More Money than God
This is a guest post from an anonymous friend. Actually is was a letter to me that I thought was hilarious and got permission to post.
———————————————————
Dear Cathy,
Earlier I mentioned that I was reading “More Money than God”, which might have been construed as an endorsement, so, in case you haven’t read it already, I thought I would save you some time by summarizing it:
Chapter {2,\ldots,(N-2)}: All the hedge fund dudes you have heard of are* sages both of human nature and of economics. When they destroy foreign currencies, it’s to correct bad governments. When they attempt to short foreign currencies but fail, it’s because they (Soros) care deeply about these developing countries and are using their money to help support them. They are huge philanthropists. They increase economic stability by being contrarian. The only time they are outsmarted is when they are outsmarted by other hedge fund titans.
Chapter N: Don’t regulate hedge funds. Regulating hedge funds would be bad for the economy and for philanthropy. There’s no need for hedge funds to be regulated. Regulate the banks or something else but for God’s sake not hedge funds. Also: no regulation!
Acknowledgments: thanks to Rubin and all my other buddies at CFR, and at Blackstone, and to Paul Tudor Jones, and all the other hedge fundies who supported me while I wrote this book for 3 years.
* They are now, but in the 60s when hedge funds started the whole “hedging” and “long-short” thing was just a distraction from organized insider trading over corned-beef sandwiches. But no one ever insider trades anymore. Except for Raj, who’s clearly not a real hedge fund guy. Who eats SIM cards? We’re not those kind of thugs.
Politicians and insider trading
There’s shit going down in Washington now around the proposed ban on insider trading of politicians (which for some weird reason up til now hasn’t been illegal). According to this New York Times article, the proposed legislation would also require certain “political intelligence firms” to register as lobbyists, and that gotten them up in a huff. From the article:
“Hedge funds, private equity funds and investment advisers — many of which are not currently registered under the Lobbying Disclosure Act — might now be required either to register or to alter their business practices to avoid the need for registration,” the bulletin said. “If, for example, a hedge fund calls a Congressional committee staffer to gather information about the status of a bill that relates to the fund’s investment decisions, the fund may need to register.”
If you can judge someone by their enemies, then this bill seems kind of like my new best friend. Let’s wait to see how much it’s watered down in the next few days:
House Republicans and their floor leader, Representative Eric Cantor of Virginia, said they would amend the bill, going to the House floor this week, to strengthen it.
But Representative Louise M. Slaughter, Democrat of New York, said, “I think ‘strengthening’ here is a euphemism for ‘weakening.’”
Preggers
The below video resonates with me, but trust me when I say it’s all about the hormones, and we do get over it, at least after weaning. In any case, I apologize (hat tip Jordan Ellenberg).
While I’m here, though, I would like to say one thing that non-pregnant people do to pregnant people, which is desex them. The maternity clothes industry was part of this until recently, making all maternity dresses (and they were all dresses) look like school-girl uniforms.
It’s like, now that you’re pregnant I’m going to treat you like an innocent child who’s never had a dirty thought in her life. But, people, how do you think we got this way?
But it’s a more general phenomenon, and you kind of act like an idiot in part because people treat you like one.
Opacity, noise, and overpopulation in finance
This is a guest post by Mekon:
When you come in to work nowadays, you have to read the blogs. The other day, two blogs I like to read both had pieces about Freddie Mac and whether it had inappropriately bet against people refinancing their homes. I’ll spare you the details, which live in the highly technical world of mortgage securitization, but the issue is that Freddie Mac had a large position in “inverse floaters,” which are worth more when people don’t refinance.
The first piece says this is fishy, because Freddie Mac also makes rules on who gets to refinance and who doesn’t. So they have lots of incentive to make the rules more stringent, block people from refinancing, and profit by doing so.
But the second piece says there’s nothing fishy here at all: Freddie Mac is probably holding the inverse floaters to hedge interest rate risk. That is, they might need them just to be neutral to interest rates (people prepay when interest rates go down), because the rest of their book is exposed the other way.
How do you tell who’s right?
The first thing to realize is that they’re actually disagreeing on facts. This isn’t like the usual economic disagreements, where people argue over principles (whether the Fed should worry about unemployment as well as inflation) or things you can’t prove (how bad the economy would have gotten without the stimulus). It should be easy to settle this one: take Freddie’s book and see how it goes up and down when interest rates go down/stay the same/go up and people prepay more or less.
I imagine we haven’t done this because we don’t have the book.
Some opacity in finance may be unavoidable, but sometimes it’s completely unnecessary and self-inflicted. These are government enterprises! Why don’t we make their books transparent? If we can’t do it right away, what about with some kind of time lag? We’re talking about their positions from 2010, for heaven’s sake!
The second thing – forgive me if I’m off base here, I’m a fan of both blogs – is that it doesn’t seem like either one of them has fully done their homework (to be fair, without being able to see into Freddie’s book, it’s not clear how they could have). Both sites followed up with more detail, but nothing that seems definitive – put another way, I still can’t tell who’s right.
I’d like to see people be more sure about the facts before publishing conclusions. I thought maybe this was just me, but then I ran across a paper by Andrew Lo which makes much the same point (see the last section). Andrew looks at 21 different books about the financial crisis and compares the range of conclusions they draw to Rashomon. And, like the Freddie example, he finds no agreement on the underlying facts. I hear his frustration when he urges: “By working with a common set of facts, we have a much better chance of responding more effectively and preparing more successfully for future crises.” Amen.
Finally, if you’ll indulge me, a little sociology. If you’ve been around finance for a while, I think you’ll agree with me that people being on loose ground with their arguments and a bit quick on the draw with their conclusions is more the norm than the exception. Put another way, there’s an awful lot of noise in finance. Why is this?
This blog has focused a lot on how finance today is both complicated and opaque. One thing I’d add is that finance isoverpopulated. I don’t just mean that we’d be better off if smart people thought more about curing cancer and avoiding famine and less about executing trades a millisecond faster or securitizing and sell some kind of risk that’s never been traded before. (But duh.)
What I mean is that finance today is so complicated and opaque that it requires extremely specialized skills to understand what’s going on. At the same time, the field employs way more people than could ever have those specialized skills. End result: many people working in finance don’t really understand it. Which makes noise an accepted part of the culture. Which in turn makes it even harder to understand what the hell is going on.
I don’t know how to fix this, but wouldn’t you feel a lot better about our financial system if we could (1) make it simpler, and (2) cut the number of people needed to operate it in half?
Women in math
This is crossposted from Naked Capitalism.
A study recently came out which was entitled “Can stereotype threat explain the gender gap in mathematics performance and achievement?”. One of the authors created and posted a video describing the paper, which you can view here.
As a preview, there seem to be four main points of the paper and the video:
- The papers on stereotype threat normalize with respect to SAT scores which is bad.
- Evidence for stereotype threat is therefore weak.
- We should therefore stop putting all of our resources into combating stereotype threat.
- We should instead do something easy like combating stereotypes themselves.
Before we go into the details of the paper, we need a bit of context. For that reason, this post is split into three parts. The first addresses a meta-issue, namely that of the “null hypothesis” in this discussion. A frustration that I have, and that I think is shared by many of the women I know in math, is that the (often unspoken) working hypothesis is that in fact women are just not as talented, and it is somehow up to us women to prove this otherwise, presumably by convincing men that we’re geniuses.
The authors of the above paper fall prey to this disingenuous line of thought, by proclaiming stereotype threat is an insufficient explanation but not offering any alternative explanations. This sets up a kind of implied false dichotomy: if it isn’t explained by such and such, it must mean girls are dumb.
Not only does this undermine serious intellectual debate, but it often turns people off from entering the debate in the first place, because they sense the manipulative nature of the discussion. But that’s a pity, since, with the correct assumption, namely that women and men have equal talents but things are holding back women, we could probably make lots of progress on what those things are.
The second part is directly related not to the paper but to the blog post which referenced the paper, which changed the conversation from “math performance gap” to the question of “why there are no women math geniuses”. This is an interesting twist, and in my opinion warrants addressing separately.
In the third part I argue directly against the paper and its conclusions.
1. The Null Hypothesis
Needless to say, I think the onus is on the scientific community to prove that women aren’t as mathematically talented as men. In other words, I do not accept the defensive position that I need to prove we are as smart: the null hypothesis is that a series of effects, one of them stereotype threat, explains any perceived difference in talent.
In his now famous lecture at NBER in 2005, Larry Summers putatively discusses the issue of why there are fewer tenured women in science and math departments at top universities. However, if you read the transcript, you will note that, when he gets to the “different availability of aptitude at the high end” part, he does us a favor of sorts by admitting what his underlying working hypothesis is: that girls aren’t as good at math. His argument using standard deviations of test scores is ridiculous, especially if you consider 1) how differently women do versus men on the same test in different conditions, 2) how much that difference has itself changed over time, and of course 3) the question of what the tests themselves are measuring.
To test why this null hypothesis is so damaging, my friend Catherine Good suggested the following thought experiment: imagine if he’d gone up to the podium and, instead of saying that women aren’t all that good at math and it was partly explained by when he’d given boyish toys to his twin girls that they took care of them instead of constructed things, he had instead substituted gender with race. Here’s the passage:
There may also be elements, by the way, of differing, there is some, particularly in some attributes, that bear on engineering, there is reasonably strong evidence of taste differences between little girls and little boys that are not easy to attribute to socialization. I just returned from Israel, where we had the opportunity to visit a kibbutz, and to spend some time talking about the history of the kibbutz movement, and it is really very striking to hear how the movement started with an absolute commitment, of a kind one doesn’t encounter in other places, that everybody was going to do the same jobs. Sometimes the women were going to fix the tractors, and the men were going to work in the nurseries, sometimes the men were going to fix the tractors and the women were going to work in the nurseries, and just under the pressure of what everyone wanted, in a hundred different kibbutzes, each one of which evolved, it all moved in the same direction. So, I think, while I would prefer to believe otherwise, I guess my experience with my two and a half year old twin daughters who were not given dolls and who were given trucks, and found themselves saying to each other, look, daddy truck is carrying the baby truck, tells me something. And I think it’s just something that you probably have to recognize.
It begs the question, why did the women in kibbutz quit working on tractors? The way Larry tells his story, he makes it clear he thinks that it’s because the women wanted it that way (thus his story about the twins). But surely it is as plausible that: 1) Men, having a vested interest in proving their manhood (which they do and in cultures around the world leads to certain types of work being seen as “manly”) weren’t keen about day care duty and/or 2) women were hesitant to cross the lines of gender stereotype (it might lead them to be perceived as being masculine, or even worse, emasculating). And it also isn’t hard to imagine that parents ooh and ahh more when small children play with what are perceived to be gender-appropriate toys and are quietly or even vocally uncomfortable when boys play with dolls and girls play with trucks.
One last word about the null hypothesis and why I’m so devoted to this issue: when I and two other girls (and, as it happens, no boys) in the 6th grade did well enough to go into a special, advanced 7th grade algebra class, my (female) teacher brought us up to the front of the room and told the three of us “I don’t see why you would challenge yourselves like this anyway since you are girls, and you won’t be needing math when you grow up.” I was the only one of the three of us to actually choose that class, and I was the only girl in the algebra class. One of my friends was one of two women in a class of 45 students studying artificial intelligence at Yale. She was expecting praise for being one of only two students to get a program to work on a particularly tough assignment. Instead, she was accused by the professor of stealing the code from her male classmate. She left the major. Until stories like this become rare, or even uncommon, I will assume that there’s too much cultural influence to figure out the real story.
Going back to Larry Summers, his lecture did two things: 1) it breathed new life into the age-old stereotype that women aren’t as good at math as men, and 2) it attributed that difference to an underlying innate ability difference- that is, he conveyed a “fixed ability mindset” regarding math (more on mindsets below). As the leader of an educational institution he introduced the two ideas that together are like a powder keg: they can undermine women’s feelings of belonging in math, which in turn informs their mathematics achievement and intrinsic motivation to remain in math.
Now more about Catherine Good. She talked at that same conference where Larry Summers put his foot in his mouth; in fact she was the speaker after Larry at that conference, and she was talking about her paper that gives evidence that the above “powder keg” message tends to push women out of math (but Larry didn’t stick around long enough to hear her talk, unfortunately). She is also an expert on stereotype threat and helped me look at the study. More on her thoughts below, but I still want to talk about the concept of “genius.”
2. Women and the concept of genius
Let’s define, as one of the commenters does from the blog, a “genius woman in math” to be any woman who has won a Fields Medal. Since there are no women who have won Fields Medals (versus 52 men), this is a pretty tight definition. I would argue, and I might in another post, that even without the above definition, the concept of “genius” is a social construct which is rarely if ever applied to women, except perhaps after they’re dead. Please comment with counterexamples if you know of any.
So here’s what I think. There are lots of reasons that women don’t win Fields Medals. I will name a few.
- Fields Medals are awarded to mathematicians under the age of 40, for some reason, and women mathematicians typically do good work into their retirement age, whereas men usually do their best work young (this also explains why Harvard has so much trouble hiring women- by the time they are convinced the woman is a genius, she’s 55 and has grandchildren and frankly probably sees the offer as tokenism).
- The commenter who defined a “math genius” as a Fields Medalist said that it would be an objective measure. But Fields Medals are awarded by a bunch of guys who decide what’s important and who’s responsible for the important results. In other words it’s a political process.
- Women don’t care as much about winning Fields Medals. This matters, because I know of men who explicitly worked on problems in order to win the Fields Medal (you know who you are). It’s a serious and bizarre case of narrow focus.
- Why is math genius defined so narrowly? I would personally define it more broadly (a topic for another post), and there’d be plenty of women geniuses. With my definition, though, I’d guess that women who are geniuses have lots of options and they often choose something they consider more personally rewarding than an academic job.
- Women’s intelligence may also manifest in different ways: note that most of the assholes on Wall Street are men. This kind of makes sense since women are typically not as driven by testosterone and competitiveness. This doesn’t mean they aren’t geniuses or that they couldn’t have done the work the men on Wall Street did (my experience proves that).
- The Fields Medal distorts the mathematical process itself, by implying that there’s a single superstar who swoops in and solves the problem that all the other people were incapable of doing. In fact mathematics as a field is an enormous collaboration, a scientific project, where everyone depends on the community around them for coming up with questions, defining the “interestingness” of questions, and giving context to results. The idea that there’s one winner out of all of this, or even one metric by which we could measure such a winner, is silly. See this post from Quomodocumque.
- Another point about genius (in any domain): research is showing that to truly express one’s genius takes thousands of hours of practice. So genius may be a latent trait but will never be expressed without many hours of hard work. This point is very often lost and is related to women in that their apparent geniusness depends to a large extent on how supportive their environment is for all that investment of time.
3. The paper against stereotype threat
I am finally ready to address (with Catherine’s help) the issues of the paper in question, which I will repeat:
- The papers on stereotype threat normalize with respect to SAT scores which is bad
In fact the author “discards” a bunch of stereotype threat studies on these grounds. However, it is totally standard to normalize with respect to some other metric (would you rather we didn’t normalize to anything?), and in fact it essentially penalizes the studies, since it has been shown that stereotype threat is in play even for the SATs. On the other hand, the standard for normalizing (this is called “including a covariate”) is that the groups being compared should not differ significantly in the covariate, presumably because it’s harder to argue that your are in fact correcting for that aspect. Because men and women sometimes do differ significantly in SAT scores, including them as covariates could be a technical violation of the rules of conducting a so-called ANCOVA.
Is this what the author is complaining about specifically? Did he, for example, check to see if the samples in the “discarded” studies actually differ in the covariate? It seems he’s making the assumption that they did, but it’s not clearly stated that they did. It’s certainly not a given that the men and women in these studies did differ in the covariate, and he needs to make that precise. If they did not, then there’s no valid argument against using SAT scores.
- Evidence for stereotype threat is therefore weak.
There is ample evidence that stereotype threat is very real. Keep in mind that the authors of this study have not shown evidence against stereotype threat, but have simply complained that they don’t like the existing studies for it. And their standard for what “replicates” the original study is overly stringent- they only wanted to include studies that found significant interactions between gender and condition. Interactions are easiest to find when you have a “crossover effect” (e.g. males are higher in condition A but lower in condition B), but often we find “span effects” in which the males and females may be equal in condition A but differ in condition B. This can also be an example of stereotype threat. For example, in a paper written by Catherine, she didn’t find a significant interaction (males and females performed equally in condition A) but when the stereotype threat was reduced, women outperformed men. To discount this and other studies as not providing evidence of stereotype threat simply because an “interaction” wasn’t found is playing games with statistics.
- We should therefore stop putting all of our resources into combating stereotype threat.
Nobody who studies stereotype threat claims it explains everything. It is part of a larger picture. The good news is that there are interventions for it (described below).
- We should instead do something easy like combating stereotypes themselves.
The idea that it’s “easy” to combat stereotypes is completely naive. There are tons of ways that stereotyping is understood to be very difficult, if not impossible, to get rid of. Some of them have to do with an evolutionary need to simplify first impressions of people (i.e. categorize) so that we can tell if they are an immediate threat to our safety. This may be the most baffling part of the whole thing, because the authors should really know better.
I want to end on a positive note, because the news is actually pretty good. There is a way to combat stereotype threat, and I’ve tried it and it works. To understand it, it helps to think about the way people think about intelligence itself. As a simplification, people either think that intelligence is fixed and rigid (you’re either born with it or you’re not) or they think that intelligence is malleable and can be learned and practiced.
It turns out that if someone believes the latter “malleable intelligence” view, then they work hard and are hopeful and stereotype threat is to a large extent alleviated. Whereas if they’re convinced of the former mindset for intelligence, the effect of stereotype threat is more pronounced. In situations where the stereotype is salient (“girls are bad at math” is salient when taking a math test), the situation itself can convey a mindset of fixed ability and all the hallmark responses that go along with that mindset then follow. To encourage a malleable view of intelligence can help combat that fixed view and thus the threat of the stereotype.
The way I used this information was as follows. I started a class in teaching proof techniques at Barnard College (there were both Barnard students and Columbia students in the class). At the beginning of every class for the first two weeks I described how mathematicians aren’t born knowing how to prove things, but rather they learn techniques, and practice them until they are proficient. Note I wasn’t directly confronting or addressing stereotypes, but rather setting up the mindset where the studies have shown stereotypes have less negative power.
The class went great, and is still going on. I will post soon about my experiences starting that class and others like it.
Raise capital gains and stop flying
There are two totally unrelated stories I want to discuss this morning, I hope you’ll forgive me.
First, take a look at this post, written by David Brin, which argues for higher capital gains tax. He points out VC’s or angel investors, in combination with entrepreneurs, are the true “job creators”, and also invest their money in a truly risky way, whereas generic rich people who only invest in established companies are taking risks but not on the same level. Yet these two classes of people are taxed at the same rate. I guess the counterarguments would be that they, the VC’s, also get more payoff (when things work out) and that they couldn’t make their investments without the fleet of passive rich people ready to invest if and when the company succeeds. Even so I think there’s a real difference.
It reminds me that, when I worked at D.E. Shaw and Lehman fell, there were lots of discussions around the water cooler about what the reaction would be by policy makers and regulators. The consensus fear was that the capital gains tax rate for hedge fund workers would be removed within weeks, if not days. Note this tax loophole allows hedge fund quants and traders to pay less taxes on their take-home pay than bankers across the street doing the same job. I don’t really know anyone who defends it, not even people who benefit from it. Please correct me if I’m wrong. Update: mostly people below the MD (managing director) level at hedge funds actually don’t get this benefit. It primarily applies to “buy and hold” people like VC’s, private equity, and long term debt firms.
Another argument I enjoy from Brin’s post is the refutation of lowering taxes in general to entice investment by rich people. As he said:
Supply Side assumes that the rich have a zillion other uses for their cash and thus have to be lured into investing it! Now ponder that nonsense statement. Roll it around and try to imagine it making a scintilla of sense! Try actually asking a very rich person. Once you have a few mansions and their contents and cars and boats and such, actually spending it all holds little attraction. Rather, the next step is using the extra to become even richer. Naturally, you invest it. Whatever the tax rates, you invest it, seeking maximum return.
This is absolutely true, and one of the funny things about (many of) the rich quants I know: they are obsessed with growing their pile, to the point of focusing more on money now that they’re rich than they ever did when they were poor physics or math graduate students. To be fair, to make the whole argument for raising taxes you’d need to consider the global response, whereby rich people essentially arb the tax systems of the various countries in search of the maximum return. Even so, I’m pretty sure the answer is not to try to compete with Caribbean island nations on how low we can tax.
Second, check out this fantastic article from the Wall Street Journal about how people respond to environmental impact issues by consuming more. In the article they describe what’s called the “Prius Fallacy: a belief that switching to an ostensibly more benign form of consumption turns consumption itself into a boon for the environment”. I love it, first of all because it’s completely snarky and second of all because it’s really true and annoying. My favorite line:
Even if you think that climate change is a left-wing crock, this ought to be a matter of gnawing concern. Global energy use is growing faster than population. It’s expected to double by midcentury, and most of the growth will be in fossil fuels. Disasters like the BP oil spill attract world-wide attention, but the main environmental, economic and geopolitical challenge with petroleum isn’t the oil that goes into the ocean; it is the oil we continue to use exactly as we intend.
By the way, I don’t claim to be particularly low-impact on the world myself: I’m flying to Amsterdam in March with my entire family, which definitely puts me on the earth’s shit list (turns out it’s all about airplane travel). For that matter I work at a company that makes it easier for consumers to buy airplane tickets. But at least I don’t pretend that buying a Prius or replacing my kitchen counters with less eco-unfriendly material makes me a good person (by the way, once you’ve got eco-unfriendly kitchen counters the damage is done. The best thing you can do for the environment at that point is never ever remodel your kitchen again. Can you handle that?!).
If I had my way, we’d know the fossil-fuel impact of every activity we engage in, and we’d be able to put ourselves on a fossil-fuel diet. Those people who carefully recycle their milk containers and buy local but also fly to East Asia every chance they get would be in for some major belt-tightening.
Data Science needs more pedagogy
Yesterday Flowing Data posted an article about the history of data science (h/t Chris Wiggins). Turns out the field and the name were around at least as early as 2001, and statistician William Cleveland was all about planning it. He broke the field down into parts thus:
- Multidisciplinary Investigation (25%) — collaboration with subject areas
- Models and Methods for Data (20%) — more traditional applied statistics
- Computing with Data (15%) — hardware, software, and algorithms
- Pedagogy (15%) — how to teach the subject
- Tool Evaluation (5%) — keeping track of new tech
- Theory (20%) — the math behind the data
First of all this is a great list, and super prescient for the time. In fact it’s an even better description of data science than what’s actually happening.
The post mentions that we probably don’t see that much theory, but I’ve certainly seen my share of theory when I go to Meetups and such. Most of the time the theory is launched into straight away and I’m on my phone googling terms for half of the talk.
The post also mentions we don’t see much pedagogy, and here I strongly concur. By “pedagogy” I’m not talking about just teaching other people what you did or how you came up with a model, but rather how you thought about modeling and why you made the decisions you did, what the context was for those decisions and what the other options were (that you thought of). It’s more of a philosophy of modeling.
It’s not hard to pinpoint why we don’t get much in the way of philosophy. The field is teeming with super nerds who are focused on the very cool model they wrote and the very nerdy open source package they used, combined with some weird insight they gained as a physics Ph.D. student somewhere. It’s hard enough to sort out their terminology, never mind expecting a coherent explanation with broad context, explained vocabulary, and confessed pitfalls. The good news is that some of them are super smart and they share specific ideas and sometimes even code (yum).
In other words, most data scientists (who make cool models) think and talk at the level of 0.02 feet, whereas pedagogy is something you actually need to step back to see. I’m not saying that no attempt is ever made at this, but my experiences have been pretty bad. Even a simple, thoughtful comparison of how different fields (bayesian statisticians, machine learners, or finance quants) go about doing the same thing (like cleaning data, or removing outliers, or choosing a bayesian prior strength) would be useful, and would lead to insights like, why do these field do it this way whereas those fields do it that way? Is it because of the nature of the problems they are trying to solve?
A good pedagogical foundation for data science will allow us to not go down the same dead end roads as each other, not introduce the same biases in multiple models, and will make the entire field more efficient and better at communicating. If you know of a good reference for something like this, please tell me.
The SEC needs handcuffs
My friend Chris Wiggins sent me this link just now, about how the SEC lets big banks get away with whatever they want to in the name of investors. Aargh!
I was discussing the impotence of the SEC with someone at the SEC recently and here’s what I said. Lots of people think you need to pay people at the SEC as much as the bankers get paid in order to have an SEC with balls, but that’s not true. It’s about power, not money. If I knew that, as an SEC employee, I’d be able to walk into Citigroup, put handcuffs on Vikram Pandit, and perp walk him out of the building, that’s a job I’d take in an instant, even at government salary.

Let them game the model
One of the most common reasons I hear for not letting a model be more transparent is that, if they did that, then people would game the model. I’d like to argue that that’s exactly what they should do, and it’s not a valid argument against transparency.
Take as an example the Value-added model for teachers. I don’t think there’s any excuse for this model to be opaque: it is widely used (all of New York City public middle and high schools for example), the scores are important to teachers, especially when they are up for tenure, and the community responds to the corresponding scores for the schools by taking their kids out or putting their kids into those schools. There’s lots at stake.
Why would you not want this to be transparent? Don’t we usually like to know how to evaluate our performance on the job? I’d like to know it if being 4 minutes late to work was a big deal, or if I need to stay late on Tuesdays in order to be perceived as working hard. In other words, given that it’s high stakes it’s only fair to let people know how they are being measured and, thus, how to “improve” with respect to that measurement.
Instead of calling it “gaming the model”, we should see it as improving our scores, which, if it’s a good model, should mean being better teachers (or whatever you’re testing). If you tell me that when someone games the model, they aren’t actually becoming a better teacher, then I’d say that means your model needs to improve, not the teacher. Moreover, if that’s true, then without transparency or with transparency, in either case, you’re admitting that the model doesn’t measure the right thing. At least when it’s transparent the problems are more obvious and the modelers have more motivation to make the model measure the right thing.
Another example: credit scoring. Why are these models closed? They affect everyone all the time. How is Visa or Mastercard winning if they don’t tell us what we need to do to earn a good credit card interest rate? What’s the worst thing that could happen, that we are told explicitly that we need to pay our bills on time? I don’t see it. Unless the models are using something devious, like people’s race or gender, in which case I’d understand why they’d want to hide that model. I suspect they aren’t, because that would be too obvious, but I also suspect they might be using other kinds of inputs (like zip codes) that are correlated to race and/ or gender. That’s the kind of thing that argues for transparency, not against it. When a model is as important as credit scores are, I don’t see an argument for opacity.
CDS data and open source ratings
What’s the current deal on credit default swap data? Is the Dodd-Frank bill going to force any CDS pricing to be publicly available?
A bit of background: a credit default swap is something like insurance you pay in case the underlying bond is defaulted on (but not exactly, see here), so it’s relatively easy to infer the default probability from its price, as long as you have a good estimate of the “recovery rate,” which is the amount the bond pays out even though it’s defaulted. This rate can vary widely, and people sometimes lose sight of how sensitive everything is to that assumed number.
Here’s the thing. I am super into the idea of an open source ratings model (see this post and this post on open source ratings models, as well as this post on open models in general), and I think having CDS data as input to the model might vastly improve it over just using quarterly filings and stock market data.
Right now the standard ratings models don’t use CDS data, but I think that’s because they’re just really old. I’d guess that some combination of the old ratings model and the new CDS market would be great for an open source ratings model. And it’s true that CDS coverage isn’t perfect (i.e. there are not liquid CDS markets on everything you’d want ratings for) but on the other hand, for what it does, the market is super timely and people really watch it (sovereign debt is a great example of this).
As of a year ago all of this data was essentially owned and monopolized by Markit, which is made up of a bunch of CDS brokers. So even if I had the money to pay for the data, for licensing reasons I wouldn’t be able to make the data open source, which sucks. I know that there’s been talk about making this data publicly available, but I’ve been so involved with stuff like the Volcker Rule, I just haven’t kept up with the current CDS transparency rules. I mean, if we aren’t going to remove the CDS market or regulate it, at the very least we should be using it. Please tell me if you know.
Alternative Banking in FT Alphaville (#OWS)
Alt Banking’s opinion piece about too-big-to-fail was published yesterday in FT Alphaville.
Woohoo!
Econned and Magnetar
Gaming the risk model
When I worked in finance, there was a pretty well-known (and well-used) method of working around the pesky requirements of having a risk model and paying attention to risk limits in your group.
Namely, you’d let a risk guy in the group for a while, long enough to write a half-decent risk model, and then you’d say thanks, and we don’t need you anymore we’ll run with this, and then you’d kick him out of the group. You’d then spend the next few years learning how to game the risk model.
In particular you’d know exactly what kind of trades you could put in that the risk model can’t “see”: things like interest rate risk or counterparty risk, that the poor risk guy didn’t think of at the time, or even better the market you trade in would have developed and changed in the last few years so you were applying the risk model to instruments it wasn’t even meant to measure.
That way you could always stay within your risk limits, as a group, even while you took larger and larger bets on things that were invisible to the risk model. As long as the world didn’t blow up, this method returned higher-than-expected profits, so your “Sharpe ratio” looked great. You got rewarded for this, and in the meantime the company you worked for took on the risk (and they typically didn’t see it as coming from your trading group but rather as some amorphous systemic risk). It’s not clear how many people how high up were in on this method, but it seemed pretty clear that they also enjoyed the ride as long as it lasted.
The CDO market
One really enormous and tragic example of this behavior is described in Yves Smith‘s brilliant book Econned, in the chapter describing the CDO market and Magnetar Capital‘s involvement.
CDOs were the reason we had a global economic crisis and not just a housing bubble. The CDO market is complicated, and you can learn a lot about it by reading the book. Suffice it to say I’m not going to be able to explain the whole thing, but let me simplify the story thus.
At the beginning (late 1980s through mid-late 1990s) there were not that many securitizations outside of the federal arena (Freddie Mac, Fannie Mae, and FHA), and they were pretty useful because they made piles of riskier but still viable-looking mortgages more predictable than individual mortgages. The top of the pile (they were separated in to groups called “tranches” depending on possible defaulting actions) were rated AAA by the big three ratings agencies (Moody’s, Fitch, and S&P) and probably deserved it, because they had a big cushion of loss protection beneath them. The lower tranches were lower rated and harder to sell, which limited the size of the overall market.
Starting around 2003 the lower-rated, harder-to-sell tranches from the BBB to the junior AAA tranche started getting resecuritized into instruments called CDOs. In fact there were riskier CDOs, called mezzanine CDOs, which consisted mainly of the BBB tranches, and “high grade” CDOs consisting mostly of old A and AA tranches. These CDOs were again tranched, with around 75% of the par value getting an AAA rating.
Yes, you heard that right: if you took a bunch of easy-to-imagine-they’d-fail low rated mortgage bond tranches (especially if you knew anything about the terms of those mortgages and how much they were counting on the housing market to continue its climb), and bundle them together, then the resulting package would, at its highest tranche, be deemed AAA. It made no sense then and it makes no sense now.
The CDS and synthetic CDO markets
Enter the credit default swaps market. The ability to buy CDS protection (insurance on the underlying bonds) on a higher tranche of the mortgage bonds (the first generation securitization) while purchasing a lower tranche made it possible for lots of people to bet that “if things go bad, they will go really bad”, while limiting their overall exposure. Moreover, the income on the lower rated tranche would fund an even bigger short position on the higher rated tranche, so this was a self-financing bet.
The demand for more cheap credit default swaps led some clever traders to realize they could create CDOs largely or entirely from credit default swaps rather than actual bonds. No need to be constrained by finding real borrowers! And you could bet against the same crap BBB bonds again and again, and have them packaged up and have most of the value of the “synthetic” or “hybrid” CDO rated AAA (again with the collusive help of the ratings agencies).
At first, the big protection sellers in the CDS market was AIG and the monoline insurers. But they only wrote CDSs on the least risky AAA CDO tranches. Later, after AIG stopped being involved, that side of the CDS market was entered into by all sorts of really dumb people, with the help from the complicit ratings agencies who kept awarding AAA ratings.
Even so, there was still a bottleneck for this re-rebundled synthetic/heavily synthetic CDO market. Namely, it was hard to find people to buy the so-called “equity tranche”, which was the tranche that would disappear first, as the first crop of the underlying loans defaulted.
Magnetar
That’s when Magnetar Capital came in. They set up deals to fail. They did this through explicitly designing the synthetic CDOs (banks gave this privelege to whomever was willing to buy the equity tranche) and by, in addition to buying the equity tranche, they bought up all of the CDS’s in the synthetic CDO.
The overall bet Magnetar Capital was taking was similar to the one above: when the market goes bad, it will go really bad. The difference is that Magnetar’s exposure was altogether very short: they set up the equity tranche to pay lots of cash in the short term (a couple of years), which would finance the cost of all of the CDSs in the hybrid CDO, which meant they didn’t just cover the exposure but magnified it multiple times. And it was again a self-financing bet, as long as they were right about the market exploding rather than slowly degrading.
How big was this? Magnetar Capital made the majority of the market in 2006, which was one of the biggest years in this market. And everything they did was legal. They also drove demand in the subprime mortgage market, during its most toxic phase, by dint of a combination of leverage and the clever manipulation of investors, specifically convincing them to post cash bonds.
WTF?
Let’s go back to the groups gaming their risk models from the beginning of this post. Same thing happened here, except the group was this entire market, and the risk guy was the combination of the ratings agencies and AIG, as well as the greedy fools who wrote CDS on mortgages in 2006. And instead of the hedge fund being on the hook for their trading group’s games, in this case it was the United States and various European governments who were on the hook.
How predictable was this whole scheme? My guess is that Goldman Sachs knew exactly what was happening and what was going to happen. They made a very intelligent bet that if and when the housing market went under, AIG would be backed by the government. In essence this entire market was an enormous bet on government bailout. Not everyone knew, of course, especially the guys who were long the market when it collapsed, but lots of people knew. The same people who right now know where the dead bodies are on the books and who aren’t coming forward with a plan to resuscitate the financial system, in fact.
At the very least I think this story argues for the treatment of CDS as insurance, with the requisite regulation. In different terms, Magnetar chose buildings where they saw arsonists enter with gallons of gasoline and matches, and bet everything on a fire in that building. The question then is, how many fire insurance claims should one entity be allowed to buy for one building?
Freddie Mac: worse than hedge funds?
Check out this outrageous article about what Freddie Mac has been doing. Seriously makes my blood boil!!
Update: Yves Smith on Naked Capitalism posted this morning about how this is maybe not such a big deal.
Medical identifiers
In this recent article in the Wall Street Journal, we are presented with two sides of a debate on whether there should be a unique medical identifier given to each patient in the U.S. healthcare system.
Both sides agree that this would help record keeping problems so much (compared to the shambles that exist today) that it would vastly improve scientists’ ability to understand and predict disease. But the personal privacy issues are sufficiently worrying for some people to conclude that the benefits do not outweigh the risks.
Once it’s really easy to track people and their medical data through the system, the data can and will be exploited for commercial purposes or worse (imagine your potential employer looking up your entire medical record in addition to your prison record and credit score).
I agree with both sides, if that’s possible, although they both have flaws: the pro-identifier trivializes the problems of computer security, and the anti-identifier trivializes the field of data anonymization. It’s just incredibly frustrating that we haven’t been able to come to some reasonable solution to this that protects individual identities while letting the record keeping become digitized and reasonable.
Done well, a functional system would have the potential to save people’s lives in the millions while not exposing vulnerable people to more discrimination and suffering. Done poorly and without serious thought, we could easily have the worst of all worlds, where corporations have all the data they can pay for and where only rich people have the ability or influence to opt out of the system.
Let’s get it together, people! We need scientists and lawyers and privacy experts and ethicists and data nerds to get together and find some intelligently thought-out middle ground.
Complexity and transparency in finance
The blog interfluidity, written by Steve Randy Waldman, posted a while back on opacity and complexity in the financial system, arguing that it is opacity and the resulting lack of understanding of risk that makes the financial system work.
Although I like a lot of what this guy writes, I don’t agree with his logic. First, he uses the idea of equilibrium from economics, which I simply don’t trust, and second, his basic assumption is that people need to not have complete information to be optimistic. But that’s simply not true: people are known to be optimistic about things that have complete clarity, like the lottery. In other words, it’s not opacity that makes finance work, it’s human nature, and we don’t need any fancy math to explain that.
Partly in response to this idea, I wrote this post on how people in the financial system make money from information they know but you don’t.
But then Steve wrote a follow-up post which I really enjoy and has a lot of interesting ideas, and I want to address some of them today. Again he assumes that we don’t want a transparent financial system because it would prevent people from buying in to it. I’d just like to argue a bit more against this before going on.
In a p.s. to the follow-up post Steve defines transparency in terms of risks. But as anyone knows who has worked in finance, transparency is broadly understood to mean that the data is available. This could be data about who bought what for how much money, or it could refer to the data of which mortgages are bundled in which CDO’s, and whose houses those refer to and what is the credit score of the mortgagees, or all of the above. Let’s just say all of the above, say we have all the data we could legally ask for about everything on the market.
That’s still not a risk model. In fact, making good risk models from so much data is really hard, and is partly why the ratings agencies existed, so that people could outsource this work. Of course it turns out those guys sucked at it too.
My point is this: a transparent system is at best a system that gives you the raw ingredients to allow you to cook up some risk soup, but it’s left up to you to do so. Every person does this differently, and most people are optimistic about both the measurement of risk and the chances of something bad happening to them (see AIG for a great example of this).
I conclude from this that transparency is a goal we should not be afraid of, because first of all it won’t be all that useful unless people have excellent modeling skills, second of all because no two firms will agree on the risks, and third of all we are so far from transparent right now that it’s laughable to be afraid of such an unlikely scenario.
Going on to the second post of Steve now, he has some good points about how we should handle the very dysfunctional and very opaque current financial system. First, he talks about the relationship between bankers and regulators and argues for strong regulation. The incentives for bankers to make things opaque are large, and the payoffs huge. This creates an incentive for bankers to essentially bribe regulators and to share in the proceeds, which in turn creates an incentive for the regulators to actually encourage opacity, since it makes it easier for them to claim they were trying to do their job but things got too complicated. This sounds like a pretty good explanation for the current problems to me, by the way. He then goes on:
… I think that high quality financial regulation is very, very difficult to provide and maintain. But for as long as we are stuck with opaque finance, we have to work at it. There are some pretty obvious things we should be doing. It is much easier for regulators to supervise and hold to account smaller, simpler banks than huge, interconnected behemoths. Banks should not be permitted to arrange themselves in ways that are opaque to regulators, and where the boundary between legitimate and illegitimate behavior is fuzzy, regulators should err on the side of conservatism. “Shadow banking” must either be made regulable, or else prohibited. Outright fraud should be aggressively sought, and when found aggressively pursued. Opaque finance is by its nature “criminogenic”, to use Bill Black’s appropriate term. We need some disinfectant to stand-in for the missing sunlight. But it’s hard to get right. If regulation will be very intensive, we need regulators who are themselves good capital allocators, who are capable of designing incentives that discriminate between high-quality investment and cost-shifting gambles. If all we get is “tough” regulation that makes it frightening for intermediaries to accept even productive risks, the whole purpose of opaque finance will be thwarted. Capital mobilized in bulk from the general public will be stalled one level up, and we won’t get the continuous investment-at-scale that opaque finance is supposed to engender. “Good” opaque finance is fragile and difficult to maintain, but we haven’t invented an alternative.
I agree with everything he said here. We need strong and smart regulators, and we need to see regulation in every part of finance. Why is this so hard? Because of the vested interests of the people in control of the system now – they’ve even invented a kind of moral philosophy around why they should be allowed to legally rape and plunder the economy. As he explains:
I think we need to pay a great deal more attention to culture and ideology. Part of what has made opaque finance particularly destructive is a culture, in banking and other elite professions, that conflates self-interest and virtue. “What the market will bear” is not a sufficient statistic for ones social contribution. Sometimes virtue and pay are inversely correlated. Really! People have always been greedy, but bankers have sometimes understood that they are entrusted with other people’s wealth, and that this fact imposes obligations as well as opportunities. That this wealth is coaxed deceptively into their care ought increase the standard to which they hold themselves. If stolen resources are placed into your hands, you have a duty to steward those resources carefully until they can be returned to their owners, even if there are other uses you would find more remunerative. Bankers’ adversarial view of regulation, their clear delight in treating legal constraint as an obstacle to overcome rather than a standard to aspire to, is perverse. Yes, bankers are in the business of mobilizing capital, but they are also in the business of regulating the allocation of capital. That’s right: bankers themselves are regulators, it is a core part of their job that should be central to their culture. Obviously, one cannot create culture by fiat. The big meanie in me can’t help but point out that what you can do by fiat is dismember organizations with clearly deficient cultures.
Hear, hear! But how?
“Where to start?”, I wondered.
Please consider purchasing a 55 gallon tub of lube from Amazon.com (pictured below). And before deciding, I suggest you read the reviews (hat tip Richard Smith via Yves Smith).

Also, please be sure to take this quiz to differentiate (if you can) between Newt Gingrich and a comic book supervillian.
Does hip-hop still exist?
I love music. I work in an open office, one big room with 45 people, which makes it pretty loud sometimes, so it’s convenient to be able to put headphones on and listen to music when I need to focus. But the truth it I’d probably be doing it anyway.
I’m serious about music too, I subscribe to Pandora as well as Spotify, because I’ll get a new band recommendation from Pandora and then I want to check their entire oeuvre on Spotify. My latest obsession: Muse, especially this song. Muse is like the new Queen. Pandora knew I’d like Muse because my favorite band is Bright Eyes, which makes me pathetically emo, but I also like the Beatles and Elliott Smith, or whatever. I don’t know exactly how the model works, but the point is they’ve pegged me and good.
In fact it’s amazing how much great music and other stuff I’ve been learning about through the recommendation models coming out of things like Pandora and Netflix; those models really work. My life has definitely changed since they came into existence. I’m much more comfortable and entertained.
But here’s the thing, I’ve lost something too.
My oldest friend sent me some mixed CDs for Christmas. I listened to them at work one recent morning, and although I like a few songs, many of the them were downright jarring. I mean, so syncopated! So raw and violent! What the hell is this?! It was hip-hop, I think, although that was a word from some far-away time and place. Does hip-hop still exist?
I’ve become my own little island of smug musical taste. When is the last time I listened to the radio and learned about a new kind of music? It just doesn’t happen. Why would I listen to the radio when there’s wifi and I can stream my own?
It made me think about the history of shared music. Once upon a time, we had no electricity and we had to make our own music. There were traveling bands of musicians (my great-grandmother was a traveling piano player and my great-grandfather was the banjo player in that troupe) that brought the hit tunes to the little towns eager for the newest sounds. Then when we got around to inventing the radio and record players, boundaries were obliterated and the world was opened up. This sharing got accelerated as the technology grew, to the point now that anyone with access to a browser can hear any kind of music they’d like.
But now this other effect has taken hold, and our universes, our personal universes, are again contracting. We are creating boundaries again, each around ourselves and with the help of the models, and we’ve even figured out how to drown out the background music in Starbucks when we pick up our lattes (we just listen to our ipods while in line).
I’d love to think that this contracting universe issue is restricted to music and maybe movies, but it’s really not. Our entire online environment and identity, and to be sure our actual environment and identity is increasingly online, is informed and created by the models that exist inside Google, Facebook, and Amazon. Google has just changed its privacy policy so that it can and will use all the information it has gleaned from your gmail account when you do a google search, for example. To avoid this, simply clear your cookies and don’t ever log in to your gmail account. In other words, there’s no avoiding this.
Keep in mind, as well, that there’s really one and only one goal of all of this, namely money. We are being shown things to make us comfortable so we will buy things. We aren’t being shown what we should see, at any level or by any definition, but rather what will flatter us sufficiently to consume. Our modeled world is the new opium.
Sturgeon
In honor of Chekhov’s 152nd birthday tomorrow, I’ve just finished reading the Lady with the Dog.
WTF: Greek debt vs. CDS
Just to be clear, if I’m a hedge fund who owns Greek bonds right now, and say I’ve hedged my exposure using CDSs, then why the fuck would I go along with a voluntary write-down of Greek debt??
From my perspective, if I do go along with it, I lose a asston of money on my bonds and my CDSs don’t get triggered because the write-down is considered “voluntary”. If I don’t go along with it, and enough other hedge funds also don’t go along with it, I either get paid in full or the CDSs I already own get triggered and I get paid in full (unless the counterparty who wrote the CDS goes under, but there’s always that risk).
Bottomline: I don’t go along with it.
None of this political finagling will change my mind. No argument for the stability of the European Union will change my mind. In fact, I will feel like arguing, hey if you force an involuntary voluntary write-down, then you are essentially making the meaning of CDS protection null and void. This is tantamount to ignoring legal contracts. And I’d have a pretty good point.
How’s this: let this shit go down, and start introducing a system that works, with a CDS market that is either reasonably regulated or nonexistent.
In the meantime, if I’m a Greek citizen, I’m wondering if I’ll ever be living in a country that has a consistent stock of aspirin again.
Updating your big data model
When you are modeling for the sake of real-time decision-making you have to keep updating your model with new data, ideally in an automated fashion. Things change quickly in the stock market or the internet, and you don’t want to be making decisions based on last month’s trends.
One of the technical hurdles you need to overcome is the sheer size of the dataset you are using to first train and then update your model. Even after aggregating your model with MapReduce or what have you, you can end up with hundreds of millions of lines of data just from the past day or so, and you’d like to use it all if you can.
The problem is, of course, that over time the accumulation of all that data is just too unwieldy, and your python or Matlab or R script, combined with your machine, can’t handle it all, even with a 64 bit setup.
Luckily with exponential downweighting, you can update iteratively; this means you can take your new aggregated data (say a day’s worth), update the model, and then throw it away altogether. You don’t need to save the data anywhere, and you shouldn’t.
As an example, say you are running a multivariate linear regression. I will ignore bayesian priors (or, what is an example of the same thing in a different language, regularization terms) for now. Then in order to have an updated coefficient vector 



So the problem simplifies to, how can we update
As I described before in this post for example, you can use exponential downweighting. Whereas before I was expounding on how useful this method is for helping you care about new data more than old data, today my emphasis is on the other convenience, which is that you can throw away old data after updating your objects of interest.
So in particular, we will follow the general rule in updating an object $T$ that it’s just some part old, some part new:
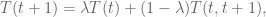
where by 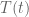
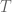
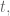


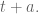
The speed at which I forget data is determined by my choice of 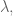
Specifically, I want to give an example of this update rule for the covariance matrix 
Namely, I claim that after updating 
Just to be really dumb, start with a univariate regression example, so where we have a single signal 

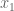


Now we get a new piece of data 
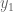

![[\mu x_1 x_2]](https://s0.wp.com/latex.php?latex=%5B%5Cmu+x_1+x_2%5D&bg=ffffff&fg=555555&s=0&c=20201002)

where by 
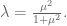
Things to convince yourself of:
- This works when we move from
pieces of data to
pieces of data.
- This works when we move from a univariate regression to a multivariate regression and we’re actually talking about square matrices.
- Same goes for the
- We don’t really have to worry about scaling; this uses the fact that everything in sight is quadratic in
, the downweighting scalar, and the final product we care about is
where, if we did decide to care about scalars, we would mutliply
- We don’t have to update one data point at a time. We can instead compute the `new part’ of the covariance matrix and the other thingy for a whole day’s worth of data, downweight our old estimate of the covariance matrix and other thingy, and then get a new version for both.
- We can also incorporate bayesian priors into the updating mechanism, although you have decide whether the prior itself needs to be downweighted or not; this depends on whether the prior is coming from a fading prior belief (like, oh I think the answer is something like this because all the studies that have been done say something kind of like that, but I’d be convinced otherwise if the new model tells me otherwise) or if it’s a belief that won’t be swayed (like, I think newer data is more important, so if I use lagged values of the quarterly earnings of these companies then the more recent earnings are more important and I will penalize the largeness of their coefficients less).

End result: we can cut our data up into bite-size chunks our computer can handle, compute our updates, and chuck the data. If we want to maintain some history we can just store the `new parts’ of the matrix and column vector per day. Then if we later decide our downweighting was too aggressive or not sufficiently aggressive, we can replay the summation. This is much more efficient as storage than holding on to the whole data set, because it depends only on the number of signals in the model (typically under 200) rather than the number of data points going into the model. So for each day you store a 200-by-200 matrix and a 200-by-1 column vector.



