Pruning doesn’t do much
We spent most of Saturday at the DataKind NYC Parks Datadive transforming data into useful form and designing a model to measure the effect of pruning. In particular, does pruning a block now prevent fallen trees or limbs later?
So, for example, we had a census of trees and we had information on which blocks were pruned. The location of a tree was given as 
The bad events are also given with reference to a point 
So we decided on a block-specific model, and we needed to match a tree to a block and a fallen tree work order to a block. We used vectors and dot-products to do this, by finding the block (given by a line segment) which is closest to the tree or work order location.
Moreover, we only know which year a block is pruned, not the actual date. That led us to model by year alone.
Therefore, the data points going into the model depend on block and on year. We had about 13,000 blocks and about 3 years of data for the work orders. (We could possibly have found more years of work order data but from a different database with different formatting problems which we didn’t have time to sort through.)
We expect the impact of pruning to die down over time. Therefore the signal we chose to measure is the reciprocal of the number of years since the last pruning, or some power of it. The impact we are trying to measure is a weighted sum of work orders, weighted by average price over the different categories of work orders (certain events are more expensive to clean up than others, like if a tree falls into a building versus one limb falls into the street).
There’s one last element, namely the number of trees; we don’t want to penalize a block for having lots of work orders just because it has lots of trees (and irrespective of pruning). Therefore our “
Altogether our model is given as:

where 
We ran the regression where we let 
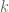
In both cases we got very very small signal, with correlations less than 1% if I remember correctly.
To be clear, the signal itself depends on knowing the last year a block was pruned, and for about half our data we didn’t have a year at all for that- when this happened we assumed it had never been pruned, and we substituted the value of 50 for # of years since pruning. Since the impact of pruning is assumed to die off, this is about the same thing as saying it had never been pruned.
The analysis is all modulo the data being correct, and our having wrangled and understood the data correctly, and possibly stupid mistakes on top of that, of course.
Moreover we made a couple of assumptions that could be wrong, namely that the pruning had taken place randomly – maybe they chose to prune blocks that had lots of sad-looking broken down trees, which would explain why lots of fallen tree events happened afterwards in spite of pruning. We also assumed that the work orders occurred whenever a problem with a tree happened, but it’s possible that certain blocks contain people who are more aggressive about getting problems fixed on their block. It’s even possible that, having seen pruners on your block sensitizes you to your trees’ health as well as the fact that there even is a city agency who is in charge of trees, which causes you to be more likely to call in a fallen limb.
Ignoring all of this, which is a lot to ignore, it looks like pruning may be a waste of money.
Read more on our wiki here. The data is available so feel free to redo an analysis!




Oh, I thought this was about the pruning of decision trees when I first saw the title. Thanks for posting the model and results, Cahty!
LikeLike
There are latex plugins for wordpress. 😛
LikeLike
I’m going to be lazy here and ask what happens when you exclude the trees for which you have no date for the last time they were pruned. This seems like an obvious easy question to ask if only to see how resistant your model is to the coding scheme you’ve chosen.
LikeLike
Sometimes it is better not to come to a conclusion. I like the column a lot except for the title and the ending.
This is a wonderful description of data analysis with the warts and all. its a great discussion of the trials and tribulations and recognition of the limits of the data and the ability to model.
But then you seem compelled to draw a conclusion “pruning doesn’t do much” (or as you state more accurately “Ignoring all of this, which is a lot to ignore, it looks like pruning MAY be a waste of money.”
That is accurate but still potentially misleading. I know you have a lot of sensible caveats but a non-data person at the parks department could well conclude they should do less pruning. Do you think they should? I don’t.
The assumption that they prune randomly seems very questionable. Also, not having tree-specific data makes it very hard to build a model with any power.
I think the parks department would have been better served if you analyzed the problem and the data and told them you need more information. Some of it (whether pruning is random) can presumably be learned fairly easily by speaking to someone in the park department. Other stuff — tree specific information — is probably much harder to get but maybe it isn’t. Maybe they have the information somewhere. If not, maybe they could do a survey (even if it didn’t cover the whole borough).
Better to clarify the questions than to come to unwarranted conclusions.
LikeLike
Jonathan,
I understand your concerns, and I agree. However, the parks people were on hand during this research and they told us the pruning was random, and they’d know better than myself of course. The other questions were similarly dealt with.
In other words, I want to keep in mind the possible problems because there’s always a chance we screwed something up, including assumptions or computer code, but it does matter how likely those things are.
In this case I think the chances are that pruning actually doesn’t do much – even when we removed all the data that didn’t have a year attached to it (a questionable thing to do), although pruning looked like it had a positive effect, that effect was still tiny. I should have mentioned this in the main post.
To answer your question, yes, I think they should stop pruning. It looks like a waste of money.
Cathy
LikeLike
OK. That makes sense. Sorry for the misunderstanding.
LikeLike
Not at all, I appreciate very much that you read it carefully and cared enough to push back.
Cathy
LikeLike
If removing that data resulted in a conclusion strongly at variance with the original (e.g., that pruning is effective), I’d say that the model (or the data coding) needs some tweaking. Maybe the trees for which there exists no data for the last time they were pruned were all done by the same crew and they were sloppy about filling out the paperwork, for example. So why would this be a questionable thing to do? What’s wrong with this logic?
It didn’t happen this time, of course. But I’ve found it’s always a good idea to do a few tests like this – they’re certainly cheap and easy enough, and maybe they’ll pick out something that’s not been properly incorporated into your model.
LikeLike