Archive
Aunt Pythia’s advice
I’d like to preface Aunt Pythia’s inaugural advice column by thanking everyone who has sent me their questions. I can’t get to everything but I’ll do my best to tackle a few a week. If you have a question you’d like to submit, please do so below.
—
Dear Aunt Pythia,
My friend just started an advice column just now. She says she only wants “real” questions. But the membrane between truth and falsity is, as we all know, much more porous and permeable than this reductive boolean schema. What should I do?
Mergatroid
Dear Mergatroid,
Thanks for the question. Aunt Pythia’s answers are her attempts to be universal and useful whilst staying lighthearted and encouraging, as well as to answer the question, as she sees it, in a judgmental and over-reaching way, so yours is a fair concern.
If you don’t think she’s understood the ambiguity of a given question, please do write back and comment. If, however, you think advice columns are a waste of time altogether in terms of information gain, then my advice is to try to enjoy them for their entertainment value.
Aunt Pythia
—
Aunt Pythia,
I have a friend who always shows up to dinner parties empty-handed. What should I do?
Mergatroid
Mergatroid,
I’m glad you asked a real question too. The answer lies with you. Why are you having dinner parties and consistently inviting someone you aren’t comfortable calling up fifteen minutes beforehand screaming about not having enough parmesan cheese and to grab some on the way?
The only reason I can think of is that you’re trying to impress them. If so, then either they’ve been impressed by now or not. Stop inviting people over who you can’t demand parmesan from, it’s a simple but satisfying litmus test.
I hope that helps,
Aunt Pythia
—
Aunt Pythia,
Is a protracted discussion of “Reaganomics” the new pick-up path for meeting babes?
Tactile in Texas
T.i.T,
No idea, try me.
A.P.
—
Aunt Pythia,
A big fan of your insightful blog, I am interested in data analysis. Seemingly, marketers I have recently met with tend to misunderstand that they can find or identify causation just by utilizing quantitative methods, even if statistical software will never tell us the estimation results are causal. I’m using causation here is in the sense of potential outcomes framework.
Without knowing the idea of counterfactual, marketers could make a mistake when they calculate marketing ROI, for instance. I am wondering why people teaching Business Statistics 101 do not emphasize that we need to justify causality, for example, by employing randomization. Do you have similar impressions or experiences, auntie?
Somewhat Lonely in Asia
Dear SLiA,
I hear you. I talked about this just a couple days ago in my blog post about Rachel’s Data Science class when David Madigan guest lectured, and it’s of course a huge methodological and ethical problem when we are talking about drugs.
In industry, people make this mistake all the time, say when they start a new campaign, ROI goes up, and they assume it’s because of the new campaign but actually it’s just a seasonal effect.
The first thing to realize is that these are probably not life-or-death mistakes, except if you count the death of startups as an actual death (if you do, stop doing it). The second is that eventually someone smart figures out how to account for seasonality, and that smart person gets to keep their job because of that insight and others like it, which is a happy story for nerds everywhere.
The third and final point is that there’s no fucking way to prove causality in these cases most of the time, so it’s moot. Even if you set up an A/B test it’s often impossible to keep the experiment clean and to make definitive inferences, what with people clearing their cookies and such.
I hope that helps,
Cathy
—
Aunt Pythia,
What are the chances (mathematically speaking) that our electorial process picks the “best” person for the job? How could it be improved?
Olympian Heights
Dear OH,
Great question! And moreover it’s a great example of how, to answer a question, you have to pick a distribution first. In other words, if you think the elections are going to be not at all close, then the electoral process does a fine job. It’s only when the votes are pretty close that it makes a difference.
But having said that, the votes are almost always close on a national scale! That’s because the data collectors and pollsters do their damndest to figure out where people are in terms of voting, and the parties are constantly changing their platforms and tones to accommodate more people. So by dint of that machine, the political feedback loop, we can almost always expect a close election, and therefore we can almost always expect to worry about the electoral college versus popular vote.
Note one perverse consequence of our two-party system is that, if both sides are weak on an issue (to pull one out of a hat I’ll say financial reform), then the people who care will probably not vote at all, and so as long as they are equally weak on that issue, they can ignore it altogether.
AP
—
Dear Aunt Pythia,
Would you believe your dad is doing dishes when I teach now?
Mom
Dear Mom,
If by “your dad” you mean my dad, then no.
AP
—
Hey AP,
I have a close friend who has regularly touted his support for Obama, including on Facebook, but I found out that he has donated almost $2000 to the Romney campaign. His political donations are a matter of public record, but I had to actually look that up online. If I don’t say anything I feel our relationship won’t be the same. Do I call him on this? What would you do?
Rom-conned in NY
Dear Rom-conned,
Since the elections are safely over, right now I’d just call this guy a serious loser.
But before the election, I’d have asked you why you suspected your friend in the first place. There must have been something about him that seemed fishy or otherwise two-faced; either that or you check on all your friends’ political donation situations, which is creepy.
My advice is to bring it up with him in a direct but non-confrontational way. Something like, you ask him if he’s ever donated to a politician. If he looks you in the eye and says no, or even worse lies and says he donated to the Obama campaign, then you have your answer.
On the other hand, he may fess up and explain why he donated to Romney – maybe pressure from his parents? or work? I’m not saying it will be a good excuse but you might at least understand it more.
I hope that helps,
Aunt Pythia
—
Yo Auntie,
Caddyshack or Animal House?
UpTheArsenal
Dear UTA,
Duh, Animal House. Why do you think I had the picture I did on my zit post?
Auntie
—
Again, I didn’t get to all the questions, but I need to save some for next week just in case nobody ever asks me another question. In the meantime, please submit yours! I seriously love doing this!
Medical research needs an independent modeling panel
I am outraged this morning.
I spent yesterday morning writing up David Madigan’s lecture to us in the Columbia Data Science class, and I can hardly handle what he explained to us: the entire field of epidemiological research is ad hoc.
This means that people are taking medication or undergoing treatments that may do they harm and probably cost too much because the researchers’ methods are careless and random.
Of course, sometimes this is intentional manipulation (see my previous post on Vioxx, also from an eye-opening lecture by Madigan). But for the most part it’s not. More likely it’s mostly caused by the human weakness for believing in something because it’s standard practice.
In some sense we knew this already. How many times have we read something about what to do for our health, and then a few years later read the opposite? That’s a bad sign.
And although the ethics are the main thing here, the money is a huge issue. It required $25 million dollars for Madigan and his colleagues to implement the study on how good our current methods are at detecting things we already know. Turns out they are not good at this – even the best methods, which we have no reason to believe are being used, are only okay.
Okay, $25 million dollars is a lot, but then again there are literally billions of dollars being put into the medical trials and research as a whole, so you might think that the “due diligence” of such a large industry would naturally get funded regularly with such sums.
But you’d be wrong. Because there’s no due diligence for this industry, not in a real sense. There’s the FDA, but they are simply not up to the task.
One article I linked to yesterday from the Stanford Alumni Magazine, which talked about the work of John Ioannidis (I blogged about his work here called “Why Most Published Research Findings Are False“), summed the situation up perfectly (emphasis mine):
When it comes to the public’s exposure to biomedical research findings, another frustration for Ioannidis is that “there is nobody whose job it is to frame this correctly.” Journalists pursue stories about cures and progress—or scandals—but they aren’t likely to diligently explain the fine points of clinical trial bias and why a first splashy result may not hold up. Ioannidis believes that mistakes and tough going are at the essence of science. “In science we always start with the possibility that we can be wrong. If we don’t start there, we are just dogmatizing.”
It’s all about conflict of interest, people. The researchers don’t want their methods examined, the pharmaceutical companies are happy to have various ways to prove a new drug “effective”, and the FDA is clueless.
Another reason for an AMS panel to investigate public math models. If this isn’t in the public’s interest I don’t know what is.
Columbia Data Science course, week 10: Observational studies, confounders, epidemiology
This week our guest lecturer in the Columbia Data Science class was David Madigan, Professor and Chair of Statistics at Columbia. He received a bachelors degree in Mathematical Sciences and a Ph.D. in Statistics, both from Trinity College Dublin. He has previously worked for AT&T Inc., Soliloquy Inc., the University of Washington, Rutgers University, and SkillSoft, Inc. He has over 100 publications in such areas as Bayesian statistics, text mining, Monte Carlo methods, pharmacovigilance and probabilistic graphical models.
So Madigan is an esteemed guest, but I like to call him an “apocalyptic leprechaun”, for reasons which you will know by the end of this post. He’s okay with that nickname, I asked his permission.
Madigan came to talk to us about observation studies, of central importance in data science. He started us out with this:
Thought Experiment
We now have detailed, longitudinal medical data on tens of millions of patients. What can we do with it?
To be more precise, we have tons of phenomenological data: this is individual, patient-level medical record data. The largest of the databases has records on 80 million people: every prescription drug, every condition ever diagnosed, every hospital or doctor’s visit, every lab result, procedures, all timestamped.
But we still do things like we did in the Middle Ages; the vast majority of diagnosis and treatment is done in a doctor’s brain. Can we do better? Can you harness these data to do a better job delivering medical care?
Students responded:
1) There was a prize offered on Kaggle, called “Improve Healthcare, Win $3,000,000.” predicting who is going to go to the hospital next year. Doesn’t that give us some idea of what we can do?
Madigan: keep in mind that they’ve coarsened the data for proprietary reasons. Hugely important clinical problem, especially as a healthcare insurer. Can you intervene to avoid hospitalizations?
2) We’ve talked a lot about the ethical uses of data science in this class. It seems to me that there are a lot of sticky ethical issues surrounding this 80 million person medical record dataset.
Madigan: Agreed! What nefarious things could we do with this data? We could gouge sick people with huge premiums, or we could drop sick people from insurance altogether. It’s a question of what, as a society, we want to do.
What is modern academic statistics?
Madigan showed us Drew Conway’s Venn Diagram that we’d seen in week 1:
 Madigan positioned the modern world of the statistician in the green and purple areas.
Madigan positioned the modern world of the statistician in the green and purple areas.
It used to be the case, say 20 years ago, according to Madigan, that academic statistician would either sit in their offices proving theorems with no data in sight (they wouldn’t even know how to run a t-test) or sit around in their offices and dream up a new test, or a new way of dealing with missing data, or something like that, and then they’d look around for a dataset to whack with their new method. In either case, the work of an academic statistician required no domain expertise.
Nowadays things are different. The top stats journals are more deep in terms of application areas, the papers involve deep collaborations with people in social sciences or other applied sciences. Madigan is setting an example tonight by engaging with the medical community.
Madigan went on to make a point about the modern machine learning community, which he is or was part of: it’s a newish academic field, with conferences and journals, etc., but is characterized by what stats was 20 years ago: invent a method, try it on datasets. In terms of domain expertise engagement, it’s a step backwards instead of forwards.
Comments like the above make me love Madigan.
Very few academic statisticians have serious hacking skills, with Mark Hansen being an unusual counterexample. But if all three is what’s required to be called data science, then I’m all for data science, says Madigan.
Madigan’s timeline
Madigan went to college in 1980, specialized on day 1 on math for five years. In final year, he took a bunch of stats courses, and learned a bunch about computers: pascal, OS, compilers, AI, database theory, and rudimentary computing skills. Then came 6 years in industry, working at an insurance company and a software company where he specialized in expert systems.
It was a mainframe environment, and he wrote code to price insurance policies using what would now be described as scripting languages. He also learned about graphics by creating a graphic representation of a water treatment system. He learned about controlling graphics cards on PC’s, but he still didn’t know about data.
Then he got a Ph.D. and went into academia. That’s when machine learning and data mining started, which he fell in love with: he was Program Chair of the KDD conference, among other things, before he got disenchanted. He learned C and java, R and S+. But he still wasn’t really working with data yet.
He claims he was still a typical academic statistician: he had computing skills but no idea how to work with a large scale medical database, 50 different tables of data scattered across different databases with different formats.
In 2000 he worked for AT&T labs. It was an “extreme academic environment”, and he learned perl and did lots of stuff like web scraping. He also learned awk and basic unix skills.
It was life altering and it changed everything: having tools to deal with real data rocks! It could just as well have been python. The point is that if you don’t have the tools you’re handicapped. Armed with these tools he is afraid of nothing in terms of tackling a data problem.
In Madigan’s opinion, statisticians should not be allowed out of school unless they know these tools.
He then went to a internet startup where he and his team built a system to deliver real-time graphics on consumer activity.
Since then he’s been working in big medical data stuff. He’s testified in trials related to medical trials, which was eye-opening for him in terms of explaining what you’ve done: “If you’re gonna explain logistical regression to a jury, it’s a different kind of a challenge than me standing here tonight.” He claims that super simple graphics help.
Carrotsearch
As an aside he suggests we go to this website, called carrotsearch, because there’s a cool demo on it.
What is an observational study?
Madigan defines it for us:
An observational study is an empirical study in which the objective is to elucidate cause-and-effect relationships in which it is not feasible to use controlled experimentation.
In tonight’s context, it will involve patients as they undergo routine medical care. We contrast this with designed experiment, which is pretty rare. In fact, Madigan contends that most data science activity revolves around observational data. Exceptions are A/B tests. Most of the time, the data you have is what you get. You don’t get to replay a day on the market where Romney won the presidency, for example.
Observational studies are done in contexts in which you can’t do experiments, and they are mostly intended to elucidate cause-and-effect. Sometimes you don’t care about cause-and-effect, you just want to build predictive models. Madigan claims there are many core issues in common with the two.
Here are some examples of tests you can’t run as designed studies, for ethical reasons:
- smoking and heart disease (you can’t randomly assign someone to smoke)
- vitamin C and cancer survival
- DES and vaginal cancer
- aspirin and mortality
- cocaine and birthweight
- diet and mortality
Pitfall #1: confounders
There are all kinds of pitfalls with observational studies.
For example, look at this graph, where you’re finding a best fit line to describe whether taking higher doses of the “bad drug” is correlated to higher probability of a heart attack:

It looks like, from this vantage point, the more drug you take the fewer heart attacks you have. But there are two clusters, and if you know more about those two clusters, you find the opposite conclusion:

Note this picture was rigged it so the issue is obvious. This is an example of a “confounder.” In other words, the aspirin-taking or non-aspirin-taking of the people in the study wasn’t randomly distributed among the people, and it made a huge difference.
It’s a general problem with regression models on observational data. You have no idea what’s going on.
Madigan: “It’s the wild west out there.”
Wait, and it gets worse. It could be the case that within each group there males and females and if you partition by those you see that the more drugs they take the better again. Since a given person either is male or female, and either takes aspirin or doesn’t, this kind of thing really matters.
This illustrates the fundamental problem in observational studies, which is sometimes called Simpson’s Paradox.
[Remark from someone in the class: if you think of the original line as a predictive model, it’s actually still the best model you can obtain knowing nothing more about the aspirin-taking habits or genders of the patients involved. The issue here is really that you’re trying to assign causality.]
The medical literature and observational studies
As we may not be surprised to hear, medical journals are full of observational studies. The results of these studies have a profound effect on medical practice, on what doctors prescribe, and on what regulators do.
For example, in this paper, entitled “Oral bisphosphonates and risk of cancer of oesophagus, stomach, and colorectum: case-control analysis within a UK primary care cohort,” Madigan report that we see the very same kind of confounding problem as in the above example with aspirin. The conclusion of the paper is that the risk of cancer increased with 10 or more prescriptions of oral bisphosphonates.
It was published on the front page of new york times, the study was done by a group with no apparent conflict of interest and the drugs are taken by millions of people. But the results were wrong.
There are thousands of examples of this, it’s a major problem and people don’t even get that it’s a problem.
Randomized clinical trials
One possible way to avoid this problem is randomized studies. The good news is that randomization works really well: because you’re flipping coins, all other factors that might be confounders (current or former smoker, say) are more or less removed, because I can guarantee that smokers will be fairly evenly distributed between the two groups if there are enough people in the study.
The truly brilliant thing about randomization is that randomization matches well on the possible confounders you thought of, but will also give you balance on the 50 million things you didn’t think of.
So, although you can algorithmically find a better split for the ones you thought of, that quite possible wouldn’t do as well on the other things. That’s why we really do it randomly, because it does quite well on things you think of and things you don’t.
But there’s bad news for randomized clinical trials as well. First off, it’s only ethically feasible if there’s something called clinical equipoise, which means the medical community really doesn’t know which treatment is better. If you know have reason to think treating someone with a drug will be better for them than giving them nothing, you can’t randomly not give people the drug.
The other problem is that they are expensive and cumbersome. It takes a long time and lots of people to make a randomized clinical trial work.
In spite of the problems, randomized clinical trials are the gold standard for elucidating cause-and-effect relationships.
Rubin causal model
The Rubin causal model is a mathematical framework for understanding what information we know and don’t know in observational studies.
It’s meant to investigate the confusion when someone says something like “I got lung cancer because I smoked”. Is that true? If so, you’d have to be able to support the statement, “If I hadn’t smoked I wouldn’t have gotten lung cancer,” but nobody knows that for sure.
Define:
to be the treatment applied to unit
(0 = control, 1= treatment),
to be the response for unit
,
to be the response for unit
.
Then the unit level causal effect is 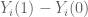
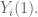
Example: 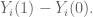
Of course, on a population level we do know how to infer that there are quite a few “1”‘s among the population, but we will never be able to assign a given individual that number.
This is sometimes called the fundamental problem of causal inference.
Confounding and Causality
Let’s say we have a population of 100 people that takes some drug, and we screen them for cancer. Say 30 out of them get cancer, which gives them a cancer rate of 0.30. We want to ask the question, did the drug cause the cancer?
To answer that, we’d have to know what would’ve happened if they hadn’t taken the drug. Let’s play God and stipulate that, had they not taken the drug, we would have seen 20 get cancer, so a rate of 0.20. We typically say the causal effect is the ration of these two numbers (i.e. the increased risk of cancer), so 1.5.
But we don’t have God’s knowledge, so instead we choose another population to compare this one to, and we see whether they get cancer or not, whilst not taking the drug. Say they have a natural cancer rate of 0.10. Then we would conclude, using them as a proxy, that the increased cancer rate is the ratio 0.30 to 0.10, so 3. This is of course wrong, but the problem is that the two populations have some underlying differences that we don’t account for.
If these were the “same people”, down to the chemical makeup of each other molecules, this “by proxy” calculation would work of course.
The field of epidemiology attempts to adjust for potential confounders. The bad news is that it doesn’t work very well. One reason is that they heavily rely on stratification, which means partitioning the cases into subcases and looking at those. But there’s a problem here too.
Stratification can introduce confounding.
The following picture illustrates how stratification could make the underlying estimates of the causal effects go from good to bad:

In the top box, the values of b and c are equal, so our causal effect estimate is correct. However, when you break it down by male and female, you get worse estimates of causal effects.
The point is, stratification doesn’t just solve problems. There are no guarantees your estimates will be better if you stratify and all bets are off.
What do people do about confounding things in practice?
In spite of the above, experts in this field essentially use stratification as a major method to working through studies. They deal with confounding variables by essentially stratifying with respect to them. So if taking aspirin is believed to be a potential confounding factor, they stratify with respect to it.
For example, with this study, which studied the risk of venous thromboembolism from the use of certain kinds of oral contraceptives, the researchers chose certain confounders to worry about and concluded the following:
After adjustment for length of use, users of oral contraceptives were at least twice the risk of clotting compared with user of other kinds of oral contraceptives.
This report was featured on ABC, and it was a big hoo-ha.
Madigan asks: wouldn’t you worry about confounding issues like aspirin or something? How do you choose which confounders to worry about? Wouldn’t you worry that the physicians who are prescribing them are different in how they prescribe? For example, might they give the newer one to people at higher risk of clotting?
Another study came out about this same question and came to a different conclusion, using different confounders. They adjusted for a history of clots, which makes sense when you think about it.
This is an illustration of how you sometimes forget to adjust for things, and the outputs can then be misleading.
What’s really going on here though is that it’s totally ad hoc, hit or miss methodology.
Another example is a study on oral bisphosphonates, where they adjusted for smoking, alcohol, and BMI. But why did they choose those variables?
There are hundreds of examples where two teams made radically different choices on parallel studies. We tested this by giving a bunch of epidemiologists the job to design 5 studies at a high level. There was zero consistency. And an addition problem is that luminaries of the field hear this and say: yeah yeah yeah but I would know the right way to do it.
Is there a better way?
Madigan and his co-authors examined 50 studies, each of which corresponds to a drug and outcome pair, e.g. antibiotics with GI bleeding.
They ran about 5,000 analyses for every pair. Namely, they ran every epistudy imaginable on, and they did this all on 9 different databases.
For example, they looked at ACE inhibitors (the drug) and swelling of the heart (outcome). They ran the same analysis on the 9 different standard databases, the smallest of which has records of 4,000,000 patients, and the largest of which has records of 80,000,000 patients.
In this one case, for one database the drug triples the risk of heart swelling, but for another database it seems to have a 6-fold increase of risk. That’s one of the best examples, though, because at least it’s always bad news – it’s consistent.
On the other hand, for 20 of the 50 pairs, you can go from statistically significant in one direction (bad or good) to the other direction depending on the database you pick. In other words, you can get whatever you want. Here’s a picture, where the heart swelling example is at the top:

Note: the choice of database is never discussed in any of these published epidemiology papers.
Next they did an even more extensive test, where they essentially tried everything. In other words, every time there was a decision to be made, they did it both ways. The kinds of decisions they tweaker were of the following types: which database you tested on, the confounders you accounted for, the window of time you care about examining (spoze they have a heart attack a week after taking the drug, is it counted? 6 months?)
What they saw was that almost all the studies can get either side depending on the choices.
Final example, back to oral bisphosphonates. A certain study concluded that it causes esophageal cancer, but two weeks later JAMA published a paper on same issue which concluded it is not associated to elevated risk of esophageal cancer. And they were even using the same database. This is not so surprising now for us.
OMOP Research Experiment
Here’s the thing. Billions upon billions of dollars are spent doing these studies. We should really know if they work. People’s lives depend on it.
Madigan told us about his “OMOP 2010.2011 Research Experiment”
They took 10 large medical databases, consisting of a mixture of claims from insurance companies and EHR (electronic health records), covering records of 200 million people in all. This is big data unless you talk to an astronomer.
They mapped the data to a common data model and then they implemented every method used in observational studies in healthcare. Altogether they covered 14 commonly used epidemiology designs adapted for longitudinal data. They automated everything in sight. Moreover, there were about 5000 different “settings” on the 14 methods.
The idea was to see how well the current methods do on predicting things we actually already know.
To locate things they know, they took 10 old drug classes: ACE inhibitors, beta blockers, warfarin, etc., and 10 outcomes of interest: renal failure, hospitalization, bleeding, etc.
For some of these the results are known. So for example, warfarin is a blood thinner and definitely causes bleeding. There were 9 such known bad effects.
There were also 44 known “negative” cases, where we are super confident there’s just no harm in taking these drugs, at least for these outcomes.
The basic experiment was this: run 5000 commonly used epidemiological analyses using all 10 databases. How well do they do at discriminating between reds and blues?
This is kind of like a spam filter test. We have training emails that are known spam, and you want to know how well the model does at detecting spam when it comes through.
Each of the models output the same thing: a relative risk (causal effect estimate) and an error.
This was an attempt to empirically evaluate how well does epidemiology work, kind of the quantitative version of John Ioannidis’s work. we did the quantitative thing to show he’s right.
Why hasn’t this been done before? There’s conflict of interest for epidemiology – why would they want to prove their methods don’t work? Also, it’s expensive, it cost $25 million dollars (of course that pales in comparison to the money being put into these studies). They bought all the data, made the methods work automatically, and did a bunch of calculations in the Amazon cloud. The code is open source.
In the second version, we zeroed in on 4 particular outcomes. Here’s the $25,000,000 ROC curve:

To understand this graph, we need to define a threshold, which we can start with at 2. This means that if the relative risk is estimated to be above 2, we call it a “bad effect”, otherwise call it a “good effect.” The choice of threshold will of course matter.
If it’s high, say 10, then you’ll never see a 10, so everything will be considered a good effect. Moreover these are old drugs and it wouldn’t be on the market. This means your sensitivity will be low, and you won’t find any real problem. That’s bad! You should find, for example, that warfarin causes bleeding.
There’s of course good news too, with low sensitivity, namely a zero false-positive rate.
What if you set the threshold really low, at -10? Then everything’s bad, and you have a 100% sensitivity but very high false positive rate.
As you vary the threshold from very low to very high, you sweep out a curve in terms of sensitivity and false-positive rate, and that’s the curve we see above. There is a threshold (say 1.8) for which your false positive rate is 30% and your sensitivity is 50%.
This graph is seriously problematic if you’re the FDA. A 30% false-positive rate is out of control. This curve isn’t good.
The overall “goodness” of such a curve is usually measured as the area under the curve: you want it to be one, and if your curve lies on diagonal the area is 0.5. This is tantamount to guessing randomly. So if your area under the curve is less than 0.5, it means your model is perverse.
The area above is 0.64. Moreover, of the 5000 analysis we ran, this is the single best analysis.
But note: this is the best if I can only use the same method for everything. In that case this is as good as it gets, and it’s not that much better than guessing.
But no epidemiology would do that!
So what they did next was to specialize the analysis to the database and the outcome. And they got better results: for the medicare database, and for acute kidney injury, their optimal model gives them an AUC of 0.92. They can achieve 80% sensitivity with a 10% false positive rate.

They did this using a cross-validation method. Different databases have different methods attached to them. One winning method is called “OS”, which compares within a given patient’s history (so compares times when patient was on drugs versus when they weren’t). This is not widely used now.
The epidemiologists in general don’t believe the results of this study.
If you go to http://elmo/omop.org, you can see the AUM for a given database and a given method.
Note the data we used was up to mid-2010. To update this you’d have to get latest version of database, and rerun the analysis. Things might have changed.
Moreover, an outcome for which nobody has any idea on what drugs cause what outcomes you’re in trouble. This only applies to when we have things to train on where we know the outcome pretty well.
Parting remarks
Keep in mind confidence intervals only account for sampling variability. They don’t capture bias at all. If there’s bias, the confidence interval or p-value can be meaningless.
What about models that epidemiologists don’t use? We have developed new methods as well (SCCS). we continue to do that, but it’s a hard problem.
Challenge for the students: we ran 5000 different analyses. Is there a good way of combining them to do better? weighted average? voting methods across different strategies?
Note the stuff is publicly available and might make a great Ph.D. thesis.
When are taxes low enough?
What with the unrelenting election coverage (go Elizabeth Warren!) it’s hard not to think about the game theory that happens in the intersection of politics and economics.
[Disclaimer: I am aware that no idea in here is originally mine, but when has that ever stopped me? Plus, I think when economists talk about this stuff they generally use jargon to make it hard to follow, which I promise not to do, and perhaps also insert salient facts which I don’t know, which I apologize for. In any case please do comment if I get something wrong.]
Lately I’ve been thinking about the push and pull of the individual versus the society when it comes to tax rates. Individuals all want lower tax rates, in the sense that nobody likes to pay taxes. On the other hand, some people benefit more from what the taxes pay for than others, and some people benefit less. It’s fair to say that very rich people see this interaction as one-sided against them: they pay a lot, they get back less.
Well, that’s certainly how it’s portrayed. I’m not willing to say that’s true, though, because I’d argue business owners and generally rich people get a lot back actually, including things like rule of law and nobody stealing their stuff and killing them because they’re rich, which if you think about it does happen in other places. In fact they’d be huge targets in some places, so you could argue that rich people get the most protection from this system.
But putting that aside by assuming the rule of law for a moment, I have a lower-level question. Namely, might we expect equilibrium at some point, where the super rich realize they need the country’s infrastructure and educational system, to hire people and get them to work at their companies and the companies they’ve invested in, and of course so they will have customers for their products and the products of the companies they’ve invested in.
So in other words you might expect that, at a certain point, these super rich people would actually say taxes are low enough. Of course, on top of having a vested interest in a well-run and educated society, they might also have sense of fairness and might not liking seeing people die of hunger, they might want to be able to defend the country in war, and of course the underlying rule of law thingy.
But the above argument has kind of broken down lately, because:
- So many companies are off-shoring their work to places where we don’t pay for infrastructure,
- and where we don’t educate the population,
- and our customers are increasingly international as well, although this is the weakest effect since Europeans can’t be counted on that so much what with their recession.
In other words, the incentive for an individual rich person to argue for lower taxes is getting more and more to be about the rule of law and not the well-run society argument. And let’s face it, it’s a lot cheaper to teach people how to use guns than it is to give them a liberal arts education. So the optimal tax rate for them would be… possibly very low. Maybe even zero, if they can just hire their own militias.
This is an example of a system of equilibrium failing because of changing constraints. There’s another similar example in the land of finance which involves credit default swaps (CDS), described very well in this NYTimes Dealbook entry by Stephen Lubben.
Namely, it used to be true that bond holders would try to come to the table and renegotiate debt when a company or government was in trouble. After all, it’s better to get 40% of their money back than none.
But now it’s possible to “insure” their bonds with CDS contracts, and in fact you can even bet on the failure of a company that way, so you actually can set it up where you’d make money when a company fails, whether you’re a bond holder or not. This means less incentive to renegotiate debt and more of an incentive to see companies go through bankruptcy.
For the record, the suggestion Lubben has, which is a good one, is to have a disclosure requirement on how much CDS you have:
In a paper to appear in the Journal of Applied Corporate Finance, co-written with Rajesh P. Narayanan of Louisiana State University, I argue that one good starting point might be the Williams Act.
In particular, the Williams Act requires shareholders to disclose large (5 percent or more) equity positions in companies.
Perhaps holders of default swap positions should face a similar requirement. Namely, when a triggering event occurs, a holder of swap contracts with a notional value beyond 5 percent of the reference entity’s outstanding public debt would have to disclose their entire credit-default swap position.
I like this idea: it’s simple and is analogous to what’s already established for equities (of course I’d like to see CDS regulated like insurance, which goes further).
[Note, however, that the equities problem isn’t totally solved through this method: you can always short your exposure to an equity using options, although it’s less attractive in equities than in bonds because the underlying in equities is usually more liquid than the derivatives and the opposite is true for bonds. In other words, you can just sell your equity stake rather than hedge it, whereas your bond you might not be able to get rid of as easily, so it’s convenient to hedge with a liquid CDS.]
Lubben’s not a perfect solution to the problem of creating incentives to make companies work rather than fail, since it adds overhead and complexity, and the last thing our financial system needs is more complexity. But it moves the incentives in the right direction.
It makes me wonder, is there an analogous rule, however imperfect, for tax rates? How do we get super rich people to care about infrastructure and education, when they take private planes and send their kids to private schools? It’s not fair to put a tax law into place, because the whole point is that rich people have more power in controlling tax laws in the first place.
Money market regulation: a letter to Geithner and Schapiro from #OWS Occupy the SEC and Alternative Banking
#OWS working groups Occupy the SEC and Alternative Banking have released an open letter to Timothy Geithner, Secretary of the U.S. Treasury, and Mary Schapiro, Chairman of the SEC, calling on them to put into place reasonable regulation of money market funds (MMF’s).
Here’s the letter, I’m super proud of it. If you don’t have enough context, I give a more background below.
What are MMFs?
Money market funds make up the overall money market, which is a way for banks and businesses to finance themselves with short-term debt. It sounds really boring, but as it turns out it’s a vital issue for the functioning of the financial system.
Really simply put, money market funds invest in things like short-term corporate debt (like 30-day GM debt) or bank debt (Goldman or Chase short-term debt) and stuff like that. Their investments also include deposits and U.S. bonds.
People like you and me can put our money into money market funds via our normal big banks like Bank of America. In face I was told by my BofA banker to do this around 2007. He said it’s like a savings account, only better. If you do invest in a MMF, you’re told how much over a dollar your investments are worth. The implicit assumption then is that you never actually lose money.
What happened in the crisis?
MMF’s were involved in some of the early warning signs of the financial crisis. In August and September 2007, there was a run on subprime-related asset backed commercial paper.
In 2008, some of the funds which had invested in short-term Lehman Brother’s debt had huge problems when Lehman went down, and they “broke the buck”. This caused wide-spread panic and a bunch of money market funds had people pulling money from them.
In order to avoid a run on the MMF’s, the U.S. stepped in and guaranteed that nobody would actually lose money. It was a perfect example of something we had to do at the time, because we would literally not have had a functioning financial system given how central the money markets were at the time, in financing the shadow banking system, but something we should have figured out how to improve on by now.
This is a huge issue and needs to be dealt with before the next crisis.
What happened in 2010?
In 2010, regulators put into place rules that tightened restrictions within a fund. Things like how much cash they had to have on hand (liquidity requirements) and how long the average duration of their investments could be. This helped address the problem of what happens within a given fund when investors take their money out of that fund.
What they didn’t do in 2010 was to control systemic issues, and in particular how to make the MMF’s robust to large-scale panic.
What about Schapiro’s two MMF proposals?
More recently, Mary Schapiro, Chairman of the SEC, made two proposals to address the systemic issues. In the first proposal, instead of having the NAV’s set at one dollar, everything is allowed to float, just like every other kind of mutual fund. The industry didn’t like it, claiming it would make MMF’s less attractive.
In the second proposal, Schapiro suggesting that MMF managers keep a buffer of capital and that a new, weird lagged way for people to remove their money from their MMF’s, namely if you want to withdraw your funds you’ll only get 97%, and later (after 30 days) you’ll get 3% if the market doesn’t take a loss. If it does take a loss, will get only part of that last 3%.
The goal of this was to distribute losses more evenly, and to give people pause in times of crisis from withdrawing too quickly and causing a bank-like run.
Unfortunately, both of Schapiro’s proposals didn’t get passed by the 5 SEC Commissioners in August 2012 – it needed a majority vote, but they only got 2.
What happened when Geithner and Blackrock entered the picture?
The third, most recent proposal, comes out of the FSOC, a new meta-regulator, whose chair is Timothy Geithner. The guys proposed to the SEC in a letter dated September 27th that they should do something about money market regulation. Specifically, the FSOC letter suggests that either the SEC should go with one of Schapiro’s two ideas or a new third one.
The third one is again proposing a weird way for people to take their money out of a MMF, but this time it definitely benefits people who are “first movers”, in other words people who see a problem first and get the hell out. It depends on a parameter, called a trigger, which right now is set at 25 basis points (so 25 cents if you have $100 invested).
Specifically, if the value of the fund falls below 99.75, any withdrawal from that point on will be subject to a “withdrawal fee,” defined to be the distance between the fund’s level and 100. So if the fund is at 99.75, you have to pay a 25 cent fee and you only get out 99.50, whereas if the fund is at 99.76, you actually get out 100. So in other words, there’s an almost 50 cents difference at this critical value.
Is this third proposal really any better than either of Schapiro’s first two?
The industry and Timmy: bff’s?
Here’s something weird: on the same day the FSOC letter was published, BlackRock, which is a firm that does an enormous amount of money market managing and so stands to win or lose big on money market regulation, published an article in which they trashed Schapiro’s proposals and embellished this third one.
In other words, it looks like Geithner has been talking directly to Blackrock about how the money market regulation should be written.
In fact Geithner has seemingly invited industry insiders to talk to him at the Treasury. And now we have his proposal, which benefits insiders and also seems to have all of the unattractiveness that the other proposals had in terms of risks for normal people, i.e. non-insiders. That’s weird.
Update: in this Bloomberg article from yesterday (hat tip Matt Stoller), it looks like Geithner may be getting a fancy schmancy job at BlackRock after the election. Oh!
What’s wrong with simple?
Personally, and I say this as myself and not representing anyone else, I don’t see what’s wrong with Schapiro’s first proposal to keep the NAV floating. If there’s risk, investors should know about it, period, end of story. I don’t want the taxpayers on the hook for this kind of crap.
The NYC subway, Aunt Pythia, my zits, and Louis CK
Please pardon the meandering nature of this post. It’s that kind of Monday morning.
——————-
So much for coming together as a city after a disaster. The New York mood was absolutely brutal on the subway this morning.
I went into the subway station in awe of the wondrous infrastructure that is the NY subway, looking for someone to make out with in sheer rapture that my kids are all in school, but after about 15 minutes I was clawing my way, along with about 15 other people, onto the backs of people already stuffed like sausages on the 2 train at 96th street.
For god’s sakes, people, look at all that space up top! Can you people who are traveling together please give each other piggy-back rides so we don’t waste so much goddamn space? Sheesh.
——————-
I’m absolutely blown away by the questions I’ve received already for my Aunt Pythia advice column: you guys are brilliant, interesting, and only a little bit abusive.
My only complaint is that the questions so far are very, very deep, and I was hoping for some very silly and/or sexual questions so I could make this kind of lighthearted and fun in between solving the world’s pressing problem.
Even so, well done. I’m worried I might have to replace mathbabe altogether just to answer all these amazing questions. Please give me more!
——————-
After some amazing on-line and off-line comments for my zit model post from yesterday, I’ve come to a few conclusions:
- Benzoyl peroxide works for lots of people. I’ll try it, what the hell.
- An amazing number of people have done this experiment.
- It may be something you don’t actually want to do. For example, as Jordan pointed out yesterday, what if you find out it’s caused by something you really love doing? Then your pleasure doing that would be blemished.
- It may well be something you really don’t want other people to do. Can you imagine how annoyingly narcissistic and smug everyone’s going to be when they solve their acne/weight/baldness problems with this kind of stuff? The peer pressure to be perfect is gonna be even worse than it currently is. Blech! I love me some heterogeneity in my friends.
——————–
Finally, and I know I’m the last person to find out about everything (except Gangnam Style, which I’ll be sure to remind you guys of quite often), but I finally got around to absolutely digging Louis CK when he hosted SNL this weekend. A crazy funny man, and now I’m going through all his stuff (or at least the stuff available to me for free on Amazon Prime).
The zit model
When my mom turned 42, I was 12 and a total wise-ass. For her present I bought her a coffee mug that had on it the phrase “Things could be worse. You could be old and still have zits”, to tease her about her bad skin. Considering how obnoxious that was, she took it really well and drank out of the mug for years.
Well, I’m sure you can all see where this is going. I’m now 40 and I have zits. I was contemplating this in the bath yesterday, wondering if I’d ever get rid of my zits and wondering if taking long hot baths helps or not. They come and go, so it seems vaguely controllable.
Then I had a thought: well, I could collect data and see what helps. After all, I don’t always have zits. I could keep a diary of all the things that I think might affect the situation: what I eat (I read somewhere that eating cheese makes you have zits), how often I take baths vs. showers, whether I use zit cream, my hormones, etc. and certainly whether or not I have zits on a given day or not.
The first step would be to do some research on the theories people have about what causes zits, and then set up a spreadsheet where I could efficiently add my daily data. Maybe a google form! I’m wild about google forms.
After collecting this data for some time I could build a model which tries to predict zittage, to see which of those many inputs actually have signal for my personal zit model.
Of course I expect a lag between the thing I do or eat or use and the actual resulting zit, and I don’t know what that lag is (do you get zits the day after you eat cheese? or three days after eating cheese?), so I’ll expect some difficulty with this or even over fitting.
Even so, this just might work!

Then I immediately felt tired because, if you think about spending your day collecting information like that about your potential zits, then you must be totally nuts.
I mean, I can imagine doing it just for fun, or to prove a point, or on a dare (there are few things I won’t do on a dare), but when it comes down to it I really don’t care that much about my zits.
Then I started thinking about technology and how it could help me with my zit model. I mean, you know about those bracelets you can wear that count your steps and then automatically record them on your phone, right? Well, how long until those bracelets can be trained to collect any kind of information you can imagine?
- Baths? No problem. I’m sure they can detect moisture and heat.
- Cheese eating? Maybe you’d have to say out loud what you’re eating, but again not a huge problem.
- Hormones? I have no idea but let’s stipulate plausible: they already have an ankle bracelet that monitors blood alcohol levels.
- Whether you have zits? Hmmm. Let’s say you could add any variable you want with voice command.
In other words, in 5 years this project will be a snap when I have my handy dandy techno bracelet which collects all the information I want. And maybe whatever other information as well, because information storage is cheap. I’ll have a bounty of data for my zit model.
This is exciting stuff. I’m looking forward to building the definitive model, from which I can conclude that eating my favorite kind of cheese does indeed give me zits. And I’ll say to myself, worth it!
Ask Aunt Pythia
Readers, I’m happy to announce an experiment for mathbabe, namely a Saturday morning advice and ethics column. Honestly I’ve always wanted to have an advice column, and I just realized yesterday that I can do it on my blog, especially on Saturday when fewer people read it anyway, so what the hell!
I’m calling my advice-giving alter ego Aunt Pythia, which my friend Becky suggested since “the Pythia” were a series of women oracles of Delphi who blazed the trail for the modern advice columnist.
The classic Pythia had a whole complicated, arduous four-step process for her “supplicants” to go through:
- Journey to Delphi,
- Preparation of the Supplicant,
- Visit to the Oracle, and
- Return Home.
I’ve decided to simplify that process a bit with a google form below, which should actually work, so please feel free to submit questions right away!
Just to give you an idea of what kind of questions you can submit, here’s a short list of conditions:
- Ask pretty much anything, although it’s obviously better if it’s funny.
- Nothing about investing advice or anything I can get sued for.
I also have prepared a sample question to get things rolling.
Dear Aunt Pythia,
I’m a physics professor, and an undergrad student has asked me for a letter of recommendation to get into grad school. Although he’s worked extremely hard, and he has some talent, I’m pretty sure he’d struggle to be a successful physicist. What do I do? — Professor X
Professor X,
I’ve been there, and it’s tricky, but I do have advice.
First of all, do keep in mind that people come with all kinds of talents, and it’s actually pretty hard to predict success. I have a friend who I went to school with who didn’t strike me as awesomely good at math but has somehow migrated towards the very kind of questions he is really good at and become a big success. So you never know, actually. Plus ultimately it’s up to them to decide what to try to do with their lives.
Second of all, feel free to ask them what their plans are. I don’t think you should up and say something like “you should go into robotics, not physics!” (no offense to those who are in robotics, this is an actual example from real life) because it would be too obviously negative and could totally depress the student, which is not a great idea.
But certainly ask, “what are your plans?” and if they say their plan is to go into grad school and become a researcher and professor, ask them if they have thought about other things in addition, that the world is a big place, and people with good quantitative skills are desperately needed, blah blah blah. Basically make it clear that their options are really pretty good if they could expand their definition of success. Who knows, they might not have even considered other stuff.
Finally, write the letter honestly. Talk about how hard the person worked and what their aspirations are. Don’t talk about how you don’t think they have talent, but don’t imply they’re awesome either, because it’s not doing them any favors and your letters end up being worthless.
I hope that helps!
Aunt Pythia
————————
Here’s the form, feel free to submit! I won’t even save your email address or real name so feel free to ask away.
Columbia Data Science course, week 9: Morningside Analytics, network analysis, data journalism
Our first speaker this week in Rachel Schutt‘s Columbia Data Science course was John Kelly from Morningside Analytics, who came to talk to us about network analysis.
John Kelly
Kelly has four diplomas from Columbia, starting with a BA in 1990 from Columbia College, followed by a Masters, MPhil and Ph.D. in Columbia’s school of Journalism. He explained that studying communications as a discipline can mean lots of things, but he was interested in network sociology and statistics in political science.
Kelly spent a couple of terms at Stanford learning survey design and game theory and other quanty stuff. He describes the Columbia program in communications as a pretty DIY set-up, where one could choose to focus on the role of communication in society, the impact of press, impact of information flow, or other things. Since he was interested in quantitative methods, he hunted them down, doing his master’s thesis work with Marc Smith from Microsoft. He worked on political discussions and how they evolve as networks (versus other kinds of discussions).
After college and before grad school, Kelly was an artist, using computers to do sound design. He spent 3 years as the Director of Digital Media here at Columbia School of the Arts.
Kelly taught himself perl and python when he spent a year in Viet Nam with his wife.
Kelly’s profile
Kelly spent quite a bit of time describing how he sees math, statistics, and computer science (including machine learning) as tools he needs to use and be good at in order to do what he really wants to do.
But for him the good stuff is all about domain expertise. He want to understand how people come together, and when they do, what is their impact on politics and public policy. His company Morningside Analytics has clients like think tanks and political organizations and want to know how social media affects and creates politics. In short, Kelly wants to understand society, and the math and stats allows him to do that.
Communication and presentations are how he makes money, so that’s important, and visualizations are integral to both domain expertise and communications, so he’s essentially a viz expert. As he points out, Morningside Analytics doesn’t get paid to just discover interesting stuff, but rather to help people use it.
Whereas a company such SocialFlow is venture funded, which means you can run a staff even if you don’t make money, Morningside is bootstrapped. It’s a different life, where we eat what we sow.
Case-attribute data vs. social network data
Kelly has a strong opinion about standard modeling through case-attribute data, which is what you normally see people feed to models with various “cases” (think people) who have various “attributes” (think age, or operating system, or search histories).
Maybe because it’s easy to store in databases or because it’s easy to collect this kind of data, there’s been a huge bias towards modeling with case-attribute data.
Kelly thinks it’s missing the point of the questions we are trying to answer nowadays. It started, he said, in the 1930’s with early market research, and it was soon being applied applied to marketing as well as politicals.
He named Paul Lazarsfeld and Elihu Katz as trailblazing sociologists who came here from Europe and developed the field of social network analysis. This is a theory based not only on individual people but also the relationships between them.
We could do something like this for the attributes of a data scientist, and we might have an arrow point from math to stats if we think math “underlies” statistics in some way. Note the arrows don’t always mean the same thing, though, and when you specify a network model to test a theory it’s important you make the arrows well-defined.
To get an idea of why network analysis is superior to case-attribute data analysis, think about this. The federal government spends money to poll people in Afghanistan. The idea is to see what citizens want and think to determine what’s going to happen in the future. But, Kelly argues, what’ll happen there isn’t a function of what individuals think, it’s a question of who has the power and what they think.
Similarly, imagine going back in time and conducting a scientific poll of the citizenry of Europe in 1750 to determine the future politics. If you knew what you were doing you’d be looking at who’s marrying who among the royalty.
In some sense the current focus on case-attribute data is a problem of what’s “under the streetlamp” – people are used to doing it that way.
Kelly wants us to consider what he calls the micro/macro (i.e. individual versus systemic) divide: when it comes to buying stuff, or voting for a politician in a democracy, you have a formal mechanism for bridging the micro/macro divide, namely markets for buying stuff and elections for politicians. But most of the world doesn’t have those formal mechanisms, or indeed they have a fictive shadow of those things. For the most part we need to know enough about the actual social network to know who has the power and influence to bring about change.
Kelly claims that the world is a network much more than it’s a bunch of cases with attributes. For example, if you only understand how individuals behave, how do you tie things together?
History of social network analysis
Social network analysis basically comes from two places: graph theory, where Euler solved the Seven Bridges of Konigsberg problem, and sociometry, started by Jacob Moreno in the 1970’s, just as early computers got good at making large-scale computations on large data sets.
Social network analysis was germinated by Harrison White, emeritus at Columbia (emeritus), contemporaneously with Columbia sociologist Robert Merton. Their essential idea was that people’s actions have to be related to their attributes, but to really understand them you also need to look at the networks that enable them to do something.
Core entities for network models
Kelly gave us a bit of terminology from the world of social networks:
- actors (or nodes in graph theory speak): these can be people, or websites, or what have you
- relational ties (edges in graph theory speak): for example, an instance of liking someone or being friends
- dyads: pairs of actors
- triads: triplets of actors; there are for example, measures of triadic closure in networks
- subgroups: a subset of the whole set of actors, along with their relational ties
- group: the entirety of a “network”, easy in the case of Twitter but very hard in the case of e.g. “liberals”
- relation: for example, liking another person
- social network: all of the above
Types of Networks
There are different types of social networks.
For example, in one-node networks, the simplest case, you have a bunch of actors connected by ties. This is a construct you’d use to display a Facebook graph for example.
In two-node networks, also called bipartite graphs, the connections only exist between two formally separate classes of objects. So you might have people on the one hand and companies on the other, and you might connect a person to a company if she is on the board of that company. Or you could have people and the things they’re possibly interested in, and connect them if they really are.
Finally, there are ego networks, which is typically the part of the network surrounding a single person. So for example it could be just the subnetwork of my friends on Facebook, who may also know each other in certain cases. Kelly reports that people with higher socioeconomic status have more complicated ego networks. You can see someone’s level of social status by looking at their ego network.
What people do with these networks
The central question people ask when given a social network is, who’s important here?
This leads to various centrality measures. The key ones are:
- degree – This counts how many people are connected to you.
- closeness – If you are close to everyone, you have a high closeness score.
- betweenness – People who connect people who are otherwise separate. If information goes through you, you have a high betweenness score.
- eigenvector – A person who is popular with the popular kids has high eigenvector centrality. Google’s page rank is an example.
A caveat on the above centrality measures: the measurement people form an industry that try to sell themselves as the authority. But experience tells us that each has their weaknesses and strengths. The main thing is to know you’re looking at the right network.
For example, if you’re looking for a highly influential blogger in the muslim brotherhood, and you write down the top 100 bloggers in some large graph of bloggers, and start on the top of the list, and go down the list looking for a muslim brotherhood blogger, it won’t work: you’ll find someone who is both influential in the large network and who blogs for the muslim brotherhood, but they won’t be influential with the muslim brotherhood, but rather with transnational elites in the larger network. In other words, you have to keep in mind the local neighborhood of the graph.
Another problem with measures: experience dictates that, although something might work with blogs, when you work with Twitter you’ll need to get out new tools. Different data and different ways people game centrality measures make things totally different. For example, with Twitter, people create 5000 Twitter bots that all follow each other and some strategic other people to make them look influential by some measure (probably eigenvector centrality). But of course this isn’t accurate, it’s just someone gaming the measures.
Some network packages exist already and can compute the various centrality measures mentioned above:
- NodeXL, a plugin for Excel,
- NetworkX for python,
- igraph also for python,
- statnet for R, and
- Jure Leskovec at Stanford is creating new network package for C which should be awesome.
Thought experiment
You’re part of an elite, well-funded think tank in DC. You can hire people and you have $10million to spend. Your job is to empirically predict the future political evolution of Egypt. What kinds of political parties will there be? What is the country of Egypt gonna look like in 5, 10, or 20 years? You have access to exactly two of the following datasets for all Egyptians:
- The Facebook network,
- The Twitter network,
- A complete record of who went to school with who,
- The SMS/phone records,
- The network data on members of all political organizations and private companies, and
- Where everyone lives and who they talk to.
Note things change over time- people might migrate off of Facebook, or political discussions might need to go underground if blogging is too public. Facebook alone gives a lot of information but sometimes people will try to be stealth. Phone records might be better representation for that reason.
If you think the above is ambitious, recall Siemens from Germany sold Iran software to monitor their national mobile networks. In fact, Kelly says, governments are putting more energy into loading field with allies, and less with shutting down the field. Pakistan hires Americans to do their pro-Pakistan blogging and Russians help Syrians.
In order to answer this question, Kelly suggests we change the order of our thinking. A lot of the reasoning he heard from the class was based on the question, what can we learn from this or that data source? Instead, think about it the other way around: what would it mean to predict politics in a society? what kind of data do you need to know to do that? Figure out the questions first, and then look for the data to help me answer them.
Morningside Analytics
Kelly showed us a network map of 14 of the world’s largest blogospheres. To understand the pictures, you imagine there’s a force, like a wind, which sends the nodes (blogs) out to the edge, but then there’s a counteracting force, namely the links between blogs, which attach them together.
Here’s an example of the arabic blogosphere:

The different colors represent countries and clusters of blogs. The size of each dot is centrality through degree, so the number of links to other blogs in the network. The physical structure of the blogosphere gives us insight.
If we analyze text using NLP, thinking of the blog posts as a pile of text or a river of text, then we see the micro or macro picture only – we lose the most important story. What’s missing there is social network analysis (SNA) which helps us map and analyze the patterns of interaction.
The 12 different international blogospheres, for example, look different. We infer that different societies have different interests which give rise to different patterns.
But why are they different? After all, they’re representations of some higher dimensional thing projected onto two dimensions. Couldn’t it be just that they’re drawn differently? Yes, but we do lots of text analysis that convinces us these pictures really are showing us something. We put an effort into interpreting the content qualitatively.
So for example, in the French blogosphere, we see a cluster that discusses gourmet cooking. In Germany we see various blobs discussing politics and lots of weird hobbies. In English we see two big blobs [mathbabe interjects: gay porn and straight porn?] They turn out to be conservative vs. liberal blogs.
In Russian, their blogging networks tend to force people to stay within the networks, which is why we see very well defined partitioned blobs.
The proximity clustering is done using the Fruchterman-Reingold algorithm, where being in the same neighborhood means your neighbors are connected to other neighbors, so really a collective phenomenon of influence.. Then we interpret the segments. Here’s an example of English language blogs:

Think about social media companies: they are each built around the fact that they either have the data or that they have a toolkit – a patented sentiment engine or something, a machine that goes ping.
But keep in mind that social media is heavily a product of organizations that pay to move the needle (i.e. game the machine that goes ping). To decipher that game you need to see how it works, you need to visualize.
So if you are wondering about elections, look at people’s blogs within “the moms” or “the sports fans”. This is more informative than looking at partisan blogs where you already know the answer.
Kelly walked us through an analysis, once he has binned the blogosphere into its segments, of various types of links to partisan videos like MLK’s “I have a dream” speech and a gotcha video from the Romney campaign. In the case of the MLK speech, you see that it gets posted in spurts around the election cycle events all over the blogosphere, but in the case of the Romney campaign video, you see a concerted effort by conservative bloggers to post the video in unison.
That is to say, if you were just looking at a histogram of links, a pure count, it might look as if it had gone viral, but if you look at it through the lens of the understood segmentation of the blogosphere, it’s clearly a planned operation to game the “virality” measures.
Kelly also works with the Berkman Center for Internet and Society at Harvard. He analyzed the Iranian blogosphere in 2008 and again in 2011 and he found much the same in terms of clustering – young anti-government democrats, poetry, conservative pro-regime clusters dominated in both years.
However, only 15% of the blogs are the same 2008 to 2011.
So, whereas people are often concerned about individuals (case-attribute model), the individual fish are less important than the schools of fish. By doing social network analysis, we are looking for the schools, because that way we learn about the salient interests of the society and how those interests are they stable over time.
The moral of this story is that we need to focus on meso-level patterns, not micro- or macro-level patterns.
John Bruner
Our second speaker of the night was John Bruner, an editor at O’Reilly who previously worked as the data editor at Forbes. He is broad in his skills: he does research and writing on anything that involved data. Among other things at Forbes, he worked on an internal database on millionaires on which he ran simple versions of social media dynamics.
Writing technical journalism
Bruner explained the term “data journalism” to the class. He started this by way of explaining his own data scientist profile.
First of all, it involved lots of data viz. A visualization is a fast way of describing the bottomline of a data set. And at a big place like the NYTimes, data viz is its own discipline and you’ll see people with expertise in parts of dataviz – one person will focus on graphics while someone else will be in charge of interactive dataviz.
CS skills are pretty important in data journalism too. There are tight deadlines, and the data journalist has to be good with their tools and with messy data (because even federal data is messy). One has to be able to handle arcane formats or whatever, and often this means parcing stuff in python or what have you. Bruner uses javascript and python and SQL and Mongo among other tools.
Bruno was a math major in college at University of Chicago, then he went into writing at Forbes, where he slowly merged back into quantitative stuff while there. He found himself using mathematics in his work in preparing good representations of the research he was uncovering about, for example, contributions of billionaires to politicians using circles and lines.
Statistics, Bruno says, informs the way you think about the world. It inspires you to write things: e.g., the “average” person is a woman with 250 followers but the median open twitter account has 0 followers. So the median and mean are impossibly different because the data is skewed. That’s an inspiration right there for a story.
Bruno admits to being a novice in machine learning.However, he claims domain expertise as quite important. With exception to people who can specialize in one subject, say at a governmental office or a huge daily, for smaller newspaper you need to be broad, and you need to acquire a baseline layer of expertise quickly.
Of course communications and presentations are absolutely huge for data journalists. Their fundamental skill is translation: taking complicated stories and deriving meaning that readers will understand. They also need to anticipate questions, turn them into quantitative experiments, and answer them persuasively.
A bit of history of data journalism
Data journalism has been around for a while, but until recently (computer-assisted reporting) was a domain of Excel power users. Still, if you know how to write an excel program, you’re an elite.
Things started to change recently: more data became available to us in the form of API’s, new tools and less expensive computing power, so we can analyze pretty large data sets on your laptop. Of course excellent viz tools make things more compelling, flash is used for interactive viz environments, and javascript is getting way better.
Programming skills are now widely enough held so that you can find people who are both good writers and good programmers. Many people are english majors and know enough about computers to make it work, for example, or CS majors who can write.
In big publications like the NYTimes, the practice of data journalism is divided into fields: graphics vs. interactives, research, database engineers, crawlers, software developers, domain expert writers. Some people are in charge of raising the right questions but hand off to others to do the analysis. Charles Duhigg at the NYTimes, for example, studied water quality in new york, and got a FOIA request to the State of New York, and knew enough to know what would be in that FOIA request and what questions to ask but someone else did the actual analysis.
At a smaller place, things are totally different. Whereas the NYTimes has 1000 people on its newsroom floor, the Economist has maybe 130, and Forbes has 70 or 80 people in their newsrooms. If you work for anything beside a national daily, you end up doing everything by yourself: you come up with question, you go get the data, you do the analysis, then you write it up.
Of course you also help and collaborate with your colleagues when you can.
Advice Bruno has for the students in initiating a data journalism project: don’t have a strong thesis before you’ve interviewed the experts. Go in with a loose idea of what you’re searching for and be willing to change your mind and pivot if the experts lead you in a new and interesting direction.
Occupy in the Financial Times
Lisa Pollack just wrote about Occupy yesterday in this article entitled “Occupy is Increasingly Well-informed”.
It was mostly about Alternative Banking‘s sister working group in London, Occupy Economics, and their recent event this past Monday at which Andy Haldane, Executive Director of Financial Stability at the Bank of England spoke and at which Lisa Pollack chaired the discussion. For more on that event see Lisa’s article here.
Lisa interviewed me yesterday for the article, and asked me (over the screaming of my three sons who haven’t had school in what feels like months), if I had a genie and one try, what would I wish for with respect to Occupy and Alt Banking. I decided that my wish would be that there’s no reason to meet anymore, that the regulators, politicians, economists, lobbyists and bank CEO’s, so the stewards or our financial system and the economy, all got together and decided to do their jobs (and the lobbyists just found other jobs).
Does that count as one wish?
I’m digging these events where Occupiers get to talk one-on-one with those rare regulators and insiders who know how the system works, understand that the system is rigged, and are courageous enough to be honest about it. Alternative Banking met with Sheila Bar a couple of months ago and we’ve got more very exciting meetings coming up as well.
The definitive visualization for Hurricane Sandy, if you’re a parent of small children
 Two small quibbles: it should be centered a much larger area, and “wine” should be replaced by “vodka”.
Two small quibbles: it should be centered a much larger area, and “wine” should be replaced by “vodka”.
An AMS panel to examine public math models?
On Saturday I gave a talk at the AGNES conference to a room full of algebraic geometers. After introducing myself and putting some context around my talk, I focused on a few models:
- VaR,
- VAM,
- Credit scoring,
- E-scores (online version of credit scores), and
- The h-score model (I threw this in for the math people and because it’s an egregious example of a gameable model).
I wanted to formalize the important and salient properties of a model, and I came up with this list:
- Name – note the name often gives off a whiff of political manipulation by itself
- Underlying model – regression? decision tree?
- Underlying assumptions – normal distribution of market returns?
- Input/output – dirty data?
- Purported/political goal – how is it actually used vs. how its advocates claim they’ll use it?
- Evaluation method – every model should come with one. Not every model does. A red flag.
- Gaming potential – how does being modeled cause people to act differently?
- Reach – how universal and impactful is the model and its gaming?
In the case of VAM, it doesn’t have an evaluation method. There’s been no way for teachers to know if the model that they get scored on every year is doing a good job, even as it’s become more and more important in tenure decisions (the Chicago strike was largely related to this issue, as I posted here).
Here was my plea to the mathematical audience: this is being done in the name of mathematics. The authority that math is given by our culture, which is enormous and possibly not deserved, is being manipulated by people with vested interests.
So when the objects of modeling, the people and the teachers who get these scores, ask how those scores were derived, they’re often told “it’s math and you wouldn’t understand it.”
That’s outrageous, and mathematicians shouldn’t stand for it. We have to get more involved, as a community, with how mathematics is wielded on the population.
On the other hand, I wouldn’t want mathematicians as a group to get co-opted by these special interest groups either and become shills for the industry. We don’t want to become economists, paid by this campaign or that to write papers in favor of their political goals.
To this end, someone in the audience suggested the AMS might want to publish a book of ethics for mathematicians akin to the ethical guidelines that are published for the society of pyschologists and lawyers. His idea is that it would be case-study based, which seems pretty standard. I want to give this some more thought.
We want to make ourselves available to understand high impact, public facing models to ensure they are sound mathematically, have reasonable and transparent evaluation methods, and are very high quality in terms of proven accuracy and understandability if they are used on people in high stakes situations like tenure.
One suggestion someone in the audience came up with is to have a mathematician “mechanical turk” service where people could send questions to a group of faceless mathematicians. Although I think it’s an intriguing idea, I’m not sure it would work here. The point is to investigate so-called math models that people would rather no mathematician laid their eyes on, whereas mechanical turks only answer questions someone else comes up with.
In other words, there’s a reason nobody has asked the opinion of the mathematical community on VAM. They are using the authority of mathematics without permission.
Instead, I think the math community should form something like a panel, maybe housed inside the American Mathematical Society (AMS), that trolls for models with the following characteristics:
- high impact – people care about these scores for whatever reason
- large reach – city-wide or national
- claiming to be mathematical – so the opinion of the mathematical community matters, or should,
After finding such a model, the panel should publish a thoughtful, third-party analysis of its underlying mathematical soundness. Even just one per year would have a meaningful effect if the models were chosen well.
As I said to someone in the audience (which was amazingly receptive and open to my message), it really wouldn’t take very long for a mathematician to understand these models well enough to have an opinion on them, especially if you compare it to how long it would take a policy maker to understand the math. Maybe a week, with the guidance of someone who is an expert in modeling.
So in other words, being a member of such a “public math models” panel could be seen as a community service job akin to being an editor for a journal: real work but not something that takes over your life.
Now’s the time to do this, considering the explosion of models on everything in sight, and I believe mathematicians are the right people to take it on, considering they know how to admit they’re wrong.
Tell me what you think.
Columbia Data Science course, week 8: Data visualization, broadening the definition of data science, Square, fraud detection
This week in Rachel Schutt’s Columbia Data Science course we had two excellent guest speakers.
The first speaker of the night was Mark Hansen, who recently came from UCLA via the New York Times to Columbia with a joint appointment in journalism and statistics. He is a renowned data visualization expert and also an energetic and generous speaker. We were lucky to have him on a night where he’d been drinking an XXL latte from Starbucks to highlight his natural effervescence.
Mark started by telling us a bit about Gabriel Tarde (1843-1904).

Tarde was a sociologist who believed that the social sciences had the capacity to produce vastly more data than the physical sciences. His reasoning was as follows.
The physical sciences observe from a distance: they typically model or incorporate models which talk about an aggregate in some way – for example, biology talks about the aggregate of our cells. What Tarde pointed out was that this is a deficiency, basically a lack of information. We should instead be tracking every atom.
This is where Tarde points out that in the social realm we can do this, where cells are replaced by people. We can collect a huge amount of information about those individuals.
But wait, are we not missing the forest for the trees when we do this? Bruno Latour weighs in on his take of Tarde as follows:
“But the ‘whole’ is now nothing more than a provisional visualization which can be modified and reversed at will, by moving back to the individual components, and then looking for yet other tools to regroup the same elements into alternative assemblages.”
In 1903, Tarde even foresees the emergence of Facebook, although he refers to a “daily press”:
“At some point, every social event is going to be reported or observed.”
Mark then laid down the theme of his lecture using a 2009 quote of Bruno Latour:
“Change the instruments and you will change the entire social theory that goes with them.”
Kind of like that famous physics cat, I guess, Mark (and Tarde) want us to newly consider
- the way the structure of society changes as we observe it, and
- ways of thinking about the relationship of the individual to the aggregate.
Mark’s Thought Experiment:
As data become more personal, as we collect more data about “individuals”, what new methods or tools do we need to express the fundamental relationship between ourselves and our communities, our communities and our country, our country and the world? Could we ever be satisfied with poll results or presidential approval ratings when we can see the complete trajectory of public opinions, individuated and interacting?
What is data science?
Mark threw up this quote from our own John Tukey:
“The best thing about being a statistician is that you get to play in everyone’s backyard”
But let’s think about that again – is it so great? Is it even reasonable? In some sense, to think of us as playing in other people’s yards, with their toys, is to draw a line between “traditional data fields” and “everything else”.
It’s maybe even implying that all our magic comes from the traditional data fields (math, stats, CS), and we’re some kind of super humans because we’re uber-nerds. That’s a convenient way to look at it from the perspective of our egos, of course, but it’s perhaps too narrow and arrogant.
And it begs the question, what is “traditional” and what is “everything else” anyway?
Mark claims that everything else should include:
- social science,
- physical science,
- geography,
- architecture,
- education,
- information science,
- architecture,
- digital humanities,
- journalism,
- design,
- media art
There’s more to our practice than being technologists, and we need to realize that technology itself emerges out of the natural needs of a discipline. For example, GIS emerges from geographers and text data mining emerges from digital humanities.
In other words, it’s not math people ruling the world, it’s domain practices being informed by techniques growing organically from those fields. When data hits their practice, each practice is learning differently; their concerns are unique to that practice.
Responsible data science integrates those lessons, and it’s not a purely mathematical integration. It could be a way of describing events, for example. Specifically, it’s not necessarily a quantifiable thing.
Bottom-line: it’s possible that the language of data science has something to do with social science just as it has something to do with math.
Processing
Mark then told us a bit about his profile (“expansionist”) and about the language processing, in answer to a question about what is different when a designer takes up data or starts to code.
He explained it by way of another thought experiment: what is the use case for a language for artists? Students came up with a bunch of ideas:
- being able to specify shapes,
- faithful rendering of what visual thing you had in mind,
- being able to sketch,
- 3-d,
- animation,
- interactivity,
- Mark added publishing – artists must be able to share and publish their end results.
It’s java based, with a simple “publish” button, etc. The language is adapted to the practice of artists. He mentioned that teaching designers to code meant, for him, stepping back and talking about iteration, if statements, etc., of in other words stuff that seemed obvious to him but is not obvious to someone who is an artist. He needed to unpack his assumptions, which is what’s fun about teaching to the uninitiated.
He next moved on to close versus distant reading of texts. He mentioned Franco Moretti from Stanford. This is for Franco:

Franco thinks about “distant reading”, which means trying to get a sense of what someone’s talking about without reading line by line. This leads to PCA-esque thinking, a kind of dimension reduction of novels.
In other words, another cool example of how data science should integrate the way the experts in various fields figure it out. We don’t just go into their backyards and play, maybe instead we go in and watch themplay and formalize and inform their process with our bells and whistles. In this way they can teach us new games, games that actually expand our fundamental conceptions of data and the approaches we need to analyze them.
Mark’s favorite viz projects
1) Nuage Vert, Helen Evans & Heiko Hansen: a projection onto a power plant’s steam cloud. The size of the green projection corresponds to the amount of energy the city is using. Helsinki and Paris.

2) One Tree, Natalie Jeremijenko: The artist cloned trees and planted the genetically identical seeds in several areas. Displays among other things the environmental conditions in each area where they are planted.

3) Dusty Relief, New Territories: here the building collects pollution around it, displayed as dust.

4) Project Reveal, New York Times R&D lab: this is a kind of magic mirror which wirelessly connects using facial recognition technology and gives you information about yourself. As you stand at the mirror in the morning you get that “come-to-jesus moment” according to Mark.

5) Million Dollar Blocks, Spatial Information Design Lab (SIDL): So there are crime stats for google maps, which are typically painful to look at. The SIDL is headed by Laura Kurgan, and in this piece she flipped the statistics. She went into the prison population data, and for every incarcerated person, she looked at their home address, measuring per home how much money the state was spending to keep the people who lived there in prison. She discovered that some blocks were spending $1,000,000 to keep people in prison.

Moral of the above: just because you can put something on the map, doesn’t mean you should. Doesn’t mean there’s a new story. Sometimes you need to dig deeper and flip it over to get a new story.
New York Times lobby: Moveable Type
Mark walked us through a project he did with Ben Rubin for the NYTimes on commission (and he later went to the NYTimes on sabbatical). It’s in the lobby of their midtown headquarters at 8th and 42nd.

It consists of 560 text displays, two walls with 280 on each, and the idea is they cycle through various “scenes” which each have a theme and an underlying data science model.
For example, in one there are waves upon waves of digital ticker-tape like scenes which leave behind clusters of text, and where each cluster represents a different story from the paper. The text for a given story highlights phrases which make a given story different from others in some information-theory sense.
In another scene the numbers coming out of stories are highlighted, so you might see on a given box “18 gorillas”. In a third scene, crossword puzzles play themselves with sounds of pencil and paper.
The display boxes themselves are retro, with embedded linux processors running python, and a sound card on each box, which makes clicky sounds or wavy sounds or typing sounds depending on what scene is playing.

The data taken in is text from NY Times articles, blogs, and search engine activity. Every sentence is parsed using Stanford NLP techniques, which diagrams sentences.
Altogether there are about 15 “scenes” so far, and it’s code so one can keep adding to it. Here’s an interview with them about the exhibit:
Project Cascade: Lives on a Screen
Mark next told us about Cascade, which was joint work with Jer Thorp data artist-in-residence at the New York Times. Cascade came about from thinking about how people share New York Times links on Twitter. It was in partnerships with bitly.
The idea was to collect enough data so that we could see someone browse, encode the link in bitly, tweet that encoded link, see other people click on that tweet and see bitly decode the link, and then see those new people browse the New York Times. It’s a visualization of that entire process, much as Tarde suggested we should do.
There were of course data decisions to be made: a loose matching of tweets and clicks through time, for example. If 17 different tweets have the same url they don’t know which one you clicked on, so they guess (the guess actually seemed to involve probabilistic matching on time stamps so it’s an educated guess). They used the Twitter map of who follows who. If someone you follow tweets about something before you do then it counts as a retweet. It covers any nytimes.com link.

Here’s a NYTimes R&D video about Project Cascade:
Note: this was done 2 years ago, and Twitter has gotten a lot bigger since then.
Cronkite Plaza
Next Mark told us about something he was working on which just opened 1.5 months ago with Jer and Ben. It’s also news related, but this is projecting on the outside of a building rather than in the lobby; specifically, the communications building at UT Austin, in Cronkite Plaza.

The majority of the projected text is sourced from Cronkite’s broadcasts, but also have local closed-captioned news sources. One scene of this project has extracted the questions asked during local news – things like “how did she react?” or “What type of dog would you get?”. The project uses 6 projectors.
Goals of these exhibits
They are meant to be graceful and artistic, but should also teach something. At the same time we don’t want to be overly didactic. The aim is to live in between art and information. It’s a funny place: increasingly we see a flattening effect when tools are digitized and made available, so that statisticians can code like a designer (we can make things that look like design) and similarly designers can make something that looks like data.
What data can we get? Be a good investigator: a small polite voice which asks for data usually gets it.
eBay transactions and books
Again working jointly with Jer Thorp, Mark investigated a day’s worth of eBay’s transactions that went through Paypal and, for whatever reason, two years of book sales. How do you visualize this? Take a look at the yummy underlying data:

Here’s how they did it (it’s ingenious). They started with the text of Death of a Salesman by Arthur Miller. They used a mechanical turk mechanism to locate objects in the text that you can buy on eBay.
When an object is found it moves it to a special bin, so “chair” or “flute” or “table.” When it has a few collected buy-able objects, it then takes the objects and sees where they are all for sale on the day’s worth of transactions, and looks at details on outliers and such. After examining the sales, the code will find a zipcode in some quiet place like Montana.
Then it flips over to the book sales data, looks at all the books bought or sold in that zip code, picks a book (which is also on Project Gutenberg), and begins to read that book and collect “buyable” objects from that. And it keeps going. Here’s a video:
Public Theater Shakespeare Machine
The last thing Mark showed us is is joint work with Rubin and Thorp, installed in the lobby of the Public Theater. The piece itself is an oval structure with 37 bladed LED displays, set above the bar.
There’s one blade for each of Shakespeare’s plays. Longer plays are in the long end of the oval, Hamlet you see when you come in.

The data input is the text of each play. Each scene does something different – for example, it might collect noun phrases that have something to do with body from each play, so the “Hamlet” blade will only show a body phrase from Hamlet. In another scene, various kinds of combinations or linguistic constructs are mined:
- “high and might” “good and gracious” etc.
- “devilish-holy” “heart-sore” “ill-favored” “sea-tossed” “light-winged” “crest-fallen” “hard-favoured” etc.
Note here that the digital humanities, through the MONK Project, offered intense xml descriptions of the plays. Every single word is given hooha and there’s something on the order of 150 different parts of speech.
As Mark said, it’s Shakespeare so it stays awesome no matter what you do, but here we see we’re successively considering words as symbols, or as thematic, or as parts of speech. It’s all data.
Ian Wong from Square
Next Ian Wong, an “Inference Scientist” at Square who dropped out of an Electrical Engineering Ph.D. program at Stanford talked to us about Data Science in Risk.
He conveniently started with his takeaways:
- Machine learning is not equivalent to R scripts. ML is founded in math, expressed in code, and assembled into software. You need to be an engineer and learn to write readable, reusable code: your code will be reread more times by other people than by you, so learn to write it so that others can read it.
- Data visualization is not equivalent to producing a nice plot. Rather, think about visualizations as pervasive and part of the environment of a good company.
- Together, they augment human intelligence. We have limited cognitive abilities as human beings, but if we can learn from data, we create an exoskeleton, an augmented understanding of our world through data.
Square
Square was founded in 2009. There were 40 employees in 2010, and there are 400 now. The mission of the company is to make commerce easy. Right now transactions are needlessly complicated. It takes too much to understand and to do, even to know where to start for a vendor. For that matter, it’s too complicated for buyers as well. The question we set out to ask is, how do we make transactions simple and easy?
We send out a white piece of plastic, which we refer to as the iconic square. It’s something you can plug into your phone or iPad. It’s simple and familiar, and it makes it easy to use and to sell.
It’s even possible to buy things hands-free using the square. A buyer can open a tab on their phone so that they can pay by saying their name.. Then the merchant taps your name on their screen. This makes sense if you are a frequent visitor to a certain store like a coffee shop.
Our goal is to make it easy for sellers to sign up for Square and accept payments. Of course, it’s also possible that somebody may sign up and try to abuse the service. We are therefore very careful at Square to avoid losing money on sellers with fraudulent intentions or bad business models.
The Risk Challenge
At Square we need to balance the following goals:
- to provide a frictionless and delightful experience for buyers and sellers,
- to fuel rapid growth, and in particular to avoid inhibiting growth through asking for too much information of new sellers, which adds needless barriers to joining, and
- to maintain low financial loss.
Today we’ll just focus on the third goal through detection of suspicious activity. We do this by investing in machine learning and viz. We’ll first discuss the machine learning aspects.
Part 1: Detecting suspicious activity using machine learning
First of all, what’s suspicious? Examples from the class included:
- lots of micro transactions occurring,
- signs of money laundering,
- high frequency or inconsistent frequency of transactions.
Example: Say Rachel has a food truck, but then for whatever reason starts to have $1000 transactions (mathbabe can’t help but insert that Rachel might be a food douche which would explain everything).
On the one hand, if we let money go through, Square is liable in the case it was unauthorized. Technically the fraudster, so in this case Rachel would be liable, but our experience is that usually fraudsters are insolvent, so it ends up on Square.
On the other hand, the customer service is bad if we stop payment on what turn out to be real payments. After all, what if she’s innocent and we deny the charges? She will probably hate us, may even sully our reputation, and in any case our trust is lost with her after that.
This example crystallizes the important challenges we face: false positives erode customer trust, false negatives make us lose money.
And since Square processes millions of dollars worth of sales per day, we need to do this systematically and automatically. We need to assess the risk level of every event and entity in our system.
So what do we do?
First of all, we take a look at our data. We’ve got three types:
- payment data, where the fields are transaction_id, seller_id, buyer_id, amount, success (0 or 1), timestamp,
- seller data, where the fields are seller_id, sign_up_date, business_name, business_type, business_location,
- settlement data, where the fields are settlement_id, state, timestamp.
Important fact: we settle to our customers the next day so we don’t have to make our decision within microseconds. We have a few hours. We’d like to do it quickly of course, but in certain cases we have time for a phone call to check on things.
So here’s the process: given a bunch (as in hundreds or thousands) of payment events, we throw each through the risk engine, and then send some iffy looking ones on to a “manual review”. An ops team will then review the cases on an individual basis. Specifically, anything that looks rejectable gets sent to ops, which make phone calls to double check unless it’s super outrageously obviously fraud.
Also, to be clear, there are actually two kinds of fraud to worry about, seller-side fraud and buyer-side fraud. For the purpose of this discussion, we’ll focus on the former.
So now it’s a question of how we set up the risk engine. Note that we can think of the risk engine as putting things in bins, and those bins each have labels. So we can call this a labeling problem.
But that kind of makes it sound like unsupervised learning, like a clustering problem, and although it shares some properties with that, it’s certainly not that simple – we don’t reject a payment and then merely stand pat with that label, because as we discussed we send it on to an ops team to assess it independently. So in actuality we have a pretty complicated set of labels, including for example:
- initially rejected but ok,
- initially rejected and bad,
- initially accepted but on further consideration might have been bad,
- initially accepted and things seem ok,
- initially accepted and later found to be bad, …
So in other words we have ourselves a semi-supervised learning problem, straddling the worlds of supervised and unsupervised learning. We first check our old labels, and modify them, and then use them to help cluster new events using salient properties and attributes common to historical events whose labels we trust. We are constantly modifying our labels even in retrospect for this reason.
We estimate performance using precision and recall. Note there are very few positive examples so accuracy is not a good metric of success, since the “everything looks good” model is dumb but has good accuracy.
Labels are what Ian considered to be the “neglected half of the data” (recall T = {(x_i, y_i)}). In undergrad statistics education and in data mining competitions, the availability of labels is often taken for granted. In reality, labels are tough to define and capture. Labels are really important. It’s not just objective function, it is the objective.
As is probably familiar to people, we have a problem with sparsity of features. This is exacerbated by class imbalance (i.e., there are few positive samples). We also don’t know the same information for all of our sellers, especially when we have new sellers. But if we are too conservative we start off on the wrong foot with new customers.
Also, we might have a data point, say zipcode, for every seller, but we don’t have enough information in knowing the zipcode alone because so few sellers share zipcodes. In this case we want to do some clever binning of the zipcodes, which is something like sub model of our model.
Finally, and this is typical for predictive algorithms, we need to tweak our algorithm to optimize it- we need to consider whether features interact linearly or non-linearly, and to account for class imbalance.. We also have to be aware of adversarial behavior. An example of adversarial behavior in e-commerce is new buyer fraud, where a given person sets up 10 new accounts with slightly different spellings of their name and address.
Since models degrade over time, as people learn to game them, we need to continually retrain models. The keys to building performance models are as follows:
- it’s not a black box. You can’t build a good model by assuming that the algorithm will take care of everything. For instance, I need to know why I am misclassifying certain people, so I’ll need to roll up my sleeves and dig into my model.
- We need to perform rapid iterations of testing, with experiments like you’d do in a science lab. If you’re not sure whether to try A or B, then try both.
- When you hear someone say, “So which models or packages do you use?” then you’ve got someone who doesn’t get it. Models and/or packages are not magic potion.
Mathbabe cannot resist paraphrasing Ian here as saying “It’s not about the package. it’s about what you do with it.” But what Ian really thinks it’s about, at least for code, is:
- readability
- reusability
- correctness
- structure
- hygiene
So, if you’re coding a random forest algorithm and you’ve hardcoded the number of trees: you’re an idiot. put a friggin parameter there so people can reuse it. Make it tweakable. And write the tests for pity’s sake; clean code and clarity of thought go together.
At Square we try to maintain reusability and readability — we structure our code in different folders with distinct, reusable components that provide semantics around the different parts of building a machine learning model: model, signal, error, experiment.
We only write scripts in the experiments folder where we either tie together components from model, signal and error or we conduct exploratory data analysis. It’s more than just a script, it’s a way of thinking, a philosophy of approach.
What does such a discipline give you? Every time you run an experiment your should incrementally increase your knowledge. This discipline helps you make sure you don’t do the same work again. Without it you can’t even figure out the things you or someone else has already attempted.
For more on what every project directory should contain, see Project Template, written by John Myles White.
We had a brief discussion of how reading other people’s code is a huge problem, especially when we don’t even know what clean code looks like. Ian stayed firm on his claim that “if you don’t write production code then you’re not productive.”
In this light, Ian suggests exploring and actively reading Github’s repository of R code. He says to try writing your own R package after reading this. Also, he says that developing an aesthetic sense for code is analogous to acquiring the taste for beautiful proofs; it’s done through rigorous practice and feedback from peers and mentors. The problem is, he says, that statistics instructors in schools usually do not give feedback on code quality, nor are they qualified to.
For extra credit, Ian suggests the reader contrasts the implementations of the caret package (poor code) with scikit-learn (clean code).
Important things Ian skipped
- how is a model “productionized”?
- how are features computed in real-time to support these models?
- how do we make sure “what we see is what we get”, meaning the features we build in a training environment will be the ones we see in real-time. Turns out this is a pretty big problem.
- how do you test a risk engine?
Next Ian talked to us about how Square uses visualization.
Data Viz at Square
Ian talked to us about a bunch of different ways the Inference Team at Square use visualizations to monitor the transactions going on at any given time. He mentioned that these monitors aren’t necessarily trying to predict fraud per se but rather provides a way of keeping an eye on things to look for trends and patterns over time and serves as the kind of “data exoskeleton” that he mentioned at the beginning. People at Square believe in ambient analytics, which means passively ingesting data constantly so you develop a visceral feel for it.
After all, it is only by becoming very familiar with our data that we even know what kind of patterns are unusual or deserve their own model. To go further into the philosophy of this approach, he said two thing:
“What gets measured gets managed,” and “You can’t improve what you don’t measure.”
He described a workflow tool to review users, which shows features of the seller, including the history of sales and geographical information, reviews, contact info, and more. Think mission control.
In addition to the raw transactions, there are risk metrics that Ian keeps a close eye on. So for example he monitors the “clear rates” and “freeze rates” per day, as well as how many events needed to be reviewed. Using his fancy viz system he can get down to which analysts froze the most today and how long each account took to review, and what attributes indicate a long review process.
In general people at Square are big believers in visualizing business metrics (sign-ups, activations, active users, etc.) in dashboards; they think it leads to more accountability and better improvement of models as they degrade. They run a kind of constant EKG of their business through ambient analytics.
Ian ended with his data scientist profile. He thinks it should be on a logarithmic scale, since it doesn’t take very long to be okay at something (good enough to get by) but it takes lots of time to get from good to great. He believes that productivity should also be measured in log-scale, and his argument is that leading software contributors crank out packages at a much higher rate than other people.
Ian’s advice to aspiring data scientists
- play with real data
- build a good foundation in school
- get an internship
- be literate, not just in statistics
- stay curious
Ian’s thought experiment
Suppose you know about every single transaction in the world as it occurs. How would you use that data?
On my way to AGNES
I’m putting the finishing touches on my third talk of the week, which is called “How math is used outside academia” and is intended for a math audience at the AGNES conference.

I’m taking Amtrak up to Providence to deliver the talk at Brown this afternoon. After the talk there’s a break, another talk, and then we all go to the conference dinner and I get to hang with my math nerd peeps. I’m talking about you, Ben Bakker.

Since I’m going straight from a data conference to a math conference, I’ll just make a few sociological observations about the differences I expect to see.
- No name tags at AGNES. Everyone knows each other already from undergrad, grad school, or summer programs. Or all three. It’s a small world.
- Probably nobody standing in line to get anyone’s autograph at AGNES. To be fair, that likely only happens at Strata because along with the autograph you get a free O’Reilly book, and the autographer is the author. Still, I think we should figure out a way to add this to math conferences somehow, because it’s fun to feel like you’re among celebrities.
- No theme music at AGNES when I start my talk, unlike my keynote discussion with Julie Steele on Thursday at Strata. Which is too bad, because I was gonna request “Eye of the Tiger”.
For the nerds: what’s wrong with this picture?
h/t Dave:

(Update! Rachel Schutt blogged about this same sign on October 2nd! Great nerd minds think alike :))
Also from the subway:

As my 10-year-old son says, the green guys actually look more endangered since
- their heads are disconnected from their bodies, and
- they are balancing precariously on single rounded stub legs.
Strata: one down, one to go
Yesterday I gave a talk called “Finance vs. Machine Learning” at Strata. It was meant to be a smack-down, but for whatever reason I couldn’t engage people to personify the two disciplines and have a wrestling match on stage. For the record, I offered to be on either side. Either they were afraid to hurt a girl or they were afraid to lose to a girl, you decide.
Unfortunately I didn’t actually get to the main motivation for the genesis of this talk, namely the realization I had a while ago that when machine learners talk about “ridge regression” or “Tikhonov regularization” or even “L2 regularization” it comes down to the same thing that quants call a very simple bayesian prior that your coefficients shouldn’t be too large. I talked about this here.
What I did have time for: I talked about “causal modeling” in the finance-y sense (discussion of finance vs. statistician definition of causal here), exponential downweighting with a well-chosen decay, storytelling as part of feature selection, and always choosing to visualize everything, and always visualizing the evolution of a statistic rather than a snapshot statistic.
They videotaped me but I don’t see it on the strata website yet. I’ll update if that happens.
This morning, at 9:35, I’ll be in a keynote discussion with Julie Steele for 10 minutes entitled “You Can’t Learn That in School”, which will be live streamed. It’s about whether data science can and should be taught in academia.
For those of you wondering why I haven’t blogged the Columbia Data Science class like I usually do Thursday, these talks are why. I’ll get to it soon, I promise! Last night’s talks by Mark Hansen, data vizzer extraordinaire and Ian Wong, Inference Scientist from Square, were really awesome.
How to measure a tree
Yesterday I went to a DataKind datadive as part of the Strata big data conference. As you might remember, I was a data ambassador a few weeks ago when we looked at pruning data, and they decided to take another look at this with better and cleaner data yesterday.
One of the people I met there was Mark Headd, the data czar/king/sultan of Philadelphia (actually, he called himself something like the “data guy” but I couldn’t resist embellishing his title on the spot). He blogs at civic.io, which is a pretty sweet url.
Mark showed me a nice app called Philly Tree Map, which is an open-source app gives information like the location, species, size, and environmental impact of each tree in Philly; it also allows users to update information or add new trees, which is fun and makes it more interactive.

They’re also using it in San Diego, and I don’t see why they can’t use it in New York as well, since I believe Parks has the tree census data.
I always love it when people get really into something (as described in my coffee douche post here), so I wanted to share with you guys the absolute tree-douchiest video ever filmed, namely the hilarious cult classic “How to Measure a Tree“, available on the FAQ page of the Philly tree map:
We’re not just predicting the future, we’re causing the future
My friend Rachel Schutt, a statistician at Google who is teaching the Columbia Data Science course this semester that I’ve been blogging every Thursday morning, recently wrote a blog post about 10 important issues in data science, and one of them is the title of my post today.
This idea that our predictive models cause the future is part of the modeling feedback loop I blogged about here; it’s the idea that, once we’ve chosen a model, especially as it models human behavior (which includes the financial markets), then people immediately start gaming the model in one way or another, both weakening the effect that the model is predicting as well as distorting the system itself. This is important and often overlooked when people build models.
How do we get people to think about these things more carefully? I think it would help to have a checklist of properties of a model using best practices.
I got this idea recently as I’ve been writing a talk about how math is used outside academia (which you guys have helped me on). In it, I’m giving a bunch of examples of models with a few basic properties of well-designed models.
It was interesting just composing that checklist, and I’ll likely blog about this in the next few days, but needless to say one thing on the checklist was “evaluation method”.
Obvious point: if you have a model which has no well-defined evaluation model then you’re fucked. In fact, I’d argue, you don’t really even have a model until you’ve chosen and defended your evaluation method (I’m talking to you, value-added teacher modelers).
But what I now realize is that part of the evaluation method of the model should consist of an analysis of how the model can or will be gamed and how that gaming can or will distort the ambient system. It’s a meta-evaluation of the model, if you will.
Example: as soon as regulators agree to measure a firm’s risk with 95% VaR on a 0.97 decay factor, there’s all sorts of ways for companies to hide risk. That’s why the parameters (95, 0.97) cannot be fixed if we want a reasonable assessment of risk.
This is obvious to most people upon reflection, but it’s not systemically studied, because it’s not required as part of an evaluation method for VaR. Indeed a reasonable evaluation method for VaR is to ask whether the 95% loss is indeed breached only 5% of the time, but that clearly doesn’t tell the whole story.
One easy way to get around this is to require a whole range of parameters for % VaR as well as a whole range of decay factors. It’s not that much more work and it is much harder to game. In other words, it’s a robustness measurement for the model.
Are healthcare costs really skyrocketing?
Yesterday we had a one-year anniversary meeting of the Alternative Banking group of Occupy Wall Street. Along with it we had excellent discussions of social security, Medicare, and ISDA, including details descriptions of how ISDA changes the rules to suit themselves and the CDS market, acting as a kind of independent system of law, which in particular means it’s not accountable to other rules of law.
Going back to our discussion on Medicare, I have a few comments and a questions for my dear readers:
I’ve been told by someone who should know that the projected “skyrocketing medical costs” which we hear so much about from politicians are based on a “cost per day in the hospital” number, i.e. as that index goes up, we assume medical costs will go up in tandem.
There’s a very good reason to consider this a biased proxy for medical costs, however. Namely, lots of things that used to be in-patient procedures (think gallbladder operations, which used to require a huge operation and many days of ICU care) are now out-patient procedures, so they don’t require a full day in the hospital.
This is increasingly true for various procedures – what used to take many days in the hospital recovering now takes fewer (or they kick you out sooner anyway). The result is that, on average, you only get to stay a whole day in the hospital if something’s majorly wrong with you, so yes the costs there are much higher. Thus the biased proxy.
A better index of cost would be: the cost of the average person’s medical expenses per year.
First question: Is this indeed how people calculate projected medical costs? It’s surprisingly hard to find a reference. That’s a bad sign. I’d really love a reference.
Next, I have a separate pet theory on why we are so willing to believe whatever we’re told about medical costs.
I’ve been planning for months to write a venty post about medical bills and HMO insurance paper mix-ups (update: wait, I did in fact write this post already). Specifically, it’s my opinion that the system is intentionally complicated so that people will end up paying stuff they shouldn’t just because they can’t figure out who to appeal to.
Note that even the idea of appealing to authority for a medical bill presumes that you’ve had a good education and experience dealing with formality. As a former customer service representative at a financial risk software company, I’m definitely qualified, but I can’t believe that the average person in this country isn’t overwhelmed by the prospect. It’s outrageous.
Part of this fear and anxiety stems from the fact that the numbers on the insurance claims are so inflated – $1200 to be seen for a dislocated finger being put into a splint, things like that. Why does that happen? I’m not sure, but I believe those are fake numbers that nobody actually pays, or at least nobody with insurance.
Second question: Why are the numbers on insurance claims so inflated? Who pays those actual numbers?
On to my theory: by extension of the above byzantine system of insurance claims and inflated prices for everything, we’re essentially primed for the line coming from politicians, who themselves (of course) lean on experts who “have studied this,” that health care costs are skyrocketing and that we can’t possibly allow “entitlements” to continue to grow the way they have been. A couple of comments:
- As was pointed out here (hat tip Deb), the fact that the numbers are already inflated so much, especially in comparison to other countries, should mean that they will tend to go down in the future, not up, as people travel away from our country to pay less. This is of course already happening.
- Even so, psychologically, we are ready for those numbers to say anything at all. $120,000 for a splint? Ok, sounds good, I hope I’m covered.
- Next, it’s certainly true that with technological advances come expensive techniques, especially for end-of-life and neonatal procedures. But on the other hand technology is also making normal, mid-life procedures (gallbladders removal) much cheaper.
- I would love to see a few histograms on this data, based on age of patient or prevalence of problem.
- I’d guess such histograms would show us the following: the overall costs structure is becoming much more fat-tailed, as the uncommon but expensive procedures are being used, but the mean costs could easily be going down, or could be projected to go down once more doctors and hospitals have invested in these technologies. Of course I have no idea if this is true.
Third question: Anyone know where such data can be found so I can draw me some histograms?
Final notes:
- The baby boomers are a large group, and they’re retiring and getting sick. But they’re not 10 times bigger than other generations, and the “exponential growth” we’ve been hearing about doesn’t get explained by this alone.
- Assume for a moment that medical costs are rising but not skyrocketing, which is my guess. Why would people (read: politicians) be so eager to exaggerate this?
Amazon’s binder reviews
If you go to amazon.com and search for “binder” or “3-ring binder” (h/t Dan), the very first hit will take you to the sale page for Avery’s Economy Binder with 1-Inch Round Ring, Black, 1 Binder (3301). The reviews are hilarious and subversive, including this one entitled “A Legitimate Binder”:
I am so excited to order this binder! My husband said that I’ve been doing such a great job of cutting out of work early to serve him meat and potatoes all these years, and he’s finally letting me upgrade from a 2-ring without pockets to a binder with 3 rings and two pockets! The pockets excite me the most. I plan to use the left pocket to hold my resume which will highlight my strongest skills which include but are not limited to laughing while eating yogurt. The right pocket will be great for keeping my stash of aspirin, in case of emergencies when I need to hold it between my knees.
Here’s another, entitled “Doesn’t work as advertised“:
Could’t bind a single damn woman with it! Most women just seem vaguely annoyed when I put it on them and it falls right off. Am I missing something? How’d Mitt do it?
Or this one, called “Such a bargain!“:
I am definitely buying this binder full of women, because even though it works the same as other male binders, you only have to pay $.77 on the dollar for it!
But my favorite one is this (called “Great with Bic lady pens”), partly because it points me to another subversive Amazon-rated product:
I’ve been having a hard time finding a job recently, and realized it was because I wasn’t in a binder. I thought the Avery Economy Binder would be perfect. It needs some tweaks, though. It kicks me out at 5pm so I can cook dinner for a family I don’t have. I also don’t seem to be making as much as the binderless men. And sometimes the rings will snag the lady parts, so maybe mine is defective.
By the way, the BIC pens for Her are a great complement to this binder. I wondered why the normal pens just didn’t feel right. It turns out, I was using man pens. The pink and purple also affirms me as a woman. You can find them here.
I know it says “for her” on the package but I, like many, assumed it was just a marketing ploy seeking to profit off of archaic gender constructs and the “war of the sexes”. Little did I realize that these pens really are for girls, and ONLY girls. Non-girls risk SERIOUS side effects should they use this product. I lent one to my 13-year-old brother, not thinking anything of it, and woke up the next morning to the sound of whinnying coming from the room across the hall. I got out of bed and went to his room to find that my worst fears had been realized:
MY LITTLE BROTHER IS NOW A UNICORN and it’s all my fault. Sure, you’d think that having a unicorn for a little brother would be great but my parents are FURIOUS – I’ve been grounded for a MONTH!!! They made an appointment for him with our family practitioner, but I’m not sure it’ll do any good, and they told me that if it couldn’t be fixed I’d have to get a job to help pay for his feed and lodging D:I repeat, boys, DO NOT USE THIS PEN. Unless you want to be a unicorn, and even then be careful because there’s no telling that you’ll suffer the same side effects.SERIOUSLY BIC IT’S REALLY REALLY IRRESPONSIBLE FOR YOU TO PUT OUT THIS PRODUCT WITHOUT A CLEAR WARNING OF THE RISK IT POSES TO NON-GIRLS. Just saying it’s “For Her” is not enough!!!!
(I’m giving it two stars because even though they got me grounded, the pens still write really nice and bring out my eyes)




{kind=link}