Archive
Who will Regulate the Superheroes on Wall Street?
This is a guest post by Elizabeth Friedrich, a member of Occupy the SEC.
Wall Street has grown to celebrate superheroes like Lloyd Blankfein and Jamie Dimon for their superior management skills and keen business sense. We have come to praise and applaud reckless risk-takers on the assumption that the markets always know best.
Insider Wall Street leaders like Jamie Dimon are viewed to possess special powers. In fact, many believe that Dimon, who led JP Morgan out of the financial crisis, is a banking prodigy who could do no wrong. But even Dimon is helpless in the face of reckless risk-taking behavior by his employees, as shown by the trader Bruno Iksil who lost $3 billion dollars and counting as part of JP Morgan’s CIO office. “Star traders” like Iksil structure their trades in such a complicated way that the average person could never understand them. We have no way of knowing whether the hedges that the CIO office put on actually “hedged” the original position. Such complexity, conveniently, can also serve as a powerful tool to refute public outcry.
The question here is this: Why create such risk in the first place? Or, more importantly: Why create the type of transactions that require a superman to oversee them?
Since the Volcker Rule is still being finalized, banking institutions will continue to take on these risks as long as they are allowed or exempted to do so. However, banks should face the same consequences as the rest of society. The “London Whale” trades created massive disruptions in an already fragile market and, ironically, they have caused unrest and disgust in the hedge fund community – the very community that loves unregulated market competition. Why don’t we hold banks to their own standards and stop giving them a pass when they fail?
Occupy the SEC will be marching today calling for the S.E.C. to investigate Jamie Dimon for violation of the disclosure requirements of Sarbanes-Oxley Act. We will also recommend that the S.E.C. make a criminal referral to the Department of Justice. Many people are frustrated with the slap-on-the-wrist treatment that Wall Streeters enjoy; random petty criminals are sentenced to hard jail time but the trader who loses billions of dollars is told not to do that again. The JP Morgan Chase debacle is symptomatic of a broken regulatory system.
Even if there are no criminal charges against Jamie Dimon, the American public would have been well-served to see Wall Street have its day in court. The S.E.C. has to uphold its foundational principles: 1) public companies offering securities to investors must tell the truth about their business, the securities, and the risks involved in investing; and 2) people who sell and trade securities must treat investors fairly and honestly, putting their investors’ interests first.
It is fairly simple: if S.E.C. officials find out that a company has done wrong they have the power to investigate, issue civil penalties, and refer the case to the Department of Justice for criminal prosecution. As many financial experts and white-collar crime lawyers have said, the S.E.C. has not fully utilized its authority, as demonstrated by the treatment of Dick Fuld and Jon Corzine.
The function of a financial institution is not merely to manage risk, but to act primarily as the steward of society’s assets and smart allocation of capital. We hope that the S.E.C will help re-examine the priorities of Too Big To Fail financial institutions. Finally, the current culture corrodes and disrupts sound business practices and stunts the rehabilitation of our current financial system. The S.E.C. is an imperfect vehicle (as evidenced by its lackluster approach to its duties leading up and during the financial crisis) but it’s the only vehicle we have. If they don’t do their job – who will?
Occupy the SEC is a group of concerned citizens, activists, and financial professionals with decades of collective experience working at many of the largest financial firms in the industry. Occupy the SEC filed a 325-page comment letter on the Volcker Rule NPR, which is available at http://occupythesec.org.
Regulation is not a dirty word
Regulation has gotten a bad rap recently. It’s a combination of it being associated to finance, or big business, and it being complicated, and involving lobbyists and lawyers – it’s sleazy and collusive by proxy, and there are specific regulators that haven’t exactly been helping the cause. Most importantly, though, the concept of regulation has been slapped with a label of “bad for business = bad for the struggling economy”.
But I’d like to argue that regulation is not a dirty word – it’s vital to a functioning economy and culture.
And the truth is, we are lacking strong and enforced regulation on businesses in this country. Sometimes we don’t have the regulation, but sometimes we do and we don’t enforce it. I want to give three examples from yesterday’s news on what we’re doing wrong.
First, consider this article about data and privacy in the internet age. It starts out by scaring you to death about how all of your information, even your DNA code, is on the web, freely accessible to predatory data gatherers. All true. And then at the end it’s got this line:
“Regulation is coming,” she says. “You may not like it, you may close your eyes and hold your nose, but it is coming.”
What? How is regulation the problem here? The problem is that there’s no regulation, it’s the wild west, and a given individual has virtually no chance against enormous corporate data collectors with their very own quant teams figuring out your next move. This is a perfect moment for concerned citizens to get into the debate about who owns their data (my proposed answer: the individual owns their own data, not the corporation that has ferreted it out of an online persona) and how that data can be used (my proposed answer: never, without my explicit permission).
Next, look at this article where Bank of America knew about the massive losses on Merrill after agreeing to acquire them in September 2008 but its CEO Ken Lewis lied to shareholders to get them to vote for the acquisition in December 2008. The fact that Lewis lied about Merrill’s expected losses is not up for debate. From the article:
… Mr. Singer declined to comment on the filing. But the document submitted to the court said that Mr. Lewis’s “sworn admissions leave no genuine dispute that his statement at the December 5 shareholder meeting reiterating the bank’s prior accretion and dilution calculations was materially false when made.”
What I want to draw your attention to is the following line from the article (emphasis mine):
…the former chief executive did not disclose the losses because he had been advised by the bank’s law firm, Wachtell, Lipton, Rosen & Katz, and by other bank executives that it was not necessary.
Just to be clear, Lewis didn’t want to tell bad news to shareholders about the acquisition, because then he’d lost his shiny new investment bank, and he checked with his lawyers and they decided he didn’t need to admit the truth. That is a pure case of unenforced regulation. It is actually illegal to do this, but the lawyers were betting they could get away with it anyway.
Finally, consider this video describing what was happening inside MF Global in the days leading up to its collapse. Namely, the borrowing of customer money is hard to track because they did it all by hand. No, I’m sorry. Nobody does stuff with money without using a computer anymore. The only reason to do this by hand is to avoid leaving a paper trail because you know you’re about to do something illegal. I’m no accounting regulation expert but I’m sure this is illegal. Another case of unenforced regulation, or at worst, regulation that should exist.
Why do people think regulation is bad again? Does it really stifle business? Is it bad for the economy? In the above cases, consider this. The fact that we don’t have clear rules will cause plenty of people to avoid using all sorts of social media at all for fear of their data being manipulated. We have plenty of people avoiding investing in banks because they don’t trust the statements of bank CEO’s. And we have people avoiding becoming customers of futures exchanges for fear their money will be stolen. These facts are definitely bad for the economy.
The truth is, business thrives in environments of clear rules and good enforcement. That means strong, relevant, and enforced regulation.
Combining priors and downweighting in linear regression
This is a continuation of yesterday’s post about understand priors on linear regression as minimizing penalty functions.
Today I want to talk about how we can pair different kinds of priors with exponential downweighting. There are two different kinds of priors, namely persistent priors and kick-off priors (I think I’m making up these terms, so there may be other official terms for these things).
Persistent Priors
Sometimes you want a prior to exist throughout the life of the model. Most “small coefficients” or “smoothness” priors are like this. In such a situation, you will aggregate today’s data (say), which means creating an 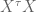

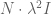
Kick-Off Priors
Other times you just want your linear regression to start off kind of “knowing” what the expected answer is. In this case you only add the prior terms to the first day’s
Example
This is confusing so I’m going to work out an example. Let’s say we have a model where we have a prior that the 1) 

Then on the first day, we find the 
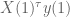
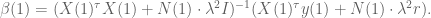
How should we choose 

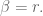

On the second day, we downweight data from the first day, and thus we also downweight the
However, we still want to remind the model to make the coefficients small – in other words a separate prior on the size of coefficients. So in fact, on the first day we will have two priors in effect, one as above and the other a simple prior on the covariance term, namely we add 
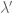

And just to be really precise, of we denote by 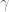
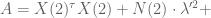
![\gamma[X(1)^\tau X(1) + N(1) \cdot \lambda^2 I + N(1) \cdot (\lambda')^2 I]](https://s0.wp.com/latex.php?latex=%5Cgamma%5BX%281%29%5E%5Ctau+X%281%29+%2B+N%281%29+%5Ccdot+%5Clambda%5E2+I+%2B+N%281%29+%5Ccdot+%28%5Clambda%27%29%5E2+I%5D&bg=ffffff&fg=555555&s=0&c=20201002)
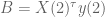
![+ \gamma[X(1)^\tau y(1) + N(1) \cdot \lambda^2 r]](https://s0.wp.com/latex.php?latex=%2B+%5Cgamma%5BX%281%29%5E%5Ctau+y%281%29+%2B+N%281%29+%5Ccdot+%5Clambda%5E2+r%5D&bg=ffffff&fg=555555&s=0&c=20201002)

An easy way to think about priors on linear regression
Every time you add a prior to your multivariate linear regression it’s equivalent to changing the function you’re trying to minimize. It sometimes makes it easier to understand what’s going on when you think about it this way, and it only requires a bit of vector calculus. Of course it’s not the most sophisticated way of thinking of priors, which also have various bayesian interpretations with respect to the assumed distribution of the signals etc., but it’s handy to have more than one way to look at things.
Plain old vanilla linear regression
Let’s first start with your standard linear regression, where you don’t have a prior. Then you’re trying to find a “best-fit” vector of coefficients 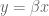
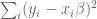
Here the various 
How do we find the minimum of that? First rewrite it in vector form, where we have a big column vector of all the different 



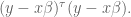
Now we appeal to an old calculus idea, namely that we can find the minimum of an upward-sloping function by locating where its derivative is zero.
Moreover, the derivative of 







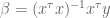
Adding a prior on the variance, or penalizing large coefficients
There are various ways people go about adding a diagonal prior – and various ways people explain why they’re doing it. For the sake of simplicity I’ll use one “tuning parameter” for this prior, called 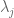
In other words, we can think of trying to minimize the following more complicated sum:
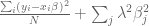
Here the 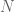

When we minimize this, we are simultaneously trying to find a “good fit” in the sense of a linear regression, and trying to find that good fit with small coefficients, since the sum on the right grows larger as the coefficients get bigger. The extent to which we care more about the first goal or the second is just a question about how large 

How do we minimize that guy? Same idea, where we rewrite it in vector form first:

Again, we set the derivative to zero and ignore the factor of 2 to get:
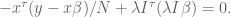
Since 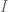
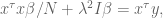
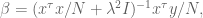
which of course can be rewritten as
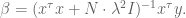
If you have a prior on the actual values of the coefficents of
Next I want to talk about a slightly fancier version of the same idea, namely when you have some idea of what you think the coefficients of 

We vectorize as

Again, we set the derivative to zero and ignore the factor of 2 to get:
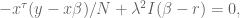
so we can conclude:

which can be rewritten as
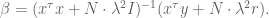
A low Fed rate: what does it mean for the 99%?
I’m no economist, so it always takes me quite a bit of puzzling to figure out macro-economic arguments. Recently I’ve been wondering about the Fed’s promise to keep rates low for extended periods of time. Specifically, I’ve been wondering this: whom does that benefit?
[As an aside, it consistently pisses me off that the people trading in the market, who claim to be all about “free markets” and against “interference” from regulators, also are the ones who whine for a Fed intervention or quantitative easing when bad economic data comes out. So which is it, do you want freedom or do you want a babysitter?]
Here’s the argument I’ve gleaned from the St. Louis Fed’s webpage. When the Fed lowers (short-term) rates, it makes it easier to borrow money, it makes it easier for banks to profit from the difference between long-term and short-term rates, and it potentially can cause inflation (and bubbles) since, now that everyone has borrowed more, there’s more demand, which raises prices. And inflation is good for debtors, because over time their debts are worth less.
One thing about the above argument stands out as false to me, at least for the majority of the 99%. Namely, many of them are already indebted up their eyeballs, so who is going to give them more money? And what would they buy with that money?
In other words, if the assumption is that everyone is getting easy loans, I haven’t seen evidence of this. Wouldn’t we be hearing about people refinancing their homes for awesome rates and thereby avoiding foreclosure? How many stories have you heard like that?
If not everyone is getting easy loans, and if in fact only the 1% and banks are getting those gorgeously low-interest loans, then it’s not clear this will be sufficient to spur demand and cause inflation. And inflation really would help the 99%, but only of course if wages kept up with it. Instead we have not seen high inflation and wages haven’t even been keeping up with what inflation we do see.
So let’s re-examine who is benefiting from low Fed rates. I’m gonna guess it’s mostly the banks, and a few private equity firms that are borrowing tons of money to buy up great swaths of foreclosed homes so they can turn around and profit on renting them out to the people who were foreclosed on.
I’m not necessarily advocating that we raise the Fed rates. But next time I hear someone say, “low Fed rates benefit debtors” I’m going to clarify, “low Fed rates benefit banks.”
One language to rule them all
Right now there seems to be a choice one has to make in languages: either it’s a high level language that a data scientist knows or can learn quickly, or it’s fast and/or production ready.
So as the quant, I’ve gotten used to prototyping in matlab or python and then, if what I have been working on goes into production, it typically needs to be explained to a developer and rewritten in java or some such.
This is a pain in the ass for two reasons. First, it takes forever to explain it, and second if we later need to change it it’s very painful to work with a different developer than the one who did it originally, but people move around a lot.
Now that I’m working with huge amounts of data, it’s gotten even more complicated – there are three issues instead of two. Namely, there’s the map-reducing type part of the modeling, where you move around and aggregate data, which, if you’re a data scientist, means some kind of high-level language like pig.
Actually there are four issues – because the huge data is typically stored in the Amazon cloud or similar, there is also the technical issue of firing up nodes in a cluster and getting them to run the code and return the answers in a place where a data scientist can find it. This is kinda technical for your typical data scientist, at least one like me who specializes in model design, and has been solved only in specific situations i.e. for specific languages (Elastic-R and Mortar Data are two examples – please tell me if you know more).
Is there a big-data solution where all the modeling can be done in one open source language and then go into production as is?
People have been telling me Clojure/ Cascalog is the answer. But as far as I know there’s no super easy way to run this on the cloud. It would be great to see that happen.
Best case/ worst case: Medicine 50 years from now
Best Case
The scientific models and, when possible, the data have been made available to the wider scientific community for vetting. Incorrect or non-robust results are questioned and thrown out by that community, interesting and surprising new results are re-tested on larger data sets under iterative and different conditions to test for universality.
The result is that a person, with the help of their doctor and thorough exams and information-gathering session, and with their informed consent to use this data for their benefit, will have a better idea of what to watch out for in terms of health risks, how to prevent certain diseases that they may be vulnerable to, and how the tried-and-true medicines would affect them.
For example, in spite of the fact that Vioxx gives some people heart attacks, it also really helps other people with joint pain that aspirin or ibuprofen can’t touch. But which people? In the future we may know the answer to this through segmentation models, which group people by their attributes (which could come under the category of daily life conditions, such as how much someone exercises, or under the category of genetic profile).
For example, we recently learned that exercise is not always good for everyone. But instead of using that unlikely possibility as an excuse not to do any exercise, we could be able to look at a given profile and tell a person if they are in the clear and what kind of exercises would be most beneficial to their health.
It wouldn’t solve every problem; people would still die, after all. But it could help people live happier and healthier lives. It depends on the open exchange of ideas among scientists as well as strong regulation about who owns personal data and how it can be used.
Worst Case
The scientific community continues its practice of essentially private data collection and models. Scientific journals become more and more places where, backed by pharmaceutical companies and insurance companies, paid Ph.D.’s boast about their latest breakthrough with no cultural standard of evidence.
Indeed there is progress in segmentation models for disease and medicine, but the data, models, and results are owned exclusively by corporations, specifically insurance companies. This leads to a death spiral in modeling, where the very people who are vulnerable to disease and need medicine or treatment the most are priced out of the insurance system and no longer have access to anything resembling reasonable medical care, even for chronic diseases such as diabetes.
And you won’t need to give your consent for those insurance companies to use your data – they will have already bought all the data that they need to know about you from data collectors, which have been gleaning information about you from your online presence since birth. These companies will know everything about you; they control and sell your data for extra profit. To them, you represent a potential customer and a potential cost, a risk/return profile like any other investment.
How to talk conservative
I finished reading “The Righteous Mind: Why Good People are Divided by Politics and Religion” and I have to say, I got a lot out of it. Even if they are just approximations to the truth, it’s interesting to consider his various positions. Near the end he talks about religion and “groupishness,” and how people are too focused on the technical aspects of religious beliefs rather than what a religion accomplishes in a community, which he claims is its main benefit.
But what I found more interesting is the beginning of the book when he discusses the different moral make-up of liberals and conservatives (and libertarians) in this country. Namely, he claims that liberals care primarily about the following three things:
- caring for the vulnerable or victimized,
- the concept of oppression from bullies – or conversely the concept of liberty, and
- the concept of proportional fairness (you deserve a part of the pie since you helped make it, but you wouldn’t deserve any if you hadn’t helped).
By contrast, conservatives care about a larger set of six things, the above three as well as:
- the concept of sanctity,
- the concept of authority – when it’s just and those in power take proper responsibility, and
- the concept of loyalty.
I took away three points. First, liberals are bad at guessing what conservatives think, because they are somewhat blind to these last three things, and when they see conservatives go on about them, they assume conservatives don’t care about the first three, which is wrong, although it’s true that they care about them differently (especially proportional fairness: whereas liberals emphasize leaving nobody out, conservatives emphasize not letting people get extra, especially if it comes from their stuff). Second, if I, as a liberal, want to communicate with a conservative, I have to talk about all six of these with some level of understanding. Finally, statistics and other rational arguments only work if the person you’re talking to already agrees with you or if they are exceptionally open-minded – in any case you have to appeal to their morals before going into stats.
With that in mind, here are two rants against the Stop, Question, and Frisk policy, one written for a liberal audience, one for a conservative audience.
Liberal version First, the stop, question, and frisk policy targets minority men almost exclusively. Second, almost 90% of the events end up without an arrest, which means it’s unwarranted intrusion and bullying- typically the reason given for the stop is a “furtive movement”, which could be absolutely anything. Finally, there is a quota system in the police department which forces each officer to perform these unwarranted searches whether or not there is cause, which inevitably leads them to target the “least likely to complain,” namely young, poor minorities. We need to stop the police abusing their privileges in this way immediately.
Conservative version What is the difference between a police force and a gang of men who walk around with guns? The answer, in the best of worlds, is authority, intentionality, and the rule of law. Police have an important job to do, which is to protect us, and to keep the streets safe. And when they do a good job, we admire them for that and count on them for their protection. But imagine if, instead of seeing your neighborhood cop as someone you can count on, he instead consistently stops you on your way home from school or work and asks you suspicious questions, and sometimes even takes your keys from your pocket, and, while you’re locked in the police car, enters your apartment and terrorizes your family. This makes you feel like you are the bad guy, even though you did nothing wrong. After a while, it would make you and your neighborhood less trusting of the authority of the cops, which would lead to reckless behavior and lawlessness, because your rights are no longer being protected. We need to stop the policy of Stop, Question, and Frisk in order to make sure the police never become just a bunch of bullies with guns.
When “extend and pretend” becomes “delay and pray”
When banks have non-performing loans, they sometimes don’t want to admit it. So instead of calling it a loss, because the debtor can’t pay, they simply rewrite the contract so that it has been extended. This way the debtor is not technically behind in payments and the creditor can pretend that the corresponding debt on their books is worth something. It’s called extend and pretend, and it’s not new.
And actually, this ploy sometimes works. After all, sometimes the debtor just needs a bit more time – they could be temporarily unable to pay for whatever reason. Indeed it would be a convenient option for people who are just in need of a few more months to get back on their feet and not lose their house (typically this offer is not extended to individuals, since their loans are too small to fret over).
Make no mistake: there is a real incentive for the banks to do this. Currently the worst example of this method is in Spain, where the banks are finding it politically impossible to admit their losses. The government doesn’t want to hear it, because they will need to bail them out, and their borrowing costs are already precariously high. The Eurozone leaders don’t want to think Spain is as bad off as Greece, because they can’t handle that kind of problem. The investors don’t want to hear it because their investments will be worth less once the news comes out (an example of asymmetric information if there ever was one – shouldn’t investors already know how much extending and pretending is really going on?). And of course the lenders themselves don’t want to admit they are working at an insolvent institution, especially when they probably each know other institutions that are even more insolvent.
What are the chances that this method of delay and pray will work for Spain? With an enormous housing bubble and 24% unemployment, not good. Most of the bad loans that have been extended after non-payment are housing market related. Half of the lenders are zombie, which means insolvent but still technically open for business. Essentially the numbers are just too high and now everybody knows it (see this Bloomberg article for the low-down on Spain).
So what should Spain be doing?
I like to point to the example of Iceland, which admitted its debts early on (although it has to be admitted they didn’t have much of a choice), defaulted on a bunch of international debt, bailed out their citizens from onerous home debt, and is recovering nicely (see this Bloomberg article for more on Iceland).
Oh, and let me add that they (Iceland) are indicting and jailing the bankers who got them into the mess, to the tune of 200 indictments. Considering the U.S. has a population 981 times as large, that would be equivalent to us indicting 196,341 bankers. In fact we’ve indicted no top bank executive, although everyone will be relieved to know the SEC “sanctioned” 39 people for the housing market debacle. Phew!
Unfortunately, it would be tough for Spain to repeat that act- it depended on the fact that Iceland has control over its economic choices, but Spain is part of the Eurozone and as such is embedded in a huge network of agreements and debts and currency with the other Eurozone nations.
In some sense, Spain is being forced into the zombie bank situation by a lack of options. Unless I’m missing something – would love to be wrong!
Biking in New York City
I’m a huge fan of biking around the city. I like to commute to work, from the Columbia University neighborhood up at 116th and Broadway to just below Houston on Varick. Since both my house and my work are within blocks from the west side of Manhattan, I can bike the whole way along the west side bike path (see, for example, this map).
It’s a gorgeous ride along the Hudson River, and there’s not one day I ride it without appreciating not being stuck in the traffic next to me on the West Side Highway. Okay, actually, last Monday was one, when I got caught in a huge thunderstorm. Luckily I had dry clothes, but for some reason no dry socks (note to self: bare feet with wet leather boots is gross). I’m also happy not to be on the subway (1 line) on Monday mornings when people are extra grumpy about going to work.
I don’t bike when it’s (already) raining, or when it’s icy, and it’s always a bummer when daylight savings starts, because it means it’s already dark by the time I leave work. But otherwise I am on the lookout for great biking days and opportunities.
A few weeks ago, on the first really gorgeous day of spring, I biked from one Occupy meeting to another, the first one up at Columbia and the second in Union Square (to see my friend Suresh Naidu speak about Radical Economics 101). I biked through Central Park, which was bursting with spring joy, and then all the way to Union Square down Broadway, which now has a beautiful bike lane. The only annoying part was Times Square, which is so full of tourists you have to walk your bike. So that’s a good sign, when the pedestrians are more dangerous than the cars.
And I also bike on other streets, although after being doored a few times and breaking someone’s windshield with my head (a long time ago in Berkeley but still) I am hugely defensive- I pretty much assume every moving car is trying to hit me and every parked car’s door is about to open. Even so, there are quite a few quiet streets I can feel safe biking down, in the middle, and although it’s not very fast, it’s certainly faster than walking. A great way to explore the city.
And I’m not alone, here’s a great essay by David Byrne in a recent New York Times Opinion column entitled “This is How We Ride”. It’s a beautifully written piece, and he describes the joys of biking in the city perfectly. He mentions that there’s a new bike-share initiative starting this summer, where there will be 10,000 bikes for rent at 420 bike stations in Manhattan, Long Island City, and Brooklyn.
That’s awesome, even if I will have to share the bike lane with even more enthusiasts. The rides are limited to 30 minutes, so not a full commute for me, but it means that if I’m already downtown and want to get to the East Side (which is always hard – I like to say that going to the East Side is like going to L.A. in terms of logistical difficulties) I will be able to hop on a bike and cross town. Cool!
Everybody lies (except me)
There’s an interesting article in the Wall Street Journal from yesterday about lying. In the article it explains that everybody lies a little bit and, yes, some people are serious liars, but the little lies are the more destructive because they are so pervasive.
It also explains that people only lie the amount they can get away with to themselves (besides maybe the out-and-out huge liars, but who knows what they’re thinking?).
When I read this article, of course, I thought to myself, I don’t lie even a little bit! And that kind of proved their point.
So here’s the thing. They also explained that people lie a bit more when they are in a situation where the consequences of lying are more abstract (think: finance) and that they lie more when they are around people they perceive as cheating (think: finance). So my conclusion is that finance is populated by liars, but that’s because of the culture that already exists there: most people just amble in as honest as anyone else and become that way.
Of course, every field has that problem, so it’s really not fair to single out finance. Except it is fair to single out any place where you can cheat easily, where there are ample opportunities to lie and profit off of lies.
One cool thing about the article is that they have a semi-solution, namely to remind people of moral rules right before the moment of possible lying. This can be reciting the ten commandments or swearing on a bible, which for some reason also works for atheists (but wouldn’t stop me from lying!), or could be as simple as making someone sign their name just before lying (or, even better, just before not lying) on their auto insurance forms.
Can we use this knowledge somehow in setting up the system of finance?
The result where people are more likely to lie when they know who the victim of their lie is may explain something about how, back when banks lent out money to people and held the money on their books, we had less fraud (but not zero fraud of course). The idea of personally knowing who the other person is in a transaction seems kind of important.
The idea that we make people swear they are telling the truth and sign their name seems easy enough, but obviously not infallible considering the robo-signing stuff. I wonder if we can use more tricks of the honesty trade and do things like make sure each person signing is also being videotaped or something, maybe that would also help.
Unfortunately another thing the article said was that having been taught ethics some time in the past actually doesn’t help. So it’s less to do with knowledge and more to do with habit (or opportunity), it seems. Food for thought as I’m planning the ethics course for data scientists.
All the good data nowadays is private – what’s the point of having a data science Ph.D.?
I go back and forth on whether there should be an undergrad major or Ph.D. program on data science. On the one hand, I am convinced it’s a burgeoning field which will need all the smart people it can get in the next few years or decades. On the other hand, I’m just not sure how capable academics really are at teaching the required skills. Let me explain.
It’s not that professors aren’t super smart and great at what they do. But the truth is, they typically don’t have access to the kind of data that’s now available to data scientists working in Google or Facebook or other tech companies (see this recent New York Times article on the subject). Even where I work, which is a medium sized start-up, I have access to data which many academics would kill for. This means I get to play with an incredibly rich resource, assuming I have built up the toolset to do so.
So while academics are creating (unrealistic) models of “influence” based on weird assumptions about how information gets propagated through networks, nerds at Facebook and Google and Foursquare just get to see it happen in real time. There’s an enormous advantage to having the data at your fingertips – you get good results fast. But then since it’s all proprietary you can’t publish it (a topic for another post).
Another thing: since academics typically don’t have this kind of big data, they also don’t have to create tools or methods for taming huge data. Sometimes I hear statisticians say that data science is just statistics, but they are typically missing the point of this “taming” aspect of data science. Namely, if we use state-of-the-art proven statistical methods on 15 terabytes of data and it takes 50 years to come up with an answer, then guess what, it doesn’t work.
At the same time, data science isn’t purely algorithmic time considerations either, and a computer scientist without a good statistical background would be equally wrong if they said that data science is just machine learning.
For that matter, data science also isn’t purely speculative research – there’s a bottomline business aspect to it, and the intention is (usually) to make profit. But there’s no way someone with a business degree that doesn’t know how to model can be a data scientist either.
End result: To teach data science for reals, you’d need to form a inter-disciplinary department across business, computer science, applied math, and statistics. Even so, I’m not sure how well strictly academic departments can really teach the nitty gritty of data science if they do collaborate across departments because they just don’t have good enough data (and by the way, this is a huge “if” – it seems politically impossible in some of the universities I’ve talked to).
On the other hand, I think it’s a good idea to try, because it is a great opportunity to teach at least some basic stuff and to instill a code of ethics in young data scientists.
The way things work now, the tech industry takes in former mathematicians, physicists, computer scientists, and statisticians and puts them on projects creating models of human behavior (I’ll include finance in that category) that are infinitely scalable and sometimes nearly infinitely scaled. Nobody is ever taught to stop and think about how their models are going to be used and how to think about the long-term effects of their models.
In spite of all the data problems and political obstacles, I feel that for the sake of this conversation, i.e. of personal responsibility of a modeler, we should go ahead and make a program, because it’s important and it isn’t gonna happen in your typical finance firm or tech startup.
Favorite bands
My 9-year-old’s favorite bands (and favorite songs):
- Queen (Bohemian Rhapsody)
- AC/DC (Back in Black)
- ABBA (Fernando)
- Green Day (American Idiot)
- Weird Al Yankovic (Canadian Idiot)
The engaged skeptic
Last night I read this article by Jane Brody in the New York Times, which was about staying optimistic and the various benefits of a can-do attitude, including health benefits.
At one point in her essay she defines optimism like this:
She wrote, “People can learn to be more optimistic by acting as if they were more optimistic,” which means “being more engaged with and persistent in the pursuit of goals.”
If you behave more optimistically, you will be likely to keep trying instead of giving up after an initial failure. “You might succeed more than you expected,” she wrote. Even if the additional effort is not successful, it can serve as a positive learning experience, suggesting a different way to approach a similar problem the next time.
But in another part of her essay it has been transformed:
Avoid negative self-talk. Instead of focusing on prospects of failure, dwell on the positive aspects of a situation.
In college, I would approach every exam, even those I had barely studied for, with the thought that I was going to do well. Time after time, this turned out to be a self-fulfilling prophecy.
So which is it? Does being optimistic mean I’ll be more engaged with an persistent in the pursuit of goals, or does it mean I’ll barely study for an exam and then talk myself into thinking I’ll do well? Because those two ways sound pretty different, if not downright opposite. And who wants to be around a lazy optimist?
I don’t want to quibble, but I think there’s a common and important conflation of the two ideas of engagement and naivety, and I’d like to separate them.
It’s possible, and very possibly more interesting, to have a can-do attitude but not be optimistic, or in other words to be an engaged skeptic.
Just because I work hard and devote myself to something doesn’t mean I’ve fooled myself into thinking it will be a piece of cake. But it does mean I don’t think it’s impossible, and it will only work if I try to make it work. It’s not likely to work but it’s worth trying. Many very hard and very worthwhile things are like that.
Finally, when Brody says “Focus on situations that you can control, and forget those you can’t”, I’d argue that’s often code for letting yourself off too easy.
I claim that, as an engaged skeptic, you shouldn’t really forget anything, because you should figure out how you can maybe affect it after all, or in some small way, or the system it lives in, even if it’s in the future, and even if the chances are it won’t work.
An open source credit rating agency now exists!
I was very excited that Marc Joffe joined the Alternative Banking meeting on Sunday to discuss his new open source credit rating model for municipal and governmental defaults, called Public Sector Credit Framework, or PCSF. He’s gotten some great press, including this article entitled, “Are We Witnessing the Start of a Ratings Revolution?”.
Specifically, he has a model which, if you add the relevant data, can give ratings to city, state, or government bonds. I’ve been interested in this idea for a while now, although more at the level of publicly traded companies to start; see this post or this post for example.
His webpage is here, and you will note that his code is available on github, which is very cool, because it means it’s truly open source. From the webpage:
The framework allows an analyst to set up and run a budget simulation model in an Excel workbook. The analyst also specifies a default point in terms of a fiscal ratio. The framework calculates annual default probabilities as the the proportion of simulation trials that surpass the default point in a given year.
On May 2, we released the initial version of the software and two sample models – one for the US and one for the State of California – which are available on this page. For PSCF project to have an impact, we need developers to improve the software and analysts to build models. If you care about the implicatiions of growing public debt or you believe that transparent, open source technology can improve the standard of rating agency practice, please join us.
If you are a developer interested in helping him out, definitely reach out to him, his email is also available on the website.
He explained a few things on Sunday I want to share with you. They are all based on the kind of conflict of interest ratings agencies now have because they are paid by the people who they rate. I’ve discussed this conflict of interest many times, most recently in this post.
First, a story about California and state bonds. In the 2000’s, California was rated A, which is much lower than AAA, which is where lots of people want their bond ratings to be. So in order to achieve “AAA status,” California paid a bond insurer which was itself rated AAA. That is, through buying the insurance, the ratings status is transferred. In all, California paid $102 million for this benefit, which is a huge amount of money. What did this really buy though?
At some point their insurer, which was 139 times leveraged, was downgraded to below A level, and that meant that the California bonds were now essentially unbacked, so down to A level, and California had to pay higher interest payments because of this lower rating.
Considering the fact that no state has actually defaulted on their bonds in decades, but insurers have, Marc makes the following points. First, states are consistently under-rated and are paying too much for debt, either through these insurance schemes, where they pay questionable rates for questionable backing, or directly to the investors when their ratings are too low. Second, there is actually an incentive for ratings agencies to under-rate states, namely it gives them more business in rating the insurers etc. In other words they have an eco system of ratings rather than a state-by-state set of jobs.
How are taxpayers in California not aware of and incensed by the waste of $102 million? I would put this in the category of “too difficult to understand” for the average taxpayer, but that just makes me more annoyed. That money could have gone towards all sorts of public resources but instead went to insurance company executives.
Marc then went on to discuss his new model, which avoids this revenue model, and therefore conflict of interest, and takes advantage of the new format, XBRL, that is making it possible to automate ratings. It’s my personal belief that it will ultimately be the standardization of financial statements in XBRL format that will cause the revolution, more than anything we can do or say about something like the Volcker rule. Mostly this is because politicians and lobbyists don’t understand what data and models can do with raw standardized data. They aren’t nerdy enough to see it for what it is.
What about a revenue model for PCSF? Right now Marc is hoping for volunteer coders and advertising, but he did mention that there are two German initiatives that are trying to start non-profit, transparent ratings agencies essentially with large endowments. One of them is called INCRA, and you can get info here. The trick is to get $400 million and then be independent of the donors. They have a complicated governance structure in mind to insulate the ratings from the donors. But let’s face it, $400 million is a lot of money, and I don’t see Goldman Sachs in line to donate money. Indeed, they have a vested interest in having all good information kept internal anyway.
We also talked about the idea of having a government agency be in charge of ratings. But I don’t trust that model any more than a for-profit version, because we’ve seen how happy governments are at being downgraded, even when they totally deserve it. Any governmental ratings agencies couldn’t be trusted to impartially rate themselves, or systemically important companies for that matter.
I’m really excited about Marc’s model and I hope it really does start a revolution. I’ll be keeping an eye on things and writing more about it as events unfold.
Buying organic doesn’t make you better than me
There was a recent study published here which described how people who viewed organic foods with annoyingly self-righteous names actually behave more selfishly than people who viewed “comfort food” or other, bland categories of food. The abstract:
Recent research has revealed that specific tastes can influence moral processing, with sweet tastes inducing prosocial behavior and disgusting tastes harshening moral judgments. Do similar effects apply to different food types (comfort foods, organic foods, etc.)? Although organic foods are often marketed with moral terms (e.g., Honest Tea, Purity Life, and Smart Balance), no research to date has investigated the extent to which exposure to organic foods influences moral judgments or behavior. After viewing a few organic foods, comfort foods, or control foods, participants who were exposed to organic foods volunteered significantly less time to help a needy stranger, and they judged moral transgressions significantly harsher than those who viewed nonorganic foods. These results suggest that exposure to organic foods may lead people to affirm their moral identities, which attenuates their desire to be altruistic.
I read the original study (and also a hilarious post riffing on it from jezebel.com), and found it interesting that the experimenters at least claimed to be unsure of the outcome of the study in advance (although they did cite another study in which people were more likely to cheat and steal after purchasing “green” products).
Specifically, they thought one of two things could happen: that the sense of elevation cause by staring at the organic labels could make them feel like part of a larger community and therefore more willing to volunteer, or else the “moral piggybacking” on a perceived good deed (i.e. organic food is good for the environment) would make them feel like they’d already done enough, and be less likely to be nice. It turns out the latter.
[As an aside, another study cited was one in which people assumed there were fewer calories in chocolate which was described as “fair trade”, which explains something to me about why those kinds of labels are so popular and also so ripe for fraud.]
The results of this study resonates with me: ever since Whole Foods opened I’ve had the impression that the people shopping there thought they’d done enough for the world simply by paying too much for produce and not being able to buy Cheerios (a pet peeve of mine). Haven’t you noticed how rude Whole Foods shoppers are? I’d rather be in a Stop and Shop check-out line any day.
In other words, I’m going through a major case of confirmation bias here. I’ve been a huge skeptic about the organic food movement since it began when I was in college at Berkeley. I’ve challenged a whole bunch of my friends on this (yes I’m an asshole) and I’ve noticed there are essentially two camps. One camp defends organic as good for the environment, the other camp defends organic as more nutritious.
For the environmentalists, my argument is that local produce is better than California organic produce, given that it’s been shipped across the country. It seems silly to me to be able to purchase organic blueberries imported from somewhere instead of locally grown blueberries. In fact I’m not sure where there’s good evidence that organic, locally grown produce is better for the environment than just locally grown produce.
The other camp defends organic as more nutritious, but that really drives me completely nuts, because if you flip that around the message is that we can let the poor people eat the toxic vegetables while we rich people eat the healthy stuff. It’s crazy! If there really is toxicity in our standard produce, then this is a huge problem for the country and we need to address it directly, rather than making a certain class of very expensive food.
Stop, Question, and Frisk policy getting stopped, questioned, and frisked
I’m happy to see that Federal District Court Judge Shira A. Scheindlin has granted class-action status to a lawsuit filed in January 2008 by the Center for Constitutional Rights which challenged the New York Police Department’s stop-and-frisk tactics.
The practice has been growing considerably in the last few years by way of a quota system for officers: an estimated 300,000 people have been stopped and frisked in New York City so far this year.
From the New York Times article on the class-action lawsuit:
In granting class-action status to the case, which was filed in January 2008 by the Center for Constitutional Rights on behalf of four plaintiffs, the judge wrote that she was giving voice to the voiceless.
“The vast majority of New Yorkers who are unlawfully stopped will never bring suit to vindicate their rights,” Judge Scheindlin wrote.
The judge said the evidence presented in the case showed that the department had a “policy of establishing performance standards and demanding increased levels of stops and frisks” that has led to an exponential growth in the number of stops.
But the judge used her strongest language in condemning the city’s position that a court-ordered injunction banning the stop-and-frisk practice would represent “judicial intrusion” and could not “guarantee that suspicionless stops would never occur or would only occur in a certain percentage of encounters.”
Judge Scheindlin said the city’s attitude was “cavalier,” and added that “suspicionless stops should never occur.”
I feel pretty awesome about this progress, since I was the data wrangler on the Data Without Borders datadive weekend and worked with the NYCLU to examine Stop, Question, and Frisk data. Some of that analysis, I’m guessing, has helped give ammunition to people trying to stop the policy – here is the wiki we made that weekend, and here’s another post I wrote a few weeks later.
For example, if you look at this editorial from the New York Times from a few days ago, you see a similar kind of analysis:
Over time, the program has grown to alarming proportions. There were fewer than 100,000 stops in 2002, but the police department carried out nearly 700,000 in 2011 and appears to be on track to exceed that number this year. About 85 percent of those stops involved blacks and Hispanics, who make up only about half the city’s population. Judge Scheindlin said the evidence showed that the unlawful stops resulted from “the department’s policy of establishing performance standards and demanding increased levels of stops and frisks.”
She noted that police officers had conducted tens of thousands of clearly unlawful stops in every precinct of the city, and that in nearly 36 percent of stops in 2009, officers had failed to list an acceptable “suspected crime.” The police are required to have a reasonable suspicion to make a stop. Only 5.37 percent of all stops between 2004 and 2009, the period of data considered by the court, resulted in arrests, an indication that a vast majority of people stopped did nothing wrong. Judge Scheindlin rebuked the city for a “deeply troubling apathy toward New Yorkers’ most fundamental constitutional rights.” The message of this devastating ruling is clear: The city must reform its abusive stop-and-frisk policy.
Woohoo! This is a great example of data analysis where it’s actually used to protect people instead of exploit them, which is pretty rare. It’s also a cool example of how open source data has been used to probe shady practices- but note that there was a separate lawsuit to force the NYPD to open source this Stop, Question, and Frisk data. They did not do it willingly, and they still don’t have the first few years of it publicly available.
Here’s another thing we could do with such data. My friend Catalina and I were talking yesterday about one of the consequences of the Stop, Question, and Frisk data as follows. From a Time Magazine article on Trayvon Martin:
in the U.S., African Americans and whites take drugs at about the same rate, but black youth are twice as likely to be arrested for it and more than five times more likely to be prosecuted as an adult for drug crimes. In New York City, 87% of residents arrested under the police department’s “stop and frisk” policy are black or Hispanic.
I’d love to see a study that breaks this down in a kind of dual way. If you’re a NYC teenager walking down the street in your own neighborhood with a joint in your pocket, what are your chances of getting put in jail a) if you’re white, b) if you’re black, c) if you’re hispanic, or d) if you’re asian?
I think those numbers would really bring home the kind of policy that we’re dealing with here. Let’s see some grad student theses coming out of this data set.
WTF with girdles?!?
The post today has absolutely nothing to do with math, finance, data science, or Occupy Wall Street. I’ll get back to that stuff after venting.
Can I just say, as a bounteous 3-time mother, that I absolutely positively don’t understand the new-found popularity of girdles?
I was going to not mention it because it seems like the girdle-pushing crowd may get more attention than they deserve simply by being thought about, but it seems like it’s hit a certain crest of popularity that forces my hand.
So here’s what happened. For whatever reason I received a SPANX catalog in the mail, and just out of sheer disbelief that there could be a whole catalog of such nonsense, I took a look inside.
And do you know what I found out? I found out that many of the things in the catalog don’t even come in my size! That’s because they go down to like size 4. No, I’m not kidding. Plus, they also have girdles for men, no shit.
Then I came across this NYT article about corsets. From the article:
At Aishti, his store in Jackson Heights, Queens, Moussa Balaghi has begun carrying girdles in size “extra small,” because, to his shock, so many teenagers and even younger girls were coming in to request them. “Only chubby fat girls used to use this; now, everybody is,” he said, shaking his head. “If she has the smallest little thing at her waist, she wants to use this.”
WTF?!
May I ask, what is a young skinny woman doing thinking about crap like this? What is the point of them? I am honestly confused. Is the point to have something strapped around you, keeping you from breathing correctly, keeping you from biking around town or bending over, and generally confirming that you’re imperfect?
I actually object to all girdles, because I like to see people love and accept their bodies, which seems kind of hard when you’re wearing an ace bandage all over your body.
Something is going on here and it smells bad.
Google’s promotion policy sucks for women
I’m going to start this post with an excerpt from a comment of reader JoanDelilah from a couple of weeks ago, commenting on my post The meritocracy myth:
And at the end of the day, this also assumes that it is right and proper for a structure to be in place which requires you to *grab* tough/interesting work to prove yourself, as opposed to it being given to you. There is competition inherent in the foundational world-view behind that statement. Why so much competition? We are supposed to be on the same team and competing with other businesses, right? What about the woman who is happy to crush any assignment she is given but simply doesn’t want to have to compete for the assignments that will “prove” her abilities? Why must she step so far out of her comfort zone just in order for the company that pays her to make use of the talents they are paying her to use?
This really nails down what I see all the time with respect to women getting promoted or even just getting recognized for their achievements.
To paraphrase it, women tend not to compete for recognition as much as men, for whatever reason. Maybe they’ve been socialized not to, maybe it is a simple question of testosterone. I will go into why I think this happens below. But for now let me just say I get super pissed when a system has been set up to diminish the success of people simply because of this personality issue.
Google is one such system. At Google, one must self-promote. I believe the rule is that, after two quarters or so of getting good reviews, you are eligible to self-promote, but you don’t have to.
And guess what? That policy sucks for women. Women don’t do it as often. I’ll bet this is statistically significant, even though I don’t have the numbers. Hey Google, do the math on this policy! And then change it!
Here’s the first part of my theory of why this happens. Women are not as secure in their accomplishments. By the way, note I am not saying women are insecure and men are secure. I think it’s more like men are over-secure and women are realistic, kind of like those studies that shows that depressed people are realists and non-depressed people are optimists. I definitely have seen men who actually think they (individually) accomplished something which clearly took a team effort. Women are less likely to “forget” the help they received in making something happen. See this amazing blog rant on the subject from a professor at NYU.
Here’s the second part. Women tend to choose mentors (i.e. bosses or advisors) that are brilliant, thoughtful, and approachable. Typically this also means that those mentors are not the kind of bullying personalities that are best suited to promote their team. Even when one doesn’t have a choice in who your boss is, I claim this approach to pairing still happens in a business when that business decides who should be the boss of a woman.
Example in pure math: Yau at Harvard is famously dynasty-building with his students, but he’s probably not someone who has a tissue box in his office (to be fair I haven’t checked). I didn’t even consider taking Yau as my advisor, in part because he was super intimidating and seemed to challenge grad students with a ring of fire.
The reward for being brave in a situation like that are that he is fiercely loyal to his students once he accepts them, and helps them get great jobs. My point is that fewer women choose Yau-like personalities as their advisor (although it has to be said that Yau has had women students, including Columbia’s Melissa Liu). And thus fewer women end up with advisors that will land them jobs and give them good advice on how to get ahead. I just don’t think women are thinking about that aspect of a mentor the way men do (it’s also possible than men don’t think about it either but are less likely to shy away from rings of fire in general due to their “optimistic” egos).
I am not saying this is an easy problem to fix, because it’s not, and the best self-promoters will always do well no matter where they work. But I do think Google can do better than this; maybe they could think of something a bit more double-blind like the orchestra auditions.
Recovery begins when addiction ends: an open letter to Jamie Dimon (#OWS)
Posted here on Naked Capitalism, written by the Alternative Banking group of Occupy Wall Street.
Please spread widely!



