When statisticians ignore statistics
This article about recidivism risk algorithms in use in Philadelphia really bothers me (hat tip Meredith Broussard). Here’s the excerpt that gets my goat:
“As a Black male,” Cobb asked Penn statistician and resident expert Richard Berk, “should I be afraid of risk assessment tools?”
“No,” Berk said, without skipping a beat. “You gotta tell me a lot more about yourself. … At what age were you first arrested? What is the date of your most recent crime? What are you charged with?”
Let me translate that for you. Cobb is speaking as a black man, then Berk, who is a criminologist and statistician, responds to Cobb as an individual.
In other words, Cobb is asking whether black men are systematically discriminated against by this recidivism risk model. Berk answers that he, individually, might not be.
This is not a reasonable answer. It’s obviously true that any process, even discriminatory processes that have disparate impact on people of color, might have exceptions. They might not always discriminate. But when someone who is not a statistician asks whether black men should be worried, then the expert needs to interpret that appropriately – as a statistical question.
And maybe I’m overreacting – maybe that was an incomplete quote, and maybe Berk, who has been charged with building a risk tool for $100,000 for the city of Philadelphia, went on to say that risk tools in general are absolutely capable of systematically discriminating against black men.
Even so, it bothers me that he said “no” so quickly. The concern that Cobb brought up is absolutely warranted, and the correct answer would have been “yes, in general, that’s a valid concern.”
I’m glad that later on he admits that there’s a trade-off between fairness and accuracy, and that he shouldn’t be the one deciding how to make that trade-off. That’s true.
However, I’d hope a legal expert could have piped in at that moment to mention that we are constitutionally guaranteed fairness, so the trade-off between accuracy and fairness should not really up for discussion at all.
Let’s hear it for Penn Station bathrooms!
I don’t know about you, but every time I go into the bathroom at Penn Station I cry a little bit.
That’s because I remember the 1980’s version of them, and believe you me, they’re so much better now. I grew up in the Boston area but I visited a bunch in high school, which means I spent way too much time in the very few available public toilet facilities. So I can appreciate me some improved amenities.
They are relatively clean! They have toilet paper, consistently! There’s soap available next to working sinks! And, probably most importantly, it’s not a threatening experience with dirty needles all over the floor.
For that matter, while I’m on the theme, have you noticed how much nicer JFK is now compared to 1988? Maybe it’s because I’ve been flying JetBlue a lot, but that terminal is nothing like the broken-down middle school experience I remember not so fondly.
That’s all I have today, just gratitude and anti-nostalgia. And I’m sure there are lots of things we miss as well from those days of New York City, but right now I can’t think of any besides cheaper rent.
National Book Awards Longlist Finalist!
It’s been an amazing two weeks – or actually, holy crap, only 10 days – since my book launched.
I found out two days ago that my book made it onto the Longlist for the National Book Award in Nonfiction, along with 9 other books. I haven’t had time to read the other books, but I did want to mention that last year’s NBA Nonfiction winner was Ta-Nehisi Coates’s excellent Between The World And Me, which I highly recommend.
What’s exciting about being on this list is that it means the ideas in the book will get exposure. So many really excellent books never get read by many people, because of bad timing, or small marketing and publicity budgets, or just bad luck. I’m so lucky to have a book that’s been given an extremely generous amount of all of that.
This week I’ve been busy on the West Coast going to book events and giving talks. My last one is today at noon in Berkeley (820 Barrows Hall). I’ve gotten almost no sleep what with jetlag, weird traveling requirements, and pure adrenaline, but it’s been absolutely incredible.
It’s been especially fantastic to meet the people who come to these events, which so far have taken place in Seattle, the San Francisco area, and a couple in New York last week. It seems like almost every person has something to tell me, a story of algorithms they encounter at work, or that their friends do, or questions about how to get a job that they can feel proud of in data science. Some of them are lawyers offering to talk to me about FOIA law or the Privacy Act. Incredible.
Some people who have read the book already will tell me it really changed their perspective, and others will tell me they’ve been waiting years for this book to be written, because it echoes their experience and long-held skepticism.
What?! Do you guys know what that means? It means the book is working!
In any case I’m overwhelmed and grateful to be able to talk to all of them and to start and continue the conversation. It’s never been more timely, and although I had hoped to get the book out sooner, I actually ended up thinking the timing couldn’t be better.
There’s only one thing. I wish I could send a message back to myself four years ago, when I decided to write the book, or even better, to Christmas 2014, when I was convinced it was an unwritable book. I’d just want to send some encouragement, a signal that it would eventually cohere. Those were some dark days, as my family can attest to.
Luckily for me, I had good friends who kept me from losing all hope. Thank you, blog readers, and thank you friends, and thank you Jordan and Laura especially, you guys are the best!
More creepy models
One of the best things about having my book out (finally!) is that once people read it, or hear interviews or read blogs about it, they sometimes sending me more examples of creepy models. I have two examples today.
The first is a company called Joberate which scores current employees (with a “J-score”) on their risk of looking for a job (hat tip Marc Sobel). Kind of like an overbearing, nosy boss, but in automated and scaled digital form. They claim they’re not creepy because they use only publicly available data.
Next, we’ve got Litify (hat tip Nikolai Avteniev), an analytics firm in law that’s attempting to put automatic scoring into litigation finance. Litify advertises itself thus:
…Litify is led by an experienced executive team, including one of the world’s most influential and successful lawyers, well known VC’s and software visionaries. Litify will transform the way legal services are delivered connecting the firm and the client with new apps and will use artificial intelligence to predict the outcome of legal matters, changing the economy of law. Litify.com will become a household consumer name for getting legal assistance and make legal advice dramatically more accessible to the people…
What could possibly go wrong?
Book talk at Occupy today!
I’ll be giving a version of my book talk at the Alt Banking meeting today. Please come!
Here are the deets:
When: 2-3pm today
Where: Room 409 of the International Affairs Building, 118th and Amsterdam
Slate Money discusses WMD
We discussed my new book, Weapons of Math Destruction, on my Slate Money podcast this week. Take a listen!

Time to unionize customer-facing bankers
Have you heard of the most recent outrage committed by a bank? Wells Fargo just got fined a total of $185 million for corrupt practices involving the accounts of depositors.
Specifically, a bunch of depositors were given accounts they didn’t sign up for, and then charged for via fees. Wells Fargo claims they have fired 5,300 low-level workers over the past five years for doing stuff like this.
But as many have pointed out, including Naked Capitalism, this is really not about low-level workers. It’s about ridiculous and unattainable sales quotas imposed on bankers, and then a complete disregard for the knock-on effects of those stupid quotas.
The fact that so much fraud went on so widely means that either the top dogs knew about it and didn’t care (I’m voting for this – after all the high pressure sales tactics were probably profitable overall even with this $185 fine) or that they had entirely insufficient controls and didn’t know about it. Either way they’re idiots, and it’s outrageous that only the underlings were fired, and not the management. For that matter the person who came up with rigid sales quotas without thinking for five minutes about what would happen next needs to get canned.
Oh wait, I just remembered: the lowest paid bank workers, who really work for very little money under tremendous pressure, have very little power. It’s time they form a union. This is not a new idea, but it’s never been more obvious.
Brian Lehrer and Barnes & Noble today!
I’ll be live on the Brian Lehrer Show today around 11:15am, talking about my book, maybe with live callers! You can listen to it at 93.9 if you’re in the New York City area, and you can stream it from wnyc.org if not.
Also, tonight I’ll be talking about my book with my buddy Felix Salmon at Barnes & Noble on the upper east side, 86th and Lexington. It starts at 7pm tonight, and more info is here.
Reviews for Weapons of Math Destruction
The reviews are coming in of my new book, Weapons of Math Destruction (also available as an audiobook, which I read myself! (clip here)). Here are some of them:
- Weapons of Math Destruction: invisible, ubiquitous algorithms are ruining millions of lives by Cory Doctorow from his blog Boingboing.net
- Weapons of Math Destruction by Peter Woit from his blog, Not Even Wrong
- Big Data Isn’t Just Watching You—It’s Making You Poorer by Pankaj Mehta on the site In These Times
- Review: Weapons of Math Destruction by Evelyn Lamb in Scientific American
- Math is racist: How data is driving inequality by Aimee Rawlins on CNN Money. Note: I would not have chosen this title, since I’m not claiming math is racist, but rather that some potentially discriminatory practices are being shielded by mathematics. I should note that journalists don’t always choose their own titles, and I think Aimee did a good job with the content of the article
- On Cathy O’Neil’s Weapons of Math Destruction by Chris Hoofnagle, on his blog at the UC Berkeley Law School
- Math Is Biased Against Women and the Poor, According to a Former Math Professor by Priya Rao on NYMag’s The Cut
There may be more I’m missing, please send me links! The coverage has been fantastic, and I’m super excited for the coming weeks and months as we finally get to discuss these issues.
Also, I’d like to urge you all to review my book on Amazon when you get a chance. The book is controversial and a few negative reviews can drag down the average pretty quickly. Having said that, please be completely honest of course!
Here’s my favorite graphic, from CNN:

Book Release! and more
Oh my god, people, today’s the day! I’m practically bursting with excitement and anxiety. I feel like throwing up all the time, but in a good way. I want to go into every bookstore I walk by, find my book, and throw up all over it. That would be so nice, right?
Also, I wanted to mention that Carrie Fisher, who is a SUPREME ROLE MODEL TO ME, has just started an advice column at the Guardian. How exciting is that?! So please, anyone who still mourns the loss of Aunt Pythia, go ahead and take a look, she’s just the best.
Also! I’m into this new report, and accompanying Medium piece, by Team Upturn on the subject of predictive policing. It explains the field in a comprehensive way, and offers a convincing critique as well.
Also! It turns out I’ll be in Berkeley next Friday, here’s the flier thanks to Professor Marion Fourcade:

I hope I see you there!
Tech industry self-regulates AI ethics in secret meetings
This morning I stumbled upon a New York Times article entitled How Tech Giants Are Devising Real Ethics for Artificial Intelligence. The basic idea, and my enormously enraged reaction to that idea, is perfectly captured in this one line:
… the basic intention is clear: to ensure that A.I. research is focused on benefiting people, not hurting them, according to four people involved in the creation of the industry partnership who are not authorized to speak about it publicly.
So we have no window into understanding how insiders – unnamed, but coming from enormously powerful platforms like Google, Amazon, Facebook, IBM, and Microsoft – think about benefit versus harm, about who gets harmed and how you measure that, and so on.
That’s not good enough. This should be an open, public discussion.
Citi Bike comes to Columbia
I’m unreasonably excited that Citi Bike has finally expanded to the area where I live, Columbia University. Here’s the situation:
Specifically, this means I can drop my kid off at school at 110th and Broadway and then bike downtown.
People, this is huge. It means I never have to get on the 1 train at rush hour again! Unless everyone else has the same plan as me, of course.
Excerpt of my book in the Guardian!
Wow, people, an excerpt of my book has been published in the Guardian this morning. How exciting is this? I hope you like it, it’s got a fancy graphic:

This is the result of my amazing Random House UK publicity team, who have been busy promoting my book in the UK.
That same team is bringing me to London at the end of September for a book tour, and as part of that I’m excited to announce I’ll be at the How To: Academy on September 27th, talking about my book, which was Tickets are available here.
Also, if you haven’t gotten enough of Weapons of Math Destruction this morning, take a look at Evelyn Lamb’s review in Scientific American.
Update: the print edition of the Guardian also looks smashing:


In Time Magazine!
The amazing and talented Rana Foroohar, whom I spoke with on Slate Money not so long ago about her fascinating book, Makers and Takers: the Rise of Finance and the Fall of American Business, has written a fantastic piece about my upcoming book for Time Magazine.
The link is here. Take a look, it’s a great piece.
Also, I was profiled as a math nerd last week by a Bloomberg journalist.
BISG Methodology
I’ve been tooling around with the slightly infamous BISG methodology lately. It’s a simple concept which takes the last name of a person, as well as the zip code of their residence, and imputes the probabilities of that person being of various races and ethnicities using the Bayes updating rule.
The methodology is implemented with the most recent U.S. census data and critically relies on the fact that segregation is widespread in this country, especially among whites and blacks, and that Asian and Hispanic last names are relatively well-defined. It’s not a perfect methodology, of course, and it breaks down in the cases that people marry people of other races, or there are names in common between races, and especially when they live in diverse neighborhoods.
The BISG methodology came up recently in this article (hat tip Don Goldberg) about the man who invented it and the politics surrounding it. Specifically, it was recently used by the CFPB to infer disparate impact in auto lending, and the Republicans who side with auto lending lobbyists called it “junk science.” I blogged about this here and, even earlier, here.
Their complaints, I believe, center around the fact that the methodology, being based on the entire U.S. population, isn’t entirely accurate when it comes to auto lending, or for that matter when it comes to mortgages, which was the CFPB’s “ground truth” testing arena.
And that’s because minorities basically have less wealth, due to a bunch of historical racist reasons, but the upshot is that this methodology assumes a random sampling of the U.S. population but what we actually see in auto financing isn’t random.
Which begs the question, why don’t we update the probabilities with the known distribution of auto lending? That’s the thing about Bayes Law, we can absolutely do that. And once we did that, the Republican’s complaint would disappear. Please, someone tell me what I’m misunderstanding.
Between you and me, I think the real gripe is something along the lines of the so-called voter fraud problem, which is not really a problem statistically but since examples can be found of mistakes, we might imagine they’re widespread. In this case, the “mistake” is a white person being offered restitution for racist auto lending practices, which happens, and is a strange problem to have, but needs to be compared to not offering restitution to a lot of people who actually deserve it.
Anyhoo, I’m planning to add the below code to github, but I recently purchased a new laptop and I haven’t added a public key yet, so I’ll get to it soon. To be clear, the below code isn’t perfect, and it only uses zip code whereas a more precise implementation would use addresses. I’m supplying this because I didn’t find it online in python, only in STATA or something crazy expensive like that. Even so, I stole their munged census data, which you can too, from this github page.
Also, I can’t seem to get the python spacing to work in WordPress, so this is really pretty terrible, but python users will be able to figure it out until I can get it on github.
%matplotlib inline
import numpy
import matplotlib
from pandas import *
import pylab
pylab.rcParams[‘figure.figsize’] = 16, 12
#Clean your last names and zip codes.
def get_last_name(fullname):
parts_list = fullname.split(‘ ‘)
while parts_list[-1] in [”, ‘ ‘,’ ‘,’Jr’, ‘III’, ‘II’, ‘Sr’]:
parts_list = parts_list[:-1]
if len(parts_list)==0:
return “”
else:
return parts_list[-1].upper().replace(“‘”, “”)
def clean_zip(fullzip):
if len(str(fullzip))<5:
return 0
else:
try:
return int(str(fullzip)[:5])
except:
return 0
Test = read_csv(“file.csv”)
Test[‘Name’] = Test[‘name’].map(lambda x: get_last_name(x))
Test[‘Zip’] = Test[‘zip’].map(lambda x: clean_zip(x))
#Add zip code probabilities. Note these are probability of living in a specific zip code given that you have a given race. They are extremely small numbers.
F = read_stata(“zip_over18_race_dec10.dta”)
print “read in zip data”
names =[‘NH_White_alone’,’NH_Black_alone’, ‘NH_API_alone’, ‘NH_AIAN_alone’, ‘NH_Mult_Total’, \
‘Hispanic_Total’,’NH_Other_alone’]
trans = dict(zip(names, [‘White’, ‘Black’, ‘API’, ‘AIAN’, ‘Mult’, ‘Hisp’, ‘Other’]))
totals_by_race = [float(F[r].sum()) for r in names]
sum_dict = dict(zip(names, totals_by_race))
#I’ll use the generic_vector down below when I don’t have better name information
generic_vector = numpy.array(totals_by_race)/numpy.array(totals_by_race).sum()
for r in names:
F[‘pct of total %s’ %(trans[r])] = F[r]/sum_dict[r]
print “ready to add zip probabilities”
def get_zip_probs(zip):
G = F[F[‘ZCTA5’]==str(zip)][[‘pct of total White’,’pct of total Black’, ‘pct of total API’, \
‘pct of total AIAN’, ‘pct of total Mult’, ‘pct of total Hisp’, \
‘pct of total Other’]]
if len(G.values)>0:
return numpy.array(G.values[0])
else:
print “no data for zip = “, zip
return numpy.array([1.0]*7)
Test[‘Prob of zip given race’] = Test[‘Zip’].map(lambda x: get_zip_probs(x))
#Next, compute the probability of each race given a specific name.
Names = read_csv(“app_c.csv”)
print “read in name data”
def clean_probs(p):
try:
return float(p)
except:
return 0.0
for cat in [‘pctwhite’, ‘pctblack’, ‘pctapi’, ‘pctaian’, ‘pct2prace’, ‘pcthispanic’]:
Names[cat] = Names[cat].map(lambda x: clean_probs(x)/100.0)
Names[‘pctother’] = Names.apply(lambda row: max (0, 1 – float(row[‘pctwhite’]) – \
float(row[‘pctblack’]) – float(row[‘pctapi’]) – \
float(row[‘pctaian’]) – float(row[‘pct2prace’]) – \
float(row[‘pcthispanic’])), axis = 1)
print “ready to add name probabilities”
def get_name_probs(name):
G = Names[Names[‘name’]==name][[‘pctwhite’, ‘pctblack’, ‘pctapi’, ‘pctaian’, ‘pct2prace’, ‘pcthispanic’, ‘pctother’]]
if len(G.values)>0:
return numpy.array(G.values[0])
else:
return generic_vector
Test[‘Prob of race given name’] = Test[‘Name’].map(lambda x: get_name_probs(x))
#Finally, use the Bayesian updating formula to compute overall probabilities of each race.
Test[‘Prod’] = Test[‘Prob of zip given race’]*Test[‘Prob of race given name’]
Test[‘Dot’] = Test[‘Prod’].map(lambda x: x.sum())
Test[‘Final Probs’] = Test[‘Prod’]/Test[‘Dot’]
Test[‘White Prob’] = Test[‘Final Probs’].map(lambda x: x[0])
Test[‘Black Prob’] = Test[‘Final Probs’].map(lambda x: x[1])
Test[‘API Prob’] = Test[‘Final Probs’].map(lambda x: x[2])
Test[‘AIAN Prob’] = Test[‘Final Probs’].map(lambda x: x[3])
Test[‘Mult Prob’] = Test[‘Final Probs’].map(lambda x: x[4])
Test[‘Hisp Prob’] = Test[‘Final Probs’].map(lambda x: x[5])
Test[‘Other Prob’] = Test[‘Final Probs’].map(lambda x: x[6])
Book Tour Events!
Readers, I’m so happy to announce upcoming public events for my book tour, which starts in 2 weeks! Holy crap!
The details aren’t all entirely final, and there may be more events added later, but here’s what we’ve got so far. I hope I see some of you soon!
—
Events for Cathy O’Neil
Author of
WEAPONS OF MATH DESTRUCTION:
How Big Data Increases Inequality and Threatens Democracy
(Crown; September 6, 2016)
–
Thursday, September 8
7:00pm
Reading/Signing/Talk with Felix Salmon
Barnes & Noble Upper East Side
150 E 86th St.
New York, NY 10028
–
Tuesday, September 13
7:30pm
In Conversation Event
1119 8th Ave.
Seattle, WA 98101
–
Wednesday, September 14
12:00pm
Democracy/Citizenship Series
57 Post St.
San Francisco, CA 94104
–
Wednesday, September 14
7:00pm
In Conversation with Lianna McSwain
51 Tamal Vista Blvd.
Corte Madera, CA 94925
–
Thursday, September 15
9:00am
San Jose Marriott
301 S. Market Street
San Jose, CA 95113
–
Tuesday, September 20
6:30pm
In Conversation with Jen Golbeck
Busboys and Poets (w/Politics & Prose)
1025 5th Street NW
Washington, D.C. 20001
–
Monday, October 3
7:00pm
Reading/Signing
1256 Mass Ave.
Cambridge, MA 02138
–
Saturday, October 22nd
12:00pm
Wisconsin Institutes for Discovery
–
For more information or to schedule an interview contact:
Sarah Breivogel, 212-572-2722, sbreivogel@penguinrandomhouse.com or
Liz Esman, 212-572-6049, lesman@penguinrandomhouse.com
Chicago’s “Heat List” predicts arrests, doesn’t protect people or deter crime
A few months ago I publicly pined for a more scientific audit of the Chicago Police Department’s “Heat List” system. The excerpt from that blogpost:
…the Chicago Police Department uses data mining techniques of social media to determine who is in gangs. Then they arrest scores of people on their lists, and finally they tout the accuracy of their list in part because of the percentage of people who were arrested who were also on their list. I’d like to see a slightly more scientific audit of this system.
Thankfully, my request has officially been fulfilled!
Yesterday I discovered via Marcos Carreiro on Twitter, that a paper has been written entitled Predictions put into practice: a quasi-experimental evaluation of Chicago’s predictive policing pilot, written by
The paper’s main result upheld my suspicions:
Individuals on the SSL are not more or less likely to become a victim of a homicide or shooting than the comparison group, and this is further supported by city-level analysis. The treated group is more likely to be arrested for a shooting.
Inside the paper, they make the following important observations. First, crime rates have been going down over time, and the “Heat List” system has not effected that trend. An excerpt:
…the statistically significant reduction in monthly homicides predated the introduction of the SSL, and that the SSL did not cause further reduction in the average number of monthly homicides above and beyond the pre-existing trend.
Here’s an accompanying graphic:
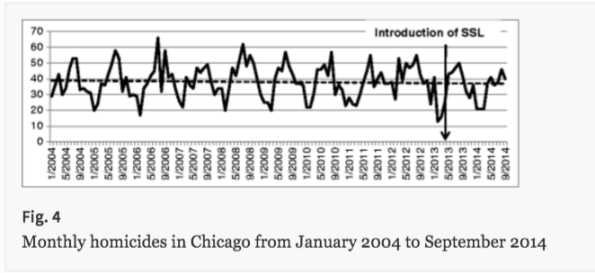
This is a really big and important point, one that smart people like Gillian Tett get thrown off by when discussing predictive policing tools. We cannot automatically attribute success to any policing policy in the context of meta-effects.
Next, being on the list doesn’t protect you:
However, once other demographics, criminal history variables, and social network risk have been controlled for using propensity score weighting and doubly-robust regression modeling, being on the SSL did not significantly reduce the likelihood of being a murder or shooting victim, or being arrested for murder.
But it does make it more likely for you to get surveilled by police:
Seventy-seven percent of the SSL subjects had at least one contact card over the year following the intervention, with a mean of 8.6 contact cards, and 60 % were arrested at some point, with a mean of 1.53 arrests. In fact, almost 90 % had some sort of interaction with the Chicago PD (mean = 10.72 interactions) during the year-long observation window. This increased surveillance does appear to be caused by being placed on the SSL. Individuals on SSL were 50 % more likely to have at least one contact card and 39 % more likely to have any interaction (including arrests, contact cards, victimizations, court appearances, etc.) with the Chicago PD than their matched comparisons in the year following the intervention. There was no statistically significant difference in their probability of being arrested or incapacitated8 (see Table 4). One possibility for this result, however, is that, given the emphasis by commanders to make contact with this group, these differences are due to increased reporting of contact cards for SSL subjects.
And, most importantly, being on the list means you are likely to be arrested for shooting, but it doesn’t cause that to be true:
In other words, the additional contact with police did not result in an increased likelihood for arrests for shooting, that is, the list was not a catalyst for arresting people for shootings. Rather, individuals on the list were people more likely to be arrested for a shooting regardless of the increased contact.
That also comes with an accompanying graphic:

From now on, I’ll refer to Chicago’s “Heat List” as a way for the police to predict their own future harassment and arrest practices.
What is alpha?
Last week on Slate Money I had a disagreement, or at least a lively discussion, with Felix Salmon and Josh Barro on the definition of alpha.
They said it was anything that a portfolio returned above and beyond the market return, given the amount of risk the portfolio was carrying. That’s not different from how wikipedia defines alpha, and I’ve seen it said in more or less this way in a lot of places. Thus the confusion.
However, while working as a quant at a hedge fund, I was taught that alpha was the return of a portfolio that was uncorrelated to the market.
It’s a confusing thing to discuss, partly because the concept of “risk” is somewhat self-referential – more on that soon – and partly because we sometimes embed what’s called the capital asset pricing model (CAPM) into our assumptions when we talk about how portfolio returns work.
Let’s start with the following regression, which refers to stock-based portfolios, and which defines alpha:

Now, the term term 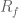

In this regression, we are fitting the coefficients 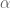


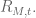
So first, defining alpha with the above regression does what I claimed it would do: it “picks off” that part of the portfolio returns that are correlated to the market and put it in the beta coefficient, and the rest is left to alpha. If beta is 1, alpha is 0, and if the error terms are all zero, you are following the market exactly.
On the other hand, the above formulation also seems to support Felix’s suggestion that alpha is the return that is not accounted for by risk. The thing is, it’s true, at least according to the CAPM theory of investing, which says you can’t do better than the market, that you’re rewarded by market your risk in a direct way, and that everyone knows this and refuses to take on other, unrewarded risks. In particular, alpha in the above equation should be zero, but anything “extra” that you earn beyond the expected market returns would be represented by alpha in the above regression.
So, are we actually agreeing?
Well, no. The two approaches to defining alpha are very different. In particular, my definition has no reference to CAPM. Say for a moment we don’t believe in CAPM. We can still run the regression above. All we’re doing, when we run that regression, is measuring the extent to which our portfolio’s returns are “explained” by its overlap with the market.
In particular, we do not expect the true risk of our portfolio to be apparent in the above equation. Which brings us to how risk is defined, and it’s weird, because it cannot be directly measured. Instead, we typically infer risk from the volatility – computed as standard deviation – of past returns.
This isn’t a terrible idea, because if something moves around wildly on a daily basis, it would appear to be pretty risky. But it’s also not the greatest idea, as we learned in 2008, because lots of credit instruments like credit default swaps move very little on a daily basis but then suddenly lose tremendous value overnight. So past performance is not always indicative of future performance.
But it’s what we’ve got, so let’s hold on to it for the discussion. The key observation is the following:
The above regression formula only displays the market-correlated risk, and the remaining risk is unmeasured. A given portfolio might have incredibly wild swings in value, but as long as they are uncorrelated to the market, they will be invisible to the above equation, showing up only in the error terms.
Said another way, alpha is not truly risk-adjusted. It’s only market-risk-adjusted.
We might have an investment portfolio with a large alpha and a small beta, and someone who only follows CAPM theory would tell me we’re amazing investors. In fact hedge funds try to minimize their relationship to market returns – that’s the “hedge” in hedge funds – and so they’d want exactly that, a large alpha, a tiny beta, and quite a bit of risk. [One caveat: some people stipulate that a lot of that uncorrelated return is fabricated through sleazy accounting.]
It’s not like I am alone here – for a long time people have been aware that there’s lots of risk that’s not represented by market risk – for example, other instrument classes and such. So instead of using a simplistic regression like the one above, people generalize everything in sight and use the Sharpe ratio, which is the ratio of returns (often relative to some benchmark or index) to risks, where risks are measured by more complicated volatility-like computations.
However, that more general concept is also imperfect, mostly because it’s complicated and highly gameable. Portfolio managers are constantly underestimating the risk they take on, partly because – or entirely because – they can then claim to have a high Sharpe ratio.
How much does this matter? People have a colloquial use for the word alpha that’s different from my understanding, which isn’t surprising. The problem lies in the possibility that people are bragging when they shouldn’t, especially when they’re hiding risk, and especially especially if your money is on the line.
The truth about clean swimming pools
There’s been a lot of complaints about the Olympic pools turning green and dirty in Rio. People seem worried that the swimmers’ health may be at risk and so on.

Well, here’s what I learned last month when my family rented a summer house with a pool. Pools that look clean are not clean. They would be better described as, “so toxic that algae cannot live in it.”
I know what I’m talking about. One weekend my band visiting the house, and the pool guy had been missing for 2 weeks straight. This is what my pool looks like:

Album cover, obviously.
Then we added an enormous vat of chemicals, specifically liquid chlorine, and about 24 hours later this is what happened:

It wasn’t easy to recreate this. I had to throw the shark’s tail at Jamie like 5 times because it kept floating away. Also, back of the album, obviously.
Now you might notice that it’s not green anymore, but it’s also not clear. To get to clear, blue water, you need to add yet another tub of some other chemical.
Long story short: don’t be deceived by “clean” pool water. There’s nothing clean about it.
Update: I’m not saying “chemicals are bad,” and please don’t compare me to the – ugh – Food Babe! I’m just saying “clean water” isn’t an appropriate description. It’s not as if it’s pure water, and we pour tons of stuff in to get it to look like that. So yes, algae and germs can be harmful! And yes, chlorine in moderate amounts is not bad for you!
Donald Trump is like a biased machine learning algorithm
Bear with me while I explain.
A quick observation: Donald Trump is not like normal people. In particular, he doesn’t have any principles to speak of, that might guide him. No moral compass.
That doesn’t mean he doesn’t have a method. He does, but it’s local rather than global.
Instead of following some hidden but stable agenda, I would suggest Trump’s goal is simply to “not be boring” at Trump rallies. He wants to entertain, and to be the focus of attention at all times. He’s said as much, and it’s consistent with what we know about him. A born salesman.
What that translates to is a constant iterative process whereby he experiments with pushing the conversation this way or that, and he sees how the crowd responds. If they like it, he goes there. If they don’t respond, he never goes there again, because he doesn’t want to be boring. If they respond by getting agitated, that’s a lot better than being bored. That’s how he learns.
A few consequences. First, he’s got biased training data, because the people at his rallies are a particular type of weirdo. That’s one reason he consistently ends up saying things that totally fly within his training set – people at rallies – but rub the rest of the world the wrong way.
Next, because he doesn’t have any actual beliefs, his policy ideas are by construction vague. When he’s forced to say more, he makes them benefit himself, naturally, because he’s also selfish. He’s also entirely willing to switch sides on an issue if the crowd at his rallies seem to enjoy that.
In that sense he’s perfectly objective, as in morally neutral. He just follows the numbers. He could be replaced by a robot that acts on a machine learning algorithm with a bad definition of success – or in his case, a penalty for boringness – and with extremely biased data.
The reason I bring this up: first of all, it’s a great way of understanding how machine learning algorithms can give us stuff we absolutely don’t want, even though they fundamentally lack prior agendas. Happens all the time, in ways similar to the Donald.
Second, some people actually think there will soon be algorithms that control us, operating “through sound decisions of pure rationality” and that we will no longer have use for politicians at all.
And look, I can understand why people are sick of politicians, and would love them to be replaced with rational decision-making robots. But that scenario means one of three things:
- Controlling robots simply get trained by the people’s will and do whatever people want at the moment. Maybe that looks like people voting with their phones or via the chips in their heads. This is akin to direct democracy, and the problems are varied – I was in Occupy after all – but in particular mean that people are constantly weighing in on things they don’t actually understand. That leaves them vulnerable to misinformation and propaganda.
- Controlling robots ignore people’s will and just follow their inner agendas. Then the question becomes, who sets that agenda? And how does it change as the world and as culture changes? Imagine if we were controlled by someone from 1000 years ago with the social mores from that time. Someone’s gonna be in charge of “fixing” things.
- Finally, it’s possible that the controlling robot would act within a political framework to be somewhat but not completely influenced by a democratic process. Something like our current president. But then getting a robot in charge would be a lot like voting for a president. Some people would agree with it, some wouldn’t. Maybe every four years we’d have another vote, and the candidates would be both people and robots, and sometimes a robot would win, sometimes a person. I’m not saying it’s impossible, but it’s not utopian. There’s no such thing as pure rationality in politics, it’s much more about picking sides and appealing to some people’s desires while ignoring others.



