Archive
Why is math research important?
As I’ve already described, I’m worried about the oncoming MOOC revolution and its effect on math research. To say it plainly, I think there will be major cuts in professional math jobs starting very soon, and I’ve even started to discourage young people from their plans to become math professors.
I’d like to start up a conversation – with the public, but starting in the mathematical community – about mathematics research funding and why it’s important.
I’d like to argue for math research as a public good which deserves to be publicly funded. But although I’m sure that we need to make that case, the more I think about it the less sure I am how to make that case. I’d like your help.
So remember, we’re making the case that continuing math research is a good idea for our society, and we should put up some money towards it, even though we have competing needs to fund other stuff too.
So it’s not enough to talk about how arithmetic helps people balance their checkbooks, say, since arithmetic is already widely known and not a topic of research.
And it’s also a different question from “Why should I study math?” which is a reasonable question from a student (with a very reasonable answer found for example here) but also not what I’m asking.
Just to be clear, let’s start our answers with “Continuing math research is important because…”.
Here’s what I got so far and also why I find the individual reasons less than compelling:
——
1) Continuing math research is important because incredibly useful concepts like cryptography and calculus and image and signal processing have and continue to come from mathematics and are helping people solve real-world problems.
This “math as tool” is absolutely true and probably the easiest way to go about making the case for math research. It’s a long-term project, we don’t know exactly what will come out next, or when, but if we follow the trend of “useful tools,” we trust that math will continue to produce for society.
After all, there’s a reason so many students take calculus and linear algebra for their majors. We could probably even put a dollar value on the knowledge they gain in such a class, which is more than one could probably say about classes in many other fields.
Perhaps we should go further – mathematics is omnipresent in the exact science. And although much of that math is basic stuff that’s been known for decades or centuries, there are probably many examples of techniques being used that would benefit from recent updates.
The problem I have with this answer is that no mathematician ever goes into math research because someday it might be useful for the real world. At least no mathematician I know. And although that wasn’t a requirement for my answers, it still strikes me as odd.
In other words, it’s an answer that, although utterly true, and one we should definitely use to make our case, will actually leave the math research community itself cold.
So where does that leave us? At least for me straight to the next reason:
2) Continuing math research is important because it is beautiful. It is an art form, and more than that, an ancient and collaborative art form, performed by an entire community. Seen in this light it is one of the crowning achievements of our civilization.
This answer allows us to compare math research directly with some other fields like philosophy or even writing or music, and we can feel like artisans, or at least craftspeople, and we can in some sense expect to be supported for the very reason they are, that our existence informs us on the most basic questions surrounding what it means to be human.
The problem I have with this is that, although it’s very true, and it’s what attracted me to math in the first place, it feels too elitist, in the following sense. If we mathematicians are performing a kind of art, like an enormous musical piece, then arguably it’s a musical piece that only we can hear.
Because let’s face it, most mathematics research – and I mean current math research, not stuff the Greeks did – is totally inaccessible to the average person. And so it’s kind of a stretch to be asking the public for support on something that they can’t appreciate directly.
3) Continuing math research is important because it trains people to think abstractly and to have a skeptical mindset.
I’ve said it before, and I’ll say it again: one of the most amazing things about mathematicians versus anyone else is that mathematicians – and other kinds of scientists – are trained to admit they’re wrong. This is just so freaking rare in the real world.
And I don’t mean they change their arguments slightly to acknowledge inconvenient truths. I mean that mathematicians, properly trained, are psyched to hear a mistake pointed out in their argument because it signifies progress. There’s no shame in being wrong – it’s an inevitable part of the process of learning.
I really love this answer but I’ll admit that there may be other ways to achieve this kind of abstract and principled mindset without having a fleet of thousands of math researchers. It’s perhaps too indirect as an answer.
——
So that’s what I’ve got. Please chime in if I’ve missed something, or if you have more to add to one of these.
Interview on Math-Frolic with Shecky Riemann
Crossposted from mathtango.
I’ve been reading Cathy O’Neil’s “Mathbabe” blog off-and-on pretty much since its inception, but either I’ve changed or her blog has, because for the last several months almost every entry seems like a gem to me. Cathy is somewhat outside-the-box of the typical math bloggers I follow… a blogger with a tad more ‘attitude’ and range of issues. She is a Harvard (PhD) graduate (also Berkeley and MIT) and a data scientist, who left the finance industry when disillusioned.
Political candidates often talk of having a “fire in the belly,” and that’s also the sense I’ve had of Cathy’s blog for awhile now. So I was very happy to learn more about the life of the blogosphere’s mathbabe, and think you will as well:
************************************
1) To start, could you tell readers a little about your diverse background and how you came to be a sort of math “freelancer” and blogger… including when did your interest in mathematics originally arise, and when did you know you wished to pursue it professionally?
I started liking math when I was 4 or 5. I remember thinking about which numbers could be divided into two equal parts and which couldn’t, and I also remember understanding about primes versus composites, and for that matter g.c.d., when I played with spirographs and taking note of different kinds of periodicities and when things overlap. Of course I didn’t have words for any of this at that point.
Later on in elementary school I got really into base 2 arithmetics in 3rd grade, and I was fascinated by the representation of the number 1 by 0.9999… in 7th grade. I was actually planning on becoming a pianist until I went to a math camp after 9th grade (HCSSiM), and ever since then I’ve known. In fact it was in that summer, when I turned 15, that I decided to become a math professor.
Long story short I spent the next 20 years achieving that goal, and then when I got there I realized it wasn’t the right speed for me. I went into finance in the Spring of 2007 and was there throughout the crisis. It opened my eyes to a lot of things that I’d been ignoring about the real world, and when I left finance in 2011 I decided to start a blog to expose some of the stuff I’d seen, and to explain it as well. I joined Occupy when it started and I’ve been an activist since then.
[Because so many carry the stereotyped image of a mathematician as someone standing at a blackboard writing inscrutable, abstract symbols, I think Cathy’s “activism” has been one of the most appealing aspects of her blog!]
2) You’re involved in quite a number of important activities/issues… what would you list as your most ardent (math-related) goals, for say the next year, and then also longer-term?
My short- or medium- term goal is to write a book called “Weapons of Math Destruction” which I recently sold to Random House. It’s for a general audience but I’ve been giving a kind of mathematical version of it to various math departments. The idea is that the modeling we’re seeing proliferate in all kinds of industries has a dark side and could be quite destructive. We need to stop blindly assuming that because it has a mathematical aspect to it that it should be considered objective or benign.
[…Love the title of the book.]
Longer term I want to promote the concept of open models, where the public has meaningful access to any models that are being used on them that are high impact and high stakes. So credit scoring models or Value-Added Teacher models are good examples of that kind of thing. I think it’s a crime that these models are opaque and yet have so much power over people’s lives. It’s like having secret laws.
3) Related to the above, you’ve been especially outspoken about various financial/banking issues and the “Occupy Wall Street” movement… I have to believe that there are both very rewarding and very frustrating/exasperating aspects to tackling those issues… care to comment?
I’d definitely say more rewarding than frustrating. Of course things don’t change overnight, especially when it comes to the public’s perception and understanding of complex issues. But I’ve seen a lot of change in the past 7 years around finance, and I expect to see more skepticism around the kind of modeling I worry about, especially in light of the NSA surveillance programs that people are up in arms over.
4) Your blog covers a wider diversity of topics than most “math” blogs. Sometimes your blogposts seem to be a combination of educating the public while also simultaneously, venting! (indeed your subheading hints at such)… how might you describe your feelings/attitude/mood when writing typical posts? And what are your favorite (math-related) subjects to write about or study?
Honestly blogging has crept into my daily schedule like a cup of coffee in the morning. It would be really hard for me to stop doing it. One way of thinking about it is that I’m naturally a person who gets kind of worked up about how people just don’t think about a subject X the right way, and if I don’t blog about those vents then they get stuck in my system and I can’t move past them. So maybe a better way of saying it is that getting my daily blog on is kind of like having an awesome poop. But then again maybe that’s too gross. Sorry if that’s too gross.
[Let’s just say that I may never think about composing blog posts in quite the same way again! 😉 ]
5) Is “Mathbabe” blog principally “a labor of love” or is it more than that for you (some sort of means to an end)? i.e., You’re writing a book and you do speaking engagements, along with other activities… is the blog a mechanism to help promote/sustain those other endeavors, or do you view it as just a recreational side activity?
I’ve been really happy with a decision to never let mathbabe be anything except fun for me. There’s no money involved at all, ever, and there never will be. Nobody pays me for anything, nobody gets paid for anything. I do it because I learn more quickly that way, and it forces me to organize my half-thoughts in a way that people can understand. And although the thinking and learning and discussions have made a bunch of things possible, I never had those goals until they just came to me.
At the same time I wouldn’t call it a side activity either. It’s more of a central activity in my life that has no other purpose than being itself.
6) Go ahead and tell us about the book you have in the works and its timetable…
It’s fun to write! I can’t believe people are willing to let me interview them! It won’t be out for a couple of years. At first I thought that was way too long but now I’m glad I have the time to do the research.
7) How do you select the topic you post about on any given day? And are there certain blogposts you’ve done that stand out as personal favorites or ones that were the most fun to work on? From the other side, which posts seem to have been most popular or attention-getting with readers?
I send myself emails with ideas. Then I wake up in the morning and look at my notes and decide which issue is exciting me or infuriating me the most.
I have different audiences that get excited about different things. The math education community is fun, they have a LOT to say on comments. People seem to like Aunt Pythia but nobody comments — I think it’s a guilty pleasure.
[Yes, I was skeptical of Aunt Pythia when you announced it (seemed a bit of a stretch), but it too is a fun read… though I most enjoy the passionate posts about issues tangential to mathematics.]
I guess it’s fair to say that people like it when I combine venting with strong political views and argumentation. My most-viewed post ever was when I complained about Nate Silver’s book.
8) What are some of the math-related books you’ve most enjoyed reading and/or ones you would particularly recommend to lay folks?
I don’t read very many math books to be honest. I’ve always enjoyed talking math with people more than reading about it.
But I have been reading a lot of mathish books in preparation for my writing. For example, I really enjoyed “How to Lie with Statistics” which I read recently and blogged about.
Most of the time I kind of hate books written about modeling, to be honest, because usually they are written by people who are big data cheerleaders. I guess the best counterexamples of that would be “The Filter Bubble,” by Eli Pariser which is great and is a kind of prequel to my book, and “Super Sad True Love Story” by Gary Shteyngart which is a dystopian sci-fi novel that isn’t actually technical but has amazing prescience with respect to the kind of modeling and surveillance — and for that matter political unrest — that I think about all the time.
9) Anything else you’d want to say to a captive audience of math-lovers, that you haven’t covered above?
Math is awesome!
[INDEED!]
************************************
Thanks so much, Cathy, for filling in a bit about yourself here. Good luck in all your endeavors!
Cathy tweets, BTW, at @mathbabedotorg and she did this fascinating interview for PBS’s “Frontline” in 2012 (largely on the financial crisis):
http://www.pbs.org/wgbh/pages/frontline/oral-history/financial-crisis/cathy-oneil/
(I highly recommend this!)
Guest Post: Beauty, even in the teaching of mathematics
This is a guest post by Manya Raman-Sundström.
Mathematical Beauty
If you talk to a mathematician about what she or he does, pretty soon it will surface that one reason for working those long hours on those difficult problems has to do with beauty.
Whatever we mean by that term, whether it is the way things hang together, or the sheer simplicity of a result found in a jungle of complexity, beauty – or aesthetics more generally—is often cited as one of the main rewards for the work, and in some cases the main motivating factor for doing this work. Indeed, the fact that a proof of known theorem can be published just because it is more elegant is one evidence of this fact.
Mathematics is beautiful. Any mathematician will tell you that. Then why is it that when we teach mathematics we tend not to bring out the beauty? We would consider it odd to teach music via scales and theory without ever giving children a chance to listen to a symphony. So why do we teach mathematics in bits and pieces without exposing students to the real thing, the full aesthetic experience?
Of course there are marvelous teachers out there who do manage to bring out the beauty and excitement and maybe even the depth of mathematics, but aesthetics is not something we tend to value at a curricular level. The new Common Core Standards that most US states have adopted as their curricular blueprint do not mention beauty as a goal. Neither do the curriculum guidelines of most countries, western or eastern (one exception is Korea).
Mathematics teaching is about achievement, not about aesthetic appreciation, a fact that test-makers are probably grateful for – can you imagine the makeover needed for the SAT if we started to try to measure aesthetic appreciation?
Why Does Beauty Matter?
First, it should be a bit troubling that our mathematics classrooms do not mirror practice. How can young people make wise decisions about whether they should continue to study mathematics if they have never really seen mathematics?
Second, to overlook the aesthetic components of mathematical thought might be to preventing our children from developing their intellectual capacities.
In the 1970s Seymour Papert , a well-known mathematician and educator, claimed that scientific thought consisted of three components: cognitive, affective, and aesthetic (for some discussion on aesthetics, see here).
At the time, research in education was almost entirely cognitive. In the last couple decades, the role of affect in thinking has become better understood, and now appears visibly in national curriculum documents. Enjoying mathematics, it turns out, is important for learning it. However, aesthetics is still largely overlooked.
Recently Nathalie Sinclair, of Simon Frasier University, has shown that children can develop aesthetic appreciation, even at a young age, somewhat analogously to mathematicians. But this kind of research is very far, currently, from making an impact on teaching on a broad scale.
Once one starts to take seriously the aesthetic nature of mathematics, one quickly meets some very tough (but quite interesting!) questions. What do we mean by beauty? How do we characterise it? Is beauty subjective, or objective (or neither? or both?) Is beauty something that can be taught, or does it just come to be experienced over time?
These questions, despite their allure, have not been fully explored. Several mathematicians (Hardy, Poincare, Rota) have speculated, but there is no definite answer even on the question of what characterizes beauty.
Example
To see why these questions might be of interest to anyone but hard-core philosophers, let’s look at an example. Consider the famous question, answered supposedly by Gauss, of the sum of the first n integers. Think about your favorite proof of this. Probably the proof that did NOT come to your mind first was a proof by induction:
Prove that S(n) = 1 + 2 + 3 … + n = n (n+1) /2
S(k + 1) = S(k) + (k + 1)
= k(k + 1)/2 + 2(k + 1)/2
= k(k + 1)/2 + 2(k + 1)/2
= (k + 1)(k + 2)/2.
Now compare this proof to another well known one. I will give the picture and leave the details to you:
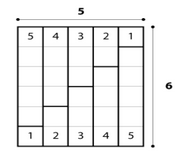
Does one of these strike you as nicer, or more explanatory, or perhaps even more beautiful than the other? My guess is that you will find the second one more appealing once you see that it is two sequences put together, giving an area of n (n+1), so S(n) = n (n+1)/2.
Note: another nice proof of this theorem, of course, is the one where S(n) is written both forwards and backwards and added. That proof also involves a visual component, as well as an algebraic one. See here for this and a few other proofs.
Beauty vs. Explanation
How often do we, as teachers, stop and think about the aesthetic merits of a proof? What is it, exactly, that makes the explanatory proof more attractive? In what way does the presentation of the proof make the key ideas accessible, and does this accessibility affect our sense of understanding, and what underpins the feeling that one has found exactly the right proof or exactly the right picture or exactly the right argument?
Beauty and explanation, while not obvious related (see here), might at least be bed-fellows. It may be the case that what lies at the bottom of explanation — a feeling of understanding, or a sense that one can ”see” what is going on — is also related to the aesthetic rewards we get when we find a particularly good solution.
Perhaps our minds are drawn to what is easiest to grasp, which brings us back to central questions of teaching and learning: how do we best present mathematics in a way that makes it understandable, clear, and perhaps even beautiful? These questions might all be related.
Workshop on Math Beauty
This March 10-12, 2014 in Umeå, Sweden, a group will gather to discuss this topic. Specifically, we will look at the question of whether mathematical beauty has anything to do with mathematical explanation. And if so, whether the two might have anything to do with visualization.
If this discussion peaks your interest at all, you are welcome to check out my blog on math beauty. There you will find a link to the workshop, with a fantastic lineup of philosophers, mathematicians, and mathematics educators who will come together to try to make some progress on these hard questions.
Thanks to Cathy, the always fabulous mathbabe, for letting me take up her space to share the news of this workshop (and perhaps get someone out there excited about this research area). Perhaps she, or you if you have read this far, would be willing to share your own favorite examples of beautiful mathematics. Some examples have already been collected here, please add yours.
Upcoming talks
A few months ago I gave a talk entitled “Start Your Own Netflix” talk that was part of the MAA Distinguished Lecture Series, the slides for which are available here and a short video version here.
Today I’m planning to modify that talk so I can give a longer and more technical version of it on Friday morning at the Department of Mathematical Science of Worcester Polytechnic Institute, where I’ve been invited to speak by Suzy Weekes.
In about a month I’m going to Berkeley for a week to give a so-called MSRI-Evans talk on Monday, February 24th, at 4pm, thanks to the kind invitation of Lauren Williams. I still haven’t decided whether to give a “The World Is Going To Hell” talk, which would be kind of the technical version of my book (and which I gave at Harvard’s IQSS recently), or whether I should give yet another version of the Netflix talk, which is cool and technical but not as doomsday. If you’re planning to attend please voice your opinion!
Finally, I’m hoping to join in a meeting of some manifestation of the Noetherian Ring while I’m at Berkeley. This is a women in math group that was started when I was an undergrad there, back in the middle ages, in something like 1992. It’s where I gave my first and second math talks and there was always free pizza. It really was a great example of how to create a supportive environment for collaborative math.
If it’s hocus pocus then it’s not math
A few days ago there was a kerfuffle over this “numberphile” video, which was blogged about in Slate here by Phil Plait in his “Bad Astronomy” column, with a followup post here with an apology and a great quote from my friend Jordan Ellenberg.
The original video is hideous and should never have gotten attention in the first place. I say that not because the subject couldn’t have been done well – it could have, for sure – but because it was done so poorly that it ends up being destructive to the public’s most basic understanding of math and in particular positive versus negative numbers. My least favorite line from the crappy video:
I was trying to come up with an intuitive reason for this I and I just couldn’t. You have to do the mathematical hocus pocus to see it.
What??
Anything that is hocus pocus isn’t actually math. And people who don’t understand that shouldn’t be making math videos for public consumption, especially ones that have MSRI’s logo on them and get written up in Slate. Yuck!
I’m not going to just vent about the cultural context, though, I’m going to mention what the actual mathematical object of study was in this video. Namely, it’s an argument that “prove” that we have the following identity:
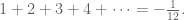
Wait, how can that be? Isn’t the left hand side positive and the right hand side negative?!
This mathematical argument is familiar to me – in fact it is very much along the lines of stuff we sometimes cover at the math summer program HCSSiM I teach at sometimes (see my notes from 2012 here). But in the case of HCSSiM, we do it quite differently. Specifically, we use it as a demonstration of flawed mathematical thinking. Then we take note and make sure we’re more careful in the future.
If you watch the video, you will see the flaw almost immediately. Namely, it starts with the question of what the value is of the infinite sum
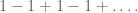
But here’s the thing, that doesn’t actually have a value. That is, it doesn’t have a value until you assign it a value, which you can do but then you might want to absolutely positively must explain how you’ve done so. Instead of that explanation, the guy in the video just acts like it’s obvious and uses that “fact,” along with a bunch of super careless moving around of terms in infinite sums, to infer the above outrageous identity.
To be clear, sometimes infinite sums do have pretty intuitive and reasonable values (even though you should be careful to acknowledge that they too are assigned rather than “true”). For example, any geometric series where each successive term gets smaller has an actual “converging sum”. The most canonical example of this is the following:
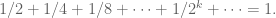
What’s nice about this sum is that it is naively plausible. Our intuition from elementary school is corroborated when we think about eating half a cake, then another quarter, and then half of what’s left, and so on, and it makes sense to us that, if we did that forever (or if we did that increasingly quickly) we’d end up eating the whole cake.
This concept has a name, and it’s convergence, and it jibes with our sense of what would happen “if we kept doing stuff forever (again at possibly increasing speed).” The amounts we’ve measured on the way to forever are called partial sums, and we make sure they converge to the answer. In the example above the partial sums are 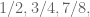
There’s a mathematical way of defining convergence of series like this that the geometric series follows but that the 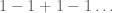
So if you want it to get within 0.00001, there’s a number N so that, after the Nth partial sum, all partial sums are within 0.00001 of the answer. And so on.
Notice that if you take the partial sums of the 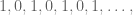
As for the first infinite sum we came across, the 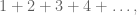
But here’s the thing. Mathematicians are pretty clever, so they haven’t stopped there, and they’ve assigned a value to the infinite sum 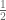
[Note: what would be really cool is if a mathematician made a video explaining the crazy-ass universe and why it’s useful and in what contexts. This might be hard and it’s not my expertise but I for one would love to watch that video.]
That doesn’t mean the identity is “true” in any intuitively plausible sense of the word. It means that mathematicians are scrappy.
Now here’s my last point, and it’s the only place I disagree somewhat (I think) with Jordan in his tweets. Namely, I really do think that the intuitive definition is qualitatively different from what I’ve termed the “crazy-ass” definition. Maybe not in a context where you’re talking to other mathematicians, and everyone is sufficiently sophisticated to know what’s going on, but definitely in the context of explaining math to the public where you can rely on number sense and (hopefully!) a strong intuition that positive numbers can’t suddenly become negative numbers.
Specifically, if you can’t make any sense of it, intuitive or otherwise, and if you have to ascribe it to “mathematical hocus pocus,” then you’re definitely doing something wrong. Please stop.
The coming Calculus MOOC Revolution and the end of math research
I don’t usually like to sound like a doomsayer but today I’m going to make an exception. I’m going to describe an effect that I believe will be present, even if it’s not as strong as I am suggesting it might be. There are three points to my post today.
1) Math research is a byproduct of calculus teaching
I’ve said it before, calculus (and pre-calculus, and linear algebra) might be a thorn in many math teachers’ side, and boring to teach over and over again, but it’s the bread and butter of math departments. I’ve heard statistics that 85% of students who take any class in math at a given college take only calculus.
Math research is essentially funded through these teaching jobs. This is less true for the super elite institutions which might have their own army of calculus adjuncts and have separate sources of funding both from NSF-like entities and private entities, but if you take the group of people I just saw at JMM you have a bunch of people who essentially depend on their take-home salary to do research, and their take-home salary depends on lots of students at their school taking service courses.
I wish I had a graph comparing the number of student enrolled in calculus each year versus the number of papers published in math journals each year. That would be a great graphic to have, and I think it would make my point.
2) Calculus MOOCs and other web tools are going to start replacing calculus teaching very soon and at a large scale
It’s already happening at Penn through Coursera. Word on the street is it is about to happen at MIT through EdX.
If this isn’t feasible right now it will be soon. Right now the average calculus class might be better than the best MOOC, especially if you consider asking questions and getting a human response. But as the calculus version of math overflow springs into existence with a record of every question and every answer provided, it will become less and less important to have a Ph.D. mathematician present.
Which isn’t to say we won’t need a person at all – we might well need someone. But chances are they won’t be tenured, and chances are they could be overseas in a call center.
This is not really a bad thing in theory, at least for the students, as long as they actually learn the stuff (as compared to now). Once the appropriate tools have been written and deployed and populated, the students may be better off and happier. They will very likely be more adept at finding correct answers for their calculus questions online, which may be a way of evaluating success (although not mine).
It’s called progress, and machines have been doing it for more than a hundred years, replacing skilled craftspeople. It hurts at first but then the world adjusts. And after all, lots of people complain now about teaching boring classes, and they will get relief. But then again many of them will have to find other jobs.
Colleges might take a hit from parents about how expensive they are and how they’re just getting the kids to learn via computer. And maybe they will actually lower tuition, but my guess is they’ll come up with something else they are offering that makes up for it which will have nothing to do with the math department.
3) Math researchers will be severely reduced if nothing is done
Let’s put those two things together, and what we see is that math research, which we’ve basically been getting for free all this time, as a byproduct of calculus, will be severely curtailed. Not at the small elite institutions that don’t mind paying for it, but at the rest of the country. That’s a lot of research. In terms of scale, my guess is that the average faculty will be reduced by more than 50%, and some faculties will be closed altogether.
Why isn’t anything being done? Why do mathematicians seem so asleep at this wheel? Why aren’t they making the case that math research is vital to a long-term functioning society?
My theory is that mathematicians haven’t been promoting their work for the simple reason that they haven’t had to, because they had this cash cow called calculus which many of them aren’t even aware of as a great thing (because close up it’s often a pain).
It’s possible that mathematicians don’t even know how to promote math to the general public, at least right now. But I’m thinking that’s going to change. We’re going to think about it pretty hard and learn how to promote math research very soon, or else we’re going back to 1850 levels of math research, where everyone knew each other and stuff was done by letter.
How worried am I about this?
For my friends with tenure, not so worried, except if their entire department is at risk. But for my younger friends who are interested in going to grad school now, I’m not writing them letters of recommendation before having this talk, because they’ll be looking around for tenured positions in about 10 years, and that’s the time scale at which I think math departments will be shrinking instead of expanding.
In terms of math PR, I’m also pretty worried, but not hopeless. I think one can really make the case that basic math research should be supported and expanded, but it’s going to take a lot of things going right and a lot of people willing to put time and organizing skills into the effort for it to work. And hopefully it will be a community effort and not controlled by a few billionaires.
Billionaire money in mathematics
During the recent JMM AMS panel I was on, where the topic was the Public Face of Math, the issue came up repeatedly that we mathematicians might want to find a billionaire who could solve all our PR problems (although we didn’t quite seem to agree on what these PR problems are).
Indeed billionaire money seemed to represent a panacea even though it originated with a slightly facetious suggestion of a super PAC for mathematics from Congressman Jerry McNerney. The idea was taken quite seriously and repeated by at least 3 audience members.
I think this happened for a few reasons. First, mathematicians are mostly apolitical and don’t think of politics or PR as part of their job. They also don’t think they’re good at that stuff, and they are happy for someone else to do it. Who else but a rich guy interested in that stuff and who “has people” who are good at it.
Second, Jim Simons has been doing good stuff for math lately and people trust him. I totally get that, and I don’t entirely disagree, although invitation-only conferences in the Virgin Islands is not my idea of easy and transparent access to ideas that many mathematicians strive for. I hear his Quanta Magazine is awesome.
Here’s the thing. We lose something when we consistently take money from rich people, which has nothing to with any specific rich person who might have great ideas and great intentions.
The first thing we lose is power, and specifically control over our own image. That might seem like a fair deal now, since at least someone is working on it, but it’s not obvious that it would always be.
It means, for example, that one person has a huge amount of influence about, say, how the math community deals with the NSA. As we know this is an recent and ongoing discussion, but it came up pretty suddenly, as issues do, and it might be weird to all of a sudden need to know what some rich guy thinks of a specific issue.
Another example of why taking money from a few super rich people might not be a great idea requires the idea of a funding feedback loop, which well articulated by Benjamin Soskis and Felix Salmon with respect to the public parks in New York City.
The basic idea is that, as public funding dries up for something like public parks (or from the NSF) and as a community gets desperate for basic operating funds, money from rich individuals seems like a godsend. But over time two things happen.
First, the public funding never ever comes back. Because, after all, why should it? It looks like everything is well-funded. And the individuals who are part of that community are not agitating for the return of that funding since they have jobs.
Second, it’s not clear that the new money will be distributed in a good governance type of way. It might be distributed based on where rich people live, in the case of parks, or what their preferred mathematical subjects are, in the case of math. And the community has no recourse on those decisions, because the entire system depends on the generosity of someone who could change his mind at any moment.
And I’m not saying NSF doesn’t have weird rubriks for which fields (and which people!) get funded as well, but at least we can have a public discussion about that and make noise. And the decisions are made by different groups of mathematicians every year.
My suggestion is that we should think about representing ourselves in this PR campaign, if we have one to wage, and we should focus efforts on things that would improve NSF funding instead of getting us addicted to private funding. And it should be a community conversation where everyone participates who cares enough.
What are the chances that will ever happen? In terms of whether typical mathematicians will ever be willing to become politically active, my vote is on “yes” and “very soon,” and the reason I say this is that I believe mathematics research is being hugely (if quietly) threatened by the oncoming Calculus MOOC Revolution, which I plan to write about very soon.
JMM
It occurs to me, as I prepare to join my panel this afternoon on Public Facing Math, that I’ve been to more Joint Math Meetings in the 7 years since I left academic math (3) than I did in the 17 years I was actually in math (2). I include my undergraduate years in that count because when I was a junior in college I went to Vancouver for the JMM and I met Cora Sadosky, which was probably my favorite conference ever.
Anyhoo I’m on my way to one of the highlights of any JMM, the HCSSiM breakfast, where we hang out with students and teachers from summers long ago and where I do my best to convince the director Kelly and myself that I should come back next summer to teach again. Then after that I spend 4 months at home convincing my family that it’s a great plan. Woohoo!

Besides the above plan, I plan to meet people in the hallways and gossip. That’s all I have ever accomplished here. I hope it is the official mission of the conference, but I’m not sure.
Two thoughts on math research papers
Today I’d like to mention two ideas I’ve been having recently on how to make being a research mathematician (even) more fun.
1) Mathematicians should consider holding public discussions about papers
First, math nerds, did you know that in statistics they have formal discussions about papers? It’s been a long-standing tradition by the Royal Statistical Society, whose motto is “Advancing the science and application of statistics, and promoting use and awareness for public benefit,” to choose papers by some criterion and then hold regular public discussions about those papers by a few experts who are not the author, about the paper. Then the author responds to their points and the whole conversation is published for posterity.
I think this is a cool idea for math papers too. One thing that kind of depressed me about math is how rarely you’d find people reading the same papers unless you specifically got a group of people together to do so, which was a lot of work. This way the work is done mostly by other people and more importantly the payoff is much better for them since everyone gets a view into the discussion.
Note I’m sidestepping who would organize this whole thing, and how the papers would be chosen exactly, but I’d expect it would improve the overall feeling that I had of being isolated in a tiny math community, especially if the conversations were meant to be penetrable.
2) There should be a good clustering method for papers around topics
This second idea may already be happening, but I’m going to say it anyway, and it could easily be a thesis for someone in CS.
Namely, the idea of using NLP and other such techniques to cluster math papers by topic. Right now the most obvious way to find a “nearby” paper is to look at the graph of papers by direct reference, but you’re probably missing out on lots of stuff that way. I think a different and possibly more interesting way would be to use the text in the title, abstract, and introduction to find papers with similar subjects.
This might be especially useful when you want to know the answer to a question like, “has anyone proved that such-and-such?” and you can do a text search for the statement of that theorem.
The good news here is that mathematicians are in love with terminology, and give weird names to things that make NLP techniques very happy. My favorite recent example which I hear Johan muttering under his breath from time to time is Flabby Sheaves. There’s no way that’s not a distinctive phrase.
The bad news is that such techniques won’t help at all in finding different fields who have come across the same idea but have different names for the relevant objects. But that’s OK, because it means there’s still lots of work for mathematicians.
By the way, back to the question of whether this has already been done. My buddy Max Lieblich has a website called MarXiv which is a wrapper over the math ArXiv and has a “similar” button. I have no idea what that button actually does though. In any case I totally dig the design of the similar button, and what I propose is just to have something like that work with NLP.
AMS Panel on The Public Face of Mathematics
A week from today I’ll be at the Joint Math Meetings in Baltimore to join a panel discussion on the Public Face of Mathematics. I’ll steal the blurb for my panel from this page:
The Public Face of Mathematics, Friday, 2:30 p.m.–4:00 p.m. Moderated by Arthur Benjamin, Harvey Mudd College. Panelists Keith Devlin, Stanford University; Jerry McNerney, U. S. Congress; Cathy O’Neil, Johnson Research Labs; Tom Siegfried, Freelance Journalist; and Steve Strogatz, Cornell University, will share ideas and lead discussion about how the mathematics community can mobilize more members to become proactive in representing mathematics to the general public and to key audiences of leaders in discussions of public policy. Sponsored by the Committee on Science Policy and the Committee on Education.
One thing I’ve already noticed that might make me different from some of the other panelists is that I don’t spend too much time explaining math to the general public, although my notes on teaching at HCSSiM might arguably be the exception. And sometimes I explain how to do modeling, but that’s not stuff I learned as a mathematician.
Mostly what I do, at least from my perspective, is comment on the culture of mathematics (for women, for example) or talk about how unfortunate it is that the public’s trust in mathematics and mathematician is being perverted into a political campaign about the (supposed) objectivity of mathematical modeling by people like Bill Gates. I specialize in calling out the misapplication of mathematical imprimatur.
Anyhoo, two questions for my readers:
- Are you going to JMM too and wanna hang with me? Please know I’m only there during the day Friday, it’s a short visit. But please contact me!
- The moderator, Art Benjamin, is asking us panelists for questions that he should ask the panel next week. Please comment below with your suggestions, and thanks!
On being a mom and a mathematician: interview by Lillian Pierce
This is a guest post by Lillian Pierce, who is currently a faculty member of the Hausdorff Center for Mathematics in Bonn, and will next year join the faculty at Duke University.
I’m a mathematician. I also happen to be a mother. I turned in my Ph.D. thesis one week before the due date of my first child, and defended it five weeks after she was born. Two and a half years into my postdoc years, I had my second child.
Now after a few years of practice, I can pretty much handle daily life as a young academic and a parent, at least most of the time, but it still seems like a startlingly strenuous existence compared to what I remember of life as just a young academic, not a parent.
Last year I was asked by the Association for Women in Mathematics to write a piece for the AWM Newsletter about my impressions of being a young mother and getting a mathematical career off the ground at the same time. I suggested that instead I interview a lot of other mathematical mothers, because it’s risky to present just one view as “the way” to tackle mathematics and motherhood.
Besides, what I really wanted to know was: how is everyone else doing this? I wanted to pick up some pointers.
I met Mathbabe about ten years ago when I was a visiting prospective graduate student and she was a postdoc. She made a deep impression on me at the time, and I am very happy that I now have the chance to interview her for the series Mathematics+Motherhood, and to now share with you our conversation.
LP: Tell me about your current work.
CO: I am a data scientist working at a small start-up. We’re trying to combine consulting engagements with a new vision for data science training and education and possibly some companies to spin off. In the meantime, we’re trying not to be creepy.
LP: That sounds like a good goal. And tell me a bit about your family.
CO: I have three kids. I got pregnant with my first son, who’s 13 now, soon after my PhD. Then I had a second child 2 years later, also while I was a postdoc. I also have a 4 year old, whom I had when I was working in finance.
LP: Did you have any notions or worries in advance about how the growth of your family would intersect with the growth of your career?
CO: I absolutely did worry about it, and I was right to worry about it, but I did not hesitate about whether to have children because it was just not a question to me about how I wanted my life to proceed. And I did not want to wait until I was tenured because I didn’t want to risk being infertile, which is a real risk. So for me it was not an option not to do it as a woman, forget as a mathematician.
LP: What was it like as a postdoc with two very young children?
CO: On the one hand I was hopeful about it, and on the other hand I was incredibly disappointed about it. The hopeful part was that the chair of my department was incredibly open to negotiating a maternity leave for postdocs, and it really was the best maternity policy that I knew about: a semester off of teaching for each baby and in total an extra year of the postdoc, since I had 2 babies. So I ended up with four years of postdoc, which was really quite generous on the one hand, but on the other hand it really didn’t matter at all. Not “not at all”—it mattered somewhat but it simply wasn’t enough to feel like I was actually competing with my contemporaries who didn’t have children. That’s on the one hand completely obvious and natural and it makes sense, because when you have small children you need to pay attention to them because they need you—and at the same time it was incredibly frustrating.
LP: It’s interesting because it’s not that you were saying “I won’t be able to compete with my contemporaries over the course of my life,” but more “I can’t compete right now.”
CO: Exactly, “I can’t compete right now” with postdocs without children. I realize—and this is not a new idea—that mathematics as a culture frontloads entirely into those 3 or 4 years after you get your PhD. Ultimately it’s not my fault, it’s not women’s fault, it’s the fault of the academic system.
LP: What metrics could departments use to be thinking more about future potential?
CO: I actually think it’s hard. It’s not just for women that it should change. It’s for the actual culture of mathematics. Essentially, the system is too rigid. And it’s not only women who get lost. The same thing that winnows the pool down right after getting a PhD—it’s a whittling process, to get rid of people, get rid of people, get rid of people until you only have the elite left—that process is incredibly punishing to women, but it’s also incredibly punishing to everybody. And moreover because of the way you get tenure and then stay in your field for the rest of your life, my feeling is that mathematics actually suffers. The reason I say this is because I work in industry now, which is a very different system, and people can reinvent themselves in a way that simply does not happen in mathematics.
LP: Do you think industry, in terms of the young career phase, gets it closer to “right” than academia currently does?
CO: Much closer to right. It’s a brutal place, don’t get me wrong, it’s brutal. I’m not saying it’s a perfect system by any stretch of the imagination. But the truth is in industry you can have a 3 year stint somewhere that is a mistake. Forget having kids, you can have a 3 year stint that was just a mistake for you. You can say “I had a bad boss and I left that place and I got a new job” and people will say “Ok.” They don’t care. One thing that I like about it is the ability to reinvent yourself. And I don’t think you see that in math. In math, your progress is charted by your publication record at a granular level. And if you’re up for tenure and there’s a 3 year gap where you didn’t publish, even if in the other years you published a lot, you still have to explain that gap. It’s like a moral responsibility to keep publishing all the time.
LP: How are you measured in industry?
CO: In industry it’s the question “what have you done for me,” and “what have you done for me lately.” It’s a shorter-term question, and there are good elements to that. One of the good elements is that as a woman you can have a baby or a couple babies and then you can pick up the slack, work your ass off, and you can be more productive after something happens. If someone gets sick, people lower their expectations for that person for some amount of time until they recover, and then expectations are higher. Mathematics by contrast has frontloaded all of the stress, especially for the elite institutions, into the 3 or 4 years to get the tenure track offer and then the next 6 years to get tenure. And then all the stress is gone. I understand why people with tenure like that. But ultimately I don’t think mathematics gets done better because of it. And certainly when the question arises “why don’t women stay in math,” I can answer that very easily: because it’s not a very good place for women, at least if they want kids.
LP: You mention on your blog that your mother is an unapologetic nerd and computer scientist; the conclusion you drew from that was that it was natural for you not to doubt that your contributions to nerd-dom and science and knowledge would be welcomed. How do you think this experience of having a mother like that inoculated you?
CO: One of the great gifts that my mother gave me as a Mother Nerd was the gift of privacy—in the sense that I did not scrutinize myself. First of all she was role-modeling something for me, so if I had any expectations it would be to be like my mom. But second of all she wasn’t asking me to think about that. I think that was one of the rarest things I had, the most unusual aspect of my upbringing as a girl. Very few of the girls that I know are not scrutinized. My mother was too busy to pay attention to my music or my art or my math. And I was left alone to decide what I wanted to do—it wasn’t about what I was good at or what other people thought of my progress. It was all about answering the question, what did I want to do. Privacy for me is having elbow space to self-define.
LP: Do you think it’s harder for parents to give that space to girls than to boys?
CO: Yes I do, I absolutely do. It’s harder and for some reason it’s not even thought about. My mother also gave me the gift of not feeling at all guilty about putting me into daycare. And that’s one of my strongest lessons, is that I don’t feel at all guilty about sending my kids to daycare. In fact I recently had the daycare providers for my 4-year-old all over for dinner, and I was telling them in all honesty that sometimes I wish I could be there too, that I could just stay there all day, because it’s just a wonderful place to be. I’m jealous of my kids. And that’s the best of all worlds. Instead of saying “oh my kid is in daycare all day, I feel bad about that,” it’s “my kid gets to go to daycare.”
LP: Where did this ability not to scrutinize come from? Where did your mother get this?
CO: I don’t know. My mother has never given me advice, she just doesn’t give advice. And when I ask her to, she says “you know more about your life than I do.”
LP: How do you deal with scrutiny now?
CO: It’s transformed as I’ve gotten older. I’ve gotten a thicker skin, partly from working in finance. I’ve gotten to the point now where I can appreciate good feedback and ignore negative feedback. And that’s a really nice place to be. But it started out, I believe, because I was raised in an environment where I wasn’t scrutinized. And I had that space to self-define.
LP: The idea of pushing back against scrutiny to clear space for self-definition is inspiring for adults as well.
CO: Women in math, especially with kids, give yourself a break. You’re under an immense amount of pressure, of scrutiny. You should think of it as being on the front lines, you’re a warrior! And if you’re exhausted, there’s a reason for it. Please go read Radhika Nagpal’s Scientific American blog post (“The Awesomest 7-Year Postdoc Ever”) for tips on how to deal with the pressure. She’s awesome. And the last thing I want to say is that I never stopped loving math. Cardinal Rule Number 1: Before all else, don’t become bitter. Cardinal Rule Number 2: Remember that math is beautiful.
How do I know if I’m good enough to go into math?
Hi Cathy,
I met you this past summer, you may not remember me. I have a question.
I know a lot of people who know much more math than I do and who figure out solutions to problems more quickly than me. Whenever I come up with a solution to a problem that I’m really proud of and that I worked really hard on, they talk about how they’ve seen that problem before and all the stuff they know about it. How do I know if I’m good enough to go into math?
Thanks,
High School Kid
Dear High School Kid,
Great question, and I’m glad I can answer it, because I had almost the same experience when I was in high school and I didn’t have anyone to ask. And if you don’t mind, I’m going to answer it to anyone who reads my blog, just in case there are other young people wondering this, and especially girls, but of course not only girls.
Here’s the thing. There’s always someone faster than you. And it feels bad, especially when you feel slow, and especially when that person cares about being fast, because all of a sudden, in your confusion about all sort of things, speed seems important. But it’s not a race. Mathematics is patient and doesn’t mind. Think of it, your slowness, or lack of quickness, as a style thing but not as a shortcoming.
Why style? Over the years I’ve found that slow mathematicians have a different thing to offer than fast mathematicians, although there are exceptions (Bjorn Poonen comes to mind, who is fast but thinks things through like a slow mathematician. Love that guy). I totally didn’t define this but I think it’s true, and other mathematicians, weigh in please.
One thing that’s incredibly annoying about this concept of “fastness” when it comes to solving math problems is that, as a high school kid, you’re surrounded by math competitions, which all kind of suck. They make it seem like, to be “good” at math, you have to be fast. That’s really just not true once you grow up and start doing grownup math.
In reality, mostly of being good at math is really about how much you want to spend your time doing math. And I guess it’s true that if you’re slower you have to want to spend more time doing math, but if you love doing math then that’s totally fine. Plus, thinking about things overnight always helps me. So sleeping about math counts as time spent doing math.
[As an aside, I have figured things out so often in my sleep that it’s become my preferred way of working on problems. I often wonder if there’s a “math part” of my brain which I don’t have normal access to but which furiously works on questions during the night. That is, if I’ve spent the requisite time during the day trying to figure it out. In any case, when it works, I wake up the next morning just simply knowing the proof and it actually seems obvious. It’s just like magic.]
So here’s my advice to you, high school kid. Ignore your surroundings, ignore the math competitions, and especially ignore the annoying kids who care about doing fast math. They will slowly recede as you go to college and as high school algebra gives way to college algebra and then Galois Theory. As the math gets awesomer, the speed gets slower.
And in terms of your identity, let yourself fancy yourself a mathematician, or an astronaut, or an engineer, or whatever, because you don’t have to know exactly what it’ll be yet. But promise me you’ll take some math major courses, some real ones like Galois Theory (take Galois Theory!) and for goodness sakes don’t close off any options because of some false definition of “good at math” or because some dude (or possibly dudette) needs to care about knowing everything quickly. Believe me, as you know more you will realize more and more how little you know.
One last thing. Math is not a competitive sport. It’s one of the only existing truly crowd-sourced projects of society, and that makes it highly collaborative and community-oriented, even if the awards and prizes and media narratives about “precocious geniuses” would have you believing the opposite. And once again, it’s been around a long time and is patient to be added to by you when you have the love and time and will to do so.
Love,
Cathy
Math pick-up lines
Wei Ho informed me of the existence of this tumblr page, which I am thinking it might help out a lot of nerds. An example:

Rubik’s cubes and Selmer groups
One of my biggest regrets when I left academic math and number theory behind in 2007 was that I never finished writing up and publishing some cool results I’d been working on with Manjul Bhargava about what we called “3x3x3 Rubik’s cubes”.
Just a teeny bit of background. Say you have a 3x3x3 matrix filled with numbers, including in the very center. So you have 27 numbers in a special 3-dimension configuration. Since there are three axis for such a cube, there are three ways of dividing such a cube into three 3×3 matrices 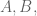
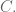
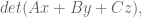
which gives you a cubic equation in three variables, or in other words a genus one curve.
Actually you get three different genus one curves, since you do it along any axis. Turns out there are crazy interesting relationships between those curves, as well as in the space of all 3x3x3 cubes.
Just talking about that stuff gets me excited, because it’s first of all a really natural construction, second of all number theoretic, and third of all it actually makes me think of solving Rubik’s cubes, which I’ve always loved.
Anyhoo, I gave my notes to a grad student Wei Ho when I left math, and she and Manjul recently came out with this preprint entitled “Coregular Spaces and genus one curves”, which is posted on the mathematical arXiv.
First, what’s freaking cool about their paper, to me personally, is that my work with Manjul has been incorporated into the paper in the form of parts of sections 3.2 and 5.1.
But what’s even more incredibly cool, to the mathematical world, is that Wei and Manjul are going to use this paper as background to understand the average size of Selmer groups of elliptic curves, a really fantastic result. Here’s the full abstract of their paper:
A coregular space is a representation of an algebraic group for which the ring of polynomial invariants is free. In this paper, we show that the orbits of many coregular irreducible representations where the number of invariants is at least two, over a (not necessarily algebraically closed) field k, correspond to genus one curves over k together with line bundles, vector bundles, and/or points on their Jacobians. In forthcoming work, we use these orbit parametrizations to determine the average sizes of Selmer groups for various families of elliptic curves.
One last thing. I am lucky enough to be a neighbor of Wei right now, as she finishes up a post-doc at Columbia, and she’s agreed to explain this stuff to me in the coming weeks. Hopefully I will remember enough number theory to understand her!
MAA Distinguished Lecture Series: Start Your Own Netflix
I’m on my way to D.C. today to give an alleged “distinguished lecture” to a group of mathematics enthusiasts. I misspoke in a previous post where I characterized the audience to consist of math teachers. In fact, I’ve been told it will consist primarily of people with some mathematical background, with typically a handful of high school teachers, a few interested members of the public, and a number of high school and college students included in the group.
So I’m going to try my best to explain three different ways of approaching recommendation engine building for services such as Netflix. I’ll be giving high-level descriptions of a latent factor model (this movie is violent and we’ve noticed you like violent movies), of the co-visitation model (lots of people who’ve seen stuff you’ve seen also saw this movie) and the latent topic model (we’ve noticed you like movies about the Hungarian 1956 Revolution). Then I’m going to give some indication of the issues in doing these massive-scale calculation and how it can be worked out.
And yes, I double-checked with those guys over at Netflix, I am allowed to use their name as long as I make sure people know there’s no affiliation.
In addition to the actual lecture, the MAA is having me give a 10-minute TED-like talk for their website as well as an interview. I am psyched by how easy it is to prepare my slides for that short version using prezi, since I just removed a bunch of nodes on the path of the material without removing the material itself. I will make that short version available when it comes online, and I also plan to share the longer prezi publicly.
[As an aside, and not to sound like an advertiser for prezi (no affiliation with them either!), but they have a free version and the resulting slides are pretty cool. If you want to be able to keep your prezis private you have to pay, but not as much as you’d need to pay for powerpoint. Of course there’s always Open Office.]
Train reading: Wrong Answer: the case against Algebra II, by Nicholson Baker, which was handed to me emphatically by my friend Nick. Apparently I need to read this and have an opinion.
Plumping up darts
Someone asked me a math question the other day and I had fun figuring it out. I thought it would be nice to write it down.
So here’s the problem. You are getting to see sample data and you have to infer the underlying distribution. In fact you happen to know you’re getting draws – which, because I’m a basically violent person, I like to think of as throws of a dart – from a uniform distribution from 0 to some unknown 
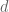

In other words, given 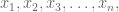
First, in order to simplify, note that all that really matters in terms of the estimate of 
Next, note you might as well assume that 
With this set-up, you’ve rephrased the question like this: if you throw ![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=555555&s=0&c=20201002)
It’s obvious from this phrasing that, as 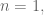
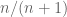
Start with a small case where you know the answer. For 

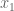
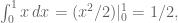
and we recover what we already know. In the next case, we need to integrate over two variables (same comment here, don’t have to divide by area of the 1×1 square base):
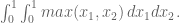
If you think about it, though, 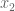
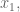

But that simplifies to:
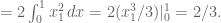
Let’s do the general case. It’s an n-fold integral over the maximum of all
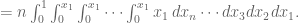
But this collapses to:
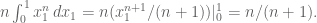
To finish the original question, take the maximum value in your collection of draws and multiply it by the plumping factor 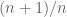
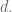
Sir Andrew Wiles smacks down unethical use of mathematics for profit
My buddy Jordan Ellenberg sent me this link to an article which covered Sir Andrew Wiles’ comments at a the opening of the Andrew Wiles Building, a housing complex for math nerds in Oxford. From the article:
Wiles claimed that the abuse of mathematics during the global financial meltdown in 2009, particularly by banks’ manipulation of complex derivatives, had tarnished his chosen subject’s reputation.
He explained that scientists used to worry about the ethical repercussions of their work and that mathematics research, which used to be removed from day-to-day life, has diverged “towards goals that you might not believe in”.
At one point Wiles said the following, which is music to my ears coming from a powerful mathematician:
One has to be aware now that mathematics can be misused and that we have to protect its good name.
Two things.
First, maybe I should invite Wiles to be on my panel of mathematicians for investigating public math models. I originally thought this should be run under the auspices of a society such as the AMS but after talking to some people I’ve given up on that and just want it to be independent.
Second, the Andrew Wiles building was evidently paid for primarily by Landon Clay, who also founded the Clay Institute and was the CEO of Eaton Vance, which an investment management firm which provides its clients with wealth management tools and advice. I’m wondering if that kind of mathematical tool was in Wiles’ mind when he made his speech, and if so, how it went over. Certainly in my experience, wealth management tools are definitely in the “weapons of math destruction” toolbox.
The art of definition
Definitions are basic objects in mathematics. Even so, I’ve never seen the art of definition explicitly taught, and I have rarely seen the need for a definition explicitly discussed.
Have you ever noticed how damn hard it is to make a good definition and yet how utterly useful a good definition can be?
The basic definitions inform the research of any field, and a good definition will lead to better theorems than a bad one. If you get them right, if you really nail down the definition, then everything works out much more cleanly than otherwise.
So for example, it doesn’t make sense to work in algebraic geometry without the concepts of affine and projective space, and varieties, and schemes. They are to algebraic geometry like circles and triangles are to elementary geometry. You define your objects, then you see how they act and how they interact.
I saw first hand how a good definition improves clarity of thought back in grad school. I was lucky enough to talk to John Tate (my mathematical hero) about my thesis, and after listening to me go on for some time with a simple object but complicated proofs, he suggested that I add an extra sentence to my basic object, an assumption with a fixed structure.
This gave me a bit more explaining to do up front – but even there added intuition – and greatly simplified the statement and proofs of my theorems. It also improved my talks about my thesis. I could now go in and spend some time motivating the definition, and then state the resulting theorem very cleanly once people were convinced.
Another example from my husband’s grad seminar this semester: he’s starting out with the concept of triangulated categories coming from Verdier’s thesis. One mysterious part of the definition involves the so-called “octahedral axiom,” which mathematicians have been grappling with ever since it was invented. As far as Johan tells it, people struggle with why it’s necessary but not that it’s necessary, or at least something very much like it. What’s amazing is that Verdier managed to get it right when he was so young.
Why? Because definition building is naturally iterative, and it can take years to get it right. It’s not an obvious process. I have no doubt that many arguments were once fought over whether the most basic definitions, although I’m no historian. There’s a whole evolutionary struggle that I can imagine could take place as well – people could make the wrong definition, and the community would not be able to prove good stuff about that, so it would eventually give way to stronger, more robust definitions. Better to start out carefully.
Going back to that. I think it’s strange that the building up of definitions is not explicitly taught. I think it’s a result of the way math is taught as if it’s already known, so the mystery of how people came up with the theorems is almost hidden, never mind the original objects and questions about them. For that matter, it’s not often discussed why we care whether a given theorem is important, just whether it’s true. Somehow the “importance” conversations happen in quiet voices over wine at the seminar dinners.
Personally, I got just as much out of Tate’s help with my thesis as anything else about my thesis. The crystalline focus that he helped me achieve with the correct choice of the “basic object of study” has made me want to do that every single time I embark on a project, in data science or elsewhere.
How much is the Stacks Project graph like a random graph?
This is a guest post from Jordan Ellenberg, a professor of mathematics at the University of Wisconsin. Jordan’s book, How Not To Be Wrong, comes out in May 2014. It is crossposted from his blog, Quomodocumque, and tweeted about at @JSEllenberg.
Cathy posted some cool data yesterday coming from the new visualization features of the magnificent Stacks Project. Summary: you can make a directed graph whose vertices are the 10,445 tagged assertions in the Stacks Project, and whose edges are logical dependency. So this graph (hopefully!) doesn’t have any directed cycles. (Actually, Cathy tells me that the Stacks Project autovomits out any contribution that would create a logical cycle! I wish LaTeX could do that.)
Given any assertion v, you can construct the subgraph G_v of vertices which are the terminus of a directed path starting at v. And Cathy finds that if you plot the number of vertices and number of edges of each of these graphs, you get something that looks really, really close to a line.
Why is this so? Does it suggest some underlying structure? I tend to say no, or at least not much — my guess is that in some sense it is “expected” for graphs like this to have this sort of property.
Because I am trying to get strong at sage I coded some of this up this morning. One way to make a random directed graph with no cycles is as follows: start with N edges, and a function f on natural numbers k that decays with k, and then connect vertex N to vertex N-k (if there is such a vertex) with probability f(k). The decaying function f is supposed to mimic the fact that an assertion is presumably more likely to refer to something just before it than something “far away” (though of course the stack project is not a strictly linear thing like a book.)
Here’s how Cathy’s plot looks for a graph generated by N= 1000 and f(k) = (2/3)^k, which makes the mean out-degree 2 as suggested in Cathy’s post.

Pretty linear — though if you look closely you can see that there are really (at least) a couple of close-to-linear “strands” superimposed! At first I thought this was because I forgot to clear the plot before running the program, but no, this is the kind of thing that happens.
Is this because the distribution decays so fast, so that there are very few long-range edges? Here’s how the plot looks with f(k) = 1/k^2, a nice fat tail yielding many more long edges:

My guess: a random graph aficionado could prove that the plot stays very close to a line with high probability under a broad range of random graph models. But I don’t really know!
Update: Although you know what must be happening here? It’s not hard to check that in the models I’ve presented here, there’s a huge amount of overlap between the descendant graphs; in fact, a vertex is very likely to be connected all but c of the vertices below it for a suitable constant c.
I would guess the Stacks Project graph doesn’t have this property (though it would be interesting to hear from Cathy to what extent this is the case) and that in her scatterplot we are not measuring the same graph again and again.
It might be fun to consider a model where vertices are pairs of natural numbers and (m,n) is connected to (m-k,n-l) with probability f(k,l) for some suitable decay. Under those circumstances, you’d have substantially less overlap between the descendant trees; do you still get the approximately linear relationship between edges and nodes?
Analyzing the complexity of the Stacks Project graphs
So yesterday I told you about the cool new visualizations now available on Johan’s Stack Project.
But how do we use these visualizations to infer something about either mathematics or, at the very least, the way we think about mathematics? Here’s one way we thought of with Pieter.
So, there’s a bunch of results, and each of them has its own subgraph of the entire graph which positions that result as the “base node” and shows all the other results which it logically depends on.
And each of those graphs has structure and attributes, the stupidest two of which are the just counts of the nodes and edges. So for each result, we have an ordered pair (#nodes, #edges). What can we infer about mathematics from these pairs?
Here’s a scatter plot of the nodes-vs-edges for each of the 10,445 results (email me if you want to play with this data yourself):
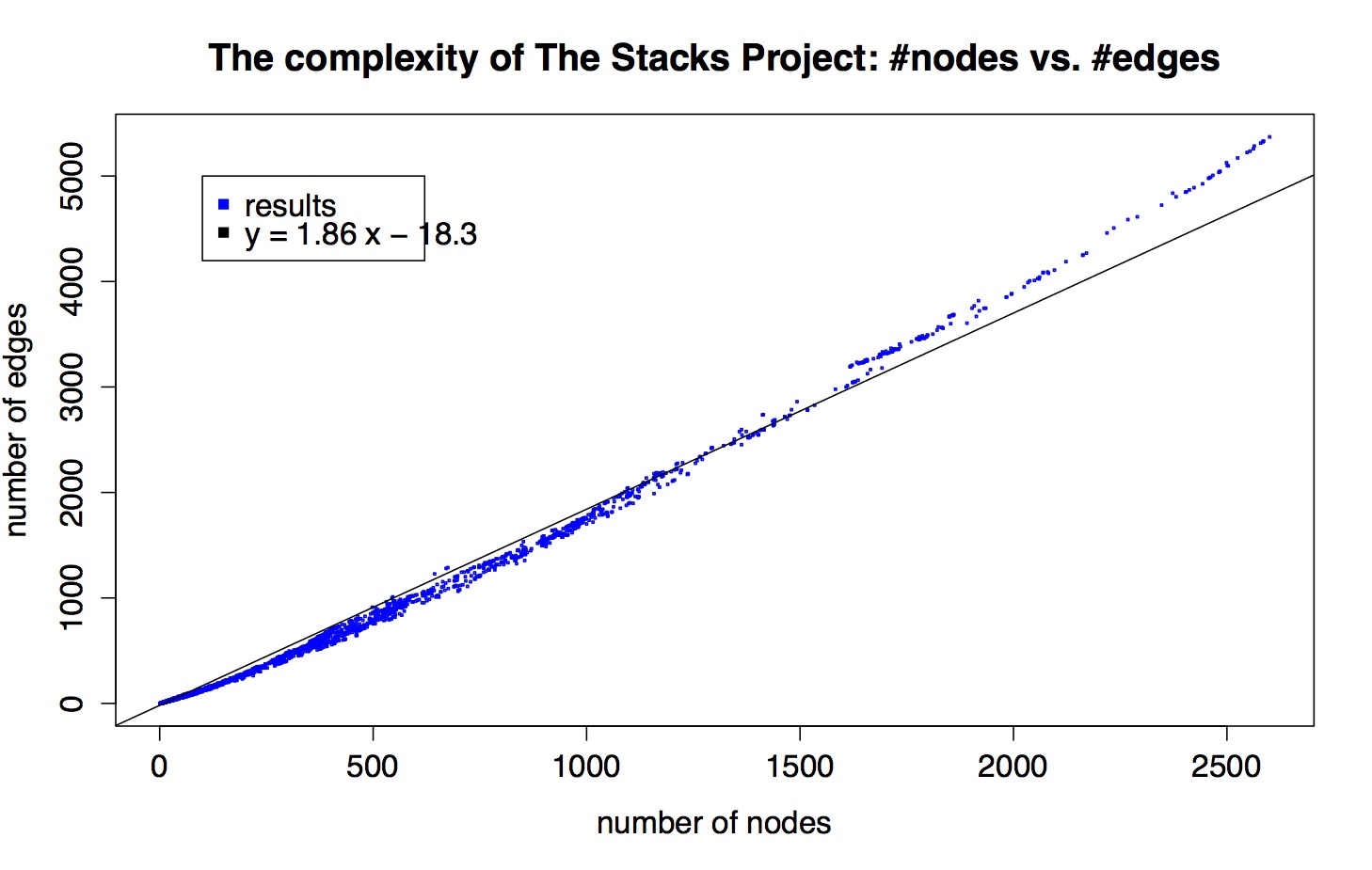
I also put a best-fit line in, just to illustrate that the scatter plot is super linear but not perfectly linear.
So there are a bunch of comments I can make about this, but I’ll limit myself to the following:
- There are a lot of points at (1,0), corresponding to remarks, axioms, beginning lemmas, definitions, and tags for sections.
- As a data person, let me just say that data is never this clean. There’s something going on, some internal structure to these graphs that we should try to understand.
- By “clean” I’m not exactly referring to the fact that things look pretty linear, although that’s weird and we should think about that. What I really mean is that things are so close to the curve that is being approximated. They’re all within a very tight border of this imaginary line. It’s super amazing.
- Let’s pretend it’s just plain straight. Does that make sense, that as graphs get more complex the edges don’t get more dense than some multiple (1.86) of of the number of nodes?
- Kind of: remember, we don’t depict all logical dependency edges, just the ones that are directly referred to in the proof of a result. So right off the bat you are less surprised that the edges aren’t growing quadratically in the number of nodes, even though the number of possible edges is of course quadratic in the number of nodes.
- Think about it this way: assume that every result that requires proof (so, that’s not a (1,0) result) refers to exactly 2 other results in its proof. Then those two child results each correspond to some subgraph of the entire graph, and say their subgraphs each have something like twice as many edges as nodes. Then, ignoring overlap, we’d see two graphs with a 2:1 ratio, then we’d see that parent node, plus two edges leading to each result, which is also a 2:1 ratio, and the disjoint union of all those graphs gives us a large graph with a 2:1 ratio.
- Then if you imagine now allowing the overlap, the ratio goes down a bit on average. In this toy model, the discrepancy between 2.0 and the slope we actually see, 1.86, is a measurement of the collapse of the two child graphs, which can be taken as a proxy for how much the two supporting results overlap as notions.
- Of course, not every result has exactly two children.
- Plus it doesn’t really explain how ridiculously consistent the plot above is. What would?
- If you think about it, the only real explanation of the consistency above is my husband brain.
- In other words, he’s humming along, thinking about stacks, and at some point, when he thinks things have gotten complicated enough, he says to himself “It’s time to wrap this stuff up and call it a result!” and then he does so. That moment, when he’s decided things are getting complicated enough, is very consistent internally to his brain.
- In other words, if someone else created the stacks project, I’d expect to see another kind of plot, possibly also very consistent, but possibly with a different slope.
- Also it’d be interesting to compare this plot to another kind of citation network graph, like the papers in the arXiv. Has anyone made that?



