Archive
Good for the IASB!
There’s an article here in the Financial Times which describes how the International Accounting Standards Board is complaining publicly about how certain financial institutions are lying through their teeth about how much their Greek debt is worth.
It’s a rare stand for them (in fact the article describes it as “unprecedented”), and it highlights just how much a difference in assumptions in your model can make for the end result:
Financial institutions have slashed billions of euros from the value of their Greek government bond holdings following the country’s second bail-out. The extent to which Greek sovereign debt losses were acknowledged has varied, with some banks and insurers writing down their holdings by a half and others by only a fifth.
It all comes down to whether the given institution decided to use a “mark to model” valuation for their Greek debt or a “mark to market” valuation. “Mark to model” valuations are used in accounting when the market is “sufficiently illiquid” that it’s difficult to gauge the market price of a security; however, it’s often used (as IASB is claiming here) as a ruse to be deceptive about true values when you just don’t want to admit the truth.
There’s an amusingly technical description of the mark to model valuation for Greek debt used by BNP Paribas here. I’m no accounting expert but my overall takeaway is that it’s a huge stretch to believe that something as large as a sovereign debt market is illiquid and needs mark to model valuation: true, not many people are trading Greek bonds right now, but that’s because they suck so much and nobody wants to sell them at their true price since then they’d have to mark down their holdings. It’s a cyclical and unacceptable argument.
In any case, it’s nice to see the IASB make a stand. And it’s an example where, although there are two possible assumptions one can make, there really is a better, more reasonable one that should be made.
That reminds me, here’s another example of different assumptions changing the end result by quite a lot. The “trillion dollar mistake” that S&P supposedly made was in fact caused by them making a different assumption than that which the White House was prepared to make:
As it turns out, the sharpshooters were wide of the target. S&P didn’t make an arithmetical error, as Summers would have us believe. Nor did the sovereign-debt analysts show “a stunning lack of knowledge,” as Treasury Secretary Tim Geithner claimed. Rather, they used a different assumption about the growth rate of discretionary spending, something the nonpartisan Congressional Budget Office does regularly in its long-term outlook.
CBO’s “alternative fiscal scenario,” which S&P used for its initial analysis, assumes discretionary spending increases at the same rate as nominal gross domestic product, or about 5 percent a year. CBO’s baseline scenario, which is subject to current law, assumes 2.5 percent annual growth in these outlays, which means less new debt over 10 years.
Is anyone surprised about this? Not me. It also goes under the category of “modeling error”, which is super important for people to know and to internalize: different but reasonable assumptions going into a mathematical model can have absolutely huge effects on the output. Put another way, we won’t be able to infer anything from a model unless we have some estimate of the modeling error, and in this case we see the modeling error involves at least one trillion dollars.
Strata data conference
So I’m giving a talk at this conference. I’m talking on Monday, September 19th, to business people, about how they should want to hire a data scientist (or even better, a team of data scientists) and how to go about hiring someone awesome.
Any suggestions?
And should I wear my new t-shirt when I’m giving my talk? Part of the proceeds of these sexy and funny data t-shirts goes to Data Without Borders! A great cause!
Why log returns?
There’s a nice blog post here by Quantivity which explains why we choose to define market returns using the log function:
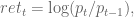
where 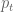

I mentioned this question briefly in this post, when I was explaining how people compute market volatility. I encourage anyone who is interested in this technical question to read that post, it really explains the reasoning well.
I wanted to add two remarks to the discussion, however, which actually argue for not using log returns, but instead using percentage returns in some situations.
The first is that the assumption of a log-normal distribution of returns, especially over a longer term than daily (say weekly or monthly) is unsatisfactory, because the skew of log-normal distribution is positive, whereas actual market returns for, say, S&P is negatively skewed (because we see bigger jumps down in times of panic). You can get lots of free market data here and try this out yourself empirically, but it also makes sense. Therefore when you approximate returns as log normal, you should probably stick to daily returns.
Second, it’s difficult to logically combine log returns with fat-tailed distributional assumptions, even for daily returns, although it’s very tempting to do so because assuming “fat tails” sometimes gives you more reasonable estimates of risk because of the added kurtosis. (I know some of you will ask why not just use no parametric family at all and just bootstrap or something from the empirical data you have- the answer is that you don’t ever have enough to feel like that will be representative of rough market conditions, even when you pool your data with other similar instruments. So instead you try different parametric families and compare.)
Mathematically there’s a problem: when you assume a student-t distribution (a standard choice) of log returns, then you are automatically assuming that the expected value of any such stock in one day is infinity! This is usually not what people expect about the market, especially considering that there does not exist an infinite amount of money (yet!). I guess it’s technically up for debate whether this is an okay assumption but let me stipulate that it’s not what people usually intend.
This happens even at small scale, so for daily returns, and it’s because the moment generating function is undefined for student-t distributions (the moment generating function’s value at 1 is the expected return, in terms of money, when you use log returns). We actually saw this problem occur at Riskmetrics, where of course we didn’t see “infinity” show up as a risk number but we saw, every now and then, ridiculously large numbers when we let people combine “log returns” with “student-t distributions.” A solution to this is to use percentage returns when you want to assume fat tails.
We didn’t make money on TARP!
There’s a pretty good article here by Gretchen Morgenson about how the banks have been treated well compared to average people- and since I went through the exercise of considering whether corporations are people, I’ve decided it’s misleading yet really useful to talk about “treating banks” well- we should keep in mind that this is shorthand for treating the people who control and profit from banks well.
On thing I really like about the article is that she questions the argument that you hear so often from the dudes like Paulson who made the decisions back then, namely that it was better to bail out the banks than to do nothing. Yes, but weren’t there alternatives? Just as the government could have demanded haircuts on the CDS’s they bailed out for AIG, they could have stipulated real conditions for the banks to receive bailout money. This is sort of like saying Obama could have demanded something in return for allowing Bush’s tax cuts for the rich to continue.
But on another issue I think she’s too soft. Namely, she says the following near the end of the article:
As for making money on the deals? Only half-true, Mr. Kane said. “Thanks to the vastly subsidized terms these programs offered, most institutions were eventually able to repay the formal obligations they incurred.” But taxpayers were inadequately compensated for the help they provided, he said. We should have received returns of 15 percent to 20 percent on our money, given the nature of these rescues.
Hold on, where did she get the 15-20%? As far as I’m concerned there’s no way that’s sufficient compensation for the future option to screw up as much as you can, knowing the government has your back. I’d love to see how she modeled the value of that. True, it’s inherently difficult to model, which is a huge problem, but I still think it has to be at least as big as the current credit card return limits! Or how about the Payday Loans interest rates?
I agree with her overall point, though, which is that this isn’t working. All of the things the Fed and the Treasury and the politicians have done since the credit crisis began has alleviated the pain of banks and, to some extent, businesses (like the auto industry). What about the people who were overly optimistic about their future earnings and the value of their house back in 2007, or who were just plain short-sighted, and who are still in debt?
It enough to turn you into an anarchist, like David Graeber, who just wrote a book about debt (here’s a fascinating interview with him) and how debt came before money. He thinks we should, as a culture, enact a massive act of debt amnesty so that the people are no longer enslaved to their creditors, in order to keep the peace.
I kind of agree- why is it so much easier for institutions to get bailed out when they’ve promised too much than it is for average people crushed under an avalanche of household debt? At the very least we should be telling people to walk away from their mortgages or credit card debts when it’s in their best interest (and we should help them understand when it is in their best interest).
What is the mission statement of the mathematician?
In the past five years, I’ve been learning a lot about how mathematics is used in the “real world”. It’s fascinating, thought provoking, exciting, and truly scary. Moreover, it’s something I rarely thought about when I was in academics, and, I’d venture to say, something that most mathematicians don’t think about enough.
It’s weird to say that, because I don’t want to paint academic mathematicians as cold, uncaring or stupid. Indeed the average mathematician is quite nice, wants to make the world a better place (at least abstractly), and is quite educated and knowledgeable compared to the average person.
But there are some underlying assumptions that mathematicians make, without even noticing, that are pretty much wrong. Here’s one: mathematicians assume that people in general understand the assumptions that go into an argument (and in particular understand that there always are assumptions). Indeed many people go into math because of the very satisfying way in which mathematical statements are either true or false- this is one of the beautiful things about mathematical argument, and its consistency can give rise to great things: hopefulness about the possibility of people being able to sort out their differences if they would only engage in rational debate.
For a mathematician, nothing is more elevating and beautiful than the idea of a colleague laying out a palette of well-defined assumptions, and building a careful theory on top of that foundation, leading to some new-found clarity. It’s not too crazy, and it’s utterly attractive, to imagine that we could apply this kind of logical process to situations that are not completely axiomatic, that are real-world, and that, as long as people understand the simplifying assumptions that are made, and as long as they understand the estimation error, we could really improve understanding or even prediction of things like the stock market, the education of our children, global warming, or the jobless rate.
Unfortunately, the way mathematical models actually function in the real world is almost the opposite of this. Models are really thought of as nearly magical boxes that are so complicated as to render the results inarguable and incorruptible. Average people are completely intimidated by models, and don’t go anywhere near the assumptions nor do they question the inner workings of the model, the question of robustness, or the question of how many other models could have been made with similar assumptions but vastly different results. Typically people don’t even really understand the idea of errors.
Why? Why are people so trusting of these things that can be responsible for so many important (and sometimes even critical) issues in our lives? I think there are (at least) two major reasons. One touches on things brought up in this article, when it talks about information replacing thought and ideas. People don’t know about how the mortgage models work. So what? They also don’t know how cell phones work or how airplanes really stay up in the air. In some way we are all living in a huge network of trust, where we leave technical issues up to the experts, because after all we can’t be experts in everything.
But there’s another issue altogether, which is why I’m writing this post to mathematicians. Namely, there is a kind of scam going on in the name of mathematics, and I think it’s the responsibility of mathematicians to call it out and refuse to let it continue. Namely, people use the trust that people have of mathematics to endow their models with trust in an artificial and unworthy way. Much in the way that cops flashing their badges can abuse their authority, people flash the mathematics badge to synthesize mathematical virtue.
I think it’s time for mathematicians to start calling on people to stop abusing people’s trust in this way. One goal of this blog is to educate mathematicians about how modeling is used, so they can have a halfway decent understanding of how models are created and used in the name of mathematics, and so mathematicians can start talking about where mathematics actually plays a part and where politics, or greed, or just plain ignorance sometimes takes over.
By the way, I think mathematicians also have another responsibility which they are shirking, or said another way they should be taking on another project, which is to educate people about how mathematics is used. This is very close to the concept of “quantitative literacy” which is explained in this recent article by Sol Garfunkel and David Mumford. I will talk in another post about what mathematicians should be doing to promote quantitative literacy.
Lagged autocorrelation plots
I wanted to share with you guys a plot I drew with python the other night (the code is at the end of the post) using blood glucose data that I’ve talked about previously in this post and I originally took a look at in this post.
First I want to motivate lagged autocorrelation plots. The idea is, given that you want to forecast something, say in the form of a time series (so a value every day or every ten minutes or whatever), the very first thing you can do is try to use past values to forecast the next value. In other words, you want to squeeze as much juice out of that orange as you can before you start using outside variable to predict future values.
Of course this won’t always work- it will only work, in fact, if there’s some correlation between past values and future values. To estimate how much “signal” there is in such an approach, we draw the correlation between values of the time series for various lags. At no (=0) lag, we are comparing a time series to itself so the correlation is perfect (=1). Typically there are a few lags after 0 which show some positive amount of correlation, then it quickly dies out.
We could also look at correlations between returns of the values, or differences of the values, in various situations. It depends on what you’re really trying to predict: if you’re trying to predict the change in value (which is usually what quants in finance do, since they want to bet on stock market changes for example), probably the latter will make more sense, but if you actually care about the value itself, then it makes sense to compute the raw correlations. In my case, since I’m interested in forecasting the blood glucose levels, which essentially have maxima and minima, I do care about the actual number instead of just the relative change in value.
Depending on what kind of data it is, and how scrutinized it is, and how much money can be made by betting on the next value, the correlations will die out more quickly. Note that, for example, if you did this with daily S&P returns and saw a nontrivial positive correlation after 1 lag, so the next day, then you could have a super simple model, namely bet that whatever happened yesterday will happen again today, and you would statistically make money on that model. At the same time, it’s a general fact that as “the market” recognizes and bets on trends, they tend to disappear. This means that such a simple, positive one-day correlation of returns would be “priced in” very quickly and would therefore disappear with new data. This tends to happen a lot with quant models- as the market learns the model, the predictability of things decreases.
However, in cases where there’s less money riding on the patterns, we can generally expect to see more linkage between lagged values. Since nobody is making money betting on blood glucose levels inside someone’s body, I had pretty high hopes for this analysis. Here’s the picture I drew:

What do you see? Basically I want you to see that the correlation is quite high for small lags, then dies down with a small resuscitation near 300 (hey, it turns out that 288 lags equals one day! So this autocorrelation lift is probably indicating a daily cyclicality of blood glucose levels). Here’s a close-up for the first 100 lags:

We can conclude that the correlation seems significant to about 30 lags, and is decaying pretty linearly.
This means that we can use the previous 30 lags to predict the next level. Of course we don’t want to let 30 parameters vary independently- that would be crazy and would totally overfit the model to the data. Instead, I’ll talk soon about how to place a prior on those 30 parameters which essentially uses them all but doesn’t let them vary freely- so the overall number of independent variables is closer to 4 or 5 (although it’s hard to be precise).
On last thing: the data I have used for this analysis is still pretty dirty, as I described here. I will do this analysis again once I decide how to try to remove crazy or unreliable readings that tend to happen before the blood glucose monitor dies.
Here’s the python code I used to generate these plots:
#!/usr/bin/env python
import csv
from matplotlib.pylab import *
import os
from datetime import datetime
os.chdir('/Users/cathyoneil/python/diabetes/')
gap_threshold = 12
dataReader = csv.DictReader(open('Jason_large_dataset.csv', 'rb'), delimiter=',', quotechar='|')
i=0
datelist = []
datalist = []
firstdate = 4
skip_gaps_datalist = []
for row in dataReader:
#print i, row["Sensor Glucose (mg/dL)"]
if not row["Raw-Type"] == "GlucoseSensorData":continue
if firstdate ==4:
print i
firstdate = \
datetime.strptime(row["Timestamp"], '%m/%d/%y %H:%M:%S')
if row["Sensor Glucose (mg/dL)"] == "":
datalist.append(-1)
else:
thisdate = datetime.strptime(row["Timestamp"], '%m/%d/%y %H:%M:%S')
diffdate = thisdate-firstdate
datelist.append(diffdate.seconds + 60*60*24*diffdate.days)
datalist.append(float(row["Sensor Glucose (mg/dL)"]))
skip_gaps_datalist.append(log(float(row["Sensor Glucose (mg/dL)"])))
i+=1
continue
print min(datalist), max(datalist)
##figure()
##scatter(arange(len(datalist)), datalist)
##
##figure()
##hist(skip_gaps_datalist, bins = 100)
##show()
def lagged_correlation(g):
d = dict(zip(datelist, datalist))
s1 = []
s2 = []
for date in datelist:
if date + 60*5 in datelist:
s1.append(d[date])
s2.append(d[date + 60*5])
return corrcoef(s1, s2)[1, 0]
figure()
plot([lagged_correlation(f) for f in range(1,900)])
Should short selling be banned?
Yesterday it was announced that the short selling ban in France, Italy, and Spain for financial stocks would be continued; there’s also an indefinite short selling ban in Belgium. What is this and does it make sense?
Short selling is mathematically equivalent to buying the negative of a stock. To see the actual mechanics of how it works, please look here.
Typically people at hedge funds use shorts to net out their exposure to the market as a whole: they will go long some bank stock they like and then go short another stock that they are neutral to or don’t like, with the goal of profiting on the difference of movements of the two – if the whole market goes up by some amount like 2%, it will only matter to them how much their long position outperformed their short. People also short stocks for direct negative forecasts on the stock, like when they detect fraud in accounting of the company, or otherwise think the market is overpricing the company. This is certainly a worthy reason to allow short selling: people who take the time to detect fraud should be rewarded, or otherwise said, people should be given an incentive to be skeptical.
If shorting the stock is illegal, then it generally takes longer for “price discovery” to happen; this is sort of like the way the housing market takes a long time to go down. People who bought a house at 400K simply don’t want to sell it for less, so they put it on the market for 400K even when the market has gone down and it is likely to sell for more like 350K. The result is that fewer people buy, and the market stagnates. In the past couple of years we’ve seen this happen in the housing market, although banks who have ownership of houses through foreclosures are much less quixotic about prices, which is why we’ve seen prices drop dramatically more recently.
The idea of banning short-selling is purely political. My favorite quote about it comes from Andrew Lo, an economist at M.I.T., who said, “It’s a bit like suggesting we take heart patients in the emergency room off of the heart monitor because you don’t want to make doctors and nurses anxious about the patient.” Basically, politicians don’t want the market to “panic” about bank stocks so they make it harder to bet against them. This is a way of avoiding knowing the truth. I personally don’t know good examples of the market driving down a bank’s stock when the bank is not in terrible shape, so I think even using the word “panic” is misleading.
When you suddenly introduce a short-selling ban, extra noise gets put into the market temporarily as people “cover their shorts”; overall this has a positive effect on the stocks in question, but it’s only temporary and it’s completely synthetic. There’s really nothing good about having temporary noise overwhelm the market except for the sake of the politicians being given a few extra days to try to solve problems. But that hasn’t happened.
Even though I’m totally against banning short selling, I think it’s a great idea to consider banning some other instruments. I actually go back and forth about the idea of banning credit default swaps (CDS), for example. We all know how much damage they can do (look at AIG), and they have a particularly explosive pay-off system, by design, since they are set up as insurance policies on bonds.
The ongoing crisis in Europe over debt is also partly due to the fact that the regulators don’t really know who owns CDS’s on Greek debt and how much there is out there. There are two ways to go about fixing this. First we could ban owning CDS unless you also own the underlying bond, so you are actually protecting your bond; this would stem the proliferation of CDS’s which hurt AIG so badly and which could also hurt the banks holding Greek bonds and who wrote Greek CDS protection. Alternatively, you could enforce a much more stringent system of transparency so that any regulator could go to a computer and do a search on where and how much CDS exposure (gross and net) people have in the world. I know people think this is impossibly difficult but it’s really not, and it should be happening already. What’s not acceptable is having a political and psychological stalemate because we don’t know what’s out there.
There are other instruments that definitely seem worthy of banning: synthetic over-the-counter instruments that seem created out of laziness (since the people who invented them could have approximated whatever hedge they wanted to achieve with standard exchange-traded instruments) and for the purpose of being difficult to price and to assess the risk of. Why not ban them? Why not ban things that don’t add value, that only add complexity to an already ridiculously complex system?
Why are we spending time banning things that make sense and ignoring actual opportunities to add clarity?
Want my advice?
For whatever reason I find myself giving a lot of advice. Actually, it’s probably because I’m an opinionated loudmouth.
The funny thing is, I pretty much always give the same advice, no matter if it’s about whether to quit a crappy job, whether to ask someone out that you have a crush on, or which city to move to. Namely, I say the following three things (in this order):
- Go for it! (this usually is all most people need, especially when talking about the crush type of advice)
- Do what you’d do if you weren’t at all insecure (great for people trying to quit a bad job or deciding between job offers)
- Do what a man would do (I usually reserve this advice for women)
I was reminded of that third piece of advice when I read this article about mothers in Germany and how they all seem to decide to quit their jobs and stay home with their kids, putatively because they don’t trust their babysitter. I say, get a better babysitter!
As an aside, let me say, I really don’t have patience for the maternal guilt thing. Probably it has something to do with the fact that my mom worked hard, and loved her job (computer scientist), and never felt guilty about it: for me that was the best role model a young nerd girl could have. When the PTA asked my mom to bake cookies, she flat out refused, and that’s what I do now. In fact I take it up a notch: when asked to bake cookies for a bake sale fund-raiser at my kids’ school (keeping in mind that this is one of those schools where the kids aren’t even allowed to eat cookies at lunch), I never forget to ask how many fathers they’ve made the cookies request to. I’m never asked a second time by the same person (however I always give them cash for the fund raising, it should be said).
It’s kind of amazing how well these three rules of thumb for advice work. I guess people usually know what they want but need some amount of help to get the nerve up to decide, to make the leap. And people consistently come back to me for advice, probably because the discussion ends up being just as much a pep talk as anything else. I’m like that guy in the corner of the ring at a fight, squirting water into the fighter’s mouth and rubbing his shoulders, saying, “You can do it, champ! Go out and get that guy!”
There may be something else going on, which is that, although I’m super opinionated, I’m also not very judgmental. In fact this guy, the “ex-moralist,” is my new hero. In this article he talks about people using their religious beliefs to guide their ethics, versus people using their moralistic beliefs (i.e. the belief in right and wrong), and how he was firmly in the second camp until one day when he lost faith in that system too – he becomes amoral. He goes on to say:
One interesting discovery has been that there are fewer practical differences between moralism and amoralism than might have been expected. It seems to me that what could broadly be called desire has been the moving force of humanity, no matter how we might have window-dressed it with moral talk. By desire I do not mean sexual craving, or even only selfish wanting. I use the term generally to refer to whatever motivates us, which ranges from selfishness to altruism and everything in between and at right angles. Mother Theresa was acting as much from desire as was the Marquis de Sade. But the sort of desire that now concerns me most is what we would want if we were absolutely convinced that there is no such thing as moral right and wrong. I think the most likely answer is: pretty much the same as what we want now.
He goes on to say that, when he argues with people, he can no longer rely on common beliefs and actually has to reason with people who disagree with him but are themselves internally consistent. He then adds:
My outlook has therefore become more practical: I desire to influence the world in such a way that my desires have a greater likelihood of being realized. This implies being an active citizen. But there is still plenty of room for the sorts of activities and engagements that characterize the life of a philosophical ethicist. For one thing, I retain my strong preference for honest dialectical dealings in a context of mutual respect. It’s just that I am no longer giving premises in moral arguments; rather, I am offering considerations to help us figure out what to do. I am not attempting to justify anything; I am trying to motivate informed and reflective choices.
I’m really excited by this concept. Am I getting fooled because he’s such a good writer? Or is it possible that he’s hit upon something that actually helps people disagree well? That we should stop assuming that the person we are talking to shares our beliefs? This is something like what I experience when I go to a foreign country- the expectation that I will meet people who agree with me is sufficiently reduced that I end up having many more interesting, puzzling and deep conversations than I do when I’m in my own country.
I’m thinking of starting to keep a list of things that encourage or discourage honest communication- this would go on the side of “encourage,” and Fox news would go on the side of “discourage.”
What about you, readers? Anything to add to my list on either side? Or any advice you need on quitting that job and finding a better one? Oh, and that guy you think is hot? Go for it.
Demographics: sexier than you think
It has been my unspoken goal of this blog to sex up math (okay, now it’s a spoken goal). There are just too many ways math, and mathematical things, are portrayed and conventionally accepted as boring and dry, and I’ve taken on the task of making them titillating to the extent possible. Anybody who has ever personally met me will not be surprised by this.
The reason I mention this is that today I’ve decided to talk about demographics, which may be the toughest topic yet to rebrand in a sexy light – even the word ‘demographics’ is bone dry (although there have been lots of nice colorful pictures coming out from the census). So here goes, my best effort:
Demographics
Is it just me, or have there been a weird number of articles lately claiming that demographic information explain large-scale economic phenomena? Just yesterday there was this article, which claims that, as the baby boomers retire they will take money out of the stock market at a sufficient rate to depress the market for years to come. There have been quite a few articles lately explaining the entire housing boom of the 90’s was caused by the boomers growing their families, redefining the amount of space we need (turns out we each need a bunch of rooms to ourselves) and growing the suburbs. They are also expected to cause another problem with housing as they retire.
Of course, it’s not just the boomers doing these things. It’s more like, they have a critical mass of people to influence the culture so that they eventually define the cultural trends of sprawling suburbs and megamansions and redecorating kitchens, which in turn give rise to bizarre stores like ‘Home Depot Expo‘. Thanks for that, baby boomers. Or maybe it’s that the marketers figure out how boomers can be manipulated and the marketers define the trends. But wait, aren’t the marketers all baby boomers anyway?
I haven’t read an article about it, but I’m ready to learn that the dot com boom was all about all of the baby boomers having a simultaneous midlife crisis and wanting to get in on the young person’s game, the economic trend equivalent of buying a sports car and dating a 25-year-old.
Then there are countless articles in the Economist lately explaining even larger scale economic trends through demographics. Japan is old: no wonder their economy isn’t growing. Europe is almost as old, no duh, they are screwed. America is getting old but not as fast as Europe, so it’s a battle for growth versus age, depending on how much political power the boomers wield as they retire (they could suck us into Japan type growth).
And here’s my favorite set of demographic forecasts: China is growing fast, but because of the one child policy, they won’t be growing fast for long because they will be too old. And that leaves India as the only superpower in the world in about 40 years, because they have lots of kids.
So there you have it, demographics is sexy. Just in case you missed it, let me go over it once again with the logical steps revealed:
Demographics – baby boomers – Bill Clinton – Monica Lewinsky – blow job under the desk. Got it?
Karaoke
When I woke up this morning the sun was unreasonably bright and the song “Wonderwall” was running in a loop in my head.
It’s not so bad working at a startup.
Machine learners are spoiled for data
I’ve been reading lots of machine learning books lately, and let me say, as a relative outsider coming from finance: machine learners sure are spoiled for data.
It’s like, they’ve built these fancy techniques and machines that take a huge amount of data and try to predict an outcome, and they always seem to start with about 50 possible signals and “learn” the right combination of a bunch of them to be better at predicting. It’s like that saying, “It is tempting, if the only tool you have is a hammer, to treat everything as if it were a nail.”
In finance, a quant gets maybe one or two or three time series, hopefully that haven’t been widely distributed so they may still have signal. The effect that this new data on a quant is key: it’s exciting almost to the point of sexually arousing to get new data. That’s right, I said it, data is sexy! We caress the data, we kiss it and go to bed with it every night (well, the in-sample part of it anyway). In the end we have an intimate relationship with each and every time series in our model. In terms of quantity, however, maybe it’s daily (so business days, 262 days per year about), for maybe 15 years, so altogether 4000 data points. Not a lot to work with but we make do.
In particular, given 50 possible signals in a pile of new data, we would first look at each time series by plotting, to be sure it’s not dirty, we’d plot the (in-sample) returns as a histogram to see what we’re dealing with, we’d regress each against the outcome, to see if anything contained signal. We’d draw lagged correlation graphs of each against the outcome. We’d draw cumulative pnl graphs over time with that univariate regression for that one potential signal at a time.
In other words, we’d explore the data in a careful, loving manner, signal by signal, without taking the data for granted, instead of stuffing the kit and kaboodle into a lawnmower. It’s more work but it means we have a sense of what’s going into the model.
I’m wondering how powerful it would be to combine the two approaches.
Is willpower a quantifiable resource?
There’s a fascinating article here about “decision fatigue,” which talks about how people lose the ability to make good decisions after they’ve made a bunch of decisions, especially if those decisions required them to exert willpower. A decision can require willpower either by virtue of being a trade-off or compromise between what one wants versus what one can afford, or by virtue of being a virtuous choice, e.g. eating a healthy snack instead of ice cream.
After making lots of decisions, people get exhausted and go for the easiest choice, which is often not the “correct” one for various reasons- it could be unhealthy or too expensive, for example. The article describes how salespeople can take advantage of this human foible by offering so many choices that, after a while, people defer to the salesperson to help them choose, thus ending up with a larger bill. It also explains that eating sugar is a quick restorative for your brain; if you’ve been exhausted by too many willpower exertions, a sugary snack will get you back on track, if only for a short while.
This all makes sense to me, but what I think is most interesting, and was really only touched on in the article, is how much this concept does or could matter in understanding our culture. For example, it talks about how this could explain why poor people eat badly- they go to the grocery store and are forced to exert willpower the entire time, with every purchase, since they constantly have to decide what they can afford; at the end of that arduous process they are exhausted and end up buying a sugary snack to replenish themselves.
I’m wondering how much of our behavior can be explained by willpower as a quantifiable resource. If we imagine that each person has some amount of stored willpower, that gets replenished through food and gets depleted through decisions, would that explain some amount of variance in behavior? Would it explain why crime gets committed at certain times?
This also reminds me of the experiments they did on kids to see which one of them could postpone reward (in the form of marshmallows) the longest. Turns out the kids who could delay gratification were more likely to get Ph.D.’s (no duh!). It is of course not always appropriate to delay gratification (and it’s certainly not in anyone’s best interest that everyone in the population should want to get a Ph.D.); on the other hand being able to plan ahead certainly is a good thing.
Since delaying gratification is a form of willpower, I’ll put it in the same category and ask, how come even at the age of four some kids can do that and others can’t (or won’t)? Is it genetically wired? Or is it practiced as a family value? Or both? Is it like strength, where some people are naturally strong but then again people can work out and make themselves much stronger?
Here’s another question about willpower, which is kind of the dual to the idea of depletion: can you have too much stored willpower? Is it like sexual energy, that needs to get used or kind of boils up on its own? I’m wondering if, when you’ve been trained all your life to exert a certain amount of willpower, and then you suddenly (through becoming extremely well-off or winning the lottery) don’t need nearly as much as you’re used to, do you somehow boil over with willpower? Does that explain why really rich people join Scientology and constantly go to spas for cleansings? Are they inventing challenges in order to exert their unused, pent-up willpower? I certainly think it’s possible.
As an example, I’ve noticed that people with too little money or with too much money are constantly worrying about money. I’m wondering if this “too much money” is coinciding with “unused willpower” and the result ironically looks similar to “not enough money” in combination with “depleted willpower”. Just an idea, but Sunday mornings are for ridiculous theories after all.
How the Value-Added Model sucks
One way people’s trust of mathematics is being abused by crappy models is through the Value-Added Model, or VAM, which is actually a congregation of models introduced nationally to attempt to assess teachers and schools and their influence on the students.
I have a lot to say about the context in which we decide to apply a mathematical model to something like this, but today I’m planning to restrict myself to complaints about the actual model. Some of these complaints are general but some of them are specific to the way the one in New York is set up (still a very large example).
The general idea of a VAM is that teachers are rewarded for bringing up their students’ test scores more than expected, given a bunch of context variables (like their poverty and last year’s test scores).
The very first question one should ask is, how good is the underlying test the kids are taking? This is famously a noisy answer, depending on how much sleep and food the kids got that day, and, with respect to the content, depends more on memory than on deep knowledge. Another way of saying this is that, if a student does a mediocre job on the test, it could be because they are learning badly at their school, or that they didn’t eat breakfast, or it could be that the teachers they have are focusing more on other things like understanding the reasons for the scientific method and creating college-prepared students by focusing on skills of inquiry rather than memorization.
This brings us to the next problem with VAM, which is a general problem with test-score cultures, namely that it is possible to teach to the test, which is to say it’s possible for teachers to chuck out their curriculums and focus their efforts on the students doing well on the test (which in middle school would mean teaching only math and English). This may be an improvement for some classrooms but in general is not.
People’s misunderstanding of this point gets to the underlying problem of skepticism of our teachers’ abilities and goals- can you imagine if, at your job, you were mistrusted so much that everyone thought it would be better if you were just given a series of purely rote tasks to do instead of using your knowledge of how things should be explained or introduced or how people learn? It’s a fact that teachers and schools that don’t teach to the test are being punished for this under the VAM system. And it’s also a fact that really good, smart teachers who would rather be able to use their pedagogical chops in an environment where they are being respected leave public schools to get away from this culture.
Another problem with the New York VAM is the way tenure is set up. The system of tenure is complex in its own right, and I personally have issues with it (and with the system of tenure in general), but in any case here’s the way it works now. New teachers are technically given three years to create a portfolio for tenure- but the VAM results of the third year don’t come back in time, which means the superintendent looking at a given person’s tenure folder only sees two years of scores, and one of them is the first year, where the person was completely inexperienced.
The reason this matters is that, depending on the population of kids that new teacher was dealing with, more or less of the year could have been spent learning how to manage a classroom. This is an effect that overall could be corrected for by a model but there’s no reason to believe was. In other words, the overall effect of teaching to kids who are difficult to manage in a classroom could be incorporated into a model but the steep learning curve of someone’s first year would be much harder to incorporate. Indeed I looked at the VAM technical white paper and didn’t see anything like that (although since the paper was written for the goal of obfuscation that doesn’t prove anything).
For a middle school teacher, the fact that they have only two years of test scores (and one year of experienced scores) going into a tenure decision really matters. Technically the breakdown of weights for their overall performance is supposed to be 20% VAM, 20% school-wide assessment, and 60% “subjective” performance evaluation, as in people coming to their classroom and taking notes. However, the superintendent in charge of looking at the folders has about 300 folders to look at in 2 weeks (an estimate), and it’s much easier to look at test scores than to read pages upon pages of written assessment. So the effective weighting scheme is measurably different, although hard to quantify.
One other unwritten rule: if the school the teacher is at gets a bad grade, then that teacher’s chances of tenure can be zero, even if their assessment is otherwise good. This is more of a political thing than anything else, in that Bloomberg doesn’t want to say that a “bad” school had a bunch of tenures go through. But it means that the 20/20/60 breakdown is false in a second way, and it also means that the “school grade” isn’t an independent assessment of the teachers’ grades- and the teachers get double punished for teaching at a school that has a bad grade.
That brings me to the way schools are graded. Believe it or not the VAM employs a binning system when they correct for poverty, which is measured in terms of the percentage of the student population that gets free school lunches. The bins are typically small ranges of percentages, say 20-25%, but the highest bin is something like 45% and higher. This means that a school with 90% of kids getting free school lunch is expected to perform on tests similarly to a school with half that many kids with unstable and distracting home lives. This penalizes the schools with the poorest populations, and as we saw above penalized the teachers at those schools, by punishing them for when the school gets a bad grade. It’s my opinion that there should never be binning in a serious model, for reasons just like this. There should always be a continuous function that is fit to the data for the sake of “correcting” for a given issue.
Moreover, as a philosophical issue, these are the very schools that the whole testing system was created to help (does anyone remember that testing was originally set up to help identify kids who struggle in order to help them?), but instead we see constant stress on their teachers, failed tenure bids, and the resulting turnover in staff is exactly the opposite of helping.
This brings me to a crucial complaint about VAM and the testing culture, namely that the emphasis put on these tests, which we’ve seen is noisy at best, reduces the quality of life for the teachers and the schools and the students to such an extent that there is no value added by the value added model!
If you need more evidence of this please read this article, which describes the rampant cheating on test in Atlanta, Georgia and which is in my opinion a natural consequence of the stress that tests and VAM put on school systems.
One last thing- a political one. There is idiosyncratic evidence that near elections, students magically do better on tests so that candidates can talk about how great their schools are. With that kind of extra variance added to the system, how can teachers and school be expected to reasonably prepare their curriculums?
Next steps: on top of the above complaints, I’d say the worst part of the VAM is actually that nobody really understands it. It’s not open source so nobody can see how the scores are created, and the training data is also not available, so nobody can argue with the robustness of the model either. It’s not even clear what a measurement of success is, and whether anyone is testing the model for success. And yet the scores are given out each year, with politicians adding their final bias, and teachers and schools are expected to live under this nearly random system that nobody comprehends. Things can and should be better than this. I will talk in another blog post about how they should be improved.
What’s with errorbars?
As an applied mathematician, I am often asked to provide errorbars with values. The idea is to give the person reading a statistic or a plot some idea of how much the value or values could be expected to vary or be wrongly estimated, or to indicate how much confidence one has in the statistic. It’s a great idea, and it’s always a good exercise to try to provide the level of uncertainty that one is aware of when quoting numbers. The problem is, it’s actually very tricky to get them right or to even know what “right” means.
A really easy way to screw this up is to give the impression that your data is flawless. Here’s a prime example of this.
More recently we’ve seen how much the government growth rate figures can really suffer from lack of error bars- the market reacts to the first estimate but the data can be revised dramatically later on. This is a case where very simple errorbars (say, showing the average size of the difference between first and final estimates of the data) should be provided and could really help us gauge confidence. [By the way, it also brings up another issue which most people think about as a data issue but really is just as much a modeling issue: when you have data that gets revised, it is crucial to save the first estimates, with a date on that datapoint to indicate when it was first known. If we instead just erase the old estimate and pencil in the new, without changing the date (usually leaving the first date), then it gives us a false sense that we knew the “corrected” data way earlier than we did.]
However, even if you don’t make stupid mistakes, you can still be incredibly misleading, or misled, by errorbars. For example, say we are trying to estimate risk on a stock or a portfolio of stocks. Then people typically use “volatility error bars” to estimate the expected range of values of the stock tomorrow, given how it’s been changing in the past. As I explained in this post, the concept of historical volatility depends crucially on your choice of how far back you look, which is given by a kind of half-life, or equivalently the decay constant. Anything that is so not robust should surely be taken with a grain of salt.
But in any case, volatility error bars, which are usually designed to be either one or two lengths of the measured historical volatility, contain only as much information as the data in the lookback window. In particular, you can get extremely confused if you assume that the underlying distribution of returns is normal, which is exactly what most people do in fact assume, even when they don’t realize they do.
To demonstrate this phenomenon of human nature, recall that during the credit crisis you’d hear things like “We were seeing things that were 25-standard deviation moves, several days in a row,” from Goldman Sachs; the implication was that this was an incredibly unlikely event, near probability zero in fact, that nobody could have foreseen. Considering what we’ve been seeing in the market in the past couple of weeks, it would be nice to understand this statement.
There were actually two flawed assumptions exposed here. First, if we have a fat-tailed distribution, then things can seem “quiet” for long stretches of time (longer than any lookback window), during which the sample volatility is a possibly severe underestimate of the standard of deviation. Then when a fat-tailed event occurs, the sample volatility spikes to being an overestimate of the standard of deviation for that distribution.
Second, in the markets, there is clustering of volatility- another way of saying this is that volatility itself is rather auto-correlated, so even if we can’t predict the direction of the return, we can still estimate the size of the return. So once the market dives 5% in one day, you can expect many more days of large moves.
In other words, the speaker was measuring the probability that we’d see several returns, 25 standard deviations away from the mean, if the distribution is normal, with a fixed standard deviation, and the returns are independent. This is indeed a very unlikely event. But in fact we aren’t dealing with normal distributions nor independent draws.
Another way to work with errorbars is to have confidence errorbars, which relies (explicitly or implicitly) on an actual distributional assumption of your underlying data, and which tells the reader how much you could expect the answer to range given the amount of data you have, with a certain confidence. Unfortunately, there are problems here too- the biggest one being that there’s really never any reason to believe your distributional assumptions beyond the fact that it’s probably convenient, and that so far the data looks good. But if it’s coming from real world stuff, a good level of skepticism is healthy.
In another post I’ll talk a bit more about confidence errorbars, otherwise known as confidence intervals, and I’ll compare them to hypothesis testing.
I.P.O. pops
I’ve decided to write about something I don’t really understand, but I’m interested in (especially because I work at a startup!): namely, how IPO’s work and why there seem to be consistent pops. Pops are jumps in share price from the offering to the opening, and then sometimes the continued pop (or would that be fizz?) for the rest of the trading day. Here’s an article about the pop associated to LinkedIn a few weeks ago. The idea behind the article is that IPO pops are really bad for the companies in question.
The way a standard IPO works is that, when a company decides to go public, they hire an investment company to help them assess their value, i.e. form a sense of how many shares can be sold, and at what price.
A certain number of people (insiders and investors at the investment bank in particular) are then given the chance to buy some shares of the new company at the offering price. This is an obvious way in which the investment bank has an incentive to create a pop- their friends will directly benefit from pops. In fact the existence of pops and their accompanying incentives have inspired some people (like Google) to use Dutch auction methods instead of the standard.
And the myth is that there are consistent pops (here are some examples of truly outrageous pops during the dotcom bubble!). Is this really true? Or is it a case of survivorship bias? Or is there on average a pop the first day which fizzles out over the next week? I actually haven’t crunched the data, but if you know please do comment.
One question I want to know is, assuming that the pop myth is true, why does it keep happening? If it’s good for the investment bank but bad for the business, you’d think that businesses would, over time, train investment banks to stop doing this quite so much- they’d get bad reputations for big pops, or even possibly would get some of their fees removed, by contract, if the pop was too big (which would mean the investment bank hadn’t done its job well). But I haven’t heard of that kind of thing.
So who else is benefitting from pops? Is it possible that the investors themselves have an incentive to see a pop? While it’s true that the investors sell a bunch of their shares into the IPO to provide sufficient “float,” which they’d obviously like to see sold at a high price, they also have the opportunity to buy a restricted number of “directed shares“, which are shares they can buy at the offering price and then immediately sell; these they’d clearly like to buy at a low price and then see a pop. So I guess it depends on the situation for a given insider whether they are selling or buying more – I don’t know what the actual mix typically is, but I imagine it really depends on the situation; for example, there are always shared created out of thin air on an IPO day, so it will depend on how much of the float is coming from the investors and how much is coming from thin air.
The most standard thing though is for someone like an employee is to have common shares (or options to buy common shares) which they can only sell 6 months (or potentially more if the options are vested) after the IPO, which I guess means they are probably somewhat neutral to the pop, depending on its long term effect.
Speaking of long term effects, I think the biggest and most persuasive argument investment banks make to investors about stock evaluation, is that it’s better to underestimate the share price than to overestimate it. The argument is that a pop may hurt the business but it’s great for investors and thus the reputation value is overall good (this argument can obviously go too far if the pop is 50% and sustained), but that an overevaluation could result in not being able to sell the shares and having a sunken ship that never gets enough wind to sail. In other words, the risks are asymmetrical. I’m not sure this is actually true but it’s probably a good scare tactic for the investment banks to use to line their friends’ pockets.
Default probabilities and recovery rates
I’ve been kind of obsessed lately with the “big three” ratings agencies S&P, Moody’s, and Fitch. I have two posts (this one and that one) where I discuss the idea of setting up open source ratings models to provide competition to them and hopefully force them to increase transparency (speaking of transparency, here’s an article which describes how well they cope with one of the transparency rules they already have).
Today I want to talk about a technical issue regarding ratings models, namely what the output is. There are basically two choices that I’ve heard about, and it turns out that S&P and Moody’s ratings have different outputs, as was explained here.
Namely, S&P models the probability of default, which is to say the probability that U.S. bonds will go through a technical default, I believe within the next year; Moody’s, on the other hand, models the “expected loss”, which is to say they model the future value of U.S. bonds by modeling the probability of default combined with the so-called “recovery rate” once the default occurs (the recovery rate is the percent of the face value of the bond that bond-holders can expect to receive after a default).
The reason this matters is that, for U.S. bonds specifically, even if default occurs technically, few people claim that the bonds wouldn’t eventually be worth face value. So S&P is modeling the probability that, through political posturing, we could end up with a technical default (i.e. not beyond the realm of possibilities), whereas Moody’s models what the value of the bond would be if that happened (i.e. face value almost certainly). It makes more sense, considering this, that S&P has downgraded U.S. debt but that Moody’s hasn’t.
This isn’t the only time such issues matter. Indeed, various different “ratings” models claim to model different things, which end up being more or less crucial depending on the situation:
- S&P: probability of default
- Fitch: probability of default
- Moody’s: expected loss
- Altman’s Z-scores: probability of corporate default
- Credit Grades: probability of default of publicly traded companies
- credit default swaps: expected loss
I threw in Credit Grades, which is a product that is offered by MSCI. One of the inputs for the Credit Grades model is the market volatility of the company in question, whereas most of the other models’ inputs are primarily accounting measurements. In particular, if the market volatility of the company is enormous, then the probability of default is increased. I wonder what it is now rating Bank of America at?
Credit default swaps are not ratings models directly- but you can infer the market’s expectation of default and recovery rate from the price of the CDS, since the cashflow of a CDS works like this: the owner of the CDS pays quarterly “insurance payments” for as long as the bond in question hasn’t defaulted, but if and when the bond defaults the writer of the CDS pays the remainder of the face value of the bond after removing the recovery rate. In other words, if the bond defaults and the recovery rate turns out to be 63%, then the CDS writer is liable for 37% of the face value of the bond.
Not to unfairly single out one issue among many that is difficult, but recovery rates are pretty difficult to model- the data is secondary market data, i.e. it’s not traded on directly but rather inferred from market prices like CDSs that are traded, and often people just assume a 40% recovery rate even when there’s no particular reason to believe it.
For that reason it’s not necessarily better information (in the sense of being more accurate) to model default with recovery rate consideration than it is to model straight out default probability, which is already hard. On the other hand, modeling expected loss like Moody’s is probably a more intuitive output, since as we’ve seen with the uproar last week, S&P is getting lots of flak for their ratings change but Moody’s has been sitting pretty.
In fact, U.S. sovereign debt is an extreme example in that we actually know the recovery rate is almost surely 100%, but in general for corporate debt different guesses at the expected recovery rates will drastically change the value of the bond (or associated CDS).
I guess the moral of this story for me is that it’s super important to know exactly what’s being modeled – I am now ready to defend S&P’s ratings change – and it’s also important to choose your model’s output well.
Are Corporations People?
Recently Mitt Romney put his foot in his mouth when trying to deal with a heckler in Iowa. He said, “Corporations are people, my friend.” He’s gotten plenty of backlash since then, even though he attempted a softer follow-up with, “Everything corporations earn ultimately goes to people. Where do you think it goes?”
It makes me wonder two things. First, why is it viscerally repulsive (to me) that he should say that, and second, beyond the gut reaction, to what extent does this statement make sense?
The New York Times summed up the feeling pretty well with the statement, “…he seemed to reinforce another image of himself: as an out-of-touch businessman who sees the world from the executive suite.” Another way to say this is that the remark exposed a world view that I don’t share, and which goes back to this post containing the following:
Conservatives, for example, see business as primarily a source of social and economic good, achieved by the market mechanism of seeking to maximize profit. They therefore think government’s primary duty regarding businesses is to see that they are free to pursue their goal of maximizing profit. Liberals, on the other hand, think that the effort to maximize profit threatens at least as much as it contributes to our societies’ well-being. They therefore think that government’s primary duty regarding businesses is to protect citizens against business malpractice.
Fair enough- Mitt Romney doesn’t claim to be a liberal, after all. He was really doing us a favor by admitting how he sees things; heck, I wish all politicians would be susceptible to heckling and would go off-script and say what they actually mean every now and then.
In this way I can come to terms with the fact that Romney is essentially protective of corporations and their “human rights,” at least as an emotional response (like when discussing tax increases). But is he factually right? Are corporations equivalent to people in a legal or ethical way?
I’m no lawyer but it seems that, in certain ways, corporations are legally treated as persons, and that this has been an ongoing legal question for 200 years. In terms of political contributions, which is somehow easier to understand but maybe less systemically important, they are certainly treated like persons, in that there is no limit to the amount of money they can contribute politically (although this issue has gone back and forth historically).
Ethically, however, there seems to me to be a huge obstacle in considering corporations equivalent to people. Namely, it seems to be much easier to ascribe the rights of people to corporations than to ascribe the responsibilities of people to corporations. In particular, what if corporations behave badly and need to be punished? How do we follow through with that in a way that makes sense? Is there a death penalty for corporations? (This question originally came to me by way of Josh Nichols-Barrer, by the way)
The most obvious direct punishment we have for corporations is fines for accounting fraud or whatever, and the most obvious indirect punishment is market capitalization loss, i.e. the stock price goes down, if it’s a publicly traded company, or if not, reputation loss, which is vague indeed. However, in those cases it’s mostly the shareholders that suffer- the corporation itself, and its management, typically lives on.
Rarely, there is direct legal action against a decision maker at the company, but that certainly can’t count as a death penalty for the corporation itself, since the toxic culture which gave rise to those decisions is left intact. Even if we got serious and closed down a company, it’s not clear what effect that would have since a new legal entity could be re-formed with similar ideals and people (although the nuisance of doing this would be pretty substantial depending on the industry). But maybe that’s the best we can do: “moral bankruptcy” proceedings. Another problem with that idea is that many of the people who were in charge of the bad decisions would be the first to jump ship and go to other corporations to try again with more stealth; that’s certainly what I’ve seen happen in finance.
From my perspective, none of the punishments described above actually deter bad behavior in a meaningful way. If we treat corporations as people, then they would be people with a permanent diplomatic immunity; this doesn’t sit well with my sense of fairness or my sense of how people respond to incentives.
Open Source Ratings Model (Part 2)
I’ve thought more about the concept of an open source ratings model, and I’m getting more and more sure it’s a good idea- maybe an important one too. Please indulge me while I passionately explain.
First, this article does a good job explaining the rot that currently exists at S&P. The system of credit ratings undermines the trust of even the most fervently pro-business entrepreneur out there. The models are knowingly games by both sides, and it’s clearly both corrupt and important. It’s also a bipartisan issue: Republicans and Democrats alike should want transparency when it comes to modeling downgrades- at the very least so they can argue against the results in a factual way. There’s no reason I can see why there shouldn’t be broad support for a rule to force the ratings agencies to make their models publicly available. In other words, this isn’t a political game that would score points for one side or the other.
Second, this article discusses why downgrades, interpreted as “default risk increases” on sovereign debt doesn’t really make sense- and uses as example Japan, which was downgraded in 2002 but still continues to have ridiculously low market-determined interest rates. In other words, ratings on governments, at least the ones that can print their own money (so not Greece), should be taken as a metaphor of their fiscal problems, or perhaps as a measurement of the risk that they will have potentially spiraling inflation when they do print their way out of a mess. An open source quantitative model would not directly try to model the failure of politicians to agree (although there are certainly market data proxies for that kind of indecision), and that’s ok: probably the quantitative model’s grade on sovereign default risk trained on corporate bonds would still give real information, even if it’s not default likelihood information. And, being open-source, it would at least be clear what it’s measuring and how.
I’ve also gotten a couple excellent comments already on my first post about this idea which I’d like to quickly address.
There’s a comment pointing out that it would take real resources to do this and to do it well: that’s for sure, but on the other hand it’s a hot topic right now and people may really want to sponsor it if they think it would be done well and widely adopted.
Another commenter had concerns of the potential for vandals to influence and game the model. But here’s the thing, the point of open source is that, although it’s impossible to avoid letting some people have more influence than others on the model (especially the maintainer), this risk is mitigated in two important ways. First of all it’s at least clear what is going on, which is way more than you can say for S&P, where there was outrageous gaming going on and nobody knew (or more correctly nobody did anything about it). Secondly, and more importantly, it’s always possible for someone to fork the open source model and start their own version if they think it’s become corrupt or too heavily influenced by certain methodologies or modeling choices. As they say, if you don’t like it, fork it.
Update! There’s a great article here about how the SEC is protecting the virtual ratings monopoly of S&P, Moody’s, and Fitch.
Open Source Ratings Model?
A couple of days ago I got this comment from a reader, which got me super excited.
His proposal is that we could start an open source ratings model to compete with S&P and Moody’s and Fitch ratings. I have made a few relevant lists which I want to share with you to address this idea.
Reasons to have an open source ratings model:
- The current rating agencies have a reputation for bad modeling; in particular, their models, upon examination, often have extremely unrealistic underlying assumptions. This could be rooted out and modified if a community of modelers and traders did their honest best to realistically model default.
- The current ratings agencies also have enormous power, as exemplified in the past few days of crazy volatile trading after S&P downgraded the debt of the U.S. (although the European debt problems are just as much to blame for that I believe). An alternative credit model, if it was well-known and trusted, would dilute their power.
- Although the rating agency shared descriptions of their models with their clients, they weren’t in fact open-source, and indeed the level of exchange probably served only to allow the clients to game the models. One of the goals of an open-source ratings model would be to avoid easy gaming.
- Just to show you how not open source S&P is currently, check out this article where they argue that they shouldn’t have to admit their mistakes. When you combine the power they wield, their reputation for sloppy reasoning, and their insistence on being protected from their mistakes, it is a pretty idiotic system.
- The ratings agencies also have a virtual lock on their industry- it is in fact incredibly difficult to open a new ratings agency, as I know from my experience at Riskmetrics, where we looked into doing so. By starting an open source ratings model, we can (hopefully) avoid issues like permits or whatever the problem was by not charging money and just listing free opinions.
Obstructions to starting an open source ratings model:
- It’s a lot of work, and we would need to set it up in some kind of wiki way so people could contribute to it. In fact it would have to me more Linux style, where some person or people maintain the model and the suggestions. Again, lots of work.
- Data! A good model requires lots of good data. Altman’s Z-score default model, which friends of mine worked on with him at Riskmetrics and then MSCI, could be the basis of an open source model, since it is being published. But the data that trains the model isn’t altogether publicly available. I’m working on this, would love to hear readers’ comments.
What is an open source model?
- The model itself is written in an open source language such as python or R and is publicly available for download.
- The data is also publicly available, and together with the above, this means people can download the data and model and change the parameters of the model to test for robustness- they can also change or tweak the model themselves.
- There is good documentation of the model describing how it was created.
- There is an account kept of how often different models are tried on the in-sample data. This prevents a kind of data fitting that people generally don’t think about enough, namely trying so many different models on one data set that eventually some model will look really good.
The Life Cycle of a Hedge Fund
When people tell me they are interested in working at a hedge fund, I always tell them a few things. First I talk about the atmosphere and culture, to make sure they would feel comfortable with it. Then I talk to them about which hedge fund they’re thinking about, because I think it makes a huge difference, especially how old a hedge fund is.
Here’s the way I explain it. When a hedge fund is new, a baby, it either works or it doesn’t. If it doesn’t, you never even hear about it, a kind of survivorship bias. So the ones you hear about work well, and their founders do extremely well for themselves.
Then the hedge fund hires a bunch of people, and this first round of people also does well, and they start filling up the ranks of MD’s (managing directors). Maybe at this point you’d say the hedge fund is an adolescent. Once you have a bunch of MD’s that are rich and smart, though, they become pretty protective of the pot of money they generate each year, especially if the pot isn’t as big as it once was, because of competition from other hedge funds.
However, this doesn’t always mean they stop hiring. In fact, they often hire people at this stage, young, smart, incredibly hard working people, who are generally screwed in the sense that they have very little chance of being successful or ever becoming MD. This is what I’d term an adult hedge fund. They have complicated rules which make sense for the existing MD’s but which keep new people from ever succeeding.
For example, when you get to a hedge fund, you start being assigned models to work on. You learn the techniques and follow the rules of the hedge fund, like making sure you don’t bet on the market, etc. If your model starts to look promising, they make sure you are not “remaking” an existing model that is currently being used. That is to say, they make sure, either by telling you what to do or asking you to do it yourself, that your bets are essentially orthogonal (in a statistical sense) to the current models. This often has the effect of removing the signal that your model had, or at least removing enough of it that your model no longer is statistically significant to go into production.
In other words, if the existing models are a relatively large collection, that perhaps spans the space of “current models that seem to work in the way we measure models” (I know this is a vague concept but I do think it means something), then you are kind of up shit’s creek to find a new model. By contrast, if you happened to start at a young hedge fund, or start your own hedge fund, then your model couldn’t be redundant, since there wouldn’t be anything to compete with it.
The older hedge funds have lots of working models, so there are lots of ways for your new, good-looking model to be swatted down before it has a chance to make money. And the way things work, you don’t ever get credit for a model that would have worked if there had been fewer models in production. In fact you only get credit if you came up with a new model which made shit tons of money.
Which is to say, under this system, the founders and the guys brought in during the first round of hiring are the most likely to get credit. Even if an MD retires, their working models don’t die, since they are algorithmic and they still work. But the money they generate goes into the company-wide pot, which is to say mostly goes to MD’s. So the MD’s have no incentive to change the system.
It also has another consequence, which is that the people hired in the second or further rounds slowly realize that their models are perfectly good but unused, and that they’ll never get promoted. So they end up leaving and starting their own funds or joining young funds, just so they can run the same models. So another consequence of adult hedge funds is that they spawn their own competition.
The only way I know of for a hedge fund to avoid this aging process is to never hire anyone after the first round. Or maybe to hire very few people, slowly, as the MD’s retire and as the models stop working and you need new ones, to be sure that the people they hire have a chance to succeed.



