Race and Police Shootings: Why Data Sampling Matters
This is a guest post by Brian D’Alessandro, who daylights as the Head of Data Science at Zocdoc and as an Adjunct Professor with NYU’s Center for Data Science. When not thinking probabilistically, he’s drumming with the indie surf rock quarter Coastgaard.
I’d like to address the recent study by Roland Fryer Jr from Harvard University, and associated NY Times coverage, that claims to show zero racial bias in police shootings. While this paper certainly makes an honest attempt to study this very important and timely problem, it ultimately suffers from issues of data sampling and subjective data preparation. Given the media attention it is receiving, and the potential policy and public perceptual implications of this attention, we as a community of data people need to comb through this work and make sure the headlines are consistent with the underlying statistics.
First thing’s first: is there really zero bias in police shootings? The evidence for this claim is, notably, derived from data drawn from a single precinct. This is a statistical red flag and might well represent selection bias. Put simply, a police department with a culture that successfully avoids systematic racial discrimination may be more willing than others to share their data than one that doesn’t. That’s not proof of cherry-picking, but as a rule we should demand that any journalist or author citing this work should preface any statistic with “In Houston, using self-reported data,…”.
For that matter, if the underlying analytic techniques hold up under scrutiny, we should ask other cities to run the same tests on their data and see what the results are more widely. If we’re right, and Houston is rather special, we should investigate what they’re doing right.
On to the next question: do those analytic techniques hold up? The short answer is: probably not.
How The Sampling Was Done
As discussed here by economist Rajiv Sethi and here by Justin Feldman, the means by which the data instances were sampled to measure racial bias in Houston police shootings is in itself potentially very biased.
Essentially, Fryer and his team sampled “all shootings” as their set of positively labeled instances, and then randomly sampled “arrests in which use of force may have been justified” (attempted murder of an officer, resisting/impeding arrest, etc.) as the negative instances. The analysis the measured racial biases using the union of these two sets.
Here is a simple Venn diagram representing the sampling scheme:
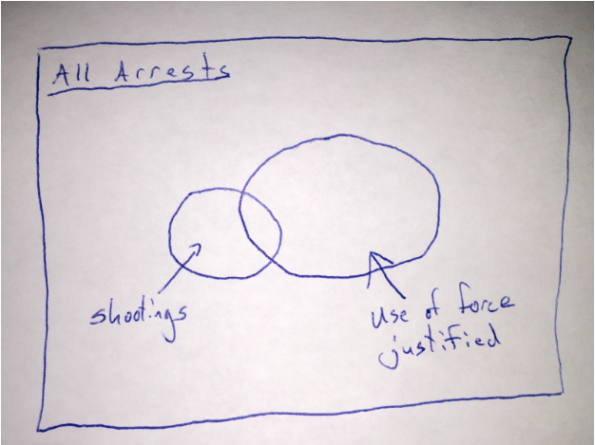
In other words, the positive population (those with shooting) is not drawn from the same distribution as the negative population (those arrests where use of force is justified). The article implies that there is no racial bias conditional on there being an arrest where use of force was justified. However, the fact that they used shootings that were outside of this set of arrests means that this is not what they actually tested.
Instead, they only show that there was no racial bias in the set that was sampled. That’s different. And, it turns out, a biased sampling mechanism can in fact undo the bias that exists in the original data population (see below for a light mathematical explanation). This is why we take great pains in social science research to carefully design our sampling schemes. In this case, if the sampling is correlated with race (which it very likely is), all bets are off on analyzing the real racial biases in police shootings.
What Is Actually Happening
Let’s accept for now the two main claims of the paper: 1) black and hispanic people are more likely to endure some force from police, but 2) this bias doesn’t exist in an escalated situation.
Well, how could one make any claim without chaining these two events together? The idea of an escalation, or an arrest reason where force is justified, is unfortunately an often subjective concept reported after the fact. Could it be possible that a an officer is more likely to find his/her life in danger when a black, as opposed to a white, suspect reaches for his wallet? Further, while unquestioned compliance is certainly the best life-preserving policy when dealing with an officer, I can imagine that an individual being roughed up by a cop is liable to push back with an adrenalized, self-preserving an instinctual use of force. I’ll say that this is likely for black and white persons, but if the black person is more likely to be in that situation in the first place, the black person is more likely to get shot from a pre-stop position.
To sum up, the issue at hand is not whether cops are more likely to shoot at black suspects who are pointing guns straight back at the cop (which is effectively what is being reported about the study). The more important questions, which is not addressed, is why are black men more likely to pushed up against the wall by a cop in the first place, or does race matter when a cop decides his/her life is in danger and believes lethal force is necessary?
What Should Have Happened
While I empathize with the data prep challenges Fryer and team faced (the Times article mentions that put a collective 3000 person hours here), the language of the article and its ensuing coverage unfortunately does not fit the data distribution induced by the method of sampling.
I don’t want to suggest in any way that the data may have been manipulated to engineer a certain result, or that the analysis team mistakenly committed some fundamental sampling error. The paper does indeed caveat the challenge here, but given that admission, I wonder why the authors were so quick to release an un-peer-reviewed working version and push it out via the NY Times.
Peer review would likely have pointed out these issues and at least push the authors to temper their conclusions. For instance, the paper uses multiple sources to show that non-lethal violence is much more likely if you are black or hispanic, controlling for other factors. I see the causal chain being unreasonably bisected here, and this is a pretty significant conceptual error.
Overall, Fryer is fairly honest in the paper about the given data limitations. I’d love for him to take his responsibility to the next level and make his data, both in raw and encoded forms, public. Given the dependency on both subjective, manual encodings of police reports and a single, biased choice of sampling method, more sensitivity analysis should be done here. Also, anyone reporting on this (Fryer himself), should make a better effort to connect the causal chain here.
Headlines are sticky, and first impressions are hard to undo.This study needs more scrutiny at all levels, with special attention to the data preparation that has been done. We need a better impression than the one already made.
The Math
The coverage of the results comes down to the following:
P(Shooting | Black, Escalation) = P(Shooting | White, Escalation)
(here I am using ‘Escalation’ as the set of arrests where use of force is considered justified. And for notational simplicity I have omitted the control variables from the conditional above).
However, the analysis actually shows that:
P(Shooting | Black, Sampled) = P(Shooting | White, Sampled),
Where (Sampled = True) if the person was either shot or the situation escalated and the person was not shot. This makes a huge difference, because with the right bias in the sampling, we could have a situation in which there is in fact bias in police shooting but not in the sampled data. We can show this with a little application of Bayes rule:
P(Shot|B, Samp) / P(Shot|W, Samp) = [P(Shot|B) / P(Shot|W)] * [P(Samp|W) / P(Samp|B)]
The above should be read as: the bias in the study depends on both the racial bias in the population (P(S|B) / P(S|W)) and the bias in the sampling. Any bias in the population can therefore effectively be undone by a sampling scheme that is also racially biased. Unfortunately, the data summarized in the study doesn’t allow us to back into the 4 terms on the right hand side of the above equality.
Review: The Wellness Syndrome
I just finished a neat little book called The Wellness Syndrome by Carl Cederström and André Spicer. They are (business school) professors in Stockholm and London, respectively, so the book has a welcome non-U.S. perspective.

The book defines the wellness syndrome to be an extension and a perversion of the concept of individual well-being. According to Cederström and Spicer, it’s not just that you are expected to care for yourself, it’s that you are blamed if you don’t, and conversely, if there’s anything at all wrong with your life, then it’s because you’ve failed to sufficiently take care of yourself. The result is that people have become utterly unaware of why things happen to them and how much power they actually have to change anything.
The wellness syndrome manifests itself in various ways:
- We are asked to “think positively” to make positive things happen to us. The funniest (read: saddest) section of the book relates to the fact that David Cameron was a big believer in this kind of positive thinking; he focused on good outcomes and ignored the bad ones, believing that somehow his personal willpower would make good things happen.
- We are asked to take care of ourselves in order to stay competitive in the workforce, to productize and commoditize ourselves. This could mean staying slim – because if you’re overweight you’re falling down on the self-optimization regiment – or it could mean engaging in the quantified self movement, keeping track of sleep, exercise, and even pooping schedules, and at the very least it requires us to monitor our attitudes.
- We are asked to enjoy ourselves while we take full personal responsibility for our own wellness, which in the age of the gig economy means we always appear happy to stay lively and infinitely employable under increasingly precarious economic conditions.
- If things don’t go well for us, if we cannot find that job or we cannot seem to lose the extra weight, we are expected to feel guilty and – this is crucial – not to blame the system for an inadequate supply of job, nor the racist, sexist, or otherwise discriminatory environment, but rather our own mindset. God forbid we ever accept any actual limit to our powers of reinvention, because that is equivalent to giving up.
- The authors point to Margaret Thatcher and Tony Blair in the UK and to Reagan and Bill Clinton in the US as creators of this notion of individual responsibility as a shield of governmental responsibility, and they frequently point out that the “positive mindset” self-help gurus thus represent a perfect pairing: a pairing, moreover, which manages to depoliticize itself as its power grows.
- The consequence: we don’t think of ourselves as political victims when we fall prey to a narcissistic worldview in which we are never fit enough, never eating enough organic kale, and never productive enough. Instead we engage in self-criticism, guilt, and renewed promises to try better next time. We internalize the shame and the definition of ourselves as “improperly optimized.”
- In the end, we all walk around with tiny little versions of Reagan’s welfare queens in our heads – or at the very least, the fear of becoming anything like her. In the UK it’s a slightly varied version called the Chav.
There are two rich topics that aren’t addressed in this book which I’d love to hear about, even if it’s just in an informal conversation with the authors. First, what about the online dating scene? How does that play into this and amplify it? From my perspective, online dating has a strong effect on how people create and wield data about themselves, and the extent to which they self-criticize, stemming from (I assume) the question of how they are being seen by potential lovers.
Second, to what extent does this concept of self-perfecting and quantifying encourage the subculture of futurism? Do people like Ray Kurzweil and others who believe they will live forever represent the most extreme version of the wellness syndrome, or do they suffer from some other disease?
I liked the book a lot. There are lots of topics in common with my upcoming book, in fact, including wellness programs and personal data collection, and other ways that employers have increasing control over our bodies and lives. And although we largely agree, it was interesting to read their more historical take on things. Also, it was a super fast read, at only 135 pages. I recommend it.
End Broken Windows Policing
Yesterday I learned about Campaign Zero, a grassroots plan to end police violence. The first step in their plan is to end Broken Windows policing. Here’s their argument:
A decades-long focus on policing minor crimes and activities – a practice called Broken Windows policing – has led to the criminalization and over-policing of communities of color and excessive force in otherwise harmless situations. In 2014, police killed at least 287people who were involved in minor offenses and harmless activities like sleeping in parks, possessing drugs, looking “suspicious” or having a mental health crisis. These activities are often symptoms of underlying issues of drug addiction, homelessness, and mental illness which should be treated by healthcare professionals and social workers rather than the police.
Having studied the effects of uneven policing myself, especially how it pertains to the data byproduct of “police events,” I could not agree more.
There was a recent New York Times article that got people’s attention. It claimed that there was no bias in police shootings of blacks over whites. What it didn’t talk about – crucially – was the chance that a given person would end up in an interaction with the police in the first place.
It’s much more likely for blacks, especially young black men, to end up in an interaction with cops. And that’s due in large part to the broken theory of Broken Windows policing.
New York City’s version of Broken Windows policing – Stop, Question, and Frisk – was particularly vile, and was eventually declared unconstitutional due to its disparate impact on minorities. The ACLU put some facts together when Stop and Frisk was at its height, including the following unbelievable statistics from 2011:
- The number of stops of young black men exceeded the entire city population of young black men (168,126 as compared to 158,406).
- In 70 out of 76 precincts, blacks and Latinos accounted for more than 50 percent of stops, and in 33 precincts they accounted for more than 90 percent of stops. In the 10 precincts with black and Latino populations of 14 percent or less (such as the 6th Precinct in Greenwich Village), black and Latino New Yorkers accounted for more than 70 percent of stops in six of those precincts.
What happens when this kind of uneven policing goes on? Lots of stupid arrests for petty crimes, for “resisting arrest,” and generally for being poor or having untreated mental health problems. About 1 in 1000 such stops are directly linked to a violent crime.
And again, since those stopped are overwhelmingly minority, it means that when City Hall decides to use predictive policing based on this data, they end up over policing the same neighborhoods, creating even more uneven and biased data. That continuing stream of data even ends up in sentencing and paroling algorithms, making it more likely for those same over-policed populations to stay in jail longer.
It’s high time we get rid of the root cause, the theory of Broken Windows, which was never proven in the first place, which optimizes on the wrong definition of success, and which further undermines community trust in the police.
When is AI appropriate?
I was invited last week to an event co-sponsored by the White House,Microsoft, and NYU called AI Now: The social and economic implications of artificial intelligence technologies in the near term. Many of the discussions were under “Chatham House Rule,” which means I get to talk about the ideas without attributing any given idea to any person.
Before I talk about some of the ideas that came up, I want to mention that the definition of “AI” was never discussed. After a while I took it to mean anything that was technological that had an embedded flow chart inside it. So, anything vaguely computerized that made decisions. Even a microwave that automatically detected whether your food was sufficiently hot – and kept heating if it wasn’t – would qualify as AI under these rules.
In particular, all of the algorithms I studied for my book certainly qualified. And some of them, like predictive policing and recidivism risk models, google search and resume filtering algorithms, were absolutely talked about and referred to as AI.
One of the questions we posed was, when is AI appropriate? Is there a class of questions that AI should not be used for, and why? More interestingly, is there AI working and making decisions right now, in some context, that should be outlawed? Or at least put on temporary suspension?
[Aside: I’m so glad we’re actually finally discussing this. Up until now it seems like wherever I go it’s taken as a given that algorithms would be an improvement over human decision-making. People still automatically assume algorithms are more fair and objective than humans, and sometimes they are, but they are by no means perfect.]
We didn’t actually have time to thoroughly discuss this question, but I’m going to throw down the gauntlet anyway.
—
Take recidivism risk models. Julia Angwin and her team at ProPublica recently demonstrated that the COMPAS model, which was being used in Broward County Florida (as well as many other places around the country), is racist. In particular, it has very different errors for blacks and for whites, with high “false positive” rates for blacks and high “false negative” rates for whites. This ends up meaning that blacks go to jail for longer, since that’s how recidivism rates are being used.
So, do we throw out recidivism modeling altogether? After all, judges by themselves are also racist; a models such as the COMPAS model might actually be improving the situation. Then again, it might be making it worse. We simply don’t know without a monitor in place. (So, let’s get some monitors in place, people! Let’s see some academic work in this area!)
I’ve heard people call for removing recidivism models altogether, but honestly I think that’s too simple. I think we should instead have a discussion on what they show, why they’re used the way they are, and how they can be improved to help people.
So, if we’re seeing way more black (men) with high recidivism risk scores, we need to ask ourselves: why are black men deemed so much more likely to return to jail? Is it because they’re generally poorer and don’t have the start-up funds necessary to start a new life? Or don’t have job opportunities when they get out of prison? Or because their families and friends don’t have a place for them to stay? Or because the cops are more likely to re-arrest them because they live in poor neighborhoods or are homeless? Or because the model’s design itself is flawed? In short, what are we measuring when we build recidivism scores?
Second, why are recidivism risk models used to further punish people who are already so disadvantaged? What is it about our punitive and vengeful justice system that makes us punish people in advance for crimes they have not yet committed? It keeps them away from society even longer and further casting them into a cycle of crime and poverty. If our goal were to permanently brand and isolate a criminal class, we couldn’t look for a better tool. We need to do better.
Next, how can we retool recidivism models to help people rather than harm them? We could use the scores to figure out who needs resources the most in order to stay out of trouble after release, to build evidence that we need to help people who leave jail rebuild their lives. How do investments in education inside help people once they get out land a job? Do states that make it hard for employers to discriminate based on prior convictions – or for that matter on race – see better results for recently released prisoners? To what extent does “broken windows policing” in a neighborhood affect the recidivism rates for its inhabitants? These are all questions we need to answer, but we cannot answer without data. So let’s collect the data.
—
Back to the question: when is AI appropriate? I’d argue that building AI is almost never inappropriate in itself, but interpreting results of AI decision-making is incredibly complicated and can be destructive or constructive, depending on how well it is carried out.
And, as was discussed at the meeting, most data scientists/ engineers have little or no training in thinking about this stuff beyond optimization techniques and when to use linear versus logistic regression. That’s a huge problem, because part of AI – a big part – is the assumption that AI can solve every problem in essentially the same way. AI teams are, generally speaking, homogenous in gender, class, and often race, and that monoculture gives rise to massive misunderstandings and narrow ways of thinking.
The short version of my answer is, AI can be made appropriate if it’s thoughtfully done, but most AI shops are not set up to be at all thoughtful about how it’s done. So maybe, at the end of the day, AI really is inappropriate, at least for now, and until we figure out how to involve more people and have a more principled discussion about what it is we’re really measuring with AI.
The arXiv should be supported by the NSF
What the fuck is wrong with the NSF? Why isn’t it supporting the arXiv?
I have been offended and enraged recently to receive pleading emails from members of the hard-working Cornell University Library arXiv Team for money. As in, please give us $5.
This is a ridiculous state of affairs.
Right now arXiv, which hosts preprints from the fields of mathematics, computer science, physics, quantitative biology, quantitative finance, and statistics, plays an absolutely pivotal role in basic research in this country, especially given the expense and time-consuming journal publishing process.
It has an operating budget of less that $1 million per year, and is somehow left begging for personal donations, supplemented by small grants from the Simons Foundation.
If you look at the mission of the National Science Foundation, it’s first part is “to promote the progress of science.” Moreover, it has an annual budget of $7.5 billion. I cannot think of a better way for it to fulfill its mission than to support the maintenance and expansion of the arXiv.
Am I wrong about this? WTF??
WMD Audiobook!
Today and yesterday I’m recording the audiobook version of my upcoming book, Weapons of Math Destruction, in a studio in the Random House building near Columbus Circle.
It’s hard work! I’m constantly having to retake sentences, either because I thought my tone was too flat (I hate flat audiobook readers!), or wasn’t emphasizing the right words, or because the words are just hard to say.
Speaking of which, I promise to never, ever write the phrase “assist statistics” in anything that might someday be read out loud, ever, anywhere. And also, you are hereby prohibited from reading this blogpost out loud.
I was pretty worried that the actual content would be bothersome to me – that I’d find tons of typos, or that things would have changed so much that the content is no longer relevant. So far, so good, though, at least to my eyes.
I’m happy with the book! Is that ok to say (not out loud!!)? I’m holding on to this delicious feeling until the nasty reviews come out. After that I’ll just cry inside at all times.
In the meantime, I’ve started a website for the book, including early reviews (i.e. blurbs, including from my buddy Jordan Ellenberg) and one actual review from Publisher’s Weekly, which I’m super happy with.
On Being Lane Bryant Fat
There was an amazing This American Life episode that aired earlier this month called Tell Me I’m Fat, centering around 4 stories about how people have dealt with being fat and the obesity epidemic more generally (hat tip Becky Jaffe).
And I plan to respond to all of them in turn, but let me mention right off the top that I didn’t think I had much to learn about this topic, but I learned a lot about this topic from listening to this episode, which was both empathetic and deep.
—
The first story could have been about me, almost. In short, it was about a woman who spent a bunch of wasted time in her youth worrying about being fat, then eventually she realized she was always going to be fat, that she was sick of apologizing for it and going on diets that didn’t work, and she came to terms with being fat. She owns it. Good for her.
What especially made me nod along was her talking about how she’d prefer the descriptor “fat” than the alternative, “overweight,” which is both a useless euphemism and a judgment, that it was somehow a temporary problem that would soon be fixed. Fuck that.
Oh, and also, she works with Dan Savage, and she called him on his fat shaming. I have always wanted someone to do that.
—
The second story was super sad, about a woman who was fat at some point but lost a bunch of weight by taking diet pills – basically speed – and found love and a good job by slimming down. She is now married to a man who admitted on tape that he wouldn’t love her if she were fat. She has a job which she claims she needs to be skinny to keep. She’s still taking (black market) diet pills. I am absolutely terrified for her.
—
The third story was what hit me. It was the story of a very fat woman of color, talking about just how hard it is to be that large. I really do get a lot of what she’s saying, but the more I think about it the more I realize I don’t get it, actually. I mean, I’ve been to restaurants where the chairs have arms and define a butt size that is simply smaller than mine. I have needed to ask for another chair. I have been extremely uncomfortable in an airplane seat.
But I’ve never been unable to fly, nor have I worried about chairs breaking beneath me. This woman does worry about this, and researches restaurants before she goes in case she cannot be accommodated. It’s a different level of humiliation and isolation. Where I feel annoyed that subway seats are too small, she is truly removed from the realm of normal.
She has a name for people like me: Lane Bryant Fat. I’m the woman who, increasingly, can find cute clothes to wear, who can talk about being fit and fat, and who can find company in a larger and larger adult population of women of size 22 or thereabouts.
She’s right, I don’t feel like a freak anymore. When I go to Brooklyn, I actually feel very normal. Even when I was in Paris I didn’t stick out very much, which was certainly very different 20 years ago.
And she’s also right that Lane Bryant Fat women don’t really get here or care about her. When I pass by people as large as she is, I do not regularly relate to them. On a normal day, some little voice inside me, some mean part of me, says, at least I haven’t let myself go that much.
Considering how hard I know I’ve tried in the past to change, you’d think I would be more enlightened about this issue, but until I heard this radio segment, I had never examined my own, internal version of fat shaming. Shame on me.
—
The last segment was about the Oral Roberts University effort in the 1970’s, I believe, to make its students lose weight as a graduation requirement. This resonated with me deeply, because it was a large scale version of what went on within my home as a child. For a time as a tweenager, I wasn’t given my allowance unless I’d lost enough weight each week. It was cruel, humiliating, and it imbued me with a shame that lasted longer than I’d care to admit.
—
This was a breakthrough, this radio program. I am so very glad this conversation has begun, and I’m so very glad it included these multiple voices, but it’s really just the beginning.
For example, here’s the thing I’m grappling with right now. I’m living in fear of becoming (type II) diabetic. I’m absolutely high risk for it: my age, my genetics, and my weight all point to it. The only thing I have going for myself is that I exercise regularly, which reduces the risk, but not entirely. So I’m on the lookout, and I’d like to think I’m prepared.
But part of that preparation includes being willing to have gastric bypass surgery, which has become much safer and is an almost miracle cure for type II diabetes. It is, in fact, the treatment of choice according to some international experts.
But at the same time, it’s a diet surgery, and if I underwent the procedure, I could expect to lose a lot of weight. For someone who has spent 20 years establishing a (Lane Bryant) fat identity, it’s actually really confusing to imagine opting for the knife. I’d feel like a turncoat.
Which isn’t to say I’d refuse it. I’ve already checked that my insurance covers the surgery. For BMI up to 40, it covers it if diabetes is present. But given that my BMI is actually above that, I could get the surgery now, without needing to “be sick.” I’m confused by this, and I don’t think I’m alone.
So what about it, This American Life? More episodes, please!
Why did the Brexit polls get it so wrong?
The Brexit vote was a huge deal, both politically and economically. Tons of polls have been telling us for weeks that’s it’d be a close contest, but since the murder of Jo Cox’s, they had mostly been pointing one way: namely, to a Remain win.
To be clear, lots of people said it was too close to call, but the bulk of yesterday’s evidence said that Remain would win by 52% to 48%, with a margin of error of around 2%. The actual results were the opposite, Remain lost by 48% to 52%.
Stock markets can also embed beliefs, and in this case they definitely seemed to think Britain would vote to remain in the EU. For that matter, there were plenty of betting markets that allowed people to bet directly on the vote, and as of yesterday the odds were steeply in favor of Remain. Even the early exit polls pointed to Remain.
So, why did all the polls get it so wrong? I have no more information that anyone else, but I have some purely unsubstantiated, backwards-looking guesses:
- Older people are much more likely to vote, and they also tended to vote Leave.
- People who voted to Leave cared more about the issue.
- People lie in polls, and given that the Leave campaign was being accused of racism, it’s maybe easier to lie towards Remain than the other way around. Also could be a reason that more “undecided” voters were secretly planning to vote Leave but didn’t want to say it out loud.
- People might have actually put money in the betting markets, including the financial markets, that have nothing to do with their belief of the outcome but rather represents a hedge for another position.
- As for the exit polls, they are easier to take in cities, where there are a lot of people, but where there also tend to be more “Remain” voters.
What do you think? Here’s some demographic info from the Guardian that may or may not help:

OIG Report: Broken Windows doesn’t work
The Office of the Inspector General for the New York Police Department (OIG-NYPD) issued a report yesterday which used statistical analysis to demonstrate that the “Broken Windows” theory of policing is flawed. From their Recommendations, page 72:
OIG-NYPD found no evidence that the drop in felony crime observed over the past six years was related to quality-of-life summonses or quality-of-life misdemeanor arrests. This suggests that there are other strategies that may be driving down crime. Between 2010 and 2015, quality-of-life enforcement rates – in particular, quality-of-life summons rates – have dramatically declined, but there has been no commensurate increase in felony crime. While the stagnant or declining felony crime rates observed in this six-year time frame may perhaps be attributable to NYPD’s other disorder reduction strategies, OIG-NYPD finds no evidence to suggest that crime control can be directly attributed to quality-of-life summonses and misdemeanor arrests. Whatever has contributed to the observed drop in felony crime remains an open question worthy of further analysis.
The report goes on to say that the NYPD should take a more data driven approach to deciding what’s actually working and what isn’t, and should “conduct an analysis to determine whether quality-of-life enforcement disproportionately impacts black and Hispanic residents, males aged 15-20, and NYCHA residents.”
Very happy about this report, it’s been a super long time coming. The NYPD has said the report is flawed, and will come back with a response within 90 days. I’m looking forward to that as well.
Gerrymandering algorithms
I’ve been thinking about gerrymandering recently, specifically how to design algorithms to gerrymander and to detect gerrymandering.
Whence “Gerrymander”?
First thing’s first. According to wikipedia (and my friend Michael Thaddeus), the term “Gerrymander” is a mash-up of a dude named Elbridge Gerry and the word “salamander.” It was concocted when Gerry got made fun of for his crazy districting of Massachusetts back in 1812 to push out the power of the Federalists:
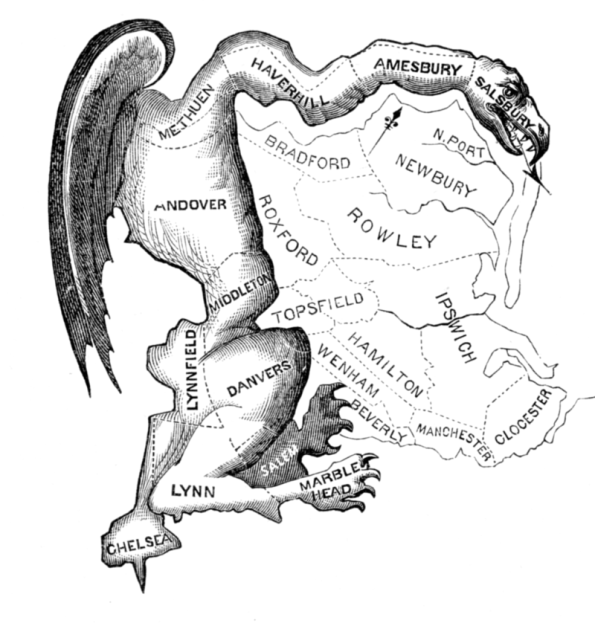
It’s true, this is depicted as a dragon. But believe me, someone thought it looked like a salamander.
How To Gerrymander
Think about it. In this crazy pseudo-democratic world of ours, we’re still voting locally and asking delegates to ride their horses to a centralized location to cast a vote for the group. The system was invented well before the internet, and it is a ridiculous and unnecessary artifact from the days when information didn’t travel well. In particular, it means you can manipulate voting at the local level, by gaming the definition of the district boundaries.
So, let’s imagine you’re in charge of drawing up districts, and you want to rig it for your party. That means you’d like your party to win as often as possible and lose as seldom as possible per district. If you think about it for a while, you’ll come up with the following observation: you should win by a thin margin but lose huge.
Theoretically that would mean building districts – a lot of them – that are 51% in your favor, and then other districts that are 100% against you.
In reality, you can’t count on anything these days, so you might want to create slightly wider margins, of maybe 55% your party, and there might be rules about how connected districts must be, so you’ll never achieve 100% loss districts.
Although clearly not very hard and fast rules.
How Not To Gerrymander
On the other side of the same question, we might ask ourselves, is there a better way? And the answer is, absolutely yes. Besides just counting all votes equally, we could draw up districts to contain similar numbers of voters and to be more or less “compact.”
If you don’t know what that really means, you can go look at the work of a computer nerd named Brian Olsen, who built a program to do just this.

Before and after Brian Olsen gets his hands on Pennsylvania
Detecting Gerrymandering
The concept of compactness is pretty convincing, and has led some to define gerrymandering to be, in effect, a measurement of the compactness of districts. More formally, there’s a so-called “Gerrymander Score” that is defined as the ratio of the perimeter to the area of districts, with some fudge factor which allows for things like rivers and coastlines.
Another approach is a “Gerrymander statistical bias” test, namely the difference between the mean and the median. Here you take the results of an election by district, and you rank them from lowest to highest for your party. So there might be a district that only voted 4% for your party, and it might go on the left end, and on the other end the district that voted 95% for your party would be on the other end. Now look at the “middle” district, and see how much that district voted for your party. Say it’s 47%. Then, if your party won 55% of the vote overall in the state – the mean in this case is 55% – there’s a big difference between 55 and 47, and you can perhaps cry foul.
I mean, this seems like a pretty good test, since if you think back to what we would do to gerrymander, in the ideal world (for us) we’d get a bunch of districts with 45% for the other side and then a few with 99% for the other side, and the median would be 45% even if the other side had way more voters overall.
Problems With Gerrymandering Detection
There’s a problem, though, which was detected by, among other people, political scientists Jowei Chen and Jonathan Rodden. Namely, if you run scenarios on non-gerrymandered, compact districts, you don’t get very “fair” results as defined by the above statistical bias test.
This is because, in reality, Democrats are more clustered than Republicans. Democrats are quite concentrated in cities and college towns, and then they are more sparse elsewhere. They, in essence, gerrymander themselves.
Said another way, if you build naive districts that are compact (so their Gerrymander Scores are good) then there will be automatic “Gerrymander statistical bias” problems. Oy vey.
Which is not to say that there isn’t actual effective and nasty Gerrymandering going on. There is, in North Carolina, Florida, Pennsylvania, Texas and Michigan for the Republicans and in California, Maryland and Illinois for the Democrats.
But what it means overall is that there’s no reason to believe we’ll ever get out of this stupid districting system, because it gives an inherent advantage to Republicans. So why would they agree to tossing it?
Adding another layer of cynicism to the “smart” city revolution
There was an interesting essay by Jacob Silverman in the New York Times last week called Just How ‘Smart’ Do You Want Your Blender to Be? (hat tip Ernie Davis).
In it, Silverman makes a few really great points. First, that we are sold “smart” products like the Nest thermostat or the my.Flow tampon or cell phones, and all we really get is surveillance and a lack of control over our own stuff (because it’s called “hacking” if we try to fiddle with our phones). Plus he goes into the old English definition of smart – a verb meaning “causing sharp pain,” as in “that smarts!” – as another reason that we might not want a smart version of everything.
All true, but I think there’s a couple of important points missing in his narrative. Specifically, I don’t think he was being sufficiently cynical.
First of all, something very old-fashioned is going on. Namely, people are marketing things as “smart” because they want to claim they have new products so they can then claim they have a business.
In other words, I’m imagining 95% of the smart products were invented like this: hey, let’s figure out an old product we can add sensor technology to and then sell it like it’s a new product. Blenders? Tampons? Can we add sensors to tampons to figure out when the tampon is drenched in blood? WOULD PEOPLE PAY FOR THAT?
The answer is, generally, no fucking way, but there’s too much money in Silicon Valley for that answer to be heard. So these ridiculous companies keep making their ridiculous, unnecessary products.
The second and more cynical point is focused on the “smart city” fad. Silverman rightly points out that we now have free “smart” wifi kiosks all over NYC but we still don’t have public bathrooms. I’d add that we have “smart” tampons but still don’t make normal tampons available to, for example, homeless women or high school girls.
That’s totally fucked up in both cases, but it’s not because we are in love with the concept of “smart” technology. It’s because that’s where the money is.
Some entrepreneurs have decided that it’d be a smart shrewd investment to install a bunch of wifi kiosks in old telephone booths, grab everyone’s telephone data as they walk by, profile them, and then tailor advertisements to them. They expect to make a big profit from this investment, which you can infer reading the misleading answer to the question, “how is LinkNYC Funded?” on their website:

Can we all agree that’s not what most people mean when they ask, how is this funded? This is more like an answer to the question, how will this make money? Please tell me if you can figure out who actually funds LinkNYC.
Let’s think, by contrast, about how public bathrooms work. They cost money to build and to maintain. And yes, having a good public bathroom system would prevent a lot of nasty things from happening, like a bunch of arrests of people for being poor and having no place to pee, not to mention poop on the street. It’s the right thing to do. But, since we don’t think we will ever get more than half a billion dollars in revenue from them, no thanks.
Similarly, it’s not profitable to give poor women tampons, it’s merely the right thing to do (and it boosts attendance rates of poor girls).
The smart city fad is a boondoggle, a way of giving public space access to private advertising companies in exchange for a few nickels and a surveillance state. It’s kind of ingenious, because it’s in a sense selling a commodity – public space, and the concept of anonymity within a large city – that we didn’t even know we could measure, never mind commoditize. And in the meantime, we cannot expect actual ongoing problems to be addressed. Because we’re too busy being smart.
The US DOE’s sunk costs into for-profit colleges
There’s been a lot of squabbling around how to deal with student debt lately, especially the debt incurred by shitty for-profit colleges. I claim these are sunk costs and should be treated as such.
If you aren’t familiar with the for-profit college boondoggle, let me break it down for you: there’s a federal aid system that guarantees loans to poor students for accredited colleges. This system has been gamed by an industry that includes Corinthian College, ITT Tech, and University of Phoenix, among others. They get accreditation through slimy and questionable means, then they lie to potential students about how great their education will be, then they collect the money.
The issue that the Department of Education (DOE) is now grappling with is this: should those students, who were misled and manipulated, be forgiven their debt?
From the side of the students, it seems pretty clear the answer should be yes. They didn’t receive proper educations, they were lied to and manipulated, and they are, by construction, quite poor. This debt will be hanging over them, making it even harder for them to eke out a living.
From the side of the government, the answer is less obvious. After all, it’s very expensive to write off a bunch of debt. And it would set a dangerous precedent. When would it stop? What if someone who went to a reasonable community college wanted to stop paying their debt? Or what about a graduate from a private college?
I’d argue that this is a sunk cost. Which is to say, the DOE fucked up when it allowed accreditation when it should not have. Once you let your standards go that far, you are on the hook. And although it looks “expensive” to forgive this debt, there’s really no other option, because it’s never getting paid back. That’s what happens when you let a predatory industry prey on the most vulnerable.
So, sunk costs. What’s good about acknowledging sunk costs is that you can learn your lesson and fix the problem that got you into this mess. When you don’t acknowledge sunk costs, you’re in the wrong mindset, hoping against hope that somehow the money will be paid back. It won’t.
What would it mean to fix this problem? We need to turn off the federal aid spigot for bad colleges. We need higher standards for accreditation.
The good news is that the DOE has just come out with recommendations for doing just that. In particular, they’re closing down one of the worst accreditation offenders.
If only they’d just forgive the debt so we could move past this ugly chapter of educational history.
Thoughts on the future of math education
This is a guest post by Kevin H. Wilson, a data scientist who usually resides in Brooklyn, but is currently in Chicago as a Mentor at the Data Science for Social Good Fellowship. In past lives he’s gotten a Ph.D. in math, worked as a data scientist at Knewton for several years, and continues to oversee programming classes in rural schools for Microsoft’s TEALS program. This note comes from that latter work and associated policy work.
Programming is a Tool and Should be Taught as Such
A very popular trend nowadays is to demand that computer science be taught in schools. Indeed, President Obama has started an initiative to bring computer science to all schools in America. Before that, Mayor DeBlasio of New York demanded computer science in all schools in the City by 2025. The Hour of Code is basically a mandatory volunteer activity in many tech firms. And a search for high school hackathons or Capture the Flag on Google reveals huge interest in this topic.
These initiatives seem to miss the broader point about computers: they have fundamentally transformed the way that we interact with the world and school should reflect that. As structured now, high school computer science initiatives tend to build programming courses. These courses tend to focus either on the “cool” things you can do with coding, like building games, or the rigorous implementation details of complicated languages, as in AP Computer Science A. Even the better courses, such as AP Computer Science Principles, often constrain the skills learned to a single classroom.
Programming, however, is simply a tool which solves other problems. Specifically, programming is a tool that allows data to be manipulated. Some of that data is static data, like a business’s annual accounts payable and receivable; and some of that data is dynamic streams, like a user’s interaction with a game she’s playing on the computer. Programming’s genius is to abstract these to the same basic paradigm, a paradigm that has made it possible for Google and Facebook and Uber and Blizzard and countless other companies to improve[1] our lives using what, by historical standards, are extremely cheap and accessible devices.
Tools, however, should be taught like tools. To properly teach a tool, it must be used in context and reinforced horizontally (across the school day in multiple subjects) and vertically (across the years as students become more comfortable with more complicated tools). These imperatives have found purchase before, often in the form of encouraging medium- or long-form writing in all subjects,[2] or in the use of (some) math in all science-based courses.[3] But our generally balkanized curricula often lead to a general perception among students (and, as students become adults, among the general populace) that knowledge is a bunch of tiny islands whose inhabitants are called the “Good at Math” or the “Good at English.”
I believe that computers and their ability to easily manipulate data offers a chance to truly redefine the mathematics curriculum, to make it more horizontal, and to refocus the tools we teach on what is actually useful and stimulating. Statistics, not calculus, should be the pinnacle achievement of high school, not relegated to box-and-whisker plots and an AP course which is accepted by relatively few universities. Algebra, the math of manipulating symbols, should be taught alongside programming. Calculus, a course which I have heard multiple people describe as “easy but for the Algebra,” should be relegated to a unit in Statistics. Trigonometric identities and conics should go away. And earlier math should focus on how and why a student arrives at an answer, and why her procedure always works, not just the answer itself.
The First Bias: Historically Computation was Hard
Why then, if this is such a good idea, hasn’t it happened already? Well, in some limited cases, it has. The Common Core math curriculum has brought statistical modeling to the forefront and clarified the balance between learning facts by rote and understanding why procedures always work. There are beautiful curricula like Bootstrap which place Algebra and Computer Science side-by-side. AP History courses have made understanding primary sources and data important to getting an A, and some teachers have gone so far as to incorporate Excel usage into their classrooms.
But there are extremely long-lived biases preventing more radical transformation. Most interesting to me is that historically statistical analysis was hard. Brahe spent an entire lifetime collecting measurements of the solar system, and Kepler spent another lifetime turning those into general rules.[4] And the annals of science is littered with famous insights made possible by introducing nicer notation. For instance, Mendeleev, inventor of the Periodic Table, is considered one of the greatest scientists in history simply because he realized that data on atoms was periodic and there was a compact and insightful way to lay out a bunch of numbers that people already had access to!
Programming allows its user to take means or do t-tests or bootstrap or graph or integrate numerically in an instant. These bread and butter techniques, as central to statistics as long division is to arithmetic, involved days and days of human computation when the curriculum was last revised. Imagine the process in the 1930s for even finding the median of 500 numbers, a task whose first step is to meticulously sort those 500 numbers. Imagine sorting 10 decks of cards into one big deck of cards. And imagine that as a necessary step to understanding. Such a requirement is a fantastic way to miss the point the first few times, and, since sorting 500 numbers doesn’t get any faster the 20th time you’ve done it, it is a severe impediment for providing reinforcement opportunities.
The Second Bias: Measuring Computational Ability is Easy
This leads to a second bias, which is toward the easily measurable. Statistics, like programming, is really a tool that allows its user to answer questions about the world around them. But the world is complex, and there shall never be a procedure as ordered as those in the traditional high school mathematics curriculum[5] which allows the user to easily capture “the truth.” If there were, then we people called “Data Scientists” would be out of a job!
This bias toward the easily measurable doesn’t just exist in schools. For instance, Kaggle is a platform for “data science contests.” Basically, teams compete to “best model” some phenomenon present in real data sets using whatever statistical techniques their hearts desire. Typically, in the end, teams submit some code, and Kaggle runs the code on some data the submitter couldn’t see ahead of time and computes a score. The highest score wins.
Any professional data scientist or statistician will tell you this is the easy part. Once you’ve got a nice CSV filled with data, it’s usually pretty clear what the battery of models are that you would probably run on that data. Indeed, there’s now a sort of “meta-Kaggle” competition where academics build algorithms that automatically write solutions to Kaggle problems! These typically do pretty well.
The hard parts about statistics and data science is what comes before you even start to model the data. How was it generated? What assumptions does that imply about your data? What does it look like? Does the data look like it reflects those assumptions?[6] And so forth.
And what do you want to do with this data and what does this imply about what metric of success you should impose? If you’re Google or Facebook, you want to sell more ads, so likely you want more profit as your ultimate metric. If you’re the Chicago Department of Public Health and you’re trying to stop children from contracting lead poisoning, then likely your ultimate metric of success is fewer children with lead poisoning. But these are long term metrics, and so how do you translate them into objectives that you can actually train against?
These questions are the hard ones, and proficiency in answering them is much harder to measure than filling in a few bubbles on a standardized test. They must include writing, long form, explaining choices made and why those choices led where they did.[7] Of course, this sort of mathematical and statistical long form writing isn’t what we typically think of as writing in schools. Instead we imagine portfolios of fictional stories or persuasive essays. This writing would be filled with tables and math and charts and executive summaries, but its ultimate goal, persuading the reader to accept its conclusions, is a completely familiar one.
To assess these skills, we must teach teachers how to teach a new form of writing, and we must grade it. Of course, long form writing takes much more time to grade than multiple choice answers, and so we must find new ways to grade this writing.
The Third Bias: Learning Happens only in the Classroom
This brings us to a third bias which prevents the curriculum from changing: the troubling view that the classroom is the sole responsibility of the teacher. This view leads to many bad behaviors, I think, but most relevant here is simply the fact that teachers and teachers alone must grade literally everything that students produce in the class. But what if some of the grading could be outsourced, or perhaps “insourced”? What if students could grade each other’s work?[8] What if teachers from other schools could grade students’ work? What if parents could grade students’ work? What if parents could grade students who aren’t their children’s work? What if members of the community at large could grade students’ work? What if somebody from the next state over or the next country over could grade students’ work?
This idea is not new. Science fairs are often graded by a “distinguished panel of (non-)experts” and AP tests which involve essays are graded in big hotel ballrooms by college faculty and high school teachers. Students critiquing each other’s work is often an integral part of creative writing classes, if not English classes in middle and high schools. In some places, they’re even letting community members grade some projects and classes.
Moreover, computers, in their capacity to move data around at will, can facilitate this process greatly. Among other things, I work with TEALS, a program out of Microsoft which helps start programming classes in schools. In particular, I help coordinate and train volunteers who live in big cities to teach programming classes for students in far flung areas of the countries. They rely on systems such as Canvas, Edmodo, and Google Classroom to interact with students on a daily basis and to collect and assess homework and plan classes with teachers.
The Fourth Bias: Teachers Must be Trained
TEALS was built, indeed, to overcome the final bias I’ll mention preventing change: teachers know how to teach the current curriculum and teacher training programs are geared toward preparing teachers to teach this curriculum. There are extremely few opportunities for teachers to learn to teach new classes or even for teachers to learn new techniques! Teachers rarely observe, much less critique, other teachers, and the current teacher promotion system typically involves jumping to administration.
This is ludicrous. Every single classroom is a hotbed of experimentation. Each child is slightly different and every area of the United States is inculcated in different norms that affect the way students learn and cooperate. Yet teachers are given very little time to reflect on their teaching, to observe each other, or to, heaven forbid, write about their work in local, regional, or national journals and conferences. It is not at all implausible to imagine a teacher promotion system which includes an academic (as in “the academy”) component.
But all this is to say that teachers, for all their professionalism and hard work, are given very few opportunities to learn and teach new subjects. And education schools, bound to churn out teachers who can tick off various certification requirements and pass particular exams, find it hard to train teachers in rarely-taught subjects. And if a teacher coming to teach a single new and interesting course is so hard, imagine how hard it would be for them to learn an entirely new curriculum or for an education school to begin to support it!
This is certainly not a theoretical concern. Common Core has gotten so much negative press in part because of an extremely botched rollout plan.[9] Teachers were not trained in it, new textbooks and other materials to support it were not ready, and the tests meant to evaluate progress in the standards were, like all new measurement devices, faulty. And this for a set of standards that, while radical in many respects, still had the same shape as what we have been teaching for a century.
On the Other Side of the Fence: Community-Based Projects
What then would lie on the other side of change if roadblocks like these could be removed? Let’s start at what I think would be the best possible end goal: a project that high school seniors would complete before graduation that would serve as the culmination of their years of study. From there we can work backwards.
What I imagine is a project which explicitly uses all the tools students have learned over their years of high school to advocate for change in their communities. This could take many forms depending on the focus the student wants to take. For instance, students focused on writing could write op-eds detailing the history of something that troubles their community and advocating for realistic change. Or perhaps, if journalism is not their cup of tea, they could write a piece of fiction which has at its heart some spiritual conflict recognizable to those in their community.
What most interests me, though, is the sort of work that computers and statistics could open up. Imagine a project in which students identified a potential problem in their community, collected and analyzed data about that problem, and then presented that report to someone who could potentially make changes to the community. Perhaps their data could come from public records, or perhaps their data could come from interviews with community members, or from some other physical collection mechanism they devise.
Imagine a world where students build hardware and place it around their community to measure the effects of pollutants or the weather or traffic. Imagine students analyzing which intersections in their town see the most deaths. Imagine students looking at their community’s finances and finding corruption with tools like Benford’s law.
Or for those who do not come up with an original idea, imagine continuing a long running project, like the school newspaper, but instead the school’s annual weather report, analyzing how the data has changed over time.
All of these projects require a broad range of skills which high schoolers should be proficient in. They require long to medium term planning, they require a reasonable amount of statistical knowledge, they require the ability to manipulate data, they require an understanding of historical trends, and they require the ability to write a piece of persuasive writing that distills and interprets large numbers of facts.
Moreover, such projects have the potential to impact their communities in profound ways. Places like the coal towns of Appalachia are desperately attempting to make their towns more amenable to investment, both in terms of dollars from outside capitalists and in terms of years of life from their progeny. From time to time I have the opportunity to ask kids in Eastern Kentucky whether they planned to stay in their hometowns after their high school graduation, and I have yet to receive a single “yes.”[10] Towns who rally around training their students to change their own thinking, I believe, will receive huge dividends.
Of course, we can daydream about these projects’ effects, but what sorts of curriculum would actually support them? I won’t pretend to remake the entire K-12 curriculum here, and so let’s focus instead on the mathematics curriculum. Further, I don’t have the space or time right now to completely reimagine the the whole of K-12, nor do I think such a reimagining at all practical, so let’s focus on high school subjects.
What Curriculum is Necessary to Support these Projects?
1. Programming and Algebra merge
First, we must teach programming. There is no hope for doing data manipulation if you don’t understand programming to some extent. The question is when and how. I believe that algebra and introductory programming are extremely synergistic subjects. I would not go so far as to say they are interchangeable, but they are both essentially arithmetic abstracted. Algebra focuses a bit more on the individual puzzle, and programming focuses a bit more on realizing the general answer, but beyond this, they fundamentally amount to the realization that when symbols stand in for data, we may begin to see the forest and not the trees.
And just how might these two things be interwoven? Well, we have some examples of what might work. The Common Core, for example, emphasizes “computational thinking” in its mathematics curricula for all grade levels, which essentially means encouraging students to learn how to turn their solutions to specific problems into solutions for more general problems.[11] As such we’re seeing a large number of new teaching materials reflect this mandate. Perhaps my favorite of these is Bootstrap, which I would highly recommend checking out.[12]
2. Geometry is replaced by Discrete Math and Data Structures
Programming, though, is only a means and not an end, so how will we employ it? Next in the traditional curriculum we find geometry. Geometry is officially the study of space and shapes, but traditionally in America it is the place where we teach students formal logic. We drill them on the equivalence of a statement and its contrapositive, we practice the masochistic yoga of two-column proofs, and we tease them with questions such as “is a quadrilateral whose opposite sides are congruent a parallelogram?”
But there isn’t anything particularly special about the SSS and AA rules when it comes to constructing logical puzzles. These sorts of puzzles are simply meant to teach their players how to produce strings of implications from collections of facts. For instance, Lewis Carroll famously constructed nonsensical logic puzzles for his tutees which entertained while abstracting the actual logical process from the distracting influences of reality.
While I find these sorts of logical puzzles entertaining, I don’t think they’re nearly as useful to students as deriving the facts they will prove themselves. Imagine instead a course in discrete math and data structures. In this course, students would still be asked to construct proofs, but the investigation of the facts would involve programming numerous examples and extrapolating the most likely answer from those examples.
Students would come much more prepared to answer questions in discrete math having essentially become familiar with induction and recursion in their programming classes. Students could also empirically discover that sorting a random list with merge sort takes quasilinear time, and then they could go forth and prove it!
Many of these types of empirical studies would also be the beginning of a statistical education. Plotting times for sorting lists of the same size would introduce the concepts of “typical” and “worst” cases, as well as the idea of “deviance”, which are at the very center of statistical conundra.
3. Algebra II begone! Enter Statistics based on Open Data Sets
This then would lead to the next course, a replacement for the traditional and terrible Algebra II. This course, which includes some subset of solutions to systems of (in)equalities, conic sections, trigonometry, and whatever else the state decided to cram in,[13] is generally a useless exercise, where there really is no good answer to the ever-present question of, “Why do we need to know this?”
Thus, I would propose to replace this course wholesale with a course on statistics, expanding on the statistical knowledge that our data structures course laid the foundation for. However, since students have experience in programming and data structures, we can go much, much further than what we traditionally expect from a traditional statistics course. We would still teach about means and medians and z-tests and t-tests, but we can also teach about the extraordinarily powerful permutation test. Here students can really come to understand the hard lessons about what exactly is randomness and what is noise and why these tests are necessary.
Moreover, in traditional statistics courses like AP Statistics, students are usually taught various rules of thumb about sample sizes being sufficiently large and are asked to apply these rules to various fictional situations. But there are a huge number of massive data sets available nowadays, which they could not manipulate without their programming experience. The focus should move away from memorized rules of thumb for small samples to the actual analysis portion and the implications of their explorations for society.[14]
Projects in this course would be multipage reports about exploring their data sets. They would include executive summaries, charts, historical analysis, and policy recommendations. This is a hugely important form of writing which is often not a part of the high school curriculum at all.
4. Machine Learning subsumes Calculus; Calculus becomes a one-month unit
Finally, the capstone class, for the most advanced students, would move away from Calculus and instead into Machine Learning. The typical way this course is taught in colleges nowadays is as an overview of various mathematical and statistical techniques from across the subject, though perhaps the two major themes are linear algebra, especially eigenvectors, and Bayesian statistics, especially the idea of priors, likelihoods, and posteriors. Along the way students would pick up all the Calculus they’ll likely need as they learn about optimizing functions.
Indeed, such a course is already being taught at some of the more elite schools in the country, and I have no doubt that anybody who could climb their way to an AP Calculus course, if taught a curriculum like the one outlined above, would be able to approach a machine learning course.
Of course, as mentioned above, the real capstone of this course of study would be the capstone project. The three previous classes contain all that is necessary to be able to approach such a project, though many other classes that students might take could be brought to bear in spectacular ways. History courses could help students put what they learn into the context of the past; biology courses might yield fruitful areas of study, e.g., around pollution; journalism courses might lead to an interest in public records.
And all throughout, the community would be involved. Perhaps they would serve as mentors for these capstone projects, or perhaps they would help grade some of the more specialized projects during the junior year. Or even better, maybe the final exam for the introductory programming course would involve teaching an Hour of Code to community volunteers. And of course the capstone project would focus around the community itself.
Why would this be better? Lessening the linearity of mathematics
One immediate pushback I’ve gotten when I tell people this story is to ask why I think kids will perform better at this curriculum than the one that we have now. Isn’t this one even harder? To which my answer is, yes, but is is both more interesting to students and their communities and begins to help solve the problem of mathematics notoriously linear structure. To understand tenth grade math requires understanding ninth grade math requires understanding eighth grade math and so forth. Moreover, there are very few places where students who somehow fell behind have a place to catch up. This wall persists even into adulthood, with many parents dreading they day they have to tell their kids, “Oh, honey, I never understood that stuff.”
This mathematical linearity is quite different from traditional humanities curricula. In these curricula, the true emphasis is on practicing the skills of history or the styles of writing or the understanding of culture. And while History has themes and English has great turns of phrase that should be memorized, missing a few for any particular reason does not preclude the student from jumping back into the subject next time around. That great writers spent their youth ignoring their teachers or participating in traditionally educational activities speaks to the flexibility of these subjects to welcome the “late bloomers” into them.
And while the proposed math curriculum does not completely refactor out prerequisites, it does begin to weaken them. This, I think, is a good thing for getting more students on board. The focus shifts from performing specific tasks (like manipulating one trigonometric expression into another) to being able to constantly improve a set of skills, specifically, looking out into the world, identifying a problem, collecting data on that problem, and using that data to help determine means to address that problem.
These skills, identifying problems and supporting the analysis of those problems with facts, is a skill whose importance is paramount. Indeed, the Common Core State Standards for English and Language Arts bring up this point as early as the Seventh Grade.[15] But as data become easier to gather and process, “facts” shall come more and more to mean monstrous collections of data. And being able to discern what “facts” are plausible from these collections of data becomes more and more important.
What next?
There are many obstacles to this dream, even without the status quo biases that I discussed at the beginning. Even the simple job of building materials, much less the community and teacher infrastructure, to support this change is massive and will take years. And though the Common Core standards are reasonable, the move to extreme standardization of the schools does preclude experimentation on the parts of individual schools and teachers with curriculum.
Where next? Immediately, the first order of business is to understand if such a high school curriculum could be built without changing the middle and elementary school curriculum too much, since changing four years worth of curriculum is already extremely disruptive.
Assuming that is the case, then there are several possibilities. One is to take the route of the Bootstrap curriculum and explicitly teach specific skills required by the current curriculum while supplementing them with computer science concepts. This runs into the problem that the school day is already pretty full, especially for high-achieving kids, and adding in new “requirements” would burden them.
Another route is to build a charter or charter-like school around such a curriculum and forsaking the traditional standardized tests. This has the problem of being risky in that if the curricular idea is terrible, then these kids will be disadvantaged relative to their peers.
Whichever way is chosen, the process will be long, involving the hours of many people, not just writing curriculum but also from the community, who themselves by design will be involved in the week-to-week of the courses, and involving the training of many educators in a relatively new type of math curriculum.
Footnotes
- Some would quibble with the word “improve.” If, dear reader, you are such a person, I implore you to replace this with “radically transform.”
- Well, except often in math, where even though mathematicians have been writing long form proofs for years, students are often stuck with the terrible two-column variety.
- Though, traditionally the “vertical” reinforcement of math has gone off the deep end into the various properties of conic sections and the opaque relationships between trigonometric functions without the aid of complex numbers. Common Core actually does a fair bit to help on this front.
- Though maybe he faked it.
- Long division, taking determinants, solving polynomials, taking formulaic derivatives all spring to mind, though there are many more.
- A piece of advice to aspiring data scientists: If you are applying for a job and they ask you to do a written test ahead of time, there should be at least one plot in your writeup. Unless your solution is brilliant, you aren’t getting hired if there’s not at least one plot.
- To what I think is its tremendous credit, this sort of writing is integral in the PARCC tests developed for Common Core-aligned curricula in some states. I have not had the chance to review the competing test, called Smarter Balance, but I would expect it would be similar.
- There are actually many teachers who use peer grading, and also quite a bit of research on its effects, some good, some bad. The point here is that we should be open to using novel methods of grading, and especially interested in exploring how computers can facilitate these novel methods.
- What I do not talk about here but which is also an essential problem with any change to the curriculum is that parents play a huge role in their children’s education, and so any change to the curriculum that involves reeducating teachers must also, to some degree, involve reeducating parents. Since this piece is about high school, by which time many parents have already “given up” on helping their students with homework because they are not “Good at Math” (a fact I do not have hard numbers for, but I have commonly experienced among my students), I’m leaving this massive issue out of the main text.
- Of course, take this with a grain of salt. I tend to only get to ask this question of kids in computer science classes.
- These solutions often take the form of “algorithms,” which are central to computer science, and thus the name “computational thinking.”
- Perhaps my favorite aspect of the Bootstrap curriculum is that they emphasize professional development, a woefully underappreciated aspect of improving the curriculum.
- There is no universal definition of Algebra II as far as I know. However, the Common Core has gone a long way to standardizing a definition. The PARCC Model Content Frameworks may be useful for the interested.
- This is not to say that warnings about small samples shouldn’t be ingrained into students as well, but here large data sets can help as well. For instance, a simple exercise for the whole class could involve giving every student a randomly sampled set of 20 rows from a very large data set and asking them to run some sort of analysis. In the end, each student would come to vastly different conclusions, and thus, come to learn that sample size matters.
- See CCSS.ELA-LITERACY.RI.7.9, which states, “Analyze how two or more authors writing about the same topic shape their presentations of key information by emphasizing different evidence or advancing different interpretations of facts.”
Delete your LinkedIn account
I deleted my LinkedIn account a few weeks ago. I was increasingly getting spammed from solicitors on the site, and all sorts of weird people kept writing to me with bogus requests. Plus the content I saw when I bothered to log in were consistently hyped up crap about magic bullets using big data. I’d had enough, even though I was mildly wistful about the job I’d once landed through the network.
Well, I’m glad I quit, because I just learned that Microsoft has made an offer for LinkedIn for $26 billion. What this means is that all that social data, the professional contacts and so on that people have built up over years and years, is being handed over to a huge and powerful corporation that can change the privacy policy whenever they’d like, it seems. This is data that people protect as personally valuable individually; it is clearly quite valuable more generally.
And I have no personal vendetta against Microsoft, but clearly they have an agenda beyond simply connecting people and suggesting careers. At the very least, they want to expand their portfolio to social networking stuff so they’re not still living in the 1990’s. I also suspect they’ll submit the LinkedIn network to experiments to see how professionals respond to various marketing campaigns. Yuck.
I’m not saying that LinkedIn had motives that were perfectly aligned with its users, but I’m seeing this as a sever drop in alignment. I think it’s time to delete your LinkedIn account.
Norman Seabrook is the absolute worst
I’m so glad that guy’s been arrested.
For years I’ve been listening to sports radio, specifically Mets broadcasts on AM710, where Seabrook would have a regular spot – already a sign that the Correction Officers’ Benevolent Association has way too much money – and there’d be this awful, deliberate attempt of disgust and fear mongering about the job of a corrections officer.
[Side comment: can someone confirm that Kars4Kids is a scam?]
The ad, which ran way too often and which made me crazy with rage, included the phrase, “We protect you from all the people who’d kill your wife and rape your daughter.” See more people complaining about that ad spot and more on this website.
What he was referring to was Riker’s prisoners. He was the union boss protecting the Rikers officers who beat those prisoners, including teenagers, when they were unarmed and often had handcuffs on.
And I get it, it’s a tough job, and union bosses protect their members. But this guy was on a different level of extreme, both in how far he’d go to protect abusive guards and the extent to which he created a war-like atmosphere between prisoners and guards. He’s a bully who leads and protects an army of bullies.
This is a guy who, in order to prevent a prisoner from testifying against one of those officers, had the entire bus system from Riker’s shut down. This is a guy who continues to allow prison guards to get away with anything at all, training them to do it behind a curtain or off camera, defending their conduct, and getting rid of investigators he doesn’t like or cannot control. This is a guy who told people to “follow the rules” so that they don’t have “to sit down at a table and come up with a story that doesn’t make any sense.”
The actual charges against Seabrook are that he invested his members’ pensions in a failing hedge fund in return for kickbacks. I’m guessing that’s not the first time something like that happened, and I’m hoping they pin a whole lot more on the guy, and that he’s never seen again. I’ve honestly had nightmares about my sons somehow fucking up and going to Riker’s, and I’d like those to end. Maybe with Seabrook gone we can finally reform that god awful hellhole.
Recent talks, useless synopses
I am giving in to the urge to be extremely snarky today. If that doesn’t suit your mood, please skip. Just in case it doesn’t come through, I really liked two of these talks.
—
Last week I introduced Carl Pomerance at the Museum of Math for his delightful talk, What We Still Don’t Know About Addition and Multiplication. His notes are here.
My synopsis: it’s easier to multiply than to factor. Sometimes you can represent numbers as the difference of two squares and factor them pretty fast. And when you can’t do that very quickly, you still can do that relatively quickly if you keep track of things.
Yesterday I spent the day at USI2016. I gave a talk in the afternoon but I also went to three talks. Here are my synopses of those talks.
Don Tapscott: Blockchain is a big deal. It will eventually solve inequality. It’s a paradigm shift. It’s all about getting Dorito customers to make commercials for the Dorito Corporation. Next stop, inequality solved by blockchain.
Andrew McAffee: Look at this graph, consumption is no longer going up for Americans if you measure it in a specific way. That means we’ve entered a new paradigm, especially because I’ve got a name for it. Also, great news, we rich people no longer need to worry about global warming because technology will solve that like it solves everything else.
Monica Lewinsky: I was the first example of cyber bullying. We need more compassion online. When you click on shame-based news articles, you are training the online clickbait algorithm, and you become part of it. Resist clicking, be nice.
In Paris
Today I’m giving a talk a USI in Paris. It’s unbelievably swank, the very first time I’ve been part of something that is, for example, taking place in the Carrousel du Louvre. I’m also staying at a ridiculous hotel with this view from my balcony:

That building on the left is the Louvre.
And yes, it’s bizarre to be in such a nice place so I can go complain about how poor people are being surveilled and mistreated. I accept all cries of “hypocrite!” that you might want to throw at me, but know that at least I’m a self-aware hypocrite.
And with that, I wanted to share a few things with you today.
First, did you know there were reparations to slave owners in Britain? Turns out, soon after slavery was abolished in 1836, slave owners in Britain got very seriously compensated, to the tune of 17 billion pounds ($24 billion) in today’s money, which was 3.5% of the government’s income that year.
Seems to me this should change our perspective on reparations. I learned this just now from the BBC, which is what I watch on TV when I’m in Paris (see also this). There’s a new project to map out the slaves and slaveowners that received money all over the world.
Second, thanks to Abe Kohen I found out that Wisconsin’s Supreme Court is considering whether recidivism risk scores deny criminal defendants due process and are discriminatory, given that they rely on proprietary source code. Very interested to see how this turns out.
And, yet again, they are relying on the fact that a defendant’s score is “one of many factors a court can consider at sentencing.” I’m not sure this makes any sense. If there’s a shit score, but it’s only one of many factors that are used in a process that’s supposed to be fair, doesn’t that mean the overall process isn’t fair?
Finally, I wanted everyone who’s interested in what it feels like to be a 40-something old lady rebel to read this essay. An excerpt:
It’s partially because I am “old” that I’ve stopped caring about what’s socially acceptable for me to do or wear. I got my first tattoo at 40. This year, I had my hair dyed teal. And you know what? It looks fantastic. My favorite pair of shoes are my Doc Martin boots, and I dare any child on the internet who’s probably younger than some of the underwear I own to try to tell me I can no longer wear them.
I mean, my hair is blue, not teal, but yes! Funny and true.
Three Ideas for defusing Weapons of Math Destruction
This is a guest post by Kareem Carr, a data scientist living in the Cambridge. He’s a fellow at Harvard’s Institute of Quantitative Social Science and an associate computational biologist at the Broad Institute of Harvard and MIT. Formerly, he has held positions at Harvard’s Molecular and Cellular Biology Department and the National Bureau of Economic Research.
When your algorithms can potentially affect the way physicians treat their dying patients, it really brings home how critical it is to do data science right. I work at a biomedical research institute where I study cancer data and ways of using it to help make better decisions. It’s a tremendously rewarding experience. I get the chance to apply data science on a massive scale and in a socially relevant way. I am passionate about the ways in which we can use automated decision processes for social good and I spend the vast majority of my time thinking about data science.
A year ago, I started working on creating a framework for assessing performance of an algorithm used heavily in cancer research. The first part of the project involved gathering all the data that we could get our hands on. The datasets had been created by different processes and had various advantages and disadvantages. First, the most valued but labor-intensive category of datasets to create had been manually curated by multiple people. More plentiful were datasets that had not been manually curated, but had been assessed by so many different algorithms that they were considered extremely well-characterized. Finally, there were the artificial datasets that had been created by simulation and for which the truth was known, but which lacked the complexity and depth of real data. Each type of dataset required careful consideration of the type of evidence it provided for proper algorithm performance. I came to really understand that validation of an algorithm and characterization of the typical errors were an essential part of the data science. The project taught me a few lessons that I think might be generally applicable.
Use open datasets
In most cases, it is preferable that algorithms be open-source and available for all to examine. If algorithms must be closed-source and proprietary, then open, curated datasets are essential for comparisons among algorithms. These may include real data that has been cleared for general use, anonymized data or high-quality artificial data. Open datasets allow us to analyze algorithms even when they are too complex to understand or when the source code is hidden. We can observe where and when they make errors and discern patterns. We can determine in what circumstances other algorithms can be better. This insight can be extremely powerful when it comes to applying algorithms in the real world.
Take manual curation seriously
Domain-specific experts, such as doctors in medicine or coaches in sports, are generally a very powerful source of information. Panels of experts are even better. While humans are by no means perfect, when careful consideration of an algorithmic result by experts implies that the algorithm has failed, it’s important to take that message seriously. It’s important to investigate if and why the algorithm failed. Even if the problem is never fixed, it is important to understand the types of errors the algorithm makes and to measure its failure rate in various circumstances.
Demand causal models
While it has become very easy to build systems which generate high-performing black-box algorithms, we must push for explainable results wherever possible. Furthermore, we should demand truly causal models rather than the merely predictive. Predictive models perform well when there are no external modifications of the system. Causal models continue to be accurate despite exogenous shocks and policy interventions. Frequently, we create the former, yet try to deploy them as if they are the latter with disastrous consequences.
All three principles have one underlying idea. Bad data science obscures and ignores the real world performance of its algorithms. It relies on little to no validation. When it does perform validation, it relies on canned approaches to validation. It doesn’t critically examine instances of bad performance with an eye towards trying to understand how and why these failures occur. It doesn’t make the nature of these failures widely known so consumers of these algorithms can deploy them with discernment and sophistication.
Good data science does the opposite. It creates algorithms which are deeply and widely understood. It allows us to understand when algorithms fail and how to adapt to those failures. It allows us to intelligently interpret the results we receive. It leads to better decision making.
Let’s stop the proliferation of weapons of math destruction with better data science!
Sketchy genetic algorithms are the worst
Math is intimidating. People who meet me and learn that I have a Ph.D. in math often say, “Oh, I suck at math.” It’s usually half hostile, because they’re not proud of this fact, and half hopeful, like they want to believe I must be some kind of magician if I’m good at it, and I might share my secrets.
Then there’s medical science, specifically anything around DNA or genetics. It’s got its own brand of whiz-bang magic and intimidation. I know because, in this case, I’m the one who is no expert, and I kind of want anything at all to be true of a “DNA test.” (You can figure out everything that might go wrong and fix it in advance? Awesome!)
If you combine those two things, you’ve basically floored almost the entire population. They remove themselves from even the possibility of critique.
That’s not always a good thing, especially when the object under discussion is an opaque and possibly inaccurate “genetic algorithm” that is in widespread use to help people make important decisions. Today I’ve got two examples of this kind of thing.
DNA Forensics Tests
The first example is something I mentioned a while ago, which was written up beautifully in the Atlantic by Matthew Shaer. Namely, DNA forensics.
There seem to be two problems in this realm. First, there’s a problem around contamination. The tests have gotten so sensitive that it’s increasingly difficult to know if the DNA being tested comes from the victim of a crime, the perpetrator of the crime, the forensics person who collected the sample, or some random dude who accidentally breathed in the same room three weeks ago. I am only slightly exaggerating.
Second, there’s a problem with consistency. People claiming to know how to perform such tests get very different results from other people claiming to know how to perform them. Here’s a quote from the article that sums up the issue:
“Ironically, you have a technology that was meant to help eliminate subjectivity in forensics,” Erin Murphy, a law professor at NYU, told me recently. “But when you start to drill down deeper into the way crime laboratories operate today, you see that the subjectivity is still there: Standards vary, training levels vary, quality varies.”
Yet, the results are being used to put people away. In fact jurors are extremely convinced by DNA evidence. From the article:
A researcher in Australia recently found that sexual-assault cases involving DNA evidence there were twice as likely to reach trial and 33 times as likely to result in a guilty verdict; homicide cases were 14 times as likely to reach trial and 23 times as likely to end in a guilty verdict.
Opioid Addiction Risk
The second example I have today comes from genetic testing of “opioid addiction risk.” It was written up in Medpage Today by Kristina Fiore, and I’m pretty sure someone sent it to me but I can’t figure out who (please comment!).
The article discusses two new genetic tests, created by companies Proove and Canterbury, which claim to accurately assess a person’s risk of becoming addicted to pain killers.
They don’t make their accuracy claims transparent (93% for Proove), and scientists not involved with the companies peddling the algorithms are skeptical for all sorts of reasonable reasons, including historical difficulty reproducing results like this.
Yet they are still being marketed as a way of saving money on worker’s comp systems, for example. So in other words, people in pain who are rated “high risk” might be denied pain meds through such a test that has no scientific backing but sounds convincing.
Enough with this intimidation. We need new standards of evidence before we let people wield scientific tools against people.
Sentencing more biased by race than by class
Yesterday I was super happy to be passed along this amazing blogpost from lawyerist.com called Uncovering Big Bias with Big Data and written by David Colarusso, a lawyer who became a data scientist (hat tip Emery Snyder).
For the article, David mines a recently opened criminal justice data set from Virginia, and asked the question, what affects the length of sentence more: income or race? His explanation of each step is readable by non-technical people, it’s a real treasure.
And, unsurprisingly to those of us who have thought about this, the answer he came up with is race, by a long margin, although he also found that class matters too.
In particular he fit his data with the outcome variable set to length of sentence in days – or rather, log(1 + that term), which he explains nicely – and he chose the attributes to be the gender of the defendant, a bunch of indicator variables to determine the race of the defendant (one for each race except white, which was the “default race,” which I thought was a nice touch), the income of the defendant, and finally the “seriousness of the charge,” a system which he built himself and explains. He gives a reasonable explanation of all of these choices except for the gender.
His conclusion:
For a black man in Virginia to get the same treatment as his Caucasian peer, he must earn more than
half a million dollars$90,000 a year.
This sentence follows directly from staring at this table for a couple of minutes, if you imagine two defendants with the same characteristics except one is white and the other is black:
It’s simplistic, and he could have made other choices, but it’s a convincing start. Don’t trust me though, take a look at his blogpost, and also his github code which includes his iPython notebook.
I am so glad people are doing this. Compared to shitty ways of using data, which end up doubling down on poor and black folks, this kind of analysis shines a light on how the system works against them, and gives me hope that one day we’ll fix it.



