Columbia Data Science course, week 6: Kaggle, crowd-sourcing, decision trees, random forests, social networks, and experimental design
Yesterday we had two guest lecturers, who took up approximately half the time each. First we welcomed William Cukierski from Kaggle, a data science competition platform.
Will went to Cornell for a B.A. in physics and to Rutgers to get his Ph.D. in biomedical engineering. He focused on cancer research, studying pathology images. While working on writing his dissertation, he got more and more involved in Kaggle competitions, finishing very near the top in multiple competitions, and now works for Kaggle. Here’s what Will had to say.
Crowd-sourcing in Kaggle
What is a data scientist? Some say it’s someone who is better at stats than an engineer and better at engineering than a statistician. But one could argue it’s actually someone who is worse at stats than a statistician. Being a data scientist is when you learn more and more about more and more until you know nothing about everything.
Kaggle using prizes to induce the public to do stuff. This is not a new idea:
- the Royal Navy in 1714 couldn’t measure longitude, and put out a prize worth $6 million in today’s dollars to get help. John Harrison, an unknown cabinetmaker, figured it out how to make a clock to solve the problem.
- In the U.S. in 2002 FOX issued a prize for the next pop solo artist, which resulted in American Idol.
- There’s also the X-prize company; $10 million was offered for the Ansari X-prize and $100 million was lost in trying to solve it. So it doesn’t always mean it’s an efficient process (but it’s efficient for the people offering the prize if it gets solved!)
There are two kinds of crowdsourcing models. First, we have the distributive crowdsourcing model, like wikipedia, which as for relatively easy but large amounts of contributions. Then, there’s the singular, focused difficult problems that Kaggle, DARPA, InnoCentive and other companies specialize in.
Somee of the problems with some crowdsourcing projects include:
- they don’t always evaluate your submission objectively. Instead they have a subjective measure, so they might just decide your design is bad or something. This leads to high barrier to entry, since people don’t trust the evaluation criterion.
- Also, one doesn’t get recognition until after they’ve won or ranked highly. This leads to high sunk costs for the participants.
- Also, bad competitions often conflate participants with mechanical turks: in other words, they assume you’re stupid. This doesn’t lead anywhere good.
- Also, the competitions sometimes don’t chunk the work into bite size pieces, which means it’s too big to do or too small to be interesting.
A good competition has a do-able, interesting question, with an evaluation metric which is transparent and entirely objective. The problem is given, the data set is given, and the metric of success is given. Moreover, prizes are established up front.
The participants are encouraged to submit their models up to twice a day during the competitions, which last on the order of a few days. This encourages a “leapfrogging” between competitors, where one ekes out a 5% advantage, giving others incentive to work harder. It also establishes a band of accuracy around a problem which you generally don’t have- in other words, given no other information, you don’t know if your 75% accurate model is the best possible.
The test set y’s are hidden, but the x’s are given, so you just use your model to get your predicted y’s for the test set and upload them into the Kaggle machine to see your evaluation score. This way you don’t share your actual code with Kaggle unless you win the prize (and Kaggle doesn’t have to worry about which version of python you’re running).
Note this leapfrogging effect is good and bad. It encourages people to squeeze out better performing models but it also tends to make models much more complicated as they get better. One reason you don’t want competitions lasting too long is that, after a while, the only way to inch up performance is to make things ridiculously complicated. For example, the original Netflix Prize lasted two years and the final winning model was too complicated for them to actually put into production.
The hole that Kaggle is filling is the following: there’s a mismatch between those who need analysis and those with skills. Even though companies desperately need analysis, they tend to hoard data; this is the biggest obstacle for success.
They have had good results so far. Allstate, with a good actuarial team, challenged their data science competitors to improve their actuarial model, which, given attributes of drivers, approximates the probability of a car crash. The 202 competitors improved Allstate’s internal model by 271%.
There were other examples, including one where the prize was $1,000 and it benefited the company $100,000.
A student then asked, is that fair? There are actually two questions embedded in that one. First, is it fair to the data scientists working at the companies that engage with Kaggle? Some of them might lose their job, for example. Second, is it fair to get people to basically work for free and ultimately benefit a for-profit company? Does it result in data scientists losing their fair market price?
Of course Kaggle charges a fee for hosting competitions, but is it enough?
[Mathbabe interjects her view: personally, I suspect this is a model which seems like an arbitrage opportunity for companies but only while the data scientists of the world haven’t realized their value and have extra time on their hands. As soon as they price their skills better they’ll stop working for free, unless it’s for a cause they actually believe in.]
Facebook is hiring data scientists, they hosted a Kaggle competition, where the prize was an interview. There were 422 competitors.
[Mathbabe can’t help but insert her view: it’s a bit too convenient for Facebook to have interviewees for data science positions in such a posture of gratitude for the mere interview. This distracts them from asking hard questions about what the data policies are and the underlying ethics of the company.]
There’s a final project for the class, namely an essay grading contest. The students will need to build it, train it, and test it, just like any other Kaggle competition. Group work is encouraged.
Thought Experiment: What are the ethical implications of a robo-grader?
Some of the students’ thoughts:
- It depends on how much you care about your grade.
- Actual human graders aren’t fair anyway.
- Is this the wrong question? The goal of a test is not to write a good essay but rather to do well in a standardized test. The real profit center for standardized testing is, after all, to sell books to tell you how to take the tests. It’s a screening, you follow the instructions, and you get a grade depending on how well you follow instructions.
- There are really two question: 1) Is it wise to move from the human to the machine version of same thing for any given thing? and 2) Are machines making things more structured, and is this inhibiting creativity? One thing is for sure, robo-grading prevents me from being compared to someone more creative.
- People want things to be standardized. It gives us a consistency that we like. People don’t want artistic cars, for example.
- Will: We used machine learning to research cancer, where the stakes are much higher. In fact this whole field of data science has to be thinking about these ethical considerations sooner or later, and I think it’s sooner. In the case of doctors, you could give the same doctor the same slide two months apart and get different diagnoses. We aren’t consistent ourselves, but we think we are. Let’s keep that in mind when we talk about the “fairness” of using machine learning algorithms in tricky situations.
Introduction to Feature Selection
“Feature extraction and selection are the most important but underrated step of machine learning. Better features are better than better algorithms.” – Will
“We don’t have better algorithms, we just have more data” –Peter Norvig
Will claims that Norvig really wanted to say we have better features.
We are getting bigger and bigger data sets, but that’s not always helpful. The danger is if the number of features is larger than the number of samples or if we have a sparsity problem.
We improve our feature selection process to try to improve performance of predictions. A criticism of feature selection is that it’s no better than data dredging. If we just take whatever answer we get that correlates with our target, that’s not good.
There’s a well known bias-variance tradeoff: a model is “high bias” if it’s is too simple (the features aren’t encoding enough information). In this case lots more data doesn’t improve your model. On the other hand, if your model is too complicated, then “high variance” leads to overfitting. In this case you want to reduce the number of features you are using.
We will take some material from a famous paper by Isabelle Guyon published in 2003 entitled “An Introduction to Variable and Feature Selection”.
There are three categories of feature selection methods: filters, wrappers, and embedded methods. Filters order variables (i.e. possible features) with respect to some ranking (e.g. correlation with target). This is sometimes good on a first pass over the space of features. Filters take account of the predictive power of individual features, and estimate mutual information or what have you. However, the problem with filters is that you get correlated features. In other words, the filter doesn’t care about redundancy.
This isn’t always bad and it isn’t always good. On the one hand, two redundant features can be more powerful when they are both used, and on the other hand something that appears useless alone could actually help when combined with another possibly useless-looking feature.
Wrapper feature selection tries to find subsets of features that will do the trick. However, as anyone who has studied the binomial coefficients knows, the number of possible size 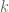


We don’t have to retrain models at each step of such an approach, because there are fancy ways to see how objective function changes as we change the subset of features we are trying out. These are called “finite differences” and rely essentially on Taylor Series expansions of the objective function.
One last word: if you have a domain expertise on hand, don’t go into the machine learning rabbit hole of feature selection unless you’ve tapped into your expert completely!
Decision Trees

We’ve all used decision trees. They’re easy to understand and easy to use. How do we construct? Choosing a feature to pick at each step is like playing 20 questions. We take whatever the most informative thing is first. For the sake of this discussion, assume we break compound questions into multiple binary questions, so the answer is “+” or “-“.
To quantify “what is the most informative feature”, we first define entropy for a random variable 
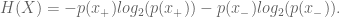
Note when 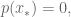

In particular, if either option has probability zero, the entropy is 0. It is maximized at 0.5 for binary variables:

which we can easily compute using the fact that in the binary case, 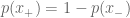
Using this definition, we define the information gain for a given feature, which is defined as the entropy we lose if we know the value of that feature.
To make a decision tree, then, we want to maximize information gain, and make a split on that. We keep going until all the points at the end are in the same class or we end up with no features left. In this case we take the majority vote. Optionally we prune the tree to avoid overfitting.
This is an example of an embedded feature selection algorithm. We don’t need to use a filter here because the “information gain” method is doing our feature selection for us.
How do you handle continuous variables?
In the case of continuous variables, you need to ask for the correct threshold of value so that it can be though of as a binary variable. So you could partition a user’s spend into “less than $5” and “at least $5” and you’d be getting back to the binary variable case. In this case it takes some extra work to decide on the information gain because it depends on the threshold as well as the feature.
Random Forests
Random forests are cool. They incorporate “bagging” (bootstrap aggregating) and trees to make stuff better. Plus they’re easy to use: you just need to specify the number of trees you want in your forest, as well as the number of features to randomly select at each node.
A bootstrap sample is a sample with replacement, which we usually take to be 80% of the actual data, but of course can be adjusted depending on how much data we have.
To construct a random forest, we construct a bunch of decision trees (we decide how many). For each tree, we take a bootstrap sample of our data, and for each node we randomly select (a second point of bootstrapping actually) a few features, say 5 out of the 100 total features. Then we use our entropy-information-gain engine to decide which among those features we will split our tree on, and we keep doing this, choosing a different set of five features for each node of our tree.
Note we could decide beforehand how deep the tree should get, but we typically don’t prune the trees, since a great feature of random forests is that it incorporates idiosyncratic noise.
Here’s what does a decision tree looks like for surviving on the Titanic.
David Huffaker, Google: Hybrid Approach to Social Research
David is one of Rachel’s collaborators in Google. They had a successful collaboration, starting with complementary skill sets, an explosion of goodness ensued when they were put together to work on Google+ with a bunch of other people, especially engineers. David brings a social scientist perspective to the analysis of social networks. He’s strong in quantitative methods for understanding and analyzing online social behavior. He got a Ph.D. in Media, Technology, and Society from Northwestern.
Google does a good job of putting people together. They blur the lines between research and development. The researchers are embedded on product teams. The work is iterative, and the engineers on the team strive to have near-production code from day 1 of a project. They leverage cloud infrastructure to deploy experiments to their mass user base and to rapidly deploy a prototype at scale.
Note that, considering the scale of Google’s user base, redesign as they scaling up is not a viable option. They instead do experiments with smaller groups of users.
David suggested that we, as data scientists, consider how to move into an experimental design so as to move to a causal claim between variables rather than a descriptive relationship. In other words, to move from the descriptive to the predictive.
As an example, he talked about the genesis of the “circle of friends” feature of Google+. They know people want to selectively share; they’ll send pictures to their family, whereas they’d probably be more likely to send inside jokes to their friends. They came up with the idea of circles, but it wasn’t clear if people would use them. How do they answer the question: will they use circles to organize their social network? It’s important to know what motivates them when they decide to share.
They took a mixed-method approach, so they used multiple methods to triangulate on findings and insights. Given a random sample of 100,000 users, they set out to determine the popular names and categories of names given to circles. They identified 168 active users who filled out surveys and they had longer interviews with 12.
They found that the majority were engaging in selective sharing, that most people used circles, and that the circle names were most often work-related or school-related, and that they had elements of a strong-link (“epic bros”) or a weak-link (“acquaintances from PTA”)
They asked the survey participants why they share content. The answers primarily came in three categories: first, the desire to share about oneself – personal experiences, opinions, etc. Second, discourse: people wanna participate in a conversation. Third, evangelism: people wanna spread information.
Next they asked participants why they choose their audiences. Again, three categories: first, privacy – many people were public or private by default. Second, relevance – they wanted to share only with those who may be interested, and they don’t wanna pollute other people’s data stream. Third, distribution – some people just want to maximize their potential audience.
The takeaway from this study was this: people do enjoy selectively sharing content, depending on context, and the audience. So we have to think about designing features for the product around content, context, and audience.
Network Analysis
We can use large data and look at connections between actors like a graph. For Google+, the users are the nodes and the edges (directed) are “in the same circle”.
Other examples of networks:
- nodes are users in 2nd life, interactions between users are possible in three different ways, corresponding to three different kinds of edges
- nodes are websites, edges are links
- nodes are theorems, directed edges are dependencies
After you define and draw a network, you can hopefully learn stuff by looking at it or analyzing it.
Social at Google
As you may have noticed, “social” is a layer across all of Google. Search now incorporates this layer: if you search for something you might see that your friend “+1″‘ed it. This is called a social annotation. It turns out that people care more about annotation when it comes from someone with domain expertise rather than someone you’re very close to. So you might care more about the opinion of a wine expert at work than the opinion of your mom when it comes to purchasing wine.
Note that sounds obvious but if you started the other way around, asking who you’d trust, you might start with your mom. In other words, “close ties,” even if you can determine those, are not the best feature to rank annotations. But that begs the question, what is? Typically in a situation like this we use click-through rate, or how long it takes to click.
In general we need to always keep in mind a quantitative metric of success. This defines success for us, so we have to be careful.
Privacy
Human facing technology has thorny issues of privacy which makes stuff hard. We took a survey of how people felt uneasy about content. We asked, how does it affect your engagement? What is the nature of your privacy concerns?
Turns out there’s a strong correlation between privacy concern and low engagement, which isn’t surprising. It’s also related to how well you understand what information is being shared, and the question of when you post something, where does it go and how much control do you have over it. When you are confronted with a huge pile of complicated all settings, you tend to start feeling passive.
Again, we took a survey and found broad categories of concern as follows:
identity theft
- financial loss
digital world
- access to personal data
- really private stuff I searched on
- unwanted spam
- provocative photo (oh shit my boss saw that)
- unwanted solicitation
- unwanted ad targeting
physical world
- offline threats
- harm to my family
- stalkers
- employment risks
- hassle
What is the best way to decrease concern and increase undemanding and control?
Possibilities:
- Write and post a manifesto of your data policy (tried that, nobody likes to read manifestos)
- Educate users on our policies a la the Netflix feature “because you liked this, we think you might like this”
- Get rid of all stored data after a year
Rephrase: how do we design setting to make it easier for people? how do you make it transparent?
- make a picture or graph of where data is going.
- give people a privacy switchboard
- give people access to quick settings
- make the settings you show them categorized by things you don’t have a choice about vs. things you do
- make reasonable default setting so people don’t have to worry about it.
David left us with these words of wisdom: as you move forward and have access to big data, you really should complement them with qualitative approaches. Use mixed methods to come to a better understanding of what’s going on. Qualitative surveys can really help.




{kind=link}
Contemplating an entropy of zero seems to be a complete disconnect from reality, a state of perfect information?
LikeLike
“Being a data scientist is when you learn more and more about more and more until you know nothing about everything.”
This is so true.
LikeLike