Archive
What is the mission statement of the mathematician?
In the past five years, I’ve been learning a lot about how mathematics is used in the “real world”. It’s fascinating, thought provoking, exciting, and truly scary. Moreover, it’s something I rarely thought about when I was in academics, and, I’d venture to say, something that most mathematicians don’t think about enough.
It’s weird to say that, because I don’t want to paint academic mathematicians as cold, uncaring or stupid. Indeed the average mathematician is quite nice, wants to make the world a better place (at least abstractly), and is quite educated and knowledgeable compared to the average person.
But there are some underlying assumptions that mathematicians make, without even noticing, that are pretty much wrong. Here’s one: mathematicians assume that people in general understand the assumptions that go into an argument (and in particular understand that there always are assumptions). Indeed many people go into math because of the very satisfying way in which mathematical statements are either true or false- this is one of the beautiful things about mathematical argument, and its consistency can give rise to great things: hopefulness about the possibility of people being able to sort out their differences if they would only engage in rational debate.
For a mathematician, nothing is more elevating and beautiful than the idea of a colleague laying out a palette of well-defined assumptions, and building a careful theory on top of that foundation, leading to some new-found clarity. It’s not too crazy, and it’s utterly attractive, to imagine that we could apply this kind of logical process to situations that are not completely axiomatic, that are real-world, and that, as long as people understand the simplifying assumptions that are made, and as long as they understand the estimation error, we could really improve understanding or even prediction of things like the stock market, the education of our children, global warming, or the jobless rate.
Unfortunately, the way mathematical models actually function in the real world is almost the opposite of this. Models are really thought of as nearly magical boxes that are so complicated as to render the results inarguable and incorruptible. Average people are completely intimidated by models, and don’t go anywhere near the assumptions nor do they question the inner workings of the model, the question of robustness, or the question of how many other models could have been made with similar assumptions but vastly different results. Typically people don’t even really understand the idea of errors.
Why? Why are people so trusting of these things that can be responsible for so many important (and sometimes even critical) issues in our lives? I think there are (at least) two major reasons. One touches on things brought up in this article, when it talks about information replacing thought and ideas. People don’t know about how the mortgage models work. So what? They also don’t know how cell phones work or how airplanes really stay up in the air. In some way we are all living in a huge network of trust, where we leave technical issues up to the experts, because after all we can’t be experts in everything.
But there’s another issue altogether, which is why I’m writing this post to mathematicians. Namely, there is a kind of scam going on in the name of mathematics, and I think it’s the responsibility of mathematicians to call it out and refuse to let it continue. Namely, people use the trust that people have of mathematics to endow their models with trust in an artificial and unworthy way. Much in the way that cops flashing their badges can abuse their authority, people flash the mathematics badge to synthesize mathematical virtue.
I think it’s time for mathematicians to start calling on people to stop abusing people’s trust in this way. One goal of this blog is to educate mathematicians about how modeling is used, so they can have a halfway decent understanding of how models are created and used in the name of mathematics, and so mathematicians can start talking about where mathematics actually plays a part and where politics, or greed, or just plain ignorance sometimes takes over.
By the way, I think mathematicians also have another responsibility which they are shirking, or said another way they should be taking on another project, which is to educate people about how mathematics is used. This is very close to the concept of “quantitative literacy” which is explained in this recent article by Sol Garfunkel and David Mumford. I will talk in another post about what mathematicians should be doing to promote quantitative literacy.
Should short selling be banned?
Yesterday it was announced that the short selling ban in France, Italy, and Spain for financial stocks would be continued; there’s also an indefinite short selling ban in Belgium. What is this and does it make sense?
Short selling is mathematically equivalent to buying the negative of a stock. To see the actual mechanics of how it works, please look here.
Typically people at hedge funds use shorts to net out their exposure to the market as a whole: they will go long some bank stock they like and then go short another stock that they are neutral to or don’t like, with the goal of profiting on the difference of movements of the two – if the whole market goes up by some amount like 2%, it will only matter to them how much their long position outperformed their short. People also short stocks for direct negative forecasts on the stock, like when they detect fraud in accounting of the company, or otherwise think the market is overpricing the company. This is certainly a worthy reason to allow short selling: people who take the time to detect fraud should be rewarded, or otherwise said, people should be given an incentive to be skeptical.
If shorting the stock is illegal, then it generally takes longer for “price discovery” to happen; this is sort of like the way the housing market takes a long time to go down. People who bought a house at 400K simply don’t want to sell it for less, so they put it on the market for 400K even when the market has gone down and it is likely to sell for more like 350K. The result is that fewer people buy, and the market stagnates. In the past couple of years we’ve seen this happen in the housing market, although banks who have ownership of houses through foreclosures are much less quixotic about prices, which is why we’ve seen prices drop dramatically more recently.
The idea of banning short-selling is purely political. My favorite quote about it comes from Andrew Lo, an economist at M.I.T., who said, “It’s a bit like suggesting we take heart patients in the emergency room off of the heart monitor because you don’t want to make doctors and nurses anxious about the patient.” Basically, politicians don’t want the market to “panic” about bank stocks so they make it harder to bet against them. This is a way of avoiding knowing the truth. I personally don’t know good examples of the market driving down a bank’s stock when the bank is not in terrible shape, so I think even using the word “panic” is misleading.
When you suddenly introduce a short-selling ban, extra noise gets put into the market temporarily as people “cover their shorts”; overall this has a positive effect on the stocks in question, but it’s only temporary and it’s completely synthetic. There’s really nothing good about having temporary noise overwhelm the market except for the sake of the politicians being given a few extra days to try to solve problems. But that hasn’t happened.
Even though I’m totally against banning short selling, I think it’s a great idea to consider banning some other instruments. I actually go back and forth about the idea of banning credit default swaps (CDS), for example. We all know how much damage they can do (look at AIG), and they have a particularly explosive pay-off system, by design, since they are set up as insurance policies on bonds.
The ongoing crisis in Europe over debt is also partly due to the fact that the regulators don’t really know who owns CDS’s on Greek debt and how much there is out there. There are two ways to go about fixing this. First we could ban owning CDS unless you also own the underlying bond, so you are actually protecting your bond; this would stem the proliferation of CDS’s which hurt AIG so badly and which could also hurt the banks holding Greek bonds and who wrote Greek CDS protection. Alternatively, you could enforce a much more stringent system of transparency so that any regulator could go to a computer and do a search on where and how much CDS exposure (gross and net) people have in the world. I know people think this is impossibly difficult but it’s really not, and it should be happening already. What’s not acceptable is having a political and psychological stalemate because we don’t know what’s out there.
There are other instruments that definitely seem worthy of banning: synthetic over-the-counter instruments that seem created out of laziness (since the people who invented them could have approximated whatever hedge they wanted to achieve with standard exchange-traded instruments) and for the purpose of being difficult to price and to assess the risk of. Why not ban them? Why not ban things that don’t add value, that only add complexity to an already ridiculously complex system?
Why are we spending time banning things that make sense and ignoring actual opportunities to add clarity?
Machine learners are spoiled for data
I’ve been reading lots of machine learning books lately, and let me say, as a relative outsider coming from finance: machine learners sure are spoiled for data.
It’s like, they’ve built these fancy techniques and machines that take a huge amount of data and try to predict an outcome, and they always seem to start with about 50 possible signals and “learn” the right combination of a bunch of them to be better at predicting. It’s like that saying, “It is tempting, if the only tool you have is a hammer, to treat everything as if it were a nail.”
In finance, a quant gets maybe one or two or three time series, hopefully that haven’t been widely distributed so they may still have signal. The effect that this new data on a quant is key: it’s exciting almost to the point of sexually arousing to get new data. That’s right, I said it, data is sexy! We caress the data, we kiss it and go to bed with it every night (well, the in-sample part of it anyway). In the end we have an intimate relationship with each and every time series in our model. In terms of quantity, however, maybe it’s daily (so business days, 262 days per year about), for maybe 15 years, so altogether 4000 data points. Not a lot to work with but we make do.
In particular, given 50 possible signals in a pile of new data, we would first look at each time series by plotting, to be sure it’s not dirty, we’d plot the (in-sample) returns as a histogram to see what we’re dealing with, we’d regress each against the outcome, to see if anything contained signal. We’d draw lagged correlation graphs of each against the outcome. We’d draw cumulative pnl graphs over time with that univariate regression for that one potential signal at a time.
In other words, we’d explore the data in a careful, loving manner, signal by signal, without taking the data for granted, instead of stuffing the kit and kaboodle into a lawnmower. It’s more work but it means we have a sense of what’s going into the model.
I’m wondering how powerful it would be to combine the two approaches.
What’s with errorbars?
As an applied mathematician, I am often asked to provide errorbars with values. The idea is to give the person reading a statistic or a plot some idea of how much the value or values could be expected to vary or be wrongly estimated, or to indicate how much confidence one has in the statistic. It’s a great idea, and it’s always a good exercise to try to provide the level of uncertainty that one is aware of when quoting numbers. The problem is, it’s actually very tricky to get them right or to even know what “right” means.
A really easy way to screw this up is to give the impression that your data is flawless. Here’s a prime example of this.
More recently we’ve seen how much the government growth rate figures can really suffer from lack of error bars- the market reacts to the first estimate but the data can be revised dramatically later on. This is a case where very simple errorbars (say, showing the average size of the difference between first and final estimates of the data) should be provided and could really help us gauge confidence. [By the way, it also brings up another issue which most people think about as a data issue but really is just as much a modeling issue: when you have data that gets revised, it is crucial to save the first estimates, with a date on that datapoint to indicate when it was first known. If we instead just erase the old estimate and pencil in the new, without changing the date (usually leaving the first date), then it gives us a false sense that we knew the “corrected” data way earlier than we did.]
However, even if you don’t make stupid mistakes, you can still be incredibly misleading, or misled, by errorbars. For example, say we are trying to estimate risk on a stock or a portfolio of stocks. Then people typically use “volatility error bars” to estimate the expected range of values of the stock tomorrow, given how it’s been changing in the past. As I explained in this post, the concept of historical volatility depends crucially on your choice of how far back you look, which is given by a kind of half-life, or equivalently the decay constant. Anything that is so not robust should surely be taken with a grain of salt.
But in any case, volatility error bars, which are usually designed to be either one or two lengths of the measured historical volatility, contain only as much information as the data in the lookback window. In particular, you can get extremely confused if you assume that the underlying distribution of returns is normal, which is exactly what most people do in fact assume, even when they don’t realize they do.
To demonstrate this phenomenon of human nature, recall that during the credit crisis you’d hear things like “We were seeing things that were 25-standard deviation moves, several days in a row,” from Goldman Sachs; the implication was that this was an incredibly unlikely event, near probability zero in fact, that nobody could have foreseen. Considering what we’ve been seeing in the market in the past couple of weeks, it would be nice to understand this statement.
There were actually two flawed assumptions exposed here. First, if we have a fat-tailed distribution, then things can seem “quiet” for long stretches of time (longer than any lookback window), during which the sample volatility is a possibly severe underestimate of the standard of deviation. Then when a fat-tailed event occurs, the sample volatility spikes to being an overestimate of the standard of deviation for that distribution.
Second, in the markets, there is clustering of volatility- another way of saying this is that volatility itself is rather auto-correlated, so even if we can’t predict the direction of the return, we can still estimate the size of the return. So once the market dives 5% in one day, you can expect many more days of large moves.
In other words, the speaker was measuring the probability that we’d see several returns, 25 standard deviations away from the mean, if the distribution is normal, with a fixed standard deviation, and the returns are independent. This is indeed a very unlikely event. But in fact we aren’t dealing with normal distributions nor independent draws.
Another way to work with errorbars is to have confidence errorbars, which relies (explicitly or implicitly) on an actual distributional assumption of your underlying data, and which tells the reader how much you could expect the answer to range given the amount of data you have, with a certain confidence. Unfortunately, there are problems here too- the biggest one being that there’s really never any reason to believe your distributional assumptions beyond the fact that it’s probably convenient, and that so far the data looks good. But if it’s coming from real world stuff, a good level of skepticism is healthy.
In another post I’ll talk a bit more about confidence errorbars, otherwise known as confidence intervals, and I’ll compare them to hypothesis testing.
Default probabilities and recovery rates
I’ve been kind of obsessed lately with the “big three” ratings agencies S&P, Moody’s, and Fitch. I have two posts (this one and that one) where I discuss the idea of setting up open source ratings models to provide competition to them and hopefully force them to increase transparency (speaking of transparency, here’s an article which describes how well they cope with one of the transparency rules they already have).
Today I want to talk about a technical issue regarding ratings models, namely what the output is. There are basically two choices that I’ve heard about, and it turns out that S&P and Moody’s ratings have different outputs, as was explained here.
Namely, S&P models the probability of default, which is to say the probability that U.S. bonds will go through a technical default, I believe within the next year; Moody’s, on the other hand, models the “expected loss”, which is to say they model the future value of U.S. bonds by modeling the probability of default combined with the so-called “recovery rate” once the default occurs (the recovery rate is the percent of the face value of the bond that bond-holders can expect to receive after a default).
The reason this matters is that, for U.S. bonds specifically, even if default occurs technically, few people claim that the bonds wouldn’t eventually be worth face value. So S&P is modeling the probability that, through political posturing, we could end up with a technical default (i.e. not beyond the realm of possibilities), whereas Moody’s models what the value of the bond would be if that happened (i.e. face value almost certainly). It makes more sense, considering this, that S&P has downgraded U.S. debt but that Moody’s hasn’t.
This isn’t the only time such issues matter. Indeed, various different “ratings” models claim to model different things, which end up being more or less crucial depending on the situation:
- S&P: probability of default
- Fitch: probability of default
- Moody’s: expected loss
- Altman’s Z-scores: probability of corporate default
- Credit Grades: probability of default of publicly traded companies
- credit default swaps: expected loss
I threw in Credit Grades, which is a product that is offered by MSCI. One of the inputs for the Credit Grades model is the market volatility of the company in question, whereas most of the other models’ inputs are primarily accounting measurements. In particular, if the market volatility of the company is enormous, then the probability of default is increased. I wonder what it is now rating Bank of America at?
Credit default swaps are not ratings models directly- but you can infer the market’s expectation of default and recovery rate from the price of the CDS, since the cashflow of a CDS works like this: the owner of the CDS pays quarterly “insurance payments” for as long as the bond in question hasn’t defaulted, but if and when the bond defaults the writer of the CDS pays the remainder of the face value of the bond after removing the recovery rate. In other words, if the bond defaults and the recovery rate turns out to be 63%, then the CDS writer is liable for 37% of the face value of the bond.
Not to unfairly single out one issue among many that is difficult, but recovery rates are pretty difficult to model- the data is secondary market data, i.e. it’s not traded on directly but rather inferred from market prices like CDSs that are traded, and often people just assume a 40% recovery rate even when there’s no particular reason to believe it.
For that reason it’s not necessarily better information (in the sense of being more accurate) to model default with recovery rate consideration than it is to model straight out default probability, which is already hard. On the other hand, modeling expected loss like Moody’s is probably a more intuitive output, since as we’ve seen with the uproar last week, S&P is getting lots of flak for their ratings change but Moody’s has been sitting pretty.
In fact, U.S. sovereign debt is an extreme example in that we actually know the recovery rate is almost surely 100%, but in general for corporate debt different guesses at the expected recovery rates will drastically change the value of the bond (or associated CDS).
I guess the moral of this story for me is that it’s super important to know exactly what’s being modeled – I am now ready to defend S&P’s ratings change – and it’s also important to choose your model’s output well.
Open Source Ratings Model (Part 2)
I’ve thought more about the concept of an open source ratings model, and I’m getting more and more sure it’s a good idea- maybe an important one too. Please indulge me while I passionately explain.
First, this article does a good job explaining the rot that currently exists at S&P. The system of credit ratings undermines the trust of even the most fervently pro-business entrepreneur out there. The models are knowingly games by both sides, and it’s clearly both corrupt and important. It’s also a bipartisan issue: Republicans and Democrats alike should want transparency when it comes to modeling downgrades- at the very least so they can argue against the results in a factual way. There’s no reason I can see why there shouldn’t be broad support for a rule to force the ratings agencies to make their models publicly available. In other words, this isn’t a political game that would score points for one side or the other.
Second, this article discusses why downgrades, interpreted as “default risk increases” on sovereign debt doesn’t really make sense- and uses as example Japan, which was downgraded in 2002 but still continues to have ridiculously low market-determined interest rates. In other words, ratings on governments, at least the ones that can print their own money (so not Greece), should be taken as a metaphor of their fiscal problems, or perhaps as a measurement of the risk that they will have potentially spiraling inflation when they do print their way out of a mess. An open source quantitative model would not directly try to model the failure of politicians to agree (although there are certainly market data proxies for that kind of indecision), and that’s ok: probably the quantitative model’s grade on sovereign default risk trained on corporate bonds would still give real information, even if it’s not default likelihood information. And, being open-source, it would at least be clear what it’s measuring and how.
I’ve also gotten a couple excellent comments already on my first post about this idea which I’d like to quickly address.
There’s a comment pointing out that it would take real resources to do this and to do it well: that’s for sure, but on the other hand it’s a hot topic right now and people may really want to sponsor it if they think it would be done well and widely adopted.
Another commenter had concerns of the potential for vandals to influence and game the model. But here’s the thing, the point of open source is that, although it’s impossible to avoid letting some people have more influence than others on the model (especially the maintainer), this risk is mitigated in two important ways. First of all it’s at least clear what is going on, which is way more than you can say for S&P, where there was outrageous gaming going on and nobody knew (or more correctly nobody did anything about it). Secondly, and more importantly, it’s always possible for someone to fork the open source model and start their own version if they think it’s become corrupt or too heavily influenced by certain methodologies or modeling choices. As they say, if you don’t like it, fork it.
Update! There’s a great article here about how the SEC is protecting the virtual ratings monopoly of S&P, Moody’s, and Fitch.
Open Source Ratings Model?
A couple of days ago I got this comment from a reader, which got me super excited.
His proposal is that we could start an open source ratings model to compete with S&P and Moody’s and Fitch ratings. I have made a few relevant lists which I want to share with you to address this idea.
Reasons to have an open source ratings model:
- The current rating agencies have a reputation for bad modeling; in particular, their models, upon examination, often have extremely unrealistic underlying assumptions. This could be rooted out and modified if a community of modelers and traders did their honest best to realistically model default.
- The current ratings agencies also have enormous power, as exemplified in the past few days of crazy volatile trading after S&P downgraded the debt of the U.S. (although the European debt problems are just as much to blame for that I believe). An alternative credit model, if it was well-known and trusted, would dilute their power.
- Although the rating agency shared descriptions of their models with their clients, they weren’t in fact open-source, and indeed the level of exchange probably served only to allow the clients to game the models. One of the goals of an open-source ratings model would be to avoid easy gaming.
- Just to show you how not open source S&P is currently, check out this article where they argue that they shouldn’t have to admit their mistakes. When you combine the power they wield, their reputation for sloppy reasoning, and their insistence on being protected from their mistakes, it is a pretty idiotic system.
- The ratings agencies also have a virtual lock on their industry- it is in fact incredibly difficult to open a new ratings agency, as I know from my experience at Riskmetrics, where we looked into doing so. By starting an open source ratings model, we can (hopefully) avoid issues like permits or whatever the problem was by not charging money and just listing free opinions.
Obstructions to starting an open source ratings model:
- It’s a lot of work, and we would need to set it up in some kind of wiki way so people could contribute to it. In fact it would have to me more Linux style, where some person or people maintain the model and the suggestions. Again, lots of work.
- Data! A good model requires lots of good data. Altman’s Z-score default model, which friends of mine worked on with him at Riskmetrics and then MSCI, could be the basis of an open source model, since it is being published. But the data that trains the model isn’t altogether publicly available. I’m working on this, would love to hear readers’ comments.
What is an open source model?
- The model itself is written in an open source language such as python or R and is publicly available for download.
- The data is also publicly available, and together with the above, this means people can download the data and model and change the parameters of the model to test for robustness- they can also change or tweak the model themselves.
- There is good documentation of the model describing how it was created.
- There is an account kept of how often different models are tried on the in-sample data. This prevents a kind of data fitting that people generally don’t think about enough, namely trying so many different models on one data set that eventually some model will look really good.
The Life Cycle of a Hedge Fund
When people tell me they are interested in working at a hedge fund, I always tell them a few things. First I talk about the atmosphere and culture, to make sure they would feel comfortable with it. Then I talk to them about which hedge fund they’re thinking about, because I think it makes a huge difference, especially how old a hedge fund is.
Here’s the way I explain it. When a hedge fund is new, a baby, it either works or it doesn’t. If it doesn’t, you never even hear about it, a kind of survivorship bias. So the ones you hear about work well, and their founders do extremely well for themselves.
Then the hedge fund hires a bunch of people, and this first round of people also does well, and they start filling up the ranks of MD’s (managing directors). Maybe at this point you’d say the hedge fund is an adolescent. Once you have a bunch of MD’s that are rich and smart, though, they become pretty protective of the pot of money they generate each year, especially if the pot isn’t as big as it once was, because of competition from other hedge funds.
However, this doesn’t always mean they stop hiring. In fact, they often hire people at this stage, young, smart, incredibly hard working people, who are generally screwed in the sense that they have very little chance of being successful or ever becoming MD. This is what I’d term an adult hedge fund. They have complicated rules which make sense for the existing MD’s but which keep new people from ever succeeding.
For example, when you get to a hedge fund, you start being assigned models to work on. You learn the techniques and follow the rules of the hedge fund, like making sure you don’t bet on the market, etc. If your model starts to look promising, they make sure you are not “remaking” an existing model that is currently being used. That is to say, they make sure, either by telling you what to do or asking you to do it yourself, that your bets are essentially orthogonal (in a statistical sense) to the current models. This often has the effect of removing the signal that your model had, or at least removing enough of it that your model no longer is statistically significant to go into production.
In other words, if the existing models are a relatively large collection, that perhaps spans the space of “current models that seem to work in the way we measure models” (I know this is a vague concept but I do think it means something), then you are kind of up shit’s creek to find a new model. By contrast, if you happened to start at a young hedge fund, or start your own hedge fund, then your model couldn’t be redundant, since there wouldn’t be anything to compete with it.
The older hedge funds have lots of working models, so there are lots of ways for your new, good-looking model to be swatted down before it has a chance to make money. And the way things work, you don’t ever get credit for a model that would have worked if there had been fewer models in production. In fact you only get credit if you came up with a new model which made shit tons of money.
Which is to say, under this system, the founders and the guys brought in during the first round of hiring are the most likely to get credit. Even if an MD retires, their working models don’t die, since they are algorithmic and they still work. But the money they generate goes into the company-wide pot, which is to say mostly goes to MD’s. So the MD’s have no incentive to change the system.
It also has another consequence, which is that the people hired in the second or further rounds slowly realize that their models are perfectly good but unused, and that they’ll never get promoted. So they end up leaving and starting their own funds or joining young funds, just so they can run the same models. So another consequence of adult hedge funds is that they spawn their own competition.
The only way I know of for a hedge fund to avoid this aging process is to never hire anyone after the first round. Or maybe to hire very few people, slowly, as the MD’s retire and as the models stop working and you need new ones, to be sure that the people they hire have a chance to succeed.
Wall Street versus us
There have been two articles in the past few days which address the mentality of people working on Wall Street versus the rest of us.
First, we have this article from William Cohen, posted on Bloomberg.com, which is the first part of a series entitled, “Ending the Moral Rot on Wall Street.” This first part doesn’t contain much new; it goes over just how obnoxious and easy to hate the various Goldman Sachs assholes were when they packaged and sold mortgage debris and then emailed their friends about how much money they stood to make. And the second (and perhaps further) parts promise to explain how we are going to address the corruption and greed. My complaint, which is totally unfounded since I haven’t read the next parts, is that this guy is not disagreeing well. In other words, he’s setting up the guys on Wall Street to be monstrous and ethically vapid. This attitude is not going to help really understand the situation, nor will it lend itself to satisfying solutions. Here’s an example of the kind of “they are monsters” prose that probably won’t help:
These crimes are being committed, he said, by people who “have already made more money than could ever be spent in one lifetime and achieved more impressive success than could ever be chronicled in one obituary. And it begs the question, is corporate culture becoming increasingly corrupt?”
Yes, it certainly does raise that question.
Second, we have this blog post by Mark Cuban, which was originally posted in 2010 but is still relevant. In it, an effort is made to understand the actual mentality of the traders on Wall Street. Namely, they are framed as hackers:
Just as hackers search for and exploit operating system and application shortcomings, traders do the same thing. A hacker wants to jump in front of your shopping cart and grab your credit card and then sell it. A high frequency trader wants to jump in front of your trade and then sell that stock to you. A hacker will tell you that they are serving a purpose by identifying the weak links in your system. A trader will tell you they deserve the pennies they are making on the trade because they provide liquidity to the market.
I recognize that one is illegal, the other is not. That isn’t the important issue.
I agree with this characterization, and moreover I applaud the effort to understand the culture. These guys actually do think they are playing fairly within the context of their “game” (and they do care that it’s legal). To change their mindset we need to actually change the rules of the game, not just complain that they are corrupt, because, like in a religious disagreement, they can easily dismiss such talk as irrelevant to their lives.
Going back to the first article, it says:
That Wall Street executives have been able to avoid any shred of responsibility for their actions in the years leading up to the crisis speaks volumes not only about an abject ethical deterioration but also about the unhealthy alliance that exists between the powerful in Washington and their patrons in New York. Our collective failure to demand redress against a Wall Street culture that remains out of control is one of the more troubling facts of life in America today.
I agree that we do need to demand redress, but not against a culture’s ethical deterioration, which is just far too vague, but rather against individual corrupt actions. In other words we need to make the punishments for well-defined evil deeds clear and we need to follow through with the consequences. In order to do this we need to demand transparency so we can start to even define evil deeds. This means some system of understanding the models that are being used, and the risks being taken, and a market consensus that the models are sufficient. It means the actual threat of losing actual money, or even going to jail, if the models being used are crappy or if it turns out you were lying about the risks you were taking – or even if you were ignorant of them.
Monday morning reading list
I’m happy to have found three really interesting articles in the New York Times this morning that I thought I’d share.
First, there’s a book review of “The Theory That Would Not Die,” a book about the history of Bayes’ law and the field of Bayesian statistics. It’s always seemed silly (and amusing) to me that there are such pissing contests between different groups of statisticians (the Bayesians versus the Frequentists), but there you are. And I guess this book is here to explain that partly it’s due to the fact that nobody took Bayes’ law seriously, so the people using it were constantly having to defend themselves. Honestly I’m just psyched that a math book is being reviewed in the first place, and written by a woman no less.
Second, there’s an interesting article about A.I.G. suing Bank of America over the mortgage bonds, with excellent background for how little litigation is actually happening due to the credit crisis, especially by our government. Reading between the lines, I would say we could summarize this attitude by our government as along the lines of the following: “Oh wow, those models are complicated. Since I don’t understand them and I don’t expect you to, even though you relied on them for your business, I will let you off the hook. After all, you can’t go to jail for not understanding math!”.
Finally, there’s a really scathing description here of how the politicians are rendering the S.E.C. impotent by giving them too much to do, taking away their power and resources, and generally trying to get micromanaging control over how they do their thing. True, it’s written by a former chairman of the S.E.C., but it’s still not a convincing way to create a powerful regulator (if that’s what anyone wants).
Adam Smith made me buy a Kindle
When I was pregnant with my third son, and working at D.E. Shaw, I got really into reading Adam Smith’s seminal work “Wealth of Nations” on the subway rides to and from work. Once the baby came, though, the problem was that the book is huge, like 1,200 pages, and impossible to read while breastfeeding. In my frustration, and to combat baby brain-rot, I bought a Kindle to continue my reading through many many exhausting hours those first few months. Totally worth it, an investment in my sanity.
This post got me remembering my personal experience with Adam Smith. Adam Smith has really gotten a bum rap. He is generally known for inventing the concept of the invisible hand, which is the idea that, as long as each person is working as hard as they can to personally profit from their labor, the overall economy will benefit from that self-interest. However, it’s often used is as an excuse for why regulations are unnecessary, because somehow, the feeling goes, the invisible hand is all we need. To tell you the truth, I don’t even remember seeing that in his book. Maybe it was there, and maybe I was getting barfed on during that page, but he definitely didn’t focus on it. He had other fascinating points though which he did reiterate.
Here’s why Wealth of Nations is so amazing. First, Smith really is incredibly good at explaining how markets work and, considering that he was inventing a field as he was writing, did so extremely well (although at times the book can be a bit repetitive, probably because he never invented notation- he just rewrote out entire phrase whenever he wanted to refer to an idea). The most basic goal of the book is to explain that it makes more sense to trade between countries so that things that are relatively cheaper to make or produce in Country A can be traded for things that are easier for Country B to make, and to generalize that to “between towns” or “between people”.
The examples he uses are really interesting, and include various layered considerations such as whether the goods are easily stored. For example, he maintains that cotton and wools should absolutely have free trade, since there is a clear advantage to having the appropriate climate for the growth of the plants, as well as the long storage. By contrast, he talks about the price of meat in England versus Argentina, being non-storable, and mentions that the price of a cow in Argentina is equal to the tip you need to give a village boy to go catch a cow (I’m paraphrasing because it was almost three years ago).
Another fascinating aspect of the book is that, since he wrote it in the 1770’s, economic conditions were really different, and he talks at length of the peasant classes in various countries. One of the most striking descriptions comes when he describes how much healthier the Irish peasants were compared to the Scottish peasants, because they ate potatoes, whereas the Scots ate oatmeal. It took me a few minutes to realize that he meant, that they only ate oatmeal. And he was saying that you could tell, by the way the 20 year olds still had teeth in Ireland, how much better a staple potatoes are than oatmeal.
He also talks about the various economies of South America and Europe and it sounds like they were doing better than Great Britain, especially Holland, which was a huge trading country back then. It’s fascinating just to understand, at the level of the average person, the peasants and the merchants, how incredibly different the world was then, something you don’t get as good a look at reading history books (at least the history books I’ve read).
Adam Smith was certainly pro-business, in the sense that he wanted a functioning and efficient system to work for all of the people in the world. However, he was well aware of the natural tendencies of people in power to abuse that power. He speaks at length against monopolies, which he thinks are a natural tendency, and claims that regulations to prevent such things are absolutely necessary.
He also talks at length about currencies and bank notes and the concept of borrowing money to be paid later. He is a proponent of usury laws- he doesn’t think it’s fair to entrap people into debt that they can’t repay (and back then I believe the consequences for unpaid debt were pretty severe). He also goes into incredible detail in describing the way Scotland went through a credit crisis, caused by a lending bubble, where people were cycling through various banks with different loans, borrowing more money to repay other debts, and which spiraled into a huge mess which caused the banking system to collapse. The Bank of England itself defaulted as well in one of his other historical accounts of lending bubbles.
One really interesting point he made about the credit crises he talks about is that, in those days, if you had money, which were called bank notes, then if you wanted to use them in another country you’d have to exchange them for gold when you left the country, and then you’d have to exchange the gold back into bank notes when you entered the next country. He claims that this system actually limited the scope of the credit crisis from going beyond the shores of Scotland; he used a kind of conservation of money argument, wherein he considered promised money, i.e. bank notes, to be only probabilistically worth something . Of course there are many parallels to be made to our current credit crisis, but that part about containing the crisis inside a country really makes me think about how much China has lent to the United States.
Adam Smith had one huge blind spot, which was the way he talked about slaves. It was a long time ago and times were different but it’s really hard to read those passages where he talks condescendingly about how naturally lazy slaves are, although he also mentions how little motivation they have. It’s totally brutal, but then again if you read the 1911 Encyclopedia Britannica you will find much the same kind of thing and worse.
Why should you care about statistical modeling?
One of the major goals of this blog is to let people know how statistical modeling works. My plan is to explain as much as I can in simple plain English, with the least amount of confusion, and the maximum amount of elucidation at every possible level, so every reader can take at least a basic understanding away.
Why? What’s so important about you knowing about what nerds do?
Well, there are different answers. First, you may be interested in it from a purely cerebral perspective – you may yourself be a nerd or a potential nerd. Since it is interesting, and since there will be I suspect many more job openings coming soon that use this stuff, there’s nothing wrong with getting technical; it may come in handy.
But I would argue that even if it’s not intellectually stimulating for you, you should know at least the basics of this stuff, kind of like how we should all know how our government is run and how to conserve energy; kind of a modern civic duty, if you will.
Civic duty? Whaaa?
Here’s why. There’s an incredible amount of data out there, more than every before, and certainly more than when I was growing up. I mean, sure, we always kept track of our GDP and the stock market, that’s old school data collection. And marketers and politicians have always experimented with different ads and campaigns and kept track of what does and what doesn’t work. That’s all data too. But the sheer volume of data that we are now collecting about people and behaviors is positively stunning. Just think of it as a huge and exponentially growing data vat.
And with that data comes data analysis. This is a young field. Even though I encourage every nerd out there to consider becoming a data scientist, I know that if a huge number of them agreed to it today, there wouldn’t be enough jobs out there for everyone. Even so, there will be, and very soon. Each CEO of each internet startup should be seriously considering hiring a data scientist, if they don’t have one already. The power in data mining is immense and it’s only growing. And as I said, the field is young but it’s growing in sophistication rapidly, for good and for evil.
And that gets me to the evil part, and with it the civic duty part.
I claim two things. First, that statistical modeling can and does get out of hand, which I define as when it starts controlling things in a way that is not intended or understood by the people who built the model (or who use the model, or whose lives are affected by the model). And second, that by staying informed about what models are, what they aren’t, what limits they have and what boundaries need to be enforced, we can, as a society, live in a place which is still data-intensive but reasonable.
To give evidence to my first claim, I point you to the credit crisis. In fact finance is a field which is not that different from others like politics and marketing, except that it is years ahead in terms of data analysis. It was and still is the most data-driven, sophisticated place where models rule and the people typically stand back passively and watch (and wait for the money to be transferred to their bank accounts). To be sure, it’s not the fault of the models. In fact I firmly believe that nobody in the mortgage industry, for example, really believed that the various tranches of the mortgage backed securities were in fact risk-free; they knew they were just getting rid of the risk with a hefty reward and they left it at that. And yet, the models were run, and their numbers were quoted, and people relied on them in an abstract way at the very least, and defended their AAA ratings because that’s what the models said. It was a very good example of models being misapplied in situations that weren’t intended or appropriate. The result, as we know, was and still is an economic breakdown when the underlying numbers were revealed to be far far different than the models had predicted.
Another example, which I plan to write more about, is the value-added models being used to evaluate school teachers. In some sense this example is actually more scary than the example of modeling in finance, in that in this case, we are actually talking about people being fired based on a model that nobody really understands. Lives are ruined and schools are closed based on the output of an opaque process which even the model’s creators do not really comprehend (I have seen a technical white paper of one of the currently used value-added models, and it’s my opinion that the writer did not really understand modeling or at best tried not to explain it if he did).
In summary, we are already seeing how statistical modeling can and has affected all of us. And it’s only going to get more omnipresent. Sometimes it’s actually really nice, like when I go to Pandora.com and learn about new bands besides Bright Eyes (is there really any band besides Bright Eyes?!). I’m not trying to stop cool types of modeling! I’m just saying, we wouldn’t let a model tell us what to name our kids, or when to have them. We just like models to suggest cool new songs we’d like.
Actually, it’s a fun thought experiment to imagine what kind of things will be modeled in the future. Will we have models for how much insurance you need to pay based on your DNA? Will there be modeling of how long you will live? How much joy you give to the people around you? Will we model your worth? Will other people model those things about you?
I’d like to take a pause just for a moment to mention a philosophical point about what models do. They make best guesses. They don’t know anything for sure. In finance, a successful model is a model that makes the right bet 51% of the time. In data science we want to find out who is twice as likely to click a button- but that subpopulation is still very unlikely to click! In other words, in terms of money, weak correlations and likelihoods pay off. But that doesn’t mean they should decide peoples’ fates.
My appeal is this: we need to educate ourselves on how the models around us work so we can spot one that’s a runaway model. We need to assert our right to have power over the models rather than the other way around. And to do that we need to understand how to create them and how to control them. And when we do, we should also demand that any model which does affect us needs to be explained to us in terms we can understand as educated people.
Why didn’t anybody invite me!?
There was an attempt yesterday morning to increase transparency on Wall St.
Three strikes against the mortgage industry
There’s a great example here of mortgage lenders lying through their teeth with statistics. Felix Salmon uncovers a ridiculous attempt to make loans look safe by cutting up the pile of mortgages in a tricky way- sound familiar at all?
And there’s a great article here about why they are lying. Namely, there is proposed legislation that would require the banks to keep 5% of the packaged mortgages on their books.
And finally here’s a great description of why they should know better. A breakdown of what banks are currently doing to avoid marking down their mortgage book.
Historical volatility on the S&P index
In a previous post I described the way people in finance often compute historical volatility, in order to try to anticipate future moves in a single stock. I’d like to give a couple of big caveats to this method as well as a worked example, namely on daily returns of the S&P index, with the accompanying python code. I will use these results in a future post I’m planning about errorbars and how people abuse and misuse them.
Two important characteristics of returns
First, market returns in general have fat-tailed distributions; things can seem “quiet” for long stretches of time (longer than any lookback window), during which the sample volatility is a possibly severe underestimate of the “true” standard of deviation of the underlying distribution (if that even makes sense – for the sake of this discussion let’s assume it does). Then when a fat-tailed event occurs, the sample volatility typically spikes to being an overestimate of the standard of deviation for that distribution.
Second, in the markets, there is clustering of volatility- another way of saying this is that volatility itself is rather auto-correlated, so even if we can’t predict the direction of the return, we can still estimate the size of the return. This is particularly true right after a shock, and there are time series models like ARCH and its cousins that model this phenomenon; they in fact allow you to model an overall auto-correlated volatility, which can be thought of as scaling for returns, and allows you to then approximate the normalized returns (returns divided by current volatility) as independent, although still not normal (because they are still fat-tailed even after removing the clustered volatility effect). See below for examples of normalized daily S&P returns with various decays.
Example: S&P daily returns
I got this data from Yahoo Finance, where they let you download daily S&P closes since 1950 to an excel spreadsheet. I could have used some other instrument class, but the below results would be stronger (especially for things like credit default swamps), not weaker- the S&P, being an index, is already the sum of a bunch of things and tends to be more normal as a result; in other words, the Central Limit Theorem is already taking effect on an intraday basis.
First let’s take a look at the last 3 years of closes, so starting in the summer of 2008:

Next we can look at the log returns for the past 3 years:

Now let’s look at how the historical volatility works out with different decays (decays are numbers less than 1 which you use to downweight old data: see this post for an explanation):

For each choice of the above decays, we can normalize the log returns. to try to remove the “volatility clustering”:



As we see, the long decay doesn’t do a very good job. In fact, here are the histograms, which are far from normal:



Here’s the python code I used to generate these plots from the data (see also R code below):
#!/usr/bin/env python
import csv
from matplotlib.pylab import *
from numpy import *
from math import *
import os
os.chdir(‘/Users/cathyoneil/python/sandp/’)
dataReader = csv.DictReader(open(‘SandP_data.txt’, ‘rU’), delimiter=’,’, quotechar=’|’)
close_list = []
for row in dataReader:
#print row[“Date”], row[“Close”]
close_list.append(float(row[“Close”]))
close_list.reverse()
close_array = array(close_list)
close_log_array = array([log(x) for x in close_list])
log_rets = array(diff(close_log_array))
perc_rets = array([exp(x)-1 for x in log_rets])
figure()
plot(close_array[-780:-1], label = “raw closes”)
title(“S&P closes for the last 3 years”)
legend(loc=2)
#figure()
#plot(log_rets, label = “log returns”)
#legend()
#figure()
#hist(log_rets, 100, label = “log returns”)
#legend()
#figure()
#hist(perc_rets, 100, label = “percentage returns”)
#legend()
#show()
def get_vol(d):
var = 0.0
lam = 0.0
var_list = []
for r in log_rets:
lam = lam*(1.0-1.0/d) + 1
var = (1-1.0/lam)*var + (1.0/lam)*r**2
var_list.append(var)
return [sqrt(x) for x in var_list]
figure()
for d in [10, 30, 100]:
plot(get_vol(d)[-780:-1], label = “decay factor %.2f” %(1-1.0/d))
title(“Volatility in the S&P in the past 3 years with different decay factors”)
legend()
for d in [10, 30, 100]:
figure()
these_vols = get_vol(d)
plot([log_rets[i]/these_vols[i-1] for i in range(len(log_rets) – 780, len(log_rets)-1)], label = “decay %.2f” %(1-1.0/d))
title(“Volatility normalized log returns (last three years)”)
legend()
figure()
plot([log_rets[i] for i in range(len(log_rets) – 780, len(log_rets)-1)], label = “raw log returns”)
title(“Raw log returns (last three years)”)
for d in [10, 30, 100]:
figure()
these_vols = get_vol(d)
normed_rets = [log_rets[i]/these_vols[i-1] for i in range(len(log_rets) – 780, len(log_rets)-1)]
hist(normed_rets, 100,label = “decay %.2f” %(1-1.0/d))
title(“Histogram of volatility normalized log returns (last three years)”)
legend()
Here’s the R code Daniel Krasner kindly wrote for the same plots:
setwd(“/Users/cathyoneil/R”)
dataReader <- read.csv(“SandP_data.txt”, header=T)
close_list <- as.numeric(dataReader$Close)
close_list <- rev(close_list)
close_log_list <- log(close_list)
log_rets <- diff(close_log_list)
perc_rets = exp(log_rets)-1
x11()
plot(close_list[(length(close_list)-779):(length(close_list))], type=’l’, main=”S&P closes for the last 3 years”, col=’blue’)
legend(125, 1300, “raw closes”, cex=0.8, col=”blue”, lty=1)
get_vol <- function(d){
var = 0
lam=0
var_list <- c()
for (r in log_rets){
lam <- lam*(1 – 1/d) + 1
var = (1 – 1/lam)*var + (1/lam)*r^2
var_list <- c(var_list, var)
}
return (sqrt(var_list))
}
L <- (length(close_list))
x11()
plot(get_vol(10)[(L-779):L], type=’l’, main=”Volatility in the S&P in the past 3 years with different decay factors”, col=1)
lines(get_vol(30)[(L-779):L], col=2)
lines(get_vol(100)[(L-779):L], col=3)
legend(550, 0.05, c(“decay factor .90”, “decay factor .97″,”decay factor .99”) , cex=0.8, col=c(1,2,3), lty = 1:3)
x11()
par(mfrow=c(3,1))
plot((log_rets[2:L]/get_vol(10))[(L-779):L], type=’l’, col=1, lty=1, ylab=”)
legend(620, 3, “decay factor .90”, cex=0.6, col=1, lty = 1)
plot((log_rets[2:L]/get_vol(30))[(L-779):L], type=’l’, col=2, lty =2, ylab=”)
legend(620, 3, “decay factor .97”, cex=0.6, col=2, lty = 2)
plot((log_rets[2:L]/get_vol(100))[(L-779):L], type=’l’, col=3, lty =3, ylab=”)
legend(620, 3, “decay factor .99”, cex=0.6, col=3, lty = 3)
x11()
plot(log_rets[(L-779):L], type=’l’, main = “raw log returns”, col=”blue”, ylab=”)
par(mfrow=c(3,1))
hist((log_rets[2:L]/get_vol(10))[(L-779):L], breaks=200, col=1, lty=1, ylab=”, xlab=”, main=”)
legend(2, 15, “decay factor .90”, cex=.8, col=1, lty = 1)
hist((log_rets[2:L]/get_vol(30))[(L-779):L], breaks=200, col=2, lty =2, ylab=”, xlab=”, main=”)
legend(2, 40, “decay factor .97”, cex=0.8, col=2, lty = 2)
hist((log_rets[2:L]/get_vol(100))[(L-779):L], breaks=200, col=3, lty =3, ylab=”, xlab=”, main=”)
legend(3, 50, “decay factor .99”, cex=0.8, col=3, lty = 3)
Is too big to fail a good thing?
I read this blog post a couple of days and it really got me thinking. This guy John Hempton from Australia is advocating the too big to fail model- in fact he things we should merge more big banks together (Citigroup and Wells Fargo) because we haven’t gone far enough!
His overall thesis is that competition in finance increases as a function of how many banks there are out there and is a bad thing for stockholders and for society, because it makes people desperate for profit, and in particular people increase their risk profiles in pursuit of profit and they blow up:
What I am advocating is – that as a matter of policy – you should deliberately give up competition in financial services – and that you should do this by hide-bound regulation and by deliberately inducing financial service firms to merge to create stronger, larger and (most importantly) more anti-competitive entities.
He acknowledges that the remaining banks will be hugely profitable, and perhaps also extremely lazy, but claims this is a good thing: we would, as a culture, essentially be paying a fee for stability. It’s something we do all the time in some sense, when we buy insurance. Insurance is a fee we pay so that disruptions and small disasters in our lives don’t completely wipe us out. So perhaps, as a culture, this would be a price worth paying?
The biggest evidence he has that this setup works well is that it works in Australia- they have four huge incompetent yet profitable banks there, and they don’t blow up. People who work there are sitting pretty, I guess, because they really are just living in a money press. There is no financial innovation because there’s no competition.
I guess I have a few different reactions to this scenario. First, it’s kind of an interesting twist on the too-big-to-fail debate, in that it’s combined with the idea I already talked about here of having a system of banks that are utilities. John is saying that, really, we don’t need to make that official, that as soon as banks are this huge, we are already done, they are essentially going to act like utilities. This is super interesting to me, but I’m not convinced it’s a necessary or even natural result of huge banks.
Second, I don’t buy that what happened in Australia will happen here- perhaps Australia squelched financial innovation through regulations and the existing boring system, but maybe the people who would have been financial innovators all just moved to the U.S. and became innovators here (there are plenty of examples of that!). In other words Australia may have made it just a bit too difficult to be competitive relative to what else is out there- if everyone tried to be that repressive to financial innovation, we may see people moving back into Australia’s financial waters (like sharks).
Third, I think what John is talking about is an example of a general phenomenon, namely that, in the limit as regulations go to infinity, there is only one bank left standing. This is because every additional regulation requires a lawyer to go over the requirements and a compliance person to make sure the rules are being followed continuously. So the more regulation, the more it behooves banks to merge so that they can share those lawyers and compliance officers to save costs. In the end the regulations have defined the environment to such an extent that there’s only one bank that can possibly follow all the rules, and knows how to because of historical reasons. And that one, last bank may as well be a government institution, albeit with better pay, especially for its managers.
But we don’t have that kind of regulatory environment, and hedge funds are alive and well. They have to follow some rules, it’s absolutely true, but it’s still possible to start a smallish hedge fund without a million lawyers.
I guess what I’m concluding is that if we had formed our very few, very huge banks because of a stifling regulatory environment, then maybe we would have an environment that is sufficiently anti-competitive to think that our banks would serve us as slightly overpaid utilities. However, that’s not why we have them – it was because of the credit crisis, and the rules and regulations haven’t changed that much since then.
At the same time, I don’t totally disagree that huge banks do become anti-competitive, just by dint of how long it takes them to make decisions and do things. But I’m not sure anti-competitive is the same thing as low-risk.
Elizabeth Warren: Moses and the Promised Land
This is a guest post by FogOfWar
In Biblical style, Elizabeth Warren (EW) was not nominated to head the CFPB (Consumer Financial Protection Bureau). Having spearheaded the movement to create the institution, pushed to make it part of the otherwise-generally-useless* Dodd Frank “Financial Reform” Bill, and spent the better part of the last two years staffing the actual CFPB and moving it into gear, she has now been deemed too controversial by what passes for a President these days.
One of my favorite EW quotes: “My first choice is a strong consumer agency. My second choice is no agency at all and plenty of blood and teeth left on the floor.” This still remains to be seen, as opposition to the CPFB (and filibuster threats to any appointment to head the Bureau) remains in the face of nominee Richard Cordray. In fact, if one were inclined to be an Obama apologist (I gave up apologizing for Obama right about here), one might view the Warren-Cordray switch as a potentially brilliant tactical maneuver, with the emphasis on “potentially”. If the opposition to the CPFB took its persona in EW, then sidestepping her personally to get the agency up and running would be worthwhile, particularly as Cordray seems at least as assertively pro-consumer as EW (a bank lobbyist described him as “Elizabeth Warren without the charm”).
Barney Frank believes gender bias played a role. Maybe yes, maybe no and the Cordray confirmation will give some evidence to that question. I suspect the Republican opposition isn’t stupid and knows that Cordray will run a good agency. If that’s right then passing over EW doesn’t really serve any purpose.
Hard to tell what a public figure is really like, but my sense is EW doesn’t have any ego attached to running the agency personally. And what she does next is really up to her, I mean who really cares what we think she should do?
Wait—this is a blog! Our Raison d’être is practically making suggestions that no one will listen to, so let’s go…
1. Run for Congress
The biggest idea floated around. Yves Smith thinks it’s a terrible idea. I’m not entirely convinced—there are many ways to make a difference in this world, and being one minority member of a large and powerful body, and thus moving the body incrementally in the right direction can be a very good thing.
Two questions though: can she win (a few early stage polls seemed to indicate no, but do early stage polls really have much predictive value on final election results? Cathy? Fivethirtyeight?), and on which party platform would she run (I vote for running as an Independent)? Any thoughts from the ground from our MA-registered voters?
2. The “Al Gore” option
EW could continue to advocate, lecture and write outside of political office. She’s good television and would be free to speak without the gag order of elected office. Definitely something to be said for this option. Just realized pulling links for this post that EW was the person from the movie “Maxed Out”. Part of me thinks “damn that was effective and she should do more of that because it was so effective” and part of me thinks “wait, that movie came out in 2006 and no one listened and no one will listen”, and then the other part goes “but it can happen—you’ve actually seen social perceptions change in the wake of Al Gore (and yes, lots and lots of other people, but sparks do matter) with real and deep impacts.”
3. The “Colin Powell” option
Y’now, being in the public light kinda sucks ass. Colin Powell passed up a run for President, and largely retired to private life, and doesn’t seem to have any complaints about it. One legitimate option is to say “I did my part, you guys fight the good fight & I’m going to hang out with my grandkids on the beach.”
Any other suggestions?
*-Paul Volker deserves a parallel post of equal length for pushing the Volker Rule through this legislation and similarly receiving the thanks of being sidelined by the TBTF bank-capital-must-increase-even-if-the-peasants-have-to-eat-cake crowd.
Measuring historical volatility
Say we are trying to estimate risk on a stock or a portfolio of stocks. For the purpose of this discussion, let’s say we’d like to know how far up or down we might expect to see a price move in one day.
First we need to decide how to measure the upness or downness of the prices as they vary from day to day. In other words we need to define a return. For most people this would naturally be defined as a percentage return, which is given by the formula:

where 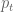


If you know your power series expansions, you will quickly realize there is not much difference between these two definitions for small returns- it’s only when we are talking about pretty serious market days that we will see a difference. One advantage of using the log returns is that they are additive- if you go down 0.01 one day, then up 0.01 the next, you end up with the same price as you started. This is not true for percentage returns (and is even more not true when you consider large movements like 50% down one day, 50% up the next).
Once we have our returns defined, we can keep a running estimate of how much we have seen it change recently, which is usually measured as a sample standard deviation, and is called a volatility estimate.
A critical decision in measuring the volatility is in choosing a lookback window, which is a length of time in the past we will take our information from. The longer the lookback window is, the more information we have to go by for our estimate. However, the shorter our lookback window, the more quickly our volatility estimate responds to new information. Sometimes you can think about it like this: if a pretty big market event occurs, how long does it take for the market to “forget about it”? That’s pretty vague but it can give one an intuition on the appropriate length of a lookback window. So, for example, more than a week, less than 4 months.
Next we need to decide how we are using the past few days worth of data. The simplest approach is to take a strictly rolling window, which means we weight each of the previous n days equally and a given day’s return is counted for those n days and then drops off the back of a window. The bad news about this easy approach is that a big return will be counted as big until that last moment, and it will completely disappear. This doesn’t jive with the sense of the ways people forget about things- they usually let information gradually fade from their memories.
For this reason we instead have a continuous look-back window, where we exponentially downweight the older data and we have a concept of the “half-life” of the data. This works out to saying that we scale the impact of the past returns depending on how far back in the past they are, and for each day they get multiplied by some number less than 1 (called the decay). For example, if we take the number to be 0.97, then for 5 days ago we are multiplying the impact of that return by the scalar 0.97^5. Then we will divide by the sum of the weights, and overall we are taking the weighted average of returns where the weights are just powers of something like 0.97. The “half-life” in this model can be inferred from the number 0.97 using these formulas as -ln(2)/ln(0.97) = 23.
Now that we have figured out how much we want to weight each previous day’s return, we calculate the variance as simply the weighted sum of the squares of the previous returns. Then we take the square root at the end to estimate the volatility.
Note I’ve just given you a formula that involves all of the previous returns. It’s potentially an infinite calculation, albeit with exponentially decaying weights. But there’s a cool trick: to actually compute this we only need to keep one running total of the sum so far, and combine it with the new squared return. So we can update our vol estimate with one thing in memory and one easy weighted average. This is easily seen as follows:
First, we are dividing by the sum of the weights, but the weights are powers of some number s, so it’s a geometric sum and the sum is given by

Next, assume we have the current variance estimate as

and we have a new return 
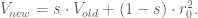
Note that I said we would use the sample standard deviation, but the formula for that normally involves removing the mean before taking the sum of squares. Here we ignore the mean, mostly because we are typically taking daily volatility, where the mean (which is hard to anticipate in any case!) is a much smaller factor than the noise. If we were to measure volatility on a longer time scale such as quarters or years, then we would not ignore the mean.
In my next post I will talk about how people use and abuse this concept of volatility, and in particular how it is this perspective that leads people to say things like, “a 6-standard deviation event took place three times in a row.”
High frequency trading: Update
I’d like to make an update to my earlier rant about high frequency trading. I got an awesome comment from someone in finance that explains that my main point is invalid, namely:
…the statement that high frequency traders tend to back away when the market gets volatile may be true, but it is demonstrably true that other, non-electronic, non-high-frequency, market makers do and have done exactly the same thing historically (numerous examples included 1987, 1998, various times in the mortgage crisis, and just the other morning in Italian government bonds when they traded 3 points wide for I believe over an hour). While there is an obligation to make markets, in general one is not obliged to make markets at any particular width; and if there were such an obligation, the economics of being a marketmaker would be really terrible, because you would be saying that at certain junctures you are obliged to be picked off (typically exactly when that has the greatest chance of bankrupting your enterprise).
My conclusion is that it’s not a clear but case that high-frequency traders actually increase the risk.
By the way, just in case it’s not clear: one of the main reasons I am blogging in the first place is so that people will set me straight if I’m wrong about the facts. So please do comment if you think I’m getting things wrong.
What is an earnings surprise?
One of my goals for this blog is to provide a minimally watered-down resource for technical but common financial terms. It annoys me when I see technical jargon thrown around in articles without any references.
My audience for a post like this is someone who is somewhat mathematically trained, but not necessarily mathematically sophisticated, and certainly not knowledgeable about finance. I already wrote a similar post about what it means for a statistic to be seasonally adjusted here.
By way of very basic background, publicly traded companies (i.e. companies you can buy stock on) announce their earnings once a quarter. They each have a different schedule for this, and their stock price often has drastic movements after the announcement, depending on if it’s good news or bad news. They usually make their announcement before or after trading hours so that it’s more difficult for news to leak and affect the price in weird ways minutes before and after the announcement, but even so most insider trading is centered around knowing and trading on earnings announcements before the official announcement. (Don’t do this. It’s really easy to trace. There are plenty of other ways to illegally make money on Wall Street that are harder to trace.)
In fact, there’s so much money at stake that there’s a whole squad of “analysts” whose job it is to anticipate earnings announcements. They are supposed to learn lots of qualitative information about the industry and the company and how it’s managed etc. Even so most analysts are pretty bad at forecasting earnings. For that reason, instead of listening to a specific analyst, people sometimes take an average of a bunch of analysts’ opinions in an effort to harness the wisdom of crowds. Unfortunately the opinions of analysts are probably not independent, so it’s not clear how much averaging is really going on.
The bottomline of the above discussion is that the concept of an earnings surprise is really only borderline technical, because it’s possible to define it in a super naive, model-free way, namely as the difference between the “consensus among experts” and the actual earnings announcement. However, there’s also a way to quantitatively model it, and the model will probably be as good or better than most analysts’ predictions. I will discuss this model now.
[As an aside, if this model works as well or better as most analysts’ opinions, why don’t analysts just use this model? One possible answer is that, as an analyst, you only get big payoffs if you make a big, unexpected prediction which turns out to be true; you don’t get much credit for being pretty close to right most of the time. In other words you have an incentive to make brash forecasts. One example of this is Meredith Whitney, who got famous for saying in October 2007 that Citigroup would get hosed. Of course it could also be that she’s really pretty good at learning about companies.]
An earnings surprise is the difference between the actual earnings, known on day t, and a forecast of the earnings, known on day t-1. So how do we forecast earnings? A simple and reasonable way to start is to use an autoregressive model, which is a fancy way of saying do a regression to tell you how past earnings announcements can be used as signals to predict future earnings announcements. For example, at first blush we may use last earning’s announcement as a best guess of this coming one. But then we may realize that companies tend to drift in the same direction for some number of quarters (we would find this kind of thing out by pooling data over lots of companies over lots of time), so we would actually care not just about what the last earnings announcement was but also the previous one or two or three. [By the way, this is essentially the same first step I want to use in the diabetes glucose level model, when I use past log levels to predict future log levels.]
The difference between two quarters ago and last quarter gives you a sense of the derivative of the earnings curve, and if you take an alternating sum over the past three you get a sense of the curvature or acceleration of the earnings curve.
It’s even possible you’d want to use more than three past data points, but in that case, since the number of coefficients you are regressing is getting big, you’d probably want to place a strong prior on those coefficients in order to reduce the degrees of freedom; otherwise we would be be fitting the coefficients to the data too much and we’d expect it to lose predictive power. I will devote another post to describing how to put a prior on this kind of thing.
Once we have as good a forecast of the earnings knowing past earnings as we can get, we can try adding macroeconomic or industry-specific signals to the model and see if we get better forecasts – such signals would bring up or bring down the earnings for the whole industry. For example, there may be some manufacturing index we could use as a proxy to the economic environment, or we could use the NASDAQ index for the tech environment.
Since there is never enough data for this kind of model, we would pool all the data we had, for all the quarters and all the companies, and run a causal regression to estimate our coefficients. Then we would calculate a earnings forecast for a specific company by plugging in the past few quarterly results of earnings for that company.



