Archive
Why are the Chicago public school teachers on strike?
The issues of pay and testing
My friend and fellow HCSSiM 2012 staff member P.J. Karafiol explains some important issues in a Chicago Sun Times column entitled “Hard facts behind union, board dispute.”
P.J. is a Chicago public school math teacher, he has two kids in the CPS system, and he’s a graduate from that system. So I think he is qualified to speak on the issues.
He first explains that CPS teachers are paid less than those in the suburbs. This means, among other things, that it’s hard to keep good teachers. Next, he explains that, although it is difficult to argue against merit pay, the value-added models that Rahm Emanuel wants to account for half of teachers evaluation, is deeply flawed.
He then points out that, even if you trust the models, the number of teachers the model purports to identify as bad is so high that taking action on that result by firing them all would cause a huge problem – there’s a certain natural rate of finding and hiring good replacement teachers in the best of times, and these are not the best of times.
He concludes with this:
Teachers in Chicago are paid well initially, but face rising financial incentives to move to the suburbs as they gain experience and proficiency. No currently-existing “value added” evaluation system yields consistent, fair, educationally sound results. And firing bad teachers won’t magically create better ones to take their jobs.
To make progress on these issues, we have to figure out a way to make teaching in the city economically viable over the long-term; to evaluate teachers in a way that is consistent and reasonable, and that makes good sense educationally; and to help struggling teachers improve their practice. Because at base, we all want the same thing: classes full of students eager to be learning from their excellent, passionate teachers.
Test anxiety
Ultimately this crappy model, and the power that it yields, creates a culture of text anxiety for teachers and principals as well as for students. As Eric Zorn (grandson of mathematician Max Zorn) writes in the Chicago Tribune (h/t P.J. Karafiol):
The question: But why are so many presumptively good teachers also afraid? Why has the role of testing in teacher evaluations been a major sticking point in the public schools strike in Chicago?
The short answer: Because student test scores provide unreliable and erratic measurements of teacher quality. Because studies show that from subject to subject and from year to year, the same teacher can look alternately like a golden apple and a rotting fig.
Zorn quotes extensively from Math for America President John Ewing’s article in Notices of the American Mathematical Society:
Analyses of (value-added model) results have led researchers to doubt whether the methodology can accurately identify more and less effective teachers. (Value-added model) estimates have proven to be unstable across statistical models, years and classes that teachers teach.
One study found that across five large urban districts, among teachers who were ranked in the top 20 percent of effectiveness in the first year, fewer than a third were in that top group the next year, and another third moved all the way down to the bottom 40 percent.
Another found that teachers’ effectiveness ratings in one year could only predict from 4 percent to 16 percent of the variation in such ratings in the following year.
The politics behind the test
I agree that the value-added model (VAM) is deeply flawed; I’ve blogged about it multiple times, for example here.
The way I see it, VAM is a prime example of the way that mathematics is used as a weapon against normal people – in this case, teachers, principals, and schools. If you don’t see my logic, ask yourself this:
Why would a overly-complex, unproved and very crappy model be so protected by politicians?
There’s really one reason, namely it serves a political function, not a mathematical one. And that political function is to maintain control over the union via a magical box that nobody completely understands (including the politicians, but it serves their purposes in spite of this) and therefore nobody can argue against.
This might seem ridiculous when you have examples like this one from the Washington Post (h/t Chris Wiggins), in which a devoted and beloved math teacher named Ashley received a ludicrously low VAM score.
I really like the article: it was written by Sean C. Feeney, Ashley’s principal at The Wheatley School in New York State and president of the Nassau County High School Principals’ Association. Feeney really tries to understand how the model works and how it uses data.
Feeney uncovers the crucial facts that, on the one hand nobody understands how VAM works at all, and that, on the other, the real reason it’s being used is for the political games being played behind the scenes (emphasis mine):
Officials at our State Education Department have certainly spent countless hours putting together guides explaining the scores. These documents describe what they call an objective teacher evaluation process that is based on student test scores, takes into account students’ prior performance, and arrives at a score that is able to measure teacher effectiveness. Along the way, the guides are careful to walk the reader through their explanations of Student Growth Percentiles (SGPs) and a teacher’s Mean Growth Percentile (MGP), impressing the reader with discussions and charts of confidence ranges and the need to be transparent about the data. It all seems so thoughtful and convincing! After all, how could such numbers fail to paint an accurate picture of a teacher’s effectiveness?
(One of the more audacious claims of this document is that the development of this evaluative model is the result of the collaborative efforts of the Regents Task Force on Teacher and Principal Effectiveness. Those of us who know people who served on this committee are well aware that the recommendations of the committee were either rejected or ignored by State Education officials.)
Feeney wasn’t supposed to do this. He wasn’t supposed to assume he was smart enough to understand the math behind the model. He wasn’t supposed to realize that these so-called “guides to explain the scores” actually represent the smoke being blown into the eyes of educators for the purposes of dismembering what’s left of the power of teachers’ unions in this country.
If he were better behaved, he would have bowed to the authority of the inscrutable, i.e. mathematics, and assume that his prize math teacher must have had flaws he, as her principal, just hadn’t seen before.
Weapons of Math Destruction
Politicans have created a WMD (Weapon of Math Destruction) in VAM; it’s the equivalent of owning an uzi factory when you’re fighting a war against people with pointy sticks.
It’s not the only WMD out there, but it’s a pretty powerful one, and it’s doing outrageous damage to our educational system.
If you don’t know what I mean by WMD, let me help out: one way to spot a WMD is to look at the name versus the underlying model and take note of discrepancies. VAM is a great example of this:
- The name “Value-Added Model” makes us think we might learn how much a teacher brings to the class above and beyond, say, rote memorization.
- In fact, if you look carefully you will see that the model is measuring exactly that: teaching to the test, but with errorbars so enormous that the noise almost completely obliterates any “teaching to the test” signal.
Nobody wants crappy teachers in the system, but vilifying well-meaning and hard-working professionals and subjecting them to random but high-stakes testing is not the solution, it’s pure old-fashioned scapegoating.
The political goal of the national VAM movement is clear: take control of education and make sure teachers know their place as the servants of the system, with no job security and no respect.
Columbia data science course, week 2: RealDirect, linear regression, k-nearest neighbors
Data Science Blog
Today we started with discussing Rachel’s new blog, which is awesome and people should check it out for her words of data science wisdom. The topics she’s riffed on so far include: Why I proposed the course, EDA (exploratory data analysis), Analysis of the data science profiles from last week, and Defining data science as a research discipline.
She wants students and auditors to feel comfortable in contributing to blog discussion, that’s why they’re there. She particularly wants people to understand the importance of getting a feel for the data and the questions before ever worrying about how to present a shiny polished model to others. To illustrate this she threw up some heavy quotes:
“Long before worrying about how to convince others, you first have to understand what’s happening yourself” – Andrew Gelman
“Agreed” – Rachel Schutt
Thought experiment: how would you simulate chaos?
We split into groups and discussed this for a few minutes, then got back into a discussion. Here are some ideas from students:
- A Lorenzian water wheel would do the trick, if you know what that is.
- Question: is chaos the same as randomness?
- Many a physical system can exhibit inherent chaos: examples with finite-state machines
- Teaching technique of “Simulating chaos to teach order” gives us real world simulation of a disaster area
- In this class w want to see how students would handle a chaotic situation. Most data problems start out with a certain amount of dirty data, ill-defined questions, and urgency. Can we teach a method of creating order from chaos?
- See also “Creating order from chaos in a startup“.
Talking to Doug Perlson, CEO of RealDirect
We got into teams of 4 or 5 to assemble our questions for Doug, the CEO of RealDirect. The students have been assigned as homework the task of suggesting a data strategy for this new company, due next week.
He came in, gave us his background in real-estate law and startups and online advertising, and told us about his desire to use all the data he now knew about to improve the way people sell and buy houses.
First they built an interface for sellers, giving them useful data-driven tips on how to sell their house and using interaction data to give real-time recommendations on what to do next. Doug made the remark that normally, people sell their homes about once in 7 years and they’re not pros. The goal of RealDirect is not just to make individuals better but also pros better at their job.
He pointed out that brokers are “free agents” – they operate by themselves. they guard their data, and the really good ones have lots of experience, which is to say they have more data. But very few brokers actually have sufficient experience to do it well.
The idea is to apply a team of licensed real-estate agents to be data experts. They learn how to use information-collecting tools so we can gather data, in addition to publicly available information (for example, co-op sales data now available, which is new).
One problem with publicly available data is that it’s old news – there’s a 3 month lag. RealDirect is working on real-time feeds on stuff like:
- when people start search,
- what’s the initial offer,
- the time between offer and close, and
- how people search online.
Ultimately good information helps both the buyer and the seller.
RealDirect makes money in 2 ways. First, a subscription, $395 a month, to access our tools for sellers. Second, we allow you to use our agents at a reduced commission (2% of sale instead of the usual 2.5 or 3%). The data-driven nature of our business allows us to take less commission because we are more optimized, and therefore we get more volume.
Doug mentioned that there’s a law in New York that you can’t show all the current housing listings unless it’s behind a registration wall, which is why RealDirect requires registration. This is an obstacle for buyers but he thinks serious buyers are willing to do it. He also doesn’t consider places that don’t require registration, like Zillow, to be true competitors because they’re just showing listings and not providing real service. He points out that you also need to register to use Pinterest.
Doug mentioned that RealDirect is comprised of licensed brokers in various established realtor associations, but even so they have had their share of hate mail from realtors who don’t appreciate their approach to cutting commission costs. In this sense it is somewhat of a guild.
On the other hand, he thinks if a realtor refused to show houses because they are being sold on RealDirect, then the buyers would see the listings elsewhere and complain. So they traditional brokers have little choice but to deal with them. In other words, the listings themselves are sufficiently transparent so that the traditional brokers can’t get away with keeping their buyers away from these houses
RealDirect doesn’t take seasonality issues into consideration presently – they take the position that a seller is trying to sell today. Doug talked about various issues that a buyer would care about- nearby parks, subway, and schools, as well as the comparison of prices per square foot of apartments sold in the same building or block. These are the key kinds of data for buyers to be sure.
In terms of how the site works, it sounds like somewhat of a social network for buyers and sellers. There are statuses for each person on site. active – offer made – offer rejected – showing – in contract etc. Based on your status, different opportunities are suggested.
Suggestions for Doug?
Linear Regression
Example 1. You have points on the plane:
(x, y) = (1, 2), (2, 4), (3, 6), (4, 8).
The relationship is clearly y = 2x. You can do it in your head. Specifically, you’ve figured out:
- There’s a linear pattern.
- The coefficient 2
- So far it seems deterministic
Example 2. You again have points on the plane, but now assume x is the input, and y is output.
(x, y) = (1, 2.1), (2, 3.7), (3, 5.8), (4, 7.9)
Now you notice that more or less y ~ 2x but it’s not a perfect fit. There’s some variation, it’s no longer deterministic.
Example 3.
(x, y) = (2, 1), (6, 7), (2.3, 6), (7.4, 8), (8, 2), (1.2, 2).
Here your brain can’t figure it out, and there’s no obvious linear relationship. But what if it’s your job to find a relationship anyway?
First assume (for now) there actually is a relationship and that it’s linear. It’s the best you can do to start out. i.e. assume

and now find best choices for 
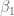

Before we find the general formula, we want to generalize with three variables now: 


Writing this with matrix notation we get:
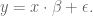
How do we calculate 
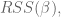

where 
To minimize 
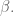
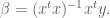
To use this, we go back to our linear form and plug in the values of
But wait, why did we assume a linear relationship? Sometimes maybe it’s a polynomial relationship.

You need to justify why you’re assuming what you want. Answering that kind of question is a key part of being a data scientist and why we need to learn these things carefully.
All this is like one line of R code where you’ve got a column of y’s and a column of x’s.:
model <- lm(y ~ x)
Or if you’re going with the polynomial form we’d have:
model <- lm(y ~ x + x^2 + x^3)
Why do we do regression? Mostly for two reasons:
- If we want to predict one variable from the next
- If we want to explain or understand the relationship between two things.
K-nearest neighbors
Say you have the age, income, and credit rating for a bunch of people and you want to use the age and income to guess at the credit rating. Moreover, say we’ve divided credit ratings into “high” and “low”.
We can plot people as points on the plane and label people with an “x” if they have low credit ratings.
What if a new guy comes in? What’s his likely credit rating label? Let’s use k-nearest neighbors. To do so, you need to answer two questions:
- How many neighbors are you gonna look at? k=3 for example.
- What is a neighbor? We need a concept of distance.
For the sake of our problem, we can use Euclidean distance on the plane if the relative scalings of the variables are approximately correct. Then the algorithm is simple to take the average rating of the people around me. where average means majority in this case – so if there are 2 high credit rating people and 1 low credit rating person, then I would be designated high.
Note we can also consider doing something somewhat more subtle, namely assigning high the value of “1” and low the value of “0” and taking the actual average, which in this case would be 0.667. This would indicate a kind of uncertainty. It depends on what you want from your algorithm. In machine learning algorithms, we don’t typically have the concept of confidence levels. care more about accuracy of prediction. But of course it’s up to us.
Generally speaking we have a training phase, during which we create a model and “train it,” and then we have a testing phase where we use new data to test how good the model is.
For k-nearest neighbors, the training phase is stupid: it’s just reading in your data. In testing, you pretend you don’t know the true label and see how good you are at guessing using the above algorithm. This means you save some clean data from the overall data for the testing phase. Usually you want to save randomly selected data, at least 10%.
In R: read in the package “class”, and use the function knn().
You perform the algorithm as follows:
knn(train, test, cl, k=3)
The output includes the k nearest (in Euclidean distance) training set vectors, and the classification labels as decided by majority vote
How do you evaluate if the model did a good job?
This isn’t easy or universal – you may decide you want to penalize certain kinds of misclassification more than others. For example, false positives may be way worse than false negatives.
To start out stupidly, you might want to simply minimize the misclassification rate:
(# incorrect labels) / (# total labels)
How do you choose k?
This is also hard. Part of homework next week will address this.
When do you use linear regression vs. k-nearest neighbor?
Thinking about what happens with outliers helps you realize how hard this question is. Sometimes it comes down to a question of what the decision-maker decides they want to believe.
Note definitions of “closeness” vary depending on the context: closeness in social networks could be defined as the number of overlapping friends.
Both linear regression and k-nearest neighbors are examples of “supervised learning”, where you’ve observed both x and y, and you want to know the function that brings x to y.
Pruning doesn’t do much
We spent most of Saturday at the DataKind NYC Parks Datadive transforming data into useful form and designing a model to measure the effect of pruning. In particular, does pruning a block now prevent fallen trees or limbs later?
So, for example, we had a census of trees and we had information on which blocks were pruned. The location of a tree was given as 
The bad events are also given with reference to a point 
So we decided on a block-specific model, and we needed to match a tree to a block and a fallen tree work order to a block. We used vectors and dot-products to do this, by finding the block (given by a line segment) which is closest to the tree or work order location.
Moreover, we only know which year a block is pruned, not the actual date. That led us to model by year alone.
Therefore, the data points going into the model depend on block and on year. We had about 13,000 blocks and about 3 years of data for the work orders. (We could possibly have found more years of work order data but from a different database with different formatting problems which we didn’t have time to sort through.)
We expect the impact of pruning to die down over time. Therefore the signal we chose to measure is the reciprocal of the number of years since the last pruning, or some power of it. The impact we are trying to measure is a weighted sum of work orders, weighted by average price over the different categories of work orders (certain events are more expensive to clean up than others, like if a tree falls into a building versus one limb falls into the street).
There’s one last element, namely the number of trees; we don’t want to penalize a block for having lots of work orders just because it has lots of trees (and irrespective of pruning). Therefore our “
Altogether our model is given as:

where 
We ran the regression where we let 
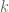
In both cases we got very very small signal, with correlations less than 1% if I remember correctly.
To be clear, the signal itself depends on knowing the last year a block was pruned, and for about half our data we didn’t have a year at all for that- when this happened we assumed it had never been pruned, and we substituted the value of 50 for # of years since pruning. Since the impact of pruning is assumed to die off, this is about the same thing as saying it had never been pruned.
The analysis is all modulo the data being correct, and our having wrangled and understood the data correctly, and possibly stupid mistakes on top of that, of course.
Moreover we made a couple of assumptions that could be wrong, namely that the pruning had taken place randomly – maybe they chose to prune blocks that had lots of sad-looking broken down trees, which would explain why lots of fallen tree events happened afterwards in spite of pruning. We also assumed that the work orders occurred whenever a problem with a tree happened, but it’s possible that certain blocks contain people who are more aggressive about getting problems fixed on their block. It’s even possible that, having seen pruners on your block sensitizes you to your trees’ health as well as the fact that there even is a city agency who is in charge of trees, which causes you to be more likely to call in a fallen limb.
Ignoring all of this, which is a lot to ignore, it looks like pruning may be a waste of money.
Read more on our wiki here. The data is available so feel free to redo an analysis!
Yesterday
I was suffering from some completely bizarre 24-hour flu yesterday, which is why I didn’t post as usual. The symptoms were weird:
What I didn’t do yesterday
- I didn’t sleep at all.
- That is to say, after my Datadive presentation shorty before noon Sunday, and after my Occupy group met Sheila Bair Sunday evening, I came home and stayed awake until I went to bed Monday night.
- So, in particular, being awake already for 24 hours by then, I didn’t write a post about whether pruning does or does not actually mitigate future disastrous events like falling trees. I owe you that post.
- I also didn’t blog about Sheila Bair. Will do soon.
- I also didn’t share my friend’s Chicago public school take on value-added testing for teachers. Stay tuned.
- Also I wanted to tell you guys about this amazing book I’m reading called Sh*tty Mom, which I didn’t do. Consider yourself told. Read immediately, even if you’re not a parent, because this will explain why your parent friends are so insane and annoying.
- I also didn’t read or write any emails, related to the fact that I was feeling like it was still about midnight for the entire day and I was wondering why people kept sending me emails in the middle of the night.
What I did yesterday
- I watched the pilot episode of Downton Abbey.
- Then I watched a few more.
- Then I finished the first season.
- Then I got my kids up, sent them or brought them to school and then came back home. Glad I did this because it meant I had to actually get dressed.
- Then I watched the second season. That’s an unbelievable amount of vegging out, an enormous investment. The kiss scene made it all worth it.
- For some reason, I also made a turkey dinner with mashed potatoes, gravy, and apple cider. No stuffing, that would have been overkill for September. Plus I couldn’t find fresh cranberries.
- Finally, and maybe it’s the turkey that did it, I felt tired, and after my 10-year-old helped me put my 3-year-old to bed, my 10-year-old then tucked me in at 7:30 last night.
I woke up feeling great! I’m back, baby!
NYC Parks datadive update: does pruning prevent future fallen trees?
After introducing ourselves, we subdivided our pruning problem into 5 problems:
- mapping tree coordinates to block segments
- defining the expected number of fallen tree events based on number of trees, size and age of trees, and species,
- accounting for weather,
- designing the model assuming the above sub-models are in shape, and
- getting the data in shape to train the model (right now the data is in pieces with different formats).
After a few hours of work, there was real progress on 1 and 5, and we’d noticed that we don’t have the age of trees, but only the size, which we can use as a proxy. Moreover, the size measurements weren’t updated after they were taken once in 2005. So it would require much more domain expertise that we currently had to incorporate a model of how fast trees grow, which we don’t have time for this weekend.
Before lunch we realized we really needed to talk about 4, namely the design of the model, so we scheduled pow-wow for after lunch.
After some discussion, we settled on a univariate regression model where the basic unit is a block of trees in Brooklyn for a given year:
So for each street block and for each year of data, we define:
Going back to the 



We ended up deciding that we can’t really account for weather in our model, since we won’t have any idea how many storms will pass through Brooklyn next year.
I left last night before we’d gotten all the data in shape so I’m eager to go back this morning to the presentation event and see if we have any hard results. Even if we don’t, I think we have a reasonable model and a very good start on it, and I think we will have helped the NYC Parks department with the question. I’ll update soon with the final results.
Datadive: NYC Park data
I’m excited to be a data ambassador this weekend for DataKind’s NYC Parks datadive. The event is sadly sold out, but you can follow along to some extent through the wiki and through this blog.

This weekend I’m in charge of herding people who are interested in the pruning project; for that reason I’ve dubbed my self the Prune Queen, which is nice and gross sounding so I love it.
The Parks department is a New York City agency that’s in charge of our urban forest here in New York. They deal with planting trees, keeping track of what trees exist, how many trees exist, and the health of all the trees in the five boroughs. When there’s a storm, and a tree falls, they get a “request order” coming from 311 calls (or occasionally other means) and if and when they decide to go deal with the problem, a “work order” is created and a team of people is sent out to fix the problem.
A fallen tree is an expensive proposition, although unavoidable considering how many trees there are in the city. The question we are trying to address this weekend is, can we mitigate the “fallen trees” problem by pruning beforehand.
In fact, there’s been lots of tree pruning already, so we can use our data science magic to see whether or not we think pruning helps. Namely:
- We’ve had various sized budgets which resulted in various levels of pruning activity in the past decade.
- When they do prune, they prune an entire block, so from one corner to the next corner. They describe these as “block segments.”
- Our data tells us when which block segments were pruned, at the year level. That is to say, we’ll be able to see if a given block segment was pruned in 2003, but we won’t know which month during 2003 it was pruned.
The first iteration of the model is this: does a block segment have fewer (than expected) “fallen tree” events right after being pruned?
We’d expect the answer to be yes, and we’d also expect the effect to decay over time. Maybe a block segment is protected from fallen tree events for a couple years after pruning, for example, but after about 7 or 8 years the effect has worn off. Something like that.
But then, if you think about it, the “expected” number of fallen tree events is actually kind of tricky.
If there are only 2 trees on a block, then even if there’s no pruning on that block, there are not likely to be lots of fallen tree events compared to another block that has 100 trees. So it would be great to have a sense of the density of trees on a given block segment.
Luckily, we do: we have a tree census, which is to say we know more or less where all the trees are in the five boroughs. This is a pretty crazy awesome data set when you think about it. This will allow us to define the tree density per block segment (once we establish a map between existing trees and block segments) and will therefore also allow us to have a first stab at what the “expected” rate of fallen tree events should be on a block-by-block basis.
Are there other things we should normalize for besides number of trees per block segment? Well, there have also been a number of severe storms, and even tornadoes, that have gone through Brooklyn in the last decade (and for some reason even more in the past few years). We also might want to account for a block which was directly in the path of a tornado, because we shouldn’t blame pruning or lack of pruning for an asston of fallen tree events if it was actually caused by a natural disaster.
Finally, we recently found out that a student at SIPA worked on a similar but different project: namely, whether pruning blocks mitigates future pruning requests. In other words, the same pruning (x) but a different effect (y). They actually had the dollar costs in mind and figured out how cost-effective pruning is. But then again, they didn’t account for the more expensive fallen tree events, so the project this weekend could change the results (I don’t actually know what their findings were, so far I’ve only heard this third hand).
How is math used outside academia?
Help me out, beloved readers. Brainstorm with me.
I’m giving two talks this semester on how math is used outside academia, for math audiences. One is going to be at the AGNES conference and another will be a math colloquium at Stonybrook.
I want to give actual examples, with fully defined models, where I can explain the data, the purported goal, the underlying assumptions, the actual outputs, the political context, and the reach of each model.
The cool thing about these talks is I don’t need to dumb down the math at all, obviously, so I can be quite detailed in certain respects, but I don’t want to assume my audience knows the context at all, especially the politics of the situation.
So far I have examples from finance, internet advertising, and educational testing. Please tell me if you have some more great examples, I want this talk to be awesome.
The ultimate goal of this project is probably an up-to-date essay, modeled after this one, which you should read. Published in the Notices of the AMS in January 2003, author Mary Poovey explains how mathematical models are used and abused in finance and accounting, how Enron booked future profits as current earnings and how they manipulated the energy market. From the essay:
Thus far the role that mathematics has played in these financial instruments has been as much inspirational as practical: people tend to believe that numbers embody objectivity even when they do not see (or understand) the calculations by which particular numbers are generated. In my final example, mathematical principles are still invisible to the vast majority of investors, but mathematical equations become the prime movers of value. The belief that makes it possible for mathematics to generate value is not simply that numbers are objective but that the market actually obeys mathematical rules. The instruments that embody this belief are futures options or, in their most arcane form, derivatives.
Slightly further on she explains:
In 1973 two economists produced a set of equations, the Black-Scholes equations, that provided the first strictly quantitative instrument for calculating the prices of options in which the determining variable is the volatility of the underlying asset. These equations enabled analysts to standardize the pricing of derivatives in exclusively quantitative terms. From this point it was no longer necessary for traders to evaluate individual stocks by predicting the probable rates of profit, estimating public demand for a particular commodity, or subjectively getting a feel for the market. Instead, a futures trader could engage in trades driven purely by mathematical equations and selected by a software program.
She ends with a bunch of great questions. Mind you, this was in 2003, before the credit crisis:
But what if markets are too complex for mathematical models? What if irrational and completely unprecedented events do occur, and when they do—as we know they do—what if they affect markets in ways that no mathematical model can predict? What if the regularity that all mathematical models assume effaces social and cultural variables that are not subject to mathematical analysis? Or what if the mathematical models traders use to price futures actually influence the future in ways the models cannot predict and the analysts cannot govern? Perhaps these are the only questions that can challenge the financial axis of power, which otherwise threatens to remake everything, including value, over in the image of its own abstractions. Perhaps these are the kinds of questions that mathematicians and humanists, working together, should ask and try to answer.
Columbia data science course, week 1: what is data science?
I’m attending Rachel Schutt’s Columbia University Data Science course on Wednesdays this semester and I’m planning to blog the class. Here’s what happened yesterday at the first meeting.
Syllabus
Rachel started by going through the syllabus. Here were her main points:
- The prerequisites for this class are: linear algebra, basic statistics, and some programming.
- The goals of this class are: to learn what data scientists do. and to learn to do some of those things.
- Rachel will teach for a couple weeks, then we will have guest lectures.
- The profiles of those speakers vary considerably, as do their backgrounds. Yet they are all data scientists.
- We will be resourceful with readings: part of being a data scientist is realizing lots of stuff isn’t written down yet.
- There will be 6-10 homework assignments, due every two weeks or so.
- The final project will be an internal Kaggle competition. This will be a team project.
- There will also be an in-class final.
- We’ll use R and python, mostly R. The support will be mainly for R. Download RStudio.
- If you’re only interested in learning hadoop and working with huge data, take Bill Howe’s Coursera course. We will get to big data, but not til the last part of the course.
The current landscape of data science
So, what is data science? Is data science new? Is it real? What is it?
This is an ongoing discussion, but Michael Driscoll’s answer is pretty good:
Data science, as it’s practiced, is a blend of Red-Bull-fueled hacking and espresso-inspired statistics.
But data science is not merely hacking, because when hackers finish debugging their Bash one-liners and Pig scripts, few care about non-Euclidean distance metrics.
And data science is not merely statistics, because when statisticians finish theorizing the perfect model, few could read a ^A delimited file into R if their job depended on it.
Data science is the civil engineering of data. Its acolytes possess a practical knowledge of tools & materials, coupled with a theoretical understanding of what’s possible.
Driscoll also refers to Drew Conway’s Venn diagram of data science from 2010:

We also may want to look at Nathan Yau’s “sexy skills of data geeks” from his “Rise of the Data Scientist” in 2009:
- Statistics – traditional analysis you’re used to thinking about
- Data Munging – parsing, scraping, and formatting data
- Visualization – graphs, tools, etc.
But wait, is data science a bag of tricks? Or is it just the logical extension of other fields like statistics and machine learning?
For one argument, see Cosma Shalizi’s posts here and here and my posts here and here, which constitute an ongoing discussion of the difference between a statistician and a data scientist.
Also see ASA President Nancy Geller’s 2011 Amstat News article, “Don’t shun the ‘S’ word,” where she defends statistics.
One thing’s for sure, in data science, nobody hands you a clean data set, and nobody tells you what method to use. Moreover, the development of the field is happening in industry, not academia.
In 2011, DJ Patil described how he and Jeff Hammerbacher, in 2008, coined the term data scientist. However, in 2001, William Cleveland wrote a paper about data science (see Nathan Yau’s post on it here).
So data science existed before data scientists? Is this semantics, or does it make sense?
It begs the question, can you define data science by what data scientists do? Who gets to define the field, anyway? There’s lots of buzz and hype – does the media get to define it, or should we rely on the practitioners, the self-appointed data scientists? Or is there some actual authority? Let’s leave these as open questions for now.
Columbia just decided to start an Institute for Data Sciences and Engineering with Bloomberg’s help. The only question is why there’s a picture of a chemist on the announcement. There are 465 job openings in New York for data scientists last time we checked. That’s a lot. So even if data science isn’t a real field, it has real jobs.
Note that most of the job descriptions ask data scientists to be experts in computer science, statistics, communication, data visualization, and to have expert domain expertise. Nobody is an expert in everything, which is why it makes more sense to create teams of people who have different profiles and different expertise, which together, as a team, can specialize in all those things.
Here are other players in the ecosystem:
- O’Reilly and their Strata Conference
- DataKind
- Meetup groups
- VC firms like Union Square Ventures are pouring big money into data science startups
- Kaggle hosts data science competitions
- Chris Wiggins, professor of applied math at Columbia, has been instrumental in connecting techy undergrads with New York start-ups through his summer internship program HackNY.
Note: wikipedia didn’t have an entry on data science until this 2012. This is a new term if not a new subject.
How do you start a Data Science project?
Say you’re working with some website with an online product. You want to track and analyse user behavior. Here’s a way of thinking about it:
- The user interacts with product.
- The product has a front end and a back end.
- The user starts taking actions: clicks, etc.
- Those actions get logged.
- The logs include timestamps; they capture all the key user activity around the product.
- The logs then get processed in pipelines: that’s where data munging, joining, and mapreducing occur.
- These pipelines generate nice, clean, massive data sets.
- These data sets are typically keyed by user, or song (like if you work at a place like Pandora), or however you want to see your data.
- These data sets then get analyzed, modeled, etc.
- They ultimately give us new ways of understanding user behavior.
- This new understanding gets embedded back into the product itself.
- We’ve created a circular process of changing the user interaction with the product by starting with examining the user interaction with the product. This differentiates the job of the data scientist from the traditional data analyst role, which might analyze users for likelihood of purchase but probably wouldn’t change the product itself but rather retarget advertising or something to more likely buyers.
- The data scientist also reports to the CEO or head of product what she’s seeing with respect to the user, what’s happening with the user experience, what are the patterns she’s seeing. This is where communication and reporting skills, as well as data viz skills and old-time story telling skills come in. The data scientist builds the narrative around the product.
- Sometimes you have to scrape the web, to get auxiliary info, because either the relevant data isn’t being logged or it isn’t actually being generated by the users.
Profile yourself
Rachel then handed out index cards and asked everyone to profile themselves (on a relative rather than absolute scale) with respect to their skill levels in the following domains:
- software engineering,
- math,
- stats,
- machine learning,
- domain expertise,
- communication and presentation skills, and
- data viz
We taped the index cards up and got to see how everyone else thought of themselves. There was quite a bit of variation, which is cool – lots of people in the class are coming from social science.
And again, a data science team works best when different skills (profiles) are represented in different people, since nobody is good at everything. It makes me think that it might be easier to define a “data science team” than to define a data scientist.
Thought experiment: can we use data science to define data science?
We broke into small groups to think about this question. Then we had a discussion. Some ideas:
- Yes: google search data science and perform a text mining model
- But wait, that would depend on you being a usagist rather than a prescriptionist with respect to language. Do we let the masses define data science (where “the masses” refers to whatever google’s search engine finds)? Or do we refer to an authority such as the Oxford English Dictionary?
- Actually the OED probably doesn’t have an entry yet and we don’t have time to wait for it. Let’s agree that there’s a spectrum, and one authority doesn’t feel right and “the masses” doesn’t either.
- How about we look at practitioners of data science, and see how they describe what they do (maybe in a word cloud for starters), and then see how people who claim to be other things like statisticians or physics or economics describe what they do, and then we can try to use a clustering algorithm or some other model and see if, when it takes as input “the stuff I do”, it gives me a good prediction on what field I’m in.
Just for comparison, check out what Harlan Harris recently did inside the field of data science: he took a survey and used clustering to define subfields of data science, which gave rise to this picture:

It was a really exciting first week, I’m looking forward to more!
Videos and a love note
A quick post today because I gotta get these kids off to their first day of school. WOOHOOO!!
- I just learned about this video which was made at the first DataKind datadive I went to (it was called Data Without Borders then). The datadive coverage is in the first 6 minutes. It’s timely because I’m doing it again this coming weekend with NYC Parks data. I hope I see you there!
- Next, please check out my friend and fellow occupier Katya’s two videos, which she produced herself: here and here. She has a gift, no?
- Finally, readers, thanks for all the awesome comments lately (and always). I really appreciate the feedback and the thought you’ve put into them, and I’ve been learning a lot. Plus I have a lot of books to read based on your suggestions.
52 Shades of Greed cards fundraiser now up: please help! (#OWS)
The 52 Shades of Greed card deck fundraiser has begun. It’s a joint project of Alternative Banking and a collection of 26 artists and illustrators (you can learn more about the team here).
We’re trying to raise $15,000 to pay for the printing costs and the art. If we raise more money we will try to hold an art show, with talks about the financial system by Alt Banking folk.
Here’s my favorite card, it’s Larry Summers, the king of hearts:

Note he’s a liquidity fairy (I blogged about that here). Or wait, maybe it’s Jamie Dimon, jack of clubs:

Please go to the fundraiser and donate now! You can get the cards as well as other goodies. Amazing!
STEM jobs and the economy
STEM jobs
You know how we’re always hearing that not enough people major in science, technology, math, and engineering? The STEM subjects? That our country is losing pace in the competition with other countries for technology and such?
True and false. True that there are plenty of jobs for people with very strong skills in these areas. On the other hand we don’t want everyone to suddenly become a scientist/engineer/mathematician/computer nerd, because the truth is we don’t really have that many jobs. It’s not like the factory jobs of yesteryear or the agricultural jobs of yesteryesteryear.
Why? These jobs by nature are idiosyncratic and typically conclude with hugely scalable results. There’s only so many social media systems we need created, only so many air traffic control programs that need to work. After a while we might actually be done with some of this. An Detroit-sized army of engineers would not be the right tool for the job, actually, we wouldn’t know what to do with them.
So when you hear calls for more people like this, take it with a grain of salt. The truth is, they are rare now, will probably stay relatively rare, and the reason there’s so much emphasis on STEM professionals is this: having skills like that is a ticket to the elite. Let me explain why I say “elite”, which is a loaded term.
The Economy
There has been plenty of documentation of the following phenomenon: instead of lots of middle class job creation, we’ve been seeing technology-driven high-paying job creation, on the one hand, and a bunch of low-paying, person-to-person jobs like working in health care as home health aides on the other hand.
Be a nerd with me and extrapolate our current system out fifty years. What do you see happening?
Here’s what I see. Continued loss of classic middle-class jobs, continued efficiency gains with highly scaled industries run by a few super techno-savvy billionaire elites. Lots of people either jobless or working in the remaining jobs that can’t be done by computers or taken off-shore, mostly involving food and healthcare. Society has been hollowed out, once and for all.
I actually believe in this, and I don’t think it’s really avoidable. On the other hand, it could either end well or badly, depending on how we deal with it, and depending on what the standard of living is for people who have been edged out of a living by the enormous technological gains we’ve made.
Do they get well-paid for the work they do find? Do they have access to healthcare? Do they have to worry about feeding themselves and their kids? Do they get told by some hypocritical blowhard politician to man up and get a job when no jobs exist? Are they in irretrievably hopeless student debt?
Women, marriages, and the rat-race
There were two articles in the Economist a couple of issues ago which involved women. First, there was an article about marriage rates, saying they’re down all across the world, and showing this graph:

As an explanation, the Economist suggests some possibilities:
First, women are often marrying later as their professional opportunities improve. Second, thanks to increased longevity, bereaved spouses are outliving their partners for longer than the widows and widowers of yesteryear. And third, changing social attitudes in many countries mean that the payoffs of marriage—financial security, sexual relations, a stable relationship—can now often be found outside the nuptial bed.
Let’s call that last possibility the “payoff” reason for not getting married, and rephrase it like this: women are saying, I’d rather not, thanks.
The second Economist article talks about why women don’t rise to the top of companies. It gives us some numbers:
America’s biggest companies hire women to fill just over half of entry-level professional jobs. But those women fail to advance proportionally: they occupy only 28% of senior managerial posts, 14% of seats on executive committees and just 3% of chief-executive roles, according to McKinsey & Company, a consultancy.
Again, as explanation, the Economist suggests some possibilities:
Several factors hold women back at work. Too few study science, engineering, computing or maths. Too few push hard for promotion. Some old-fashioned sexism persists, even in hip, liberal industries. But the biggest obstacle (at least in most rich countries) is children.
Do you know what I’m not seeing? I’m not seeing the payoff reason listed. I’m not seeing the possibility that women decide I’d rather not, thanks.
Considering what we know about internal culture at places like McKinsey & Company and other consultancies, or finance firms, or technology firms, etc., I’m wondering why that wasn’t listed.
Remember, these are educated, smart women being hired at these companies. They have lots of options in general, so I’m not willing to to assume they are all just going home to take care of their kids once they leave their corporation. More likely, they’re leaving because they decide it’s just not going to be their best option.
And yeah, it is hard to have kids and work, but that’s not the only reason to leave a large corporation. Take for example the heroine of the article, Marissa Mayer, the new CEO of Yahoo! (emphasis mine):
Ms Mayer of Yahoo! is an inspiration to many, but a hard act to follow. She boasts of putting in 90-hour weeks at Google. She believes that “burn-out” is for wimps. She says that she will take two weeks’ maternity leave and work throughout it. If she can turn around the internet’s biggest basket case while dandling a newborn on her knee it will be the greatest triumph for working women since winning the right to wear trousers to the office (which did not happen until 1994 in California).
WTF?! She’s an inspiration to who, HR at her company? Who does that? She’s gotta be psychotic – but wait, that’s what’s selected for. I’d like to see another article come out where the Economist asks the question, Why are smart men willing to spend their lives in the quest of leading these companies, considering how awful the conditions are?
In any case, I personally would like to go on record saying Marissa Mayer is not a role model for me.
You know who is, though? This woman I met when she was 80, who had just learned to be a professional potter, and had had various totally fascinating careers before that, including as a ship-builder. She had five kids. She ran away with her current husband at 40. Since I met her she became a writer. My god, this woman is amazing.
Women, and some men, have the power to re-invent themselves, to become more and more interesting and creative as they grow older. That is, to me, inspiring. They are my role models. Keep learning! Keep exploring!
I’m not asking you to agree with me on what is inspiring, but I am asking the Economist to be consistent. If we can manage to believe that not all women see the point in getting married, then can’t we stretch ourselves, just a bit, and imagine that not all women can see the point in staying inside a corporate machine for their entire lives, slowly losing their identity and their ambition in the petty internal rat-races of the idiosyncratic culture of whatever firm they happen to belong to, just so, at the end, they can have too much money and not enough time? Sheesh.
Fair versus equal
In this multimedia presentation, Alan Honick explores the concept of fairness with archaeologist Brian Hayden. It’s entitled “The Evolution of Fairness”, and it’s published by Pacific Standard Magazine.
It’s a series of small writings and short videos which studies evidence of the emergence of inequality in the archaeological record of fishing at a place called Keatley Creek in British Columbia. While it isn’t the most convenient thing to go through, it’s worth the effort. Here are the highlights for me:
When the main concern of the people living at Keatley Creek was subsistence, their society was egalitarian – they shared everything and it wasn’t okay to hoard. Specifically, anyone found trying to game the system was ejected from society, which typically meant death.
As fishing technology improved, the average person could provide for themselves in normal times quite easily, and private ownership became acceptable and common. Those who game the system were no longer ejected, partly because the definitions were different.
At this point, Hayden suggests, people began to do things in small groups that seemed perfectly fair (“I’ll give you 20 fish loaves if you let me marry your daughter” or “Come to my feast tonight and invite me to your feast next week”) and moreover seemed like a private arrangement, until it became sufficiently widespread so that two things happened:
- The guys who didn’t have or couldn’t borrow 20 fish loaves couldn’t get married, or similarly the guys who couldn’t afford to serve a feast never entered into the feast-sharing ritual, and
- The truly rich guys would sometimes have a feast for everyone, which meant the poorer would “get something for nothing” and everyone would gain. Another way of saying this is that the poorer people would allow themselves to be coopted into the unequal system by the price of this free food. Those people who didn’t give feasts or cooperate with the free feasts were outcasts.
An interesting thing happened when Hayden goes to villages in the Mayan Highlands in Mexico and Guatemala which has similar size and social structure as the one on Keatley Creek (see the video on this page). He interviewed people about how the “rich” behaved in times of starvation. Did they take on a managerial role? Did they share and help out in bad times? This is referred to as “communitarian”.
Turns out, no, they exploited the people in the village in the hopes of having better status by the time things got better. They sold maize at exorbitant prices, took outrageous amounts of land for maize, etc. The driving force was individual self-interest.
The overall narrative describes the shifting definition of fairness as things became less and less equal, and how eventually the elite, who essentially got to define fairness, didn’t need to listen to the objections of the poor at all, because they had no power.
Sound familiar?
The author Alan Honick concludes by looking at our society and asks whether campaign finance laws, and Citizens United, is that different in effect from what we saw happening on Keatley Creek. He also points out that, because we humans are so individually obsessed with increasing our status, we can’t seem to get together to address really important issues such as global warming.
Stuff you might want to know about
I have a backlog of things to tell you about that I think are either awesome or scary but important:
- In the awesome category, my friend Anupam just started a new company that helps get volunteers get connected with animal shelters. It’s called BarkLoudly , and you can learn more about it here.
- Again in the awesome category, there’s been progress on seeing if scientific claims can be reproduced. This is for lab experiments, which I’d think would be harder than what I want to do for data models, but what do I know. It’s called The Reproducibility Initiative, run by the Science Exchange, and you can also read about it in this article from Slate.
- On the scary side, read this article by my friend Moe on the questionable constitutionality of student debt laws in this country, and this article on how hard it is to get rid of student debt even through the “undue hardship” route, which involves a “certainty of hopelessness” test. Outrageous.
- Also in the scary category, an argument against the new pill for HIV, written by an entertaining blogger.
Automated call centers and superorganisms
Once upon a time there were people who worked in the insurance office and you could talk to them on the phone or even in person (annoying emphasis intentional).
Now everything is online and you need to call an automated call center to try to conduct business if there’s been an accident or they made a mistake or if you have a question which isn’t “how much do I owe the insurance company?”.
Recently my friend Becky got stuck in the penetralia of an automated call center and she likened the experience to the life of an ant and specifically to the “superorganism hypothesis” of myrmecologist E. O. Wilson (BTW, who here doesn’t love the word “myrmecologist”?). Her description:
Whether or not this is an accurate representation of their inner state, ants have long been described as having an automaton’s machine-like nature, one in which individual identity is subsumed under the totalitarian will of the collective in Borg-like, Communist wetdream fashion.
That’s how I feel when I’m lost in the labyrinthine bowels of automated customer service hell. I’m part of a network that works profitably at the superorganism level, but doesn’t serve the interests of the individual in the slightest, nor cares to nor purports to, driven as it is by the spare logic of collective efficiency.
Question: what is less human than the rigid caste societies of Army ants marching hollowly and inexorably on their prey, driven by the dictates of their genes?
Answer: only the hollowed-out computer-generated voice of the quasi-British phone operator who demands that you enter your social security number over and over again as an exercise in surrendering your will to a corporation whose power role in the financial arrangement is made ever more apparent to both parties by the dawning impossibility of ever speaking to a human at the end of the interminable and ultimately futile phone call.
Powerful analogy; I’ve tended to use the herded cows analogy myself. To entertain myself in the painful waits, I often emit audible “moos” to emphasize the forced passivity I object to. It sometimes backfires and interprets my sounds as a menu choice, though, so I’m thinking of going with the ants, who I don’t think make much noise.
A few thoughts:
- If you know you need to talk to a person eventually and that there’s no point going through all the stages, sometimes just dialing “0 0 0 0 0 0 0 0” a bunch of times will put you straight through. I usually try this straight away the first time I call. Sometimes it works, sometimes it totally fails and I have to call back. Worth a try.
- I wonder how efficient these call centers really are. I have a theory that people simply give up and pay (or default on) their incorrect bills rather than having to deal with this irredeemably opaque system.
- I also wonder what the built-up learned passivity does to us as a society. Having worked as a customer support person myself, I know that there are probably nice people at the other end of the system, and if I could only get through to them, which is a big if, they’d be super informed and helpful. But most people probably don’t think of it that way.
Citigroup’s plutonomy memos
Maybe I’m the last person who’s hearing about the Citigroup “plutonomy memos”, but they’re blowning me away.
Wait, now that I look around, I see that Yves Smith at Naked Capitalism posted about this on October 15, 2009, almost three years ago, and called for people to protest the annual meetings of the American Bankers Association. Man, that’s awesome.
So yeah, I’m a bit late.
But just in case you didn’t hear about the plutonomy memos (h/t Nicholas Levis), which were featured on Michael Moore’s “Capitalism: a Love Story” as well, then you’ll have to read this post immediately and watch Bill Moyer’s clip at the end as well.
The basic story, if you’re still here, is that certain “global strategists” inside Citigroup drafted some advice about investing based on their observation that rich people have all the money and power. They even invented a new word for this, namely “plutonomy.” This excerpt from one of the three memos kind of sums it up:
We project that the plutonomies (the U.S., UK, and Canada) will likely see even more income inequality, disproportionately feeding off a further rise in the profit share in their economies, capitalist-friendly governments, more technology-driven productivity, and globalization… Since we think the plutonomy is here, is going to get stronger… It is a good time to switch out of stocks that sell to the masses and back to the plutonomy basket.
The lawyers for Citigroup keep trying to make people take down the memos, but they’re easy to find once you know to look for them. Just google it.
Nothing that surprising, economically speaking, except for maybe the fact that their reaction, far from being outrage, is something bordering on gleeful. But they aren’t totally complacent:
Low-end developed market labor might not have much economic power, but it does have equal voting power with the rich.
This equal voting power seems to be a pretty serious concern for their plans. They go on to say:
A third threat comes from the potential social backlash. To use Rawls-ian analysis, the invisible hand stops working. Perhaps one reason that societies allow plutonomy, is because enough of the electorate believe they have a chance of becoming a Pluto-participant. Why kill it off, if you can join it? In a sense this is the embodiment of the “American dream”. But if voters feel they cannot participate, they are more likely to divide up the wealth pie, rather than aspire to being truly rich.
Could the plutonomies die because the dream is dead, because enough of society does not believe they can participate? The answer is of course yes. But we suspect this is a threat more clearly felt during recessions, and periods of falling wealth, than when average citizens feel that they are better off. There are signs around the world that society is unhappy with plutonomy – judging by how tight electoral races are.
But as yet, there seems little political fight being born out on this battleground.
This explains to me why Occupy was treated the way it was by Bloomberg’s cops and the entrenched media like the New York Times (and nationally) – the idea that people are opting out and no longer believe they have a chance of being a Pluto-participant is essentially the most threatening thing they can think of. Interestingly, they also say this:
A related threat comes from the backlash to “Robber-barron” economies. The
population at large might still endorse the concept of plutonomy but feel they have lost out to unfair rules. In a sense, this backlash has been epitomized by the media coverage and actual prosecution of high-profile ex-CEOs who presided over financial misappropriation. This “backlash” seems to be something that comes with bull markets and their subsequent collapse. To this end, the cleaning up of business practice, by high-profile champions of fair play, might actually prolong plutonomy.
This is what Dodd-Frank has done, to some extent: a law that makes things seem like they’re getting better, or at least confuses people long enough so they lose their fighting spirit.
Finally, from the third memo:
➤ What could go wrong?
Beyond war, inflation, the end of the technology/productivity wave, and financial collapse, we think the most potent and short-term threat would be societies demanding a more ‘equitable’ share of wealth.
Note the perspective: what could go wrong. Lest we wonder who inititated class warfare.
School starts next week
I know I’m not alone when I say, thank god school starts next week. These kids need to be back in school.
Not that I don’t adore the little lovemuffins, or that I don’t enjoy spending time with them, or that I enjoy hearing them whine about homework. It’s been great, and we’ve watched quite a few good movies in the past few days (for some reason they didn’t enjoy “12 Angry Men” or “Contact” as much as they should have, though).
Don’t get me wrong, I am happy for them to have summer vacation. I just wish we could all take a pill about a week before school actually starts that puts us in a coma for exactly one week. Is that too much to ask?
It wouldn’t help to make summer one week shorter, either. That would just move up the insanity one week sooner. No good. We need that pill.
I’m not employed right now, and I’m trying to find time to write and to plan my future. But it’s kind of hard to do that when my three sons are actively coming up with ways to simultaneously talk louder than anyone knew was humanly possible and to fight ferociously about such things like who gets to play with the cardboard boxes from the last Fresh Direct delivery.
I’m not gonna lie, I’ll be glad when they’re gone. I’m counting the hours. T minus 166.
The country is going to hell, whaddya gonna do.
Yesterday I finished reading Chris Hayes’s book “Twilight of the Elites,” and although I enjoyed it, I have to say it was more about the elites than about their twilight.
He focused on the enormous distance between people in society, how the myth of meritocracy is widening that gap (with healthy references to Karen Ho’s book Liquidated, which I blogged about here), and how, as the entrenched elite get more and more entrenched, they get less and less competent.
But Hayes didn’t really paint a picture of how things would end, although he mentioned the Tea Party and Occupy as possible important sources of resistance, not unlike Barofsky’s recent book Bailout (which I blogged about here), in which Barofsky appealed to the righteous anger of the people to whom government is no longer accountable.
Well, I guess Hayes did add one wrinkle which surprised me. He said it would be the upper middle class, educated class that actually foments the coming revolution. Oh, and the bloggers (because the mainstream media is so captured they’re useless). So me and my friends.
His argument is that we are the ones sufficiently educated and sufficiently insiderish that we will be at the window, with our faces pressed against the glass, looking in at the true insider elites, and seeing how stupid and incompetent those guys are, and how they are rigging the system against the rest of us, and we’ll eventually explode with disgust and righteous anger and that will signal the end.
Kind of feels like that’s already happened, but maybe I’m being impatient.
Two things I really enjoyed about his book:
First, the fact that practically everyone thinks they’re an underdog and has fought tooth and nail to succeed in this world. Absolutely true, including the guys I worked with in finance. I think the phrase he used is “people born on third base think they hit a triple”.
Second, he does a really good job describing the never-can-be-too-rich culture of our country; his example of going to Davos is an excellent one and brings that concept to life perfectly.
It’s enough to get you kind of depressed overall, though. If we are to believe this book’s thesis, our entrenched elite and dysfunctional political structure and economic system are doomed to fail at some future moment, and the best we can hope for is a moment where the hypocrisy collapses in on itself. What is there to look forward to exactly?
I asked that of a friend of mine, and how it was getting me down. His advice to me was to own it more. To make the coming apocalypse an event, kind of like the 4th of July or a vacation, that you plan for and enjoy thinking about.
He said plenty of people do this, it’s in fact a huge industry of doom and gloom. The country is going to hell, whaddya gonna do, he said, might as well have some fun with it.
What? Who are these doom and gloom people? Start here, where Dmitry Orlov compares the preparedness of the US to the former USSR for the coming inevitable apocalypse. He calls this the “Collapse Gap”.
It’s got some great points (although he can’t both say that lawlessness ensues and people take what they want, and also say that people behind in their mortgages will be homeless) and it’s really funny as well, in a completely cynical, Russian way of course. My favorite lines:
One area in which I cannot discern any Collapse Gap is national politics. The ideologies may be different, but the blind adherence to them couldn’t be more similar.
It is certainly more fun to watch two Capitalist parties go at each other than just having the one Communist party to vote for. The things they fight over in public are generally symbolic little tokens of social policy, chosen for ease of public posturing. The Communist party offered just one bitter pill. The two Capitalist parties offer a choice of two placebos. The latest innovation is the photo finish election, where each party buys 50% of the vote, and the result is pulled out of statistical noise, like a rabbit out of a hat.
What makes us fat
I recently finished a book that made rethink being fat, and the cause of the worldwide “obesity epidemic”. Rethink in a good way.
Namely, it suggested the following possibility. What if, rather than getting fat because we are overeating, we overeat because we are getting fat? Another way of thinking about this is that there’s something going on that makes us both store fat away and overeat – that they are both symptomatic of some other problem.
In particular, this would imply that the fact of being fat is not a moral weakness, not a mere lack of willpower. Since I long ago dismissed the willpower hypothesis myself (I don’t seem to have trouble with other aspects of my life which require planning and willpower, why do I have so much trouble with this even though I’ve seriously tried?), this idea comes as something of a “duh” moment, but a welcome one.
To get in the appropriate mindset for this idea, think for a moment about all of the studies you hear about feeding animals such as rats, rabbits, monkeys, pigs, etc. different diets, and noting that sometimes the diet makes them super fat, and sometimes it doesn’t. Sometimes the animals are bred to have a genetic defect, or a pituitary or other gland is removed, and that has an effect on their fatness as well. In other words, there’s some kind of internal chemical thing going on with these animals which causes this condition.
Bottomline: we never accuse the fat mice of lacking will power.
So what is this thing that causes overeating and fat accumulation? The theory given in the book is as follows.
Fat cells are active little chemical warehouses which accept fat molecules and allow fat molecules to leave in two separate (but not unrelated) processes. Rather than thinking of fat as being stored there until the moment it is needed, instead think of the flow of fat molecules both into and out of each fat cell as two constant processes, so it’s actually better to consider the rate of those flows, the inward rate and the outward rate.
Suppose the outward rate of the fat molecules is somehow suppressed compared to the inward rate. So the fat molecules are being allowed into the fat cells just fine but they aren’t leaving the fat cells easily. What would happen?
In the short term, this would happen: lacking the appropriate amount of energy, the overall system would feel internally starved and get super hungry and quickly cause the animal to overeat to compensate for the lack of available energy.
In the longer term, the number of fat cells (or maybe the size of the average fat cell) would increase until the energy flow is sufficient to satisfy the internal needs of the system. In other words, the animal would gain a certain amount of weight (in the form of fat) and stay there, once the internal equilibrium is reached. This jives with the fact that people seem to have a certain “set point” of weight, including overweight. Indeed the amount of fat an animal has in equilibrium allows us to estimate how suppressed the outward flow of energy is.
What causes this suppressed outward rate? The book suggests that it’s elevated insulin. And what causes chronic elevated insulin? The book suggests that the main culprit is refined carbohydrates.
In particular, the author, Gary Taubes, suggests that by avoiding refined carbohydrates such as flour, sugar, and corn syrup, we can bring our insulin levels down to reasonable levels and the outward rate of fat from fat cells will no longer be suppressed.
Not everyone reacts in exactly the same way to refined carbs (i.e. not all insulin responses are identical) and scaled definitely matters, so eating 180 pounds of sugar a year is worse than 90 pounds a year, according to the theory. Moreover, things get progressively worse over time and it takes about 20 years of carb overloading to have such effects.
It’s easier said than done to avoid such foods as an individual living in our culture (nothing at Starbucks, nothing at a newsstand, almost nothing at a bodega), but one thing I like about this theory is that it actually explains the obesity epidemic pretty well: as the author points out, massively scaled refined carbohydrates have only been consumed at such rates for a short while, and the correlations with weight gain are pretty high.
Moreover, and I know this from personally avoiding most carbs for the past 6 months (which I started doing for another, related reason – I hadn’t read the book yet!). I’ve lost weight easily, and I haven’t ever been hungry, even compared to what I used to experience when I wasn’t dieting at all. According to the theory, my fat cells are releasing fat easily because my insulin levels are low, which means I don’t have internal starvation, which in turn explains my complete lack of hunger.
Also in the book: he claims we don’t actually know eating saturated fat raises cholesterol, nor that high cholesterol causes heart disease except when it’s super high, but then again it also seems to be bad to have super low cholesterol. I gotta hand it to this guy, he’s not afraid of going against conventional wisdom, at the risk of being ridiculed, which he most definitely has been.
But that doesn’t make me dismiss his theories, because I’m pretty sure he’s right when he says epidemiology is fraught with politics and bad selection bias.
It’s certainly an interesting book, and who knows, he may be right on some or all scores. On the other hand, maybe it doesn’t matter that much – not many people want to or are willing to avoid carbs, and maybe it’s not environmentally sustainable, although I don’t eat more meat than I used to, just more salad.
We are now ruling out the idea that people don’t exercise enough as the cause for being fat, and as we’ve attempted to follow the advice of the so-called experts, everyone seems to just get fatter all the time. As far as I’m concerned, all conventional bets are off.
#OWS update
I’m happy to show you that Alternative Banking now has a working blog, thanks to a newer member Nicholas Levis. He blogged recently about a Reality Sandwich event I went to last Wednesday, where David Graeber, author of Debt: the first 5000 years was speaking. Interesting and stimulating.
We also have a playing card project called “52 Shades of Greed” which is coming out soon. Check out some of the amazing art here.
Finally, we are about to launch a Kickstarter campaign for our “move your money” app, as soon as I figure out how to accept the money without doing something illegal. Please tell me if you have experience with such things!
More exciting things in the works which I can’t talk about yet. I’ll keep you updated.



