Everyone has a crush on me
So I have been getting some feedback lately on how I always assume everyone has a crush on me. People know this is my typical assumption because I say things like, “oh yeah that guy totally has a crush on me.” And when I say “feedback,” what I mean is people joyfully accusing me of lying, or maybe just outraged by my preposterous claims, usually in a baffled and friendly manner. Just a few comments about this.
First of all, I also have a crush on everyone else. Just as often as I say “that lady has a crush on me,” I am known to say, “Oh my god I have a huge crush on her.” It’s more fun that way!
Second of all, there are all sorts of great consequences of thinking someone has a crush on you. To name a few:
- It’s not a sexual thing at all, it’s more like a willingness to think the other person is super awesome. I have crush on all sorts of people, men and women, etc. etc.. No categories left uncrushed except meanies.
- When you act like someone has a crush on you, they are more likely to develop a crush on you. This is perhaps the most important point and should be first, but I wanted to get the first point out of the way. It’s what I call a positive feedback loop.
- It makes you feel great to be around someone if they have a crush on you, or even if you just think they do.
- What’s the worst thing that can happen? Answer: that you’re wrong, and they don’t have a crush on you, but then they’ll just walk away thinking that you were weirdly happy to see them, which is not so bad, and may in fact make them crush out on you. See what I mean?
- It’s a nice world to live in where a majority of the people you run into have a crush on you. Try it and see for yourself!
The platonic solids
I managed to record this week’s Slate Money podcast early so I could drive up to HCSSiM for July 17th, and the Yellow Pig Day celebration. I missed the 17 talk but made it in time for yellow pig carols and cake.
This morning my buddy Aaron decided to let me talk to the kids in the last day of his workshop. First Amber is working out the formula for the Euler Characteristic of a planar graph with the kids and after that I’ll help them count the platonic solids using stereographic projection. If we have time we’ll talk about duals (update: we had time!).

I can never remember which one is the icosahedron.
Tonight at Prime Time I’ll play a game or two of Nim with them.
The future of work
People who celebrate the monthly jobs report getting better nowadays often forget to mention a few facts:
- the new jobs are often temporary or part-time, with low wages
- the old lost jobs, which we lose each month, were often full-time with higher wages
I could go on, and I have, and mention the usual complaints about the definition of the unemployment rate. But instead I’ll take a turn into a thought experiment I’ve been having lately.
Namely, what is the future of work?
It’s important to realize that in some sense we’ve been here before. When all the farming equipment got super efficient and we lost agricultural jobs by the thousands, people swarmed to the cities and we started building things with manufacturing. So if before we had “the age of the farm,” we then entered into “the age of stuff.” And I don’t know about you but I have LOTS of stuff.
Now that all the robots have been trained and are being trained to build our stuff for us, what’s next? What age are we entering?
I kind of want to complain at this point that economists are kind of useless when it comes to questions like this. I mean, aren’t they in charge of understanding the economy? Shouldn’t they have the answer here? I don’t think they have explained it if they do.
Instead, I’m pretty much left considering various science fiction plots I’ve heard about and read about over the years. And my conclusion is that we’re entering “the age of service.”
The age of service is a kind of pyramid scheme where rich people employ individuals to service them in various ways, and then those people are paid well so they can hire slightly less rich people to service them, and so on. But of course for this particular pyramid to work out, the rich have to be SUPER rich and they have to pay their servants very well indeed for the trickle down to work out. Either that or there has to be a wealth transfer some other way.
So, as with all theories of the future, we can talk about how this is already happening.
I noticed this recent Bloomberg View article about how rich people don’t have normal doctors like you and me. They just pay out of pocket for super expensive service outside the realm of insurance. This is not new but it’s expanding.
Here’s another example of the future of jobs, which I should applaud because at least someone has a job but instead just kind of annoys me. Namely, the increasing frequency where I try to make a coffee date with someone (outside of professional meetings) and I have to arrange it with their personal assistant. I feel like, when it comes to social meetings, if you have time to be social, you have time to arrange your social calendar. But again, it’s the future of work here and I guess it’s all good.
More generally: there will be lots of jobs helping out old people and sick people. I get that, especially as the demographics tilt towards old people. But the mathematician in me can’t help but wonder, who will take care of the old people who used to be taking care of the old people? I mean, they by definition don’t have lots of extra cash floating around because they were at the bottom of the pyramid as younger workers.
Or do we have a system where people actually change jobs and levels as they age? That’s another model, where oldish people take care of truly old people and then at some point they get taken care of.
Of course, much like the Star Trek world, none of this has strong connection to the economy as it is set up now, so it’s hard to imagine a smooth transition to a reasonable system, and I’m not even claiming my ideas are reasonable.
By the way, by my definition most people who write computer programs – especially if they’re writing video games or some such – are in a service industry as well. Pretty much anyone who isn’t farming or building stuff in manufacturing is working in service. Writers, poets, singers, and teachers included. Hell, the future could be pretty awesome if we arrange things well.
Anyhoo, a whimsical post for Thursday, and if you have other ideas for the future of work and how that will work out economically, please comment.
Two great articles about standardized tests
In the past 12 hours I’ve read two fascinating articles about the crazy world of standardized testing. They’re both illuminating and well-written and you should take a look.
First, my data journalist friend Meredith Broussard has an Atlantic piece called Why Poor Schools Can’t Win At Standardized Testing wherein she tracks down the money and the books in the Philadelphia public school system (spoiler: there’s not enough of either), and she makes the connection between expensive books and high test scores.
Here’s a key phrase from her article:
Pearson came under fire last year for using a passage on a standardized test that was taken verbatim from a Pearson textbook.
The second article, in the New Yorker, is written by Rachel Aviv and is entitled Wrong Answer. It’s a close look, with interviews, of the cheating scandal from Atlanta, which I have been studying recently. The article makes the point that cheating is a predictable consequence of the high-stakes “data-driven” approach.
Here’s a key phrase from the Aviv article:
After more than two thousand interviews, the investigators concluded that forty-four schools had cheated and that a “culture of fear, intimidation and retaliation has infested the district, allowing cheating—at all levels—to go unchecked for years.” They wrote that data had been “used as an abusive and cruel weapon to embarrass and punish.”
Putting the two together, it’s pretty clear that there’s an acceptable way to cheat, which is by stocking up on expensive test prep materials in the form of testing company-sponsored textbooks, and then there’s the unacceptable way to cheat, which is where teachers change the answers. Either way the standardized test scoring regime comes out looking like a penal system rather than a helpful teaching aid.
Before I leave, some recent goodish news on the standardized testing front (hat tip Eugene Stern): Chris Christie just reduced the importance of value-added modeling for teacher evaluation down to 10% in New Jersey.
The Platform starts today
Hey my class starts today, I’m totally psyched!
The syllabus is up on github here and I prepared an iPython notebook here showing how to do basic statistics in python, and culminating in an attempt to understand what a statistically significant but tiny difference means, in the context of the Facebook Emotion study. Here’s a useless screenshot which I’m including because I’m proud:

If you want to follow along install anaconda on your machine and type “ipython notebook –pylab inline” into a terminal. Then you can just download this notebook and run it!
Most of the rest of the classes will feature an awesome guest lecturer, and I’m hoping to blog about those talks with their permission, so stay tuned.
Surveillance in NYC
There’s a CNN video news story explaining how the NYC Mayor’s Office of Data Analytics is working with private start-up Placemeter to count and categorize New Yorkers, often with the help of private citizens who install cameras in their windows. Here’s a screenshot from the Placemeter website:
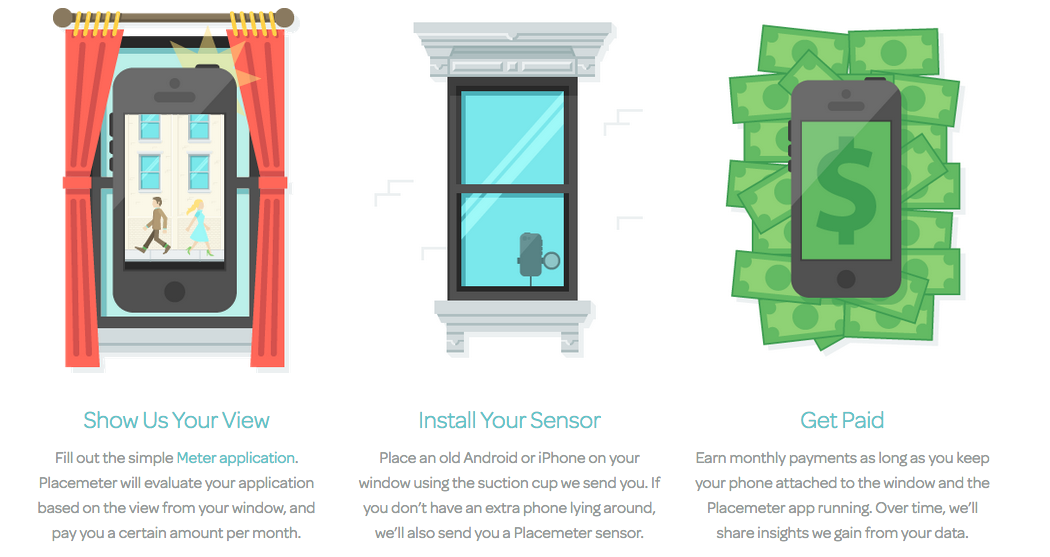
From placemeter.com
You should watch the video and decide for yourself whether this is a good idea.
Personally, it disturbs me, but perhaps because of my priors on how much we can trust other people with our data, especially when it’s in private hands.
To be more precise, there is, in my opinion, a contradiction coming from the Placemeter representatives. On the one hand they try to make us feel safe by saying that, after gleaning a body count with their video tapes, they dump the data. But then they turn around and say that, in addition to counting people, they will also categorize people: gender, age, whether they are carrying a shopping bag or pushing strollers.
That’s what they are talking about anyway, but who knows what else? Race? Weight? Will they use face recognition software? Who will they sell such information to? At some point, after mining videos enough, it might not matter if they delete the footage afterwards.
Since they are a private company I don’t think such information on their data methodologies will be accessible to us via Freedom of Information Laws either. Or, let me put that another way. I hope that MODA sets up their contract so that such information is accessible via FOIL requests.
Aunt Pythia’s advice
Aunt Pythia welcomes you after one week away celebrating her middle son’s and the nation’s birthday. She’s not sure she will be able to incorporate such a topic into the Q&A so she’s jumping on the opportunity to spread the love emanating from this video (hat tip Mike Hill):
It comes from this webpage entitled Putting the Crotch Into Crochet which you really need to check out if the above video titillates, which really how could it not.
To business! Aunt Pythia is doing a speed round today, after grabbing her oldest from a JFK redeye and before making said son his favorite breakfast of banana and chocolate chip pancakes.
You ready? Strap on your seat belts, we’re still driving the luxury Winnebego!
Without further ado, let’s begin. And please, after enjoying the on-board cheese and cracker snacks, do your best to
think of something to ask Aunt Pythia at the bottom of the page!
By the way, if you don’t know what the hell Aunt Pythia is talking about, go here for past advice columns and here for an explanation of the name Pythia.
——
Dear Aunt Pythia,
Seven years ago I was diagnosed with a brain tumor. It’s grow in back four times since, once during chemotherapy. Doctors consistently toss around words like “inevitable” and “incurable” when talking about my tumor and its recurrence.
But still, I have probably at least a decade, maybe more, depending on how medical science goes. And that’s a long time to spend alone.
But when I go out on dates, I feel like I’m leading women on by not disclosing my potential expiration date. When in a relationship would you recommend revealing this key fact?
Not Left Brained
Dear NLB,
First of all, I am sorry this is happening to you, it sucks.
Second of all, this is your private information, and you have no obligation to tell people private stuff before you’re ready. When you go on a date with someone, that’s merely an offer to spend an evening with someone, and most people don’t think beyond that 4 hour obligation, nor should you.
At the same time, you do have the obligation to not mislead, as everyone does. So third of all, that means that you wouldn’t want to start living with someone or otherwise get serious without them knowing your status.
I imagine this kind of thing comes up almost immediately in relationships, possible even as soon as the first date, when a woman might ask you if you want children. My suggestion is to tell her, or anyone else mentioning long term plans, that you don’t have long-term plans for anything, nor are you expecting to. That is sufficiently vague – yet also sufficiently transparent – so nobody would accuse you of being misled. Women who want kids, say, or to get married, will interpret that appropriately. It will also sort out people who hang out with you simply to enjoy your company, which I assume is what you’re going for.
Good luck!
Aunt Pythia
——
Dear Auntie P,
I’m a woman in a graduate program which is heavily female-dominated (so not math, clearly). Like most grad students, I’ve got some dear friends and some real stinkers in my cohort, with plenty in between.
I was having lunch this week with one of the newer students, “Belle”, in the program. Ostensibly this was a working lunch, but somehow Belle managed to squeeze in the fact that she was in a new and exciting relationship with another woman in the program, “Linda”.
The problem is that I’m much better friends with Linda than I am with Belle, and Linda isn’t out. To anyone (or at least anyone in the program), including me. Well, until now.
How do I handle this? Do I gently inform Belle that Linda is closeted and she needs to get her approval before outing her, even to her friends? Or do I hope that she notices on her own what she’s doing, and notices before she does something damaging? Also, when I’m around Linda, do I continue to act as if I know nothing about her sexuality? (Honestly, this isn’t that hard, since her personal life is not something she brings up much.) Also, when I’m in a social situation where both of them are present, do I act as if I don’t know they’re together (and be awkward towards Belle) or as if I do (thus putting Linda in a bind)?
Closets Inform Every Lunch I Take Out
Dear CIELITO,
Nice sign-off! I had to use a Spanish dictionary, but I’m impressed.
OK so first I’ll give you good advice and then I’ll tell you what I’d do.
The good advice is to stay out of it and pretend you are oblivious. It’s really none of your business and you don’t want to get in the middle of something potentially messy.
The thing I’d do is tell Linda what happened, so she can address it with Belle if in fact it’s not what she wants. After all, Linda is your friend and she should know what’s going on.
Tell me what happens!
Auntie P
——
Dear Aunt Pythia,
I still wonder if brute force, generate and test is a viable method for discovering good parameter settings for a system. I don’t like how long the programs take to run, but they seem to provide good information. I assume that you would have a better idea, just because you probably would be in the “neat” perspective, while I am definitely, and in long standing, a “scruffy”.
Lost in Space
Dear Lost,
I have practically no idea what you’re talking about but I like people who call themselves both lost and a scruffy. As for brute force optimization, yes go ahead but remember to have a clean data set to test your parameters on, because you’re surely overfitting.
Aunt Pythia
——
Dear Aunt Pythia,
To what extent are women obliged to “stand and fight” when working in fields that are male-dominated and where they feel slighted on a regular basis? I am tired of seeing people to go my male colleagues for information in which I have superior expertise, for example. And god forbid you should be a woman working in computational/applied mathematics since applied math is already looked down upon. Even male TA’s are disrespectful.
On the one hand, if all the women are pushed away, we have no women to serve as role models for the next generation. On the other, each of us has only one life to live. I feel that I deserve to be happy, deserve to be respected, and so on.
I am pretty fed up. I don’t want to become one of the bitter and bitchy ones, and I don’t want to give up my career goals. Any thoughts?
Woman in Computing
Dear WiC,
There is absolutely no obligation at all to stand and fight, by any woman or man, whatsoever. It’s a silly argument that one should role model for a position that’s miserable. It’s almost ludicrously bait and switch, in fact.
Having said that, there’s usually a reason that people are competitive with each other. In business it’s almost always about money (or status, but those two are highly correlated). In academics it’s all about status, and men do it to each other as well, although the fight is dirtier when it’s directed towards women.
So, I’m not sure this will help, but if you see the fighting and competition as a direct product of the system, it might help you to take it less personally. Personally, I’ve been in so many different contexts, and I exist as such a threat against other people (both men and women), that I recognize sexist pushback almost as a sport (how does sexist pushback work in journalism? Oh, that’s how).
I’m not saying it never gets to me, because it does, but not for long. Because in the end it’s an external distraction, and staying external is always a mistake, just look at the dieting industry.
My best advice is to keep your eyes on the prize: figure out what your agenda is, and go for it. And don’t be surprised that, as you get closer to the goal, people will be more threatened, not less, and they will embarrass themselves with bad behavior. Don’t get distracted, because you have to stay internally focused.
In other words, it’s not about some vague obligation to society. It’s about a very real obligation towards yourself, which you set.
Good luck!
Aunt P
——
Please submit your well-specified, fun-loving, cleverly-abbreviated question to Aunt Pythia!
The Lede Program students are rocking it
Yesterday was the end of the first half of the Lede Program, and the students presented their projects, which were really impressive. I am hoping some of them will be willing to put them up on a WordPress site or something like that in order to showcase them and so I can brag about them more explicitly. Since I didn’t get anyone’s permission yet, let me just say: wow.
During the second half of the program the students will do another project (or continue their first) as homework for my class. We’re going to start planning for that on the first day, so the fact that they’ve all dipped their toes into data projects is great. For example, during presentations yesterday I heard the following a number of times: “I spent most of my time cleaning my data” or “next time I will spend more time thinking about how to drill down in my data to find an interesting story”. These are key phrases for people learning lessons with data.
Since they are journalists (I’ve learned a thing or two about journalists and their mindset in the past few months) they love projects because they love deadlines and they want something they can add to their portfolio. Recently they’ve been learning lots of geocoding stuff, and coming up they’ll be learning lots of algorithms as well. So they’ll be well equipped to do some seriously cool shit for their final project. Yeah!
In addition to the guest lectures I’m having in The Platform, I’ll also be reviewing prerequisites for the classes many of them will be taking in the Computer Science department in the fall, so for example linear algebra, calculus, and basic statistics. I just bought them all a copy of How to Lie with Statistics as well as The Cartoon Guide to Statistics, both of which I adore. I’m also making them aware of Statistics Done Wrong, which is online. I am also considering The Cartoon Guide to Calculus, which I have but I haven’t read yet.
Keep an eye out for some of their amazing projects! I’ll definitely blog about them once they’re up.
Great news: for-profit college Corinthian to close
I’ve talked before about the industry of for-profit colleges which exists largely to game the federal student loan program. They survive almost entirely on federal student loans of their students, while delivering terrible services and worthless credentials.
Well, good news: one of the worst of the bunch is closing its doors. Corinthian College, Inc (CCI) got caught lying about job placement of its graduates (in some cases, they said 100% when the truth was closer to 0%). They were also caught advertising programs they didn’t actually have.
But here’s what interests me the most, which I will excerpt from the California Office of the Attorney General:
CCI’s predatory marketing efforts specifically target vulnerable, low-income job seekers and single parents who have annual incomes near the federal poverty line. In internal company documents obtained by the Department of Justice, CCI describes its target demographic as “isolated,” “impatient,” individuals with “low self-esteem,” who have “few people in their lives who care about them” and who are “stuck” and “unable to see and plan well for future.”
I’d like to know more about how they did this. I’m guessing it was substantially online, and I’m guessing they got help from data warehousing services.
After skimming the complaint I’m afraid it doesn’t include such information, although it does say that the company advertised programs it didn’t have and then tricked potential students into filling out information about them so CCI could follow up and try to enroll them. Talk about predatory advertising!
Update: I’m getting some information by checking out their recent marketing job postings.
Zephyr Teachout to visit Alt Banking this Sunday
I’m excited to announce that Zephyr Teachout, a Fordham Law School professor who is running against Andrew Cuomo for Governor of New York, will be coming to speak to the Alternative Banking group next Sunday, July 13th, from 3pm-5pm in the usual place, Room 409 of the International Affairs Building at 118th and Amsterdam. More about Alt Banking on our website.
Title: Teachout-Wu vs. Cuomo-Hochul in the Democratic Primary in New York!
Description: Come hear candidate Teachout talk about her anti-corruption trust-busting campaign against Governor Cuomo.
Background: Teachout is an antitrust and media expert who served as the Director of Internet organizing for the 2004 Howard Dean Presidential Campaign. She co-founded A New Way Forward, an organization built to break up the power of big banks. Teachout was the first national director of the Sunlight Foundation. More here.
If we have time after talking to Zephyr we will discuss Stiglitz’s article, The Myth Of America’s Golden Age.
Please make time to come hear Zephyr, and please spread the word.
What constitutes evidence?
My most recent Slate Money podcast with Felix Salmon and Jordan Weissmann was more than usually combative. I mean, we pretty much always have disagreements, but Friday it went beyond the usual political angles.
Specifically, Felix thought I was jumping too quickly towards a dystopian future with regards to medical data. My claim was that, now that the ACA has motivated hospitals and hospital systems to keep populations healthy – a good thing in itself – we’re seeing dangerous side-effects involving the proliferation of health profiling and things like “health scores” attached to people much like we now have credit scores. I’m worried that such scores, which are created using data not covered under HIPAA, will be used against people when they try to get a job.
Felix asked me to point to evidence of such usage.
Of course, it’s hard to do that, partly because it’s just the beginning of such data collection – although the FTC’s recent report pointed to data warehouses that already puts people into categories such as “diabetes interest” – and also because it’s proprietary all the way down. In other words, web searches and the like are being legally collected and legally sold and then it’s legal to use risk scores or categories to filter job applications. What’s illegal is to use HIPAA-protected data such as disability status to remove someone from consideration for a job, but that’s not what’s happening.
Anyhoo, it’s made me think. Am I a conspiracy theorist for worrying about this? Or is Felix lacking imagination if he requires evidence to believe it? Or some combination? This is super important to me because if I can’t get Felix, or someone like Felix, to care about this issue, I’m afraid it will be ignored.
This kind of thing came up a second time on that same show, when Felix complained that the series of articles (for example this one from NY Magazine) talking about money laundering in New York real estate also lacked evidence. But that’s also tricky since the disclosure requirements on real estate are not tight. In other words, they are avoiding collecting evidence of money laundering, so it’s hard to complain there’s a lack of data. From my perspective the journalists investigating this article did a good job finding examples of laundering and showing it was easy to set up (especially in Delaware). But Felix wasn’t convinced.
It’s a general question I have, actually, and I’m glad to be involved with the Lede Program because it’s actually my job to think about this kind of thing, especially in the context of journalism. Namely, when do we require data – versus anecdotal evidence – to believe in something? And especially when the data is being intentionally obscured?
Critical Questions for Big Data by danah boyd & Kate Crawford
I’m teaching a class this summer in the Lede Program, starting in mid-July, which is called The Platform. Here’s the course description:
This course begins with the idea that computing tools are the products of human ingenuity and effort. They are never neutral and carry with them the biases of their designers and their design process. “Platform studies” is a new term used to describe investigations into these relationships between computing technologies and the creative or research products that they help to generate. How you understand how data, code, and algorithms affect creative practices can be an effective first step toward critical thinking about technology. This will not be purely theoretical, however, and specific case studies, technologies, and project work will make the ideas concrete.
Since my first class is coming soon, I’m actively thinking about what to talk about and which readings to assign. I’ve got wonderful guest lecturers coming, and for the most part the class will focus on those guest lecturers and their topics, but for the first class I want to give them an overview of a very large subject.
I’ve decided that danah boyd and Kate Crawford’s recent article, Critical Questions for Big Data, is pretty much perfect for this goal. I’ve read and written a lot about big data but even so I’m impressed by how clearly and comprehensively they have laid out their provocations. And although I’ve heard many of the ideas and examples before, some of them are new to me, and are directly related to the theme of the class, for example:
Twitter and Facebook are examples of Big Data sources that offer very poor archiving and search functions. Consequently, researchers are much more likely to focus on something in the present or immediate past – tracking reactions to an election, TV finale, or natural disaster – because of the sheer difficulty or impossibility of accessing older data.
Of course the students in the Lede are journalists, not academic researchers, which the article mostly addresses, and moreover they are not necessarily working with big data per se, but even so they are increasingly working with social media data, and moreover they are probably covering big data even if they don’t directly analyze it. So I think it’s still relevant to them. Or another way to express this is that one thing we will attempt to do in class is examine the extent to which their provocations are relevant.
Here’s another gem, directly related to the Facebook experiment I discussed yesterday:
As computational scientists have started engaging in acts of social science, there is a tendency to claim their work as the business of facts and not interpretation. A model may be mathematically sound, an experiment may seem valid, but as soon as a researcher seeks to understand what it means, the process of interpretation has begun. This is not to say that all interpretations are created equal, but rather that not all numbers are neutral.
In fact, what with this article and that case study, I’m pretty much set for my first day, after combining them with a discussion of the students’ projects and some related statistical experiments.
I also hope to invite at least one of the authors to come talk to the class, although I know they are both incredibly busy. Danah boyd, who recently came out with a book called It’s Complicated: the social lives of networked teens, also runs the Data & Society Research Institute, a NYC-based think/do tank focused on social, cultural, and ethical issues arising from data-centric technological development. I’m hoping she comes and talks about the work she’s starting up there.
Thanks for a great case study, Facebook!
I’m super excited about the recent “mood study” that was done on Facebook. It constitutes a great case study on data experimentation that I’ll use for my Lede Program class when it starts mid-July. It was first brought to my attention by one of my Lede Program students, Timothy Sandoval.
My friend Ernest Davis at NYU has a page of handy links to big data articles, and at the bottom (for now) there are a bunch of links about this experiment. For example, this one by Zeynep Tufekci does a great job outlining the issues, and this one by John Grohol burrows into the research methods. Oh, and here’s the original research article that’s upset everyone.
It’s got everything a case study should have: ethical dilemmas, questionable methodology, sociological implications, and questionable claims, not to mention a whole bunch of media attention and dissection.
By the way, if I sound gleeful, it’s partly because I know this kind of experiment happens on a daily basis at a place like Facebook or Google. What’s special about this experiment isn’t that it happened, but that we get to see the data. And the response to the critiques might be, sadly, that we never get another chance like this, so we have to grab the opportunity while we can.
Aunt Pythia’s advice
Aunt Pythia has missed you guys, and apologizes for the last two weeks of lost advice-giving opportunities. Her metaphorical advice bus broke down, but it’s back on the road again, it’s got a full tank of gas, and we’re ready to drive anywhere. It’s kind of a luxury winnebego advice bus today, I’m thinking. Here’s the exterior:

Action shot!
And here’s the interior, before the Aunt Pythia advice seekers get there:

The disco ball is currently recessed.
Aunt Pythia is either up in front, driving, or she’s reading her new and already beloved copy of The Cartoon Guide to Statistics by Larry Gonick and Wollcott Smith.
Without further ado, let’s begin. And please, after enjoying the on-board cheese and cracker snacks, do your best to
think of something to ask Aunt Pythia at the bottom of the page!
By the way, if you don’t know what the hell Aunt Pythia is talking about, go here for past advice columns and here for an explanation of the name Pythia.
——
Dear Aunt Pythia,
Thank you for publishing my responses to your Alternative Dating Questions a while back: that was fun! As for getting the “dog or cat” question wrong, it was probably the easiest of the ten for me to answer, on the grounds that when I was young, most of the local canine population decided to redress the “humans eat hotdogs” balance on me, even though I never liked the damned things myself. So I am prejudiced – but with good reason.
I’ve now tried out your questions on my friend Female And Remote And Well As Yummy, and these are her answers (and mine):
- 1.How sexual are you? (super important question) This morning – not very; Approx 8/10 (but sometimes only 2/10, and occasionally 11/10)
- How much fun are you? (people are surprisingly honest when asked this) 7/10; In the right company, this can reach 4/10
- How awesome do you smell? (might need to invent technology for this one) I smell fantastic; Only about 3/10, I’m afraid, but I could scrub up a bit
- What bothers you more: the big bank bailout or the idea of increasing the minimum wage? The big bank bailout; Neither – both bore me
- Do you like strong personalities or would you rather things stay polite? Strong personalities; I’d rather things stay polite?
- What do you love arguing about more: politics or aesthetics? Æsthetics [she didn’t actually answer with the ligatured a and e, but it’s a cultural difference we’ve discussed many times, so I felt justified in correcting her]; Politics, just
- Where would you love to visit if you could go anywhere? England; The Antarctic
- Do you want kids? Yes (I’m happy with those I’ve got); No
- Dog person or cat person? A cat person; A cat person
- Do you sometimes wish the girl could be the hero, and not always fall for the hapless dude at the end? Absolutely; Yes
So my question for you this week (if it’s not greedy to have another one so soon) is: Does Aunt Pythia think there is chemistry here? And if not, what does she think to the chances of at least a little physics?
Kind regards
Male And Deluded
Dear Male and Deluded,
A match made in heaven! First because you’re both cat people, and second because she agreed to fill out this ridiculous questionnaire, which she’d only do if she was interested, and which you’d only ask her to do if you were interested, the vital ingredient. I’d go easy on the spelling corrections though.
Just to be clear, though, the original point of the questionnaire was that normal dating site questions don’t actually supply you with useful information, and I thought we could improve them. So the real question is, after seeing her answers, are you more interested in her? I thought so.
Aunt Pythia
——
Dear Aunt Pythia,
I’m very sorry about the length of the last letter. I wasn’t in a very good way at the time of writing, and I understand if it wasn’t very comprehensible. I also managed to figure out the answer to my other question (I’m sticking with just doing as much physics as possible and hoping that my record in grad courses makes up for my previous idiocy. Hope you aren’t offended). I’ll keep this as concise as I’m capable of being.
The impossible happened. I have a girlfriend. Combined with my research starting to pick up, a possible end to my financial troubles, a grad school opportunity just peaking up on the horizon, and a good, if not perfect GPA this year (we’ll see), things are looking up. I’ve never felt this positive about my prospects in a while, in spite of the challenges I’m still facing. So, my frame of mind isn’t like it was last time, to be clear. I have two questions about my relationship:
1) I’m going to be in Germany for the summer doing research and we really haven’t been in a relationship for long. We are both a little worried about this and hope to keep going over the summer. Any suggestions for keeping the “flame” alive? She was coming off a pretty rough period when she met me, and was distraught when I was leaving, and I’ve never handled this before.
2) It all feels a little anticlimactic. Is that normal? Part of this might be my insights about life (I finally agreed to get therapy shortly after my first run in here, and it’s helped), about the fact that there is nothing wrong with being a loner and that I shouldn’t try to force myself to be otherwise. But part of it is I don’t feel as *crazy* about the person as I feel I would be about a girlfriend. It could be that what I feel should be isn’t realistic. Though I strongly enjoy her company (we’re both a little weird), I don’t even desire the sex like I thought I would. Is that normal for early relationships in life, when you are figuring everything out, or is there something else going on? I mean, I don’t plan on marrying her or anything, so isn’t that OK? I also occasionally worry about her stability and her place in life, than feel like a hypocrite because I just got some of those issues fixed.
Don’t take any of this to mean that I regret getting into the relationship, it has been a plus so far in my life.
PS: (you can cut this out if you want)
To clarify what I meant, Isaac Newton spent his entire life celibate and isolated. Sheen more than hasn’t and has probably had a lot more fun. Yet, I know who I’d rather be, and in my more misanthropic moments, I think Isaac Newton knew what he was doing. Sex is fun and should be encouraged. But ultimately, it pales in importance to other things. It’s so funny, it seems to be the worst of both worlds in America, with the sex-obsession and the puritanism simultaneously occurring.
I have a LOT of opinions and ideas for the world. Funny you mention the Ukraine, I’m ridiculously interested particularly about foreign policy/politics-I sometimes catch myself thinking about that when I need to do physics. I occasionally bore my girlfriend to tears. I had (have) a lot of problems socially, but believe me, that’s not one of them. Back when I was searching for a girlfriend, I tried to use these interests (foreign policy, literature, history, other cultures, supercomputers-the title I mentioned comes from a play) to meet people and became frustrated when it didn’t work out like I planned. I met the good lady on a dating website that I had long since given up on. The trouble is talking about mundane, day to day things or subjects that I have no interest in. When she wishes to talk about her field of interest, I try my best to hang on, but it can be tough.
Draußen vor der Tür
Dear Draußen,
Here’s the thing. Last time I cut out a bunch of your letter, but this time I left it all, except I did edit a bit (there are spaces before parentheses as well as after) to make things readable. I’m not sure why I’ve decided to do this except that I like to share my pain with my readers. I hope you appreciate this, readers!
A few things. First, congratulations on finding a girlfriend. As to whether the feeling of anti-climax is normal, I guess it depends on what exactly you expected but I’m afraid it isn’t very normal, at least not in my experience. I mean, falling in love is a rush, with dopamine and all that good stuff, so I’m going to guess you aren’t actually falling in love. Maybe your positive feelings are just relief that you’re no longer alone? That’s not the same thing.
Next, the thing about “I don’t plan on marrying her or anything, so …” makes me feel weird. Note I’m not suggesting that you should marry her, but even so it seems like you’re prematurely categorizing her as someone you won’t take seriously, which I think is strange and self-defeating. I might be wrong, and it’s quite possible I’m just responding to cultural norm which I don’t like, namely that men avoid commitment like it’s a punishment, but it just seems like, with that attitude you might not let the relationship succeed.
Finally, the last line of the letter: When she wishes to talk about her field of interest, I try my best to hang on, but it can be tough. This makes me think that either you are seriously one of the most single-minded people in the world, only interested in your immediate field, or you have very little respect for or common interest with your girlfriend, or some combination of those things. This is another red flag, but I’m not sure how you can address is besides looking for a girlfriend who works in the same field as you.
One last meta thing, and I hope I’m not being too tough on you, because you’ve obviously made progress.
I sense that you are someone who consistently sees things in terms of how they affect you. So, for example, you mention that the relationship “has been a plus so far in my life“. But if you are too self-absorbed, you will miss the two most crucial elements of successful relationships: first, enjoying making the other person happy and, what is the flip side of the same coin, feeling grateful that the other person will put up with you. I spend about half of my time being grateful that my partner puts up with me, which is probably not enough, and that gratitude makes my marriage work better.
Does that make sense? Can you be grateful for her patience with you, and can you take pleasure in making her feel secure and loved? If you can, and if you can do that consistently, then I don’t think your Germany trip will be too tough.
Good luck,
Aunt Pythia
——
Dear Aunt Pythia,
I’ve passed my stats PhD qualifying exams and have been meeting with an adviser for several months, but want to leave my PhD and become a Data Scientist (or something like that). The problem is I haven’t interned since acquiring my stats skills.
Should I apply for semester internships (these can be completed while taking a course or two and doing research at my program) and a summer 2015 internship and then leave my program (hopefully with a job secured)? Should I also be applying for jobs this coming school year? I’m hesitant to apply for jobs right now as I’d like to improve my computation skills and will be taking a Machine Learning course in the fall. Should I tell my adviser? I don’t want to have to leave the program yet as many internships require you to be in a grad program, and many jobs require past internship experience.
Thank you so much your time!
— Slightly Hyperventilating
Dear Slightly,
If I’m a company looking for a data scientist I’m super happy to hire you after you’ve passed your quals, taken Machine Learning, and acquired keen computational skills. So yes, it’s a great plan.
As for telling your advisor, I think it depends on what they are like and whether they think everyone should be an academic or at least strive to be. Maybe ask other students of this advisor who have left or stayed and see what advice they give?
Good luck, and tell me how it goes!
Aunt Pythia
——
Aunt Pythia,
Final exams (3rd year university) are around the corner and though I have studied throughout the year I feel I’m still falling short of knowing enough to pass these exams. I keep saying if I don’t pass my finals at least I can retake them but this doesn’t seem to calm my nerves.
Are there any suggestions you can offer to chill (please spare me the British prewar ‘keep calm…’ quotes)?
Thanks,
Anxious about failing
Dear Anxious,
My guess is this advice is coming a little late, but here it is anyway: get together with other students – more than one other, and on separate days – who are also studying for this test and ask them questions and have them ask you stuff. It will surprise you how much you already know and it will solidify your learning to explain stuff to other people.
Good luck!
Auntie P
——
Please submit your well-specified, fun-loving, cleverly-abbreviated question to Aunt Pythia!
We are not ready for health data mining
There have been two articles very recently about how great health data mining could be if we could only link up all the data sets. Larry Page from Google thinks so, which doesn’t surprise anyone, and separately we are seeing that the consequence of the new medical payment system through the ACA is giving medical systems incentives to keep tabs on you through data providers and find out if you’re smoking or if you need to fill up on asthma medication.
And although many would consider this creepy stalking, that’s not actually my problem with it. I think Larry Page is right – we might be able to save lots of lives if we could mine this data which is currently siloed through various privacy laws. On the other hand, there are reasons those privacy laws exist. Let’s think about that for a second.
Now that we have the ACA, insurers are not allowed to deny Americans medical insurance coverage because of a pre-existing condition, nor are they allowed to charge more, as of 2014. That’s good news on the health insurance front. But what about other aspects of our lives?
For example, it does not generalize to employers. In other words, a large employer like Walmart might take into account your current health and your current behaviors and possibly even your DNA to predict future behaviors, and they might decide not to give jobs to anyone at risk of diabetes, say. Even if medical insurance casts were taken out of the picture, which they haven’t been, they’d have incentives not to hire unhealthy people.
Mind you, there are laws that prevent employers from looking into HIPAA-protected health data, but not Acxiom data, which is entirely unregulated. And if we “opened up all the data” then the laws would be entirely moot. It would be a world where, to get a job, the employer got to see everything about you, including your future health profile. To some extent this is already happening.
Perhaps not everyone thinks of this as bad. After all, many people think smokers should pay more for insurance, why not also work harder to get a job? However, lots of the information gleaned from this data – even behaviors – have much more to do with poverty levels than circumstance than with conscious choice. In other words, it’s another stratification of society along the lucky/unlucky birth lottery spectrum. And if we aren’t careful, we will make it even harder for poor people to eke out a living.
I’m all for saving lives but let’s wait for the laws to catch up with the good intentions. Although to be honest, it’s not even clear how the law should be written, since it’s not clear what “medical” data is nowadays nor how we could gather evidence that a private employer is using it against someone improperly.
Unsolicited advice about having kids
You know how it’s better to have a discussion with someone when you’re calm and they haven’t just done something that drives you absolutely nuts? Well I’m going to generalize to the parenting advice realm: best time to give parenting advice is not when you’ve just seen a kid get poorly parented or a parent stress out about stupid stuff. Best time is when you’re alone in your pajamas, nowhere near other people’s kids. That way those of you who have kids won’t feel defensive.
Also, here’s another rule about parenting advice: never take parenting advice from anyone, because the people who are actually eager to give it are usually super weird. Look at Tiger Mom as Exhibit A.
In spite of that very wise second rule, I’ma go ahead and give some advice that’s pretty good, if I do say so myself in my own weird way.
- Before having kids, think of all the reasons not to. They’re loud, expensive, and they weigh you down immensely. You will never be able to stay up with friends after 10pm again if you do it. So don’t do it.
- Unless… unless you just absolutely cannot help it because of all those freaking hormones and how cute they look in summer dresses (boys included, yes, they don’t care, they’re babies). Then do it, but think hard and plan well for the noise, the expense, and the inconvenience.
- In terms of how you parent a baby: think long-term about stuff. Are you gonna want to get up a million times every night for the rest of your life? No, you’re not. So figure out how to get the damn baby to sleep through the night. This cannot be forced until the kid is 6 months or so, and the moment you can manipulate their sleep is characterized by the moment they can try to manipulate their sleep and stay awake to hang out with you. That’s when you start the 6pm bedtime ritual, including songs and books and 6:30 lights out. They will cry for like 10 minutes three nights in a row and after that you will be golden. Long term thinking, remember. Even if they cry for an hour, it’s an investment for a lifetime, namely yours.
- In terms of how you parent a little kid: think super long-term about stuff. Don’t raise your voice unless they are doing something actually dangerous, like walking into traffic or sticking a fork into an outlet. Make sure you let them get really dirty and try to eat weird things, too – their tongues are like extra hands at this age, it helps them explore the world. The only thing a little kid really needs is regular meals and a 6 or maybe 7pm bedtime ritual. They can spend 2 hours ripping up a newspaper for entertainment. Once a week baths would be good.
- In terms of how you parent a school age kid: think super duper long-term about stuff. If you do their homework for them, they will never do it themselves. So let them figure that out, but do remind them to do it if they’re forgetful. If you structure all their time, they will never figure out what they love to do, so make sure they get bored sometimes. Keep lots of good books and nerdy puzzles and interesting people around the house but don’t make them “do math” with you unless they ask for it. Don’t make them take music lessons. Instead, wait for them to beg for music lessons, and then say no for a while until you’re really sure they want them. Don’t just tell them to be nice, exhibit nice behavior to them and to others in front of them. Reward them for pointing out your hypocrisies, and make them watch Star Trek: The Next Generation (or equivalent) with you for its moral education and for the popcorn, and have fun listening to them pointing out the bad physics. And the most important of all: enjoy them and have fun with them, because that’s the best kind of way to role model for your kids, plus it’s fun, and they’re people who will move away pretty soon and you’ll miss them.
- In terms of how you parent an older kid, I have no idea because my oldest kid is 14. But so far we’re having a blast. I’m pretty sure they’re already mostly raised in terms of my role anyway by the time they’re 12.
One last, general thing for today’s anxious parents: don’t feel guilty, you’re doing your best. Guilt is a waste of time and gets in the way of enjoying the popcorn.
The dark matter of big data
A tiny article in The Cap Times was recently published (hat tip Jordan Ellenberg) which describes the existence of a big data model which claims to help filter and rank school teachers based on their ability to raise student test scores. I guess it’s a kind of pre-VAM filtering system, and if it was hard to imagine a more vile model than the VAM, here you go. The article mentioned that the Madison School Board was deliberating on whether to spend $273K on this model.
One of the teachers in the district wrote her concerns about this model in her blog and then there was a debate at the school board meeting, and a journalist covered the meeting, so we know about it. But it was a close call, and this one could have easily slipped under the radar, or at least my radar.
Even so, now I know about it, and once I looked at the website of the company promoting this model, I found links to an article where they name a customer, for example in the Charlotte-Mecklenburg School District of North Carolina. They claim they only filter applications using their tool, they don’t make hiring decisions. Cold comfort for people who got removed by some random black box algorithm.
I wonder how many of the teachers applying to that district knew their application was being filtered through such a model? I’m going to guess none. For that matter, there are all sorts of application screening algorithms being regularly used of which applicants are generally unaware.
It’s just one example of the dark matter of big data. And by that I mean the enormous and growing clusters of big data models that are only inadvertently detectable by random small-town or small-city budget meeting journalism, or word-of-mouth reports coming out of conferences or late-night drinking parties with VC’s.
The vast majority of big data dark matter is still there in the shadows. You can only guess at its existence and its usage. Since the models themselves are proprietary, and are generally deployed secretly, there’s no reason for the public to be informed.
Let me give you another example, this time speculative, but not at all unlikely.
Namely, big data health models arising from the quantified self movement data. This recent Wall Street Journal article entitled Can Data From Your Fitbit Transform Medicine? articulated the issue nicely:
A recent review of 43 health- and fitness-tracking apps by the advocacy group Privacy Rights Clearinghouse found that roughly one-third of apps tested sent data to a third party not disclosed by the developer. One-third of the apps had no privacy policy. “For us, this is a big trust issue,” said Kaiser’s Dr. Young.
Consumer wearables fall into a regulatory gray area. Health-privacy laws that prevent the commercial use of patient data without consent don’t apply to the makers of consumer devices. “There are no specific rules about how those vendors can use and share data,” said Deven McGraw, a partner in the health-care practice at Manatt, Phelps, and Phillips LLP.
The key is that phrase “regulatory gray area”; it should make you think “big data dark matter lives here”.
When you have unprotected data that can be used as a proxy of HIPAA-protected medical data, there’s no reason it won’t be. So anyone who wants stands to benefit from knowing health-related information about you – think future employers who might help pay for future insurance claims – will be interested in using big data dark matter models gleaned from this kind of unregulated data.
To be sure, most people nowadays who wear fitbits are athletic, trying to improve their 5K run times. But the article explained that the medical profession is on the verge of suggesting a much larger population of patients use such devices. So it could get ugly real fast.
Secret big data models aren’t new, of course. I remember a friend of mine working for a credit card company a few decades ago. Her job was to model which customers to offer subprime credit cards to, and she was specifically told to target those customers who would end up paying the most in fees. But it’s become much much easier to do this kind of thing with the proliferation of so much personal data, including social media data.
I’m interested in the dark matter, partly as research for my book, and I’d appreciate help from my readers in trying to spot it when it pops up. For example, I remember begin told that a certain kind of online credit score is used to keep people on hold for customer service longer, but now I can’t find a reference to it anywhere. We should really compile a list at the boundaries of this dark matter. Please help! And if you don’t feel comfortable commenting, my email address is on the About page.
You are not Google’s customer
I’m going to write one of those posts where many of you will already understand my point. In fact it might be old hat for a majority of my readers, yet it’s still important enough for me to mention just in case there are a few people out there who don’t know how the modern business model is set up.
Namely, like this. As a gmail and Google Search user, you are not a customer of Google. You are the product. The customers of Google are the ones who advertise to you. Your interaction with Google is, from the perspective of the business operation, that you give them information which they harvest so they can advertise to you in a more targeted way, thus increasing the likelihood of you clicking. The fact that you get a service from these interactions is great, because it means you’ll come back to give Google and its customers more information about you soon.
This misunderstanding, once you see it as such, can be clarifying. For example, when people talk about anti-trust and Google, they should talk about whether the customers of Google have any other serious choice. And since the customers of Google are advertisers, not gmailers or searchers, the alternatives aren’t hotmail or Bing. Rather they are other advertising outlets. And a very good case can be made that Google does violate anti-trust laws in that sense, just ask Nathan Newman.
It also explains why something like the recent European “right to be forgotten” law seems so strange and unreasonable to the powers that be at Google. It’d be like a meat farm where the cows go on strike and demand better food. Cows are the product, and they aren’t supposed to complain. They’re not even supposed to be heard. At worst we treat them better when our customers demand it, not when the cows do.
I was reminded about this ubiquitous business model yesterday, and newly enraged by its consequences, when reading this article entitled Held Captive by Flawed Credit Reports (hat tip Linda Brown) about the credit score agency Experian and how they utterly disregard the laws trying to protect consumers from mistakes in their credit reports. The problem here is that, to the giant company Experian, its customers are giant companies like Verizon which send credit score requests millions of times a day and pay for each score. Mere people, whose mortgage application is being denied because of mistakes, are the product, not the customer, and they are almost by definition unimportant.
And it seems that the law which is supposed to protect these people, namely the Fair Credit Reporting Act, first passed in 1970, doesn’t have enough teeth behind it to make the big credit scoring agencies sit up and pay attention. It’s all about the scale of the fines compare to the scale of the business. This is well explained in the article (emphasis mine):
Last year, the Federal Trade Commission found that 5 percent of consumers — or an estimated 10 million people — had an error on one of their credit reports that could have resulted in higher borrowing costs.
The F.T.C., which oversees the industry along with the Consumer Financial Protection Bureau, has been busy bringing cases in this arena. Since 2000, it has filed 18 enforcement actions against reporting bureaus; 13 were district court actions that generated $25.7 million in penalties.
Consumers have also won in the courts, on occasion. Last year, an Oregon consumer was awarded $18.4 million in punitive damages by a jury after she sued Equifax for inserting errors into her credit report. But the fines, settlements and judgments paid by the larger companies are not even close to a rounding error. Experian generated $4.8 billion in revenue for the year ended March 2014, and its after-tax profit of $747 million in the period was more than twice its 2013 figure.
Million versus billion. It seems like the cows don’t have much leverage.
Guest post: What is the goal of a college calculus course?
This is a guest post by Nathan, who recently finished graduate school in math, and will begin a post-doc in the fall. He loves teaching young kids, but is still figuring out how to motivate undergraduates.
The question
Like most mathematicians in academia, I’m teaching calculus in the fall. I taught in grad school, but the syllabus and assignments were already set. This time I’ll be in charge, so I need to make some design decisions, like the following:
- Are calculators/computers/notes allowed on the exams?
- Which purely technical skills must students master (by a technical skill I mean something like expanding rational functions into partial fractions: a task which is deterministic but possibly intricate)?
- Will students need to write explanations and/or proofs?
I have some angst about decisions like these, because it seems like each one can go in very different directions depending on what I hope the students are supposed to get from the course. If I’m listing the pros and cons of permitting calculators, I need some yardstick to measure these pros and cons.
My question is: what is the goal of a college calculus course?
I’d love to have an answer that is specific enough that I can use it to make concrete decisions like the ones above. Part of my angst is that I’ve asked many people this question, including people I respect enormously for their teaching, but often end up with a muddled answer. And there are a couple stock answers that come to mind, but each one doesn’t satisfy me for one reason or another. Here’s what I have so far.
The contenders.
To teach specific tasks that are necessary for other subjects.
These tasks would include computing integrals and derivatives, converting functions to power series or Fourier series, and so forth.
Intuitive understanding of functions and their behavior.
This is vague, so here’s an example: a couple years ago, a friend in medical school showed me a page from his textbook. The page concerned whether a certain drug would affect heart function in one way or in the opposite way (it caused two opposite effects), and it showed a curve relating two involved parameters. It turned out that the essential feature was that this curve was concave down. The book did not use the phrase “concave down,” though, and had a rather wordy explanation of the behavior. In this situation, a student who has a good grasp of what concavity is and what its implications are is better equipped to understand the effect described in the book. So if a student has really learned how to think about concavity of functions and its implications, then she can more quickly grasp the essential parts of this medical situation.
To practice communicating with precision.
I’m taking “communication” in a very wide sense here: carefully showing the steps in an integral calculation would count.
Not Satisfied
I have issues with each of these as written. I don’t buy number 1, because the bread and butter of calculus class, like computing integrals, isn’t something most doctors or scientists will ever do again. Number 2 is a noble goal, but it’s overly idealistic; if this is the goal, then our success rate is less than 10%. Number 3 also seems like a great goal, relevant for most of the students, but I think we’d have to write very different sorts of assignments than we currently do if we really want to aim for it.
I would love to have a clear and realistic answer to this question. What do you think?
Clearwater Festival and Pete Seeger
After recording my weekly Slate Money podcast this morning I will be off to the Clearwater Festival in Croton-on-Hudson. The weather’s supposed to be gorgeous all weekend, which is good because I’m camping in a tent, and the last few times I went to bluegrass or folk festivals and camped in a tent it rained and I ended up sleeping in puddles. If you’ve never done that, let me tell you that there’s something gross and creepy about wet pillows.
My bandmate Jamie, who plays the mandolin and washboard, convinced me not only to go but to be a volunteer at this festival, which as it turns out means I’ll be preparing food in the kitchen. There are 1,000 volunteers at this festival, so who knows how many people go; I’m preparing for a lot of diced carrots and onions no matter what. Or maybe I’ll be doing dishes. I love doing dishes for some reason.
So this Clearwater Festival was Pete Seeger’s baby, he came every year, and since he passed away this past winter, the entire weekend will be a tribute to his life and his work. Some incredible musicians are going to be there to honor Pete, and I am hoping my kitchen duties don’t conflict with my old favorite, Marty Sexton (Sunday at 4pm), as well as my new favorite, John Fullbright (Saturday at 2:30).
Stuff I’ve packed for the trip: tent, sleeping bag, pillow (dry so far), bluegrass juice (of the Jack Daniels variety), my fiddle, my banjo, a wooden bowl and utensils, and some metal coffee cups and shot glasses. Oh, and some clothes.
You should totally come by for either day or for the whole weekend if you’re nearby and in the mood for some really old hippy reminiscences! And really, who isn’t.



