Columbia data science course, week 2: RealDirect, linear regression, k-nearest neighbors
Data Science Blog
Today we started with discussing Rachel’s new blog, which is awesome and people should check it out for her words of data science wisdom. The topics she’s riffed on so far include: Why I proposed the course, EDA (exploratory data analysis), Analysis of the data science profiles from last week, and Defining data science as a research discipline.
She wants students and auditors to feel comfortable in contributing to blog discussion, that’s why they’re there. She particularly wants people to understand the importance of getting a feel for the data and the questions before ever worrying about how to present a shiny polished model to others. To illustrate this she threw up some heavy quotes:
“Long before worrying about how to convince others, you first have to understand what’s happening yourself” – Andrew Gelman
“Agreed” – Rachel Schutt
Thought experiment: how would you simulate chaos?
We split into groups and discussed this for a few minutes, then got back into a discussion. Here are some ideas from students:
- A Lorenzian water wheel would do the trick, if you know what that is.
- Question: is chaos the same as randomness?
- Many a physical system can exhibit inherent chaos: examples with finite-state machines
- Teaching technique of “Simulating chaos to teach order” gives us real world simulation of a disaster area
- In this class w want to see how students would handle a chaotic situation. Most data problems start out with a certain amount of dirty data, ill-defined questions, and urgency. Can we teach a method of creating order from chaos?
- See also “Creating order from chaos in a startup“.
Talking to Doug Perlson, CEO of RealDirect
We got into teams of 4 or 5 to assemble our questions for Doug, the CEO of RealDirect. The students have been assigned as homework the task of suggesting a data strategy for this new company, due next week.
He came in, gave us his background in real-estate law and startups and online advertising, and told us about his desire to use all the data he now knew about to improve the way people sell and buy houses.
First they built an interface for sellers, giving them useful data-driven tips on how to sell their house and using interaction data to give real-time recommendations on what to do next. Doug made the remark that normally, people sell their homes about once in 7 years and they’re not pros. The goal of RealDirect is not just to make individuals better but also pros better at their job.
He pointed out that brokers are “free agents” – they operate by themselves. they guard their data, and the really good ones have lots of experience, which is to say they have more data. But very few brokers actually have sufficient experience to do it well.
The idea is to apply a team of licensed real-estate agents to be data experts. They learn how to use information-collecting tools so we can gather data, in addition to publicly available information (for example, co-op sales data now available, which is new).
One problem with publicly available data is that it’s old news – there’s a 3 month lag. RealDirect is working on real-time feeds on stuff like:
- when people start search,
- what’s the initial offer,
- the time between offer and close, and
- how people search online.
Ultimately good information helps both the buyer and the seller.
RealDirect makes money in 2 ways. First, a subscription, $395 a month, to access our tools for sellers. Second, we allow you to use our agents at a reduced commission (2% of sale instead of the usual 2.5 or 3%). The data-driven nature of our business allows us to take less commission because we are more optimized, and therefore we get more volume.
Doug mentioned that there’s a law in New York that you can’t show all the current housing listings unless it’s behind a registration wall, which is why RealDirect requires registration. This is an obstacle for buyers but he thinks serious buyers are willing to do it. He also doesn’t consider places that don’t require registration, like Zillow, to be true competitors because they’re just showing listings and not providing real service. He points out that you also need to register to use Pinterest.
Doug mentioned that RealDirect is comprised of licensed brokers in various established realtor associations, but even so they have had their share of hate mail from realtors who don’t appreciate their approach to cutting commission costs. In this sense it is somewhat of a guild.
On the other hand, he thinks if a realtor refused to show houses because they are being sold on RealDirect, then the buyers would see the listings elsewhere and complain. So they traditional brokers have little choice but to deal with them. In other words, the listings themselves are sufficiently transparent so that the traditional brokers can’t get away with keeping their buyers away from these houses
RealDirect doesn’t take seasonality issues into consideration presently – they take the position that a seller is trying to sell today. Doug talked about various issues that a buyer would care about- nearby parks, subway, and schools, as well as the comparison of prices per square foot of apartments sold in the same building or block. These are the key kinds of data for buyers to be sure.
In terms of how the site works, it sounds like somewhat of a social network for buyers and sellers. There are statuses for each person on site. active – offer made – offer rejected – showing – in contract etc. Based on your status, different opportunities are suggested.
Suggestions for Doug?
Linear Regression
Example 1. You have points on the plane:
(x, y) = (1, 2), (2, 4), (3, 6), (4, 8).
The relationship is clearly y = 2x. You can do it in your head. Specifically, you’ve figured out:
- There’s a linear pattern.
- The coefficient 2
- So far it seems deterministic
Example 2. You again have points on the plane, but now assume x is the input, and y is output.
(x, y) = (1, 2.1), (2, 3.7), (3, 5.8), (4, 7.9)
Now you notice that more or less y ~ 2x but it’s not a perfect fit. There’s some variation, it’s no longer deterministic.
Example 3.
(x, y) = (2, 1), (6, 7), (2.3, 6), (7.4, 8), (8, 2), (1.2, 2).
Here your brain can’t figure it out, and there’s no obvious linear relationship. But what if it’s your job to find a relationship anyway?
First assume (for now) there actually is a relationship and that it’s linear. It’s the best you can do to start out. i.e. assume

and now find best choices for 
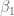

Before we find the general formula, we want to generalize with three variables now: 


Writing this with matrix notation we get:
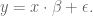
How do we calculate 
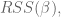

where 
To minimize 
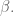
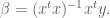
To use this, we go back to our linear form and plug in the values of
But wait, why did we assume a linear relationship? Sometimes maybe it’s a polynomial relationship.

You need to justify why you’re assuming what you want. Answering that kind of question is a key part of being a data scientist and why we need to learn these things carefully.
All this is like one line of R code where you’ve got a column of y’s and a column of x’s.:
model <- lm(y ~ x)
Or if you’re going with the polynomial form we’d have:
model <- lm(y ~ x + x^2 + x^3)
Why do we do regression? Mostly for two reasons:
- If we want to predict one variable from the next
- If we want to explain or understand the relationship between two things.
K-nearest neighbors
Say you have the age, income, and credit rating for a bunch of people and you want to use the age and income to guess at the credit rating. Moreover, say we’ve divided credit ratings into “high” and “low”.
We can plot people as points on the plane and label people with an “x” if they have low credit ratings.
What if a new guy comes in? What’s his likely credit rating label? Let’s use k-nearest neighbors. To do so, you need to answer two questions:
- How many neighbors are you gonna look at? k=3 for example.
- What is a neighbor? We need a concept of distance.
For the sake of our problem, we can use Euclidean distance on the plane if the relative scalings of the variables are approximately correct. Then the algorithm is simple to take the average rating of the people around me. where average means majority in this case – so if there are 2 high credit rating people and 1 low credit rating person, then I would be designated high.
Note we can also consider doing something somewhat more subtle, namely assigning high the value of “1” and low the value of “0” and taking the actual average, which in this case would be 0.667. This would indicate a kind of uncertainty. It depends on what you want from your algorithm. In machine learning algorithms, we don’t typically have the concept of confidence levels. care more about accuracy of prediction. But of course it’s up to us.
Generally speaking we have a training phase, during which we create a model and “train it,” and then we have a testing phase where we use new data to test how good the model is.
For k-nearest neighbors, the training phase is stupid: it’s just reading in your data. In testing, you pretend you don’t know the true label and see how good you are at guessing using the above algorithm. This means you save some clean data from the overall data for the testing phase. Usually you want to save randomly selected data, at least 10%.
In R: read in the package “class”, and use the function knn().
You perform the algorithm as follows:
knn(train, test, cl, k=3)
The output includes the k nearest (in Euclidean distance) training set vectors, and the classification labels as decided by majority vote
How do you evaluate if the model did a good job?
This isn’t easy or universal – you may decide you want to penalize certain kinds of misclassification more than others. For example, false positives may be way worse than false negatives.
To start out stupidly, you might want to simply minimize the misclassification rate:
(# incorrect labels) / (# total labels)
How do you choose k?
This is also hard. Part of homework next week will address this.
When do you use linear regression vs. k-nearest neighbor?
Thinking about what happens with outliers helps you realize how hard this question is. Sometimes it comes down to a question of what the decision-maker decides they want to believe.
Note definitions of “closeness” vary depending on the context: closeness in social networks could be defined as the number of overlapping friends.
Both linear regression and k-nearest neighbors are examples of “supervised learning”, where you’ve observed both x and y, and you want to know the function that brings x to y.




Excellent summary.
LikeLike