Guest post, The Vortex: A Cookie Swapping Game for Anti-Surveillance
This is a guest post by Rachel Law, a conceptual artist, designer and programmer living in Brooklyn, New York. She recently graduated from Parsons MFA Design&Technology. Her practice is centered around social myths and how technology facilitates the creation of new communities. Currently she is writing a book with McKenzie Wark called W.A.N.T, about new ways of analyzing networks and debunking ‘mapping’.
Let’s start with a timely question. How would you like to be able to change how you are identified by online networks? We’ll talk more about how you’re currently identified below, but for now just imagine having control over that process for once – how would that feel? Vortex is something I’ve invented that will try to make that happen.
Namely, Vortex is a data management game that allows players to swap cookies, change IPs and disguise their locations. Through play, individuals experience how their browser changes in real time when different cookies are equipped. Vortex is a proof of concept that illustrates how network collisions in gameplay expose contours of a network determined by consumer behavior.
What happens when users are allowed to swap cookies?
These cookies, placed by marketers to track behavioral patterns, are stored on our personal devices from mobile phones to laptops to tablets, as a symbolic and data-driven signifier of who we are. In other words, to the eyes of the database, the cookies are us. They are our identities, controlling the way we use, browse and experience the web. Depending on cookie type, they might follow us across multiple websites, save entire histories about how we navigate and look at things and pass this information to companies while still living inside our devices.
If we have the ability to swap cookies, the debate on privacy shifts from relying on corporations to follow regulations to empowering users by giving them the opportunity to manage how they want to be perceived by the network.
What are cookies?
The corporate technological ability to track customers and piece together entire personal histories is a recent development. While there are several ways of doing so, the most common and prevalent method is with HTTP cookies. Invented in 1994 by a computer programmer, Lou Montulli, HTTP cookies were originally created with the shopping cart system as a way for the computer to store the current state of the session, i.e. how many items existed in the cart without overloading the company’s server. These session histories were saved inside each user’s computer or individual device, where companies accessed and updated consumer history constantly as a form of ‘internet history’. Information such as where you clicked, how to you clicked, what you clicked first, your general purchasing history and preferences were all saved in your browsing history and accessed by companies through cookies.
Cookies were originally implemented to the general public without their knowledge until the Financial Times published an article about how they were made and utilized on websites without user knowledge on February 12th, 1996 . This revelation led to a public outcry over privacy issues, especially since data was being gathered without the knowledge or consent of users. In addition, corporations had access to information stored on personal computers as the cookie sessions were stored on your computer and not their servers.
At the center of the debate was the issue on third-party cookies, also known as “persistent” or “tracking” cookies. When you are browsing a webpage, there may be components on the page that are hosted on the same server, but different domain. These external objects then pass cookies to you if you click an image, link or article. They are then used by advertising and media mining corporations to track users across multiple sites to garner more knowledge about the users browsing patterns to create more specific and targeted advertising.
In August 2013, Wall Street Journal ran an article on how Mac users were being unfairly targeted by travel site Orbitz with advertisements that were 13% more expensive than PC users. New York Times followed it up with a similar article in November 2012 about how the data collected and re-sold to advertisers. These advertisers would analyze users buying habits to create micro-categories where the personal experiences were tailored to maximize potential profits.
What does that mean for us?
The current state of today’s internet is no longer the same as the carefree 90s of ‘internet democracy’ and utopian ‘cyberspace’. Mediamining exploits invasive technologies such as IP tracking, geolocating and cookies to create specific advertisements targeted to individuals. Browsing is now determined by your consumer profile what you see, hear and the feeds you receive are tailored from your friends’ lists, emails, online purchases etc. The ‘Internet’ does not exist. Instead, it is many overlapping filter bubbles which selectively curate us into data objects to be consumed and purchased by advertisers.
This information, though anonymous, is built up over time and used to track and trace an individual’s history – sometimes spanning an entire lifetime. Who you are, and your real name is irrelevant in the overall scale of collected data, depersonalizing and dehumanizing you into nothing but a list of numbers on a spreadsheet.
The superstore Target, provides a useful case study for data profiling in its use of statisticians on their marketing teams. In 2002, Target realized that when a couple is expecting a child, the way they shop and purchase products changes. But they needed a tool to be able to see and take advantage of the pattern. As such, they asked mathematicians to come up with algorithms to identify behavioral patterns that would indicate a newly expectant mother and push direct marketing materials their way. In a public relations fiasco, Target had sent maternity and infant care advertisements to a household, inadvertedly revealing that their teenage daughter was pregnant before she told her parents .
This build-up of information creates a ‘database of ruin’, enough information that marketers and advertisers know more about your life and predictive patterns than any single entity. Databases that can predict whether you’re expecting, or when you’ve moved, or what stage of your life or income level you’re at… information that you have no control over where it goes to, who is reading it or how it is being used. More importantly, these databases have collected enough information that they know secrets such as family history of illness, criminal or drug records or other private information that could potentially cause harm upon the individual data point if released – without ever needing to know his or her name.
What happens now is two terrifying possibilities:
- Corporate databases with information about you, your family and friends that you have zero control over, including sensitive information such as health, criminal/drug records etc. that are bought and re-sold to other companies for profit maximization.
- New forms of discrimination where your buying/consumer habits determine which level of internet you can access, or what kind of internet you can experience. This discrimination is so insidious because it happens on a user account level which you cannot see unless you have access to other people’s accounts.
Here’s a visual describing this process:
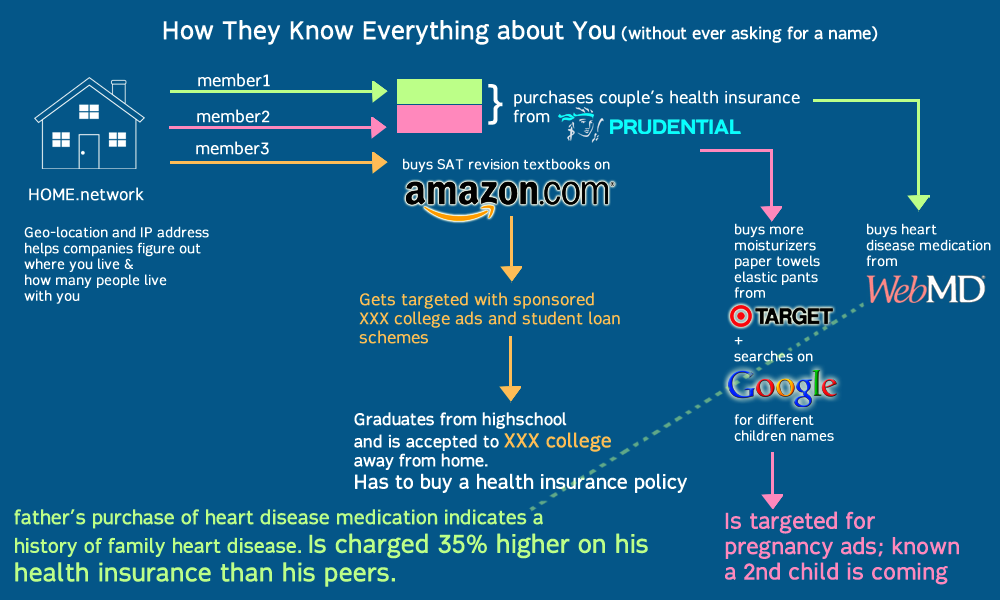
What can Vortex do, and where can I download a copy?
As Vortex lives on the browser, it can manage both pseudo-identities (invented) as well as ‘real’ identities shared with you by other users. These identity profiles are created through mining websites for cookies, swapping them with friends as well as arranging and re-arranging them to create new experiences. By swapping identities, you are essentially ‘disguised’ as someone else – the network or website will not be able to recognize you. The idea is that being completely anonymous is difficult, but being someone else and hiding with misinformation is easy.
This does not mean a death knell for online shopping or e-commerce industries. For instance, if a user decides to go shoe-shopping for summer, he/she could equip their browser with the cookies most associated and aligned with shopping, shoes and summer. Targeted advertising becomes a targeted choice for both advertisers and users. Advertisers will not have to worry about misinterpreting or mis-targeting inappropriate advertisements i.e. showing tampon advertisements to a boyfriend who happened to borrow his girlfriend’s laptop; and at the same time users can choose what kind of advertisements they want to see. (i.e. Summer is coming, maybe it’s time to load up all those cookies linked to shoes and summer and beaches and see what websites have to offer; or disable cookies it completely if you hate summer apparel.)
Currently the game is a working prototype/demo. The code is licensed under creative commons and will be available on GitHub by the end of summer. I am trying to get funding to make it free, safe & easy to use; but right now I’m broke from grad school and a proper back-end to be built for creating accounts that is safe and cannot be intercepted. If you have any questions on technical specs or interest in collaborating to make it happen – particularly looking for people versed in python/mongodb, please email me: Rachel@milkred.net.




“Wall Street Journal ran an article on how Mac users were being unfairly targeted by travel site Orbitz with advertisements that were 13% more expensive than PC users.”
I thought when I read this that the prices were 13% higher for the same services. But that is not so; according to the story, Mac and PC users get the same prices, but Mac users get fancier hotel rooms and such pushed to the top of the list. Unless the user choose to order results by price, or one of the other options under his or her control.
What is unfair about that?
BTW, it was 2012, not 2013.
LikeLike
Good clarification, and one that was widely misunderstood when it was originally reported. Basically, you say po-TAY-toe, I say po-TAH-toe… you get shown po-TAY-toe simply because you like it, and vice versa. Everyone is seemingly happy, and benefits.
There is a murky side to this as alluded to in this and a previous post, but bespoke marketing messages are generally viewed as acceptable so long as perceived benefits outweigh perceived costs on both sides of the equation. Opacity that obfuscates “perceived” vs “reality” probably serves to mitigate true advancement.
LikeLike
Will consumers will get better treatment from sellers if they obfuscate their identities and behaviors? I’d rather deal with a transparent entity, whether I’m a seller, consumer, or investor. I don’t see how building a reputation for secrecy and identity theft will make you a person I’d want to deal with. If I’m a retailer and observed this behavior, I’d assume the worst and charge a far higher premium to serve you than any transparent customer. If I’m an investor or customer, I’d look elsewhere to do business.
LikeLike
Depending on how you do it the retailer will never know. Also, you’ve hit the nail on the head in terms of expectations: if and when people stop shopping at websites that are too nosy, then retailers will respond. Not before.
LikeLike
Keep the information coming. I think this would have a huge audience and thanks for the healthcare focus. The data selling that goes on in healthcare is huge. Only the “Query Master” knows for sure:) I have also posed the question a couple of times about the consumer mobile apps and devices as far as their solvency as a company, in other words could they exist, sell a product or app and show a profit without selling data? I think we might be surprised if someone ever dug in deep here to really explore this question.
I said a while back that data selling is “an epidemic” and the error factors and flaws are rising as more gets sold. Think about it when you have to go back and correct erroneous information gathered on you, you’re on your own dime, but the corporations and banks have profited in a huge way on selling your data, i.e. credit for one. I rarely turn on the location app on my cell phone, only use it if I need to find a store, etc.and that’s it. I would love to see a project like this take off, we need it, and crowd fund it so development can continue maybe and keep it open source. I only mention the crowd funding to help the developers only and not to sell the project by all means and this is nice keeping it open source for sure and just don’t want to see it go away if the proof of concept here works:)
Insurance is not the same business it used to be and the graphic here I’m sure will open some eyes. I see a lot of subsidiary companies created which do things that perhaps under a corporate name would not be kosher, legal or whatever. They don’t hide fact that the company is a subsidiary of a health insurer but they don’t come out and advertise it either. I just did a post about United and they have more subsidiaries than Carter has pills and I keep finding new ones all the time. The latest shows a huge grip into the military with dealing with VA disability claims and the DOD with providing “event” services which per their website depicts doing a massive project of physicals, immunizations, etc. on troops ready to be deployed or sent on an occupational health mission somewhere…very interesting stuff and I would say there’s some folks in there who have some pretty high clearances so in viewing this with all the NSA chatter…makes one think for sure.
United of course is well known from their old Ingenix division (which the name became so bad with this affiliation they had to change it to Optum) of being a huge data seller and got into trouble with their model for “safe and customary charges” a couple years ago to where they low balled the numbers and then on top of that, all the other major insurers licensed that model! AMA settled class action last year and hospitals and doctors received minimal compensation. The model was in use for 15 years for out of network charges. It also doesn’t hurt my feelings too much to see United replace AT&T as #15 on the Dow most shorted stock list today according to Forbes:)
Keep the information flowing and again thanks for the healthcare focus too. I would love to become a “cookie swapper”:) I still say we need some kind of licensing with data selling and a federal site that discloses who sells what kind of data and to who for consumers..and it would lend a path of regulation of some sort as now it’s just out of hand and the danger of being used out of context lives among us.
LikeLike
Wow forget pee tests…just call Target!
LikeLike
is that shirt your wearing –the mathbabe shirt what size is it im ordering one for the msis Date: Thu, 13 Jun 2013 10:55:29 +0000 To: bnthdntht@hotmail.com
LikeLike
Odd thing…
Earlier today I searched and read the Wall Street Journal article mentioned in this post. Now I learn from my wife that I have Recommended it on Facebook. This is most remarkable, since I have not actually logged on to my Facebook in at least a few days, probably weeks. I’m almost sure I even turned off the computer in the interim. And I have certainly read many of WSJ articles without this happening.
Did you guys do this? Have I participated in a piece of “conceptual art”? Written in Python, perhaps? If so, nicely done! And it does rather make your point either way.
LikeLike