Open Forum next Friday
I went back to Occupy Wall Street two nights ago after work. I hadn’t been there since last Friday, and all of the tents made the place awfully depressing. I was getting kind of skeeved out when I found myself next to the “red structure” and in the middle of the beginning of an “Open Forum” about Media Justice.
It was the first time I was an actual human microphone for a meeting, and the speeches were really good (they explained net neutrality and the cell phone industry). I was super impressed, and afterwards I introduced myself to the organizer. She explained it’s part of the Education and Empowerment working group.
Bottomline is, I’m giving an Open Forum about the financial system next Friday, November 4th. Very exciting! This format is exactly what I was hoping for when I tried to do the “teach-in” a couple of weeks ago. It’s also a chance to hand out my flyer.
I have to go write a speech consisting of 4-word phrases now. Kind of like poetry.
Is Big Data Evil?
Back when I was growing up, your S.A.T. score was a big deal, but I feel like I lived in a relatively unfettered world of anonymity compared to what we are creating now. Imagine if your SAT score decided your entire future.
Two days ago I wrote about Emanuel Derman’s excellent new book “Models. Behaving. Badly.” and mentioned his Modeler’s Hippocratic Oath, which I may have to restate on every post from now on:
- I will remember that I didn’t make the world, and it doesn’t satisfy my equations.
- Though I will use models boldly to estimate value, I will not be overly impressed by mathematics.
- I will never sacrifice reality for elegance without explaining why I have done so.
- Nor will I give the people who use my model false comfort about its accuracy. Instead, I will make explicit its assumptions and oversights.
- I understand that my work may have enormous effects on society and the economy, many of them beyond my comprehension.
I mentioned that every data scientist should sign at the bottom of this page. Since then I’ve read three disturbing articles about big data. First, this article in the New York Times, which basically says that big data is a bubble:
This is a common characteristic of technology that its champions do not like to talk about, but it is why we have so many bubbles in this industry. Technologists build or discover something great, like railroads or radio or the Internet. The change is so important, often world-changing, that it is hard to value, so people overshoot toward the infinite. When it turns out to be merely huge, there is a crash, in railroad bonds, or RCA stock, or Pets.com. Perhaps Big Data is next, on its way to changing the world.
In a way I agree, but let’s emphasize the “changing the world” part, and ignore the hype. The truth is that, beyond the hype, the depth of big data’s reach is not really understood yet by most people, especially people inside big data. I’m not talking about the technological reach, but rather the moral and philosophical reach.
Let me illustrate my point by explaining the gist of the other two articles, both from the Wall Street Journal. The second article describes a model which uses the information on peoples’ credit card purchases to direct online advertising at them:
MasterCard earlier this year proposed an idea to ad executives to link Internet users to information about actual purchase behaviors for ad targeting, according to a MasterCard document and executives at some of the world’s largest ad companies who were involved in the talks. “You are what you buy,” the MasterCard document says.
MasterCard doesn’t collect people’s names or addresses when processing credit-card transactions. That makes it tricky to directly link people’s card activity to their online profiles, ad executives said. The company’s document describes its “extensive experience” linking “anonymized purchased attributes to consumer names and addresses” with the help of third-party companies.
MasterCard has since backtracked on this plan:
The MasterCard spokeswoman also said the idea described in MasterCard’s April document has “evolved significantly” and has “changed considerably” since August. After the company’s conversations with ad agencies, MasterCard said, it found there was “no feasible way” to connect Internet users with its analysis of their purchase history. “We cannot link individual transaction data,” MasterCard said.
How loudly can you hear me say “bullshit”? Even if they decide not to do this because of bad public relations, there are always smaller third-party companies who don’t even have a PR department:
Credit-card issuers including Discover Financial Services’ Discover Card, Bank of America Corp., Capital One Financial Corp. and J.P. Morgan Chase & Co. disclose in their privacy policies that they can share personal information about people with outside companies for marketing. They said they don’t make transaction data or purchase-history information available to outside companies for digital ad targeting.
The third article talks about using credit scores, among other “scoring” systems, to track and forecast peoples’ behavior. They model all sorts of things, like the likelihood you will take your pills:
Experian PLC, the credit-report giant, recently introduced an Income Insight score, designed to estimate the income of a credit-card applicant based on the applicant’s credit history. Another Experian score attempts to gauge the odds that a consumer will file for bankruptcy.
Rival credit reporter Equifax Inc. offers an Ability to Pay Index and a Discretionary Spending Index that purports to indicate whether people have extra money burning a hole in their pocket.
Understood, this is all about money. This is, in fact, all about companies ranking you in terms of your potential profitability to them. Just to make sure we’re all clear on the goal then:
The system “has been incredibly powerful for consumers,” said Mr. Wagner.
Ummm… well, at least it’s nice to see that it’s understood there is some error in the modeling:
Eric Rosenberg, director of state-government relations for credit bureau TransUnion LLC, told Oregon state lawmakers last year that his company can’t show “any statistical correlation” between the contents of a credit report and job performance.
But wait, let’s see what the CEO of Fair Isaac Co, one of the companies creating the scores, says about his new system:
“We know what you’re going to do tomorrow”
This is not well aligned with the fourth part of the Modeler’s Hippocratic Oath (MHO). The article goes on to expose some of the questionable morality that stems from such models:
Use of credit histories also raises concerns about racial discrimination, because studies show blacks and Hispanics, on average, have lower credit scores than non-Hispanic whites. The U.S. Equal Employment Opportunity Commission filed suit last December against the Kaplan Higher Education unit of Washington Post Co., claiming it discriminated against black employees and applicants by using credit-based screens that were “not job-related.”
Let me make the argument for these models before I explain why I think they’re flawed.
First, in terms of the credit card information, you should all be glad that the ads coming to us online are so beautifully tailored to your needs and desires- it’s so convenient, almost like someone read your mind and anticipated you’d be needing more vacuum cleaner bags at just the right time! And in terms of the scoring, it’s also very convenient that people and businesses somehow know to trust you, know that you’ve been raised with good (firm) middle-class values and ethics. You don’t have to argue my way into a new credit card or a car purchase, because the model knows you’re good for it. Okay, I’m done.
The flip side of this is that, if you don’t happen to look good to the models, you are funneled into a shitty situation, where you will continue to look bad. It’s a game of chutes and ladders, played on an enormous scale.
[If there’s one thing about big data that we all need to understand, it’s the enormous scale of these models.]
Moreover, this kind of cyclical effect will actually decrease the apparent error of the models: this is because if we forecast you as being uncredit-worthy, and your life sucks from now on and you have trouble getting a job or a credit card and when you do you have to pay high fees, then you are way more likely to be a credit risk in the future.
One last word about errors: it’s always scary to see someone on the one hand admit that the forecasting abilities of a model may be weak, but on the other hand say things like “we know what you’re going to do tomorrow”. It’s a human nature thing to want something to work better than it does, and that’s why we need the IMO (especially the fifth part).
This all makes me think of the movie Blade Runner, with its oppressive sense of corporate control, where the seedy underground economy of artificial eyeballs was the last place on earth you didn’t need to show ID. There aren’t any robots to kill (yet) but I’m getting the feeling more and more that we are sorting people at birth, or soon after, to be winners or losers in this culture.
Of course, collecting information about people isn’t new. Why am I all upset about it? Here are a few reasons, which I will expand on in another post:
- There’s way more information about people nowadays than their Social Security Number; the field of consumer information gathering is huge and growing exponentially
- All of those quants who left Wall Street are now working in data science and have real skills (myself included)
- They also typically don’t have any qualms; they justify models like this by saying, hey we’re just using correlations, we’re not forcing people to behave well or badly, and anyway if I don’t make this model someone else will
- The real bubble is this: thinking these things work, and advocating their bulletproof convenience and profitability (in the name of mathematics)
- Who suffers when these models fail? Answer: not the corporations that use them, but rather the invisible people who are designated as failures.
What’s your short list of actionable complaints?
After reading this article from the New York Times about what Volcker says still needs to be done about the financial system (the title of his speech was “Three Years Later: Unfinished Business in Financial Reform”), I’m wondering if he wants to join the #OWS Alternative Banking working group. He’s got his own “short list of actionable complaints” list, not that different from mine:
- make capital requirements for banks tough and enforceable,
- make derivatives more standardized and transparent,
- ensure auditors are truly independent by rotating them periodically,
- end too big to fail,
- create and enforce reserve requirements and capital requirements for money market funds, and
- get rid of Fannie and Freddie, or at least make a plan to.
He also pointed to the weakness of the ratings agencies as one of the big reasons for the credit crisis, so I assume that “making the ratings agencies accountable” may be on the list too, at least in the top 10.
I was interviewed last night about being on the Alternative Banking working group for #OWS (I will link to the article if and when it comes out), and I mentioned this speech as well as the general fact that many of these problems named above are really non-partisan, especially “Too Big to Fail”. This column from the New York Times, written by former IMF chief economist Simon Johnson points this out as well.
That makes me encouraged and depressed at the same time. Encouraged because there really does seem to be a consensus about what’s terribly wrong with at least some of the most obvious issues, but depressed because in spite of this we haven’t solved any of them. To make this vague sense of depression precise, just take a look at what has happened to the original “Volcker Rule”: it has expanded by a factor of 100, from 3 to 300 pages, making it impossibly difficult to understand or probably to follow (unless you have fancy lawyers who do nothing else besides find loopholes). It’s reminiscent of our tax code. Speaking of which, here’s yet another “short list of actionable complaints” to fix that.
I’m enjoying how many people are now coming up with personal short lists of actionable complaints (even if it’s in response to complete stalemate of the political process). It’s a way of claiming and maintaining our freedom and agency. It isn’t as easy at is seems, because you have to sort out the important from the annoying, and the actionable from the existential. If you haven’t already, I encourage you to write your own short list, and feel free to post it here.
Emanuel Derman’s Models.Behaving.Badly.
This morning I want to talk about Emanuel Derman’s beautifully written and wise new book “Models. Behaving. Badly.”, available in some book stores now and on Amazon starting tomorrow.
It is in some sense an expanded version of this essay he wrote in January 2009 with Paul Wilmott. I particularly like the end of the essay where they present the “Modeler’s Hippocratic Oath”:
- I will remember that I didn’t make the world, and it doesn’t satisfy my equations.
- Though I will use models boldly to estimate value, I will not be overly impressed by mathematics.
- I will never sacrifice reality for elegance without explaining why I have done so.
- Nor will I give the people who use my model false comfort about its accuracy. Instead, I will make explicit its assumptions and oversights.
- I understand that my work may have enormous effects on society and the economy, many of them beyond my comprehension.
This was written in direct reaction to the financial crisis of 2008, clearly, but I think data scientists should all be asked to sign at the bottom of the page. As I’ve said before, financial modelers are just data scientists working in the most sophisticated (under some metrics) subfield of data science; just as they have ridiculous powers of profit using their methods, data scientists in other fields have ridiculous powers as well, sometimes in ways that affect people even more directly than money. Modelers absolutely need to be aware of and wary of these powers. This oath is an excellent step towards that.
In the book, Derman sets up a dichotomy between models and theories. For him, theories are stand-alone descriptions of how things are, whereas models are relative descriptions of how things work, by analogy. He also differentiates between the models (and theories) and the way that humans ascribe truth to them, which is to me the most profound and important message of his book. I’ll discuss below.
His examples of theories come mostly from physics: he has a really beautiful explanation of the evolution of the theory of electro-magnetism, for example, which actually explains how people can sometimes develop theories using temporary models. One idea that emerges is that, sometimes, models work out so well that they eventually become part of the theory. The obvious love that Derman has for physics (which he trained in as a young man) shines through this entire part of the book, and it’s beautiful and intimate reading.
Another example Derman gives of a theory was Spinoza’s theory of human emotion, wherein the basic objects were pleasure and pain, and everything was a derivative of those. For example, love is defined as “pleasure associated with an external object,” pity as “pain arising from another’s hurt.” My favorite: to Spinoza, cruelty is “the desire to inflict pain on someone you love.”
To Derman, Spinoza’s theory is a theory, even though it’s not mathematical, and even though it may not be even “true” in the sense that you could just as well have an alternative theory (although it may not be as beautiful). It is a theory, then, because it describes a mini universe of existence without depending on an assumed external frame of reference. It describes emotions themselves rather than comparing them to something else.
What then is a model? It is something that tried to explain (and predict) the behavior of something through analogy or proxy; its accuracy depends on external conditions. He talks about the Black-Scholes option pricing model as a good model in that, in its purest form, it is actually a model for the price of something depending on the abstract concept of “risk”. Then the fact that it can be misused is due more to the fact that people incorrectly proxy risk itself as described by some brownian motion somewhere. With a better model of risk, then, we’d be happy to use Black-Scholes.
Of course Black-Scholes, or rather its use, is not what caused the financial crisis. It was rather the Efficient Market Model and its corollary the Capital Asset Pricing Model that he considers much more dangerous (I agree). He describes these models very clearly, for the uninitiated, and talk about their ubiquitous use in the vocabulary of finance (and how money mangers describe their Sharpe ratios, which is a ratio of their (past) return and their perceived risk, as if they are meaningful statistics).
The basic mistake people make in ascribing power to their financial models, he says, is that they depend on human beings and their actions to be as predictable as physics. Electrons, it turns out, are much more predictable than people with money on the line.
He also goes into a beautiful riff on how there is, but shouldn’t be, a “Fundamental Theorem of Finance.” Not only is it not fundamental (and not even understandable), but there shouldn’t even be such a thing, because it depends on a model which isn’t true, and cannot deserve the name “theorem”, and moreover can only serve as a false sense of security. This kind of mathematical idolatry, he believes, is at the very root of the problem which led us into the financial crisis. Agreed.
Another aspect of the book I want to bring up, because I find it fascinating, is the way we model things in our lives. As Derman correctly points out, we each model our futures; he describes growing up in South Africa during Apartheid and his involvement with a youth Zionist movement, and how he felt pressure to model his life in a very precise way from the youth leaders there, to move to Israel and work as a laborer (examples among many of how sometimes people blithely model other peoples’ lives as well as their own). He then went on to talk about studying physics, moving to finance and his early desire to find a “theory of everything” in finance.
It may be reasonable to say that, until we die, we are on an endless quest for the perfect model for ourselves. In other words, it’s not only that we use models for our internal lives, but we intensely desire models as well – they give us pleasure, they alleviate our worries and stress. We have trouble letting go of our internal models, even when they don’t work (or we even ignore their failure completely; this was described in a recent New York Times article on confidence). When we model the person we love loving us back, it gives us enormous strength and hope. We model our future success: getting tenure, a promotion, or a child. We model our gods.
But our models are not always realistic, and they don’t always account for bad conditions; just look at the Eurozone for one huge example of this. Sometimes our beloved doesn’t care, and sometimes we don’t get tenure.
The most essential question for me then is: how do we react in that moment when we realize our model is bad? Otherwise put, how do we disagree with ourselves? It’s an excruciating moment that we can learn from – do we take away from a moment like that only the pain? Or do we grab hold of it as an opportunity for growth? Can I train myself to be the kind of person who learns from her broken models?
A related question, which I will take up in another post, is whether the people in finance (or mathematics, or data science) are people who react well to their models failing.
Shareholder Value
This is a guest post by Mekon:
It was late August, 1990. The barely-above-mediocre Boston Red Sox (record: 73-57) led the definitely-mediocre Toronto Blue Jays (record: 67-64) by 6½ games in the American League East. Unsure his team could hold off the hard-charging Jays with a month left in the season, Sox general manager Lou Gorman decided to shore up his bullpen. He offered the Houston Astros a young minor league prospect named Jeff Bagwell for aging-but-competent relief pitcher Larry Andersen. The Astros, long out of the race, said yes. What happened next is the stuff of legend, sort of:
- In September, the Sox went from flirting with mediocrity to wrapping it in a loving embrace (a 15-17 record down the stretch), but still managed to hold off the mighty Jays by 2 games.
- As the Sox staggered to the division title, Andersen chipped in 22 innings in 15 games with 1 save and a good ERA (1.23). If you believe in the Win Shares statistic they quote here, Mr. Aging-but-Competent contributed the equivalent of about 1 win.
- In the playoffs, the 88-74 Red Sox faced the defending World Series champion Oakland A’s (record: 103-59). The A’s won all four games, by an aggregate score of 20-4. Andersen pitched three innings and gave up two runs. He was charged with the loss in the first game when he gave up a run in the 7th inning of a 1-1 game just before the A’s broke the game open.
- The A’s, overwhelming favorites to repeat as World Series champs, lost the Series to the 91-71 Cincinnati Reds in four straight. You never know, do you, baseball fans?
- Andersen was declared a free agent after the season ended. He left the Sox, signed with the San Diego Padres, and pitched in the majors for another four years. Somewhere along the way, “aging-but-competent” became just “aging,” as he compiled an aggregate record of 8-8.
- The Astros promoted Bagwell to the major leagues in 1991. He was the 1991 rookie-of-the-year, the 1994 MVP, and the face of the franchise for 15 seasons. He retired with an exceptional lifetime OPS (On-base Plus Slugging average, today’s batting statistic of choice) of .948, as well as 449 home runs, currently 35th of all time. In his first year of Hall of Fame eligibility (2011), he got about 40% of the vote, a figure dragged down by suspicions of steroid use.
- In later years, Gorman appeared to look back on the trade with pride: “I called Bob Watson and made the trade, Bagwell for Andersen. Andersen would strengthen our bullpen and help us win the Eastern Division title, and we’d go on to face the A’s,” Gorman would write. “He was exactly what we needed to bolster the pen at a critical juncture in our run at the division title.”
- Red Sox fans and ownership agreed. At the Sox’ 1990 holiday dinner, owner and chair Jean Yawkey announced a $2.5M bonus for Gorman for “enhancing ticketholder value” by getting the team to the playoffs. Grateful fans gave him a loud ovation on Opening Day the following April. While a few cranky Boston Globe writers made fun of the Bagwell-for-Andersen trade over the next few years, the public didn’t buy it. As the Sox finished well out of the running each of the next four years, fans always found comfort in the thrilling playoff run of 1990.
OK, I made that last one up: everyone, except apparently Gorman, realized almost from the outset that trading away Bagwell for Andersen was a disaster. As the Sox stumbled through the next several years (see, I didn’t make it all up), poor Lou, who had actually had a pretty good career as a major league GM, became a laughingstock, finally losing his job in 1993. His name still shows up near the top of any “Worst Trades Ever” list that baseball writers feel obligated to make every year around the trading deadline. You could even argue that teams became more cautious about holding on to their minor league prospects after seeing how badly Gorman and the Sox screwed up.
All well and good. But what if I told you that outside sports, in the world of business and finance, the little piece of fiction I put at the end of the Bagwell-for-Andersen story actually isn’t fiction at all?
Shareholder value. Google the phrase and you’ll find almost 5 million links. Virtually all of them (or at least the first five I checked) equate it with the value of the firm or the share price. If you think that’s just a shortcut, it’s not: at the end of every year, companies whose stock grew in price that year give their CEO’s hefty bonuses for – you guessed it – boosting shareholder value. The trouble with all this is that it misses the dimension that Sox fans demanding Lou Gorman’s head understood very well: time.
Say you’re a shareholder in IBM. Maybe you bought (or received) your stock outright, or maybe you gave some money to a manager and had them buy the stock, either directly in your name or pooled with money from other people just like you (i.e., through a fund). Either way, you are, in financial parlance, an asset owner (as distinguished from an asset manager, who manages what you, the owner, hold).
But step back a bit: why do you own this asset, anyway? You’re not going to consume it, like you might a gallon of milk or a car. You don’t get any pleasure from it, like you might from a piece of art that hangs on the wall. The only reason to own a share of IBM is so you can sell it. Hopefully at a high price. And if you own IBM stock now to sell it later, you have to think about time. When will you sell it? Five minutes from now? Five years from now?
When you’ll sell is driven by why. Essentially, there can be two reasons:
- You want to spend the money. You sell your IBM shares and use the proceeds to buy a car, or a house, or a nice picture, or to send your kids to college. A variant of this is that you expect to need the money soon (your kids are going to college next year), and you don’t want to risk IBM decreasing in value, so you sell your shares and put the money in the bank (or in another low-risk asset) until you need it.
- You (or an asset manager acting on your behalf) decide to replace IBM with an asset you like better. Time is embedded implicitly here too: if you’re selling IBM to buy AAPL, you expect AAPL to do better than IBM over some time horizon. Which could be until you need the money, or it could be sooner. For example, I might plan to hold AAPL for a year (over which time I expect it to do better than IBM), and reevaluate what I hold after that.
Asset owners who sell because of (1) are called buy-and-hold investors. Asset owners who sell because of (2) are called traders. Rebalancing, where you hold assets for some period of time, then decide whether to replace them, is essentially a disciplined form of trading.
Now that we know why asset holders sell, we can talk about when. Take buy-and-hold investors first. If you’re selling assets to fund expenses, you’re usually either buying something big (a house or a car, not a gallon of milk) or you no longer have income (you’re retired). Now, truly large expenses are rare, and people usually retire late in life, so asset sales by buy-and-hold investors are spread out across time. In any given year, only a small minority of buy-and-hold investors need to sell assets to raise funds.
Traders initially seem more complicated, and probably are. But we can capture them pretty well by saying they sell when they see a new asset they think will get them better future returns. The more they like the return profile of an asset they already hold, the more they behave like buy-and-hold investors.
Now let’s ask again: what is true shareholder value? Given what we know about asset owners, what is in their best interest? A related question: who benefits when the stock price goes up? Shareholders, surely. But that’s only half the answer. The full answer is shareholders who sell.
Let’s look at buy-and-hold investors first. If the stock price goes up over a year, it benefits investors who sell that year. The remaining investors realize the gains only to the extent that those gains persist when they sell. Since they sell at different times, there’s only one way to benefit them as a group: enhance the value of the company consistently over time.
Of course, once you realize that boosting the share price over the short term doesn’t actually enhance value for most shareholders, you also see that immediate stock price gains are a terrible measure of a CEO’s performance. Red Sox fans understood this right away, and did all they could to run out of town the guy who boosted the short-term stock price (likelihood of making the 1990 playoffs) at the expense of long-term value (Jeff Bagwell’s career).
If you don’t believe me, here’s Warren Buffett making a related point:
“If you expect to be a net saver during the next 5 years, should you hope for a higher or lower stock market during that period? Many investors get this one wrong. Even though they are going to be net buyers of stocks for many years to come, they are elated when stock prices rise and depressed when they fall. This reaction makes no sense. Only those who will be sellers of equities in the near future should be happy at seeing stocks rise. Prospective purchasers should much prefer sinking prices.”
Now, this doesn’t mean you should manage a company to make the stock price drop, in part because there’s a big difference between existing shareholders and prospective ones. But the intuition is the same: investors should worry about the stock price when they buy and sell, and at no other time, and CEO’s should worry about shareholder value across time, not in the short term.
We know, though, that not all asset owners are buy-and-hold investors. Does the presence of traders – whether disciplined rebalancers, day traders, or high-frequency hedge funds – change things? Should it make management pay more attention to short-term stock price movements?
Let’s start with the basics: when you own an asset, its price matters only when you sell, and traders sell when another asset has a better return profile (or when they need to raise funds). Ignoring the latter, and assuming other assets’ profiles don’t change, we conclude that a rising stock price benefits traders if it comes with a worsening future return profile. (By the way, rapidly rising asset prices do usually mean worse expected future returns – but that’s a longer discussion.) That’s clearly no way to run a company, but it’s worth articulating two important reasons why:
- It harms the rest of their shareholders, who plan to keep their shares for longer and want a good future return profile (duh).
- In the aggregate, it even harms short-term traders. Remember, we’re taking asset owners’ points of view here, and even asset owners who are traders need to get their long-term returns from somewhere!
In a little more detail, imagine a world where all companies are managed for the (supposed) benefit of short-term traders, maximizing short-term stock price growth and (purposely or not) making longer-term growth prospects less attractive. So now a year (say) goes by, and all stock prices have gone up a bunch (i.e., there’s a bubble). Asset owners who are traders want to take their profits and invest in another asset that’s more attractive in the long-term – but what? If all companies focus on short-term profit, then all assets are worse in the long term. So, as an asset owner, you’ve made some money, but what are you going to retire on?
Put another way, there’s no way to trade out of the economy – from a global point of view, everyone’s a buy-and-hold investor. If companies manage for the benefit of short-term traders, even traders lose.
So why do we keep rewarding CEO’s for short-term stock price boosts? Every Red Sox fan knew Lou Gorman was mismanaging the team, so why can’t the best minds in business and finance see it? Or does something about the system pervert perspectives and incentives? I’ll take that on in another post.
Credit Unions in NYC flyer
Also from FogOfWar; see also this post where FoW discusses “Why Credit Unions?”:

Why Credit Unions? (#OWS) (part 1)
This is a guest post by FogOfWar. See also the “Credit Unions in NYC flyer“.
Moving your money from a megabank to a credit union or community development bank makes for a good sound bite, but is it really an action that can have an impact in the right direction? I think so (although the matter is not free from doubt), and thought it would be worthwhile to lay out thoughts on the subject as a follow-up to the “What is a Credit Union?” post.
I’ll focus this discussion on credit unions, rather than community development banks or smaller locally owned banks as that’s where my knowledge lies.
Credit Unions are not Too Big To Fail
A quick google search indicates the largest credit union in America is Navy FCU with $34Bn in assets. (Internationally, it may be the Dutch Rabobank, although I’ve never gotten a good handle on whether Rabo is still a cooperative or not.) Individual credit unions fail regularly, just like individual banks, but there isn’t one CU that’s in danger of crashing the entire financial system in the same manner as BAC, C, JPM or WF.
During the 2008 crisis and aftermath the only credit unions that got a federal bailout were the corporate credit unions. There’s a good article about that here. The corporate credit unions definitely got into trouble buying structured products and I don’t want to gloss this fact over. There’s a split between the retail credit unions, who are going to have to pay for these mistakes, and the corporate credit unions which made the bad investments as well as the NCUA, who was asleep at the switch when the corporate CUs were making that investment. Also worth noting that the NCUA has filed suit against the banks for selling crap product to the corporate CUs.
The corporate credit union bailout was small proportionate to the overall credit union size. $30 bn of gov’t backed bonds equates to $270 bn proportionate for banks—less than ½ of the official state of TARP and a small fraction of the overall size of the taxpayer support given to the large (non-CU) banks indirectly through TAF, TSLF, PDFC, TARP, TALF, etc.,… (see this for an explanation of term).
All in all, I’d say CUs come out somewhat ahead by this measure.
Volker Rule/Glass Steagall
Unlike commercial banks, credit unions never revoked the Glass Steagall act and remained segmented as “pure” traditional banking entities. This means that CUs don’t mingle traditional banking (deposits, checking accounts, loans to customers), with investment banking activities (IPOs, M&A advisory) or derivatives trading or sales desks, let alone prop desk frontrunning of client information.
There’s a lot of ink out there on Volker and Glass Steagall. In short, it seems like a good idea, if not sufficient as a complete solution, to keep traditional banking segmented from investment banking and proprietary trading. The core point is that trading risk should not infect the core banking business putting it (and the taxpayer standing behind the federal deposit insurance) at risk. Very good recent example of this here.
CUs come out dramatically ahead on this measure.
Lobbying—just as bad?
Credit Unions do lobby, largely through two groups, CUNA and NAFCU. In fact, NAFCU has been an opponent of the CPFB, and the CU lobby got itself removed from the debit swipe fee cap.
There was a time I can remember when CUNA and NAFCU just went up to the hill to remind Congress that they existed and defend against the ABA’s occasional attempts to change the tax status of CUs. It seems times have, rather unfortunately, changed.
Regrettably, no advantage to Credit Unions here.
Part 2 will talk about investments in local communities, democratic control (the good, the bad and the ugly) and securitization/mortgage transfers.
FoW
Math in Business
Here’s an annotated version of my talk at M.I.T. a few days ago. There was a pretty good turnout, with lots of grad students, professors, and I believe some undergraduates.
What are the options?
First let’s talk about the different things you can do with a math degree.
Working as an academic mathematician
You all know about this, since you’re here. In fact most of your role models are probably professors. More on this.
Working at a government institution
I don’t have personal experience, but there are plenty of people I know who are perfectly happy working for the spooks or NASA.
Working as a quant in finance
This means trying to predict the market in one way or another, or modeling how the market works for the sake of measuring risk.
Working as a data scientist
This is my current job, and it is kind of vague, but it generally means dealing with huge data sets to locate, measure, visualize, and forecast patterns. Quants in finance are examples of data scientists, and they work in the most, or one of the most, developed subfield of data science.
Cultural Differences
I care a lot about the culture of my job, as I think women in general tend to. For that reason I’m going to try to give a quick and exaggerated description of the cultures of these various options and how they differ from each other.
Feedback is slow in academics
I’m still waiting for my last number theory paper to get published, and I left the field in 2007. That hurts. But in general it’s a place for people who have internal feedback mechanisms and don’t rely on external ones. If you’re a person who knows that you’re thinking about the most important question in the world and you don’t need anyone to confirm that, then academics may be a good cultural fit. If, on the other hand, you are wondering half the time why you’re working on this particular problem, and whether the answer really matters or ever will matter to someone, then academics will be a tough place for you to live.
Institutions are painfully bureaucratic
As I said before, I don’t have lots of personal experience here, but I’ve heard that good evidence that working at a government institution is sometimes painful in terms of waiting for things that should obviously happen actually happen. On the other hand I’ve also head lots of women say they like working for institutions and that they are encouraged to become managers and grow groups. We will talk more about this idea of being encouraged to be organized.
Finance firms are cut-throat
Again, exaggerating for effect, but there’s a side effect of being in a place whose success is determined along one metric (money), and that is that people are typically incredibly competitive with each other for their perceived value with respect to that metric. Kind of like a bunch of gerbils in a case with not quite enough food. On the other hand, if you love that food yourself, you might like that kind of struggle.
Startups are unstable
If you don’t mind wondering if your job is going to exist in 1 or 2 months, then you’ll love working at a startup. It’s an intense and exciting journey with a bunch of people you’d better trust or you’ll end up really hating them.
Outside academics, mathematicians have superpowers
One general note that you, being inside academics right now, may not be aware of: being really fucking good at math is considered a superpower by the people outside. This is because you can do stuff with your math that they actually don’t know how to do, no matter how much time they spend trying. This power is good and bad, but in any case it’s very different than you may be used to.
Going back to your role models: you see your professors, they’re obviously really smart, and you naturally may want to become just like them when you grow up. But looking around you, you notice there are lots of good math students here at M.I.T. (or wherever you are) and very few professor jobs. So there is this pyramid, where lots of people a the bottom are all trying to get these fancy jobs called math professorships.
Outside of math, though, it’s an inverted world. There are all of these huge data sets, needing analysis, and there are just very few places where people are getting trained to do stuff like that. So M.I.T. is this tiny place inside the world, which cannot possibly produce enough mathematicians to satisfy the demand.
Another way of saying this is that, as a student in math, you should absolutely be aware that it’s easier to get a really good job outside the realm of academics.
Outside academics, you get rewarded for organizational skills (punished within)
One other big cultural difference I want to mention is that inside academics, you tend to get rewarded for avoiding organizational responsibilities, with some exceptions perhaps if you organize conferences or have lots of grad students. Outside of academics, though, if you are good at organizing, you generally get rewarded and promoted and given more responsibility for managing a group of nerds. This is another personality thing- some math nerds love the escape from organizing, or just plain suck at it, and maybe love academics for that reason, whereas some math nerds are actually quite nurturing and don’t mind thinking about how systems should be set up and maintained, and if those people are in academics they tend to be given all of the “housekeeping” in the department, which is almost always bad for their career.
Mathematical Differences
Let’s discuss how the actual work you would do in these industries is different. Exaggeration for effect as usual.
Academic freedom is awesome but can come with insularity
If you really care about having the freedom to choose what math you do, then you absolutely need to stay in academics. There is simply no other place where you will have that freedom. I am someone who actually does have taste, but can get nerdy and interested in anything that is super technical and hard. My taste, in fact, is measured in part by how much I think the answer actually matters, defined in various ways: how many people care about the answer and how much of an impact would knowing the answer make? These properties are actually more likely to be present in a business setting. But some people are totally devoted to their specific field of mathematics.
The flip side of academic freedom is insularity; since each field of mathematics gets to find its way, there tend to be various people doing things that almost nobody understands and maybe nobody will ever care about. This is more or less frustrating to you depending on your personality. And it doesn’t happen in business: every question you seriously work on is important, or at least potentially important, for one reason or another to the business.
You don’t decide what to work on in business but the questions can be really interesting
Modeling with data is just plain fascinating, and moreover it’s an experimental science. Every new data set requires new approaches and techniques, and you feel like a mad scientist in a lab with various tools that you’ve developed hanging on the walls around you.
You can’t share proprietary information with the outside world when you work in business or for the government
The truth is, the actual models you create are often the crux of the profit in that business, and giving away the secrets is giving away the edge.
On the other hand, sometimes you can and it might make a difference
The techniques you develop are something you generally can share with the outside world. This emerging field of data science can potentially be put to concrete and good use (more on that later).
In business, more emphasis on shallower, short term results
It’s all about the deadlines, the clients, and what works.
On the other hand, you get much more feedback
It’s kind of nice that people care about solving urgent problems when… you’ve just solved an urgent problem.
Which jobs are good for women?
Part of what I wanted to relay today is those parts of these jobs that I think are particularly suitable for women, since I get lots of questions from young women in math wondering what to do with themselves.
Women tend to care about feedback
And they tend to be more sensitive to it. My favorite anecdote about this is that, when I taught I’d often (not always) see a huge gender difference right after the first midterm. I’d see a young woman coming to office hours fretting about an A- and I’d have to flag down a young man who got a C, and he’d say something like, “Oh, I’m not worried, I’ll just study and ace the final.” There’s a fundamental assumption going on here, and women tend to like more and more consistent feedback (especially positive feedback).
One of my most firm convictions about why there are not more women math professors out there is that there is virtually no feedback loop after graduating with a Ph.D., except for some lucky people (usually men) who have super involved and pushy advisors. Those people tend to be propelled by the will of their advisor to success, and lots of other people just stay in place in a kind of vacuum. I’ve seen lots of women lose faith in themselves and the concept of academics at this moment. I’m not sure how to solve this problem except by telling them that there’s more feedback in business. I do think that if people want to actually address the issue they need to figure this out.
Women tend to be better communicators
This is absolutely rewarded in business. The ability to hold meetings, understand people’s frustrations and confusions and explain in new terms so that they understand, and to pick up on priorities and pecking orders is absolutely essential to being successful, and women are good at these things because they require a certain amount of empathy.
In all of these fields, you need to be self-promoting
I mention this because, besides needing feedback and being good communicators, women tend to not be as self-promoting as men, and this is something that they should train themselves out of. Small things like not apologizing help, as does being very aware of taking credit for accomplishments. Where men tend to say, “then I did this…”, women tend to say, “then my group did this…”. I’m not advocating being a jerk, but I am advocating being hyper aware of language (including body language) and making sure you don’t single yourself out for not being a stand-out.
The tenure schedule sucks for women
I don’t think I need to add anything to this.
No “summers off” outside academics… but maybe that’s a good thing
Academics don’t actually take their summers off anyway. And typically the women are the ones who end up dealing more with the kids over the summer, which could be awesome if that’s what they want but also tends to add a bias in terms of who gets papers written.
How do I get a job like that?
Lots of people have written to me asking how to prepare themselves for a job in data science (I include finance in this category, but not the governmental institutions. I have no idea how to get a job at NASA or the NSA).
Get a Ph.D. (establish your ability to create)
I’m using “Ph.D.” as a placeholder here for something that proves you can do original creative building. But it’s a pretty good placeholder; if you don’t have a Ph.D. but you are a hacker and you’ve made something that works and does something new and clever, that may be sufficient too. But if you’ve just followed your nose, and done well in your courses then it will be difficult to convince someone to hire you. Doing the job well requires being able to create ad hoc methodology on the spot, because the assumptions in developed theory never actually happen with real data.
Know your way around a computer
Get to the point where you can make things work on your computer. Great if you know how unix and stuff like cronjobs (love that word) work, but at the very least know to google everything instead of bothering people.
Learn python or R, maybe java or C++
Python and R are the very basic tools of a data scientist, and they allow quick and dirty data cleaning, modeling, measuring, and forecasting. You absolutely need to know one of them, or at the very least matlab or SAS or STATA. The good news is that none of these are hard, they just take some time to get used to.
Acquire some data visualization skills
I would guess that half my time is spent visualizing my results in order to explain them to non-quants. A crucial skill (both the pictures and the explanations).
Learn basic statistics
And I mean basic. But on the other hand I mean really, really, learn it. So that when you come across something non-standard (and you will), you can rewrite the field to apply to your situation. So you need to have a strong handle on all the basic stuff.
Read up on machine learning
There are lots of machine learners out there, and they have a vocabulary all their own. Take the Stanford Machine Learning classor something to learn this language.
Emphasize your communication skills and follow-through
Most of the people you’ll be working with aren’t trained mathematicians, and they absolutely need to know that you will be able to explain your models to them. At the same time, it’s amazing how convincing it is when you tell someone, “I’m a really good communicator.” They believe you. This also goes back to my “do not be afraid to self-promote” theme.
Practice explaining what a confidence interval is
You’d be surprised how often this comes up, and you should be prepared, even in an interview. It’s a great way to prep for an interview: find someone who’s really smart, but isn’t a mathematician, and ask them to be skeptical. Then explain what a confidence interval is, while they complain that it makes no sense. Do this a bunch of times.
Other stuff
I wanted to throw in a few words about other related matters.
Data modeling is everywhere (good data modelers aren’t)
There’s an asston of data out there waiting to be analyzed. There are very few people that really know how to do this well.
The authority of the inscrutable
There’s also a lot of fraud out there, related to the fact that people generally are mathematically illiterate or are in any case afraid of or intimidated by math. When people want to sound smart they throw up an integral, and it’s a conversation stopper. It is a pretty evil manipulation, and it’s my opinion that mathematicians should be aware of this and try to stop it from happening. One thing you can do: explain that notation (like integrals) is a way of writing something in shorthand, the meaning of which you’ve already agreed on. Therefore, by definition, if someone uses notation without that prior agreement, it is utterly meaningless and adds rather than removes confusion.
Another aspect of the “authority of the inscrutable” is the overall way that people claimed to be measuring the risk of the mortgage-backed securities back before and during the credit crisis. The approach was, “hey you wouldn’t understand this, it’s math. But trust us, we have some wicked smart math Ph.D.’s back there who are thinking about this stuff.” This happens all the time in business and it’s the evil side of the superpower that is mathematics. It’s also easy to let this happen to you as a mathematician in business, because above all it’s flattering.
Open source data, open source modeling
I’m a huge proponent of having more visibility into the way that modeling affects us all in our daily lives (and if you don’t know that this is happening then I’ve got news for you). A particularly strong example is the Value-added modeling movement currently going on in this country which evaluates public teachers and schools. The models and training data (and any performance measurements) are proprietary. They should not be. If there’s an issue of anonymity, then go ahead and assign people randomly.
Not only should the data that’s being used to train the model be open source, but the model itself should be too, with the parameters and hyper-parameters in open-source code on a website that anyone can download and tweak. This would be a huge view into the robustness of the models, because almost any model has sub-modeling going on that dramatically affects the end result but that most modelers ignore completely as a source of error. Instead of asking them about that, just test it for yourself.
Meetups
The closest thing to academics lectures in data science is called “Meetups”. They are very cool. I wrote about them previously here. The point of them is to create a community where we can share our techniques (without giving away IP) and learn about new software packages. A huge plus for the mathematician in business, and also a great way to meet other nerds.
Data Without Borders
I also wanted to mention that, once you have a community of nerds such as is gathered at Meetups, it’s also nice to get them together with their diverse skills and interests and do something cool and valuable for the world, without it always being just about money. Data Without Borders is an organization I’ve become involved with that does just that, and there are many others as well.
Please feel free to comment or ask me more questions about any of this stuff. Hope it is helpful!
Some really terrible ideas
I’m in the middle of writing up my talk about “math in business”. Turns out I can talk faster than I can type, since it’s taking me much longer to write this up that in took for me to say.
In the meantime I want to share with you some really terrible ideas I’ve seen in the news lately.
The prize goes to this idea of how to make the ratings agencies better in Europe. Namely, by banning them when they don’t like them. From the Wall Street Journal article:
In a press conference, Barnier acknowledged this was a “difficult” issue and said that Europe needed to “reduce its dependency on ratings.”
While Barnier gave no further details on the idea of banning some sovereign ratings, a person familiar with the situation explained when the ratings suspension or ban could be appropriate.
The official said the ban would only be used in a “specific” set of circumstances.
That could include if the consequences of a ratings move led to “volatility” or a threat to financial stability. The person also said that the ratings could be banned if there were “imminent changes to the creditworthiness of a state because of negotiations” on a bailout program.
It would be one thing if we had gotten the overall impression that the ratings agencies have been exaggerating a problem through their sovereign ratings… but I don’t have that impression, do you? Um, I have an idea, instead of banning them, how about we instead force them to explain their reasoning? How is turning off the heart rate monitor going to help the patient?
Next up, I just want to say how much I hate articles with misleading titles like this one. Now that I link to it I realize the title has been changed from “Jobless Claims in U.S. Dropped Last Week” to “Jobless Claims in U.S. Decreased Last Week.” This is slightly better but I’ll still complain: the drop from 409,000 to 403,000 is clearly not statistically significant, as anyone who knows any statistics could see just by how small that relative shift is. But even worse if you read the article, you’ll see that last week’s numbers had come in at 404,000 at this week had been corrected to 409,000. So the actual news should have read “U.S. Jobless Claims Changed Not At All”. I guess that’s not a snazzy title.
Here’s not such a bad idea: making people own the underlying sovereign bonds if they buy CDS contracts on them. I’ve seen enough damage cause by “not knowing where the CDS’s live” with regard to Greek debt to know that uncontrolled selling of CDS contracts needs to be curbed – even better if we can make people transparent about their holdings, of course, but that’s kind of a pipe dream.
However, you’ll notice in the article that it’s kind of a weird rule, where countries can “opt out” of the ban if they want to. When would they want to do that? From the Bloomberg article:
The opt out-clause won over some critics of possible bans.
“I never signed up to the belief that a ban on uncovered sovereign CDS would have any positive impact,” Syed Kamall, who represents London in the EU Parliament, said in an e-mailed statement. “However, I’m reassured that member states will have the ability to opt out of the ban, if they see signals that sovereign debt markets are distressed.”
So, I’m guessing that means that some people think that when nobody’s willing to buy their bonds, they will become willing if they can find some A.I.G.-like entity that is willing to sell CDS contracts on those bonds for way less than they’re worth? I don’t get it. Please explain if you do.
And also I don’t like how this idea of no naked CDS contracts is being lumped in with the idea of no short selling- maybe because there’s also the word “naked” associated with that? Let’s not get confused: naked short selling is already illegal. But short selling itself isn’t and shouldn’t be.
Topology of financial modeling
After my talk on Monday there were lots of questions and comments, which is always awesome (will blog the contents soon).
One person in the audience asked me if I’d ever heard of CompTop, which I hadn’t. And actually, even though I vaguely understand what they’re talking about, I still don’t understand it sufficiently to blog about it- but it reminds me of something else which I would like to blog about, and which combines topology and modeling.
Maybe they’re even the same thing! But if so (especially if so), I’d like to get my idea down onto electronic paper before I read theirs. This is kind of like my thing about not googling something until you’ve tried to work it out for yourself.
So here’s the setup. In different fields in finance, there’s a “space” you work in. I worked in Futures, which you’ve heard of because when they talk about the price of barrels of oil going up (or maybe down, but you don’t hear about it as much when that happens), they are actually talking about futures prices. This also happens with basic food prices such as corn and wheat; corn and oil are linked of course through ethanol production. There are also futures on the S&P (or any other major stock index), bonds, currencies, other commodities, or even options on stock indices.
The general idea, which is given away by the name, is that when you buy a futures contract, you are placing a bet on the future price of something. Futures were started as a way for farmers to hedge their risks when they were growing food. But clearly other things have happened since then.
There’s a way of measuring the dimension of this space of instruments, which is less trivial than counting them. For example, there is a “2 year U.S. bond” future as well as a “5 year U.S. bond future” and you may guess (and you’d be right) that these don’t really represent independent dimensions.
Indeed there’s a concept of independence which one can use coming from statistics (so, statistical independence), which is pretty subjective in that it depends on what time period and how much data you use to measure it (and lately we’ve seen less independence in general). But even so, you can go blithely forward and count how many dimensions your space has, and you generally got something like 15, at least before the credit crisis hit. This process is called PCA, and I’ll write a post on it sometime.
Depending on which instruments you counted, and how liquid you expected them to be, you could get a few more “independent” instruments, but you also may be fooling yourself with idiosyncratic noise caused by those instruments being not very liquid. So there are some subtleties.
Once you have your space measured in terms of dimension, you can choose a basis and look at things along the basis vectors. You can see how your different models behave, for example. You might see how the bond model you worked on places no bet on the basis vectors corresponding to lean hog futures.
That made me wonder the following question. If we can measure the space of instruments, can we also measure the space of models? Is this some kind of dual? If so, is there some kind of natural upper bound on the number of (independent) models we could ever have which all make profit?
Note there’s also a way of making sure that models are statistically independent, so this part of the question is well-defined. But it’s not clear what property of the space of instruments you are measuring when you ask for a model on that space which “makes profit”.
Another related question is whether such a question can really only be asked at a given time horizon (if it can be asked at all). I’ll explain.
The horizon of a model is essentially how long you expect a given bet to last in terms of time. For example, a weekly horizon model is something you’d typically only see on a slow-moving instrument class like bonds. There are plenty of daily models on equities, but there are also incredibly hyper fast “high frequency” models, say on currencies, which care about the speed of light and how different computers in the same room, being at different internal temperatures, can’t place consistent timestamps on ticker data.
These different horizons have such different textures, it makes me wonder if the question of an upper bound on the number of profitable models, if true, is true at each horizon.
Another related question: what about topological weirdness inside the space of instruments? If you plot some of this (take as a baby model three instruments that are essentially independent, choose a time horizon, and plot the simultaneous returns) the main characteristic you’ll see is that it’s a bounded blob. But inside that blob are certainly inconsistencies; in particular the density is not everywhere the same. Is the lack of consistency a signal that there’s a model there? Does the market know about holes, for example? Maybe not, which would mean that the space of (profitable) models is perhaps better understood as a space whose basis consists of something like “holes in the instrument space”, rather than a dual.
This is verging on something like what CompTop is talking about. Maybe. I’ll have to go read what they’re doing now.
David Graeber on Occupy Wall Street
Could I love David Graeber any more? He wrote a fantastic book which I’ve blogged about here just in case you missed it.
Check out his account, cross posted from Naked Capitalism, on being one of the original Occupiers of Wall Street (I feel like I should have guessed this but I didn’t).
I hope he gets onto the Alternative Banking working group.
Alternative Banking System
I just got invited to join the Alternative Banking System working group from Occupy Wall Street. It’s run by Carne Ross, who has written a book called the Leaderless Revolution. I’m excited to meet the group this coming weekend. It looks like there will be many interesting and unconventional thinkers there.
I got back last night from my Cambridge, where I spoke to people about doing math in business. I will write up my notes from that talk soon and post them, and they will include my suggestions for how to prepare yourself to be a data scientist if you’re an academic mathematician. This is a first stab at a longer term project I have to define a possible “data science curriculum”.
What is a Credit Union? (#OWS)
This is a guest post by FogOfWar:
There’s been a call (associated with the “Occupy Wall Street” movement) for consumers to move their bank accounts from large TBTF banks into local credit unions. Nov. 5th is the target date. This is a similar message to one Arianna Huffington gave a few years back.
The above inspire a quick post on the subject of “What is a Credit Union and why is it different from a mega-bank?”
What can I do at a Credit Union?
Pretty much all the same stuff you can do at a bank. They have checking accounts (although they call them “share accounts”, it’s the same thing), savings accounts, CDs, credit cards, debit cards, auto loans, mortgages, lines of credit. All of the stuff a normal bank offers. Some of the smaller CUs (just like some of the smaller banks) don’t offer everything, but it’s substantially the same.
The only difference in services is that you generally can’t make investments (stocks, bonds, etc.) through your credit union. IMHO, this isn’t much of a downside, as the brokers associated with major banks generally aren’t as good as the standalone retail brokers (like Fidelity, Vanguard, TIAA-CREF, etc.)
The other difference is that you can’t just walk off the street and open a credit union account; you have to be eligible in their “field of membership” (more on that below).
How are the rates?
It varies, but in general you’ll get better rates at a credit union than at a bank (certainly than at a megabank). An easy way to check is to look at your checking account statement now (or call your bank) and see what the APY is (Annual Percentage Yield), and then check the credit union to see the APY on their basic share draft account.
There are credit unions with sucky rates out there (often the really small ones—they have a lot of operational costs), but I’ve usually found that I get better rates on savings and better rates on loans from a CU.
What’s the real difference?
The real difference is ownership. Banks are owned by outside investors—usually people who own the stock for a big bank—and they need to pay those owners a profit in the form of dividends (or share repurchases which are economically equivalent). Credit Unions are owned by their depositors (called “members”). That’s why the “checking account” is called a “share account”—you own a “share” (another name for stock) in the credit union. The board of directors is elected at an annual meeting, one person, one vote. BoD members are not paid for serving on the board.
This also explains why Credit Unions can offer better rates: they don’t have to pay a profit to their stockholders, instead that “profit” is returned back to you, the owners. Note that CUs are also exempt from corporate tax, and this makes some difference, but IMHO, it’s the absence of needing to pay dividends that really gives CUs the ability to pay better rates to their customer/owners.
Am I supporting the community when I deposit with a Credit Union?
There’s a good argument that yes, you are. Credit Union’s make loans back to the people in their membership. So the money you put on deposit is being leant back to people in the community of the credit union. Credit unions don’t trade derivatives or run speculative investment books. By and large they make loans to members and then hold on to those loans (i.e., they don’t “securitize” those loans out to other people).
For those who know the movie It’s a Wonderful Life, it’s a pretty good description of how a credit union can work within a community. Technically the movie describes a Thrift (somewhat similar), but it could just as easily been about a CU.
Who is eligible to join a Credit Union?
Each credit union has a “field of membership”. Some are employment-based, so you are eligible if you or an immediate family member works at a certain place. For example, NBC has a credit union for its NY employees. Note that NBC does not own the credit union, the CU is owned by its members (one person, one vote), it’s just that the credit union is there for NBC employees.
Some credit unions are associational. A good example of this is church credit unions (which are pretty common). There are also Community Development Credit Unions, which are set in lower-income areas and anyone in the area can join (Lower East Side People’s FCU is a good example).
There are a number of educational credit unions—these vary, but often faculty, students, employees and alumni are all eligible to join. Again, note that the university does not own the credit union—the CU is owned by the members—it’s just the prerequisite to join that particular credit union.
How do I find a credit union I can join?
There are some “credit union locators” online, but the one’s I’ve seen kinda suck. I’d say try a Google search. So if you live in Boise, I’d search for “Boise Credit Unions”. You can also try www.ncua.gov, which will give you all the credit unions in a particular area. I tend to like the larger credit unions (at least $20m in assets), as they tend to have hit a size where they’re operationally more together (making mistakes on your money is no fun).
You can also ask at the HR department at your job “hey, does working here make me eligible to join a credit union?” If they say “no”, you can say “why not? Is anyone working on having us join up with a good CU?”
Are there any downsides?
There aren’t a lot of ATMs, so every time you need cash & use a bank ATM, you’ll be paying that ridiculous fee. This can definitely suck, although one way around it is to have a debit card and take cash back all the time when you buy stuff (there’s no charge for taking cash back on a debit card—it’s just a question of whether the merchant lets you do it, and most supermarkets and drug stores do).
Also, this makes depositing paper checks a pain in the ass: you actually have to put them in an envelope and mail them to the credit union. How did society function before we had the internet?
Also, if it’s a work credit union, you can check to see if they have a branch at your office—this can make things a lot easier.
Anyway, that’s a quick rundown. Sure I missed something, but I’ll drop it in the comments if I remember later.
Here’s a flyer I made for OWS which contains information on a few credit unions in New York City:
FoW
Datadive update
I left my datadive team at 9:15pm last night hard at work, visualizing the data in various ways as well as finding interesting inconsistencies. I will try to post some actual results later, but I want to wait for them to be (somewhat) finalized. For now I can make some observations.
- First, I really can’t believe how cool it is to meet all of these friendly and hard-working nerds who volunteered their entire weekend to clean and dig through data. It’s a really amazing group and I’m proud of how much they’ve done.
- Second, about half of the data scientists are women. Awesome and unusual to see so many nerd women outside of academics!
- Third, data cleaning is hard work and is a huge part of the job of a data scientist. I should never forget that. Having said that, though, we might want to spend some time before the next datadive pre-cleaning and formatting the data so that people have more time to jump into the analytics. As it is we learned a lot about data cleaning as a group, but next time we could learn a lot about comparing methodology.
- Statistical software packages such as Stata have trouble with large (250MB) files compared to python, probably because of the way they put everything into memory at once. So it’s cool that everyone comes to a datadive with their own laptop and language, but some thought should be put into what project they work on depending on this information.
- We read Gelman, Fagan and Kiss’s article about using the Stop and Frisk data to understand racial profiling, with the idea that we could test it out on more data or modify their methodology to slightly change the goal. However, they used crime statistics data that we don’t have and can’t find and which are essential to a good study.
- As an example of how crucial crime data like this is, if you hear the statement, “10% of the people living in this community are black but 50% of the people stopped and frisked are black,” it sounds pretty damning, but if you add “50% of crimes are committed by blacks” then it sound less so. We need that data for the purpose of analysis.
- Why is crime statistics data so hard to find? If you go to NYPD’s site and search for crime statistics, you get really very little information, which is not broken down by area (never mind x and y coordinates) or ethnicity. That stuff should be publicly available. In any case it’s interesting that the Stop and Frisk data is but the crime stats data isn’t.
- Oh my god check out our wiki, I just looked and I’m seeing some pretty amazing graphics. I saw some prototypes last night and I happen to know that some of these visualizations are actually movies, showing trends over time. Very cool!
- One last observation: this is just the beginning. The data is out there, the wiki is set up, and lots of these guys want to continue their work after this weekend is over. That’s what I’m talking about.
NYCLU: Stop Question and Frisk data
As I mentioned yesterday, I’m the data wrangler for the Data Without Borders datadive this weekend. There are three N.G.O.’s participating: NYCLU (mine), MIX, and UN Global Pulse. The organizations all pitched their data and their questions last night to the crowd of nerds, and this morning we are meeting bright and early (8am) to start crunching.
I’m particularly psyched to be working with NYCLU on Stop and Frisk data. The women I met from NYCLU last night had spent time at Occupy Wall Street the previous day giving out water and information to the protesters. How cool!
The data is available here. It’s zipped in .por format, which is to say it was collected and used in SPSS, a language that’s not open source. I wanted to get it into csv format for the data miners this morning, but I have been having trouble. Sometimes R can handle .por files but at least my install of R is having trouble with the years 2006-2009. Then we tried installing PSPP, which is an open source version of SPSS, and it seemed to be able to import the .por files and then export as csv, in the sense that it didn’t throw any errors, but actually when we looked we saw major flaws. Finally we found a program called StatTransfer, which seems to work (you can download a trial version for free) but unless you pay $179 for the package, it actually doesn’t transfer all of the lines of the file for you.
If anyone knows how to help, please make a comment, I’ll be checking my comments. Of course there could easily be someone at the datadive with SPSS on their computer, which would solve everything, but on the other hand it could also be a major pain and we could waste lots of precious analyzing time with formatting issues. I may just buckle down and pay $179 but I’d prefer to find an open source solution.
UPDATE (9:00am): Someone has SPSS! We’re totally getting that data into csv format. Next step: set up Dropbox account to share it.
UPDATE (9:21am): Have met about 5 or 6 adorable nerds who are eager to work on this sexy data set. YES!
UPDATE (10:02am): People are starting to work in small groups. One guy is working on turning the x- and y-coordinates into latitude and longitude so we can use mapping tools easier. These guys are awesome.
UPDATE (11:37am): Now have a mapping team of 4. Really interesting conversations going on about statistically rigorous techniques for human rights abuses. Looking for publicly available data on crime rates, no luck so far… also looking for police officer id’s on data set but that seems to be missing. Looking also to extend some basic statistics to all of the data set and aggregated by months rather than years so we can plot trends. See it all take place on our wiki!
UPDATE (12:24pm): Oh my god, we have a map. We have officer ID’s (maybe). We have awesome discussions around what bayesian priors are reasonable. This is awesome! Lunch soon, where we will discuss our morning, plan for the afternoon, and regroup. Exciting!
UPDATE (2:18pm): Nice. We just had lunch, and I managed to get a sound byte about every current project, and it’s just amazing how many different things are being tried. Awesome. Will update soon.
UPDATE (7:10pm): Holy shit I’ve been inside crunching data all day while the world explodes around me.
Data Without Borders: datadive weekend!
I’m really excited to be a part of the datadive this weekend organized by Data Without Borders. From their website:
Selected NGOs will work with data enthusiasts over the weekend to better understand their data, create analyses and insights, and receive free consultations.
I’ve been asked to be a “data wrangler” at the event, which means I’m going to help project manage one of the projects of the weekend, which is super exciting. It means I get to hear about cool ideas and techniques as they happen. We’re expecting quite a few data scientists, so the amount of nerdiness should be truly impressive, as well as the range of languages and computing power. I’m borrowing a linux laptop since my laptop isn’t powerful enough for the large data and the crunching. I’ve got both python and R ready to go.
I can’t say (yet) who the N.G.O. is or what exactly the data is or what the related questions are, but let me say, very very cool. One huge reason I started this blog was to use data science techniques to answer questions that could actually really matter to people. This is my first real experience with that kind of non-commercial question and data set, and it’s really fantastic. The results of the weekend will be saved and open.
I’ll be posting over the weekend about the project as well as showing interim results, so stay tuned!
Wall Street and the protests
Today I want to update you on my involvement with the Occupy Wall Street protest and also make an observation about the defensive behavior we see by the Wall Streeters themselves.
Update
Yesterday after work I went back to the protests and looked around to offer a teach-in. Unfortunately it hadn’t been sufficiently organized: the contact who had originally invited me wasn’t around, and hadn’t confirmed with me on email, and nobody else knew anything. It was also very windy, threatening rain, and the noise of the drumming was overbearing. There were drumming circles on two of the four corners of the square, and in the other two corners there were already meetings going on. It would be great if the protests could restrict the drumming area so that people could actually talk.
However, I kind of suspected this would happen, so I wasn’t disappointed. I handed out some flyers with a few friends that met me down there, and I met a few new really interesting and engaging people. I got re-invited to give a teach-in by a very nice man named Rock, who took my information. Rock suggested a daytime talk sometime around noon, and this sounds about right. Hopefully this will pan out, but even if it doesn’t now I have a flyer to distribute and it’s a conversation starter if nothing else. One of my friends also suggested having a t-shirt made with the phrase, “ask me about the financial system” printed on it. I think this is a great idea. I will go back down and be involved when I can make the time.
Also, I wanted to share Matt Taibbi’s column about the protest. His five top demands have a lot in common with the ones we came up with here.
Act Crazy
You know how some people win fights even though they’re not big or strong? They act totally crazy and angry, and it works because it confuses their opponents. This is what I think the tactic of the big bosses on Wall Street is right now. They’ve got Tim Geithner talking about it:
“They react to what is pretty modest, common sense observations about the system as if they are deep affronts to the dignity of their profession. And I don’t understand why they are so sensitive,” Geithner said at a forum hosted by The Atlantic and the Aspen Institute.
We’ve also seen Paul Krugman address this:
Last year, you may recall, a number of financial-industry barons went wild over very mild criticism from President Obama. They denounced Mr. Obama as being almost a socialist for endorsing the so-called Volcker rule, which would simply prohibit banks backed by federal guarantees from engaging in risky speculation. And as for their reaction to proposals to close a loophole that lets some of them pay remarkably low taxes — well, Stephen Schwarzman, chairman of the Blackstone Group, compared it to Hitler’s invasion of Poland.
The overall idea is to act like they are the victims somehow. Actually there’s another article in Bloomberg about the Wall St suffering, which I find fascinating as a phrase, and which contains passages like this one:
Bankers aren’t optimistic about those gains. Options Group’s Karp said he met last month over tea at the Gramercy Park Hotel in New York with a trader who made $500,000 last year at one of the six largest U.S. banks.
The trader, a 27-year-old Ivy League graduate, complained that he has worked harder this year and will be paid less. The headhunter told him to stay put and collect his bonus.
Here’s the thing. They are suffering, in exactly the same way that a child who is spoiled suffers when they are told they can’t get a toy in a store that they want even though they have one at home just like it. But that’s not real need, that’s a temper tantrum. It’s the parents’ responsibility to ignore that kind of posturing and establish reasonable expectations. But the analogy becomes kind of painful here, because who are the parents?
I guess you’d want them to be the government, or the regulators, but the problem is that those groups have shown the same lack of imagination (or fear) of a new world as the people on Wall Street.
So even though the protests are disorganized and sometimes annoying, the very fact that they are putting pressure on the system to fundamentally change is why I will continue to support them.

Bayesian regressions (part 2)
In my first post about Bayesian regressions, I mentioned that you can enforce a prior about the size of the coefficients by fiddling with the diagonal elements of the prior covariance matrix. I want to go back to that since it’s a key point.
Recall the covariance matrix represents the covariance of the coefficients, so those diagonal elements correspond to the variance of the coefficients themselves, which is a natural proxy for their size.
For example, you may just want to make sure the coefficients don’t get too big, or in other words there’s a penalty for large coefficients. Actually there’s a name for just having this prior, and it’s called L2 regularization. You just set the prior to be 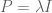
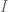

You’re going to end up adding this prior to the actual sample covariance matrix as measured by the data, so don’t worry about the prior matrix being invertible (but definitely do make sure it’s symmetrical).

Moreover, you can have many different priors, corresponding to different parts of the covariance matrix, and you can add them all up together to get a final prior.

From my first post, I had two priors, both on the coefficients of lagged values of some time series. First, I expect the signal to die out logarithmically or something as we go back in time, so I expect the size of the coefficients to die down as a power of some parameter. In other words, I’ll actually have two parameters: one for the decrease on each lag and one overall tuning parameter. My prior matrix will be diagonal and the 
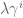
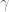
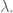
My second prior was that the entries should vary smoothly, which I claimed was enforceable by fiddling with the super and sub diagonals of the covariance matrix. This is because those entries describe the covariance between adjacent coefficients (and all of my coefficients in this simple example correspond to lagged values of some time series).
In other words, ignoring the variances of each variable (since we already have a handle on the variance from our first prior), we are setting a prior on the correlation between adjacent terms. We expect the correlation to be pretty high (and we can estimate it with historical data). I’ll work out exactly what that second prior is in a later post, but in the end we have two priors, both with tuning parameters, which we may be able to combine into one tuning parameter, which again determines the strength of the overall prior after adding the two up.
Because we are tamping down the size of the coefficients, as well as linking them through a high correlation assumption, the net effect is that we are decreasing the number of effective coefficients, and the regression has less work to do. Of course this all depends on how strong the prior is too; we could make the prior so weak that it has no effect, or we could make it so strong that the data doesn’t effect the result at all!
In my next post I will talk about combining priors with exponential downweighting.
Koo: don’t be surprised by the crappy economy
First I wanted to thank you for the wonderful comments I’ve been enjoying and compiling from my last post about what’s corrupt about the financial system and what should be done about it. Even if I don’t end up doing the teach-in (hopefully I will! In any case I’ll go down there, even if it’s just to try to set up the teach-in for a later date) I think this is a really fantastic and important discussion. I’m putting together a final list of issues tonight and I think I’ll make a flyer to bring tomorrow, so if I don’t actually conduct the teach-in (yet) I’ll at least be able to give the info booth the flyers.
And it’s not too late! Please keep the comments coming.
Today I want to start a discussion on Richard Koo’s book, which is about Japan’s so-called “lost decade” (a reader suggested this book to me, and it’s fascinating, so thanks! And please feel free to make more suggestions for my reading list).
You can actually get a pretty good overview of his book by watching this excellent interview by Koo. For those of you, like me, whose sound doesn’t work on their computers, here’s his basic thesis:
- After the housing bubble in Japan burst, a bunch of firms, banks and otherwise, became technically insolvent. This meant that, although they had cash flow, they owed more than their assets.
- Because they were insolvent, they didn’t maximize profits like in normal times; instead they minimized debts.
- In other words, they didn’t borrow money to grow their businesses, like you’d expect in normal circumstances, which is proved by looking at data showing that corporate borrowing went down even as interest rates lowered to zero.
- The CEO’s didn’t talk about this because they don’t want anyone to know they’re insolvent!
- Investors are also somewhat blind to this, because they typically look at growth and cash flow issues.
- Japan’s government made massive investments in order to cover the lack of private investments.
- Rather than this being a mistake, this was absolutely essential to the Japanese economy and prevented a massive depression.
- Moreover, the idea that Japan had a lost decade is false: actually, there was a lot going on in that decade (actually, 15 years) but people didn’t see it. Namely, the balance sheets were slowly improved over the entire economy.
- This is a lesson for us all: any time there’s a massive credit bubble which breaks, we can expect a balance sheet recession where behavior like this is the rule. The U.S. economy right now is an example of this.
I have a few comments about this. I wanted to mention that I’m only about halfway through the book so it’s possible that Koo addresses some of these issues but on the other hand the book was published in 2009 but was clearly written before the U.S. credit crisis was really full-blown:
- A friend of mine who recently traveled to Japan noted that the people there live extremely well. In fact, if he hadn’t been told that their country has been in recession for nearly twenty years then he’d have never guessed it. This supports Koo’s claim that the Japanese government absolutely did the right thing by bankrolling the economy when it did. It also brings up a very basic question: how do we measure success? And why do we listen to economists when they tell us how to define success?
- Not every country can do what Japan did in terms of investing in its economy, although the U.S. probably can. In other words, it depends on how other countries see your credit risk whether you can go ahead and bail out an entire economy.
- Some of the businesses in the U.S. are clearly not technically insolvent; we’ve already seen ample evidence of cash hoarding. On the other hand, I guess if sufficiently many are, then the overall environment can be affected like Koo describes.
- In general it makes me wonder, how many of the firms out there today are technically insolvent? How insolvent? How long will it take for those that are to either fail outright or pay back their loans? If we go by this article, then the answer is pretty alarming, at least for the banks.
In general I like Koo’s book in that it introduces a new paradigm which explains something as totally self-evident that had been mysterious. It’s pretty bad news for us, though, for two reasons. First, it means we could be in this (by which I mean stagnant growth) for a long, long time, and second, considering the hyperbolic political situation, it’s not clear that the government will end up responding appropriately, which means we may be in it for even longer.




{kind=link}