Archive

Bayesian regressions (part 2)
In my first post about Bayesian regressions, I mentioned that you can enforce a prior about the size of the coefficients by fiddling with the diagonal elements of the prior covariance matrix. I want to go back to that since it’s a key point.
Recall the covariance matrix represents the covariance of the coefficients, so those diagonal elements correspond to the variance of the coefficients themselves, which is a natural proxy for their size.
For example, you may just want to make sure the coefficients don’t get too big, or in other words there’s a penalty for large coefficients. Actually there’s a name for just having this prior, and it’s called L2 regularization. You just set the prior to be 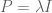
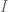

You’re going to end up adding this prior to the actual sample covariance matrix as measured by the data, so don’t worry about the prior matrix being invertible (but definitely do make sure it’s symmetrical).

Moreover, you can have many different priors, corresponding to different parts of the covariance matrix, and you can add them all up together to get a final prior.

From my first post, I had two priors, both on the coefficients of lagged values of some time series. First, I expect the signal to die out logarithmically or something as we go back in time, so I expect the size of the coefficients to die down as a power of some parameter. In other words, I’ll actually have two parameters: one for the decrease on each lag and one overall tuning parameter. My prior matrix will be diagonal and the 
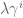
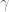
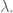
My second prior was that the entries should vary smoothly, which I claimed was enforceable by fiddling with the super and sub diagonals of the covariance matrix. This is because those entries describe the covariance between adjacent coefficients (and all of my coefficients in this simple example correspond to lagged values of some time series).
In other words, ignoring the variances of each variable (since we already have a handle on the variance from our first prior), we are setting a prior on the correlation between adjacent terms. We expect the correlation to be pretty high (and we can estimate it with historical data). I’ll work out exactly what that second prior is in a later post, but in the end we have two priors, both with tuning parameters, which we may be able to combine into one tuning parameter, which again determines the strength of the overall prior after adding the two up.
Because we are tamping down the size of the coefficients, as well as linking them through a high correlation assumption, the net effect is that we are decreasing the number of effective coefficients, and the regression has less work to do. Of course this all depends on how strong the prior is too; we could make the prior so weak that it has no effect, or we could make it so strong that the data doesn’t effect the result at all!
In my next post I will talk about combining priors with exponential downweighting.
Koo: don’t be surprised by the crappy economy
First I wanted to thank you for the wonderful comments I’ve been enjoying and compiling from my last post about what’s corrupt about the financial system and what should be done about it. Even if I don’t end up doing the teach-in (hopefully I will! In any case I’ll go down there, even if it’s just to try to set up the teach-in for a later date) I think this is a really fantastic and important discussion. I’m putting together a final list of issues tonight and I think I’ll make a flyer to bring tomorrow, so if I don’t actually conduct the teach-in (yet) I’ll at least be able to give the info booth the flyers.
And it’s not too late! Please keep the comments coming.
Today I want to start a discussion on Richard Koo’s book, which is about Japan’s so-called “lost decade” (a reader suggested this book to me, and it’s fascinating, so thanks! And please feel free to make more suggestions for my reading list).
You can actually get a pretty good overview of his book by watching this excellent interview by Koo. For those of you, like me, whose sound doesn’t work on their computers, here’s his basic thesis:
- After the housing bubble in Japan burst, a bunch of firms, banks and otherwise, became technically insolvent. This meant that, although they had cash flow, they owed more than their assets.
- Because they were insolvent, they didn’t maximize profits like in normal times; instead they minimized debts.
- In other words, they didn’t borrow money to grow their businesses, like you’d expect in normal circumstances, which is proved by looking at data showing that corporate borrowing went down even as interest rates lowered to zero.
- The CEO’s didn’t talk about this because they don’t want anyone to know they’re insolvent!
- Investors are also somewhat blind to this, because they typically look at growth and cash flow issues.
- Japan’s government made massive investments in order to cover the lack of private investments.
- Rather than this being a mistake, this was absolutely essential to the Japanese economy and prevented a massive depression.
- Moreover, the idea that Japan had a lost decade is false: actually, there was a lot going on in that decade (actually, 15 years) but people didn’t see it. Namely, the balance sheets were slowly improved over the entire economy.
- This is a lesson for us all: any time there’s a massive credit bubble which breaks, we can expect a balance sheet recession where behavior like this is the rule. The U.S. economy right now is an example of this.
I have a few comments about this. I wanted to mention that I’m only about halfway through the book so it’s possible that Koo addresses some of these issues but on the other hand the book was published in 2009 but was clearly written before the U.S. credit crisis was really full-blown:
- A friend of mine who recently traveled to Japan noted that the people there live extremely well. In fact, if he hadn’t been told that their country has been in recession for nearly twenty years then he’d have never guessed it. This supports Koo’s claim that the Japanese government absolutely did the right thing by bankrolling the economy when it did. It also brings up a very basic question: how do we measure success? And why do we listen to economists when they tell us how to define success?
- Not every country can do what Japan did in terms of investing in its economy, although the U.S. probably can. In other words, it depends on how other countries see your credit risk whether you can go ahead and bail out an entire economy.
- Some of the businesses in the U.S. are clearly not technically insolvent; we’ve already seen ample evidence of cash hoarding. On the other hand, I guess if sufficiently many are, then the overall environment can be affected like Koo describes.
- In general it makes me wonder, how many of the firms out there today are technically insolvent? How insolvent? How long will it take for those that are to either fail outright or pay back their loans? If we go by this article, then the answer is pretty alarming, at least for the banks.
In general I like Koo’s book in that it introduces a new paradigm which explains something as totally self-evident that had been mysterious. It’s pretty bad news for us, though, for two reasons. First, it means we could be in this (by which I mean stagnant growth) for a long, long time, and second, considering the hyperbolic political situation, it’s not clear that the government will end up responding appropriately, which means we may be in it for even longer.
What’s wrong with Wall Street and what should be done about it?
I am trying to figure out the top five (or so) most important corrupt and actionable issues related to the financial system. I’m going to compile this list in order to conduct a “teach-in” at the Occupy Wall Street protest next week. The tentative date is Wednesday, October 12, at 5:30pm.
I’d love to hear your thoughts: please tell me if I’m missing something or got something wrong or left something out.
The list I have so far:
- Investment bankers trading their books and taking outrageous risks which lead to government-backed bailouts because they are “too big to fail”. The related action in the U.S. might be the “Volcker rule” (i.e. reinstating something like Glass-Steagall); unfortunately it’s being watered down as you read this.
- Ratings agencies in collusion with their clients. The actions here would be changing the pay structure of the ratings agencies and opening up the methods, as well as having better regulatory oversight. We also need to change the structure of ratings agencies, and either make it easier to form an agency or make the agencies that already exist and have government protection actually accountable for their “opinions”.
- SEC and other regulators in collusion with the industry. The action here would be to nurture and maintain an adversarial relationship between regulators and bankers. We’ve seen too many people skip from the SEC to the banks they were regulating and then back. There should be rules against this (how about a minimum time requirement of 5 years between jobs on the opposite sides?). There should also be much better funding for the SEC and the other regulators, so they can actually meet their expanded mandate.
- Conflict of interest issues from economists and business school professors. If you’ve seen “Inside Job” then you’ll know all about how professors at various universities use their credentials to back up questionable practices. Moreover, they are often not even required to expose their industry connections when they do expert witnessing or write “academic” papers. The action here would be, at the very least, to force full disclosure for all such appearances and all publications. I’ve heard some good news in this direction but there obviously should be a standard.
- Rampant buying of politicians and influence of lobbyists from the financial industry. This is maybe more of a political problem than a financial one so I’m willing to chuck this off the list. Please tell me if you have something else in mind. Someone has suggested the opaque and elevated pension fund management system. Although I consider that pretty corrupt, I’m not sure it’s as important as other issues to the average person. I’m on the fence.
Saturday afternoon quickie
Two things.
- If I see another fucking article about how the world is going to miss Steve Jobs I’m going to puke. He made and sold overpriced gadgets for fucks sake! It’s hero worship plain and simple, maybe even a sick cult.
- I am happy that I’ve been invited to give a “teach-in” at Occupy Wall Street next Wednesday at 5:30 (tentative date and time). I’ve promised an overview of the 5 top corrupt things in the financial system. I’d really appreciate your thoughts: what is your top 5 list? I want them to be both important and relatively actionable. So far I’ve got:
- Volcker rule (i.e. reinstating something like Glass-Steagall); it’s being watered down as you read this.
- Ratings agencies in collusion with their clients
- SEC and other regulators in collusion with the industry
- Rampant buying of politicians and influence of lobbyists from the financial industry
- Incredibly poor incentives for the individuals in the industry, both in terms of salary and whistleblowing
Habits
This is a guest post by my friend Tara Mathur:
I don’t need to read Tiger Mother to know that I don’t have one. I don’t remember either of my parents putting a lot of pressure on me to do things – even to study, although I developed that habit on my own.
As kids we develop some habits on our own, but we pick up a lot of habits from our parents.
We learn habits from our parents in a few ways. One is by mirroring them. For example, my parents have always read in bed before going to sleep and so have I; it’s so natural to me that until I got married I thought this was something everyone did.
Another is by having our parents make us do something repeatedly. For example, when we first brushed our teeth it probably seemed like a pain to do, but our parents kept making us do it, and it became automatic.
How can we cultivate new habits as adults?
(And am I the only one who associates the word “will-power” with pain and failure? People use that word when they’re talking about doing something really hard, against their natural tendencies. I hear that word and think, how is this gonna last?)
In the last few years I’ve become a big fan of a blog called Zen Habits written by Leo Babauta. He’s made big positive changes in his life – getting out of debt, quitting smoking, running marathons, starting a successful writing career – by focusing on habits rather than goals. Even though big goals are sexy and easy to get excited about, it’s the daily habits, built up baby step by baby step, which last and which comprise most of our life. By definition, when something is a habit we don’t have to rely on willl-power to stick with it. It’s effortless, automatic behavior. Leo emphasizes starting small and focusing on one habit at a time.
This could apply to any positive change we’d like to make in our life. BJ Fogg, a human behavior expert who runs the Persuasive Technology Lab at Stanford, sums up the three steps to cultivate a new habit as follows:
- Make it tiny. To create a new habit, you must first simplify the behavior. Make it tiny, even ridiculous. (examples: floss one tooth, walk for three minutes, do two push-ups)
- Find a spot. Find a spot in your existing routine where this tiny new behavior could fit. Put it after some act that is a solid habit for you, like brushing teeth or eating lunch. One key to a new habit is this simple: you need to find what it comes after.
- Train the cycle. Now focus on doing the tiny behavior as part of your routine – every day, on cycle. At first you’ll need reminders. But soon the tiny behavior will get more automatic. Keep the behavior simple until it becomes a solid habit. That’s the secret to success.
That’s it! He says. Just keep your tiny habit going. Believe in baby steps. Eventually it will naturally expand to the bigger behavior, without much effort.
(There are other tricks too. I’ve also read that you’ll pick up a habit more quickly if you surround yourself with people who already have the habit you want — though I’m not sure if it will last when you’re no longer around those people. Try it and see what works.)
Financial Terms Dictionary
I’ve got a bunch of things to mention today. First, I’ll be at M.I.T. in less than two weeks to give a talk to women in math about working in business. Feel free to come if you are around and interested!
Next, last night I signed up for this free online machine learning course being offered out of Stanford. I love this idea and I really think it’s going to catch on. There are groups here in New York that are getting together to talk about the class and do homework. Very cool!
Next, I’m going back to the protests after work. The media coverage has gotten better and Matt Stoller really wrote a great piece and called on people to stop criticizing and start helping, which is always my motto. For my part, I’m planning to set up some kind of Finance Q&A booth at the demonstration with some other friends of mine in finance. It’s going to be hard since I don’t have lots of time but we’ll try it and see. One of my artistic friends came up with this:
 Finally, one last idea. I wanted to find a funny way to help people understand financial and economic stuff, so I thought of starting a “Financial Terms Dictionary”, which would start with an obscure phrase that economists and bankers use and translate it into plain English. For example, under “injection of liquidity” you might see “the act of printing money and giving it to the banks”.
Finally, one last idea. I wanted to find a funny way to help people understand financial and economic stuff, so I thought of starting a “Financial Terms Dictionary”, which would start with an obscure phrase that economists and bankers use and translate it into plain English. For example, under “injection of liquidity” you might see “the act of printing money and giving it to the banks”.
I’d love comments and suggestions for the Financial Terms Dictionary! I’ll start a separate page for it if it catches on.
Bayesian regressions (part 1)
I’ve decided to talk about how to set up a linear regression with Bayesian priors because it’s super effective and not as hard as it sounds. Since I’m not a trained statistician, and certainly not a trained Bayesian, I’ll be coming at it from a completely unorthodox point of view. For a more typical “correct” way to look at it see for example this book (which has its own webpage).
The goal of today’s post is to abstractly discuss “bayesian priors” and illustrate their use with an example. In later posts, though, I promise to actually write and share python code illustrating bayesian regression.
The way I plan to be unorthodox is that I’m completely ignoring distributional discussions. My perspective is, I have some time series (the 

A “bayesian prior” can be thought of as equivalent to data you’ve already seen before starting on your dataset. Since we think of the signals (the 
The information you need to know about the
Let me illustrate with an example. Suppose you are working on the simplest possible model: you are taking a single time series and seeing how earlier values of 
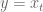
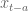
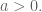
What is your prior for this? Turns out you already have one (two actually) if you work in finance. Namely, you expect the signal of the most recent data to be stronger than whatever signal is coming from older data (after you decide how many past signals to use by first looking at a lagged correlation plot). This is just a way of saying that the sizes of the coefficients should go down as you go further back in time. You can make a prior for that by working on the diagonal of the covariance matrix.
Moreover, you expect the signals to vary continuously- you (probably) don’t expect the third-from recent variable 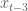
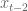
In my next post I’ll talk about how to combine exponential down-weighting of old data, which is sacrosanct in finance, with bayesian priors. Turns out it’s pretty interesting and you do it differently depending on circumstances. By the way, I haven’t found any references for this particular topic so please comment if you know of any.
My friend the coffee douche
About a year ago or so, I went with my friend to a new coffee store in lower Manhattan that he was super excited about. He knew the name of their espresso machine (the Slayer) and kept going on about how amazing the espresso made from this machine must be, if done right. I was happy to go, first because I needed coffee and second because I just like my friend and like it when people get really into things. On the way there I told him that the way he was waxing poetic about the Slayer really defined him as an all-out “coffee douche”. He took it well- in fact I think he actually loved the title. Coffee douches rarely get rewarded with titles, I realized.
I used to be a coffee douche myself. Or at least a potential coffee douche. I worked at Coffee Connection in my youth, which was eventually bought out by Starbucks but in its time gave lots of people in the Boston area pretty good coffee. I hung with the owner, especially once I decided to go to Berkeley, because that’s where he went for undergrad and where he learned to love good coffee (he told me he fell in love at Istanbul Express, I wonder if that place still exists). At some point I knew how many seconds of roasting produced each style (I never liked Italian Roast myself- too burnt) and the characteristics of the different coffees from all over the world (mmm… Sumatra).
Over time, though, I lost it. Something about having kids. I’m now at the level of carrying around Nodoz in my purse just in case I’m traveling and there’s no coffee machine in the hotel room (or in case those tiny little packages of grounds are insufficient). I still enjoy a good cup of Sumatra but I’m almost equally happy going to 7 Eleven. So you can see that coffee douchery is at best a fond memory for me.
When we got to the store, we were immediately asked at the door if we were “press”. Umm, no, what’s going on? It turned out that Sylvia was the guest barista! She was 3 time Brazilian pull champion!! I inferred that this meant there are actually competitions for making espresso. My friend was getting more and more excited and agitated. We got our pictures taken before and after the coffee drinks arrived. Or rather, our cups and saucers were- I think we may have only accidentally entered a frame or two. Sylvia was very gracious and hard-working at the same time. I think I managed to shake her hand, just for the celebrity moment of it all.
As an aside, I noticed something about the whole coffee movement thing when I was checking out Sylvia and her methods. Everything there has a fetishized whiff to it. The coffee machine was the Slayer, the various implements were wooden of some kind of hardwood that they were happy to explain in detail, and although I can’t remember all the names of the implements, I got the distinct impression that there may be a sex shop in the back room with leather and wooden tools very similar to the coffee tools. Maybe just me.
Here’s a close-up sexy shot of the Slayer (if you look carefully at the reflections you will note at least 3 people there admiring its shiny round parts), taken from the website of RBC coffee:

I don’t think I’ve ever been under such pressure to enjoy my espresso, but it was pretty good (I think). Near the end of drinking it, we seemed to be peppered with technical questions from the people there, including the owner of the store, the owner of the coffee plantation that supplied the store, and the guy who roasted the coffee beans. It was a triumvirate of coffee! I was glad I had my coffee douche with me!! He impressed them with his idiosyncratic knowledge (I remember his sympathy combined with pride when he mentioned that he was aware that there were laws against roasting in Manhattan but not in Brooklyn, so did they roast in Brooklyn? They did).
When I left, I was invigorated. Here are these people, completely obsessed and fascinated with coffee and everything pertaining to coffee. In some sense it struck me as a waste of time, but in a larger sense it was very very cool. That’s what’s interesting and fun about humans, after all, that they get totally nerdy and into things that other people can’t relate to, and they really improve our knowledge as a community about the best way to do that thing. There are probably people somewhere who are as into park benches as these guys are into coffee, and thanks to them the park benches are getting more and more comfy and beautifully designed and long-lasting, at least if you know where to go for really excellent park benches.
Data science: tools vs. craft
I’ve enjoyed how many people are reading the post I wrote about hiring a data scientist for a business. It’s been interesting to see how people react to it. One consistent reaction is that I’m just saying that a data scientist needs to know undergraduate level statistics.
On some level this is true: undergrad statistics majors can learn everything they need to know to become data scientists, especially if they also take some computer science classes. But I would add that it’s really not about familiarity with a specific set of tools that defines a data scientist. Rather, it’s about being a craftsperson (and a salesman) with those tools.
To set up an analogy: I’m not a chef because I know about casserole dishes.
By the way, I’m not trying to make it sound super hard and impenetrable. First of all I hate it when people do that and second of all it’s not at all impenetrable as a field. In fact I’d say it the other way: I’d prefer smart nerdy people to think they could become data scientists even without a degree in statistics, because after all basic statistics is pretty easy to pick up. In fact I’ve never studied statistics in school.
To get to the heart of the matter, it’s more about what a data scientist does with their sometimes basic tools than what the tools are. In my experience the real challenges are things like
- Defining the question in the first place: are we asking the question right? Is an answer to this question going to help our business? Or should we be asking another question?
- Once we have defined the question, we are dealing with issues like dirty data, too little data, too much data, data that’s not at all normally distributed, or that is only a proxy to our actual problem.
- Once we manhandle the data into a workable form, we encounter questions like, is that signal or noise? Are the errorbars bigger than the signal? How many more weeks or months of data collection will we need to go through before we trust this signal enough to bet the business on it?
- Then of course we go back to: should we have asked a different question that would have not been as perfect an answer but would have definitely given us an answer?
In other words, once we boil something down to a question in statistics it’s kind of a breeze. Even so, nothing is ever as standard as you would actually find in a stats class – the chances of being asked a question similar to a stats class is zero. You always need to dig deeply enough into your data and the relevant statistics to understand what the basic goal of that t-test or statistic was and modify the standard methodology so that it’s appropriate to your problem.
My advice to the business people is to get someone who is really freaking smart and who has also demonstrated the ability to work independently and creatively, and who is very good at communicating. And now that I’ve written the above issues down, I realize that another crucial aspect to the job of the data scientist is the ability to create methodology on the spot and argue persuasively that it is kosher.
A useful thing for this last part is to have broad knowledge of the standard methods and to be able to hack together a bit of the relevant part of each; this requires lots of reading of textbooks and research papers. Next, the data scientist has to actually understand it sufficiently to implement it in code. In fact the data scientist should try a bunch of things, to see what is more convincing and what is easier to explain. Finally, the data scientist has to sell it to everyone else.
Come to think of it the same can be said about being a quant at a hedge fund. Since there’s money on the line, you can be sure that management wants you to be able to defend your methodology down to the tiniest detail (yes, I do think that being a quant at a hedge fund is a form of a data science job, and this guy woman agrees with me).
I would argue that an undergrad education probably doesn’t give enough perspective to do all of this, even though the basic mathematical tools are there. You need to be comfortable building things from scratch and dealing with people in intense situations. I’m not sure how to train someone for the latter, but for the former a Ph.D. can be a good sign, or any person that’s taken on a creative project and really made something is good too. They should also be super quantitative, but not necessarily a statistician.
“Our organization does not reward failure” – Koch
You have to check out this Bloomberg article about Koch Industries. Although it rambles a bit at times, it’s absolutely mesmerizing and horrible. Here’s the main premise, which bizarrely comes near the end of the article:
For six decades around the world, Koch Industries has blazed a path to riches — in part, by making illicit payments to win contracts, trading with a terrorist state, fixing prices, neglecting safety and ignoring environmental regulations. At the same time, Charles and David Koch have promoted a form of government that interferes less with company actions.
The phrase “our organization does not reward failure” comes from a book in 2007 written by one of the Koch brothers where he somehow fails to discuss a pipeline explosion that had recently killed two teenagers in Oklahoma:
The 570-mile-long pipeline carrying liquid butane from Medford, Oklahoma, to Mont Belvieu, Texas had corroded so badly that one expert, Edward Ziegler, likened it to Swiss cheese. The company didn’t give 40 of the 45 families near the explosion site — including the Smalley and Stone families — any information about what to do in case of an emergency, the NTSB wrote.
The article is complete, in that it even has a spiteful twin brother of one of the Koch brothers appearing to give away his brothers for stealing.
The Senate held hearings in May 1989 after Bill Koch, David Koch’s twin brother, told a U.S. Senate special committee on investigations that Koch Industries was stealing oil on American Indian reservations, cheating the federal government of royalties.
The investigators caught Koch Oil’s employees falsifying records so that the company would get more crude than it paid for, shortchanging Indian families, Elroy said. Koch’s records showed that the company took 1.95 million barrels of oil it didn’t pay for from 1986 to 1988, according to data compiled by the Senate.
One thing that fascinating to me is that there are two whistle-blowers in the story, both women who were essentially fired for having ethics (one reported on bribes and the other on toxic gas dumping, both sued the company after leaving). Doesn’t it seem like women are more often whistle-blowers? Especially if you consider the fact that high ranking people in these kinds of companies with access to the kind of information that whistle-blowers need to uncover fraud are typically men.
These Koch brothers are seriously despicable, and really all they seem to care about is the ability to make money without having to worry about rules, even basic rules of morality. They currently largely bankroll the Tea Party. It’s a scary thought that I could someday live in a country whose president owes a favor to these guys.
First day of calculus class
Last night I had dinner with a friend who is a post-doc in math, and she was mentioning that her students, especially in the lower-level calculus classes, generally don’t refer to her as “professor.” This would be fine since she’s not yet a professor, but she also mentioned they do refer to graduate student men in the same department as professor. She’s a young looking woman, and my guess is they simply don’t know better. Here’s what my advice to her was (and as usual, I’d give this advice to both men and women).
On the first day of class, introduce yourself and put your name on the board, explain when and where you got a Ph.D., what your field of research is, what your current job is, as well as office hours and homework policies. In addition, wear a button-down shirt that first day of class. It’s kind of ridiculous but it works, in the sense that the students will be more impressed with you, which translates into them behaving more respectfully.
Moreover, it’s totally appropriate and not manipulative to explain your credentials. It’s probably most important for calculus, because generally those students don’t really want to be there, at least not all of them. Upper level classes contain students who are more psyched about math and eager to like their professors. I say this partly from experience, partly from talking to other people about their experiences, and partly via information I glean from the student evaluations I’ve read.
Speaking of evaluations, at some point I want to write about the noise that come from calculus evaluations, because that may as well be an entire subfield of statistics in itself. For example, I think there may be more variation depending on semester than depending on professor, due to the way kids take calculus in high school. In general it’s really hard to infer how good a job you did teaching based on calculus evaluations.
However, there is some signal. I remember reading about a study that said when some guy who was teaching two sections was introduced the first day in one of the sections by a distinguished-looking professor who went on about the instructor’s credentials, that class had much better end-of-semester evaluations, even though the content of the two sections was identical. Even more evidence that you should formally introduce yourself, if not bring in a friend for the job.
Is the Onion actually America’s finest news source?
Have you noticed that some of the best reporting nowadays is satire? I feel like I learn most of the news I know from reading newspapers online, but I’m unusual: most people, especially young people, seem to get their news from the Daily Show and Colbert, as well as the Onion.
And it’s not just the writing, which is generally excellent and intelligent, as well as hilariously entertaining. It’s the topics themselves that are incisive and that get to the heart of what’s ridiculous or dysfunctional about our financial, cultural, and political systems.
What if we started a newspaper that took its cues directly from the Onion, and rewrote every article in a straight, anti-satire way? Would that newspaper be better or worse than the New York Times? I claim it would be more bizarre but also more relevant to our lives. It may miss entire swaths of typical news coverage but then again it would cover certain things in a more holistic light.
For example, what would a anti-satirist do with this article? Or this one? Just having someone seriously articulate why these things are so funny would be a good start, and an article I’d love to read.




{kind=link}