Archive
Model Thinking (part 2)
I recently posted about the new, free online course Model Thinking. I’ve watched more videos now and I am prepared to make more comments.
For the record, the lecturer, Scott Page, is by all accounts a great guy, and indeed he seems super nice on video. I’d love to have him over for dinner with my family someday (Professor Page, please come to my house for dinner when you’re in town).
In spite of liking him, though, pretty much every example he gives as pro-modeling is, for me, an anti-modeling example. Maybe I should make a complementary series of YouTube comment videos. It’s not totally true, of course- I just probably don’t notice the things we agree on. But I do notice the topics on which we disagree:
- He talks a lot about how models make us clearer thinkers. But what he really seems to mean is that they make us stupider thinkers. His example is that, in order to decide who to vote for for president, we can model this decision as depending on two things: the likability of the person in question (presumably he assumes we want our president to be likable), and the extent to which that person is “as left” or “as right” as we are. I don’t know about you, but I actually care about specific issues and where people stand on them, and which issues I consider likely to come up for consideration in the next election cycle. Like, if I like someone for his “stick it to the banks” approach but he’s anti-abortion, then I think about whether abortion is likely to actually become illegal. And by the way, I don’t particularly care if my president is likable, I’d rather have him or her effective.
- He bizarrely chooses “financial interconnectedness” as a way of seeing how cool models are, and he shows a graph where the nodes are the financial institutions (Goldman Sachs, JP Morgan, etc.) and the edges are labeled with an interconnectedness score, bigger meaning more interconnected. He shows that, according to this graph, back in 2008 it shows we knew to bail out AIG but that it was definitely okay to let Lehman fail. I’m wondering if he really meant that this was an example of how your model could totally fail because your “interconnectedness scoring” sucked, but he didn’t seem to be tongue in cheek.
- He then talked about measuring the segregation of a neighborhood, either by race or by income, and he used New York and Chicago as examples. I won’t go into lots of details, but he gave a score to each block, like the census maps do with coloring, and he used those scores to develop a new score which was supposed to measure the segregation of each block. The problem I have with this segregation score is that it depends very heavily on the definition of the overall area you are considering. If you enlarge your definition of the New York City to include the suburbs, then the segregation score of New York City may (probably would) be completely different. This seems to be a really terrible characteristic of such a metric.
- My second problem with his segregation score is that, at the end, he had overall segregation numbers for Philly and Detroit, and then showed the maps and mentioned that, looking at the maps, you wouldn’t really notice that one is more segregated than the other (Philly more than Detroit), but knowing the scores you do know that. Umm.. I’d like to rather say, if you are getting scores that are not fundamentally obvious from looking at these pictures, then maybe it’s because your score sucks. What does having a “good segregation score” mean if not that it captures something you can see through a picture?
- One thing I liked was a demonstration of Schelling’s Segregation Model, which shows that, if you have a group of people who are not all that individually racist, you can still end up with a neighborhood which is very segregated.
I’m looking forward to watching more videos with my skeptical eye. After all, the guy is really a sweetheart, and I do really care about the idea of teaching people about modeling.
Creepy model watch
I really feel like I can’t keep up with all of the creepy models coming out and the news articles about them, so I think I’ll just start making a list. I would appreciate readers adding to my list in the comment section. I think I’ll move this to a separate page on my blog if it comes out nice.
- I recently blogged about a model that predicts student success in for-profit institutions, which I claim is really mostly about student debt and default,
- but here’s a model which actually goes ahead and predicts default directly, it’s a new payday-like loan model. Oh good, because the old payday models didn’t make enough money or something.
- Of course there’s the teacher value-added model which I’ve blogged about multiple times, most recently here. And here’s a paper I’d like everyone to read before they listen to anyone argue one way or the other about the model (h/t Joshua Batson). The abstract is stunning: Recently, educational researchers and practitioners have turned to value-added models to evaluate teacher performance. Although value-added estimates depend on the assessment used to measure student achievement, the importance of outcome selection has received scant attention in the literature. Using data from a large, urban school district, I examine whether value-added estimates from three separate reading achievement tests provide similar answers about teacher performance. I find moderate-sized rank correlations, ranging from 0.15 to 0.58, between the estimates derived from different tests. Although the tests vary to some degree in content, scaling, and sample of students, these factors do not explain the differences in teacher effects. Instead, test timing and measurement error contribute substantially to the instability of value-added estimates across tests. Just in case that didn’t come through, they are saying that the results of the teacher value-added test scores are very very noisy.
- That reminds me, credit scoring models are old but very very creepy, wouldn’t you agree? What’s in them that they want to conceal them?
- Did you read about how Target predicts pregnancy? Extremely creepy.
- I’m actually divided about whether it’s the creepiest though, because I think the sheer enormity of information that Facebook collects about us is the most depressing thing of all.
Before I became a modeler, I wasn’t personally offended by the idea that people could use my information. I thought, I’ve got nothing to hide, and in fact maybe it will make my life easier and more efficient for the machine to know me and my habits.
But here’s how I think now that I’m a modeler and I see how this stuff gets made and I see how it gets applied. That we are each giving up our data, and it’s so easy to do we don’t think about it, and it’s being used to funnel people into success or failure in a feedback loop. And the modelers, the people responsible for creating these things and implementing them, are always already the successes, they are educated and are given good terms on their credit cards and mortgages because they have a nifty high tech job. So the makers get to think of how much easier and more convenient their lives are now that the models see how dependable they are as consumers.
But when there are funnels, there’s always someone who gets funneled down.
Think about how it works with insurance. The idea of insurance is to pool people so that when one person gets sick, the medical costs for that person are paid from the common fund. Everyone pays a bit so it doesn’t break the bank.
But if we have really good information, we begin to see how likely people are to get sick. So we can stratify the pool. Since I almost never get sick, and when I do it’s just strep throat, I get put into a very nice pool with other people who never get sick, and we pay very very little and it works out great for us. But other people have worse luck of the DNA draw and they get put into the “pretty sick” pool and their premium gets bigger as their pool gets sicker until they are really sick and the premium is actually unaffordable. We are left with a system where the people who need insurance the most can’t be part of the system anymore. Too much information ruins the whole idea of insurance and pooled risk.
I think modern modeling is analogous. When people offer deals, they can first check to see if the people they are offering deals are guaranteed to pay back everything. In other words, the businesses (understandably) want to make very certain they are going to profit from each and every customer, and they are getting more and more able to do this. That’s great for customers with perfect credit scores, and it makes it easier for people with perfect credit scores to keep their perfect credit scores, because they are getting the best deals.
But for people with bad credit scores, they get the rottenest deals, which makes a larger and larger percentage of their takehome pay (if they even get a job considering their credit scores) go towards fees and high interest rates. This of course creates an environment in which it’s difficult to improve their credit score- so they default and their credit score gets worse instead of better.
So there you have it, a negative feedback loop and a death spiral of modeling.
What data science _should_ be doing
I recently read this New York Times article about a company that figures out how to get the best deal when you rent a car. The company is called AutoSlash and the idea is you book with them and they keep looking for good deals, coupons, or free offers every day until you actually need the car.
Wait a minute, a data science model that actually directly improves the lives of its customers? Why can’t we have more of these? Obviously the car companies absolutely hate this idea. But what are they going to do, stop offering online shopping?
Why don’t we see this in every category of shopping? It seems to me that you could do something like this and start a meta-marketplace, where you buy something and then, depending on how long you’re willing to wait until delivery, the model looks for a better online deal, in exchange for a small commission. Then you’d have to make sure that on average the commission is paying for itself with better deals, but my guess is it would work if you allowed it a few days to search per purchase. Or if you really are a doubter, fix a minimum wait time and let the company take some (larger) percentage of the difference between the initial price and the eventual best price.
Another way of saying this, is that when you go online to buy something, depending on the scale (say it’s on the expensive side) you probably shop around for a few days or weeks. Why do that in person? Just have a computer do it for you and tell you at the end what deal it gave you. Don’t get bombarded by ads, let the computer get bombarded by ads for you.
A modeled student
There’s a recent article from Inside Higher Ed (hat tip David Madigan) which focuses on a new “Predictive Analytics Reporting Framework” that tracks students’ online learning and predicts their outcomes, like whether they will finish the classes they’re taking or drop out. Who’s involved? The University of Phoenix among others:
A broad range of institutions (see factbox) are participating. Six major for-profits, research universities and community colleges — the sort of group that doesn’t always play nice — are sharing the vault of information and tips on how to put the data to work.
I don’t know about you but I’ve read the wikipedia article about for-profit universities and I don’t have a great feeling about their goals. In the “2010 Pell Grant Fraud controversy” section you can find this:
Out of the fifteen sampled, all were found to have engaged in deceptive practices, improperly promising unrealistically high pay for graduating students, and four engaged in outright fraud, per a GAO report released at a hearing of the Health, Education, Labor and Pensions Committee held on August 4, 2010.[28]
Anyhoo, back to the article. They track people online and make suggestions for what classes people may want to take:
The data set has the potential to give institutions sophisticated information about small subsets of students – such as which academic programs are best suited for a 25-year-old male Latino with strength in mathematics, for example. The tool could even become a sort of Match.com for students and online universities, Ice said.
That makes me wonder- what would I have been told to do as a white woman with strength in math, if such a program had existed when I went to college? Maybe I would have been pushed to become something that historical data said I’d be best suited for? Maybe something safe, like actuarial work? What if this had existed when my mother was at MIT in applied math in the early ’60’s? Would they have had a suggestion for her?
Aside from snide remarks, let me make two direct complaints about this idea. First, I despise the idea of funneling people into chutes and ladders-type career projections based on their external attributes rather than their internal motives and desires. This kind of model, which as all models is based on historical data, is potentially a way to formally adopt racist and sexist policies. It codifies discrimination.
The second complaint: this is really all about money. In the article they mention that the model has already helped them decide whether Pell grants are being issued to students “correctly”:
Students can only receive the maximum Pell Grant award when they take 12 credit hours, which “forces people into concurrency,” said Phil Ice, vice president of research and development for the American Public University System and the project’s lead investigator. “So the question becomes, is the current federal financial aid structure actually setting these individuals up for failure?”
In other words, it looks like they are going to try to use the results of this model to persuade the government to change the way Pell Grants are distributed. Now, I’m not saying that the Pell Grant program is perfect; maybe it should be changed. But I am saying that this model is all about money and helping these online universities figure out which students will be most profitable. I’m familiar with constructing such models, because I was a quant at a hedge fund once and I know how these guys think. You can bet this model is proprietary, too- you wouldn’t want people to see into how they are being funneled too much, it might get awkward.
The article doesn’t she away from such comparisons either. From the article:
The project appears to have built support in higher education for the broader use of Wall Street-style slicing and dicing of data. Colleges have resisted those practices in the past, perhaps because some educators have viewed “data snooping” warily. That may be changing, observers said, as the project is showing that big data isn’t just good for hedge funds.
Just to be clear, they are saying it’s also good for for-profit institutions, not necessarily the students in them.
I’d like to see a law passed that forced such models to be open-sourced at the very very least. The Bill and Melinda Gates Foundation is funding this, who know how to reach those guys to make this request?
How Big Pharma Cooks Data: The Case of Vioxx and Heart Disease
This is cross posted from Naked Capitalism.
Yesterday I caught a lecture at Columbia given by statistics professor David Madigan, who explained to us the story of Vioxx and Merck. It’s fascinating and I was lucky to get permission to retell it here.
Disclosure
Madigan has been a paid consultant to work on litigation against Merck. He doesn’t consider Merck to be an evil company by any means, and says it does lots of good by producing medicines for people. According to him, the following Vioxx story is “a line of work where they went astray”.
Yet Madigan’s own data strongly suggests that Merck was well aware of the fatalities resulting from Vioxx, a blockbuster drug that earned them $2.4b in 2003, the year before it “voluntarily” pulled it from the market in September 2004. What you will read below shows that the company set up standard data protection and analysis plans which they later either revoked or didn’t follow through with, they gave the FDA misleading statistics to trick them into thinking the drug was safe, and set up a biased filter on an Alzheimer’s patient study to make the results look better. They hoodwinked the FDA and the New England Journal of Medicine and took advantage of the public trust which ultimately caused the deaths of thousands of people.
The data for this talk came from published papers, internal Merck documents that he saw through the litigation process, FDA documents, and SAS files with primary data coming from Merck’s clinical trials. So not all of the numbers I will state below can be corroborated, unfortunately, due to the fact that this data is not all publicly available. This is particularly outrageous considering the repercussions that this data represents to the public.
Background
The process for getting a drug approved is lengthy, requires three phases of clinical trials before getting FDA approval, and often takes well over a decade. Before the FDA approved Vioxx, less than 20,000 people tried the drug, versus 20,000,000 people after it was approved. Therefore it’s natural that rare side effects are harder to see beforehand. Also, it should be kept in mind that for the sake of clinical trials, they choose only people who are healthy outside of the one disease which is under treatment by the drug, and moreover they only take that one drug, in carefully monitored doses. Compare this to after the drug is on the market, where people could be unhealthy in various ways and could be taking other drugs or too much of this drug.
Vioxx was supposed to be a new “NSAID” drug without the bad side effects. NSAID drugs are pain killers like Aleve and ibuprofen and aspirin, but those had the unfortunate side effects of gastro-intestinal problems (but those are only among a subset of long term users, such as people who take painkillers daily to treat chronic pain, such as people with advanced arthritis). The goal was to find a pain-killer without the GI side effects. The underlying scientific goal was to find a COX-2 inhibitor without the COX-1 inhibition, since scientists had realized in 1991 that COX-2 suppression corresponded to pain relief whereas COX-1 suppression corresponded to GI problems.
Vioxx introduced and withdrawn from the market
The timeline for Vioxx’s introduction to the market was accelerated: they started work in 1991 and got approval in 1999. They pulled Vioxx from the market in 2004 in the “best interest of the patient”. It turned out that it caused heart attacks and strokes. The stock price of Merck plummeted and $30 billion of its market cap was lost. There was also an avalanche of lawsuits, one of the largest resulting in a $5 billion settlement which was essentially a victory for Merck, considering they made a profit of $10 billion on the drug while it was being sold.
The story Merck will tell you is that they “voluntarily withdrew” the drug on September 30, 2004. In a placebo-controlled study of colon polyps in 2004, it was revealed that over a time period of 1200 days, 4% of the Vioxx users suffered a “cardiac, vascular, or thoracic event” (CVT event), which basically means something like a heart attack or stroke, whereas only 2% of the placebo group suffered such an event. In a group of about 2400 people, this was statistically significant, and Merck had no choice but to pull their drug from the market.
It should be noted that, on the one hand Merck should be applauded for checking for CVT events on a colon polyps study, but on the other hand that in 1997, at the International Consensus Meeting on COX-2 Inhibition, a group of leading scientists issued a warning in their Executive Summary that it was “… important to monitor cardiac side effects with selective COX-2 inhibitors”. Moreover, in an internal Merck email as early as 1996, it was stated there was a “… substantial chance that CVT will be observed.” In other words, Merck knew to look out for such things. Importantly, however, there was no subsequent insert in the medicine’s packaging that warned of possible CVT side-effects.
What the CEO of Merck said
What did Merck say to the world at that point in 2004? You can look for yourself at the four and half hour Congressional hearing (seen on C-SPAN) which took place on November 18, 2004. Starting at 3:27:10, the then-CEO of Merck, Raymond Gilmartin, testifies that Merck “puts patients first” and “acted quickly” when there was reason to believe that Vioxx was causing CVT events. Gilmartin also went on the Charlie Rose show and repeated these claims, even go so far as stating that the 2004 study was the first time they had a study which showed evidence of such side effects.
How quickly did they really act though? Were there warning signs before September 30, 2004?
Arthritis studies
Let’s go back to the time in 1999 when Vioxx was FDA approved. In spite of the fact that it was approved for a rather narrow use, mainly for arthritis sufferers who needed chronic pain management and were having GI problems on other meds (keeping in mind that Vioxx was way more expensive than ibuprofen or aspirin, so why would you use it unless you needed to), Merck nevertheless launched an ad campaign with Dorothy Hamill and spent $160m (compare that with Budweiser which spent $146m or Pepsi which spent $125m in the same time period).
As I mentioned, Vioxx was approved faster than usual. At the time of its approval, the completed clinical studies had only been 6- or 12-week studies; no longer term studies had been completed. However, there was one underway at the time of approval, namely a study which compared Aleve with Vioxx for people suffering from osteoarthritis and rheumatoid arthritis.
What did the arthritis studies show? These results, which were available in late 2003, showed that the CVT events were more than twice as likely with Vioxx as with Aleve (CVT event rates of 32/1304 = 0.0245 with Vioxx, 6/692 = 0.0086 with Aleve, with a p-value of 0.01). As we see this is a direct refutation of the fact that CEO Gilmartin stated that they didn’t have evidence until 2004 and acted quickly when they did.
In fact they had evidence even before this, if they bothered to put it together (in fact they stated a plan to do such statistical analyses but it’s not clear if they did them- or in any case there’s so far no evidence that they actually did these promised analyses).
In a previous study (“Table 13”), available in February of 2002, the could have seen that, comparing Vioxx to placebo, we saw a CVT event rate of 27/1087 = 0.0248 with Vioxx versus 5/633 = 0.0079 with placebo, with a p-value of 0.01. So, three times as likely.
In fact, there was an even earlier study (“1999 plan”), results of which were available in July of 2000, where the Vioxx CVT event rate was 10/427 = 0.0234 versus a placebo event rate of 1/252 = 0.0040, with a p-value of 0.05 (so more than 5 times as likely). This p-value can be taken to be the definition of statistically significant. So actually they knew to be very worried as early as 2000, but maybe they… forgot to do the analysis?
The FDA and pooled data
Where was the FDA in all of this?
They showed the FDA some of these numbers. But they did something really tricky. Namely, they kept the “osteoarthritis study” results separate from the “rheumatoid arthritis study” results. Each alone were not quite statistically significant, but together were amply statistically significant. Moreover, they introduced a third category of study, namely the “Alzheimer’s study” results, which looked pretty insignificant (more on that below though). When you pooled all three of these study types together, the overall significance was just barely not there.
It should be mentioned that there was no apparent reason to separate the different arthritic studies, and there is evidence that they did pool such study data in other places as a standard method. That they didn’t pool those studies for the sake of their FDA report is incredibly suspicious. That the FDA didn’t pick up on this is probably due to the fact that they are overworked lawyers, and too trusting on top of that. That’s unfortunately not the only mistake the FDA made (more below).
Alzheimer’s Study
So the Alzheimer’s study kind of “saved the day” here. But let’s look into this more. First, note that the average age of the 3,000 patients in the Alzheimer’s study was 75, it was a 48-month study, and that the total number of deaths for those on Vioxx was 41 versus 24 on placebo. So actually on the face of it it sounds pretty bad for Vioxx.
There were a few contributing reasons why the numbers got so mild by the time the study’s result was pooled with the two arthritis studies. First, when really old people die, there isn’t always an autopsy. Second, although there was supposed to be a DSMB as part of the study, and one was part of the original proposal submitted to the FDA, this was dropped surreptitiously in a later FDA update. This meant there was no third party keeping an eye on the data, which is not standard operating procedure for a massive drug study and was a major mistake, possibly the biggest one, by the FDA.
Third, and perhaps most importantly, Merck researchers created an added “filter” to the reported CVT events, which meant they needed the doctors who reported the CVT event to send their info to the Merck-paid people (“investigators”), who looked over the documents to decide whether it was a bonafide CVT event or not. The default was to assume it wasn’t, even though standard operating procedure would have the default assuming that there was such an event. In all, this filter removed about half the initially reported CVT events, and about twice as often the Vioxx patients had their CVT event status revoked as for the placebo patients. Note that the “investigator” in charge of checking the documents from the reporting doctors is paid $10,000 per patient. So presumably they wanted to continue to work for Merck in the future.
The effect of this “filter” was that, instead of it seeming 1.5 times as likely to have a CVT event if you were taking Voixx, it seemed like it was only 1.03 as likely, with a high p-score.
If you remove the ridiculous filter from the Alzheimer’s study, then you see that as of November 2000 there was statistically significant evidence that Vioxx caused CVT events in Alzheimer patients.
By the way, one extra note. Many of the 41 deaths in the Vioxx group were dismissed as “bizarre” and therefore unrelated to Vioxx. Namely, car accidents, falling of ladders, accidentally eating bromide pills. But at this point there’s evidence that Vioxx actually accelerates Alzheimer’s disease itself, which could explain those so-called bizarre deaths. This is not to say that Merck knew that, but rather that one should not immediately dismiss the concept of statistically significant just because it doesn’t make intuitive sense.
VIGOR and the New England Journal of Medicine
One last chapter in this sad story. There was a large-scale study, called the VIGOR study, with 8,000 patients. It was published in the New England Journal of Medicine on November 23, 2000. See also this NPR timeline for details. They didn’t show the graphs which would have emphasized this point, but they admitted, in a deceptively round-about way, that Vioxx has 4 times the number of CVT events than Aleve. They hinted that this is either because Aleve is protective against CVT events or that Vioxx is bad for it, but left it open.
But Bayer, which owns Aleve, issued a press release saying something like, “if Aleve is protective for CVT events then it’s news to us.” Bayer, it should be noted, has every reason to want people to think that Aleve is protective against CVT events. This problem, and the dubious reasoning explaining it away, was completely missed by the peer review system; if it had been spotted, Vioxx would have been forced off the market then and there. Instead, Merck purchased 900,000 preprints of this article from the NE Journal of Medicine, which is more than the number of practicing doctors in the U.S.. In other words, the Journal was used as a PR vehicle for Merck.
The paper emphasized that Aleve has twice the rate of ulcers and bleeding, at 4%, whereas Vioxx had a rate of only 2% among chronic users. When you compare that to the elevated rate of heart attack and death (0.4% to 1.2%) of Vioxx over Aleve, though, the reduced ulcer rate doesn’t seem all that impressive.
A bit more color on this paper. It was written internally by Merck, after which non-Merck authors were found. One of them is Loren Laine. Loren helped Merck develop a sound-bite interview which was 30 seconds long and was sent to the news media and run like a press interview, even though it actually happened in Merck’s New Jersey office (with a backdrop to look like a library) with a Merck employee posing as a neutral interviewer. Some smart lawyer got the outtakes of this video made available as part of the litigation against Merck. Check out this youtube video, where Laine and the fake interviewer scheme about spin and Laine admits they were being “cagey” about the renal failure issues that were poorly addressed in the article.
The damage done
Also on the Congress testimony I mentioned above is Dr. David Graham, who speaks passionately from minute 41:11 to minute 53:37 about Vioxx and how it is a symptom of a broken regulatory system. Please take 10 minutes to listen if you can.
He claims a conservative estimate is that 100,000 people have had heart attacks as a result of using Vioxx, leading to between 30,000 and 40,000 deaths (again conservatively estimated). He points out that this 100,000 is 5% of Iowa, and in terms people may understand better, this is like 4 aircraft falling out of the sky every week for 5 years.
According to this blog, the noticeable downwards blip in overall death count nationwide in 2004 is probably due to the fact that Vioxx was taken off the market that year.
Conclusion
Let’s face it, nobody comes out looking good in this story. The peer review system failed, the FDA failed, Merck scientists failed, and the CEO of Merck misled Congress and the people who had lost their husbands and wives to this damaging drug. The truth is, we’ve come to expect this kind of behavior from traders and bankers, but here we’re talking about issues of death and quality of life on a massive scale, and we have people playing games with statistics, with academic journals, and with the regulators.
Just as the financial system has to be changed to serve the needs of the people before the needs of the bankers, the drug trial system has to be changed to lower the incentives for cheating (and massive death tolls) just for a quick buck. As I mentioned before, it’s still not clear that they would have made less money, even including the penalties, if they had come clean in 2000. They made a bet that the fines they’d need to eventually pay would be smaller than the profits they’d make in the meantime. That sounds familiar to anyone who has been following the fallout from the credit crisis.
One thing that should be changed immediately: the clinical trials for drugs should not be run or reported on by the drug companies themselves. There has to be a third party which is in charge of testing the drugs and has the power to take the drugs off the market immediately if adverse effects (like CVT events) are found. Hopefully they will be given more power than risk firms are currently given in finance (which is none)- in other words, it needs to be more than reporting, it needs to be an active regulatory power, with smart people who understand statistics and do their own state-of-the-art analyses – although as we’ve seen above even just Stats 101 would sometimes do the trick.
New online course: model thinking
There’s a new course starting soon, taught by Scott Page, about “model thinking” (hat tip David Laxer). The course web site is located here and some preview lectures are here. From the course description:
In this class, I present a starter kit of models: I start with models of tipping points. I move on to cover models explain the wisdom of crowds, models that show why some countries are rich and some are poor, and models that help unpack the strategic decisions of firm and politicians.
The models cover in this class provide a foundation for future social science classes, whether they be in economics, political science, business, or sociology. Mastering this material will give you a huge leg up in advanced courses. They also help you in life.
In other words, this guy is seriously ambitious. Usually around people who are this into modeling I get incredibly suspicious and skeptical, and this is no exception. I’ve watched the first two videos and I’ve come across the following phrases:
- Models make us think better
- Models are better than we are
- Models make us humble
The third one is particularly strange since his evidence that models make us humble seems to come from the Dutch tulip craze, where a linear model of price growth was proven wrong, and the recent housing boom, where people who modeled housing prices as always going up (i.e. most people) were wrong.
I think I would have replaced the above with the following:
- Models can make us come to faster conclusions, which can work as rules of thumb, but beware of when you are misapplying such shortcuts
- Models make us think we are better than we actually are: beware of overconfidence in what is probably a ridiculous oversimplification of what may be a complicated real-world situation
- Models sometimes fail spectacularly, and our overconfidence and misapplication of models helps them do so.
So in other words I’m looking forward to disagreeing with this guy a lot.
He seems really nice, by the way.
I should also mention that in spite of anticipating disagreeing fervently with this guy, I think what Coursera is doing by putting up online courses is totally cool. Check out some of their other offerings here.
How unsupervised is unsupervised learning?
I was recently at a Meetup and got into a discussion with Joey Markowitz about the difference between supervised, unsupervised, and partially (semi-) supervised learning.
For those who haven’t heard of this stuff, a bit of explanation. These are general categories of models. In every model there’s input data, and in some models there’s also a known quantity you are trying to predict, starting from the input data.
Not surprisingly, supervised learning is what finance quants do, because they always know what they’re going to predict: the money. Unsupervised means you don’t really know what you are looking for in advance. A good example of this is “clustering” algorithms, where you input the data and the number of clusters and the algorithm finds the “best” way of clustering the data into that many clusters (with respect to some norm in N-space where N is the number of attributes of the input data). As a toy example, you could have all your friends write down how much they like various kinds of foods (tofu, broccoli, garlic, ice cream, buttered toast) and after clustering you might find a bunch of people live in the “we love tofu, broccoli, and garlic” cluster and the others live over in the “we love ice cream and buttered toast” cluster.
I hadn’t heard of the phrase “partially supervised learning,” but it turns out it just means you train your model both on labeled and unlabeled data. Usually there’s a domain expert who doesn’t have time to classify all of the data, but the algorithm is augmented by their partial information. So, again a toy example, if the algorithm is classifying photographs, it may help for a human to go through some of them and classify them “porn” vs. “not porn” (because I know it when I see it).
Joey had some interesting thoughts about what’s really going on with supervised vs. unsupervised; he claims that “unsupervised” should really be called “indirectly supervised”. He followed up with this email:
I currently think about unsupervised learning as indirectly supervised learning. The primary reason is because once you implement an unsupervised learning algorithm it eventually becomes part of a large package, and that larger package is evaluated. Indirectly you can back out from the package evaluation the effectiveness of different implementations/seeds of the unsupervised learning algorithm.
So simply put, the unsupervised learning algorithm is only unsupervised in isolation, and indirectly supervised once part of a larger picture. If you distill this further the evaluation metric for unsupervised algorithms are project specific and developed through error analysis whereas for supervised algorithms the metric is specific to the algorithm, irrespective to the project.
supervised learning: input data -> learning algorithm -> problem non-specific cost metric -> output
unsupervised learning: input data -> learning algorithm -> problem specific cost metric -> output
The main question is… once you formulate evaluation metric for an unsupervised algorithm specific to your project… can it still be called unsupervised?
This is a good question. One stupid example of this is that, if in the tofu-broccoli-ice cream example above, we had forced three clusters instead of the more natural two clusters, then after we look at the result we may say, shit this is really a two-cluster problem. That moment when we switch the number of clusters to two is, of course, supervising the so-called unsupervised process.
I think though that Joey’s remark runs deeper than that, and is perhaps an example of how we trick ourselves into thinking we’ve successfully algorithmized a process when in fact we have made an awful lot of choices.
Data Science needs more pedagogy
Yesterday Flowing Data posted an article about the history of data science (h/t Chris Wiggins). Turns out the field and the name were around at least as early as 2001, and statistician William Cleveland was all about planning it. He broke the field down into parts thus:
- Multidisciplinary Investigation (25%) — collaboration with subject areas
- Models and Methods for Data (20%) — more traditional applied statistics
- Computing with Data (15%) — hardware, software, and algorithms
- Pedagogy (15%) — how to teach the subject
- Tool Evaluation (5%) — keeping track of new tech
- Theory (20%) — the math behind the data
First of all this is a great list, and super prescient for the time. In fact it’s an even better description of data science than what’s actually happening.
The post mentions that we probably don’t see that much theory, but I’ve certainly seen my share of theory when I go to Meetups and such. Most of the time the theory is launched into straight away and I’m on my phone googling terms for half of the talk.
The post also mentions we don’t see much pedagogy, and here I strongly concur. By “pedagogy” I’m not talking about just teaching other people what you did or how you came up with a model, but rather how you thought about modeling and why you made the decisions you did, what the context was for those decisions and what the other options were (that you thought of). It’s more of a philosophy of modeling.
It’s not hard to pinpoint why we don’t get much in the way of philosophy. The field is teeming with super nerds who are focused on the very cool model they wrote and the very nerdy open source package they used, combined with some weird insight they gained as a physics Ph.D. student somewhere. It’s hard enough to sort out their terminology, never mind expecting a coherent explanation with broad context, explained vocabulary, and confessed pitfalls. The good news is that some of them are super smart and they share specific ideas and sometimes even code (yum).
In other words, most data scientists (who make cool models) think and talk at the level of 0.02 feet, whereas pedagogy is something you actually need to step back to see. I’m not saying that no attempt is ever made at this, but my experiences have been pretty bad. Even a simple, thoughtful comparison of how different fields (bayesian statisticians, machine learners, or finance quants) go about doing the same thing (like cleaning data, or removing outliers, or choosing a bayesian prior strength) would be useful, and would lead to insights like, why do these field do it this way whereas those fields do it that way? Is it because of the nature of the problems they are trying to solve?
A good pedagogical foundation for data science will allow us to not go down the same dead end roads as each other, not introduce the same biases in multiple models, and will make the entire field more efficient and better at communicating. If you know of a good reference for something like this, please tell me.
Let them game the model
One of the most common reasons I hear for not letting a model be more transparent is that, if they did that, then people would game the model. I’d like to argue that that’s exactly what they should do, and it’s not a valid argument against transparency.
Take as an example the Value-added model for teachers. I don’t think there’s any excuse for this model to be opaque: it is widely used (all of New York City public middle and high schools for example), the scores are important to teachers, especially when they are up for tenure, and the community responds to the corresponding scores for the schools by taking their kids out or putting their kids into those schools. There’s lots at stake.
Why would you not want this to be transparent? Don’t we usually like to know how to evaluate our performance on the job? I’d like to know it if being 4 minutes late to work was a big deal, or if I need to stay late on Tuesdays in order to be perceived as working hard. In other words, given that it’s high stakes it’s only fair to let people know how they are being measured and, thus, how to “improve” with respect to that measurement.
Instead of calling it “gaming the model”, we should see it as improving our scores, which, if it’s a good model, should mean being better teachers (or whatever you’re testing). If you tell me that when someone games the model, they aren’t actually becoming a better teacher, then I’d say that means your model needs to improve, not the teacher. Moreover, if that’s true, then without transparency or with transparency, in either case, you’re admitting that the model doesn’t measure the right thing. At least when it’s transparent the problems are more obvious and the modelers have more motivation to make the model measure the right thing.
Another example: credit scoring. Why are these models closed? They affect everyone all the time. How is Visa or Mastercard winning if they don’t tell us what we need to do to earn a good credit card interest rate? What’s the worst thing that could happen, that we are told explicitly that we need to pay our bills on time? I don’t see it. Unless the models are using something devious, like people’s race or gender, in which case I’d understand why they’d want to hide that model. I suspect they aren’t, because that would be too obvious, but I also suspect they might be using other kinds of inputs (like zip codes) that are correlated to race and/ or gender. That’s the kind of thing that argues for transparency, not against it. When a model is as important as credit scores are, I don’t see an argument for opacity.
Medical identifiers
In this recent article in the Wall Street Journal, we are presented with two sides of a debate on whether there should be a unique medical identifier given to each patient in the U.S. healthcare system.
Both sides agree that this would help record keeping problems so much (compared to the shambles that exist today) that it would vastly improve scientists’ ability to understand and predict disease. But the personal privacy issues are sufficiently worrying for some people to conclude that the benefits do not outweigh the risks.
Once it’s really easy to track people and their medical data through the system, the data can and will be exploited for commercial purposes or worse (imagine your potential employer looking up your entire medical record in addition to your prison record and credit score).
I agree with both sides, if that’s possible, although they both have flaws: the pro-identifier trivializes the problems of computer security, and the anti-identifier trivializes the field of data anonymization. It’s just incredibly frustrating that we haven’t been able to come to some reasonable solution to this that protects individual identities while letting the record keeping become digitized and reasonable.
Done well, a functional system would have the potential to save people’s lives in the millions while not exposing vulnerable people to more discrimination and suffering. Done poorly and without serious thought, we could easily have the worst of all worlds, where corporations have all the data they can pay for and where only rich people have the ability or influence to opt out of the system.
Let’s get it together, people! We need scientists and lawyers and privacy experts and ethicists and data nerds to get together and find some intelligently thought-out middle ground.
Does hip-hop still exist?
I love music. I work in an open office, one big room with 45 people, which makes it pretty loud sometimes, so it’s convenient to be able to put headphones on and listen to music when I need to focus. But the truth it I’d probably be doing it anyway.
I’m serious about music too, I subscribe to Pandora as well as Spotify, because I’ll get a new band recommendation from Pandora and then I want to check their entire oeuvre on Spotify. My latest obsession: Muse, especially this song. Muse is like the new Queen. Pandora knew I’d like Muse because my favorite band is Bright Eyes, which makes me pathetically emo, but I also like the Beatles and Elliott Smith, or whatever. I don’t know exactly how the model works, but the point is they’ve pegged me and good.
In fact it’s amazing how much great music and other stuff I’ve been learning about through the recommendation models coming out of things like Pandora and Netflix; those models really work. My life has definitely changed since they came into existence. I’m much more comfortable and entertained.
But here’s the thing, I’ve lost something too.
My oldest friend sent me some mixed CDs for Christmas. I listened to them at work one recent morning, and although I like a few songs, many of the them were downright jarring. I mean, so syncopated! So raw and violent! What the hell is this?! It was hip-hop, I think, although that was a word from some far-away time and place. Does hip-hop still exist?
I’ve become my own little island of smug musical taste. When is the last time I listened to the radio and learned about a new kind of music? It just doesn’t happen. Why would I listen to the radio when there’s wifi and I can stream my own?
It made me think about the history of shared music. Once upon a time, we had no electricity and we had to make our own music. There were traveling bands of musicians (my great-grandmother was a traveling piano player and my great-grandfather was the banjo player in that troupe) that brought the hit tunes to the little towns eager for the newest sounds. Then when we got around to inventing the radio and record players, boundaries were obliterated and the world was opened up. This sharing got accelerated as the technology grew, to the point now that anyone with access to a browser can hear any kind of music they’d like.
But now this other effect has taken hold, and our universes, our personal universes, are again contracting. We are creating boundaries again, each around ourselves and with the help of the models, and we’ve even figured out how to drown out the background music in Starbucks when we pick up our lattes (we just listen to our ipods while in line).
I’d love to think that this contracting universe issue is restricted to music and maybe movies, but it’s really not. Our entire online environment and identity, and to be sure our actual environment and identity is increasingly online, is informed and created by the models that exist inside Google, Facebook, and Amazon. Google has just changed its privacy policy so that it can and will use all the information it has gleaned from your gmail account when you do a google search, for example. To avoid this, simply clear your cookies and don’t ever log in to your gmail account. In other words, there’s no avoiding this.
Keep in mind, as well, that there’s really one and only one goal of all of this, namely money. We are being shown things to make us comfortable so we will buy things. We aren’t being shown what we should see, at any level or by any definition, but rather what will flatter us sufficiently to consume. Our modeled world is the new opium.
Updating your big data model
When you are modeling for the sake of real-time decision-making you have to keep updating your model with new data, ideally in an automated fashion. Things change quickly in the stock market or the internet, and you don’t want to be making decisions based on last month’s trends.
One of the technical hurdles you need to overcome is the sheer size of the dataset you are using to first train and then update your model. Even after aggregating your model with MapReduce or what have you, you can end up with hundreds of millions of lines of data just from the past day or so, and you’d like to use it all if you can.
The problem is, of course, that over time the accumulation of all that data is just too unwieldy, and your python or Matlab or R script, combined with your machine, can’t handle it all, even with a 64 bit setup.
Luckily with exponential downweighting, you can update iteratively; this means you can take your new aggregated data (say a day’s worth), update the model, and then throw it away altogether. You don’t need to save the data anywhere, and you shouldn’t.
As an example, say you are running a multivariate linear regression. I will ignore bayesian priors (or, what is an example of the same thing in a different language, regularization terms) for now. Then in order to have an updated coefficient vector 



So the problem simplifies to, how can we update
As I described before in this post for example, you can use exponential downweighting. Whereas before I was expounding on how useful this method is for helping you care about new data more than old data, today my emphasis is on the other convenience, which is that you can throw away old data after updating your objects of interest.
So in particular, we will follow the general rule in updating an object $T$ that it’s just some part old, some part new:
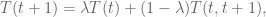
where by 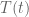
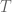
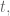


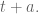
The speed at which I forget data is determined by my choice of 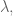
Specifically, I want to give an example of this update rule for the covariance matrix 
Namely, I claim that after updating 
Just to be really dumb, start with a univariate regression example, so where we have a single signal 

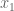


Now we get a new piece of data 
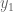

![[\mu x_1 x_2]](https://s0.wp.com/latex.php?latex=%5B%5Cmu+x_1+x_2%5D&bg=ffffff&fg=555555&s=0&c=20201002)

where by 
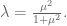
Things to convince yourself of:
- This works when we move from
pieces of data to
pieces of data.
- This works when we move from a univariate regression to a multivariate regression and we’re actually talking about square matrices.
- Same goes for the
- We don’t really have to worry about scaling; this uses the fact that everything in sight is quadratic in
, the downweighting scalar, and the final product we care about is
where, if we did decide to care about scalars, we would mutliply
- We don’t have to update one data point at a time. We can instead compute the `new part’ of the covariance matrix and the other thingy for a whole day’s worth of data, downweight our old estimate of the covariance matrix and other thingy, and then get a new version for both.
- We can also incorporate bayesian priors into the updating mechanism, although you have decide whether the prior itself needs to be downweighted or not; this depends on whether the prior is coming from a fading prior belief (like, oh I think the answer is something like this because all the studies that have been done say something kind of like that, but I’d be convinced otherwise if the new model tells me otherwise) or if it’s a belief that won’t be swayed (like, I think newer data is more important, so if I use lagged values of the quarterly earnings of these companies then the more recent earnings are more important and I will penalize the largeness of their coefficients less).

End result: we can cut our data up into bite-size chunks our computer can handle, compute our updates, and chuck the data. If we want to maintain some history we can just store the `new parts’ of the matrix and column vector per day. Then if we later decide our downweighting was too aggressive or not sufficiently aggressive, we can replay the summation. This is much more efficient as storage than holding on to the whole data set, because it depends only on the number of signals in the model (typically under 200) rather than the number of data points going into the model. So for each day you store a 200-by-200 matrix and a 200-by-1 column vector.
Data Scientist degree programs
Prediction: in the next 10 years we will see the majority of major universities start masters degree programs, or Ph.D. programs, in data science, data analytics, business analytics, or the like. They will exist somewhere in the intersection of the fields of statistics, operations research, and computer science, and business. They will teach students how to use machine learning algorithms and various statistical methods, and how to design expert systems. Then they will send these newly minted data scientists out to work at McKinsey, Google, Yahoo, and possibly Data Without Borders.
The questions yet unanswered:
- Relevance: will they also teach the underlying theory well enough so that the students will know when the techniques are applicable?
- Skepticism: will they in general teach enough about robustness in order for the emerging data scientists to be sufficiently skeptical of the resulting models?
- Ethics: will they incorporate understanding the impact of the models so that students will think to understand the ethical implications of modeling? Will they have a well-developed notion of the Modeler’s Hippocratic Oath by then?
- Open modeling: will they focus narrowly on making businesses more efficient or will they focus on developing platforms which are open to the public and allow people more views into the models, especially when the models in question affect that public?
Open questions. And important ones.
Here’s one that’s already been started at the University of North Carolina, Charlotte.
Bad statistics debunked: serial killers and cervixes
If you saw this story going around about how statisticians can predict the activity of serial killers, be sure to read this post by Cosma Shalizi where he brutally tears down the underlying methodology. My favorite part:
Since Simkin and Roychowdhury’s model produces a power law, and these data, whatever else one might say about them, are not power-law distributed, I will refrain from discussing all the ways in which it is a bad model. I will re-iterate that it is an idiotic paper — which is different from saying that Simkin and Roychowdhury are idiots; they are not and have done interesting work on, e.g., estimating how often references are copied from bibliographies without being read by tracking citation errors4. But the idiocy in this paper goes beyond statistical incompetence. The model used here was originally proposed for the time intervals between epileptic fits. The authors realize that
[i]t may seem unreasonable to use the same model to describe an epileptic and a serial killer. However, Lombroso [5] long ago pointed out a link between epilepsy and criminality.
That would be the 19th-century pseudo-scientist3 Cesare Lombroso, who also thought he could identify criminals from the shape of their skulls; for “pointed out”, read “made up”. Like I said: idiocy.
Next, if you’re anything like me, you’ve had way too many experiences giving birth without pain control, even after begging continuously and profusely for some, because of some poorly derived statistical criterion that should never have been applied to anyone. This article debunks that among others related to babies and childbirth.
In particular, it suggests what I always suspected, namely that people misunderstand the effect of using epidurals because they don’t control for the fact that in the case of a long difficult birth you are more likely to get everything, which brings down the average outcome among people with epidurals but doesn’t at all prove causation.
Pregnant ladies, I suggest you print out this article and bring it with you to your OB appointments.
Open Models (part 1)
A few days ago I posted about how riled up I was to see the Heritage Foundation publish a study about teacher pay which was obviously politically motivated. In the comment section a skeptical reader challenged me on a few things. He had some great points, and I’d love to address them all, but today I will only address the most important one, namely:
…the criticism about this particular study could be leveled to any study funded by any think tank, from the lowly ones, to the more prestigious ones, which have near-academic status (e.g. Brookings or Hoover). But indeed, most social scientists have a political bias. Piketty advised Segolene Goyal. Does it invalidate his study on inequality in America? Rogoff is a republican. Should one dismiss his work on debit crises? I think the best reaction is not to dismiss any study, or any author for that sake, on the basis of their political opinion, even if we dislike their pre-made tweets (which may have been prepared by editors that have nothing to do with the authors, by the way). Instead, the paper should be judged on its own merit. Even if we know we’ll disagree, a good paper can sharpen and challenge our prior convictions.
Agreed! Let’s judge papers on their own merits. However, how can we do that well? Especially when the data is secret and/or the model itself is only vaguely described, it’s impossible. I claim we need to demand more information in such cases, especially when the results of the study are taken seriously and policy decisions are potentially made based on them.
What should we do?
Addressing this problem of verifying modelling results is my goal with defining open source models. I’m not really inventing something new, but rather crystallizing and standardizing something that is already in the air (see below) among modelers who are sufficiently skeptical of the underlying incentives that modelers and their institutions have to look confident.
The basic idea is that we cannot and should not trust models that are opaque. We should all realize how sensitive models are to design decisions and tuning parameters. In the best case, this means we, the public, should have access to the model itself, manifested as a kind of app that we can play with.
Specifically, this means we can play around with the parameters and see how the model changes. We can input new data and see what the model spits out. We can retrain the model altogether with a slightly different assumption, or with new data, or with a different cross validation set.
The technology to allow us to do this all exists – even the various ways we can anonymize sensitive data so that it can still be semi-public. I will go further into how we can put this together in later posts. For now let me give you some indication of how badly this is needed.
Already in the Air
I was heartened yesterday to read this article from Bloomberg written by Victoria Stodden and Samuel Arbesman. In it they complain about how much of science depends on modeling and data, and how difficult it is to confirm studies when the data (and modeling) is being kept secret. They call on federal agencies to insist on data sharing:
Many people assume that scientists the world over freely exchange not only the results of their experiments but also the detailed data, statistical tools and computer instructions they employed to arrive at those results. This is the kind of information that other scientists need in order to replicate the studies. The truth is, open exchange of such information is not common, making verification of published findings all but impossible and creating a credibility crisis in computational science.
Federal agencies that fund scientific research are in a position to help fix this problem. They should require that all scientists whose studies they finance share the files that generated their published findings, the raw data and the computer instructions that carried out their analysis.
The ability to reproduce experiments is important not only for the advancement of pure science but also to address many science-based issues in the public sphere, from climate change to biotechnology.
How bad is it now?
You may think I’m exaggerating the problem. Here’s an article that you should read, in which the case is made that most published research is false. Now, open source modeling won’t fix all of that problem, since a large part of is it the underlying bias that you only publish something that looks important (you never publish results explaining all the things you tried but didn’t look statistically significant).
But think about it, that’s most published research. I’d like to posit that it’s the unpublished research that we should be really worried about. Note that banks and hedge funds don’t ever publish their research, obviously, because of proprietary reasons, but that this doesn’t improve the verifiability problems.
Indeed my experience is that very few people in the bank or hedge fund actually vet the underlying models, partly because they don’t want information to leak and partly because those models are really hard. You may argue that the models are carefully vetted, since big money is often at stake. But I’d reply that actually, you’d be surprised.
How about on the internet? Again, not published, and we don’t have reason to believe that they are more correct than published scientific models. And those models are being used day in and day out and are drawing conclusions about you (what is your credit score, whether you deserve a certain loan) every time you click.
We need a better way to verify models. I will attempt to outline specific ideas of how this should work in further posts.
Politics of teacher pay disguised as data science
I am super riled up about this report coming out of the Heritage Foundation. It’s part of a general trend of disguising a political agenda as data science. For some reason, this seems especially true in education.
The report claims to prove that public school teachers are overpaid. As proof of its true political goals, let me highlight a screen shot of the “summary” page (which has no technical details of the methods in the paper):

I’m sorry, but are you pre-writing my tweets for me now? Are you seriously suggesting that you have investigated the issue of public school teacher pay in an unbiased and professional manner with those pre-written tweets, Heritage Foundation?
If you read the report, which I haven’t had time to really do yet, you will notice how few equations there are, and how many words. I’m not saying that you need equations to explain math, but it sure helps when your goal is to be precise.
And I’d also like to say, shame on you, New York Times, for your coverage of this. You allow the voices of the authors, from the American Enterprise Institute and the Heritage Foundation, as well as another political voice from the Reason Foundation. But you didn’t ask a data scientist to look at the underlying method.
The truth is, you can make the numbers say whatever you want, and good data scientists (or quants, or statisticians) know this. The stuff they write in their report is almost certainly not the whole story, and it’s obviously politically motivated. I’d love to be hired to research their research and see what kind of similar results they’ve left out of the final paper.
Differential privacy
Do you know what’s awesome about writing a blog? Sometimes you’re left with a technical question, and someone with the technical answer comes right along and comments. It’s like magic.
That’s what happened to me when I wrote a post about privacy vs. openness and suggested that the world needs more people to think about anonymizing data. Along comes Aaron Roth who explains to me that the world is already doing that. Cool!
He sent me a few links to survey articles (here and here) on a concept called differential privacy. The truth is, though, I got confused and ended up just reading the wikipedia entry on it anyway.
The setup is that there is some data, stored in a database, and there’s some “release mechanism” that allows outside users to ask questions about the data- this is called querying for a statistic. Each row of the data is assumed to be associated with a person, so for example could contain their test scores on some medical test, as well as other private information that identifies them.
The basic question is, how can we set up the mechanism so that the users can get as much useful information as possible while never exposing an individual’s information?
Actually the exact condition posed is even a bit more nuanced: how can we set up the mechanism so that any individual, whether they are in the database or not, is indifferent to being taken out or added?
This is a kind of information theory question, and it’s tricky. First they define a metric of information loss or gain when you take out exactly one person from the database- how much do the resulting statistics change? Do they change enough for the outside user to infer (with confidence) what the statistics were for that lost record? If so, not good.
For example, if the user queries for the mean test score of a population with and without a given record (call the associated person the “flip-flopper” (my term)), and gets the exact answer both times, and knows how many people were in the population (besides the flip-flopper), then the user could figure out the exact test score of the flip-flopper.
One example of making this harder for the user, which is a bad one for a reason I’ll explain shortly, is to independently “add noise” to a given statistic after computing it. Then the answers aren’t exact in either case, so you’d have a low confidence in your resulting guess at the test score of the flip-flopper, assuming of course that the population is large and their test score isn’t a huge outlier.
But this is a crappy solution in the sense that I originally wanted to use an anonymization method for, namely to set up an open source data center to allow outside users (i.e. you) go query to their hearts’ content. A given user could simply query the same thing over and over, and after a million queries (depending on how much noise we’ve added) would get a very good approximation of the actual answer (i.e. the actual average test score). The added noise would be canceled out.
So instead, you’d have to add noise in a different way, i.e. not independently, to each statistic. Another possibility is to add noise to the original data, but that doesn’t feel as good to me, especially for the privacy of outliers, unless the noise is really noisy. But then again maybe that’s exactly what you do, so that any individual’s numbers are obfuscated but on a large enough scale you have a good sense of the statistics. I’ll have to learn more about it.
Aaron offered another possibility which I haven’t really understood yet, namely for the mechanism to be stateful. In fact I’m not sure what that means, but it seems to have something to do with it being aware of other databases. I’ve still got lots more to learn, obviously, which is exactly how I like to feel about interesting things.
Economist versus quant
There’s an uneasy relationship between economists and quants. Part of this stems from the fact that each discounts what the other is really good at.
Namely, quants are good at modeling, whereas economists generally are not (I’m sure there are exceptions to this rule, so my apologies to those economists who are excellent modelers); they either oversimplify to the point of uselessness, or they add terms to their models until everything works but by then the models could predict anything. Their worst data scientist flaw, however, is the confidence they have, and that they project, in their overfit models. Please see this post for examples of that overconfidence.
On the other hand, economists are good at big-picture thinking, and are really really good at politics and influence, whereas most quants are incapable of those things, partly because quants are hyper aware of what they don’t know (which makes them good modelers), and partly because they are huge nerds (apologies to those quants who have perspective and can schmooze).
Economists run the Fed, they suggest policy to politicians, and generally speaking nobody else has a plan so they get heard. The sideline show of the two different schools of mainstream economics constantly at war with each other doesn’t lend credence to their profession (in fact I consider it a false dichotomy altogether) but again, who else has the balls and the influence to make a political suggestion? Not quants. They basically wait for the system to be set up and then figure out how to profit.
I’m not suggesting that they team up so that economists can teach quants how to influence people more. That would be really scary. However, it would be nice to team up so that the underlying economic model is either reasonably adjusted to the data, or discarded, and where the confidence of the model’s predictions is better known.
To that end, Cosma Shalizi is already hard at work.
Generally speaking, economic models are ripe for an overhaul. Let’s get open source modeling set up, there’s no time to lose. For example, in the name of opening up the Fed, I’d love to see their unemployment prediction model be released to the public, along with the data used to train it, and along with a metric of success that we can use to compare it to other unemployment models.
Is Stop, Question and Frisk racist?
A few weeks ago I was a “data wrangler” at the first Data Without Borders datadive weekend. My group of volunteer data scientists was exploring the NYPD “Stop, Question and Frisk” data from the previous few years. I blogged about it here and here.
One thing we were interested in exploring was the extent to which this policy, whereby people can be stopped, questioned, and frisked for merely looking suspicious (to the cops) is racist. This is what I said in my second post:
We read Gelman, Fagan and Kiss’s article about using the Stop and Frisk data to understand racial profiling, with the idea that we could test it out on more data or modify their methodology to slightly change the goal. However, they used crime statistics data that we don’t have and can’t find and which are essential to a good study.
As an example of how crucial crime data like this is, if you hear the statement, “10% of the people living in this community are black but 50% of the people stopped and frisked are black,” it sounds pretty damning, but if you add “50% of crimes are committed by blacks” then it sound less so. We need that data for the purpose of analysis.
Why is crime statistics data so hard to find? If you go to NYPD’s site and search for crime statistics, you get really very little information, which is not broken down by area (never mind x and y coordinates) or ethnicity. That stuff should be publicly available. In any case it’s interesting that the Stop and Frisk data is but the crime stats data isn’t.
I still think it is outrageous that we don’t have open source crime statistics in New York, where Bloomberg claims to be such a friend to data and to openness.
And I also still think that, in order to prove racism in the strict sense of the above discussion, we need that data.
However, my overall opinion has changed about whether we have enough data already to say if this policy is broadly racist. It is. My mind changed reading this article from the New York Times a couple of weeks ago. It was written by a young black man from New York, describing his experiences first-hand being stopped, questioned, and frisked. The entire article is excellently written and you should take a look; here’s an excerpt:
For young people in my neighborhood, getting stopped and frisked is a rite of passage. We expect the police to jump us at any moment. We know the rules: don’t run and don’t try to explain, because speaking up for yourself might get you arrested or worse. And we all feel the same way — degraded, harassed, violated and criminalized because we’re black or Latino. Have I been stopped more than the average young black person? I don’t know, but I look like a zillion other people on the street. And we’re all just trying to live our lives.
The argument for this policy is that it improves crime statistics. For some people, especially if they aren’t young and aren’t constant targets of the policy, it’s probably a price worth paying to live in a less crime-ridden area.
And we all want there to be less crime, of course, but what we really want is something even more fundamental, which is a high quality of life. Part of that is not being victimized by crooks, but another part of that is not being (singled out and) victimized by authority either.
I think a good thought experiment is to consider how they could make the policy colorblind. One obvious way is to have cops in every neighborhood performing stop, question and frisk to random people. The argument against this is, of course, that we don’t have enough cops or enough money to do something like that.
Instead, to be more realistic about resources, we could have groups of cops randomly be assigned to neighborhoods on a given day for such stops. If you think the policy is such a good crime deterrent, than you can even weight the probability of a given neighborhood by the crime rate in that neighborhood. (As an aside, I would love to see whether there’s statistically significant reason to believe that this policy does, in fact, deter crime. So often mayors and policies take credit for lowered crime rates in a given city when in fact crime rates are going down all over the country in a kind of seasonality way.) So in this model the cops are more likely to land in a high-crime area, but eventually by the laws of statistics they will visit every neighborhood.
My guess is that, the very first time the Upper East Side is chosen randomly, and a white hedge fund manager is stopped, questioned, and frisked by a cop, who takes away his key and enters his apartment, terrorizing his family while he’s handcuffed in the back of a cop car, is the very last day this policy is in place.
A good data scientist is hard to find
As a data scientist at an internet start-up, I am something of a quantitative handyman. I go where there is need for quantitative thinking. Since the business model of my company is super quantitative, this means I have lots of work. I have recently categorized the kind of things I do into 4 bins:
- I visualize data for business people to digest. This is a kind of fancy data science-y way of saying I design reports. It’s actually a hugely critical part of the business, since our clients are less quantitative than we are and need to feel like they understand the situation, so clear, honest, and easily digestible visuals is a priority.
- I forecast behavior using models. This means I forecast what users on a website will do, based on their attributes and historical precedent for what people who shared their attributes did in the past, and I also do things like stress test the business itself, in order to answer questions like, what would happen to our revenue stream if one of our advertisers jumped out of the auction?
- I measure. This is where the old-school statistics comes in, in deciding whether things are statistically significant and what is our confidence interval. It’s related to reporting as well, but it’s a separate task.
- I help decide whether business ideas are quantitatively reasonable. Will there be enough data to answer this question? How long will we need to collect data to have a statistically significant answer to that? This is kind of like being a McKinsey consultant on data steroids.
So why is it so hard to find a good data scientist?
Here’s why. Most data scientists don’t really think that 3 and 4 above are their job. It is far less sexy to try to honestly find the confidence interval of a prediction than it is to model behavior. Data scientists are considered magical when they forecast behavior that was hitherto unknown, and they are considered total downers when they tell their CEO, hey there’s just not enough data to start that business you want to start, or hey this data is actually really fat-tailed and our confidence intervals suck.
In other words, it’s something like what the head of risk management had to face at a big bank taking risks in 2007. There’s a responsibility to warn people that too much confidence in the models is bad, but then there’s the political reality of the situation, where you just want to be liked and you don’t actually have the power to stop the relevant decisions anyway. And there’s the added issue in a start-up that they are your models, and you want them to be liked (and to be invincible).
It’s far easier to focus on visualizing and modeling, or to stay even sexier and more mystical, just modeling itself, and let the business make decisions that could ultimately not work out, or act on data that’s pure noise.
How do you select for a good data scientist? Look for one that speaks clearly, directly, and emphasizes skepticism. Look for one that is ready to vent about how people trust models too much, and also someone who’s pushy enough to speak up at a meeting and be that annoying person who holds people back from drinking too much kool-aid.



