Race and Police Shootings: Why Data Sampling Matters
This is a guest post by Brian D’Alessandro, who daylights as the Head of Data Science at Zocdoc and as an Adjunct Professor with NYU’s Center for Data Science. When not thinking probabilistically, he’s drumming with the indie surf rock quarter Coastgaard.
I’d like to address the recent study by Roland Fryer Jr from Harvard University, and associated NY Times coverage, that claims to show zero racial bias in police shootings. While this paper certainly makes an honest attempt to study this very important and timely problem, it ultimately suffers from issues of data sampling and subjective data preparation. Given the media attention it is receiving, and the potential policy and public perceptual implications of this attention, we as a community of data people need to comb through this work and make sure the headlines are consistent with the underlying statistics.
First thing’s first: is there really zero bias in police shootings? The evidence for this claim is, notably, derived from data drawn from a single precinct. This is a statistical red flag and might well represent selection bias. Put simply, a police department with a culture that successfully avoids systematic racial discrimination may be more willing than others to share their data than one that doesn’t. That’s not proof of cherry-picking, but as a rule we should demand that any journalist or author citing this work should preface any statistic with “In Houston, using self-reported data,…”.
For that matter, if the underlying analytic techniques hold up under scrutiny, we should ask other cities to run the same tests on their data and see what the results are more widely. If we’re right, and Houston is rather special, we should investigate what they’re doing right.
On to the next question: do those analytic techniques hold up? The short answer is: probably not.
How The Sampling Was Done
As discussed here by economist Rajiv Sethi and here by Justin Feldman, the means by which the data instances were sampled to measure racial bias in Houston police shootings is in itself potentially very biased.
Essentially, Fryer and his team sampled “all shootings” as their set of positively labeled instances, and then randomly sampled “arrests in which use of force may have been justified” (attempted murder of an officer, resisting/impeding arrest, etc.) as the negative instances. The analysis the measured racial biases using the union of these two sets.
Here is a simple Venn diagram representing the sampling scheme:
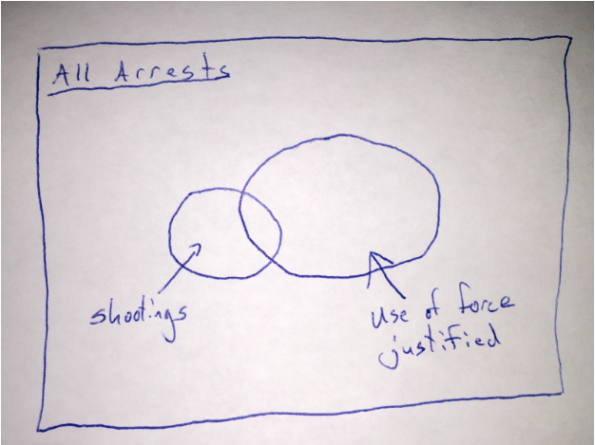
In other words, the positive population (those with shooting) is not drawn from the same distribution as the negative population (those arrests where use of force is justified). The article implies that there is no racial bias conditional on there being an arrest where use of force was justified. However, the fact that they used shootings that were outside of this set of arrests means that this is not what they actually tested.
Instead, they only show that there was no racial bias in the set that was sampled. That’s different. And, it turns out, a biased sampling mechanism can in fact undo the bias that exists in the original data population (see below for a light mathematical explanation). This is why we take great pains in social science research to carefully design our sampling schemes. In this case, if the sampling is correlated with race (which it very likely is), all bets are off on analyzing the real racial biases in police shootings.
What Is Actually Happening
Let’s accept for now the two main claims of the paper: 1) black and hispanic people are more likely to endure some force from police, but 2) this bias doesn’t exist in an escalated situation.
Well, how could one make any claim without chaining these two events together? The idea of an escalation, or an arrest reason where force is justified, is unfortunately an often subjective concept reported after the fact. Could it be possible that a an officer is more likely to find his/her life in danger when a black, as opposed to a white, suspect reaches for his wallet? Further, while unquestioned compliance is certainly the best life-preserving policy when dealing with an officer, I can imagine that an individual being roughed up by a cop is liable to push back with an adrenalized, self-preserving an instinctual use of force. I’ll say that this is likely for black and white persons, but if the black person is more likely to be in that situation in the first place, the black person is more likely to get shot from a pre-stop position.
To sum up, the issue at hand is not whether cops are more likely to shoot at black suspects who are pointing guns straight back at the cop (which is effectively what is being reported about the study). The more important questions, which is not addressed, is why are black men more likely to pushed up against the wall by a cop in the first place, or does race matter when a cop decides his/her life is in danger and believes lethal force is necessary?
What Should Have Happened
While I empathize with the data prep challenges Fryer and team faced (the Times article mentions that put a collective 3000 person hours here), the language of the article and its ensuing coverage unfortunately does not fit the data distribution induced by the method of sampling.
I don’t want to suggest in any way that the data may have been manipulated to engineer a certain result, or that the analysis team mistakenly committed some fundamental sampling error. The paper does indeed caveat the challenge here, but given that admission, I wonder why the authors were so quick to release an un-peer-reviewed working version and push it out via the NY Times.
Peer review would likely have pointed out these issues and at least push the authors to temper their conclusions. For instance, the paper uses multiple sources to show that non-lethal violence is much more likely if you are black or hispanic, controlling for other factors. I see the causal chain being unreasonably bisected here, and this is a pretty significant conceptual error.
Overall, Fryer is fairly honest in the paper about the given data limitations. I’d love for him to take his responsibility to the next level and make his data, both in raw and encoded forms, public. Given the dependency on both subjective, manual encodings of police reports and a single, biased choice of sampling method, more sensitivity analysis should be done here. Also, anyone reporting on this (Fryer himself), should make a better effort to connect the causal chain here.
Headlines are sticky, and first impressions are hard to undo.This study needs more scrutiny at all levels, with special attention to the data preparation that has been done. We need a better impression than the one already made.
The Math
The coverage of the results comes down to the following:
P(Shooting | Black, Escalation) = P(Shooting | White, Escalation)
(here I am using ‘Escalation’ as the set of arrests where use of force is considered justified. And for notational simplicity I have omitted the control variables from the conditional above).
However, the analysis actually shows that:
P(Shooting | Black, Sampled) = P(Shooting | White, Sampled),
Where (Sampled = True) if the person was either shot or the situation escalated and the person was not shot. This makes a huge difference, because with the right bias in the sampling, we could have a situation in which there is in fact bias in police shooting but not in the sampled data. We can show this with a little application of Bayes rule:
P(Shot|B, Samp) / P(Shot|W, Samp) = [P(Shot|B) / P(Shot|W)] * [P(Samp|W) / P(Samp|B)]
The above should be read as: the bias in the study depends on both the racial bias in the population (P(S|B) / P(S|W)) and the bias in the sampling. Any bias in the population can therefore effectively be undone by a sampling scheme that is also racially biased. Unfortunately, the data summarized in the study doesn’t allow us to back into the 4 terms on the right hand side of the above equality.




Reblogged this on bayesianbiologist and commented:
When reading headlines about findings from data, always ask: “To what population does this conclusion apply?” Brian D’Alessandro explains eloquently why sampling matters.
LikeLiked by 1 person
Yes, as Brian pointed out, “In other words, the positive population (those with shooting) is not drawn from the same distribution as the negative population (those arrests where use of force is justified).” I loved the Venn diagram!
How would we describe the data-set from which the positive population (those with shooting) is drawn? What is the context, and how does it differ from data-set from which the negative population was drawn?
This is not about “sampling” as such, but rather about how we construct data-sets that are then sampled on. They are two separate steps.
LikeLike
Here is a sociological view of the escalation of violence between police and blacks that moves far beyond number crunching. “Can the war between cops and blacks be de-escalated?”
http://sociological-eye.blogspot.com/2016/07/can-war-between-cops-and-blacks-be-de.html
LikeLike
It’s the BIG BOX, “All Arrests” that is too slippery for me. Here is why, from Ruby Payne, which aligns well with Collins.
http://www.ahaprocess.com/how-does-poverty-influence-the-baltimore-situation/
How does poverty influence the Baltimore situation?
http://www.ahaprocess.com/store/tactical-communication-book/
Tactical Communication: Mastering effective interactions with citizens of diverse economic backgrounds (First Responder Edition) – Book
LikeLike
Ok, so if I understand correctly Mr D’Alessandro argues that there is bias in stops, but agrees with Dr Fryer that there is no bias in shootings. What I don’t see is the actual argument that criminals of color are more likely to be stopped because of bias, as opposed to suspected criminal behavior.
We know from official statistics on murder (https://ucr.fbi.gov/crime-in-the-u.s/2014/crime-in-the-u.s.-2014/tables/table-43) that show about equal number of arrests for white vs black or African american persons, despite the fact that that there are about 5x as many whites in the US; per capita rates are really different. Of course you could argue that there is a racial bias in arrests, but that does not make sense to me for the following reasons.
If there is a murder victim – does it make sense that witnesses are so racist as to point to a random black person rather than apprehend an actual white murderer? Or that police would be so racist as to try to finger a random black person so that actual white perpetrator would go free? If someone would argue that police is biased against persons of color in term of very ambiguous and minor crimes like “loitering” or “obstructing pedestrian traffic” I could see this as possible. But for a serious crimes like murder I don’t believe this to be possible on a major wide scale for entire country.
LikeLike
Bias happens on the margins, not in clear cut cases. You don’t know what exactly the person looked like, but shown a “scary” black dude, you point at them. Or it goes to court and the all-white (thanks to non-blind peremptory challenges) jury takes every word that comes out of police’s mouth as gospel.
LikeLike
But that’s exactly why it makes sense to use statistics to detect it.
LikeLike
OV. I don’t argue that there is bias in stops, or that there is no bias in shootings. I simply report what is claimed in the article, and then question the validity of those claims. I do posit that even if the claims were accepted at face value, they still prove nothing, since the core premise of them is broken.
LikeLike
I fully intend to read this, but for now let me just say, thanks for turning me on to the band! They sound great!
LikeLike
Thanks for this, Brian. Have I got the following right? If police are more likely to escalate with blacks than whites, this will *deflate* the study’s estimate for p(shot|black)/p(shot|white) by increasing a denominator.
LikeLike
Even if Fryer is correct in all his conclusions, you have to wonder whether they generalize to other cities. And it’s impossible to know. You can study only those police departments that gather this kind of data (all the different levels of police use of force in different situations) and are willing to make the data available. Those departments are not likely to be representative of all departments.
LikeLike
There is a potential reason why:
P(Shooting | Black, Sampled) = P(Shooting | White, Sampled)
And that is that reaction time is the limiting factor. In the only experimental paper I could find on the subject (go to section 4) http://bit.ly/29EHbQw any high threat situation where the subject is holding a gun is essentially a limiting factor – officers may be trained to focus on this outcome to a much greater degree than race. The single variable of a firearm – removes potential racial bias from the other distributions.
LikeLike
I found this in Randall Collins (confirming your point):
Adding together any or all of these factors increases tension. Bodily this is experienced as adrenaline rush, the flight-or-fight arousal. The biggest danger with an adrenaline spike is the loss of perception and fine motor control. When heart rate races to 150 beat per minute or more, fine motor control is lost. An officer may reach for a gun when he thinks he is reaching for handcuffs or a taser. Trigger fingers produce wild or uncontrollable firing. Officers in shootouts report time distortions like going into a bubble, vision turning into a blur or tunnel vision on only one part of the scene. Hearing often goes out so that they don’t hear their own gunshots; voices become incomprehensible. It is a situation ripe for miscommunication and misperception.
Adrenaline-produced distortions explain why shooting incidents happen where it turns out the suspect did not have a gun, or was reaching for an ID; situations where stops for trivial reasons blow up into killings. Since adrenaline takes time to subside, the cop may empty the magazine of his gun, even after the suspect is motionless on the ground. Catching these details on video certainly looks like an atrocity.
Teaching awareness of body signs and emotional control
What can be done? The key is training cops to keep their bodily tension under control. Sociologist Geoffrey Alpert found that officers who are better at controlling the escalation of force have a more deliberate and refined sense of timing in the moves of both sides. More attention to such micro-details should train more police officers up to a high level of competence. ….
http://sociological-eye.blogspot.com/2016/07/can-war-between-cops-and-blacks-be-de.html
LikeLike
Reblogged this on Scott Andrew Hutchins and commented:
You really can’t trust New York Times headlines.
LikeLike