N%281%29+%5Ccdot+%5Clambda%5E2+I+%2B+N%281%29+%5Ccdot+%28%5Clambda%27%29%5E2+I%5D&bg=ffffff&fg=555555&s=0&c=20201002)
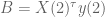
![+ \gamma[X(1)^\tau y(1) + N(1) \cdot \lambda^2 r]](https://s0.wp.com/latex.php?latex=%2B+%5Cgamma%5BX%281%29%5E%5Ctau+y%281%29+%2B+N%281%29+%5Ccdot+%5Clambda%5E2+r%5D&bg=ffffff&fg=555555&s=0&c=20201002)

An easy way to think about priors on linear regression
Every time you add a prior to your multivariate linear regression it’s equivalent to changing the function you’re trying to minimize. It sometimes makes it easier to understand what’s going on when you think about it this way, and it only requires a bit of vector calculus. Of course it’s not the most sophisticated way of thinking of priors, which also have various bayesian interpretations with respect to the assumed distribution of the signals etc., but it’s handy to have more than one way to look at things.
Plain old vanilla linear regression
Let’s first start with your standard linear regression, where you don’t have a prior. Then you’re trying to find a “best-fit” vector of coefficients 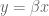
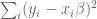
Here the various 
How do we find the minimum of that? First rewrite it in vector form, where we have a big column vector of all the different 



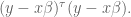
Now we appeal to an old calculus idea, namely that we can find the minimum of an upward-sloping function by locating where its derivative is zero.
Moreover, the derivative of 







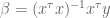
Adding a prior on the variance, or penalizing large coefficients
There are various ways people go about adding a diagonal prior – and various ways people explain why they’re doing it. For the sake of simplicity I’ll use one “tuning parameter” for this prior, called 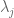
In other words, we can think of trying to minimize the following more complicated sum:
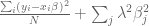
Here the 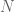

When we minimize this, we are simultaneously trying to find a “good fit” in the sense of a linear regression, and trying to find that good fit with small coefficients, since the sum on the right grows larger as the coefficients get bigger. The extent to which we care more about the first goal or the second is just a question about how large 

How do we minimize that guy? Same idea, where we rewrite it in vector form first:

Again, we set the derivative to zero and ignore the factor of 2 to get:
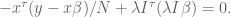
Since 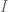
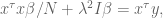
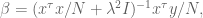
which of course can be rewritten as
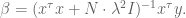
If you have a prior on the actual values of the coefficents of
Next I want to talk about a slightly fancier version of the same idea, namely when you have some idea of what you think the coefficients of 

We vectorize as

Again, we set the derivative to zero and ignore the factor of 2 to get:
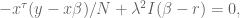
so we can conclude:

which can be rewritten as
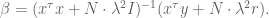
One language to rule them all
Right now there seems to be a choice one has to make in languages: either it’s a high level language that a data scientist knows or can learn quickly, or it’s fast and/or production ready.
So as the quant, I’ve gotten used to prototyping in matlab or python and then, if what I have been working on goes into production, it typically needs to be explained to a developer and rewritten in java or some such.
This is a pain in the ass for two reasons. First, it takes forever to explain it, and second if we later need to change it it’s very painful to work with a different developer than the one who did it originally, but people move around a lot.
Now that I’m working with huge amounts of data, it’s gotten even more complicated – there are three issues instead of two. Namely, there’s the map-reducing type part of the modeling, where you move around and aggregate data, which, if you’re a data scientist, means some kind of high-level language like pig.
Actually there are four issues – because the huge data is typically stored in the Amazon cloud or similar, there is also the technical issue of firing up nodes in a cluster and getting them to run the code and return the answers in a place where a data scientist can find it. This is kinda technical for your typical data scientist, at least one like me who specializes in model design, and has been solved only in specific situations i.e. for specific languages (Elastic-R and Mortar Data are two examples – please tell me if you know more).
Is there a big-data solution where all the modeling can be done in one open source language and then go into production as is?
People have been telling me Clojure/ Cascalog is the answer. But as far as I know there’s no super easy way to run this on the cloud. It would be great to see that happen.
Best case/ worst case: Medicine 50 years from now
Best Case
The scientific models and, when possible, the data have been made available to the wider scientific community for vetting. Incorrect or non-robust results are questioned and thrown out by that community, interesting and surprising new results are re-tested on larger data sets under iterative and different conditions to test for universality.
The result is that a person, with the help of their doctor and thorough exams and information-gathering session, and with their informed consent to use this data for their benefit, will have a better idea of what to watch out for in terms of health risks, how to prevent certain diseases that they may be vulnerable to, and how the tried-and-true medicines would affect them.
For example, in spite of the fact that Vioxx gives some people heart attacks, it also really helps other people with joint pain that aspirin or ibuprofen can’t touch. But which people? In the future we may know the answer to this through segmentation models, which group people by their attributes (which could come under the category of daily life conditions, such as how much someone exercises, or under the category of genetic profile).
For example, we recently learned that exercise is not always good for everyone. But instead of using that unlikely possibility as an excuse not to do any exercise, we could be able to look at a given profile and tell a person if they are in the clear and what kind of exercises would be most beneficial to their health.
It wouldn’t solve every problem; people would still die, after all. But it could help people live happier and healthier lives. It depends on the open exchange of ideas among scientists as well as strong regulation about who owns personal data and how it can be used.
Worst Case
The scientific community continues its practice of essentially private data collection and models. Scientific journals become more and more places where, backed by pharmaceutical companies and insurance companies, paid Ph.D.’s boast about their latest breakthrough with no cultural standard of evidence.
Indeed there is progress in segmentation models for disease and medicine, but the data, models, and results are owned exclusively by corporations, specifically insurance companies. This leads to a death spiral in modeling, where the very people who are vulnerable to disease and need medicine or treatment the most are priced out of the insurance system and no longer have access to anything resembling reasonable medical care, even for chronic diseases such as diabetes.
And you won’t need to give your consent for those insurance companies to use your data – they will have already bought all the data that they need to know about you from data collectors, which have been gleaning information about you from your online presence since birth. These companies will know everything about you; they control and sell your data for extra profit. To them, you represent a potential customer and a potential cost, a risk/return profile like any other investment.
Everybody lies (except me)
There’s an interesting article in the Wall Street Journal from yesterday about lying. In the article it explains that everybody lies a little bit and, yes, some people are serious liars, but the little lies are the more destructive because they are so pervasive.
It also explains that people only lie the amount they can get away with to themselves (besides maybe the out-and-out huge liars, but who knows what they’re thinking?).
When I read this article, of course, I thought to myself, I don’t lie even a little bit! And that kind of proved their point.
So here’s the thing. They also explained that people lie a bit more when they are in a situation where the consequences of lying are more abstract (think: finance) and that they lie more when they are around people they perceive as cheating (think: finance). So my conclusion is that finance is populated by liars, but that’s because of the culture that already exists there: most people just amble in as honest as anyone else and become that way.
Of course, every field has that problem, so it’s really not fair to single out finance. Except it is fair to single out any place where you can cheat easily, where there are ample opportunities to lie and profit off of lies.
One cool thing about the article is that they have a semi-solution, namely to remind people of moral rules right before the moment of possible lying. This can be reciting the ten commandments or swearing on a bible, which for some reason also works for atheists (but wouldn’t stop me from lying!), or could be as simple as making someone sign their name just before lying (or, even better, just before not lying) on their auto insurance forms.
Can we use this knowledge somehow in setting up the system of finance?
The result where people are more likely to lie when they know who the victim of their lie is may explain something about how, back when banks lent out money to people and held the money on their books, we had less fraud (but not zero fraud of course). The idea of personally knowing who the other person is in a transaction seems kind of important.
The idea that we make people swear they are telling the truth and sign their name seems easy enough, but obviously not infallible considering the robo-signing stuff. I wonder if we can use more tricks of the honesty trade and do things like make sure each person signing is also being videotaped or something, maybe that would also help.
Unfortunately another thing the article said was that having been taught ethics some time in the past actually doesn’t help. So it’s less to do with knowledge and more to do with habit (or opportunity), it seems. Food for thought as I’m planning the ethics course for data scientists.
All the good data nowadays is private – what’s the point of having a data science Ph.D.?
I go back and forth on whether there should be an undergrad major or Ph.D. program on data science. On the one hand, I am convinced it’s a burgeoning field which will need all the smart people it can get in the next few years or decades. On the other hand, I’m just not sure how capable academics really are at teaching the required skills. Let me explain.
It’s not that professors aren’t super smart and great at what they do. But the truth is, they typically don’t have access to the kind of data that’s now available to data scientists working in Google or Facebook or other tech companies (see this recent New York Times article on the subject). Even where I work, which is a medium sized start-up, I have access to data which many academics would kill for. This means I get to play with an incredibly rich resource, assuming I have built up the toolset to do so.
So while academics are creating (unrealistic) models of “influence” based on weird assumptions about how information gets propagated through networks, nerds at Facebook and Google and Foursquare just get to see it happen in real time. There’s an enormous advantage to having the data at your fingertips – you get good results fast. But then since it’s all proprietary you can’t publish it (a topic for another post).
Another thing: since academics typically don’t have this kind of big data, they also don’t have to create tools or methods for taming huge data. Sometimes I hear statisticians say that data science is just statistics, but they are typically missing the point of this “taming” aspect of data science. Namely, if we use state-of-the-art proven statistical methods on 15 terabytes of data and it takes 50 years to come up with an answer, then guess what, it doesn’t work.
At the same time, data science isn’t purely algorithmic time considerations either, and a computer scientist without a good statistical background would be equally wrong if they said that data science is just machine learning.
For that matter, data science also isn’t purely speculative research – there’s a bottomline business aspect to it, and the intention is (usually) to make profit. But there’s no way someone with a business degree that doesn’t know how to model can be a data scientist either.
End result: To teach data science for reals, you’d need to form a inter-disciplinary department across business, computer science, applied math, and statistics. Even so, I’m not sure how well strictly academic departments can really teach the nitty gritty of data science if they do collaborate across departments because they just don’t have good enough data (and by the way, this is a huge “if” – it seems politically impossible in some of the universities I’ve talked to).
On the other hand, I think it’s a good idea to try, because it is a great opportunity to teach at least some basic stuff and to instill a code of ethics in young data scientists.
The way things work now, the tech industry takes in former mathematicians, physicists, computer scientists, and statisticians and puts them on projects creating models of human behavior (I’ll include finance in that category) that are infinitely scalable and sometimes nearly infinitely scaled. Nobody is ever taught to stop and think about how their models are going to be used and how to think about the long-term effects of their models.
In spite of all the data problems and political obstacles, I feel that for the sake of this conversation, i.e. of personal responsibility of a modeler, we should go ahead and make a program, because it’s important and it isn’t gonna happen in your typical finance firm or tech startup.
An open source credit rating agency now exists!
I was very excited that Marc Joffe joined the Alternative Banking meeting on Sunday to discuss his new open source credit rating model for municipal and governmental defaults, called Public Sector Credit Framework, or PCSF. He’s gotten some great press, including this article entitled, “Are We Witnessing the Start of a Ratings Revolution?”.
Specifically, he has a model which, if you add the relevant data, can give ratings to city, state, or government bonds. I’ve been interested in this idea for a while now, although more at the level of publicly traded companies to start; see this post or this post for example.
His webpage is here, and you will note that his code is available on github, which is very cool, because it means it’s truly open source. From the webpage:
The framework allows an analyst to set up and run a budget simulation model in an Excel workbook. The analyst also specifies a default point in terms of a fiscal ratio. The framework calculates annual default probabilities as the the proportion of simulation trials that surpass the default point in a given year.
On May 2, we released the initial version of the software and two sample models – one for the US and one for the State of California – which are available on this page. For PSCF project to have an impact, we need developers to improve the software and analysts to build models. If you care about the implicatiions of growing public debt or you believe that transparent, open source technology can improve the standard of rating agency practice, please join us.
If you are a developer interested in helping him out, definitely reach out to him, his email is also available on the website.
He explained a few things on Sunday I want to share with you. They are all based on the kind of conflict of interest ratings agencies now have because they are paid by the people who they rate. I’ve discussed this conflict of interest many times, most recently in this post.
First, a story about California and state bonds. In the 2000’s, California was rated A, which is much lower than AAA, which is where lots of people want their bond ratings to be. So in order to achieve “AAA status,” California paid a bond insurer which was itself rated AAA. That is, through buying the insurance, the ratings status is transferred. In all, California paid $102 million for this benefit, which is a huge amount of money. What did this really buy though?
At some point their insurer, which was 139 times leveraged, was downgraded to below A level, and that meant that the California bonds were now essentially unbacked, so down to A level, and California had to pay higher interest payments because of this lower rating.
Considering the fact that no state has actually defaulted on their bonds in decades, but insurers have, Marc makes the following points. First, states are consistently under-rated and are paying too much for debt, either through these insurance schemes, where they pay questionable rates for questionable backing, or directly to the investors when their ratings are too low. Second, there is actually an incentive for ratings agencies to under-rate states, namely it gives them more business in rating the insurers etc. In other words they have an eco system of ratings rather than a state-by-state set of jobs.
How are taxpayers in California not aware of and incensed by the waste of $102 million? I would put this in the category of “too difficult to understand” for the average taxpayer, but that just makes me more annoyed. That money could have gone towards all sorts of public resources but instead went to insurance company executives.
Marc then went on to discuss his new model, which avoids this revenue model, and therefore conflict of interest, and takes advantage of the new format, XBRL, that is making it possible to automate ratings. It’s my personal belief that it will ultimately be the standardization of financial statements in XBRL format that will cause the revolution, more than anything we can do or say about something like the Volcker rule. Mostly this is because politicians and lobbyists don’t understand what data and models can do with raw standardized data. They aren’t nerdy enough to see it for what it is.
What about a revenue model for PCSF? Right now Marc is hoping for volunteer coders and advertising, but he did mention that there are two German initiatives that are trying to start non-profit, transparent ratings agencies essentially with large endowments. One of them is called INCRA, and you can get info here. The trick is to get $400 million and then be independent of the donors. They have a complicated governance structure in mind to insulate the ratings from the donors. But let’s face it, $400 million is a lot of money, and I don’t see Goldman Sachs in line to donate money. Indeed, they have a vested interest in having all good information kept internal anyway.
We also talked about the idea of having a government agency be in charge of ratings. But I don’t trust that model any more than a for-profit version, because we’ve seen how happy governments are at being downgraded, even when they totally deserve it. Any governmental ratings agencies couldn’t be trusted to impartially rate themselves, or systemically important companies for that matter.
I’m really excited about Marc’s model and I hope it really does start a revolution. I’ll be keeping an eye on things and writing more about it as events unfold.
Stop, Question, and Frisk policy getting stopped, questioned, and frisked
I’m happy to see that Federal District Court Judge Shira A. Scheindlin has granted class-action status to a lawsuit filed in January 2008 by the Center for Constitutional Rights which challenged the New York Police Department’s stop-and-frisk tactics.
The practice has been growing considerably in the last few years by way of a quota system for officers: an estimated 300,000 people have been stopped and frisked in New York City so far this year.
From the New York Times article on the class-action lawsuit:
In granting class-action status to the case, which was filed in January 2008 by the Center for Constitutional Rights on behalf of four plaintiffs, the judge wrote that she was giving voice to the voiceless.
“The vast majority of New Yorkers who are unlawfully stopped will never bring suit to vindicate their rights,” Judge Scheindlin wrote.
The judge said the evidence presented in the case showed that the department had a “policy of establishing performance standards and demanding increased levels of stops and frisks” that has led to an exponential growth in the number of stops.
But the judge used her strongest language in condemning the city’s position that a court-ordered injunction banning the stop-and-frisk practice would represent “judicial intrusion” and could not “guarantee that suspicionless stops would never occur or would only occur in a certain percentage of encounters.”
Judge Scheindlin said the city’s attitude was “cavalier,” and added that “suspicionless stops should never occur.”
I feel pretty awesome about this progress, since I was the data wrangler on the Data Without Borders datadive weekend and worked with the NYCLU to examine Stop, Question, and Frisk data. Some of that analysis, I’m guessing, has helped give ammunition to people trying to stop the policy – here is the wiki we made that weekend, and here’s another post I wrote a few weeks later.
For example, if you look at this editorial from the New York Times from a few days ago, you see a similar kind of analysis:
Over time, the program has grown to alarming proportions. There were fewer than 100,000 stops in 2002, but the police department carried out nearly 700,000 in 2011 and appears to be on track to exceed that number this year. About 85 percent of those stops involved blacks and Hispanics, who make up only about half the city’s population. Judge Scheindlin said the evidence showed that the unlawful stops resulted from “the department’s policy of establishing performance standards and demanding increased levels of stops and frisks.”
She noted that police officers had conducted tens of thousands of clearly unlawful stops in every precinct of the city, and that in nearly 36 percent of stops in 2009, officers had failed to list an acceptable “suspected crime.” The police are required to have a reasonable suspicion to make a stop. Only 5.37 percent of all stops between 2004 and 2009, the period of data considered by the court, resulted in arrests, an indication that a vast majority of people stopped did nothing wrong. Judge Scheindlin rebuked the city for a “deeply troubling apathy toward New Yorkers’ most fundamental constitutional rights.” The message of this devastating ruling is clear: The city must reform its abusive stop-and-frisk policy.
Woohoo! This is a great example of data analysis where it’s actually used to protect people instead of exploit them, which is pretty rare. It’s also a cool example of how open source data has been used to probe shady practices- but note that there was a separate lawsuit to force the NYPD to open source this Stop, Question, and Frisk data. They did not do it willingly, and they still don’t have the first few years of it publicly available.
Here’s another thing we could do with such data. My friend Catalina and I were talking yesterday about one of the consequences of the Stop, Question, and Frisk data as follows. From a Time Magazine article on Trayvon Martin:
in the U.S., African Americans and whites take drugs at about the same rate, but black youth are twice as likely to be arrested for it and more than five times more likely to be prosecuted as an adult for drug crimes. In New York City, 87% of residents arrested under the police department’s “stop and frisk” policy are black or Hispanic.
I’d love to see a study that breaks this down in a kind of dual way. If you’re a NYC teenager walking down the street in your own neighborhood with a joint in your pocket, what are your chances of getting put in jail a) if you’re white, b) if you’re black, c) if you’re hispanic, or d) if you’re asian?
I think those numbers would really bring home the kind of policy that we’re dealing with here. Let’s see some grad student theses coming out of this data set.
Ideas for two thesis problems in data science
Natural Language Processing on math overflow
You know about math overflow? It’s a site where grad students in math (or anyone) go and pose questions, and other people can answer them. There are lots of uninteresting, unanswered questions (like questions that are too easy and the person should be able to look up) and there are some really popular ones and some really dumb ones. Sometimes there are interesting ones.
Here’s a thesis idea, come up with a metric for “interestingness” and try to forecast the interestingness of a question from its language. Might as well also try to forecast its popularity while you’re at it. That way, if you make a good model, some of the more interesting questions will get higher in the queue and people will have a better time at the site.
Genealogy graphs in different fields
You know about the mathematics genealogy project? It shows everyone with a Ph.D. in math and considers them to be “descended” from their advisor in a family-tree like structure. For example, I’m here, and if I got up through my ancestors in 7 steps I get to Jacobi. Actually there are lots of ways to go up since a bunch of people have more than one advisor – I’m also 7 steps away from Poisson, 8 from Lagrange and Laplace, and 9 from Euler. This is probably not because I’m so cool but because there just weren’t many mathematicians back then- probably most people descended from Euler. And because we have this cool data set we can see if that’s true!
Here’s what I think someone should do, besides visualizing this graph in an awesome way (which by itself would be really cool, has anyone done that?). They should draw the graph for other fields as well and try to see if there are graph properties that characterize mathematics as distinct from other disciplines like Physics or Law or History.



