Sentencing more biased by race than by class
Yesterday I was super happy to be passed along this amazing blogpost from lawyerist.com called Uncovering Big Bias with Big Data and written by David Colarusso, a lawyer who became a data scientist (hat tip Emery Snyder).
For the article, David mines a recently opened criminal justice data set from Virginia, and asked the question, what affects the length of sentence more: income or race? His explanation of each step is readable by non-technical people, it’s a real treasure.
And, unsurprisingly to those of us who have thought about this, the answer he came up with is race, by a long margin, although he also found that class matters too.
In particular he fit his data with the outcome variable set to length of sentence in days – or rather, log(1 + that term), which he explains nicely – and he chose the attributes to be the gender of the defendant, a bunch of indicator variables to determine the race of the defendant (one for each race except white, which was the “default race,” which I thought was a nice touch), the income of the defendant, and finally the “seriousness of the charge,” a system which he built himself and explains. He gives a reasonable explanation of all of these choices except for the gender.
His conclusion:
For a black man in Virginia to get the same treatment as his Caucasian peer, he must earn more than
half a million dollars$90,000 a year.
This sentence follows directly from staring at this table for a couple of minutes, if you imagine two defendants with the same characteristics except one is white and the other is black:
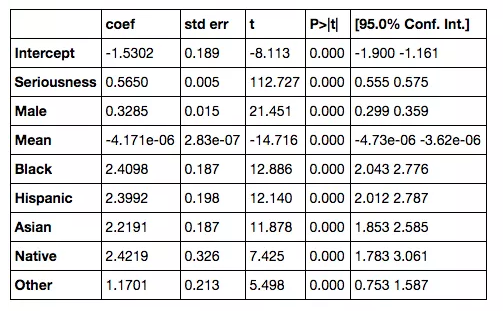
It’s simplistic, and he could have made other choices, but it’s a convincing start. Don’t trust me though, take a look at his blogpost, and also his github code which includes his iPython notebook.
I am so glad people are doing this. Compared to shitty ways of using data, which end up doubling down on poor and black folks, this kind of analysis shines a light on how the system works against them, and gives me hope that one day we’ll fix it.




Cathy:
Wow. We partnered with David nine years ago when he was a high school teacher and amateur coder who wanted YouTubers votes to affect what questions CNN asked the presidential candidates. The result was 10questions.com. Then he went to law school. Now this: he’s a “justice coder.” I love it.
LikeLike
I don’t understand how you could deduce that black men don’t have the same treatment than any other race. It seems you have a cultural bias here: you presuppose that race has no incidence on actions of persons and that the only cause of differences between sentences is due to racism of judges.
LikeLike
Who has the bias?
Anyway, we accounted for the seriousness of the charge. You could ask what other “information” we didn’t account for.
LikeLike
Class and race obviously also enter the picture when it comes to charges and convictions. I wonder if those might be more class-based than sentencing.
LikeLike
Thanks for writing this up – it is a good walk through of the data and research methods. Everyone should keep in mind, though, that this is a single study of one stage of the CJ process in one state. The big question we want to answer about bias is cumulative advantage and disadvantage through the process (law making, arrest, charging, adjudication and sentencing). Those around at the sentencing stage and included in this study have already been exposed to race and class bias in other stages.
Also, and very important, the author does not control for criminal history (see “Finding Feature”). This is a huge omission as seriousness of the present crime and criminal history are the two axes for all sentencing guidelines. Criminal history is also connected to bias for both poor and minorities, so scholars are unclear about what it means to ‘control’ for it.
LikeLike
I agree!
LikeLike
Thanks for posting this! I dug into his analysis a bit, and here are my thoughts: https://adventuresindatascience.wordpress.com/2016/06/03/uncovering-big-bias-with-big-data-a-review/
LikeLike