Why people hate Wegovy
I’ve been on Wegovy now for seven months. I’ve lost a ton of weight – about 60 pounds – and my risk of getting diabetes has gone way *way* down. I think it’s a total fucking miracle. But there are people on the left and the right that hate what’s happening. I have been observing these arguments with interest.
On the right, it’s a matter of not being sufficiently ashamed. It’s the notion that losing weight should be a form of repentance for sin, and if you take the easy way out, by just taking in chemicals, it’s not honest (read: painful and doomed to failure) enough. That’s why you see lots of people hiding the fact that they’re on one of the semiglutide miracle drugs (others are Ozempic and Mounjaro, and there are many more to come). I obviously disagree that one should be ashamed of being fat, and I wrote a whole book about it. My premise is that it’s not even actually a choice, and therefore it’s unreasonable to expect people to conform to a norm that has them “making a better choice.”
On the left, it’s kind of different but kind of the same. It’s that people should *not* be ashamed of their weight, and everyone should learn to be happy with their weight whatever it happens to be.
Now, that’s a worthy goal of course, and if it were just a matter of aesthetic norms, it might even be achievable! But this is not the case. It’s actually a pain in the ass to carry around 100 extra pounds: it’s hard on your knees, your hips, your joints in general. It carries a huge risk of diabetes. It’s hard or impossible to fit into airplane seats. And yes, they should make airplane seats bigger. But if you look at my list, that won’t address most of the actual problems of actually being 100 pounds overweight.
I’m choosing my words carefully. If someone is only slightly overweight, which I’ll define as 40 pounds or less, then it really is mostly an aesthetic problem for them. I should know, I’m now in the category, and I do not see the point of losing more weight.
We still fit into clothes and seats and are only at mild or even zero extra risk for most health problems. And moreover, overweight but not really fat people are typically the ones who talk their doctors into getting a prescription, then they lose a bunch of unwanted weight for aesthetic reasons, and then they talk about it confessionally.
So, to be clear, fuck those people, and there are a lot of them. They are just vain and I don’t care about them. And they might arguably be taking on more risk of side effects than benefits, except psychic benefits which are harder to measure.
Who I *do* care about are the huge number of people who have diabetes or almost have diabetes, who struggle to walk up hills and stairs, and for whom Wegovy or other drugs would be a miracle, as it is for me, if it became affordable and widely available. The risks are much lower than the benefits for this population. And although I say that as a person that’s had very little in the way of side effects – some running to the bathroom every now and then and that’s it – I suspect that most people are like me, and you just mostly hear about the people for whom Wegovy doesn’t work, because who is going to publish an article about drugs that work great?
Also consider the strong possibility that the meds will be improved and will get even better with fewer side effects. We are already learning of some of its other miraculous health effects. And of course, while it may be true that it has longer term deleterious effects, I’ll take a few more years of not getting diabetes, which has well known and absolutely awful side effects.
If you’ve read Susan Sontag’s Illness as Metaphor, you’ll know that people used to be blamed for getting cancer. Now we (mostly) know better. I am looking forward to the day, which I predict will come soon, when anti-fatness medicine will be standard, affordable, and accessible, and people will wonder why there was ever such a stigma attached to fatness or for that matter why there was ever a stigma attached to treating fatness with a miracle drug.
Fat shaming food columnist in WaPo
It’s kind of amazing but here we are: a food columnist writes about how diets are shams, how they statistically don’t work, and they play on people’s desires to live a different life – all good things to point out – and yet – yet!! – the piece ends with her describing how she, in fact, loses weight on diets anyway, because, and I quote:
My hat is off to the people who are comfortable at whatever weight they are and focus on other aspects of their health. Unfortunately, I’m not one of them; being fat made me unhappy.
https://www.washingtonpost.com/food/2023/01/23/weight-loss-diets-fasting-keto/
So, we are left to assume that it is after all a choice, and that dieting does work, but just not commercial dieting? Give me a break lady.
When you admit that diets don’t work, stop with the fat shaming.
Can we embed dignity into social media?
I’m working on a philosophy paper with an ethicist named William Cochran. I’ll post a link to it once it’s written but in the meantime I have decided to use this neglected space to think through parts of my work on the paper.
Namely, I’m trying to work out whether it’s possible or practical to embed dignity into social media. That sounds like a hard question to make precise, and my approach is to make use of Donna Hick’s amazing work, which came out of peace treaty negotiations, and you can learn about here or read her book Dignity.
Specifically for our purposes, Donna has a list of required conditions for dignity, which can be found here.
There are ten of them, and I was thinking of taking off bite sized chunks, namely to work with one or two at a time and think through how the design of social media’s algorithms or space on the platform itself could be redesigned (if necessary) to confer that particular condition of dignity.
The thing I’ll say before beginning is that, as of now, I don’t think this is being done well, and as a result I consider the human experience on social media to be mostly bad if not toxic. And yes, I do understand that people get a lot out of it too, which is why we should try to make it better rather than to abandon it.
Also, even if we do embed dignity into social media in an upheaval of design, which is hard enough to imagine: I do not think that means it will always be a great place to be. We should know by now that it’s a tool, and depending on how that tool is used it could be wielded as a weapon, as the Rohingya in Myanman learned in 2017.
Finally, I fully expect this to be hard, maybe impossible. But I want to try anyway, and I’d love comments from my always thoughtful readers if you think I’ve missed something or I’m being too blithe or optimistic. Thank you in advance.
So, let’s start with the first essential element of dignity:
Acceptance of Identity
https://www.ikedacenter.org/thinkers-themes/thinkers/interviews/hicks/elements
Approach people as neither inferior nor superior to you; give others the freedom to express their authentic selves without fear of being negatively judged; interact without prejudice or bias, accepting how race, religion, gender, class, sexual orientation, age, disability, etc. are at the core of their identities. Assume they have integrity.
The first part of this, the expressions part, looks pretty straightforward. On a social media platform, we should be able to self-identify in various ways, and we should be able to control how we are identified. All of that is easy to program. The second part is where it gets tricky, though: how do we do so without fear of being judged? Fully half of the evil shit going on now on social media is related to ridiculous, bigoted attacks on the basis of identity. How do we protect a given person from that? Automated bots looking for hate speech does not and will not work, and having an army of underpaid workers scanning for such speech is expensive and deeply awful to them.
It’s possible my experiment is already over, before it’s begun. But I have a couple of ideas nonetheless:
First, Make it much harder to broadcast bigoted views. This could be done iteratively, first by hiding identity-related information from people that have not been invited into a particular space on social media, and next by making general broadcasts (of anything) be held up to much higher scrutiny.
There’s always been a balance struck in social media of making it easy to connect people, for the sake of building enough of a network to keep somebody interested in spending time there, with making sure unwanted people aren’t invading spaces and making them toxic for the group that’s happy to be there. Folks such as Facebook group moderators (or other group moderators on other social media) do a lot of this work, for example.
So, here’s a model that might do the trick (one of many). Imagine a social media that is formed as a series of hotel rooms set off of a main hallway, where you really don’t know who is inside yet, you have to apply to go in, and there’s a moderation system that will kick you out if you don’t conform to rules. That might be too much of a burden to be instant fun, but it also might lead to better conversations and way less disbursement of hate speech. Does such a social media like this already exist?
On the other hand, there are going to be plenty of folks who actually want to engage in bigotry. They would clearly set up their rooms to be hate speech and bigot friendly. Would that be ok, or would there also need to be super-moderators who kick out rooms for violating rules?
Next, is there a third model that is somewhere in between the one that exists now, where you can pay to broadcast your views practically anywhere, and the much more zipped up model I outlined above? The critical use case is that someone should be able to identify themselves in all sorts of ways without fear of being yelled out or judged.
I’m also kind of prepared to be told that’s just what we humans do, there’s no way to build a policy that bypasses that. And when I say kind of, I just want to point out that on Ravelry, which is my knitting and crocheting community website, I don’t see a lot of this. I really don’t. And I think it’s because it’s already got something to talk about, so we don’t have to name call, because we’re busy.
ChatGPT: neither wise nor threatening
There’s been a huge amount of hubbub in the tech press lately around the newest generation of chatbots, with ChatGPT being the version that is most celebrated and/or feared.
I don’t think the celebration or the fear is warranted.
First of all, we don’t need to fear that ChatGPT is going to replace humans. It doesn’t have a model for truth; it’s simply writing words and phrases that are akin to the patterns it has observed in the historical speech it was fed. So in other words, it’s not actually answering a question thoughtfully or relevantly. Any kind of thoughtfulness that might be observed in its output is a combination of the human wisdom that is embedded in its training data and the projected credit that we tend to give others when we hear them making an attempt to formulate thoughts.
But what about students cheating by using ChatGPT instead of doing their own writing? The thing about technology is that it is interfering with the very weak proxies we have of measuring student learning, namely homework and tests. The truth is, the internet has allowed students to cheat on homework for a long long time, and for that matter many tests, and now they have a slightly better (albeit still imperfect) way to cheat. It’s just another reminder that it’s actually really hard to know how much someone has learned something, and especially if we’re not talking to them directly but relying on some scaled up automated or nearly automated system to measure it for us. I’m guessing there will be much more one-to-one oral exams in the future, at least when it comes to high stakes tests of knowledge. And for that matter, there will be fewer such tests, because many sorts of “knowledge” that humans once needed to memorize might not be necessary if the internet is always available.
Next, I do not think we have cause to celebrate either. There is no wisdom in ChatGPT or the other like that. To illustrate this point, consider Galactica, an AI that was introduced and then pulled by Meta, the parent company of Facebook. Galactica was trained on scientific papers to churn out scientific-ese paragraphs. It was pretty good at it. Actually I like this characterization, that it was a bullshit generator.
Galactica was supposed to help scientists write their paper, and help everybody look up scientific knowledge. It sometimes worked but often just made shit up. Deep fakes but for science.
Anyway, here’s one thing it will never do: create new science. And that’s why there’s nothing here to be all that excited about.
Another way to say it is that Galactica can show us what is “easy” about writing science papers: the language, jargon, third person authoritative style, etc. versus what is hard: the new ideas. Galactica can do all the easy stuff but none of the hard stuff, and so why should we be impressed?
US News & World Reports Rankings Rely on Blind Trust
Have you been keeping up with the drama around the US News & World Reports college ranking and law school ranking models?
Well, I have, mostly, and it’s in large part because of my friend Michael Thaddeus who gets a ton of credit for pointing out how Columbia was totally lying about their self-reported numbers, which has kicked off a huge amount of scrutiny of the model and self-scrutiny by the colleges to why they still engage with it.
The thing I want to talk about today is this article, which describes a “law dean rebellion” where a bunch of law schools quite rightly questioned the value of the rankings system and decided to get out, and how US News is begging them to stay and offering to rejigger the formula a little bit to appease them.
I’m particularly interested in this story because I devoted a large part of a chapter of my book to it. It was essentially the first Weapon of Math Destruction, if you will, because it was the first opaque scoring system that had widespread and devastating impact, in large part because it was crappy from the get go, but parents really cared about it in spite of that, and so colleges were forced to reckon with it, and they ended up gaming it so badly (see above) that everything got warped, including most importantly the lives of teenagers, and education got worse, and most expensive, and nobody won, except maybe the huge number of people who now work in administration.
Anyhoo, that’s all pretty well understood and many times demonstrated. But what I wanted to point out about this new story is just how perfectly it demonstrates my favorite refrain about algorithms, namely that they are opinions embedded in math.
Because, get this, here are the ways that US News wants to tweak its formula, according to the piece:
- less weight for “reputation”
- more weight for “do students do public service”
- nothing about student debt
- nothing about how the schools spend money
By contrast, here are the things that the deans are purported to want adjusted:
- credit for diversity
- credit for loan forgiveness and financial aid
- credit for public service by students
As you can see, there is one thing in common but a lot not in common, and more importantly, these are all stabs in the dark as to how a given person might actually decide to value a given school. In other words, it’s all opinion, it’s always been opinion, and the US News folks are finding themselves old fashioned and flat footed because their opinions are archaic, undependable, and totally reliant on a public that just trusts numbers because they “seem scientific.”
THIS IS NOW AN ARCHIVE
I’ve stopped blogging, but I’m keeping mathbabe.org around as an archive, which I hope you enjoy!
Cathy
The Shame Machine has arrived!
Look what came in the mail today, I’m so psyched!

Who starts blogging in 2021?
It’s a reasonable question: who starts blogging in 2021? After all, it’s an old fashioned writing form, and not so many people spend their days reading blogs when there are Twitter TLs and Facebook feeds to scroll through.
Well, the answer is my son Aise does. And I’m totally behind it.
As I’ve mentioned here before, blogging is a great way to get an idea out there, fully formed, on a daily or nearly daily basis. It’s good practice with making arguments, and forming precise claims with evidence, and most of all it gets you past the initial idea formation stage (the first blogpost on a topic) to the next one, where you get to ask, so what? or what next? kinds of questions. Personally, I never would have written a book without this blog, and of course my readers, who are the best blog readers ever.
Anyway, you’ve seen me crossposting his first three posts, about hyperinflation, seasonal adjustments, and the so-called housing shortage.
He’s now started his own blog here, and in the past three days he wrote about how he was right to worry about the job report, how homeownership is overrated, and how we should definitely worry about the growth of the economy. What’s more, he has plenty of data to support his arguments.
Congratulations, Aise!
There is Not a Housing Shortage; There is a Home Price Bubble
This is a guest post by Aise O’Neil. Crossposted here.
Homelessness is the greatest moral evil of our time. It is hard to be critical of any economic trends or rhetoric that seems focused in the direction of increasing home construction, given the context of homelessness. However, the increase of housing supply does not have a directly proportional relationship with the population of housed people.
The rental vacancy rate hit an all time high following the great recession after several boom years for housing construction. At the same time, the boom in housing supply gave way to a boom in foreclosures, leading many empty houses to be held by banks for years.
In other words, an increase in housing supply may not actually house new people. eIt may just mean more second homes or it may allow more students to move out of their parents’ households.
So, while the long term effects of more private housing supply would be positive, it will not be nearly as positive as the long term effects of public housing affordable to all people.
Having said that, the goal of this essay is to demonstrate that a housing price bubble – as well as a temporary boom in home construction – are happening and that their existence is being obfuscated by the home construction industry.
People Say There Is a Housing Shortage, But They Are Wrong:
News stories regarding our nation’s ostensible housing shortage have appeared on CNBC, Yahoo, NASDAQ, Fox Business, Bloomberg, the Washington Post and many other news sites. It certainly would explain the explosive growth in home prices we have been observing recently. According to the Case-Schiller home price index, home prices have grown 13.17% from March 2020 to March 2021.
The argument for a housing shortage seems pretty clear. Covid and the public policy impact of Covid seems to have caused the price of things used to make houses go up. The price of lumber, for instance, has increased dramatically. Similar things have happened to additional building materials. Furthermore there is a belief among many people that our country is in the midst of a labor shortage, which would lead to more expensive labor costs in home construction.
However, I have my own explanation. I say there is a bubble in home prices.
There are a lot of reasons to believe a bubble may exist. In response to the outbreak of Covid-19 and the subsequent economic downturn, the FED cut interest rates to the lowest overall levels they’ve ever been in American history. According to Freddie Mac, 30-year fixed rate mortgage interest rates hit an all-time low on the week of January 7th, 2021.
At the same time, the concentration of the outbreak in major cities, civil unrest and the possibility of tax hikes in municipalities facing new fiscal challenges has contributed to the problem of white flight to the suburbs. The consequence of white flight and low borrowing cost has set off a speculative bidding war as home prices grow higher and higher.
As the two factors started to push up the price of housing, people feel compelled to buy into the market to capture some of the price gains. Hence the price increases in home prices are self-sustaining for now.
While both the housing bubble and the housing shortage arguments are intuitive and seem to feasibly explain the rise in prices (one from a rise in demand the other from a lack of supply), the bubble idea is more supported by the data.
Here’s why. Both theories would tell us that there would be a frantic market for home purchases, rising prices and low housing inventory as demand for housing exceeds supply (or supply undershoots demand).
However, the bubble theory tells us that home prices should go up first and that this should increase home production. This increase in home production would then explain rising building material cost.
The shortage theory, on the other hand, tells us that building material cost and labor cost should go up first. Then, home production should fall as it becomes more expensive. The resulting shortage of new homes on the market would thus explain the rising prices.
The big difference between these two ideas is that if there is a bubble in housing, we should expect more home production, but if there is a shortage we should expect less.
In fact, home production has gone up and one can see that in the data. New home starts, a measure of home construction graphed below, has continued to grow through the crisis, despite a slight dip at the very beginning:

Real Private Residential Investment, another measure of home construction, has dipped then risen through the pandemic as the graph below shows:

Finally, new home sales are higher during the pandemic than they were before, showing that there is no shortage of new real estate entering the housing market:

Motivation Behind the Shortage Framing
Why are we hearing the wrong explanation for high home prices? The line behind the housing shortage is being intentionally pushed by some industry leaders in home construction.
For instance, the National Association of Home Builders (NAHB) has a page warning about the “housing affordability crisis,” framing it as a shortage-driven issue. In an interview with NASDAQ, the Chief Economist of the NAHB, claimed the housing shortage could be resolved by getting rid of regulations related to zoning, building safety and employee rights.
If you work for the NAHB it is your job to advocate for such reforms regardless of the context.
Furthermore, representatives of the NAHB don’t actually want home prices to fall. Nonetheless, they are go-to interview guests of the financial guests when reporters want an expert to explain why home prices are rising. Most of the economic experts in the housing market work for construction companies or related enterprises and have an agenda.
Conclusion:
A lot of high level information you get from the news you read is not the truth so much as a lobby’s version of the truth. The job of the news is not just to provide facts to us but to interpret the fats for us. Unless you’re a powerful corporation or association of small corporations, that interpretation is probably not being done in your own interests.
The housing bubble has increased the population of people for whom homeownership is unaffordable. The people we should worry about are those who cannot even afford homerentership and find themselves out in the cold. Bubbles are one of many pieces of evidence that markets aren’t efficient. They are a good reason to think ending homelessness might be a more important goal than keeping markets free. Housing bubbles are a good reason to think that houses are good to live in, not gamble with.
Seasonal Adjustments Will Skew Labor Reports
This is a guest post by Aise O’Neil.
I think that the next two labor reports will overstate job growth because of a technical issue, namely Seasonal Adjustments. To explain why I will explain 1) what seasonal adjustments are and 2) why they will overestimate the strength of the labor market this year.
Explanation of Seasonal Adjustments:
The idea of seasonally adjusting data is that the meaning of a data point can depend on the time of year. For instance, say the government is reporting on a value, like fuel oil, which is known to go up in January each year as people use it more in the winter. If one is trying to notice trends in the price of fuel oil, they would like a data series on fuel oil that accounts for the usual January spikes and shows the unusual changes.
The mechanisms for calculating seasonal adjustments are complicated, vary by government department, and often require a few college courses on econometrics to understand. The essential idea is that governments can look at recent data to estimate how much higher or lower a value gets in a particular month relative to a long-term trend. For instance, oil prices might be 1% higher in January than their longer-term trend according to recent data. When new seasonally adjusted data is reported, it will include the raw data plus an adjustment based on the estimates of how high or low the data is because of the time of year. For instance, when oil prices are released in the CPI report in January, the new seasonally adjusted data point may be 1% lower than the raw data in order to adjust for the fact that the raw data will show particularly high prices in January.
Seasonal adjustments to incoming data are made using estimates of seasonal trends which come from analyzing recent historical data. As more data comes in, seasonal adjustments to recent historical data can and will be retroactively revised.
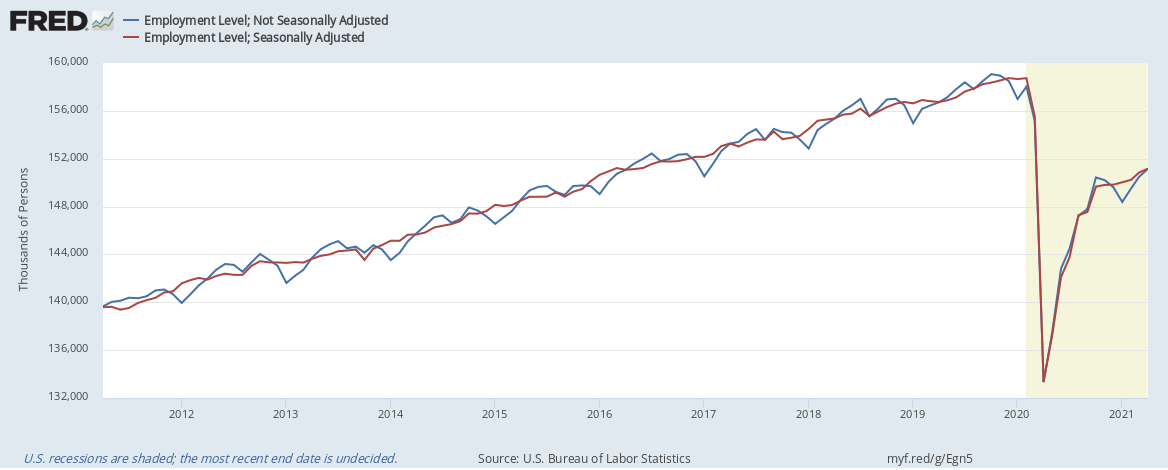
For example, the Bureau of Labor Statistics (BLS), which releases both the CPI and Current Employment Statistics (“CES”) Report seasonally adjusts incoming data based on data from the past 5 years and revises it based on incoming data for the next 5 years. The CES is the source of the “unemployment rate” and monthly job growth figures which the media often reports on. The chart below is an example of BLS seasonal adjustments in action. It shows the seasonally adjusted and non seasonally adjusted estimates of the same thing: the population of employed people in the US. Without the seasonally adjusted data series we would normally see reports of employment going up or down based on the time of year, not underlying trends in the economy.
Why Seasonal Adjustments Will Overstate Job Growth
It’s pretty clear that seasonally adjusted data is going to give a better sense of what’s happening in the economy than data which isn’t seasonally adjusted. However, seasonal adjustments aren’t perfect. Seasonal adjustments to incoming data will be based on rigorous analysis of historical data and will implicitly presume incoming data will display the same seasonal trends as past data. I’d argue that the disruption Covid has made to schooling is going to disrupt seasonal trends in employment.
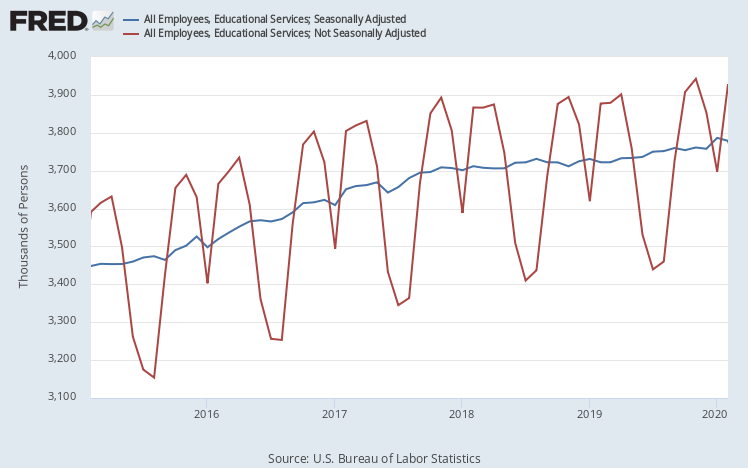
Normally the summer (and to a lesser extent winter) breaks will reduce overall employment for two reasons. Firstly, employment in education declines during summer and winter breaks. This can be seen in the graph below which depicts the seasonally adjusted and non-seasonally adjusted levels of employment in education. It includes data from 5 years prior to the Covid recession.
Secondly, parents have to look after their children and this will keep them out of the workforce. So employment levels should decline during school breaks. This would especially be true for women because women are more likely to be single parents and may bear more responsibility of looking after children generally even in two-parent heterosexual households. The graph below depicts the level of female employment in the United States divided by the overall level of employment. This is calculated using seasonally adjusted and non seasonally adjusted data series. It covers the 5 years prior to the Covid Recession. The relative female employment consistently falls in non seasonally adjusted terms going into the summer.

Both of these factors changed in the Covid era, because of virtual learning. In such an environment, certain seasonal jobs like janitorial staff, cafeteria workers, IT workers, and so on aren’t as prevalent as they used to be. The seasonal fluctuation coming directly from education is thus weaker. Additionally, many parents have had to stay out of the workforce to look after their kids throughout the year during online schooling. That means the seasonal fluctuation of summer break starting or ending is less important too.
With weaker seasonal effects now, seasonal adjustments which are based on historical data will over-account for them. When seasonal effects of the school holidays starting/ending will depress/increase employment, the seasonally adjusted levels of employment should show an increase/decrease.
One way to confirm this speculation is to look at what happens to both indicators of labor market health from August to September. That period is the strongest time for relative female employment growth as well as educational employment growth as a lot of schools start their fall semester in late August. As a consequence, the seasonally adjusted figures in both cases show a decline in seasonally adjusted terms. The graphs below show seasonally adjusted education employment and relative female employment over the past year to show the apparent weakness at the beginning of fall.
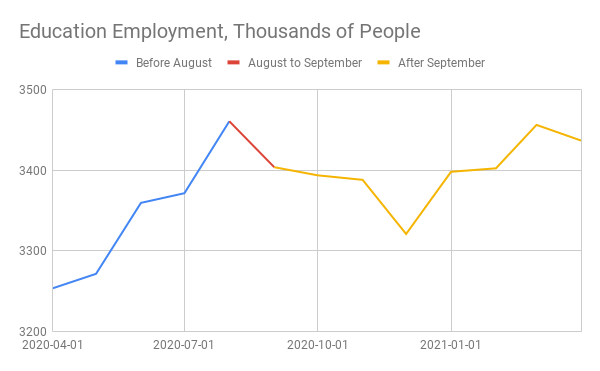
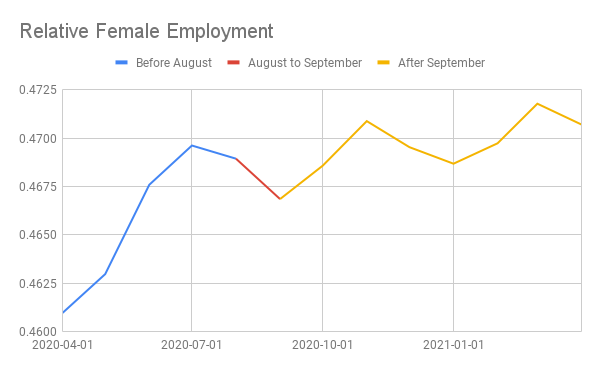
Both indicators of labor market health in seasonally adjusted terms fell significantly from August to September of 2020. This is because the start of the school year failed to create as many jobs for women and educators as it normally does, so in seasonally adjusted terms it showed a drop. In raw terms, the actual levels of relative female employment and employment in education increased, as is usual for that time of year.
In this same fashion, one can expect that the start of summer break will destroy less jobs than it normally does. As a result, in seasonally adjusted terms, the May and June jobs report will likely show strong job creation. This misleading seasonally adjusted data will be what the media reports in terms of the unemployment rate and monthly job creation.
Is Hyperinflation Coming?
This is a guest post by Aise O’Neil.
Inflation is growing out of control, or so we are told. Tucker Carlson recently said, “we wound up with frightening levels of inflation,” blaming such levels on the policies of the Biden administration. Glenn Beck published a youtube video entitled “How to Prepare for Hyperinflation in America.”
But it’s not just rightwing cranks who are panicking about inflation. Leading industrialists, like Warren Buffet, are concerned too. For that matter, financiers in the bond market are betting on high inflation. The 5-year breakeven inflation rate, a measure of expected inflation priced into the bond market recently hit a new high for the past decade: 2.72%. At the same time, the cpi index in April 2021, was 4.16% higher than it was in April 2020. That’s another record for a decade. And it’s likely that when this month’s CPI index comes out it will show an even higher percentage change from a year prior.
But even though CPI inflation is hitting records (and so is PCE inflation), there are three reasons to believe the numbers are misleading. Firstly, one has to consider factors which are making usual inflation indicators overstate the actual inflation rate. Second, one should consider better methods of tracking long term inflation trends, like median inflation. Thirdly, economic theory has something to say.
Reason #1: Normal Measures of Inflation Are Giving False Signals
There are two main indices used to track overall inflation that ordinary people might hear about. Both of them use year-on-year measures, which skew readings about a year after something weird happens.
Their names are CPI (“consumer price index”) and the PCE index (“Personal Consumption Expenditures Index”). Each month the government publishes a CPI and a PCE index for last month. We can measure how much prices have changed by looking at the differences in indexes. If the CPI is growing at an approximate rate of 2% a year, we could say CPI inflation is 2%.
When we hear about inflation rates, we normally are hearing about the “annual” inflation which is the % change in an index from a month to the same month next year. So we hear that “inflation was 4.16% in April 2021” we should think that prices are estimated to have risen about 4.16% from April 2020 to April 2021. Essentially, annual inflation is not a data point but a cumulative 12-month sum of data points. When that number is higher than it was last month, that could tell us about what happened recently in terms of the CPI/PCE index, or it could tell us about what happened to the CPI/PCE index last year. For instance, from March to April 2021, the annual CPI inflation went from 2.62% to 4.16%. This is because from March to April 2021 the CPI went up .76%; but from March to April 2020 it fell .7%.
If price changes of plus or minus .7% a month seem kind of volatile, that’s because they are. Volatility is particularly high in both the CPI and PCE index at the moment because of the effects the shutdown, it’s aftershock and reopening have been having on prices. The graph to the bottom left shows monthly changes in the CPI, measured in log-%. The data is seasonally adjusted by the government so seasonal factors have little to do with the behavior of the data. The blue line is the data and the red line is the average monthly inflation rate for December 2018 to December 2019. On the bottom right, one can see data on annual inflation measured in log-% changes to the cpi. The blue line is still the data and the red line is the inflation rate from December of 2018 to December of 2019.
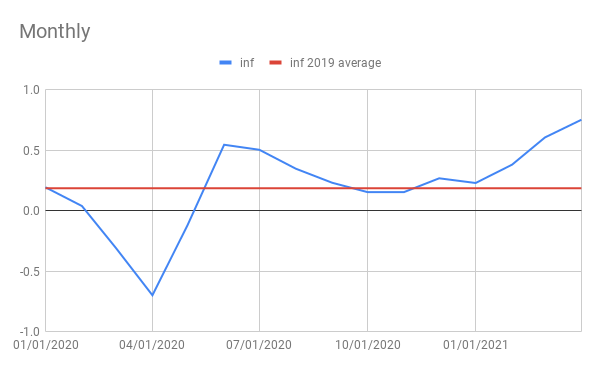
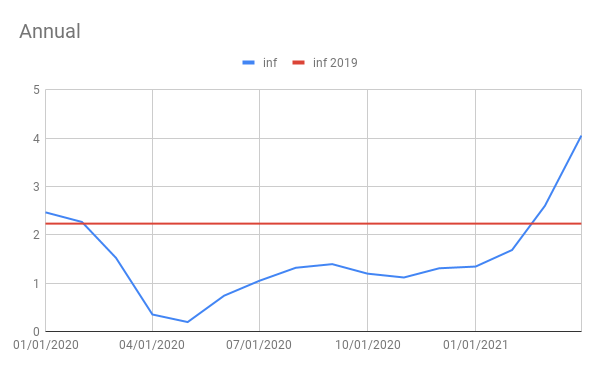
The point of the red line in both graphs is to give a sense of normal levels of inflation. The purpose of a monthly and annual inflation graph side by side is to show that monthly inflation tells some information that annual inflation does not. Both of these graphs are in terms of CPI data, but PCE index data would give similar results.
In terms of monthly inflation, what we saw at the early part of 2020 was extremely low, even negative inflation. This was a temporary phenomenon which occurred as prices for certain goods crashed at the beginning of the shutdown. For instance, when people stopped driving as much oil prices crashed. A few months later and prices slightly rebounded as companies like oil rigs cut back production. Afterwards, monthly inflation seemed to be at normal levels until now where the rollout of the vaccine is allowing for the economy to open up again.
What effect is this having on annual inflation? For about a year after the shutdown, annual inflation gave low readings because the shutdown crash in prices occured over the 1 year time frame to estimate annual inflation. Right now, two things are happening; 1) The volatile and temporary weak monthly inflation readings are falling out of the one year average, and 2) Volatile and temporarily strong inflation readings are coming into the average. This is going to mean an appearance of accelerating inflation.
Additionally, when the current month’s CPI comes out on June 10th, 1 year inflation will cover the rebound in prices shortly after the shutdown along with the spike in prices experienced during the re-opening. While prices did grow strongly from May to August of 2020, that was an aftershock of declining prices from February to May of 2020. The next annual inflation figure will cover the aftershock of the shutdown price decline but not the price decline itself, while at the same time it will include price growth we are experiencing during the re-opening. If prices grow from April to May 2021 as much as they did from March to April, then annual CPI inflation could be as high as 5.05%. This will be scary to some if they don’t understand that it is just temporary shocks.
Reason #2: Better Long-term Inflation Measures
It should be clear now that CPI and PCE index data often has to be scrutinized and can be quite volatile. For that reason many economists attempt to find less volatile measures of inflation. The Cleveland Branch of the Federal Reserve has developed multiple ways to measure underlying trends in inflation. They have developed 2 very good ones: Median CPI and Median PCE inflation. While standard PCE and CPI inflation measure inflation through finding changes to the average levels of prices in an index (it’s slightly more complicated for PCE); median inflation finds the weighted median change of prices in an index. The graphs below compare historical standard and median inflation (in log-% terms) and show how median CPI inflation is more stable and reliable and is not indicating a risk of rising inflation.
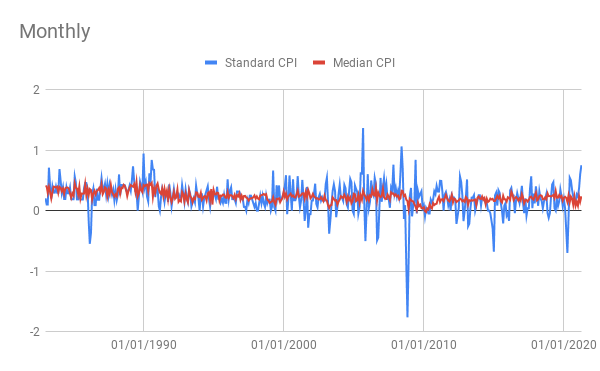
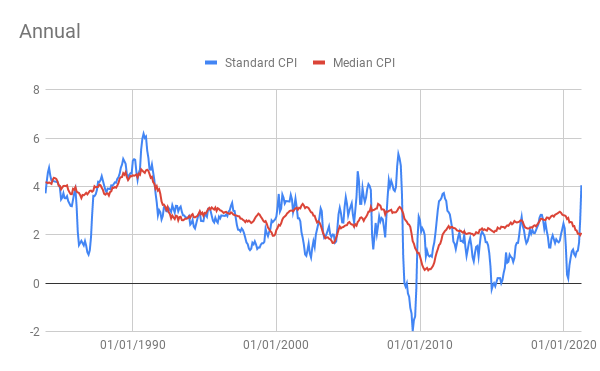
Reason #3: Economic Theory
Economic theory tells us that inflation is determined by three things. The first is shocks of the forms I’ve been explaining so far (like the shutdown causing commodity prices to drop). Overall, these impacts will be short-lived and average out to 0 in the long term.
The second relates to how inflation declines during recessions and grows during expansions. If due to a lack of strong spending, a lot of resources like land labor and capital go unused, the prices for those inputs will decline lowering production cost. This can be observed in the graphs above which show a decline in inflation following the early 90s recession, a slight dip following the 2002-2003 recession and a large dip following the great recession of 2008. Recently annual inflation has dipped down again according to median inflation. This is because we have entered another recession.
Thirdly, embedded inflation is a very important long-term determinant of inflation. Oftentimes, economic actors set prices in response to or in anticipation of inflation which then determines inflation. Hence, factors like catch-up inflation and expected inflation are useful in modeling inflation and are thought to give it a good deal of inertia.
In conclusion, what theory tells us is that it is unlikely we will go from inflation persistently undershooting 2% PCE for years to hyperinflation. It is also probably a good idea for economic policymakers to ignore transitory shocks to the best extent possible.
Finally, the most important question to determine where inflation will be headed when the virus is dealt with is: How high will unemployment be? If we cannot ensure a full, rapid recovery to this economic crisis, and likely we can’t, then inflation will probably be heading down, not up.
Conclusion
Overall the conclusion from this is one should not personally be too worried about hyperinflation. Furthermore, one should not pay too much attention to the ideas of Tucker Carlson and Glenn Beck (that’s a more general rule).
Finally, if one wants to make some money, one should realize that betting on rising inflation is a winning bet on wall street right now. It will likely continue to be until June 10th where the next CPI report comes out showing a yearly inflation rate in the vicinity of 4.5% to 5%. However, this high inflation is illusory and eventually wall street will catch on.
The Swing-State Power of Black Voters Is Real
I wrote an uncharacteristically non-nerdy political opinion piece for Bloomberg, my way of finding yet another way of celebrating Stacey Abrams:
The Swing-State Power of Black Voters Is Real
After the 2020 election, discouragement campaigns shouldn’t work anymore.
For more of my Bloomberg pieces, go here.
Let’s Detox From Polling
I cannot believe I fell, once again, for the polling that gave me the information I wanted to hear. It is indeed an emotional addiction, rather than a scientific curiosity, and I think we’d all be better off shedding our addiction to political polling. My latest Bloomberg Opinion column:
Polling Failed. It’s Time to Kick the Addiction
Doubling down won’t help Americans understand themselves.
For more of my Bloomberg columns, go here.
Get ready for an epic hangover
In my latest Bloomberg post, I make the case that, in the best case scenario that Trump is gone in January, we have a massive amount of work to catch up on, especially with regard to combatting the power and malevolence of big tech.
If Biden Wins, Prepare for an Epic Policy Hangover
There’s so much to fix beyond what Trump has broken.
For more of my Bloomberg columns, go here.
We need more pre-existing condition clauses, not fewer
In today’s Bloomberg column, I wrote about how we should protect our medical “pre-existing condition” clause and agitate for many more:
This Essential Part of Obamacare Needs Expanding
The problem of pre-existing conditions extends far beyond health.
For more of my Bloomberg columns, go here.
A working vaccine might not end well
I wrote a Bloomberg column in which I argued that we’re terrible at anticipating feedback loops, especially in the world of coronavirus. One consequence of this is that we keep overreacting to good news by making things worse. I’m worried that, once a safe and effective vaccine is announced, people will change their behavior dramatically, undermining the good news and making it effectively bad.
People, Please Don’t Throw Your Masks Away
They can keep saving lives even after a vaccine becomes available.
You can read more of my Bloomberg pieces here.
TikTok’s Algorithm Cannot Be Trusted
My newest Bloomberg column is one in which I explain what I know about recommendation engines, which concludes with my claim that whoever controls TikTok’s algorithm can of course tamp down or emphasize whatever kind of content they want, misinformation or otherwise (and to be clear, being able to manipulate recommendation algorithms is in general a good thing!):
TikTok’s Algorithm Can’t Be Trusted
If it operates like other recommendation engines, it can be used for good or for evil.
Read my other Bloomberg columns here.
Three Updates
Good afternoon! I hope you are well. I have three updates for mathbabe readers.
First, I wrote a new Bloomberg column, in which I suggest that the recent algorithmic grading scandals in the UK (the IB exam and the A-levels) are just the beginning of an oncoming mutant army of crap algorithms:
Mutant Algorithms Are Coming for Your Education
Grading scandals are just the beginning.
Next, I reviewed mathematician Eugenia Cheng’s new book, X+Y: A Mathematician’s Manifesto on Rethinking Gender for the New York Times:
Third, I was in a movie that’s coming out on Netflix tomorrow called The Social Dilemma:
Documentary Filmmaker Jeff Orlowski Uncovers Invisible Threat With ‘The Social Dilemma’
Finally, I wanted to draw your attention to two new pieces:
- Meredith Broussard’s op-ed in the New York Times today When Algorithms Give Real Students Imaginary Grades
- Yael Eisenstein’s new TED talk, How Facebook Profits from Polarization.
School reopening is a disaster. This is deliberate.
Hi all,
After talking to a bunch of my friends and acquaintances in public education I’ve realized that not only is the school reopening plan a total freaking disaster, but it’s absolutely deliberately so. My newest Bloomberg piece:
School Reopening Is a Disaster in the Making
From New York City to Florida, students and teachers are pawns in a political game.
You can read more of my Bloomberg columns here.
I’m taking Trump seriously
Yesterday I wrote a new Bloomberg column in which I took Trump seriously when he repeated for the nth time that our problem is that we do too many tests, which thus shows too many confirmed COVID-19 cases.
And when I say “seriously”, what I mean is I thought through what kind of model of the world Trump must have in his head that would be consistent with this statement. For him, metrics like case counts or TV ratings are somehow more real than people dying of coronavirus. It’s weird but consistently true, and I think we should understand it. Here’s my column:
Here’s More Evidence That Trump Is an Algorithm
The president is focused on data, independent of substance.
You can read more of my Bloomberg columns here.



