Archive
Aunt Pythia’s advice – sex edition
I’m afraid the concept of “giving advice” has been taken down a notch this week, considering how many ridiculous examples we have right now of people are giving advice as a way of congratulating themselves. It’s enough to confuse an advice columnist and put her into an existential angst spiral.
However, it’s not going to stop Aunt Pythia!
At most it will divert her to talk exclusively about something that nobody doesn’t love reading, namely sex. It’s a tried and true last resort of the advice columnist: let out the dirty laundry of yourself and everybody who dares bare themselves to you. I don’t see where this could go wrong.
Having said that, I’m not promising to be exclusive like this every week. I’ll probably cheat on you people every now and then and answer questions about how to get a job in data science or something. Also, my guest advice columnist next week, Aunt Orthoptera, will answer whatever questions she chooses (from a grasshopper’s perspective, of course).
By the way, if you don’t know what you’re in for, go here for past advice columns and here for an explanation of the name Pythia. Most importantly,
Please submit your smutty sex questions at the bottom of this column!
——
Dear Aunt Pythia,
How can I make compatible my sexual attraction for dominant women and my fear of being controlled?
Horny in Montana
Dear Horny,
Let me start out by admitting honestly that I have no direct advice for you. I just don’t know how to resolve issues surrounding sexuality, and I’d be deeply skeptical of anybody who claims to be able to do so.
Sexuality is a crazy thing, a super entrenched and powerful force, and there’s just nothing and nobody who can change it for you once it’s on a roll. Sometimes people seem to be able to change it for themselves, mainly by repressing it, but that’s always so amazing, not to mention deeply threatening, I wouldn’t proffer it as advice.
I sometimes think of my own sexuality as having a personality, and an agenda, that I can only observe, not control. The best case scenario for me has evolved into trying not to be too judgmental of it and to and make sure nothing unsafe happens. I’m like a benign referee of my own dirty urges.
Having said that, I have two pieces of indirect advice for you. First, it would probably be useful to separate sex play with “normal life” and realize that you can ask someone to dominate you in the bedroom, and even pretend to control you, and even actually control you, whilst remaining nothing like that outside the bedroom. That’s totally normal and common and it might help in the sense that you’d actually have control over being controlled: it would happen if and when you wanted it.
The second piece of advice I have it totally selfish, namely, please don’t blame the women of the world for your unresolved problems. Just because you’re both attracted and afraid of these dominant women doesn’t mean they have a responsibility to deal with your confusion and frustration. Don’t take it out on them.
I hope that helps,
Aunt Pythia
——
Dear Aunt Pythia,
What would you say to a woman who told you that she is not able to make a commitment to anyone because she regularly finds herself in search of romance (not originating from sexual desires) with other people? Do you think this is a common behavior?
Itchy Litchi
Dear Itchy,
There are three stages of understanding in this story, at least for me.
First, you know yourself (I’ll refer to “you” even though you might have been asking on behalf of someone else) pretty well if you avoid commitment based on a theoretical understanding of your roaming eye. Most people I know throw themselves into commitment in spite of really good evidence that they won’t be able to sustain it, due to their cognitive biases.
Second, you claim your romantic urges for other people are not sexual. Theoretically this may be true, but in my experience romantic urges are always sexual if you probe deep enough or if they get strong enough. So either I’m a sex maniac (possible) or else you’re in denial about those nonsexual romantic urges.
Third, let’s put the above two together: A) you know yourself deeply, and B) you’re in total denial. The second conclusion makes me rethink the first, honestly, and I come to the conclusion that the first conclusion was wrong. You aren’t avoiding commitment because you know yourself so well, but rather because you’re avoiding commitment for some reason. Maybe you’re afraid of commitment? Maybe you’re afraid of sexual urges, which is why you both avoid commitment and avoid admitting your romantic urges are sexual?
Finally, if this question was actually written by, say, a man who wanted to understand the reasoning a woman gave him for why she couldn’t commit to him: she just wasn’t that into you. And yes that’s a very common behavior.
I hope that helps!
Auntie P
——
Dear Aunt Pythia,
I just studied the “Authentic Women’s Penis Size Preference Chart” (I say “studied” because I need to convert everything to metric units to make any sense of it) and, while – unlike many men, I am told – I am not too concerned about length, I feel that the ideal circumference IS REALLY BIG, at least for a man’s penis. Is this for real? Are women looking all their life for that eluding ideal-sized penis or am I just unlucky?
Concerned Reader
Dear Concerned,
Once again here’s the chart for the readers who missed it last time:

To answer your primary question, it’s not the length, it’s the girth. A truer statement has never been said. Of course, there are exceptions to that rule, namely if the length is truly miniscule.
Now, I do have some comforting words for you, you’ll be happy to know. Namely, my guess is that women responding to this very scientific poll had a biased measurement error. Namely, they didn’t have (probably) an erect penis handy and a flexible measuring tape as well, by their side, whilst answering the poll (apologies to the women who did!).
So what they did is they eyeballed the “circumference” measurement by imaging holding a penis in their hand like an OK sign:

And then, since it’s hard to measure a circle, they then straightened out their fingers. The reason this is so biased is that your fingers and thumb are actually quite a bit longer once you’ve stopped making the OK sign.
There may be a measurement bias of up to 50% on this. Probably not, but I’m trying to make you feel better.
I hope that helps!
Aunt Pythia
——
Please please please submit questions! Especially if they are grasshopper-related!
Data audits and data strategies
There are lots of start-up companies out there that want to have a data team, because they heard somewhere that they should leverage big data, but they don’t know what it really means, what they can expect from such a team, or how to get started. They also don’t really know how to hire qualified people, or what qualifications to look for.
Finally, they often don’t know what kinds of questions are answerable through data, nor what data they should be collecting to answer those questions. So even if they did manage to hire a data scientist or a data team, those guys might be literally sitting on their hands for six months until they have enough data to start work.
It’s a common situation and could end up a big waste time and money. What these companies need is something I like to call a “data audit” followed by a “data strategy”.
Data Audit
First thing’s first. Do you actually need a data team? Is your company a data science company or is it a traditional-style company that happens to collect data? It would be a waste of resources to form a data team you don’t need. There’s no reason every single company needs to consider itself part of the big data revolution just to be cool.
Here’s how you tell. Let’s say that, as of now, you’re using incoming data to monitor and report on what’s happening with the business and to keep tabs on various indicators to make sure things aren’t going to hell. Absolutely every company should do this, but it honestly could be set up by a good data analyst working closely with the end-users, i.e. the business peeps.
What are the high-level goals of using data in the business? In particular, is there a way that, if you could really know how customers or clients were interacting with your product, that you would change the product to respond to the data? Because that feedback loop is the hallmark of a true data science engine (versus data analytics).
Here are some extreme examples to give you an idea of what I’m talking about. If you make shoes, then you need data to see how sales are and which shoes are getting sold faster so you can kick up production in certain areas. You need to see how sales are seasonal so you know to stop making quite so many shoes at a certain point in the deep of winter. But that’s about it, and you should be able to make do with data analysis.
If, on the other hand, you are building a recommendation engine, say for music, then you need to constantly refresh and improve your recommendation model. Your model is your product, and you need a data team.
Not all examples are this easy. Sometimes you can use new kinds of data models to improve your product even if it seems somewhat traditional, depending on how much data you are able to collect about how your clients use your product. It all depends on what kinds of questions you are asking and what data you have access to. Of course, you might want to go out and collect data that you hadn’t bothered to do before, which could bring you from the first category to the second.
Say you decide you really are a data science company, or want to be one. What’s next?
Pose a bunch of questions you think you’ll need to answer and a bunch of data you think should be useful to answer them.
The heart of a data audit is a (preliminary) plan for choosing, collecting, and storing data, as well as figuring out the initial shape of the data pipeline and infrastructure. Do you store data in the cloud? Is it unstructured or do you set up some overnight jobs to put stuff into some type of database? Do you aggregate data and throw some stuff away, or do you keep absolutely everything?
The most important issue above is whether you’re collecting enough data. Truth be told, you could probably throw it all into an unstructured pile on S3 for now and figure out pipelines later. It might not be the best way to do it but if you are short for time and attention, it’s possible, and storage is cheap. But make sure you’re collecting the right stuff!
You’d be surprised how many startups want to ask good questions about their customers to improve their product, and have gone to some trouble to figure out what those questions are, but don’t bother to collect the relevant information. They might do things like count the number of users, or collect a timestamp for whenever a user logs in, but they don’t actually keep track of the interaction. It’s essential that you collect pertinent information if you want to use this data to check things are working or to predict people’s desires or needs.
So if you think customers might be all ditching your site at critical moments, then definitely tag their departure as well as their arrival, and keep track of where they were and what they were doing when they bailed.
Note I’m not necessarily being creepy here. You definitely want to know how people interact with your product and your site, and it doesn’t need to be personal information you’re collecting about your users. It could be kept aggregate. You could find out that 45% of people leave your site when you ask them for their phone number, and then you might decide it’s not worth it to do that.
Speaking of creepy, another critical thing to consider during your data audit is privacy controls and encryption methods. Are you saving data legally? Are you protecting it legally? Are you informing your users appropriately about how and what data will be stored? Are you planning to remain consistent with your stated privacy policy? Do you respect people’s “Do Not Track” option?
At the end of a data audit, you might still have a vague idea of what exactly you can do with your data, but you should have a bunch of possible ideas, as well as guesses at what kind of attributes would contribute to the kind of behavior you’re considering tracking.
Then, after you start collecting high-quality data and figuring out the basic questions you care about, you will probably have to wait a few weeks or months to start training and implementing your models. This is a good time to make sure your data infrastructure is in place and doesn’t have major bugs.
Data Strategy
Ok, now you’ve collected lots of data and you also have a bunch of questions you think may be answerable. It’s time to prioritize your questions and form a plan. For each question on your list, you’ll need to think about the following issues:
- Is it a monitor or an algorithm?
- Is it short-term, one-time analysis or should you set it up as a dashboard?
- How much data will you need to train the model?
- What is your expectation of the signal in the data you’re collecting?
- How useful will the results of the model be considering the range of signal and the quality of the answer?
- Do you need to go find proxy data? Should you start now?
- Which algorithms should you consider?
- What’s your evaluation method?
- Is it scalable?
- Can you do a baby version first or does it only make sense to go deep?
- Can you do a simpler version of it that’s much cheaper to build?
- How long will it probably take to train?
- How fast can it update?
- Will it be a pain to integrate it to the realtime system?
- What are the costs if it doesn’t work?
- What are the costs of not trying it? What else could you be doing with that time?
- How is the feedback loop expected to work?
- What is the impact of this model on the users?
- What is the impact of this model on the world at large? This is especially important if you’re creepy. Don’t be creepy.
Also, you need a team to build your models. How do you hire? Who do you hire? Some of these answers depend on your above plan. If there’s a lot of realtime updating for your models you’ll need more data engineers and fewer pure modelers. If you need excellent-looking results from your work you’ll need more data viz nerds.
You should consider hiring a consultant just to interview for you. It’s really hard to interview for data scientists if nobody is an expert in data science, and you might end up with someone who knows how to sounds smart but can’t build anything. Or you could end up with someone who can build anything but has no idea what their choices really mean.
The ultimate goal at the end of a data audit and strategy is to end up with a reasonable expectation of what having a data science team will accomplish, how long it will take, how deep an investment it is, and how to do it.
“The problem here is not the message. The problem is the messenger.”
Today’s post is basically going to consist of me wishing I’d written this Gawker piece which was actually written by Hamilton Nolan and was entitled “It Would Be Great if Millionaires Would Not Lecture Us on ‘Living With Less’”.
To enjoy it as much as I did, you’d have to read this New York Times Opinion piece first, in which Graham Hill, who made a bajillion dollars in the dot com era, realizes he had too much stuff and now has less stuff and is telling us how great it is. Most cloying line: “the things I consumed ended up consuming me.”
At the risk of quoting Nolan’s entire article (the title of my post is his), let me start you with this:
There is something about achieving great financial success that seduces people into believing that they are life coaches. This problem seems particularly endemic to the tech millionaire set. You are not simply Some Fucking Guy Who Sold Your Internet Company For a Lot of Money; you are a lifestyle guru, with many important and penetrating insight about How to Live that must be shared with the common people.
We would humbly request that this stop.
I’ll skip over some parts and get to where he talks about Amanda Palmer:
The problem here is not the message. The problem is the messenger. More specifically, it is the messenger using his own life as supporting evidence for the message. Were Graham Hill to simply write a fact-based essay arguing that Americans should cut down on material possessions in order to save the environment and gain peace of mind, he would doubtless hear a chorus of support. But for Graham Hill, a young millionaire who was fortunate enough to sell his “pre-Netscape browser” at the high point of the internet bubble, to say to the average American, “My journey through the perils of great wealth has bestowed me with wisdom that is directly applicable to you” is simply false. It is no wonder that Hill loved the recent TED talk by millionaire musician Amanda Palmer, in which she argued that it was perfectly fair for her to, for example, accept a free night of lodging in the home of poor Honduran immigrants and not pay them for it, because the beauty of her music is payment enough. Both are insulated enough from the realities of personal finance to forget about them entirely.
True! And I’d add more in the Amanda Palmer case. She and I went to the same high school and I have known her since she was in 7th grade.
I’ll tell you what. She’s not your average artist. She’s hugely exhibitionist. This has worked great for her, but is not a typical artistic personality. In fact she’s essentially a cult leader. So yes, when you’re an artist/ cult leader, it makes sense to “let your fans pay you”. But if you’re a typical starving, introverted, sensitive soul, then not so much. How can she speak for all artists and ask them to do stuff just like her? Or rather, why does she think it would scale?
Mind you, I’m guilty of this problem too. When I give advice, which I do all the time, I pretty much always tell people what works for me. But my evidence that the same approach would work for them is slight.
That begs the question, how do we do better than this? How do we tailor our advice to make it useful?
I kind of hate TED talks
The good
There are good things about TED talks. It’s nice to have a thoughtful articulate person saying something a little bit new and a little bit different. OK I’m done.
The annoying
Then there are annoying things about TED talks. People are so ridiculously polished. No idea is that perfect! Rumor has it that, after getting professionally trained for their TED performances, the producers then remove all the “umms” and awkward silences to make it even more perfect. Yuck.
Here’s one way to think about it: TED talks aren’t as good as blogs because they’re not interactive – the audience is expected to receive and not talk back. That’s why I prefer to blog in my underwear and bathrobe, imagining my friends on their living room sofas, also wearing pajamas, and objecting to my stupidity. And that’s why I like the feedback and the comments. It makes my ideas better.
At the same time, TED talks are not as deep as books, where you have enough time and space to actually think through an argument. How could you really develop a deep thought in 20 minutes? You just can’t.
Instead, you have a manipulation of the past which often result in simulated emotional responses, much like how the soundtrack to Amy Tan’s “The Joy Luck Club” makes me cry every time I hear it, no matter what emotional state I’m actually in.
The essence of what’s annoying about TED talks is perfectly parodied by Onion Talks, especially this one:
The evil
But what I really hate about TED talks is the curating of ideas that it represents. I realize that any gatekeeper will do this, but I’m particularly concerned about the TED byline, “Ideas Worth Spreading”. According to whom?
Who gets invited to those things? Whose ideas are interesting but non-threatening enough for the TED audience?
And how often do other, rawer ideas get ignored? How appealing do I have to make my idea to rich people in order to be an insider in this mini self-congratulatory universe?
Here’s an example of what I’m talking about written by a woman who was uninvited to give a TED talk under suspicious circumstances (with a follow-up here). Granted, it’s a TEDx situation, but it’s the same problem. The paragraph I worry about most:
Looking back, I must admit that upon learning of this invitation some of my colleagues and I questioned TEDx Manhattan’s commitment to serving as a platform for looking at our food system from a non-privileged perspective. Changing the Way We Eat is not a venue for the common person. The website makes no mention of available scholarships to enable low-income people or students to attend the pricey one day conference. Not only must attendees pay $135 for the privilege of sitting and listening, they also have to apply, explaining why they deserve to be part of the audience and then hope to be selected! Unless the Glynwood Institute does real serious targeted outreach to communities of color (which I haven’t seen and was the primary purpose of my screening party), their set up is going to result in the exclusion of low-income and people of color, regardless of whether it is intentional. I received feedback from a past attendee that presenters referenced poor people and people of color only as being the recipients of charity or service. I think Changing the Way We Eat needed to hear my voice in order to change the way the mainstream food movement thinks about poverty, food access, hunger, and food system change.
Black Scholes and the normal distribution
There have been lots of comments and confusion, especially in this post, over what people in finance do or do not assume about how the markets work. I wanted to dispel some myths (at the risk of creating more).
First, there’s a big difference between quantitative trading and quantitative risk. And there may be a bunch of other categories that also exist, but I’ve only worked in those two arenas.
Markets are not efficient
In quantitative trading, nobody really thinks that “markets are efficient.” That’s kind of ridiculous, since then what would be the point of trying to make money through trading? We essentially make money because they aren’t. But of course that’s not to say they are entirely inefficient. Some approaches to removing inefficiency, and some markets, are easier than others. There can be entire markets that are so old and well-combed-over that the inefficiencies (that people have thought of) have been more or less removed and so, to make money, you have to be more thoughtful. A better way to say this is that the inefficiencies that are left are smaller than the transaction costs that would be required to remove them.
It’s not clear where “removing inefficiency” ends and where a different kind of trading begins, by the way. In some sense all algorithmic trades that work for any amount of time can be thought of as removing inefficiency, but then it becomes a useless concept.
Also, you can see from the above that traders have a vested interest to introduce new kinds of markets to the system, because new markets have new inefficiencies that can be picked off.
This kind of trading is very specific to a certain kind of time horizon as well. Traders and their algorithms typically want to make money in the average year. If there’s an inefficiency with a time horizon of 30 years it may still exist but few people are patient enough for it (I should add that we also probably don’t have good enough evidence that they’d work, considering how quickly the markets change). Indeed the average quant shop is going in the opposite direction, of high speed trading, for that very reason, to find the time horizon at which there are still obvious inefficiencies.
Black-Scholes
A long long time ago, before Black Monday in 1987, people didn’t know how to price options. Then Black-Scholes came out and traders started using the Black-Scholes (BS) formula and it worked pretty well, until Black Monday came along and people suddenly realized the assumptions in BS were ridiculous. Ever since then people have adjusted the BS formula. Everyone.
There are lots of ways to think about how to adjust the formula, but a very common one is through the volatility smile. This allows us to remove the BS assumption of constant volatility (of the underlying stock) and replace it with whatever inferred volatility is actually traded on in the market for that strike price and that maturity. As this commenter mentioned, the BS formula is still used here as a convenient reference to do this calculation. If you extend your consideration to any maturity and any strike price (for the same underlying stock or thingy) then you get a volatility surface by the same reasoning.
Two things to mention. First, you can think of the volatility smile/ surface as adjusting the assumption of constant volatility, but you can also ascribe to it an adjustment of the assumption of a normal distribution of the underlying stock. There’s really no way to extricate those two assumptions, but you can convince yourself of this by a thought experiment: if the volatility stays fixed but the presumed shape of the distribution of the stocks gets fatter-tailed, for example, then option prices (for options that are far from the current price) will change, which will in turn change the implied volatility according to the market (i.e. the smile will deepen). In other words, the smile adjusts for more than one assumption.
The other thing to mention: although we’ve done a relatively good job adjusting to market reality when pricing an option, when we apply our current risk measures like Value-at-Risk (VaR) to options, we still assume a normal distribution of risk factors (one of the risk factors, if we were pricing options, would be the implied volatility). So in other words, we might have a pretty good view of current prices, but it’s not at all clear we know how to make reasonable scenarios of future pricing shifts.
Ultimately, this assumption of normal distributions of risk factors in calculating VaR is actually pretty important in terms of our view of systemic risks. We do it out of computational convenience, by the way. That and because when we use fatter-tailed assumptions, people don’t like the answer.
Team Turnstile: how do NYC neighborhoods recover from extreme weather events?
I wanted to give you the low-down on a data hackathon I participated in this weekend, which was sponsored by the NYU Institute for Public Knowledge on the topic of climate change and social information. We were assigned teams and given a very broad mandate. We had only 24 hours to do the work, so it had to be simple.
Our team consisted of Venky Kannan, Tom Levine, Eric Schles, Aaron Schumacher, Laura Noren, Stephen Fybish, and me.
We decided to think about the effects of super storms on different neighborhoods. In particular, to measure the recovery time of the subway ridership in various neighborhoods using census information. Our project was inspired by this “nofarehikes” map of New York which tries to measure the impact of a fare hike on the different parts of New York. Here’s a copy of our final slides.
Also, it’s not directly related to climate change, but rather rests on the assumption that with climate change comes more frequent extreme weather events, which seems to be an existing myth (please tell me if the evidence is or isn’t there for that myth).
We used three data sets: subway ridership by turnstile, which only exists since May 2010, the census of 2010 (which is kind of out of date but things don’t change that quickly) and daily weather observations from NOAA.
Using the weather map and relying on some formal definitions while making up some others, we came up with a timeline of extreme weather events:
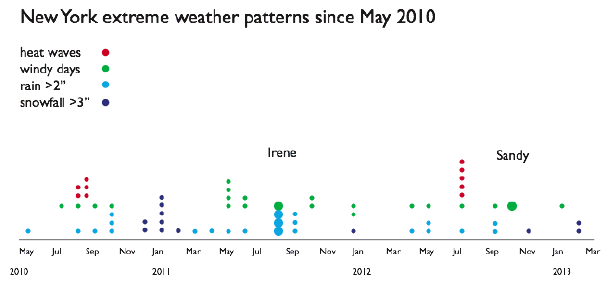
Then we looked at subway daily ridership to see the effect of the storms or the recovery from the storms:
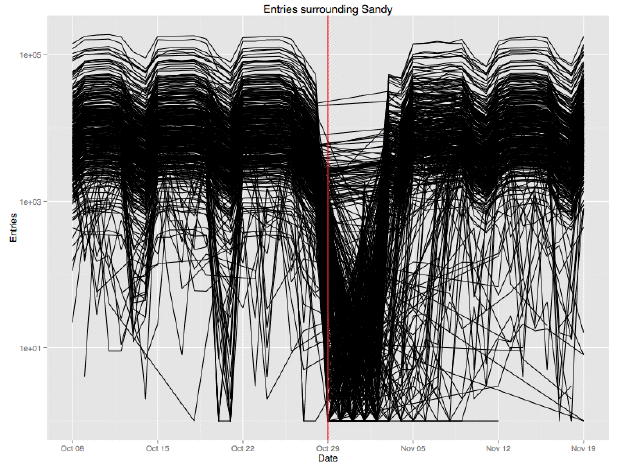
 We broke it down to individual stations. Here’s a closeup around Sandy:
We broke it down to individual stations. Here’s a closeup around Sandy:
Then we used the census tracts to understand wealth in New York:
 And of course we had to know which subway stations were in which census tracts. This isn’t perfect because we didn’t have time to assign “empty” census tracts to some nearby subway station. There are on the order of 2,000 census tracts but only on the order of 800 subway stations. But again, 24 hours isn’t alot of time, even to build clustering algorithms.
And of course we had to know which subway stations were in which census tracts. This isn’t perfect because we didn’t have time to assign “empty” census tracts to some nearby subway station. There are on the order of 2,000 census tracts but only on the order of 800 subway stations. But again, 24 hours isn’t alot of time, even to build clustering algorithms.
Finally, we attempted to put the data together to measure which neighborhoods have longer-than-expected recovery times after extreme weather events. This is our picture:

Interestingly, it looks like the neighborhoods of Manhattan are most impacted by severe weather events, which is not in line with our prior [Update: I don’t think we actually computed the impact on a given resident, but rather just the overall change in rate of ridership versus normal. An impact analysis would take into account the relative wealth of the neighborhoods and would probably look very different].
There are tons of caveats, I’ll mention only a few here:
- We didn’t have time to measure the extent to which the recovery time took longer because the subway stopped versus other reasons people might not sure the subway. But our data is good enough to do this.
- Our data might have been overwhelmingly biased by Sandy. We’d really like to do this with much longer-term data, but the granular subway ridership data has not been available for long. But the good news is we can do this from now on.
- We didn’t have bus data at the same level, which is a huge part of whether someone can get to work, especially in the outer boroughs. This would have been great and would have given us a clearer picture.
- When someone can’t get to work, do they take a car service? How much does that cost? We’d love to have gotten our hands on the alternative ways people got to work and how that would impact them.
- In general we’d have like to measure the impact relative to their median salary.
- We would also have loved to have measured the extent to which each neighborhood consisted of salary versus hourly wage earners to further understand how a loss of transportation would translate into an impact on income.
Modeling fraud in the financial system
Today we have a guest post by Dan Tedder. Actually it’s a letter he sent me after listening to my EconTalk podcast with Russ Roberts which he kindly agreed to let me post. Dan’s bio is below the letter.
I think this letter is profound (although I don’t completely agree about the Markov stuff), because it points out something that I see as a commonly held blindspot by people who think about regulation and modeling. Namely, that any systemic risk model of the financial system that doesn’t take account of lying isn’t worth the memory it takes up on a computer.
That brings us to the following question: can we incorporate lies into models? Can we anticipate and model fraud itself, in addition to the underlying system? Or do we give up on models and rely on skeptical people to ferret out lies? Or possibly some hybrid?
——
Hi Cathy,
I really liked your interview, and I think you are right on in pointing to a lack of ethics. I would say further that what we need is rigorous honesty in all aspects of the financial system. I agree with your objections to conflicts of interest. Allowing such conflicts to exist demonstrates a lack of rigorous honesty on the part of the participants. In my opinion a lot of bankers and folks on Wall Street should be headed to jail. The inability of the SEC to file charges and prosecute them further demonstrates the lack of honesty and character in the financial system and the government. So why am I telling you things you already know?
My father was a successful businessman. Years ago I was invited to invest in an ice cream franchise by another faculty member. I spent several days developing models using Excel. Finally, I decided to talk to my father. I called him and he immediately asked me to tell him about the present owners and their accounting. I told him the husband was in jail and accounting was five years behind. Further, his wife was probably taking money out of the till.
He stopped me right there, and pointed out that I needed to look no further. The present owners were not honest and therefore the opportunity was too risky. No telling what liabilities they had incurred and passed on to the franchise. I felt like an idiot. My modeling was a total waste of time because it assumed the present owners were honest. In fact, they were dishonest and no defensible model could be constructed based upon their accounting or lack thereof.
I think the complexity of our present financial problems will largely disappear if we try to focus more on the obvious. First, it is obvious that bankers, accountants, modelers, and other participants must be rigorously honest. Second, George Box, a statistician at the University of Wisconsin, studied the stock market and found through time series analysis that stock market prices are Markov processes. So in modeling stock prices we need only worry about today and tomorrow. The best indicator of tomorrow’s price is today’s price. The best indicator of what will happen tomorrow is where we are today, and probably our models of the larger process should also be Markovian. Third, apply the KISS method, “Keep it simple, stupid.” Instead of worrying about the mathematical model, worry about the honesty of the participants. The financial system cannot tolerate dishonesty. Making sure the bankers are honest will go a long way toward balancing the books.
Regards, Dan
——
Daniel William Tedder is Associate Professor Emeritus, School of Chemical and Biomolecular Engineering, and Adjunct Professor, School of Mechanical Engineering, both at the Georgia Institute of Technology. He attended Kenyon College and received a Bachelor’s in Chemical Engineering at the Georgia Institute of Technology. He obtained MS and PhD degrees in Chemical Engineering at the University of Wisconsin, Madison. He was a staff engineer in the Chemical Technology Division of the Oak Ridge National Laboratory before joining the faculty at Georgia Tech. He served as an independent technical reviewer at the Nuclear Regulatory Commission after retiring from Georgia Tech. He has numerous publications, has edited 11 books, and has authored one book, Preliminary Chemical Process Design and Economics, which is available from Amazon. He is an expert in chemical separations and in actinide partitioning, an advanced method for radioactive waste management.
Aunt Pythia’s advice
You’ve stumbled upon yet another week’s worth of worthy questions that will be awkwardly sidestepped by mathbabe’s alter ego Aunt Pythia.
By the way, if you don’t know what you’re in for, go here for past advice columns and here for an explanation of the name Pythia. Most importantly,
Please submit your question at the bottom of this column!
I’ve officially run out of questions so this is for real.
Please come up with something before I do.
——
Dear Aunt Pythia,
I just moved to NYC from a small university town, and I’m finding it much harder to meet nerd girls. Most of the nerd hangout spots that I’ve found are male dominated, and I meet mostly artists at the bars and coffee shops. Do you have any suggestions beyond trolling the nearest physics department?
Nice, Easygoing Roamer Drawn Swiftly Around Real, Engaging Hackers On Town
Dear NERDSAREHOT,
Let me suggest you enroll in Meetup yesterday and sign yourself up for all the nerd meetups you can find. There are plenty of cute nerd girls who go to those, and it’s a perfect situation for you to ask someone to have a beer afterwards. Also consider getting involved in weekend hackathons, which attract lots of nerd girls as well.
By the way, these events are still male dominated, but that’s a good thing. Nerd girls should have their pick. It’s one of the many advantages of being a nerd girl and it aint going away.
Aunt Pythia
——
Dear Aunt Pythia,
I recently got a job as a data scientist, and I’m feeling like my stats skills are woefully inadequate. I have a master’s in pure math and I work as a programmer, but I’ve never taken a statistics class. What books would you recommend I read to get up to speed on statistics? I’m looking for something with examples that’s applicable to my work (not too much definition/theorem/proof), but that isn’t scared of the math.
Regretting Spurning Statistics
Dear RSS,
Congratulations! Can you write back and tell everyone how you got the job? Guest post?
Honestly I learned stats (the stuff I know anyway) by reading wikipedia extensively. It’s surprisingly good. Also, the book I’m writing with Rachel Schutt will contain some good explanations of how stats is used in data science, thanks of course to Rachel, not me. She’s working on the causality chapter right now.
In general my advice to you is, draw lots of pictures, including a histogram as well as a time-value scatter plot of every data set you use, and every data set you generate as well. You’d be surprised by how quickly you learn the statistics that is relevant to your dataset when you’re intimately familiar with its properties.
Good luck!
Aunt Pythia
——
Dear Aunt Pythia,
I have been reading up on regression to the mean originally as described by Galton. He notes that the sons’ height data had reduced variance versus the height data of the preceding fathers’ generation. If this is so, wouldn’t the grandsons’ generation have even more reduced variance in height compared with the 2nd generations’ height…and so on down the generation lineage. Therefore wouldn’t the variance in succeeding generations get narrower and narrower and approach some limit? Where am I going wrong with this, or am I misunderstanding something?
MeanIQ
Dear MeanIQ,
Thanks for bringing my attention to this, it’s clearly an important historical part of linear regression and I’d never heard of it.
You’re absolutely right to think that Galton was wrong. Galton’s working theory was that two people have children by averaging their characteristics, which is just not how genetics works (as we now know). Not only would what you say be true, that after a few generations everyone would be the exact same height, but we’d also see that, if you went backwards in time, there’d be people of arbitrary height, tall and short.
As for why he saw larger variance in older generations, my best guess is that he had a selection bias. Maybe the decreasing variance he observed was due to environmental factors such as the quality and size of the local food supply, where the “current” generation were localized (and so more consistent) but the “older” generation had come from various other places where they were either better fed or less well fed, which would lead to an increased variance.
There’s another totally different interpretation for the phrase “regression to the mean” which is also confusing though. Namely, the idea that if your first measurement of something is extreme, then your second measurement will tend to be less so. The problem with this is that you have to have a notion of “extreme” in the first place. And if you do, then it’s kind of obvious (and also kind of dumb).
Aunt Pythia
——
Dear Aunt Pythia,
Is the Mathbabe religious?
I really like the new mathbabe logo/marque. The typeface is totally flapper and I really like those bulbous upside down B’s, and the offsetting of the bottom text in order to give the text texture. But when I look at the symbolology of the whole logo/marque I can’t help but wonder if the Mathbabe is religious. The T looks like a deproportioned Greek cross, and the alpha above it suggests that there should be an omega below it somewhere. So clearly the new logo/marque has some Christian symbolology, and my eyes keep looking for more. Maybe the A’s are three sided figures that represent the Trinity, and the M represents a firmament that has fallen, and therefore symbolologizes our fallen state.
Anyway, it’s cool if you are religious, as lots of great mathematicians were devout people, and some were even priests, like Bayes. And if you’re not that’s cool too. I see you describe sex both profanely and sacredly, so I know you are a spiritual person. And it’s cool if you don’t want to answer either. I respect that religion is a personal matter. Just saw your new logo/marque and was wondering.
Semi-semiotic
Dear Semi-semiotic,
Honestly I have so little religious background that I am not even sure if you’re kidding (but the “symbolologizes” kind of gives you away).
For the record, my parents were atheists who made fun of me when I told them I believed in God in first grade (I think I learned about the idea of God from a babysitter). One of their favorite stories of my childhood is when my first grade teacher, a devout Catholic, called up my parents in alarm over my essay which said “I believe in God but please don’t tell my parents” and my mom was like, “Har har that’s a good one, thanks” and hung up on her. Not that my mom is a rude person, she isn’t.
Two more points: First, I plan to refer to myself in third person from now on as “The Mathbabe”, and second, when did I ever refer to sex sacredly? That’s bullshit. Blasphemy even.
Aunt Pythia
——
Please please please submit questions, thanks! I’m desperate!
Unintended Consequences of Journal Ranking
I just read this paper, written by Björn Brembs and Marcus Munafò and entitled “Deep Impact: Unintended consequences of journal rank”. It was recently posted on the Computer Science arXiv (h/t Jordan Ellenberg).
I’ll give you a rundown on what it says, but first I want to applaud the fact that it was written in the first place. We need more studies like this, which examine the feedback loop of modeling at a societal level. Indeed this should be an emerging scientific or statistical field of study in its own right, considering how many models are being set up and deployed on the general public.
Here’s the abstract:
Much has been said about the increasing bureaucracy in science, stifling innovation, hampering the creativity of researchers and incentivizing misconduct, even outright fraud. Many anecdotes have been recounted, observations described and conclusions drawn about the negative impact of impact assessment on scientists and science. However, few of these accounts have drawn their conclusions from data, and those that have typically relied on a few studies. In this review, we present the most recent and pertinent data on the consequences that our current scholarly communication system has had on various measures of scientific quality (such as utility/citations, methodological soundness, expert ratings and retractions). These data confirm previous suspicions: using journal rank as an assessment tool is bad scientific practice. Moreover, the data lead us to argue that any journal rank (not only the currently-favored Impact Factor) would have this negative impact. Therefore, we suggest that abandoning journals altogether, in favor of a library-based scholarly communication system, will ultimately be necessary. This new system will use modern information technology to vastly improve the filter, sort and discovery function of the current journal system.
The key points in the paper are as follows:
- There’s a growing importance of science and trust in science
- There’s also a growing rate (x20 from 2000 to 2010) of retractions, with scientific misconduct cases growing even faster to become the majority of retractions (to an overall rate of 0.02% of published papers)
- There’s a larger and growing “publication bias” problem – in other words, an increasing unreliability of published findings
- One problem: initial “strong effects” get published in high-ranking journal, but subsequent “weak results” (which are probably more reasonable) are published in low-ranking journals
- The formal “Impact Factor” (IF) metric for rank is highly correlated to “journal rank”, defined below.
- There’s a higher incidence of retraction in high-ranking (measured through “high IF”) journals.
- “A meta-analysis of genetic association studies provides evidence that the extent to which a study over-estimates the likely true effect size is positively correlated with the IF of the journal in which it is published”
- Can the higher retraction error in high-rank journal be explained by higher visibility of those journals? They think not. Journal rank is bad predictor for future citations for example. [mathbabe inserts her opinion: this part needs more argument.]
- “…only the most highly selective journals such as Nature and Science come out ahead over unselective preprint repositories such as ArXiv and RePEc”
- Are there other measures of excellence that would correlate with IF? Methodological soundness? Reproducibility? No: “In fact, the level of reproducibility was so low that no relationship between journal rank and reproducibility could be detected.
- More about Impact Factor: The IF is a metric for the number of citations to articles in a journal (the numerator), normalized by the number of articles in that journal (the denominator). Sounds good! But:
- For a given journal, IF is not calculated but is negotiated – the publisher can (and does) exclude certain articles (but not citations). Even retroactively!
- The IF is also not reproducible – errors are found and left unexplained.
- Finally, IF is likely skewed by the fat-tailedness of citations (certain articles get lots, most get few). Wouldn’t a more robust measure be given by the median?
Conclusion
- Journal rank is a weak to moderate predictor of scientific impact
- Journal rank is a moderate to strong predictor of both intentional and unintentional scientific unreliability
- Journal rank is expensive, delays science and frustrates researchers
- Journal rank as established by IF violates even the most basic scientific standards, but predicts subjective judgments of journal quality
Long-term Consequences
- “IF generates an illusion of exclusivity and prestige based on an assumption that it will predict subsequent impact, which is not supported by empirical data.”
- “Systemic pressures on the author, rather than increased scrutiny on the part of the reader, inflate the unreliability of much scientific research. Without reform of our publication system, the incentives associated with increased pressure to publish in high-ranking journals will continue to encourage scientiststo be less cautious in their conclusions (or worse), in an attempt to market their research to the top journals.”
- “It is conceivable that, for the last few decades, research institutions world-wide may have been hiring and promoting scientists who excel at marketing their work to top journals, but who are not necessarily equally good at conducting their research. Conversely, these institutions may have purged excellent scientists from their ranks, whose marketing skills did not meet institutional requirements. If this interpretation of the data is correct, we now have a generation of excellent marketers (possibly, but not necessarily also excellent scientists) as the leading figures of the scientific enterprise, constituting another potentially major contributing factor to the rise in retractions. This generation is now in charge of training the next generation of scientists, with all the foreseeable consequences for the reliability of scientific publications in the future.
The authors suggest that we need a new kind of publishing platform. I wonder what they’d think of the Episciences Project.
Poseurs should not own the backlash against data science poseurs
I’ve noticed a recent trend in coverage of data science. Namely, there’s backlash against the hype and the over-promising, intentional or not, of data science and data scientists. People are beginning to develop smell tests for big data and raise incredulous eyebrows at certain claims.
This is a good thing. We data scientists should welcome the backlash, first because it’s inevitable, and second because it allows us to have a much-needed conversation about how to behave and what is reasonable to claim or even hope for with respect to big data. There is a poseur problem in big data, after all.
But, fellow data nerds, let’s take this as a cue to start an internal discussion about data science skepticism. Let’s make sure that it’s coming from our community, or at least the surrounding technical community, rather than from yet another set of poseurs who don’t actually know what data is and would only serve to lampoon and discredit our emerging field rather than improve it. We should be the ones leading the charge and admitting when we’re full of shit. We need to own the backlash.
Let me give you an example. A serious data scientist friend of mine recently got asked to be interviewed as part of a conversation on data science skepticism. After thinking hard about what her contribution could be, she wrote back to accept the offer, but was then told she was “off the hook” because they’d found someone else who was “perfect for the assignment.” It turned out to be a journalist who had previously interviewed her. That was his credential for this conversation.
But how can you actually have informed skepticism if you are not yourself an expert?
Another example. David Brooks recently wrote a column wherein he declared himself a data science skeptic and then followed that up by referring to no fewer than eight random statistical studies that made no coherent sense and had no overall point. My conclusion: this is the wrong man to lead the charge against poseurs in data science.
If we are going to rebel against big data soundbites, let’s not do it in soundbites. Instead, let’s talk to people on the inside, who see specific problems in the field and are willing to talk openly about them.
I liked the recent Strata talk by Kate Crawford entitled “Untangling Algorithmic Illusions from Reality in Big Data” (h/t Alan Fekete) which discusses bias in data using very concrete examples, and asks us to examine the objectivity of our “facts”.
For example, she talked about a smart phone app that finds potholes in Boston and report them to the City, and how on the one hand it was cool but on the other it would mean that, if naively applied, richer neighborhoods like Lincoln would get better services than Roxbury. She explained an important point: data analysis is not objective, which most people know. But often the data itself is not either – it was collected in a certain way with particular selection biases.
We need more conversations like this or else we will be leaving a hole which will be filled with loud, uninformed skeptics who would be right to raise the alarm.
One last thing. I’m aware that tons of people, especially serious academic statisticians and computer scientists, criticize data scientists for a totally different reason, namely that we are overly self-promoting (although academics have their own status plays).
But I don’t apologize for that. The truth is, a data scientist is a hybrid between a business person and a researcher. And this is a good thing, not a bad thing: it means the world gets direct access to the modeler, and can challenge any hyperbolic claims by asking for details, rather than having to go through a marketing person who acts (usually quite poorly) as a nerd interpreter. I for one would rather represent my work directly to the world (and be called a self-promoter) then to be kept in the back room.
WTF happened to feminism?!
I usually don’t talk about feminism per se, because honestly I usually don’t think about it. Thanks to role models like my mom, who was an MIT co-ed in the ’60’s and an original nerd, helping develop the internet at Bolt Beranek and Newman and teaching computer science at UMass Boston, I’ve never for one second doubted my personal right to be a thoughtful, argumentative, and ambitious woman. I learned from my mom, and from other trailblazers, that I can pursue my personal interests and trust that the world will welcome my contributions.
Two events in the past week have made me think about how confusing this message has become for today’s growing girls, however.
First, the Sheryl Sandberg thing. To be honest, I haven’t read the book. But I have read this Washington Post article describing the book, and here’s my take on it: a corporate branding campaign loosely tied to women, but mostly pushing forward the agenda of how to be a company drone. From the article:
Sandberg’s understanding of leadership so perfectly internalizes the power structures of institutions created and dominated by men that it cannot conceive of women’s leadership outside of those narrow spaces. Does this also explain why, for Sandberg, the biggest threat to our ability to occupy a position of leadership is a woman’s desire to have a child? This is what men have been telling us for years.
Sandberg may miss so many women in her movement simply because her brand of gender equity is almost entirely privatized, doled out from employer to employee. Women, she advises, will find their way to the top through telling employers upfront about their childbearing plans, through learning how to negotiate pay raises (say “we” instead of “I,” Sandberg cautions, though the collective here is the corporation), through comportment exercises, as taught through Lean In’s web videos.
Like I said in this post, wouldn’t an actual feminist agenda include saying “The hell with this!” to a corporation that is so stifling that all our imaginations could bring us is better maternity leave negotiation tactics with the Borg? Resistance is futile, man!
Here’s the second thing that pissed me off this week. Harvard MBA Rachel Greenwald tells women what makes men not call back after a date.
Answer? As it turns out, anything where you have an opinion and they feel intimidated by you. Solution? Dumb it down, sex it up, and act like a toy. That way, in her words, you’ll be empowered, because they’re all calling you back, and the choice is yours. The choice, I’d add, from a long list of wimps. No thank you.
The video:
Can we do better than this, people??
A blogging parliament
Last night I found myself watching Steve Waldman’s talk at the 2011 Economic Bloggers Forum at the Kaufman Foundation. I’m a big fan of Waldman’s blog Interfluidity. His talk was interesting and thought-provoking, like his writing. I suggest you watch it.
After expressing outrage at the failure of control systems and the political system after the financial crisis, Waldman asks the question, why are we where we are? His answer: there’s a monopoly of power in this country even as information itself is increasingly available. The monopoly of power is extremely correlated, of course, to the rising wealth inequality, beautifully visualized in this recent video (h/t Leon Kautsky, Debika Shome) by Politizane.
The solution, he hopes, may include the blogosphere (although it’s not a perfect place either, with its own revolving doors, weird incentives and possibly conflicts of interest). The work of bloggers is valuable social capital, Steve argues, so how do we deploy it?
Steve introduced the concept of policy entrepreneurs, which have three characteristics:
- They are sources of information in the form policy ideas. They possible even write laws.
- They have some kind of certification in order to cover the policy maker’s ass.
- They exert some kind of influence on policy makers, to create incentives for their policy goals.
In other words, a policy entrepreneur is someone in the business of shaping policy makers’ agendas.
If you stop there, you might think “lobbyist,” and you’d be right. But the problem with our current lobbyist system is not the above three characteristics, but rather that it’s a such a closed system. In other words, you essentially need to be rich to be an influential lobbyist (or at least, as an influential lobbyist, you are backed by enormous wealth), but then that increases the monopolistic nature of political power. It doesn’t solve our “monopoly of power” problem.
The question becomes, is there a way for normal people, or groups of people, to be policy entrepreneurs?
One possible solution, Waldman suggests, is to from a parliament of bloggers. Since groups are taken seriously, can bloggers form official groups in which they gain consensus around a topic and issue policy?
An intriguing idea, and I like it because it’s not really abstract: if bloggers decided to try this, they could literally just form a group, call ourselves a name, and start issuing policy proposals. Of course they’d probably not get anywhere unless we had influence or leverage.
Does something like this already exist? The closest thing I can think of is the hacker group Anonymous – although they might not be bloggers, they might be. They’re anonymous. I’m going to guess they are active on the web even if they don’t specifically blog. In any case, let’s see if they qualify as policy entrepreneurs in the above sense.
- They don’t issue specific policy proposals, but they certainly object clearly to policies they don’t like.
- Their credentials lie in their unparalleled ability to take control of information systems.
- Likewise, their leverage is fierce in this domain.
In all, I don’t think Anonymous fits the bill – they’re too devoted to anarchy to deliver policy in the sense that Waldman suggests, and their tools are too crude to make fine points. This might have to do with the nature of hackers in general (keeping in mind that Anonymous stand for something far more extreme than the average hacker), which I read about in an essay by Paul Graham yesterday (h/t Chris Wiggins):
Here’s another problem: aren’t bloggers in general kind of their own 1%? Is policy via a “parliament of bloggers” not enough of an improvement to the current system of insiders?
What about if Occupy got into the idea of being a vehicle of policy entrepreneurship? Even though we tend not to support specific political candidates in Occupy, we do consistently think about policy and decide whether to endorse a given bill or policy proposal. Could we, instead of commenting on existing policy, start thinking about proposing new policy, even to the point of writing new laws?
On the one hand such work requires enormously long discussions and difficult-to-obtain consensus, but on the other hand we have the knowledge, the abilities, and the moral persuasion. Do we have the influence? And would Occupiers think exerting influence on policy in the current corrupt system tantamount to selling out?
HSBC Action today at noon
Here’s what I’m doing today at lunch time.
——
FOR IMMEDIATE RELEASE Monday, March 4, 2013
Occupy Wall Street Pickets At HSBC in New York
The action
HSBC To Issue Annual Earnings Report on Monday, March 4, 2013. These are the same unindicted criminals that admitted to money-laundering for drug cartels.
We Demand Justice for Executive Criminals & An End to “Too Big to Jail”!
Picket at HSBC New York Headquarters – Noon to 1:30pm
Gather on the steps of the New York Public Library Main Branch, 41st St. & Fifth Ave. See more at #OWSaltbanking and at our Facebook page for the event.
NEW YORK CITY – The “Occupy Wall Street – Alternative Banking” working group today continues its campaign to call on local, state and federal criminal and financial authorities to pursue prosecutions of executives at HSBC responsible for the bank’s admitted record of laundering money for drug cartels and alleged terrorists.
On Monday, March 4, as HSBC announces its annual earnings for 2012, OWS Alt Banking will rally at noon on the steps of the New York Public Library, Main Branch, across the street from HSBC’s New York headquarters.
The Story In Brief
In a recent settlement with the US Department of Justice, HSBC admitted to laundering billions of dollars for Mexican and Colombian drug cartels over many years. HSBC also admitted violating US sanctions regimes on Iran and on entities that the US government designates as “terrorist.”
Under the deal with DOJ, HSBC was forced to pay a $1.9 billion institutional penalty, which represents only six weeks worth of HSBC’s 2011 profits. The Justice Department agreed not to prosecute bank officials and other persons responsible for the admitted severe criminal conduct. All executive salaries and bonuses will be paid in full – some on deferred schedules. US financial authorities also declined to pull the criminal bank’s license to operate in the US.
Reportedly, authorities feared that jailing any of the megabank’s executives or shutting down its operations would cause its collapse and set off other bank collapses. This highlights the continuing systemic danger of “Too Big To Fail,” which also means “Too Big To Jail.” Thus OWS Alternative Banking is also calling on regulatory and legislative authorities finally to break up the big banks that dominate financial markets and can act with such impunity thanks to their sheer size.
Additional Context
OWS Alternative Banking Group points out that not to prosecute the HSBC executives responsible for money laundering to the full extent of the law diminishes the law and sends the wrong message. It creates an incentive for other banks to engage in the same criminal conduct.
Banks are being told that if they are big enough, they can commit any institutional crime without fear that personal punishments will follow, and in the confidence that institutional penalties will be minor in comparison to the profits made by breaking the law.
What message does this send to the American people, and to the world? “The war on drugs” and “the war on terror” rage on as centerpieces of US global policy.
In the United States, hundreds of thousands of people, predominantly people of color, have been imprisoned for often minor drug offenses. This has destroyed the futures of many young people and contributed to the biggest prison-industrial complex in the world.
In Mexico and Colombia, the US government supports a “drug war” in which literally thousands of people are murdered, often by the military personnel of those nations acting as death squads. In Pakistan, Yemen and other nations, US military drones bomb targeted persons – often killing their families or neighbors – on suspicion of “terrorism,” without trial or appeal.
In the US, executives at Islamic charities accused of funneling money to organizations designated as terrorist have received multiple life sentences. How is this different from HSBC’s conduct in helping to maintain the finances of drug cartels and alleged terrorists? Money laundering is absolutely essential to the business of the illegal drug trade. Furthermore, money launderers make the fattest profits out of all participants in the illegal drug trade.
Why are the banker-criminals getting a free pass? Why do we allow a two-tier justice system, with harsh punishments for minor drug offenders and rewards and impunity for the biggest offenders of all?
Therefore OWS Alternative Banking is asking for fair prosecution of the HSBC criminals and for ethical practices and staffing to replace the blatant abuse of customer money and good will. HSBC’s license to operate in the United States must be pulled.
The further message is to break up the big banks. They can no longer be considered too big too fail and allowed to commit blatant crimes of fraud and money laundering at US taxpayers’ expense.
Given the United Nations estimate of $400 billion in drug money laundered annually, it is nearly impossible that this enormous volume of dirty cash does not in large part go through the other big Wall Street and City of London banks.
“IT IS A DARK DAY FOR THE RULE OF LAW.” – New York Times, 12/11/2012
“Apparently non-violent demonstration against corrupt banking is subject to more criminal scrutiny than actual corrupt banking.” – Village Voice, 12/26/2012
Nasty reader comments and blogging
I’m pretty sure you guys know this already, but I love my regular readers and commenters. It’s a large part of why I blog – I feel like I’m having a super interesting cocktail party every morning in my underwear. I’m investing in the quality of the rest of my day, stealing a moment before my family wakes up so I can articulate one single idea. The payoff is, most of the time, dependably good conversation that lasts all day, or even more than a day, as your comments and emails come in.
Of course, there are sometimes nasty people and comments in addition to thoughtful ones. Not everyone interprets me as trying to figure stuff out, they think I’m being intentionally asinine or manipulative. Or sometimes they just don’t agree with me, and instead of explaining their reasoning they just yell. Or sometimes they are just jerks, getting out their aggression on a stranger.
My first rule is to allow comments that disagree with me, as long as the reasons are articulated and as long as the comment isn’t abusive. Rude is ok, “you are stupid” is not ok.
My second rule is to have a thick skin. I can completely ignore the sentiment of an abusive commenter calling me names, because first of all I’ve heard it all before and second I’m pretty sure it’s not about me.
I’m not saying it doesn’t bother me at all, because obviously it’s a pain to have to go through my email and make sure people are being civil.
For example, whenever I get onto the top 10 of Hacker News, which has been a few times now, I’ve noticed a huge wave of nasty comments. Of course this could be a direct result of how many people I get (thousands per hour), but I don’t think so – the ratio of interesting to abusive comments coming from Hacker News traffic is tiny. It creates nasty work for me, which I feel compelled to do because letting nasty comments stay on my blog makes me feel violated and intentionally misunderstood.
This morning I found this article via Naked Capitalism regarding reader comments, and how nasty ones make subsequent readers evaluate the message differently, and in particular, more negatively. In other words, my intuition was right – it’s super important to curate comments.
My experience with Hacker News has also given me sympathy for Izabella Laba‘s position that she doesn’t accept comments on her blog (read this post for example). She puts herself out there, with strong opinions, and many of her posts are important and thought-provoking. And by the same token people can get pretty threatened by what she has to say. I can well imagine what her experience has been. What if every day was a Hacker News day? What if a majority of comments contained ridiculous and personal attacks? Yuck.
Makes me even more grateful to have you guys.
Aunt Pythia’s advice
You’ve stumbled upon yet another week’s worth of worthy questions that will be awkwardly sidestepped by mathbabe’s alter ego Aunt Pythia.
By the way, if you don’t know what you’re in for, go here for past advice columns and here for an explanation of the name Pythia. Most importantly,
Please submit your question at the bottom of this column!
——
Aunt Pythia,
I graduated seven years ago and since then I’ve been working in finance. (I was a floor clerk when Bear Stearns took a nosedive and the words “too big to fail” reared their ugly head.) Now I’m finally ready to flee this flaming cesspool. Do you have any advice on how to get out without suffering a major career setback? I have some skills relevant to data science — python, SQL, some tinkering with Hadoop — but I don’t have any formal training in either computer science or in statistics, and I don’t know a soul outside the financial industry. Is there a way out, or am I stuck here forever?
Lonely in Finance
Dear Lonely,
You are not stuck. Quit your job, live off your savings, and start networking in another space. What do you want to do? What turns you on? Take a leap of faith and get yourself moving. Of course it will be a career setback! Because you are going to begin anew! That’s a good thing, not a bad thing.
I’ll be you don’t have 3 kids and a mortgage even, and yet you still somehow feel like you need to be completely safe. You don’t! You have highly marketable skills, and yes you’ll have to develop even more, but for god’s sake don’t stay in a flaming cesspool just because the money’s good. That is something you know you will regret on your deathbed.
Get the fuck out.
Aunt Pythia
——
Dear Aunt Pythia,
I’m terrible at asking for advice, because whenever I think of a problem I immediately dismiss it as too silly, or too easy, or I convince myself that I know the answer. Sometimes I don’t ask for help because I feel too much like I’m mooching people’s time, or something like that. How can I get better at asking for advice?
Acrimoniously Chancing Ridiculously-Off Name, You Minx
p.s. Too meta? Or not meta enough?
Dear ACRONYM,
You’re right to be worried. Asking a question is a tough business, and it’s all about timing.
Say, for example, you came up to me on a packed subway car at rushhour, when I was reading my kindle (current book: Mostly Harmless Econometrics), say, and you poked me in my back and said, “hey buddy I’ve got a problem and you’re the person that’s gonna solve it!”. In that situation, and I have to be honest here, I’d be somewhat reluctant to consider your problem as one of my own.
Or, imagine you approached me while I was in the women’s lavatory stall at a public bathroom, and, say, wrote down your question on the back of the bathroom tissue and scooted it over to me on the floor, again I can’t promise you I’d appreciate it (unless you were asking me for more toilet paper, then we’d be good).
However, this being an advice column, I’m pretty confident I’ve made a safe place for even silly questions (and questions that are too easy are even better, because they make me feel smart!). That’s what Saturday mornings are for: I love doing this, and you are helping me do this!
Love,
Auntie P
p.s. Just meta enough!
——
Dear Aunt Pythia,
Our culture would have us believe that we are nothing if we are not statistically above average, preferably gifted. Being successful is practically considered a matter of common courtesy. Nonetheless, most of us stubbornly persist in a state of statistical mediocrity, defiantly average. How can we quell our culture’s craving for exceptionalism?
Average Without Being Mean
Dear Average,
I’ve never met someone who thinks they are actually average. I might meet someone who will tell me they’re bad at tests or that they suck at math, but people generally know better than to stop there when self-assessing (hopefully! unless they’re actually really depressed).
After all, a given person has their own personal passions and interests and each develops their own skills and natural talents. While it may be true that someone is born with average potential for a certain thing, it’s more a matter of their passion and time spent practicing that thing than anything about their inherent ability that makes them good or great at something.
In other words, to exist in a state of (supposed) statistical mediocrity is to submit entirely to external measures of generic skills. Who would do that, and why? If I was against standardized testing before, this idea makes me double down.
In terms of our culture, I don’t know how to avoid these kind of “cravings for exceptionalism” if you want to work as a data scientist in a tech startup, for example, because of the competitive nature of that industry. But there are plenty of jobs where being a thoughtful, hard-working person who isn’t a jerk is welcomed.
Aunt Pythia
——
Dear Aunt Pythia,
I have a PhD in math and have been interested in getting a job as a data scientist. I have been following your blog, following a few classes online, and talking to people from my program about other resources. I have been applying for jobs in California for over a month now, and since I have no established experience with analyzing big data sets, I have not received any requests for interviews. I would appreciate any advice you can offer!
Searching in California
Dear Searching,
I wish I had a better answer, because it kind of drives me nuts how hard it is for people like you to get a good job. But first I’d examine your reasoning: how do you know it’s because of a lack of experience analyzing big data sets that you haven’t gotten an interview? I’m not saying that’s not relevant, but I’m pretty sure it will be a combination of factors – including connections. Plus, what is your “program”? Are you still a student? Are you in an academic institution? Possible things you might try:
- finding a class that will give you mad skillz working with big data sets
- reading “Mostly Harmless Econometrics“
- networking with other Ph.D.’s you know who already have a job in industry
- going to data conferences or tech meetups and introducing yourself to a bunch of people
- finding out about internship possibilities
- going to data hackathons and working alongside someone who knows the ropes
Good luck!
Aunt Pythia
——
Please please please submit questions, thanks!
Prices in the junk bond market
There are various ways of deciding how valuable something is. People spend some amount of time talking about “the current value of future earnings til the end of time” as a rule-of-thumb measurement. That sometimes works (i.e. jives with what the selling price is), but it’s certainly not robust – in a given case, plenty of people think there’s a good reason a stock should be worth more than that, if their personal growth projections are rosy (you could argue that they are still valuing future earnings, but they’ve got a different projection than, say, the current dividends continued as is. Another possibility is that they’re simply valuing future values coming from other people). Similarly, some stocks are underpriced with respect to this baseline. Could it be that they’re cooking their books? If they don’t last til the end of time then they could hardly be making earnings til then (Groupon).
Of course when you go down that road, nothing lasts til the end of time. Never mind companies, the industry in which the company sits will be dead before too long unless it’s food or cosmetics.
Anyway, throw out the future earnings price for a moment, and replace it by something else entirely: there’s a certain amount of money invested in the (international) market at a given moment, and it has to go somewhere. I think of it as a big pot that sloshes around and achieves equilibrium depending on various things like relative interest rates in different countries, and to a lesser extent, regulation in different countries and access to markets. Like, the carry trade is kind of a big deal, and depends almost entirely on the Japanese interest rate being tiny.
Of course it’s not really that simple, since people can and do remove money from the market at certain times – it’s not a closed system. But not as much money is removed as you might think, because if you think about it, lots of people have set up their livelihoods to be investing large pots of money, so they need to appear busy.
Articles like this one from Bloomberg make me think about the “where should we put our money that we need to invest somewhere?” effect is particularly strong right now. We see people “chasing yield” in the junk bond market, buying junk bonds that have positive yields because their options are limited while the Fed keeps the rates really low (this is not a side-effect of the Fed’s keeping the rates low, it’s their goal. They want people to invest in financing businesses, which is what buying junk bonds is).
But they (the investors) all want the same stuff, so the prices are too low high, which is another way of saying the yields are a lot lower than they’d otherwise be if there were other things to buy. This might be a good example of where the price of junk debt is not particularly good at exposing the actual risk of default. Well, it might be an ok indicator of the very short-term default rate, but that’s just because money is so cheap right now, businesses in trouble can just borrow more. It’s kind of a set-up for a bubble.
The article makes the point that once the Fed raises rates, people will flee this market, since they will actually be able to make money again with less risky bonds. The slower actors will be left with much-reduced-in-value junk debt. The big pot of money which is the market will have an entirely new equilibrium point, and there will be lots of death and destruction in the transition. It’s become even more crucial than usual to time the Fed’s moves, but keep in mind money managers are going to stay in there as long as they possibly can because they don’t want to miss yield while their bonuses depend on it (“opportunity costs”). It’s a game of chicken.
Staying with the meta-analysis, can someone do a back-of-the-envelope estimate of how much built-in interest rate risk we’ve taken on by the issuance of so much junk debt in the overall international portfolio? Is it sizeable?
Is mathematics a vehicle for control fraud?
Bill Black
A couple of nights I ago I attended this event at Columbia on the topic of “Rent-Seeking, Instability and Fraud: Challenges for Financial Reform”.
The event was great, albeit depressing – I particularly loved Bill Black‘s concept of control fraud, which I’ll talk more about in a moment, as well as Lynn Turner‘s polite description of the devastation caused by the financial crisis.
To be honest, our conclusion wasn’t a surprise: there is a lack of political will in Congress or elsewhere to fix the problems, even the low-hanging obvious criminal frauds. There aren’t enough actual police to take on the job of dealing with the number of criminals that currently hide in the system (I believe the statistic was that there are about 1,000,000 people in law enforcement in this country, and 2,500 are devoted to white-collar crime), and the people at the top of the regulatory agencies have been carefully chosen to not actually do anything (or let their underlings do anything).
Even so, it was interesting to hear about this stuff through the eyes of a criminologist who has been around the block (Black was the guy who put away a bunch of fraudulent bankers after the S&L crisis) and knows a thing or two about prosecuting crimes. He talked about the concept of control fraud, and how pervasive control fraud is in the current financial system.
Control Fraud
Control fraud, as I understood him to describe it, is the process by which a seemingly legitimate institution or process is corrupted by a fraudulent institution to maintain the patina of legitimacy.
Once you say it that way, you recognize it everywhere, and you realize how dirty it is, since outsiders to the system can’t tell what’s going on – hey, didn’t you have overseers? Didn’t they say everything was checking out ok? What the hell happened?
So for example, financial firms like Bank of America used control fraud in the heart of the housing bubble via their ridiculous accounting methods. As one of the speakers mentioned, the accounting firm in charge of vetting BofA’s books issued the same exact accounting description for many years in the row (literally copy and paste) even as BofA was accumulating massive quantities of risky mortgage-backed securities (update: I’ve been told it’s called an “Auditors Report” and it has required language. But surely not all the words are required? Otherwise how could it be called a report?). In other words, the accounting firm had been corrupted in order to aid and abet the fraud.
“Financial Innovation”
To get an idea of the repetitive nature and near-inevitability of control fraud, read this essay by Black, which is very much along the lines of his presentation on Tuesday. My favorite passage is this, when he addresses how our regulatory system “forgot about” control fraud during the deregulation boom of the 1990’s:
On January 17, 1996, OTS’ Notice of Proposed Rulemaking proposed to eliminate its rule requiring effective underwriting on the grounds that such rules were peripheral to bank safety.
“The OTS believes that regulations should be reserved for core safety and soundness requirements. Details on prudent operating practices should be relegated to guidance.
Otherwise, regulated entities can find themselves unable to respond to market innovations because they are trapped in a rigid regulatory framework developed in accordance with conditions prevailing at an earlier time.”
This passage is delusional. Underwriting is the core function of a mortgage lender. Not underwriting mortgage loans is not an “innovation” – it is a “marker” of accounting control fraud. The OTS press release dismissed the agency’s most important and useful rule as an archaic relic of a failed philosophy.
Here’s where I bring mathematics into the mix. My experience in finance, first as a quant at D.E. Shaw, and then as a quantitative risk modeler at Riskmetrics, convinced me that mathematics itself is a vehicle for control fraud, albeit in two totally different ways.
Complexity
In the context of hedge funds and/or hard-core trading algorithms, here’s how it works. New-fangled complex derivatives, starting with credit default swaps and moving on to CDO’s, MBS’s, and CDO+’s, got fronted as “innovation” by a bunch of economists who didn’t really know how markets work but worked at fancy places and claimed to have mathematical models which proved their point. They pushed for deregulation based on the theory that the derivatives represented “a better way to spread risk.”
Then the Ph.D.’s who were clever enough to understand how to actually price these instruments swooped in and made asstons of money. Those are the hedge funds, which I see as kind of amoral scavengers on the financial system.
At the same time, wanting a piece of the action, academics invented associated useless but impressive mathematical theories which culminated in mathematics classes throughout the country that teach “theory of finance”. These classes, which seemed scientific, and the associated economists described above, formed the “legitimacy” of this particular control fraud: it’s math, you wouldn’t understand it. But don’t you trust math? You do? Then allow us to move on with rocking our particular corner of the financial world, thanks.
Risk
I also worked in quantitative risk, which as I see it is a major conduit of mathematical control fraud.
First, we have people putting forward “risk estimates” that have larger errorbars then the underlying values. In other words, if we were honest about how much we can actually anticipate price changes in mortgage backed securities in times of panic, then we’d say something like, “search me! I got nothing.” However, as we know, it’s hard to say “I don’t know” and it’s even harder to accept that answer when there’s money on the line. And I don’t apologize for caring about “times of panic” because, after all, that’s why we care about risk in the first place. It’s easy to predict risk in quiet times, I don’t give anyone credit for that.
Never mind errorbars, though- the truth is, I saw worse than ignorance in my time in risk. What I actually saw was a rubberstamping of “third part risk assessment” reports. I saw the risk industry for what it is, namely a poor beggar at the feet of their macho big-boys-of-finance clients. It wasn’t just my firm either. I’ve recently heard of clients bullying their third party risk companies into allowing them to replace whatever their risk numbers were by their own. And that’s even assuming that they care what the risk reports say.
Conclusion
Overall, I’m thinking this time is a bit different, but only in the details, not in the process. We’ve had control fraud for a long long time, but now we have an added tool in the arsenal in the form of mathematics (and complexity). And I realize it’s not a standard example, because I’m claiming that the institution that perpetuated this particular control fraud wasn’t a specific institution like Bank of America, but rather then entire financial system. So far it’s just an idea I’m playing with, what do you think?
How much are the taxpayers subsidizing too-big-to-fail banks, if not $83 billion per year?
There’s been lots of controversy over the Bloomberg editorial I wrote about a few days ago. The article, which is here, used an IMF study to do a back-of-the-envelope calculation on how much the yearly taxpayer subsidy is for the too-big-to-fail banks.
Since then, there have been lots of people coming out of the woodwork complaining about their interpretation of the paper, about their assumptions, and about the result. I also had someone doing that on my comments, which I appreciate.
Then, more recently, Bloomberg doubled down on their original number, which is exciting stuff in the world of wonky modeling.
Here’s where I am:
- This question is important- possibly the most important question about the current financial system, as it relates to the average taxpayer. Wouldn’t you want to know how much something you’ve bought costs?
- And I’m absolutely smitten by the Bloomberg editorial staff for raising the question and coming out with a model and an answer.
- That doesn’t mean it’s perfect. They were relatively sloppy (but not as sloppy as some people claim).
- I’m no expert either, but I’m absolutely intrigued by this question and the possible answers.
- But since I’m a modeler, I know it’s a lot easier to push over a model by complaining about an assumption than it is to come up with a better model that doesn’t make such stupid assumptions.
- So anyone who complains should also offer an alternative.
- Because we need to know the answer to this, and since there’s not one answer, we need to have this argument, publicly.
- And after all what’s the point of modeling if we can’t answer this?
One more thing. Matt Levine at Dealbreaker has come up with his own model, here, but I’m not sure it’s more convincing than Bloomberg’s. In particular his conclusion is that TBTF banks actually subsidize us (not really).
So what is it? Where’s your model?
We need this public discussion and we need thoughtful arguments about the existing models. Let’s do this!
Ninja Warrior – Sasuke
If you having trouble falling asleep some time, but you’re too tired to actually read things that require anything more than amusement, amazement, and bafflement, then let me suggest you watch a bit of Sasuke, also known as the Japanese version of American Ninja Warrior (hat tip Johan de Jong).
I dare you to watch only five minutes of the following final round (here’s the competition from the beginning if you are hardcore) in which the last surviving American gets expelled almost immediately and it’s down to the last few Japanese competitors. It’s extra fun for it to be in Japanese because then you get to add in dubbing, kind of like Iron Chef used to be back before it became Americanized:
The overburdened prior
At my new job I’ve been spending my time editing my book with Rachel Schutt (who is joining me at JRL next week! Woohoo!). It’s called Doing Data Science and it’s based on these notes I took when she taught a class on data science at Columbia last semester. Right now I’m working on the alternating least squares chapter, where we learned from Matt Gattis how to build and optimize a recommendation system. A very cool algorithm.
However, to be honest I’ve started to feel very sorry for the one parameter we call 
Let me tell you, the world is asking too much from this little guy, and moreover most of the big-data world is too indifferent to its plight. Let me explain.

First, he’s supposed to reflect an actual prior belief – namely, his size is supposed to reflect a mathematical vision of how big we think the coefficients in our solution should be.
In an ideal world, we would think deeply about this question of size before looking at our training data, and think only about the scale of our data (i.e. the input), the scale of the preferences (i.e. the recommendation system output) and the quality and amount of training data we have, and using all of that, we’d figure out our prior belief on the size or at least the scale of our hoped-for solution.
I’m not statistician, but that’s how I imagine I’d spend my days if I were: thinking through this reasoning carefully, and even writing it down carefully, before I ever start my training. It’s a discipline like any other to carefully state your beliefs beforehand so you know you’re not just saying what the data wants to hear.
But then there’s the next thing we ask of our parameter 
Because our algorithm isn’t a closed form solution, but rather we are discovering coefficients of two separate matrices 

The fact that this algorithm will in fact stop is not obvious, and in fact it isn’t always true.
It is (mostly*) true, however, if our little
And people say that all the time. When you say, “hey what if that algorithm doesn’t converge?” They say, “oh if
But that’s kind of like worrying about your teenage daughter getting pregnant so you lock her up in her room all the time. You’ve solved the immediate problem by sacrificing an even bigger goal.
Because let’s face it, if the prior
By the way, there’s a discipline here too, and I’d suggest that if the algorithm doesn’t converge you might also want to consider reducing your number of latent variables rather than increasing your
Finally, we have one more job for our little
In other words, in reality most of the above nonsense about
This is one example among many where having the ability to push a button that makes something hard seem really easy might be doing more harm than good. In this case the button says “optimize with respect to
I’ve said it before and I’ll say it again: you do need to know about inverting a matrix, and other math too, if you want to be a good data scientist.
* There’s a change-of-basis ambiguity that’s tough to get rid of here, since you only choose the number of latent variables, not their order. This doesn’t change the overall penalty term, so you can minimize that with large enough



