Archive
Measuring historical volatility
Say we are trying to estimate risk on a stock or a portfolio of stocks. For the purpose of this discussion, let’s say we’d like to know how far up or down we might expect to see a price move in one day.
First we need to decide how to measure the upness or downness of the prices as they vary from day to day. In other words we need to define a return. For most people this would naturally be defined as a percentage return, which is given by the formula:

where 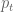


If you know your power series expansions, you will quickly realize there is not much difference between these two definitions for small returns- it’s only when we are talking about pretty serious market days that we will see a difference. One advantage of using the log returns is that they are additive- if you go down 0.01 one day, then up 0.01 the next, you end up with the same price as you started. This is not true for percentage returns (and is even more not true when you consider large movements like 50% down one day, 50% up the next).
Once we have our returns defined, we can keep a running estimate of how much we have seen it change recently, which is usually measured as a sample standard deviation, and is called a volatility estimate.
A critical decision in measuring the volatility is in choosing a lookback window, which is a length of time in the past we will take our information from. The longer the lookback window is, the more information we have to go by for our estimate. However, the shorter our lookback window, the more quickly our volatility estimate responds to new information. Sometimes you can think about it like this: if a pretty big market event occurs, how long does it take for the market to “forget about it”? That’s pretty vague but it can give one an intuition on the appropriate length of a lookback window. So, for example, more than a week, less than 4 months.
Next we need to decide how we are using the past few days worth of data. The simplest approach is to take a strictly rolling window, which means we weight each of the previous n days equally and a given day’s return is counted for those n days and then drops off the back of a window. The bad news about this easy approach is that a big return will be counted as big until that last moment, and it will completely disappear. This doesn’t jive with the sense of the ways people forget about things- they usually let information gradually fade from their memories.
For this reason we instead have a continuous look-back window, where we exponentially downweight the older data and we have a concept of the “half-life” of the data. This works out to saying that we scale the impact of the past returns depending on how far back in the past they are, and for each day they get multiplied by some number less than 1 (called the decay). For example, if we take the number to be 0.97, then for 5 days ago we are multiplying the impact of that return by the scalar 0.97^5. Then we will divide by the sum of the weights, and overall we are taking the weighted average of returns where the weights are just powers of something like 0.97. The “half-life” in this model can be inferred from the number 0.97 using these formulas as -ln(2)/ln(0.97) = 23.
Now that we have figured out how much we want to weight each previous day’s return, we calculate the variance as simply the weighted sum of the squares of the previous returns. Then we take the square root at the end to estimate the volatility.
Note I’ve just given you a formula that involves all of the previous returns. It’s potentially an infinite calculation, albeit with exponentially decaying weights. But there’s a cool trick: to actually compute this we only need to keep one running total of the sum so far, and combine it with the new squared return. So we can update our vol estimate with one thing in memory and one easy weighted average. This is easily seen as follows:
First, we are dividing by the sum of the weights, but the weights are powers of some number s, so it’s a geometric sum and the sum is given by

Next, assume we have the current variance estimate as

and we have a new return 
Note that I said we would use the sample standard deviation, but the formula for that normally involves removing the mean before taking the sum of squares. Here we ignore the mean, mostly because we are typically taking daily volatility, where the mean (which is hard to anticipate in any case!) is a much smaller factor than the noise. If we were to measure volatility on a longer time scale such as quarters or years, then we would not ignore the mean.
In my next post I will talk about how people use and abuse this concept of volatility, and in particular how it is this perspective that leads people to say things like, “a 6-standard deviation event took place three times in a row.”
Happiest being sad
I’m done with math camp, and I am stopping off in Harvard Square on the way home to New York. I collected my two older sons from their first stint at overnight camp yesterday evening, a two-week middle-of-the-woods experience complete with a cold lake, dirty socks and sticky bunk beds. They were actually happy to see me, I could tell by the way they let me hug them in front of other people. I cried when I realized they had each grown two inches.
The past few days have been incredibly emotional. Somehow I started to pine for the program and for the students at the program before it had ended, and now I seem to miss my kids even though I have them back. I’m a mess of yearning, for a million things at once, and it seems like I’ve set myself up for this.
Of course when I think about it I absolutely have, and I guess the only real question is why I’m surprised. I keep falling in love with people and experiences that often even love me back, and even though I’m an experienced piner it doesn’t get any less painful. And yet it seems like the only alternative, if it is a choice I could even make, would be to close myself off from that openness and compassion and live in a careless void. That is certainly more terrifying to me than the safety of wistful suffering.
My friend Moon came to the program a couple of nights ago and gave a kick-ass talk to the students about the Banach-Tarski paradox. She stuck around that night for dinner and asked the program director, who has been doing this for 40 years, whether I had ever been shy. The director said, “No, Cathy was never shy, but she was memorable for the fact that she always said the same thing whenever someone started a conversation with her.” I had no idea what that could have been, and to tell you the truth I was a little worried what he’d say. So Moon asked, and he said the phrase was, “I love math!” It brought back a clear memory of the passion I had then and still have, and hopefully will always have. I am happy to be this sad.
What tensor products taught me about living my life
When I was a junior in college, I went to the Budapest Semesters in Math. I got really bummed while I was there, and I was thinking of leaving math, when a friend of mine back home sent me Silverman and Tate’s book on elliptic curves. That book restored my faith in math and I decided to become a number theorist. I went back to Berkeley and enrolled in Hendrik Lenstra’s Class Field Theory class, which was the second semester of a grad number theory class, and in Ken Ribet’s second semester grad algebra class. Since I’d missed the first semester of each, I pretty much got my ass kicked. I lived and breathed algebra and p-adics and local-glocal principles for the next three months. It was pretty awesome and incredibly challenging. The moment of my biggest frustration happened when we learned about tensor products over arbitrary rings with zero divisors.
I kept trying to understand these rings, and in particular the elements of these rings. I wasn’t asking much: I just wanted to figure out the most basic properties of tensor products. And it seemed like a moral issue. I felt strongly that if I really really wanted to feel like I understand this ring, which is after all a set, then at least I should be able to tell you, with moral authority, whether an element is zero or not. For fuck’s sake!
I couldn’t do it. In fact all the proofs I came up with involved the universal property of tensor products, never the elements themselves. It was incredibly unsatisfying, it was like I could only describe the outside of an alien world instead of getting to know its inhabitants.
After a few months, though, I realized something. I hadn’t gotten any better at understanding tensor products, but I was getting used to not understanding them. It was pretty amazing. I no longer felt anguished when tensor products came up; I was instead almost amused by their cunning ways.
Every now and then something like that happens in my life. Something that I start out desperately wanting to understand, to analyze, and to own. It’s practically a moral imperative! And I consider myself a person who gets stuff done! How can I let this lie unexplained?
Then after a few days it turns out, no, I still don’t understand it, but it actually makes me like it more. In fact now I look forward to things like that; little puzzles of human existence, where, for perhaps small examples (like when you work over a field) you can understand the issue entirely, but overall you realize it’s harder than that, and moreover you shouldn’t kill yourself over it. You can remain content maybe knowing how to describe some of its properties, while allowing it to maintain its secrets, because life is actually more interesting that way.
Follow up on: math contests kind of suck
I have been really impressed with the comments and thoughts of my first post about how I think math contests kind of suck. Thinking about it some more, I’d like to make two corrections to my original thoughts as well as a clarification.
The first correction is that it’s the MAA, not the NSF, that mysteriously only seems to support contests, or at least for the most part supports contests and not enrichment. The NSF, as has been pointed out in the comments, mysteriously supports primarily college-level math enrichment (through REUs) instead of high-school level stuff, but that’s a different mystery.
The second correction is that, instead of saying about contests “most people don’t get close to winning, and in particular give those people the impression that because they lost a contest they don’t “have it” when it comes to math,” I should have said, “most people don’t get close to winning, and for the subset of people who care about winning, in gives them the impression that because they lost a contest they don’t “have it” when it comes to math.” In other words, I’m not discussing the subpopulation who don’t care if they win. (To those people I’d say: you are rare and you are lucky.)
Except I am discussing them, and this is where the clarification comes in. My point about girls is this: girls are more likely to be in the subpopulation of kids who care, and therefore more likely to be disappointed in themselves. In fact I would add that girls are more likely to underestimate their performance, even if it was great, and moreover they are more likely to do badly in the presence of the negative stereotype that tells them girls aren’t good at math.
These are all statistical statements. In particular, an argument that won’t convince me I’m wrong is something like: I’m a guy and I didn’t care if I won or lost and I loved (or hated) contests. That just means you are not in the population of kids I am talking about. Another argument that won’t convince me I’m wrong goes like this: I’m a guy and I cared and I did awesome. In fact won’t even really change my mind if a woman writes and said she cared and did badly (or well) but loved (or hated) them anyway. Because what I’m talking about is essentially a statistical statement, and idiosyncratic examples probably won’t change my mind.
In fact I’d argue that it’s very very difficult to prove or disprove my claim, at least with comments, because there’s a strong survivorship bias in place, namely that people who got scared away from math won’t be reading my blog at all. In order to give evidence to support or discredit my claim we would have to look at examples of populations which were or weren’t exposed to enrichment, versus contests, versus perhaps something else (like no math outside their classroom) and see who became mathematicians. Oh wait here’s something.
By the way, it’s important to make clear that I’m not suggesting stripping contest math out of the picture altogether. I think there’s a case to be made that they’re better than nothing. But we don’t need to settle for nothing! However, I think we should be creating alternatives that are not competitive or timed. I was very happy to hear about the month-long test and I also heard about a team 24-hour test (does anyone know the name of that and if it still exists?)
Two last tangentially related issues:
- I would argue that any time a bunch of nerd kids get together they have a blast. So we definitely should be getting math nerd kids together. We just shouldn’t be having them compete against each other. I claim they’d have an even better time that way.
- Also, has anyone else noticed the prevalence of girls who are good at competitions and very involved fathers? It’s really interesting. My dad is a mathematician too, and many (but not all) of the women mathematicians I know have heavily involved and/or mathematical dads.
_Love_ you people
I’d like to make a shout-out today to a bunch of people.
First, my readers, who are gorgeous, sexy, and brilliant people. Thanks for reading.
Second, my commenters, who are thoughtful, gorgeous, sexy, and brilliant people, especially when they back me the fuck up. Go, you people! I’m nearly at a 3-to-1 comment-to-post ratio, which makes me feel pretty awesome. I’ve learned a whole bunch and met some pretty amazing people recently through their comments. I’ve actually been please to discover that I really enjoy being disagreed with and argued with- it makes it so much faster to learn. So keep the (constructive) criticisms coming!
Next, I’d like to throw out a bunch of links to blogs which I really like. Actually I recently created a blog roll so there’s that. But in particular I’d like you to check out some of my favorites:
- My good friend Jordan Ellenberg has a wonderful blog entitled “Quomodocumque“, whatever that means (oh wait! it means “whatever” in Latin; I wonder if that is meant sarcastically), in which he muses about math (Rubik’s cubes included!) and… whatever.
- Just in case you’ve somehow missed the whole String Theory Debate, please inform yourself at Peter Woit’s blog called “Not Even Wrong”. When I taught at the Columbia math department, as a Barnard math professor, I used to eat lunch with Peter every day at the Mill Korean on Broadway and 112th. What was adorable about Peter is that every frigging day, and I mean every day, he’d read the menu, look a bit confused, and then order beef fried rice. And then he’d give me his Chiclets at the end of the meal. I’m not sure why this story would recommend his blog to you but it certainly endears him to me. His blog rocks btw.
- Andrew Gelman’s blog titled Statistical Modeling, Causal Inference, and Social Science has a pretty awesome post today about economists (who doesn’t love hating on economists?!).
- I just found this blog, Quantivity, which contains impressively informed finance stuff, and is more technical than what I’m going for.
- Check out a new game theory blog, called Nuclear Chicken Collusion, which comes up with very readable, fun versions of fancy ideas. Their most recent post talks about the probability of there being a god and what it means for you.
High frequency trading: Update
I’d like to make an update to my earlier rant about high frequency trading. I got an awesome comment from someone in finance that explains that my main point is invalid, namely:
…the statement that high frequency traders tend to back away when the market gets volatile may be true, but it is demonstrably true that other, non-electronic, non-high-frequency, market makers do and have done exactly the same thing historically (numerous examples included 1987, 1998, various times in the mortgage crisis, and just the other morning in Italian government bonds when they traded 3 points wide for I believe over an hour). While there is an obligation to make markets, in general one is not obliged to make markets at any particular width; and if there were such an obligation, the economics of being a marketmaker would be really terrible, because you would be saying that at certain junctures you are obliged to be picked off (typically exactly when that has the greatest chance of bankrupting your enterprise).
My conclusion is that it’s not a clear but case that high-frequency traders actually increase the risk.
By the way, just in case it’s not clear: one of the main reasons I am blogging in the first place is so that people will set me straight if I’m wrong about the facts. So please do comment if you think I’m getting things wrong.
High frequency trading
This morning there was an article in the New York Times describing high frequency traders- what they do and how they want people to like them. I’m of the mind that there’s not much to like.
NOTE: Please see update!
High frequency traders are basic, old-fashioned opportunists. They buy somewhere and try to sell somewhere else cheaper. They have expensive technology and colocate next to exchanges to deal with speed-of-light issues to shave off tiny fractions of seconds for their trades. They notice a currency change in Brazil and trade on it in the US before anyone else notices. That kind of thing.
They will tell you that they are useful to the market, because they have set the bid-ask spread smaller than it used to be. Back in the day, there were official “market makers” who would maintain a book of certain instruments, and would be the go-to person for anyone who wanted to buy or sell. In return for the service they would charge a fee, which would be this so-called spread. Moreover, they were required to offer to buy and to sell in all kinds of trading environments (the spreads could get pretty wide of course).
It’s true that those spreads have gotten smaller since high-frequency traders have come to dominate. They have substantially replaced the old-school market makers and claim to be doing a better job. However, it’s also true that high-frequency traders aren’t required to be there. So when the going gets tough they completely vanish. This happens in moments of panic, and it can easily be true that their ability to vanish at will can also create more panics more often (I’d love some evidence to support or deny this theory), since from their perspective, at the first sign of weirdness, they may as well pull out until the dust settles.
The analogy I like to come up with is a little story about chores. Suppose you have someone who comes and helps you with your cleaning, mostly dishes, every day, for a small fee. Since you have kids and a job, the small fee seems to be worth it. After a while someone else comes along and offers to do your dishes every day! for free!! What a deal! You can’t resist. However, it turns out that, if the kitchen actually gets really dirty and needs to be mopped up or seriously cleaned, the free-dishes guy is nowhere to be found and you’re on your own, just when all the kids are sick and there’s a product release at work. Maybe not such a great deal after all.
Math contests kind of suck
I’m going to annoy quite a few people with this post, but I’ve been thinking about this for a while and it comes down to this: I think math contests for kids kind of suck.
Here’s the short version of my argument.
Math contests discourage most people who take them, because most people don’t get close to winning, and in particular give those people the impression that because they lost a contest they don’t “have it” when it comes to math. At the same time, although they are encouraging for a few people, it’s not clear to me that the kind of encouragement they give those kids is healthy. Finally, they are bad for women.
Now I will argue this more thoroughly.
The way math contests are set up nowadays, they start in middle school, at the school level, and if a student does well at a given test they move on to a larger stage, perhaps at the state level, and they typically culminate in a national test, or sometimes even an international test (in the case of the IMO).
This system sets up nearly all the participating students for a feeling afterwards of having not been good enough. It encourages competition over collaboration, which is a huge problem in my opinion, but even worse, it tends to make young people feel like they aren’t smart enough to be mathematicians. It is in fact well-documented that people seem to think that one is either born good at math or not, in spite of the fact that there’s ample evidence that practicing math competition-type problems makes you good at them (why else would Stuyvesant kids consistently beat other kids? Is it really possible that smart people somehow know to be born in New York?). The bottomline is that these extremely young, impressionable kids get early impressions that the contests are measuring their genetic abilities, and that they aren’t cutting it.
When I was in middle school, there were no math contests. I was lucky enough to have a great teacher in 7th grade, who let us nerds debate amongst ourselves for an entire class whether 0.999999… is equal to 1 or not. He put himself in the position of a mediator. It was a great moment for me, and made me realize how much creativity and originality could be involved in the process of making and understanding math.
When I got to high school, I was on the math team, and although I wasn’t bad, I also wasn’t good – and I felt bad about that, consistently. In fact there were definitely moments when I doubted my chances at becoming a mathematician. It is really a testament to my internal love for mathematics, combined with finding this math camp that I’m teaching at now, that motivated me to become a mathematician. If I had not had that 7th grade teacher, and if I had had earlier experiences being so-so at math contests, it’s possible I would have been turned off of math altogether.
Perhaps you are thinking, well of course there’s a selection process for math contests, because they select for people who are good at math! I discussed this with another mathematician today and he refined that argument as follows: some people are good at understanding concepts but can’t work out the details, and some people are good at working out details by rote but don’t understand the concepts- you can’t really be a good mathematician without both, and perhaps the contests select for the details people, but after all you need that aspect.
But I would go further: although I agree you can’t be a good mathematician without both, I don’t think the contests select for the details people. They actually select for people who do or don’t understand the concepts (probably do for the higher level tests) but who in any case are extremely fast at the details. I have never been particularly fast at working out the details of something from the conceptual understanding (for example, it takes me a long time to solve a 7x7x7 Rubik’s cube) but it turns out the Rubik’s cube doesn’t mind. And in fact mathematics in real life isn’t a timed tests- the idea that you need to be original and creative really quickly is just a silly, arbitrary way to select for talent.
I guess if you could have math competitions that aren’t timed then I might start being okay with them. Especially if they were collaborative.
The reason I claim math contests are bad for math is that women are particularly susceptible to feelings that they aren’t good enough or talented enough to do things, and of course they are susceptible to negative girls-in-math stereotypes to begin with. It’s not really a mystery to me, considering this, that fewer girls than boys win these contests – they don’t practice them as much, partly because they aren’t expected by others, nor do they expect themselves, to be good at them. It’s even possible that boys brains develop differently which makes them faster at certain things earlier- I don’t know and I don’t care, because I don’t think that the speed issue is correlated to later deep thought or mathematical creativity.
Finally, I don’t necessarily think that winning math contests is even all that good for the winners either. In spite of the fact that many of my favorite people are mathematicians who were excellent at contests, I also know quite a few people who were absolutely dominant in math contests in their youth who really seemed to suffer later on from that, especially in grad school. From my armchair psychologist’s perspective, I think it’s because they got addicted to the rush of doing math really fast and really well, and winning all these prizes, and when they get to grad school and realize how hard math really is, they can’t stand it.
One related complaint to this rant: it seems like there is way money out there for math contests for young people than there is for math enrichment programs like the program I’m working at now (I’m looking at you, NSF). Why is this? Probably a combination of the fact that’s it’s easier to organize, it seems quantitatively measurably “successful” because there’s a winner at the end, and maybe even because it makes the United States look good compared to other countries to have a winning IMO team- in other words, spin. Booo! How about throwing a little bit of money towards programs that sponsor a sense of collaborative, exploratory mathematics and which encourages women?
Before I get people too riled up, I will say this in favor of math contests: they do tend to expose kids to different kinds of math than is normally offered in their classrooms, which can be really great, and expansive, for kids that have drab math curriculums with drab teachers. Lots of kids first find out there’s math beyond quadratic equations by going to a math contest. That’s cool, but can’t we do it in a better way?
What is an earnings surprise?
One of my goals for this blog is to provide a minimally watered-down resource for technical but common financial terms. It annoys me when I see technical jargon thrown around in articles without any references.
My audience for a post like this is someone who is somewhat mathematically trained, but not necessarily mathematically sophisticated, and certainly not knowledgeable about finance. I already wrote a similar post about what it means for a statistic to be seasonally adjusted here.
By way of very basic background, publicly traded companies (i.e. companies you can buy stock on) announce their earnings once a quarter. They each have a different schedule for this, and their stock price often has drastic movements after the announcement, depending on if it’s good news or bad news. They usually make their announcement before or after trading hours so that it’s more difficult for news to leak and affect the price in weird ways minutes before and after the announcement, but even so most insider trading is centered around knowing and trading on earnings announcements before the official announcement. (Don’t do this. It’s really easy to trace. There are plenty of other ways to illegally make money on Wall Street that are harder to trace.)
In fact, there’s so much money at stake that there’s a whole squad of “analysts” whose job it is to anticipate earnings announcements. They are supposed to learn lots of qualitative information about the industry and the company and how it’s managed etc. Even so most analysts are pretty bad at forecasting earnings. For that reason, instead of listening to a specific analyst, people sometimes take an average of a bunch of analysts’ opinions in an effort to harness the wisdom of crowds. Unfortunately the opinions of analysts are probably not independent, so it’s not clear how much averaging is really going on.
The bottomline of the above discussion is that the concept of an earnings surprise is really only borderline technical, because it’s possible to define it in a super naive, model-free way, namely as the difference between the “consensus among experts” and the actual earnings announcement. However, there’s also a way to quantitatively model it, and the model will probably be as good or better than most analysts’ predictions. I will discuss this model now.
[As an aside, if this model works as well or better as most analysts’ opinions, why don’t analysts just use this model? One possible answer is that, as an analyst, you only get big payoffs if you make a big, unexpected prediction which turns out to be true; you don’t get much credit for being pretty close to right most of the time. In other words you have an incentive to make brash forecasts. One example of this is Meredith Whitney, who got famous for saying in October 2007 that Citigroup would get hosed. Of course it could also be that she’s really pretty good at learning about companies.]
An earnings surprise is the difference between the actual earnings, known on day t, and a forecast of the earnings, known on day t-1. So how do we forecast earnings? A simple and reasonable way to start is to use an autoregressive model, which is a fancy way of saying do a regression to tell you how past earnings announcements can be used as signals to predict future earnings announcements. For example, at first blush we may use last earning’s announcement as a best guess of this coming one. But then we may realize that companies tend to drift in the same direction for some number of quarters (we would find this kind of thing out by pooling data over lots of companies over lots of time), so we would actually care not just about what the last earnings announcement was but also the previous one or two or three. [By the way, this is essentially the same first step I want to use in the diabetes glucose level model, when I use past log levels to predict future log levels.]
The difference between two quarters ago and last quarter gives you a sense of the derivative of the earnings curve, and if you take an alternating sum over the past three you get a sense of the curvature or acceleration of the earnings curve.
It’s even possible you’d want to use more than three past data points, but in that case, since the number of coefficients you are regressing is getting big, you’d probably want to place a strong prior on those coefficients in order to reduce the degrees of freedom; otherwise we would be be fitting the coefficients to the data too much and we’d expect it to lose predictive power. I will devote another post to describing how to put a prior on this kind of thing.
Once we have as good a forecast of the earnings knowing past earnings as we can get, we can try adding macroeconomic or industry-specific signals to the model and see if we get better forecasts – such signals would bring up or bring down the earnings for the whole industry. For example, there may be some manufacturing index we could use as a proxy to the economic environment, or we could use the NASDAQ index for the tech environment.
Since there is never enough data for this kind of model, we would pool all the data we had, for all the quarters and all the companies, and run a causal regression to estimate our coefficients. Then we would calculate a earnings forecast for a specific company by plugging in the past few quarterly results of earnings for that company.
I love math nerd kids
So I’m almost at the end of my second week here at HCSSiM, and the pathetic truth is I already miss these kids. They are so freaking adorable, and of course I miss my own kids so much, that the emotional turmoil of the situation combines to create the reality that I am actually nostalgic for each moment with them before that moment happens. Pathetic!! It’s something about identifying with their nerdy selves finding each other and figuring out that they have a community of nerds that accepts them… whatever, now I’m tearing up. Pitiful.
As for what I’m teaching them, the first week it was number theory, number theory, and more number theory. Can you tell I like number theory? At the end of the first week I looked around and I saw a bunch of earnest faces wondering if I was going to prove yet another thing about relatively prime numbers and solving polynomials modulo n and I thought to myself, these kids are going to think there’s no other examples of proof by induction! How shameless! So this week I talked about graph theory. Next week: I’m going back to number theory. Yes I know, but it’s AWESOME. I’m going to talk about Farey numbers and continued fractions and maybe the Pell equation. They will know all about the golden ratio and maybe we’ll even measure each other’s faces. I can’t wait.
Last night we went to the director’s house and ate corn on the cob (we made the kids husk the corn- did you know teenagers today have mostly never husked corn before in their lives?) and pizza and we played “Mafia,” which was hilarious and sweetly innocent.
This weekend is “Yellow Pig day” at the camp program, which is a day where we celebrate yellow pigs and the number 17. We take this incredibly seriously, including making t-shirts with yellow pigs, having a 4-hour (feels like 17) talk about interesting properties of the number 17, and finally, singing yellow pig carols and eating a yellow pig cake at the end. It’s a wild time for math nerd kids. They will remember this and each other for the rest of their lives. Woohoo!!
Did I mention that I was a minor celebrity last night because I solved a 7x7x7 Rubik’s cube in front of them? This is status at its best. I even showed them my trick, and one of the kids came back to me at breakfast this morning proudly displaying his cube with a 3-cycle. Update: he has solved his entire cube using 3-cycles. Now he’s moving on to a dodecahedron puzzle.
LOVE these kids.
Motivating transparency: what we could do about too big to fail
In this previous post, I promised a follow-up post about how we can devise a system in which large banks are actually motivated to be transparent about what is inside their portfolios. We have also discussed why the current system doesn’t work this way and that the banks have every reason to obfuscate their holdings, and in fact make loads of money by doing so. This makes appropriate external risk management difficult or impossible.
I have actually thought about this problem quite a bit since that post, and I (and a friend in finance) have come up with two quasi ideas, which hopefully together add up to be as good as one complete idea. The first comes under the category, “add stuff to what we have now”, whereas the second comes under the category, “initiate a new system which will over time replace the one we have”. Both of these systems rely on a good understanding of the underlying problem of the current system, namely the concept of “too big to fail.”
If you’re reading this and you have comments about either idea, please do comment. We are hoping for lots of feedback so we can improve the details.
Too Big to Fail
Recall that the way it works when hedge funds want to trade stuff: they have prime brokers, i.e. banks like Deutche and Goldman Sachs and Bank of America (see list of the biggies here). When the brokers don’t like the trade, or think it’s not sufficiently liquid, or think that the hedge fund may fail for any reason, they demand that the hedge funds post margin. That way if the bet goes sour there is a limited amount of risk that the brokerage could lose. As soon as a position starts to look riskier, which could happen because of recent volatility or lack of price transparency, the amount of margin that needs to be posted normally increases, putting pressure on the hedge fund to liquidate suspicious assets.
In other words, there is a real cost to hedge funds for trading in illiquid or complex securities, namely their cash is tied up in bank accounts with their brokers. This is not to say that they don’t take large risks, but there is a limit of how much risk they can take because of the “posting margin” system.
By contrast, big banks don’t post margins. They trade with hedge funds, of course, since hedge funds trade with them, but it’s the banks who demand margin, not the hedge funds (actually there’s a historical exception to this rule, namely Paulson’s hedge fund demanded margin from its brokers during the 2008 financial crisis).
This asymmetrical situation begs the question, why do hedge funds have to post margin but the big banks don’t? Two reasons: first, banks have access to Federal funds, and second, they are deemed to big to fail. [I admit I don’t know exactly why the access to Federal funds is granted to banks, nor do I understand exactly what the effect is. But I do think it’s a pertinent fact which is why I’ve included it here. Please do comment if you know more! Also note it may be a red herring since Goldman Sachs didn’t have access to Fed funds until the crisis.]
This “too big to fail” guarantee is a huge problem, which has only gotten more precise (since we’ve seen the bailout and now everyone knows the guarantee is there) and larger (because, in the end, the net result of all the 2008 crisis is fewer, larger banks) and about which absolutely nothing seems to be getting done. The disingenuous whining of greedy bankers like Jamie Dimon serves as a smokescreen for the fact that, if anything, banks are presumably waltzing into the next phase of their life with more power and fewer checks than they could have dreamed about in August 2008.
Idea #1: make banks post margins
“Too big to fail” means that it is assumed that the bank will be rescued by the government if it makes huge bad bets that threaten to bring them down. Two of the reasons the government can be counted on to bail out banks are first, that the deposits of normal Americans are at risk, which is discussed below in Idea #2, and second, that a bankruptcy would be catastrophically complicated, which we discuss here. One result of the guarantee is that hedge funds don’t bother demanding margins, which makes the banks riskier, which makes the “too big to fail” guarantee even worse.
What if the lawmakers enforced a symmetry of posted margins? We have to be precise, because actually there are different kinds of margins that traders are forced to post.
First, there’s the margin you post in the sense of “keep $x as a deposit for the position”, the thinking being that even if things go south, the broker could liquidate at something better than $x below current marked price in a hurry. This is the initial margin.
Next there’s the “your position lost $10 today, so you need to give me $10” (this is called variation margin). This is the most likely way to get margin called.
The idea here is to require brokers to post initial margin just as hedge funds do now. More precisely, the idea would be to let the two parties negotiate on the initial margin, which could be more for hedge funds since they may well be riskier, but then once it’s set to have complete symmetry of variation margin.
Occasionally, in risky environments, the initial margin of $x is increased, which causes a lot of unraveling, and possibly cascading waves of problems which set off a panic. We’d need to have rules about how often this can happen to avoid the “symmetric of variation margin” rule from being bypassed with lots of initial margin modifications. The symmetry aspect should keep the margin contracts from allowing this to happen too often.
The overall goal would be to devise a system that would:
- Encourage the posting and calling of (variation) margins,
- Encourage sufficient sizing of initial margin,
- Encourage early calls and liquidating if there is doubt that a variation margin call could be met, and
- Simplify the bankruptcy rules on ownership of assets, especially for illiquid or complex assets.
The initial margin can be thought of as the dollar amount a price could move by between a margin call and it being paid. It should not be thought of as an asset for either party (and therefore the accounting of the various margins should be carefully considered, but I’m no accounting expert), and certainly should not be able to be recycled to buy more stuff, i.e. add to ones leverage, or offered towards capital requirements. Moreover, if it is indeed symmetric, that would mean if a bank claims to only need to post n dollars in initial margin, then the hedge fund can turn around and use that same number for that same trade, at least up to an understood discount.
As for bankruptcy, we should start with the following. When a margin call is made by one side and it isn’t met, the person making the call:
- keeps ALL the margin,
- gets the security, and
- is a (super-senior level of seniority) claimaint to the variation margin they posted with the counterparty.
Moreover, rules 1 and 2 above do not go into a bankruptcy filing if one occurs (in particular, if the security is a swap, it’s just torn up). This is a key point since that means the bankruptcy is simplified and at the same time the security is back in liquid hands. All over, this setup, or one like it, encourage hedge funds to margin call frequently (banks already do that), which is a good thing, and as described above is a further incentive to invest in liquid, non-complex securities, which in the end creates transparency.
The above idea doesn’t deal directly with desired property 2, and may well cause margins to be lower. One possibility to encourage margins to be of sufficient size would be to allow either party to “put” the security in question on to the other party at a cost of giving up the initial margin posted.
Idea #2: grow a separate system of utility deposit banks
Besides incredibly complicated bankruptcy filings with infinitely many counterparties, one of the major reasons those banks really are too big to fail is that they hold deposits, and the government doesn’t want people to worry that their life savings are at risk, causing a run on the banks and chaos. Another way to get around this, at least eventually, is to create new “utility banks” at the state level which do not trade securities (beyond very basic one like interest rate swaps and treasuries), don’t take large risks, and have FDIC guarantees on savings.
In order to get consumers to switch to banks like this, the government should intentionally create incentives for people to transfer their deposits from “too big to fail” banks to these utility banks. A list of incentives could start with reasonable, transparent fees, and the eventual loss of FDIC insurance guarantee at non-utility banks. Then people who want to stay with risk-taking banks can do so knowing that, as long as bankruptcy laws eventually get simplified, the “too big to fail” guaranteed will in fact be gone.
Moreover, another layer of separation between depositors and utility banks should be the requirement that, even with the restricted kinds of trades allowed for utility banks, they should be done in separate corporate entities (since banks are always a mishmash of many companies anyway).
This idea is not new, and can be seen for example in this article. In fact it is incredibly obvious: admit that what we have now is a guarantee for a get-out-of-jail card for greedy bankers, and transfer that guarantee to a banking system that we’ve created to be boring, along the lines of the post office.
Bank accounting link
I wanted to share this link with you; it is both interesting and relevant to another post I’m working on (a follow up to this one) that will describe two ideas I’m contemplating regarding how to systematically change the way big banks are motivated to behave in the presence of the “too big to fail” guarantee.
Its goal is to describe how banks will behave in a given situation with a mortgage, but the thought process generalizes quite well to how banks behave in general, and in particular how accounting considerations trump utility to the depositors and even the long-term shareholders. It also explains, to those of us who were wondering, why Obama’s mortgage modification plan was never going to work.
Short Post!
I’ve been told my posts are intimidatingly long, what with the twitter generation’s sound byte attention span. Normally I’d say, screw that! It’s because my ideas are so freaking nuanced they can’t be condensed to under a paragraph without losing their essence!
But today I acquiesce; here’s a short post containing at most one idea.
Namely, I’ve been getting pretty strong reactions online and offline regarding my post about whether an academic math job is a crappy job. I just want to set the record straight: I’m not even saying it’s a crappy job, I’m simply talking about someone else’s essay which describes it that way. But moreover, even if I were saying that, I would only be saying it’s crappy (which I’m not) compared to other jobs that very very smart mathy people could get. Obviously in the grand scheme of things it’s a very good job- safe working conditions, regular hours, well-respected, etc., and many people in this world have far crappier jobs and would love a job with those conditions. But relative to other jobs that math people could be getting, it may not be the best.
Many professors of math (you know who you are) have this weird narrow world view, that they feed their students, which goes something like, “if you want to be a success, you should be exactly like me (which is to say, an academic)”. So anyone who gets educated in a math department is apt to run into all these people who define success as getting tenure in an academic math department, and they just don’t know about or consider other kinds of gigs. It would be nice if there was a way to get a more balanced view of the pros and cons of all of the options.
Weekend Reading
FogOfWar and I have compiled a short list of weekend reading for you that you may enjoy:
- What’s the right way to think about China’s economy?
- Is Japan’s “lost decades” a media myth?
- Can I hear a FUCK YEAH for Elizabeth Warren? I feel a follow-up post coming on how much she rocks.
- Get ready to be depressed by how few natural resources there really are.
- This essay really pins Robert Rubin to the wall in a totally awesome way. I will add more in another post.
- The Republicans are holding the entire nation for ransom over the possibility of default. Is it all political posturing? Or is it for the sake of the insanely shitty idea of a tax repatriation holiday? Here’s another article about this crappy idea; when Bloomberg makes you out as a selfish bastard then you know you’re a truly selfish bastard. I’m convinced that the politicians (and union leaders) arguing for this are just counting on the average person not understanding the actual issues well enough to know how evil it is (and how much kickback they must be getting). Another example of asymmetric information that really gets my goat.
- I think it’s fair to say we all need a little more of this in our lives.
Adding-up rules and Hockey Sticks
So I’m at the math program HCSSiM, teaching for three weeks in a “workshop,” which means I am responsible for teaching 12 teenagers the basic language and techniques of math- things like induction, proof by contradiction, the pigeon-hole principle, and how to correctly use phrases like “without loss of generality we can assume…” and “the following is a well-defined function…”, as well as familiarity with basic group theory, graph theory, number theory, cardinality, and fun things like Pascal’s triangle.
It’s really beautiful, classical math, and the students are eager and fantastically bright. They are my temporary brood, and I adore them and feed them chocolate at evening problem sets.
It’s also a fine opportunity to do some silly math doodling just for fun, the only rules being you can’t use a computer to look anything up until you’re done, and you can only use the stuff your kids at the program already learned. I’m going to describe what my mom and I, and then a junior (Amber Verser) and senior (Benji Fisher) staff member at the math program, figured out in the last couple of days. It’s super cool and turns out is at least 400 years old.
One of the most common examples of proof by induction is the formula for the sum of the counting numbers up to n:
1 + 2 + 3 + … + n = n(n+1)/2
And then, once you figure that out, you move on to the next case:
1^2 + 2^2 + 3^2 + … + n^2 = n(n+1)(2n+1)/6.
If you’re really into it, you can put the next case on the problem set:
1^3 + 2^3 + 3^3 + … + n^3 = (n(n+1)/2)^2.
Two obvious patterns are emerging when you add up successive dth powers up to n.
- It’s a polynomial of degree d+1, and
- The roots of the polynomial are symmetric about -1/2 (mom noticed this!).
How do you prove those two facts?
If you think it’s totally easy, stop reading now and give it a shot. There are about a million things you could try and none of them seem to work. I’ll wait.
…okay, let’s say you gave up, or already know, or don’t care. (Why are you reading still if you don’t care?!)
First let’s generalize the question to, if we add up values of some degree d polynomial for values i=0, 1, 2, …, n, then we want to prove the result is a degree d+1 polynomial in n. That this is equivalent to the first statement above is pretty easy to see by just re-arranging the terms of the double sum over i and over the terms of the polynomial in question. But it still seems like you need to know at least the answer to the question of what is a formula for 0^d + 1^d + 2^d + … + n^d, which is of course where we started.
But that’s where Pascal’s triangle comes in! We can generate Pascal’s triangle by the familiar “add up two consecutive numbers and put the answer below,” but we also can think of the element on the nth row and kth (tilted) column of Pascal’s triangle as the number of ways to choose k things from n things, which is referred to as “n choose k”, and where we start both the row and column counts at 0, not at 1. That definition satisfies the addition law because, if we have n things, we can label one as “special,” and then the choice of size k subsets of the n things divide into two categories: the size k subsets that contain the special guy and the ones that don’t. If they do, then we need only find k-1 other things in the remaining n-1 size set, and the number of ways to do that is given by the element on row n-1 and column k-1. If they don’t contain the special guy, we need to find k things in the remaining n-1 size set, and the number of ways to do that is given by the element on row n-1 and column k.
On the other hand, we also know a formula for the numbers in Pascal’s triangle: the guy on the nth row and kth column is given by a degree k polynomial in n, namely n!/k!(n-k)!. (This is because we can label all of the guys 1 through n, and just take the first k guys, and there are n! ways to label n things, but we don’t actually care about the order among the first k or among the last n-k.)
For example, in the second column, where we are looking at “n choose 2” for various n, we have the equation n(n-1)/2. This is a LOT like n^2 but has extra terms sticking on the end of lower order. When you’re looking at the third column, you’re working with the formula n(n-1)(n-2)/6, which is like the basic polynomial n^3 with extra stuff. In other words, the formula for “n choose k” is a degree k polynomial in n which we can think of as being a stand-in for n^k. Awesome.
The last ingredient is something called the “Hockey Stick Theorem,” which you gotta love just because of the name. It states that if we add up the values along a column, from the top of the rows down to the nth row, then the sum will be the number just below and to the right, and the entire picture will resemble a hockey stick.
The proof of the Hockey Stick Theorem is trivial- the answer is of course the sum of the two above it, and we have one in the sum already, but the other isn’t… but that other is the sum of the two above it, one of which is again already in the sum but the other isn’t… and you keep going until you get to the top edge of Pascal’s triangle, where the missing number is just 0.
Why does the Hockey Stick Theorem give us what we want? Going back to our generalized statement, we want to show the sum of values on a (any) degree d polynomial for i = 0, 1, 2, …, n is a degree d+1 polynomial. Well, use the dth column and make a hockey stick from the top to row n. Then the sum is on the (n+1)st row, in the (d+1)st column, which we know is a degree d+1 polynomial in n. Woohoo!
One way of looking at this is that we were actually asking the wrong question: instead of asking what the sum of the dth powers is we should have perhaps been asking what the sum of the dth column of Pascal’s triangle is; in other words, there is a better basis for the vector space of polynomials than x^d, namely “x choose d”. In fact, if there were an agreement in the world that actually the “x choose d” polynomials should be the standard basis, (by the way, these basis polynomials would be called “Pascalinomials”!) then the hockey stick theorem would be the last word on how do those things add up. As it stands, to figure out the actual formula for the sum of the dth powers for i=0, 1, 2, …, n, we need to write the first row of the change-of-basis matrix from one basis to the other.
As for the second question, we simply need to extend the definition of the sum F(n) of dth powers from 0 to n to the case where n is negative, by iteratively using the relation:
F(n) = F(n-1) + n^d, or
F(n-1) = F(n) – n^d.
Then we have F(0) = 0, F(-1) = 0, F(-2) = (-1)^(d+1), F(-3) = (-1)^(d+1) – (-2)^d = (-1)^(d+1)(1^d + 2^d) …, and it’s easy to prove that, for any n,
F(n) = (-1)^(d+1)F(-n-1).
This means that if we have a root at -1/2 + a, we also have a root at -1/2 – a = -(-1/2 +a) -1.
Does an academic job in math really suck?
My cousin recently sent me a link to this article about women in science. Actually it’s really about jobs in science, and how much they suck, and how women are too practical to want them. It’s definitely interesting- and pretty widely read, as well, although I’d never seen it. It makes a few excellent points, especially about the crappy amount of money and feedback one gets as an academic, two issues which were definitely part of my personal decision to leave my academic career.
I think his overall argument, though, is simultaneously too practical-minded and not practical-minded enough. And although his essay is about science, I’ll concentrate on how it relates to math.
It’s too practical in that it doesn’t really understand the attraction- the nearly carnal desire- people have to math. It essentially assumes that after some amount of time, maybe 20 years, people will lose interest in their subject, perhaps because they are getting poorly paid.
Is this really true? Maybe for some people this is true, but the nerds I know are nerds for life – they don’t wake up one day thinking math isn’t cool after all. And from what I know about people, they acclimate pretty thoroughly to their standard of living by the time they are 40.
It’s not practical enough, though, because it doesn’t get at one of the most important reasons women leave math, namely because they are married and maybe have kids and they simply can’t be that person who moves across the country for a visiting semester in Berkeley because their husband has a job already and it’s not in Berkeley.
[As a side note, if someone wants to actually encourage women in math, and they are loaded, I would encourage them to set up a fund that would pay costs for quality childcare and airplane tickets for kids when woman go to math conferences. You don’t even need to help organize the babysitting, just pay for it. It would help out a lot of young women and free them up to go to way more conferences, evening the playing field with young men.]
In fact there are plenty of women who are super nerdy and would love to go do math across the country, but when it comes to choosing between that lifestyle and having a family life, they will choose the family life more times than not. Really it’s the “nomadic monk” system itself that is crappy for women at that moment, even if they are theoretically happy to be a poor nerd for the rest of their lives.
I have another complaint (which will make it sound like I don’t like the essay but actually I do). It says that people in science don’t have the ability to switch careers, essentially because they don’t have the money. But that’s really not true, at least in math, and I’m a testament to the possibility of switching careers. One thing a nerd is really good at is learning new things quickly.
I also thought that there was something missing about the alternative jobs he mentions, in industry or otherwise, which is that, yes you do get paid better outside of academics, but on the other hand pretty much any nonacademic job requires you to have a boss, which can be really fine or really horrible, and restricts your vacation time to 3 or 4 weeks. By contrast the quality of life as an academic is, if not luxurious, at least much more under one’s control.
Glucose Prediction Model: absorption curves and dirty data
In this post I started visualizing some blood glucose data using python, and in this post my friend Daniel Krasner kindly rewrote my initial plots in R.
I am attempting to show how to follow the modeling techniques I discussed here in order to try to predict blood glucose levels. Although I listed a bunch of steps, I’m not going to be following them in exactly the order I wrote there, even though I tried to make them in more or less the order we should at least consider them.
For example, it says first to clean the data. However, until you decide a bit about what your model will be attempting to do, you don’t even know what dirty data really means or how to clean it. On the other hand, you don’t want to wait too long to figure something out about cleaning data. It’s kind of a craft rather than a science. I’m hoping that by explaining the steps the craft will become apparent. I’ll talk more about cleaning the data below.
Next, I suggested you choose in-sample and out-of-sample data sets. In this case I will use all of my data for my in-sample data since I happen to know it’s from last year (actually last spring) so I can always ask my friend to send me more recent data when my model is ready for testing. In general it’s a good idea to use at most two thirds of your data as in-sample; otherwise your out-of-sample test is not sufficiently meaningful (assuming you don’t have that much data, which always seems to be the case).
Next, I want to choose my predictive variables. First, we should try to see how much mileage we can get out of predicting future blood glucose levels with past glucose levels. Keeping in mind that the previous post had us using log levels instead of actual glucose levels, since then the distribution of levels is more normal, we will actually be trying to predict log glucose levels (log levels) knowing past log glucose levels.
One good stare at the data will tell us there’s probably more than one past data point that will be needed, since we see that there is pretty consistent moves upwards and downwards. In other words, there is autocorrelation in the log levels, which is to be expected, but we will want to look at the derivative of the log levels in the near past to predict the future log levels. The derivative can be computed by taking the difference of the most recent log level and the previous one to that.
Once we have the best model we can with just knowing past log levels, we will want to add reasonable other signals. The most obvious candidates are the insulin intakes and the carb intakes. These are presented as integer values with certain timestamps. Focusing on the insulin for now, if we know when the insulin is taken and how much, we should be able to model how much insulin has been absorbed into the blood stream at any given time, if we know what the insulin absorption curve looks like.
This leads to the question of, what does the insulin (rate of) absorption curve look like? I’ve heard that it’s pretty much bell-shaped, with a maximum at 1.5 hours from the time of intake; so it looks more or less like a normal distribution’s probability density function. It remains to guess what the maximum height should be, but it very likely depends linearly on the amount of insulin that was taken. We also need to guess at the standard deviation, although we have a pretty good head start knowing the 1.5 hours clue.
Next, the carb intakes will be similar to the insulin intake but trickier, since there is more than one type of carb and different types get absorbed at different rates, but are all absorbed by the bloodstream in a vaguely similar way, which is to say like a bell curve. We will have to be pretty careful to add the carb intake model, since probably the overall model will depend dramatically on our choices.
I’m getting ahead of myself, which is actually kind of good, because we want to make sure our hopeful path is somewhat clear and not too congested with unknowns. But let’s get back to the first step of modeling, which is just using past log glucose levels to predict the next glucose level (we will later try to expand the horizon of the model to predict glucose levels an hour from now).
Looking back at the data, we see gaps and we see crazy values sometimes. Moreover, we see crazy values more often near the gaps. This is probably due to the monitor crapping out near the end of its life and also near the beginning. Actually the weird values at the beginning are easy to take care of- since we are going to work causally, we will know there had been a gap and the data just restarted, so we we will know to ignore the values for a while (we will determine how long shortly) until we can trust the numbers. But it’s much trickier to deal with crazy values near the end of the monitor’s life, since, working causally, we won’t be able to look into the future and see that the monitor will die soon. This is a pretty serious dirty data problem, and the regression we plan to run may be overly affected by the crazy crapping-out monitor problems if we don’t figure out how to weed them out.
There are two things that may help. First, the monitor also has a data feed which is trying to measure the health of the monitor itself. If this monitor monitor is good, it may be exactly what we need to decide, “uh-oh the monitor is dying, stop trusting the data.” The second possible saving grace is that my friend also measured his blood glucose levels manually and inputted those numbers into the machine, which means we have a way to check the two sets of numbers against each other. Unfortunately he didn’t do this every five minutes (well actually that’s a good thing for him), and in particular during the night there were long gaps of time when we don’t have any manual measurements.
A final thought on modeling. We’ve mentioned three sources of signals, namely past blood glucose levels, insulin absorption forecasts, and carbohydrate absorption forecasts. There are a couple of other variables that are known to effect the blood glucose levels. Namely, the time of day and the amount of exercise that the person is doing. We won’t have access to exercise, but we do have access to timestamps. So it’s possible we can incorporate that data into the model as well, once we have some idea of how the glucose is effected by the time of day.
Cookies
About three months ago I started working at an internet company which hosts advertising platforms. It’s a great place to work, with a bunch of fantastically optimistic, smart people who care about their quality of life. I’m on the tech team along with the team of developers which is led by this super smart, cool guy who looks like Keanu Reeves from the Matrix.
I’ve learned a few things about how the internet works and how information is collected about people who are surfing the web, and the bottom line is I clear my cookies now after every session of browsing. Now that I know the ways information travels the risks of retaining cookies seem to outweigh the benefits. First I’ll explain how the system works and then I’ll try to make a case for why it’s creepy, and finally, why you may not care at all.
Basically you should think of yourself, when you surf the web, as analogous to someone on the subway coming home from Macy’s with those enormous red and white shopping bags. You are a walking advertisement for your past, your consumer tastes, and your style, not to mention your willingness to purchase. Moreover, beyond that, you are also carrying around information about your political beliefs, religious beliefs, and temperament. The longer you browse between cookie cleanings, the more precise a picture you’ve painted of yourself for the sites you visit and for third parties (explained below) who get their hands on your information.
Just to give you a flavor of what I’m talking about, you probably are already aware that when you go to a site like, say, Amazon, the site assigns you a cookie to recognize you as a guest; when you return a week later it knows you and says, “Hi, Catherine!”. That’s on the low end of creepy since you have an account with Amazon and it’s convenient for the site to not ask you who you are every time you visit.
However, you may not be aware that Amazon can also see and parce the cookies that other sites, like Google (correction: a reader has pointed out to me that Google doesn’t let this happen, sorry. I was getting confused between the cookie and the “referring url”, which tells a site where the user has come from when they first get to the site. That does contain Google search terms), places on your web signature. In other words Amazon, or any other site that knows how to look, can figure out what other sites’ label of you says. Some cookies are encrypted but not all of them, and I think the general rule is to not encrypt- after all, the people who have the tools to read the cookies all benefit from that information being easy to read. From the perspective of Google, moreover, this information is helping improve your user experience. It should be added that Google and many other companies give you the option of opting out of receiving cookies, but to do so you have to figure out it’s happening and then how to opt out (which isn’t hard).
One last layer of cookie collection is this: there are other companies which lurk on websites (like Amazon, although I’m not an expert on exactly when and where this happens) which can also see your cookies and tag you with additional cookies, or even change your existing cookies (this is considered rude but not prevented). This is where, for me, the creep factor gets going. Those third parties certainly have less riding on their brand, since of course you don’t even see them, so they have less motivation to act honorably with the information they collect about you. For the most part, though, they are just looking to see what kind of advertisement you may be weak for and, once they figure it out, they show you exactly that model of showerhead that you searched for three weeks ago but decided was too expensive to buy. If you want to stop seeing that freaking showerhead popping up everywhere, clear thy cookies.
Here’s why I don’t like this; it’s not about the ubiquitous showerhead, which is just annoying. Think about rich people and how they experience their lives. I touched on this in a previous post about working at D.E. Shaw, but to summarize, rich people think they are always right, and that’s a pretty universal rule, which is to say anyone who becomes rich will probably succumb to that pretty quickly. Why, though? My guess is that everyone around them is aware of their money and is always trying to make them happy in the hope that they at some point could have some of that money. So they effectively live in a cocoon of rightness, which after a while seems perfectly logical and normal.
How that concept manifests itself in this conversation about cookies is that, in a small but meaningful way, that’s exactly what happens to the user when he or she is browsing the web with lots of cookies. Every time Joe encounters a site, the site and all third-party advertisers have the ability to see that Joe is a Republican gun-owner, and the ads shown to Joe will be absolutely in line with that part of the world. Similarly the cookies could expose Dan as a liberal vegetarian and he sees ads that never shake his foundations. It’s like we are funneled into a smaller and smaller world and we see less and less that could challenge our assumptions. This is an isolating thought, and it’s really happening.
At the same time, people sometimes want to be coddled, and I’m one of those people. Sometimes I enjoy it when my favorite yarn store advertises absolutely gorgeous silk-cashmere blends at me, or shows me to a rant against greedy bankers, and no I’d rather not replace them with Viagra ads. So it’s also a question of how much does this matter. For me it matters, but I also like New York City because it is dirty and gritty and all these people from all over the world live there and sweat on each other on the subway and it makes me feel like part of a larger community- I like to mix it up and have it mixed up.
I’d also like to mention another kind of reason you may want to clear your cookies: you get better deals. A general rule of internet advertising is that you don’t need to show good deals to loyalists. So if you don’t have cookies proving you have an account on Netflix, you may get an advertisement offering you three free months of membership. Or if you want to get more free articles on the New York Times website, clear your cookies and the site will have no idea who you are. There are many such examples like this.
Lastly, I’d like to point out that you probably don’t need to worry about this. After all, many browsers will clear your cookies but also clear your usernames and passwords, and you may never be able to get some of those back. And maybe you don’t mind being coddled while online. Maybe it’s the one place where you get to feel understood. Why question that?
Fair Foods
This post will only be indirectly quantitative, and not a rant, so I guess that means I will have to either apologize or change my mission statement. Sorry. Oh and by the way I do have lots of ideas for quantitative blogs coming up, topics to include:
- clear your cookies! how internet companies track your every click
- update on the diabetes model
- is being a mathematician just a crappy job?
- shout-outs to other nerd bloggers who are sending me readers
So yesterday I loaded up the (rental) car to the brim, with my mom, my two older sons, a guitar (for me) and an air conditioning unit (for my mom), and drove out to Amherst for the math program I’m teaching in for three weeks.
Before I left I visited my friend Nancy at Fair Foods in Dorchester.
I drove to her house early, getting there at maybe 8:30am. She wasn’t home- she had me meet her at a church near Codman Square, where she was making a drop. When I got there I helped her unload a van full of maybe 40 or so boxes of vegetables and fruit, with a few 50-pound bags of carrots and potatoes. She got on the van and handed me the boxes and I carried them over to a sidewalk, while the woman, Marie, who was accepting the drop, carried some smaller boxes into the basement. Nancy introduced me to Marie as her daughter, and introduced Marie to me as the beautiful, wise Haitian woman who was a professional cook and would turn all of these vegetables into a delicious feast for her congregation. Nancy and Marie talked about the church, and the fact that it was shared between two different congregations, one Haitian immigrant and one African-American, and how the church was run.
After a while it didn’t seem like Marie was going to get the help she was expecting to carry the larger boxes into the basement, so Nancy and I moved all of the boxes down there, temporarily rigging a window to be a de facto dumb waiter to avoid three corners and some stairs. There were tomatoes, white potatoes, red potatoes, carrots, ugli fruit, limes, lettuce, string beans, wax beans, and others I can’t remember. Almost all of these were in great condition, but some needed sorting before going into the feast. Marie asked for corn for the 4th of July- since the food that is collected is surplus, a given request may be hard to fill, especially around a holiday, which Nancy explained. But then she said that if we got corn we would call Marie right away.
After we finished unloading the van I was soaked in sweat; it reminded me of how incredibly strong I’d gotten working one summer for Nancy, unloading trucks all day (as well as loading them at the Chelsea Produce Market every morning at 7) and driving around the city in the big yellow truck making drops to churches, senior centers, and youth centers, and holding dollar-a-bag sites in vacant parking lots and sidestreets. That was in 1992; and Nancy, who was born in 1950, has been doing the program ever since, with various peoples’ help.
Nancy mentioned that before I’d gotten there she had gone into the church and listened to the singing and the praying of the Haitian congregation, and that it had been seriously beautiful. Marie insisted on us coming inside. We sat in the pews as the woman leading the small prayer group of about 8 people, mostly women, was talking to one woman who was clearly in distress. Perhaps she was in mourning. They were speaking in Creole, which I don’t understand (although I know some French so every now and then I can pick up a word or two), but it was viscerally moving how kindly the leader was speaking to the sad woman seated in front of her. After she allowed that woman to finish, she looked up and welcomed us in English and asked us our names. Marie explained in Creole something about us, probably that we had just brought in the food for the July 4th meal, and we were instantly welcomed by the entire group. After that they told us they were wrapping up their prayer session and would stand and have a group prayer.
Everyone stood, except for the mourning woman who was holding her head in her hands. And at once everyone started praying, but the interesting thing was they were all saying different prayers, and it was fascinating to watch and listen to how they could be both praying together and praying individually. I could make out a few words from Marie’s prayer, which near the beginning was quiet and included lots of words like “please” and “hope”, but which, like everyone else’s, became louder and more fervent and contained more words like “thank you” and “hallelujah”. It ended by everyone holding their hands up to the front of them and giving thanks. Everyone ended at exactly the same time.
After the prayer group ended, there were lots of hugs and hand shaking. Many of the women wanted to talk to Nancy and she probably ended up hugging and being hugged by everyone there. There was a deep human connection inside that little church, which is pretty different from my normal assumptions about piousness and rules-based religions. Connection and empathy.
After we left the church we went to a playground and sat and had coffee together, and Nancy laid something down that was pretty thick. She talked about her disillusionment with her generation- the hippy generation- how they made all these promises but then didn’t follow through- the words she uses is didn’t apply themselves. She talked about having faith in her generation up to the “We Are the World” moment, and then waiting, and seeing nothing come out of it, and how bitter that had made her feel, how disappointed. She said it took her years to get over that, and now she feels like those years of her life, until recently in fact, are in some sense unaccounted for, both because she’s been sick and because she was somewhat paralyzed with anger.
She went on to say that she’s in a new phase now, she’s accepted the lazy fact of life that the people she was counting on, if anything, have made the world a worse place, not a better one, but that she’s decided to love them and love the world anyway, and to continue to make human connections with individuals, because it makes her have faith in a different way, a more diffuse but a stronger faith that won’t be disappointed.
It’s interesting to me that Nancy would ever describe her life as unaccounted for or her feelings as bitter. When I met her in 1989, she had been diagnosed with MS and lived in a huge old house with very little working anything (and what was working she’d installed herself- wired the electricity and installed plumbing). She had a great Dane and a broken-down donated truck, and when I came to her we spent the whole night cleaning out and reorganizing the truck. Whenever the truck’s insurance was due, or the phone was about to be cut off, we’d get a check for $50 and it would be a miracle, and I always felt like if I was ever going to believe in something it would be because of her.
I fell in love with her and with her approach to problem solving- namely, do the right thing, and go figure how to with bare knuckles and sweat. Over the years she’s been better or worse off with her health, but she’s never given up and, to be honest, I never sensed bitterness from her. Maybe these are relative notions, that bitterness from her is like frustration from someone else. Unaccountability from the woman who moves tons of food a week, that will otherwise be thrown away, into the homes of impoverished, mostly immigrant households, who know her and appreciate her act of kindness and take part in that act, would mean… what? to other people. Hard to say.
Did you have a happy childhood?
For whatever reason, I’ve been thinking about my childhood recently. Partly it’s the post I wrote about why I chose to call myself “mathbabe”, partly it’s an old essay of Jonathan Franzen’s that got me all riled up (in a good way). Plus I’m traveling to the math camp of my youth to teach, and stopping on the way in Harvard Square at my parents’ house; that’s enough to make you reconsider your memories in short order.
I have never understood what people mean when they talk about carefree, happy childhoods. I think I’ve always assumed this to be some kind of ironic joke, or maybe a plastered-over memory, a convenient approach to pain management. While it’s true that children have fewer responsibilities than grown-ups, it’s really not the responsibilities of adulthood that weigh me down (says the woman with three kids), or ever did. For me it was the constant awareness of my helplessness and impotence, my inability to decide my own fate, my feeling of having to wait forever for freedom, that got to me. I was also teased, but not relentlessly, and I did have friends, and moreover I wasn’t thought of (I don’t think) as a worrying child. From the outside people may have imagined me as a normal albeit nerdy kid. However, I always identified with the oppressed, and I had a keen sense of fairness which was constantly being challenged by reality. When we studied the “Manifest Destiny” in third grade, it killed me to think of the white man’s assumptions. When I saw a kid getting bullied at school, it tore me up that I didn’t know how to put an end to it and no teachers bothered. The list goes on, you get the idea. Also, I had an internal standard that was painfully high- I wanted to become a musician, a pianist, but never thought I’d be good enough, and I questioned my creativity, since what I really wanted to do was compose. When I decided to become a mathematician I started worrying about my thesis (I was 16). By the way, lest people get the wrong impression, my parents never put pressure on me to play music (in fact they openly discouraged me since it was expensive) and thought my worrying about my thesis was downright amusing. This was all internally generated. In short, I was a struggler, at best of times a striver, but never ever carefree and happy.
I have always been attracted to other people who struggle and strive; for the most part my closest friends are, like me, in constant flux with respect to their identities and their goals and even the interpretation of the most basic cultural assumptions like toenail polish and the role of the FDIC.
This brings me to the Franzen essay, where he talks about being isolated in childhood as a reader, and spending the rest of your life trying to find and form a community with other isolated readers. As an aside, Franzen makes a distinction in this essay between isolated readers and isolated math or technology nerds. He basically said that math nerds are isolated because they are autistic, incapable of social interaction, whereas readers are isolated because they feel more deeply and can’t relate to artificiality. I’m not sure whether to argue that math nerds aren’t all autistic or just count myself as both a reader and a math nerd and be proud of out-isolating Franzen, no easy task. Basically, I agree with Franzen. From my perspective upon meeting someone I am always looking for that inner torture, the hallmark of an examined life. It doesn’t make you happy, perhaps, but it makes you real, and moreover interesting.
But here’s the thing, I was blindsided this week by the discovery that my husband, of all people, had a happy childhood. He insists on this, even when I ask him if perhaps he’s misremembering his inner turmoil– he claims no. He moreover avers that, at the age of 12, he decided to become a mathematician and has never looked back, never once questioned that decision. Is this possible? That I’m married to a man who had a happy childhood? For all I know, it is true and moreover it may be exactly why I have a happy marriage. Maybe strugglers need to be married to non-strugglers to maintain some kind of balance. I don’t know, I’m still thinking about it. It does explain something that I’ve always been confused by, though- when my husband comes across an ethical or moral decision, he does so painlessly and makes a decision instantaneously. I now think this is because he just doesn’t think about things like that in between those moments, and so he’s got a clarity of consciousness which allows him to make snap decisions. When I come across such dilemmas, I am much more confused and ambivalent. I usually decide it’s a matter of opinion. I’m wondering if it’s this element of our differences that makes our marriage work.




{kind=link}
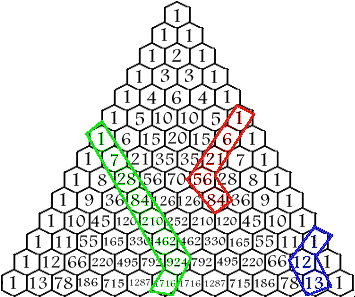{kind=link}
{kind=link}
{kind=link}