Bayesian regressions (part 1)
I’ve decided to talk about how to set up a linear regression with Bayesian priors because it’s super effective and not as hard as it sounds. Since I’m not a trained statistician, and certainly not a trained Bayesian, I’ll be coming at it from a completely unorthodox point of view. For a more typical “correct” way to look at it see for example this book (which has its own webpage).
The goal of today’s post is to abstractly discuss “bayesian priors” and illustrate their use with an example. In later posts, though, I promise to actually write and share python code illustrating bayesian regression.
The way I plan to be unorthodox is that I’m completely ignoring distributional discussions. My perspective is, I have some time series (the 

A “bayesian prior” can be thought of as equivalent to data you’ve already seen before starting on your dataset. Since we think of the signals (the 
The information you need to know about the
Let me illustrate with an example. Suppose you are working on the simplest possible model: you are taking a single time series and seeing how earlier values of 
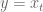
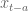
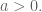
What is your prior for this? Turns out you already have one (two actually) if you work in finance. Namely, you expect the signal of the most recent data to be stronger than whatever signal is coming from older data (after you decide how many past signals to use by first looking at a lagged correlation plot). This is just a way of saying that the sizes of the coefficients should go down as you go further back in time. You can make a prior for that by working on the diagonal of the covariance matrix.
Moreover, you expect the signals to vary continuously- you (probably) don’t expect the third-from recent variable 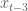
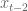
In my next post I’ll talk about how to combine exponential down-weighting of old data, which is sacrosanct in finance, with bayesian priors. Turns out it’s pretty interesting and you do it differently depending on circumstances. By the way, I haven’t found any references for this particular topic so please comment if you know of any.




{kind=link}
I’m having trouble following, although I might have an idea from http://en.wikipedia.org/wiki/Bayesian_linear_regression, if that is really related. Is it something like this for a model where the response depends on the two most recent signals?
y_i = b_0 x_i + b_1 x_{i-1} + e_i
The e_i are iid N(0,sigma^2). The correct coefficients (b_0, b_1) as well as sigma are unknown, but we presume from the start that our particular problem was picked at random from a space of possibilities with known prior distribution. Then as we make observations, we can use Bayes to form a posterior distribution of what the bs and sigma are likely to be given our observations. Having done that, you can deduce statistics about the bs, eg, maybe the distribution center bears a relationship to the least squares solution that fits observations.
There may be an art to picking a prior distribution that results in a tractable posterior distribution, and to make iteration nice, you want them in the same family. The Wikipedia link suggests something like normal in bs times inverse-gamma in sigma is a good choice.
Now the bs are a 2D random variable with prior and posterior covariance matrices in this framework. And the off-diagonals represent autocorrelation over one period in this case, and in larger models, further diagonals represent autocorrelation over greater periods? So if you have a feel for the autocorrelation from the beginning, your prior distribution on the bs should respect that rather than require the observations to force that to develop in posterior distributions? I’m basing this take on a nice OLS write up: http://cran.r-project.org/doc/contrib/Fox-Companion/appendix-timeseries-regression.pdf
My rendition is pretty botched, but maybe there was some use in laying it out. And for next steps you will look at cases where in some sense (b0, b1, b2, …) can be thought of as an exponentially decreasing sequence?
LikeLike
Cathy, you might like this post from John Baez’s blog, Azimuth
LikeLike
The closest I’ve come to finding EWMA-style regression in a Bayesian context are state-space methods, where adding state variance effectively down-weights older data. My reference for this is Bayesian Forecasting and Dynamic Models, by West and Harrison.
LikeLike
Very cool, thanks! I just bought a copy on Amazon.
LikeLike
Came across this, and have been desperately seeking the Part 2 with Code examples! See my question in the Pystatsmodels group on the topic! https://groups.google.com/d/msg/pystatsmodels/ShG-9RyYTYg/PPR2F-lfF_QJ
LikeLike
Look in my book “Doing Data Science”. My chapter on finance.
LikeLike
OK, Bought it 🙂 The book looks quite useful in general, Skimmed the Finance chapter, looks helpful, but I still have a way to go 🙂 Before I can build something that does as well as my simplistic projection noted above.. The Bayesian time series examples still seem to me to be pretty “rough”? not sure if that is the right term but continuing to build knowledge, Thanks!
LikeLike
Tom,
Happy to hear feedback, thanks!
Cathy
LikeLike