Archive
I love me some nerd girls
Last night I was waiting for a bus to go hang with my Athena Mastermind group, which consists of a bunch of very cool Barnard student entrepreneurs and their would-be role models (I say would-be because, although we role models are also very cool, I often think the students are role modeling for us).
As I was waiting at the bus stop, I overheard two women talking about the new Applied Data Science class that just started at Columbia, which is being taught by Ian Langmore, Daniel Krasner and Chang She. I knew about this class because Ian came to advertise it last semester in Rachel Schutt’s Intro to Data Science class which I blogged. One of the women at the bus stop had been in Rachel’s class and the other is in Ian’s.
Turns out I just love overhearing nerd girls talking data science at the bus stop. Don’t you??
And to top off the nerd girl experience, I’m on my way today to Nebraska to give a talk to a bunch of undergraduate women in math about what they can do with math outside of academia. I’m planning it to be an informative talk, but that’s really just cover to its real goal, which is to give a pep talk.
My experience talking to young women in math, at least when they are grad students, is that they respond viscerally to encouragement, even if it’s vague. I can actually see their egos inflate in the audience as I speak, and that’s a good thing, that’s why I’m there.
As a community, I’ve realized, nerd girls going through grad school are virtually starved for positive feedback, and so my job is pretty clear cut: I’m going to tell them how awesome they are and answer their questions about what it’s like in the “real world” and then go back to telling them how awesome they are.
By the end they sit a bit straighter and smile a bit more after I’m done, after I’ve told them, or reminded them at least, how much power they have as nerd girls – how many options they have, and how they don’t have to be risk-averse, and how they never need to apologize.
Tomorrow my audience is undergraduates, which is a bit trickier, since as an undergrad you still get consistent feedback in the form of grades. So I will tailor my information as well as my encouragement a bit, and try not to make grad school sound too scary, because I do think that getting a Ph.D. is still a huge deal. Comment below if you have suggestions for my talk, please!
Columbia Data Science course, week 12: Predictive modeling, data leakage, model evaluation
This week’s guest lecturer in Rachel Schutt’s Columbia Data Science class was Claudia Perlich. Claudia has been the Chief Scientist at m6d for 3 years. Before that she was a data analytics group at the IBM center that developed Watson, the computer that won Jeopardy!, although she didn’t work on that project. Claudia got her Ph.D. in information systems at NYU and now teaches a class to business students in data science, although mostly she addresses how to assess data science work and how to manage data scientists. Claudia also holds a masters in Computer Science.
Claudia is a famously successful data mining competition winner. She won the KDD Cup in 2003, 2007, 2008, and 2009, the ILP Challenge in 2005, the INFORMS Challenge in 2008, and the Kaggle HIV competition in 2010.
She’s also been a data mining competition organizer, first for the INFORMS Challenge in 2009 and then for the Heritage Health Prize in 2011. Claudia claims to be retired from competition.
Claudia’s advice to young people: pick your advisor first, then choose the topic. It’s important to have great chemistry with your advisor, and don’t underestimate the importance.
Background
Here’s what Claudia historically does with her time:
- predictive modeling
- data mining competitions
- publications in conferences like KDD and journals
- talks
- patents
- teaching
- digging around data (her favorite part)
Claudia likes to understand something about the world by looking directly at the data.
Here’s Claudia’s skill set:
- plenty of experience doing data stuff (15 years)
- data intuition (for which one needs to get to the bottom of the data generating process)
- dedication to the evaluation (one needs to cultivate a good sense of smell)
- model intuition (we use models to diagnose data)
Claudia also addressed being a woman. She says it works well in the data science field, where her intuition is useful and is used. She claims her nose is so well developed by now that she can smell it when something is wrong. This is not the same thing as being able to prove something algorithmically. Also, people typically remember her because she’s a woman, even when she don’t remember them. It has worked in her favor, she says, and she’s happy to admit this. But then again, she is where she is because she’s good.
Someone in the class asked if papers submitted for journals and/or conferences are blind to gender. Claudia responded that it was, for some time, typically double-blind but now it’s more likely to be one-sided. And anyway there was a cool analysis that showed you can guess who wrote a paper with 80% accuracy just by knowing the citations. So making things blind doesn’t really help. More recently the names are included, and hopefully this doesn’t make things too biased. Claudia admits to being slightly biased towards institutions – certain institutions prepare better work.
Skills and daily life of a Chief Data Scientist
Claudia’s primary skills are as follows:
- Data manipulation: unix (sed, awk, etc), Perl, SQL
- Modeling: various methods (logistic regression, nearest neighbors, k-nearest neighbors, etc)
- Setting things up
She mentions that the methods don’t matter as much as how you’ve set it up, and how you’ve translated it into something where you can solve a question.
More recently, she’s been told that at work she spends:
- 40% of time as “contributor”: doing stuff directly with data
- 40% of time as “ambassador”: writing stuff, giving talks, mostly external communication to represent m6d, and
- 20% of time in “leadership” of her data group
At IBM it was much more focused in the first category. Even so, she has a flexible schedule at m6d and is treated well.
The goals of the audience
She asked the class, why are you here? Do you want to:
- become a data scientist? (good career choice!)
- work with data scientist?
- work for a data scientist?
- manage a data scientist?
Most people were trying their hands at the first, but we had a few in each category.
She mentioned that it matters because the way she’d talk to people wanting to become a data scientist would be different from the way she’d talk to someone who wants to manage them. Her NYU class is more like how to manage one.
So, for example, you need to be able to evaluate their work. It’s one thing to check a bubble sort algorithm or check whether a SQL server is working, but checking a model which purports to give the probability of people converting is different kettle of fish.
For example, try to answer this: how much better can that model get if you spend another week on it? Let’s face it, quality control is hard for yourself as a data miner, so it’s definitely hard for other people. There’s no easy answer.
There’s an old joke that comes to mind: What’s the difference between the scientist and a consultant? The scientists asks, how long does it take to get this right? whereas the consultant asks, how right can I get this in a week?
Insights into data
A student asks, how do you turn a data analysis into insights?
Claudia: this is a constant point of contention. My attitude is: I like to understand something, but what I like to understand isn’t what you’d consider an insight. My message may be, hey you’ve replaced every “a” by a “0”, or, you need to change the way you collect your data. In terms of useful insight, Ori’s lecture from last week, when he talked about causality, is as close as you get.
For example, decision trees you interpret, and people like them because they’re easy to interpret, but I’d ask, why does it look like it does? A slightly different data set would give you a different tree and you’d get a different conclusion. This is the illusion of understanding. I tend to be careful with delivering strong insights in that sense.
For more in this vein, Claudia suggests we look at Monica Rogati‘s talk “Lies, damn lies, and the data scientist.”
Data mining competitions
Claudia drew a distinction between different types of data mining competitions.
On the one hand you have the “sterile” kind, where you’re given a clean, prepared data matrix, a standard error measure, and where the features are often anonymized. This is a pure machine learning problem.
Examples of this first kind are: KDD Cup 2009 and 2011 (Netflix). In such competitions, your approach would emphasize algorithms and computation. The winner would probably have heavy machines and huge modeling ensembles.
On the other hand, you have the “real world” kind of data mining competition, where you’re handed raw data, which is often in lots of different tables and not easily joined, where you set up the model yourself and come up with task-specific evaluations. This kind of competition simulates real life more.
Examples of this second kind are: KDD cup 2007, 2008, and 2010. If you’re competing in this kind of competition your approach would involve understanding the domain, analyzing the data, and building the model. The winner might be the person who best understands how to tailor the model to the actual question.
Claudia prefers the second kind, because it’s closer to what you do in real life. In particular, the same things go right or go wrong.
How to be a good modeler
Claudia claims that data and domain understanding is the single most important skill you need as a data scientist. At the same time, this can’t really be taught – it can only be cultivated.
A few lessons learned about data mining competitions that Claudia thinks are overlooked in academics:
- Leakage: the contestants best friend and the organizers/practitioners worst nightmare. There’s always something wrong with the data, and Claudia has made an artform of figuring out how the people preparing the competition got lazy or sloppy with the data.
- Adapting learning to real-life performance measures beyond standard measures like MSE, error rate, or AUC (profit?)
- Feature construction/transformation: real data is rarely flat (i.e. given to you in a beautiful matrix) and good, practical solutions for this problem remains a challenge.
Leakage
Leakage refers to something that helps you predict something that isn’t fair. It’s a huge problem in modeling, and not just for competitions. Oftentimes it’s an artifact of reversing cause and effect.
Example 1: There was a competition where you needed to predict S&P in terms of whether it would go up or go down. The winning entry had a AUC (area under the ROC curve) of 0.999 out of 1. Since stock markets are pretty close to random, either someone’s very rich or there’s something wrong. There’s something wrong.
In the good old days you could win competitions this way, by finding the leakage.
Example 2: Amazon case study: big spenders. The target of this competition was to predict customers who spend a lot of money among customers using past purchases. The data consisted of transaction data in different categories. But a winning model identified that “Free Shipping = True” was an excellent predictor
What happened here? The point is that free shipping is an effect of big spending. But it’s not a good way to model big spending, because in particular it doesn’t work for new customers or for the future. Note: timestamps are weak here. The data that included “Free Shipping = True” was simultaneous with the sale, which is a no-no. We need to only use data from beforehand to predict the future.
Example 3: Again an online retailer, this time the target is predicting customers who buy jewelry. The data consists of transactions for different categories. A very successful model simply noted that if sum(revenue) = 0, then it predicts jewelry customers very well?
What happened here? The people preparing this data removed jewelry purchases, but only included people who bought something in the first place. So people who had sum(revenue) = 0 were people who only bought jewelry. The fact that you only got into the dataset if you bought something is weird: in particular, you wouldn’t be able to use this on customers before they finished their purchase. So the model wasn’t being trained on the right data to make the model useful. This is a sampling problem, and it’s common.
Example 4: This happened at IBM. The target was to predict companies who would be willing to buy “websphere” solutions. The data was transaction data + crawled potential company websites. The winning model showed that if the term “websphere” appeared on the company’s website, then they were great candidates for the product.
What happened? You can’t crawl the historical web, just today’s web.
Thought experiment
You’re trying to study who has breast cancer. The patient ID, which seemed innocent, actually has predictive power. What happened?

In the above image, red means cancerous, green means not. it’s plotted by patient ID. We see three or four distinct buckets of patient identifiers. It’s very predictive depending on the bucket. This is probably a consequence of using multiple databases, some of which correspond to sicker patients are more likely to be sick.
A student suggests: for the purposes of the contest they should have renumbered the patients and randomized.
Claudia: would that solve the problem? There could be other things in common as well.
A student remarks: The important issue could be to see the extent to which we can figure out which dataset a given patient came from based on things besides their ID.
Claudia: Think about this: what do we want these models for in the first place? How well can you predict cancer?
Given a new patient, what would you do? If the new patient is in a fifth bin in terms of patient ID, then obviously don’t use the identifier model. But if it’s still in this scheme, then maybe that really is the best approach.
This discussion brings us back to the fundamental problem that we need to know what the purpose of the model is and how is it going to be used in order to decide how to do it and whether it’s working.
Pneumonia
During an INFORMS competition on pneumonia predictions in hospital records, where the goal was to predict whether a patient has pneumonia, a logistic regression which included the number of diagnosis codes as a numeric feature (AUC of 0.80) didn’t do as well as the one which included it as a categorical feature (0.90). What’s going on?
This had to do with how the person prepared the data for the competition:

The diagnosis code for pneumonia was 486. So the preparer removed that (and replaced it by a “-1”) if it showed up in the record (rows are different patients, columns are different diagnoses, there are max 4 diagnoses, “-1” means there’s nothing for that entry).
Moreover, to avoid telling holes in the data, the preparer moved the other diagnoses to the left if necessary, so that only “-1″‘s were on the right.
There are two problems with this:
- If the column has only “-1″‘s, then you know it started out with only pneumonia, and
- If the column has no “-1″‘s, you know there’s no pneumonia (unless there are actually 5 diagnoses, but that’s less common).
This was enough information to win the competition.
Note: winning competition on leakage is easier than building good models. But even if you don’t explicitly understand and game the leakage, your model will do it for you. Either way, leakage is a huge problem.
How to avoid leakage
Claudia’s advice to avoid this kind of problem:
- You need a strict temporal cutoff: remove all information just prior to the event of interest (patient admission).
- There has to be a timestamp on every entry and you need to keep
- Removing columns asks for trouble
- Removing rows can introduce inconsistencies with other tables, also causing trouble
- The best practice is to start from scratch with clean, raw data after careful consideration
- You need to know how the data was created! I only work with data I pulled and prepared myself (or maybe Ori).
Evaluations
How do I know that my model is any good?
With powerful algorithms searching for patterns of models, there is a serious danger of over fitting. It’s a difficult concept, but the general idea is that “if you look hard enough you’ll find something” even if it does not generalize beyond the particular training data.
To avoid overfitting, we cross-validate and we cut down on the complexity of the model to begin with. Here’s a standard picture (although keep in mind we generally work in high dimensional space and don’t have a pretty picture to look at):

The picture on the left is underfit, in the middle is good, and on the right is overfit.
The model you use matters when it concerns overfitting:

So for the above example, unpruned decision trees are the most over fitting ones. This is a well-known problem with unpruned decision trees, which is why people use pruned decision trees.
Accuracy: meh
Claudia dismisses accuracy as a bad evaluation method. What’s wrong with accuracy? It’s inappropriate for regression obviously, but even for classification, if the vast majority is of binary outcomes are 1, then a stupid model can be accurate but not good (guess it’s always “1”), and a better model might have lower accuracy.
Probabilities matter, not 0’s and 1’s.
Nobody makes decisions on binary outcomes. I want to know the probability I have breast cancer, I don’t want to be told yes or no. It’s much more information. I care about probabilities.
How to evaluate a probability model
We separately evaluate the ranking and the calibration. To evaluate the ranking, we use the ROC curve and calculate the area under it, typically ranges from 0.5-1.0. This is independent of scaling and calibration. Here’s an example of how to draw an ROC curve:

Sometimes to measure rankings, people draw the so-called lift curve:

The key here is that the lift is calculated with respect to a baseline. You draw it at a given point, say 10%, by imagining that 10% of people are shown ads, and seeing how many people click versus if you randomly showed 10% of people ads. A lift of 3 means it’s 3 times better.
How do you measure calibration? Are the probabilities accurate? If the model says probability of 0.57 that I have cancer, how do I know if it’s really 0.57? We can’t measure this directly. We can only bucket those predictions and then aggregately compare those in that prediction bucket (say 0.50-0.55) to the actual results for that bucket.
For example, here’s what you get when your model is an unpruned decision tree, where the blue diamonds are buckets:
 A good model would show buckets right along the x=y curve, but here we’re seeing that the predictions were much more extreme than the actual probabilities. Why does this pattern happen for decision trees?
A good model would show buckets right along the x=y curve, but here we’re seeing that the predictions were much more extreme than the actual probabilities. Why does this pattern happen for decision trees?
Claudia says that this is because trees optimize purity: it seeks out pockets that have only positives or negatives. Therefore its predictions are more extreme than reality. This is generally true about decision trees: they do not generally perform well with respect to calibration.
Logistic regression looks better when you test calibration, which is typical:

Takeaways:
- Accuracy is almost never the right evaluation metric.
- Probabilities, not binary outcomes.
- Separate ranking from calibration.
- Ranking you can measure with nice pictures: ROC, lift
- Calibration is measured indirectly through binning.
- Different models are better than others when it comes to calibration.
- Calibration is sensitive to outliers.
- Measure what you want to be good at.
- Have a good baseline.
Choosing an algorithm
This is not a trivial question and in particular small tests may steer you wrong, because as you increase the sample size the best algorithm might vary: often decision trees perform very well but only if there’s enough data.
In general you need to choose your algorithm depending on the size and nature of your dataset and you need to choose your evaluation method based partly on your data and partly on what you wish to be good at. Sum of squared error is maximum likelihood loss function if your data can be assumed to be normal, but if you want to estimate the median, then use absolute errors. If you want to estimate a quantile, then minimize the weighted absolute error.
We worked on predicting the number of ratings of a movie will get in the next year, and we assumed a poisson distributions. In this case our evaluation method doesn’t involve minimizing the sum of squared errors, but rather something else which we found in the literature specific to the Poisson distribution, which depends on the single parameter 

Charity direct mail campaign
Let’s put some of this together.
Say we want to raise money for a charity. If we send a letter to every person in the mailing list we raise about $9000. We’d like to save money and only send money to people who are likely to give – only about 5% of people generally give. How can we do that?
If we use a (somewhat pruned, as is standard) decision tree, we get $0 profit: it never finds a leaf with majority positives.
If we use a neural network we still make only $7500, even if we only send a letter in the case where we expect the return to be higher than the cost.
This looks unworkable. But if you model is better, it’s not. A person makes two decisions here. First, they decide whether or not to give, then they decide how much to give. Let’s model those two decisions separately, using:

Note we need the first model to be well-calibrated because we really care about the number, not just the ranking. So we will try logistic regression for first half. For the second part, we train with special examples where there are donations.
Altogether this decomposed model makes a profit of $15,000. The decomposition made it easier for the model to pick up the signals. Note that with infinite data, all would have been good, and we wouldn’t have needed to decompose. But you work with what you got.
Moreover, you are multiplying errors above, which could be a problem if you have a reason to believe that those errors are correlated.
Parting thoughts
We are not meant to understand data. Data are outside of our sensory systems and there are very few people who have a near-sensory connection to numbers. We are instead meant to understand language.
We are not mean to understand uncertainty: we have all kinds of biases that prevent this from happening and are well-documented.
Modeling people in the future is intrinsically harder than figuring out how to label things that have already happened.
Even so we do our best, and this is through careful data generation, careful consideration of what our problem is, making sure we model it with data close to how it will be used, making sure we are optimizing to what we actually desire, and doing our homework in learning which algorithms fit which tasks.
O’Reilly book deal signed for “Doing Data Science”
I’m very happy to say I just signed a book contract with my co-author, Rachel Schutt, to publish a book with O’Reilly called Doing Data Science.
The book will be based on the class Rachel is giving this semester at Columbia which I’ve been blogging about here.
For those of you who’ve been reading along for free as I’ve been blogging it, there might not be a huge incentive to buy it, but I can promise you more and better math, more explicit usable formulas, some sample code, and an overall better and more thought-out narrative.
It’s supposed to be published in May with a possible early release coming up at the end of February, in time for the O’Reilly Strata Santa Clara conference, where Rachel will be speaking about it and about other stuff curriculum related. Hopefully people will pick it up in time to teach their data science courses in Fall 2013.
Speaking of Rachel, she’s also been selected to give a TedXWomen talk at Barnard on December 1st, which is super exciting. She’s talking about advocating for the social good using data. Unfortunately the event is invitation-only, otherwise I’d encourage you all to go and hear her words of wisdom. Update: word on the street is that it will be video-taped.
Columbia data science course, week 2: RealDirect, linear regression, k-nearest neighbors
Data Science Blog
Today we started with discussing Rachel’s new blog, which is awesome and people should check it out for her words of data science wisdom. The topics she’s riffed on so far include: Why I proposed the course, EDA (exploratory data analysis), Analysis of the data science profiles from last week, and Defining data science as a research discipline.
She wants students and auditors to feel comfortable in contributing to blog discussion, that’s why they’re there. She particularly wants people to understand the importance of getting a feel for the data and the questions before ever worrying about how to present a shiny polished model to others. To illustrate this she threw up some heavy quotes:
“Long before worrying about how to convince others, you first have to understand what’s happening yourself” – Andrew Gelman
“Agreed” – Rachel Schutt
Thought experiment: how would you simulate chaos?
We split into groups and discussed this for a few minutes, then got back into a discussion. Here are some ideas from students:
- A Lorenzian water wheel would do the trick, if you know what that is.
- Question: is chaos the same as randomness?
- Many a physical system can exhibit inherent chaos: examples with finite-state machines
- Teaching technique of “Simulating chaos to teach order” gives us real world simulation of a disaster area
- In this class w want to see how students would handle a chaotic situation. Most data problems start out with a certain amount of dirty data, ill-defined questions, and urgency. Can we teach a method of creating order from chaos?
- See also “Creating order from chaos in a startup“.
Talking to Doug Perlson, CEO of RealDirect
We got into teams of 4 or 5 to assemble our questions for Doug, the CEO of RealDirect. The students have been assigned as homework the task of suggesting a data strategy for this new company, due next week.
He came in, gave us his background in real-estate law and startups and online advertising, and told us about his desire to use all the data he now knew about to improve the way people sell and buy houses.
First they built an interface for sellers, giving them useful data-driven tips on how to sell their house and using interaction data to give real-time recommendations on what to do next. Doug made the remark that normally, people sell their homes about once in 7 years and they’re not pros. The goal of RealDirect is not just to make individuals better but also pros better at their job.
He pointed out that brokers are “free agents” – they operate by themselves. they guard their data, and the really good ones have lots of experience, which is to say they have more data. But very few brokers actually have sufficient experience to do it well.
The idea is to apply a team of licensed real-estate agents to be data experts. They learn how to use information-collecting tools so we can gather data, in addition to publicly available information (for example, co-op sales data now available, which is new).
One problem with publicly available data is that it’s old news – there’s a 3 month lag. RealDirect is working on real-time feeds on stuff like:
- when people start search,
- what’s the initial offer,
- the time between offer and close, and
- how people search online.
Ultimately good information helps both the buyer and the seller.
RealDirect makes money in 2 ways. First, a subscription, $395 a month, to access our tools for sellers. Second, we allow you to use our agents at a reduced commission (2% of sale instead of the usual 2.5 or 3%). The data-driven nature of our business allows us to take less commission because we are more optimized, and therefore we get more volume.
Doug mentioned that there’s a law in New York that you can’t show all the current housing listings unless it’s behind a registration wall, which is why RealDirect requires registration. This is an obstacle for buyers but he thinks serious buyers are willing to do it. He also doesn’t consider places that don’t require registration, like Zillow, to be true competitors because they’re just showing listings and not providing real service. He points out that you also need to register to use Pinterest.
Doug mentioned that RealDirect is comprised of licensed brokers in various established realtor associations, but even so they have had their share of hate mail from realtors who don’t appreciate their approach to cutting commission costs. In this sense it is somewhat of a guild.
On the other hand, he thinks if a realtor refused to show houses because they are being sold on RealDirect, then the buyers would see the listings elsewhere and complain. So they traditional brokers have little choice but to deal with them. In other words, the listings themselves are sufficiently transparent so that the traditional brokers can’t get away with keeping their buyers away from these houses
RealDirect doesn’t take seasonality issues into consideration presently – they take the position that a seller is trying to sell today. Doug talked about various issues that a buyer would care about- nearby parks, subway, and schools, as well as the comparison of prices per square foot of apartments sold in the same building or block. These are the key kinds of data for buyers to be sure.
In terms of how the site works, it sounds like somewhat of a social network for buyers and sellers. There are statuses for each person on site. active – offer made – offer rejected – showing – in contract etc. Based on your status, different opportunities are suggested.
Suggestions for Doug?
Linear Regression
Example 1. You have points on the plane:
(x, y) = (1, 2), (2, 4), (3, 6), (4, 8).
The relationship is clearly y = 2x. You can do it in your head. Specifically, you’ve figured out:
- There’s a linear pattern.
- The coefficient 2
- So far it seems deterministic
Example 2. You again have points on the plane, but now assume x is the input, and y is output.
(x, y) = (1, 2.1), (2, 3.7), (3, 5.8), (4, 7.9)
Now you notice that more or less y ~ 2x but it’s not a perfect fit. There’s some variation, it’s no longer deterministic.
Example 3.
(x, y) = (2, 1), (6, 7), (2.3, 6), (7.4, 8), (8, 2), (1.2, 2).
Here your brain can’t figure it out, and there’s no obvious linear relationship. But what if it’s your job to find a relationship anyway?
First assume (for now) there actually is a relationship and that it’s linear. It’s the best you can do to start out. i.e. assume

and now find best choices for 
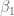

Before we find the general formula, we want to generalize with three variables now: 


Writing this with matrix notation we get:
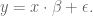
How do we calculate 
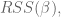

where 
To minimize 
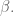
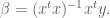
To use this, we go back to our linear form and plug in the values of
But wait, why did we assume a linear relationship? Sometimes maybe it’s a polynomial relationship.

You need to justify why you’re assuming what you want. Answering that kind of question is a key part of being a data scientist and why we need to learn these things carefully.
All this is like one line of R code where you’ve got a column of y’s and a column of x’s.:
model <- lm(y ~ x)
Or if you’re going with the polynomial form we’d have:
model <- lm(y ~ x + x^2 + x^3)
Why do we do regression? Mostly for two reasons:
- If we want to predict one variable from the next
- If we want to explain or understand the relationship between two things.
K-nearest neighbors
Say you have the age, income, and credit rating for a bunch of people and you want to use the age and income to guess at the credit rating. Moreover, say we’ve divided credit ratings into “high” and “low”.
We can plot people as points on the plane and label people with an “x” if they have low credit ratings.
What if a new guy comes in? What’s his likely credit rating label? Let’s use k-nearest neighbors. To do so, you need to answer two questions:
- How many neighbors are you gonna look at? k=3 for example.
- What is a neighbor? We need a concept of distance.
For the sake of our problem, we can use Euclidean distance on the plane if the relative scalings of the variables are approximately correct. Then the algorithm is simple to take the average rating of the people around me. where average means majority in this case – so if there are 2 high credit rating people and 1 low credit rating person, then I would be designated high.
Note we can also consider doing something somewhat more subtle, namely assigning high the value of “1” and low the value of “0” and taking the actual average, which in this case would be 0.667. This would indicate a kind of uncertainty. It depends on what you want from your algorithm. In machine learning algorithms, we don’t typically have the concept of confidence levels. care more about accuracy of prediction. But of course it’s up to us.
Generally speaking we have a training phase, during which we create a model and “train it,” and then we have a testing phase where we use new data to test how good the model is.
For k-nearest neighbors, the training phase is stupid: it’s just reading in your data. In testing, you pretend you don’t know the true label and see how good you are at guessing using the above algorithm. This means you save some clean data from the overall data for the testing phase. Usually you want to save randomly selected data, at least 10%.
In R: read in the package “class”, and use the function knn().
You perform the algorithm as follows:
knn(train, test, cl, k=3)
The output includes the k nearest (in Euclidean distance) training set vectors, and the classification labels as decided by majority vote
How do you evaluate if the model did a good job?
This isn’t easy or universal – you may decide you want to penalize certain kinds of misclassification more than others. For example, false positives may be way worse than false negatives.
To start out stupidly, you might want to simply minimize the misclassification rate:
(# incorrect labels) / (# total labels)
How do you choose k?
This is also hard. Part of homework next week will address this.
When do you use linear regression vs. k-nearest neighbor?
Thinking about what happens with outliers helps you realize how hard this question is. Sometimes it comes down to a question of what the decision-maker decides they want to believe.
Note definitions of “closeness” vary depending on the context: closeness in social networks could be defined as the number of overlapping friends.
Both linear regression and k-nearest neighbors are examples of “supervised learning”, where you’ve observed both x and y, and you want to know the function that brings x to y.
Is science a girl thing?
One of the reasons I chose to call this blog “mathbabe” is that when I searched that term, I found a website, now defunct (woohoo!), where semi-naked women were adorning math.
This pissed me off, because I want math babes to be doing math.
If you get that (what’s not to get?) then you might see why the European Commission’s latest effort to inspire girls to do science is truly repugnant (hat tip Debbie Berebichez, a.k.a. Science Babe).
It’s a commercial where you see a standard male scientist (in a white lab coat no less) being surprised, and, we assume, aroused, when three girly models come in, giggle, dance, and generally adorn the commercial.
At the end they put on lab goggles in the style of an ironic accessory. They’re all wearing high heels and there’s even lipstick in a few shots for some unexplained reason (are we supposed to infer that wearing lipstick makes you more scientific-alicious?).
And although there are a couple of shots of an actual female writing what could be actual formulas on a hyped-up whiteboard, that’s more than balanced by some other shots of the models with unmistakable come-hither looks, gestures and blown kisses.
People. At the European Commission. Do you have no advisors!? Do you have no common sense? Who vetted this garbage video?!?
I’d like to see us get to the point where our slogan is more along the lines of:
Science, it’s for really smart women
And our video consists of cool, funky women giving actual talks and lectures or actually working on experiments. Maybe they’re wearing heels, but for sure they’re not acting like complete fucking idiots. How’s that?
I personally could suggest about 40 people for such a video. Not hard to do.
On being an alpha female
About 8 months ago I found out I’m an alpha female. What happened was, one day at work my boss mentioned that he and everyone else is afraid of me. I looked around and realized he was pretty much right (there are exceptions).
I went home to my husband and mentioned how weird it was that people at work are afraid of me, and he said, “No, it’s not weird at all. Don’t you realize that you’re constantly giving people the impression that you’re about to take away their toy and break it??”. No, I hadn’t realized that – and that sounds pretty awful! Am I really that mean? Then he told me I was an alpha male living in a woman’s body.
If you google “alpha male in a woman’s body,” (without the quotes) which I did, you come upon the phrase “alpha female” pretty quickly.
It came as a surprise to me – I’d always thought I am nice. But it wasn’t a surprise to anyone else; in fact when I mentioned my realization to my close friends, each and every one of them laughed out loud that I hadn’t known this about myself. One of my friends told me it was less that I was about breaking toys and more about how I call out people’s bullshit, which is something I have to admit I relish doing.
Upon further reflection I had to admit to myself that I am nice, but only to people who I think are nice themselves. So I guess that means I’m not just simply nice. And if I enjoy calling people on their bullshit, that’s not exactly nice either.
Over the past 8 months, I’ve been slowly observing my alpha femaleness, and at this point I can honestly say I’m comfortable with it. I own it now. It’s kind of fun to know about it, because of how people react to me, without me intentionally doing anything.
How I now think about my alpha femaleness is that it lends me authority. It’s a kind of portable power. Not always, of course, and sometimes I am in situations where I’m totally incompetent, and sometimes I run into someone who completely ignores my alpha femaleness or is themselves an alpha male and competes. I usually really like them.
I’ve also realize how much my life has been informed by this property; my life has been, for the most part, much easier than it could have been without this property. And I want to acknowledge that because most people aren’t like this and don’t have this advantage.
For example: I interview really well. I speak with perceived confidence even when I don’t feel confident, and that comes across well in interviews.
In fact all my life people have mentioned to me that “things seem easy” to me, even in situations where I felt completely insecure and flustered. I used to lift weights at the gym with my buddies in college, and they would not really spot me on the bench press because they were convinced I didn’t need help. I almost dropped the weights on my neck a couple of times calling my friends over from the other side of the room. So in retrospect maybe it was a sign I’m an alpha female, but at the time I was just baffled.
It’s good and bad. When people perceive you as more confident and more comfortable in a situation than you actually are, it’s about 80% good and 20% bad, and could be the opposite depending on the situation. It’s bad when it’s dangerous and you really don’t know what you’re doing (that happened to me when I was driving an ATV once, and luckily when I turned it over in a mud pit I didn’t actually break my legs, but I could have) and it’s totally convenient when you’re presenting stuff or in an interview.
Why am I mentioning all of this? Because I think it might help people, especially women in math or in tech, to learn to think a bit more like an alpha female, and I want to give some tips on how to do it. It’s like injecting a shot of testosterone at the right time.
These tips can be used in specific situations like an interview or a talk or at a work meeting. Feel free to ignore these tips if you hate everything about the idea, which I would totally understand too. In fact when I first learned about it myself, I was offended by it on a matter of principle, but I’ve come to think of it more like a mysterious part of the human experience, on the same page as pheromones and how women have the same menstrual cycle when they live together.
Tips on how to think and act like an alpha female
- When you’re asked to describe your accomplishments, talk about yourself the way your best friend would describe you. So in other words with pride and enthusiasm for your accomplishments, without being embarrassed. Don’t lie or exaggerate, but don’t underplay anything.
- Let there be silence. If you’ve finished what you’re saying and you’re done, wait for someone else to say something.
- If you want credit, give credit first. Generosity is, in my experience, contagious. So if you want to get credit for contributing something to a project, start out by talking about how awesome your collaborators have been on the project. This gets people thinking about credit in a generous way, and it also gives you authority for bestowing it as the first person who brought it up. Note this is different from what I see lots of people do, namely not mentioning credit themselves and waiting passively for someone else to raise it (and to share it).
- Ignore titles and hierarchy. Those things are silly. You can talk to anyone at any time if you have a good idea.
- If you want feedback, give feedback. This includes to your boss (see previous tip). If you want to find out how you stand with someone, the best thing to do is to tell someone else how they stand with you. People love hearing about themselves. This works best when you can say something nice, but it also works when it’s a difficult conversation.
- Define your narrative. When your standing is in question, put out your version of the story first, for a couple of reasons – one is that you define the scope of the question, and the other is that your narrative is now the standard, and any one refuting it has to refute it.
- When you’re in a meeting and want to bring your point across in a room full of alpha males, think about defending or arguing for an idea, rather than for yourself. It helps with gaining confidence in your argument.
- Of course it also helps if your argument is water-tight, so practice making your points in your mind, and write them down beforehand if that helps.
- Develop a thick skin. When you say what you think first, there are plenty of people who might take offense and jump on you and be vicious. Sometimes it’s just a show of power. Keep an observer’s eye on that kind of reaction, and don’t take it personally, because it’s almost never about you really, it’s maybe about their relationship with their mom or something.
- At the same time, what’s cool about putting yourself out there is that people react and often point out how your thinking is flawed or lazy and you get to learn really, really quickly. Learning is the best part!
The fake problem of fake geek girls, and how to be a sexy man nerd
My friend Rachel Schutt recently sent me this Forbes article by Tara Tiger Brown on the so-called problem of too many fake geek girls stealing the thunder and limelight from us true geek girls.
The working definition of geek seems to be someone who is obsessively interested in something (I would argue that you don’t get to be a geek if your obsession is art, for example, I’d like to define it to be an obsession with something technical). She also claims that “true geeks” don’t do something for airtime. From the article:
Girls who genuinely like their hobby or interest and document what they are doing to help others, not garner attention, are true geeks. The ones who think about how to get attention and then work on a project in order to maximize their klout, are exhibitionists.
I kind of like this but I kind of don’t too. I like this because, like you, I have run into many many people (men and women) who loudly claim technical knowledge that they don’t seem to actually have, which is annoying and exhibitionistic. And yes, it’s annoying to see people like that doing things like giving things like Ted talks on “big data” when you seriously doubt they know how to program a linear regression. But again, men and women.
At the same time, there’s no reason someone can’t be both a true geek and an exhibitionist, and it seems kind of funny for a Forbes magazine writer to be claiming the authentic rights to the former but not the latter.
If there’s one thing I’d like to avoid, it’s peer pressure that, as a girl geek, I have to have a certain personality. I like the fact that girl geeks are sometimes shy and sometimes outspoken, sometimes humble and sometimes arrogant, sometimes demure and sometimes slutty. It makes it way more interesting during technical chats.
What’s the asymmetry between men and women here? According to Tara Tiger Brown, women think they’ll get attention from men by acting like a geek but my experience is that men don’t think they’ll get attention from women by acting like a geek.
I think this is a mistake that man geeks are making. For me, and for essentially all my female friends, being really fucking good at some thing is extremely sexy. Man geeks are, therefore, very sexy, if they are in fact really fucking good at something and not just posing. Maybe they just need to realize that and own it a bit more.
Next time, instead of apologizing for doing something nerdy, I suggest you (a man geek I’m imagining talking to right now) figure out how to describe what skill you mastered and talk about it as an accomplishment.
No: I’m kind of tired today, sorry. I stayed up all night playing with my computer. Should we reschedule?
Yes: Last night I implemented dynamic logistic regression and managed to get it to converge on 30 terabytes of streaming data in under 3 hours. And it’s all open source, I just checked in into github. That was awesome! But now I need to sleep. Wanna take a nap with me?
Google’s promotion policy sucks for women
I’m going to start this post with an excerpt from a comment of reader JoanDelilah from a couple of weeks ago, commenting on my post The meritocracy myth:
And at the end of the day, this also assumes that it is right and proper for a structure to be in place which requires you to *grab* tough/interesting work to prove yourself, as opposed to it being given to you. There is competition inherent in the foundational world-view behind that statement. Why so much competition? We are supposed to be on the same team and competing with other businesses, right? What about the woman who is happy to crush any assignment she is given but simply doesn’t want to have to compete for the assignments that will “prove” her abilities? Why must she step so far out of her comfort zone just in order for the company that pays her to make use of the talents they are paying her to use?
This really nails down what I see all the time with respect to women getting promoted or even just getting recognized for their achievements.
To paraphrase it, women tend not to compete for recognition as much as men, for whatever reason. Maybe they’ve been socialized not to, maybe it is a simple question of testosterone. I will go into why I think this happens below. But for now let me just say I get super pissed when a system has been set up to diminish the success of people simply because of this personality issue.
Google is one such system. At Google, one must self-promote. I believe the rule is that, after two quarters or so of getting good reviews, you are eligible to self-promote, but you don’t have to.
And guess what? That policy sucks for women. Women don’t do it as often. I’ll bet this is statistically significant, even though I don’t have the numbers. Hey Google, do the math on this policy! And then change it!
Here’s the first part of my theory of why this happens. Women are not as secure in their accomplishments. By the way, note I am not saying women are insecure and men are secure. I think it’s more like men are over-secure and women are realistic, kind of like those studies that shows that depressed people are realists and non-depressed people are optimists. I definitely have seen men who actually think they (individually) accomplished something which clearly took a team effort. Women are less likely to “forget” the help they received in making something happen. See this amazing blog rant on the subject from a professor at NYU.
Here’s the second part. Women tend to choose mentors (i.e. bosses or advisors) that are brilliant, thoughtful, and approachable. Typically this also means that those mentors are not the kind of bullying personalities that are best suited to promote their team. Even when one doesn’t have a choice in who your boss is, I claim this approach to pairing still happens in a business when that business decides who should be the boss of a woman.
Example in pure math: Yau at Harvard is famously dynasty-building with his students, but he’s probably not someone who has a tissue box in his office (to be fair I haven’t checked). I didn’t even consider taking Yau as my advisor, in part because he was super intimidating and seemed to challenge grad students with a ring of fire.
The reward for being brave in a situation like that are that he is fiercely loyal to his students once he accepts them, and helps them get great jobs. My point is that fewer women choose Yau-like personalities as their advisor (although it has to be said that Yau has had women students, including Columbia’s Melissa Liu). And thus fewer women end up with advisors that will land them jobs and give them good advice on how to get ahead. I just don’t think women are thinking about that aspect of a mentor the way men do (it’s also possible than men don’t think about it either but are less likely to shy away from rings of fire in general due to their “optimistic” egos).
I am not saying this is an easy problem to fix, because it’s not, and the best self-promoters will always do well no matter where they work. But I do think Google can do better than this; maybe they could think of something a bit more double-blind like the orchestra auditions.
The meritocracy myth
Jack and Larry
Recently a Wall Street Journal article described what I’ll call a “Larry Summers” moment for women in business. Namely, Jack Welch, the former CEO of General Electric, spoke to a bunch of women about how if they work hard enough they’ll be appreciated and get ahead. From the article:
He had this advice for women who want to get ahead: Grab tough assignments to prove yourself, get line experience, and embrace serious performance reviews and the coaching inherent in them.
“Without a rigorous appraisal system, without you knowing where you stand…and how you can improve, none of these ‘help’ programs that were up there are going to be worth much to you,” he said. Mr. Welch said later that the appraisal “is the best way to attack bias” because the facts go into the document, which both parties have to sign.
Just as in the case of Larry Summer’s now-famous 2005 speech about women in science and math, a bunch of women left Welch’s talk in frustration.
There is no such thing as a meritocracy
Having been in academic mathematics and a quant in a hedge fund, I’d guess I’ve experienced what comes closest in many people’s minds as the closest to a meritocratic system. But my experience is that it’s anything but, even in these highly quantitative settings.
Instead, as it probably is everywhere, the job environment is a huge social game where it matters, a lot, what kind of priorities you demonstrate and what kind of other signals you give off or respond to. We don’t expect people to play golf and smoke cigars in academia but caring about teaching, or worse, getting a teaching award, can be the kiss of death.
I’m not saying that your personal efforts don’t matter at all, because they do, and you do need to produce stuff, and at a certain rate, but even “personal efforts” are first of all received in the context of a social order (i.e. the perceived importance of your efforts at the very least is a social invention), and second of all they’re are not really personal – one frames the questions one answers with the help of the community, so it’s important you have a good connection and social acceptance in that community (i.e. access to the experts).
Business in more generality is even less meritocratic- there’s a specific requirement that you must “play well with others,” which is absent from academics (mercifully). This means that instead of being an implicit social game, it’s been made very explicit. This is where people promote their work, take credit for others’ work, learn to say what people want to hear, etc. The performance review is a circle-jerk event for such empty-headed manipulations, which makes it particularly ironic that Welch suggested women take the criticism in an appraisal so seriously.
In my experience, it is unbelievably useful for these social games to have an alpha personality, which just kind of means you assume you’re in charge even when it’s not explicitly a situation where someone’s in charge. People respond to such personalities on a chemical level and there’s really nothing a so-called meritocratic system can do about that.
In other words, I’m not holding my breath for a truly meritocratic system. It’s just not what humans evolved for. Let’s acknowledge that and work on how to make the system responsive to good ideas anyway (whatever the system is).
Successful people want to believe that there is such a thing as meritocracy
This begs the question, why do people like Jack Welch and Larry Summers hold on so tight to the myth of meritocracy? My theory is that it serves a two-fold goal: as advertisement for new people and as a validation of the winners in the system.
People want to feel like they are entering a level playing field then the best thing you can do is advertise it as a meritocracy, because it’s human nature to think that you’re better than average. So everyone wants to enter such a field, assuming they will rise to the top.
At the same time, the `winners’ of the social game want desperately to think they did amazing stuff in order to be so successful. They hold on to the myth of meritocracy as a religious belief, and it is pure dogma by the time they reach upper management. This plays into another part of human nature where we discount luck and the infrastructure that led to our success and take it as a sign of our personal choices. Lots of people in finance in general suffer from this diseased mindset but actually anyone who is high enough up in their respective `meritocratic system’ does too.
That’s my simple explanation for why these guys can go in front of a bunch of women and be so unbelievably tone-deaf. They are true believers, because their entire egos are built on this belief, and it doesn’t matter how much counter-evidence is presented to them, even in the form of humans in the room with them.
One last thought. If I saw people leaving a room in disgust when I was giving a talk, I imagine I’d be slightly aghast- I might even pause and ask them what’s wrong. But I guess that’s because I’m not alpha enough.
How to teach someone how to prove something
In a couple of my posts (most recently here), I’ve talked about the need for a course early on in undergraduate math classes on proof techniques.
The goals of the class are two-fold: first, teach the students basic skills, and second demystify the concept of proof. The students should come away from the class thinking, no it’s not magic, and I’ve learned how to do this stuff, and there are a few basic techniques which seem to come in handy.
Today I want to go further into what a curriculum for such a course might look like.
And I will, in a moment, but first I want to explain something. It’s actually a really important and dangerous question, how to teach such a course, because it could go wildly wrong, and sometimes does. From my commenter Jordan:
… “Numbers, Equations, and Proofs,” which I started at Princeton in 2002 and which is still going as well. Though here’s an interview with a dude who was an ace math competition dude and found the course so hard as to drive him out of the math major! So maybe it’s no longer as “for everyone” as I designed it to be….
This struck me, how perverted Jordan’s class became. For that matter, Math 55 at Harvard could have started out as a good idea as well, but by the time I got to Harvard as a grad student it was the reason so few math majors ever stuck at Harvard and why there were especially few women.
I remember Noam Elkies taught it while I was there and was famous for asking questions in class and getting students to compete to answer them quickly. It makes sense that he’d run a class like this, because he’s so fast and clever, and he’s naturally wondering, am I the fastest and clevererest of them all? But rather than a place where proof is demystified and people feel safe asking dumb questions, he’d created the polar opposite, a live quiz show of clever competition. Ew!
In order to combat this downfall and decay, I think the class needs to have a clearly stated mission as well as built-in curriculum requirements that works against ostentatious displays of cleverness, which indeed only serve to further the “I got it but you don’t” stereotype of math skills (but which mathematicians themselves are incentivized to further since that magical aura comes in handy).
For example, when I taught it, I let the students hand in homework again and again until they got a score they liked. Of course, this depending on me having an awesome grader (and a relatively small class), which luckily I had.
Also, I asked each student to give a presentation to the class on some proof they particularly enjoyed, and I sat through a preview of their presentation and gave them extensive advice on board work and eye contact, which took a lot of work but really helped them prepare and also boosted their egos while at the same time increased their sympathy with each other and with me.
But of course the most important thing was that I clearly stated at the beginning of each class in the first two weeks that proving things in math was a skill like any other that you get good at through practice. And when I left Barnard Dusa McDuff took over the class and still teaches it, so I know it’s in good hands.
If I hadn’t had Dusa, I’d probably have written a manifesto to be given to each person who would teach the class after me. Of course anyone could have just thrown that away but it’s an idea.
As for content, I taught them really basic proof techniques, so induction, proof by contradiction, the pigeon-hole principle, and some epsilon-delta practice. We covered some basic logic, graph theory, group theory, ordinals, and basic analysis. We constructed the reals two ways and the complex numbers once and talked for a long time about whether “i” is real and what that even means. We used A Transition to Higher Mathematics, which I recommend with a few reservations (please tell me if you’ve found a better text for something like this!).
Everything was done super explicitly and carefully, no rushing. I said things three times in three different ways. I wasn’t expecting people to be fast or clever, because I know intelligence works in different ways and that this stuff was completely new to most of the students. And at least one student in the class, who had been an artist, is now a grad student in math at Berkeley.
Looking over my post I realize I spent way more time talking about the tone of the class than the content, but that’s totally appropriate, since I think of this class as an introduction to the culture of mathematics (or rather the culture I wish we had) just as much as mathematics itself.
After all, there really is no time limit on good ideas, and you do get to do it over if you make a mistake, and going over things slowly gives you more time to ask good questions and find mistakes.
On the making of a girl nerd
Today I want to discuss the process by which girls become math and cs nerds.
I could be tempted to talk primarily about my own story, since I’m a huge nerd. And I will talk about my story, but my focus is going to be on the girls of my generation who could have become nerds but didn’t. I’m hoping we can learn some lessons so that future generations will have more nerd girls.
Both my parents are nerds. My mother has a Ph.D. in applied math and my father has a Ph.D. in pure math. Moreover, I was on the math team in high school, found out about a math camp, and went to it for two summers, with the full support of my family.
I want to go over these details again, because I want to point out that they gave me an enormous advantage to becoming a successful nerd.
First, my parents being nerds: I have found an amazing correlation between women with math Ph.D.’s and women whose fathers are mathematicians. I don’t think this is random- indeed I think it means two things. First, that girls with mathematician dads have an easy time imagining themselves as mathematicians (and an even easier time if their mom is too). Second, that girls without mathematician dads don’t. Otherwise you wouldn’t be able to explain the statistics I have.
Second, the math camp experience. I went to math camp in spite of it being an extremely uncool summer endeavor, according to my classmates at school. Yet I didn’t care, and went anyway, mostly because I was already a complete outsider, a fat girl on the math team (but a mathbabe when I got there!).
Two things about this. First, most smart girls around me in Lexington High School, and there were a lot of them, would not have been willing to go to math camp and ruin their reputations. Most of them were relatively popular, and wanted to keep it that way. I had nothing to lose in that aspect and knew it. This kind of thinking may seem silly to us as grownups but seemed like life or death choices then.
Second, the advantage having been to math camp gave me when I got to college was phenomenal. I knew how to prove things by induction, by contradiction, and using the pigeon-hole principle. I knew basic group theory, graph theory, and real analysis. This gave me a jump-start in all of my undergrad math major classes. I was an elite, and what I could do seemed like magic to the kids who were math majors who didn’t know that stuff.
The thing about math is that people get into this mindset about being good at it: they think that you either have it or you don’t (see this post for more on the mindset). So the experience for the other kids, boys and girls, going to an algebra class and sitting next to me and a few other kids from math camp backgrounds was understandably intimidating and made them think they couldn’t compete. But I believe that, considering the social constructs and the kind of confidence girls and boys are trained to have (or not have), it was particularly daunting for other girls to see their competition in a small group of elite nerds who already knew all the answers.
I’m not advocating closing math camps. In fact, I am going back to teach at my high school math camp in July for three weeks (woohoo!). What I am advocating is thinking seriously about the selection process for young nerds and how much it weeds out girls. We can do better.
For example, Harvey Mudd is doing better by careful thought and attention to the issue. Namely, they are changing the introduction to programming class to be more appealing for non-math-or-cs-camp nerds. From the New York Times article:
Known as CS 5, the course focused on hard-core programming, appealing to a particular kind of student — young men, already seasoned programmers, who dominated the class. This only reinforced the women’s sense that computer science was for geeky know-it-alls.
“Most of the female students were unwilling to go on in computer science because of the stereotypes they had grown up with,” said Zachary Dodds, a computer scientist at Mudd. “We realized we were helping perpetuate that by teaching such a standard course.”
To reduce the intimidation factor, the course was divided into two sections — “gold,” for those with no prior experience, and “black” for everyone else. Java, a notoriously opaque programming language, was replaced by a more accessible language called Python. And the focus of the course changed to computational approaches to solving problems across science.
This sounds like a brilliant idea, and one that we should all consider (and python rocks!). It is reminiscent of the “Introduction to Proofs” class which I started with Karen Edwards and Sara Robinson in 1993 at UC Berkeley as an undergrad and which is still going, as well as the class I started at in 2006 at Barnard College, which is also still going. The dual goals of such a class are to teach basic proof techniques to people interested in the major (who probably didn’t go to math camp) and to show people that being able to prove things isn’t magic, it just takes practice and knowing techniques.
Let’s get more campuses across the country to think about all the math and cs nerds they are missing out on by teaching the same old math (or cs) major classes every year. This is a curriculum change that is easy, fun to teach, and completely worthwhile.
Today is Sonia Kovalevsky Day
Sometimes I imagine what my life would have been life if I’d been born way earlier, like in 1850. Knowing how difficult it was back then to be a female mathematician, and not wanting to assume some special property like I was born royalty or otherwise incredibly rich, I usually settle on something like a farmer’s life, with 7 kids and a butter churn, Little-House-on-the-Prairie style. To satisfy my nerdy urges I imagine myself knitting difficult patterns and formally organizing the community’s crop rotations.
I really don’t have much insight into what it must have been like back then, but even a short thought experiment like this helps me appreciate the story of Sofia Kovalevskaya, who was indeed born in Moscow in 1850 and unbelievably contributed majorly to mathematics, even though (hat tip Robert Lipshitz):
- it was illegal to go to university in Russia at the time so she had a faux marriage in order to get permission from her husband to go abroad to study,
- got a Ph.D. in Berlin studying under some famous men (Helmholtz, Kirchhoff and Bunsen in Heidelberg, Weirstrass), becoming the first woman in Europe to ever get hold the degree,
- after which time nobody in Germany would let her work so she did various jobs including installing streetlamps,
- and finally managed to get some kind of weird position in Sweden (here‘s a more complete bio).
Did I mention that she eventually had a kid with her husband and then died at the age of 41 from the flu?
I’d really love to go back in time for a day, find Sweden, and buy that amazing woman a drink (and I’d try to arrange to slip some antibiotics into said drink).
Today we are celebrating Sonia at Barnard College (here’s the schedule), where for the nth time (where n is at least 5) we’re having a Sonia Kovalevsky Day with a crowd of young women mathematicians, 9th graders from the Urban Assembly Institute of Math & Science for Young Women, will come and enjoy math talks from Barnard and Columbia professors and then engage in a team competition (with their teachers, which is my favorite part) to see who will win incredibly small prizes but for which they will all scream their heads off for 2 hours. It’s fun!
I started this tradition when I was a Barnard math professor back in 2006 with my friend Kiri Soares who runs the UA Institute, and that fact that it’s still going makes me very happy. Every time I go I try to teach the students how to solve the Rubiks cube using a few tricks which stem from group theory. It’s fun to do and they all get to take home their cubes, along with other math toys and goodies. Mmmm… math toys.

It’s all mom’s fault
Maybe it’s because I grew up with an unapologetic working mother, but I am confused and enraged by all the cultural norms concerning mothers and how everything is their fault.
When I grew up in the 1970’s I had all sorts of role models of mothering. I was lucky to live next door to Sally, I met MA (Mary Ann) in puberty, and of course there was my own mom. All of these women were fiercely devoted to their choices: Sally and MA stayed home with their young kids but as their kids grew up, devoted more and more time to other things. My mom was a computer science professor my entire life. It goes without saying (but just for the record I’ll say it here) that I support people doing what they want to and need to for their own private reasons, no questions asked.
Sure, there were differences in interactions between my mom and these other surrogate moms. My mom didn’t have a lot of extra time to shop or cook, for example. But on the other hand she was a great role model for me in showing me how to be happy with what you do and have kids at the same time. And some things she didn’t have time for I was lucky enough to get from other things and people.
Here it is, thirty years later, and lots things have changed for working mothers. Some things have gotten easier: there’s online shopping, so I can provide my three sons with clothes and food without leaving home, which was a major struggle for my mom. Some things have gotten harder: school and daycare has gotten more expensive (more on that below). Other things haven’t changed so much, which itself is strange.
Here’s an article that got me pissed off enough to write this post. It’s a New York Times piece about an Olympic swimmer who, after taking time off and having two children, has returned to swimming and is actually competitive at the age of 40. I am so completely impressed by her, but for some reason the Times sees it as appropriate to deliver the following lines:
Evans said she had been criticized on social networking sites for training when she should be home with her children. But she has set up her schedule so her main swimming workout takes place in the morning, from 5:30 to 7:30, so she can make it home in time for breakfast. Her crazy hours are not lost on her daughter, who recently asked, “Why do you swim in the dark, Mommy?”
…
Willson’s job in technology sales allows him to work from home. He can chip in with the children when needed and behold the force of nature that is his wife.
First of all, how is it appropriate to mention idiots on Facebook? It is so entirely defensive and out of place. If I’m training for the Olympics, probably for the very last time in my life, my kids will be psyched for me to do my best, even if it means missing breakfast sometimes. And why is there always a mention of the martyred husband? Just imagine this was a male swimmer coming back to the Olympics after not swimming for 15 years, do we hear about his wife? No we don’t. Ridiculous, and the New York Times should do better. If they mention idiots on Facebook, they should also mention how they are idiots.
Here’s another story that got me incredibly pissed (if you were looking for a happy post this morning, I apologize). It’s about a public ad campaign in Georgia with billboard pictures of fat kids looking unhappy. This is insane and insulting on so many levels I don’t really know where to start, but let me start with the intended target: the mom. Yes, it’s mom’s fault that there are fat kids, and these billboards are telling mom not to let their kids get fat.
As an aside, it’s also now officially okay to blame mom for making her kids fat, as it’s also officially okay to blame the kids themselves. It’s government-sponsored bullying. Never mind the fact that they’ve shown nutrition education and exercise doesn’t actually cause people to lose weight (i.e. understanding where calories are hidden in food doesn’t magically make them leave cheeseburgers). Never mind that nobody has come up with a viable plan for how to address this issue. Let’s blame moms anyway, because then we are taking this issue seriously.
It makes you wonder why women want to become moms at all considering all the things we are signing up for. Oh and wait, actually lots of women aren’t having kids, but interestingly a recent paper came out showing women who are highly educated are having more kids. Here’s the abstract for that paper:
Conventional wisdom suggests that in developed countries income and fertility are negatively correlated. We present new evidence that between 2001 and 2009 the cross-sectional relationship between fertility and women’s education in the U.S. is U-shaped. At the same time, average hours worked increase monotonically with women’s education. This pattern is true for all women and mothers to newborns regardless of marital status. In this paper, we advance the marketization hypothesis for explaining the positive correlation between fertility and female labor supply along the educational gradient. In our model, raising children and home-making require parents’ time, which could be substituted by services bought in the market such as baby-sitting and housekeeping. Highly educated women substitute a significant part of their own time for market services to raise children and run their households, which enables them to have more children and work longer hours. Finally, we use our model to shed light on differences between the U.S. and Western Europe in fertility and women’s time allocated to labor supply and home production. We argue that higher inequality in the U.S. lowers the cost of baby-sitting and housekeeping services and enables U.S. women to have more children, spend less time on home production and work more than their European counterparts.
Also interesting is this interview, where they describe the results of another paper which tracked women vs. men in various fields of science, including math. It looks like evidence for my post about meritocracy and horizon bias, i.e. the idea that women self-select out of certain fields because they are just not very appealing. From the interview:
The women who come in to academic science careers tend to be so highly motivated that they stay. They limit the number of children they have. Other studies have shown that female academics have fewer children than other professional women, such as lawyers. Female graduates see women scientists working very hard in what they feel are less fair conditions, and it puts them off. Societal factors also make it harder for women to have such demanding careers–women tend to manage family problems, for example.
By the way, I am not insufferably sad about mothers and their fates. I make fun of mothers too, and this article about passive parents is one I could have written. From the article:
But seriously, what is the deal with asking our children to behave? “Maybe you should get down?” What the hell is wrong with you lady? She’s four. There’s no room for negotiating here. I’m all for giving my kids choices to make them feel like they’re in control of something, blah, blah, blah, but this is not the time. “Maybe” should be reserved for times like: “Do you want to wear a dress today or MAYBE a skirt?”
I could go on and on about the passivity of modern yuppie parents, and I’d be right (hey I live in the Upper West Side so you know I’d be right). But if you think about it for a minute, this is just another manifestation of the same thing: it’s all mom’s fault. These women are performing a mother role instead mothering from the stomach, and it’s because they are made insecure by all the incredible bullshit out there about how to be a good mom and what other people are going to think if they scream at their kid in public or if their kid starts to scream. We have taught our mothers to be insecure, and to feel at fault, and oh yes, to be the target of bullying ad campaigns as well.
People, let’s get it together and solve problems instead of pointing fingers. I’m looking at you, Santorum.
Women in math
This is crossposted from Naked Capitalism.
A study recently came out which was entitled “Can stereotype threat explain the gender gap in mathematics performance and achievement?”. One of the authors created and posted a video describing the paper, which you can view here.
As a preview, there seem to be four main points of the paper and the video:
- The papers on stereotype threat normalize with respect to SAT scores which is bad.
- Evidence for stereotype threat is therefore weak.
- We should therefore stop putting all of our resources into combating stereotype threat.
- We should instead do something easy like combating stereotypes themselves.
Before we go into the details of the paper, we need a bit of context. For that reason, this post is split into three parts. The first addresses a meta-issue, namely that of the “null hypothesis” in this discussion. A frustration that I have, and that I think is shared by many of the women I know in math, is that the (often unspoken) working hypothesis is that in fact women are just not as talented, and it is somehow up to us women to prove this otherwise, presumably by convincing men that we’re geniuses.
The authors of the above paper fall prey to this disingenuous line of thought, by proclaiming stereotype threat is an insufficient explanation but not offering any alternative explanations. This sets up a kind of implied false dichotomy: if it isn’t explained by such and such, it must mean girls are dumb.
Not only does this undermine serious intellectual debate, but it often turns people off from entering the debate in the first place, because they sense the manipulative nature of the discussion. But that’s a pity, since, with the correct assumption, namely that women and men have equal talents but things are holding back women, we could probably make lots of progress on what those things are.
The second part is directly related not to the paper but to the blog post which referenced the paper, which changed the conversation from “math performance gap” to the question of “why there are no women math geniuses”. This is an interesting twist, and in my opinion warrants addressing separately.
In the third part I argue directly against the paper and its conclusions.
1. The Null Hypothesis
Needless to say, I think the onus is on the scientific community to prove that women aren’t as mathematically talented as men. In other words, I do not accept the defensive position that I need to prove we are as smart: the null hypothesis is that a series of effects, one of them stereotype threat, explains any perceived difference in talent.
In his now famous lecture at NBER in 2005, Larry Summers putatively discusses the issue of why there are fewer tenured women in science and math departments at top universities. However, if you read the transcript, you will note that, when he gets to the “different availability of aptitude at the high end” part, he does us a favor of sorts by admitting what his underlying working hypothesis is: that girls aren’t as good at math. His argument using standard deviations of test scores is ridiculous, especially if you consider 1) how differently women do versus men on the same test in different conditions, 2) how much that difference has itself changed over time, and of course 3) the question of what the tests themselves are measuring.
To test why this null hypothesis is so damaging, my friend Catherine Good suggested the following thought experiment: imagine if he’d gone up to the podium and, instead of saying that women aren’t all that good at math and it was partly explained by when he’d given boyish toys to his twin girls that they took care of them instead of constructed things, he had instead substituted gender with race. Here’s the passage:
There may also be elements, by the way, of differing, there is some, particularly in some attributes, that bear on engineering, there is reasonably strong evidence of taste differences between little girls and little boys that are not easy to attribute to socialization. I just returned from Israel, where we had the opportunity to visit a kibbutz, and to spend some time talking about the history of the kibbutz movement, and it is really very striking to hear how the movement started with an absolute commitment, of a kind one doesn’t encounter in other places, that everybody was going to do the same jobs. Sometimes the women were going to fix the tractors, and the men were going to work in the nurseries, sometimes the men were going to fix the tractors and the women were going to work in the nurseries, and just under the pressure of what everyone wanted, in a hundred different kibbutzes, each one of which evolved, it all moved in the same direction. So, I think, while I would prefer to believe otherwise, I guess my experience with my two and a half year old twin daughters who were not given dolls and who were given trucks, and found themselves saying to each other, look, daddy truck is carrying the baby truck, tells me something. And I think it’s just something that you probably have to recognize.
It begs the question, why did the women in kibbutz quit working on tractors? The way Larry tells his story, he makes it clear he thinks that it’s because the women wanted it that way (thus his story about the twins). But surely it is as plausible that: 1) Men, having a vested interest in proving their manhood (which they do and in cultures around the world leads to certain types of work being seen as “manly”) weren’t keen about day care duty and/or 2) women were hesitant to cross the lines of gender stereotype (it might lead them to be perceived as being masculine, or even worse, emasculating). And it also isn’t hard to imagine that parents ooh and ahh more when small children play with what are perceived to be gender-appropriate toys and are quietly or even vocally uncomfortable when boys play with dolls and girls play with trucks.
One last word about the null hypothesis and why I’m so devoted to this issue: when I and two other girls (and, as it happens, no boys) in the 6th grade did well enough to go into a special, advanced 7th grade algebra class, my (female) teacher brought us up to the front of the room and told the three of us “I don’t see why you would challenge yourselves like this anyway since you are girls, and you won’t be needing math when you grow up.” I was the only one of the three of us to actually choose that class, and I was the only girl in the algebra class. One of my friends was one of two women in a class of 45 students studying artificial intelligence at Yale. She was expecting praise for being one of only two students to get a program to work on a particularly tough assignment. Instead, she was accused by the professor of stealing the code from her male classmate. She left the major. Until stories like this become rare, or even uncommon, I will assume that there’s too much cultural influence to figure out the real story.
Going back to Larry Summers, his lecture did two things: 1) it breathed new life into the age-old stereotype that women aren’t as good at math as men, and 2) it attributed that difference to an underlying innate ability difference- that is, he conveyed a “fixed ability mindset” regarding math (more on mindsets below). As the leader of an educational institution he introduced the two ideas that together are like a powder keg: they can undermine women’s feelings of belonging in math, which in turn informs their mathematics achievement and intrinsic motivation to remain in math.
Now more about Catherine Good. She talked at that same conference where Larry Summers put his foot in his mouth; in fact she was the speaker after Larry at that conference, and she was talking about her paper that gives evidence that the above “powder keg” message tends to push women out of math (but Larry didn’t stick around long enough to hear her talk, unfortunately). She is also an expert on stereotype threat and helped me look at the study. More on her thoughts below, but I still want to talk about the concept of “genius.”
2. Women and the concept of genius
Let’s define, as one of the commenters does from the blog, a “genius woman in math” to be any woman who has won a Fields Medal. Since there are no women who have won Fields Medals (versus 52 men), this is a pretty tight definition. I would argue, and I might in another post, that even without the above definition, the concept of “genius” is a social construct which is rarely if ever applied to women, except perhaps after they’re dead. Please comment with counterexamples if you know of any.
So here’s what I think. There are lots of reasons that women don’t win Fields Medals. I will name a few.
- Fields Medals are awarded to mathematicians under the age of 40, for some reason, and women mathematicians typically do good work into their retirement age, whereas men usually do their best work young (this also explains why Harvard has so much trouble hiring women- by the time they are convinced the woman is a genius, she’s 55 and has grandchildren and frankly probably sees the offer as tokenism).
- The commenter who defined a “math genius” as a Fields Medalist said that it would be an objective measure. But Fields Medals are awarded by a bunch of guys who decide what’s important and who’s responsible for the important results. In other words it’s a political process.
- Women don’t care as much about winning Fields Medals. This matters, because I know of men who explicitly worked on problems in order to win the Fields Medal (you know who you are). It’s a serious and bizarre case of narrow focus.
- Why is math genius defined so narrowly? I would personally define it more broadly (a topic for another post), and there’d be plenty of women geniuses. With my definition, though, I’d guess that women who are geniuses have lots of options and they often choose something they consider more personally rewarding than an academic job.
- Women’s intelligence may also manifest in different ways: note that most of the assholes on Wall Street are men. This kind of makes sense since women are typically not as driven by testosterone and competitiveness. This doesn’t mean they aren’t geniuses or that they couldn’t have done the work the men on Wall Street did (my experience proves that).
- The Fields Medal distorts the mathematical process itself, by implying that there’s a single superstar who swoops in and solves the problem that all the other people were incapable of doing. In fact mathematics as a field is an enormous collaboration, a scientific project, where everyone depends on the community around them for coming up with questions, defining the “interestingness” of questions, and giving context to results. The idea that there’s one winner out of all of this, or even one metric by which we could measure such a winner, is silly. See this post from Quomodocumque.
- Another point about genius (in any domain): research is showing that to truly express one’s genius takes thousands of hours of practice. So genius may be a latent trait but will never be expressed without many hours of hard work. This point is very often lost and is related to women in that their apparent geniusness depends to a large extent on how supportive their environment is for all that investment of time.
3. The paper against stereotype threat
I am finally ready to address (with Catherine’s help) the issues of the paper in question, which I will repeat:
- The papers on stereotype threat normalize with respect to SAT scores which is bad
In fact the author “discards” a bunch of stereotype threat studies on these grounds. However, it is totally standard to normalize with respect to some other metric (would you rather we didn’t normalize to anything?), and in fact it essentially penalizes the studies, since it has been shown that stereotype threat is in play even for the SATs. On the other hand, the standard for normalizing (this is called “including a covariate”) is that the groups being compared should not differ significantly in the covariate, presumably because it’s harder to argue that your are in fact correcting for that aspect. Because men and women sometimes do differ significantly in SAT scores, including them as covariates could be a technical violation of the rules of conducting a so-called ANCOVA.
Is this what the author is complaining about specifically? Did he, for example, check to see if the samples in the “discarded” studies actually differ in the covariate? It seems he’s making the assumption that they did, but it’s not clearly stated that they did. It’s certainly not a given that the men and women in these studies did differ in the covariate, and he needs to make that precise. If they did not, then there’s no valid argument against using SAT scores.
- Evidence for stereotype threat is therefore weak.
There is ample evidence that stereotype threat is very real. Keep in mind that the authors of this study have not shown evidence against stereotype threat, but have simply complained that they don’t like the existing studies for it. And their standard for what “replicates” the original study is overly stringent- they only wanted to include studies that found significant interactions between gender and condition. Interactions are easiest to find when you have a “crossover effect” (e.g. males are higher in condition A but lower in condition B), but often we find “span effects” in which the males and females may be equal in condition A but differ in condition B. This can also be an example of stereotype threat. For example, in a paper written by Catherine, she didn’t find a significant interaction (males and females performed equally in condition A) but when the stereotype threat was reduced, women outperformed men. To discount this and other studies as not providing evidence of stereotype threat simply because an “interaction” wasn’t found is playing games with statistics.
- We should therefore stop putting all of our resources into combating stereotype threat.
Nobody who studies stereotype threat claims it explains everything. It is part of a larger picture. The good news is that there are interventions for it (described below).
- We should instead do something easy like combating stereotypes themselves.
The idea that it’s “easy” to combat stereotypes is completely naive. There are tons of ways that stereotyping is understood to be very difficult, if not impossible, to get rid of. Some of them have to do with an evolutionary need to simplify first impressions of people (i.e. categorize) so that we can tell if they are an immediate threat to our safety. This may be the most baffling part of the whole thing, because the authors should really know better.
I want to end on a positive note, because the news is actually pretty good. There is a way to combat stereotype threat, and I’ve tried it and it works. To understand it, it helps to think about the way people think about intelligence itself. As a simplification, people either think that intelligence is fixed and rigid (you’re either born with it or you’re not) or they think that intelligence is malleable and can be learned and practiced.
It turns out that if someone believes the latter “malleable intelligence” view, then they work hard and are hopeful and stereotype threat is to a large extent alleviated. Whereas if they’re convinced of the former mindset for intelligence, the effect of stereotype threat is more pronounced. In situations where the stereotype is salient (“girls are bad at math” is salient when taking a math test), the situation itself can convey a mindset of fixed ability and all the hallmark responses that go along with that mindset then follow. To encourage a malleable view of intelligence can help combat that fixed view and thus the threat of the stereotype.
The way I used this information was as follows. I started a class in teaching proof techniques at Barnard College (there were both Barnard students and Columbia students in the class). At the beginning of every class for the first two weeks I described how mathematicians aren’t born knowing how to prove things, but rather they learn techniques, and practice them until they are proficient. Note I wasn’t directly confronting or addressing stereotypes, but rather setting up the mindset where the studies have shown stereotypes have less negative power.
The class went great, and is still going on. I will post soon about my experiences starting that class and others like it.
Followup: Change academic publishing
I really appreciate the amazing and immediate feedback I got from my post yesterday about changing the system of academic publishing. Let me gather the things I’ve learned or thought about in response:
First, I learned that mathoverflow is competitive and you “do well” on it if you’re quick and clever. Actually I didn’t know this, and since it is online I naively assumed people read it when they had time and so the answers to questions kind of drifted in over time. I kind of hate competitive math, and yes I wouldn’t like that to be the single metric deciding my tenure or job.
Next, ArXiv already existed when I left math, but I don’t think it’s all that good a “solution” either, because it’s treated mostly as a warehouse for papers, and there is not much feedback (although I’ve heard there’s way more in physics). Correct me if I’m wrong here.
I don’t want to sound like a pessimist, because the above two things really do function and add a lot to the community. I’m just pointing out that they aren’t perfect.
We, the mathematics community, should formally set out to be creative and thoughtful about different ways to collaborate and to document collaboration, and to score it for depth as well as helpfulness, etc. Let’s keep inventing stuff until we have a system which is respected and useful. The reason people may not be putting time into this right now is that they won’t be rewarded for it, but I say do it anyway and worry about that later. Let’s start brainstorming about what that system would look like.
That gets to another crucial point, which is that the people we have to convince are really not each other so much as deans and provosts of universities who are super conservative and want to be absolutely sure that the people they award tenure to are contributing citizens and will be for 40 years. We need to convince them to reconsider their definitions of “mathematical contributions”. How are we going to do this?
My first guess is that deans and provosts would listen to “experts in the field” quite a bit. This is good news, because it means that in some sense we just need to wait until the experts in the field come from the generation of people who invented (or at least appreciate) these tools. There are probably other issues though, which I don’t know about. I’d love to get comments from a dean or a provost on this one.
Change academic publishing
My last number theory paper just came out. I received it last week, so that makes it about 5 years since I submitted it – I know this since I haven’t even done number theory for 5 years. Actually I had already submitted it to a journal, and they took more than a year to reject it, so it’s been at least 6 years since I finished writing it.
One of the reasons I left academics was the painfully slow pace of being published, plus the feeling I got that, even when my papers did come out, nobody read them. I felt that way because I never read any papers, or at least I rarely read the new papers out of the new journals. I did read some older papers, ones that were recommended to me.
In other words I’m a pretty impatient person and the pace was killing me.
And I went to plenty of talks, but that process is of course very selective, and I would mostly be at a conference, or inside my own department. It led me to feel like I was mathematically isolated in my field as well as being incredibly impatient.
Plus, when you find yourself building a reputation more through giving talks and face-to-face interactions, you realize that much of that reputation is based on how you look and how well you give talks, and it stops seeming like mathematics is a just society, where everyone is judged based on their theorems. In fact it doesn’t feel like that at all.
I was really happy to see this article in the New York Times yesterday about how scientists are starting to collaborate online. This has got to be the future as far as I’m concerned. For example, the article mentions mathoverflow.net, which is a super awesome site where mathematicians pose and answer questions, and get brownie points if their answers are consistently good.
It’s funny how nowadays, to get tenure, you need to have a long list of publications, but brownie points for answering lots of questions on a community website for mathematicians doesn’t buy you anything. It’s totally ass backwards in terms of what we should actually be encouraging for a young mathematician. We should be hoping that young person is engaged in doing and explaining mathematics clearly, for its own sake. I can’t think of a better way of judging such a thing than mathoverflow.net points.
Maybe we also need to see that they can do original work. Why does it have to go through a 5 year process and be printed on paper? Why can’t we do it online and have other people read and rate (and correct) current research?
I know that people would respond that this would make lots of crappy papers seem on equal par with good, well thought-out papers, but I disagree. I think, first of all, that crap would be identified and buried, and that people would be more willing to referee online, since on the one hand it wouldn’t be resented, free work for publishers, and on the other hand, people would get more immediate and direct feedback and that would be cool and it would inspire people to work at it.
In other words, we can’t compare it to an ideal world where everyone’s papers are perfectly judged (not happening now) and where the good and important papers are widely read. We need to compare it to what we have now, which is highly dysfunctional.
That begs another huge question, which is why papers at all? Why not just contributions to projects that can be done online? For example my husband has an online open source project called the stacks project, but he feels like he can’t really urge anyone, especially if they’re young, to help out on it, because any work they do wouldn’t be recognized by their department. This is in spite of the fact that there’s already a system in place to describe who did what and who contributed what, and there are logs for corrections etc.; in other words, there’s a perfectly good way of seeing how much a given mathematician contributed to the project.
I honestly don’t see why we can’t, as a culture, acclimate to the computer age and start awarding tenure, or jobs, to people who have made major contributions to mathematics, rather than narrowly fulfilled some publisher’s fantasy. I also wonder if, when it finally happens, it will be a more enticing job prospect for smart but impatient people like myself who thrive on feedback. Probably so.
See also the follow-up post to this one.
Meritocracy and horizon bias
I read this article yesterday about racism in Silicon Valley. It’s interesting, written by an interesting guy named Eric Ries, and it touches on stuff I’ve thought about like stereotype threat and the idea that diverse teams perform better than homogeneous ones.
In spite of liking the article pretty well, I take issue with two points.
In the beginning of the article Ries lays down some ground rules, and one of them is that “meritocracy is good.” Is it really good? Always? And to what limit? People are born with talent just as they’re born rich or poor, and what makes talent a better or more fair way of sorting people? Or are we just claiming it’s more efficient?
Actually I could go on but this blog post kind of says everything I wanted to say on the matter. As an aside, I’m kind of sick of the way people use the idea of “meritocracy” to overpay people who they justify as having superhuman qualifications (I’m looking at you, CEO’s) or a ridiculous, massively scaleable amount of luck (most super rich entrepreneurs).
Second, I’m going to coin a term here, but I’m sure someone else has already done so. Namely, I consider it horizon bias to think that wherever you are, whatever you do, is the coolest place in the world and that everyone else is just super jealous of you and wishes they had that job. So you don’t look beyond your horizon to see that there are other jobs that may be more attractive to people. The reason this comes up is the following paragraph:
What accounts for the decidedly non-diverse results in places like Silicon Valley? We have two competing theories. One is that deliberate racisms keeps people out. Another is that white men are simply the ones that show up, because of some combination of aptitude and effort (which it is depends on who you ask), and that admissions to, say Y Combinator, simply reflect the lack of diversity of the applicant pool, nothing more.
I’d like to offer a third option, namely that only white guys show up because that’s who thinks working in Silicon Valley is an attractive idea. I know it’s kind of like the second option above, but it’s not exactly. The qualification “because of some combination of aptitude and effort” is the difference.
Let’s say I’m considering moving to Silicon Valley to work. But all of my images of that place come from movies and my experiences with my actual friends in the dotcom bubble era who slept under their desks at night. Plus I know that the housing market out there is crazy and that the commute sucks. Finally, I’d picture myself working with lots of single, ambitious, and arrogant young men who believe in meritocracy (code for: use vaguely libertarian philosophical arguments to act ruthlessly). I can imagine that these facts keep plenty of non-white non-men away.
Next, going on to the point about horizon bias. People who already work in Silicon Valley already selected themselves as people who think it’s a great deal. And then they sit around wondering why it’s not a more diverse place, in spite of having everything awesomely meritocratic.
Going back to the article, Ries mentions this idea that diverse teams outperform homogeneous ones. I’d like to look at that in light of horizon bias and ask whether that’s the wrong way to look at it. In other words maybe it’s more a function of what the common goal is, which leads to a diverse team if the common goal is broadly attractive, than how the exact team was created. If goals are super attractive, attractive enough to draw diverse people, then maybe those goals deserve success more.
For example, one of the strengths of Occupy Wall Street has been the diversity of its membership. People of all ages, all backgrounds, and all races have been coming together to speak for the 99%. It’s of course fitting, since 99% does represent lots of people, but I’d like to point out that it is diverse because the cause resonates with so many people, which makes it successful.
Another example. I worked at the math department at M.I.T., which is famously not diverse. And I saw the “Truth Values” play recently which made me think about that experience some more. There’s lots of horizon bias in math, because there’s this assumption that everyone who was ever a math major should want to someday become a math professor (at M.I.T. no less). So it’s easy enough to wring your hands when you see that, although 45% of the undergrad math majors are women, and 40% of the grad students in math are women (I’m making these numbers up by the way), only 1% of the tenured faculty at the top places are women (again totally made up).
And of course there’s real discrimination involved (trust me), but there’s also the possibility that a bunch of women just never wanted to be a professor, they just wanted to get a Ph.D. for whatever reason. But the horizon bias at the top places assumes that everyone would want to become a professor.
On the one hand I’m just making things worse, because I’m pointing out that in addition to the real discrimination that takes place for those women who actually do want to become professors, there’s also this natural but invisible self-selection thing going on where women leave the professorship train at some point. Seems like I’ve made one problem into two.
On the other hand, we can address this horizon bias, if it exists. But instead of addressing it by blotting out the names of candidates on applications (a good idea by the way, and one I think I’ll start using), we would need to address it by looking at the actual company or department or culture and see why it’s less than attractive to people who aren’t already there. It’s a bigger and harder kind of change.
Truth Values
Just two quick things today.
First, I’m going to see Truth Values: One girl’s romp through M.I.T.’s male math maze this Saturday, with a couple of buddies of mine. It’s been recommended to me by a bunch of my math friends, and tickets are available here. It’s slightly scary how much I anticipate I have in common with the writer and performer Gioio De Cari. Also I think I may have taught a class in the classroom of this picture, maybe even with this haircut:

Second, I wanted to share a poem with you, written by Mary Oliver:
We will be known as a culture that feared death
and adored power, that tried to vanquish insecurity
for the few and cared little for the penury of the
many. We will be known as a culture that taught
and rewarded the amassing of things, that spoke
little if at all about the quality of life for
people (other people), for dogs, for rivers. All
the world, in our eyes, they will say, was a
commodity. And they will say that this structure
was held together politically, which it was, and
they will say also that our politics was no more
than an apparatus to accommodate the feelings of
the heart, and that the heart, in those days,
was small, and hard, and full of meanness.
Math in Business
Here’s an annotated version of my talk at M.I.T. a few days ago. There was a pretty good turnout, with lots of grad students, professors, and I believe some undergraduates.
What are the options?
First let’s talk about the different things you can do with a math degree.
Working as an academic mathematician
You all know about this, since you’re here. In fact most of your role models are probably professors. More on this.
Working at a government institution
I don’t have personal experience, but there are plenty of people I know who are perfectly happy working for the spooks or NASA.
Working as a quant in finance
This means trying to predict the market in one way or another, or modeling how the market works for the sake of measuring risk.
Working as a data scientist
This is my current job, and it is kind of vague, but it generally means dealing with huge data sets to locate, measure, visualize, and forecast patterns. Quants in finance are examples of data scientists, and they work in the most, or one of the most, developed subfield of data science.
Cultural Differences
I care a lot about the culture of my job, as I think women in general tend to. For that reason I’m going to try to give a quick and exaggerated description of the cultures of these various options and how they differ from each other.
Feedback is slow in academics
I’m still waiting for my last number theory paper to get published, and I left the field in 2007. That hurts. But in general it’s a place for people who have internal feedback mechanisms and don’t rely on external ones. If you’re a person who knows that you’re thinking about the most important question in the world and you don’t need anyone to confirm that, then academics may be a good cultural fit. If, on the other hand, you are wondering half the time why you’re working on this particular problem, and whether the answer really matters or ever will matter to someone, then academics will be a tough place for you to live.
Institutions are painfully bureaucratic
As I said before, I don’t have lots of personal experience here, but I’ve heard that good evidence that working at a government institution is sometimes painful in terms of waiting for things that should obviously happen actually happen. On the other hand I’ve also head lots of women say they like working for institutions and that they are encouraged to become managers and grow groups. We will talk more about this idea of being encouraged to be organized.
Finance firms are cut-throat
Again, exaggerating for effect, but there’s a side effect of being in a place whose success is determined along one metric (money), and that is that people are typically incredibly competitive with each other for their perceived value with respect to that metric. Kind of like a bunch of gerbils in a case with not quite enough food. On the other hand, if you love that food yourself, you might like that kind of struggle.
Startups are unstable
If you don’t mind wondering if your job is going to exist in 1 or 2 months, then you’ll love working at a startup. It’s an intense and exciting journey with a bunch of people you’d better trust or you’ll end up really hating them.
Outside academics, mathematicians have superpowers
One general note that you, being inside academics right now, may not be aware of: being really fucking good at math is considered a superpower by the people outside. This is because you can do stuff with your math that they actually don’t know how to do, no matter how much time they spend trying. This power is good and bad, but in any case it’s very different than you may be used to.
Going back to your role models: you see your professors, they’re obviously really smart, and you naturally may want to become just like them when you grow up. But looking around you, you notice there are lots of good math students here at M.I.T. (or wherever you are) and very few professor jobs. So there is this pyramid, where lots of people a the bottom are all trying to get these fancy jobs called math professorships.
Outside of math, though, it’s an inverted world. There are all of these huge data sets, needing analysis, and there are just very few places where people are getting trained to do stuff like that. So M.I.T. is this tiny place inside the world, which cannot possibly produce enough mathematicians to satisfy the demand.
Another way of saying this is that, as a student in math, you should absolutely be aware that it’s easier to get a really good job outside the realm of academics.
Outside academics, you get rewarded for organizational skills (punished within)
One other big cultural difference I want to mention is that inside academics, you tend to get rewarded for avoiding organizational responsibilities, with some exceptions perhaps if you organize conferences or have lots of grad students. Outside of academics, though, if you are good at organizing, you generally get rewarded and promoted and given more responsibility for managing a group of nerds. This is another personality thing- some math nerds love the escape from organizing, or just plain suck at it, and maybe love academics for that reason, whereas some math nerds are actually quite nurturing and don’t mind thinking about how systems should be set up and maintained, and if those people are in academics they tend to be given all of the “housekeeping” in the department, which is almost always bad for their career.
Mathematical Differences
Let’s discuss how the actual work you would do in these industries is different. Exaggeration for effect as usual.
Academic freedom is awesome but can come with insularity
If you really care about having the freedom to choose what math you do, then you absolutely need to stay in academics. There is simply no other place where you will have that freedom. I am someone who actually does have taste, but can get nerdy and interested in anything that is super technical and hard. My taste, in fact, is measured in part by how much I think the answer actually matters, defined in various ways: how many people care about the answer and how much of an impact would knowing the answer make? These properties are actually more likely to be present in a business setting. But some people are totally devoted to their specific field of mathematics.
The flip side of academic freedom is insularity; since each field of mathematics gets to find its way, there tend to be various people doing things that almost nobody understands and maybe nobody will ever care about. This is more or less frustrating to you depending on your personality. And it doesn’t happen in business: every question you seriously work on is important, or at least potentially important, for one reason or another to the business.
You don’t decide what to work on in business but the questions can be really interesting
Modeling with data is just plain fascinating, and moreover it’s an experimental science. Every new data set requires new approaches and techniques, and you feel like a mad scientist in a lab with various tools that you’ve developed hanging on the walls around you.
You can’t share proprietary information with the outside world when you work in business or for the government
The truth is, the actual models you create are often the crux of the profit in that business, and giving away the secrets is giving away the edge.
On the other hand, sometimes you can and it might make a difference
The techniques you develop are something you generally can share with the outside world. This emerging field of data science can potentially be put to concrete and good use (more on that later).
In business, more emphasis on shallower, short term results
It’s all about the deadlines, the clients, and what works.
On the other hand, you get much more feedback
It’s kind of nice that people care about solving urgent problems when… you’ve just solved an urgent problem.
Which jobs are good for women?
Part of what I wanted to relay today is those parts of these jobs that I think are particularly suitable for women, since I get lots of questions from young women in math wondering what to do with themselves.
Women tend to care about feedback
And they tend to be more sensitive to it. My favorite anecdote about this is that, when I taught I’d often (not always) see a huge gender difference right after the first midterm. I’d see a young woman coming to office hours fretting about an A- and I’d have to flag down a young man who got a C, and he’d say something like, “Oh, I’m not worried, I’ll just study and ace the final.” There’s a fundamental assumption going on here, and women tend to like more and more consistent feedback (especially positive feedback).
One of my most firm convictions about why there are not more women math professors out there is that there is virtually no feedback loop after graduating with a Ph.D., except for some lucky people (usually men) who have super involved and pushy advisors. Those people tend to be propelled by the will of their advisor to success, and lots of other people just stay in place in a kind of vacuum. I’ve seen lots of women lose faith in themselves and the concept of academics at this moment. I’m not sure how to solve this problem except by telling them that there’s more feedback in business. I do think that if people want to actually address the issue they need to figure this out.
Women tend to be better communicators
This is absolutely rewarded in business. The ability to hold meetings, understand people’s frustrations and confusions and explain in new terms so that they understand, and to pick up on priorities and pecking orders is absolutely essential to being successful, and women are good at these things because they require a certain amount of empathy.
In all of these fields, you need to be self-promoting
I mention this because, besides needing feedback and being good communicators, women tend to not be as self-promoting as men, and this is something that they should train themselves out of. Small things like not apologizing help, as does being very aware of taking credit for accomplishments. Where men tend to say, “then I did this…”, women tend to say, “then my group did this…”. I’m not advocating being a jerk, but I am advocating being hyper aware of language (including body language) and making sure you don’t single yourself out for not being a stand-out.
The tenure schedule sucks for women
I don’t think I need to add anything to this.
No “summers off” outside academics… but maybe that’s a good thing
Academics don’t actually take their summers off anyway. And typically the women are the ones who end up dealing more with the kids over the summer, which could be awesome if that’s what they want but also tends to add a bias in terms of who gets papers written.
How do I get a job like that?
Lots of people have written to me asking how to prepare themselves for a job in data science (I include finance in this category, but not the governmental institutions. I have no idea how to get a job at NASA or the NSA).
Get a Ph.D. (establish your ability to create)
I’m using “Ph.D.” as a placeholder here for something that proves you can do original creative building. But it’s a pretty good placeholder; if you don’t have a Ph.D. but you are a hacker and you’ve made something that works and does something new and clever, that may be sufficient too. But if you’ve just followed your nose, and done well in your courses then it will be difficult to convince someone to hire you. Doing the job well requires being able to create ad hoc methodology on the spot, because the assumptions in developed theory never actually happen with real data.
Know your way around a computer
Get to the point where you can make things work on your computer. Great if you know how unix and stuff like cronjobs (love that word) work, but at the very least know to google everything instead of bothering people.
Learn python or R, maybe java or C++
Python and R are the very basic tools of a data scientist, and they allow quick and dirty data cleaning, modeling, measuring, and forecasting. You absolutely need to know one of them, or at the very least matlab or SAS or STATA. The good news is that none of these are hard, they just take some time to get used to.
Acquire some data visualization skills
I would guess that half my time is spent visualizing my results in order to explain them to non-quants. A crucial skill (both the pictures and the explanations).
Learn basic statistics
And I mean basic. But on the other hand I mean really, really, learn it. So that when you come across something non-standard (and you will), you can rewrite the field to apply to your situation. So you need to have a strong handle on all the basic stuff.
Read up on machine learning
There are lots of machine learners out there, and they have a vocabulary all their own. Take the Stanford Machine Learning classor something to learn this language.
Emphasize your communication skills and follow-through
Most of the people you’ll be working with aren’t trained mathematicians, and they absolutely need to know that you will be able to explain your models to them. At the same time, it’s amazing how convincing it is when you tell someone, “I’m a really good communicator.” They believe you. This also goes back to my “do not be afraid to self-promote” theme.
Practice explaining what a confidence interval is
You’d be surprised how often this comes up, and you should be prepared, even in an interview. It’s a great way to prep for an interview: find someone who’s really smart, but isn’t a mathematician, and ask them to be skeptical. Then explain what a confidence interval is, while they complain that it makes no sense. Do this a bunch of times.
Other stuff
I wanted to throw in a few words about other related matters.
Data modeling is everywhere (good data modelers aren’t)
There’s an asston of data out there waiting to be analyzed. There are very few people that really know how to do this well.
The authority of the inscrutable
There’s also a lot of fraud out there, related to the fact that people generally are mathematically illiterate or are in any case afraid of or intimidated by math. When people want to sound smart they throw up an integral, and it’s a conversation stopper. It is a pretty evil manipulation, and it’s my opinion that mathematicians should be aware of this and try to stop it from happening. One thing you can do: explain that notation (like integrals) is a way of writing something in shorthand, the meaning of which you’ve already agreed on. Therefore, by definition, if someone uses notation without that prior agreement, it is utterly meaningless and adds rather than removes confusion.
Another aspect of the “authority of the inscrutable” is the overall way that people claimed to be measuring the risk of the mortgage-backed securities back before and during the credit crisis. The approach was, “hey you wouldn’t understand this, it’s math. But trust us, we have some wicked smart math Ph.D.’s back there who are thinking about this stuff.” This happens all the time in business and it’s the evil side of the superpower that is mathematics. It’s also easy to let this happen to you as a mathematician in business, because above all it’s flattering.
Open source data, open source modeling
I’m a huge proponent of having more visibility into the way that modeling affects us all in our daily lives (and if you don’t know that this is happening then I’ve got news for you). A particularly strong example is the Value-added modeling movement currently going on in this country which evaluates public teachers and schools. The models and training data (and any performance measurements) are proprietary. They should not be. If there’s an issue of anonymity, then go ahead and assign people randomly.
Not only should the data that’s being used to train the model be open source, but the model itself should be too, with the parameters and hyper-parameters in open-source code on a website that anyone can download and tweak. This would be a huge view into the robustness of the models, because almost any model has sub-modeling going on that dramatically affects the end result but that most modelers ignore completely as a source of error. Instead of asking them about that, just test it for yourself.
Meetups
The closest thing to academics lectures in data science is called “Meetups”. They are very cool. I wrote about them previously here. The point of them is to create a community where we can share our techniques (without giving away IP) and learn about new software packages. A huge plus for the mathematician in business, and also a great way to meet other nerds.
Data Without Borders
I also wanted to mention that, once you have a community of nerds such as is gathered at Meetups, it’s also nice to get them together with their diverse skills and interests and do something cool and valuable for the world, without it always being just about money. Data Without Borders is an organization I’ve become involved with that does just that, and there are many others as well.
Please feel free to comment or ask me more questions about any of this stuff. Hope it is helpful!
Alternative Banking System
I just got invited to join the Alternative Banking System working group from Occupy Wall Street. It’s run by Carne Ross, who has written a book called the Leaderless Revolution. I’m excited to meet the group this coming weekend. It looks like there will be many interesting and unconventional thinkers there.
I got back last night from my Cambridge, where I spoke to people about doing math in business. I will write up my notes from that talk soon and post them, and they will include my suggestions for how to prepare yourself to be a data scientist if you’re an academic mathematician. This is a first stab at a longer term project I have to define a possible “data science curriculum”.



