Archive
War of the machines, college edition
A couple of people have sent me this recent essay (hat tip Leon Kautsky) written by Elijah Mayfield on the education technology blog e-Literate, described on their About page as “a hobby weblog about educational technology and related topics that is maintained by Michael Feldstein and written by Michael and some of his trusted colleagues in the field of educational technology.”
Mayfield’s essay is entitled “Six Ways the edX Announcement Gets Automated Essay Grading Wrong”. He’s referring to the recent announcement, which was written about in the New York Times last week, about how professors will soon be replaced by computers in grading essays. He claims they got it all wrong and there’s nothing to worry about.
I wrote about this idea too, in this post, and he hasn’t addressed my complaints at all.
First, Mayfield’s points:
- Journalists sensationalize things.
- The machine is identifying things in the essays that are associated with good writing vs. bad writing, much like it might learn to distinguish pictures of ducks from pictures of houses.
- It’s actually not that hard to find the duck and has nothing to do with “creativity” (look for webbed feet).
- If the machine isn’t sure it can spit back the essay to the professor to read (if the professor is still employed).
- The machine doesn’t necessarily reward big vocabulary words, except when it does.
- You’d need thousands of training examples (essays on a given subject) to make this actually work.
- What’s so really wonderful is that a student can get all his or her many drafts graded instantaneously, which no professor would be willing to do.
Here’s where I’ll start, with this excerpt from near the end:
“Can machine learning grade essays?” is a bad question. We know, statistically, that the algorithms we’ve trained work just as well as teachers for churning out a score on a 5-point scale. We know that occasionally it’ll make mistakes; however, more often than not, what the algorithms learn to do are reproduce the already questionable behavior of humans. If we’re relying on machine learning solely to automate the process of grading, to make it faster and cheaper and enable access, then sure. We can do that.
OK, so we know that the machine can grade essays written for human consumption pretty accurately. But it hasn’t had to deal with essays written for machine consumption yet. There’s major room for gaming here, and only a matter of time before there’s a competing algorithm to build a great essay. I even know how to train that algorithm. Email me privately and we can make a deal on profit-sharing.
And considering that students will be able to get their drafts graded as many times as they want, as Mayfield advertised, this will only be easier. If I build an essay that I think should game the machine, by putting in lots of (relevant) long vocabulary words and erudite phrases, then I can always double check by having the system give me a grade. If it doesn’t work, I’ll try again.
And the essays built this way won’t get caught via the fraud detection software that finds plagiarism, because any good essay-builder will only steal smallish phrases.
One final point. The fact that the machine-learning grading algorithm only works when it’s been trained on thousands of essays points to yet another depressing trend: large-scale classes with the same exact assignments every semester so last year’s algorithm can be used, in the name of efficiency.
But that means last year’s essay-building algorithm can be used as well. Pretty soon it will just be a war of the machines.
Aunt Pythia’s advice
A couple of sad updates on Aunt Pythia.
First, someone hacked my Aunt Pythia spreadsheet and added hundreds of bizarre and offensive questions (at least they seemed intended to offend, but luckily Aunt Pythia doesn’t offend easily), which I then erased in huge blocks. This means if you actually had a valid question in the last week it has been, sadly, removed.
Second, possibly because of all the removed stuff, Aunt Pythia has no smutty sex questions to answer and has resorted to answering sober and serious leftover questions. But don’t fear! Aunt Pythia will do her best to sex up the answers anyway.
If you don’t know what you’re in for, go here for past advice columns and here for an explanation of the name Pythia. Most importantly,
Please submit your smutty sex (or otherwise) questions at the bottom of this column!
——
Aunt Pythia,
What do you think of Sheryl Sandberg and Malissa Mayer as role models/advice givers to young women? I ask you because I am confident you will give a measured response, not the reflexively pro or reflexively con reactions they seem to get.
Female enduring mostly masculine explanations
Dear Femme,
I’m going to preface my remarks by admitting I still haven’t read Sandberg’s book. But I have read enough reviews to get a feeling for what she’s going for. I have a bunch of comments:
- Do women sometimes undermine themselves by not going for things whole-heartedly and holding back? Yes, yes they do. So do men, of course. There are lots of people in this world who have missed opportunities by not giving things a real chance. Maybe this happens more often for women – I’d not be too surprised to hear that (but I also think I have an explanation, see below).
- On the other hand, I fundamentally question how bad we should feel when highly educated women choose not to try for a promotion that will require them to travel half the time and work 80 hours a week. Why would someone want that lifestyle? Why would that be their route to happiness? This is a death bed consideration, and if you ask me I’d rather not have death bed regrets about missing out on all of my personal interests, hobbies, adventures, friends, and family because I was so sure that promotion was important.
- In fact, I think highly educated women like Mayer and Sandberg, and myself for that matter, are luckier than the men they compete with. The truth is women actually have more options than men because society’s expectations are so much narrower for men. Want to leave the corporate scene after your second kid and start writing children’s books? Ok fine. That would be really weird for a man to do.
- In fact, where are the academic papers which assume that women leave the rat race by choice, to maximize their utility functions? Why don’t we assume that women have different options than men and that the fact that only 15% of women run large companies is a result of most qualified women deciding “I’d rather not, thank you”? I’m not saying that’s the only underlying effect but I honestly think it’s part of it. Plus, if we looked at it that way then the culture inside the corporation could be analysed a bit more, and we might start to understand what’s so unappealing about it. If we made it more appealing to women, they might decide to stay longer.
- Or for that matter, that women have different utility functions altogether, and that they leave the rat-race or stay in a job which doesn’t require 80 hours a week because they are (locally) maximizing their utility?
- It wouldn’t surprise me, if such a study were done, to figure out that (highly educated) women are actually happier than (highly educated) men in general, at least the women who have quality daycare.
In other words, I get some of their advice but I question their narrow perspective and narrow definition of success.
I hope that helps!
Aunt Pythia
——
Dear Aunt Pythia,
I’m almost finished with my masters in pure math. But now I’m doubting about becoming a high school teacher or do something in companies. I like children and I dislike most aspects of corporate culture, but the burn out rate for teachers is very high. Can you give me pros and cons about either career path?
Doubting
Dear D,
It’s a tough time for teachers out there. Read this resignation letter (h/t Chris Wiggins) if you haven’t already. An excerpt:
With regard to my profession, I have truly attempted to live John Dewey’s famous quotation (now likely cliché with me, I’ve used it so very often) that “Education is not preparation for life, education is life itself.” This type of total immersion is what I have always referred to as teaching “heavy,” working hard, spending time, researching, attending to details and never feeling satisfied that I knew enough on any topic. I now find that this approach to my profession is not only devalued, but denigrated and perhaps, in some quarters despised. STEM rules the day and “data driven” education seeks only conformity, standardization, testing and a zombie-like adherence to the shallow and generic Common Core, along with a lockstep of oversimplified so-called Essential Learnings. Creativity, academic freedom, teacher autonomy, experimentation and innovation are being stifled in a misguided effort to fix what is not broken in our system of public education and particularly not at Westhill.
On the other hand, there’s definitely a severe need for good math teachers. So I don’t want to utterly discourage you. One possibility is to try out teaching for a couple of years and then decide whether to stick with it or not (although the learning curve for teaching is steep, so keep in mind it gets easier over time). Have you talked to people at Math for America?
Also, do some research about where you want to teach, and make sure you land in a school which values their teachers and gives lots of clear feedback and doesn’t just submit blindly to the testing borg. Talk to the principal about that stuff beforehand.
Good luck!
Aunt Pythia
——
Aunt P,
My wife and I have been enjoying a politico/sci-fi drama called Continuum, which features model and actress Rachel Nichols, a Columbia University grad with a double major in math and economics. What’s more, the show has serious undertones implying the Occupy movement is spot-on. Now I have this fantasy of a series of action movies centered around a demure blogger by day and a sexy fighter for the people by night who uses her succubi powers to enervate and destroy evil banksters. Isn’t this something we should get on Kickstarter right away?
Distinguished Opinion Maker
Dear DOM,
I haven’t seen the show, but I dig the idea of a superhero blogger, bien sûr!
Just one quibble about the use of “succubi” though:
succubi plural of suc·cu·bus
|
Noun
|
Are you suggesting that the main character flies around at night sleeping with banksters for the good of society (note I threw in the ability to fly because that’s what awesome superheroes do)? I’m a bit confused on that point, because I don’t think it makes for good TV. Not to mention I’m not sure how that shows the banksters the error of their ways. Here’s the image I found when I google image searched “banksters”:

I mean they’re healthy enough but I’m not sure they’re porn star material. It’s all about taste though. Whatever floats your boat.
Tell me if and when you’ve started the Kickstarter campaign, please! I want to keep tabs on how much money people will contribute towards this fetching concept.
Auntie P
——
Aunt Pythia,
I’m defending my dissertation soon! Woohoo! I’m curious to know what Aunt Pythia thinks about the following things: (a) board vs. slide talk, (b) how to pitch a talk about your research to mathematicians who aren’t specialists in your field, and (c) what to wear. It seems to me like (c) can’t possibly be separated from the issue of gender, so let’s pretend I’m female. (The underlying question is: how do I impress a room full of people in 40 minutes without spewing jargon or dressing like PhD Barbie?)
Nervous in Nebraska
Dear NiN,
This one’s easy. The answer is that it doesn’t matter one bit because we all know this is a formality and you’re all done! You’re getting your degree! YEAH!! Congratulations.
If I were you I’d wear something bright and celebratory, like the peacock you must feel yourself to be. And I’d say slide so you don’t get your bright clothes chalky.
Love,
Aunt Pythia
——
Please please please submit questions!
A public-facing math panel
I’m returning from two full days of talking to mathematicians and applied mathematicians at Cornell. I was really impressed with the people I met there – thoughtful, informed, and inquisitive – and with the kind reception they gave me.
I gave an “Oliver Talk” which was joint with the applied math colloquium on Thursday afternoon. The goal of my talk was to convince mathematicians that there’s a very bad movement underway whereby models are being used against people, in predatory ways, and in the name of mathematics. I turned some people off, I think, by my vehemence, but then again it’s hard not get riled up about this stuff, because it’s creepy and I actually think there’s a huge amount at stake.
One thing I did near the end of my talk was bring up (and recruit for) the idea of a panel of mathematicians which defines standards for public-facing models and vets the current crop.
The first goal of such a panel would be to define mathematical models, with a description of “best practices” when modeling people, including things like anticipating impact, gaming, and feedback loops of models, and asking for transparent and ongoing evaluation methods, as well as having minimum standards for accuracy.
The second goal of the panel would be to choose specific models that are in use and measure the extent to which they pass the standards of the above best practices rubric.
So the teacher value-added model, I’d expect, would fail in that it doesn’t have an evaluation method, at least that is made public, nor does it seem to have any accuracy standards, even though it’s widely used and is high impact.
I’ve had some pretty amazing mathematicians already volunteer to be on such a panel, which is encouraging. What’s cool is that I think mathematicians, as a group, are really quite ethical and can probably make their voices heard and trusted if they set their minds to it.
Ina Drew: heinously greedy or heinously incompetent?
Last night I went to an event at Barnard where Ina Drew, ex-CIO head of JP Morgan Chase, who oversaw the London Whale fiasco, was warmly hosted and interviewed by Barnard president Debora Spar.
[Aside: I was going to link to Ina Drew’s wikipedia entry in the above paragraph, but it was so sanitized that I couldn’t get myself to do it. She must have paid off lots of wiki editors to keep herself this clean. WTF, wikipedia??]
A little background in case you don’t know who this Drew woman is. She was in charge of balance-sheet risk management and somehow managed to not notice losing $6.2 billion dollars in the group she was in charge of, which was meant to hedge risk, at least according to CEO Jamie Dimon. She made $15 million per year for her efforts and recently retired.
In her recent Congressional testimony (see Example 3 in this recent post), she threw the quants with their Ph.D.’s under the bus even though the Senate report of the incident noted multiple risk limits being exceeded and ignored, and then risk models themselves changed to look better, as well as the “whale” trader Bruno Iksil‘s desire to get out of his losing position being resisted by upper management (i.e. Ina Drew).
I’m not going to defend Iksil for that long, but let’s be clear: he fucked up, and then was kept in his ridiculous position by Ina Drew because she didn’t want to look bad. His angst is well-documented in the Senate report, which you should read.
Actually, the whole story is somewhat more complicated but still totally stupid: instead of backing out of certain credit positions the old-fashioned and somewhat expensive way, the CIO office decided to try to reduce its capital requirements via reducing (manipulated) VaR, but ended up increasing their capital requirements in other, non-VaR ways (specifically, the “comprehensive risk measure”, which isn’t as manipulable as VaR). Read more here.
Maybe Ina is going to claim innocence, that she had no idea what was going on. In that case, she had no control over her group and its huge losses. So either she’s heinously greedy or heinously incompetent. My money’s on “incompetent” after seeing and listening to her last night. My live Twitter feed from the event is available here.
We featured Ina Drew on our “52 Shades of Greed” card deck as the Queen of diamonds:

Back to the event.
Why did we cart out Ina Drew in front of an audience of young Barnard women last night? Were we advertising a career in finance to them? Is Drew a role model for these young people?
The best answers I can come up with are terrible:
- She’s a Barnard mom (her daughter was in the audience). Not a trivial consideration, especially considering the potential donor angle.
- President Spar is on the board of Goldman Sachs and there’s a certain loyalty among elites, which includes publicly celebrating colossal failures. Possible, but why now? Is there some kind of perverted female solidarity among women that should be in jail but insist on considering themselves role models? Please count me out of that flavor of feminism.
- President Spar and Ina Drew actually don’t think Drew did anything wrong. This last theory is the weirdest but is the best supported by the tone of the conversation last night. It gives me the creeps. In any case I can no longer imagine supporting Barnard’s mission with that woman as president. It’s sad considering my fond feelings for the place where I was an assistant professor for two years in the math department and which treated me well.
Please suggest other ideas I’ve failed to mention.
New creepy model: job hiring software
Warmup: Automatic Grading Models
Before I get to my main take-down of the morning, let me warm up with an appetizer of sorts: have you been hearing a lot about new models that automatically grade essays?
Does it strike you that’s there’s something wrong with that idea but you don’t know what it is?
Here’s my take. While it’s true that it’s possible to train a model to grade essays similarly to what a professor now does, that doesn’t mean we can introduce automatic grading – at least not if the students in question know that’s what we’re doing.
There’s a feedback loop, whereby if the students know their essays will be automatically graded, then they will change what they’re doing to optimize for good automatic grades rather than, say, a cogent argument.
For example, a student might download a grading app themselves (wouldn’t you?) and run their essay through the machine until it gets a great grade. Not enough long words? Put them in! No need to make sure the sentences make sense, because the machine doesn’t understand grammar!
This is, in fact, a great example where people need to take into account the (obvious when you think about them) feedback loops that their models will enter in actual use.
Job Hiring Models
Now on to the main course.
In this week’s Economist there is an essay about the new widely-used job hiring software and how awesome it is. It’s so efficient! It removes the biases of of those pesky recruiters! Here’s an excerpt from the article:
The problem with human-resource managers is that they are human. They have biases; they make mistakes. But with better tools, they can make better hiring decisions, say advocates of “big data”.
So far “the machine” has made observations such as:
- Good if candidate uses browser you need to download like Chrome.
- Not as bad as one might expect to have a criminal record.
- Neutral on job hopping.
- Great if you live nearby.
- Good if you are on Facebook.
- Bad if you’re on Facebook and every other social networking site as well.
Now, I’m all for learning to fight against our biases and hire people that might not otherwise be given a chance. But I’m not convinced that this will happen that often – the people using the software can always train the model to include their biases and then point to the machine and say “The machine told me to do it”. True.
What I really object to, however, is the accumulating amount of data that is being collected about everyone by models like this.
It’s one thing for an algorithm to take my CV in and note that I misspelled my alma mater, but it’s a different thing altogether to scour the web for my online profile trail (via Acxiom, for example), to look up my credit score, and maybe even to see my persistence score as measured by my past online education activities (soon available for your 7-year-old as well!).
As a modeler, I know how hungry the model can be. It will ask for all of this data and more. And it will mean that nothing you’ve ever done wrong, no fuck-up that you wish to forget, will ever be forgotten. You can no longer reinvent yourself.
Forget mobility, forget the American Dream, you and everyone else will be funneled into whatever job and whatever life the machine has deemed you worthy of. WTF.
Hey WSJ, don’t blame unemployed disabled people for the crap economy
This morning I’m being driven crazy by this article in yesterday’s Wall Street Journal entitled “Workers Stuck in Disability Stunt Economic Recovery.”
Even the title makes the underlying goal of the article crystal clear: the lazy disabled workers are to blame for the crap economy. Lest you are unconvinced that anyone could make such an unreasonable claim of causation, here’s a tasty excerpt from the article that spells it out:
Economic growth is driven by the number of workers in an economy and by their productivity. Put simply, fewer workers usually means less growth.
Since the recession, more people have gone on disability, on net, than new workers have joined the labor force. Mr. Feroli estimated the exodus to disability costs 0.6% of national output, equal to about $95 billion a year.
“The greater cost is their long-term dependency on transfers from the federal government,” Mr. Autor said, “placing strain on the soon-to-be exhausted Social Security Disability trust fund.”
The underlying model here, then, is that there’s a bunch of people who have the choice between going on disability or “joining the labor force” and they’ve all chosen to go on disability. I wonder where their evidence is that people really have that choice, considering the unemployment numbers and participation rate numbers we see nowadays.
For example, the unemployment rate for youths is now 22.9%, and the participation rate for them has gone from 59.2% in December 2007, to 54.5% today. This is probably not because so many kids under the age of 25 are disabled, I suspect. If you look at the overall labor participation rate, it’s dropped from 66.0 in December 2007 to 63.3 in March 2013. Most of the people who have left the work force are also not disabled. They’ve been discouraged for some other mysterious reason. I’m gonna go ahead and guess it’s because they can’t find a job.
This leads me to ask the following question from the journalists LESLIE SCISM and JON HILSENRATH who wrote the article: Where is your evidence of causation??
Here’s another example from the article of a seriously fucked-up understanding of cause and effect:
With overall participation down, the labor force—a measure of people working and people looking for work—is barely growing.
They consistently paint the picture whereby people decide to stop working, and then yucky things happen, in this case the labor force stops growing. Damn those lazy people.
They even bring in a fancy word from physics to describe the problem, namely hysteresis. Now, they didn’t understand or correctly define the term, but it doesn’t really matter, because the point of using a fancy term from physics was not to add to the clarity of the argument but rather to impress.
The goal here is, in fact, that if enough economists use sophisticated language to describe the various effects, we will all be able to blame people with bad backs, making $13.6K per year, on why our economy sucks, rather than the rich assholes in finance who got us into this mess and are currently buying $2 million dollar personal offices instead of going to jail.
Just to be clear, that’s $1,130 a month, which I guess represents so enticing a lifestyle that the people currently enjoying it ‘are “pretty unlikely to want to forfeit economic security for a precarious job market”‘ according to M.I.T. economist David Autor. I’d love to have David Autor spell out, for us, exactly what’s economically secure about that kind of monthly check.
The rest of the article is in large part a description of how people get onto SSDI, insinuating that the people currently on it are not really all that disabled or worthy of living high on the hog, and are in any case never ever leaving.
How’s this for a slightly different take on the situation: there are of course some people who are faking something, that’s always the case. But in general, the people on SSDI need to be there, and before the recession might have had the kind of employers who kept them on even though they often called in sick, out of loyalty and kindness, because they didn’t want to fire them. But when the recession struck those employers had to cut them off, or they went out of business completely. Now those people can’t find work and don’t have many options. In other words, the recession caused the SSDI program to grow. That doesn’t mean it caused a bunch of people to get sick, but it does mean that sick people are more dependent on SSDI because there are fewer options.
By the way, read the comments of this article, there are some really good ones (“What were people with injuries and no high-value job skills to do? Is the number of people in the social security disability program the problem or the symptom?”) as well as some really outrageous ones (‘The current situation makes the picture of the “Welfare Queen” of the 1980s look like an honest citizen’).
Tweenage angst, RSS feeds, and upcoming talks
Tweenage angst
Do you remember when you were just entering puberty, and absolutely everything was embarrassing? Even your mere existence twisted you in agony?
Well, I just brought my nearly-11-year-old and just-barely-13-year-old sons to their yearly checkups, and let me tell you, it’s painful to be within 10 feet of such exquisite awkwardness: how can you poke and prod this body to some universal understanding of science if I don’t even know its functions or potential grace? If I can’t even imagine it ever being graceful??
RSS feeds
I deleted a post (“Papers I’ve been reading lately”) which had some offending unknown characters that WordPress couldn’t handle, and most people can now read mathbabe again on their readers, except for some reason for people who read mathbabe via WordPress itself. My advice to those people: start using some other reader. Maybe feedly?
Upcoming talks
I’m giving three talks in the next two weeks.
- The first one is this Thursday at the Cornell math department, where I’m once again talking about Weapons of Math Destruction.
- The second one is in Emanuel Derman’s Financial Engineering Practitioner’s Seminar next Monday at Columbia, where I’ll talk about recommendation systems and MapReduce, taking material from Doing Data Science, specifically the chapters contributed by Matt Gattis and David Crawshaw.
- Finally, I’ll be giving the NYC Machine Learning Meetup next Thursday. The announcement of this
is going to be posted some time later this morningis now up, and the content will be similar to the Columbia talk.
Elizabeth Fischer talks about climate modeling at Occupy today
I’m really excited to be going to the pre-meeting talk of my Occupy group today. We’re having a talk by Elizabeth Fischer, who is a post-doc at NASA GISS, a laboratory focused largely on climate change up here in the Columbia neighborhood.
She is coming to talk with us about her work investigating the long-term behavior of ice sheets in a changing climate. Before joining GISS, Dr. Fischer was a quant on Wall Street, working on statistical arbitrage, trade execution, simulation/modeling platforms, signal development, and options trading. I met her when we were both students at math camp in 1988, but we reconnected this past summer at the reunion.
The actual title of her talk is “The History of CO2: Past, Present and Future” and it’s open to the public, so please come if you can (it’s at 2:00 pm in room 409 here but more details are here).
After Elizabeth, we’ll be having our usual Occupy meeting. Topics this week include our plans for a Citigroup and HSBC picket later this month, our panel submissions to the Left Forum in June, our plans for May Day, and continued work on writing a book modeled after the Debt Resistor’s Operations Manual.
Housekeeping – RSS feed for mathbabe broken, possibly fixed
I’ve been trying to address the problem people have been having with their RSS feed for mathbabe. Thanks to my nerd-girl friend Jennifer Rubinovitz, I’ve changed some settings in my WordPress settings and now I can view all of my posts when I open up RSSOwl. But in order for your reader to get caught up I have a feeling you’ll need to somehow refresh it or maybe get rid of mathbabe and then re-subscribe. I’ll update as I learn more (please tell me what’s working for you!).
Aunt Pythia’s advice
Aunt Pythia is excited to discuss the following topics today: sex with students, how to get men to stop trivializing women near you, and how to feel attractive.
Did you expect and hope for something less titillating? Then please unsubscribe from my RSS feed immediately (speaking of which, can someone help me give advice to people getting bumped off of Google Reader? How do you get your daily dose of mathbabe? Please comment below).
If you don’t know what you’re in for, go here for past advice columns and here for an explanation of the name Pythia. Most importantly,
Please submit your smutty sex questions at the bottom of this column!
——
Dear Aunt Pythia,
I teach online using a chat-based tutoring system, which creates some interesting situations. I get a lot of comments from students like, “hey, you’re hot, let’s hookup tonite.” I don’t take them up on those requests for many reasons, including
- I don’t want to get fired,
- I don’t want to go to jail,
- I’m in a happily committed relationship,
- I don’t get paid enough to make last minute cross-country flights,
- I already have enough people and activities vying for my spare time.
I usually just write boring stuff like “please focus on your lesson” or “sorry, I’m not allowed to do that.” But, just for fun, and assuming the students were of legal age, etc, what does a math-babe say when a student asks to hook up or hang out, whether virtually or face-to-face?
Might Actually Teach Humans
Dear MATH,
From your concerns about going to jail, which seem to be alleviated in the scenario where the student is old enough, I’m going to assume you tutor high school students as well as older students. If this is the case, then let me congratulate you on making the wise decision to avoid such opportunities. High school students are best left to each other, with a bunch of well-meaning advice, a few copies of “Our Bodies, Ourselves,” and boxes and boxes of condoms.
For that matter, the same could be said about college-age students. Leave those guys alone too, they’re still developing.
With that, I’ll assume that you and the student in question are both grownups, i.e. about 23 or older. And for the sake of this question I’ll assume that you’re not a college professor teaching grad students, since I don’t want to become an expert on the nationwide norms of professorial conduct this morning.
Even so, if you are formally teaching a student in any capacity, and thus responsible for their grade and/or feedback, then I’d certainly expect you to avoid expressing romantic or sexual interest in your student until after the grades are turned in, lest it be construed as creepy pressure for a good grade. But even then it might not be ok – what if you might someday write them a letter of recommendation? In that case a romantic relationship would make that extremely difficult. I’d say that the formal relationship of teacher-student pretty much rules out sex for quite a while. I’m not saying it never happens, obviously, but it’s best to avoid.
Now, to your situation: you’re a tutor. You’re a grownup. The students you teach are grownups. There’s presumably no grade given by a tutor, and considering it’s chat-based and online, there might be an army of tutors that the student can turn to if they decide you’re bad in bad (true? about the army, not about you being bad in bed). I really don’t see a problem here.
That’s not a green flag to start flirting with all of your students, that would be creepy and weird and could easily get you fired. Don’t be creepy.
I hope that helps!
Aunt Pythia
——
Dear Aunt Pythia,
I have a history of my male friends talking to me about women they are dating in a way that makes me feel unattractive. I can think of (at least) two things that contribute to my feeling unattractive:
- I assume if they thought I was attractive, they wouldn’t talk to me about other women.
- They talk about other women in simplifying terms that seems to reduce women down to a few dimensions of attractiveness (skinny, high heels, dumb, girly and deferential), and I don’t fit into the space they’ve defined.
What do I do to make this stop?
Feeling Unattractive, Chasing Knowledge
Dear FUCK,
Sounds like you hang out with a bunch of dudes who have forgotten the golden rule of PUA’s (Pick-Up Artists), namely don’t share the secrets!!
Just kidding – PUA’s love sharing their secrets, because it gives them yet another chance to brag about their conquests.
I’m really glad you wrote. It pisses me off when the nasty way a given man thinks about women and sex leaks onto other people. Especially because this trivializing posture towards women is actually an silly act of self-defense and insecurity on the part of the man you’re hanging out with. It’s not enough that they feel insecure, they’ve got to make everyone around them that way too. Lame.
By the way, I’m not at all sure that, if a man starts talking about sex with other women around you, that’s he’s not also interested in you. It might be his awkward, awful way of expressing interest. But that doesn’t mean it’s meant to make you feel attractive. It sounds like one of his ways of getting laid is by making women feel unattractive and trivial. It might even be a script he wishes you to follow. Not cool.
Here are some options you have:
- Next time you’re in the conversation with him, you might anticipate his modus operandi and start talking about sexual attraction before he does. You could, for example, talk about attributes you honestly like in men like, say, the strength of ego not to trivialize women.
- Another possibility is you could talk to him directly about this issue (assuming he’s an important enough friend of yours that you’re willing to go there). Tell him that, when he trivializes women around you, it makes you feel unattractive, and you’re pretty sure that it’s unintentional but in any case you’re wondering why he does it. You might want to ask him how he’d feel if you did the same thing in terms of men.
- Another possibility is you could just up and tell him you don’t want to hear about his conquests.
- Finally, you could just find other men to hang out with who have figured out honest and direct ways to deal with women. Maybe because they’re not from an English-speaking country.
Good luck!
Auntie P
——
Dear Aunt Pythia,
I walk around society feeling unattractive and I don’t know what signals to look for in my interactions with other people that they think I am attractive. I’m not looking for Glamour Magazine kind of advice. But Aunt Pythia kind of advice. How do I know if other people find me attractive? I assume for the most part they don’t.
Feeling Unattractive, Chasing Knowledge, I Need Guidance
Dear FUCKING,
Good questions this week! I’ve come up with an idea which I hope will help.
Namely, I think one of the main ways women get feedback about their attractiveness is through other women. For whatever reasons (some of them no doubt reasonable, some of them not), our culture deems it inappropriate for men to go up to women with direct feedback on their attractiveness. But girlfriends can play this role, especially if you ask them to.
So my first piece of advice is, if you’re looking for feedback and advice on your attractiveness, go ask your girlfriends.
That’s not to say all girlfriends are created equal. There are some girlfriends that are competitive and jealous of their friends, and will give you weird advice that makes you think you need to be skinny, high heeled, dumb, girly and deferential to be attractive, kinda like the douchey man you talked to above. These bad girlfriends, by the way, are also the women who write the advice tips for Glamour Magazine. It’s a bad sign if they tell you about a great diet they heard of.
The kind of girlfriend you’re looking for is the kind that, when you express ambivalence about your attractiveness, instantly proclaims you hot as hell and offers to take you out shopping for clothes that show off your boobs (or some other body part of which you’re particularly proud). Or better yet, whips out the nearest catalog and goes through it page-by-page with you, showing you what to look for that will flatter your incredible body.
Good luck finding yourself some awesome girlfriends!
Love,
Aunt Pythia
——
Please please please submit questions!
Guest post by Julia Evans: How I got a data science job
This is a guest post by Julia Evans. Julia is a data scientist & programmer who lives in Montréal. She spends her free time these days playing with data and running events for women who program or want to — she just started a Montréal chapter of pyladies to teach programming, and co-organize a monthly meetup called Montréal All-Girl Hack Night for women who are developers.
I asked mathbabe a question a few weeks ago saying that I’d recently started a data science job without having too much experience with statistics, and she asked me to write something about how I got the job. Needless to say I’m pretty honoured to be a guest blogger here 🙂 Hopefully this will help someone!
Last March I decided that I wanted a job playing with data, since I’d been playing with datasets in my spare time for a while and I really liked it. I had a BSc in pure math, a MSc in theoretical computer science and about 6 months of work experience as a programmer developing websites. I’d taken one machine learning class and zero statistics classes.
In October, I left my web development job with some savings and no immediate plans to find a new job. I was thinking about doing freelance web development. Two weeks later, someone posted a job posting to my department mailing list looking for a “Junior Data Scientist”. I wrote back and said basically “I have a really strong math background and am a pretty good programmer”. This email included, embarrassingly, the sentence “I am amazing at math”. They said they’d like to interview me.
The interview was a lunch meeting. I found out that the company (Via Science) was opening a new office in my city, and was looking for people to be the first employees at the new office. They work with clients to make predictions based on their data.
My interviewer (now my manager) asked me about my role at my previous job (a little bit of everything — programming, system administration, etc.), my math background (lots of pure math, but no stats), and my experience with machine learning (one class, and drawing some graphs for fun). I was asked how I’d approach a digit recognition problem and I said “well, I’d see what people do to solve problems like that, and I’d try that”.
I also talked about some data visualizations I’d worked on for fun. They were looking for someone who could take on new datasets and be independent and proactive about creating model, figuring out what is the most useful thing to model, and getting more information from clients.
I got a call back about a week after the lunch interview saying that they’d like to hire me. We talked a bit more about the work culture, starting dates, and salary, and then I accepted the offer.
So far I’ve been working here for about four months. I work with a machine learning system developed inside the company (there’s a paper about it here). I’ve spent most of my time working on code to interface with this system and make it easier for us to get results out of it quickly. I alternate between working on this system (using Java) and using Python (with the fabulous IPython Notebook) to quickly draw graphs and make models with scikit-learn to compare our results.
I like that I have real-world data (sometimes, lots of it!) where there’s not always a clear question or direction to go in. I get to spend time figuring out the relevant features of the data or what kinds of things we should be trying to model. I’m beginning to understand what people say about data-wrangling taking up most of their time. I’m learning some statistics, and we have a weekly Friday seminar series where we take turns talking about something we’ve learned in the last few weeks or introducing a piece of math that we want to use.
Overall I’m really happy to have a job where I get data and have to figure out what direction to take it in, and I’m learning a lot.
K-Nearest Neighbors: dangerously simple
I spend my time at work nowadays thinking about how to start a company in data science. Since there are tons of companies now collecting tons of data, and they don’t know what do to do with it, nor who to ask, part of me wants to design (yet another) dumbed-down “analytics platform” so that business people can import their data onto the platform, and then perform simple algorithms themselves, without even having a data scientist to supervise.
After all, a good data scientist is hard to find. Sometimes you don’t even know if you want to invest in this whole big data thing, you’re not sure the data you’re collecting is all that great or whether the whole thing is just a bunch of hype. It’s tempting to bypass professional data scientists altogether and try to replace them with software.
I’m here to say, it’s not clear that’s possible. Even the simplest algorithm, like k-Nearest Neighbor (k-NN), can be naively misused by someone who doesn’t understand it well. Let me explain.
Say you have a bunch of data points, maybe corresponding to users on your website. They have a bunch of attributes, and you want to categorize them based on their attributes. For example, they might be customers that have spent various amounts of money on your product, and you can put them into “big spender”, “medium spender”, “small spender”, and “will never buy anything” categories.
What you really want, of course, is a way of anticipating the category of a new user before they’ve bought anything, based on what you know about them when they arrive, namely their attributes. So the problem is, given a user’s attributes, what’s your best guess for that user’s category?
Let’s use k-Nearest Neighbors. Let k be 5 and say there’s a new customer named Monica. Then the algorithm searches for the 5 customers closest to Monica, i.e. most similar to Monica in terms of attributes, and sees what categories those 5 customers were in. If 4 of them were “medium spenders” and 1 was “small spender”, then your best guess for Monica is “medium spender”.
Holy shit, that was simple! Mathbabe, what’s your problem?
The devil is all in the detail of what you mean by close. And to make things trickier, as in easier to be deceptively easy, there are default choices you could make (and which you would make) which would probably be totally stupid. Namely, the raw numbers, and Euclidean distance.
So, for example, say your customer attributes were: age, salary, and number of previous visits to your website. Don’t ask me how you know your customer’s salary, maybe you bought info from Acxiom.
So in terms of attribute vectors, Monica’s might look like:

And the nearest neighbor to Monica might look like:
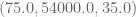
In other words, because you’re including the raw salary numbers, you are thinking of Monica, who is 22 and new to the site, as close to a 75-year old who comes to the site a lot. The salary, being of a much larger scale, is totally dominating the distance calculation. You might as well have only that one attribute and scrap the others.
Note: you would not necessarily think about this problem if you were just pressing a big button on a dashboard called “k-NN me!”
Of course, it gets trickier. Even if you measured salary in thousands (so Monica would now be given the attribution vector 
Another problem is redundancy – if you have a bunch of attributes that are essentially redundant, i.e. that are highly correlated to each other, then including them all is tantamount to multiplying the scale of that factor.
Another problem is not all your attributes are even numbers, so you have string attributes. You might think you can solve this by using 0’s and 1’s, but in the case of k-NN, that becomes just another scaling problem.
One way around this might be to first use some kind of dimension-reducing algorithm, like PCA, to figure out what attribute combinations to actually use from the get-go. That’s probably what I’d do.
But that means you’re using a fancy algorithm in order to use a completely stupid algorithm. Not that there’s anything wrong with that, but it indicates the basic problem, which is that doing data analysis carefully is actually pretty hard and maybe should be done by professionals, or at least under the supervision of a one.
We don’t need more complicated models, we need to stop lying with our models
The financial crisis has given rise to a series of catastrophes related to mathematical modeling.
Time after time you hear people speaking in baffled terms about mathematical models that somehow didn’t warn us in time, that were too complicated to understand, and so on. If you have somehow missed such public displays of throwing the model (and quants) under the bus, stay tuned below for examples.
A common response to these problems is to call for those models to be revamped, to add features that will cover previously unforeseen issues, and generally speaking, to make them more complex.
For a person like myself, who gets paid to “fix the model,” it’s tempting to do just that, to assume the role of the hero who is going to set everything right with a few brilliant ideas and some excellent training data.
Unfortunately, reality is staring me in the face, and it’s telling me that we don’t need more complicated models.
If I go to the trouble of fixing up a model, say by adding counterparty risk considerations, then I’m implicitly assuming the problem with the existing models is that they’re being used honestly but aren’t mathematically up to the task.
But this is far from the case – most of the really enormous failures of models are explained by people lying. Before I give three examples of “big models failing because someone is lying” phenomenon, let me add one more important thing.
Namely, if we replace okay models with more complicated models, as many people are suggesting we do, without first addressing the lying problem, it will only allow people to lie even more. This is because the complexity of a model itself is an obstacle to understanding its results, and more complex models allow more manipulation.
Example 1: Municipal Debt Models
Many municipalities are in shit tons of problems with their muni debt. This is in part because of the big banks taking advantage of them, but it’s also in part because they often lie with models.
Specifically, they know what their obligations for pensions and school systems will be in the next few years, and in order to pay for all that, they use a model which estimates how well their savings will pay off in the market, or however they’ve invested their money. But they use vastly over-exaggerated numbers in these models, because that way they can minimize the amount of money to put into the pool each year. The result is that pension pools are being systematically and vastly under-funded.
Example 2: Wealth Management
I used to work at Riskmetrics, where I saw first-hand how people lie with risk models. But that’s not the only thing I worked on. I also helped out building an analytical wealth management product. This software was sold to banks, and was used by professional “wealth managers” to help people (usually rich people, but not mega-rich people) plan for retirement.
We had a bunch of bells and whistles in the software to impress the clients – Monte Carlo simulations, fancy optimization tools, and more. But in the end, the banks and their wealth managers put in their own market assumptions when they used it. Specifically, they put in the forecast market growth for stocks, bonds, alternative investing, etc., as well as the assumed volatility of those categories and indeed the entire covariance matrix representing how correlated the market constituents are to each other.
The result is this: no matter how honest I would try to be with my modeling, I had no way of preventing the model from being misused and misleading to the clients. And it was indeed misused: wealth managers put in absolutely ridiculous assumptions of fantastic returns with vanishingly small risk.
Example 3: JP Morgan’s Whale Trade
I saved the best for last. JP Morgan’s actions around their $6.2 billion trading loss, the so-called “Whale Loss” was investigated recently by a Senate Subcommittee. This is an excerpt (page 14) from the resulting report, which is well worth reading in full:
While the bank claimed that the whale trade losses were due, in part, to a failure to have the right risk limits in place, the Subcommittee investigation showed that the five risk limits already in effect were all breached for sustained periods of time during the first quarter of 2012. Bank managers knew about the breaches, but allowed them to continue, lifted the limits, or altered the risk measures after being told that the risk results were “too conservative,” not “sensible,” or “garbage.” Previously undisclosed evidence also showed that CIO personnel deliberately tried to lower the CIO’s risk results and, as a result, lower its capital requirements, not by reducing its risky assets, but by manipulating the mathematical models used to calculate its VaR, CRM, and RWA results. Equally disturbing is evidence that the OCC was regularly informed of the risk limit breaches and was notified in advance of the CIO VaR model change projected to drop the CIO’s VaR results by 44%, yet raised no concerns at the time.
I don’t think there could be a better argument explaining why new risk limits and better VaR models won’t help JPM or any other large bank. The manipulation of existing models is what’s really going on.
Just to be clear on the models and modelers as scapegoats, even in the face of the above report, please take a look at minute 1:35:00 of the C-SPAN coverage of former CIO head Ina Drew’s testimony when she’s being grilled by Senator Carl Levin (hat tip Alan Lawhon, who also wrote about this issue here).
Ina Drew firmly shoves the quants under the bus, pretending to be surprised by the failures of the models even though, considering she’d been at JP Morgan for 30 years, she might know just a thing or two about how VaR can be manipulated. Why hasn’t Sarbanes-Oxley been used to put that woman in jail? She’s not even at JP Morgan anymore.
Stick around for a few minutes in the testimony after Levin’s done with Drew, because he’s on a roll and it’s awesome to watch.
Guest post: Divest from climate change
This is a guest post by Akhil Mathew, a junior studying mathematics at Harvard. He is also a blogger at Climbing Mount Bourbaki.
Climate change is one of those issues that I heard about as a kid, and I assumed naturally that scientists, political leaders, and the rest of the world would work together to solve it. Then I grew up and realized that never happened.
Carbon dioxide emissions are continuing to rise and extreme weather is becoming normal. Meanwhile, nobody in politics seems to want to act, even when major scientific organizations — and now the World Bank — have warned us in the strongest possible terms that the current path towards 
A little frustrated, I decided to show up last fall at my school’s umbrella environmental group to hear about the various programs. Intrigued by a curious-sounding divestment campaign, I went to the first meeting. I had zero knowledge of or experience with the climate movement, and did not realize what it was going to become.
Divestment from fossil fuel companies is a simple and brilliant idea, popularized by Bill McKibben’s article “Global Warming’s Terrifying New Math.” As McKibben observes, there are numerous reasons to divest, both ethical and economic. The fossil fuel reserves of these companies — a determinant of their market value — are five(!) times what scientists estimate can be burned to stay within 2 degree warming.
Investing in fossil fuels is therefore a way of betting on climate change. It’s especially absurd for universities to invest in them, when much of the research on climate change took place there. The other side of divestment is symbolic. It’s not likely that Congress will be able to pass a cap-and-trade or carbon tax system anytime soon, especially when fossil fuel companies are among the biggest contributors to political campaigns.
A series of university divestments would draw attention to the problem. It would send a message to the world: that fossil fuel companies should be shunned, for basing their business model on climate change and then for lying about its dangers. This reason echoes the apartheid divestment campaigns of the 1980s. With support from McKibben’s organization 350.org, divestment took off last fall to become a real student movement, and today, over 300 American universities have active divestment campaigns from their students. Four universities — Unity College, Hampshire College, Sterling College, and College of the Atlantic — have already divested. Divestment is spreading both to Canadian universities and to other non-profit organizations. We’ve been covered in the New York Times, endorsed by Al Gore, and, on the other hand, recently featured in a couple of rants by Fox News.
Divest Harvard
At Harvard, we began our fall semester with a small group of us quietly collecting student petition signatures, mostly by waiting outside the dining halls, but occasionally by going door-to-door among dorms. It wasn’t really clear how many people supported us: we received a mix of enthusiasm, indifference, and occasional amusement from other students.
But after enough time, we made it to 1,000 petition signatures. That was enough to allow us to get a referendum on the student government ballot. The ballot is primarily used to elect student government leaders, but it was our campaign that rediscovered the use of referenda as a tool of student activism. (Following us, two other worthy campaigns — one on responsible investment more generally and one about sexual assault — also created their own referenda.)
After a week of postering and reaching out to student groups, our proposition—that Harvard should divest—won with 72% of the undergraduate student vote. That was a real turning point for us. On the one hand, having people vote on a referendum isn’t the same as engaging in the one-on-one conversations that we did when convincing people to sign our petition. On the other hand, the 72% showed that we had a real majority in support.
The statistic was quickly picked up by the media, since we were the first school to win a referendum on divestment (UNC has since had a winning referendum with 77% support). That was when the campaign took off. People began to take us seriously.
The Harvard administration, which had previously said that they had no intention of considering divestment, promised a serious, forty-five minute meeting with us. We didn’t get what we had aimed for — a private meeting with President Drew Faust — but we had acquired legitimacy from the administration. We were hopeful that we might be able to negotiate a compromise, and ended our campaign last fall satisfied, plotting the trajectory of our campaign at our final meeting.

The spring semester started with a flurry of additional activity and new challenges. On the one hand, we had to plan for the meeting with the administration—more precisely, the Corporation Committee on Social Responsibility. (The CCSR is the subgroup of the Harvard Corporation that decides on issues such as divestment.)
But we also knew that the fight couldn’t be won solely within the system. We had to work on building support on campus, from students and faculty, with rallies and speakers; we also had to reach out to alumni and let them know about our campaign. Fortunately, the publicity generated last semester had brought in a larger group of committed students, and we were able to split our organization into working groups to handle the greater responsibilities.
In Februrary, we got our promised meeting with three members the administration. With three representatives from our group meeting with the CCSR, we had a rally with about 40 people outside to show support:
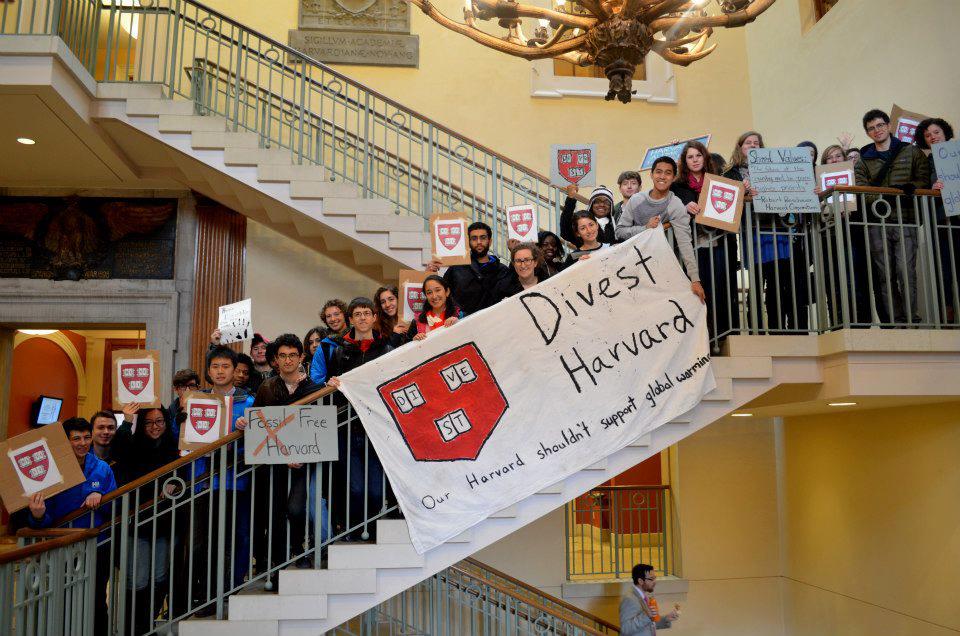
In the meeting, the administration representatives reiterated their concern about climate change, but questioned divestment as a tool.
Unfortunately, since the meeting, they have continued to reiterate their “presumption against divestment” (a phrase they have used with previous movements). This is the debate we—and students across the nation—are going to have to win.
Divestment alone isn’t going to slow the melting of the Arctic, but it’s a powerful tool to draw attention to climate change and force action from our political system—as it did against apartheid in the 1980s.
And there isn’t much time left. One of the most inspirational things I’ve heard this semester was at the Forward on Climate rally in Washington, D.C. last month, which most of our group attended. Addressing a crowd of 40,000 people, Bill McKibben said “All I ever wanted to see was a movement of people to stop climate change, and now I’ve seen it.”
To me, that’s one of the exciting and hopeful aspects about divestment—that it’s a movement of the people. It’s fundamentally an issue of social justice that we’re facing, and our group’s challenge is to convince Harvard to take it seriously enough to stand up against the fossil fuel industry.
In the meantime, our campaign has been trying to build support from student groups, alumni, and faculty. In a surprise turnaround, one of our members convinced alumnus Al Gore to declare his support for the divestment movement at a recent event on campus. We organized a teach-in the Tuesday before last featuring writer and sociologist Juliet Schor.
On April 11, we will be holding a large rally outside Massachusetts Hall to close out the year and to show support for divestment; we’ll be presenting our petition signatures to the administration. Here’s our most recent picture, taken for the National Day of Action, with some supportive friends from the chess club:

Thanks to Joseph Lanzillo for proofreading a draft of this post.
Giving isn’t the secret
I don’t know if you read this article (h/t Radhika Sainath) on a hyperactive professor and Organizational Psychology researcher, Adam Grant, who always helps people when they ask and has a theory about giving. He claims that generous giving is the answer to getting ahead and feeling and being successful.
Well, as a “strategic giver” myself, let me tell you that giving isn’t the way to get ahead. Not as expressed by Grant, anyway*.
If you look carefully at the story, it reveals a bunch of things. Here are a few of them:
- Grant has a stay-at-home wife who deals with the kids all the time. Even so, she doesn’t seem all that psyched about how much time he devotes to helping other people (“Sometimes I tell him, ‘Adam — just say no,’ ”).
- He works all the time and misses sleep to get stuff done.
- He engages in high-profile strategic helping – he helps colleagues and students.
- Moreover, he does it in exaggerated and dramatic ways, leading to people talking about him and thanking him profusely, generally giving him attention.
- Considering that his area of research is how to get people to work hard and be more efficient through helping each other, this attention directly in line with his goal of gaining status.
- Just to be clear, he isn’t researching how to get other people to have high status like him, but rather how to get people to work harder in boring-ass jobs.
Put it all together, and you’ve got this disconnect between the way he applies “helping” to himself and to the subjects in his research.
He researches people in call centers, for example, and figures out how to get them to really believe in their work by seeing someone who benefitted from the associated scholarship program. But working harder doesn’t get them more status, it just makes them tired. The other examples in the article are similar. Actually some of them get grosser. Here’s a tasty excerpt from the article:
Jerry Davis, a management professor who taught Grant at the University of Michigan and is generally a fan of [Adam Grant]’s work, couldn’t help making a pointed critique about its inherent limits when they were on a panel together: “So you think those workers at the Apple factory in China would stop committing suicide if only we showed them someone who was incredibly happy with their iPhone?”
So what does he means by “giving” when he’s considering other people? Working really hard in a dead-end job? Kinda reminds me of this review of Sheryl Sandberg’s “Lean In” book, written by ex-Facebook disgruntled speech writer Kate Losse. Here’s my favorite line from that bitter essay:
For Sandberg, pregnancy must be converted into a corporate opportunity: a moment to convince a woman to commit further to her job. Human life as a competitor to work is the threat here, and it must be captured for corporate use, much in the way that Facebook treats users’ personal activities as a series of opportunities to fill out the Facebook-owned social graph.
In other words, Grant, like Sandberg, is selling us a message of working really hard with the underlying promise that it will make us successful, especially if we do it because we just love working really hard.
What?
First, it really matters what you work on and who you are helping. If you are not a strategic helper, you end up wasting your time for no good reason. How many times have we seen people who end up doing their job plus someone else’s job, without any thanks or extra money?
If you work really hard on a project which nobody cares about, nobody appreciates it. True.
And if you aren’t a political animal, able to smell out the projects and people that are worth working on extra hard and helping, then you’re pretty much out of luck.
But let’s take one step back from the terrible advice being given by Grant and Sandberg. What are their actual goals? Is it possible that they really think just by working extra hard at whatever shit corporate job we have will leave us successful and fulfilled? Are they that blind to other people’s options? Do they really know nobody in their private lives who found fulfillment by quitting their dead-end corporate job and became a poor but happy poet?
Here’s what Kate Losse says, and I think she hit the nail on the head:
Sandberg is betting that for some women, as for herself, the pursuit of corporate power is desirable, and that many women will ramp up their labor ever further in hopes that one day they, too, will be “in.” And whether or not those women make it, the companies they work for will profit by their unceasing labor.
Similarly, Grant’s personal academic success comes from getting people to work harder. His incentive is to get you to work harder, not be fulfilled. Just to be clear.
* I actually do think giving is a wonderful thing, but certainly not exclusively at work, and it’s not a secret.
Value-added model doesn’t find bad teachers, causes administrators to cheat
There’ve been a couple of articles in the past few days about teacher Value-Added Testing that have enraged me.
If you haven’t been paying attention, the Value-Added Model (VAM) is now being used in a majority of the states (source: the Economist):

But it gives out nearly random numbers, as gleaned from looking at the same teachers with two scores (see this previous post). There’s a 24% correlation between the two numbers. Note that some people are awesome with respect to one score and complete shit on the other score:

Final thing you need to know about the model: nobody really understands how it works. It relies on error terms of an error-riddled model. It’s opaque, and no teacher can have their score explained to them in Plain English.
Now, with that background, let’s look into these articles.
First, there’s this New York Times article from yesterday, entitled “Curious Grade for Teachers: Nearly All Pass”. In this article, it describes how teachers are nowadays being judged using a (usually) 50/50 combination of classroom observations and VAM scores. This is different from the past, which was only based on classroom observations.
What they’ve found is that the percentage of teachers found “effective or better” has stayed high in spite of the new system – the numbers are all over the place but typically between 90 and 99 percent of teachers. In other words, the number of teachers that are fingered as truly terrible hasn’t gone up too much. What a fucking disaster, at least according to the NYTimes, which seems to go out of its way to make its readers understand how very much high school teachers suck.
A few things to say about this.
- Given that the VAM is nearly a random number generator, this is good news – it means they are not trusting the VAM scores blindly. Of course, it still doesn’t mean that the right teachers are getting fired, since half of the score is random.
- Another point the article mentions is that failing teachers are leaving before the reports come out. We don’t actually know how many teachers are affected by these scores.
- Anyway, what is the right number of teachers to fire each year, New York Times? And how did you choose that number? Oh wait, you quoted someone from the Brookings Institute: “It would be an unusual profession that at least 5 percent are not deemed ineffective.” Way to explain things so scientifically! It’s refreshing to know exactly how the army of McKinsey alums approach education reform.
- The overall article gives us the impression that if we were really going to do our job and “be tough on bad teachers,” then we’d weight the Value-Added Model way more. But instead we’re being pussies. Wonder what would happen if we weren’t pussies?
The second article explained just that. It also came from the New York Times (h/t Suresh Naidu), and it was a the story of a School Chief in Atlanta who took the VAM scores very very seriously.
What happened next? The teachers cheated wildly, changing the answers on their students’ tests. There was a big cover-up, lots of nasty political pressure, and a lot of good people feeling really bad, blah blah blah. But maybe we can take a step back and think about why this might have happened. Can we do that, New York Times? Maybe it had to do with the $500,000 in “performance bonuses” that the School Chief got for such awesome scores?
Let’s face it, this cheating scandal, and others like it (which may never come to light), was not hard to predict (as I explain in this post). In fact, as a predictive modeler, I’d argue that this cheating problem is the easiest thing to predict about the VAM, considering how it’s being used as an opaque mathematical weapon.
Aunt Pythia’s advice
Many thanks to Aunt Orthoptera for her fascinating, insect-related advice from last week.
Aunt Pythia is psyched to be back, is psyched to refer to herself in the third person, and is psyched to continue her sex and dating advice far beyond what anyone asked for or wants.
If you don’t know what you’re in for, go here for past advice columns and here for an explanation of the name Pythia. Most importantly,
Please submit your smutty sex questions at the bottom of this column!
——
Aunt Pythia,
After how long without any sign of interest from any member of the (or an) appropriate sex should you give up on trying to date? Also, how do you get over a crush on someone who likes you as a friend and who you want to be friends with when breaking off contact is not an option?
Forever Alone Probably
Dear FAP,
Thank you so much for the question. Over my vacation I read The Game: Penetrating the Secret Society of Pickup Artists by Neil Strauss and I’m dying to talk about it. You’ve given me the perfect excuse to do just that!
According to the book, if you’re a man, you should do a bunch of things to get laid with “really hot chicks”, among them:
- Get used to people saying no to you – don’t dwell on one relationship.
- Dress and appear confident, which means think about how your appearance and actions come off to other people.
- Ignore your “target” (i.e. the really hot chick you’re interested in) until you’ve …
- won the admiration of the alpha male of the group by doing magic tricks (no shit).
- Learn how to “neg” your target once you deign to pay attention to her, which means insult her in playful (read: obnoxious) ways such as (not a hyperbole) carrying around a piece of lint so you can pretend you found it on her outfit and then say, “How long has this been on your shoulder?”
- Once you have her attention, have interesting things to say and…
- generally pay her attention and know how to talk.
- Make it clear that you’re interested in continuing to spend time with her (without be creepy).
Here’s my take on this weird and disturbing set of instructions: it’s not rocket science that it works but it’s unduly evil.
The pick-up artists who studied up and tested out these techniques collected a lot of data and tried out a lot of things. They started out completely dweeby and socially awkward and ended up being able to hold a conversation with a women in a nightclub. They were essentially on-the-ground data scientists.
But they made a classic mistake of data scientists, namely they overfit. They came to the conclusion that they needed to do magic tricks and be assholes to get laid. But just because that didn’t prevent them from getting laid, it doesn’t mean they needed to do that. My theory is that it was a replacement for actually having something interesting to say.
Let me give advice to anyone, man or woman, that I think will help you in terms of meeting people and dating. In fact, this is also my advice for people who aren’t interested in dating but who want to be able to engage socially in any situation.
It’s easy – I’ll just add one thing they forgot about (having a life) and which they replaced by a bunch of unnecessary, stupid and quasi-evil shit:
- Get used to people saying no to you – don’t dwell on one relationship (unless it’s making you happy to do so!).
- Dress and appear confident, which means think about how your appearance and actions come off to other people.
- Work on being an interesting person with cool life goals.
- Once you have someone’s attention, have interesting things to say and…
- generally pay attention to that person and know how to talk.
- Make it clear that you’re interested in continuing to spend time with that person (without be creepy).
Now, to answer your questions.
I don’t think you should give up if you’re actually interested in dating. But I do think you should think about getting over your crush, or at least ignoring your crush sometimes (not the person, the feelings) so that you actually allow yourself to meet other people and find them fascinating. Otherwise, like it or not, you’ll close yourself off to new people and experiences.
Next, keep in mind that the most exciting things to whatever new person you’ve just met is that a) you’re interested in them, b) you’re paying attention to them, and c) you want to spend more time with them whilst d) you’re an interesting person with cool life goals.
About the crush: it won’t seem tragic to have a crush on someone who doesn’t reciprocate when you also have other romantic relationships brewing. In fact it’ll seem cool and awesome to be near someone that attractive.
I hope that helps!
Aunt Pythia
——
Dear Aunt Pythia,
I’ve sometimes noticed on receipts instead of just a single charge for something, a single charge plus a duplicate, plus a credit to nullify the duplicate. This has happened often enough to make me suspicious that these duplicate/credits aren’t appearing by accident. I’ve only noticed it happening at venues owned by large corporations. The most recent occurrence was a checking deposit at a bank, that appeared in duplicate on my statement along with the usual credit/retraction. I wonder, do these fake transactions serve some books-cooking purpose?
Curious Observer-Participant
Dear COP,
I’ve decided to answer this question even though it has nothing to do with sex because, first of all, it’s a fascinating observation and second of all, I think it could do with a bit of data collecting.
Readers, please check your receipts for the next few days for this weird phenomenon. And accountant readers, please explain this weird phenomenon if it does indeed indicate a book-cooking purpose.
Auntie P
——
Dear Aunt Orthoptera,
I have spent the last couple of years modelling the beheavioural neuroscience behind the always respectable Acrididae. Recently, I came across this strange species of primate called Homo sapien. Unlike regular folks who rub their legs against each other when they are gregarious, these primates like to make sounds at each other or send symbols or pictures!
I would very much like to study them and was wondering which part of industrial data science would find my skill set (math, biology, neuroscience) useful. Also have you seen my cousin Melanoplus spretus? I haven’t seen him in a while.
Solitary Schistocerca americana
p.s. here’ my picture:

Dear SSa,
I decided to answer your letter even though it’s addressed to Aunt Orthoptera because it’s about sex.
I wanted to repeat a point about the mating rituals of humans which my friend Laura made recently. Namely, every man she knows somehow knows about The Game: Penetrating the Secret Society of Pickup Artists by Neil Strauss (see above description), even though most women have never heard of it.
At the same time, every woman she knows somehow knows about another book called All the Rules: Time-tested Secrets for Capturing the Heart of Mr. Right by Ellen Fein, even though no man has ever heard of that. [Aunt Pythia’s personal note: I’d never heard of the latter book either]
Both of these are more or less instruction manuals for getting what you want from the opposite sex. Or maybe a better way of describing them would be manipulation manuals. Not much there in terms of adult honesty and saying what you really feel. Makes you wonder if we’re so very different from grasshoppers rubbing their legs together after all.
Food for thought!
Aunt Pythia
——
Please please please submit questions!
WTF is happening in Cyprus?
One thing I kept track of while I was away was the ongoing, intensely interesting situation in Cyprus. For those of you who have been following it just as closely, this will not be new, and please correct me if you think I’ve gotten something wrong.
Background
Cyprus banks have recently gotten deeply in trouble, partly because of their heavy investment in Greek government bonds which as you remember were semi-defaulted on in spite of them being “risk-weighted” at zero, and partly because of an enormous amount of Russian money they hold (Russian businessmen enjoy lowering their taxes by funneling their money to Cyprus), which created a severely bloated financial sector.
To be fair, just having deposits of rich Russian businessmen doesn’t make you fragile. But it’s just not done in banking, I guess, to simply hold on to money – you have to invest it somewhere, and they invested poorly.
To get an idea of how bloated the finance sector is and how badly the banks were hurting, if the Cyprus government was to give them the money they need, it would be 70% of GDP, and they’re already about 90% of GDP in debt. Even so, that’s only 17.2 billion Euros, or a bit more than twice Steven Cohen’s personal fortune ($10 billion) even after his firm, SAC Capital Advisors, settled with the SEC for insider trading “without admitting nor denying wrongdoing”.
What are the options?
- Do we ask the government of Cyprus to prop up the failing banks? Then it (the government) would be underwater and people would stop investing in its bonds and we’d need a bailout of the government. In other words, we’d just be handing the hot potato to the people.
- Does the EU or IMF loan money to government to give to the banks?
- Or to banks directly? Either way this would feel wrong to the northern European taxpayers, who would be essentially bailing out a bunch of Russian businessmen. Europeans are suffering from bailout fatigue, and German elections are coming up, making this even stronger.
- Or do we make the banks deal with their solvency issues themselves? After all, their shareholders, bond holders, and depositors all represent money they have which they can theoretically keep.
- Or some combination? Actually, all plans below are combo plans, whereby the banks make themselves solvent and then, after that, the EU/IMF team kicks in a few billion euros. Whether it will be enough money after the ricochet effects of the plan is not at all clear.
Plan #1: anti-FDIC insurance.
The plan as of more than a week ago was to take money from all the accounts as well as bond holders and shareholders. This included even the so-called insured deposits of accounts below 100,000 Euros.
So normal people, who thought their money was insured, would be paying 6.7% of their savings into a so-called “bail-in” fund, and people with more money in their accounts would be paying 9.9%.
This was across-the-board, by the way, for all Cyprus banks, independent of how much trouble a given bank was in. The banks closed down before this was announced so people couldn’t grab their money.
Compare that to the US version of a bailout from 2008, when shareholders got partially screwed, bondholders were left whole, deposits were untouched, but taxpayers were on the hook (and still are).
Plan #1 was baldfaced: it was saying to the average person in Cyprus, “Hey we fucked up the banks, can we take your money to fix it?”. It was incredible that anyone thought it would work. The ramifications of such an anti-FDIC insurance would be immediate and contagious, namely everyone in any related country would immediately start pulling their money out of banks. Why keep your money in an institution where you’re surely losing 7% when you can hide your money in a suitcase with only a small chance of it getting stolen?
Reaction by public: Hell No
Needless to say, the people in Cyprus didn’t like the plan. In fact, they strongly objected to directly paying for the mistakes of rich bankers and to protect Russians. They protested loudly and the Cypriotic politicians heard them, and voted down plan #1.
Plan #2
Since plan #1 failed, how about we just take money from uninsured depositors? Oh, and also make it bank-specific. So the banks that are in bigger poo-poo would seize more of their deposits than the banks that were in less poo-poo. That makes sense, and seems to be the current plan.
Problems with the current plan
There are a few problems with the new plan. But mostly they are what I’d call transition costs versus long-term problems. Easy for me to say, since I don’t live in Cyprus.
Rich people moving their money
First, rich people everywhere will no longer park lots of money in uninsured accounts in weak banks. Rich people have lots of options, though, so don’t feel too bad for them. They will instead put their money into lots of little accounts in lots of places, each of which will be insured. If this means they distribute their money over more banks, this is good for the banking system because it diversifies the capital and we’d end up with lots of biggish banks instead of a few enormous banks.
I’m not sure what the technical rules are, though. Say I’m stinking rich. Can I open 15 Bank of America accounts, each with $250K and so FDIC-insured? If I can’t do that for my local Bank of America branch, can I use Bank of America subsidiaries? Are the rules the same in the US and Europe? These rules are all of a sudden more important.
This is a transition cost, and within a few months all of the rich people will have their accounts insured or hidden.
Job losses
Second, there will be severe job losses in the bloated finance sector in Cyprus. Right now there are protests by workers from Laiki Bank, which is the worst off Cyprus bank, because they’re poised to lose their jobs. Again, it’s easy for me to say since I don’t live in Cyprus, but that’s what happens when you have an industry that’s too big – at some point it gets smaller and people lose jobs. I was around when the same thing happened to fisherman off the coast of New England, and it wasn’t pretty.
Again, though, it’s transitional. At some point the number of people working in banks in Cyprus will be reasonable. The question is whether they will have found another industry to replace finance.
Capital controls

The banks re-opened today, and of course people are standing in line to get cash, but things generally seem calm.
The big problem for businesses in Cyprus is that various “temporary” capital controls (which just means limits on taking money out of the country and on taking money from your bank) have been put into place that may lead to long-term problems.
Update (hat tip commenter badmax): many Russians already took their money out before the capital controls were imposed.
Euros don’t flow into and out of Cyprus effortlessly anymore, so the so-called monetary union has been broken. Depending on how quickly those rules are removed, and how quickly Cyprus comes up with other things to do, this could be a huge problem for the country.
Take-aways
- What’s become blatantly clear by following this process is that there is no actual process. Things are being made up as they go along by a bunch of economists and finance ministers. A lot of faith in their abilities was lost permanently when they hatched plan #1 which was so obviously stupid.
- Going back to that stupid plan, whereby normal depositors were supposed to pay for the mistakes of banks at the expense of their insured deposits. It was so bald-faced that the citizens rebelled, and politicians listened. So just to be clear, there has been actual input by average people in this process. The economists and finance ministers have lost face and the people have found a voice.
- This is not to say that the Cyprus people are sitting pretty. They are not, and by some estimates the economy of Cyprus is poised to contract by 20%. This may lead to more bailouts or Cyprus leaving the Eurozone for good.
Leila Schneps is a mystery writer!
I’m back! I missed you guys bad.
My experience with Seattle in the last 8 days has convinced me of something I rather suspected, namely I’m a huge New York snob and can’t exist happily anywhere else. I will spare you the details (they have to do with cars, subways, and being an asshole pedestrian) but suffice it to say, glad to be home.
Just a few caveats on complaining about my vacation:
- I enjoyed visiting the University of Washington and giving the math colloquium there as well as a “Math Day” talk where I showed kids the winning strategy for Nim (as well as other impartial two-player games) following my notes from last summer.
- I enjoyed reading Leon and Becky’s guest posts. Thanks guys!
- And then there was the time spent with my darling family. Of course, goes without saying, it’s always magical to get to the point where your kids have invented a whole new language of insults after you’ve outlawed certain words: “Shut your fidoodle, you syncopathic lardle!”
Of all the topics I want to write about today, I’ve decided to go with the most immediate and surprising one : Leila Schneps is now a mystery writer! How cool is that? She’s written a book with her daughter, Math on Trial: How Numbers Get Used and Abused in the Courtroom, currently in stock and available on Amazon. And she wrote an op-ed for the New York Times talking about it (hat tip Chris Wiggins).
I know Leila from having been her grad student assistant at the GWU Summer Program for Women in Math the first year it existed, in 1995. She taught undergrads about Galois cohomology and interpreted elements of 
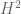
I love the premise of the book she’s written. She finds a bunch of historical examples where mathematics is used in trials to the detriment of justice, and people get unfairly jailed (or, less often, let free). From the op-ed (emphasis mine):
Decades ago, the Harvard law professor Laurence H. Tribe wrote a stinging denunciation of the use of mathematics at trial, saying that the “overbearing impressiveness” of numbers tends to “dwarf” other evidence. But we neither can nor should throw math out of the courtroom. Advances in forensics, which rely on data analysis for everything from gunpowder to DNA, mean that quantitative methods will play an ever more important role in judicial deliberations.
The challenge is to make sure that the math behind the legal reasoning is fundamentally sound. Good math can help reveal the truth. But in inexperienced hands, math can become a weapon that impedes justice and destroys innocent lives.
Go Leila!
Data science code of conduct, Evgeny Morozov
I’m going on an 8-day long trip to Seattle with my family this morning and I’m taking the time off from mathbabe. But don’t fret! I have a crack team of smartypants skeptics who are writing for me while I’m gone. I’m very much looking forward to seeing what Leon and Becky come up with.
In the meantime, I’ll leave you with two things I’m reading today.
First, a proposed Data Science Code of Professional Conduct. I don’t know anything about the guys at Rose Business Technologies who wrote it except that they’re from Boulder Colorado and have had lots of fancy consulting gigs. But I am really enjoying their proposed Data Science Code. An excerpt from the code after they define their terms:
(c) A data scientist shall rate the quality of evidence and disclose such rating to client to enable client to make informed decisions. The data scientist understands that evidence may be weak or strong or uncertain and shall take reasonable measures to protect the client from relying and making decisions based on weak or uncertain evidence.
(d) If a data scientist reasonably believes a client is misusing data science to communicate a false reality or promote an illusion of understanding, the data scientist shall take reasonable remedial measures, including disclosure to the client, and including, if necessary, disclosure to the proper authorities. The data scientist shall take reasonable measures to persuade the client to use data science appropriately.
(e) If a data scientist knows that a client intends to engage, is engaging or has engaged in criminal or fraudulent conduct related to the data science provided, the data scientist shall take reasonable remedial measures, including, if necessary, disclosure to the proper authorities.
(f) A data scientist shall not knowingly:
- fail to use scientific methods in performing data science;
- fail to rank the quality of evidence in a reasonable and understandable manner for the client;
- claim weak or uncertain evidence is strong evidence;
- misuse weak or uncertain evidence to communicate a false reality or promote an illusion of understanding;
- fail to rank the quality of data in a reasonable and understandable manner for the client;
- claim bad or uncertain data quality is good data quality;
- misuse bad or uncertain data quality to communicate a false reality or promote an illusion of understanding;
- fail to disclose any and all data science results or engage in cherry-picking;
Read the whole Code of Conduct here (and leave comments! They are calling for comments).
Second, my favorite new Silicon Valley curmudgeon is named Evgeny Morozov, and he recently wrote an opinion column in the New York Times. It’s wonderfully cynical and makes me feel like I’m all sunshine and rainbows in comparison – a rare feeling for me! Here’s an excerpt (h/t Chris Wiggins):
Facebook’s Mark Zuckerberg concurs: “There are a lot of really big issues for the world that need to be solved and, as a company, what we are trying to do is to build an infrastructure on top of which to solve some of these problems.” As he noted in Facebook’s original letter to potential investors, “We don’t wake up in the morning with the primary goal of making money.”
Such digital humanitarianism aims to generate good will on the outside and boost morale on the inside. After all, saving the world might be a price worth paying for destroying everyone’s privacy, while a larger-than-life mission might convince young and idealistic employees that they are not wasting their lives tricking gullible consumers to click on ads for pointless products. Silicon Valley and Wall Street are competing for the same talent pool, and by claiming to solve the world’s problems, technology companies can offer what Wall Street cannot: a sense of social mission.
Read the whole thing here.
Modeling in Plain English
I’ve been enjoying my new job at Johnson Research Labs, where I spend a majority of the time editing my book with my co-author Rachel Schutt. It’s called Doing Data Science (now available for pre-purchase at Amazon), and it’s based on these notes I took last semester at Rachel’s Columbia class.
Recently I’ve been working on Brian Dalessandro‘s chapter on logistic regression. Before getting into the brass tacks of that algorithm, which is especially useful when you are trying to predict a binary outcome (i.e. a 0 or 1 outcome like “will click on this ad”), Brian discusses some common constraints to models.
The one that’s particularly interesting to me is what he calls “interpretability”. His example of an interpretability constraint is really good: it turns out that credit card companies have to be able to explain to people why they’ve been rejected. Brain and I tracked down the rule to this FTC website, which explains the rights of consumers who own credit cards. Here’s an excerpt where I’ve emphasized the key sentences:
You Also Have The Right To…
- Have credit in your birth name (Mary Smith), your first and your spouse’s last name (Mary Jones), or your first name and a combined last name (Mary Smith Jones).
- Get credit without a cosigner, if you meet the creditor’s standards.
- Have a cosigner other than your spouse, if one is necessary.
- Keep your own accounts after you change your name, marital status, reach a certain age, or retire, unless the creditor has evidence that you’re not willing or able to pay.
- Know whether your application was accepted or rejected within 30 days of filing a complete application.
- Know why your application was rejected. The creditor must tell you the specific reason for the rejection or that you are entitled to learn the reason if you ask within 60 days. An acceptable reason might be: “your income was too low” or “you haven’t been employed long enough.” An unacceptable reason might be “you didn’t meet our minimum standards.” That information isn’t specific enough.
- Learn the specific reason you were offered less favorable terms than you applied for, but only if you reject these terms. For example, if the lender offers you a smaller loan or a higher interest rate, and you don’t accept the offer, you have the right to know why those terms were offered.
- Find out why your account was closed or why the terms of the account were made less favorable, unless the account was inactive or you failed to make payments as agreed.
The result of this rule is that credit card companies must use simple models, probably decision trees, to make their rejection decisions.
It’s a new way to think about modeling choice, to be sure. It doesn’t necessarily make for “better” decisions from the point of view of the credit card company: random forests, a generalization of decision trees, are known to be more accurate, but are arbitrarily more complicated to explain.
So it matters what you’re optimizing for, and in this case the regulators have decided we’re optimizing for interpretability rather than accuracy. I think this is appropriate, given that consumers are at the mercy of these decisions and relatively powerless to act against them (although the FTC site above gives plenty of advice to people who have been rejected, mostly about how to raise their credit scores).
Three points to make about this. First, I’m reading the Bankers New Clothes, written by Anat Admati and Martin Hellwig (h/t Josh Snodgrass), which is absolutely excellent – I’m planning to write up a review soon. One thing they explain very clearly is the cost of regulation (specifically, higher capital requirements) from the bank’s perspective versus from the taxpayer’s perspective, and how it genuinely seems “expensive” to a bank but is actually cost-saving to the general public. I think the same thing could be said above for the credit card interpretability rule.
Second, it makes me wonder what else one could regulate in terms of plain english modeling. For example, what would happen if we added that requirement to, say, the teacher value-added model? Would we get much-needed feedback to teachers like, “You don’t have enough student participation”? Oh wait, no. The model only looks at student test scores, so would only be able to give the following kind of feedback: “You didn’t raise scores enough. Teach to the test more.”
In other words, what I like about the “Modeling in Plain English” idea is that you have to be able to first express and second back up your reasons for making decisions. It may not lead to ideal accuracy on the part of the modeler but it will lead to much greater clarity on the part of the modeled. And we could do with a bit more clarity.
Finally, what about online loans? Do they have any such interpretability rule? I doubt it. In fact, if I’m not wrong, they can use any information they can scrounge up about someone to decide on who gets a loan, and they don’t have to reveal their decision-making process to anyone. That seems unreasonable to me.



