Debiasing techniques in science
My buddy Ernie Davis just sent me an article, published in Nature, called How scientists fool themselves – and how they can stop. It’s really pretty great – a list of ways scientists fool themselves, essentially through cognitive biases, and another list of ways they can try to get around those biases.
There’s even an accompanying graphic which summarizes the piece:
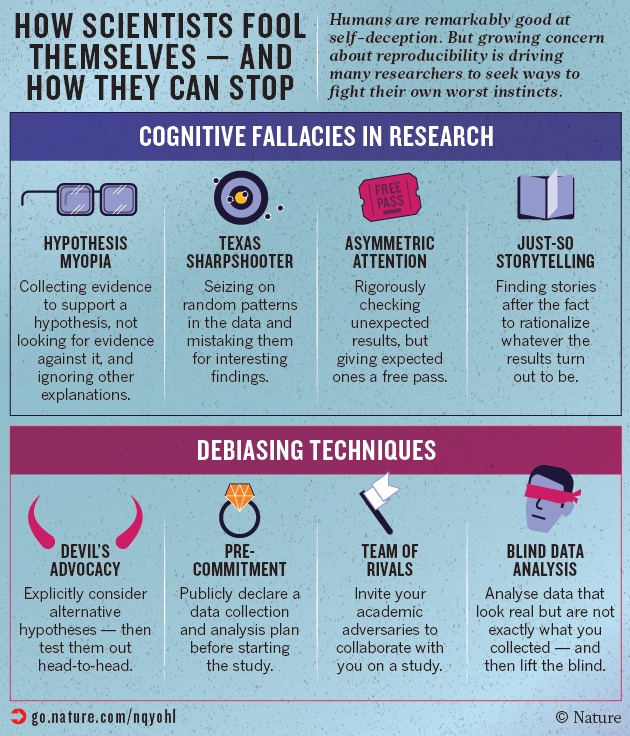
I’ve actually never heard of “blind data analysis” before, but I think it’s an interesting idea. However, it’s not clear how it would exactly work in a typical data science situation, where you perform exploratory data analysis to see what the data looks like, and you form a “story” based on that.
One thing they mentioned in the article but not in the graphic is the importance of having your research open sourced, which I think is the way to let the “devil’s advocacy” and “team of rivals” approaches actually happen in practice.
It’s all the rage nowadays to have meta analyses. I’d love for someone to somehow measure the ability of the above debiasing techniques to see which work well, and under what circumstances.




Rule 99: If you are going to make hypotheses based on the data you have just collected then go out and get some fresh data to test them on.
LikeLike
Sounds like another name for bootstrapping.
LikeLike
Not to me.
LikeLiked by 2 people
Oops, meant this to be a reply to the Target Shuffling comment below.
LikeLike
Blind data analysis is close to what John Elder calls Target Shuffling. A explanation of this technique is here: http://semanticommunity.info/@api/deki/files/30744/Elder_-_Target_Shuffling_Sept.2014.pdf
LikeLike
Target Shuffling sounds like a fancy name for simulation to build a sampling distribution. We talk about this in my intro stats course! The (free, open source) textbook Introduction to Statistics with Randomization and Simulation explains it. https://www.openintro.org/
My favorite related technique is Graphical Inference, where you do the same with plots you think show something interesting. Either permute the data or generate null data from a model, then compare your real data plot to a variety of null data plots. bit.ly/graphical_inference
LikeLike
I advise PhD students to understand cognitive biases, and then to take steps to maximize their intensity. It is very rarely the case that the problem they will face is bias; a much bigger problem is (in Bayesian terms) not having any good ideas in your prior at all. So it’s important for us to take active steps to think thoughts that were previously unthinkable to us.
The best way to do this is to join a large, active research group which takes a position/uses methods you consider extreme and impractical (but not obviously wrong). To fit in with your new coworkers, you will find yourself adopting views you would have rejected previously. In other words, groupthink is awesome, and we should use it more.
LikeLiked by 1 person
Academics are coddled in our academic culture. I discover my own bias by requiring my students submit all papers with their names only on the back, upside down. After reading and grading them all blind, I reveal. My bias is almost always the same: as soon I connect a person to a poor grade, I instantly and uncontrollably try to find excuses to raise it. I’ve been doing this for years; the bias towards not harming students persists despite knowing it all too well.
I also ask the class whether other instructors read blind. I’m astonished that other instructors don’t. Does no one care to learn thr bias? Does no one care to be self-critical? We profs are given significant power and authority, yet little accountability. If all professors were required to read blind first in our classes, the culture might shift a bit towards a recognition of the pervasiveness of bias. I bet that would improve the quality of our research.
LikeLiked by 1 person
What should one do in cases where one has already had a look under the hood, but wishes to proceed in as honest a way as possible? Specifically, I wrote a review paper that discussed killing interactions between cats and other carnivore species. One of the reviewer comments rightfully suggested that the paper would be significantly improved by extending the analysis to include all of Carnivora.
So, I’ve already done a great deal of analysis on a subset of the data, and so understand its characteristics. Therefore, hypotheses aren’t truly a priori, and I already have some indication of the broad scale patterns.
Is it just best to admit the ‘under the hood’ work in the paper?
LikeLike
This is a good article. My one qualm is with precommitment. It seems even if one precommitted to an analysis and reporting plan, one could still game the system by selecting hypotheses and experiments more likely to be amenable to the chosen plan. It would be better to have an adversary choose the analysis and reporting plan prior to experimentation, keeping the researcher blind to the choice. This could be accomplished by using a computer or calling on a trusted colleague who doesn’t have a vested interested in one’s results.
LikeLike