Archive
The fake problem of fake geek girls, and how to be a sexy man nerd
My friend Rachel Schutt recently sent me this Forbes article by Tara Tiger Brown on the so-called problem of too many fake geek girls stealing the thunder and limelight from us true geek girls.
The working definition of geek seems to be someone who is obsessively interested in something (I would argue that you don’t get to be a geek if your obsession is art, for example, I’d like to define it to be an obsession with something technical). She also claims that “true geeks” don’t do something for airtime. From the article:
Girls who genuinely like their hobby or interest and document what they are doing to help others, not garner attention, are true geeks. The ones who think about how to get attention and then work on a project in order to maximize their klout, are exhibitionists.
I kind of like this but I kind of don’t too. I like this because, like you, I have run into many many people (men and women) who loudly claim technical knowledge that they don’t seem to actually have, which is annoying and exhibitionistic. And yes, it’s annoying to see people like that doing things like giving things like Ted talks on “big data” when you seriously doubt they know how to program a linear regression. But again, men and women.
At the same time, there’s no reason someone can’t be both a true geek and an exhibitionist, and it seems kind of funny for a Forbes magazine writer to be claiming the authentic rights to the former but not the latter.
If there’s one thing I’d like to avoid, it’s peer pressure that, as a girl geek, I have to have a certain personality. I like the fact that girl geeks are sometimes shy and sometimes outspoken, sometimes humble and sometimes arrogant, sometimes demure and sometimes slutty. It makes it way more interesting during technical chats.
What’s the asymmetry between men and women here? According to Tara Tiger Brown, women think they’ll get attention from men by acting like a geek but my experience is that men don’t think they’ll get attention from women by acting like a geek.
I think this is a mistake that man geeks are making. For me, and for essentially all my female friends, being really fucking good at some thing is extremely sexy. Man geeks are, therefore, very sexy, if they are in fact really fucking good at something and not just posing. Maybe they just need to realize that and own it a bit more.
Next time, instead of apologizing for doing something nerdy, I suggest you (a man geek I’m imagining talking to right now) figure out how to describe what skill you mastered and talk about it as an accomplishment.
No: I’m kind of tired today, sorry. I stayed up all night playing with my computer. Should we reschedule?
Yes: Last night I implemented dynamic logistic regression and managed to get it to converge on 30 terabytes of streaming data in under 3 hours. And it’s all open source, I just checked in into github. That was awesome! But now I need to sleep. Wanna take a nap with me?
Personal Democracy Hackathon today
This Morning I’m going to the CUNY Graduate School of Journalism to pitch the Credit Union Findr Webapp to a bunch of developers at today’s Personal Democracy Hackathon. Hopefully they’ll be interested enough to work on our geo-problem of credit union eligibility, namely taking in an address and finding the credit unions you become eligible for through your address. All open source of course.
Update: We’ve got two teams working, one on our webpage and our geo-locator project. Woohoo!
Hangover cure
After a long night of vodkas and karaoke, there’s one sure method for feeling brand new once again, namely listening to Empire State of Mind, really loud, over and over.
At least I hope so.
p.s. The first year anniversary of mathbabe.org is coming up next Monday, please come up with suggestions for how to celebrate!
What if the bond markets priced in actual risk?
A friend sent me this article written by Daniel Gross, which talks about how taxpayers in Europe and in the U.S. are paying for the mistakes of bondholders. First he starts with Ireland:
When Ireland’s large private banks collapsed spectacularly a few years ago, the Irish government formally assumed the debts of the private banks. To ensure that bondholders of Irish banks would remain whole, the government undertook a massive bailout. To pay for it, it has inflicted vicious austerity on its populace.
He moves on to Greece:
As Liz Alderman and Jack Ewing reported in the New York Times this week, about two-thirds of the $177 billion in European aid to Greece given since May 2010 has been used to make payments to bondholders and other lenders. The upshot: Greece is imposing significant austerity on its citizens for the sake of preserving the value of bondholders.
And the U.S.:
Yes, it’s true that the U.S. in 2008 and 2009 acted to keep bondholders from taking big losses. The taxpayers formally assumed the debt of Fannie Mae and Freddie Mac without insisting bondholders take any haircut, just as the Irish taxpayers formally assumed the debts of their large banks. That was a big and expensive mistake. In a time of austerity, the U.S. government is channeling tax payer funds to make interest payments on bonds that were first issued by for-profit entities.
He points out that Spain appears to be taking the same approach, and that the actual people of Ireland and Greece are having second thoughts about paying all these bills, expressed through who they are voting for. I believe it’s left to the reader to wonder what’s going to happen to Spain.
Gross suggests a different tact for governments to use, namely to ignore old debt and to provide insurance for new debt issued by the banks and other private companies. The U.S. did this during the crisis, it was called the Temporary Liquidity Guarantee Program. His point is that we’ve made money off this program and we’ve let lots of really insolvent banks fail as well.
On the other hand, I’d argue, we haven’t let the big banks fail, so there’s a limit to its effectiveness (but I won’t blame this program for that, because that’s a problem of political will). And it’s of course not altogether clear that the insurance it sold was sold at market value, since if it had been, I’m guessing it wouldn’t have been such a boon to a given company to issue debt and pay for insurance versus just issuing debt at a higher risk premium. In other words, I think the “Liquidity” in “Temporary Liquidity Guarantee Program” is key.
But he’s got it basically right- taxpayers are definitely on the hook for risky bets other people took. And backups and guarantees by governments definitely skews the bond market. Specifically, big companies end up paying less than they should given their risk, and the taxpayers foot the bill in situations of default (which aren’t allowed to actually be defaults with respect to the bondholders).
So sufficiently big companies are paying too little for debt. That’s about half the story though. The other half is how normal people are paying too much for debt.
For example, with student debt, Bloomberg recently reported that private issuers of student debt are charging as much as credit card companies:
Tovar, who lives with her parents in the Chicago suburb of Blue Island, owes $55,600 to Chase Student Loans, a unit of JPMorgan, according to a May 17 statement provided by her. A loan for $24,794 carries an interest rate of 10.25 percent, as does a second loan for more than $2,619. A third for $28,187 has a rate of 8.97 percent. She has a balance of $42,326 in loans from a different lender.
Given that these loans are effectively undischargable through bankruptcy, what is the real risk for private issuers in getting their money back? What would a fair market price be for these loans? And why don’t we have a fair market?
Who will Regulate the Superheroes on Wall Street?
This is a guest post by Elizabeth Friedrich, a member of Occupy the SEC.
Wall Street has grown to celebrate superheroes like Lloyd Blankfein and Jamie Dimon for their superior management skills and keen business sense. We have come to praise and applaud reckless risk-takers on the assumption that the markets always know best.
Insider Wall Street leaders like Jamie Dimon are viewed to possess special powers. In fact, many believe that Dimon, who led JP Morgan out of the financial crisis, is a banking prodigy who could do no wrong. But even Dimon is helpless in the face of reckless risk-taking behavior by his employees, as shown by the trader Bruno Iksil who lost $3 billion dollars and counting as part of JP Morgan’s CIO office. “Star traders” like Iksil structure their trades in such a complicated way that the average person could never understand them. We have no way of knowing whether the hedges that the CIO office put on actually “hedged” the original position. Such complexity, conveniently, can also serve as a powerful tool to refute public outcry.
The question here is this: Why create such risk in the first place? Or, more importantly: Why create the type of transactions that require a superman to oversee them?
Since the Volcker Rule is still being finalized, banking institutions will continue to take on these risks as long as they are allowed or exempted to do so. However, banks should face the same consequences as the rest of society. The “London Whale” trades created massive disruptions in an already fragile market and, ironically, they have caused unrest and disgust in the hedge fund community – the very community that loves unregulated market competition. Why don’t we hold banks to their own standards and stop giving them a pass when they fail?
Occupy the SEC will be marching today calling for the S.E.C. to investigate Jamie Dimon for violation of the disclosure requirements of Sarbanes-Oxley Act. We will also recommend that the S.E.C. make a criminal referral to the Department of Justice. Many people are frustrated with the slap-on-the-wrist treatment that Wall Streeters enjoy; random petty criminals are sentenced to hard jail time but the trader who loses billions of dollars is told not to do that again. The JP Morgan Chase debacle is symptomatic of a broken regulatory system.
Even if there are no criminal charges against Jamie Dimon, the American public would have been well-served to see Wall Street have its day in court. The S.E.C. has to uphold its foundational principles: 1) public companies offering securities to investors must tell the truth about their business, the securities, and the risks involved in investing; and 2) people who sell and trade securities must treat investors fairly and honestly, putting their investors’ interests first.
It is fairly simple: if S.E.C. officials find out that a company has done wrong they have the power to investigate, issue civil penalties, and refer the case to the Department of Justice for criminal prosecution. As many financial experts and white-collar crime lawyers have said, the S.E.C. has not fully utilized its authority, as demonstrated by the treatment of Dick Fuld and Jon Corzine.
The function of a financial institution is not merely to manage risk, but to act primarily as the steward of society’s assets and smart allocation of capital. We hope that the S.E.C will help re-examine the priorities of Too Big To Fail financial institutions. Finally, the current culture corrodes and disrupts sound business practices and stunts the rehabilitation of our current financial system. The S.E.C. is an imperfect vehicle (as evidenced by its lackluster approach to its duties leading up and during the financial crisis) but it’s the only vehicle we have. If they don’t do their job – who will?
Occupy the SEC is a group of concerned citizens, activists, and financial professionals with decades of collective experience working at many of the largest financial firms in the industry. Occupy the SEC filed a 325-page comment letter on the Volcker Rule NPR, which is available at http://occupythesec.org.
Regulation is not a dirty word
Regulation has gotten a bad rap recently. It’s a combination of it being associated to finance, or big business, and it being complicated, and involving lobbyists and lawyers – it’s sleazy and collusive by proxy, and there are specific regulators that haven’t exactly been helping the cause. Most importantly, though, the concept of regulation has been slapped with a label of “bad for business = bad for the struggling economy”.
But I’d like to argue that regulation is not a dirty word – it’s vital to a functioning economy and culture.
And the truth is, we are lacking strong and enforced regulation on businesses in this country. Sometimes we don’t have the regulation, but sometimes we do and we don’t enforce it. I want to give three examples from yesterday’s news on what we’re doing wrong.
First, consider this article about data and privacy in the internet age. It starts out by scaring you to death about how all of your information, even your DNA code, is on the web, freely accessible to predatory data gatherers. All true. And then at the end it’s got this line:
“Regulation is coming,” she says. “You may not like it, you may close your eyes and hold your nose, but it is coming.”
What? How is regulation the problem here? The problem is that there’s no regulation, it’s the wild west, and a given individual has virtually no chance against enormous corporate data collectors with their very own quant teams figuring out your next move. This is a perfect moment for concerned citizens to get into the debate about who owns their data (my proposed answer: the individual owns their own data, not the corporation that has ferreted it out of an online persona) and how that data can be used (my proposed answer: never, without my explicit permission).
Next, look at this article where Bank of America knew about the massive losses on Merrill after agreeing to acquire them in September 2008 but its CEO Ken Lewis lied to shareholders to get them to vote for the acquisition in December 2008. The fact that Lewis lied about Merrill’s expected losses is not up for debate. From the article:
… Mr. Singer declined to comment on the filing. But the document submitted to the court said that Mr. Lewis’s “sworn admissions leave no genuine dispute that his statement at the December 5 shareholder meeting reiterating the bank’s prior accretion and dilution calculations was materially false when made.”
What I want to draw your attention to is the following line from the article (emphasis mine):
…the former chief executive did not disclose the losses because he had been advised by the bank’s law firm, Wachtell, Lipton, Rosen & Katz, and by other bank executives that it was not necessary.
Just to be clear, Lewis didn’t want to tell bad news to shareholders about the acquisition, because then he’d lost his shiny new investment bank, and he checked with his lawyers and they decided he didn’t need to admit the truth. That is a pure case of unenforced regulation. It is actually illegal to do this, but the lawyers were betting they could get away with it anyway.
Finally, consider this video describing what was happening inside MF Global in the days leading up to its collapse. Namely, the borrowing of customer money is hard to track because they did it all by hand. No, I’m sorry. Nobody does stuff with money without using a computer anymore. The only reason to do this by hand is to avoid leaving a paper trail because you know you’re about to do something illegal. I’m no accounting regulation expert but I’m sure this is illegal. Another case of unenforced regulation, or at worst, regulation that should exist.
Why do people think regulation is bad again? Does it really stifle business? Is it bad for the economy? In the above cases, consider this. The fact that we don’t have clear rules will cause plenty of people to avoid using all sorts of social media at all for fear of their data being manipulated. We have plenty of people avoiding investing in banks because they don’t trust the statements of bank CEO’s. And we have people avoiding becoming customers of futures exchanges for fear their money will be stolen. These facts are definitely bad for the economy.
The truth is, business thrives in environments of clear rules and good enforcement. That means strong, relevant, and enforced regulation.
Combining priors and downweighting in linear regression
This is a continuation of yesterday’s post about understand priors on linear regression as minimizing penalty functions.
Today I want to talk about how we can pair different kinds of priors with exponential downweighting. There are two different kinds of priors, namely persistent priors and kick-off priors (I think I’m making up these terms, so there may be other official terms for these things).
Persistent Priors
Sometimes you want a prior to exist throughout the life of the model. Most “small coefficients” or “smoothness” priors are like this. In such a situation, you will aggregate today’s data (say), which means creating an 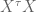

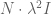
Kick-Off Priors
Other times you just want your linear regression to start off kind of “knowing” what the expected answer is. In this case you only add the prior terms to the first day’s
Example
This is confusing so I’m going to work out an example. Let’s say we have a model where we have a prior that the 1) 

Then on the first day, we find the 
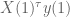
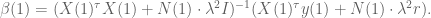
How should we choose 

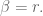

On the second day, we downweight data from the first day, and thus we also downweight the
However, we still want to remind the model to make the coefficients small – in other words a separate prior on the size of coefficients. So in fact, on the first day we will have two priors in effect, one as above and the other a simple prior on the covariance term, namely we add 
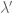

And just to be really precise, of we denote by 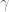
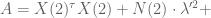
![\gamma[X(1)^\tau X(1) + N(1) \cdot \lambda^2 I + N(1) \cdot (\lambda')^2 I]](https://s0.wp.com/latex.php?latex=%5Cgamma%5BX%281%29%5E%5Ctau+X%281%29+%2B+N%281%29+%5Ccdot+%5Clambda%5E2+I+%2B+N%281%29+%5Ccdot+%28%5Clambda%27%29%5E2+I%5D&bg=ffffff&fg=555555&s=0&c=20201002)
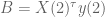
![+ \gamma[X(1)^\tau y(1) + N(1) \cdot \lambda^2 r]](https://s0.wp.com/latex.php?latex=%2B+%5Cgamma%5BX%281%29%5E%5Ctau+y%281%29+%2B+N%281%29+%5Ccdot+%5Clambda%5E2+r%5D&bg=ffffff&fg=555555&s=0&c=20201002)

An easy way to think about priors on linear regression
Every time you add a prior to your multivariate linear regression it’s equivalent to changing the function you’re trying to minimize. It sometimes makes it easier to understand what’s going on when you think about it this way, and it only requires a bit of vector calculus. Of course it’s not the most sophisticated way of thinking of priors, which also have various bayesian interpretations with respect to the assumed distribution of the signals etc., but it’s handy to have more than one way to look at things.
Plain old vanilla linear regression
Let’s first start with your standard linear regression, where you don’t have a prior. Then you’re trying to find a “best-fit” vector of coefficients 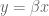
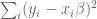
Here the various 
How do we find the minimum of that? First rewrite it in vector form, where we have a big column vector of all the different 



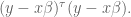
Now we appeal to an old calculus idea, namely that we can find the minimum of an upward-sloping function by locating where its derivative is zero.
Moreover, the derivative of 







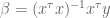
Adding a prior on the variance, or penalizing large coefficients
There are various ways people go about adding a diagonal prior – and various ways people explain why they’re doing it. For the sake of simplicity I’ll use one “tuning parameter” for this prior, called 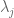
In other words, we can think of trying to minimize the following more complicated sum:
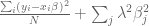
Here the 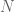

When we minimize this, we are simultaneously trying to find a “good fit” in the sense of a linear regression, and trying to find that good fit with small coefficients, since the sum on the right grows larger as the coefficients get bigger. The extent to which we care more about the first goal or the second is just a question about how large 

How do we minimize that guy? Same idea, where we rewrite it in vector form first:

Again, we set the derivative to zero and ignore the factor of 2 to get:
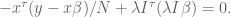
Since 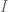
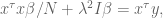
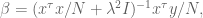
which of course can be rewritten as
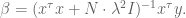
If you have a prior on the actual values of the coefficents of
Next I want to talk about a slightly fancier version of the same idea, namely when you have some idea of what you think the coefficients of 

We vectorize as

Again, we set the derivative to zero and ignore the factor of 2 to get:
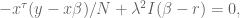
so we can conclude:

which can be rewritten as
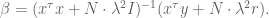
A low Fed rate: what does it mean for the 99%?
I’m no economist, so it always takes me quite a bit of puzzling to figure out macro-economic arguments. Recently I’ve been wondering about the Fed’s promise to keep rates low for extended periods of time. Specifically, I’ve been wondering this: whom does that benefit?
[As an aside, it consistently pisses me off that the people trading in the market, who claim to be all about “free markets” and against “interference” from regulators, also are the ones who whine for a Fed intervention or quantitative easing when bad economic data comes out. So which is it, do you want freedom or do you want a babysitter?]
Here’s the argument I’ve gleaned from the St. Louis Fed’s webpage. When the Fed lowers (short-term) rates, it makes it easier to borrow money, it makes it easier for banks to profit from the difference between long-term and short-term rates, and it potentially can cause inflation (and bubbles) since, now that everyone has borrowed more, there’s more demand, which raises prices. And inflation is good for debtors, because over time their debts are worth less.
One thing about the above argument stands out as false to me, at least for the majority of the 99%. Namely, many of them are already indebted up their eyeballs, so who is going to give them more money? And what would they buy with that money?
In other words, if the assumption is that everyone is getting easy loans, I haven’t seen evidence of this. Wouldn’t we be hearing about people refinancing their homes for awesome rates and thereby avoiding foreclosure? How many stories have you heard like that?
If not everyone is getting easy loans, and if in fact only the 1% and banks are getting those gorgeously low-interest loans, then it’s not clear this will be sufficient to spur demand and cause inflation. And inflation really would help the 99%, but only of course if wages kept up with it. Instead we have not seen high inflation and wages haven’t even been keeping up with what inflation we do see.
So let’s re-examine who is benefiting from low Fed rates. I’m gonna guess it’s mostly the banks, and a few private equity firms that are borrowing tons of money to buy up great swaths of foreclosed homes so they can turn around and profit on renting them out to the people who were foreclosed on.
I’m not necessarily advocating that we raise the Fed rates. But next time I hear someone say, “low Fed rates benefit debtors” I’m going to clarify, “low Fed rates benefit banks.”
One language to rule them all
Right now there seems to be a choice one has to make in languages: either it’s a high level language that a data scientist knows or can learn quickly, or it’s fast and/or production ready.
So as the quant, I’ve gotten used to prototyping in matlab or python and then, if what I have been working on goes into production, it typically needs to be explained to a developer and rewritten in java or some such.
This is a pain in the ass for two reasons. First, it takes forever to explain it, and second if we later need to change it it’s very painful to work with a different developer than the one who did it originally, but people move around a lot.
Now that I’m working with huge amounts of data, it’s gotten even more complicated – there are three issues instead of two. Namely, there’s the map-reducing type part of the modeling, where you move around and aggregate data, which, if you’re a data scientist, means some kind of high-level language like pig.
Actually there are four issues – because the huge data is typically stored in the Amazon cloud or similar, there is also the technical issue of firing up nodes in a cluster and getting them to run the code and return the answers in a place where a data scientist can find it. This is kinda technical for your typical data scientist, at least one like me who specializes in model design, and has been solved only in specific situations i.e. for specific languages (Elastic-R and Mortar Data are two examples – please tell me if you know more).
Is there a big-data solution where all the modeling can be done in one open source language and then go into production as is?
People have been telling me Clojure/ Cascalog is the answer. But as far as I know there’s no super easy way to run this on the cloud. It would be great to see that happen.



