Lobbyists have another reason to dominate public commenting #OWS
Before I begin this morning’s rant, I need to mention that, as I’ve taken on a new job recently and I’m still trying to write a book, I’m expecting to not be able to blog as regularly as I have been. It pains me to say it but my posts will become more intermittent until this book is finished. I’ll miss you more than you’ll miss me!
On to today’s bullshit modeling idea, which was sent to me by both Linda Brown and Michael Crimmins. It’s a new model built in part by the former chief economist for the Commodity Futures Trading Commission (CFTC) Andrei Kirilenko, who is now a finance professor at Sloan. In case you don’t know, the CFTC is the regulator in charge of futures and swaps.
I’ll excerpt this New York Times article which describes the model:
The algorithm, he says, uncovers key word clusters to measure “regulatory sentiment” as pro-regulation, anti-regulation or neutral, on a scale from -1 to +1, with zero being neutral.
If the number assigned to a final rule is different from the proposed one and closer to the number assigned to all the public comments, then it can be inferred that the agency has taken the public’s views into account, he says.
Some comments:
- I know really smart people that use similar sentiment algorithms on word clusters. I have no beef with the underlying NLP algorithm.
- What I do have a problem with is the apparent assumption that the “the number assigned to all the public comments” makes any sense, and in particular whether it takes into account “the public’s view”.
- It sounds like the algorithm dumps all the public comment letters into a pot and mixes it together to get an overall score. The problem with this is that the industry insiders and their lobbyists overwhelm public commenting systems.
- For example, go take a look at the list of public letters for the Volcker Rule. It’s not unlike this graphic on the meetings of the regulators on the Volcker Rule:
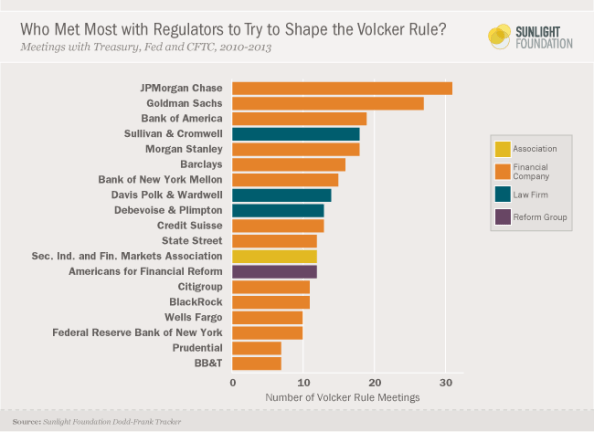
- Besides dominating the sheer number of letters, I’ll bet the length of each letter is also much longer on average for such parties with very fancy lawyers.
- Now think about how the NLP algorithm will deal with this in a big pot: it will be dominated by the language of the pro-industry insiders.
- Moreover, if such a model were to be directly used, say to check that public commenting letters were written in a given case, lobbyists would have even more reason to overwhelm public commenting systems.
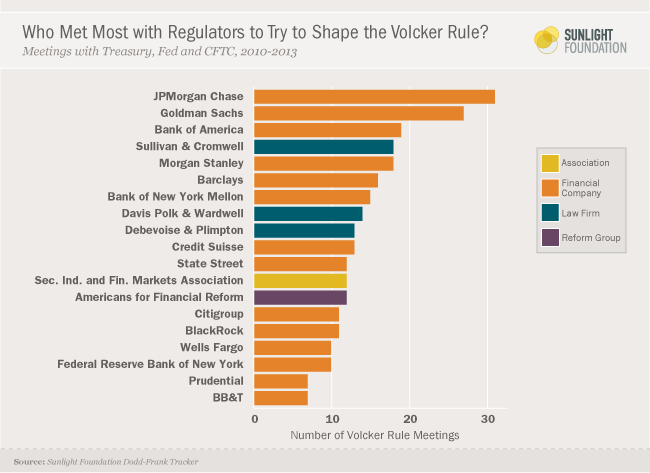
The take-away is that this is an amazing example of a so-called objective mathematical model set up to legitimize the watering down of financial regulation by lobbyists.
Update: I’m willing to admit I might have spoken too soon. I look forward to reading the paper on this algorithm and taking a deeper look instead of relying on a newspaper.




As a concerned citizen/modeler, did you try contacting Andrei Kirilenko with this? How do you know his nlp algorithm is not bucketing comments by their source first – did you ask him for the details or source code?
From what my economics grad student friends tell me, he was a rare regulator who was pushing for wider access to government’s data. A lot of legitimate (data-, not hysteria-driven) research about HFT came from his project of letting researchers look at cftc’s futures trading data.
I would think he’d welcome comments or improvements to his models. Not clear why ranting on your blog is more helpful.
LikeLike
I think you are misjudging the paper. It explicitly addresses the question of who is commenting — and finds (quelle surprise!) that financial insiders are the ones with influence.
So, I think this could be useful, if only to document what we might have suspected was the case.
I’m sure it can be improved, but I’m not sure that calling it a “bullshit modelling idea” is justified.
Congrats on the job (but we’ll miss your blog).
LikeLike
In your defense, the NYT missed that point too. Reading the NYT “The researchers found that the agency very often heeded the public’s views when writing its final rules. ”
The “public comments” that the paper found had influence were specifically comments from the financial industry. (see Section 4.2 of the paper “Who does the government listen to?”
“We find that only comments written by fi nance professionals such as traders, asset managers,and bankers have a statistically signi cant predictive eff ect on the RegRank of the final rules.
LikeLike