Archive
The Value Added Teacher Model Sucks
Today I want you to read this post (hat tip Jordan Ellenberg) written by Gary Rubinstein, which is the post I would have written if I’d had time and had known that they released the actual Value-added Model scores to the public in machine readable format here.
If you’re a total lazy-ass and can’t get yourself to click on that link, here’s a sound bite takeaway: a scatter plot of scores for the same teacher, in the same year, teaching the same subject to kids in different grades. So, for example, a teacher might teach math to 6th graders and to 7th graders and get two different scores; how different are those scores? Here’s how different:

Yeah, so basically random. In fact a correlation of 24%. This is an embarrassment, people, and we cannot let this be how we decide whether a teacher gets tenure or how shamed a person gets in a newspaper article.
Just imagine if you got publicly humiliated by a model with that kind of noise which was purportedly evaluating your work, which you had no view into and thus you couldn’t argue against.
I’d love to get a meeting with Bloomberg and show him this scatter plot. I might also ask him why, if his administration is indeed so excited about “transparency,” do they release the scores but not the model itself, and why they refuse to release police reports at all.
Open Models (part 2)
In my first post about open models, I argued that something needs to be done but I didn’t really say what.
This morning I want to outline how I see an open model platform working, although I won’t be able to resist mentioning a few more reasons we urgently need this kind of thing to happen.
The idea is for the platform to have easy interfaces both for modelers and for users. I’ll tackle these one at a time.
Modeler
Say I’m a modeler. I just wrote a paper on something that used a model, and I want to open source my model so that people can see how it works. I go to this open source platform and I click on “new model”. It asks for source code, as well as which version of which open source language (and exactly which packages) it’s written in. I feed it the code.
It then asks for the data and I either upload the data or I give it a url which tells the platform the location of the data. I also need to explain to the platform exactly how to transform the data, if at all, to prepare it for feeding to the model. This may require code as well.
Next, I specify the extent to which the data needs to stay anonymous (hopefully not at all, but sometimes in the case of medical data or something, I need to place security around the data). These anonymity limits will translate into the kinds of visualizations and results that can be requested by users but not the overall model’s aggregated results.
Finally, I specify which parameters in my model were obvious “choices” (like tuning parameters, or prior strengths, or thresholds I chose for cleaning data). This is helpful but not necessary, since other people will be able to come along later and add things. Specifically, they might try out new things like how many signals to use, which ones to use, and how to normalize various signals.
That’s it, I’m done, and just to be sure I “play” the model and make sure that the results jive with my published paper. There’s a suite of visualization tools and metrics of success built into the model platform for me to choose from which emphasize the good news for my model. I’ve created an instance of my model which is available for anyone to take a look at. This alone would be major progress, and the technology already exists for some languages.
User
Now say I’m a user. First of all, I want to be able to retrain the model and confirm the results, or see a record that this has already been done.
Next, I want to be able to see how the model predicts a given set of input data (that I supply). Specifically, if I’m a teacher and this is the open-sourced value added teacher model, I’d like to see how my score would have varied if I’d had 3 fewer students or they had had free school lunches or if I’d been teaching in a different district. If there were a bunch of different models, I could see what scores my data would have produced in different cities or different years in my city. This is a good start for a robustness test for such models.
If I’m also a modeler, I’d like to be able to play with the model itself. For example, I’d like to tweak the choices that have been made by the original modeler and retrain the model, seeing how different the results are. I’d like to be able to provide new data, or a new url for data, along with instructions for using the data, to see how this model would fare on new training data. Or I’d like to think of this new data as updating the model.
This way I get to confirm the results of the model, but also see how robust the model is under various conditions. If the overall result holds only when you exclude certain outliers and have a specific prior strength, that’s not good news.
I can also change the model more fundamentally. I can make a copy of the model, and add another predictor from the data or from new data, and retrain the model and see how this new model performs. I can change the way the data is normalized. I can visualize the results in an entirely different way. Or whatever.
Depending on the anonymity constraints of the original data, there are things I may not be able to ask as a user. However, most aggregated results should be allowed. Specifically, the final model with its coefficients.
Records
As a user, when I play with a model, there is an anonymous record kept of what I’ve done, which I can choose to put my name on. On the one hand this is useful for users because if I’m a teacher, I can fiddle with my data and see how my score changes under various conditions, and if it changes radically, I have a way of referencing this when I write my op-ed in the New York Times. If I’m a scientist trying to make a specific point about some published result, there’s a way for me to reference my work.
On the other hand this is useful for the original modelers, because if someone comes along and improves my model, then I have a way of seeing how they did it. This is a way to crowdsource modeling.
Note that this is possible even if the data itself is anonymous, because everyone in sight could just be playing with the model itself and only have metadata information.
More on why we need this
First, I really think we need a better credit rating system, and so do some guys in Europe. From the New York Times article (emphasis mine):
Last November, the European Commission proposed laws to regulate the ratings agencies, outlining measures to increase transparency, to reduce the bloc’s dependence on ratings and to tackle conflicts of interest in the sector.
But it’s not just finance that needs this. The entirety of science publishing is in need of more transparent models. From the nature article’s abstract:
Scientific communication relies on evidence that cannot be entirely included in publications, but the rise of computational science has added a new layer of inaccessibility. Although it is now accepted that data should be made available on request, the current regulations regarding the availability of software are inconsistent. We argue that, with some exceptions, anything less than the release of source programs is intolerable for results that depend on computation. The vagaries of hardware, software and natural language will always ensure that exact reproducibility remains uncertain, but withholding code increases the chances that efforts to reproduce results will fail.
Finally, the field of education is going through a revolution, and it’s not all good. Teachers are being humiliated and shamed by weak models, which very few people actually understand. Here’s what the teacher’s union has just put out to prove this point:

Is Big Data Evil?
Back when I was growing up, your S.A.T. score was a big deal, but I feel like I lived in a relatively unfettered world of anonymity compared to what we are creating now. Imagine if your SAT score decided your entire future.
Two days ago I wrote about Emanuel Derman’s excellent new book “Models. Behaving. Badly.” and mentioned his Modeler’s Hippocratic Oath, which I may have to restate on every post from now on:
- I will remember that I didn’t make the world, and it doesn’t satisfy my equations.
- Though I will use models boldly to estimate value, I will not be overly impressed by mathematics.
- I will never sacrifice reality for elegance without explaining why I have done so.
- Nor will I give the people who use my model false comfort about its accuracy. Instead, I will make explicit its assumptions and oversights.
- I understand that my work may have enormous effects on society and the economy, many of them beyond my comprehension.
I mentioned that every data scientist should sign at the bottom of this page. Since then I’ve read three disturbing articles about big data. First, this article in the New York Times, which basically says that big data is a bubble:
This is a common characteristic of technology that its champions do not like to talk about, but it is why we have so many bubbles in this industry. Technologists build or discover something great, like railroads or radio or the Internet. The change is so important, often world-changing, that it is hard to value, so people overshoot toward the infinite. When it turns out to be merely huge, there is a crash, in railroad bonds, or RCA stock, or Pets.com. Perhaps Big Data is next, on its way to changing the world.
In a way I agree, but let’s emphasize the “changing the world” part, and ignore the hype. The truth is that, beyond the hype, the depth of big data’s reach is not really understood yet by most people, especially people inside big data. I’m not talking about the technological reach, but rather the moral and philosophical reach.
Let me illustrate my point by explaining the gist of the other two articles, both from the Wall Street Journal. The second article describes a model which uses the information on peoples’ credit card purchases to direct online advertising at them:
MasterCard earlier this year proposed an idea to ad executives to link Internet users to information about actual purchase behaviors for ad targeting, according to a MasterCard document and executives at some of the world’s largest ad companies who were involved in the talks. “You are what you buy,” the MasterCard document says.
MasterCard doesn’t collect people’s names or addresses when processing credit-card transactions. That makes it tricky to directly link people’s card activity to their online profiles, ad executives said. The company’s document describes its “extensive experience” linking “anonymized purchased attributes to consumer names and addresses” with the help of third-party companies.
MasterCard has since backtracked on this plan:
The MasterCard spokeswoman also said the idea described in MasterCard’s April document has “evolved significantly” and has “changed considerably” since August. After the company’s conversations with ad agencies, MasterCard said, it found there was “no feasible way” to connect Internet users with its analysis of their purchase history. “We cannot link individual transaction data,” MasterCard said.
How loudly can you hear me say “bullshit”? Even if they decide not to do this because of bad public relations, there are always smaller third-party companies who don’t even have a PR department:
Credit-card issuers including Discover Financial Services’ Discover Card, Bank of America Corp., Capital One Financial Corp. and J.P. Morgan Chase & Co. disclose in their privacy policies that they can share personal information about people with outside companies for marketing. They said they don’t make transaction data or purchase-history information available to outside companies for digital ad targeting.
The third article talks about using credit scores, among other “scoring” systems, to track and forecast peoples’ behavior. They model all sorts of things, like the likelihood you will take your pills:
Experian PLC, the credit-report giant, recently introduced an Income Insight score, designed to estimate the income of a credit-card applicant based on the applicant’s credit history. Another Experian score attempts to gauge the odds that a consumer will file for bankruptcy.
Rival credit reporter Equifax Inc. offers an Ability to Pay Index and a Discretionary Spending Index that purports to indicate whether people have extra money burning a hole in their pocket.
Understood, this is all about money. This is, in fact, all about companies ranking you in terms of your potential profitability to them. Just to make sure we’re all clear on the goal then:
The system “has been incredibly powerful for consumers,” said Mr. Wagner.
Ummm… well, at least it’s nice to see that it’s understood there is some error in the modeling:
Eric Rosenberg, director of state-government relations for credit bureau TransUnion LLC, told Oregon state lawmakers last year that his company can’t show “any statistical correlation” between the contents of a credit report and job performance.
But wait, let’s see what the CEO of Fair Isaac Co, one of the companies creating the scores, says about his new system:
“We know what you’re going to do tomorrow”
This is not well aligned with the fourth part of the Modeler’s Hippocratic Oath (MHO). The article goes on to expose some of the questionable morality that stems from such models:
Use of credit histories also raises concerns about racial discrimination, because studies show blacks and Hispanics, on average, have lower credit scores than non-Hispanic whites. The U.S. Equal Employment Opportunity Commission filed suit last December against the Kaplan Higher Education unit of Washington Post Co., claiming it discriminated against black employees and applicants by using credit-based screens that were “not job-related.”
Let me make the argument for these models before I explain why I think they’re flawed.
First, in terms of the credit card information, you should all be glad that the ads coming to us online are so beautifully tailored to your needs and desires- it’s so convenient, almost like someone read your mind and anticipated you’d be needing more vacuum cleaner bags at just the right time! And in terms of the scoring, it’s also very convenient that people and businesses somehow know to trust you, know that you’ve been raised with good (firm) middle-class values and ethics. You don’t have to argue my way into a new credit card or a car purchase, because the model knows you’re good for it. Okay, I’m done.
The flip side of this is that, if you don’t happen to look good to the models, you are funneled into a shitty situation, where you will continue to look bad. It’s a game of chutes and ladders, played on an enormous scale.
[If there’s one thing about big data that we all need to understand, it’s the enormous scale of these models.]
Moreover, this kind of cyclical effect will actually decrease the apparent error of the models: this is because if we forecast you as being uncredit-worthy, and your life sucks from now on and you have trouble getting a job or a credit card and when you do you have to pay high fees, then you are way more likely to be a credit risk in the future.
One last word about errors: it’s always scary to see someone on the one hand admit that the forecasting abilities of a model may be weak, but on the other hand say things like “we know what you’re going to do tomorrow”. It’s a human nature thing to want something to work better than it does, and that’s why we need the IMO (especially the fifth part).
This all makes me think of the movie Blade Runner, with its oppressive sense of corporate control, where the seedy underground economy of artificial eyeballs was the last place on earth you didn’t need to show ID. There aren’t any robots to kill (yet) but I’m getting the feeling more and more that we are sorting people at birth, or soon after, to be winners or losers in this culture.
Of course, collecting information about people isn’t new. Why am I all upset about it? Here are a few reasons, which I will expand on in another post:
- There’s way more information about people nowadays than their Social Security Number; the field of consumer information gathering is huge and growing exponentially
- All of those quants who left Wall Street are now working in data science and have real skills (myself included)
- They also typically don’t have any qualms; they justify models like this by saying, hey we’re just using correlations, we’re not forcing people to behave well or badly, and anyway if I don’t make this model someone else will
- The real bubble is this: thinking these things work, and advocating their bulletproof convenience and profitability (in the name of mathematics)
- Who suffers when these models fail? Answer: not the corporations that use them, but rather the invisible people who are designated as failures.
Math in Business
Here’s an annotated version of my talk at M.I.T. a few days ago. There was a pretty good turnout, with lots of grad students, professors, and I believe some undergraduates.
What are the options?
First let’s talk about the different things you can do with a math degree.
Working as an academic mathematician
You all know about this, since you’re here. In fact most of your role models are probably professors. More on this.
Working at a government institution
I don’t have personal experience, but there are plenty of people I know who are perfectly happy working for the spooks or NASA.
Working as a quant in finance
This means trying to predict the market in one way or another, or modeling how the market works for the sake of measuring risk.
Working as a data scientist
This is my current job, and it is kind of vague, but it generally means dealing with huge data sets to locate, measure, visualize, and forecast patterns. Quants in finance are examples of data scientists, and they work in the most, or one of the most, developed subfield of data science.
Cultural Differences
I care a lot about the culture of my job, as I think women in general tend to. For that reason I’m going to try to give a quick and exaggerated description of the cultures of these various options and how they differ from each other.
Feedback is slow in academics
I’m still waiting for my last number theory paper to get published, and I left the field in 2007. That hurts. But in general it’s a place for people who have internal feedback mechanisms and don’t rely on external ones. If you’re a person who knows that you’re thinking about the most important question in the world and you don’t need anyone to confirm that, then academics may be a good cultural fit. If, on the other hand, you are wondering half the time why you’re working on this particular problem, and whether the answer really matters or ever will matter to someone, then academics will be a tough place for you to live.
Institutions are painfully bureaucratic
As I said before, I don’t have lots of personal experience here, but I’ve heard that good evidence that working at a government institution is sometimes painful in terms of waiting for things that should obviously happen actually happen. On the other hand I’ve also head lots of women say they like working for institutions and that they are encouraged to become managers and grow groups. We will talk more about this idea of being encouraged to be organized.
Finance firms are cut-throat
Again, exaggerating for effect, but there’s a side effect of being in a place whose success is determined along one metric (money), and that is that people are typically incredibly competitive with each other for their perceived value with respect to that metric. Kind of like a bunch of gerbils in a case with not quite enough food. On the other hand, if you love that food yourself, you might like that kind of struggle.
Startups are unstable
If you don’t mind wondering if your job is going to exist in 1 or 2 months, then you’ll love working at a startup. It’s an intense and exciting journey with a bunch of people you’d better trust or you’ll end up really hating them.
Outside academics, mathematicians have superpowers
One general note that you, being inside academics right now, may not be aware of: being really fucking good at math is considered a superpower by the people outside. This is because you can do stuff with your math that they actually don’t know how to do, no matter how much time they spend trying. This power is good and bad, but in any case it’s very different than you may be used to.
Going back to your role models: you see your professors, they’re obviously really smart, and you naturally may want to become just like them when you grow up. But looking around you, you notice there are lots of good math students here at M.I.T. (or wherever you are) and very few professor jobs. So there is this pyramid, where lots of people a the bottom are all trying to get these fancy jobs called math professorships.
Outside of math, though, it’s an inverted world. There are all of these huge data sets, needing analysis, and there are just very few places where people are getting trained to do stuff like that. So M.I.T. is this tiny place inside the world, which cannot possibly produce enough mathematicians to satisfy the demand.
Another way of saying this is that, as a student in math, you should absolutely be aware that it’s easier to get a really good job outside the realm of academics.
Outside academics, you get rewarded for organizational skills (punished within)
One other big cultural difference I want to mention is that inside academics, you tend to get rewarded for avoiding organizational responsibilities, with some exceptions perhaps if you organize conferences or have lots of grad students. Outside of academics, though, if you are good at organizing, you generally get rewarded and promoted and given more responsibility for managing a group of nerds. This is another personality thing- some math nerds love the escape from organizing, or just plain suck at it, and maybe love academics for that reason, whereas some math nerds are actually quite nurturing and don’t mind thinking about how systems should be set up and maintained, and if those people are in academics they tend to be given all of the “housekeeping” in the department, which is almost always bad for their career.
Mathematical Differences
Let’s discuss how the actual work you would do in these industries is different. Exaggeration for effect as usual.
Academic freedom is awesome but can come with insularity
If you really care about having the freedom to choose what math you do, then you absolutely need to stay in academics. There is simply no other place where you will have that freedom. I am someone who actually does have taste, but can get nerdy and interested in anything that is super technical and hard. My taste, in fact, is measured in part by how much I think the answer actually matters, defined in various ways: how many people care about the answer and how much of an impact would knowing the answer make? These properties are actually more likely to be present in a business setting. But some people are totally devoted to their specific field of mathematics.
The flip side of academic freedom is insularity; since each field of mathematics gets to find its way, there tend to be various people doing things that almost nobody understands and maybe nobody will ever care about. This is more or less frustrating to you depending on your personality. And it doesn’t happen in business: every question you seriously work on is important, or at least potentially important, for one reason or another to the business.
You don’t decide what to work on in business but the questions can be really interesting
Modeling with data is just plain fascinating, and moreover it’s an experimental science. Every new data set requires new approaches and techniques, and you feel like a mad scientist in a lab with various tools that you’ve developed hanging on the walls around you.
You can’t share proprietary information with the outside world when you work in business or for the government
The truth is, the actual models you create are often the crux of the profit in that business, and giving away the secrets is giving away the edge.
On the other hand, sometimes you can and it might make a difference
The techniques you develop are something you generally can share with the outside world. This emerging field of data science can potentially be put to concrete and good use (more on that later).
In business, more emphasis on shallower, short term results
It’s all about the deadlines, the clients, and what works.
On the other hand, you get much more feedback
It’s kind of nice that people care about solving urgent problems when… you’ve just solved an urgent problem.
Which jobs are good for women?
Part of what I wanted to relay today is those parts of these jobs that I think are particularly suitable for women, since I get lots of questions from young women in math wondering what to do with themselves.
Women tend to care about feedback
And they tend to be more sensitive to it. My favorite anecdote about this is that, when I taught I’d often (not always) see a huge gender difference right after the first midterm. I’d see a young woman coming to office hours fretting about an A- and I’d have to flag down a young man who got a C, and he’d say something like, “Oh, I’m not worried, I’ll just study and ace the final.” There’s a fundamental assumption going on here, and women tend to like more and more consistent feedback (especially positive feedback).
One of my most firm convictions about why there are not more women math professors out there is that there is virtually no feedback loop after graduating with a Ph.D., except for some lucky people (usually men) who have super involved and pushy advisors. Those people tend to be propelled by the will of their advisor to success, and lots of other people just stay in place in a kind of vacuum. I’ve seen lots of women lose faith in themselves and the concept of academics at this moment. I’m not sure how to solve this problem except by telling them that there’s more feedback in business. I do think that if people want to actually address the issue they need to figure this out.
Women tend to be better communicators
This is absolutely rewarded in business. The ability to hold meetings, understand people’s frustrations and confusions and explain in new terms so that they understand, and to pick up on priorities and pecking orders is absolutely essential to being successful, and women are good at these things because they require a certain amount of empathy.
In all of these fields, you need to be self-promoting
I mention this because, besides needing feedback and being good communicators, women tend to not be as self-promoting as men, and this is something that they should train themselves out of. Small things like not apologizing help, as does being very aware of taking credit for accomplishments. Where men tend to say, “then I did this…”, women tend to say, “then my group did this…”. I’m not advocating being a jerk, but I am advocating being hyper aware of language (including body language) and making sure you don’t single yourself out for not being a stand-out.
The tenure schedule sucks for women
I don’t think I need to add anything to this.
No “summers off” outside academics… but maybe that’s a good thing
Academics don’t actually take their summers off anyway. And typically the women are the ones who end up dealing more with the kids over the summer, which could be awesome if that’s what they want but also tends to add a bias in terms of who gets papers written.
How do I get a job like that?
Lots of people have written to me asking how to prepare themselves for a job in data science (I include finance in this category, but not the governmental institutions. I have no idea how to get a job at NASA or the NSA).
Get a Ph.D. (establish your ability to create)
I’m using “Ph.D.” as a placeholder here for something that proves you can do original creative building. But it’s a pretty good placeholder; if you don’t have a Ph.D. but you are a hacker and you’ve made something that works and does something new and clever, that may be sufficient too. But if you’ve just followed your nose, and done well in your courses then it will be difficult to convince someone to hire you. Doing the job well requires being able to create ad hoc methodology on the spot, because the assumptions in developed theory never actually happen with real data.
Know your way around a computer
Get to the point where you can make things work on your computer. Great if you know how unix and stuff like cronjobs (love that word) work, but at the very least know to google everything instead of bothering people.
Learn python or R, maybe java or C++
Python and R are the very basic tools of a data scientist, and they allow quick and dirty data cleaning, modeling, measuring, and forecasting. You absolutely need to know one of them, or at the very least matlab or SAS or STATA. The good news is that none of these are hard, they just take some time to get used to.
Acquire some data visualization skills
I would guess that half my time is spent visualizing my results in order to explain them to non-quants. A crucial skill (both the pictures and the explanations).
Learn basic statistics
And I mean basic. But on the other hand I mean really, really, learn it. So that when you come across something non-standard (and you will), you can rewrite the field to apply to your situation. So you need to have a strong handle on all the basic stuff.
Read up on machine learning
There are lots of machine learners out there, and they have a vocabulary all their own. Take the Stanford Machine Learning classor something to learn this language.
Emphasize your communication skills and follow-through
Most of the people you’ll be working with aren’t trained mathematicians, and they absolutely need to know that you will be able to explain your models to them. At the same time, it’s amazing how convincing it is when you tell someone, “I’m a really good communicator.” They believe you. This also goes back to my “do not be afraid to self-promote” theme.
Practice explaining what a confidence interval is
You’d be surprised how often this comes up, and you should be prepared, even in an interview. It’s a great way to prep for an interview: find someone who’s really smart, but isn’t a mathematician, and ask them to be skeptical. Then explain what a confidence interval is, while they complain that it makes no sense. Do this a bunch of times.
Other stuff
I wanted to throw in a few words about other related matters.
Data modeling is everywhere (good data modelers aren’t)
There’s an asston of data out there waiting to be analyzed. There are very few people that really know how to do this well.
The authority of the inscrutable
There’s also a lot of fraud out there, related to the fact that people generally are mathematically illiterate or are in any case afraid of or intimidated by math. When people want to sound smart they throw up an integral, and it’s a conversation stopper. It is a pretty evil manipulation, and it’s my opinion that mathematicians should be aware of this and try to stop it from happening. One thing you can do: explain that notation (like integrals) is a way of writing something in shorthand, the meaning of which you’ve already agreed on. Therefore, by definition, if someone uses notation without that prior agreement, it is utterly meaningless and adds rather than removes confusion.
Another aspect of the “authority of the inscrutable” is the overall way that people claimed to be measuring the risk of the mortgage-backed securities back before and during the credit crisis. The approach was, “hey you wouldn’t understand this, it’s math. But trust us, we have some wicked smart math Ph.D.’s back there who are thinking about this stuff.” This happens all the time in business and it’s the evil side of the superpower that is mathematics. It’s also easy to let this happen to you as a mathematician in business, because above all it’s flattering.
Open source data, open source modeling
I’m a huge proponent of having more visibility into the way that modeling affects us all in our daily lives (and if you don’t know that this is happening then I’ve got news for you). A particularly strong example is the Value-added modeling movement currently going on in this country which evaluates public teachers and schools. The models and training data (and any performance measurements) are proprietary. They should not be. If there’s an issue of anonymity, then go ahead and assign people randomly.
Not only should the data that’s being used to train the model be open source, but the model itself should be too, with the parameters and hyper-parameters in open-source code on a website that anyone can download and tweak. This would be a huge view into the robustness of the models, because almost any model has sub-modeling going on that dramatically affects the end result but that most modelers ignore completely as a source of error. Instead of asking them about that, just test it for yourself.
Meetups
The closest thing to academics lectures in data science is called “Meetups”. They are very cool. I wrote about them previously here. The point of them is to create a community where we can share our techniques (without giving away IP) and learn about new software packages. A huge plus for the mathematician in business, and also a great way to meet other nerds.
Data Without Borders
I also wanted to mention that, once you have a community of nerds such as is gathered at Meetups, it’s also nice to get them together with their diverse skills and interests and do something cool and valuable for the world, without it always being just about money. Data Without Borders is an organization I’ve become involved with that does just that, and there are many others as well.
Please feel free to comment or ask me more questions about any of this stuff. Hope it is helpful!
Datadive update
I left my datadive team at 9:15pm last night hard at work, visualizing the data in various ways as well as finding interesting inconsistencies. I will try to post some actual results later, but I want to wait for them to be (somewhat) finalized. For now I can make some observations.
- First, I really can’t believe how cool it is to meet all of these friendly and hard-working nerds who volunteered their entire weekend to clean and dig through data. It’s a really amazing group and I’m proud of how much they’ve done.
- Second, about half of the data scientists are women. Awesome and unusual to see so many nerd women outside of academics!
- Third, data cleaning is hard work and is a huge part of the job of a data scientist. I should never forget that. Having said that, though, we might want to spend some time before the next datadive pre-cleaning and formatting the data so that people have more time to jump into the analytics. As it is we learned a lot about data cleaning as a group, but next time we could learn a lot about comparing methodology.
- Statistical software packages such as Stata have trouble with large (250MB) files compared to python, probably because of the way they put everything into memory at once. So it’s cool that everyone comes to a datadive with their own laptop and language, but some thought should be put into what project they work on depending on this information.
- We read Gelman, Fagan and Kiss’s article about using the Stop and Frisk data to understand racial profiling, with the idea that we could test it out on more data or modify their methodology to slightly change the goal. However, they used crime statistics data that we don’t have and can’t find and which are essential to a good study.
- As an example of how crucial crime data like this is, if you hear the statement, “10% of the people living in this community are black but 50% of the people stopped and frisked are black,” it sounds pretty damning, but if you add “50% of crimes are committed by blacks” then it sound less so. We need that data for the purpose of analysis.
- Why is crime statistics data so hard to find? If you go to NYPD’s site and search for crime statistics, you get really very little information, which is not broken down by area (never mind x and y coordinates) or ethnicity. That stuff should be publicly available. In any case it’s interesting that the Stop and Frisk data is but the crime stats data isn’t.
- Oh my god check out our wiki, I just looked and I’m seeing some pretty amazing graphics. I saw some prototypes last night and I happen to know that some of these visualizations are actually movies, showing trends over time. Very cool!
- One last observation: this is just the beginning. The data is out there, the wiki is set up, and lots of these guys want to continue their work after this weekend is over. That’s what I’m talking about.
Bayesian regressions (part 1)
I’ve decided to talk about how to set up a linear regression with Bayesian priors because it’s super effective and not as hard as it sounds. Since I’m not a trained statistician, and certainly not a trained Bayesian, I’ll be coming at it from a completely unorthodox point of view. For a more typical “correct” way to look at it see for example this book (which has its own webpage).
The goal of today’s post is to abstractly discuss “bayesian priors” and illustrate their use with an example. In later posts, though, I promise to actually write and share python code illustrating bayesian regression.
The way I plan to be unorthodox is that I’m completely ignoring distributional discussions. My perspective is, I have some time series (the 

A “bayesian prior” can be thought of as equivalent to data you’ve already seen before starting on your dataset. Since we think of the signals (the 
The information you need to know about the
Let me illustrate with an example. Suppose you are working on the simplest possible model: you are taking a single time series and seeing how earlier values of 
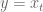
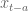
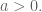
What is your prior for this? Turns out you already have one (two actually) if you work in finance. Namely, you expect the signal of the most recent data to be stronger than whatever signal is coming from older data (after you decide how many past signals to use by first looking at a lagged correlation plot). This is just a way of saying that the sizes of the coefficients should go down as you go further back in time. You can make a prior for that by working on the diagonal of the covariance matrix.
Moreover, you expect the signals to vary continuously- you (probably) don’t expect the third-from recent variable 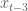
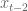
In my next post I’ll talk about how to combine exponential down-weighting of old data, which is sacrosanct in finance, with bayesian priors. Turns out it’s pretty interesting and you do it differently depending on circumstances. By the way, I haven’t found any references for this particular topic so please comment if you know of any.
Data science: tools vs. craft
I’ve enjoyed how many people are reading the post I wrote about hiring a data scientist for a business. It’s been interesting to see how people react to it. One consistent reaction is that I’m just saying that a data scientist needs to know undergraduate level statistics.
On some level this is true: undergrad statistics majors can learn everything they need to know to become data scientists, especially if they also take some computer science classes. But I would add that it’s really not about familiarity with a specific set of tools that defines a data scientist. Rather, it’s about being a craftsperson (and a salesman) with those tools.
To set up an analogy: I’m not a chef because I know about casserole dishes.
By the way, I’m not trying to make it sound super hard and impenetrable. First of all I hate it when people do that and second of all it’s not at all impenetrable as a field. In fact I’d say it the other way: I’d prefer smart nerdy people to think they could become data scientists even without a degree in statistics, because after all basic statistics is pretty easy to pick up. In fact I’ve never studied statistics in school.
To get to the heart of the matter, it’s more about what a data scientist does with their sometimes basic tools than what the tools are. In my experience the real challenges are things like
- Defining the question in the first place: are we asking the question right? Is an answer to this question going to help our business? Or should we be asking another question?
- Once we have defined the question, we are dealing with issues like dirty data, too little data, too much data, data that’s not at all normally distributed, or that is only a proxy to our actual problem.
- Once we manhandle the data into a workable form, we encounter questions like, is that signal or noise? Are the errorbars bigger than the signal? How many more weeks or months of data collection will we need to go through before we trust this signal enough to bet the business on it?
- Then of course we go back to: should we have asked a different question that would have not been as perfect an answer but would have definitely given us an answer?
In other words, once we boil something down to a question in statistics it’s kind of a breeze. Even so, nothing is ever as standard as you would actually find in a stats class – the chances of being asked a question similar to a stats class is zero. You always need to dig deeply enough into your data and the relevant statistics to understand what the basic goal of that t-test or statistic was and modify the standard methodology so that it’s appropriate to your problem.
My advice to the business people is to get someone who is really freaking smart and who has also demonstrated the ability to work independently and creatively, and who is very good at communicating. And now that I’ve written the above issues down, I realize that another crucial aspect to the job of the data scientist is the ability to create methodology on the spot and argue persuasively that it is kosher.
A useful thing for this last part is to have broad knowledge of the standard methods and to be able to hack together a bit of the relevant part of each; this requires lots of reading of textbooks and research papers. Next, the data scientist has to actually understand it sufficiently to implement it in code. In fact the data scientist should try a bunch of things, to see what is more convincing and what is easier to explain. Finally, the data scientist has to sell it to everyone else.
Come to think of it the same can be said about being a quant at a hedge fund. Since there’s money on the line, you can be sure that management wants you to be able to defend your methodology down to the tiniest detail (yes, I do think that being a quant at a hedge fund is a form of a data science job, and this guy woman agrees with me).
I would argue that an undergrad education probably doesn’t give enough perspective to do all of this, even though the basic mathematical tools are there. You need to be comfortable building things from scratch and dealing with people in intense situations. I’m not sure how to train someone for the latter, but for the former a Ph.D. can be a good sign, or any person that’s taken on a creative project and really made something is good too. They should also be super quantitative, but not necessarily a statistician.




{kind=link}